四叉堆在GO中的应用-定时任务timer
堆作为必须掌握的数据结构之一,在众多场景中也得到了广泛的应用。
比较典型的,如java中的优先队列PriorityQueue、算法中的TOP-K问题、最短路径Dijkstra算法等,在这些经典应用中堆都担任着灵魂般的角色。
理论基础
binary heap
再一起回忆一下堆的一个性质:堆总是一棵完全二叉树。有些文章中也将堆称为二叉堆(binary heap)。
在堆中,再根据堆顶点为最大值与最小值,分为大顶堆与小顶堆。


新增一个元素,需要进行sift-up操作,其时间复杂度为O(logN)
构造二叉堆,有两种方式:
- 一种是比较简单的方式:遍历每个元素进行sift-up,其时间复杂度为O(N*logN)
- 另一种是将元素以完全二叉树进行存储,遍历每个非叶子节点自下而上构建子堆,其时间负载度为O(N)
删除堆顶元素,需要对堆末尾元素进行sift-down,其时间复杂度也为O(logN)。
堆排序的过程是在构建好堆后再逐个删除堆顶元素,其时间复杂度O(N+(N-1)*logN),约为O(NlogN)
堆排序整体运行过程动画如下:

d-ary deap
除了二叉堆外,还有三叉堆、四叉堆、五叉堆这些N叉堆,即维基百科中的d-ary heap。
The d-ary heap or d-heap is a priority queue data structure, a generalization of the binary heap in which the nodes have d children instead of 2.

N叉堆与二叉堆进行对比,由于N叉堆树的高度更低,上推(sift-up)过程的时间复杂度是二叉堆的O(logN2)倍,即新增元素时则会更快。
删除堆顶元素时进行sift-down操作,时间复杂度为O(N * log s / log N)。(N为维度,s为堆中节点个数)
在N叉堆中,四叉堆由于综合性能相对稳定在N叉堆中脱颖而出。
测试数据可参考:https://vearne.cc/archives/39627
GO中的应用(time.ticker源码分析)
在有了理论基础后,再看下四叉堆在GO中的应用-timer(定时任务)。
ticker用法
在go项目中,可以使用go自带的time.ticker进行简单的定时任务。示例代码如下:
// 新建一个ticker,定设置周期为1秒
ticker := time.NewTicker(time.Second * 3)
// 在一个协程接收ticker的channel回调
go func() {for {<-ticker.C// 周期到达后,输出当前时间fmt.Println("tick-->", time.Now().String())}
}()
time.Sleep(time.Hour)
输出示例为:
……
tick--> 2023-10-08 21:01:30.1830277 +0800 CST m=+3.009288301
tick--> 2023-10-08 21:01:33.1811243 +0800 CST m=+6.007384901
tick--> 2023-10-08 21:01:36.179331 +0800 CST m=+9.005591601
……
以上一个定时任务代码就完成了
ticker结构
以上简短的代码便完成一个定时任务的功能,再来探究一下它的原理。
一个Ticker由两部分组成:
- 一个接收消息的channel
- 一个runtimeTimer结构体
type Ticker struct {C <-chan Time // The channel on which the ticks are delivered.r runtimeTimer
}type runtimeTimer struct {pp uintptrwhen int64period int64f func(any, uintptr) // NOTE: must not be closurearg anyseq uintptrnextwhen int64status uint32
}
从NewTicker方法入手:
func NewTicker(d Duration) *Ticker {if d <= 0 {panic(errors.New("non-positive interval for NewTicker"))}c := make(chan Time, 1)t := &Ticker{C: c,r: runtimeTimer{when: when(d), //下次触发时间period: int64(d),//运行周期f: sendTime,//触发时执行的动作arg: c,},}startTimer(&t.r)//启动Timerreturn t
}// sendTime does a non-blocking send of the current time on c.
func sendTime(c any, seq uintptr) {select {case c.(chan Time) <- Now()://将当前时间发送给等待的channeldefault://channel缓存区满了,不执行任何操作}
}
以上代码在NewTicker方法中创建了一个Ticker,并调用了startTimer方法。
且runtimeTimer与一个ticker是一对一的关系,用一个堆来存储所有的定时任务,则一个ticker是一个节点。
startTimer方法
startTimer在time包下无法找到实现代码,需要在go源码的runtime下查看。

如上图所示,源码在src/runtime/time.go文件中。
// startTimer adds t to the timer heap.
//
//go:linkname startTimer time.startTimer
func startTimer(t *timer) {if raceenabled {racerelease(unsafe.Pointer(t))}addtimer(t)
}// Note: this changes some unsynchronized operations to synchronized operations
// addtimer adds a timer to the current P.
// This should only be called with a newly created timer.
// That avoids the risk of changing the when field of a timer in some P's heap,
// which could cause the heap to become unsorted.
func addtimer(t *timer) {// when must be positive. A negative value will cause runtimer to// overflow during its delta calculation and never expire other runtime// timers. Zero will cause checkTimers to fail to notice the timer.if t.when <= 0 {throw("timer when must be positive")}if t.period < 0 {throw("timer period must be non-negative")}if t.status.Load() != timerNoStatus {throw("addtimer called with initialized timer")}t.status.Store(timerWaiting)when := t.when// Disable preemption while using pp to avoid changing another P's heap.mp := acquirem()pp := getg().m.p.ptr()lock(&pp.timersLock)cleantimers(pp)doaddtimer(pp, t)unlock(&pp.timersLock)wakeNetPoller(when)releasem(mp)
}
addtimer方法为关键方法。看懂addtimer的整体方法需要对go中的GMP模型有一定的了解。
G(gorountine协程),M(thread线程),P(processor处理器)

咱们这里仅看主流程,直接看doaddtimer方法。
doaddtimer方法(新增节点)
// doaddtimer adds t to the current P's heap.
// The caller must have locked the timers for pp.
func doaddtimer(pp *p, t *timer) {// Timers rely on the network poller, so make sure the poller// has started.if netpollInited.Load() == 0 {// netpool如未初始化则进行初始化netpollGenericInit()}if t.pp != 0 {throw("doaddtimer: P already set in timer")}// 给timer绑定pt.pp.set(pp)i := len(pp.timers)// 将此timer添加到p的timer集合中,放到堆的末尾pp.timers = append(pp.timers, t)// 堆内新增了元素,进行上推操作在保持堆的特性siftupTimer(pp.timers, i)if t == pp.timers[0] {pp.timer0When.Store(t.when)}// p的timer计数器加1pp.numTimers.Add(1)
}
再来详细学习下4叉堆的siftup具体是如何操作的。
siftupTimer方法中的t为堆的所有元素,i为要进行siftup元素的索引,也就是新增的元素索引。
siftupTimer方法如下:
func siftupTimer(t []*timer, i int) int {// 判断新增元素的正确性if i >= len(t) {badTimer()}// 获取出新增元素的具体运行时间when := t[i].whenif when <= 0 {badTimer()}// 新增元素的值tmp := t[i]for i > 0 {// 获取出新增元素的父节点索引,四叉堆时父节点索引为(i-1)/4p := (i - 1) / 4 // parentif when >= t[p].when {// 新增元素的运行时间晚于父节点,则无需继续siftupbreak}// 将原父节点位置往下降一级t[i] = t[p]// 新增元素的位置往上提升一级i = p}if tmp != t[i] {// 新增元素的值在最后确定了位置后才赋值,而不是每次都进行交换t[i] = tmp}return i
}
runtimer方法(执行/删除节点)
当timer堆中维护好后,就可以准备执行timer堆中的timer了。
此过程为持续从堆顶取出timer,判断timer是否达到了执行的条件(时间、状态),如果条件满足就执行此timer。
执行timer的方法为time中的runtimer方法,执行时主要关注runOneTimer方法。源码如下:
func runtimer(pp *p, now int64) int64 {for {// 获取出当前p的堆顶timert := pp.timers[0]if t.pp.ptr() != pp {throw("runtimer: bad p")}// 对堆顶timer的状态进行判断switch s := t.status.Load(); s {case timerWaiting:if t.when > now {// Not ready to run.return t.when}if !t.status.CompareAndSwap(s, timerRunning) {// 已在运行,不重复运行continue}// Note that runOneTimer may temporarily unlock// pp.timersLock.runOneTimer(pp, t, now)return 0case timerDeleted:if !t.status.CompareAndSwap(s, timerRemoving) {continue}dodeltimer0(pp)if !t.status.CompareAndSwap(timerRemoving, timerRemoved) {badTimer()}pp.deletedTimers.Add(-1)if len(pp.timers) == 0 {return -1}case timerModifiedEarlier, timerModifiedLater:if !t.status.CompareAndSwap(s, timerMoving) {continue}t.when = t.nextwhendodeltimer0(pp)doaddtimer(pp, t)if !t.status.CompareAndSwap(timerMoving, timerWaiting) {badTimer()}case timerModifying:// Wait for modification to complete.osyield()case timerNoStatus, timerRemoved:// Should not see a new or inactive timer on the heap.badTimer()case timerRunning, timerRemoving, timerMoving:// These should only be set when timers are locked,// and we didn't do it.badTimer()default:badTimer()}}
}// runOneTimer runs a single timer.
// The caller must have locked the timers for pp.
// This will temporarily unlock the timers while running the timer function.
//
//go:systemstack
func runOneTimer(pp *p, t *timer, now int64) {if raceenabled {ppcur := getg().m.p.ptr()if ppcur.timerRaceCtx == 0 {ppcur.timerRaceCtx = racegostart(abi.FuncPCABIInternal(runtimer) + sys.PCQuantum)}raceacquirectx(ppcur.timerRaceCtx, unsafe.Pointer(t))}// 取出timer中的function和参数f := t.farg := t.argseq := t.seqif t.period > 0 {// tick类型的timer,以实际运行时间和固定周期计算出下次运行时间// Leave in heap but adjust next time to fire.delta := t.when - nowt.when += t.period * (1 + -delta/t.period)if t.when < 0 { // check for overflow.t.when = maxWhen}// siftdown堆顶节点,重新调整堆siftdownTimer(pp.timers, 0)if !t.status.CompareAndSwap(timerRunning, timerWaiting) {badTimer()}updateTimer0When(pp)} else {// 非tick类型的timer,执行删除// Remove from heap.dodeltimer0(pp)if !t.status.CompareAndSwap(timerRunning, timerNoStatus) {badTimer()}}if raceenabled {// Temporarily use the current P's racectx for g0.gp := getg()if gp.racectx != 0 {throw("runOneTimer: unexpected racectx")}gp.racectx = gp.m.p.ptr().timerRaceCtx}unlock(&pp.timersLock)// 执行timer的function和参数f(arg, seq)lock(&pp.timersLock)if raceenabled {gp := getg()gp.racectx = 0}
}
在删除堆顶节点时执行的是siftdownTimer方法。其源码如下:
// siftdownTimer puts the timer at position i in the right place
// in the heap by moving it down toward the bottom of the heap.
func siftdownTimer(t []*timer, i int) {n := len(t)if i >= n {badTimer()}// 获取出要调整节点的执行时间when := t[i].whenif when <= 0 {badTimer()}tmp := t[i]for {// c为调整节点的最左子节点,从左往右第1个c := i*4 + 1 // left child// c3为调整节点的中间节点,从左往右第3个c3 := c + 2 // mid childif c >= n {break}// 最左子节点的下次执行时间w := t[c].when// 左边第2个节点的执行时间比最左子节点执行时间更先执行if c+1 < n && t[c+1].when < w {// 左边部分timer排序交换,最先执行的排左边w = t[c+1].whenc++}// 判断中间节点是否存在if c3 < n {// 中间子节点的timer执行时间w3 := t[c3].whenif c3+1 < n && t[c3+1].when < w3 {// 同上,将最先执行的往左排w3 = t[c3+1].whenc3++}// 子节点整体做对比,左侧与右侧对比if w3 < w {// 将最先执行的放在左边w = w3c = c3}}if w >= when {// 堆已调整完毕break}// 将最左的子节点向上升一级t[i] = t[c]// 原i向下降一级i = c}if tmp != t[i] {// 将siftdown节点调整到最终确定的位置t[i] = tmp}
}
某一个timer运行时,会判断此timer是否为周期性timer,周期性timer会将堆顶节点进行移除,再计算出下次执行时间,并使用sift-down将此timer下沉到适当的位置,以整体满足堆的特性。
dodeltimer0(临时性timer)
从runOneTimer方法中可以看到有两个分支,分别为:
- timer有period(周期性定时任务类型)
- timer无period(仅计时类型)
前面看的siftdownTimer是周期性定时任务会执行的方法。如果为临时性定时任务,如倒计时或time.sleep场景中,则最终运行的为dodeltimer0方法。
源码如下:
// dodeltimer0 removes timer 0 from the current P's heap.
// We are locked on the P when this is called.
// It reports whether it saw no problems due to races.
// The caller must have locked the timers for pp.
func dodeltimer0(pp *p) {if t := pp.timers[0]; t.pp.ptr() != pp {throw("dodeltimer0: wrong P")} else {t.pp = 0}// 获取到堆中的最后一个节点last := len(pp.timers) - 1if last > 0 {// 最后一个节点放到堆顶pp.timers[0] = pp.timers[last]}// 删除堆中的原末尾节点pp.timers[last] = nilpp.timers = pp.timers[:last]if last > 0 {// 对放到堆顶的原末尾节点进行siftdown操作siftdownTimer(pp.timers, 0)}// 更新timer集合updateTimer0When(pp)n := pp.numTimers.Add(-1)if n == 0 {// If there are no timers, then clearly none are modified.pp.timerModifiedEarliest.Store(0)}
}
从源码可以看出,当临时性timer触发后会将此节点删除不会再次入堆。这个过程咱们所了解的常规堆排序的过程是一致的,只是这里用的是四叉堆堆排序中用的是二叉堆。
proc.checkTimers(运行检测)
前面所提到的持续从堆顶取timer,并判断是否满足执行条件的步骤在proc.checkTimers方法中,也就是它才是timer执行的入口。此方法的上层调度可通过跟踪源码查看到,后期再详细深入探究。
timer与robfig/cron对比
由于参与的GO项目中有常看到另一个框架https://github.com/robfig/cron,看着源码不太多就浅浅看了下,总结出以下几点:
- cron是基于timer开发的,底层内部仍是使用的timer
- cron支持的任务最小周期为秒,timer的最小周期无限制
- cron中的某一任务是可能并行运行的,而timer.tick中的同一任务不会出现同时运行的情况
比较关键的点为第3点,具体选择时看具体的应用场景
总结
- 在数据量不太大的情况下,四叉堆的综合性能比二叉堆更优
- GO中time.timer和time.tick是使用四叉堆实现的
- time.tick的任务每次运行后会重新入堆,time.timer的任务每次运行后会从堆顶删除
相关文章:
四叉堆在GO中的应用-定时任务timer
堆作为必须掌握的数据结构之一,在众多场景中也得到了广泛的应用。 比较典型的,如java中的优先队列PriorityQueue、算法中的TOP-K问题、最短路径Dijkstra算法等,在这些经典应用中堆都担任着灵魂般的角色。 理论基础 binary heap 再一起回忆…...

Flow深入浅出系列之使用Kotlin Flow自动刷新Android数据的策略
Flow深入浅出系列之在ViewModels中使用Kotlin FlowsFlow深入浅出系列之更聪明的分享 Kotlin FlowsFlow深入浅出系列之使用Kotlin Flow自动刷新Android数据的策略 Flow深入浅出系列之使用Kotlin Flow自动刷新Android数据的策略 讨论在Android应用程序中使用Kotlin Flow高效加载…...

AC修炼计划(AtCoder Regular Contest 165)
传送门:AtCoder Regular Contest 165 - AtCoder 本次习题参考了樱雪猫大佬的题解,大佬的题解传送门如下:Atcoder Regular Contest 165 - 樱雪喵 - 博客园 (cnblogs.com) A - Sum equals LCM 第一题不算特别难 B - Sliding Window Sort 2 对…...

【Express】登录鉴权 JWT
JWT(JSON Web Token)是一种用于实现身份验证和授权的开放标准。它是一种基于JSON的安全传输数据的方式,由三部分组成:头部、载荷和签名。 使用jsonwebtoken模块,你可以在Node.js应用程序中轻松生成和验证JWT。以下是j…...
【微服务 SpringCloud】实用篇 · Ribbon负载均衡
微服务(4) 文章目录 微服务(4)1. 负载均衡原理2. 源码跟踪1)LoadBalancerIntercepor2)LoadBalancerClient3)负载均衡策略IRule4)总结 3. 负载均衡策略3.1 负载均衡策略3.2 自定义负载…...

zabbix-proxy代理服务器配置
下载zabbix源 rpm -Uvh https://repo.zabbix.com/zabbix/5.0/rhel/7/x86_64/zabbix-release-5.0-1.el7.noarch.rpm 安装 yum -y install zabbix-proxy-mysql zabbix_get 查看相关文件路径 rpm -ql zabbix-proxy-mysql 创建数据库 mysq -uroot -proot mysql> create database…...

【python零基础入门学习】python进阶篇之OOP - 面向对象的程序设计
本站以分享各种运维经验和运维所需要的技能为主 《python零基础入门》:python零基础入门学习 《python运维脚本》: python运维脚本实践 《shell》:shell学习 《terraform》持续更新中:terraform_Aws学习零基础入门到最佳实战 《k8…...

中国xx集团信息技术工程师面试
进入面试间,坐着三位面试官,压力扑面而来,三位面试官先做了自我介绍,介绍了一下面试的流程后才开始面试。 一、自我介绍 不多说。 二、看你学过数据挖掘这门课,能简单介绍一下有哪些章节,学了些什么&…...
Jmeter接口自动化测试 —— Jmeter下载安装及入门
jmeter简介 Apache JMeter是Apache组织开发的基于Java的压力测试工具。用于对软件做压力测试,它最初被设计用于Web应用测试,但后来扩展到其他测试领域。 下载 下载地址:Apache JMeter - Download Apache JMeter 安装 由于Jmeter是基于Java的…...

ARM 学习笔记2 初识Cortex-M33与STM32G4
入门 ARM Cortex-M系列处理器的差异与联系:【ARM Cortex-M 系列 1 – Cortex-M0, M3, M4, M7, M33 差异】两本书籍的英文版和中文版 Definitive Guide to Arm Cortex-M23 and Cortex-M33 Processors Arm Cortex-M23和Cortex-M33微处理器权威指南ST的介绍页 Arm Cor…...
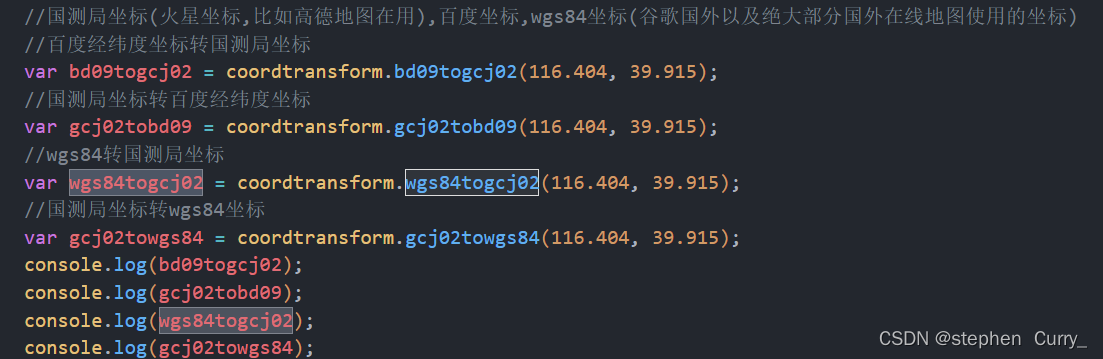
vue中使用coordtransform 互相转换坐标系
官方网站:https://www.npmjs.com/package/coordtransform 在使用高德sdk时,其返回的坐标在地图上显示时有几百米的偏移,这是由于高德用的是 火星坐标(GCJ02),而不是wgs84坐标。为了消除偏移,将G…...

双线性插值详解
双线性插值的原理网上资料非常多,本文重点介绍双线性插值实现的两种方式: 角对齐(coner_align = True) 和 边对齐(coner_align = False)。两种不能的方式下去实现双线性插值,目标图像中的每个像素点,它是如何计算取值的,本文会通过原理结合代码的方式将实现细节讲清楚。 1…...

C++ “”
&加上有时候会加速 如果想该对象跟着函数变化一定要加“&” 在题目函数里面定义的 例如 vector<vector<bool>> visited(grid.size(),vector<bool>(grid[0].size(),false)); 如果自己定义的新void dfs(vector<vector<bool>>…...

计算机三级有必要考吗?计算机三级有哪些科目?
在大学期间,计算机等级考试是一门很火热的考试,很多小伙伴通过二级考试以后在究竟是报考三级还是四级之间徘徊,下面肉丸子就来给大家分析一下,究竟有没有必要考计算机三级考试,以及计算机三级考试的科目有哪些…...
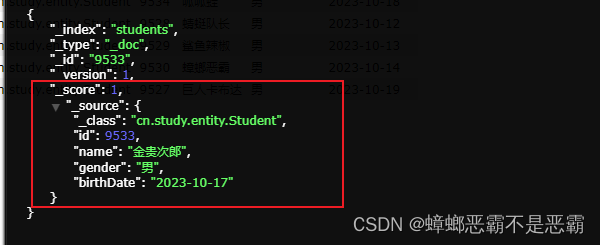
6.5 Elasticsearch(五)Spring Data Elasticsearch - 增删改查API
文章目录 1.Spring Data Elasticsearch2.案例准备2.1 在 Elasticsearch 中创建 students 索引2.2 案例测试说明 3.创建项目3.1 新建工程3.2 新建 springboot module,添加 spring data elasticsearch 依赖3.3 pom.xml 文件3.4 application.yml 配置 4.Student 实体类…...

XPS—专项文献阅读-科学指南针
XPS(X-ray Photoelectron Spectroscopy),X射线光电子能谱,可以说是材料研究中必不可少的一类分析测试手段了。今天我们就来讲讲,什么情况下我们需要用到XPS,以及拿到数据之后应该怎样进行数据处理分析。 XP…...
电脑办公助手之桌面便签,助力高效率办公
在现代办公的快节奏中,大家有应接不暇的工作,每天面对着复杂的工作任务,总感觉时间不够用,而且工作无厘头。对于这种状态,大家可以选择在电脑上安装一款好用的办公便签软件来辅助日常办公。 敬业签是一款专为办公人士…...

【面试题】2023虹软计算机视觉一面
来源:投稿 作者:LSC 编辑:学姐 1.自我介绍 2.介绍了自己的项目,并提问项目,讲了30分钟 3.介绍centernet,它和其他目标检测模型有什么区别 4.介绍yolov5 5.介绍focal loss 6.双线性插值和最近邻插值的区…...

板带纠偏控制系统伺服比例阀放大器
板带纠偏控制系统是集光、机、电、液四方面有机结合在一起的全闭环电液伺服系统,是用途广泛的机电一体化高新技术产品。 板带纠偏控制系统可广泛地应用于机械、冶金、造纸、橡胶、织带、纺织印染、电镀、塑膜胶片等诸多行业的不同种类的带材生产线的在线纠偏。 板…...

视频I420裸流保存为文件
1、从TvCamera的ABK回调的OnImageReceived出来的是I420的数据,保存文件的方式如下: void OnImageReceived(const uint8_t* data, size_t size, uint16_t widht, uint16_t height) { .............. FILE *fp fopen("test.yuv", "wb&quo…...

GHelper:华硕笔记本性能优化与硬件控制的开源解决方案
GHelper:华硕笔记本性能优化与硬件控制的开源解决方案 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Sc…...

如何通过手机号快速找回QQ号?解锁Python工具的5个实用技巧
如何通过手机号快速找回QQ号?解锁Python工具的5个实用技巧 【免费下载链接】phone2qq 项目地址: https://gitcode.com/gh_mirrors/ph/phone2qq 忘记QQ号是许多用户都会遇到的困扰,尤其是在更换设备或长期未登录后。phone2qq作为一款开源的Python…...

实战应用:基于快马平台构建项目级UI颜色规范管理工具
今天想和大家分享一个最近在项目中用到的实用工具——基于InsCode(快马)平台搭建的UI颜色规范管理系统。作为一个经常要和设计系统打交道的前端开发者,我发现在团队协作中,颜色代码的管理常常是个痛点,这次尝试用快马平台快速实现了一个解决方…...

QPdf:Qt生态下的PDF渲染技术深度解析与现代应用实践
QPdf:Qt生态下的PDF渲染技术深度解析与现代应用实践 【免费下载链接】qpdf PDF viewer widget for Qt 项目地址: https://gitcode.com/gh_mirrors/qpd/qpdf 在Qt应用开发中,PDF文档处理一直是个技术痛点。传统方案要么依赖平台原生组件导致跨平台…...

SEO_影响搜索引擎排名的关键SEO因素分析
SEO:影响搜索引擎排名的关键SEO因素分析 在当今信息爆炸的时代,网站的流量和曝光度直接决定了一个品牌的市场竞争力。搜索引擎优化(SEO)是提升网站在搜索结果中排名的重要手段。本文将从多个角度分析影响搜索引擎排名的关键SEO因…...
AgentCPM-Report参数详解:Pixel Epic中‘智力同步率’实时监控原理
AgentCPM-Report参数详解:Pixel Epic中智力同步率实时监控原理 1. 像素史诗的独特设计理念 Pixel EpicWisdom Terminal将严肃的科研工作转化为一场视觉化的冒险游戏。在这个16-bit像素风格的界面中,AgentCPM-Report大模型被具象化为一位"贤者&quo…...

Nunchaku-flux-1-dev性能调优:针对STM32嵌入式设备演示的图片预处理
Nunchaku-flux-1-dev性能调优:针对STM32嵌入式设备演示的图片预处理 最近在折腾一个智能门禁项目,需要在STM32上跑人脸识别。想法挺简单,本地抓拍人脸,然后传给云端的大模型Nunchaku-flux-1-dev去分析。结果一上手就发现…...

3个技巧教你玩转Dify工作流:从新手到高手的完整指南
3个技巧教你玩转Dify工作流:从新手到高手的完整指南 【免费下载链接】Awesome-Dify-Workflow 分享一些好用的 Dify DSL 工作流程,自用、学习两相宜。 Sharing some Dify workflows. 项目地址: https://gitcode.com/GitHub_Trending/aw/Awesome-Dify-Wo…...

2026年Turnitin AI检测对留学生论文的影响:检测标准和应对方案
2026年Turnitin AI检测对留学生论文的影响:检测标准和应对方案 同一篇论文,知网52%,维普38%,万方21%。 为什么差这么多?不是平台乱搞,而是检测算法和判断标准不一样。理解了Turnitin AI检测背后的逻辑&am…...

【learn-claude-code】S06ContextCompact - 上下文压缩:上下文会满,你需要腾出空间
核心理念 “上下文会满,你需要腾出空间” – 三层压缩策略,实现无限会话。 源码:https://github.com/xiayongchao/learn-claude-code-4j/blob/main/src/main/java/org/jc/agents/S06ContextCompact.java原版:https://github.com…...