【数据结构】线性表(二)单链表及其基本操作(创建、插入、删除、修改、遍历打印)
目录
前文、线性表的定义及其基本操作(顺序表插入、删除、查找、修改)
四、线性表的链接存储结构
1. 单链表(C语言)
a. 链表节点结构
b. 创建新节点
c. 在链表末尾插入新节点
d. 删除指定节点
e. 修改指定节点的数据
f. 遍历链表并打印
g. 主函数
C语言代码整合
Cpp代码整合
前文、线性表的定义及其基本操作(顺序表插入、删除、查找、修改)
按照线性表结点间的逻辑顺序依次将它们存储于一组地址连续的存储单元中的存储方式被称为线性表的顺序存储方式。
按顺序存储方式存储的线性表具有顺序存储结构,一般称之为顺序表。换言之,在程序中采用定长的一维数组,按照顺序存储方式存储的线性表,被称为顺序表。若顺序表中的元素按其值有序,则称其为有序顺序表。
在高级程序设计语言中,“数组”这种数据类型同样具有随机存储的特性,因此用高级程序设计语言实现线性表的顺序存储结构时,通常选择数组。因此,数组的长度就是顺序表的最大长度(MaxSize),顺序表的实际长度为length,其值必须小于等于MaxSize。

【数据结构】线性表(一)线性表的定义及其基本操作(顺序表插入、删除、查找、修改)-CSDN博客![]() https://blog.csdn.net/m0_63834988/article/details/132089038?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_63834988/article/details/132089038?spm=1001.2014.3001.5501
四、线性表的链接存储结构
顺序表的优点是存取速度快。但是,无论是插入一个结点,还是删除一个结点,都需要调整一批结点的地址。要克服该缺点,就必须给出一种不同于顺序存储的存储方式。用链接存储方式存储的线性表被称为链表,可以克服上述缺点。
链表中的结点用存储单元(若干个连续字节)来存放,存储单元之间既可以是(存储空间上)连续的,也可以是不连续的,甚至可以零散地分布在存储空间中的任何位置。换言之,链表中结点的逻辑次序和物理次序之间并无必然联系。最重要的是,链表可以在不移动结点位置的前提下根据需要随时添加删除结点,动态调整。

1. 单链表(C语言)
在链接存储结构中,插入和删除操作相对于顺序存储结构而言更加高效,时间复杂度为O(1)。而查找操作的时间复杂度为O(n)。
a. 链表节点结构
typedef struct Node {int data;struct Node* next;
} Node; 链表节点的结构体 Node,包含一个整数数据 data 和一个指向下一个节点的指针 next
b. 创建新节点
Node* createNode(int data) {Node* newNode = (Node*)malloc(sizeof(Node));if (newNode != NULL) {newNode->data = data;newNode->next = NULL;}return newNode;
}- 创建一个新的节点并返回指向该节点的指针:
- 使用
malloc分配了节点的内存空间; - 将传入的数据赋值给节点的
data字段,并将next字段设置为NULL。
- 使用
c. 在链表末尾插入新节点
void insertAtEnd(Node** head, int data) {Node* newNode = createNode(data);if (newNode == NULL) {printf("内存分配失败!\n");return;}if (*head == NULL) {*head = newNode;} else {Node* temp = *head;while (temp->next != NULL) {temp = temp->next;}temp->next = newNode;}printf("已在链表末尾插入节点:%d", data);
}- 调用
createNode函数创建一个新节点; - 检查内存分配是否成功;
- 如果成功,则根据链表是否为空来确定新节点的位置。
- 若链表为空,则将新节点设置为头节点;
- 否则,遍历链表找到最后一个节点,并将最后一个节点的
next指针指向新节点。
d. 删除指定节点
void deleteNode(Node** head, int data) {if (*head == NULL) {printf("链表为空!\n");return;}Node* temp = *head;Node* prev = NULL;if (temp != NULL && temp->data == data) {*head = temp->next;free(temp);printf("已删除节点:%d", data);return;}while (temp != NULL && temp->data != data) {prev = temp;temp = temp->next;}if (temp == NULL) {printf("节点 %d 不存在!\n", data);return;}prev->next = temp->next;free(temp);printf("已删除节点:%d", data);
}- 检查链表是否为空,如果为空则输出相应的提示信息。
- 遍历链表,找到要删除的节点。
- 如果找到了节点,则修改前一个节点的
next指针,使其跳过要删除的节点,并释放该节点的内存空间。 - 如果没有找到要删除的节点,则输出相应的提示信息。
- 如果找到了节点,则修改前一个节点的
e. 修改指定节点的数据
void modifyNode(Node* head, int oldData, int newData) {if (head == NULL) {printf("链表为空!\n");return;}Node* temp = head;while (temp != NULL) {if (temp->data == oldData) {temp->data = newData;printf("已将节点 %d 修改为 %d\n", oldData, newData);return;}temp = temp->next;}printf("节点 %d 不存在!\n", oldData);
}查找~删除~修改……这里不重复介绍,懂的都懂,不懂我也没办法
f. 遍历链表并打印
void printList(Node* head) {if (head == NULL) {printf("链表为空!\n");return;}Node* temp = head;printf("链表节点数据:");while (temp != NULL) {printf("%d ", temp->data);temp = temp->next;}printf("\n");
}- 检查链表是否为空,如果为空则输出相应的提示信息。
- 使用一个临时指针变量
temp来遍历链表,依次访问每个节点并打印其数据。
g. 主函数
nt main() {Node* head = NULL; // 头节点insertAtEnd(&head, 1);insertAtEnd(&head, 2);insertAtEnd(&head, 3);printList(head);deleteNode(&head, 2);printList(head);deleteNode(&head, 4);return 0;
}- 创建了一个头节点
head; - 调用
insertAtEnd函数三次,在链表末尾插入了三个节点; - 调用
printList函数打印链表的节点数据; - 调用
deleteNode函数删除链表中的一个节点,并再次打印链表的节点数据; - 调用
deleteNode函数尝试删除一个不存在的节点。

C语言代码整合
#include <stdio.h>
#include <stdlib.h>// 定义链表节点结构
typedef struct Node {int data;struct Node* next;
} Node;// 创建新节点
Node* createNode(int data) {Node* newNode = (Node*)malloc(sizeof(Node));if (newNode != NULL) {newNode->data = data;newNode->next = NULL;}return newNode;
}// 在链表末尾插入新节点
void insertAtEnd(Node** head, int data) {Node* newNode = createNode(data);if (newNode == NULL) {printf("内存分配失败!\n");return;}if (*head == NULL) {*head = newNode;} else {Node* temp = *head;while (temp->next != NULL) {temp = temp->next;}temp->next = newNode;}printf("已在链表末尾插入节点:%d", data);
}// 删除指定节点
void deleteNode(Node** head, int data) {if (*head == NULL) {printf("链表为空!\n");return;}Node* temp = *head;Node* prev = NULL;if (temp != NULL && temp->data == data) {*head = temp->next;free(temp);printf("已删除节点:%d", data);return;}while (temp != NULL && temp->data != data) {prev = temp;temp = temp->next;}if (temp == NULL) {printf("节点 %d 不存在!\n", data);return;}prev->next = temp->next;free(temp);printf("已删除节点:%d", data);
}
// 修改指定节点的数据
void modifyNode(Node* head, int oldData, int newData) {if (head == NULL) {printf("链表为空!\n");return;}Node* temp = head;while (temp != NULL) {if (temp->data == oldData) {temp->data = newData;printf("已将节点 %d 修改为 %d\n", oldData, newData);return;}temp = temp->next;}printf("节点 %d 不存在!\n", oldData);
}
// 遍历链表并打印节点数据
void printList(Node* head) {if (head == NULL) {printf("链表为空!\n");return;}Node* temp = head;printf("链表节点数据:");while (temp != NULL) {printf("%d ", temp->data);temp = temp->next;}printf("\n");
}// 主函数测试链表操作
int main() {Node* head = NULL; // 头节点insertAtEnd(&head, 1);insertAtEnd(&head, 2);insertAtEnd(&head, 3);printList(head);deleteNode(&head, 2);printList(head);deleteNode(&head, 4);return 0;
}Cpp代码整合
与C语言基本相同,这里不再过多介绍
#include <iostream>// 定义链表节点结构
class Node {
public:int data;Node* next;// 构造函数Node(int data) : data(data), next(nullptr) {}
};// 链表类
class LinkedList {
private:Node* head;public:// 构造函数LinkedList() : head(nullptr) {}// 析构函数,用于释放链表内存~LinkedList() {Node* current = head;while (current != nullptr) {Node* next = current->next;delete current;current = next;}}// 在链表末尾插入新节点void insertAtEnd(int data) {Node* newNode = new Node(data);if (head == nullptr) {head = newNode;} else {Node* temp = head;while (temp->next != nullptr) {temp = temp->next;}temp->next = newNode;}std::cout << "已在链表末尾插入节点:" << data << std::endl;}// 删除指定节点void deleteNode(int data) {if (head == nullptr) {std::cout << "链表为空!" << std::endl;return;}Node* temp = head;Node* prev = nullptr;if (temp != nullptr && temp->data == data) {head = temp->next;delete temp;std::cout << "已删除节点:" << data << std::endl;return;}while (temp != nullptr && temp->data != data) {prev = temp;temp = temp->next;}if (temp == nullptr) {std::cout << "节点 " << data << " 不存在!" << std::endl;return;}prev->next = temp->next;delete temp;std::cout << "已删除节点:" << data << std::endl;}// 修改指定节点的数据void modifyNode(int oldData, int newData) {if (head == nullptr) {std::cout << "链表为空!" << std::endl;return;}Node* temp = head;while (temp != nullptr) {if (temp->data == oldData) {temp->data = newData;std::cout << "已将节点 " << oldData << " 修改为 " << newData << std::endl;return;}temp = temp->next;}std::cout << "节点 " << oldData << " 不存在!" << std::endl;}// 遍历链表并打印节点数据void printList() {if (head == nullptr) {std::cout << "链表为空!" << std::endl;return;}Node* temp = head;std::cout << "链表节点数据:";while (temp != nullptr) {std::cout << temp->data << " ";temp = temp->next;}std::cout << std::endl;}
};int main() {LinkedList list;list.insertAtEnd(1);list.insertAtEnd(2);list.insertAtEnd(3);list.printList();list.deleteNode(2);list.printList();list.deleteNode(4);return 0;
}
相关文章:
【数据结构】线性表(二)单链表及其基本操作(创建、插入、删除、修改、遍历打印)
目录 前文、线性表的定义及其基本操作(顺序表插入、删除、查找、修改) 四、线性表的链接存储结构 1. 单链表(C语言) a. 链表节点结构 b. 创建新节点 c. 在链表末尾插入新节点 d. 删除指定节点 e. 修改指定节点的数据 f. …...
)
label的作用是什么?是怎么用的?(1)
Label(标签)在不同的上下文中有不同的作用和用途。以下是几种常见的用途和用法: 1. 数据标注:在机器学习和数据科学中,标签用于标识数据样本的类别或属性。标注数据是监督学习中的一项重要任务,它为算法提…...

C- 使用原子变量实现自旋锁
自旋锁 自旋锁(Spinlock)是一种常用于多线程编程中的低开销锁,其特点是当线程尝试获取锁而锁已被其他线程占用时,该线程会处于一个持续的忙等待(busy-wait)状态,直到它可以获取到锁为止。这种方…...

汇编的指令
减法类指令: 不带借位的减法: sub dest,src;dest(dest)-(src) 注意: 1、源操作数和目的操作数不能同时为段寄存器或存储单元 2、对标志位有影响,主要影响CF、ZF、OF、SF。 带借位的减法: sbb dest,src;dest(dest)-(…...

《数据结构、算法与应用C++语言描述》使用C++语言实现数组队列
《数据结构、算法与应用C语言描述》使用C语言实现数组队列 定义 队列的定义 队列(queue)是一个线性表,其插入和删除操作分别在表的不同端进行。插入元素的那一端称为队尾(back或rear),删除元素的那一端称…...

零基础如何学习自动化测试
现在很多测试人员有些急于求成,没有任何基础想当然的,要在一周内上手自动化测试。 在自动化的过程中时候总有人会犯很低级的问题,有语法问题,有定位问题,而且有人居然连__init__.py 文件名都弄错误,还有将…...

系统架构师备考倒计时16天(每日知识点)
1.信息化战略与实施 2.UML图(12个) 3.结构化设计(耦合) 4.SMP与AMP的区别(多核处理器的工作方式) 多核处理器一般有SMP和AMP两种不同的工作方式: SMP(对称多处理技术):将2颗完全一样的处理器封…...
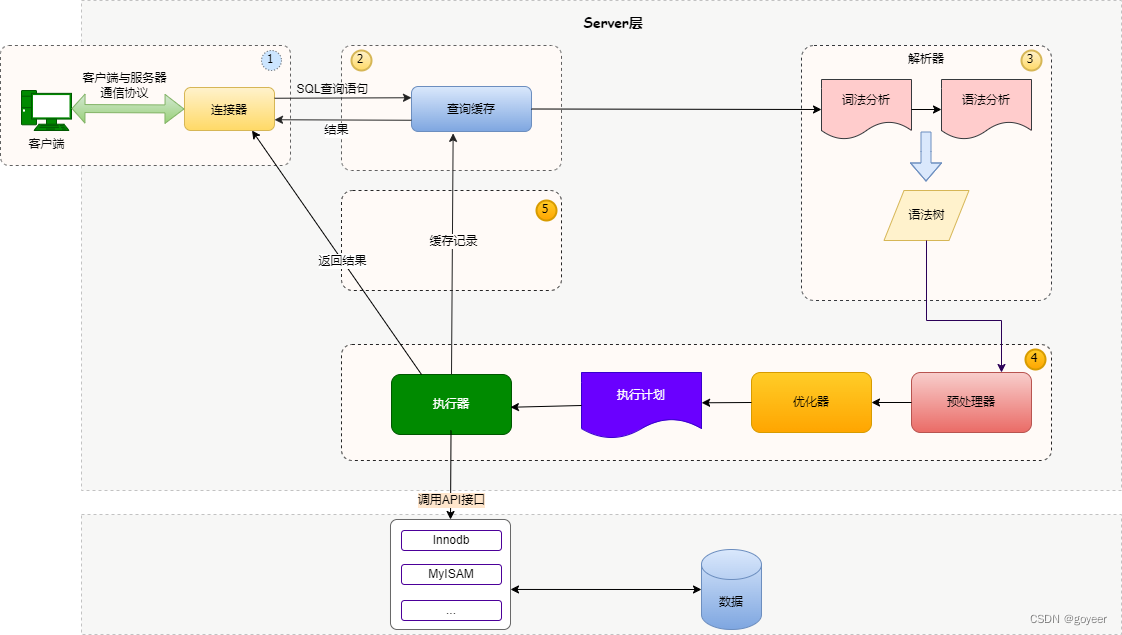
【MySQL系列】- Select查询SQL执行过程详解
【MySQL系列】- Select查询SQL执行过程详解 文章目录 【MySQL系列】- Select查询SQL执行过程详解一、SQL查询语句的执行过程二、SQL执行过程详解2.1. 连接器2.2. 查询缓存2.3. 分析器2.4. 优化器2.5. 执行器 三、undo log 和 redo log作⽤3.1. redo log (重做日志&a…...

软考高级信息系统项目管理师系列之:信息系统项目管理师论文评分参考标准
软考高级信息系统项目管理师系列之:信息系统项目管理师论文评分参考标准 论文满分是 75 分,论文评分可分为优良、及格与不及格 3 个档次。评分的分数可分为: 60 分至 75 分优良(相当于百分制 80 分至 100 分)。45 分至 59 分及格(相当于百分制 60 分至 79 分)。0 分至 44 分…...

MyBatis--多案例让你熟练使用CRUD操作
目录 一、前期准备 二、两种实现CRUD方式 三、增加数据(INSERT) 四、删除数据(DELETE) 五、查询数据(SELECT) 六、更新数据(UPDATE) 一、前期准备 1.创建maven项目并在pom文件…...

用Python造轮子
目录 背景安装setuptools库准备要打包的代码创建setup.py文件打包生成whl文件把库装到电脑上使用这个库 背景 如何把自己写的代码,打包成库方便其他人使用 安装setuptools库 正所谓想要富先修路,先把造轮子要用的库装上 pip install wheel pip insta…...
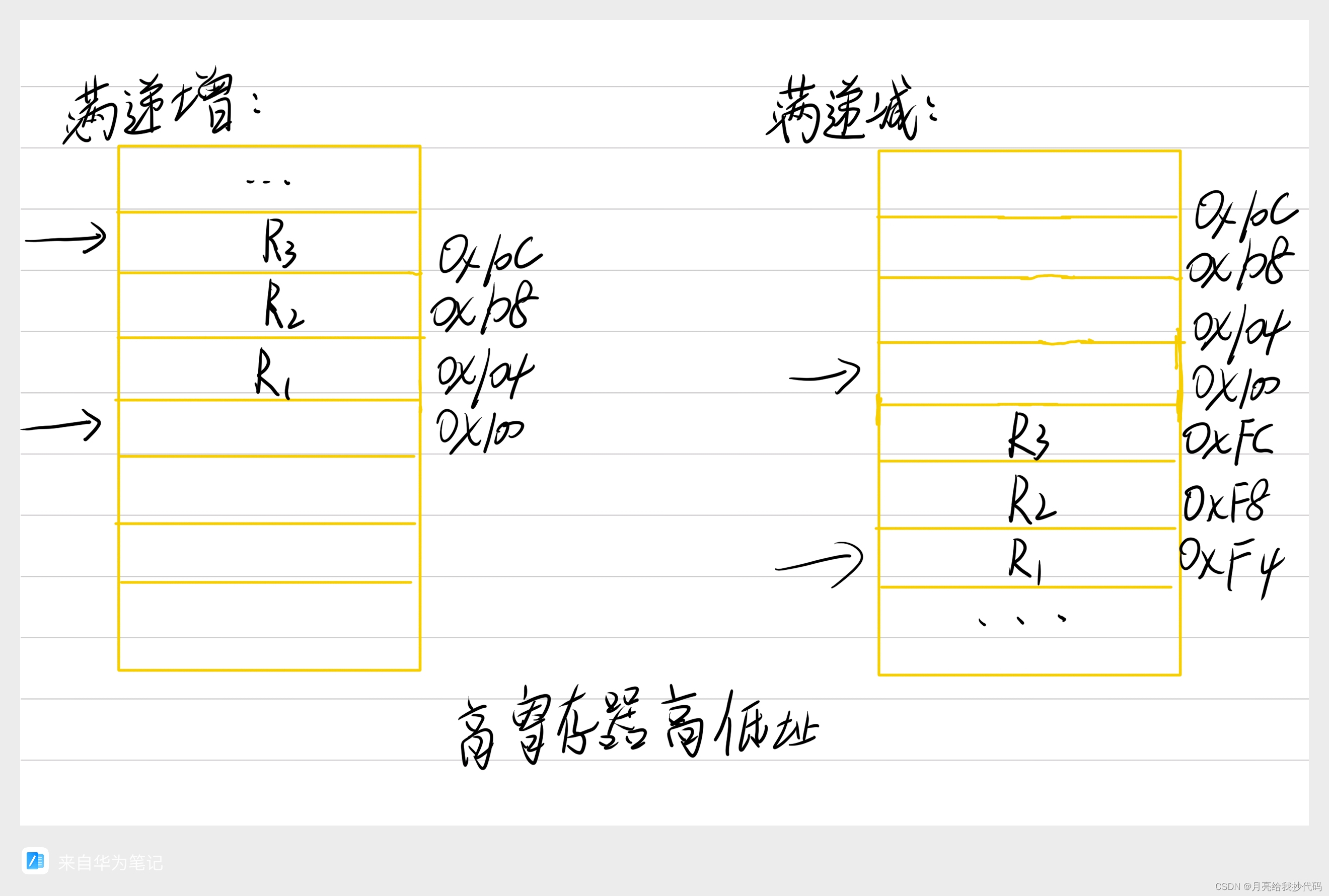
ARM 堆栈寻址类型区分
文章目录 堆栈指向分类堆栈指向数据分类满递增与满递减空递增与空递减 堆栈指向分类 根据堆栈指针的指向的方向不同,可以划分为向上生成型和向下生成型。 向上生成型: 随着数据的入栈,堆栈的指针逐渐增大,称为:递增…...

每日一练 | 网络工程师软考真题Day43
1、在生成树协议〔STP〕IEEE 802.1d中,根据 来选择根交换机。 A.最小的MAC地址 B.最大的MAC地址 C.最小的交换机ID D.最大的交换机ID 2、在快速以太网物理层标准中,使用两对5类无屏蔽双绞线的是 。 A&…...

jsonXML格式化核心代码
json格式化: 依赖: <dependency><groupId>com.jayway.jsonpath</groupId><artifactId>json-path</artifactId><version>2.6.0</version><scope>compile</scope> </dependency> string t…...
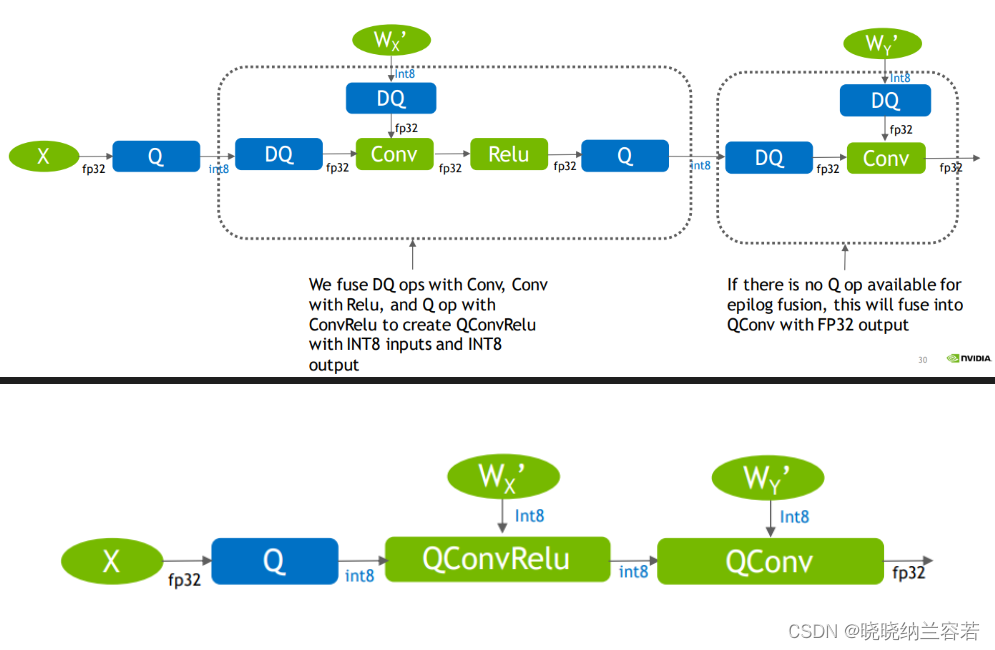
PTQ量化和QAT量化
目录 1--PTQ量化 2--QAT量化 1--PTQ量化 PTQ量化表示训练后量化(Post Training Quantization)。使用一批校准数据对训练好的模型进行校准,将训练好的FP32网络直接转换为定点计算的网络,过程中无需对原始模型进行任何训练&#x…...
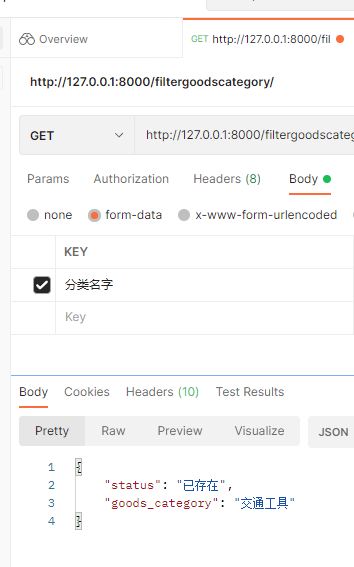
【Django 02】数据表构建、数据迁移与管理
1. Django 构建数据表创建与数据迁移 1.1 数据表创建 1.1.1 模块功能 如前所述,models.py文件主要用一个 Python 类来描述数据表。运用这个类,可以通过简单的 Python 代码来创建、检索、更新、删除 数据库中的记录而无需写一条又一条的SQL语句。今天的例子就是在…...
一天吃透Java集合面试八股文
内容摘自我的学习网站:topjavaer.cn 常见的集合有哪些? Java集合类主要由两个接口Collection和Map派生出来的,Collection有三个子接口:List、Set、Queue。 Java集合框架图如下: List代表了有序可重复集合,…...

高级深入--day36
Settings Scrapy设置(settings)提供了定制Scrapy组件的方法。可以控制包括核心(core),插件(extension),pipeline及spider组件。比如 设置Json Pipeliine、LOG_LEVEL等。 参考文档:Settings — Scrapy 1.0.5 文档 内置设置参考手册 BOT_NAME 默认: scrapybot 当您使用 sta…...
Jmeter接口测试工具的一些使用小技巧
如何使用英文界面的JMeter Jmeter启动时会自动判断操作系统的locale 并选择合适的语言启动,所以,我们启动jmeter后,其会出现一个倍感亲切的中文界面。但由于jmeter本身的汉化工作做得不好,你会看到有未被汉化的选项及元件的参数。…...
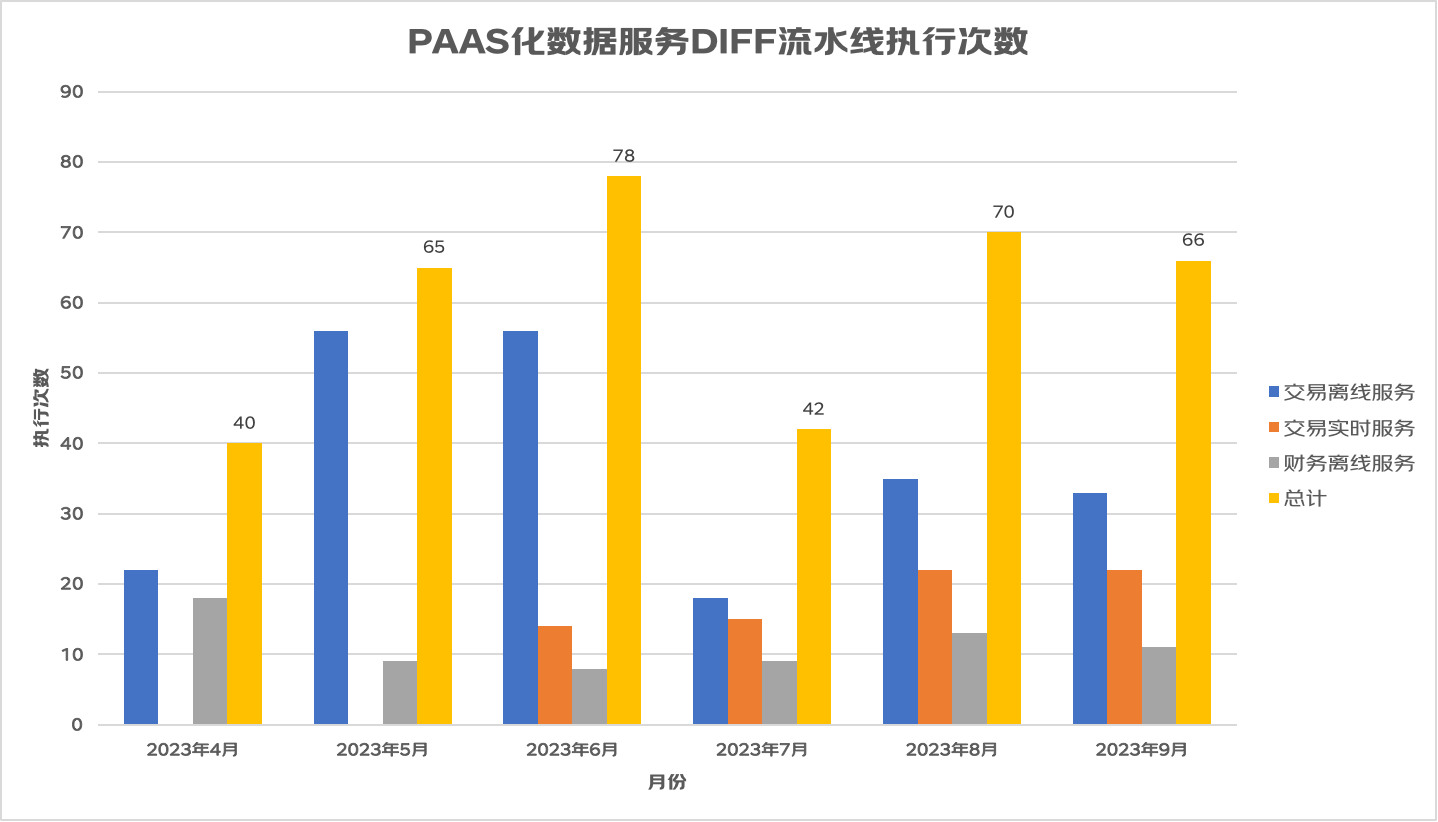
黄金眼PAAS化数据服务DIFF测试工具的建设实践 | 京东云技术团队
一、背景介绍 黄金眼PAAS化数据服务是一系列实现相同指标服务协议的数据服务,各个服务间按照所生产指标的主题作划分,比如交易实时服务提供实时交易指标的查询,财务离线服务提供离线财务指标的查询。黄金眼PAAS化数据服务支撑了黄金眼APP、黄…...

Gridforms响应式设计原理:如何让表单在手机、平板和桌面端完美适配
Gridforms响应式设计原理:如何让表单在手机、平板和桌面端完美适配 【免费下载链接】gridforms Data entry can be beautiful 项目地址: https://gitcode.com/gh_mirrors/gr/gridforms Gridforms是一个专注于数据录入体验的响应式表单解决方案,通…...

5分钟掌握STDF-Viewer:半导体测试数据分析的图形化神器
5分钟掌握STDF-Viewer:半导体测试数据分析的图形化神器 【免费下载链接】STDF-Viewer A free GUI tool to visualize STDF (semiconductor Standard Test Data Format) data files. 项目地址: https://gitcode.com/gh_mirrors/st/STDF-Viewer STDF-Viewer是一…...
)
本地部署 SQLite 数据库管理工具 SQLite Web 并实现外部访问( Linux 版本)
SQLite Web 是一款轻量级的、基于 Web 的图形化界面工具,用于浏览和管理 SQLite 数据库文件,它通常以一个独立的可执行文件或 Python 包的形式存在,让用户可以通过浏览器方便地查看、查询、编辑和管理 .db 或 .sqlite 等 SQLite 数据库。本文…...

编程分析企业奖罚制度执行数据,优化奖罚标准,做到赏罚分明,调动全体员工职场工作积极性。
定位是:商务智能(BI) Python 人力资源数据分析,可直接用于课程设计、技术博客或企业内部管理优化原型。⚠️ 说明:本方案不评价企业文化优劣、不站队劳资任何一方,仅提供数据建模与分析框架。一、实际应用…...

CFS调度器:从公平算法到内核实现全景解析
1. CFS调度器的设计哲学与公平性实现 Linux内核的CFS(Completely Fair Scheduler)调度器诞生于2007年,取代了之前的O(1)调度器。它的核心设计理念可以用一个简单的比喻理解:想象CPU时间是一块披萨,CFS要确保每个进程都…...

从零上手RP2040:为树莓派Pico注入MicroPython灵魂
1. 为什么选择MicroPython? 对于刚接触树莓派Pico(RP2040)的新手来说,选择MicroPython作为开发语言是个明智的决定。这就像第一次学骑自行车时选择带辅助轮的车子——它降低了入门门槛,让你能快速感受到编程的乐趣。Mi…...

【软考高级架构】论文范文20——论软件设计方法及其应用
论软件设计方法及其应用 摘要 软件设计是将需求分析结果转换为软件体系结构和内部实现细节的关键活动,设计方法的选择直接影响系统的可维护性、可扩展性和开发效率。结构化设计、面向对象设计、数据驱动设计等经典方法各有侧重,在不同场景下展现出独特的优势。本文以笔者主…...

2026本地视频怎么去水印?5款免费去水印软件对比和实用方法指南
很多人都遇到过这个问题:辛辛苦苦保存下来的视频、素材库里的片段,上面都贴了水印,想要二次编辑或重新发布时,这些水印就成了"眼中钉"。本地视频怎么去水印?2026年有哪些靠谱的免费去水印方法?今…...

基于LangChain构建AI智能体:从核心架构到生产部署实战
1. 项目概述与核心价值最近在GitHub上看到一个名为“GenAI_Agents”的项目,作者是NirDiamant。这个项目名本身就很有意思,它直指当前AI领域最火热、也最具想象力的方向之一:智能体(Agents)。简单来说,这个项…...

解锁网盘文件下载新体验:LinkSwift直链解析工具完全指南
解锁网盘文件下载新体验:LinkSwift直链解析工具完全指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天…...