MyBatis--多案例让你熟练使用CRUD操作

目录
一、前期准备
二、两种实现CRUD方式
三、增加数据(INSERT)
四、删除数据(DELETE)
五、查询数据(SELECT)
六、更新数据(UPDATE)
一、前期准备
1.创建maven项目并在pom文件中导入相关jar包
<dependencies><!-- mysql连接驱动--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.33</version></dependency><!-- junit5测试--><dependency><groupId>org.junit.jupiter</groupId><artifactId>junit-jupiter-api</artifactId><version>5.10.0</version><scope>test</scope></dependency><!-- 导入@Data等注解 简化实体类--><dependency><groupId>cn.itlym.shoulder</groupId><artifactId>lombok</artifactId><version>0.1</version></dependency><!-- mybatis核心--><dependency><groupId>org.mybatis</groupId><artifactId>mybatis</artifactId><version>3.5.7</version></dependency></dependencies>2.创建CURD使用到的大学生实体类
@Data
public class UnderGraduate {
// 大学生的属性private String name;private String major;private int id;private String gender;
}
3.数据库准备对应实体类的表
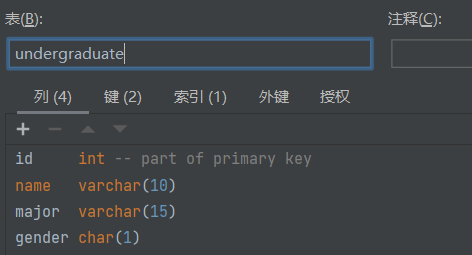
4.创建对应业务需求的接口
//业务接口
public interface UnderGraduateMapper {
// 增删查改
// 增加 public int insertNew(UnderGraduate underGraduate);// 删除public int deleteById();// 查找public UnderGraduate selsctById();// 修改public int updateById();
}5. 相关mappers与mybatis配置
mapper配置
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd"><!--此处的namespace修改为对应的接口全类名-->
<mapper namespace="com.alphamilk.mapper.UnderGraduateMapper">
<!-- <insert id="insertNew">-->
<!-- insert into undergraduate.undergraduate(id, name, major, gender) values (#{id},#{name},#{major},#{gender})-->
<!-- </insert>-->
</mapper>jdbc资源类配置
jdbc.driver = com.mysql.cj.jdbc.Driver
jdbc.url = jdbc:mysql://localhost:3306/对应数据库名称
jdbc.username = mysql
jdbc.password = xxxxxxmybatis配置
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN""http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration><!-- 注意在配置文件中使用配置标签的顺序是properties?,settings?,typeAliases?,typeHandlers?,objectFactory?,objectWrapperFactory?,reflectorFactory?,plugins?,environments?,databaseIdProvider?,mappers?如果不按照此顺序执行则会报错
--><properties resource="jdbc.properties"/><environments default="development"><environment id="development"><transactionManager type="JDBC"/><dataSource type="POOLED"><property name="driver" value="${jdbc.driver}"/><property name="url" value="${jdbc.url}"/><property name="username" value="${jdbc.username}"/><property name="password" value="${jdbc.password}"/></dataSource></environment></environments><mappers>
<!-- 此处的mapper标签使用配置里的UnderGraduate.xml的路径--><mapper resource="mappers/UnderGraduateMapper.xml"/></mappers>
</configuration>6.建立对应测试类,测试代码
public class CRUDTEST {@Testpublic void Test() throws IOException {
// 获取mybatis配置资源InputStream is = Resources.getResourceAsStream("mybatis-config.xml");
// 创建SqlSessionFactoryBuilder对象SqlSessionFactoryBuilder sqlSessionFactoryBuilder = new SqlSessionFactoryBuilder();
// 根据获取资源is build一个对应SqlSessionFactorySqlSessionFactory sqlSessionFactory = sqlSessionFactoryBuilder.build(is);
// 通过SqlSessionFactory 获取SqlSession,并开启自动提交SqlSession sqlSession = sqlSessionFactory.openSession(true);
// 通过SqlSession获取对应mapper对象UnderGraduateMapper mapper = sqlSession.getMapper(UnderGraduateMapper.class);// 此处调用mapper对象测试功能// 关闭SqlSessionsqlSession.close();}
}
二、两种实现CRUD方式
在MyBatis中有两种方式可以实现增删查改的功能,分别是通过XML配置与注解类配置
1.XML配置
优点:
- 灵活性高:可以使用 MyBatis 提供的各种标签,构建复杂的查询语句。
- 易于维护:SQL 语句和 Java 代码分离,提高了程序的可读性和可维护性。
- 明确的映射关系:可以使用
resultMap标签明确地指定查询结果和 Java 对象之间的映射关系。
缺点:
- 学习成本高:使用 MyBatis 的 XML 配置需要学习一些额外的标签和配置方式。
- 冗余度高:相对于注解配置,XML 配置要更冗长,需要编写大量的 XML 标签。
- 不够直观:XML 配置需要打开多个文件进行编辑,不如注解配置那样直观。
有四种基本的增删查改标签对应分别是<insert>、<delete>、<select>、<update>
各个标签中的常用属性
特殊标签
标签内嵌标签
<foreach>标签
作用:用于遍历集合之中多个成员,常用于批量导入成员
标签内的常用属性
- collection:指定要遍历的集合或数组的属性名。可以是一个 List、Set 或数组对象。
- item:指定在遍历过程中每个元素的别名,可以在标签内部使用该别名来引用当前遍历的元素。
- open:指定循环开始时的字符串,在第一次遍历之前输出。
- close:指定循环结束时的字符串,在最后一次遍历之后输出。
- separator:指定每次遍历之间的分隔符,即每个元素之间的分隔符。
- index:指定当前遍历元素的索引,可用于获取当前遍历元素在集合中的位置(仅适用于 List 或数组)。
示例:
<insert id="batchInsert" parameterType="java.util.List">INSERT INTO user (name, age) VALUES<foreach collection="list" item="item" separator=",">(#{item.name}, #{item.age})</foreach>
</insert>
以上示例演示了一个批量插入用户数据的 SQL 语句。其中,collection 属性指定了要遍历的集合属性名 "list",item 属性指定了遍历过程中每个元素的别名 "item",separator 属性指定了每次遍历之间的分隔符逗号。在循环体内部,可以通过 #{item.name} 和 #{item.age} 引用当前遍历的元素的属性。
<resultMap>标签
作用:定义数据库查询结果映射到Java对象的规则。
标签内的常用属性
- id:给<resultMap>标签指定一个唯一的ID。
- type:指定映射的Java对象类型,即查询结果将会映射到该类型的对象上。
- extends:指定继承的父级<resultMap>,可以继承父级的映射规则。
- autoMapping:如果设置为true,则自动进行数据库列名和Java属性名的映射;如果设置为false,则需要手动进行映射,默认值为true。
- <id>:用于定义主键字段的映射规则。
- <result>:用于定义普通字段的映射规则。
示例:
<resultMap id="userResultMap" type="com.example.User"><id column="id" property="id"/><result column="name" property="name"/><result column="age" property="age"/>
</resultMap>
以上示例定义了一个名为"userResultMap"的<resultMap>,映射到类型为com.example.User的Java对象。它包含三个映射规则:id、name和age,分别将数据库的id、name和age字段映射到User对象的id、name和age属性上。
<selectKey>
作用:在执行插入数据操作后,返回数据库生成的主键值,并将其设置到指定的属性中。
标签内的常用属性:
- keyProperty:指定将生成的主键值设置到哪个属性中,一般是插入对象中的主键属性。
- order:指定执行 <selectKey> 标签的顺序,有
BEFORE和AFTER两个选项。BEFORE表示在插入语句之前执行该标签,AFTER表示在插入语句之后执行该标签。 - resultType:指定生成主键值的数据类型,可以是整数类型、长整数类型、字符串类型等。
- statementType:指定生成主键值的 SQL 语句类型,有
PREPARED和CALLABLE两个选项。一般使用PREPARED,表示使用预编译的 SQL 语句。
示例:
<insert id="insertUser" parameterType="User"><selectKey keyProperty="id" order="AFTER" resultType="int">SELECT LAST_INSERT_ID()</selectKey>INSERT INTO user (name, age) VALUES (#{name}, #{age})
</insert>
以上示例演示了插入用户数据时如何获取数据库生成的主键值。首先,在插入语句之后执行 <selectKey> 标签(order="AFTER"),通过 SELECT LAST_INSERT_ID() 获取主键值,然后将该值设置到 id 属性中。最后,执行插入语句将数据插入数据库。
2.注解方法使用
优点:
- 简单易懂:注解配置使用起来比较简单,不需要额外的学习成本。
- 代码整洁:相对于 XML 配置,注解配置要更加简洁,不需要编写大量的 XML 标签。
- 直观:注解配置非常直观,能够快速地通过 Java 代码进行查询操作。
缺点:
- 灵活性低:注解配置不能使用 MyBatis 提供的所有标签,因此在构建复杂的查询语句时可能会有所不便。
- 缺乏明确的映射关系:注解配置中的 SQL 语句和 Java 对象之间的映射关系较为隐式,不够明确。
MyBatis提供常用的增删查改注解对应分别是@insert、@delete、@select、@update
三、增加数据(INSERT)
通过XML配置实现功能
1.增加一个大学生用户(xml配置)
思路:通过 <insert> 标签定义了一个插入语句,将 UnderGraduate 对象的属性插入到数据库的 undergraduate 表中。
业务接口:
// 增加一个大学生用户public int insertNew(UnderGraduate underGraduate);业务接口的实现:
<!-- 插入一个大学生用户--><insert id="insertNew" parameterType="com.alphamilk.pojo.UnderGraduate">insert into undergraduate.undergraduate(id, name, major, gender) values (#{id},#{name},#{major},#{gender})</insert>测试类代码:
// 此处使用mapper对象进行测试功能// 创建对应对象UnderGraduate undergraduate = new UnderGraduate();undergraduate.setId(3);undergraduate.setName("测试用户");undergraduate.setMajor("测试专业");undergraduate.setGender("男");//实现业务接口功能mapper.insertNew(undergraduate);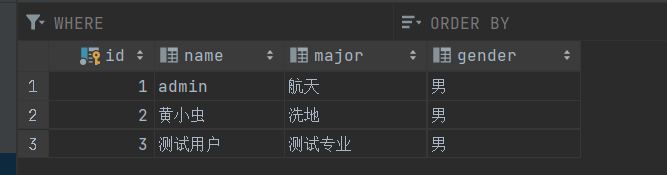
2.批量增加一些大学生用户(xml 配置)
思路:通过 <insert> 标签结合 <foreach> 标签实现批量插入多个 UnderGraduate 对象到数据库的 undergraduate 表中
业务接口:
// 批量增加新用户public int batchNewGuy(List<UnderGraduate> underGraduateList);业务接口实现:
<insert id="batchNewGuy" parameterType="java.util.List">insert into undergraduate(id, name, major, gender)VALUES
# foreach标签中属性 collection -集合 item -集合中遍历的元素 separator -分隔符<foreach collection="list" item="item" separator=",">(#{item.id},#{item.name},#{item.major},#{item.gender})</foreach></insert>
测试代码:
// 此处使用mapper对象进行测试功能// 创建对应对象集合listList<UnderGraduate> underGraduateList = new ArrayList<>();// 添加第1个学生UnderGraduate underGraduate1 = new UnderGraduate();underGraduate1.setName("张三");underGraduate1.setMajor("计算机科学与技术");underGraduate1.setGender("男");underGraduate1.setId(4);underGraduateList.add(underGraduate1);// 添加第2个学生UnderGraduate underGraduate2 = new UnderGraduate();underGraduate2.setName("李四");underGraduate2.setMajor("电子信息工程");underGraduate2.setGender("男");underGraduate2.setId(5);underGraduateList.add(underGraduate2);// 添加第3个学生UnderGraduate underGraduate3 = new UnderGraduate();underGraduate3.setName("王五");underGraduate3.setMajor("自动化");underGraduate3.setGender("女");underGraduate3.setId(6);underGraduateList.add(underGraduate3);//实现业务接口功能mapper.batchNewGuy(underGraduateList);
3.插入新大学生并返回自增主键值(xml配置)
思路:通过 <selectKey> 标签获取自增主键值,并将其设置到 UnderGraduate 对象的 id 属性上。
业务接口:
// 增加新用户并返回主键值public int insertNewGuyAndReturnId(UnderGraduate underGraduate);业务实现:
<!-- 插入新用户并返回主键id的值-->
<insert id="insertNewGuyAndReturnId" parameterType="com.alphamilk.pojo.UnderGraduate"><selectKey keyProperty="id" resultType="java.lang.Integer" order="AFTER">
# oder属性:
#
# BEFORE: 在插入语句执行之前触发获取自增主键值的操作。这通常适用于数据库系统在插入数据时立即生成自增主键值的情况。
#
# AFTER: 在插入语句执行之后触发获取自增主键值的操作。这通常适用于数据库系统在插入数据后才生成自增主键值的情况。select last_insert_id()</selectKey>insert into undergraduate(id, name, major, gender)values(#{id},#{name},#{major},#{gender})
</insert>测试类:
// 此处使用mapper对象进行测试功能//创建新的对象UnderGraduate NewGuy = new UnderGraduate();NewGuy.setName("王维");NewGuy.setMajor("文学");NewGuy.setGender("男");//实现业务接口功能int ReceivedKeyValue = mapper.insertNewGuyAndReturnId(NewGuy);System.out.println("获取到的主键值为:"+NewGuy.getId());// 关闭sqlSession对象sqlSession.close();

通过注解类配置实现功能
// 增加用户@Insert("insert into undergraduate.undergraduate(id, name, major, gender) values (#{id},#{name},#{major},#{gender})")public int insertNew(UnderGraduate underGraduate);// 增加新用户并返回主键值@Insert("insert into undergraduate.undergraduate(id, name, major, gender) VALUES (#{id},#{name},#{major},#{gender})")@Options(useGeneratedKeys = true , keyProperty = "id" , keyColumn = "id")public int insertNewGuyAndReturnId(UnderGraduate underGraduate);四、删除数据(DELETE)
通过XML配置实现功能
1.根据id删除某个大学生用户
业务接口
//1.通过id删除public int deleteById(int id);业务实现
<!-- 根据id删除用户--><delete id="deleteById" parameterType="java.lang.Integer">delete from undergraduatewhere id = #{id}</delete>测试类
// 根据id删除用户mapper.deleteById(9);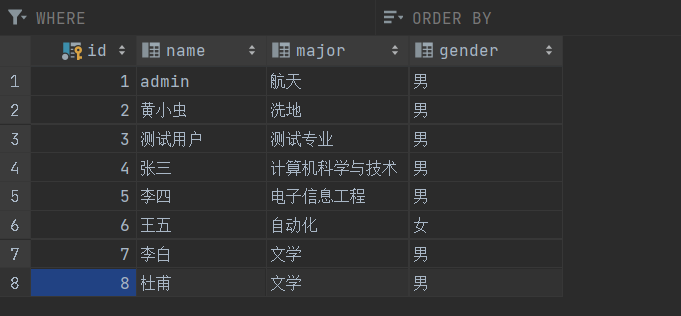
2.根据条件删除某个大学生用户
业务接口:
//2.通过条件删除public int deleteByCondition(String condition);业务接口实现:
<!-- 根据条件删除用户--><delete id="deleteByCondition" parameterType="java.lang.String">delete from undergraduatewhere ${condition}</delete>测试类:
// 根据条件删除用户String condition = "id > 6";mapper.deleteByCondition(condition);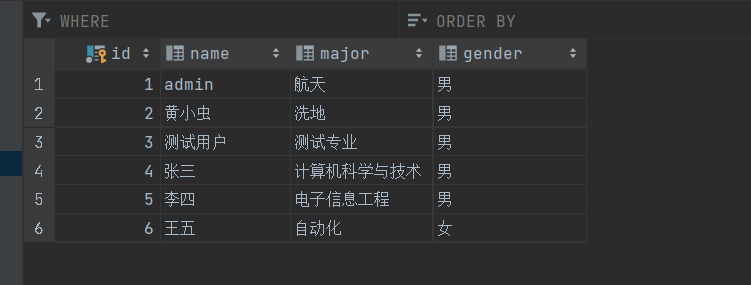
3.批量删除用户
<delete id="deleteBatch" parameterType="java.util.List">DELETE FROM UnderGraduateWHERE id IN<foreach collection="list" item="id" separator="," open="(" close=")">#{id}</foreach>
</delete>
open、close属性 讲解:
在上述示例中,<foreach> 标签中的 collection 属性指定了要遍历的集合对象,item 属性指定了集合中的元素变量名,separator 属性指定了元素之间的分隔符。
对于给定的 idList 集合,循环遍历会将集合中的每个元素作为参数传递给 SQL 语句中的 #{id} 表达式。open 属性设置为 (,close 属性设置为 ),使得生成的 SQL 片段为 (item1, item2, item3)。如下所示
DELETE FROM table_name
WHERE id IN (item1, item2, item3)
通过注解类配置实现功能
业务测试接口:
//1.通过id删除@Delete("delete from undergraduate.undergraduate where id = #{id}")public int deleteById(int id); //2.通过条件删除@Delete("delete from undergraduate.undergraduate where ${condition}")public int deleteByCondition(String condition);五、查询数据(SELECT)
通过XML配置实现功能
1.根据id查询用户(xml配置)
业务接口:
//1.根据id查找用户public UnderGraduate selectById(int id);业务实现:
<!-- 根据id查询用户--><select id="selectById" parameterType="java.lang.Integer" resultType="com.alphamilk.pojo.UnderGraduate">select * from undergraduatewhere id = #{id}</select>测试类:
//创建对象UnderGraduate graduate;
// 使用功能graduate = mapper.selectById(1);
// 输出用户System.out.println(graduate);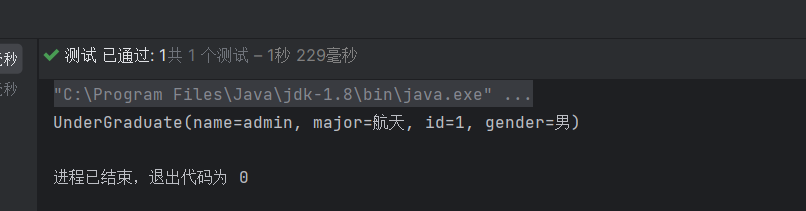
2.根据多变量查询单一用户(xml配置)
当业务接口有多个变量时候,那么需要加上@Param注解
业务接口:
//2.根据多参数查询单一用户public UnderGraduate selectByParams(@Param("name") String name,@Param("id") int id);业务实现:
<!-- 根据多参数查询某一用户--><select id="selectByParams" resultType="com.alphamilk.pojo.UnderGraduate">select * from undergraduatewhere id = #{id} and name = #{name}</select>测试类:
//创建对象UnderGraduate graduate;
// 使用功能graduate = mapper.selectByParams("admin",1);
// 输出用户System.out.println(graduate);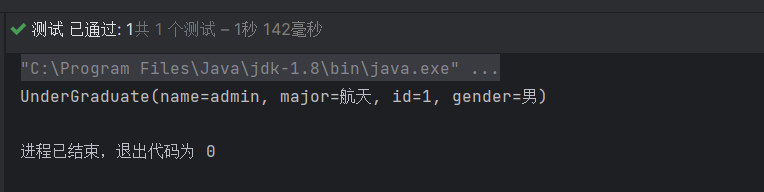
3.根据条件查询多个用户(xml配置)
业务接口:
//3.根据条件查询用户集合public List<UnderGraduate> selectListByCondition(String condition);业务实现:
<!--根据条件查询用户集合-->
<select id="selectListByCondition" parameterType="java.lang.String" resultType="com.alphamilk.pojo.UnderGraduate">select *from undergraduatewhere ${condition};
</select>测试代码:
//创建list对象List<UnderGraduate> list;
// 使用功能list = mapper.selectListByCondition("id > 1");
// 输出用户System.out.println(list);
4.自定义查询结果集(通过注解@select )
业务接口:
//4.通过注解方式查询@Select("SELECT name , major FROM undergraduate.undergraduate where id = #{id}")public UnderGraduate selectByMap(int id);测试类代码:
UnderGraduate underGraduate = mapper.selectByMap(1);System.out.println(underGraduate); 通过注解类配置实现功能
通过注解类配置实现功能
//1.根据id查找用户@Select("select * from undergraduate.undergraduate where id = #{id}")public UnderGraduate selectById(int id);
//2.根据多参数查询单一用户@Select("select * from undergraduate.undergraduate where name = #{name} and id = #{id}")public UnderGraduate selectByParams(@Param("name") String name,@Param("id") int id);
//3.根据条件查询用户集合@Select("select * from undergraduate.undergraduate where ${condition}")public List<UnderGraduate> selectListByCondition(String condition);六、更新数据(UPDATE)
通过XML配置实现功能
1.根据id修改性别
业务接口:
//通过id更改名称public int updateNameById(@Param("id") int id,@Param("newName")String name);业务实现:
<!--根据id修改name--><update id="updateNameById">update undergraduateset name = #{newName}where id = #{id}</update>测试类代码:
mapper.updateNameById(1,"荒天帝");UnderGraduate underGraduate = mapper.selectByMap(1);System.out.println(underGraduate.getName());
通过注解类配置实现功能
//通过id更改名称@Update("update undergraduate.undergraduate set name = #{name} where id = #{id}")public int updateNameById(@Param("id") int id,@Param("newName")String name);相关文章:
MyBatis--多案例让你熟练使用CRUD操作
目录 一、前期准备 二、两种实现CRUD方式 三、增加数据(INSERT) 四、删除数据(DELETE) 五、查询数据(SELECT) 六、更新数据(UPDATE) 一、前期准备 1.创建maven项目并在pom文件…...

用Python造轮子
目录 背景安装setuptools库准备要打包的代码创建setup.py文件打包生成whl文件把库装到电脑上使用这个库 背景 如何把自己写的代码,打包成库方便其他人使用 安装setuptools库 正所谓想要富先修路,先把造轮子要用的库装上 pip install wheel pip insta…...
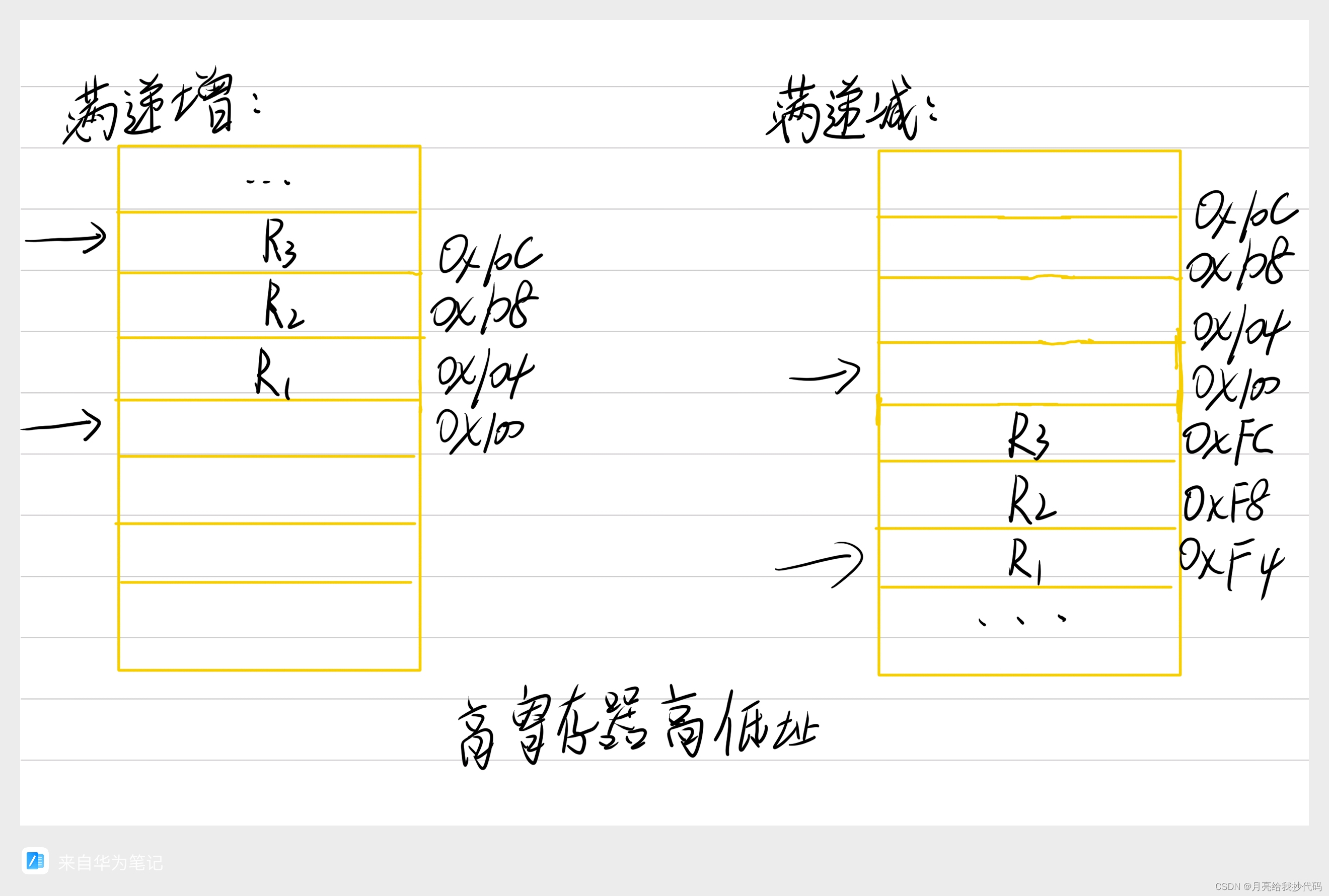
ARM 堆栈寻址类型区分
文章目录 堆栈指向分类堆栈指向数据分类满递增与满递减空递增与空递减 堆栈指向分类 根据堆栈指针的指向的方向不同,可以划分为向上生成型和向下生成型。 向上生成型: 随着数据的入栈,堆栈的指针逐渐增大,称为:递增…...

每日一练 | 网络工程师软考真题Day43
1、在生成树协议〔STP〕IEEE 802.1d中,根据 来选择根交换机。 A.最小的MAC地址 B.最大的MAC地址 C.最小的交换机ID D.最大的交换机ID 2、在快速以太网物理层标准中,使用两对5类无屏蔽双绞线的是 。 A&…...

jsonXML格式化核心代码
json格式化: 依赖: <dependency><groupId>com.jayway.jsonpath</groupId><artifactId>json-path</artifactId><version>2.6.0</version><scope>compile</scope> </dependency> string t…...
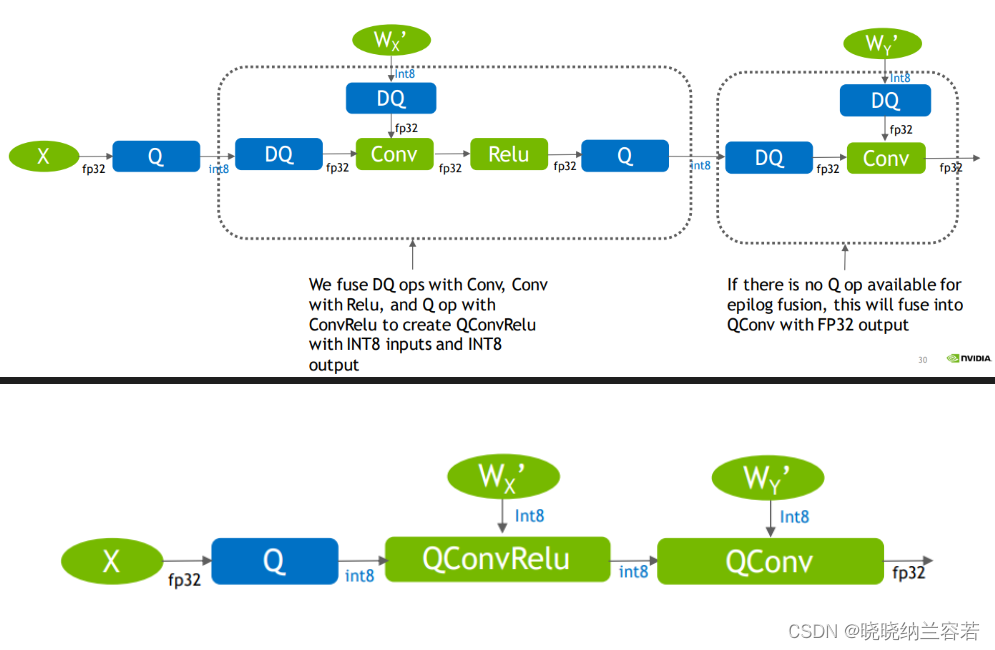
PTQ量化和QAT量化
目录 1--PTQ量化 2--QAT量化 1--PTQ量化 PTQ量化表示训练后量化(Post Training Quantization)。使用一批校准数据对训练好的模型进行校准,将训练好的FP32网络直接转换为定点计算的网络,过程中无需对原始模型进行任何训练&#x…...
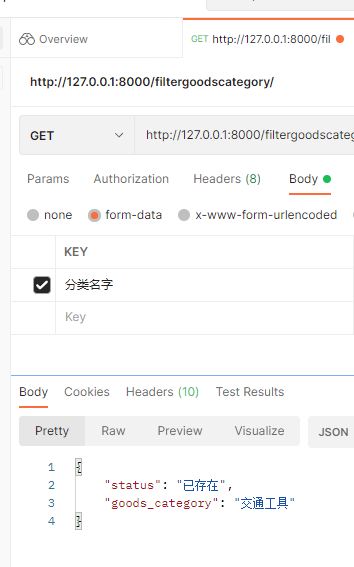
【Django 02】数据表构建、数据迁移与管理
1. Django 构建数据表创建与数据迁移 1.1 数据表创建 1.1.1 模块功能 如前所述,models.py文件主要用一个 Python 类来描述数据表。运用这个类,可以通过简单的 Python 代码来创建、检索、更新、删除 数据库中的记录而无需写一条又一条的SQL语句。今天的例子就是在…...
一天吃透Java集合面试八股文
内容摘自我的学习网站:topjavaer.cn 常见的集合有哪些? Java集合类主要由两个接口Collection和Map派生出来的,Collection有三个子接口:List、Set、Queue。 Java集合框架图如下: List代表了有序可重复集合,…...

高级深入--day36
Settings Scrapy设置(settings)提供了定制Scrapy组件的方法。可以控制包括核心(core),插件(extension),pipeline及spider组件。比如 设置Json Pipeliine、LOG_LEVEL等。 参考文档:Settings — Scrapy 1.0.5 文档 内置设置参考手册 BOT_NAME 默认: scrapybot 当您使用 sta…...
Jmeter接口测试工具的一些使用小技巧
如何使用英文界面的JMeter Jmeter启动时会自动判断操作系统的locale 并选择合适的语言启动,所以,我们启动jmeter后,其会出现一个倍感亲切的中文界面。但由于jmeter本身的汉化工作做得不好,你会看到有未被汉化的选项及元件的参数。…...
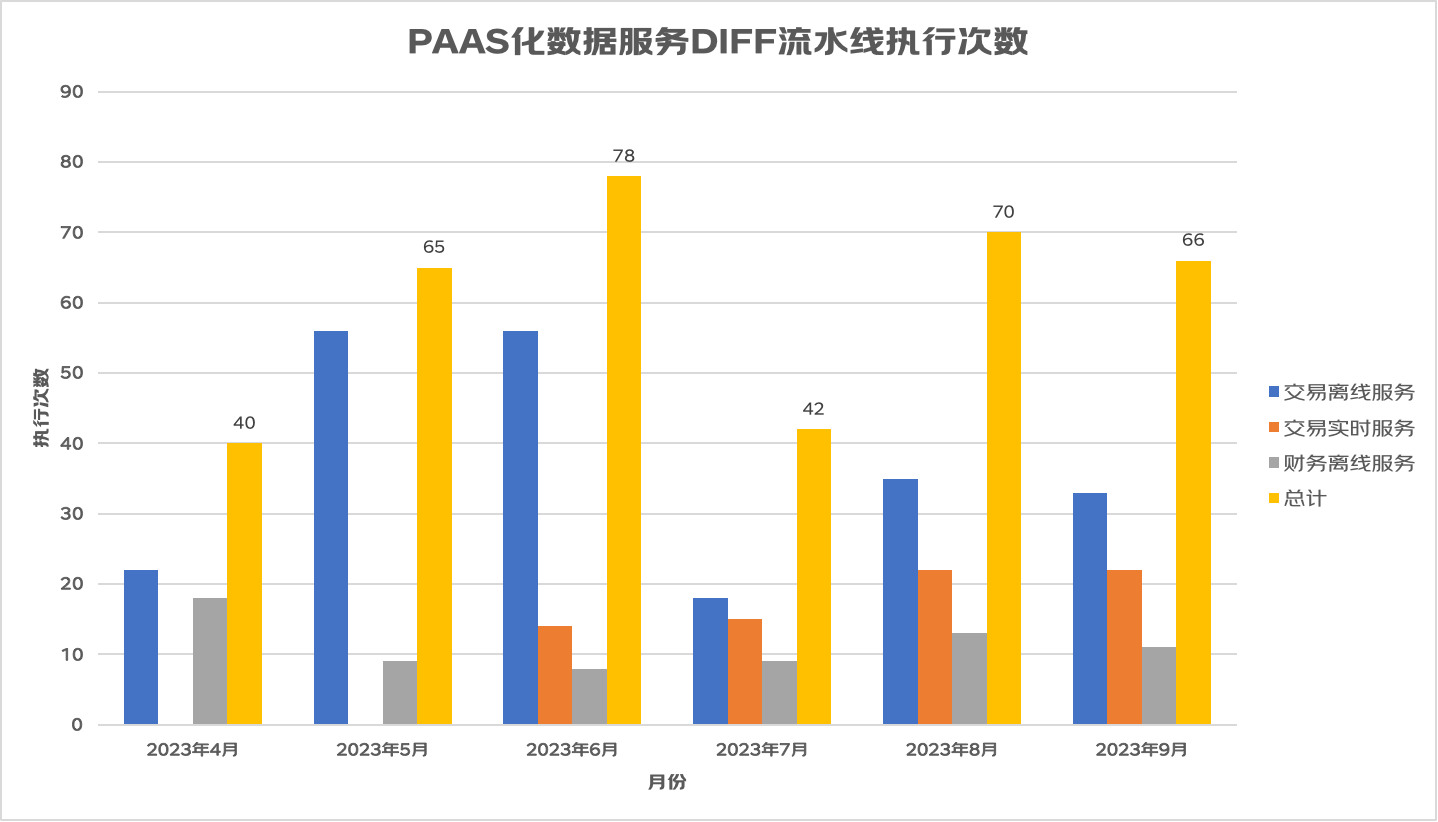
黄金眼PAAS化数据服务DIFF测试工具的建设实践 | 京东云技术团队
一、背景介绍 黄金眼PAAS化数据服务是一系列实现相同指标服务协议的数据服务,各个服务间按照所生产指标的主题作划分,比如交易实时服务提供实时交易指标的查询,财务离线服务提供离线财务指标的查询。黄金眼PAAS化数据服务支撑了黄金眼APP、黄…...
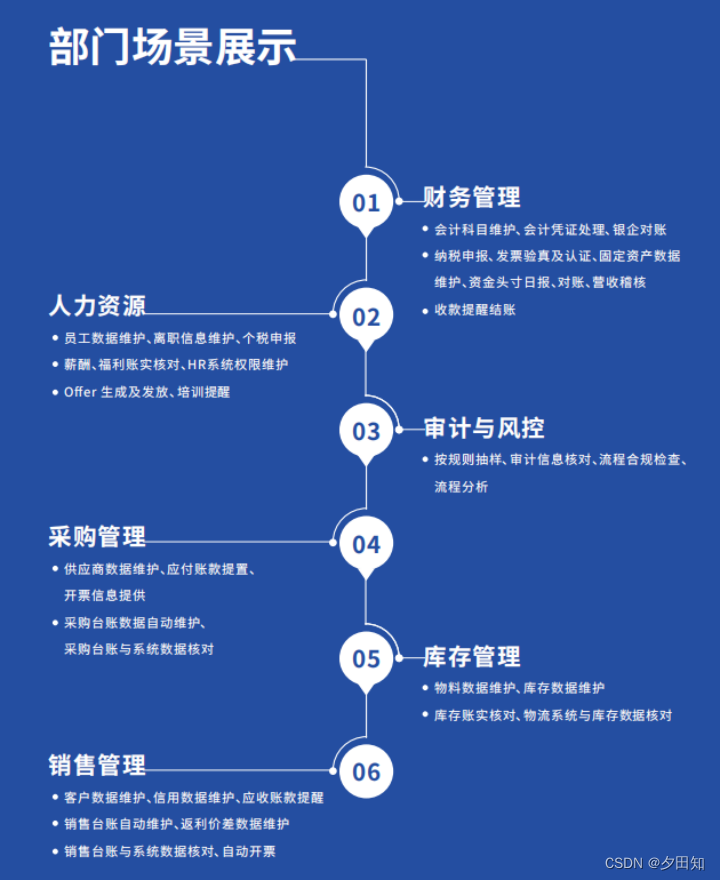
深入了解RPA业务流程自动化的关键要素
在RPA业务流程自动化实施过程中,哪些因素起着至关重要的作用?这其实没有一个通用的答案,每一个RPA业务流程自动化的部署,都需要结合具体场景去调整,并且进行全面的规划。 首当其冲是要关注以下几点: 1、专…...

CSS记录
1.标准的CSS的盒子模型?与低版本IE的盒子模型有什么不同的? 标准盒子模型box-sizing: border-box; 宽度内容的宽度(content) border padding margin 低版本IE盒子模型:宽度内容宽度(contentborderpaddin…...

Kotlin中类型转换
在 Kotlin 中,类型转换是一种常见的操作,用于将一个数据类型转换为另一个数据类型。在本篇博客中,我们将介绍 Kotlin 中的类型转换,并提供示例代码演示智能类型转换、强制类型转换以及可空类型的转换。 智能类型转换是 Kotlin 中…...

P7557 [USACO21OPEN] Acowdemia S
典型二分: #include<bits/stdc.h> using namespace std; #define int long long const int N1e510; int n,a[N],k,l; bool check(int x) {int cnt0,ans0;for(int i1; i<x; i) {if(a[i]>x) {cnt;continue;}else{if(x-a[i]>k)return false;else{ansans…...

如何确认栈中申请的变量地址
一般一个程序被加载到内存后执行而成为一个进程。进程在内存中是分区域加载的,分别是代码段、数据段、bss段等等。 函数中定义的变量一般存在于栈中。现在我们通过实验验证一下,函数中定义的变量,到底存在与进程哪个位置。 1.测试程序 #in…...

【STM32】--基础了解
一、STM32来历背景 1.从51到STM32 (1)单片机有很多种 (2)STM32内核使用ARM,但是ARM不一定是STM32 (3)ATM32是当前主流的32位高性能单片机 (4)STM32的特点:高…...
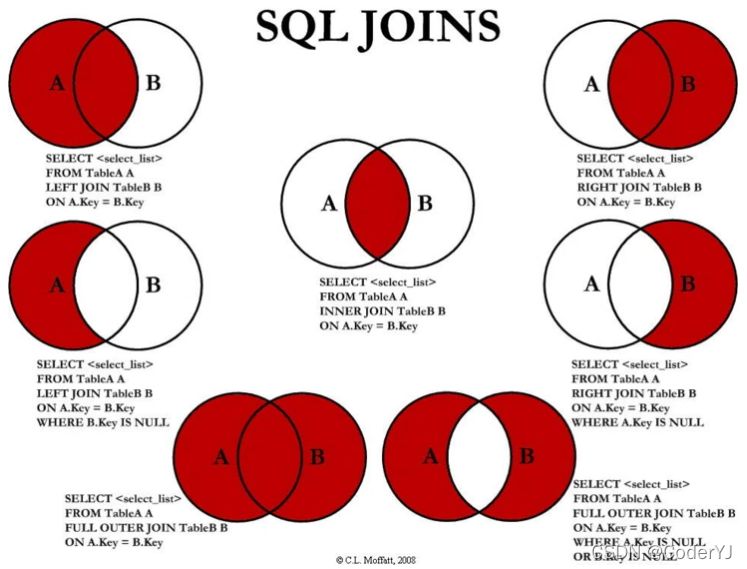
join、inner join、left join、right join、outer join的区别
内连接 inner join(等值连接):只显示两表联结字段相等的行,(很少用到,最好别用); 外连接 left join:以左表为基础,显示左表中的所有记录,不管是否与关联条件相匹配,而右表中的数据只显示与关联条件相匹配的记录,不匹配…...
小程序中如何使用自定义组件应用及搭建个人中心布局
一,自定义组件 从小程序基础库版本 1.6.3 开始,小程序支持简洁的组件化编程。所有自定义组件相关特性都需要基础库版本 1.6.3 或更高。 开发者可以将页面内的功能模块抽象成自定义组件,以便在不同的页面中重复使用;也可以将复杂的…...
pyest+appium实现APP自动化测试,思路全总结在这里
01、appium环境搭建 安装nodejs http://nodejs.cn/ 为什么要安装nodejs? 因为appium这个工具的服务端是由nodejs语言开发的 安装jdk,并且配置环境变量 为什么要装jdk? 因为我们要测试安卓,那么安卓的调试环境需要依赖jdk …...

ClassiCube多平台适配技术:从桌面到移动再到游戏主机的实现细节
ClassiCube多平台适配技术:从桌面到移动再到游戏主机的实现细节 【免费下载链接】ClassiCube Custom Minecraft Classic / ClassiCube client written in C from scratch (formerly ClassicalSharp in C#) 项目地址: https://gitcode.com/gh_mirrors/cla/ClassiCu…...
)
别让你的AI模型‘偏心’:用Python实战解决机器学习公平性问题(附代码)
别让你的AI模型‘偏心’:用Python实战解决机器学习公平性问题(附代码) 在信贷审批系统中,女性申请者的通过率比男性低23%;在招聘算法中,35岁以上候选人的简历筛选通过率骤降40%——这些真实案例揭示了一个残…...

深度可分离CNN量化优化:PROM方法解析
1. 深度可分离CNN量化现状与挑战 在移动端和边缘计算场景中,卷积神经网络(CNN)的部署面临两大核心矛盾:模型精度与计算资源之间的权衡,以及理论计算量与实际硬件效率的差距。传统量化方法通常采用"一刀切"策略,对所有卷…...

氯气,氯水,液溴,溴水,溴的四氯化碳溶液,碘单质,碘水的颜色分别是什么?
一、氯气(Cl₂)及其溶液物质颜色备注氯气(气体)黄绿色常温下为有刺激性气味的气体氯水(水溶液)淡黄绿色因溶解少量氯气分子(Cl₂)所致;久置后因生成HClO和HCl,…...

NotebookLM摘要质量断崖式下滑?揭秘92%用户忽略的3个语义锚点校准技巧
更多请点击: https://intelliparadigm.com 第一章:NotebookLM摘要质量断崖式下滑的真相溯源 近期大量用户反馈 NotebookLM 生成的摘要出现关键信息遗漏、逻辑断裂与事实扭曲等现象,部分案例中摘要准确率较 2023 年底下降超 40%。这一退化并非…...

如何零代码构建专业级在线PPT编辑工具:5大核心技术解析
如何零代码构建专业级在线PPT编辑工具:5大核心技术解析 【免费下载链接】PPTist PowerPoint-ist(/pauəpɔintist/), An online presentation application that replicates most of the commonly used features of MS PowerPoint, allowing f…...

2025届毕业生推荐的AI辅助论文网站解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 当下,学术研究越发受到人们的重视,在此种背景状况之下,论…...

OpenUPM安全最佳实践:保护你的Unity包注册表完全指南 [特殊字符]
OpenUPM安全最佳实践:保护你的Unity包注册表完全指南 🔒 【免费下载链接】openupm OpenUPM - Open Source Unity Package Registry (UPM) 项目地址: https://gitcode.com/gh_mirrors/op/openupm OpenUPM作为开源Unity包管理器(UPM&…...

告别商业收费与审核枷锁:深度拆解 Open-Generative-AI,构建 MIT 开源、零过滤的私有化视频生成工作站
发布日期: 2026-05-18标签: #Open-Generative-AI #Sora #Flux #Veo #AI视频生成 #私有化部署一、 引言在 2026 年,大模型生成图像与视频(Text-to-Video)的技术已经炉火纯青,但创作者们依然面临着三大难以言…...

aivectormemory:轻量级向量记忆库,为AI应用开发提供灵活存储方案
1. 项目概述:向量记忆库的“新玩家”最近在折腾AI应用开发,特别是涉及到需要让模型“记住”大量私有知识或者进行复杂对话的场景时,一个绕不开的核心组件就是向量数据库。大家熟知的Pinecone、Weaviate、Milvus这些方案固然强大,但…...