【MySQL系列】- Select查询SQL执行过程详解
【MySQL系列】- Select查询SQL执行过程详解
文章目录
- 【MySQL系列】- Select查询SQL执行过程详解
- 一、SQL查询语句的执行过程
- 二、SQL执行过程详解
- 2.1. 连接器
- 2.2. 查询缓存
- 2.3. 分析器
- 2.4. 优化器
- 2.5. 执行器
- 三、undo log 和 redo log作⽤
- 3.1. redo log (重做日志)
- redo log什么时候产生?
- redo log什么时候删除?
- 3.2. undo log(回滚日志)
- undo log什么时候产生
- undo log什么时候删除
- 四、脏页是什么?何时刷新脏页
- 4.1 mysql脏页
- 4.2 刷脏页的时机
- 五、sql优化或你做过哪些方面的优化
- 六、包含子查询语句的SELECT语句的执行过程
一、SQL查询语句的执行过程
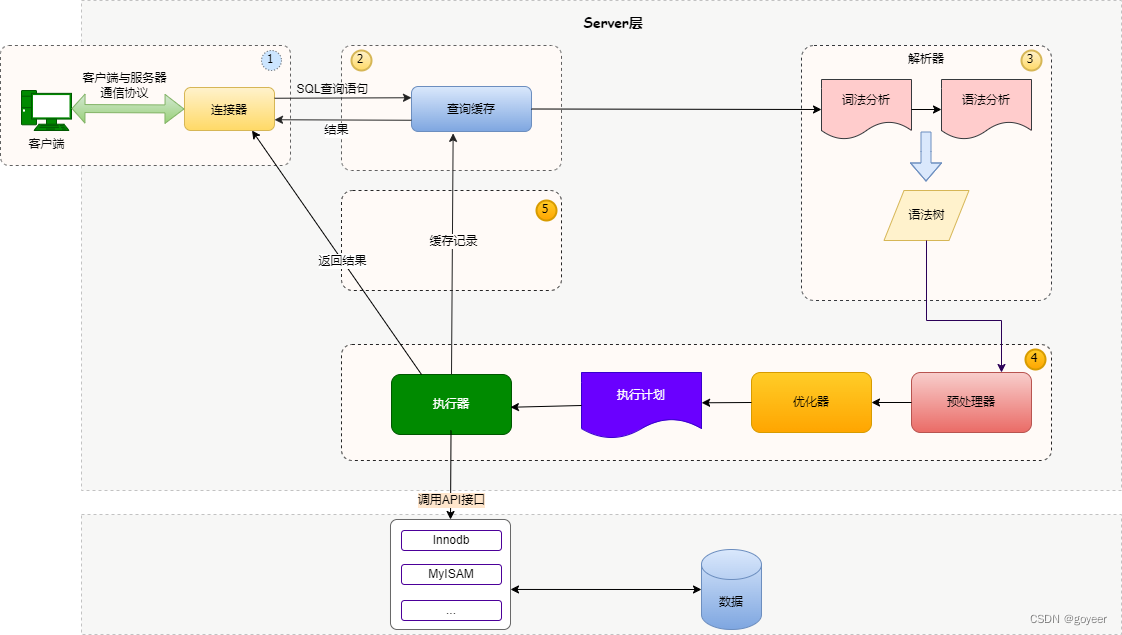
二、SQL执行过程详解
一条SQL语句从发送到数据并返回结果,主要经历以下几个过程:
- 连接器:
- 查询缓存:如果开启了查询缓存,则会经过这一步,但是大多数情况下都不是开启的,也不建议开启;MySQL8.0之后也删除了这一块功能。
- 分析器:
- 优化器
- 执行器
2.1. 连接器
如果想对MySQL进行操作,第一步建立数据库连接,这个过程就是连接器来完成的,它主要负责与客户端的通信,验证用户名和密码是否正确等。大多数的应用系统会在第一次启动的时候建立好一定数量的数据库连接池,这个就是通过连接器与数据库提前建立好连接。
2.2. 查询缓存
开启了查询缓存,在select查询语句过来的时候会先到查询缓存看之前是不是执行过这条语句,查询缓存存储的数据是以键值对的形式进行存储(类似与Map),key就是查询的SQL语句,VALUE是查询的结果。由于查询缓存这一块那么重要而且MySQL8.0之后也删除了。
2.3. 分析器
对客户端传过来的SQL进行分析,包括预处理与解析过程,并进行关键词的提取、解析,并组成一个解析树。主要提取如/update/delete/or/in/where/group by/having/count/limit等这个的关键词。
select * from user where id=1
例如这样的一条语句,在分析器中就通过语义规则器将select from where这些关键词提取和匹配出来,将用户的匹配字段和自定义语句识别出来,这个阶段也会做一些校验,比如效验user表是否存在,表中是否有id字段等。
2.4. 优化器
经过前面的步骤,数据库已经知道SQL可以执行了,接下来优化器会根据执行计划选择最优的选择,匹配合适的索引,选择最佳的方案。
2.5. 执行器
执行器会调用对应的存储引擎执行 sql。主流的存储引擎是MyISAM 和 Innodb。
三、undo log 和 redo log作⽤
3.1. redo log (重做日志)
确保事务的持久性。防止在发生故障的时间点,尚有脏页未写入磁盘,在重启mysql服务的时候,根据redo log进行重做,从而达到事务的持久性这一特性。
redo log什么时候产生?
事务开始之后就产生redo log,redo log的落盘并不是随着事务的提交才写入的,而是在事务的执行过程中,便开始写入redo log文件中。
redo log什么时候删除?
当对应事务的脏页写入到磁盘之后,redo log的使命也就完成了,redo log占用的空间就可以被重用(被覆盖)。
3.2. undo log(回滚日志)
保存了事务发生之前的数据的一个版本,可以用于回滚,同时可以提供多版本并发控制下的读(MVCC),也即非锁定读。
undo log什么时候产生
事务开始之前,将当前数据的版本生成undo log,undo 也会产生 redo 来保证undo log的可靠性。
undo log什么时候删除
当事务提交之后,undo log并不能立马被删除,而是放入待清理的链表,由purge线程判断是否由其他事务在使用undo段中表的上一个事务之前的版本信息,决定是否可以清理undo log的日志空间。
undo log 和redo log 主要用来保证事务相关操作,除此之外还有binlog(二进制日志,用于主从复制和基于时间点的还原等)、errorlog(错误日志)等
四、脏页是什么?何时刷新脏页
4.1 mysql脏页
当内存数据页和磁盘数据页上的内容不一致时,我们称这个内存页为脏页,内存数据写入磁盘后,内存页上的数据和磁盘页上的数据就一致了,我们称这个内存页为干净页。
4.2 刷脏页的时机
- redo log写满时,没有空间了,此时需要将checkpoint向前推进,推进的这部分日志对应的脏页刷入到磁盘,此时所有的更新全部阻塞,写的性能变为0,必须待刷一部分脏页后才能更新。
- 系统内存不足时,需要将一部分数据页淘汰掉,如果淘汰的是脏页,需要先将脏页同步到磁盘。
- MySQL认为空闲的时候进行刷新。
- MySQL正常关闭之前,会把所有脏页刷入磁盘。
五、sql优化或你做过哪些方面的优化
- 考虑where和order等涉及的字段上建立索引,当然索引不是越多越好,建的多影响更新、插入性能。
- 字段已经有索引了,则需要避免索引失效,如:避免对索引字段进行计算操作(如num+1等),避免使用函数,避免索引字段使用not,<>,!=,IS NULL,IS NOT NULL,LIKE等,同时要注意索引字段的顺序,遵循最左匹配原则。
- 避免使用DISTINCT,order等耗资源的操作
- select语句中避免使用select * from 使用明确的字段代替*号
- 多表关联查询时,数据量小的表在前,数据量大的表在后
- 针对复杂的SQL语句,考虑拆分成多个单条语句,在业务上处理
六、包含子查询语句的SELECT语句的执行过程
-
解析SQL语句:将SQL语句解析成语法树,并对语法树进行语义分析。语法树是一个树状结构,它将SQL语句中的各个元素按照一定的规则组织起来,以便数据库引擎进行处理。
-
执行子查询:对子查询进行解析和语义分析,并生成子查询的结果集。子查询是一个嵌套在外部查询中的查询,它可以返回一组值,这组值可以作为外部查询的过滤条件或计算条件。子查询可以是一个SELECT语句、一个表达式、一个常量或者一个函数调用。
子查询的执行过程类似于普通的SELECT语句的执行过程,也需要进行解析、优化和执行。数据库引擎会首先解析子查询,然后生成执行计划,最后执行查询并返回结果集。如果子查询中包含其他子查询,则需要按照嵌套的层次依次执行。子查询的结果集可以存储在内存或者磁盘中,以便后续查询操作快速访问。
-
执行外部查询:使用子查询的结果集进行处理,生成一个临时的虚拟表格。该表格包含了所有符合外部查询条件的行和子查询结果集中的所有行。外部查询可以使用该虚拟表格进行排序、分组、聚合等操作。如果外部查询中包含了GROUP BY、HAVING、ORDER BY、DISTINCT等关键字,那么在处理过程中需要对临时表格进行分组、聚合、排序等操作。
-
返回结果集:将临时表格中的数据按照需要的顺序返回给用户。如果存在LIMIT限制,则只返回指定的行数。在返回结果集之前,数据库引擎还需要对结果集进行格式化,包括将日期、时间等数据类型转换成适当的格式,将NULL值转换成适当的表示方式等。
需要注意的是,在执行包含子查询语句的SELECT语句时,数据库引擎会优化查询计划,以提高查询性能。通常情况下,数据库引擎会将子查询的结果集存储在内存或者磁盘中,以便后续查询操作快速访问。另外,如果外部查询中的WHERE条件能够过滤掉大部分不符合条件的行,那么数据库引擎也会尽可能地减少扫描的数据量,以提高查询性能。
相关文章:
【MySQL系列】- Select查询SQL执行过程详解
【MySQL系列】- Select查询SQL执行过程详解 文章目录 【MySQL系列】- Select查询SQL执行过程详解一、SQL查询语句的执行过程二、SQL执行过程详解2.1. 连接器2.2. 查询缓存2.3. 分析器2.4. 优化器2.5. 执行器 三、undo log 和 redo log作⽤3.1. redo log (重做日志&a…...

软考高级信息系统项目管理师系列之:信息系统项目管理师论文评分参考标准
软考高级信息系统项目管理师系列之:信息系统项目管理师论文评分参考标准 论文满分是 75 分,论文评分可分为优良、及格与不及格 3 个档次。评分的分数可分为: 60 分至 75 分优良(相当于百分制 80 分至 100 分)。45 分至 59 分及格(相当于百分制 60 分至 79 分)。0 分至 44 分…...

MyBatis--多案例让你熟练使用CRUD操作
目录 一、前期准备 二、两种实现CRUD方式 三、增加数据(INSERT) 四、删除数据(DELETE) 五、查询数据(SELECT) 六、更新数据(UPDATE) 一、前期准备 1.创建maven项目并在pom文件…...

用Python造轮子
目录 背景安装setuptools库准备要打包的代码创建setup.py文件打包生成whl文件把库装到电脑上使用这个库 背景 如何把自己写的代码,打包成库方便其他人使用 安装setuptools库 正所谓想要富先修路,先把造轮子要用的库装上 pip install wheel pip insta…...
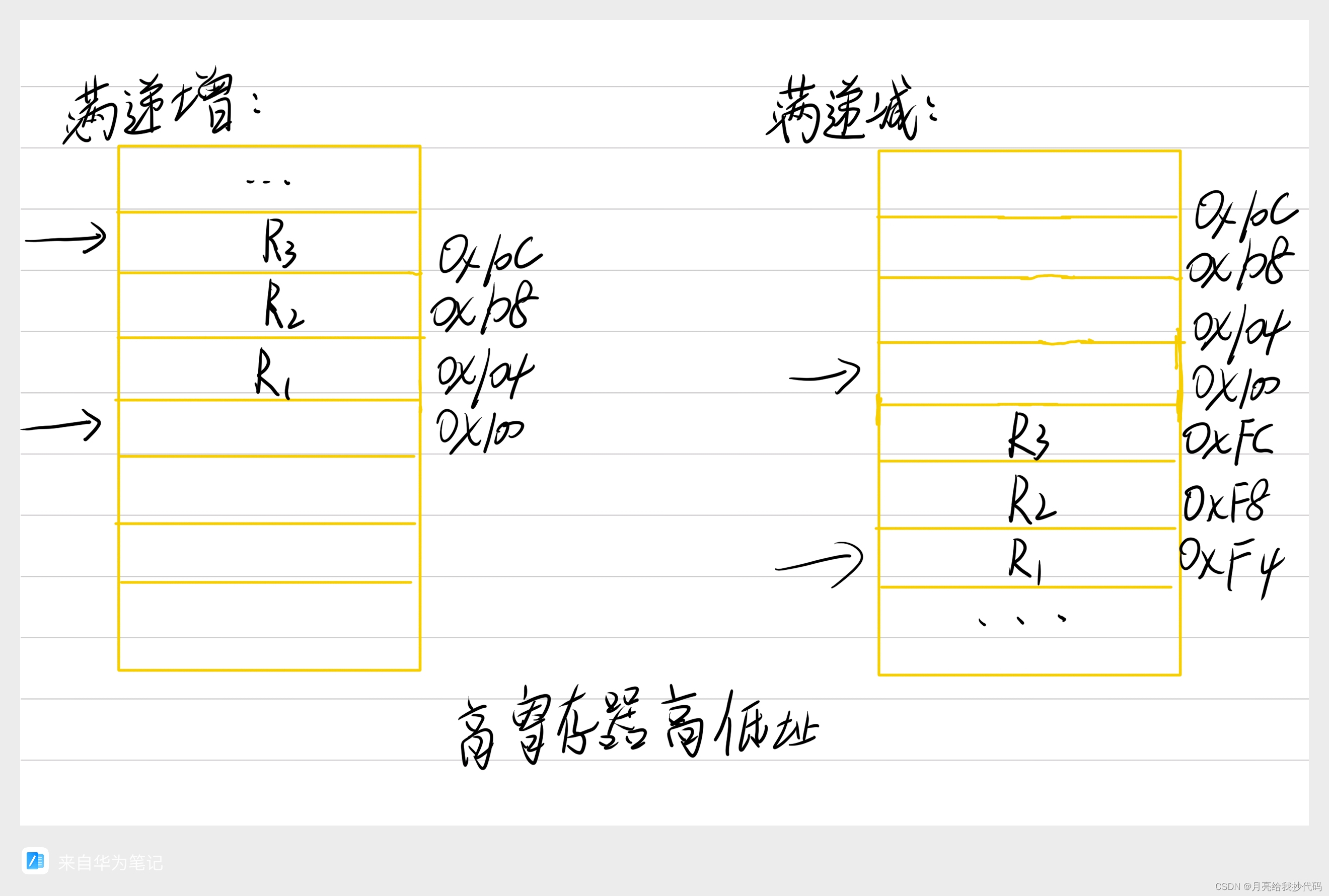
ARM 堆栈寻址类型区分
文章目录 堆栈指向分类堆栈指向数据分类满递增与满递减空递增与空递减 堆栈指向分类 根据堆栈指针的指向的方向不同,可以划分为向上生成型和向下生成型。 向上生成型: 随着数据的入栈,堆栈的指针逐渐增大,称为:递增…...

每日一练 | 网络工程师软考真题Day43
1、在生成树协议〔STP〕IEEE 802.1d中,根据 来选择根交换机。 A.最小的MAC地址 B.最大的MAC地址 C.最小的交换机ID D.最大的交换机ID 2、在快速以太网物理层标准中,使用两对5类无屏蔽双绞线的是 。 A&…...

jsonXML格式化核心代码
json格式化: 依赖: <dependency><groupId>com.jayway.jsonpath</groupId><artifactId>json-path</artifactId><version>2.6.0</version><scope>compile</scope> </dependency> string t…...
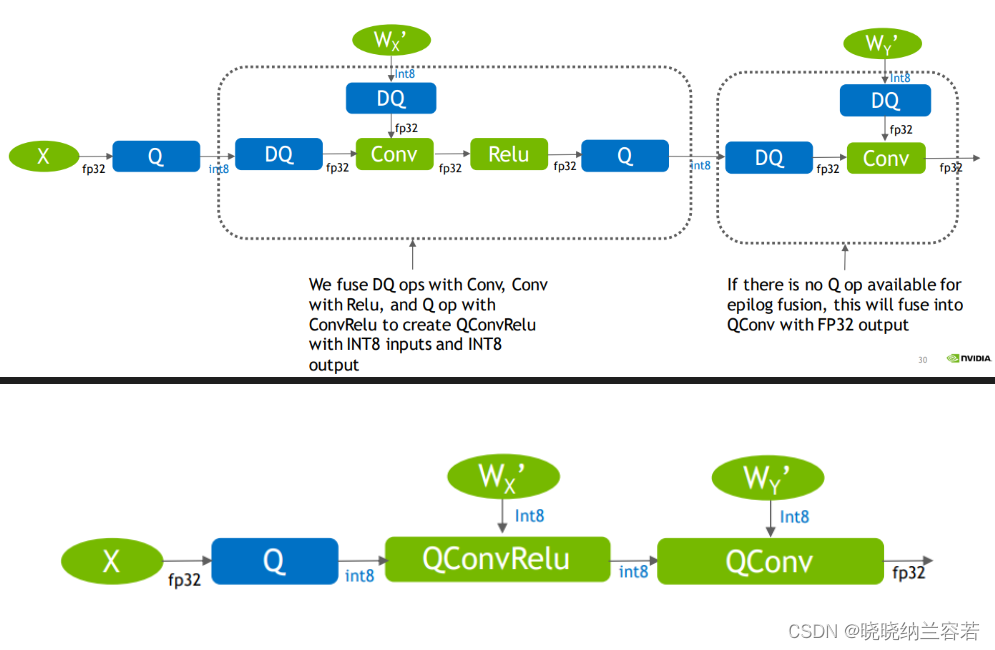
PTQ量化和QAT量化
目录 1--PTQ量化 2--QAT量化 1--PTQ量化 PTQ量化表示训练后量化(Post Training Quantization)。使用一批校准数据对训练好的模型进行校准,将训练好的FP32网络直接转换为定点计算的网络,过程中无需对原始模型进行任何训练&#x…...
【Django 02】数据表构建、数据迁移与管理
1. Django 构建数据表创建与数据迁移 1.1 数据表创建 1.1.1 模块功能 如前所述,models.py文件主要用一个 Python 类来描述数据表。运用这个类,可以通过简单的 Python 代码来创建、检索、更新、删除 数据库中的记录而无需写一条又一条的SQL语句。今天的例子就是在…...
一天吃透Java集合面试八股文
内容摘自我的学习网站:topjavaer.cn 常见的集合有哪些? Java集合类主要由两个接口Collection和Map派生出来的,Collection有三个子接口:List、Set、Queue。 Java集合框架图如下: List代表了有序可重复集合,…...

高级深入--day36
Settings Scrapy设置(settings)提供了定制Scrapy组件的方法。可以控制包括核心(core),插件(extension),pipeline及spider组件。比如 设置Json Pipeliine、LOG_LEVEL等。 参考文档:Settings — Scrapy 1.0.5 文档 内置设置参考手册 BOT_NAME 默认: scrapybot 当您使用 sta…...
Jmeter接口测试工具的一些使用小技巧
如何使用英文界面的JMeter Jmeter启动时会自动判断操作系统的locale 并选择合适的语言启动,所以,我们启动jmeter后,其会出现一个倍感亲切的中文界面。但由于jmeter本身的汉化工作做得不好,你会看到有未被汉化的选项及元件的参数。…...
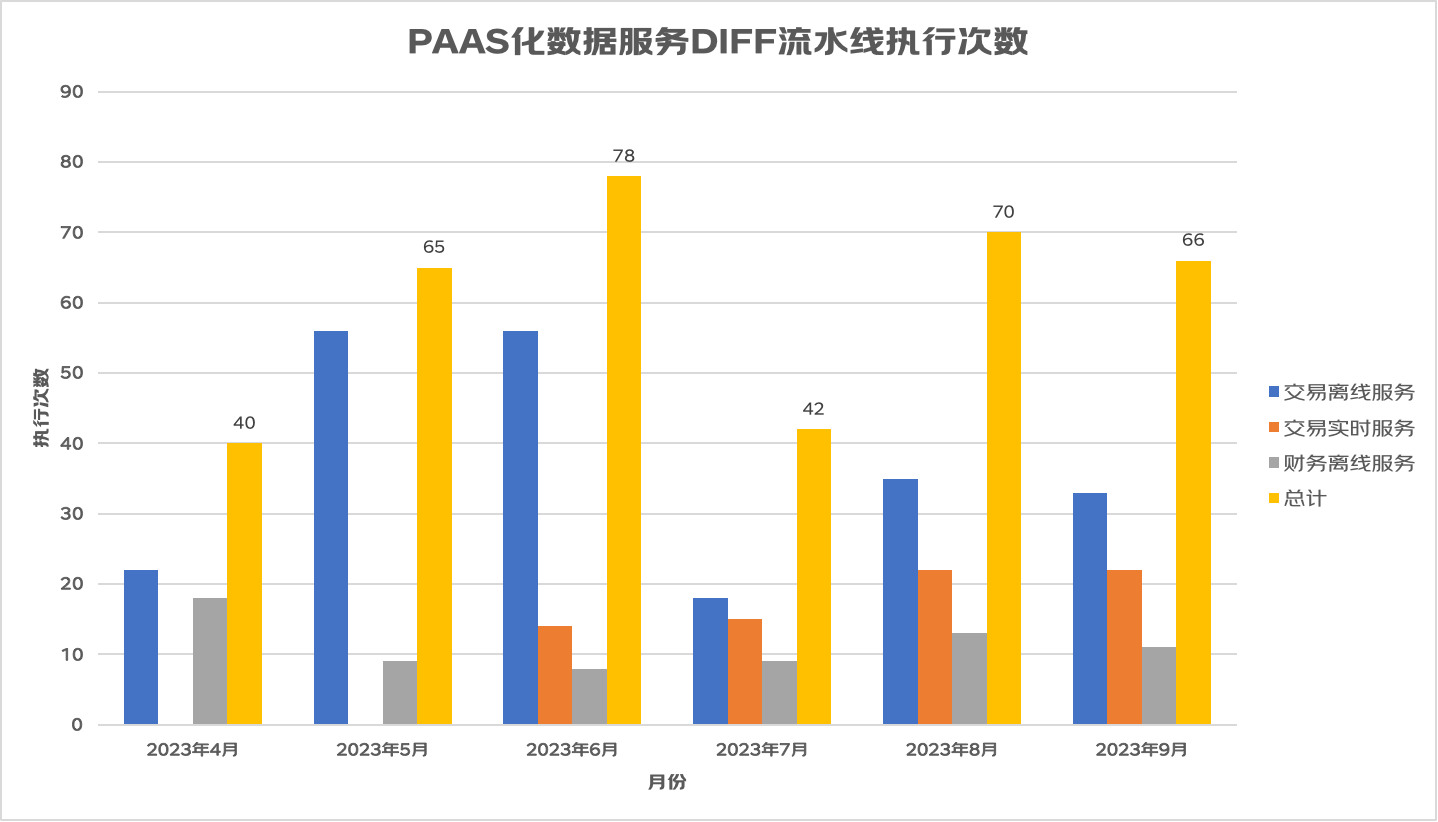
黄金眼PAAS化数据服务DIFF测试工具的建设实践 | 京东云技术团队
一、背景介绍 黄金眼PAAS化数据服务是一系列实现相同指标服务协议的数据服务,各个服务间按照所生产指标的主题作划分,比如交易实时服务提供实时交易指标的查询,财务离线服务提供离线财务指标的查询。黄金眼PAAS化数据服务支撑了黄金眼APP、黄…...
深入了解RPA业务流程自动化的关键要素
在RPA业务流程自动化实施过程中,哪些因素起着至关重要的作用?这其实没有一个通用的答案,每一个RPA业务流程自动化的部署,都需要结合具体场景去调整,并且进行全面的规划。 首当其冲是要关注以下几点: 1、专…...

CSS记录
1.标准的CSS的盒子模型?与低版本IE的盒子模型有什么不同的? 标准盒子模型box-sizing: border-box; 宽度内容的宽度(content) border padding margin 低版本IE盒子模型:宽度内容宽度(contentborderpaddin…...

Kotlin中类型转换
在 Kotlin 中,类型转换是一种常见的操作,用于将一个数据类型转换为另一个数据类型。在本篇博客中,我们将介绍 Kotlin 中的类型转换,并提供示例代码演示智能类型转换、强制类型转换以及可空类型的转换。 智能类型转换是 Kotlin 中…...

P7557 [USACO21OPEN] Acowdemia S
典型二分: #include<bits/stdc.h> using namespace std; #define int long long const int N1e510; int n,a[N],k,l; bool check(int x) {int cnt0,ans0;for(int i1; i<x; i) {if(a[i]>x) {cnt;continue;}else{if(x-a[i]>k)return false;else{ansans…...

如何确认栈中申请的变量地址
一般一个程序被加载到内存后执行而成为一个进程。进程在内存中是分区域加载的,分别是代码段、数据段、bss段等等。 函数中定义的变量一般存在于栈中。现在我们通过实验验证一下,函数中定义的变量,到底存在与进程哪个位置。 1.测试程序 #in…...

【STM32】--基础了解
一、STM32来历背景 1.从51到STM32 (1)单片机有很多种 (2)STM32内核使用ARM,但是ARM不一定是STM32 (3)ATM32是当前主流的32位高性能单片机 (4)STM32的特点:高…...
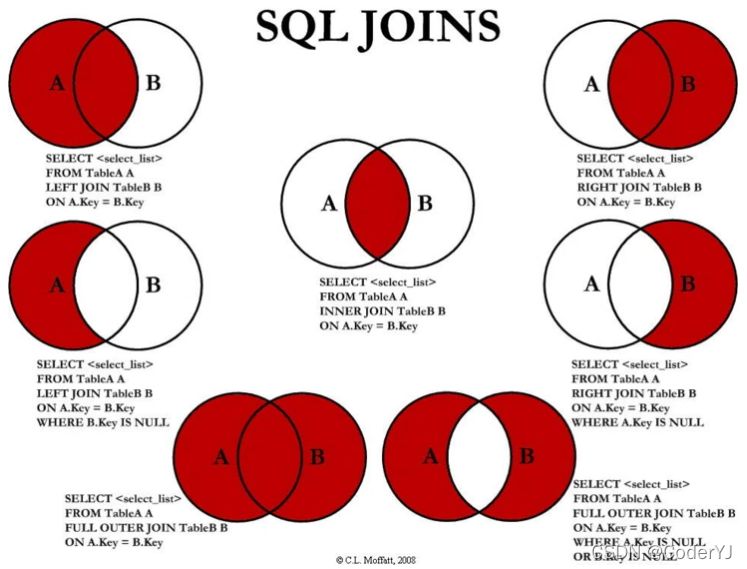
join、inner join、left join、right join、outer join的区别
内连接 inner join(等值连接):只显示两表联结字段相等的行,(很少用到,最好别用); 外连接 left join:以左表为基础,显示左表中的所有记录,不管是否与关联条件相匹配,而右表中的数据只显示与关联条件相匹配的记录,不匹配…...

Real World Rails实战:10个高效学习Rails开发的最佳实践
Real World Rails实战:10个高效学习Rails开发的最佳实践 【免费下载链接】real-world-rails Real World Rails applications and their open source codebases for developers to learn from 项目地址: https://gitcode.com/gh_mirrors/re/real-world-rails …...

2025最新 SpringCloud 教程,Seat-原理-四种事务模式,总结,笔记72,笔记73
2025最新 SpringCloud 教程,Seat-原理-四种事务模式,总结,笔记72,笔记73 一、参考资料 Seat-原理-四种事务模式 🔗 总结 🔗 二、笔记总结...
)
5G入网第一步:手把手拆解Msg3 PUSCH传输的时频资源分配(附避坑指南)
5G入网第一步:手把手拆解Msg3 PUSCH传输的时频资源分配(附避坑指南) 当5G终端尝试接入网络时,随机接入流程中的Msg3 PUSCH传输往往是工程师们遇到的第一个技术深水区。作为首个由基站调度的上行共享信道传输,Msg3承载着…...
)
[通俗易懂]从“生产者-消费者”模型秒懂Java泛型PECS原则(别再死记硬背了)
1. 从超市购物理解PECS原则 想象你正在超市采购水果。水果区有各种水果篮:有的专放苹果,有的专放香蕉,还有个"混合水果区"放各种水果。这时候你会发现两个有趣的现象: 从水果区取水果:你可以从任何水果篮里安…...

3个技巧让窗口管理更智能:如何用开源工具提升专注力?
3个技巧让窗口管理更智能:如何用开源工具提升专注力? 【免费下载链接】AlwaysOnTop Make a Windows application always run on top 项目地址: https://gitcode.com/gh_mirrors/al/AlwaysOnTop 想象一下这样的工作场景:你正在编写代码…...

如何用OpenWebRTC实现音视频通话:完整开发教程
如何用OpenWebRTC实现音视频通话:完整开发教程 【免费下载链接】openwebrtc A cross-platform WebRTC client framework based on GStreamer 项目地址: https://gitcode.com/gh_mirrors/op/openwebrtc OpenWebRTC是一个基于GStreamer的跨平台WebRTC客户端框架…...

简单认识显卡
学习视频来自B站(从零开始认识显卡):https://www.bilibili.com/video/BV1xE421j7Uv 这是你最近在玩的电脑游戏,形态各异的建筑、细节丰富的车辆,一切都很真实,它们的本质其实是一个个不同位置的点ÿ…...

AMD Ryzen处理器底层调试技术解析:SMUDebugTool的架构设计与实践应用
AMD Ryzen处理器底层调试技术解析:SMUDebugTool的架构设计与实践应用 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地…...

低压电工-电子技术常识
一、导体、绝缘体、半导体(按电阻率划分)1. 划分标准单位是 Ω・cm(欧姆・厘米),不是单纯欧姆 (Ω),是电阻率专用单位:欧姆・厘米 Ω⋅cm,也可以用 Ω⋅m(欧姆・米&#…...

为什么你的NotebookLM总“读不懂”Nature论文?生信老炮拆解7类专业语义断层及5种Prompt工程修复方案
更多请点击: https://kaifayun.com 第一章:NotebookLM生物技术研究 NotebookLM 是 Google 推出的基于 AI 的研究协作者工具,专为知识密集型工作流设计。在生物技术领域,它可高效整合海量文献、实验报告与基因组数据库摘要&#x…...