Picnic master project interview
picnic
- Picnic master project interview
- 1. Topics
- 1.1 Systematically identify similar/interchangeable articles
- 1.2 Understanding changing customer behaviour
- 2. interview
- 等后续
Picnic master project interview
1. Topics
1.1 Systematically identify similar/interchangeable articles
Data integration
Data management for machine learning
Complexity theory
Description
At Picnic, we currently have an assortment of some 8k articles. However, in practice, many play a similar role from the customer’s perspective - a customer wants to buy e.g. cola or bananas, but there will be multiple colas or multiple bananas that the vast majority of customers will only buy one variety of. Likewise, if a customer wants to cook a certain meal, say pasta bolognese, there will be many different collections of articles that could represent this; and for the role of ‘minced meat’, there could be a number of varieties of minced meat in different sizes and of different origin, including vegetarian and vegan options. These are similar concepts, they are a sort of ‘product archetype’ that play a certain role in a customer’s shopping.
However, for different types of product archetypes, and also for different products within certain archetypes, the behaviour might be slightly different. Some articles might be directly interchangeable (e.g. two brands of bananas, or two sizes of exactly the same product), but others not or only in one direction (minced meat vs the vegan option). In some categories, a customer will only buy one product from the archetype in a specific shopping session, while in others (e.g. zoutjes) customers regularly buy multiple. And finally, what should be shown might also depend on the context (where in the app, e.g. in search or in recipe) and on the customer.
This project aims to formalise these inter-product relations. Can we systematically identify these product archetypes? Can we quantify how interchangeable two products are, in different contexts? What different contexts are relevant? And is it generally possible to generate context-specific sets of products by starting from a broad archetype and applying filters or re-ranking, or is this too simplistic?
Work Environment
Picnic Technologies is known for its innovative approach to grocery shopping and delivery. The work environment reflects this innovative and dynamic culture. A lot of creativity, open communication, and a willingness to come up with new ideas!
Expectations
We’re aiming for quality thesis work where the intern is able to deepdive into the topic at hand within the context of potentially applying it to Picnic’s business on the long term, with guidance from Picnic of course. We require at least 5 months, full-time internships; there’s an online code test and two interviews in the process.
1.2 Understanding changing customer behaviour
Modelling complex systems & networks
Data integration
Algorithms and datastructures
Description
Customer preference changes over time. Customers might switch their shopping behaviour for various reasons, e.g.:
-they find a similar but cheaper/better-tasting/preferable alternative
-they start or stop buying certain types of products online (e.g. some customers are wary of fresh products from online)
-their tastes change
-their diet changes
-their family/living situation changes
At Picnic, we have an extensive and very well-maintained Data Warehouse, where relational databases store e.g. personal purchasing behaviour, historical status changes of articles and customer addresses, and so on. There is also considerable data on in-app events that can give insights in how customers are using the app, how they navigate and what actions are performed. Such factual information is quite reliable; other data points such as family size or number of pets are self-reported and require interpretation. Knowledge of SQL is required to unlock this primary source of relevant data; in addition, Python is the language of choice in the Data Science team.
There are a number of interesting research questions in this direction, which can be further refined during the thesis. the A first question is how shopping behaviour changes over time, and if specific stages can be identified during this change in behaviour. This requires systematic detection of patterns in the available historical purchasing data, potentially also including relevant in-app events. Depending on the type of shopping behaviour we are interested in, different kinds of dynamics may occur; i.e., it might be a simple case of transitioning to a different product, but also wider changes in behaviour such as ‘ordering more sustainably’, ‘becoming a more mature customer’ (whatever that means exactly is an open question), or ‘switching to a vegetarian diet’ are of interest.
A similar, but more forward-looking question is whether we can predict behaviour change trajectories for current customers. From the academical point of view, this allows for a validation of the more historically focused analysis in step 1. Likewise, If we can observe customers that are likely to exhibit certain future purchasing behaviour, this can be used to show e.g. more relevant products, choose promotions that might induce them to explore new categories, or proactively reach out to avoid (partial) customer churn. That brings us to a next question: is it possible to nudge customer behaviour via e.g. recommendations or presentation to induce healthier or more sustainable choices? And in what ways can this be achieved, i.e. what are the articles or methods that are best suited to do so? Can different customer groups be identified here that may need to be treated in distinct ways? This is a research question that not only brings recommendation systems directly into play, but is also a next step from the business perspective. Eventually, alignment will be necessary with business-facing and tech teams for implementation of such nudging experiments, but it is certainly possible to validate the research and see if the nudging predictions hold water in real life.
Work Environment
Picnic Technologies is known for its innovative approach to grocery shopping and delivery. The work environment reflects this innovative and dynamic culture. A lot of creativity, open communication, and a willingness to come up with new ideas!
2. interview
- selft intro?
用了个人网站讲解
提到了腾讯做软件 - 体现自己技术实用的理念
讲自己knowledge organization课有用 - 上过的课?
讲了研一的服务课等,编程课 - 会什么技术?
先说服务的大理念
再说python/C#/java - 为什么picnic?
讲大二对零售感兴趣
讲公司电车服务,green IT - 为什么这两个项目?
第一个是知识图谱
第二个是用户画像,推荐系统 - Q&A?
- 公司多少人?
好几百 - 在哪?
overamstel - 什么部门?
tech - data science - 收几个人?
1 - hybrid?
2-3 days per week on-site - subsidy?
800 - future career?
possibile - future interview?
- python测试
- 技术面
- coffee chat
- 公司多少人?
等后续
人挺多的估计,等等吧
相关文章:

Picnic master project interview
picnic Picnic master project interview1. Topics1.1 Systematically identify similar/interchangeable articles1.2 Understanding changing customer behaviour 2. interview等后续 Picnic master project interview 1. Topics 1.1 Systematically identify similar/inte…...
nginx部署vue项目(访问路径加前缀)
nginx部署vue项目(访问路径加前缀) nginx部署vue项目,访问路径加前缀分为两部分: (1)修改vue项目; (2)修改nginx配置; vue项目修改 需注意,我这是vue-cli3配置&#x…...
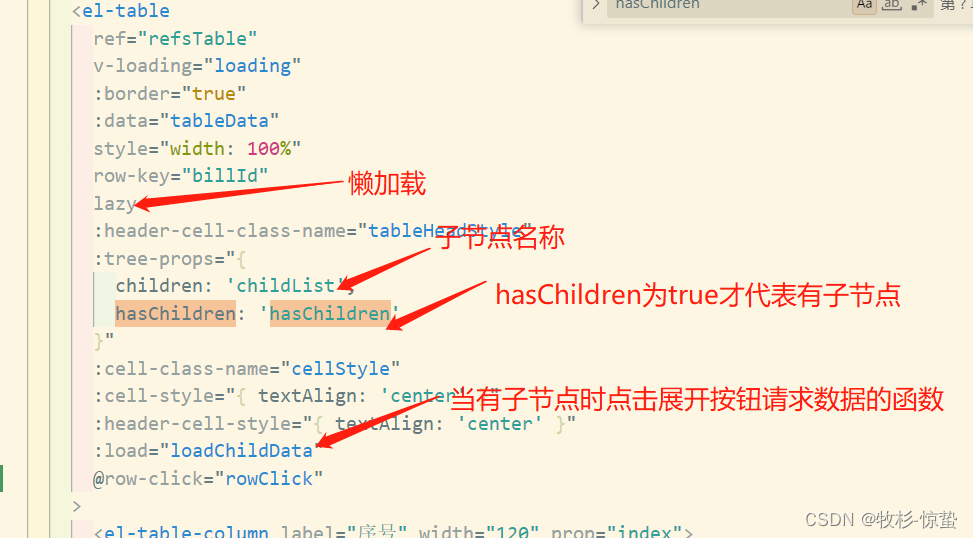
element-ui中表格树类型数据的显示
项目场景: 1:非懒加载的情况 1:效果展示 2:问题描述以及解决 1:图片展示 2:html <-- default-expand-all 代表默认展开 如果不展开删除就行 --> <el-tableref"refsTable"v-loadin…...

【扩散模型】如何用最几毛钱生成壁纸
通过学习扩散模型了解到了统计学的美好,然后顺便记录下我之前文生图的基础流程~ 扩散模型简介 这次是在DataWhale的组队学习里学习的,HuggingFace开放扩散模型学习地址 扩散模型训练时通过对原图增加高斯噪声,在推理时通过降噪来得到原图&…...
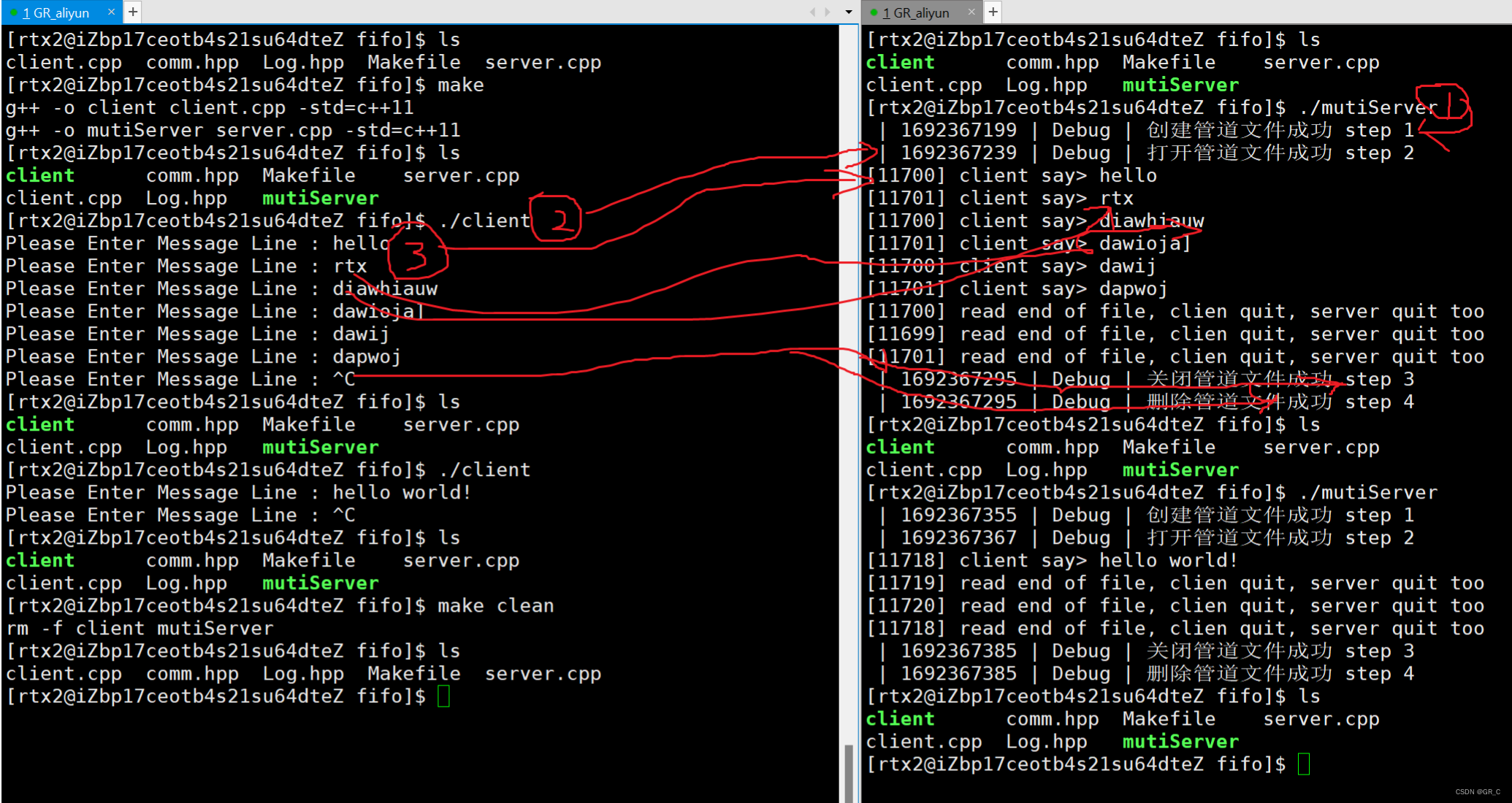
零基础Linux_17(进程间通信)VSCode环境安装+进程间通信介绍+pipe管道mkfifo
目录 1. VSCode环境安装 1.1 使用VSCode 1.2 远程链接到Linux机器 1.3 VSCode调试 2. 进程间通讯介绍 2.1 进程间通讯的概念和意义 2.2 进程间通讯的策略和本质 3. 管道 3.1 管道介绍 3.2 匿名管道介绍 3.3 匿名管道示例代码 3.3.1 建立管道的pipe 3.3.2 匿名管道…...

Redis的BitMap使用
Redis的BitMap使用 Redis 为我们提供了位图这一数据结构,每个用户每天的登录记录只占据一位,365天就是365位,仅仅需要46字节就可存储,极大地节约了存储空间。 位图不是实际的数据类型,而是一组面向位的操作 在被视为…...

java并发编程之基础与原理1
java多线程基础 下面说一下线程的7种状态 下面我重点来说一下阻塞状态 阻塞状态是可以分很多种的: 下面用另外一张图来说明这种状态 简单说一下线程的启动原理 下面说一下java中的线程 java线程的异步请求方式 上面就会先把main执行出来,等阻塞结束之后…...
 从数学上来讲什么意思)
⟨A⟩ = Tr(ρA) 从数学上来讲什么意思
当给定一个具体的密度矩阵ρ和一个可观测量A时,我们可以通过数值计算来演示〈A〉 Tr(ρA) 的应用。 假设我们有以下密度矩阵和可观测量: ρ [0.6 0.3; 0.3 0.4] A [1 0; 0 -1] 我们首先计算ρA的乘积: ρA [0.6 0.3; 0.3 0.4] * [1 0…...

Vue中的v-model指令的原理是什么?
在Vue中,v-model是一个双向绑定指令,它的原理是将表单元素的值与Vue实例中的数据属性进行双向绑定。当表单元素的值发生变化时,会自动更新Vue实例中对应的数据属性;反之,当Vue实例中的数据属性发生变化时,也…...
2023服务端测试开发必备技能:Mock测试
什么是mock测试 Mock 测试就是在测试活动中,对于某些不容易构造或者不容易获取的数据/场景,用一个Mock对象来创建以便测试的测试方法。 Mock测试常见场景 无法控制第三方系统接口的返回,返回的数据不满足要求依赖的接口还未开发完成&#…...
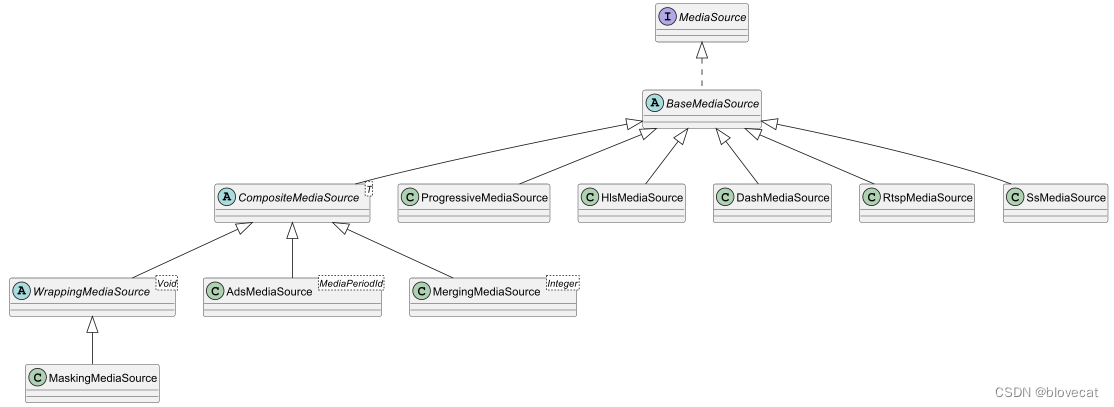
ExoPlayer架构详解与源码分析(5)——MediaSource
系列文章目录 ExoPlayer架构详解与源码分析(1)——前言 ExoPlayer架构详解与源码分析(2)——Player ExoPlayer架构详解与源码分析(3)——Timeline ExoPlayer架构详解与源码分析(4)—…...

控制一个游戏对象的旋转和相机的缩放
介绍 这段代码是一个Unity游戏开发脚本,它用于控制一个游戏对象的旋转和相机的缩放。以下是代码的主要功能: 控制游戏对象的旋转: 通过按下Q键和W键,用户可以选择以逆时针或顺时针方向绕游戏对象的Y轴进行旋转。旋转角度和速度可…...

【数据结构】线性表(二)单链表及其基本操作(创建、插入、删除、修改、遍历打印)
目录 前文、线性表的定义及其基本操作(顺序表插入、删除、查找、修改) 四、线性表的链接存储结构 1. 单链表(C语言) a. 链表节点结构 b. 创建新节点 c. 在链表末尾插入新节点 d. 删除指定节点 e. 修改指定节点的数据 f. …...
)
label的作用是什么?是怎么用的?(1)
Label(标签)在不同的上下文中有不同的作用和用途。以下是几种常见的用途和用法: 1. 数据标注:在机器学习和数据科学中,标签用于标识数据样本的类别或属性。标注数据是监督学习中的一项重要任务,它为算法提…...

C- 使用原子变量实现自旋锁
自旋锁 自旋锁(Spinlock)是一种常用于多线程编程中的低开销锁,其特点是当线程尝试获取锁而锁已被其他线程占用时,该线程会处于一个持续的忙等待(busy-wait)状态,直到它可以获取到锁为止。这种方…...

汇编的指令
减法类指令: 不带借位的减法: sub dest,src;dest(dest)-(src) 注意: 1、源操作数和目的操作数不能同时为段寄存器或存储单元 2、对标志位有影响,主要影响CF、ZF、OF、SF。 带借位的减法: sbb dest,src;dest(dest)-(…...

《数据结构、算法与应用C++语言描述》使用C++语言实现数组队列
《数据结构、算法与应用C语言描述》使用C语言实现数组队列 定义 队列的定义 队列(queue)是一个线性表,其插入和删除操作分别在表的不同端进行。插入元素的那一端称为队尾(back或rear),删除元素的那一端称…...

零基础如何学习自动化测试
现在很多测试人员有些急于求成,没有任何基础想当然的,要在一周内上手自动化测试。 在自动化的过程中时候总有人会犯很低级的问题,有语法问题,有定位问题,而且有人居然连__init__.py 文件名都弄错误,还有将…...

系统架构师备考倒计时16天(每日知识点)
1.信息化战略与实施 2.UML图(12个) 3.结构化设计(耦合) 4.SMP与AMP的区别(多核处理器的工作方式) 多核处理器一般有SMP和AMP两种不同的工作方式: SMP(对称多处理技术):将2颗完全一样的处理器封…...
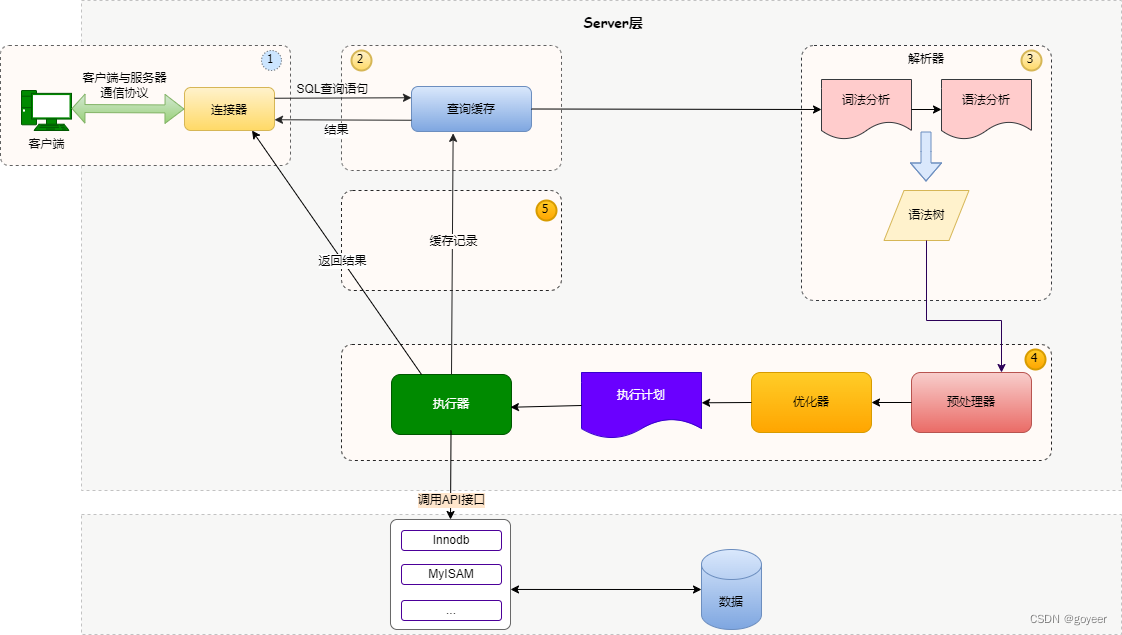
【MySQL系列】- Select查询SQL执行过程详解
【MySQL系列】- Select查询SQL执行过程详解 文章目录 【MySQL系列】- Select查询SQL执行过程详解一、SQL查询语句的执行过程二、SQL执行过程详解2.1. 连接器2.2. 查询缓存2.3. 分析器2.4. 优化器2.5. 执行器 三、undo log 和 redo log作⽤3.1. redo log (重做日志&a…...

Browser-Use 实战指南:让 AI 自己操控浏览器的 7 个实用场景
Browser-Use 实战指南:让 AI 自己操控浏览器的 7 个实用场景 你打开浏览器,搜索、填表、采集数据、截图、下载文件。这些每天重复的动作,能不能让 AI 替你干? Browser-Use 给了一个相当干脆的答案:把浏览器交给 AI&…...
)
气候模型结果难解读?NotebookLM因果推理模块深度拆解(附GFDL-ESM4输出可复现分析链)
更多请点击: https://kaifayun.com 第一章:NotebookLM气候研究辅助 NotebookLM 是 Google 推出的基于 AI 的研究协作者,专为处理长文档、技术报告与多源数据而设计。在气候科学研究中,它可快速解析 IPCC 报告、CMIP6 模型输出摘要…...

随机化、盲法、匹配:让你的研究更接近“可信因果”——控制额外变量的策略与实验内部效度提升
在科研写作和研究设计中,很多人把注意力放在“用了什么统计方法”上,却忽视了一个更根本的问题:你的研究结果,真的是干预或自变量造成的吗?如果不是,那么即使你的 p 值很小、回归系数显著、模型拟合很好&am…...
)
别再一行行读DXF了!用C#和netDxf库5分钟搞定CAD数据提取(附完整代码)
用C#和netDxf库高效解析DXF文件的实战指南 在CAD数据处理领域,DXF文件解析一直是开发者面临的常见挑战。传统的手动解析方法不仅耗时费力,还容易出错。本文将带你探索如何利用C#和netDxf库快速实现DXF文件的高效解析,彻底告别逐行读取的原始方…...

PUBG罗技鼠标宏终极配置指南:5分钟快速上手完美压枪
PUBG罗技鼠标宏终极配置指南:5分钟快速上手完美压枪 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求生》中难以控制的…...

Windows右键菜单终极清理:3个简单步骤让您的右键菜单重获新生
Windows右键菜单终极清理:3个简单步骤让您的右键菜单重获新生 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 我们都有过这样的经历:在桌…...
)
保姆级教程:从零开始给SkyWalking Agent写一个自定义日志插件(Logback篇)
深入SkyWalking Agent插件开发:构建自定义日志组件的完整方法论 在分布式系统的监控领域,SkyWalking以其强大的全链路追踪能力广受开发者青睐。但很多团队在基础监控之外,往往需要根据业务特点定制专属的监控指标——比如在日志中嵌入用户ID、…...

NotebookLM问答功能深度解析:如何用3步配置让AI精准理解你的PDF/网页文档?
更多请点击: https://intelliparadigm.com 第一章:NotebookLM问答功能深度解析:如何用3步配置让AI精准理解你的PDF/网页文档? NotebookLM 是 Google 推出的面向研究者与知识工作者的实验性 AI 工具,其核心能力在于基于…...

嵌入式Linux嵌入式Linux驱动开发:板级DTS实操与完整实战演练——从修改设备树到点亮LED的完整闭环
嵌入式Linux嵌入式Linux驱动开发:板级DTS实操与完整实战演练——从修改设备树到点亮LED的完整闭环 仓库已经开源!所有教程,主线内核移植,跑新版本imx-linux/uboot都在这里,或者一起来尝试跑7.0的Linux!欢迎…...
)
NotebookLM生物技术研究落地难?92%实验室尚未启用的3个隐藏功能(内部白皮书首次公开)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM生物技术研究落地难?92%实验室尚未启用的3个隐藏功能(内部白皮书首次公开) NotebookLM 作为 Google 推出的实验性 AI 助手,其在生物技术领域的…...