Hadoop-MapReduce
Hadoop-MapReduce
文章目录
- Hadoop-MapReduce
- 1 MapRedcue的介绍
- 1.1 MapReduce定义
- 1.2 MapReduce的思想
- 1.3MapReduce优点
- 1.4MapReduce的缺点
- 1.5 MapReduce进程
- 1.6 MapReduce-WordCount
- 1.6.1 job的讲解
- 2 Hadoop序列化
- 2.1 序列化的定义
- 2.2 hadoop序列化和java序列化的区别
- 3 MapReduce 的原理
- 3.1 MapReduce 工作的过程
- 3.2 InputFormat 数据输入
- 3.2.1 切片
- 3.2.2 FileInputFormat
- 3.2.3 TextInputFormat
- 3.2.4 CombineTextInputFormat
- 3.3 MapReduce工作机制
- 3.3.1 MapTask工作机制
- 3.3.2 Partition分区
- 3.3.3 Combiner合并
- 3.3.4 ReduceTask工作机制
- 3.3.5 shuffle机制
- 3.3.6 排序的解释
- 4 数据压缩
- 4.1 压缩算法对比
- 4.2 压缩位置选择
1 MapRedcue的介绍
1.1 MapReduce定义
MapReduce是一个进行分布式运算的编程框架,使用户开发基于hadoop进行数据分析的核心框架。 MapReduce 核心功能就是将用户编写的业务逻辑代码和自带的默认组件整合成一个完整的 分布式运算程序,并发运行在一个 Hadoop 集群上。
1.2 MapReduce的思想
MapReduce的思想核心是分而治之,适用于大规模数据处理场景。
map负责分,将复杂的任务拆解成可以并行计算的若干个任务来处理
reduce负责合,对map阶段的结果进行全局汇总
比如说:老师作业留的有点多,一个人写太费劲了,就可以用MapReduce这种分而治之的思想,将作业进行map处理,分给不同的人,最后所有写完的部分发到群里进行reduce汇总,复杂的作业简简单单。
1.3MapReduce优点
易于编程
MapReduce将做什么和怎么做分开了,提供了一些接口,程序员只需关注应用层上的问题。具体如何实现并行计算任务则被隐藏了起来。
扩展性
当计算资源不足时,可以增加机器来提高扩展能力
高容错
一台机器挂了,可以将计算任务转移到另一台节点上进行
适合PB级海量数据的离线处理
1.4MapReduce的缺点
不擅长实时计算
无法做到在毫秒级别返回结果
不擅长流式计算
MapReduce处理的数据源只能是静态的,不能动态变化
不擅长DAG(有向无环图)计算
每个MR作业处理结束,结果都会写入到磁盘,造成大量的磁盘IO,导致性能低下
1.5 MapReduce进程
一个MapReduce程序在分布式运行时有三类的实例进程
- MrAppMaster : 负责整个程序的过程调度及状态协调
- MapTask : 负责Map阶段的数据处理流程
- ReduceTask : 负责Reduce阶段的数据处理流程
1.6 MapReduce-WordCount
import java.io.IOException;
import java.util.StringTokenizer;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordCount {public static class TokenizerMapperextends Mapper<Object, Text, Text, IntWritable>{private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Context context) throws IOException, InterruptedException {StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {word.set(itr.nextToken());context.write(word, one);}}}public static class IntSumReducerextends Reducer<Text,IntWritable,Text,IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key, result);}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance(conf, "word count");job.setJarByClass(WordCount.class);job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(IntSumReducer.class);job.setReducerClass(IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}
}
以上代码实现了两个类:TokenizerMapper和IntSumReducer,它们分别实现了Map和Reduce功能。
Map函数将输入的每一行文本进行分词,并将每个单词映射为一个键值对,其中键为单词,值为1,然后将这些键值对输出给Reduce函数。
Reduce函数将相同键的值相加,并将最终结果输出。
在这个例子中,CombinerClass被设置为相同的Reducer类,用于在Map任务结束后本地合并中间结果,以减少网络传输。
最后,将输入文件和输出文件的路径作为命令行参数传递给main函数,并启动MapReduce作业。
1.6.1 job的讲解
在Hadoop MapReduce程序中,Job对象是用来定义和运行一个MapReduce作业的。
Job对象的主要功能是封装了整个MapReduce作业的配置和运行信息,包括输入数据和输出数据的路径、Mapper类和Reducer类的设置、中间结果的输出类型和格式、作业的提交方式等。
在main函数中,我们创建一个Job对象并设置它的相关属性。
Job.getInstance()方法返回一个新的Job实例,其中的Configuration对象用来指定作业的一些配置信息。
setJarByClass()方法用来设置作业的jar包,它的参数是定义MapReduce作业的主类。
setMapperClass()、setCombinerClass()和setReducerClass()方法用来指定Mapper、Combiner和Reducer的实现类。
setOutputKeyClass()和setOutputValueClass()方法分别用来设置MapReduce作业的输出键和输出值的类型。
FileInputFormat.addInputPath()和FileOutputFormat.setOutputPath()方法用来指定输入文件和输出文件的路径。
最后,我们调用job.waitForCompletion()方法来提交并运行作业,并等待作业完成。
如果作业成功完成,waitForCompletion()方法将返回true,否则返回false。
如果作业失败,我们可以通过job.getJobState()方法来获取作业的状态信息,或者查看作业的日志信息来进行排错和调试。
2 Hadoop序列化
2.1 序列化的定义
序列化就是将内存中对象转换成字节序列,便于存储到磁盘和网络传输
反序列化时将字节序列或磁盘中的持久化数据转换成内存中的对象
一般来说,对象只能在本地进程中使用,不能通过网络发送到另一台计算机
序列化可以存储对象,可以将对象发送到远程计算机
2.2 hadoop序列化和java序列化的区别
Hadoop序列化和Java序列化都是将对象转换为字节序列以便于在网络上传输或者存储到磁盘等持久化存储介质中。它们的主要区别在于以下几点:
-
序列化速度和效率不同:Hadoop序列化比Java序列化更快,因为它采用的是二进制格式,而Java序列化采用的是基于文本的XML或JSON格式。
-
支持的数据类型不同:Hadoop序列化支持的数据类型比Java序列化更多,包括基本类型、数组、集合、映射、枚举、自定义类等。
-
序列化后的数据大小不同:Hadoop序列化生成的字节流比Java序列化生成的字节流更小,因为它使用更紧凑的二进制格式,这对于在网络上传输和存储到磁盘等介质中非常重要。
-
可移植性不同:Java序列化生成的字节流只能被Java程序读取,而Hadoop序列化生成的字节流可以被任何语言的程序读取,因为它使用了通用的二进制格式。
总的来说,Hadoop序列化更适合用于大规模数据的处理和分布式计算,而Java序列化更适合用于小规模数据的传输和存储。
3 MapReduce 的原理
3.1 MapReduce 工作的过程
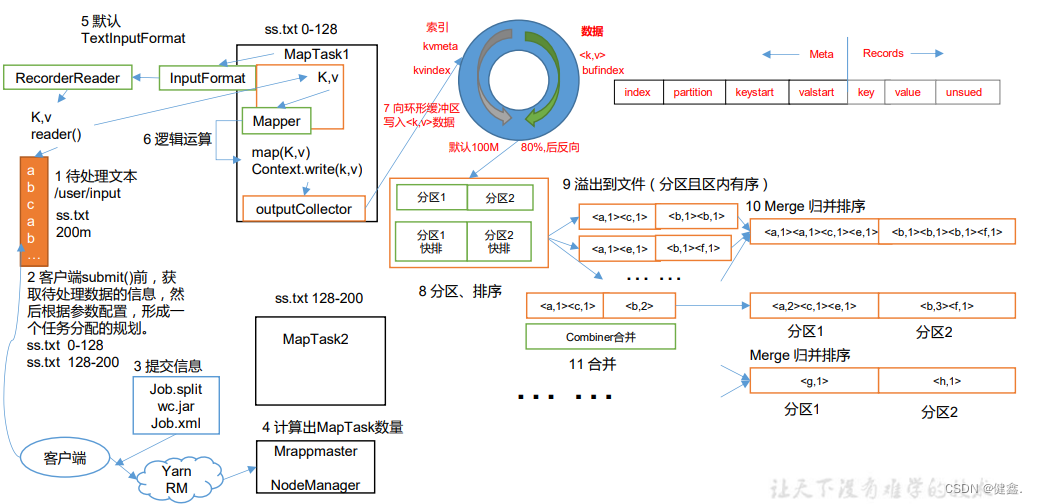
数据输入:MapReduce从Hadoop分布式文件系统(HDFS)中读取输入数据,并将其分成固定大小的数据块,每个数据块大小通常为64MB。
Map阶段:在Map阶段,MapReduce将每个数据块分发给一组可扩展的计算节点,每个计算节点运行Map函数来处理它们分配的数据块。Map函数将输入数据转换为一组键值对(Key-Value Pairs)的形式,这些键值对可以被后续的Reduce函数处理。
Shuffle阶段:在Map函数处理完数据之后,MapReduce框架将所有的键值对按照它们的键进行排序,并将相同键的值合并在一起。这个过程通常被称为“Shuffle”。
Reduce阶段:在Reduce阶段,MapReduce框架将合并后的键值对发送到一组可扩展的计算节点。每个节点运行Reduce函数来处理它们收到的所有键值对,并生成最终的输出结果。
数据输出:在Reduce函数处理完数据之后,MapReduce将输出结果写入HDFS中。
这些步骤中,Map和Reduce函数是由开发者自行编写的,它们实现了具体的业务逻辑。MapReduce框架提供了分布式计算的基础设施,负责管理计算节点、任务分配、故障处理等任务,以保证整个计算过程的可靠性和高效性。
总的来说,MapReduce框架的原理是将大数据集划分成多个小数据块,然后将这些数据块分发给多个计算节点并行处理,最后将处理结果合并为一个最终结果。它通过这种方式来充分利用集群中的计算资源,提高计算效率和数据处理能力。
3.2 InputFormat 数据输入
3.2.1 切片
数据块:Block时HDFS在物理上对数据进行切块,是HDFS存储数据的单位
数据切片:数据切片是在逻辑上对输入进行切片。切片是MR程序计算输入数据的单位,一个切片会启动一个MapTask
客户端提交job时的切片数决定了map阶段的并行度
默认情况下,切片大小为BlockSize
切片不会考虑数据整体,是对每个文件进行单独切片
3.2.2 FileInputFormat
在MapReduce中,FileInputFormat是一个抽象类,用于定义如何将文件分割成输入数据块并生成适合Mapper处理的RecordReader。它是MapReduce中的输入格式类之一,用于读取Hadoop分布式文件系统(HDFS)或本地文件系统中的数据。
FileInputFormat包括两个关键方法:getSplits()和createRecordReader()。
getSplits()方法将输入文件划分成适合Map任务的数据块,每个数据块对应一个Map任务。该方法返回一个InputSplit对象的数组,其中每个InputSplit表示一个文件数据块。
createRecordReader()方法创建一个RecordReader对象,用于读取InputSplit中的数据块。RecordReader负责读取一个数据块中的所有记录,并将它们转换成key-value对。
FileInputFormat还提供了一些其他的方法,如isSplitable()用于判断一个文件是否可以被划分成多个数据块。
Hadoop提供了一些预定义的FileInputFormat类,如TextInputFormat用于读取文本文件,SequenceFileInputFormat用于读取SequenceFile格式的文件等,用户也可以通过继承FileInputFormat自定义输入格式类。
3.2.3 TextInputFormat
TextInputFormat是FileInputFormat默认的实现类,按行读取每条记录
key为该行的起始字节偏移量,为LongWritable类型
value 为这一行的内容,不包括终止符,为Text类型
3.2.4 CombineTextInputFormat
TextInputFormat是按文件进行规划分片,不管文件有多小,都是是一个单独的切片,这样会产生大量的MapTask,效率低下
CombineTextInputFormat用于小文件过多的场景,可以将多个小文件在逻辑上划分到一个切片
决定哪些块放入同一个分片时,CombineTextInputFormat会考虑到节点和机架的因素,所以在MR作业处理输入的速度不会下降
CombineTextInputFormat不仅可以很好的处理小文件,在处理大文件时也有好处,因为它在每个节点生成了一个分片,分片可能又多个块组成,CombineTextInputFormat使map操作中处理的数据量和HDFS中文件块的大小的耦合度降低了
3.3 MapReduce工作机制
3.3.1 MapTask工作机制
- 读取输入数据:MapTask通过InputFormat获得RecordReader,从输入InputSplit中解析出KV
- Map阶段:将解析出的KV交给map()函数处理,产生一系列新的KV
- Collect收集:数据处理完成之后,会调用OutputCollector.collect()输出结果。在该函数的内部,会生成KV分区,写入环形缓冲区中
- Spill阶段:环形缓冲区满了之后,MR会将数据写到本地磁盘,形成一个临时文件,在写入之前,会对数据进行一次排序
- merge阶段:所有数据处理完毕之后,MapTask会对所有临时文件进行一次合并,确保只生成一个数据文件
Spill阶段详情:
- 通过快速排序对环形缓冲区内的数据进行排序,先按照partition(后面会介绍)编号进行排序,然后再按照K进行排序。排序过后,数据以分区为单位聚集,分区内的所有数按照K有序
- 按照分区编号由小到大将分区数据写入工作目录下的临时文件 output/spillN.out(N表示当前溢写的次数),如果设置了combiner(后面会介绍),则写入文件之前,还会将分区中的数据进行一次聚集操作
- 将分区数据的元数据写入到内存索引数据结构SpillRecord中,每个分区的元数据包括临时文件的偏移量、压缩前后的数据大小,如果内存索引大于1MB,会将内存索引写到文件 output.spillN.out.index中
3.3.2 Partition分区
在MapReduce计算模型中,Map任务会将生成的键值对按照键进行排序,并将其划分到不同的分区中。分区的数量通常等于Reduce任务的数量。具体来说,Map任务会按照Partitioner函数定义的分区规则对键值对进行划分。Partitioner函数将每个键值对映射到一个分区编号,然后Map任务将其输出到对应的分区中。
Partitioner函数通常是由用户自定义实现的,其作用是将键值对映射到一个特定的分区。Hadoop提供了默认的Partitioner实现,即HashPartitioner,它将键哈希后取模得到分区编号,从而实现对键值对的划分。在实际应用中,用户可以根据自己的需求自定义Partitioner函数,以便将键值对划分到特定的分区中。
如果ReduceTask数量 > Partition数量,会产生多个空的输出文件
如果ReduceTask数量 < Partition数量,会导致有分区的数据无处安放,会Exception
如果ReduceTask数量 = 1,则不管有多少个分区文件,最终都会只产生一个文件
3.3.3 Combiner合并
Combiner在每个mapTask所在的节点运行
Combiner对每个MapTask的输出进行局部汇总,减少reduce阶段的负担
Combiner使用的前提是不能影响业务逻辑
3.3.4 ReduceTask工作机制
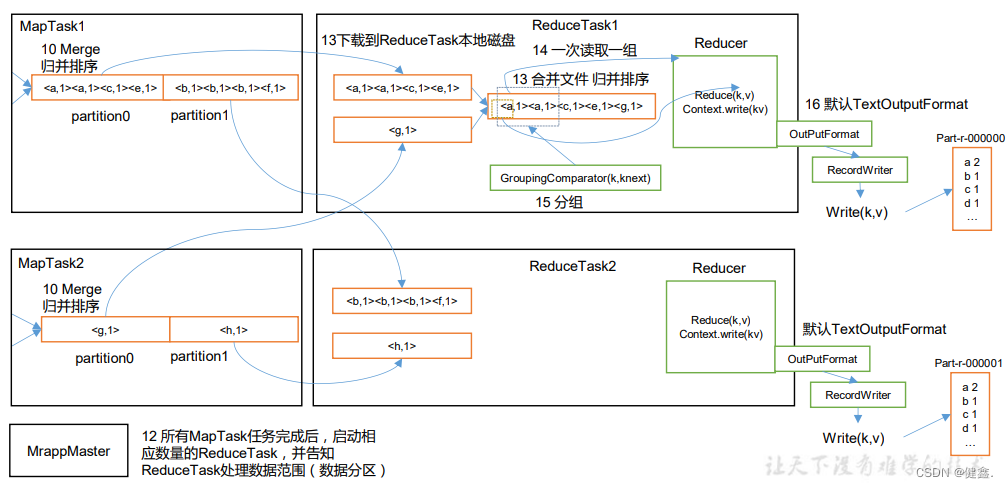
Copy:拉取数据,Reduce进程启动copy进程(Fetcher),通过HTTP的方式请求maptask获取自己的文件,map task分区表示每个map task属于哪个reduce task
Merge:ReduceTask启动两个线程对内存和磁盘中的文件进行合并,防止文件过多。当内存中的数据达到一定阈值时,就会启动内存到磁盘的merge,与map端的相似。直到没有map端的数据才结束
合并排序:将数据合并成一个大数据,并进行排序
对排序后的数据调用reduce方法:对键相同的键值对调用reduce方法,每次调用会产生零个或多个键值对,最后将输出的键值对存入HDFS。
3.3.5 shuffle机制
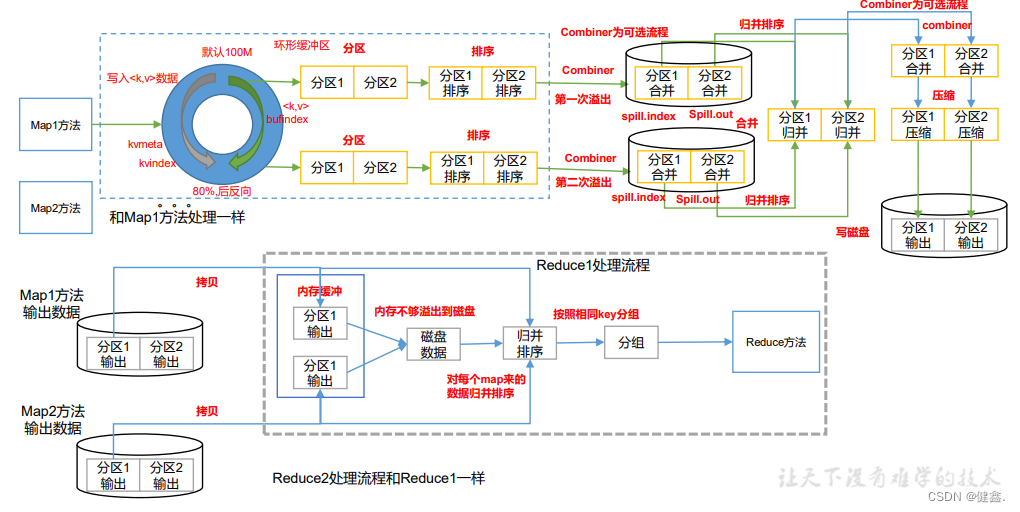
Shuffle阶段的过程可以分为三个阶段:
Map端的输出:Map任务将生成的键值对按照键排序,并将其划分到不同的分区中。如果Map任务的输出缓存区已满,则需要将其溢出到本地磁盘的临时文件中。
数据传输:在Shuffle阶段中,Map任务的输出需要传输到Reduce任务所在的节点,以便Reduce任务可以从中提取和合并数据。数据传输是Shuffle阶段的关键步骤,其速度和效率直接影响整个MapReduce作业的性能。
Reduce端的输入:Reduce任务需要从本地磁盘读取属于自己的分区的临时文件,并对同一个分区中的键值对进行合并和排序。Reduce任务将合并后的结果输出到最终的输出文件中。
Shuffle阶段是MapReduce计算模型中非常重要的一个阶段,它的性能和效率对整个作业的执行时间和性能影响非常大。因此,优化Shuffle阶段的性能和效率是MapReduce应用程序优化的一个关键方向。
3.3.6 排序的解释
MapTask和ReduceTask对key进行排序是为了方便后续的数据处理和计算。
具体来说,对于MapTask而言,对输出的key进行排序可以将具有相同key值的记录聚合在一起,方便ReduceTask进行处理。
而对于ReduceTask而言,对输入的key进行排序可以让具有相同key值的记录相邻排列,方便进行聚合和计算。
一般来说,在Map任务中,对键值对进行快速排序的次数是一次,即将数据写入环形缓冲区之前对其中的键值对进行排序。这是因为,对于同一个Map任务的输出,在Map输出的环形缓冲区中进行快速排序即可满足Reduce任务在Shuffle阶段的需求,而不需要进行额外的排序。
在Shuffle阶段,如果存在多个环形缓冲区需要合并,Reduce任务会对它们进行归并排序。这是因为,不同Map任务的输出在Shuffle阶段需要合并,而这些输出之间的顺序是无序的,因此需要进行排序以便进行合并。这次排序是对整个数据集进行的,而不是对单个Map任务的输出进行的。
当Reduce任务接收到来自多个Map任务的中间结果时,它会对同一个分区内的所有键值对进行排序。这里采用的排序算法一般也是归并排序,因为归并排序的时间复杂度是O(nlogn),且适合对大量数据进行排序。这次排序也是对整个数据集进行的,而不是对单个Map任务的输出进行的。
因此,总体来说,Shuffle阶段需要进行多次排序,具体排序的次数可能因具体实现而有所不同。但无论是哪种具体实现,Shuffle阶段都需要对整个数据集进行排序以便后续的计算和处理。
4 数据压缩
4.1 压缩算法对比
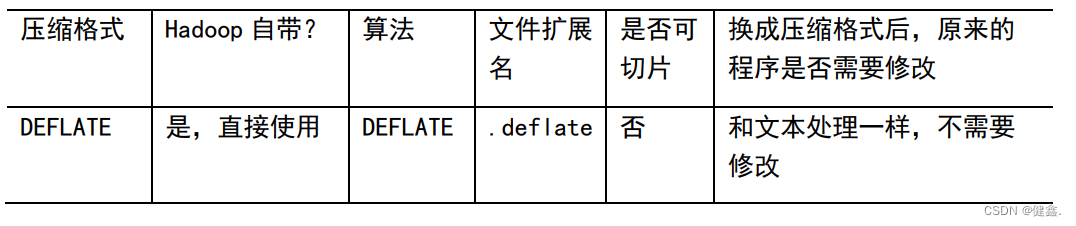
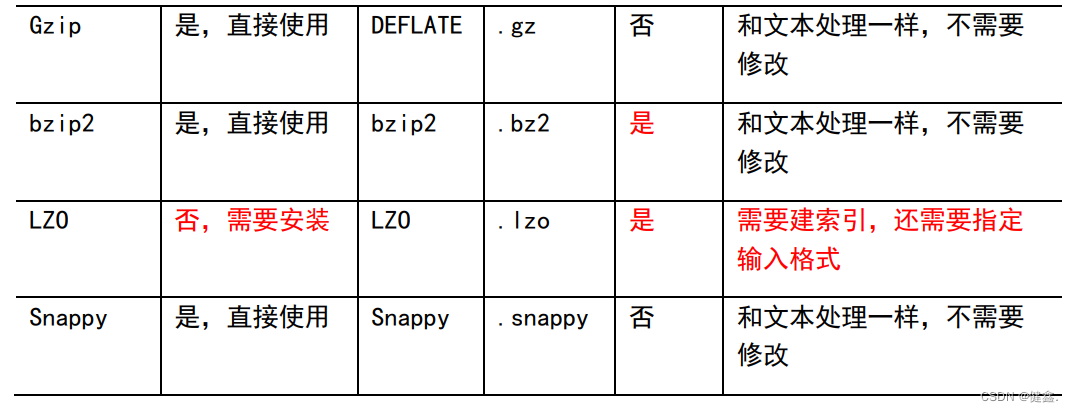
4.2 压缩位置选择

相关文章:
Hadoop-MapReduce
Hadoop-MapReduce 文章目录Hadoop-MapReduce1 MapRedcue的介绍1.1 MapReduce定义1.2 MapReduce的思想1.3MapReduce优点1.4MapReduce的缺点1.5 MapReduce进程1.6 MapReduce-WordCount1.6.1 job的讲解2 Hadoop序列化2.1 序列化的定义2.2 hadoop序列化和java序列化的区别3 MapRedu…...

ChatGPT来了,软件测试工程师距离失业还远吗?
小伙伴们前一段是不是都看到过ChatGPT的相关视频,那它到底是什么?对软件测试行业会有什么影响? 今天汇智妹就用一篇文章来给大家讲清楚。 一、ChatGPT是什么? 简单来说,ChatGPT是一款人工智能聊天机器人,…...

【项目实战】Linux服务管理 之 开启/关闭防火墙
一、service命令是什么? service命令用于对系统服务进行管理,比如 启动(start)停止(stop)重启(restart)查看状态(status) service命令本身是一个shell脚本…...
OSS存储使用之centOS系统ossfs挂载
以CentOS7系统为例 下载CentOS系统支持的ossfs工具的版本,以下载CentOS 7.0 (x64)版本为例,可以通过wget命令进行安装包的下载 wget http://gosspublic.alicdn.com/ossfs/ossfs_1.80.6_centos7.0_x86_64.rpm 也可以通过yum命令来进行安装包的下载 sud…...
配置)
【项目实战】SpringBoot多环境(dev、test、prod)配置
一、三套环境介绍 1.1 开发环境(dev) 开发环境是程序猿们专门用于开发的服务器,配置可以比较随意 为了开发调试方便,一般打开全部错误报告。 1.2 测试环境(test) 一般是克隆一份生产环境的配置 一个程序在测试环境工作不正常,那么肯定不能把它发布到生产机上。 有些…...
Laravel框架01:composer和Laravel简介
Laravel框架01:composer和Laravel简介一、Composer介绍二、创建Laravel项目三、Laravel目录结构四、Laravel启动方式一、Composer介绍 composer 是PHP中用来管理依赖关系的工具。类似于Javascript的NPM。composer官网:https://getcomposer.org/安装结束…...

【bug】Transformer输出张量的值全部相同?!
【bug】Transformer输出张量的值全部相同?!现象原因解决现象 输入经过TransformerEncoderLayer之后,基本所有输出都相同了。 核心代码如下, from torch.nn import TransformerEncoderLayer self.trans TransformerEncoderLayer…...
【LeetCode】剑指 Offer(8)
目录 题目:剑指 Offer 21. 调整数组顺序使奇数位于偶数前面 - 力扣(Leetcode) 题目的接口: 解题思路: 代码: 过啦!!! 题目:剑指 Offer 24. 反转链表 - …...
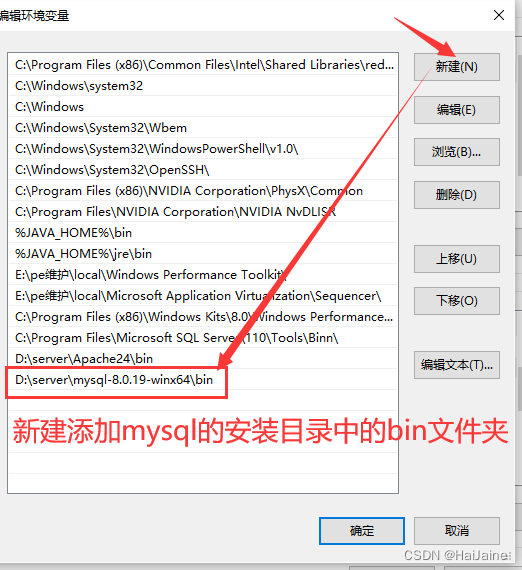
安装MySQL数据库
安装MySQL数据库 获取软件:https://dev.mysql.com/downloads/mysql/ 下载完成后进行解压操作 若安装目录里没有my.ini配置文件,则需要新建一个my.ini的配置文件。 编辑my.ini配置文件,将配置文件中的内容修改成下面内容 [client] # 设置…...
手写Android性能监测工具,支持Fps/流量/内存/启动等
App性能如何量化:如何衡量一个APP性能好坏?直观感受就是:启动快、流畅、不闪退、耗电少等感官指标,反应到技术层面包装下就是:FPS(帧率)、界面渲染速度、Crash率、网络、CPU使用率、电量损耗速度等…...
Java IO)
Java知识复习(三)Java IO
1、IO流 IO流:数据传输过程类似于水流,故称IO流 IO流的的40多个类都是从4个抽象类基类中派生出来的,前者是字节,后者是字符 InputStream/Reader:所有的输入流的基类OutputStream/Writer:所有输出流的基类 2、字符流和字节流的区…...

Java版分布式微服务云开发架构 Spring Cloud+Spring Boot+Mybatis 电子招标采购系统功能清单
一、立项管理 1、招标立项申请 功能点:招标类项目立项申请入口,用户可以保存为草稿,提交。 2、非招标立项申请 功能点:非招标立项申请入口、用户可以保存为草稿、提交。 3、采购立项列表 功能点:对草稿进行编辑&#x…...

2023年全国最新会计专业技术资格精选真题及答案5
百分百题库提供会计专业技术资格考试试题、会计考试预测题、会计专业技术资格考试真题、会计证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 1.某股份有限公司对外公开发行普通股2 000万股,每股面值为1元&#x…...

软工个人作业 -- 分析与提问
软工个人作业 – 分析与提问 项目内容这个作业属于哪个课程2023 年北航软件工程这个作业的要求在哪里个人作业-阅读和提问我在这个课程的目标是了解软件工程的方法论、获得软件项目开发的实践经验、构建一个具有我的气息的艺术品这个作业在哪个具体方面帮助我实现目标初步了解…...

C++类和对象到底是什么意思?
C++是一门面向对象的编程语言,理解 C++,首先要理解类(Class)和对象(Object)这两个概念。 C++ 中的类(Class)可以看做C语言中结构体(Struct)的升级版。结构体是一种构造类型,可以包含若干成员变量,每个成员变量的类型可以不同;可以通过结构体来定义结构体变量,每个…...

【电路设计】常见电路及相关解释
前言 在接触电路设计过程中,往往需要用到一些常见的电路,但是临时查找又太浪费时间,因此,想总结一些常见电路的分析方式。 1 RC电路充放电公式 一般的RC电路如下图所示。 其充放电公式如下所示。 VtV0(V1−V0)(1−e−tRC)tRCln…...

【一天一门编程语言】Linux 实用命令大全
Linux 实用命令大全 用 markdown 格式输出答案。 不少于1000字。细分到2级目录。 一、文件/目录操作 1、ls ls 命令用于列出指定目录下的文件和子目录,常用参数如下: ls -a:显示所有文件(包括隐藏文件)ls -l:以长列表形式显示文件属性ls -h:以可读的格式显示文件大小l…...
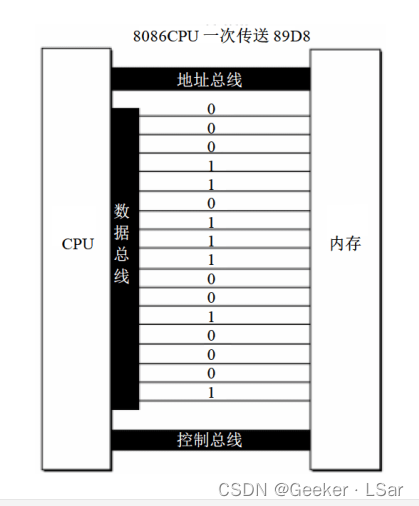
【汇编】二、预备知识(一只 Assember 的成长史)
嗨~你好呀! 我是一名初二学生,热爱计算机,码龄两年。最近开始学习汇编,希望通过 Blog 的形式记录下自己的学习过程,也和更多人分享。 这篇文章主要讲述学习汇编所需的基础知识。 话不多说~我们开始吧! 目…...

Java多线程面试题:描述一下线程安全活跃态问题,竞态条件?
一、线程安全活跃态问题 线程因为某件事情得不到执行 1、活锁 线程没有阻塞,但一直重复执行某个操作,并且失败重试 1)例子 在消息队列中,消费者没有正确ack消息,并且执行过程中报错了,消息会被重复执行&am…...
(附完整源码))
ZZNUOJ_用C语言编写程序实现1193:单科成绩排序(结构体专题)(附完整源码)
题目描述 有一学生成绩表,包括学号、姓名、3门课程成绩。请按要求排序输出:若输入1,则按第1门课成绩降序输出成绩表,若输入为i(1<i<3),则按第i门课成绩降序输出成绩表。 输入 首先输入一个整数n(1<…...

家居用品展行业深度分析:格局、痛点与前景
家居用品展是家居产业的风向标与商贸核心枢纽,2026年行业正处于存量焕新、设计驱动、数智赋能的关键转型期。本文从发展现状、核心格局、痛点拆解、趋势机遇、前景预判五大维度,深度剖析家居用品展行业的底层逻辑与发展脉络,助力从业者把握行…...
”)
超自动化运维,您需要的是“可信执行平台(TEP)”
在AI智能体与自动化工具蓬勃发展的今天,各类开源框架与轻量工具层出不穷。它们让“用自然语言驱动电脑做事”的愿景触手可及——文件操作、脚本执行、浏览器控制,一切看似高效便捷。然而,当我们将视线从个人桌面转向企业的数据中心、核心生产…...

ICode竞赛Python三级通关秘籍:用if else控制飞船和机器人走迷宫
ICode竞赛Python三级通关秘籍:用if else控制飞船和机器人走迷宫 在ICode国际青少年编程竞赛的Python三级训练场中,掌握if else条件判断是解锁迷宫挑战的关键。不同于枯燥的语法练习,我们将通过飞船(Spaceship)和机器人(Dev)的视角,…...

跨境漫游通信解析:全球漫游物联网卡的适配逻辑与行业应用
在跨境物联网行业中,除固定单一国家投放的设备外,有大量终端设备存在跨区域流动、多国家部署、不定向出海的使用需求。车载定位、跨境物流终端、移动式工控、巡回检测设备,这类硬件无法限定单一运营商网络,对多国网络切换、信号漫…...

丹麦语语音合成总不“像真人”?揭秘ElevenLabs最新v3.2引擎中未公开的3个丹麦语重音标记开关,限前200名开发者速查
更多请点击: https://intelliparadigm.com 第一章:丹麦语语音合成的“真人感”困局本质 丹麦语语音合成长期面临“真人感”缺失的核心挑战,其根源并非单纯的数据量不足或模型容量有限,而是深植于该语言独特的音系结构与韵律特征之…...

3步解锁百度文库纯净阅读:告别广告干扰的智能解决方案
3步解锁百度文库纯净阅读:告别广告干扰的智能解决方案 【免费下载链接】baidu-wenku fetch the document for free 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wenku 你是否曾在百度文库找到宝贵资料却被广告栏、推荐模块和导航菜单包围,…...

告别臃肿:Win11Debloat让你的Windows 11系统焕然一新
告别臃肿:Win11Debloat让你的Windows 11系统焕然一新 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and cus…...
:声调准确率92.6%、连读自然度行业首破88分)
ElevenLabs湖南话TTS深度评测(2024真实场景压测报告):声调准确率92.6%、连读自然度行业首破88分
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs湖南话语音技术概览 ElevenLabs 作为全球领先的语音合成平台,其多语言支持能力持续扩展,但需明确指出:截至 2024 年底,ElevenLabs 官方模型库*…...
)
ElevenLabs客家话语音合规红线预警:GDPR+《生成式AI服务管理暂行办法》双框架下,3类方言数据采集授权漏洞与2种语音指纹脱敏方案(含可审计代码模板)
更多请点击: https://codechina.net 第一章:ElevenLabs客家话语音合规红线预警总览 ElevenLabs 作为前沿的AI语音合成平台,其多语言支持能力持续扩展,但对客家话等非标准化方言的生成存在明确的合规边界。平台未将客家话列入官方…...

MASA模组中文汉化包:为中文玩家打造的完整界面本地化解决方案
MASA模组中文汉化包:为中文玩家打造的完整界面本地化解决方案 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 还在为Minecraft中复杂的英文模组界面而困扰吗?MAS…...