C现代方法(第9章)笔记——函数
文章目录
- 第9章 函数
- 9.1 函数的定义和调用
- 9.1.1 函数定义
- 9.1.2 函数调用
- 9.2 函数声明
- 9.3 实际参数
- 9.3.1 实际参数的转换
- 9.3.2 数组型实际参数
- 9.3.3 变长数组形式参数(C99)
- 9.3.4 在数组参数声明中使用static(C99)
- 9.3.5 复合字面量
- 9.4 return语句
- 9.5 程序终止
- 9.5.1 exit函数
- 9.6 递归
- 9.6.1 快速排序算法
- 9.7 泛型选择(C1X)
- 问与答
- 总结
第9章 函数
——如果你有一个带了10个参数的过程,那么你很可能还遗漏了一些参数。
函数简单来说就是一连串语句,这些语句被组合在一起,并被指定了一个名字。虽然“函数”这个术语来自数学,但是C语言的函数不完全等同于数学函数。
在C语言中,函数不一定要有参数,也不一定要计算数值。(在某些编程语言中,“函数”需要返回一个值,而“过程”不返回值。C语言没有这样的区别。)函数是C程序的构建块。每个函数本质上是一个自带声明和语句的小程序。可以利用函数把程序划分成小块,这样便于人们理解和修改程序。由于不必重复编写要多次使用的代码,函数可以使编程不那么单调乏味。此外,函数可以复用:一个函数最初可能是某个程序的一部分,但可以将其用于其他程序。
到目前为止,我们的程序都是只由一个
main函数构成的。本章将学习如何编写除main函数以外的其他函数,并更加深入地了解main函数本身。9.1节介绍定义和调用函数的方法;9.2节讨论函数的声明,以及它和函数定义的差异;接下来,9.3节讲述参数是怎么传递给函数的。余下的部分讨论return语句(9.4 节)、与程序终止相关的问题(9.5 节)和递归(9.6 节)。
9.1 函数的定义和调用
假设我们经常需要计算两个double类型数值的平均值。C语言没有“求平均值”函数,但是可以自己定义一个。下面就是这个函数:
double average(double a, double b)
{ return (a + b) / 2;
}
位于函数开始处的单词
double表示average函数的返回类型(return type),也就是每次调用该函数时返回数据的类型。标识符a和标识符b[即函数的形式参数(形参,parameter)]表示在调用average函数时需要提供的两个数。每一个形式参数都必须有类型(正像每个变量有类型一样),这里选择了double作为a和b的类型。(这看上去有点奇怪,但是单词double必须出现两次:一次为a,另一次为b。)函数的形式参数本质上是变量,其初始值在调用函数的时候才提供。
每个函数都有一个带有花括号的执行部分,称为函数体(body)。因此,每个函数体都是一个复合语句(5.2.1节)。average函数的函数体由一对花括号,以及其中的return语句组成。执行return语句会使函数“返回”到调用它的地方,表达式(a+b)/2的值将作为函数的返回值。
为了调用函数,需要写出函数名及跟随其后的
实际参数(argument)列表。例如,average(x, y)是对average函数的调用。实际参数用来给函数提供信息。在此例中,函数average需要知道求哪两个数的平均值。调用average(x, y)的效果就是把变量x和变量y的值复制给形式参数a和b,然后执行average函数的函数体。实际参数不一定是变量,任何正确类型的表达式都可以,average(5.1, 8.9)和average(x/2, y/3)都是合法的函数调用。
我们把average函数的调用放在需要使用其返回值的地方。例如,为了计算并显示出x和y的平均值,可以写为
printf("Average: %g\n", average(x, y));
这条语句产生如下效果:
- 以变量
x和变量y作为实际参数调用average函数。 - 把
x和y的值复制给a和b。 average函数执行自己的return语句,返回a和b的平均值。printf函数显示出函数average的返回值。(average函数的返回值成了函数printf的一个实际参数。)
注意!!我们没有保存
average函数的返回值,程序显示这个值后就把它丢弃了。如果需要在稍后的程序中用到返回值,可以把这个返回值赋值给变量:
//这条语句调用了average函数,然后把它的返回值存储在变量avg中。
avg = average(x, y);
现在把average函数放在一个完整的程序中来使用。下面的程序读取了3个数并且计算它们的平均值,每次计算一对数的平均值(其中值得一提的是,这个程序表明可以根据需要多次调用一个函数):
/*
average.c
---Computes pairwise averages of three numbers
*/#include <stdio.h> double average(double a, double b)
{ return (a + b) / 2;
} int main(void)
{ double x, y, z; printf("Enter three numbers: "); scanf("%lf%lf%lf", &x, &y, &z); printf("Average of %g and %g: %g\n", x, y, average(x, y)); printf("Average of %g and %g: %g\n", y, z, average(y, z)); printf("Average of %g and %g: %g\n", x, z, average(x, z)); return 0;
} /*
Enter three numbers: 3.5 9.6 10.2
Average of 3.5 and 9.6: 6.55
Average of 9.6 and 10.2: 9.9
Average of 3.5 and 10.2: 6.85
*/注意,这里把average函数的定义放在了main函数的前面。在9.2节我们将看到,把average函数的定义放在main函数的后面可能会有问题。
不是每个函数都返回一个值。例如,进行输出操作的函数可能不需要返回任何值。为了指示出不带返回值的函数,需要指明这类函数的返回类型是
void。(void是一种没有值的类型。)思考下面的函数,这个函数用来显示信息T minus n and counting,其中n的值在调用函数时提供:
void print_count(int n)
{ printf("T minus %d and counting\n", n);
}
函数print_count有一个形式参数n,参数的类型为int。此函数没有返回任何值,所以用void指明它的返回值类型,并且省略了return语句。既然print_count函数没有返回值,那么不能使用调用average函数的方法来调用它。print_count函数的调用必须自成一个语句:
print_count(i);
下面这个程序在循环内调用了10次print_count函数:
/*
countdown.c
---Prints a countdown
*/#include <stdio.h> void print_count(int n)
{ printf("T minus %d and counting\n", n);
} int main(void)
{ int i; for (i = 10; i > 0; --i) print_count(i); return 0;
}最开始,变量i的值为10。第一次调用print_count函数时,i被复制给n,所以变量n的值也是10。因此,第一次调print_count函数会显示:
T minus 10 and counting
随后,函数print_count返回到被调用的地方,而这个地方恰好是for语句的循环体。for语句再从调用离开的地方重新开始,先让变量i自减变成9,再判断i是否大于0。由于判断结果为真,因此再次调用函数print_count,这次显示:
T minus 9 and counting
每次调用print_count函数时,变量i的值都不同,所以print_count函数会显示10条不同的信息。
有些函数根本没有形式参数。思考下面这个
print_pun函数,它在每次调用时显示一条双关语:
void print_pun(void)
{ printf("To C, or not to C: that is the question.\n");
}
圆括号中的单词void表明print_pun函数没有实际参数。(这里使用void作为占位符,表示“这里没有任何东西”。)
调用不带实际参数的函数时,只需要写出函数名,并且在后面加上一对圆括号:print_pun();,注意!!即使没有实际参数也必须给出圆括号。
下面这个小程序测试了
print_pun函数:
/* Prints a bad pun */ #include <stdio.h> void print_pun(void)
{ printf("To C, or not to C: that is the question.\n");
} int main(void)
{ print_pun(); return 0;
}
程序首先从main函数中的第一条语句开始执行,这里碰巧第一句就是print_pun函数调用。开始执行print_pun函数时,它会调用printf函数显示字符串。当printf函数返回时,print_pun函数也就返回到了main函数。
9.1.1 函数定义
函数定义的一般格式如下:
返回类型 函数名(形式参数)
复合语句
函数的“返回类型”是函数返回值的类型。下列规则用来管理返回类型。
- 函数不能返回数组,但关于返回类型没有其他限制。
- 指定返回类型是
void类型,说明函数没有返回值。 - 如果省略返回类型,
C89会假定函数返回值的类型是int类型,但在C99中这是不合法的。
一些程序员习惯把返回类型放在函数名的上边:
double
average(double a, double b)
{ return (a + b) / 2;
}
/*
如果返回类型很冗长,比如unsigned long int类型,那么把返回类型单独放在一行是非常有用的。
*/
函数名后边有一串形式参数列表。需要在每个形式参数的前面说明其类型,形式参数间用逗号进行分隔。如果函数没有形式参数,那么在圆括号内应该出现void。注意:即使几个形式参数具有相同的数据类型,也必须分别说明每个形式参数的类型。
下面的形参列表写法是错误的:
double average(double a, b) /*** WRONG ***/
{ return (a + b) / 2;
}
这里的复合语句是函数体,函数体由一对花括号,以及内部的声明和语句组成。例如,average函数可以写为:
double average(double a, double b)
{ double sum; /* declaration */ sum = a + b; /* statement */ return sum / 2; /* statement */
}
函数体内声明的变量专属于此函数,其他函数不能对这些变量进行检查或修改。在C89中,变量声明必须出现在语句之前。在C99中,变量声明和语句可以混在一起,只要变量在第一次使用之前进行声明就行。(有些C99之前的编译器也允许声明和语句混合。)
对于返回类型为
void的函数(本书称为“void函数”),其函数体可以只是一对花括号(空的复合语句):
void print_pun(void)
{
}
程序开发过程中留下空函数体是有意义的。因为没有时间完成函数,所以为它预留下空间,以后可以再回来编写它的函数体。
9.1.2 函数调用
函数调用由函数名和跟随其后的实际参数列表组成,其中实际参数列表用圆括号括起来:
average(x, y)
print_count(i)
print_pun()
注意!!如果丢失圆括号,那么将无法进行函数调用,比如print_pun;语句就是错误的,这样的结果是合法(但没有意义)的表达式语句,虽然看上去正确,但是不起任何作用。一些编译器会发出一条类似“statement with no effect”的警告。
void函数调用的后边始终跟着分号,使得该调用成为语句:
print_count(i);
print_pun();
另外,非void函数调用会产生一个值,该值可以存储在变量中,进行测试、显示或者用于其他用途,比如:
avg = average(x, y); if (average(x, y) > 0) printf("Average is positive\n");printf("The average is %g\n", average(x, y));
如果不需要非void函数返回的值,总是可以将其丢弃:
average(x, y); /* discards return value */
为了清楚地表明函数返回值是被故意丢掉的,C语言允许在函数调用前加上
(void):
(void) printf("Hi, Mom!\n");
我们所做的工作就是把printf函数的返回值强制类型转换(7.4节)成void类型。(在C语言中,“强制转换成void”是对“抛弃”的一种客气说法。)使用(void)可以使别人知道代码编写者是故意抛弃返回值的,而不是忘记了。但是,C语言库中大量函数的返回值通常会被丢掉,在调用它们时都使用(void)会很麻烦,因此本书没有这样做。
为了弄清楚如何使程序变得更加容易理解,现在来编写一个程序,检查一个数是否为素数。这个程序将提示用户输入一个数,然后给出一条消息说明此数是否为素数:
/*
prime.c
---Tests whether a number is prime
*/#include <stdbool.h> /* c99 only */
#include <stdio.h> bool is_prime(int n)
{ int divisor; if (n <= 1) return false; for (divisor = 2; divisor * divisor <= n; divisor++) if (n % divisor == 0) return false; return true;
} int main(void)
{ int n; printf("Enter a number: "); scanf("%d", &n); if (is_prime(n)) printf("Prime\n"); else printf("Not prime\n"); return 0;
} /*
Enter a number: 34
Not prime
*/
注意,
main函数包含一个名为n的变量,而is_prime函数的形式参数也叫n。一般来说,在一个函数中可以声明与另一个函数中的变量同名的变量。这两个变量在内存中的地址不同,所以给其中一个变量赋新值不会影响另一个变量。(形式参数也具有这一性质。)10.1节会更详细地讨论这个问题。如
is_prime函数所示,函数可以有多条return语句。但是,在任何一次函数调用中只能执行其中一条return语句,这是因为到达return语句后函数就会返回到调用点。在9.4节我们会更深入地学习return语句。
9.2 函数声明
从前面的程序中可以看出,函数的定义总是放置在调用点的上面。事实上,C语言并没有要求函数的定义必须放置在调用点之前。假如我们在main函数后面定义一个函数:
#include <stdio.h> int main(void)
{ double x, y, z; printf("Enter three numbers: "); scanf("%lf%lf%lf", &x, &y, &z); printf("Average of %g and %g: %g\n", x, y, average(x, y)); printf("Average of %g and %g: %g\n", y, z, average(y, z)); printf("Average of %g and %g: %g\n", x, z, average(x, z));return 0;
} double average (double a, double b)
{ return (a + b) / 2;
}
当遇到main函数中第一个average函数调用时,编译器没有任何关于average函数的信息:编译器不知道average函数有多少形式参数、形式参数的类型是什么,也不知道average函数的返回值是什么类型。但是,编译器不会给出出错消息,而是假设average函数返回int型的值(回顾9.1节的内容,可以知道函数返回值的类型默认为int型)。我们可以说编译器为该函数创建了一个隐式声明(implicit declaration)。编译器无法检查传递给average的实参个数和实参类型,只能进行默认实参提升(9.3节)并期待最好的情况发生。当编译器在后面遇到average的定义时,它会发现函数的返回类型实际上是double而不是int,从而我们得到一条出错消息。
为了避免定义前调用的问题,一种方法是使每个函数的定义都出现在其调用之前。可惜的是,有时候无法进行这样的安排;而且即使可以这样安排,程序也会因为函数定义的顺序不自然而难以阅读。
幸运的是,C语言提供了一种更好的解决办法:在调用前声明每个函数。函数声明(
function declaration)使得编译器可以先对函数进行概要浏览,而函数的完整定义以后再给出。函数声明类似于函数定义的第一行,不同之处是在其结尾处有分号:
//函数的声明必须与函数的定义一致
返回类型 函数名(形式参数);
下面是为average函数添加了声明后程序的样子:
#include <stdio.h> double average(double a, double b); /* 声明 */ int main(void)
{ double x, y, z; printf("Enter three numbers: "); scanf("%lf%lf%lf", &x, &y, &z); printf("Average of %g and %g: %g\n", x, y, average(x, y)); printf("Average of %g and %g: %g\n", y, z, average(y, z)); printf("Average of %g and %g: %g\n", x, z, average(x, z)); return 0;
} double average(double a, double b) /* 定义 */
{ return (a + b) / 2;
}
为了与过去的那种圆括号内为空的函数声明风格相区别,我们把正在讨论的这类函数声明称为函数原型(function prototype)。 原型为如何调用函数提供了完整的描述:提供了多少实际参数、这些参数应该是什么类型,以及返回的结果是什么类型。
顺便提一句,函数原型可以不需要说明函数形式参数的名字,只要显示他们的类型就可以了:
double average(double, double);
通常最好是不要省略形式参数的名字,因为这些名字可以说明每个形式参数的目的,并且提醒程序员在函数调用时实际参数的出现次序。当然,省略形式参数的名字也有一定的道理,有些程序员喜欢这样做。
C99遵循这样的规则:在调用一个函数之前,必须先对其进行声明或定义。调用函数时,如果此前编译器未见到该函数的声明或定义,会导致出错。
9.3 实际参数
复习下形式参数和实际参数的差异:
形式参数(parameter)出现在函数定义中,它们以假名字来表示函数调用时需要提供的值;实际参数(argument)是出现在函数调用中的表达式。
在C语言中,实际参数是
值传递的:调用函数时,计算出每个实际参数的值并且把它赋给相应的形式参数。在函数执行过程中,对形式参数的改变不会影响实际参数的值,这是因为形式参数中包含的是实际参数值的副本。从效果上来说,每个形式参数的行为好像是把变量初始化成与之匹配的实际参数的值。实际参数的值传递既有利也有弊。因为形式参数的修改不会影响到相应的实际参数,所以可以把形式参数作为函数内的变量来使用,这样可以减少真正需要的变量数量。思考下面这个函数,此函数用来计算数
x的n次幂:
int power(int x, int n)
{ int i, result = 1; for (i = 1; i <= n; i++) result = result * x; return result;
}
因为n只是原始指数的副本,所以可以在函数体内修改它,也就不需要使用变量i了:
int power(int x, int n)
{ int result = 1; while (n-- > 0) result = result * x; return result;
}
可惜的是,C语言对实际参数值传递的要求使它很难编写某些类型的函数。例如,假设我们需要一个函数,它把
double型的值分解成整数部分和小数部分。因为函数无法返回两个数,所以可以尝试把两个变量传递给函数并且修改它们:
void decompose(double x, long int_part, double frac_part)
{ int_part = (long) x; /* drops the fractional part of x */ frac_part = x – int_part;
}
假设采用下面的方法调用这个函数:
decompose(3.14159, i, d);
在调用开始时,程序把3.14159复制给x,把i的值复制给int_part,而且把d的值复制给frac_part。然后,decompose函数内的语句把3赋值给int_part,把.14159赋值给frac_part,接着函数返回。可惜的是,变量i和变量d不会因为赋值给int_part和frac_part而受到影响,所以它们在函数调用前后的值是完全一样的。正如将在11.4节看到的那样,稍做一点额外的工作就可以使decompose函数运转起来。但是,我们首先需要介绍更多C语言的特性。
9.3.1 实际参数的转换
C语言允许在实际参数的类型与形式参数的类型不匹配的情况下进行函数调用。管理如何转换实际参数的规则与编译器是否在调用前遇到函数的原型(或者函数的完整定义)有关。
- 编译器在调用前遇到原型。就像使用赋值一样,每个实际参数的值被隐式地转换成相应形式参数的类型。例如,如果把
int类型的实际参数传递给期望得到double类型数据的函数,那么实际参数会被自动转换成double类型。 - 编译器在调用前没有遇到原型。编译器执行默认实参提升:(1)把
float类型的实际参数转换成double类型;(2)执行整值提升,即把char类型和short类型的实际参数转换成int类型。(C99实现了整数提升。)
9.3.2 数组型实际参数
数组经常被用作实际参数。当形式参数是一维数组时,可以(而且是通常情况下)不说明数组的长度:
int f(int a[]) /* no length specified */
{ ...
}
实际参数可以是元素类型正确的任何一维数组。只有一个问题:f函数如何知道数组是多长呢?可惜的是,C语言没有为函数提供任何简便的方法来确定传递给它的数组的长度;如果函数需要,我们必须把长度作为额外的参数提供出来。
请注意!!虽然可以用运算符
sizeof计算出数组变量的长度,但是它无法给出关于数组型形式参数的正确答案:
int f(int a[])
{ int len = sizeof(a) / sizeof(a[0]); /*** WRONG: not the number of elements in a ***/ ...
}
下面的函数说明了一维数组型实际参数的用法。当给出具有int类型值的数组a时,sum_array函数返回数组a中元素的和。因为sum_array函数需要知道数组a的长度,所以必须把长度作为第二个参数提供出来。
int sum_array(int a[], int n)
{ int i, sum = 0; for (i = 0; i < n; i++) sum += a[i]; return sum;
}
其中,sum_array函数的原型有下列形式:
int sum_array(int a[], int n);- 通常情况下,如果愿意的话,则可以省略形式参数的名字:
int sum_array(int [], int);
在调用
sum_array函数时,第一个参数是数组的名字,第二个参数是这个数组的长度。例如:
#define LEN 100 int main(void)
{ int b[LEN], total; ... total = sum_array(b, LEN); ...
}
注意!!在把数组名传递给函数时,不要在数组名的后边放置方括号:
total = sum_array(b[], LEN); /*** WRONG ***/
一个关于数组型实际参数的重要论点:函数无法检测传入的数组长度的正确性。我们可以利用这一点来告诉函数,数组的长度比实际情况小。假设,虽然数组b有100个元素,但是实际仅存储了50个数。通过书写下列语句可以对数组的前50个元素进行求和:
total = sum_array(b, 50); /* sums first 50 elements *//*
sum_array函数将忽略另外50个元素。
(事实上,sum_array函数甚至不知道另外50个元素的存在!),
如果将50改成150,则会超出数组的末尾,从而导致未定义的行为,引发错误。
*/
关于数组型实际参数的另一个重要论点是,函数可以改变数组型形式参数的元素,并且改变会在相应的实际参数中体现出来。例如,下面的函数通过在每个数组元素中存储0来修改数组(因为数组名本质上是其第一个元素的地址):
void store_zeros(int a[], int n)
{ int i; for (i = 0; i < n; i++) a[i] = 0;
}
函数调用store_zeros(b, 100);会在数组b的前100个元素中存储0。数组型实际参数的元素可以修改,这似乎与C语言中实际参数的值传递相矛盾。事实上这并不矛盾,但现在没法解释,等到指针章节再解释。
如果形式参数是多维数组,声明参数时只能省略第一维的长度。例如,如果修改
sum_array函数使得a是一个二维数组,我们可以不指出行的数量,但是必须指定列的数量:
#define LEN 10 int sum_two_dimensional_array(int a[][LEN], int n)
{ int i, j, sum = 0; for (i = 0; i < n; i++) for (j = 0; j < LEN; j++) sum += a[i][j]; return sum;
}
不能传递具有任意列数的多维数组是很讨厌的。幸运的是,我们经常可以通过使用指针数组(13.7节)解决这种困难。C99中的变长数组形式参数则提供了一种更好的解决方案。
9.3.3 变长数组形式参数(C99)
如果使用变长数组形式参数,我们可以显式地说明数组a的长度就是n:
int sum_array(int n, int a[n])
{ ...
}
第一个
参数(n)的值确定了第二个参数(a)的长度。注意,这里交换了形式参数的顺序,使用变长数组形式参数时参数的顺序很重要。请注意!下面的
sum_array函数定义是非法的:
int sum_array(int a[n], int n) /*** WRONG ***/
{ ...
}
//编译器会在遇到int a[n]时显示出错消息,因为此前它没有见过n。
对于新版本的sum_array函数,其函数原型有好几种写法:
- 一种写法是使其看起来跟函数定义一样:
int sum_array(int n, int a[n]); - 另一种写法是用
*(星号)取代数组长度:int sum_array(int n, int a[*]);, - 函数声明时,形式参数的名字是可选的。如果第一个参数定义被省略了,那么就没有办法说明数组
a的长度是n,而星号的使用则为我们提供了一个线索——数组的长度与形式参数列表中前面的参数相关:int sum_array(int, int [*]); - 另外,方括号为空也是合法的。在声明数组参数时我们经常这么做:
int sum_array(int n, int a[]);、int sum_array(int, int []);,但是让括号为空不是一个很好的选择,因为这样并没有说明n和a之间的关系。
一般来说,变长数组形式参数的长度可以是任意表达式。例如,假设我们要编写一个函数来连接两个数组
a和b,要求先复制a的元素,再复制b的元素,把结果写入第三个数组c:
int concatenate(int m, int n, int a[m], int b[n], int c[m+n])
{ ...
}
数组c的长度是a和b的长度之和。这里用于指定数组c长度的表达式只用到了另外两个参数;但一般来说,该表达式可以使用函数外部的变量,甚至可以调用其他函数。
一维变长数组形式参数通过指定数组参数的长度使得函数的声明和定义更具描述性。但是,由于没有进行额外的错误检测,数组参数仍然有可能太长或太短。
如果变长数组参数是多维的,则更加实用。之前,我们尝试过写一个函数来实现二维数组中元素相加。原始的函数要求数组的列数固定。如果使用变长数组形式参数,则可以推广到任意列数的情况:
int sum_two_dimensional_array(int n, int m, int a[n][m])
{ int i, j, sum = 0; for (i = 0; i < n; i++) for (j = 0; j < m; j++) sum += a[i][j]; return sum;
}
这个函数的原型可以是以下几种(行可以为空,但是列不能):
int sum_two_dimensional_array(int n, int m, int a[n][m]);int sum_two_dimensional_array(int n, int m, int a[*][*]);int sum_two_dimensional_array(int n, int m, int a[][m]);int sum_two_dimensional_array(int n, int m, int a[][*]);
9.3.4 在数组参数声明中使用static(C99)
C99允许在数组参数声明中使用关键字static(C99之前static关键字就已经存在,18.2节会讨论它的传统用法)。在下面这个例子中,将
static放在数字3之前,表明数组a的长度至少可以保证是3:
int sum_array(int a[static 3], int n)
{ ...
}
这样使用static不会对程序的行为有任何影响。static的存在只不过是一个“提示”,C编译器可以据此生成更快的指令来访问数组。(如果编译器知道数组总是具有某个最小值,那么它可以在函数调用时预先从内存中取出这些元素值,而不是在遇到函数内部需要用到这些元素的语句时才取出相应的值。)
最后,关于static还有一点值得注意:如果数组参数是多维的,static仅可用于第一维(例如,指定二维数组的行数)。
9.3.5 复合字面量
回到sum_array函数,当调用sum_array函数时,第一个参数通常是(用于求和的)数组的名字。例如,可以这样调用sum_array:
int b[] = {3, 0, 3, 4, 1};
total = sum_array(b, 5);
这样写的唯一问题是需要把
b作为一个变量声明,并在调用前进行初始化。如果b不作他用,这样做其实有点浪费。在
C99中,可以使用复合字面量来避免该问题,复合字面量是通过指定其包含的元素而创建的没有名字的数组。下面调用sum_array函数,第一个参数就是一个复合字面量:
total = sum_array((int []){3, 0, 3, 4, 1}, 5);
在这个例子中,复合字面量创建了一个由5个整数(3、0、3、4 和 1)组成的数组。这里没有对数组的长度做特别的说明,其长度是由复合字面量的元素个数决定的。当然也可以显式地指明长度,如(int[4]){1, 9, 2, 1},这种方式等同于(int[]){1, 9, 2, 1}。
一般来说,复合字面量的格式如下:先在一对圆括号内给定类型名,随后是一个初始化器,用来指定初始值。因此,可以在复合字面量的初始化器中使用指示器( 8.1 节)一样,而且同样可以不提供完全的初始化(未初始化的元素默认被初始化为0)。例如,复合字面量
(int[10]){8, 6}有10个元素,前两个元素的值为8和6,剩下的元素值为0。
函数内部创建的复合字面量可以包含任意的表达式,不限于常量。例如:
total = sum_array((int []){2 * i, i + j, j * k}, 3);
//其中i、j、k 都是变量。
复合字面量为左值(4.2节),所以其元素的值可以改变。如果要求其值为“只读”,可以在类型前加上
const,如(const int []){5, 4}。
9.4 return语句
非void的函数必须使用return语句来指定将要返回的值。return语句有如下格式:
return 表达式;
该表达式经常只有常量或变量:
return 0;
return status;
但它也可能是更加复杂的表达式。例如,在return语句的表达式中看到条件运算符是很平常的:
return n >= 0 ? n : 0;
如果
return语句中表达式的类型和函数的返回类型不匹配,那么系统会把表达式的类型隐式地转换成返回类型。例如,如果声明函数返回int类型值,但是return语句包含double类型表达式,那么系统会把表达式的值转换成int类型。
如果没有给出表达式,return语句可以出现在返回类型为void的函数中:
return; /* return in a void function *
如果把表达式放置在上述这种return语句中,则会抛出一个编译时错误。
下面的例子中,在给出负的实际参数时,
return语句会导致函数立刻返回:
void print_int(int i)
{ if (i < 0) return; printf("%d", i);
}
//如果i小于0,print_int将直接返回,不会调用printf。
return语句可以出现在void函数的末尾:
void print_pun(void)
{ printf("To C, or not to C: that is the question.\n"); return; /* OK, but not needed */
}
//return语句不是必需的,因为在执行完最后一条语句后函数将自动返回。
如果非void函数到达了函数体的末尾(也就是说没有执行return语句),那么如果程序试图使用函数的返回值,其行为是未定义的。有些编译器会在发现非void函数可能到达函数体末尾时产生“control reaches end of non-void function”这样的警告消息。
9.5 程序终止
既然main是函数,那么它必须有返回类型。正常情况下,main函数的返回类型是int类型,因此我们目前见到的main函数都是这样定义的:
int main(void)
{ ...
}
以往的C程序常常省略main的返回类型,这其实是利用了返回类型默认为int类型的传统:
main(void)
{ ...
}
但省略返回类型在C99中是不合法的,所以最好不要这样做。省略main函数参数列表中的void是合法的,但是(从编程风格的角度看)最好显式地表明main函数没有参数。[后面将看到,main函数有时是有两个参数的,通常名为argc和argv( 13.7 节)。]
main函数返回的值是状态码,在某些操作系统中程序终止时可以检测到状态码。如果程序正常终止,main函数应该返回0;为了表示异常终止,main函数应该返回非0的值(实际上,这一返回值也可以用于其他目的)即使不打算使用状态码,确保每个C程序都返回状态码也是一个很好的实践,因为以后运行程序的人可能需要测试状态码。
9.5.1 exit函数
在
main函数中执行return语句是终止程序的一种方法,另一种方法是调用exit函数,此函数属于<stdlib.h>头(26.2节)。传递给exit函数的实际参数和main函数的返回值具有相同的含义:两者都说明程序终止时的状态。为了表示正常终止,传递0:
exit(0); /* normal termination */
因为0有点模糊,所以C语言允许用EXIT_SUCCESS来代替(效果是相同的):
exit(EXIT_SUCCESS); /* normal termination */
传递EXIT_FAILURE表示异常终止:
exit(EXIT_FAILURE); /* abnormal termination */
EXIT_SUCCESS和EXIT_FAILURE都是定义在<stdlib.h>中的宏。EXIT_SUCCESS和EXIT_FAILURE的值都是由实现定义的,通常分别是0和1。
作为终止程序的方法,
return语句和exit函数关系紧密。事实上,main函数中的语句return 表达式;等价于exit(表达式);
return语句和exit函数之间的差异是,不管哪个函数调用exit函数都会导致程序终止,return语句仅当由main函数调用时才会导致程序终止。一些程序员只使用exit函数,以便更容易定位程序中的全部退出点。
9.6 递归
如果函数调用它本身,那么此函数就是递归的(recursive)。例如,利用公式n!= n×(n-1)!,下面的函数可以递归地计算出n!的结果:
int fact(int n)
{ if (n <= 1) return 1; else return n * fact(n - 1);
}
有些编程语言极度依赖递归,另一些编程语言则甚至不允许使用递归。
C语言介于两者的中间:它允许递归,但是大多数C程序员并不经常使用递归。一旦被调用,
fact函数就会仔细地测试“终止条件”,被调用时,它会立即检查参数是否小于或等于1;为了防止无限递归,所有递归函数都需要某些类型的终止条件。
9.6.1 快速排序算法
实际上,递归经常作为分治法(divide-and-conquer)的结果自然地出现。这种称为分治法的算法设计方法把一个大问题划分成多个较小的问题,然后采用相同的算法分别解决这些小问题。分治法的经典示例就是流行的排序算法——快速排序(quicksort)。快速排序算法的操作如下(为了简化,假设要排序的数组的下标从1到n)。
- 选择数组元素
e(作为“分割元素”),然后重新排列数组,使得元素从1一直到i-1都是小于或等于e的,元素i包含e,而元素从i+1一直到n都是大于或等于e的(最关键的一步)。 - 通过递归地采用快速排序方法,对从
1到i-1的元素进行排序。 - 通过递归地采用快速排序方法,对从
i+1到n的元素进行排序。
执行完第
(1)步后,元素e处在正确的位置上。因为e左侧的元素全都是小于或等于e的,所以第(2)步对这些元素进行排序时,这些小于或等于e的元素也会处在正确的位置上。类似的推理也可以应用于e右侧的元素。该算法依赖于两个命名为
low和high的标记,这两个标记用来跟踪数组内的位置。开始时,low指向数组中的第一个元素,high指向末尾元素。首先把第一个元素(分割元素)复制给其他地方的一个临时存储单元,从而在数组中留出一个“空位”。接下来,从右向左移动high,直到high指向小于分割元素的数时停止。然后把这个数复制给low指向的空位,这将产生一个新的空位(high指向的)。现在从左向右移动low,寻找大于分割元素的数。一旦找到时,就把这个找到的数复制给high指向的空位。重复执行此过程,交替操作low和high直到两者在数组中间的某处相遇时停止。此时,两个标记都指向空位,只要把分割元素复制给空位就够了。最后,分割元素左侧的所有元素都小于或等于
分割元素e,而其右侧的所有元素都大于或等于分割元素e。
开发一个名为quicksort的递归函数,此函数采用快速排序算法对数组元素进行排序。为了测试函数,将由main函数往数组中读入10个元素,调用quicksort函数对该数组进行排序,然后显示数组中的元素:
/*
qsort.c
--Sorts an array of integers using Quicksort algorithm
*/#include <stdio.h>
#define N 10 void quicksort(int a[], int low, int high);
int split(int a[], int low, int high); int main(void)
{ int a[N], i; printf("Enter %d numbers to be sorted: ", N); for (i = 0; i < N; i++) scanf("%d", &a[i]); quicksort(a, 0, N - 1); printf("In sorted order: "); for (i = 0; i < N; i++) printf("%d ", a[i]); printf("\n"); return 0;
} void quicksort(int a[], int low, int high)
{ int middle; if (low >= high) return; middle = split(a, low, high); quicksort(a, low, middle - 1); quicksort(a, middle + 1, high);
} int split(int a[], int low, int high)
{ int part_element = a[low]; for (;;) { while (low < high && part_element <= a[high])high--; if (low >= high) break; a[low++] = a[high]; while (low < high && a[low] <= part_element) low++; if (low >= high) break; a[high--] = a[low]; } a[high] = part_element; return high;
}/*
Enter 10 numbers to be sorted: 9 16 47 82 4 66 12 3 25 51
In sorted order: 3 4 9 12 16 25 47 51 66 82
*/
快速排序算法小结(如何改进其性能):
- 改进分割算法。上面介绍的方法不是最有效的。我们不再选择数组中的第一个元素作为分割元素。
更好的方法是取第一个元素、中间元素和最后一个元素的中间值。分割过程本身也可以加速。特别是在两个while循环中避免测试low < high是可能的。 - 采用不同的方法进行小数组排序。不再递归地使用快速排序法,用一个元素从头到尾地检查数组。针对小数组(比如元素数量少于
25个的数组)更好的方法是采用较为简单的方法。 - 使得快速排序非递归。虽然快速排序本质上是递归算法,并且递归格式的快速排序是最容易理解的,但是实际上若去掉递归会更高效。
改进快速排序的细节可以参考
算法设计方面的书,如Robert Sedgewick的《算法:C语言实现(第1-4部分)基础知识、数据结构、排序及搜索(原书第3版)》。
9.7 泛型选择(C1X)
有时候你可能希望用同一个名字编写好几个函数,因为它们实现类似的功能,只是参数和返回类型不同。这在其他一些高级语言(比如C++)里很容易,因为它们提供函数重载,但C语言不支持这种做法。
实际上,
C标准库已经用了这种手段。从C99开始,C标准库用泛型宏(27.5节)来统一数学函数的各个版本。比如对于正弦函数,为了应对double、float、long double、double _Complex、float _Complex和long double _Complex这些类型的参数,标准库定义了相应的函数:sin、sinf、sinl、csin、csinf和csinl。有了泛型宏之后,我们可以直接用sin来调用它们而不必关心调用的实际上是哪个版本,因为泛型宏可以根据我们传入的参数找到对应的版本。问题在于,虽然
C99的标准库使用了这项技术,但并没有在语言(语法)层面上提供任何支持。为了从语言层面上解决这种需求,从C11开始,C标准引入了泛型选择(generic selection),它是一个表达式,其语法为
_Generic(表达式,泛型关联列表)
这里,泛型关联列表由一个或多个泛型关联组成,如果泛型关联多于一个,则它们之间用逗号“,”分隔。泛型关联的语法为
类型名:表达式
default:表达式
泛型选择是基本表达式,它在程序翻译期间求值,其主要目的是从多个备选的表达式中挑出一个作为结果。泛型选择表达式的类型就是被挑选出的那个表达式的类型;泛型选择表达式的值取决于被挑选出的那个表达式的值。下面通过一个实例来解释泛型选择表达式的功能。
#include <stdio.h>
#include <math.h>
#include <complex.h> #define sin(x) _Generic(x,\ float:sinf,\ double:sin,\ long double:sinl,\ float _Complex:csinf,\ double _Complex:csin,\ long double _Complex:csinl)(x) int main(void)
{ printf("%f\n", sin(.5f)); // S double _Complex d = sin(.3+.5i); printf("%.2f%+.2f*I", creal (d), cimag (d)); return 0;
}
/*
0.479426
0.33+0.50*I
*/
在以上代码中,标识符sin被定义为宏,虽然在头文件<math.h>里也声明了一个同名的函数,但预处理器会先将它识别为宏名并做宏替换。另外,虽然我们在这里将泛型选择表达式定义为宏体,但泛型选择表达式和宏没有任何关系,这个例子有其特殊性:我们是希望用同一个宏名sin来应付不同类型的操作数,并依靠泛型选择表达式解析出与此操作数的类型相匹配的库函数。
以语句
S为例,在预处理期间,C实现将其展开为(为了方便阅读,利用续行符做了对齐处理):
printf("%f\n", _Generic(.5f, \ float:sinf, \ double:sin, \ long double:sinl, \ float _Complex:csinf, \ double _Complex:csin, \ long double _Complex:csinl) \ (x));
在泛型选择表达式中,第一个表达式称为控制表达式(上例中的.5f),它并不求值,C实现只提取它的类型信息。接着,如果某个泛型关联中的类型名和控制表达式的类型兼容(匹配),则泛型选择的结果表达式就是该泛型关联中的表达式。
在上例中,表达式
.5f的类型是float,则最终选择的是表达式sinf。这就是说,在程序翻译期间,上述语句进一步被简化为以下等价形式:
printf("%f\n", sinf(x));
此外,在同一个泛型选择中,不允许两个或多个泛型关联的类型名所指定的类型互相兼容。换句话说,不允许控制表达式匹配多个泛型关联的类型名。
如果需要,可以使用一个
default泛型关联。它的价值在于,如果控制表达式的类型和任何一个泛型关联的类型名所指定的类型都不兼容(匹配),则自动选择default泛型关联中的表达式。但是,一个泛型选择中只允许有一个default泛型关联。特别注意!!泛型选择不能识别数组类型,因为数组类型的表达式会被转换为指向其首元素的指针。
问与答
问1:一些
C语言书出现了采用了不同于“形式参数”和“实际参数”的术语,是否有标准术语?
答:正如对待C语言的许多其他概念一样,没有通用的术语标准,但是C89和C99标准采用形式参数和实际参数。请记住,在不会产生混乱的情况下,有时会故意模糊两个术语的差异,采用参数表示两者中的任意一个。
问2:一些编程语言允许过程和函数互相嵌套。
C语言是否允许函数定义嵌套呢?
答:不允许。C语言不允许一个函数的定义出现在另一个函数体中。这个限制可以使编译器简单化。
问3:为什么编译器允许函数名后面不跟着圆括号?
答:在后面某一章中会看到,编译器把后面不跟圆括号的函数名看作指向函数的指针(17.7节)。指向函数的指针有合法的应用,因此编译器不能自动假定函数名不带圆括号是错误的。语句print_pun;是合法的,因为编译器会把print_pun看作指针(并进一步看作表达式),从而使得上述语句被视为有效(虽然没有意义)的表达式语句。
问4:在函数调用
f(a, b)中,编译器如何知道逗号是标点符号还是运算符呢?
答:函数调用中的实际参数不能是任意的表达式,而必须是标准文档中,位于赋值表达式前面的那些表达式,这些表达式不能用逗号作为运算符,除非逗号是在圆括号中的。换句话说,在函数调用f(a, b)中,逗号是标点符号;而在f((a, b))中,逗号是运算符。
问5:函数原型中形式参数的名字是否需要和后面函数定义中给出的名字相匹配?
答:不需要。一些程序员利用这一特性,在原型中给参数一个较长名字,然后在实际定义中使用较短的名字。或者,说法语的程序员可以在函数原型中使用英语名字,然后在函数定义中切换成更为熟悉的法语名字。
问6:我始终不明白为什么要提供函数原型。只要把所有函数的定义放置在
main函数的前面,不就没有问题了吗?
答:错。首先,你是假设只有main函数调用其他函数,当然这是不切实际的。实际上,某些函数会相互调用。如果把所有的函数定义放在main的前面,就必须仔细斟酌它们之间的顺序,因为调用未定义的函数可能会导致大问题。
然而,问题还不止这些。假设有两个函数相互调用(这可不是刻意找麻烦)。无论先定义哪个函数,都将导致对未定义的函数的调用。
但是,还有更麻烦的!一旦程序达到一定的规模,在一个文件中放置所有的函数是不可行的。当遇到这种情况时,就需要函数原型告诉编译器在其他文件中定义的函数。
问7:为什么有的程序员在函数原型中故意省略参数名字?保留这些名字不是更方便吗?
答:省略原型中的参数名字通常是出于防御目的。如果恰好有一个宏的名字跟参数一样,预处理时参数的名字会被替换,从而导致相应的原型被破坏。这种情况在一个人编写的小程序中不太可能出现,但在很多人编写的大型应用程序中是可能出现的。
问8:把函数的声明放在另一个函数体内是否合法?
答:合法。下面是一个示例:
int main(void)
{ double average(double a, double b); ...
}
average函数的这个声明只有在main函数体内是有效的。如果其他函数需要调用average函数,那么它们每一个都需要声明它。
这种做法的好处是便于阅读程序的人弄清楚函数间的调用关系。(在这个例子中,main函数将调用average函数。)另外,如果几个函数需要调用同一个函数,那么可能是件麻烦事。最糟糕的情况是,在程序修改过程中试图添加或移除声明可能会很麻烦。基于这些原因,本书将始终把函数声明放在函数体外。
问9:如果几个函数具有相同的返回类型,能否把它们的声明合并?例如,既然
print_pun函数和print_count函数都具有void型的返回类型,那么下面的声明合法吗?
void print_pun(void), print_count(int n);
答:合法。事实上,C语言甚至允许把函数声明和变量声明合并在一起:
double x, y, average(double a, double b);
但是,并不推荐这么做,这可能会使程序显得有点混乱。
问10:如果指定一维数组型形式参数的长度,会发生什么?
答:编译器会忽略长度值。思考下面的例子:
double inner_product(double v[3], double w[3]);
除了注明inner_product函数的参数应该是长度为3的数组以外,指定长度并不会带来什么其他好处。编译器不会检查参数实际上的长度是否为3,所以不会增加安全性。事实上,这种做法会产生误导,因为这种写法暗示只能把长度为3的数组传递给inner_product函数,但实际上可以传递任意长度的数组。
问11:为什么可以留着数组中第一维的参数不进行说明,但是其他维数必须说明呢?
答:首先,需要知道C语言是如何传递数组的。就像12.3节解释的那样,在把数组传递给函数时,是把指向数组第一个元素的指针给了函数。
其次,需要知道取下标运算符是如何工作的。假设a是要传给函数的一维数组。在书写语句a[i] = 0;时,编译器计算出a[i]的地址,方法是用i乘以每个元素的大小,并把乘积加到数组a表示的地址(传递给函数的指针)上。这个计算过程没有依靠数组a的长度,这说明了为什么可以在定义函数时忽略数组长度。
那么多维数组怎么样呢?回顾一下就知道,C语言是按照行主序存储数组的,即首先存储第0行的元素,然后是第1行的元素,以此类推。假设a是二维数组型的形式参数,并有语句a[i][j] = 0;
编译器产生指令执行如下:
- 用
i乘以数组a中每行的大小; - 把乘积的结果加到数组
a表示的地址上; - 用
j乘以数组a中每个元素的大小; - 把乘积的结果加到第二步计算出的地址上。
为了产生这些指令,编译器必须知道a数组中每一行的大小,行的大小由列数决定。底线:程序员必须声明数组a拥有的列的数量。
问12:为什么一些程序员把
return语句中的表达式用圆括号括起来?
答:因为这种写法不是必需的,而且对可读性没有任何帮助,所以本书不使用这些圆括号。(Kernighan和Ritchie显然也同意这一点,在《C程序设计语言》第2版中,return语句就没有圆括号了。)
问13:非
void函数试图执行不带表达式的return语句时会发生什么?
答:这依赖于C语言的版本。在C89中,执行不带表达式的非void语句会导致未定义的行为(但只限于程序试图使用函数返回值的情况)。在C99中,这样的语句是不合法的,编译器会报错。
问14:如何通过测试
main的返回值来判断程序是否正常终止?
答:这依赖于使用的操作系统。许多操作系统允许在“批处理文件”或“Shell脚本”内测试main的返回值,这类文件包含可以运行几个程序的命令。例如,Windows批处理文件中的if errorlevel 1 命令会导致在上一个程序终止时的状态码大于等于1时执行命令。
在UNIX系统中,每种Shell都有自己测试状态码的方法。在Bourne Shell中,变量$?包含上一个程序的运行状态。C Shell也有类似的变量,但是名字是$status。
问15:在编译
main函数时,为什么编译器会产生“control reaches end of non-void function”这样的警告?
答:尽管main函数有int作为返回类型,但编译器已经注意到main函数没有return语句。在main的末尾放置语句return 0;将保证编译顺利通过。顺便说一下,即使编译器不反对没有return语句,这也是一种好习惯。
用C99编译器编译程序时,这一警告不会出现。在C99中,main函数的最后可以不返回值,标准规定在这种情况下main自动返回0。
问16:对于前一个问题,为什么不把
main函数的返回类型定义为void呢?
答:虽然这种做法非常普遍,但是根据C89标准,这是非法的。即使它不是非法的,这种做法也不好,因为它假设没有人会测试程序终止时的状态。
C99允许为main声明“由实现定义的行为”(返回类型可以不是int型,也可以不是标准规定的参数),从而使得这样的行为合法化了。但是,这样的用法是不可移植的,所以最好还是把main的返回类型声明为int。
问17:如果函数
f1调用函数f2,而函数f2又调用了函数f1,这样合法吗?
答:是合法的。这是一种间接递归的形式,即函数f1的一次调用导致了另一次调用。(但是必须确保函数f1和函数f2最终都可以终止!)
总结
本文是博主阅读《C语言程序设计:现代方法(第2版·修订版)》时所作笔记,日后会持续更新后续章节笔记。欢迎各位大佬阅读学习,如有疑问请及时联系指正,希望对各位有所帮助,Thank you very much!
相关文章:
笔记——函数)
C现代方法(第9章)笔记——函数
文章目录 第9章 函数9.1 函数的定义和调用9.1.1 函数定义9.1.2 函数调用 9.2 函数声明9.3 实际参数9.3.1 实际参数的转换9.3.2 数组型实际参数9.3.3 变长数组形式参数(C99)9.3.4 在数组参数声明中使用static(C99)9.3.5 复合字面量 9.4 return语句9.5 程序终止9.5.1 exit函数 9.…...

【算法练习Day23】 复原 IP 地址子集子集 II
📝个人主页:Sherry的成长之路 🏠学习社区:Sherry的成长之路(个人社区) 📖专栏链接:练题 🎯长路漫漫浩浩,万事皆有期待 文章目录 复原 IP 地址子集子集 II总…...

fastadmin框架token验证
在FastAdmin框架中,Token验证是一种常见的身份验证方法,用于确保用户请求的安全性和合法性。本文将介绍如何在FastAdmin框架中实现Token验证。 什么是Token验证? Token验证是一种基于令牌(Token)的身份验证方式。在这种方式下,用…...

了解 AI :了解 AI 方面的一些术语 (中英文对照)
本心、输入输出、结果 文章目录 了解 AI :了解 AI 方面的一些术语 (中英文对照)前言AI 方面的一些术语 (中英文对照)AI 方面的一些术语 (中英文对照) - 文字版弘扬爱国精神 了解 AI :…...

【Python学习笔记】对象、方法
1. 对象方法定义 对象通常都拥有属于自己的 方法(英文叫 method )。 对象的方法其实可以看成是对象所拥有的函数。也就是说 这个方法,是属于这个对象的函数。 调用对象的方法,和调用函数差不多,只要在前面加上 所属…...

企业IT资产设备折旧残值如何计算
环境: 企业/公司 IT资产 问题描述: 企业IT设备折旧残值如何计算? 解决方案: 1.按三年折旧 净值原值-月折旧额折旧月份 , 月折旧额原值(1-3%)/36 折旧月份ROUND(E2*(1-3%)/36,2) 2.净值E2-F2*G2...

Linux性能优化--性能工具:下一步是什么
13.0 概述 本章是对一些事情的思索,包括:Linux性能工具的当前状态,哪些仍需要改进以及为什么Linux是当前一个相当不错的进行性能调查的平台。 阅读本章后,你将能够: 了解Linux性能工具箱的漏洞,以及一些理…...

网工内推 | IT主管、高级网工,上市公司,必须持有HCIE认证
01 深圳市飞荣达科技股份有限公司 招聘岗位:高级网络工程师 职责描述: 1. 参与、负责集团公司IT基础技术架构的规划设计、实施及维护、性能优化,包括数据中心机房、网络架构、虚拟化平台、信息安全设备及灾备系统等; 2. 负责集团…...
bulldog 靶机
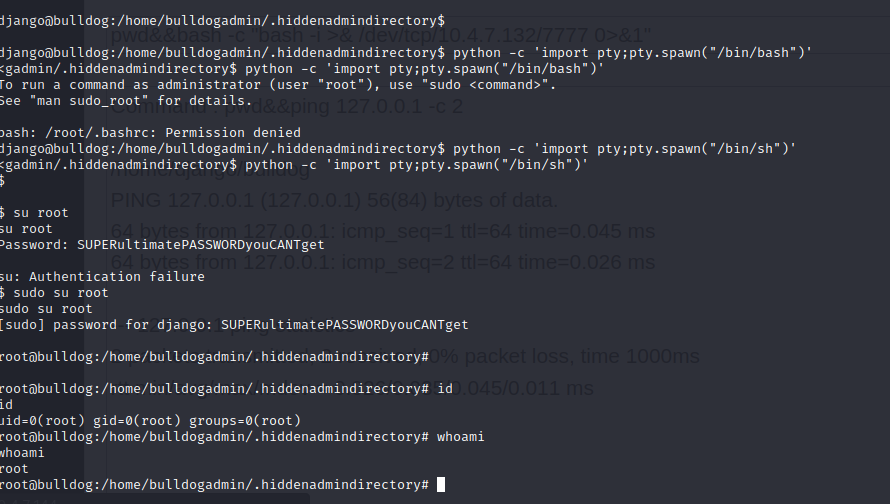
bulldog 信息搜集 存活检测 详细扫描 后台网页扫描 网页信息搜集 正在开发的如果你正在读这篇文章,你很可能是Bulldog Industries的承包商。恭喜你!我是你们的新老板,组长艾伦布鲁克。CEO解雇了整个开发团队和员工。因此,我们需要迅速招到一…...
如何借助边缘智能网关打造智慧城市便民驿站
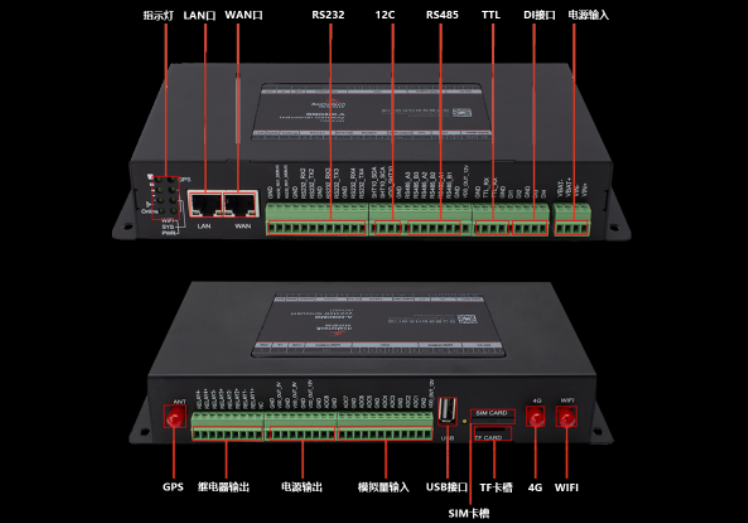
智慧城市驿站是一类提供多样化便利服务的新型智能公共设施,通过融合物联网技术、边缘智能技术、新能源技术等,为城市居民整合提供休闲、购物、卫生、广告、安全等公共服务,进一步提升日常生活体验。本篇就为大家介绍如何基于边缘智能网关&…...

谈谈电商App的压测
背景 最近恰逢双十一,大大小小的电商app在双十一之前都会做一次压测,曾经在小公司工作的时候很想知道大公司是如何压测的,有什么高深的压测工具没,本文就来揭露一下 压测真相 在确认使用什么压测工具进行压测之前,我…...

VsCode修改侧边栏字体大小——用缩放的方法
缩放界面字体百分比(包括编辑器界面) 如果只修改文本编辑区的字体大小,可以在File -> Preferences -> Settings 中修改font的大小。但是侧边栏的字体不会改变,所以可以使用缩放的方法先修改整个界面的字体大小,…...
基于Java的农资采购销售管理系统设计与实现(源码+lw+部署文档+讲解等)
文章目录 前言具体实现截图论文参考详细视频演示为什么选择我自己的网站自己的小程序(小蔡coding) 代码参考数据库参考源码获取 前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作者&am…...

【AIGC核心技术剖析】扩大富有表现力的人体姿势和形状估计SMPLer-X模型
富有表现力的人体姿势和形状估计 (EHPS) 将身体、手和面部运动捕捉与众多应用结合起来。尽管取得了令人鼓舞的进展,但当前最先进的方法仍然在很大程度上依赖于有限的训练数据集。在这项工作中,我们研究了将 EHPS 扩展到第一个通用基础模型(称为 SMPLer-X),以 ViT-Huge 作为…...
【C++面向对象】1. 类、对象
文章目录 【 1. 类 & 对象的定义 】1.1 类的定义1.2 对象的定义 【 2. 类的成员 】2.1 数据成员2.2 成员函数类的内部定义成员函数类的外部定义成员函数成员函数的访问实例 【 3. 类的访问修饰符 】3.1 public 公有成员3.2 private 私有成员3.3 protected 保护成员3.4 继承…...
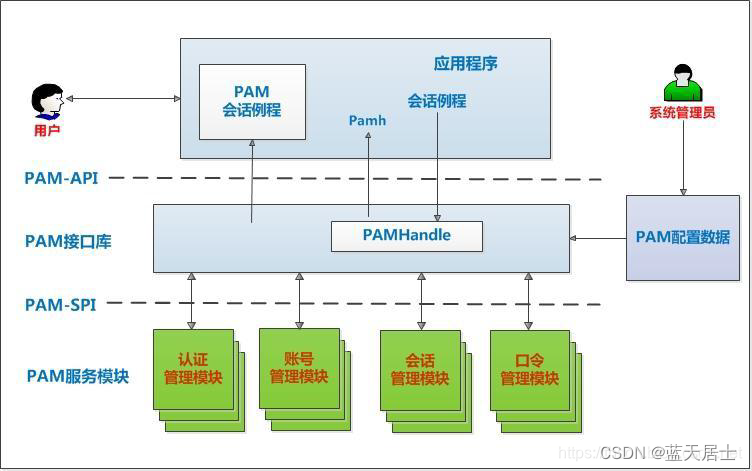
PAM从入门到精通(十三)
接前一篇文章:PAM从入门到精通(十二) 本文参考: 《The Linux-PAM Application Developers Guide》 先再来重温一下PAM系统架构: 更加形象的形式: 五、主要函数详解 11. pam_open_session 概述&…...

Stable Diffusion WebUI几种解决手崩溃的方法
1. 添加与手相关负面提示词 如何提价提示词呢? 首先有一个embeddings模型文件bad-hands-5,我们可以去各个大模型网站去搜,我是在C站上面下载的。 附上C站地址:https://civitai.com/ 下载好之后,你需要将文件放入stable-diffusion-webui\embeddings目录中。位置如下所示…...

kr 第三阶段(一)16 位汇编
为什么要学习 16 位汇编? 16 位汇编包含了大部分 32 位汇编的知识点。有助于在学习内核的两种模式。 实模式:访问真实的物理内存保护模式:访问虚拟内存 有助于提升调试能力,调试命令与 OllyDbg 和 WinDebug 通用。可以学习实现反…...

power point导出pdf保留字体
在 slides 中用到非自带的字体,如 [1],想导出成 pdf 文件(因为导出成图,如 png,放大会蒙),并在别人电脑里也保留字体。除了让别人也装上相应字体,可以: 参考 [2]&#x…...

云务器迁移(腾讯云>华为云)
自己平时除了写些bug外还喜欢玩玩服务器,这不前几年买了一个域名,当时服务器买的是阿里云的,想着域名备案挺麻烦的就一直用着,只是在服务器到期后会重新购买其他运营商的(关键是续不起🤫) 这不最…...

CLIP-GmP-ViT-L-14GPU算力适配:ViT-L模型显存占用分析与推理加速实践
CLIP-GmP-ViT-L-14 GPU算力适配:ViT-L模型显存占用分析与推理加速实践 1. 引言 当你拿到一个像 CLIP-GmP-ViT-L-14 这样强大的视觉-语言模型时,第一反应可能是兴奋——它拥有接近90%的ImageNet准确率,能精准理解图片和文字的关系。但当你尝…...

【QuantDev必藏】:为什么92%的C++交易系统仍在用malloc——深度剖析jemalloc/tcmalloc/mimalloc在L3缓存穿透场景下的失效临界点
第一章:金融高频交易系统内存分配的底层挑战与现实困境在纳秒级竞争的金融高频交易(HFT)场景中,内存分配不再是语言运行时的“黑盒服务”,而是决定订单延迟、吞吐一致性与系统可预测性的关键路径。传统堆分配器&#x…...
)
C++高频交易内存池性能跃迁指南(从42μs到1.7μs的97.6%时延压缩路径)
第一章:C高频交易内存池性能跃迁全景图在毫秒乃至微秒级竞争的高频交易系统中,动态内存分配已成为关键性能瓶颈。标准 malloc 与 new 操作引入的锁争用、TLB抖动及堆碎片问题,直接导致订单延迟波动增大、吞吐量不可预测。现代低延迟内存池通过…...

Phi-4-mini-reasoning镜像部署案例:低成本GPU环境下高效推理落地实录
Phi-4-mini-reasoning镜像部署案例:低成本GPU环境下高效推理落地实录 1. 项目背景与模型介绍 Phi-4-mini-reasoning是一个基于合成数据构建的轻量级开源模型,专注于高质量、密集推理的数据处理能力。作为Phi-4模型家族的一员,它特别针对数学…...

OpenClaw替代方案:Qwen2.5-VL-7B与其他自动化工具对比
OpenClaw替代方案:Qwen2.5-VL-7B与其他自动化工具对比 1. 自动化工具选型的核心考量 当我们需要选择一款自动化工具时,通常会面临几个关键问题:这个工具能否理解我的需求?它能在我的设备上安全运行吗?它是否足够灵活…...

掰开揉碎魔改claudecode后,我盯着 Claude Code 跑了一圈,终于看懂顶级 AI Agent是如何炼成的
开头先来一句狠的很多人以为,Claude Code 之所以强,是因为模型更聪明。但我把它运行时真正生效的 Payload 抓出来之后,结论反而更明确了:顶级 AI Agent 的差距,很多时候不在模型本身,而在它背后那套“怎么约…...

OpenClaw移动办公:Phi-3-mini-128k-instruct通过钉钉审批电子合同
OpenClaw移动办公:Phi-3-mini-128k-instruct通过钉钉审批电子合同 1. 为什么需要移动审批电子合同? 上周三我在高铁上收到法务同事的紧急消息:"有个供应商合同今天必须签完,但关键条款需要你确认"。当时手边既没电脑也…...

07_Cursor之语言支持与扩展生态
关键字:语言支持, VS Code扩展, 跨平台, Electron, Python开发, 扩展生态 07_Cursor之语言支持与扩展生态 Cursor知识体系 Cursor知识体系(续) | -- 生态支持层 | -- 多语言支持 | | -- 通用LLM支持 | | -- 自动语言检测 | | …...

OpenClaw与千问3.5-35B-A3B-FP8低成本方案:自建模型接口替代OpenAI高价调用
OpenClaw与千问3.5-35B-A3B-FP8低成本方案:自建模型接口替代OpenAI高价调用 1. 为什么需要替代OpenAI高价调用 去年冬天的一个深夜,我盯着OpenAI API账单上那个刺眼的数字——$127.83,这只是一个月的测试费用。当时我正在用OpenClaw做一个自…...

javaweb企业多模块系统 企业门户网站的设计与实现
目录同行可拿货,招校园代理 ,本人源头供货商功能模块划分技术实现要点扩展性设计安全防护措施项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作同行可拿货,招校园代理 ,本人源头供货商 功能模块划分 用户模块 注册与登录&…...