Cocos Creator3.8 项目实战(十)使用 protobuf详细教程
在 Cocos Creator 中使用 protobuf.js 库可以方便地进行协议的序列化和反序列化。
下面是使用 protobuf.js 的详细说明:
一、protobuf环境安装
1、安装 npm
protobuf环境安装安装需要使用 npm 命令进行,因此首先需要安装 npm 。
如果你还没安装 npm , 请参考:windows安装npm教程 。
2、全局安装pbjs
打开命令行工具,输入以下命令
npm install -g pbjs
安装成功后 C:\Users\Administrator\AppData\Roaming\npm 显示如下信息:



二、 Cocos Creator 中使用 protobuf.js 库
确定了模块格式和导出方式,就可以在脚本资源里使用 protobufjs 这个模块。
1、创建协议文件
在项目中创建一个 .proto 文件,定义协议结构
例如,创建一个名为 message.proto 的文件,内容如下:
syntax = "proto3";message Player {string name = 1;int32 level = 2;
}
```
这里定义了一个名为 Player 的消息类型,包含 name 和 level 两个字段。

2、将 protobuf 中的 proto 文件编译成TypeScript 文件
pbjs 指令的使用可以查看 官方文档:pbjs地址

我们以打包上面生成的 message.proto 文件为例,进行演示。
命令行执行:
pbjs D:/test/3/proto/message.proto --ts D:/test/3/proto/message.ts
打包完成后,在 D:/test/3/proto/ 目录,生成了 message.ts 文件,如下:

message.ts 文件内容如下:
export interface Player {name?: string;level?: number;
}export function encodePlayer(message: Player): Uint8Array {let bb = popByteBuffer();_encodePlayer(message, bb);return toUint8Array(bb);
}function _encodePlayer(message: Player, bb: ByteBuffer): void {// optional string name = 1;let $name = message.name;if ($name !== undefined) {writeVarint32(bb, 10);writeString(bb, $name);}// optional int32 level = 2;let $level = message.level;if ($level !== undefined) {writeVarint32(bb, 16);writeVarint64(bb, intToLong($level));}
}export function decodePlayer(binary: Uint8Array): Player {return _decodePlayer(wrapByteBuffer(binary));
}function _decodePlayer(bb: ByteBuffer): Player {let message: Player = {} as any;end_of_message: while (!isAtEnd(bb)) {let tag = readVarint32(bb);switch (tag >>> 3) {case 0:break end_of_message;// optional string name = 1;case 1: {message.name = readString(bb, readVarint32(bb));break;}// optional int32 level = 2;case 2: {message.level = readVarint32(bb);break;}default:skipUnknownField(bb, tag & 7);}}return message;
}export interface Long {low: number;high: number;unsigned: boolean;
}interface ByteBuffer {bytes: Uint8Array;offset: number;limit: number;
}function pushTemporaryLength(bb: ByteBuffer): number {let length = readVarint32(bb);let limit = bb.limit;bb.limit = bb.offset + length;return limit;
}function skipUnknownField(bb: ByteBuffer, type: number): void {switch (type) {case 0: while (readByte(bb) & 0x80) { } break;case 2: skip(bb, readVarint32(bb)); break;case 5: skip(bb, 4); break;case 1: skip(bb, 8); break;default: throw new Error("Unimplemented type: " + type);}
}function stringToLong(value: string): Long {return {low: value.charCodeAt(0) | (value.charCodeAt(1) << 16),high: value.charCodeAt(2) | (value.charCodeAt(3) << 16),unsigned: false,};
}function longToString(value: Long): string {let low = value.low;let high = value.high;return String.fromCharCode(low & 0xFFFF,low >>> 16,high & 0xFFFF,high >>> 16);
}// The code below was modified from https://github.com/protobufjs/bytebuffer.js
// which is under the Apache License 2.0.let f32 = new Float32Array(1);
let f32_u8 = new Uint8Array(f32.buffer);let f64 = new Float64Array(1);
let f64_u8 = new Uint8Array(f64.buffer);function intToLong(value: number): Long {value |= 0;return {low: value,high: value >> 31,unsigned: value >= 0,};
}let bbStack: ByteBuffer[] = [];function popByteBuffer(): ByteBuffer {const bb = bbStack.pop();if (!bb) return { bytes: new Uint8Array(64), offset: 0, limit: 0 };bb.offset = bb.limit = 0;return bb;
}function pushByteBuffer(bb: ByteBuffer): void {bbStack.push(bb);
}function wrapByteBuffer(bytes: Uint8Array): ByteBuffer {return { bytes, offset: 0, limit: bytes.length };
}function toUint8Array(bb: ByteBuffer): Uint8Array {let bytes = bb.bytes;let limit = bb.limit;return bytes.length === limit ? bytes : bytes.subarray(0, limit);
}function skip(bb: ByteBuffer, offset: number): void {if (bb.offset + offset > bb.limit) {throw new Error('Skip past limit');}bb.offset += offset;
}function isAtEnd(bb: ByteBuffer): boolean {return bb.offset >= bb.limit;
}function grow(bb: ByteBuffer, count: number): number {let bytes = bb.bytes;let offset = bb.offset;let limit = bb.limit;let finalOffset = offset + count;if (finalOffset > bytes.length) {let newBytes = new Uint8Array(finalOffset * 2);newBytes.set(bytes);bb.bytes = newBytes;}bb.offset = finalOffset;if (finalOffset > limit) {bb.limit = finalOffset;}return offset;
}function advance(bb: ByteBuffer, count: number): number {let offset = bb.offset;if (offset + count > bb.limit) {throw new Error('Read past limit');}bb.offset += count;return offset;
}function readBytes(bb: ByteBuffer, count: number): Uint8Array {let offset = advance(bb, count);return bb.bytes.subarray(offset, offset + count);
}function writeBytes(bb: ByteBuffer, buffer: Uint8Array): void {let offset = grow(bb, buffer.length);bb.bytes.set(buffer, offset);
}function readString(bb: ByteBuffer, count: number): string {// Sadly a hand-coded UTF8 decoder is much faster than subarray+TextDecoder in V8let offset = advance(bb, count);let fromCharCode = String.fromCharCode;let bytes = bb.bytes;let invalid = '\uFFFD';let text = '';for (let i = 0; i < count; i++) {let c1 = bytes[i + offset], c2: number, c3: number, c4: number, c: number;// 1 byteif ((c1 & 0x80) === 0) {text += fromCharCode(c1);}// 2 byteselse if ((c1 & 0xE0) === 0xC0) {if (i + 1 >= count) text += invalid;else {c2 = bytes[i + offset + 1];if ((c2 & 0xC0) !== 0x80) text += invalid;else {c = ((c1 & 0x1F) << 6) | (c2 & 0x3F);if (c < 0x80) text += invalid;else {text += fromCharCode(c);i++;}}}}// 3 byteselse if ((c1 & 0xF0) == 0xE0) {if (i + 2 >= count) text += invalid;else {c2 = bytes[i + offset + 1];c3 = bytes[i + offset + 2];if (((c2 | (c3 << 8)) & 0xC0C0) !== 0x8080) text += invalid;else {c = ((c1 & 0x0F) << 12) | ((c2 & 0x3F) << 6) | (c3 & 0x3F);if (c < 0x0800 || (c >= 0xD800 && c <= 0xDFFF)) text += invalid;else {text += fromCharCode(c);i += 2;}}}}// 4 byteselse if ((c1 & 0xF8) == 0xF0) {if (i + 3 >= count) text += invalid;else {c2 = bytes[i + offset + 1];c3 = bytes[i + offset + 2];c4 = bytes[i + offset + 3];if (((c2 | (c3 << 8) | (c4 << 16)) & 0xC0C0C0) !== 0x808080) text += invalid;else {c = ((c1 & 0x07) << 0x12) | ((c2 & 0x3F) << 0x0C) | ((c3 & 0x3F) << 0x06) | (c4 & 0x3F);if (c < 0x10000 || c > 0x10FFFF) text += invalid;else {c -= 0x10000;text += fromCharCode((c >> 10) + 0xD800, (c & 0x3FF) + 0xDC00);i += 3;}}}}else text += invalid;}return text;
}function writeString(bb: ByteBuffer, text: string): void {// Sadly a hand-coded UTF8 encoder is much faster than TextEncoder+set in V8let n = text.length;let byteCount = 0;// Write the byte count firstfor (let i = 0; i < n; i++) {let c = text.charCodeAt(i);if (c >= 0xD800 && c <= 0xDBFF && i + 1 < n) {c = (c << 10) + text.charCodeAt(++i) - 0x35FDC00;}byteCount += c < 0x80 ? 1 : c < 0x800 ? 2 : c < 0x10000 ? 3 : 4;}writeVarint32(bb, byteCount);let offset = grow(bb, byteCount);let bytes = bb.bytes;// Then write the bytesfor (let i = 0; i < n; i++) {let c = text.charCodeAt(i);if (c >= 0xD800 && c <= 0xDBFF && i + 1 < n) {c = (c << 10) + text.charCodeAt(++i) - 0x35FDC00;}if (c < 0x80) {bytes[offset++] = c;} else {if (c < 0x800) {bytes[offset++] = ((c >> 6) & 0x1F) | 0xC0;} else {if (c < 0x10000) {bytes[offset++] = ((c >> 12) & 0x0F) | 0xE0;} else {bytes[offset++] = ((c >> 18) & 0x07) | 0xF0;bytes[offset++] = ((c >> 12) & 0x3F) | 0x80;}bytes[offset++] = ((c >> 6) & 0x3F) | 0x80;}bytes[offset++] = (c & 0x3F) | 0x80;}}
}function writeByteBuffer(bb: ByteBuffer, buffer: ByteBuffer): void {let offset = grow(bb, buffer.limit);let from = bb.bytes;let to = buffer.bytes;// This for loop is much faster than subarray+set on V8for (let i = 0, n = buffer.limit; i < n; i++) {from[i + offset] = to[i];}
}function readByte(bb: ByteBuffer): number {return bb.bytes[advance(bb, 1)];
}function writeByte(bb: ByteBuffer, value: number): void {let offset = grow(bb, 1);bb.bytes[offset] = value;
}function readFloat(bb: ByteBuffer): number {let offset = advance(bb, 4);let bytes = bb.bytes;// Manual copying is much faster than subarray+set in V8f32_u8[0] = bytes[offset++];f32_u8[1] = bytes[offset++];f32_u8[2] = bytes[offset++];f32_u8[3] = bytes[offset++];return f32[0];
}function writeFloat(bb: ByteBuffer, value: number): void {let offset = grow(bb, 4);let bytes = bb.bytes;f32[0] = value;// Manual copying is much faster than subarray+set in V8bytes[offset++] = f32_u8[0];bytes[offset++] = f32_u8[1];bytes[offset++] = f32_u8[2];bytes[offset++] = f32_u8[3];
}function readDouble(bb: ByteBuffer): number {let offset = advance(bb, 8);let bytes = bb.bytes;// Manual copying is much faster than subarray+set in V8f64_u8[0] = bytes[offset++];f64_u8[1] = bytes[offset++];f64_u8[2] = bytes[offset++];f64_u8[3] = bytes[offset++];f64_u8[4] = bytes[offset++];f64_u8[5] = bytes[offset++];f64_u8[6] = bytes[offset++];f64_u8[7] = bytes[offset++];return f64[0];
}function writeDouble(bb: ByteBuffer, value: number): void {let offset = grow(bb, 8);let bytes = bb.bytes;f64[0] = value;// Manual copying is much faster than subarray+set in V8bytes[offset++] = f64_u8[0];bytes[offset++] = f64_u8[1];bytes[offset++] = f64_u8[2];bytes[offset++] = f64_u8[3];bytes[offset++] = f64_u8[4];bytes[offset++] = f64_u8[5];bytes[offset++] = f64_u8[6];bytes[offset++] = f64_u8[7];
}function readInt32(bb: ByteBuffer): number {let offset = advance(bb, 4);let bytes = bb.bytes;return (bytes[offset] |(bytes[offset + 1] << 8) |(bytes[offset + 2] << 16) |(bytes[offset + 3] << 24));
}function writeInt32(bb: ByteBuffer, value: number): void {let offset = grow(bb, 4);let bytes = bb.bytes;bytes[offset] = value;bytes[offset + 1] = value >> 8;bytes[offset + 2] = value >> 16;bytes[offset + 3] = value >> 24;
}function readInt64(bb: ByteBuffer, unsigned: boolean): Long {return {low: readInt32(bb),high: readInt32(bb),unsigned,};
}function writeInt64(bb: ByteBuffer, value: Long): void {writeInt32(bb, value.low);writeInt32(bb, value.high);
}function readVarint32(bb: ByteBuffer): number {let c = 0;let value = 0;let b: number;do {b = readByte(bb);if (c < 32) value |= (b & 0x7F) << c;c += 7;} while (b & 0x80);return value;
}function writeVarint32(bb: ByteBuffer, value: number): void {value >>>= 0;while (value >= 0x80) {writeByte(bb, (value & 0x7f) | 0x80);value >>>= 7;}writeByte(bb, value);
}function readVarint64(bb: ByteBuffer, unsigned: boolean): Long {let part0 = 0;let part1 = 0;let part2 = 0;let b: number;b = readByte(bb); part0 = (b & 0x7F); if (b & 0x80) {b = readByte(bb); part0 |= (b & 0x7F) << 7; if (b & 0x80) {b = readByte(bb); part0 |= (b & 0x7F) << 14; if (b & 0x80) {b = readByte(bb); part0 |= (b & 0x7F) << 21; if (b & 0x80) {b = readByte(bb); part1 = (b & 0x7F); if (b & 0x80) {b = readByte(bb); part1 |= (b & 0x7F) << 7; if (b & 0x80) {b = readByte(bb); part1 |= (b & 0x7F) << 14; if (b & 0x80) {b = readByte(bb); part1 |= (b & 0x7F) << 21; if (b & 0x80) {b = readByte(bb); part2 = (b & 0x7F); if (b & 0x80) {b = readByte(bb); part2 |= (b & 0x7F) << 7;}}}}}}}}}return {low: part0 | (part1 << 28),high: (part1 >>> 4) | (part2 << 24),unsigned,};
}function writeVarint64(bb: ByteBuffer, value: Long): void {let part0 = value.low >>> 0;let part1 = ((value.low >>> 28) | (value.high << 4)) >>> 0;let part2 = value.high >>> 24;// ref: src/google/protobuf/io/coded_stream.cclet size =part2 === 0 ?part1 === 0 ?part0 < 1 << 14 ?part0 < 1 << 7 ? 1 : 2 :part0 < 1 << 21 ? 3 : 4 :part1 < 1 << 14 ?part1 < 1 << 7 ? 5 : 6 :part1 < 1 << 21 ? 7 : 8 :part2 < 1 << 7 ? 9 : 10;let offset = grow(bb, size);let bytes = bb.bytes;switch (size) {case 10: bytes[offset + 9] = (part2 >>> 7) & 0x01;case 9: bytes[offset + 8] = size !== 9 ? part2 | 0x80 : part2 & 0x7F;case 8: bytes[offset + 7] = size !== 8 ? (part1 >>> 21) | 0x80 : (part1 >>> 21) & 0x7F;case 7: bytes[offset + 6] = size !== 7 ? (part1 >>> 14) | 0x80 : (part1 >>> 14) & 0x7F;case 6: bytes[offset + 5] = size !== 6 ? (part1 >>> 7) | 0x80 : (part1 >>> 7) & 0x7F;case 5: bytes[offset + 4] = size !== 5 ? part1 | 0x80 : part1 & 0x7F;case 4: bytes[offset + 3] = size !== 4 ? (part0 >>> 21) | 0x80 : (part0 >>> 21) & 0x7F;case 3: bytes[offset + 2] = size !== 3 ? (part0 >>> 14) | 0x80 : (part0 >>> 14) & 0x7F;case 2: bytes[offset + 1] = size !== 2 ? (part0 >>> 7) | 0x80 : (part0 >>> 7) & 0x7F;case 1: bytes[offset] = size !== 1 ? part0 | 0x80 : part0 & 0x7F;}
}function readVarint32ZigZag(bb: ByteBuffer): number {let value = readVarint32(bb);// ref: src/google/protobuf/wire_format_lite.hreturn (value >>> 1) ^ -(value & 1);
}function writeVarint32ZigZag(bb: ByteBuffer, value: number): void {// ref: src/google/protobuf/wire_format_lite.hwriteVarint32(bb, (value << 1) ^ (value >> 31));
}function readVarint64ZigZag(bb: ByteBuffer): Long {let value = readVarint64(bb, /* unsigned */ false);let low = value.low;let high = value.high;let flip = -(low & 1);// ref: src/google/protobuf/wire_format_lite.hreturn {low: ((low >>> 1) | (high << 31)) ^ flip,high: (high >>> 1) ^ flip,unsigned: false,};
}function writeVarint64ZigZag(bb: ByteBuffer, value: Long): void {let low = value.low;let high = value.high;let flip = high >> 31;// ref: src/google/protobuf/wire_format_lite.hwriteVarint64(bb, {low: (low << 1) ^ flip,high: ((high << 1) | (low >>> 31)) ^ flip,unsigned: false,});
}3、代码中测试打包出来的typescript脚本
因为pbjs打包后protobufjs代码是直接集成在 message.ts 文件中的,因此不需要我们再去引用protobufjs库。
import { _decorator, Component, log } from 'cc';
const { ccclass, property } = _decorator;import{Player,encodePlayer,decodePlayer} from "./message"@ccclass('main')
export class main extends Component {onLoad() {const player:Player = {name:"John",level:10,} // 将消息对象序列化为二进制数据const binaryData:Uint8Array = encodePlayer(player);// 从二进制数据中反序列化为消息对象const deserializedPlayer = decodePlayer(binaryData);// 访问消息对象的字段console.log(deserializedPlayer.name); // 输出: Johnconsole.log(deserializedPlayer.level); // 输出: 10}start() {}update(deltaTime: number) {}
}运行打印结果如下:

好了,Cocos Creator 3.8中如何如何将 proto文件打包成typescript 脚本,以及如何使用 protobuf 的教程到此就结束。如果觉得我的博文帮到了您,您的赞关注是对我最大的支持。如遇到什么问题,可评论区留言。
相关文章:
Cocos Creator3.8 项目实战(十)使用 protobuf详细教程
在 Cocos Creator 中使用 protobuf.js 库可以方便地进行协议的序列化和反序列化。 下面是使用 protobuf.js 的详细说明: 一、protobuf环境安装 1、安装 npm protobuf环境安装安装需要使用 npm 命令进行,因此首先需要安装 npm 。 如果你还没安装 npm …...
)
第七章:最新版零基础学习 PYTHON 教程—Python 列表(第八节 -在 Python 中获取列表作为用户的输入)
我们经常遇到需要将数字/字符串作为用户输入的情况。在本文中,我们将了解如何使用Python从用户处获取输入列表。 目录 使用Loop在 Python 中获取用户输入的列表 Python3...

Simple RPC - 02 通用高性能序列化和反序列化设计与实现
文章目录 概述设计实现通用的序列化接口通用的序列化实现【推荐】 vs 专用的序列化实现专用序列化接口定义序列化实现 概述 网络传输和序列化这两部分的功能相对来说是非常通用并且独立的,在设计的时候,只要能做到比较好的抽象,这两部的实现…...
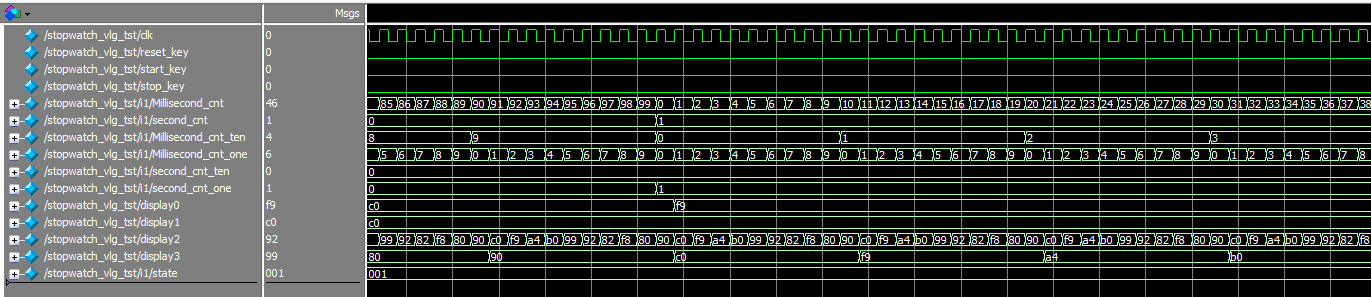
简单秒表设计仿真verilog跑表,源码/视频
名称:简单秒表设计仿真 软件:Quartus 语言:Verilog 代码功能: 秒表显示最低计时为10ms,最大为59:99,超出返回00:00 具有复位、启动、暂停三个按键 四个数码管分别显示4个时间数字。 演示…...

【发布】Photoshop ICO 文件格式插件 3.0
备注:本文原文首发于博客园: https://www.cnblogs.com/hoodlum1980/p/17766287.html 【简介】 Photoshop ICO 插件是为 Photoshop 开发的功能扩展插件,使得 Photoshop 可以直接读写 ICO 格式文件。由于 Photoshop 具有强大的像素位图编辑功…...
负载均衡、代理和动静分离的战略
一、Nginx简介 1.1 概述 Nginx (“engine x”) 是一个高性能的 HTTP 和 反向代理服务器,特点是占有内存少,并发能力强,能经受高负载的考验,有报告表明能支持高达 50,000 个并发连接数 。 1.2正向代理与反向代理 1.2.1正向代理 正向代理:如果把局域网外的 Internet 想象…...

Gitlab用户角色权限Guest、Reporter、Developer、Master、Owner
Gitlab用户在组中有角色权限:Guest、Reporter、Developer、Master、Owner Gitlab权限管理 Guest:可以创建issue、发表评论,不能读写版本库 Reporter:可以克隆代码,不能提交,QA、PM可以赋予这个权限 Deve…...

C#上位机序列9: 批量读写+事件广播+数据类型处理
一、源码结构: 二、运行效果: 三、源码解析 1. 读取配置文件及创建变量信息(点位名称,地址,数据类型(bool/short/int/float/long/double)) 2. 异步任务处理:读任务&…...

科技资讯|2023全球智能手表预估出货1.3亿块,智能穿戴提升AI功能
根据集邦咨询公布的最新报告,受全球经济低迷影响,2023 年全球智能手表出货量预估为 1.3 亿块。苹果以超过 30% 的份额领先,其次是三星(接近 10%)、华为、Garmin、Fitbit 等。 报告认为苹果、三星和华为等主要智能手表…...

技术架构之术
架构特征 1、结构性特征 易理解、可复用、可移植、可扩展、可配置、可维护、可测试 2、运行时特征 可靠性、稳定性、高安全、可伸缩、易用性、可用性、高性能、可观测 3、交付性特征 高效率、高适配、标准化、灵活性、易定制、统一性、开放性 如何开展我们的架构工作 价值分…...
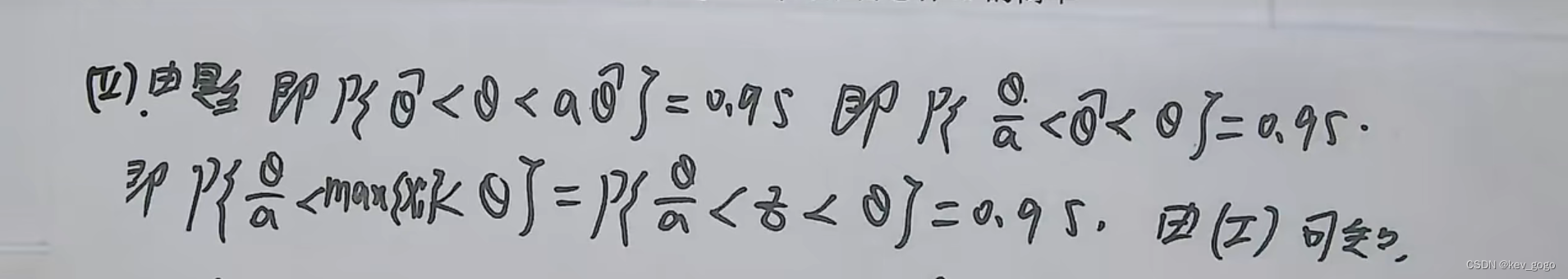
【自用重要】概率论中θ和θ尖的区别【计算时的一般方法】
θ就相当于x,是一个值。 θ尖就相当于X,是一个量。 在做分布函数的时候,最好把θ尖换成Z的形式,因为他们都是量,这样比较好看。 在做不等式的时候,一般把量放在中间进行计算,因为随机变量有分…...
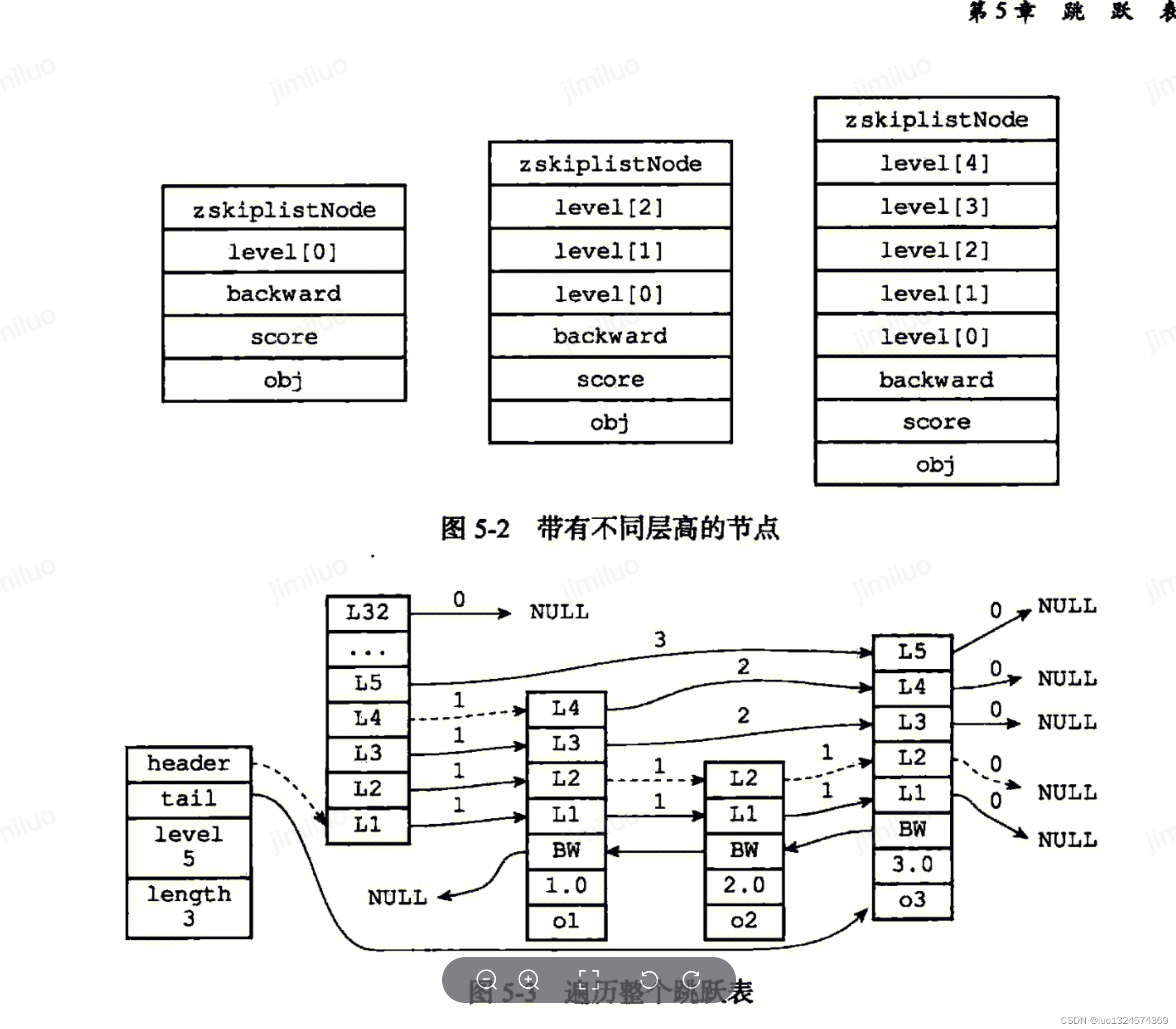
Redis设计与实现笔记 - 数据结构篇
Redis设计与实现笔记 - 数据结构篇 相信在我们日常使用中,会经常跟 Redis 打交道。数据结构 String、Hash、List、Set 和 ZSet 都是常用的数据类型。对于使用场景,我们可以滔滔不绝地说很多,但是我们从来就没有关心过它们的底层实现…...
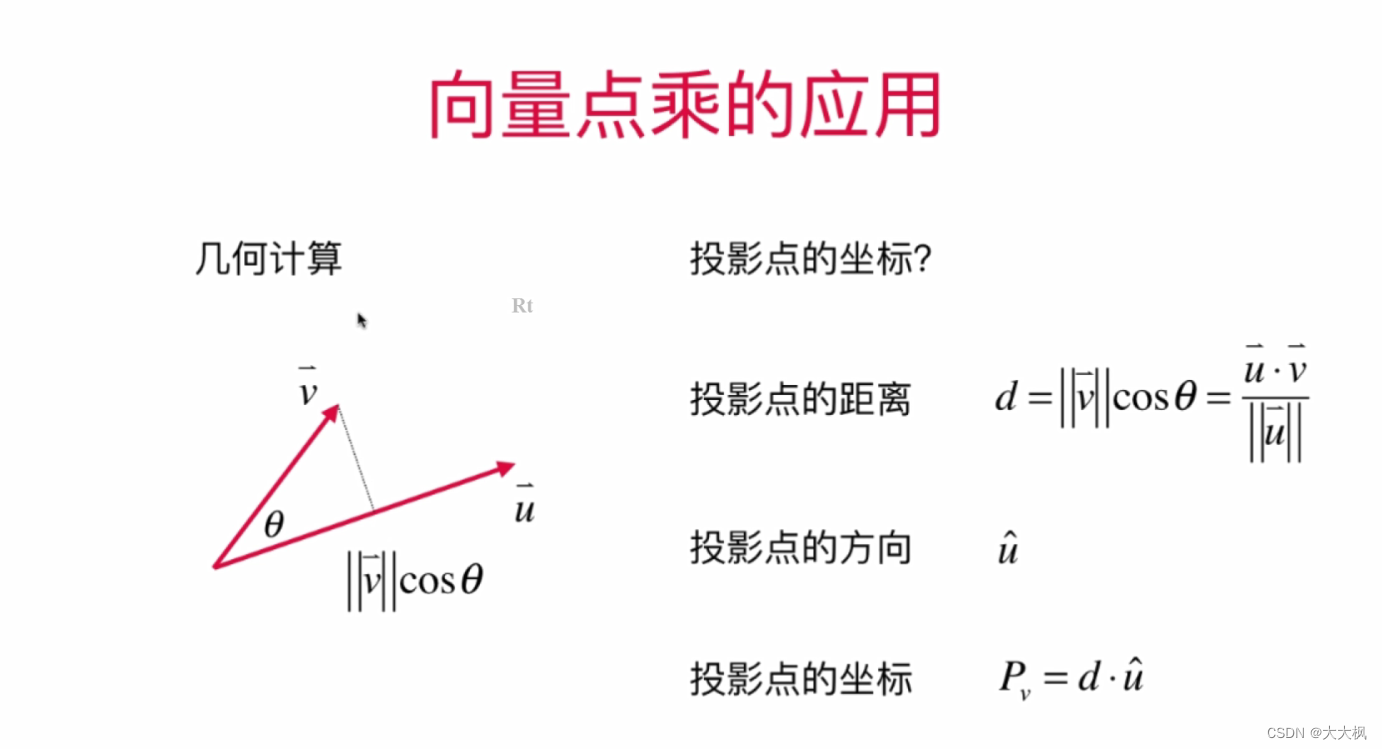
线性代数-Python-01:向量的基本运算 -手写Vector -学习numpy的基本用法
文章目录 代码目录结构Vector.py_globals.pymain_vector.pymain_numpy_vector.py 一、创建属于自己的向量1.1 在控制台测试__repr__和__str__方法1.2 创建实例测试代码 二、向量的基本运算2.1 加法2.2 数量乘法2.3 向量运算的基本性质2.4 零向量2.5 向量的长度2.6 单位向量2.7 …...
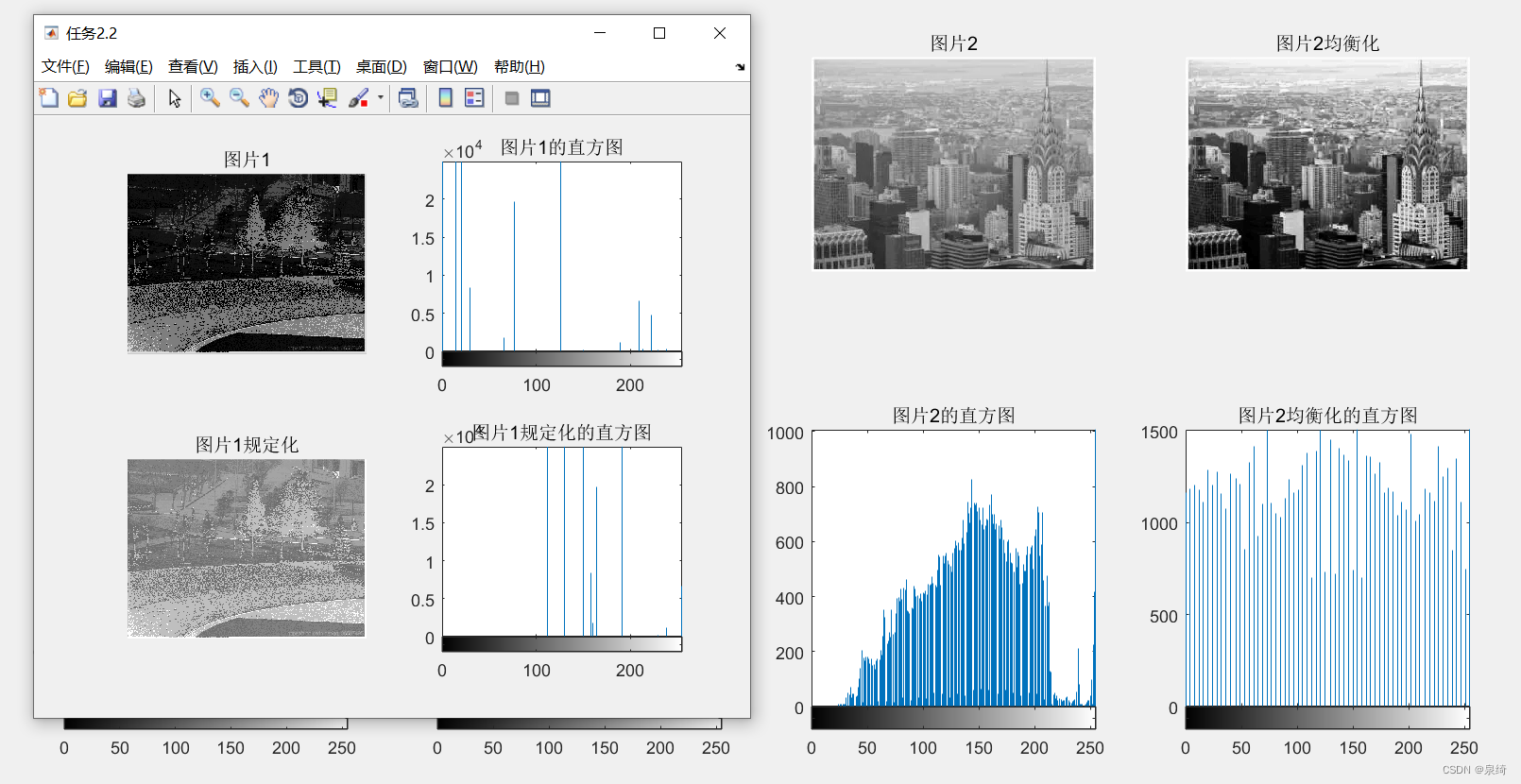
数字图像处理实验记录二(直方图和直方图均衡化)
文章目录 一、基础知识1,什么是直方图2,直方图有什么用3,直方图均衡化4、原理代码实现 二、实验要求任务1:任务2: 三、实验记录任务1:任务2: 四、结果展示任务1:任务2: 五…...

大数据Flink(九十九):SQL 函数的解析顺序和系统内置函数
文章目录 SQL 函数的解析顺序和系统内置函数 一、SQL 函数...
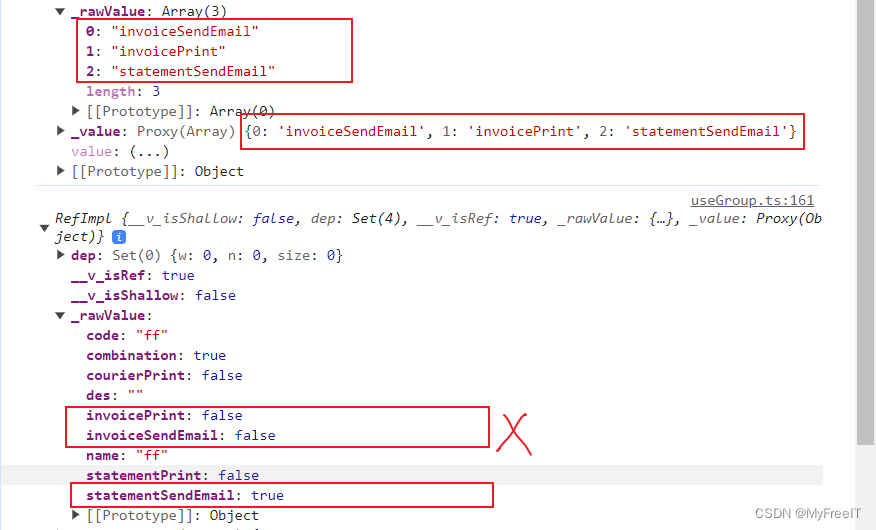
TODO Vue typescript forEach的bug,需要再核實
forEach 一個string[],只有最後一個匹配條件有效,其它條件無效。 所以,只能替換成普通的for循環。 console.log(taskList)// for (const _task of taskList.value) {// if (_task invoiceSendEmail) {// form.value.invoiceSendEmail…...

简记一个错误
简记一个Flutter错误: Using hardware rendering with device sdk gphone64 x86 64. If you notice graphics artifacts, consider enabling software rendering with “–enable-software-rendering”. Launching lib\main.dart on sdk gphone64 x86 64 in debug …...

第四次作业
1.打印各种图形 A.矩形 a int(input("请输入行数: ")) i 0 while i < a:print("*"*10)i1 结果: B.直角三角形 a int(input("请输入行数: ")) i 0 while i<a:print("*"*(i1))i1 结果: C.反直角三角形 …...

面试问题整理总结
1.自我介绍 2.为什么想转测试 想换一个方向,测试开发在一定程度上也是属于开发,而且站在测试的角度能看到全局的东西更多,对需求的理解需要更深”,之前的开发工作比较专一,测试的视野更加开阔,想要站在更高…...

进阶JAVA篇- Collection 类的常用的API与 Collection 集合的遍历方式
目录 1.0 Collection 类的说明 1.1 Collection 类中的实例方法 2.0 Collection 集合的遍历方式(重点) 2.1 使用迭代器( Iterator )进行遍历 2.2 使用增强型 for 循环进行遍历 2.3 使用 Java 8的 Stream API 进行遍历(使…...

嵌入式开发中的静态代码分析工具实战指南
1. 嵌入式代码静态分析工具概述作为一名嵌入式开发工程师,我深知在资源受限的MCU环境中,代码质量直接决定了产品的稳定性和可靠性。传统的C语言编译器虽然能发现语法错误,但对代码设计缺陷和潜在风险往往无能为力。这正是静态代码分析工具的价…...

Linux音频音量太小?别急着改代码,试试amixer这个终端神器
Linux音频音量调整终极指南:告别代码级修改,掌握amixer命令行艺术 当你在深夜调试语音识别项目时,突然发现树莓派录制的样本几乎听不见;或是准备录制技术教程视频时,Ubuntu系统的输出音量小得可怜——这种场景下&#…...

程序员鼓励师的消亡:当ChatGPT学会调情时
凌晨三点的代码战场凌晨三点的办公室,最后一行代码刚刚通过测试。疲惫的测试工程师瘫在椅上,屏幕右下角突然弹出消息:“亲爱的debug战士,今天的你又一次战胜了bug宇宙呢~(眨眼emoji)”。这不是人类同事的关…...

【硬核】K8s GPU调度从入门到“精通”:不止Device Plugin,还有MIG、DRA和那些你踩过的坑
K8s GPU调度从入门到“精通”:不止Device Plugin,还有MIG、DRA和那些你踩过的坑你以为把GPU挂上K8s就万事大吉了?错!调度策略、硬隔离、软隔离、抢占回收…每一个环节都可能是你烧钱的坑。本文从实战出发,手把手教你如…...

从SRCNN到WDSR:图像超分辨率核心演进路径与关键技术剖析
1. 图像超分辨率技术的基础认知 当你用手机拍下一张照片却发现放大后模糊不清时,图像超分辨率技术就能派上用场。这项技术就像给图像装上"显微镜",能将低分辨率图片转化为清晰的高分辨率版本。不同于简单的插值放大,它通过深度学习…...

轻舟体重管理大模型:赋能减重全病程管理,构建智能体重健康生态
在“健康中国2030”战略深入推进的背景下,慢性病防控与全民体重管理已成为公共卫生体系的重要议题。随着肥胖及相关代谢性疾病发病率持续上升,传统的体重干预模式已难以满足全人群、全生命周期的健康管理需求。在此趋势下,基于人工智能技术的…...

2026顶空气体分析仪TOP5|权威评测与选购指南
顶空气体分析仪,又叫顶空残氧仪,主要用于测量封闭容器中顶部空间氧气与二氧化碳的浓度。随着市场需求越来越大,市面上品牌五花八门,新手选购易踩雷、难抉择。本次榜单严格遵循客观数据真实口碑原则,综合公司背景、技术…...

能源在线监测管理系统平台[fu源码]
EMS能源管理系统 基于 Vue3 / Spring Boot/Spring Cloud & Alibaba 微服务架构 项目技术框架 RuoYi-Cloud 基础框架上开发而成 源智优控AI能源大脑,能源AI版,即将上线 仓库地址: https://gitee.com/guangdong122/energy-management …...
线程安全 synchronized 同步锁)
JAVA重点基础、进阶知识及易错点总结(17)线程安全 synchronized 同步锁
🚀 Java 巩固进阶 第17天 主题:线程安全 & synchronized 同步锁 —— 并发编程的第一道防线📅 进度概览:今天攻克 多线程最核心难题:线程安全。这是面试必考、生产环境必用的知识点,直接决定你的代码能…...

3步实现GitHub资源精准提取:开发者必备的效率工具
3步实现GitHub资源精准提取:开发者必备的效率工具 【免费下载链接】DownGit github 资源打包下载工具 项目地址: https://gitcode.com/gh_mirrors/dow/DownGit 你是否曾遇到这样的困境:急需从GitHub仓库中获取一个特定文件夹,却不得不…...