pytorch里常用操作(持续更新)
对不起我脑子不太记事儿每次变换都得想想想所以干脆汇总一下算了,当然也有一些不是torch包里面的但是没有关系hhh 官方文档里有一堆不太常用的,这里整理的都是自己比较常用的
张量操作
torch.tensor:从Python列表或NumPy数组创建张量
torch.zeros/ones:创建全零/一张量
torch.zeros(10,4)就是创建[10,4]的全零张量
torch.rand:创建随机张量
torch.cat:沿指定维度拼接张量
torch.stack:在新的维度上堆叠张量
torch.stack(tensors, dim=0, out=None)
tensors:要堆叠的输入张量的列表或元组。dim:指定要堆叠的新维度的索引。默认是0。out:可选参数,用于指定结果张量的输出
e.g
假设我们有两个张量 tensor1 和 tensor2,它们的形状都是 (3, 4),并且我们想将它们堆叠在一个新的维度上,创建一个新的形状为 (2, 3, 4) 的张量。
# 创建两个张量
tensor1 = torch.tensor([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
tensor2 = torch.tensor([[-1, -2, -3, -4], [-5, -6, -7, -8], [-9, -10, -11, -12]])# 使用torch.stack将它们堆叠在一个新的维度上
stacked_tensor = torch.stack((tensor1, tensor2), dim=0)torch.reshape:改变张量的形状。
torch.transpose:交换张量的维度。
torch.transpose(input, dim0, dim1)
input:要进行维度交换的输入张量。dim0:要交换的第一个维度的索引。dim1:要交换的第二个维度的索引。
假设我们有一个形状为 (3, 4) 的张量,现在想要交换它的维度,创建一个新的张量,使其形状为 (4, 3)。
# 创建一个形状为 (3, 4) 的张量
input_tensor = torch.tensor([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])# 使用 torch.transpose 进行维度交换
transposed_tensor = torch.transpose(input_tensor, 0, 1)torch.arange: 用于创建一个包含指定范围内的数值的一维张量
# 开始,结尾,间隔;和索引比较像
arr = torch.arange(10,100,10) #[10, 20, 30, 40, 50, 60, 70, 80, 90]
torch.meshgrid: 网格图
根据提供的x,y轴的范围得到一张网格的里面的点的xy坐标
torch.flatten(tensor,dim) : 把tensor压缩,dim表示压缩的维度
torch.unsqueeze:在张量中插入新的维度
new_tensor = torch.unsqueeze(input, dim)
input是要插入新维度的输入张量。dim是要插入新维度的位置,通常是一个非负整数。
y = torch.tensor([[1, 2], [3, 4],[5, 6]]) # torch.Size[3,2]
y_new_1 = torch.unsqueeze(y, 0) #torch.Size[1, 3, 2]
y_new_2 = torch.unsqueeze(y, 1) # torch.Size[3, 1, 2]
y_new_3 = torch.unsqueeze(y, 2) # torch.Size[3, 2, 1]
一些非torch包的操作
[:, :, :None]最后一维扩一维
A;2d,B:1d B[i*cols+j] = A[i,j] 把二阶张量变成一阶
permute(): 矩阵转置
数学操作
torch.add/sub:张量相加/减
torch.mul/div:张量相乘/除
torch.sum:计算张量的和
torch.mean:计算张量的平均值
torch.max/min:找到张量中的最大/小值
torch.abs:计算张量的绝对值
torch.exp:计算输入张量中元素的指数(exponential)
x = torch.tensor([1.0, 2.0, 3.0])
exp_x = torch.exp(x) # [e^1.0, e^2.0, e^3.0]
索引和切片
tensor[idx]:根据索引获取张量中的元素。
tensor[start:end]:切片操作。
tensor[:, 1]:选取指定列。
tensor[condition]:使用布尔条件进行索引。
自动求导
torch.autograd.Variable:创建自动求导的变量。
backward():计算梯度。
grad:访问梯度值。
no_grad():上下文管理器,用于禁用梯度计算。
神经网络模块
torch.nn.Module:创建神经网络模块
torch.nn.Linear:定义全连接层
这个层通常用于神经网络中,用来实现从输入到输出的线性变换,其中包括权重矩阵和偏置项。
# 创建一个 Linear 层
input_size = 10
output_size = 5
linear_layer = nn.Linear(input_size, output_size)# 随机生成一个输入张量
input_data = torch.randn(1, input_size) # 这里创建一个形状为 (1, input_size) 的随机输入张量# 使用线性层进行前向传播
output = linear_layer(input_data)# 查看权重和偏置
weights = linear_layer.weight
bias = linear_layer.biasprint("输入张量:", input_data)
print("输出张量:", output)
print("权重矩阵:", weights)
print("偏置项:", bias)这个示例中,首先创建了一个 nn.Linear 层,指定输入特征的数量和输出特征的数量。然后,随机生成一个输入张量 input_data,并通过将其传递给 linear_layer 来进行前向传播。线性层会应用权重矩阵和偏置项,生成输出张量。
nn.Linear 层在神经网络中通常用于连接不同层之间的神经元,执行线性变换的作用,帮助网络学习数据的特征表示。
torch.nn.Conv2d:定义卷积层
torch.nn.ReLU:ReLU激活函数
torch.nn.CrossEntropyLoss:交叉熵损失函数
torch.nn.optim:包含各种优化器,如SGD、Adam等
torch.nn.LayerNorm:用于层归一化
层归一化是一种用于神经网络的正则化技术,有助于加速训练和提高模型的鲁棒性。输入输出的形状并不会改变
import torch
import torch.nn as nn# 创建一个 LayerNorm 层
input_size = 10
layer_norm = nn.LayerNorm(input_size)# 随机生成一个输入张量
input_data = torch.randn(1, input_size) # 创建一个形状为 (1, input_size) 的随机输入张量# 使用 LayerNorm 层进行前向传播
output = layer_norm(input_data)print("输入张量:", input_data)
print("LayerNorm 后的输出张量:", output) #shape[1,input_size]torch.nn.Parameter:将张量标记为模型参数(可训练的参数)
将张量封装为 torch.nn.Parameter 对象后,它会被自动注册为模型的可训练参数,并在反向传播(backpropagation)期间更新它的值。这对于构建神经网络模型非常有用,因为神经网络的权重和偏置通常需要在训练期间进行优化。
# 创建一个普通的张量
tensor_data = torch.tensor([1.0, 2.0, 3.0])# 将张量包装为一个模型参数·1
parameter = nn.Parameter(tensor_data)# 打印参数
print(parameter) #Parameter containing: tensor([1., 2., 3.], requires_grad=True)
一起使用的是register_buffer
用于将张量注册为模型的缓冲区(buffer)
注册为缓冲区的张量不会被视为模型的可训练参数,也不会在反向传播期间更新。它们用于保存模型的固定状态信息,例如统计信息(均值、方差等)、预训练的权重或任何其他不需要进行梯度更新的张量。
register_buffer 的主要作用是将这些张量添加到模型的状态字典中,以便在保存和加载模型时一并保存和加载。这对于确保模型的一致性和可重现性非常有用。
class CustomModel(nn.Module):def __init__(self):super(CustomModel, self).__init__()# 创建一个常量张量作为缓冲区self.register_buffer('constant_tensor', torch.tensor([1.0, 2.0, 3.0]))# 创建模型实例
model = CustomModel()# 打印模型缓冲区
for name, buffer in model.named_buffers():print(name, buffer)torch.nn.MultiheadAttention:实现多头注意力机制
多头注意力机制允许模型同时关注输入中的不同部分,以提高模型性能
定义多头注意力模块
- embed_dim: 输入的维度
- num_heads: 头的数量,用于并行处理不同部分的注意力
- dropout: 可选的丢弃率
attention = nn.MultiheadAttention(embed_dim, num_heads, dropout=0.1)# 输入数据 (query, key, value),通常是三个相同形状的张量
query = torch.randn(seq_length, batch_size, embed_dim)
key = torch.randn(seq_length, batch_size, embed_dim)
value = torch.randn(seq_length, batch_size, embed_dim)# 调用多头注意力模块
output, attention_weights = attention(query, key, value)# output 是注意力机制的输出,attention_weights 是注意力权重
e.g
import torch
import torch.nn as nn# 定义多头注意力模块
embed_dim = 128
num_heads = 4
attention = nn.MultiheadAttention(embed_dim, num_heads)# 输入数据 (query, key, value)
seq_length = 10
batch_size = 32
query = torch.randn(seq_length, batch_size, embed_dim)
key = torch.randn(seq_length, batch_size, embed_dim)
value = torch.randn(seq_length, batch_size, embed_dim)# 调用多头注意力模块
output, attention_weights = attention(query, key, value)print("Output shape:", output.shape)
print("Attention weights shape:", attention_weights.shape)
数据加载和处理
torch.utils.data.Dataset:创建自定义数据集。
torch.utils.data.DataLoader:数据加载器。
transforms模块:用于数据预处理和转换。
相关文章:
)
pytorch里常用操作(持续更新)
对不起我脑子不太记事儿每次变换都得想想想所以干脆汇总一下算了,当然也有一些不是torch包里面的但是没有关系hhh 官方文档里有一堆不太常用的,这里整理的都是自己比较常用的 张量操作 torch.tensor:从Python列表或NumPy数组创建张量 torc…...
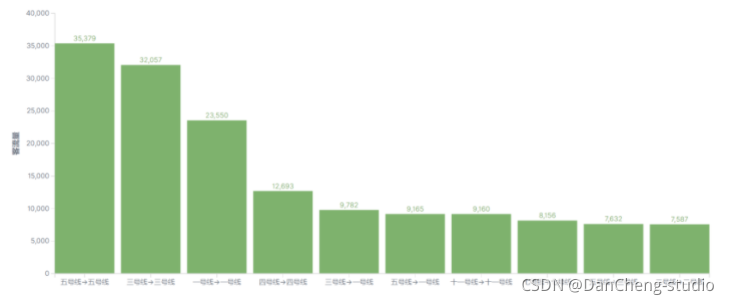
地铁大数据客流分析系统 设计与实现 计算机竞赛
文章目录 1 前言1.1 实现目的 2 数据集2.2 数据集概况2.3 数据字段 3 实现效果3.1 地铁数据整体概况3.2 平均指标3.3 地铁2018年9月开通运营的线路3.4 客流量相关统计3.4.1 线路客流量排行3.4.2 站点客流量排行3.4.3 入站客流排行3.4.4 整体客流随时间变化趋势3.4.5 不同线路客…...

00后都到适婚年龄啦!90后的还在低调什么?
当你的想法还停留在00后读书时代,其实大部分00后早已步入工作社会,还有不少人已经步入婚姻。广东金媒人婚恋,无论是广州、深圳、东莞、佛山举办活动的参与者中,00后的男生女生都占了不少。 广州深圳这样一二线城市的单身年轻人群&…...

reactnative使用七牛云上传图片
安装react-native-qiniu npm install react-native-qiniu --save 上传文件 import Qiniu,{Auth,ImgOps,Conf,Rs,Rpc} from react-native-qiniu;// 初始化七牛云配置 // Qiniu.region.z0:华东地区(默认值)。 // Qiniu.region.z1:…...

在JavaScript中,如何创建一个数组或对象?
在JavaScript中,可以使用以下方式创建数组和对象: 一:创建数组(Array): 1:使用数组字面量(Array Literal)语法,使用方括号 [] 包裹元素,并用逗号分隔: let array1 = []; // 空数组 let array2 = [1, 2, 3]; // 包含三个数字的数组 let array3 = [apple, banana,…...

001.第一个C语言项目
Visual studio2022的使用 创建第一个C语言项目和源文件 https://blog.csdn.net/qq_45037165/article/details/124520286 第一个C语言项目 #include<stdio.h> int main() {printf("Hello World");return 0; }运行结果: 第一行为库函数࿰…...

luffy项目后端轮播图接口
后台主页功能 需求 根据原型图,分析出首页需要配合俩接口 轮播图接口(要写) 查询所有轮播图 推荐课程接口(暂时先不写) 设计表 轮播图表:Banner 写轮播图接口 查询所有轮播图 轮播图表 写一个公共表模型且只用于继承 fr…...
如何通过Photoshop将视频转换成GIF图片
一、应用场景 1、将视频转有趣动图发朋友圈 2、写CSDN无法上传视频,而可以用GIF动图替代 3、其他 二、实现步骤 1、打开Photoshop APP 2、点击文件——导入——视频帧到图层 3、选择视频文件 4、配置视频信息,按照图片提示配置完毕之后点击确定&…...

书单|1024程序员狂欢节充能书单!
点击链接进入图书专题 1024程序员节 “IT有得聊”是机械工业出版社旗下IT专业资讯和服务平台,致力于帮助读者在广义的IT领域里,掌握更专业、更实用的知识与技能,快速提升职场竞争力。 点击蓝色微信名可快速关注我们。 一年一度的1024程序员…...

GRS认证与TC交易证明的区别
TC(Transaction Certificate)交易证书是由认证单位向其客户出具再生含量证明,证明本次 销售产品符合GRS标准。TC交易证书上列明 卖方(seller),买方(buyer),收货方 (consi…...
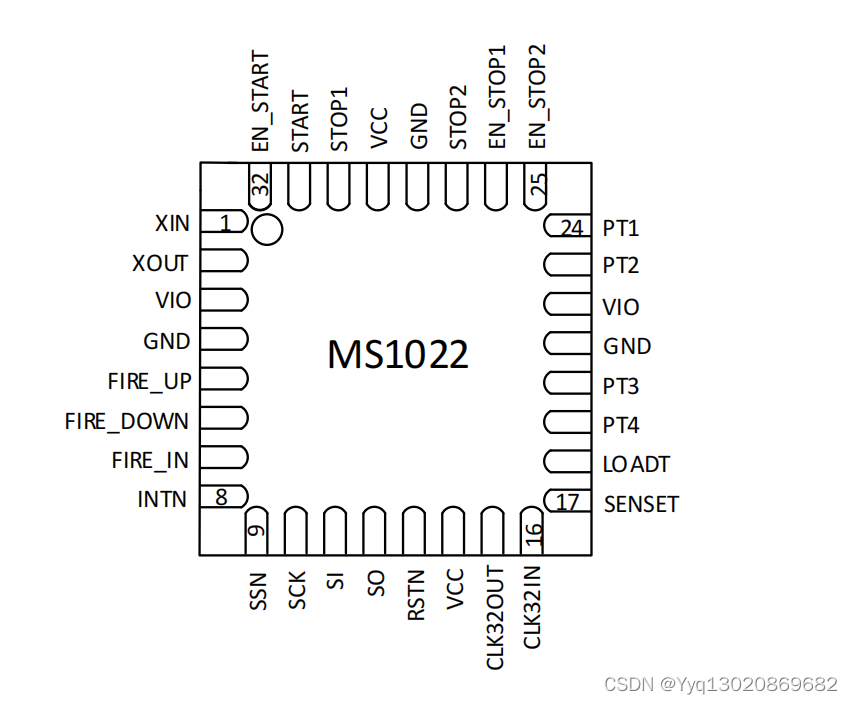
高精度时间测量(TDC)电路MS1022
MS1022 是一款高精度时间测量电路,内部集成了模拟比 较器、模拟开关、施密特触发器等器件,从而大大简化了外 围电路。同时内部增加了第一波检测功能,使抗干扰能力大 大提高。通过读取第一个回波脉冲的相对宽度,用户可以获 得接…...

js关键字
JavaScript 的关键字是指有特殊含义的单词,它们不能用作标识符,比如变量名、函数名等。 以下是 JavaScript 的关键字列表及其解释: true:布尔值 truefalse:布尔值 falsenull:表示一个空值或空对象引用und…...
《算法通关村第二关——指定区间反转问题解析》
《算法通关村第二关——指定区间反转问题解析》 题目描述 给你单链表的头指针head和两个整数left和right,其中left < right 。 请你反转从位置left到位置right的链表节点,返回反转后的链表。 示例1: 输入: head [1,2,3,4,5…...

掌控安全Update.jsp SQL注入
0x01 漏洞介绍 亿赛通电子文档安全管理系统是国内最早基于文件过滤驱动技术的文档加解密产品之一,保护范围涵盖终端电脑(Windows、Mac、Linux系统平台)、智能终端(Android、IOS)及各类应用系统(OA、知识管理…...
)
C#将图片转换为ICON格式(程序运行图标)
介绍: C#创建窗体项目后左上角有显示图标,这个图标会在运行的时候显示在下面进程这里,但是必须是ico格式的图片才可以导入使用。以下是将图片打开后保存为ico格式代码。 代码如下: main函数测试 new 将图片转换成icon格式(&qu…...
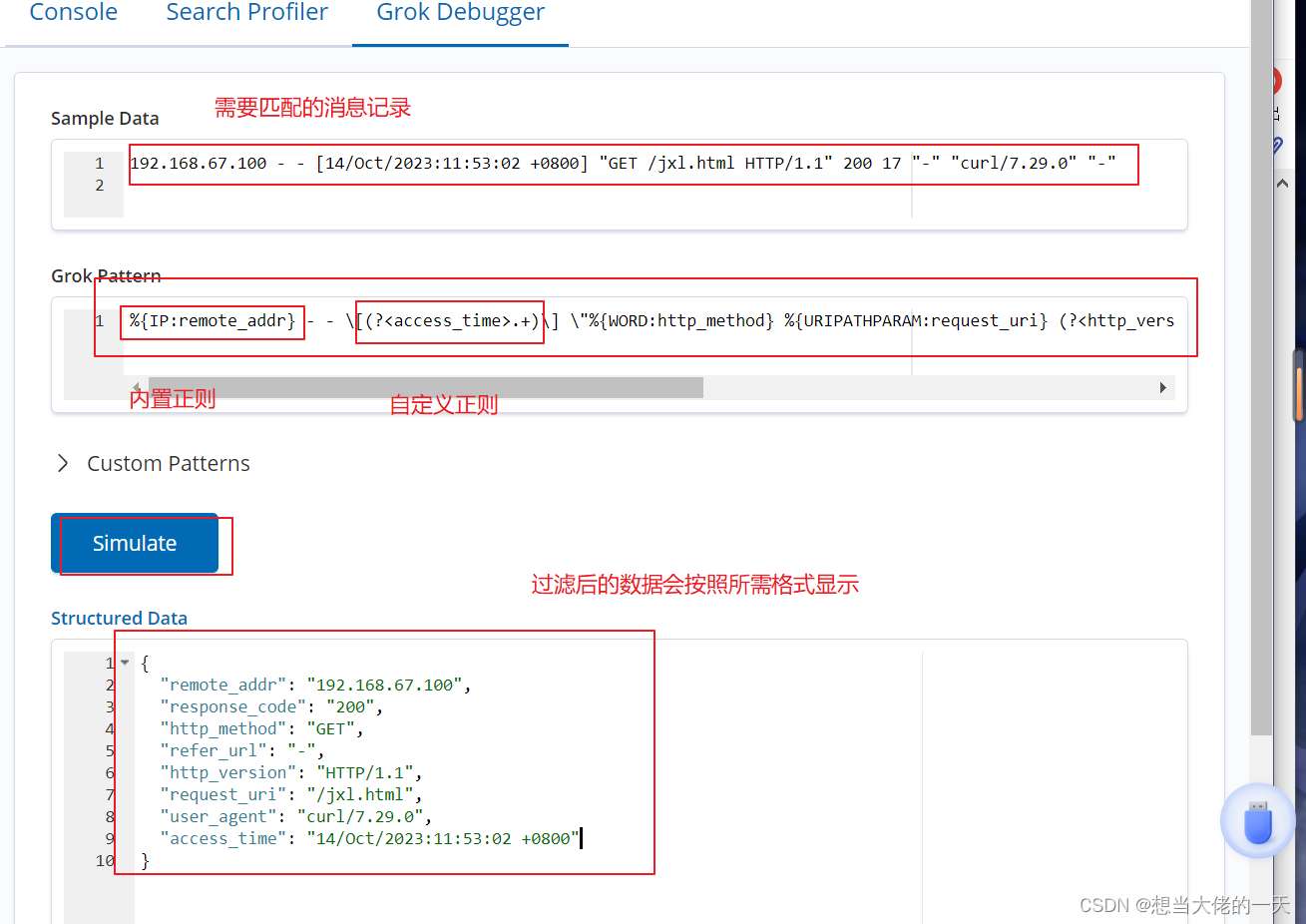
ELK架构Logstash的相关插件:grok、multiline、mutate、date的详细介绍
文章目录 1. grok (正则捕获插件)1.1 作用1.2 正则表达式的类型1.2.1 内置正则表达式1.2.2 自定义正则表达式 2. mutate (数据修改插件)2.1 作用2.2 常见配置选项2.3 应用实例 3. multiline (多行合并插件)3.1 作用3.2 常用配置项及示例3.2.1…...
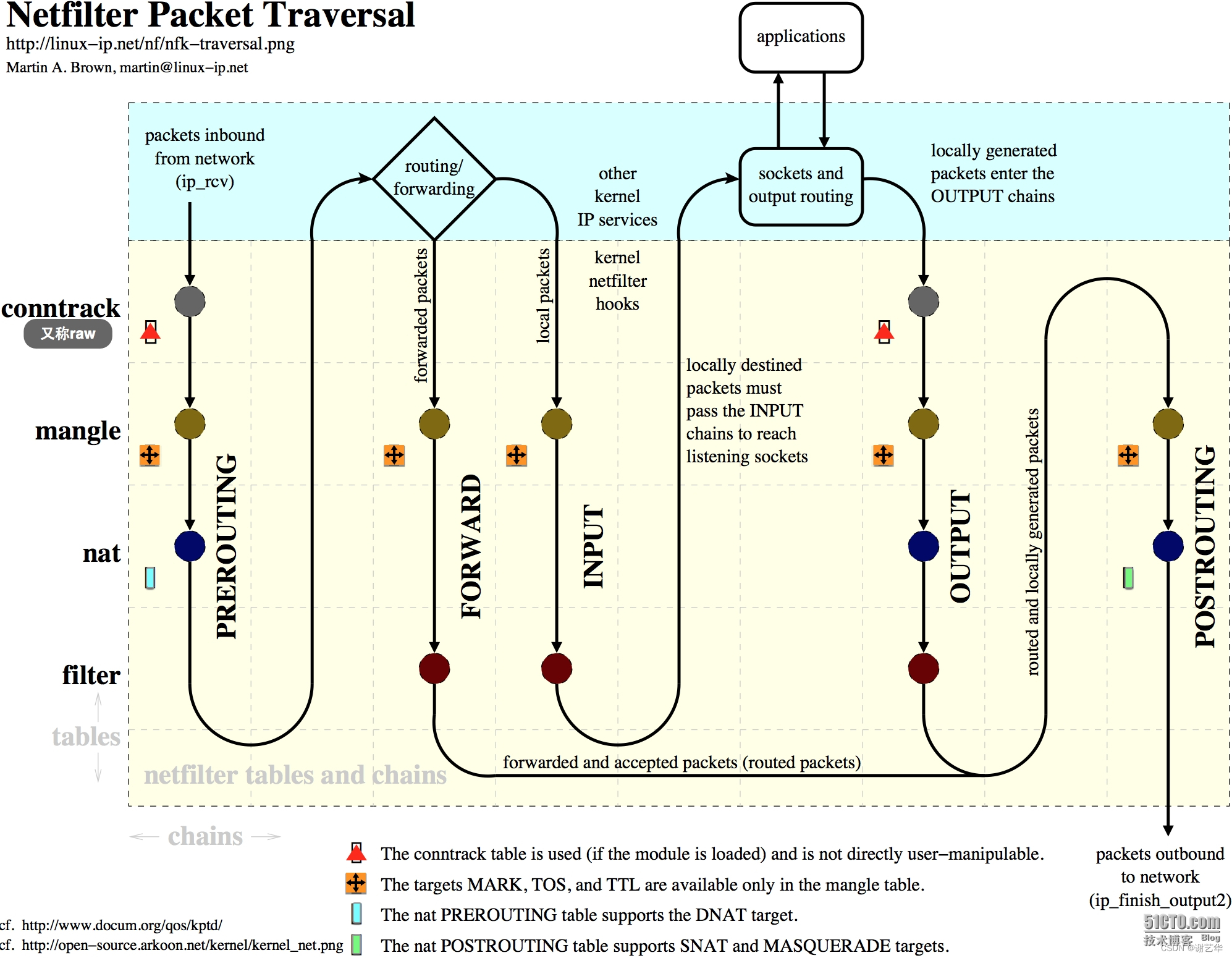
linux 防火墙介绍以及iptables的使用
背景介绍 在前几天,于工发现我们内部的150服务器7554端口被外网访问了。该应用提供着内部的摄像头资源。为了避免被入侵,于是我添加了一些iptables规则,防止外网的访问。 解决方式 解决方式有两种: 关闭公司公网路由器对150服务…...

原码、反码、补码在汇编中的应用
原文章:知乎 原码和二进制类似,不过它有符号位。正数符号位为0,负数为1 。 例:40000 0100 ,-41000 0100 原码是人脑最容易理解和计算的表示方式。 但是这在计算机中计算就出了问题,这两个(4…...
【红日靶场】vulnstack5-完整渗透过程
系列文章目录 【红日靶场】vulnstack1-完整渗透过程 【红日靶场】vulnstack2-完整渗透过程 【红日靶场】vulnstack3-完整渗透过程 【红日靶场】vulnstack4-完整渗透过程 文章目录 系列文章目录描述虚拟机密码红队思路 一、环境初始化二、开始渗透外网打点上线cs权限提升域信息…...
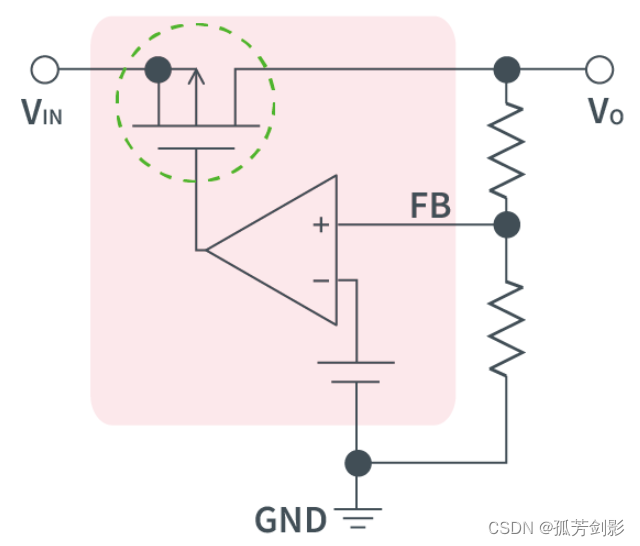
嵌入式平台的电源总结
本文引注: https://mp.weixin.qq.com/s/PuSxHDFbJjjHEReukLSvyg 1.AC的定义 Alternating Current(交流)的首字母缩写。AC是大小和极性(方向)随时间呈周期性变化的电流。电流极性在1秒内的变化次数被称为频率,以Hz为单位…...
)
保姆级教程:用Coze零代码搞定一个能聊天的微信公众号机器人(附服务器配置避坑指南)
零基础打造微信公众号智能助手:Coze平台全流程实战指南 在内容营销竞争白热化的今天,公众号运营者面临两大痛点:一是用户互动需求日益精细化,二是人力客服成本居高不下。据行业数据显示,接入智能对话系统的公众号用户留…...

K8s集群里Nginx和Traefik怎么和平共处?一个真实场景下的双Ingress Controller配置实战
Kubernetes集群中Nginx与Traefik双Ingress Controller共存实践 在Kubernetes生产环境中,我们经常会遇到需要同时运行多个Ingress Controller的场景。比如,一个已经稳定运行Nginx Ingress Controller的集群,现在希望引入Traefik来管理特定Nam…...

技术日报|免费Claude Code工具连冠再揽4007星总量破万,build-your-own-x逼近50万星上榜
🌟 TrendForge 每日精选 - 发现最具潜力的开源项目 📊 今日共收录 13 个热门项目🌐 智能中文翻译版 - 项目描述已自动翻译,便于理解🏆 今日最热项目 Top 10 🥇 Alishahryar1/free-claude-code 项目简介: 在…...

如何高效使用网盘直链解析工具:8大平台全攻略终极指南
如何高效使用网盘直链解析工具:8大平台全攻略终极指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...

量子比特态矢量模拟的内存爆炸难题,如何用RAII+SIMD+稀疏张量压缩将内存占用降低92%?
更多请点击: https://intelliparadigm.com 第一章:量子比特态矢量模拟的内存爆炸难题 在经典计算机上模拟 n 个量子比特的通用量子电路时,系统状态必须用 $2^n$ 维复向量表示——即希尔伯特空间中的态矢量。当 n 增至 30,所需内存…...

别再让缓存背锅了!用webpack给Vue2打包文件加时间戳和压缩的保姆级教程
彻底解决Vue2打包缓存问题:时间戳与压缩实战指南 每次项目更新后,总有用户反馈页面显示异常,而开发者却坚称代码已经部署。这种"薛定谔的更新"状态,往往源于浏览器缓存机制在作祟。本文将手把手教你如何通过webpack配置…...
)
树莓派SPI接口不够用?用CH347 USB转接芯片轻松扩展(附W25Q16/SSD1306/TLC5615实战)
树莓派SPI接口不够用?用CH347 USB转接芯片轻松扩展(附W25Q16/SSD1306/TLC5615实战) 当你在树莓派上同时连接多个SPI设备时,是否遇到过接口不足的困扰?原生SPI总线数量有限,而外设需求却在不断增加。CH347 U…...

逆向分析一个Android TV加密遥控器Dongle:协议、CRC校验与安全设计探讨
Android TV加密遥控器协议逆向实战:从抓包到安全评估 当你的指尖轻触遥控器按键时,一组加密数据正穿越无线信道,经历着复杂的校验与验证过程。这种看似简单的交互背后,隐藏着一套精密的通信协议和安全机制。本文将带你深入Android…...

163MusicLyrics终极指南:如何快速获取网易云和QQ音乐的歌词文件
163MusicLyrics终极指南:如何快速获取网易云和QQ音乐的歌词文件 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 你是否曾经遇到过这样的情况:下载…...
详解)
位深度(Bit Depth)详解
位深度(Bit Depth)详解 位深度是数字图像和视频中的一个重要概念,它决定了每个像素可以表示的颜色数量和精度。一、基本概念 位深度(Bit Depth),也称为色彩深度或量化精度,是指用于表示每个像素…...