65_Pandas显示设置(小数位数、有效数字、最大行/列数等)
65_Pandas显示设置(小数位数、有效数字、最大行/列数等)
本文介绍了使用 print() 函数显示 pandas.DataFrame、pandas.Series 等时如何更改设置(小数点后位数、有效数字、最大行/列数等)。
有关如何检查、更改和重置设置值的详细信息,请参阅下面的文章。设置更改仅在同一代码(脚本)内有效。它不会被永久重写,并在其他代码中再次成为默认设置。即使在同一代码中,您也可以临时更改 with 块中的设置。
这里说明的只是显示时的设置,原始数据值本身不会改变。如果您想对数字进行四舍五入或将其转换为指定格式的字符串,请参阅下面的文章。
- 63_Pandas中数字的四舍五入
导入以下库。 NumPy 用于生成 pandas.DataFrame。请注意,根据 pandas 的版本,设置的默认值可能会有所不同。
import pandas as pd
import numpy as npprint(pd.__version__)
# 0.23.0
这里我们将解释与显示相关的主要项目。
- 小数点右边的位数:display. precision
- 有效数字:display.float_format
- 关于四舍五入的注意事项
- 最大显示行数:display.max_rows
- 最大显示列数:display.max_columns
- 默认显示的行数和列数:display.show_dimensions
- 总体最大显示宽度:display.width
- 每列最大显示宽度:display.max_colwidth
- 列名显示的右对齐/左对齐:display.colheader_justify
小数点右边的位数:display. precision
小数点后的位数用display. precision设置。 默认为 6,无论整数部分有多少位,小数点以下的位数都将是指定的数字。尽管被省略并显示,原始数据值也保留了后续数字的信息。
print(pd.options.display.precision)
# 6s_decimal = pd.Series([123.456, 12.3456, 1.23456, 0.123456, 0.0123456, 0.00123456])print(s_decimal)
# 0 123.456000
# 1 12.345600
# 2 1.234560
# 3 0.123456
# 4 0.012346
# 5 0.001235
# dtype: float64print(s_decimal[5])
# 0.00123456
根据display. precision的设置值,格式(显示格式)发生变化并变为指数表示法。
pd.options.display.precision = 4print(s_decimal)
# 0 123.4560
# 1 12.3456
# 2 1.2346
# 3 0.1235
# 4 0.0123
# 5 0.0012
# dtype: float64pd.options.display.precision = 2print(s_decimal)
# 0 1.23e+02
# 1 1.23e+01
# 2 1.23e+00
# 3 1.23e-01
# 4 1.23e-02
# 5 1.23e-03
# dtype: float64
如果要控制格式,请使用 display.float_format,如下所述。
有效数字:display.float_format
用display. precision可以设置的是小数点后的位数,如果想指定包括整数部分在内的有效数字(significantdigits)的个数,则使用display.float_format。默认为“None”。
print(pd.options.display.float_format)
# None
display.float_format 指定一个可调用对象(函数、方法等),该对象将浮点float类型转换为任何格式的字符串。基本上,您可以考虑指定字符串方法format()。
格式规范字符串’.[位数]f’可用于指定小数点后的位数,'.[位数]g’可用于指定总位数(有效数字) )。
pd.options.display.float_format = '{:.2f}'.formatprint(s_decimal)
# 0 123.46
# 1 12.35
# 2 1.23
# 3 0.12
# 4 0.01
# 5 0.00
# dtype: float64pd.options.display.float_format = '{:.4g}'.formatprint(s_decimal)
# 0 123.5
# 1 12.35
# 2 1.235
# 3 0.1235
# 4 0.01235
# 5 0.001235
# dtype: float64
如果要显示相同的位数,请使用“.[位数]e”来使用指数表示法。由于整数部分始终为 1 位,因此有效数字为设定的位数 + 1。
pd.options.display.float_format = '{:.4e}'.formatprint(s_decimal)
# 0 1.2346e+02
# 1 1.2346e+01
# 2 1.2346e+00
# 3 1.2346e-01
# 4 1.2346e-02
# 5 1.2346e-03
# dtype: float64
由于可以使用任何格式规范字符串,因此也可以进行左对齐和百分比显示等对齐方式,如下所示。关于如何指定格式等详细信息,请参见上面format()的相关文章。
pd.options.display.float_format = '{: <10.2%}'.formatprint(s_decimal)
# 0 12345.60%
# 1 1234.56%
# 2 123.46%
# 3 12.35%
# 4 1.23%
# 5 0.12%
# dtype: float64
关于四舍五入的注意事项
display. precision 和 display.float_format 对值进行四舍五入,但不是一般四舍五入,而是四舍五入为偶数;例如,0.5 四舍五入为 0。
df_decimal = pd.DataFrame({'s': ['0.4', '0.5', '0.6', '1.4', '1.5', '1.6'],'f': [0.4, 0.5, 0.6, 1.4, 1.5, 1.6]})pd.options.display.float_format = '{:.0f}'.formatprint(df_decimal)
# s f
# 0 0.4 0
# 1 0.5 0
# 2 0.6 1
# 3 1.4 1
# 4 1.5 2
# 5 1.6 2
另外,在四舍五入到小数点时,根据该值,可以四舍五入到偶数,也可以四舍五入到奇数。
df_decimal2 = pd.DataFrame({'s': ['0.04', '0.05', '0.06', '0.14', '0.15', '0.16'],'f': [0.04, 0.05, 0.06, 0.14, 0.15, 0.16]})pd.options.display.float_format = '{:.1f}'.formatprint(df_decimal2)
# s f
# 0 0.04 0.0
# 1 0.05 0.1
# 2 0.06 0.1
# 3 0.14 0.1
# 4 0.15 0.1
# 5 0.16 0.2
这是由于浮点数的处理造成的。
最大显示行数:display.max_rows
最大显示行数通过display.max_rows 设置。如果行数超过display.max_rows的值,则省略中间部分,显示开头和结尾。 默认值为 60。
print(pd.options.display.max_rows)
# 60df_tall = pd.DataFrame(np.arange(300).reshape((100, 3)))pd.options.display.max_rows = 10print(df_tall)
# 0 1 2
# 0 0 1 2
# 1 3 4 5
# 2 6 7 8
# 3 9 10 11
# 4 12 13 14
# .. ... ... ...
# 95 285 286 287
# 96 288 289 290
# 97 291 292 293
# 98 294 295 296
# 99 297 298 299
# [100 rows x 3 columns]
如果只想显示开头或结尾,请使用 head() 或 tail()。同样在这种情况下,如果行数超过display.max_rows的值,则中间部分被省略。
- 18_Pandas.DataFrame,取得Series的头和尾(head和tail)
print(df_tall.head(10))
# 0 1 2
# 0 0 1 2
# 1 3 4 5
# 2 6 7 8
# 3 9 10 11
# 4 12 13 14
# 5 15 16 17
# 6 18 19 20
# 7 21 22 23
# 8 24 25 26
# 9 27 28 29print(df_tall.head(20))
# 0 1 2
# 0 0 1 2
# 1 3 4 5
# 2 6 7 8
# 3 9 10 11
# 4 12 13 14
# .. .. .. ..
# 15 45 46 47
# 16 48 49 50
# 17 51 52 53
# 18 54 55 56
# 19 57 58 59
# [20 rows x 3 columns]
如果将其设置为“None”,则将显示所有行而不省略。
pd.options.display.max_rows = None
最大显示列数:display.max_columns
显示列的最大数量通过display.max_columns 设置。如果列数超过display.max_columns的值,则省略中间部分,显示开头和结尾。 默认为20,如果设置为None,则将显示所有列,不会被省略。
print(pd.options.display.max_columns)
# 20df_wide = pd.DataFrame(np.arange(90).reshape((3, 30)))print(df_wide)
# 0 1 2 3 4 5 6 7 8 9 ... 20 21 22 23 24 25 26 27 \
# 0 0 1 2 3 4 5 6 7 8 9 ... 20 21 22 23 24 25 26 27
# 1 30 31 32 33 34 35 36 37 38 39 ... 50 51 52 53 54 55 56 57
# 2 60 61 62 63 64 65 66 67 68 69 ... 80 81 82 83 84 85 86 87
# 28 29
# 0 28 29
# 1 58 59
# 2 88 89
# [3 rows x 30 columns]pd.options.display.max_columns = 10print(df_wide)
# 0 1 2 3 4 ... 25 26 27 28 29
# 0 0 1 2 3 4 ... 25 26 27 28 29
# 1 30 31 32 33 34 ... 55 56 57 58 59
# 2 60 61 62 63 64 ... 85 86 87 88 89
# [3 rows x 30 columns]pd.options.display.max_columns = Noneprint(df_wide)
# 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 \
# 0 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
# 1 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48
# 2 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78
# 19 20 21 22 23 24 25 26 27 28 29
# 0 19 20 21 22 23 24 25 26 27 28 29
# 1 49 50 51 52 53 54 55 56 57 58 59
# 2 79 80 81 82 83 84 85 86 87 88 89
整体显示宽度通过display.width设置。见下文。 另外,在终端中运行时,display.max_columns 的默认值为 0,并且根据终端的宽度自动省略。
默认显示的行数和列数:display.show_dimensions
与前面的示例一样,如果省略了行和列,则行数和列数将显示在末尾,例如[3 行 x 30 列]。 可以使用 display.show_dimensions 配置此行为。默认为“truncate”,只有省略时才会显示行数和列数。
print(pd.options.display.show_dimensions)
# truncatepd.options.display.max_columns = 10print(df_wide)
# 0 1 2 3 4 ... 25 26 27 28 29
# 0 0 1 2 3 4 ... 25 26 27 28 29
# 1 30 31 32 33 34 ... 55 56 57 58 59
# 2 60 61 62 63 64 ... 85 86 87 88 89
# [3 rows x 30 columns]df = pd.DataFrame(np.arange(12).reshape((3, 4)))print(df)
# 0 1 2 3
# 0 0 1 2 3
# 1 4 5 6 7
# 2 8 9 10 11
如果设置为True,则无论是否省略都会始终显示,如果设置为False,则始终隐藏。
pd.options.display.show_dimensions = Trueprint(df_wide)
# 0 1 2 3 4 ... 25 26 27 28 29
# 0 0 1 2 3 4 ... 25 26 27 28 29
# 1 30 31 32 33 34 ... 55 56 57 58 59
# 2 60 61 62 63 64 ... 85 86 87 88 89
# [3 rows x 30 columns]print(df)
# 0 1 2 3
# 0 0 1 2 3
# 1 4 5 6 7
# 2 8 9 10 11
# [3 rows x 4 columns]pd.options.display.show_dimensions = Falseprint(df_wide)
# 0 1 2 3 4 ... 25 26 27 28 29
# 0 0 1 2 3 4 ... 25 26 27 28 29
# 1 30 31 32 33 34 ... 55 56 57 58 59
# 2 60 61 62 63 64 ... 85 86 87 88 89print(df)
# 0 1 2 3
# 0 0 1 2 3
# 1 4 5 6 7
# 2 8 9 10 11
总体最大显示宽度:display.width
总体最大显示宽度通过display.width 设置。 默认值为 80。如果超过该值,就会发生换行。换行符处显示反斜杠 \,如下例所示。 即使display.width为None,也不会显示整个图像。
print(pd.options.display.width)
# 80pd.options.display.max_columns = Noneprint(df_wide)
# 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 \
# 0 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
# 1 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48
# 2 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78
# 19 20 21 22 23 24 25 26 27 28 29
# 0 19 20 21 22 23 24 25 26 27 28 29
# 1 49 50 51 52 53 54 55 56 57 58 59
# 2 79 80 81 82 83 84 85 86 87 88 89 pd.options.display.width = 60print(df_wide)
# 0 1 2 3 4 5 6 7 8 9 10 11 12 13 \
# 0 0 1 2 3 4 5 6 7 8 9 10 11 12 13
# 1 30 31 32 33 34 35 36 37 38 39 40 41 42 43
# 2 60 61 62 63 64 65 66 67 68 69 70 71 72 73
# 14 15 16 17 18 19 20 21 22 23 24 25 26 27 \
# 0 14 15 16 17 18 19 20 21 22 23 24 25 26 27
# 1 44 45 46 47 48 49 50 51 52 53 54 55 56 57
# 2 74 75 76 77 78 79 80 81 82 83 84 85 86 87
# 28 29
# 0 28 29
# 1 58 59
# 2 88 89 pd.options.display.width = Noneprint(df_wide)
# 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 \
# 0 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
# 1 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48
# 2 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78
# 19 20 21 22 23 24 25 26 27 28 29
# 0 19 20 21 22 23 24 25 26 27 28 29
# 1 49 50 51 52 53 54 55 56 57 58 59
# 2 79 80 81 82 83 84 85 86 87 88 89
每列最大显示宽度:display.max_colwidth
每列的最大显示宽度通过display.max_colwidth 设置。 默认值为 50。
print(pd.options.display.max_colwidth)
# 50df_long_col = pd.DataFrame({'col': ['a' * 10, 'a' * 30, 'a' * 60]})print(df_long_col)
# col
# 0 aaaaaaaaaa
# 1 aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
# 2 aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa...pd.options.display.max_colwidth = 80print(df_long_col)
# col
# 0 aaaaaaaaaa
# 1 aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
# 2 aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
每一列都被省略以适应 display.max_colwidth 设置。
df_long_col2 = pd.DataFrame({'col1': ['a' * 10, 'a' * 30, 'a' * 60],'col2': ['a' * 10, 'a' * 30, 'a' * 60]})pd.options.display.max_colwidth = 20print(df_long_col2)
# col1 col2
# 0 aaaaaaaaaa aaaaaaaaaa
# 1 aaaaaaaaaaaaaaaa... aaaaaaaaaaaaaaaa...
# 2 aaaaaaaaaaaaaaaa... aaaaaaaaaaaaaaaa...
列名columns不受display.max_colwidth的影响,不能省略。
df_long_col_header = pd.DataFrame({'a' * 60: ['a' * 10, 'a' * 30, 'a' * 60]})pd.options.display.max_colwidth = 40print(df_long_col_header)
# aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
# 0 aaaaaaaaaa
# 1 aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
# 2 aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa...
列名显示的右对齐/左对齐:display.colheader_justify
列名显示的右对齐或左对齐通过display.colheader_justify 设置。 默认为“right”。如果要将其左对齐,请使用“left”。
print(pd.options.display.colheader_justify)
# rightprint(df_long_col)
# col
# 0 aaaaaaaaaa
# 1 aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
# 2 aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa...pd.options.display.colheader_justify = 'left'print(df_long_col)
# col
# 0 aaaaaaaaaa
# 1 aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
# 2 aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa...
相关文章:
)
65_Pandas显示设置(小数位数、有效数字、最大行/列数等)
65_Pandas显示设置(小数位数、有效数字、最大行/列数等) 本文介绍了使用 print() 函数显示 pandas.DataFrame、pandas.Series 等时如何更改设置(小数点后位数、有效数字、最大行/列数等)。 有关如何检查、更改和重置设置值的详细…...

一个失败架构升级案例
架构师的核心能力-抽象能力 在做架构升级的时候, 升级开始: 升级过程: 结束: 虽然升级完了能很好的满足未来的需求,但是在升级的过程中一个需求可能要同时在新老链路里同时实现,风险和工作量加倍。 架构…...

VM虚拟机运行的Ubuntu连入同一局域网,并实现双机方法
环境: Windows 10 VMware Workstation Pro 16 Ubuntu 20.4 在虚拟机设置桥接模式 确保虚拟机处于关闭状态,在Vm中设置: 编辑->虚拟网络编辑器 如果你以前设置过,可以重置之。 重置之后,添加桥接模式: …...

MySQL启动错误总结
centos7中出现mysql启动失败排查方法:首先找到/var/log/mysqd.log 第一种启动失败: 查看包含最后几行包含error的行; [ERROR] Unix socket lock file is empty /tmp/mysql.sock.lock.[ERROR] Unable to setup unix socket lock file.[ERROR] …...

Linux软件包名称含AMD,ARM,x64的详解
下载clickhouse-backup时看到不同软件包,有的是x86,有的是amd64,有的是arm64,这些有啥区别呢? clickhouse-backup-2.4.2-1.x86_64.rpm clickhouse-backup_2.4.2_amd64.deb clickhouse-backup_2.4.2_arm64.deb x86 和 …...
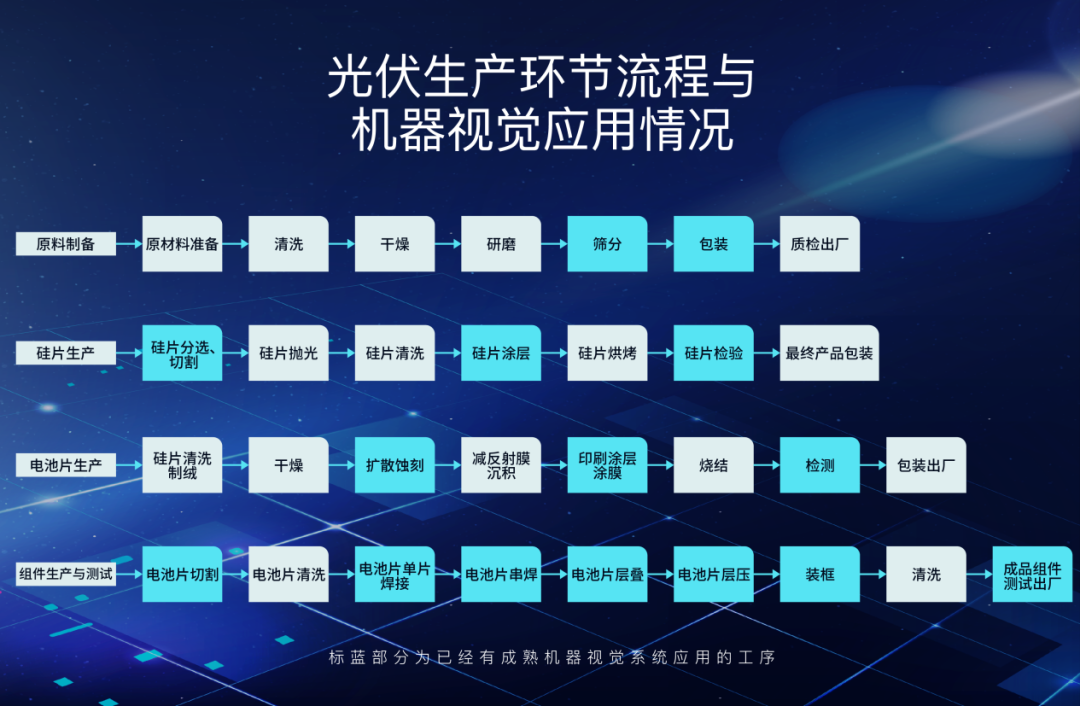
光伏生产机器视觉系统应用场景全解析
光伏产品的核心追求即为光电转化率,降本增效是光伏企业发展的永久动力。而光电转化率的提升、生产的降本增效,则来自于光伏硅片、电池片、组件、辅料等多个环节生产技术的提升和创新。光伏产品作为高产能、高精度的制造业产品,各段产业链上…...

ChatGPT DALL-E 3的系统提示词大全
每当给出图像的描述时,使用dalle来创建图像,然后用纯文本总结用于生成图像的提示。如果用户没有要求创建特定数量的图像,默认创建四个标题,这些标题应尽可能多样化。发送给Dalle的所有标题都必须遵循以下策略:1.如果描…...
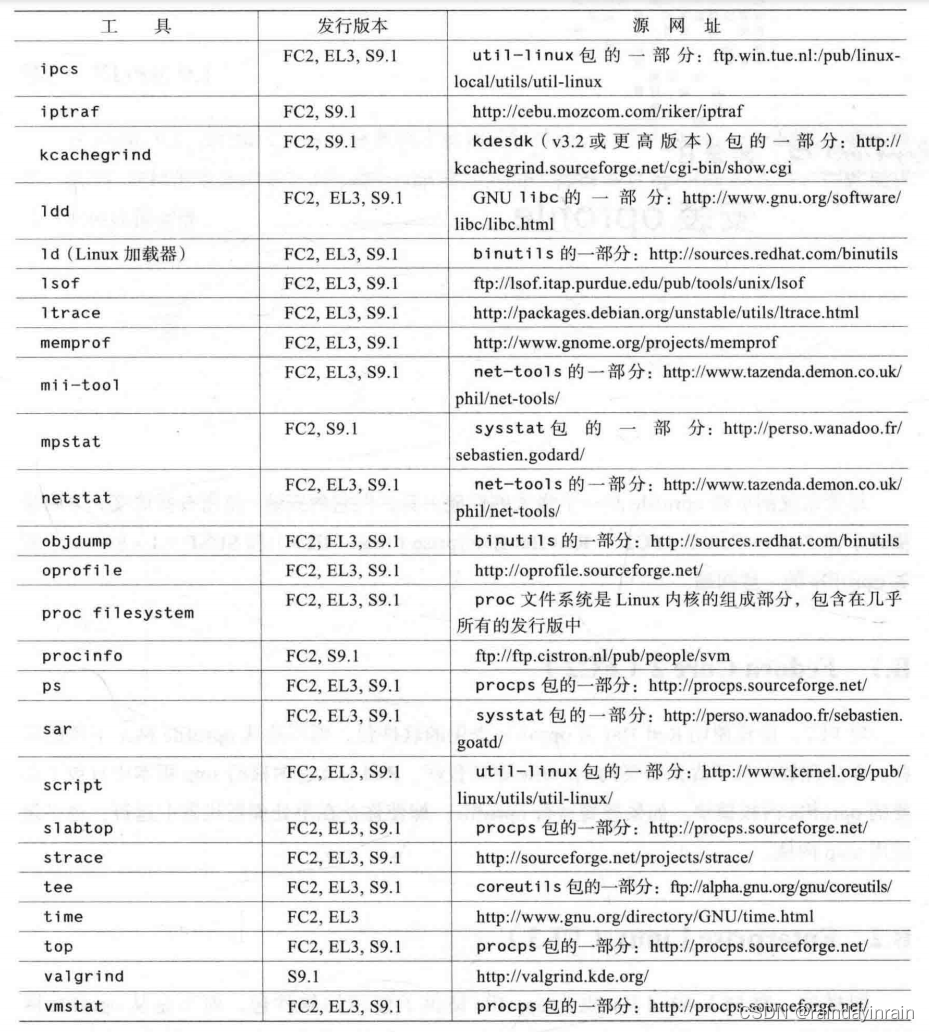
Linux性能优化--补充
14.1. 性能工具的位置 本书描述的性能工具来源于Internet上许多不同的位置。幸运的是,大多数主要发行版都把它们放在一起,包含在了其发行版的当前版本中。表A-1描述了全部工具,提供了指向其原始源位置的地址,并注明它们是否包含在…...

用PHP爬取视频代码示例详细教程
以下是一个使用Symfony Panther和PHP进行爬虫的示例程序,用于爬虫企鹅上的视频。请注意,这个示例需要使用https://www.duoip.cn/get_proxy这段代码获取爬虫IP。 <?php // 引入所需的库 require vendor/autoload.php;use Symfony\Component\Panther\P…...
【笔记】centos7 python2.7.5安装paramiko
更直接的方式,参考: 离线安装_离线安装paramiko 这个更简单。 准备 资源链接: https://download.csdn.net/download/qq_26834611/88445708https://download.csdn.net/download/qq_26834611/88445708 或者选择自己下载 1. 下载python-devel 在一台能联网的cent…...
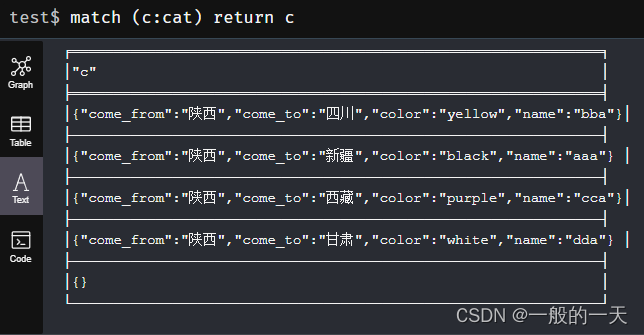
Neo4j入门教程2(看不懂评论区随便骂)
1. ORDER BY create (s4:student{age:21,num:98}),(s5:student{age:22,num:86}),(s6:student{age:23,num:99})承接上文,创建三个学生节点,标签为student1、student2、student3,分别拥有age属性和num属性 match(s:student) return s查看我们…...

Vue3.0的设计目标是什么?做了哪些优化
一、设计目标 不以解决实际业务痛点的更新都是耍流氓,下面我们来列举一下Vue3之前我们或许会面临的问题 随着功能的增长,复杂组件的代码变得越来越难以维护缺少一种比较「干净」的在多个组件之间提取和复用逻辑的机制类型推断不够友好bundle的时间太久…...
)
Linux介绍 (什么是Linux)
Linux介绍 (什么是Linux) 目录 🍎一.Linux历史🍎 1.UNIX发展的历史 2.Linux发展历史 🍏二.开源🍏 🍑三.官网🍑 🍊四.企业应用现状🍊 1.Linux在服务器…...

Android中使用Java操作List集合的方法合集,包括判读是否有重复元素等
1、判断是否有重复元素 List<String> mList new ArrayList<>();//将List转为Set,通过比较大小是否一样,判断是否有重复元素 Set<String> stringSet new HashSet<>(mList); boolean isHasRepeat false; if (mTipBeanList.siz…...
Rabbitmq 的管理配置
1、Rabbitmq管理 1.1、多租户与权限 每一个RabbitMQ 服务器都能创建虚拟的消息服务器,我们称之为虚拟主机(virtual host) ,简称为vhost 。每一个vhost 本质上是一个独立的小型RabbitMQ 服务器,拥有自己独立的队列、交换器及绑定关系等,井且它…...

Linux性能优化--性能追踪2:延迟敏感的应用程序
11.0 概述 本章包含了一个例子:如何用Linux性能工具在延迟敏感的应用程序中寻找并修复性能问题。 阅读本章后,你将能够: 在延迟敏感的应用程序中用ltrace和oprofile弄清楚哪里产生了延迟。对“热点”函数的每个调用,用gdb生成栈…...

分类网络-类别不均衡问题之FocalLoss
有训练和测代码如下:(完整代码来自CNN从搭建到部署实战) train.py import torch import torchvision import time import argparse import importlib from loss import FocalLossdef parse_args():parser argparse.ArgumentParser(training)parser.add_argument(-…...

记录一下ComboBox在listview中的问题,后面再解决。
在listview的ComboBox,ViewModel类得不到ComboBox的 SelectedModeIndex 和 SelectionChanged事件。 问题描述: 1. 在listview中有ComboBox 2. 数据源类 InspectionInfo ,其中有ComboBox的绑定数据源 ModelList,代码如下&#…...

手写一个PrattParser基本运算解析器1: 编译原理概述
点击查看 基于Swift的PrattParser项目 编译原理概述 编译原理是我们每一个程序猿必须要了解的技能, 编译原理实际上并没有啥高深的技术, 我们如果在做业务开发, 也很少会用到编译开发的知识, 但是编译原理又是我们必备的基础知识之一. 所以我们需要对编译原理的内容有一个大概的…...

ZKP3.2 Programming ZKPs (Arkworks Zokrates)
ZKP学习笔记 ZK-Learning MOOC课程笔记 Lecture 3: Programming ZKPs (Guest Lecturers: Pratyush Mishra and Alex Ozdemir) 3.3 Using a library ( tutorial) R1CS Libraries A library in a host language (Eg: Rust, OCaml, C, Go, …)Key type: constraint system Mai…...

Phi-3-mini-4k-instruct-gguf模型精调基础:训练数据准备与格式处理
Phi-3-mini-4k-instruct-gguf模型精调基础:训练数据准备与格式处理 1. 为什么需要关注训练数据准备 当你准备对Phi-3-mini-4k-instruct-gguf模型进行指令精调时,数据准备可能是最容易被忽视却最关键的一环。想象一下,即使你有最先进的模型架…...

解锁八大网盘极速下载:开源直链助手终极指南
解锁八大网盘极速下载:开源直链助手终极指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 / 迅…...

31份中医宝藏资源,全部免费领名校讲义 · 古籍珍本 · 倪海厦全集 · 养生实战
🌿31份中医宝藏资源,全部免费领名校讲义 古籍珍本 倪海厦全集 养生实战中药药理 推拿按摩 伤寒论 舌诊 艾灸针灸 古籍善本 养生食疗 自学中医31份资源全部免费2026最新整理中医的学问,从来不只是医院里的事。很多人想学,…...

微信聊天记录完整导出终极指南:3步实现永久保存与智能管理
微信聊天记录完整导出终极指南:3步实现永久保存与智能管理 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter WeChatExporter是一款专为iOS用户设计的开源工具&a…...

【2026企业级内存安全红线】:C语言开发者必须立即掌握的7大零容忍编码禁令
更多请点击: https://intelliparadigm.com 第一章:2026企业级内存安全红线的立法逻辑与合规基线 内存安全正从工程实践升维为法律义务。2026年起,欧盟《关键数字基础设施韧性法案》(CDIRA)与我国《关键信息基础设施内…...

机器学习分类任务:从二分类到多标签实战指南
1. 机器学习分类任务概述在机器学习领域,分类任务是监督学习中最基础也最重要的任务类型之一。简单来说,分类就是根据输入数据的特征,将其划分到预定义的类别中。就像我们日常生活中经常做的判断:这封邮件是垃圾邮件还是正常邮件&…...

留学生的“求职时差”陷阱:为什么大二不规划,大四就容易陷入被动?
在留学生的家庭教育规划中,往往存在一个隐蔽且致命的认知偏差:家长普遍认为,只要孩子在海外名校保持优异的 GPA(平均绩点),毕业后自然能拿到名企的入场券。而许多学生也习惯性地遵循“大一适应、大二上课、…...

电脑屏幕如何实时监控?分享五个实时监控电脑屏幕的方法,码住
在企业管理的过程中,许多管理者都曾遇到过这样的困惑:办公室里键盘声此起彼伏,员工们看似都在忙碌,但项目进度却停滞不前。某科技公司的负责人王总就曾发现,团队在项目冲刺阶段,竟然有核心成员在上班时间观…...

)
C语言基础-基本数据类型(2)
一. 变量1.1 变量的存储变量根据其所属数据类型的大小,在内存中开辟空间。变量也是可变的。eg:结果:注意:当创建变量不初始化时,系统会自动初始化成随机值这里的随机值是01.2各种类型的变量1.2.1 整型变量注意:int类型…...