36 机器学习(四):异常值检测|线性回归|逻辑回归|聚类算法|集成学习
文章目录
- 异常值检测
- 箱线图
- z-score
- 保存模型 与 使用模型
- 回归的性能评估
- 线性回归
- 正规方程的线性回归
- 梯度下降的线性回归
- 原理介绍
- L1 和 L2 正则化的介绍
- api介绍------LinearRegression
- api介绍------SGDRegressor
- 岭回归 和 Lasso 回归
- 逻辑回归
- 基本使用
- 原理介绍
- 正向原理介绍
- 损失函数 与 反向更新
- 接口介绍
- 聚类算法初识
- k-means
- 模型的评估
- 代码
- 集成学习
- 偏差和方差
- Adaboost(原理略写)------Boosting
- GBDT (原理略写)------Boosting
- 区分梯度提升和梯度下降
- 自己做一个hard bagging
- soft bagging
- BaggingClassifier的api接口介绍
- RandomForestClassifier的api接口介绍
- ExtraTreesClassifie
- bossting
异常值检测
这边就讲解其中一种方法,详细可见别人的博客:
箱线图
如果一个值大于3/4分位值+1.5 IQR 他就是异常值
如果一个值小于1/4分位值-1.5 IQR 他就是异常值
z-score
标准化后的值大于某一个阈值 也可以当作异常值处理
保存模型 与 使用模型
# 保存模型
joblib.dump(对应的训练器, "./tmp/test.pkl")# 使用模型 此时model就是对应的训练器
model = joblib.load("./tmp/test.pkl")
回归的性能评估
这边只给出一种,注意和之前的分类的混淆矩阵的那些相对比:
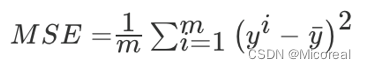
接口:
sklearn.metrics.mean_squared_errormean_squared_error(y_true,y_pred).均方误差回归损失
y_true:真实值
y_pred:预测值
return:浮点数结果线性回归
正规方程的线性回归
# 正则化的 线性回归预测房子的价格
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
import joblib
from sklearn.metrics import mean_squared_error
# 基本的操作(数据准备) 之前都见多了 不过值得关注的是这边多采用了对于y也进行标准化,定义了两个标准器
# ----------------------------------------------------------------------
lb = load_boston()
x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.25, random_state=1)
print(x_train.shape)
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)# 对y的标准化
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train.reshape(-1, 1)) # 目标值是一维的,这里需要传进去2维的
y_test = std_y.transform(y_test.reshape(-1, 1))
print('-'*20)
# ----------------------------------------------------------------------# estimator预测
# 正规方程求解方式预测结果,正规方程进行线性回归
lr = LinearRegression()
lr.fit(x_train, y_train)
# 训练结束 打印出对应的w
print(lr.coef_) #回归系数可以看特征与目标之间的相关性
y_predict = lr.predict(x_test)
# 预测测试集的房子价格,通过inverse得到真正的房子价格
y_lr_predict = std_y.inverse_transform(y_predict)
# 保存训练好的模型
joblib.dump(lr, "./tmp/test.pkl")
# 模型加载
model = joblib.load("./tmp/test.pkl")
print("正规方程测试集里面每个房子的预测价格:", y_lr_predict)
print("正规方程的均方误差:", mean_squared_error(y_test, y_predict))
输出:
# # 输出:这个数据集不知道为什么用不了了
# (379, 13)
# --------------------
# [[-0.12026411 0.15044778 0.02951803 0.07470354 -0.28043353 0.22170939
# 0.02190624 -0.35275513 0.29939558 -0.2028089 -0.23911894 0.06305081
# -0.45259462]]
# 正规方程测试集里面每个房子的预测价格:
# [[32.37816533]
# `````````````
# [26.00459084]]
# 正规方程的均方误差: 0.2758842244225054
梯度下降的线性回归
# 梯度下降去进行房价预测,数据量大要用这个
# 默认可以去调 eta0 = 0.008,会改变learning_rate
# learning_rate='optimal',alpha会影响学习率的值,由alpha来算学习率
from sklearn.linear_model import SGDRegressorsgd = SGDRegressor(eta0=0.008, penalty='l1', alpha=0.005)
# # 训练
sgd.fit(x_train, y_train)
#
print('梯度下降的回归系数', sgd.coef_)
#
# 预测测试集的房子价格
y_sgd_predict = std_y.inverse_transform(sgd.predict(x_test).reshape(-1, 1))
y_predict = sgd.predict(x_test)
print("梯度下降测试集里面每个房子的预测价格:", y_sgd_predict)
print("梯度下降的均方误差:", mean_squared_error(y_test, y_predict))
print("梯度下降的原始房价量纲均方误差:", mean_squared_error(std_y.inverse_transform(y_test), y_sgd_predict))
输出:
梯度下降的回归系数 [-0.09161381 0.07894594 -0.01997965 0.07736127 -0.18054122 0.266221080. -0.23891603 0.09441201 -0.02523685 -0.22153748 0.06690733-0.4268276 ]
梯度下降测试集里面每个房子的预测价格:
[[30.32788625]
··············[25.98775391]]
梯度下降的均方误差: 0.2782778128254135
梯度下降的原始房价量纲均方误差: 22.087751747792876原理介绍
这边由于线性回归比较简单,介绍就比较简略。
我们实际上的训练就是为了训练出:下面这个w向量,然后最后得到合适的w,可以用来预测好的数据。
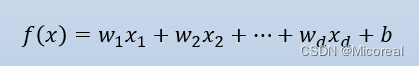
判断误差使用损失函数进行判断:
其中一种:最小二乘法
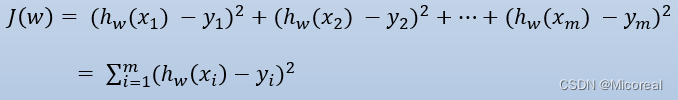
而如何去反向更新w,这就是机器学习与深度学习的一大重大的特征:
而上面给出的两个接口,则是分别采用两种不同的方式去进行的更新w
方式一:正规方程(LinearRegression)
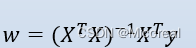
但这个也有问题,就是有些就没有这个矩阵的逆,这就有很大的局限,甚至这个方程求解的速度也不快。
方式二:梯度下降(SGD)
还有很多梯度
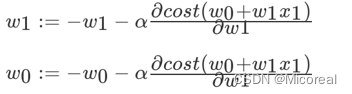
L1 和 L2 正则化的介绍
当我们训练机器学习模型时,我们希望它能够在新数据上表现良好。但是,如果我们使用过于复杂的模型,例如具有大量特征或参数的模型,就会出现过拟合的问题。 过拟合是指模型在训练数据上表现良好,但在新数据上表现不佳的情况。为了避免过拟合,我们可以使用正则化技术。
正则化是一种用于控制模型复杂度的技术,通常应用于线性回归、逻辑回归和神经网络等机器学习模型中。 正则化通过向模型的损失函数中添加一个惩罚项来防止模型过拟合。 这个惩罚项会惩罚模型的权重参数,使其趋向于较小的值。 正则化分为L1正则化(Lasso正则化)和L2正则化(Ridge正则化),它们分别对应不同的惩罚项类型。
L1正则化(Lasso正则化)通过向损失函数中添加权重向量中各个元素的绝对值之和来惩罚权重参数。 L1正则化可以产生稀疏权重向量,即其中许多元素为零。 这使得L1正则化成为特征选择的一种方法。
L2正则化(Ridge正则化)通过向损失函数中添加权重向量中各个元素的平方和来惩罚权重参数。 L2正则化可以防止过拟合并提高模型的泛化能力

api介绍------LinearRegression
# 通过正规方程优化
sklearn.linear_model.LinearRegression(fit_intercept=True)
参数:
fit_intercept:是否计算偏置属性:
LinearRegression.coef_:回归系数
LinearRegression.intercept_:偏置
api介绍------SGDRegressor
# SGDRegressor类实现了随机梯度下降学习,它支持不同的loss函数和正则化惩罚项来拟合线性回归模型。
sklearn.linear_model.SGDRegressor(loss="squared_loss", fit_intercept=True, learning_rate ='invscaling', eta0=0.01)参数:
loss:损失类型loss=”squared_loss”: 普通最小二乘法‘squared_error’‘huber’‘epsilon_insensitive’‘squared_epsilon_insensitive’
fit_intercept:是否计算偏置
learning_rate : 'constant': eta = eta0'optimal': eta = 1.0 / (alpha * (t + t0)) [default]'invscaling': eta = eta0 / pow(t, power_t)
eta0: default=0.01 eta0float,默认值=0.01
power_t=0.25:存在父类当中
对于一个常数值的学习率来说,可以使用learning_rate=’constant’ ,并使用eta0来指定学习率。
early_stopping:损失没有改进,提前停止训练 penalty是惩罚,分为L1和L2
alpha:值越高,正则化力度越强补充 这个不是参数:t 和 执行的次数正相关属性:
SGDRegressor.coef_:回归系数
SGDRegressor.intercept_:偏置
岭回归 和 Lasso 回归
实际上就是上面加上正则化的回归,岭就是加上L2的线性回归,Lasso就是加上L1的线性回归。
这边给出接口:
sklearn.linear_model.Ridgesklearn.linear_model.Lasso
具体的接口参数到官网上查找
逻辑回归
逻辑回归是一个很重要的模型,虽然叫做回归,但是实际上确是一个二分类器,关于逻辑回归的理解,关系到后面对于深度学习的理解,所以这一块需要重点关注。
基本使用
# 逻辑回归做二分类进行癌症预测(根据细胞的属性特征)
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report,roc_auc_score
from sklearn.preprocessing import StandardScaler
# 数据准备
# 构造列标签名字
column = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape','Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin', 'Normal Nucleoli','Mitoses', 'Class']
# 读取数据 预测是否患病
data = pd.read_csv("./dataset/breast-cancer-wisconsin.data.txt",names=column)
# 缺失值进行处理
data = data.replace(to_replace='?', value=np.nan)
#直接删除,哪一行有空值,就删除对应的样本
data = data.dropna()
print(data.info())
print('-'*20)# 进行数据的分割
x_train, x_test, y_train, y_test = train_test_split(data[column[1:10]], data[column[10]], test_size=0.25,random_state=1)
# 进行标准化处理
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)# 逻辑回归预测 C正则化力度 solver 默认是 'liblinear'
lg = LogisticRegression(C=0.8, solver='newton-cg')
lg.fit(x_train, y_train)
y_predict = lg.predict(x_test)# 正确率判断
print("准确率:\n", lg.score(x_test, y_test))
# 得出对应分类的概率 会得到两个数 前者是不患病的概率 后者是患病的概率
print("概率是:\n",lg.predict_proba(x_test)[0])# 为什么还要看下召回率,labels和target_names对应
# macro avg 平均值 weighted avg 加权平均值
print("召回率:\n", classification_report(y_test, y_predict, labels=[2, 4], target_names=["良性", "恶性"]))
#AUC计算要求是二分类,不需要是0和1
print("AUC指标:\n", roc_auc_score(y_test, y_predict))
输出:
<class 'pandas.core.frame.DataFrame'>
Index: 683 entries, 0 to 698
Data columns (total 11 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 Sample code number 683 non-null int64 1 Clump Thickness 683 non-null int64 2 Uniformity of Cell Size 683 non-null int64 3 Uniformity of Cell Shape 683 non-null int64 4 Marginal Adhesion 683 non-null int64 5 Single Epithelial Cell Size 683 non-null int64 6 Bare Nuclei 683 non-null object7 Bland Chromatin 683 non-null int64 8 Normal Nucleoli 683 non-null int64 9 Mitoses 683 non-null int64 10 Class 683 non-null int64
dtypes: int64(10), object(1)
memory usage: 64.0+ KB
None
--------------------
准确率:0.9824561403508771
概率是:[0.95194977 0.04805023]
召回率:precision recall f1-score support良性 0.97 1.00 0.99 111恶性 1.00 0.95 0.97 60accuracy 0.98 171macro avg 0.99 0.97 0.98 171
weighted avg 0.98 0.98 0.98 171AUC指标:0.975
原理介绍
正向原理介绍
输入:
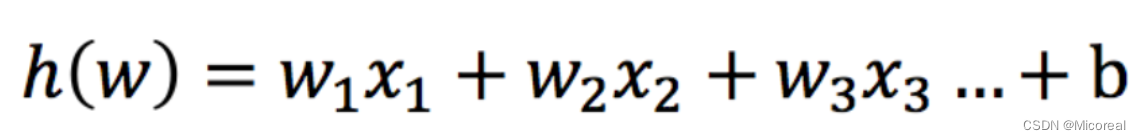
逻辑回归的输入就是一个线性回归,他把这个值作为输入。
然后得到的值我们称为z,再输入到激活函数当中:
这边举一个最广为人知的激活函数sigmoid:
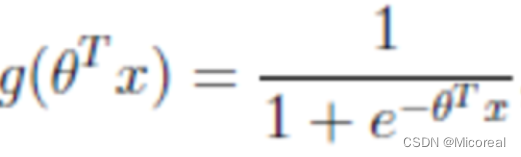
这个不是很好看懂,实际上就是g(z) = 1/(1+exp(-z))
然后我们的值就会经过这个激活函数,把这些值映射到【0,1】之间,而且也是正好映射-∞映射到0,0映射到0.5,+∞映射到1,这样子,然后我们再对于我们映射到的值判断属于0-0.5 输出的就是0,0.5-1输出的就是1 从而进行分类。
例子:
但有了这个正向的原理,那我们该怎么反向去更新那些参数w呢?
损失函数 与 反向更新
当然数学家也使用这个交叉熵给出了答案
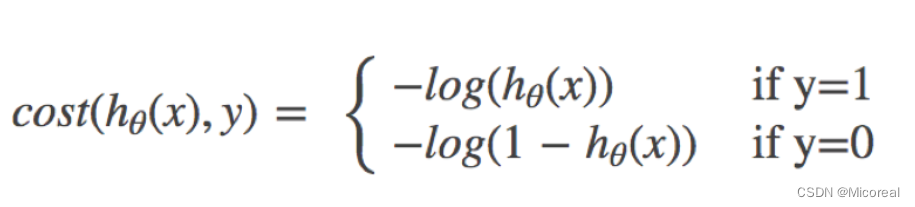
结合完整的:
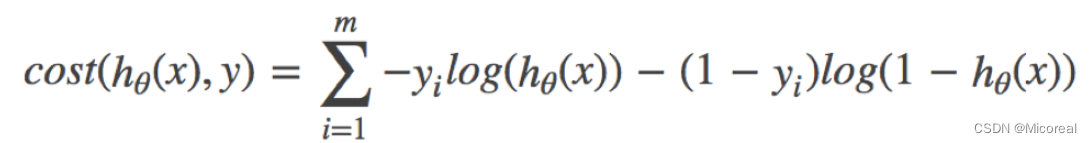
计算的例子:

知道了损失函数,那我们就该去反向更新w(想要使用梯度下降进行更新),自然想到的就是链式求导法则:
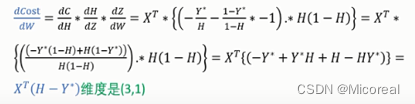
这边给出别人的计算哈,!OxO !
如此,我们知道了梯度,也就可以按照对应的梯度下降算法进行优化w。
接口介绍
sklearn.linear_model.LogisticRegression(solver='liblinear', penalty=‘l2’, C = 1.0)solver可选参数:{'liblinear', 'sag', 'saga','newton-cg', 'lbfgs'},(优化器,或者就是说就是那个学习率,不过是随着时间的变化而变化的)默认: 'liblinear';用于优化问题的算法。对于小数据集来说,“liblinear”是个不错的选择,而“sag”和'saga'对于大型数据集会更快。对于多类问题,只有'newton-cg', 'sag', 'saga'和'lbfgs'可以处理多项损失;“liblinear”仅限于“one-versus-rest”分类。penalty:正则化的种类C:正则化力度
聚类算法初识
这边主要介绍的就是k-means算法,也是无监督算法的典型。
k-means
1、随机设置K个特征空间内的点作为初始的聚类中心
2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
4、如果计算得出的新中心点与原中心点一样,那么结束,否则重新进行第二步过程
api接口:
sklearn.cluster.KMeans(n_clusters=8)参数:
n_clusters:开始的聚类中心数量
整型,缺省值=8,生成的聚类数,即产生的质心(centroids)数。方法:
estimator.fit(x)
estimator.predict(x)
estimator.fit_predict(x)
计算聚类中心并预测每个样本属于哪个类别,相当于先调用fit(x),然后再调用predict(x)
模型的评估
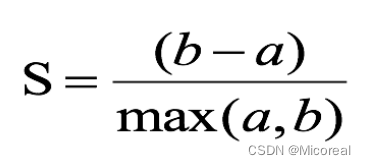
计算样本i到同簇其他样本的平均距离ai,ai 越小样本i的簇内不相似度越小,说明样本i越应该被聚类到该簇。
计算样本i到最近簇Cj 的所有样本的平均距离bij,称样本i与最近簇Cj 的不相似度,定义为样本i的簇间不相似度:bi =min{bi1, bi2, …, bik},bi越大,说明样本i越不属于其他簇。
求出所有样本的轮廓系数后再求平均值就得到了平均轮廓系数。
平均轮廓系数的取值范围为[-1,1],系数越大,聚类效果越好。
簇内样本的距离越近,簇间样本距离越远
代码
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score# 1.获取数据
order_product = pd.read_csv("./data/instacart/order_products__prior.csv")
products = pd.read_csv("./data/instacart/products.csv")
orders = pd.read_csv("./data/instacart/orders.csv")
aisles = pd.read_csv("./data/instacart/aisles.csv")# 2.数据基本处理
table1 = pd.merge(order_product, products, on=["product_id", "product_id"])
table2 = pd.merge(table1, orders, on=["order_id", "order_id"])
table = pd.merge(table2, aisles, on=["aisle_id", "aisle_id"])
table = pd.crosstab(table["user_id"], table["aisle"])
table = table[:1000]# 3.特征工程 — pca
transfer = PCA(n_components=0.9)
data = transfer.fit_transform(table)# 4.机器学习(k-means)
estimator = KMeans(n_clusters=8, random_state=22)
estimator.fit_predict(data)# 5.模型评估
silhouette_score(data, y_predict)
集成学习
集成学习一般分为两种:
- Boosting(串行):它的基本思路是将基分类器层层叠加,每一层在训练的时候,对前一层基分类器分错的样本,给予更高的权重。
- Bagging(并行):Bagging 方法更像是一个集体决策的过程,每个个体都进行单独学习,学习的内容可以相同,也可以不同,也可以部分重叠。但由于个体之间存在差异性,最终做出的判断不会完全一致。在最终做决策时,每个个体单独作出判断,再通过投票的方式做出最后的集体决策。
集成学习一般可分为以下 3 个步骤。
(1)找到误差互相独立的基分类器。
(2)训练基分类器。
(3)合并基分类器的结果。
合并基分类器的方法有 voting 和 stacking 两种。前者是用投票的方式,将获得
最多选票的结果作为最终的结果。后者是用串行的方式,把前一个基分类器的结果输出到下一个分类器,将所有基分类器的输出结果相加(或者用更复杂的算法融合,比如把各基分类器的输出作为特征,使用逻辑回归作为融合模型进行最后的结果预测)作为最终的输出。
偏差和方差
讲解讲不清楚,这边直接给出一个图例:
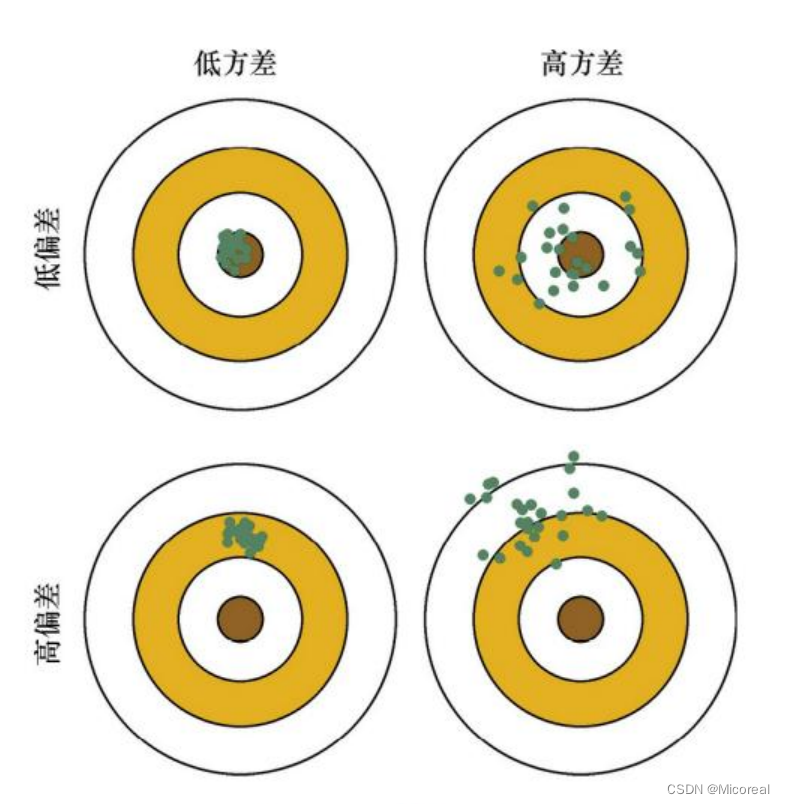
Bagging 能够提高弱分类器性能的原因是降低了方差,Boosting 能够提升弱分类器性能的原因是降低了偏差。
Adaboost(原理略写)------Boosting
Adaboost的基本实现步骤如下:
- 初始化训练数据的权重向量,使每个样本的权重相等。
- 训练一个弱分类器,并计算其在训练数据上的错误率。
- 根据分类器的错误率更新训练数据的权重向量,使被错误分类的样本的权重增加,而被正确分类的样本的权重减少。
- 重复步骤2和3,直到达到指定数量的弱分类器或直到训练数据完全正确分类。
- 将所有弱分类器组合成一个强分类器。
在实现Adaboost时,我们需要选择一个基础分类器作为弱分类器。 常用的基础分类器包括决策树、神经网络和支持向量机等。
GBDT (原理略写)------Boosting
Gradient Boosting(梯度提升) 是 Boosting 中的一大类算法,其基本思想是根据当前模型损失函数的负梯度信息来训练新加入的弱分类器,然后将训练好的弱分类器以累加的形式结合到现有模型中。算法 1 描述了 Gradient Boosting 算法的基本流程,在每一轮迭代中,首先计算出当前模型在所有样本上的负梯度,然后以该值为目标训练一个新的弱分类器进行拟合并计算出该弱分类器的权重,最终实现对模型的更新。
比如一开始GBDT(x,y) 下一步: GBDT(x,y真实-y)
区分梯度提升和梯度下降

自己做一个hard bagging
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt# 准备数据
from sklearn import datasets
x, y = datasets.make_moons(n_samples=1000, noise=0.3, random_state=42)
plt.scatter(x[y == 0, 0], x[y == 0, 1])
plt.scatter(x[y == 1, 0], x[y == 1, 1])
plt.show()输出:
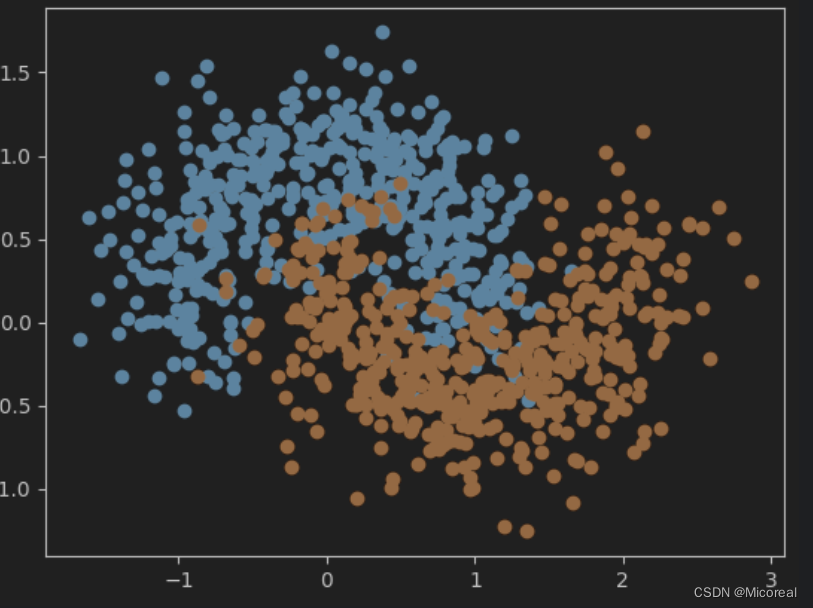
#默认分割比例是75%和25%
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifierx_train, x_test, y_train, y_test = train_test_split(x, y, random_state=42)log_clf = LogisticRegression()
log_clf.fit(x_train, y_train)
log_clf.score(x_test, y_test)svm_clf = SVC()
svm_clf.fit(x_train, y_train)
svm_clf.score(x_test, y_test)dt_clf = DecisionTreeClassifier()
dt_clf.fit(x_train, y_train)
dt_clf.score(x_test, y_test)#训练好模型,测试集做预测
y_predict1 = log_clf.predict(x_test)
y_predict2 = svm_clf.predict(x_test)
y_predict3 = dt_clf.predict(x_test)
from sklearn.metrics import accuracy_score# 自己做一个bagging并行 hard bagging
y_predict = np.array((y_predict1 + y_predict2 + y_predict3) >= 2, dtype='int')#accuracy_score计算准确率的
print(accuracy_score(y_test, y_predict))
输出:
0.908
我们直接进行相加,其实有一个问题,就比如说我们上面不是定义了三个基分类器,三个训练出来的模型,得出的效果有高有低,而我们给予其相同的权重进行累加,这明显是不对的,我们需要进行修改成soft bagging,加上他们每个人对应的猜对的概率。
调用接口写的hard bagging
from sklearn.ensemble import VotingClassifier#hard模式就是少数服从多数
voting_clf = VotingClassifier(estimators=[('log_clf', LogisticRegression()),('svm_clf', SVC()),('dt_clf', DecisionTreeClassifier())], voting='hard')voting_clf.fit(x_train, y_train)
print(voting_clf.score(x_test, y_test))
输出:
0.908
soft bagging
当然也可以自己写一个,但这里避免麻烦就直接调用接口了
# hard和soft区别请看课件解释
voting_clf2 = VotingClassifier(estimators=[('log_clf', LogisticRegression()),('svm_clf', SVC(probability=True)), #支持向量机中需要加入probability('dt_clf', DecisionTreeClassifier())], voting='soft')
voting_clf2.fit(x_train, y_train)
print(voting_clf2.score(x_test, y_test))
输出:
0.916
BaggingClassifier的api接口介绍
from sklearn.tree import DecisionTreeClassifier #用决策树集成上千模型
from sklearn.ensemble import BaggingClassifier # 这个可以搭配别的模型进行使用# n_estimators指定了随机森林中决策树的数量 max_samples指定了每个决策树使用的样本数
# bootstrap指定了是否使用有放回抽样来生成每个决策树的训练数据 这个一般都是有放回 除非数据量很大
# oob_score=True 拿没有取到的数据集作为测试集 概率上统计有37%的数据是随机不到的
# n_jobs 使用多少个cpu核心在跑 如果是-1的话就是使用所有的核心跑
# max_features指定了在寻找最佳分割时要考虑的特征数量
# bootstrap_features指定了是否在寻找最佳分割时对特征进行有放回抽样
bagging_clf = BaggingClassifier(DecisionTreeClassifier(), n_estimators=10, max_samples=100, bootstrap=True,oob_score=True,n_jobs=1)
bagging_clf.fit(x_train, y_train)
print(bagging_clf.score(x_test, y_test))
输出:
0.912
RandomForestClassifier的api接口介绍
这个直接就是定义了是用决策树进行拼接,自行去sklearn上查找也可,这边就提一嘴是bagging的算法
rc_clf2 = RandomForestClassifier(n_estimators=500, max_leaf_nodes=16,random_state=666,oob_score=True, n_jobs=-1)
rc_clf2.fit(x, y)
rc_clf2.oob_score_
输出:
0.92
ExtraTreesClassifie
ExtraTreesClassifier是一种基于决策树的集成学习算法,它通过随机化特征选择和样本选择来构建多个决策树,并将它们的预测结果进行平均来得到最终的预测结果。与传统决策树不同的是,ExtraTreesClassifier在选择划分属性时不再从所有属性中选择最优属性,而是从一个随机子集中选择最优属性。这样可以增加基学习器之间的差异性,提高模型的泛化能力ExtraTreesClassifier可以用于二元分类和多类别分类问题,并且在实践中表现良好。如果您需要使用决策树作为基学习器,则可以考虑使用ExtraTreesClassifier。
提高泛化能力,避免过拟合现象。
from sklearn.ensemble import ExtraTreesClassifieret_clf = ExtraTreesClassifier(n_estimators=500, oob_score=True,bootstrap=True, n_jobs=-1)
et_clf.fit(x, y)
et_clf.oob_score_
bossting
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
ada_clf = AdaBoostClassifier(DecisionTreeClassifier(), n_estimators=500)
ada_clf.fit(x_train, y_train)
ada_clf.score(x_test, y_test)
输出:
0.892
from sklearn.ensemble import GradientBoostingClassifiergb_clf = GradientBoostingClassifier(max_depth=2, n_estimators=30)
gb_clf.fit(x_train, y_train)
gb_clf.score(x_test, y_test)
输出:
0.9
boosting链接
相关文章:
36 机器学习(四):异常值检测|线性回归|逻辑回归|聚类算法|集成学习
文章目录 异常值检测箱线图z-score 保存模型 与 使用模型回归的性能评估线性回归正规方程的线性回归梯度下降的线性回归原理介绍L1 和 L2 正则化的介绍api介绍------LinearRegressionapi介绍------SGDRegressor 岭回归 和 Lasso 回归 逻辑回归基本使用原理介绍正向原理介绍损失…...
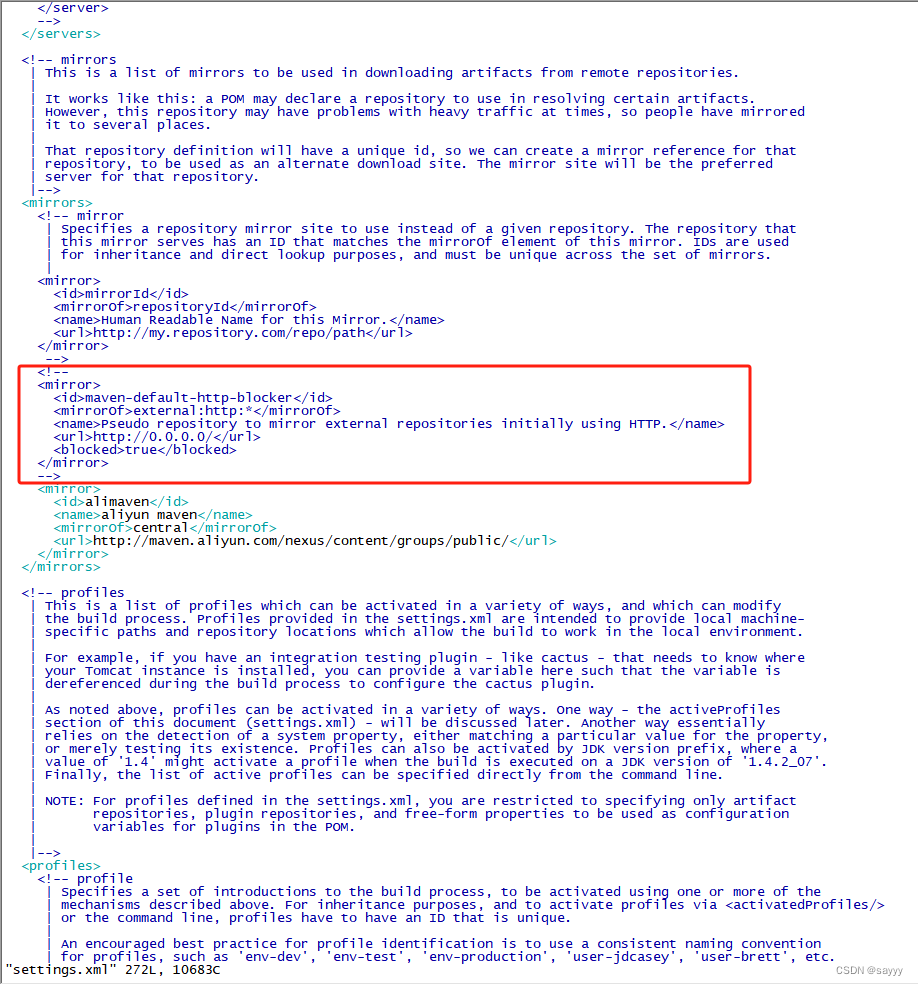
maven-default-http-blocker (http://0.0.0.0/): Blocked mirror for repositories
前言 略 说明 新设备上安装了mvn 3.8.5,编译新项目出错: [ERROR] Non-resolvable parent POM for com.admin.project:1.0: Could not transfer artifact com.extend.parent:pom:1.6.9 from/to maven-default-http-blocker (http://0.0.0.0/): Bl…...
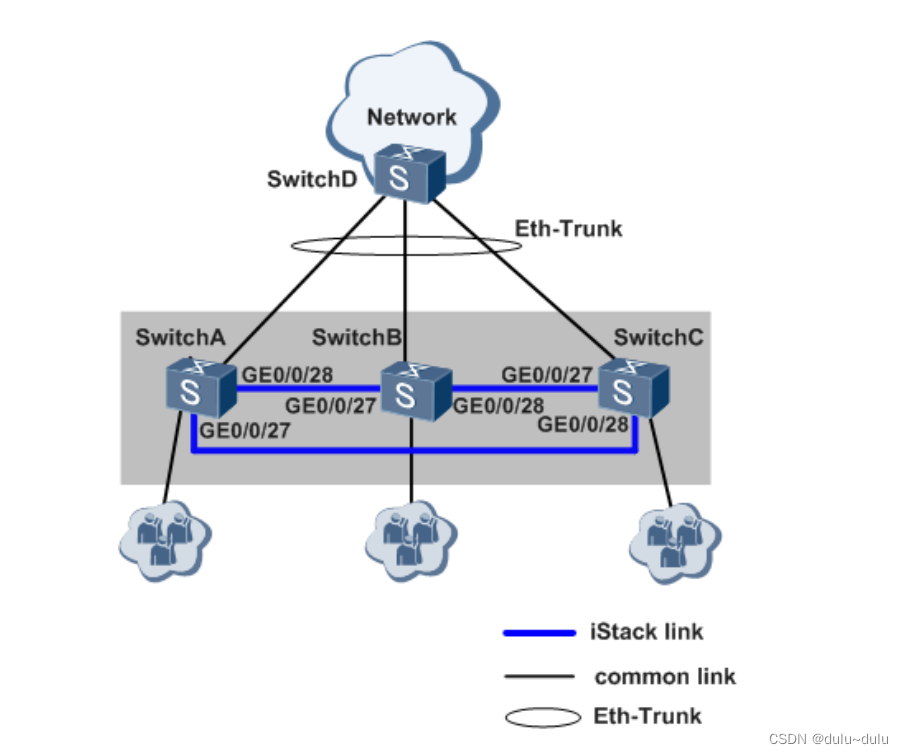
盒式交换机堆叠配置
目录 1.配置环形拓扑堆叠 2.设备组建堆叠 3.设备组件堆叠 堆叠 istack,是指将多台支持堆叠特性的交换机设备组合在一起,从逻辑上组合成一台交换设备。如图所示,SwitchA与 SwitchB 通过堆叠线缆连接后组成堆叠 istack,对于上游和…...
openEuler 服务器安装 JumpServer (all-in-one 模式)
openEuler 服务器安装 JumpServer JumpServer 简介什么是 JumpServer ?JumpServer 的各种类型资产JumpServer 产品特色或优势JumpServer 符合 4A 规范 JumpServer 系统架构应用架构组件说明 JumpServer 安装部署环境要求网络端口网络端口列表防火墙常用命令 在线脚本…...

vue3后台管理系统之路由守卫
下载进度条 pnpm install nprogress //路由鉴权:鉴权,项目当中路由能不能被的权限的设置(某一个路由什么条件下可以访问、什么条件下不可以访问) import router from /router import setting from ./setting // eslint-disable-next-line typescript-eslint/ban-ts-comment /…...

微信小程序连接数据库与WXS的使用
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是Java方文山,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的专栏《微信小程序开发实战》。🎯Ἲ…...

django 项目基本配置
项目工程初始化 安装框架 pip install django使用命令创建项目 django-admin startproject 项目名称效果 根目录创建apps用以放置所有包 切换至apps目录创建子应用 python ../manage.py startapp usermuxi_shop_back/settings.py # Build paths inside the project lik…...
JAVA基础(JAVA SE)学习笔记(六)面向对象编程(基础)
前言 1. 学习视频: 尚硅谷Java零基础全套视频教程(宋红康2023版,java入门自学必备)_哔哩哔哩_bilibili 2023最新Java学习路线 - 哔哩哔哩 第二阶段:Java面向对象编程 6.面向对象编程(基础) 7.面向对象编程&…...

吉利高端品牌领克汽车携手体验家,重塑智能创新的汽车服务体验
浙江吉利控股集团(以下简称“吉利集团”)始建于1986年,1997年进入汽车行业,一直专注实业,专注技术创新和人才培养,坚定不移地推动企业转型升级和可持续发展。现资产总值超5100亿元,员工总数超过…...

短视频矩阵系统源码(搭建)
短视频矩阵源码的开发路径分享如下: 1、首先,确定项目需求和功能,包括用户上传、编辑、播放等。 2、其次,搭建开发环境,选择合适的开发工具和框架。 3、然后,进行项目架构设计和数据库设计,确…...

k8s 实战 常见异常事件 event 及解决方案分享
k8s 实战 常见异常事件 event 及解决方案分享 集群相关 Coredns容器或local-dns容器 重启集群中的coredns组件发生重启(重新创建),一般是由于coredns组件压力较大导致oom,请检查业务是否异常,是否存在应用容器无法解析域名的异常。如果是l…...

【Python机器学习】sklearn.datasets回归任务数据集
为什么回归分析在数据科学中如此重要,而sklearn.datasets如何助力这一过程? 回归分析是数据科学中不可或缺的一部分,用于预测或解释数值型目标变量(因变量)和一个或多个预测变量(自变量)之间的关系。sklearn.datasets模块提供了多种用于回归分析的数据集,这些数据集常…...
)
Springboot写电商系统(2)
Springboot写电商系统(2) 1.新增收货地址1.创建t_addresss数据库表2.创建Address实体类3.数据库操作的持久层1.接口写抽象方法2.xml写方法映射sql3.测试 4.前后数据交互的业务层1.sql操作的异常抛出2.交互方法的接口定义3.接口的方法实现4.测试 5.与前端…...

SpringBoot中过滤器与拦截器的区别
SpringBoot中过滤器与拦截器的区别 过滤器和拦截器的区别: ①拦截器是基于java的反射机制的,而过滤器是基于函数回调。 ②拦截器不依赖与servlet容器,过滤器依赖与servlet容器。 ③拦截器只能对action请求起作用,而过滤器则可以对…...

SystemVerilog(2)——数据类型
一、概述 和Verilog相比,SV提供了很多改进的数据结构。它们具有如下的优点: 双状态数据类型:更好的性能,更低的内存消耗队列、动态和关联数组:减少内存消耗,自带搜索和分类功能类和结构:支持抽…...

记一次Postgresql从堆叠注入到RCE
本次研究过程来自一次某cms的代码审计实战,整个环境部署的相对较好,postgresql、web权限都有单独的用户管理,web目录不可写、服务器不能出网等限制。不过比较幸运的是所有的数据操作都是用同一个superuser权限的postgresql用户来执行的。 限…...
通用FIFO设计深度8宽度64,verilog仿真,源码和视频
名称:通用FIFO设计深度8宽度64,verilog仿真 软件:Quartus 语言:verilog 本代码为FIFO通用代码,其他深度和位宽可简单修改以下参数得到 reg [63:0] ram [7:0];//RAM。深度8,宽度64 代码功能:…...

尝试进行表格处理
꧂ input输入多行文本,3个回车结束꧁ 用input输入如果你想要使用 input 输入多行文本,可以在输入时按照以下方式来终止输入: text while True:line input("请输入文本(按回车继续,按3个回车结束)…...
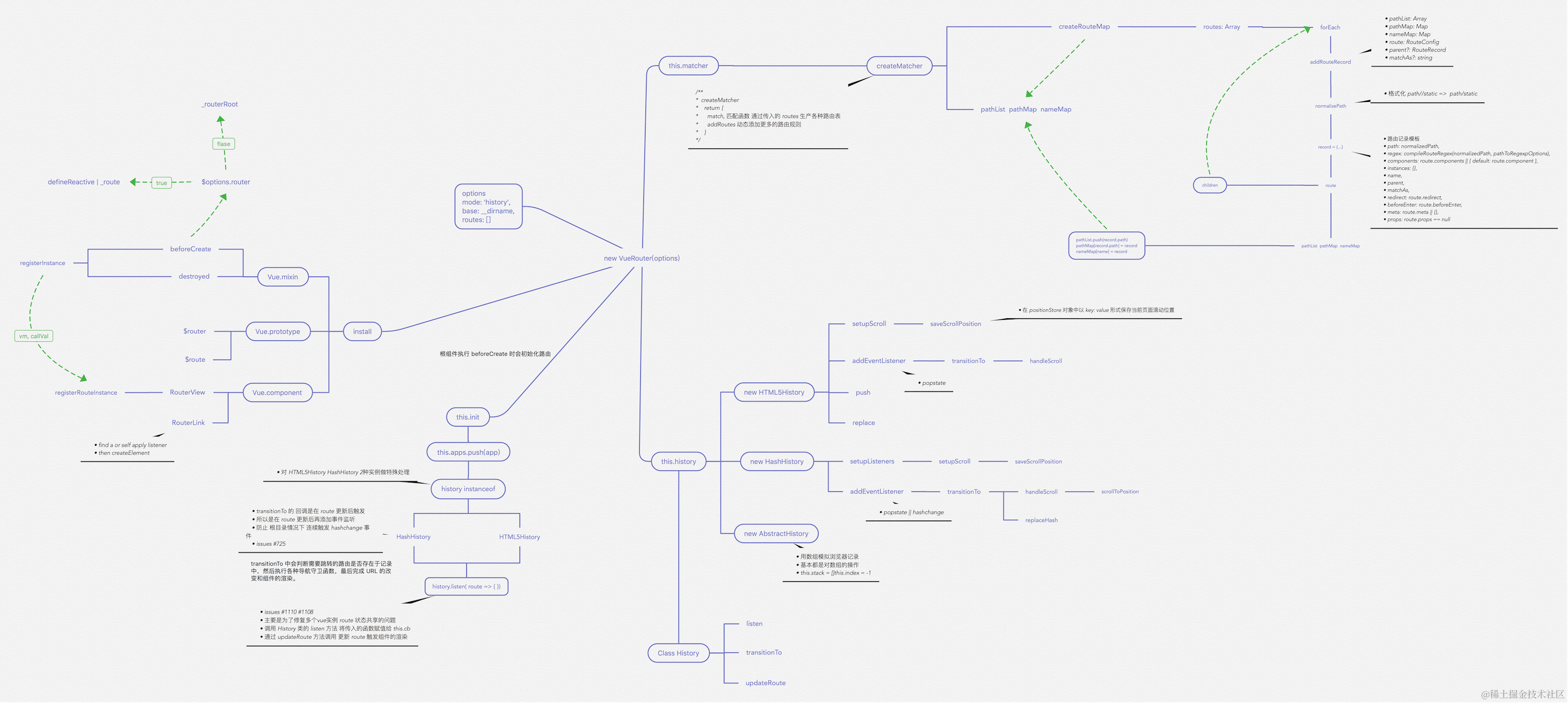
VueRouter 源码解析
重要函数思维导图 路由注册 在开始之前,推荐大家 clone 一份源码对照着看。因为篇幅较长,函数间的跳转也很多。 使用路由之前,需要调用 Vue.use(VueRouter),这是因为让插件可以使用 Vue export function initUse(Vue: GlobalAP…...

云原生之Docker
docker 初识Docker什么是DockerDocker与虚拟机Docker相关术语及架构镜像和容器DockerHubDocker架构 Docker命令镜像操作命令容器操作命令数据卷命令 自定义镜像镜像结构Dockerfile DockerCompose安装常用命令 初识Docker 什么是Docker docker是一个快速交付应用,运…...

MT5 Zero-Shot中文增强镜像效果展示:直播话术实时多样性生成
MT5 Zero-Shot中文增强镜像效果展示:直播话术实时多样性生成 1. 项目介绍与核心价值 MT5 Zero-Shot Chinese Text Augmentation 是一个基于 Streamlit 和阿里达摩院 mT5 模型构建的本地化 NLP 工具。这个工具专门针对中文文本处理,能够在保持原意不变的…...

一张表说清网络底层:看完你也能当半个“网管”
网络基础知识(详细版)一、什么是网络?网络是通过传输介质(网线、光纤、无线电波)和网络设备(路由器、交换机等)将两台以上计算机或智能设备连接起来,实现数据通信和资源共享的系统。…...

WPF依赖属性三大回调实战:从PropertyChanged到Validate,一个真实案例讲透
WPF依赖属性三大回调实战:从PropertyChanged到Validate,一个真实案例讲透 在WPF开发中,依赖属性是实现数据绑定、样式和动画等功能的核心机制。但很多开发者在自定义控件时,往往只停留在基础用法上,对依赖属性的三大回…...

终极指南:3步快速实现Cursor Pro永久免费破解
终极指南:3步快速实现Cursor Pro永久免费破解 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial reque…...

TV Bro:专为智能电视优化的开源浏览器,让大屏上网更简单
TV Bro:专为智能电视优化的开源浏览器,让大屏上网更简单 【免费下载链接】tv-bro Simple web browser for android optimized to use with TV remote 项目地址: https://gitcode.com/gh_mirrors/tv/tv-bro 在智能电视上浏览网页一直是个挑战——传…...

边缘视觉语言模型压缩技术:STTF与ANC算法解析
1. 边缘视觉语言模型压缩技术概述在智能边缘设备快速普及的今天,从可穿戴设备到无人机再到自主传感器,对能够在有限功耗、内存和延迟条件下保持高精度的机器学习模型需求日益迫切。视觉语言模型(VLMs)和多模态系统虽然在云端基础设施上表现出色ÿ…...

MATLAB翼型分析终极指南:用XFOILinterface快速完成气动性能计算
MATLAB翼型分析终极指南:用XFOILinterface快速完成气动性能计算 【免费下载链接】XFOILinterface 项目地址: https://gitcode.com/gh_mirrors/xf/XFOILinterface 在航空航天工程和流体力学研究中,翼型气动性能分析是一个基础而关键的任务。传统上…...
)
用SpaceMouse玩转机器人仿真:Robosuite+Python实战配置指南(避坑HID权限问题)
用SpaceMouse玩转机器人仿真:RobosuitePython实战配置指南(避坑HID权限问题) 在机器人仿真与控制领域,3D输入设备能大幅提升操作效率。SpaceMouse作为专业级六自由度控制器,其精准的空间定位能力特别适合机械臂轨迹调试…...

FLUX.1-Krea-Extracted-LoRA快速上手:bash /root/start.sh启动原理与日志查看方法
FLUX.1-Krea-Extracted-LoRA快速上手:bash /root/start.sh启动原理与日志查看方法 1. 模型概述 FLUX.1-Krea-Extracted-LoRA 是一款基于 FLUX.1-dev 基础模型的真实感图像生成模型,通过提取的 LoRA 风格权重为图像注入专业摄影级别的真实感美学。该模型…...

暗黑3智能按键助手:5分钟快速上手,彻底告别手指疲劳的终极指南
暗黑3智能按键助手:5分钟快速上手,彻底告别手指疲劳的终极指南 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 还在为暗黑3高…...