从零开始搭建第一个django项目
目录
- 配置环境
- 创建 Django 项目和 APP
- 项目组成
- 子目录文件组成
- 应用文件组成
- 配置 settings.py
- 启动项目
- 数据表创建
- models.py
- Django-models的常用字段和常用配置
- Django-admin 引入admin后台和管理员
- 外键
- views.py
- urls.py
- postman接口测试
- QuerySet
- Instance功能
- APIView 的概念
- views.py
- url.py
- 序列化器serializers
- serializer.py
- 测试
- Django-DRF 路由组件
- Django-DRF 自定义函数
- 参考
配置环境
创建虚拟环境
conda create -n erp-env python=3.9
激活虚拟环境
conda activate erp-env
requirements.txt文件
decorator==5.1.1
Django==4.2.3
django-debug-toolbar==4.1.0
django-extensions==3.2.3
django-filter==23.2
django-rest-framework==0.1.0
djangorestframework==3.14.0
drf-spectacular==0.26.3
- Django 是一个 Python web 框架,提供许多功能,如 ORM、认证、表单、模板等,它可以帮助你更快、更轻松地开发 web 应用程序。
- DRF(django-rest-framework) 是一个基于 Django 的强大而灵活的 RESTful 框架,它提供了许多工具和库,可帮助你快速开发基于 RESTful API 的 web 应用程序。
- Django-Filter 是一个基于 Django 的库,它提供了一种简单、灵活的方式来过滤 Django 模型的查询集。Django-Filter 的 API 允许开发者使用简单的查询表达式,构建和应用复杂的过滤器,从而在查询集中选择和排除数据。
- DRF Spectacular 是 DRF 的 OpenAPI 规范工具。它可以自动构建和生成 OpenAPI 规范文档,并提供方便的 API 测试工具,使你能够更加轻松地创建、测试和维护 RESTful API。同时,它也支持集成 Django Filter,允许你通过 URL 参数过滤查询数据。
进入requirements.txt文件所在目录
cd C:\Users\gxx\Desktop\djangolearning
安装python库
pip install -r requirements.txt
或者
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple


创建 Django 项目和 APP
创建项目文件夹
django-admin startproject erp
(1)
进入manage.py所在路径
cd C:\Users\gxx\Desktop\djangolearning\erp
创建 APP
python manage.py startapp test1
(2)
或者
进入指定路径
cd C:\Users\gxx\Desktop\djangolearning\erp\apps
创建 APP
django-admin startapp test2

项目组成
- 项目名文件夹
- 子目录下同名子文件夹
- manage.py文件
manage.py提供了一种命令行工具,允许你以多种方式与该Django项目进行交互。如:python manage.py help,能列出它所能做的事情。注意,此文件一般情况下不需要改动。 - 应用文件夹
子目录文件组成

- _init_.py: 是一个空文件,作用是所在的这个目录可以被当作包使用。
- settings.py:该Django项目整体配置文件。(该文件非常重要,建议认真理解这个文件中可用的设置类型及其默认值。)
- urls.py:Django项目的URL设置。可视其为你的django网站的目录。
- asgi.py与wsgi.py:常见的网关接口协议:CGI,FastCGI,WSGI,ASGI。asgi.py是异步服务器网关接口项目配置文件。ASGI描述了Python Web应用程序和Web服务器之间的通用接口。与WSGI不同的是,ASGI允许每个应用程序有多个异步事件。另外,ASGI支持同步和异步应用程序。开发人员可以将原有的同步WSGI Web应用程序迁移到ASGI,也可以使用ASGI构建新的异步Web应用程序。
应用文件组成

-
_init_.py 是一个空文件,作用同前。
-
admin.py 文件跟网站的后台管理相关。
-
models.py 文件跟数据库操作相关。主要用一个 Python 类来描述数据表。运用这个类,你可以通过简单的 Python 的代码来创建、检索、更新、删除 数据库中的记录而无需写一条又一条的SQL语句。
-
views.py 包含了页面的业务逻辑,接收浏览器请求,进行处理,返回页面操作相关。
-
tests.py 文件用于开发测试用例,在实际开发中会有专门的测试人员使用。
-
apps.py 文件夹是django1.10之后增加的,通常里面包含对应用的配置。
-
migrations:django 1.8之后推出的migrations机制使django数据模式管理更容易。migrations机制有两个指令,makemigrations和migrate。makemigrations指令是用models里面的model和当前的migrations代码里面的model做对比,如果有新的修改,就生成新migrations代码。migrate指令是用migrations目录中代码文件和django数据库django_migrations表中的代码文件做对比,如果表中没有,那就对没有的文件按顺序及依赖关系做migrate apply,然后再把代码文件名加进migrations表中。
-
migrations文件夹 里面自动生成了_init_.py文件
配置 settings.py
加入安装的库和新增的APP
'test1','rest_framework','django_filters','drf_spectacular',

启动项目
启动Django服务
python manage.py runserver

点击http://127.0.0.1:8000

数据表创建
模块功能
如前所述,models.py文件主要用一个 Python 类来描述数据表。运用这个类,可以通过简单的 Python 代码来创建、检索、更新、删除
数据库中的记录而无需写一条又一条的SQL语句。在model.py中创建两个表:产品分类表和产品信息表。
models.py
产品分类表和产品信息表
from django.db.models import *# Create your models here.
## 产品分类表
class GoodsCategory(Model):"""产品分类"""name = CharField(max_length=64, verbose_name='分类名称')remark = CharField(max_length=64, null=True, verbose_name='备注', blank=True)## 产品表
class Goods(Model):"""产品"""# 外键category = ForeignKey(GoodsCategory, on_delete=SET_NULL, related_name='goods_set', null=True, verbose_name='产品分类',blank=True, )# on_deletenumber = CharField(max_length=32, verbose_name='产品编号')name = CharField(max_length=64, verbose_name='产品名称')barcode = CharField(max_length=32, null=True, blank=True, verbose_name='条码')spec = CharField(max_length=64, null=True, blank=True, verbose_name='规格')shelf_life_days = IntegerField(null=True, verbose_name='保质期天数')purchase_price = FloatField(default=0, verbose_name='采购价')retail_price = FloatField(default=0, verbose_name='零售价')remark = CharField(max_length=128, null=True, blank=True, verbose_name='备注')
合并数据库
这两个命令是Django框架中的关键命令,用于进行数据库迁移。当你修改了Django模型后,你需要运行这两个命令,以将这些更改应用到数据库中。
python manage.py makemigrations
这个命令用于生成迁移脚本。当你更新了模型文件之后,需要运行该命令,Django会检测模型的改变,然后自动生成相应的迁移脚本,存储在 migrations/目录下。通常来说,你需要针对每个应用运行一次该命令。
python manage.py migrate
这个命令用于将迁移脚本应用到数据库中。当你在模型文件中进行更改之后,需要先通过 makemigrations命令生成迁移脚本,然后运行该命令将这些脚本应用到数据库中。对于新的迁移脚本,Django会逐个执行它们,从而更新数据库结构。对于已经执行过的脚本,Django会跳过它们,避免重复执行。
这两个命令是Django框架中非常重要的命令,在修改数据库相关内容时必须时刻清醒地记住使用它们。
在终端运行命令

Django-models的常用字段和常用配置
常用字段
CharField 用于存储字符串类型,有最大长度限制
IntegerField 用于存储整数类型
FloatField用于存储浮点数类型
BooleanField 用于存储布尔类型
DateField 用于存储日期类型
DateTimeField 用于存储日期和时间类型
ImageField 用于存储图片类型
FileField 用于存储文件类型
ForeignKey 外键 用于表示数据库表之间的关联关系
OneToOneField 一对一 用于表示一对一的关联关系
ManyToManyField 多对多 用于表示多对多的关联关系
常用配置
max_length 字段的最大长度限制,可以应用于多种不同的字段类型。
verbose_name 字段的友好名称,便于在管理员后台可视化操作时使用。
default 指定字段的默认值。
null 指定字段是否可以为空。
null=True 设置允许该字段为 NULL 值
blank 指定在表单中输入时是否可以为空白。
choices 用于指定字段的可选值枚举列表,在最上面定义
字段定义
class DeliveryMaterial(Model):class Status(TextChoices):QUALIFIED = ('qualified', '良品')
UNQUALIFIED = ('unqualified', '不良品')status = CharField(max_length=32, choices=Status.choices, default=Status.QUALIFIED, verbose_name='状态')
TextChoices 是 Django 3.0 引入的一个枚举类,用于在模型字段中创建可选择的、文本值的选项。
related_name 指定在多对多等关系中反向使用的名称。
on_delete 指定如果外键关联的对象被删除时应该采取什么操作。
Django-admin 引入admin后台和管理员
创建后台 admin 管理员
在终端运行命令
python manage.py createsuperuser
python manage.py runserver

打开网址 http://127.0.0.1:8000/admin


配置
在admin.py文件中注册你的模型:
from django.contrib import admin
from .models import *
# Register your models here.admin.site.register(Goods)
admin.site.register(GoodsCategory)

外键
models.py
category = ForeignKey(GoodsCategory,on_delete=SET_NULL,related_name='goods_set',null=True,verbose_name='产品分类')
on_delete 设置当外键对应的数据被删除时的反应
null=True
概念
外键是一种用于建立表之间关联关系的约束,通常指的是一个模型中的一个或多个字段的值必须符合另一个模型中对应字段的值。
views.py
# Create your views here.
from django.shortcuts import render
from rest_framework.response import Response
from .models import *
from rest_framework.decorators import api_view
from django.shortcuts import get_object_or_404# Create your views here.
# GET
# POST# 函数式编程
@api_view(['POST', 'GET'])
def InsertGoodsCategory(request):category_name = request.data.get('分类名字')# 获取分类对象或创建新的分类对象category, created = GoodsCategory.objects.get_or_create(name=category_name)# 判断是否已存在分类if not created:return Response({"status": "已存在", "goods_category": category_name}, status=200)else:return Response({"message": f"Successfully inserted category '{category_name}'."})@api_view(['POST', 'GET'])
def FilterGoodsCategory(request):data = request.data.get('分类名字')goods = GoodsCategory.objects.filter(name=data)if goods.exists():return Response({"status": "已存在", "goods_category": data}, status=200)else:return Response({"status": "不存在", "goods_category": data}, status=404)urls.py
- 放入路由
import os
import sys
os.chdir(os.path.dirname(__file__))
sys.path.append("..")
from django.contrib import admin
from django.urls import path
from test1.views import *
from django.urls import include
from rest_framework import routersurlpatterns = [path('admin/', admin.site.urls),path('filtergoodscategory/', FilterGoodsCategory),path('insertgoodscategory/', InsertGoodsCategory),# path('filtergoodscategoryapi/', FilterGoodsCategoryAPI.as_view()),# path('getgoods/', GetGoods.as_view()),
]
运行项目
python manage.py runserver
postman接口测试
- 使用postman针对
insertGoodsCategory/和filtergoodscategory/API接口进行测试,测试结果如下
http://127.0.0.1:8000/insertgoodscategory/

http://127.0.0.1:8000/filtergoodscategory/


QuerySet
从数据库中查询结果存放的集合称为 QuerySet。 Django ORM用到三个类:Manager、QuerySet、Model。每个Model都有一个默认的
manager实例,名为objects。Django的ORM通过Model的objects属性提供各种数据操作的接口(API),并通过 Model.objects 方法返回QuerySet,生产符合查询条件的列表,列表中包含多个 Instance。
class QuerySet(model=None, query=None, using=None)[source]
其具有两大特色
(1) 惰性:若这个对象中包含了需要的数据且需要使用时,它会去DB中获取数据,否则不会获取。 比如说在内部,创建、过滤、切片和传递一个QuerySet,而没有进行真正的数据执行,不会真实操作数据库,被称为惰性。
(2)缓存使用同一个查询集,第一次使用时会发生数据库的查询,然后Django会把结果缓存下来,再次使用这个查询集时会使用缓存的数据,减少了数据库的查询次数。
操作说明
设定:已存在数据表定义如下:
class Goods(DjangoPeople):
{
number = CharField(max_length=32, verbose_name=‘编号’)
name = CharField(max_length=64, verbose_name=‘名称’)
unit = CharField(max_length=64, verbose_name=‘单位’)
remark = CharField(max_length=256, verbose_name=‘备注’)
}
all() :返回模型的所有对象,它的效果等价于不带任何条件的 filter() 方法。
如:
DjangoPeople.objects.all() # 查询所有 语句。
filter()(**kwargs) 用于返回符合条件的所有数据。
如:
DjangoPeople.objects.filter(name=“abc”) #取出name="abc"的DjangoPeople成员
又如:
DjangoPeople.objects.filter(name=“x”).filter(unit=“y”) #取出name="x"且unit="y"的DjangoPeople成员
get() 方法与 filter() 的作用类似,用于返回符合条件的单个对象但是可能会返回多个值
delete() :可以删除符合条件的所有对象
如:
catagories_to_delete=DjangoPeople.objects.filter(name=“abc”)
deleted_count= categories_to_delete.delete()
update() :将符合条件的所有对象的某个字段值进行更新
create() 是 save() 方法的快捷方式,用于创建并保存一个新的对象。
如:
created_category = DjangoPeople.objects.create(name="abc")
count() :返回符合条件的对象数量
order_by() :对返回的对象进行排序,默认为升序。降序则在字段名前面加负号。
QuerySet其他的其接口定义,用法类似,这里不再一一赘述,需要运用,可查阅Django官网。

Instance功能
Instance指的是一个 Django 模型的单个实例,也就是数据库中的一行数据。相比于 QuerySet(查询集合),它是针对单个对象的操作,用于创建、更新或者删除单个模型实例。
创建一个对象:
Obj = Model(attr1=val1, attr2=val2),Obj.save()
更新一个对象:
Obj = Model.objects.get(id=xxx),Obj.attr1 = val1,Obj.save()
删除一个对象:
Obj = Model.objects.get(id=xxx),Obj.delete()
QuerySet 适用于需要查找多个对象或进行聚合操作的场景,而 Instance 适用于单独对象的创建、修改和删除操作。
APIView 的概念
APIview 是 Django REST Framework 提供的一个视图类。它和 Django 中的 view 类有些相似,但是又有一些不同之处。APIview 可以处理基于 HTTP 协议的请求,并返回基于内容协商的响应,它旨在提供一个易于使用且灵活的方式来构建 API 视图。
views.py
首先,self 表示当前实例对象,这里指的是视图类的实例对象。
request 表示当前的请求对象,包含了客户端发送的信息,例如请求头、请求体等。
pk 是 path 参数 int:pk,用于获取请求中的产品 ID。
format 表示客户端请求的响应格式,例如 JSON、XML 等。这个参数通常不需要指定,会根据客户端发送的 Accept 请求头来自动选择响应格式。如果客户端指定了响应格式,那么我们可以从请求中获取到这个参数并且做出相应的处理。
在这个方法中,我们需要通过 pk 参数获取到对应的产品数据,并将其序列化成 JSON 格式并返回给客户端。具体的实现方式可以参考序列化器文档和 Django ORM 文档。


from django.shortcuts import render
from rest_framework.response import Response
from .models import *
from rest_framework.decorators import api_view
from django.shortcuts import get_object_or_404
from rest_framework.views import APIView
from .serializer import *
from rest_framework.decorators import actionfrom django.db.models import Q
from rest_framework.viewsets import ModelViewSet#### modelviewset
class GoodsCategoryViewSet(ModelViewSet):# 指定查询集(用到的数据)queryset = GoodsCategory.objects.all()# 指定查询集用到的序列化容器serializer_class = GoodsCategorySerilizer@action(detail=False, methods=['get'])def latest(self, request):latest_obj = GoodsCategory.objects.latest('id')print(latest_obj)return Response("helllo 你调用了自定义的函数")@action(detail=False, methods=['get', 'post'])def delete_example(self, request):name = request.data.get('name')# 删除名称为 'name' 的商品categories_to_delete = GoodsCategory.objects.filter(name=name)# 使用delete()方法删除对象deleted_count = categories_to_delete.delete()print(f"Deleted {deleted_count} categories.")@action(detail=False, methods=['get', 'post'])def create_example(self, request):name = request.data.get('name')# 使用create()方法创建新的商品分类对象created_category = GoodsCategory.objects.create(name)print("Created category:", created_category)# Create your views here.# GET
# POST#### 函数式编程
@api_view(['POST', 'GET'])
def FilterGoodsCategory(request):if request.method == 'GET':print(request.method)if request.method == 'POST':print(request.method)data = request.data.get('分类名字')goods_category = get_object_or_404(GoodsCategory, name=data)print(goods_category)# ans = Goods.objects.filter(category=goods_category).all().values()# print(ans)goods = Goods.objects.filter(category=goods_category)serializer = GoodsSerializer(goods, many=True) # 请确保导入合适的序列化器# 输出对象 和 数据类型print("object type:", type(Goods.objects))print("object.all() type:", type(Goods.objects.all()))print("object.all().values type:", type(Goods.objects.all().values()))# Instanceprint("object.get(id=1) type:", type(Goods.objects.get(id=1)))return Response(serializer.data)# return Response(ans)@api_view(['POST', 'GET'])
def InsertGoodsCategory(request):category_name = request.data.get('分类名字')# 获取分类对象或创建新的分类对象category, created = GoodsCategory.objects.get_or_create(name=category_name)# 判断是否已存在分类if not created:return Response({"status": "已存在", "goods_category": category_name}, status=200)else:return Response({"message": f"Successfully inserted category '{category_name}'."})@api_view(['POST', 'GET'])
def FilterGoodsCategory(request):data = request.data.get('分类名字')goods = GoodsCategory.objects.filter(name=data)if goods.exists():return Response({"status": "已存在", "goods_category": data}, status=200)else:return Response({"status": "不存在", "goods_category": data}, status=404)#### APIView
class GetGoods(APIView):def get(self, request):data = Goods.objects.all()serializer = GoodsSerializer(instance=data, many=True)print(serializer.data)return Response(serializer.data)def post(self, request):# 从请求数据中提取字段request_data = {"category": request.data.get("Goodscategory"),"number": request.data.get("number"),"name": request.data.get("name"),"barcode": request.data.get("barcode"),"spec": request.data.get("spec"),"shelf_life_days": request.data.get("shelf_life_days"),"purchase_price": request.data.get("purchase_price"),"retail_price": request.data.get("retail_price"),"remark": request.data.get("remark"),}# 使用 create() 方法创建新的商品对象new_goods = Goods.objects.create(**request_data)# 对创建的对象进行序列化,并作为响应返回serializer = GoodsSerializer(instance=new_goods)return Response(serializer.data)# 面向对象编程
class FilterGoodsCategoryAPI(APIView):# request 表示当前的请求对象# self 表示当前实例对象def get(self, request, format=None):print(request.method)return Response('ok')def post(self, request, format=None):print(request.method)return Response('ok')def put(self, request, format=None):print(request.method)return Response('ok')
url.py

import os
import sys
os.chdir(os.path.dirname(__file__))
sys.path.append("..")from django.contrib import admin
from django.urls import pathfrom test1.views import *
from django.urls import include
from rest_framework import routers# 创建DefaultRouter对象,用于生成路由
router = routers.DefaultRouter()
# 将视图集注册到路由器上,字符串里的是URL路径的前缀
router.register('GoodsCategory', GoodsCategoryViewSet)urlpatterns = [path('admin/', admin.site.urls),path('filtergoodscategory/', FilterGoodsCategory),path('insertgoodscategory/', InsertGoodsCategory),path('filtergoodscategoryapi/', FilterGoodsCategoryAPI.as_view()),path('getgoods/', GetGoods.as_view()),
]
# 把生成的url 添加到项目的url配置中
urlpatterns += router.urls序列化器serializers
序列化器的作用
序列化将 queryset 和 instance 转换为 json/xml/yaml 返回给前端
反序列化与序列化则相反
定义序列化器
定义类,继承自 Serializer
通常新建一个 serializers.py 文件 撰写序列化内容
suah as 目前只支持
read_only 只读
label 字段说明信息
max_length 最大长度
serializer.py
在应用文件夹(test1)下新建serializer.py文件
from rest_framework.serializers import *
from .models import *class GoodsCategorySerilizer(ModelSerializer):class Meta:model = GoodsCategoryfields = '__all__'# 构建产品序列化器
class GoodsSerializer(ModelSerializer):# 外键字段相关的数据 需要单独写category = GoodsCategorySerilizer()class Meta:# 指定需要序列化的表model = Goods# 指定我们需要序列化的字段fields = '__all__'
a. 序列化单个对象
-
获取对象
data = Goods.objects.get(id=1) -
创建序列化器
sberializer = GoodsSerializer(instance=data) -
转换数据
print(serializer.data) -
注意点:
instance是一个参数,用于指定要序列化或反序列化的 Python 对象。具体来说,它是一个类实例(Class Instance),通常是指一个从数据库或其他数据源中检索出来的模型实例(Model Instance)。当我们需要将一个模型实例转换为 JSON 或其他格式时,可以使用 Django 的序列化器(Serializer)来实现。
-
输出:
{'id': 1, 'number': '1', 'name': '第一个产品', 'purchase_price': 100.0, 'retail_price': 150.0, 'remark': '测试产品'}
b. 序列化多个对象
data = Goods.objects.all() # 获取对象# 创建序列化器,many表示序列化多个对象,默认为单个serializer = GoodsSerializer(instance=data,many=True)print(serializer.data) # 转换数据# 输出:[OrderedDict([('id', 1), ('number', '1'), ('name', '第一个产品'), ('purchase_price', 100.0), ('retail_price', 150.0), ('remark', '测试产品')]), OrderedDict([('id', 2), ('number', '123'), ('name', '产品2'), ('purchase_price', 123.0), ('retail_price', 4123.0), ('remark', '测试产品2')])]

测试
python manage.py runserver
打开网页http://127.0.0.1:8000/admin/





http://127.0.0.1:8000/getgoods/


Django-DRF 路由组件
DefaultRouter是Django REST framework中提供的一个路由器类,用于自动生成URL路由。
路由器是将URL与视图函数或视图集关联起来的一种机制。Django REST framework的路由器通过简单的配置可以自动生成标准的URL路由,从而减少了手动编写URL路由的工作量。
DefaultRouter的使用方法
urls.py

使用 routers.DefaultRouter()创建了一个默认的路由器对象,并使用 router.register()方法注册了一个视图集,GoodsCategoryViewSet。这样可以自动为这个视图集生成对应的URL路由,并将其添加到 urlpatterns中。
http://127.0.0.1:8000/GoodsCategory/

Django-DRF 自定义函数
自定义函数是什么?
from rest_framework.decorators import action
@action 是 Django REST framework 中的一个装饰器,用于将自定义函数转换为视图集的一个动作。@action 装饰器提供了一种定义自定义函数的方式,这些函数并不直接对应于标准的 CRUD 操作(Create-Read-Update-Delete),而是实现一些其他的自定义行为或业务逻辑。
“@action 装饰器”用于在 ViewSet 中创建自定义动作(custom action),为 ViewSet 提供了更灵活应用且 @action 只在ViewSet视图集中生效。视图集中附加action装饰器可接收两个参数:
(1)methods: 声明该action对应的请求方式.
(2)detail: True/False声明该action的路径是否是action对应的请求方式。

其中,detail=False 表示该动作不需要处理单个对象,而是处理整个集合;
被 @action 装饰的函数需要作为方法定义在视图集类中,并且在使用 router.register() 注册视图集时,需要指定 basename 参数,以确保该动作的 URL 能够正确映射到视图集。
参考
https://github.com/Joe-2002/sweettalk-django4.2#readme
相关文章:
从零开始搭建第一个django项目
目录 配置环境创建 Django 项目和 APP项目组成 子目录文件组成应用文件组成 配置 settings.py启动项目 数据表创建models.pyDjango-models的常用字段和常用配置 Django-admin 引入admin后台和管理员外键views.pyurls.pypostman接口测试 QuerySetInstance功能APIView 的概念…...

Godot2D角色导航-自动寻路教程(Godot获取导航路径)
文章目录 开始准备获取路径全局点坐标 开始准备 首先创建一个导航场景,具体内容参考下列文章: Godot实现角色随鼠标移动 然后我们需要设置它的导航目标位置,具体关于位置的讲解在下面这个文章: Godot设置导航代理的目标位置 获取…...

用c++写一个高精度计算的减法运算
这段代码是一个用C编写的程序,它实现了两个大整数的减法运算。 #include<iostream> #include<cstdio> #include<cstring> using namespace std;int main(){int a[256],b[256],c[256],lena,lenb,lenc,i;char n[256],n1[256]"1001",n2[2…...

基于白鲸优化的BP神经网络(分类应用) - 附代码
基于白鲸优化的BP神经网络(分类应用) - 附代码 文章目录 基于白鲸优化的BP神经网络(分类应用) - 附代码1.鸢尾花iris数据介绍2.数据集整理3.白鲸优化BP神经网络3.1 BP神经网络参数设置3.2 白鲸算法应用 4.测试结果:5.M…...
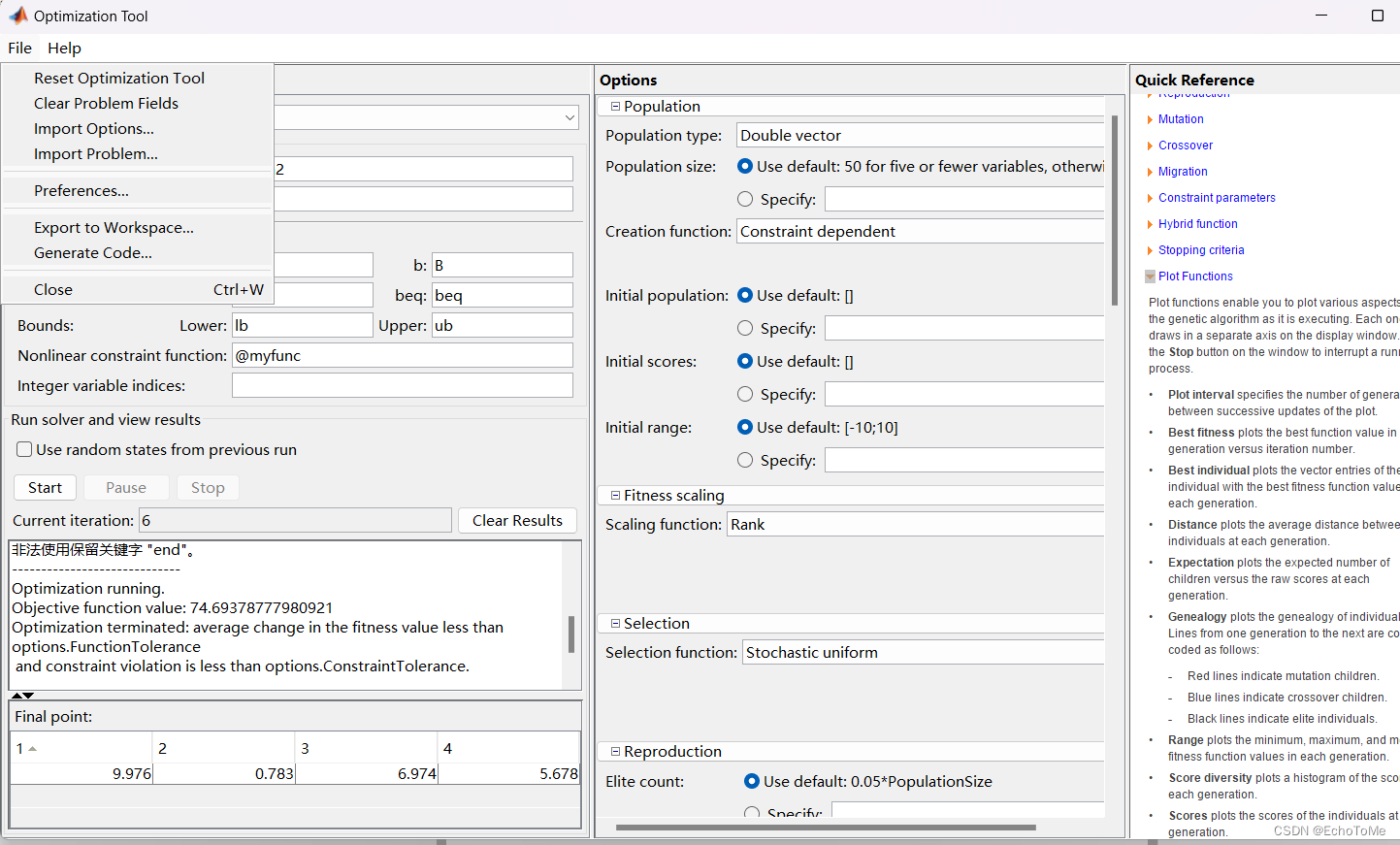
Matlab遗传算法工具箱——一个例子搞懂遗传算法
解决问题 我们一般使用遗传算法是用来处理最优解问题的,下面是一个最优解问题的例子 打开遗传算法工具箱 ①在Matlab界面找到应用程序选项,点击应用程序(英文版的Matlab可以点击App选项) ②找到Optimization工具箱,点击打开 创建所需要…...
Coreldraw2020最新64位电脑完整版本下载教程
安装之前所有的杀毒软件都要退出。无论是360,腾讯管家,或者电脑自带的安全中心,要不然会阻止安装。 CorelDRAW2020版win下载如下:https://wm.makeding.com/iclk/?zoneid55678 CorelDRAW2020版mac下载如下:https://wm.makeding.com/iclk/?…...
第一节——vue安装+前端工程化
作者:尤雨溪 官网:简介 | Vue.js 脚手架文档 创建一个项目 | Vue CLI 一、概念(了解) 是一套用于构建用户界面的渐进式框架。与其它大型框架不同的是,Vue 被设计为可以自底向上逐层应用。Vue 的核心库只关注视图层&…...
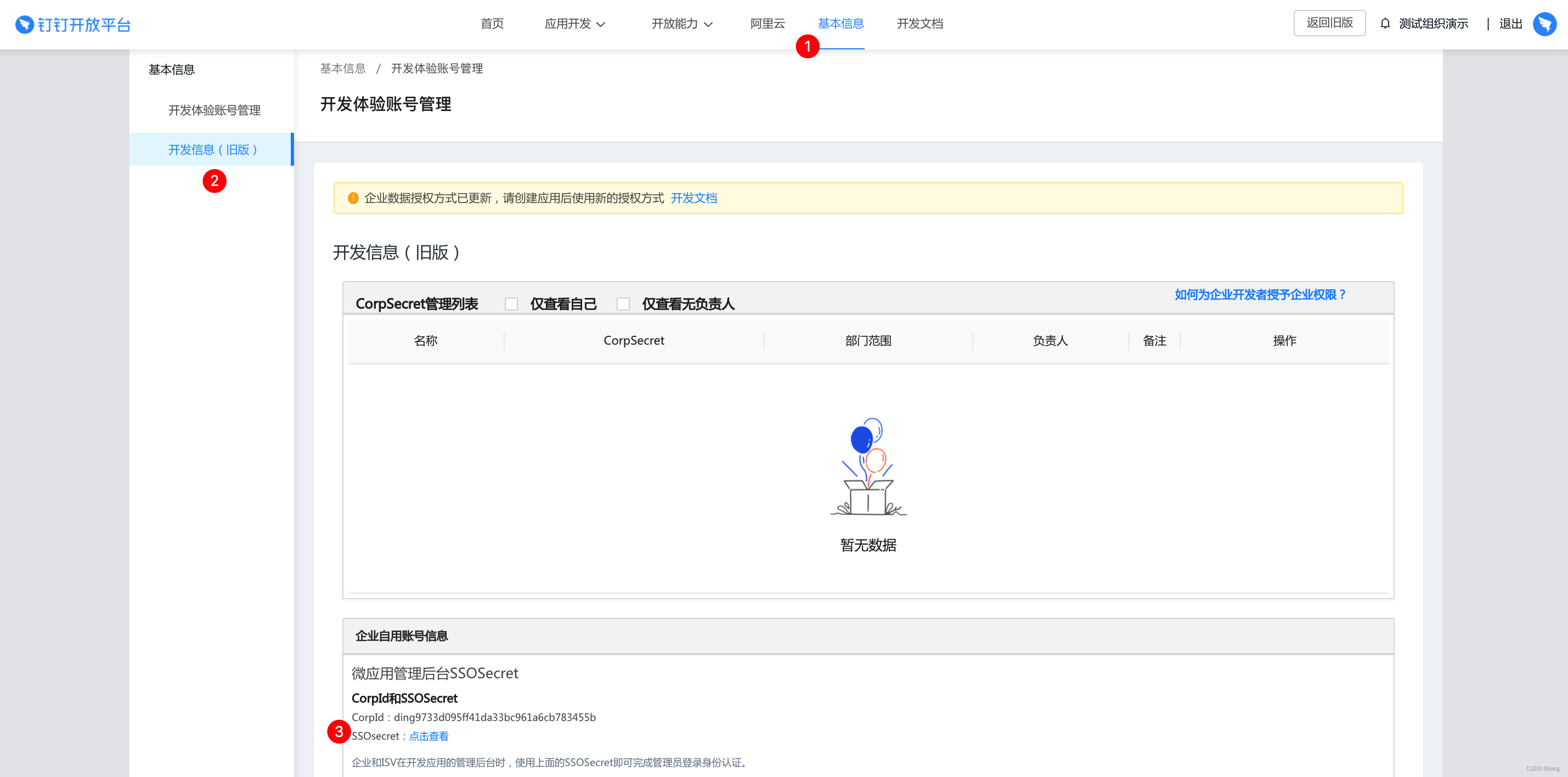
vue集成钉钉单点登录
初始环境判断 判断是否是来自钉钉环境的访问,返回:boolean类型值 window.navigator.userAgent.includes("DingTalk")前端引入vue中钉钉相关的依赖,并获取钉钉的临时授权码 import * as dingtalk from dingtalk-jsapi; let that …...
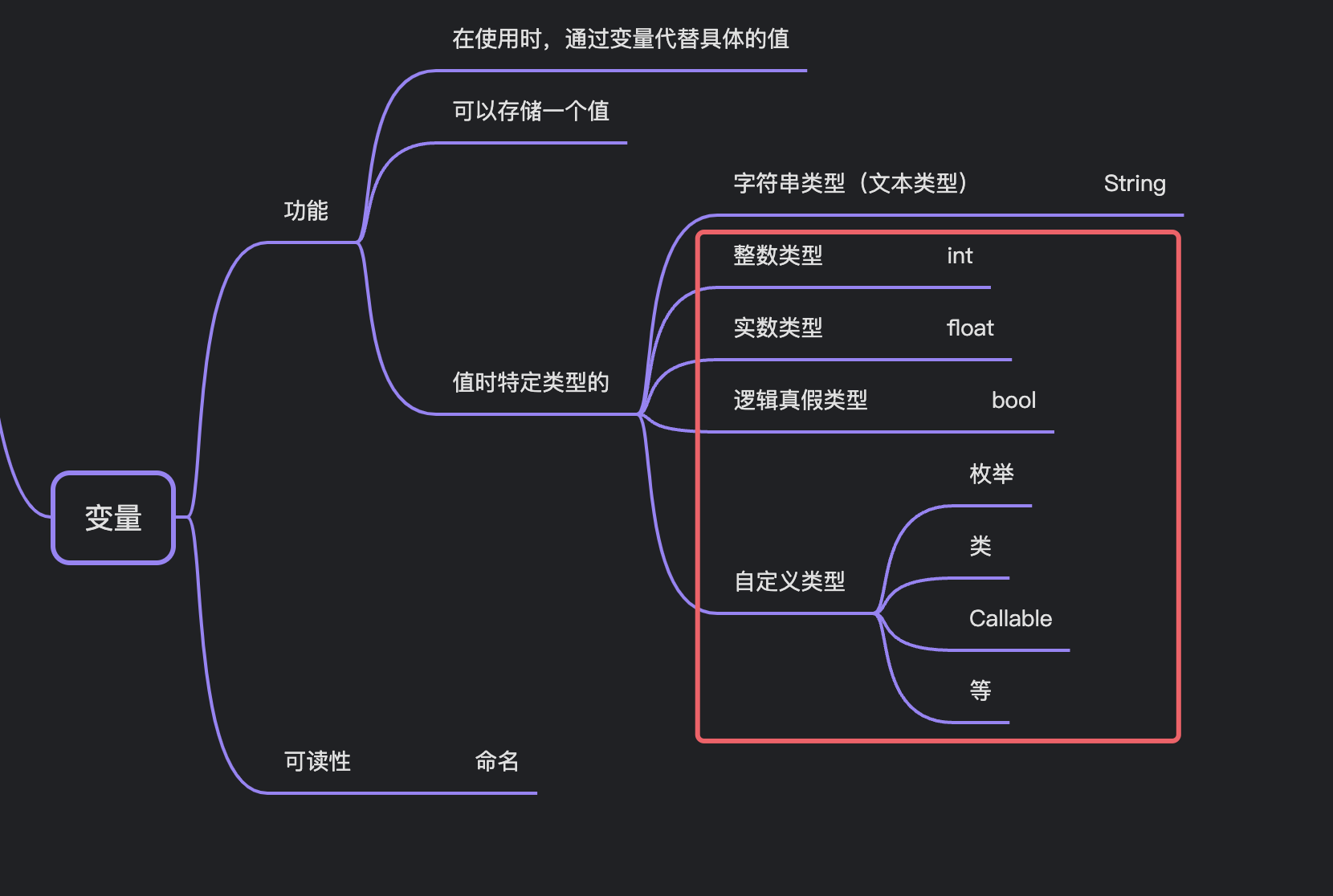
凉鞋的 Godot 笔记 203. 变量的常用类型
203. 变量的常用类型 在上一篇,我们对变量进行了概述和简介,知识地图如下: 我们已经接触了,变量的字符串类型,以及一些功能。 在这一篇,我们尝试多接触一些变量的类型。 首先是整数类型。 整数类型 整…...

【现场问题】批量新建工作流的问题
批量建工作流的优势和劣势 关于批量建工作流的优势缺点 关于批量建工作流的优势 不需要手动,直接一键建立,同时节点的批量建立也成功了 缺点 1、机器识别,一次性成形,没有办法手动的去干涉这东西 2、大数据量的表需要单独处理的…...
)
动态规划14(Leetcode516最长回文子序列)
代码: class Solution {public int longestPalindromeSubseq(String s) {int n s.length();int[][] dp new int[n][n];for(int in-1;i>0;i--){dp[i][i] 1;char c1 s.charAt(i);for(int ji1;j<n;j){char c2 s.charAt(j);if(c1c2){dp[i][j] dp[i1][j-1]2…...
 简介和目标)
写一个简单的解释器(0) 简介和目标
解释语言和编译语言 编译语言,是指其编译器生成的可执行文件为机器码,可以直接在计算机上运行的语言,比如说 C/C \texttt{C/C} C/C 。 解释语言,是指经由解释器生成的可执行文件为字节码文件,只能运行在特殊的虚拟机…...

通过Chain Prompts方式将LLM的能力引入测试平台:正交实验测试用例生成
通过Chain Prompts方式将LLM的能力引入测试平台:正交实验测试用例生成 Chain Prompts Chain Prompts是指在一个对话或文本生成任务中,将前一个提示的输出作为下一个提示的输入,形成一个连续的链条。这种方法常常用于创建连贯的、有上下文关联的文本。在对话系统中,这种方…...

M-BUS和modbus的区别是什么?
M-BUS与Modbus是两种在工业自动化和楼宇自动化领域广泛应用的通信协议。那么,这两种通信协议有哪些区别呢?下面,就由小编带大家一起来了解下吧! 一、简介 M-BUS(Multi-dropBus,多点通信总线)和Modbus(莫迪波特率)都是用于设备和系统之间通信…...

CSS 滚动驱动动画 timeline-scope
timeline-scope 语法兼容性 timeline-scope 看到 scope 就知道这个属性是和范围有关, 没错, timeline-scope 就是用来修改一个具名时间线(named animation timeline)的范围. 我们介绍过的两种时间线 scroll progress timeline 和 view progress timeline, 使用这两种时间线(通…...

R语言时间序列分析
目录 概述 1、什么是时间序列分析 2、时间序列分析的应用 时间序列的基本操作...

房产中介小程序,二手房小程序带H5公众号,房产门户PC版,房产中介,房产经纪人
套餐一:源码=1500 套餐二:全包服务 包服务器+APP+认证小程序+H5+PC+采集=2000(全包服务三年) 可以封装打包APP 一、付费发布信息 支持付费发布、刷新、置顶房源信息; 二、个人发布信息 支持个人和房产经纪人发布房源信息; 三、新房楼盘模块 支持新房楼盘功能,后台添加…...

Docker 部署
1 完全清除旧版本docker for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; doneImages, containers, volumes, and networks stored in /var/lib/docker/ arent automatically removed when y…...
)
ffmpeg推流+nginx转发+拉流(RTMP拉流)
参考:https://blog.csdn.net/weixin_43796767/article/details/117307845 1.搭建支持rtmp转发的nginx服务 git clone https://github.com/arut/nginx-rtmp-module wget http://nginx.org/download/nginx-1.8.0.tar.gz tar -xvf nginx-1.8.0.tar.gz cd nginx-1.8.0/ ./confi…...
)
【Python第三方包】解析和生成二维码(pyqrcode包)
文章目录 前言一、安装pyqrcode包二、生成二维码2.1 二维码生成基础使用2.2 自定义二维码样式颜色设置错误纠正级别尺寸设置三、解析二维码总结前言 在现代信息时代,二维码(QR码)已经成为了快速传递信息的常见方式。Python提供了多种第三方包,用于生成和解析二维码。其中,…...

如何快速搭建个人AI助手?Open WebUI完整指南让你轻松掌控本地AI
如何快速搭建个人AI助手?Open WebUI完整指南让你轻松掌控本地AI 【免费下载链接】open-webui User-friendly AI Interface (Supports Ollama, OpenAI API, ...) 项目地址: https://gitcode.com/GitHub_Trending/op/open-webui 想象一下,你正在处理…...

Nintendo Switch大气层系统完全指南:从零开始解锁你的游戏主机
Nintendo Switch大气层系统完全指南:从零开始解锁你的游戏主机 【免费下载链接】Atmosphere-stable 大气层整合包系统稳定版 项目地址: https://gitcode.com/gh_mirrors/at/Atmosphere-stable 想要让你的Nintendo Switch拥有更多可能性吗?大气层&…...

5步掌握novelWriter:开源小说写作神器的高效创作指南
5步掌握novelWriter:开源小说写作神器的高效创作指南 【免费下载链接】novelWriter novelWriter is an open source plain text editor designed for writing novels. 项目地址: https://gitcode.com/gh_mirrors/no/novelWriter novelWriter是一款专为小说创…...

图像篡改检测的“火眼金睛”是如何炼成的?深入浅出解读MVSS-Net的多视图与多尺度设计
MVSS-Net:图像篡改检测领域的多视角多尺度革命 在数字图像处理技术飞速发展的今天,图像篡改检测已成为维护数字内容真实性的关键技术屏障。传统检测方法在面对日益精妙的篡改手段时显得力不从心,而深度学习技术的引入为这一领域带来了新的曙光…...
)
STM32缺货别慌!手把手教你无缝替换APM32F103C8T6(附CubeMX+Jlink实战)
STM32缺货危机下的国产替代实战:APM32F103C8T6迁移全指南 当STM32F103系列芯片的供货周期从常规的8周延长到52周,价格飙升5倍时,我们团队正在为一个工业控制器项目赶进度。面对客户"要么两周内交付样品,要么终止合作"的…...

吊打大模型幻觉!保姆级RAG原理+极简实战代码,新手一秒看懂
吊打大模型幻觉!保姆级RAG原理极简实战代码,新手一秒看懂 前言:拒绝晦涩干货,通俗讲透RAG 很多小伙伴初学大模型的时候,都会遇到一个让人崩溃的问题:AI瞎编乱造! 问它最新技术,它一问…...

Elasticsearch 底层存储与写入链路:从 Segment 到 Merge,一篇搞懂
Elasticsearch 底层存储与写入链路:从 Segment 到 Merge,一篇搞懂 作者:皮蛋0solo粥 | 发布日期:2026-04-22 标签:Elasticsearch、Lucene、Segment、写入链路、搜索引擎、底层原理 目录 引言:先建立正确的…...

基于OpenAI CUA构建AI自动化任务:从原理到实践
1. 项目概述与核心价值最近在折腾AI驱动的自动化任务,特别是让AI模型直接操作浏览器完成一些重复性工作,OpenAI官方开源的openai-cua-sample-app项目就成了一个绝佳的参考。这个项目本质上是一个演示应用,展示了如何通过OpenAI的Responses AP…...

MATLAB图表导出终极指南:export_fig工具箱完整教程
MATLAB图表导出终极指南:export_fig工具箱完整教程 【免费下载链接】export_fig A MATLAB toolbox for exporting publication quality figures 项目地址: https://gitcode.com/gh_mirrors/ex/export_fig 你是否曾经为MATLAB图表导出的各种问题而烦恼&#x…...

一键批量导出语雀文档为本地Markdown的完整解决方案
一键批量导出语雀文档为本地Markdown的完整解决方案 【免费下载链接】yuque-exporter export yuque to local markdown 项目地址: https://gitcode.com/gh_mirrors/yuq/yuque-exporter 在数字化创作时代,内容迁移成为许多创作者面临的挑战。当语雀平台定位转…...