GAN.py
原代码地址:github.com/zqhang/MTGFLOW
目录
def ConvEncoder()
def ConvDecoder()
class CNNAE(torch.nn.Module):
class R_Net(torch.nn.Module):
class D_Net(torch.nn.Module):
def R_Loss()
def D_Loss()
def R_WLoss()
def D_WLoss()
def train_model()
def train_single_epoch()
def validate_single_epoch()
def test_single_epoch()
def ConvEncoder()
这个函数定义了一个卷积编码器,用于将输入数据进行特征提取。
def ConvEncoder(activation=nn.LeakyReLU, in_channels:int=3, n_c:int=64, k_size:int=5):"""定义卷积编码器模型,将输入数据进行卷积和批量归一化处理。参数:activation: 激活函数,默认为 LeakyReLU。in_channels: 输入数据的通道数,默认为 3(通常是 RGB 图像的通道数)。n_c: 卷积核的数量,也是输出的通道数,默认为 64。k_size: 卷积核的大小,默认为 5。返回:enc: 卷积编码器模型。"""# 创建一个顺序模型(Sequential Model),按顺序添加层enc = nn.Sequential(# 第一个卷积层:输入通道数为 in_channels,输出通道数为 n_c,卷积核大小为 k_size,# 步幅为 2,填充为 2,使用激活函数 activationnn.Conv1d(in_channels, n_c, k_size, stride=2, padding=2),# 批量归一化层,处理卷积层的输出nn.BatchNorm1d(n_c),# 激活函数activation(),# 第二个卷积层:输入通道数为 n_c,输出通道数为 n_c*2,卷积核大小为 k_size,# 步幅为 2,填充为 2,使用激活函数 activationnn.Conv1d(n_c, n_c*2, k_size, stride=2, padding=2),# 批量归一化层,处理卷积层的输出nn.BatchNorm1d(n_c*2),# 激活函数activation(),# 第三个卷积层:输入通道数为 n_c*2,输出通道数为 n_c*4,卷积核大小为 k_size,# 步幅为 2,填充为 2,使用激活函数 activationnn.Conv1d(n_c*2, n_c*4, k_size, stride=2, padding=2),# 批量归一化层,处理卷积层的输出nn.BatchNorm1d(n_c*4),# 激活函数activation())# 返回卷积编码器模型return enc
def ConvDecoder()
创建一个包含卷积转置层的序列模型,用于将低维特征映射回原始输入图像的高维空间。在生成对抗网络(GAN)等模型中,该函数通常用作生成器网络的一部分,负责将潜在空间(随机噪声或其他低维表示)映射为逼真的图像。卷积转置层与普通卷积层相反,它将输入扩大(上采样)而不是缩小(下采样),从而实现从低维到高维的映射。函数返回创建的卷积转置层模型。
def ConvDecoder(activation=nn.LeakyReLU, in_channels:int=3, n_c:int=64, k_size:int=5):# activation:激活函数,默认为 LeakyReLU# in_channels:输入图像的通道数,默认为3(通常是RGB图像)# n_c:卷积核的通道数,默认为64# k_size:卷积核的大小,默认为5# 定义一个包含卷积转置层的序列模型decoder = nn.Sequential(# 第一个卷积转置层,将输入通道数扩大4倍,然后输出通道数减半nn.ConvTranspose1d(n_c*4, n_c*2, k_size, stride=2, padding=2, output_padding=0),torch.nn.BatchNorm1d(n_c*2), # 批归一化层,对输出进行归一化activation(), # 激活函数,将输出进行非线性变换# 第二个卷积转置层,将输入通道数减半,然后输出通道数减半torch.nn.ConvTranspose1d(n_c*2, n_c, k_size, stride=2, padding=2, output_padding=1),torch.nn.BatchNorm1d(n_c), # 批归一化层,对输出进行归一化activation(), # 激活函数,将输出进行非线性变换# 第三个卷积转置层,将输入通道数减半,然后输出通道数与输入图像的通道数相同torch.nn.ConvTranspose1d(n_c, in_channels, k_size, stride=2, padding=2, output_padding=1))return decoder
class CNNAE(torch.nn.Module):
这段代码定义了一个基于卷积神经网络的自动编码器模型(CNNAE)。自动编码器是一种无监督学习模型,它可以学习输入数据的紧凑表示(编码),然后再将这个紧凑表示解码为原始输入数据的重构。在这个模型中,编码器和解码器都是使用卷积神经网络实现的。模型的初始化方法(__init__)中设置了输入图像的通道数、卷积核数量和卷积核大小,并创建了编码器和解码器。前向传播方法(forward)定义了输入数据的处理过程,首先通过编码器获得特征表示,然后通过解码器将特征表示解码为重构的图像。这种结构使得模型可以学习到输入数据的有效表示,用于图像的压缩和重构等任务。
class CNNAE(torch.nn.Module):"""自动编码器模型,使用卷积神经网络(CNN)实现"""def __init__(self, in_channels:int = 3, n_channels:int = 16, kernel_size:int = 5):# 初始化方法,定义了模型的结构和参数super(CNNAE, self).__init__()# 设置输入图像的通道数、卷积核数量、卷积核大小self.in_channels = in_channelsself.n_c = n_channelsself.k_size = kernel_size# 创建编码器(使用ConvEncoder类),指定激活函数和参数activation = torch.nn.LeakyReLUself.encoder = ConvEncoder(activation, in_channels, n_channels, kernel_size)# 创建解码器(使用ConvDecoder类),指定激活函数和参数self.decoder = ConvDecoder(activation, in_channels, n_channels, kernel_size)def forward(self, x:torch.Tensor):# 前向传播方法,定义了输入数据的处理过程# 输入x是一个张量(Tensor),代表输入图像# 使用编码器对输入图像进行编码,得到特征表示zz = self.encoder.forward(x)# 使用解码器对特征表示进行解码,得到重构的图像x_outx_out = self.decoder.forward(z)# 返回重构的图像x_outreturn x_out
class R_Net(torch.nn.Module):
作用: 这段代码定义了一个名为R_Net的PyTorch模型类,表示一个带有噪音的卷积自编码器。该模型包括一个Encoder和一个Decoder,Encoder用于将输入数据编码为隐藏表示,Decoder用于将隐藏表示解码为重构输出。在前向传播过程中,可以选择是否在输入中添加噪音。该模型的主要作用是学习输入数据的压缩表示,并尽可能地恢复出原始输入数据,同时能够处理带有噪音的输入。
class R_Net(torch.nn.Module):# 定义一个名为R_Net的PyTorch模型类,继承自torch.nn.Module基类def __init__(self, activation=torch.nn.LeakyReLU, in_channels:int=3, n_channels:int=16,kernel_size:int=5, std:float=0.2):# 初始化方法,用于定义模型的结构和参数# 参数说明:# activation: 激活函数,默认为LeakyReLU# in_channels: 输入图像的通道数,默认为3(RGB图像)# n_channels: 卷积层的通道数,表示卷积核的数量,默认为16# kernel_size: 卷积核的大小,默认为5# std: 添加噪音时使用的标准差,默认为0.2super(R_Net, self).__init__()# 调用父类的构造函数,必须在子类构造函数的开始处调用self.activation = activation# 将传入的激活函数赋值给类属性self.activationself.in_channels = in_channelsself.n_c = n_channelsself.k_size = kernel_sizeself.std = std# 将传入的参数赋值给相应的类属性self.Encoder = ConvEncoder(activation, in_channels, n_channels, kernel_size)# 创建一个卷积编码器(使用给定的激活函数和参数)self.Decoder = ConvDecoder(activation, in_channels, n_channels, kernel_size)# 创建一个卷积解码器(使用给定的激活函数和参数)def forward(self, x:torch.Tensor, noise:bool=True):# 定义前向传播方法,定义模型的计算过程# 参数说明:# x: 输入的张量,通常是图像数据,类型为torch.Tensor# noise: 是否在输入中添加噪音,默认为Truex_hat = self.add_noise(x) if noise else x# 如果noise为True,则在输入中添加噪音,否则不添加# 添加噪音的操作由self.add_noise函数完成z = self.Encoder.forward(x_hat)# 将带有噪音的输入x_hat通过Encoder模块进行编码,得到隐藏表示zx_out = self.Decoder.forward(z)# 将隐藏表示z通过Decoder模块进行解码,得到重构的输出x_outreturn x_out# 返回重构的输出def add_noise(self, x):# 定义一个函数,用于在输入中添加噪音# 参数说明:# x: 输入的张量,通常是图像数据,类型为torch.Tensornoise = torch.randn_like(x) * self.std# 生成与输入x相同大小的随机噪音,乘以self.std得到具有指定标准差的噪音x_hat = x + noise# 将噪音添加到输入x上,得到带有噪音的输入x_hatreturn x_hat# 返回带有噪音的输入x_hat
class D_Net(torch.nn.Module):
这段代码定义了一个名为D_Net的类,表示一个卷积神经网络的判别器模型。该模型接收输入图像,并输出一个单一的值,用于表示输入图像是真实样本还是生成样本。类中的forward方法定义了模型的前向传播逻辑,将输入图像通过卷积层和全连接层进行处理,得到最终的判别结果。_compute_out_dim方法用于计算卷积层输出的特征维度,以便为全连接层指定输入维度。
class D_Net(torch.nn.Module):def __init__(self, in_resolution:int, activation=torch.nn.LeakyReLU, in_channels:int=3, n_channels:int=16, kernel_size:int=5):# 初始化D_Net类,定义判别器的结构super(D_Net, self).__init__()# 设置激活函数和输入分辨率、通道数、卷积核大小self.activation = activationself.in_resolution = in_resolutionself.in_channels = in_channelsself.n_c = n_channelsself.k_size = kernel_size# 创建一个卷积编码器(CNN Encoder),使用给定的激活函数和参数self.cnn = ConvEncoder(activation, in_channels, n_channels, kernel_size)# 计算D网络卷积部分输出的维度self.out_dim = self._compute_out_dim()# 创建一个全连接层,将卷积部分的输出映射到一个单一的输出值(用于二元分类)self.fc = torch.nn.Linear(self.out_dim, 1)def _compute_out_dim(self):# 计算卷积部分的输出维度,用于全连接层的输入维度test_x = torch.Tensor(1, self.in_channels, self.in_resolution)# 冻结卷积层的参数,防止在计算过程中被修改for p in self.cnn.parameters():p.requires_grad = False# 通过卷积部分得到输出,然后计算输出的维度test_x = self.cnn(test_x)out_dim = torch.prod(torch.tensor(test_x.shape[1:])).item()# 解冻卷积层的参数,以便在训练中更新它们for p in self.cnn.parameters():p.requires_grad = Truereturn out_dimdef forward(self, x:torch.Tensor):# 前向传播函数,对输入图像进行判别# 使用卷积层处理输入图像x = self.cnn(x)# 将卷积层输出的特征图展平成一维向量x = torch.flatten(x, start_dim=1)# 通过全连接层得到最终的判别结果out = self.fc(x)return out
def R_Loss()
def R_Loss(d_net: torch.nn.Module, x_real: torch.Tensor, x_fake: torch.Tensor, lambd: float) -> dict:# d_net 是判别器模型,用于判别生成样本的真实性。# x_real 是真实样本的张量。# x_fake 是生成样本的张量。# lambd 是用于权衡重构损失和生成损失的权重参数。# pred 是生成样本经过判别器的输出,表示生成样本被判别为真实样本的概率。# y 是与pred相同大小的张量,其所有元素都是1,用于计算生成损失。pred = d_net(x_fake)y = torch.ones_like(pred)#rec_loss 是重构损失,使用均方误差(MSE)衡量生成样本x_fake与真实样本x_real之间的差异,即生成样本与真实样本的相似度。rec_loss = F.mse_loss(x_fake, x_real)# gen_loss 是生成损失,使用二元交叉熵(Binary Cross Entropy)损失函数计算生成样本被判别为真实样本的损失,即判别器预测与实际标签的差异。gen_loss = F.binary_cross_entropy_with_logits(pred, y) # generator loss# L_r 是最终的损失函数,它由生成损失和重构损失以及二者的权重参数lambd加权组成。L_r = gen_loss + lambd * rec_loss# 函数返回一个字典,包含了重构损失(rec_loss)、生成损失(gen_loss)和最终的损失(L_r)。# 这些损失值用于监控和优化生成模型的性能。通常,生成模型的目标是最小化生成损失,同时保持生成样本与真实样本的相似性,即最小化重构损失。return {'rec_loss' : rec_loss, 'gen_loss' : gen_loss, 'L_r' : L_r}def D_Loss()
这段代码定义了一个函数D_Loss,它计算了给定判别器(d_net)对真实样本(x_real)和生成样本(x_fake)的损失。函数首先使用判别器对真实样本和生成样本进行预测,得到预测结果。然后,为真实样本和生成样本分别创建标签(1表示真实样本,0表示生成样本)。接着,使用二元交叉熵损失函数(F.binary_cross_entropy_with_logits)分别计算真实样本和生成样本的损失(real_loss和fake_loss)。最后,将这两个损失相加,得到最终的判别器损失。该函数用于训练生成对抗网络(GAN)中的判别器,目的是使判别器能够正确区分真实样本和生成样本。
def D_Loss(d_net: torch.nn.Module, x_real: torch.Tensor, x_fake: torch.Tensor) -> torch.Tensor:# 输入参数:# d_net: 判别器模型# x_real: 真实样本# x_fake: 生成样本# 利用判别器对真实样本进行预测,得到预测结果pred_real = d_net(x_real)# 利用判别器对生成样本进行预测(使用detach()来阻止梯度回传),得到预测结果pred_fake = d_net(x_fake.detach())# 为真实样本和生成样本创建标签,1表示真实样本,0表示生成样本y_real = torch.ones_like(pred_real)y_fake = torch.zeros_like(pred_fake)# 使用二元交叉熵损失函数计算真实样本和生成样本的损失# real_loss表示真实样本的损失,fake_loss表示生成样本的损失real_loss = F.binary_cross_entropy_with_logits(pred_real, y_real)fake_loss = F.binary_cross_entropy_with_logits(pred_fake, y_fake)# 返回真实样本和生成样本损失的总和作为最终的判别器损失return real_loss + fake_loss
def R_WLoss()
这段代码定义了一个函数R_WLoss,它计算了生成对抗网络(GAN)中的损失。函数使用给定的判别器(d_net)对生成样本(x_fake)进行预测,并通过 sigmoid 激活函数将预测结果映射到 [0, 1] 范围内。然后,函数计算了两个损失项:重建损失(rec_loss,使用均方误差)和生成损失(gen_loss,Wasserstein G loss)。最后,函数计算了总的损失(L_r),其中重建损失被乘以权重 lambd。函数返回一个包含损失信息的字典,其中包括重建损失、生成损失和总损失。这些损失用于优化生成器网络。
def R_WLoss(d_net: torch.nn.Module, x_real: torch.Tensor, x_fake: torch.Tensor, lambd: float) -> dict:# 输入参数:# d_net: 判别器模型# x_real: 真实样本# x_fake: 生成样本# lambd: 重建损失的权重# 使用判别器对生成样本进行预测,得到预测结果,并经过 sigmoid 激活函数pred = torch.sigmoid(d_net(x_fake))# 计算重建损失(均方误差)rec_loss = F.mse_loss(x_fake, x_real)# 计算生成损失(Wasserstein G loss: - E[ D(G(x)) ])gen_loss = -torch.mean(pred)# 计算总损失(L_r = 生成损失 + 重建损失 * 权重 lambd)L_r = gen_loss + lambd * rec_loss# 返回损失信息的字典,包括重建损失、生成损失和总损失return {'rec_loss': rec_loss, 'gen_loss': gen_loss, 'L_r': L_r}
def D_WLoss()
这段代码定义了一个函数D_WLoss,它计算了生成对抗网络(GAN)中鉴别器的损失。函数使用给定的判别器(d_net)对真实样本(x_real)和生成样本(x_fake)进行预测,并通过 sigmoid 激活函数将预测结果映射到 [0, 1] 范围内。然后,函数计算了两个损失项:真实样本的损失(-E[D(x_real)])和生成样本的损失(E[D(x_fake)])。这两个损失项相加后得到鉴别器的总损失,这个损失用于优化鉴别器网络。
def D_WLoss(d_net: torch.nn.Module, x_real: torch.Tensor, x_fake: torch.Tensor) -> torch.Tensor:# 输入参数:# d_net: 判别器模型# x_real: 真实样本# x_fake: 生成样本# 使用判别器对真实样本和生成样本进行预测,得到预测结果,并通过 sigmoid 激活函数pred_real = torch.sigmoid(d_net(x_real))pred_fake = torch.sigmoid(d_net(x_fake.detach()))# 计算鉴别器的损失(Wasserstein D loss: -E[D(x_real)] + E[D(x_fake)])dis_loss = -torch.mean(pred_real) + torch.mean(pred_fake)# 返回鉴别器损失return dis_loss
def train_model()
这段代码定义了一个函数train_model,用于训练生成对抗网络(GAN)的生成器和判别器模型。函数接受多个参数,包括生成器模型(r_net)、判别器模型(d_net)、训练数据加载器(train_loader)、测试数据加载器(test_loader)等等。函数中包含了训练循环,每个epoch会进行一次训练和测试,并根据需要保存模型。
def train_model(args, r_net: torch.nn.Module,d_net: torch.nn.Module,train_loader: torch.utils.data.DataLoader,test_loader: torch.utils.data.DataLoader,r_loss = R_Loss,d_loss = D_Loss,lr_scheduler = None,optimizer_class = torch.optim.Adam,optim_r_params: dict = {},optim_d_params: dict = {},learning_rate: float = 0.001,scheduler_r_params: dict = {},scheduler_d_params: dict = {},batch_size: int = 1024,max_epochs: int = 40,epoch_step: int = 1,save_step: int = 5,lambd: float = 0.2,device: torch.device = torch.device('cuda'),save_path: str = ".") -> tuple:# 参数说明:# args: 其他训练参数的配置# r_net: 生成器模型# d_net: 判别器模型# train_loader: 训练数据的数据加载器# test_loader: 测试数据的数据加载器# r_loss: 生成器的损失函数,默认为R_Loss# d_loss: 判别器的损失函数,默认为D_Loss# lr_scheduler: 学习率调度器,默认为None# optimizer_class: 优化器类型,默认为torch.optim.Adam# optim_r_params: 生成器优化器的参数,默认为空字典# optim_d_params: 判别器优化器的参数,默认为空字典# learning_rate: 初始学习率,默认为0.001# scheduler_r_params: 生成器学习率调度器的参数,默认为空字典# scheduler_d_params: 判别器学习率调度器的参数,默认为空字典# batch_size: 批大小,默认为1024# max_epochs: 最大训练轮数,默认为40# epoch_step: 每隔多少轮打印训练信息,默认为1# save_step: 每隔多少轮保存模型,默认为5# lambd: R_Loss中的lambda参数,默认为0.2# device: 训练设备,默认为'cuda'# save_path: 模型保存路径,默认为当前目录# 创建生成器和判别器的优化器optim_r = optimizer_class(r_net.parameters(), lr=learning_rate, **optim_r_params)optim_d = optimizer_class(d_net.parameters(), lr=learning_rate, **optim_d_params)# 创建学习率调度器if lr_scheduler:scheduler_r = lr_scheduler(optim_r, **scheduler_r_params)scheduler_d = lr_scheduler(optim_d, **scheduler_d_params)logger = log() # 日志记录器# 开始训练循环for epoch in range(max_epochs):start = timer() # 记录每轮开始时间# 训练一个epoch并获取训练指标train_metrics = train_single_epoch(r_net, d_net, optim_r, optim_d, r_loss, d_loss, train_loader, lambd, device)# 测试模型并获取测试指标gt, pre = test_metrics = test_single_epoch(r_net, d_net, r_loss, d_loss, test_loader, device)# 记录测试结果# logger.print_result(gt, pre, (r_net, d_net), args.seed, args)time = timer() - start # 记录每轮训练时间# 每隔一定轮数打印训练信息if epoch % epoch_step == 0:print(f'Epoch {epoch}:')# print('Train Metrics:', train_metrics)# print('Test Metrics:', test_metrics)# print(f'TIME: {time:.2f} s')# 学习率调度器进行一步学习率更新if lr_scheduler:scheduler_r.step()scheduler_d.step()# 每隔一定轮数保存模型# if epoch % save_step == 0:# torch.save(r_net.state_dict(), os.path.join(save_path, "r_net_{}.pt".format(epoch)))# torch.save(d_net.state_dict(), os.path.join(save_path, "d_net_{}.pt".format(epoch)))# print(f'Saving model on epoch {epoch}')# 返回训练好的生成器和判别器模型return (r_net, d_net)
def train_single_epoch()
这段代码定义了一个函数`train_single_epoch`,用于训练一个epoch。在每个batch的训练中,首先将真实数据传入判别器,计算判别器损失,并更新判别器的参数。然后,将真实数据传入生成器生成假数据,计算生成器损失(包括重构损失和对抗损失),并更新生成器的参数。最后,将每个batch的损失累加,并计算每个样本的平均损失。函数返回一个包含平均损失的字典。
def train_single_epoch(r_net, d_net, optim_r, optim_d, r_loss, d_loss, train_loader, lambd, device) -> dict:# 参数说明:# r_net: 生成器模型# d_net: 判别器模型# optim_r: 生成器的优化器# optim_d: 判别器的优化器# r_loss: 生成器的损失函数# d_loss: 判别器的损失函数# train_loader: 训练数据的数据加载器# lambd: R_Loss中的lambda参数# device: 训练设备r_net.train() # 设置生成器为训练模式d_net.train() # 设置判别器为训练模式train_metrics = {'rec_loss': 0, 'gen_loss': 0, 'dis_loss': 0} # 初始化训练指标for data, _, idx in train_loader:x = data.to(device) # 将数据移动到指定设备上x = torch.transpose(x, dim0=2, dim1=3) # 调整输入数据的维度x_real = x.reshape(x.shape[0], x.shape[1] * x.shape[2], x.shape[3]) # 调整输入数据的形状x_fake = r_net(x_real) # 通过生成器生成假数据d_net.zero_grad() # 判别器梯度清零dis_loss = d_loss(d_net, x_real, x_fake) # 计算判别器损失dis_loss.backward() # 反向传播并更新判别器参数optim_d.step() # 判别器优化器更新r_net.zero_grad() # 生成器梯度清零r_metrics = r_loss(d_net, x_real, x_fake, lambd) # 计算生成器损失,包含重构损失和对抗损失r_metrics['L_r'].backward() # 反向传播并更新生成器参数optim_r.step() # 生成器优化器更新# 累加每个batch的损失train_metrics['rec_loss'] += r_metrics['rec_loss']train_metrics['gen_loss'] += r_metrics['gen_loss']train_metrics['dis_loss'] += dis_loss# 计算每个样本的平均损失train_metrics['rec_loss'] = train_metrics['rec_loss'].item() / (len(train_loader.dataset) / train_loader.batch_size)train_metrics['gen_loss'] = train_metrics['gen_loss'].item() / (len(train_loader.dataset) / train_loader.batch_size)train_metrics['dis_loss'] = train_metrics['dis_loss'].item() / (len(train_loader.dataset) / train_loader.batch_size)return train_metrics # 返回训练指标字典
def validate_single_epoch()
这段代码定义了一个函数validate_single_epoch,用于在验证集上评估模型。与训练过程类似,首先将真实数据传入判别器,计算判别器损失。然后,将真实数据传入生成器生成假数据,计算生成器损失。最后,将每个batch的损失累加,并计算每个样本的平均损失。函数返回一个包含平均损失的字典。
def validate_single_epoch(r_net, d_net, r_loss, d_loss, valid_loader, device) -> dict:# 参数说明:# r_net: 生成器模型# d_net: 判别器模型# r_loss: 生成器的损失函数# d_loss: 判别器的损失函数# valid_loader: 验证数据的数据加载器# device: 训练设备r_net.eval() # 设置生成器为评估模式d_net.eval() # 设置判别器为评估模式valid_metrics = {'rec_loss': 0, 'gen_loss': 0, 'dis_loss': 0} # 初始化验证指标with torch.no_grad():for data, _, idx in valid_loader:x = data.to(device) # 将数据移动到指定设备上x = torch.transpose(x, dim0=2, dim1=3) # 调整输入数据的维度x_real = x.reshape(x.shape[0], x.shape[1] * x.shape[2], x.shape[3]) # 调整输入数据的形状x_fake = r_net(x_real) # 通过生成器生成假数据dis_loss = d_loss(d_net, x_real, x_fake) # 计算判别器损失r_metrics = r_loss(d_net, x_real, x_fake, 0) # 计算生成器损失,lambda参数为0表示不使用重构损失# 累加每个batch的损失valid_metrics['rec_loss'] += r_metrics['rec_loss']valid_metrics['gen_loss'] += r_metrics['gen_loss']valid_metrics['dis_loss'] += dis_loss# 计算每个样本的平均损失valid_metrics['rec_loss'] = valid_metrics['rec_loss'].item() / (len(valid_loader.dataset) / valid_loader.batch_size)valid_metrics['gen_loss'] = valid_metrics['gen_loss'].item() / (len(valid_loader.dataset) / valid_loader.batch_size)valid_metrics['dis_loss'] = valid_metrics['dis_loss'].item() / (len(valid_loader.dataset) / valid_loader.batch_size)return valid_metrics # 返回验证指标字典
def test_single_epoch()
这段代码定义了一个函数test_single_epoch,用于在测试集上评估模型。与验证过程类似,首先将真实数据传入判别器,计算判别器损失,并将损失值添加到损失列表中。然后,将损失列表的元素合并为一个Tensor,并将NaN值替换为0。接着,使用roc_auc_score函数计算ROC AUC得分,并将结果打印出来。函数返回真实标签和负的损失值,用于ROC AUC计算。
def test_single_epoch(r_net, d_net, r_loss, d_loss, test_loader, device) -> dict:# 参数说明:# r_net: 生成器模型# d_net: 判别器模型# r_loss: 生成器的损失函数# d_loss: 判别器的损失函数# test_loader: 测试数据的数据加载器# device: 训练设备r_net.eval() # 设置生成器为评估模式d_net.eval() # 设置判别器为评估模式valid_metrics = {'rec_loss': 0, 'gen_loss': 0, 'dis_loss': 0} # 初始化验证指标loss = [] # 初始化损失列表with torch.no_grad():for data, _, idx in test_loader:x = data.to(device) # 将数据移动到指定设备上x = torch.transpose(x, dim0=2, dim1=3) # 调整输入数据的维度x_real = x.reshape(x.shape[0], x.shape[1] * x.shape[2], x.shape[3]) # 调整输入数据的形状dis_loss = d_net(x_real).squeeze().cpu() # 计算判别器损失,并将结果移回CPUloss.append(dis_loss) # 将损失添加到损失列表中loss = torch.cat(loss) # 将损失列表合并为一个Tensorloss = np.nan_to_num(loss) # 将NaN值替换为0auc_score = roc_auc_score(np.asarray(test_loader.dataset.label, dtype=int), -loss) # 计算ROC AUC得分print('roc_test', auc_score) # 打印测试集的ROC AUC得分return np.asarray(test_loader.dataset.label, dtype=int), -loss # 返回真实标签和负的损失值(用于ROC AUC计算)
相关文章:

GAN.py
原代码地址:github.com/zqhang/MTGFLOW 目录 def ConvEncoder() def ConvDecoder() class CNNAE(torch.nn.Module): class R_Net(torch.nn.Module): class D_Net(torch.nn.Module): def R_Loss() def D_Loss()…...
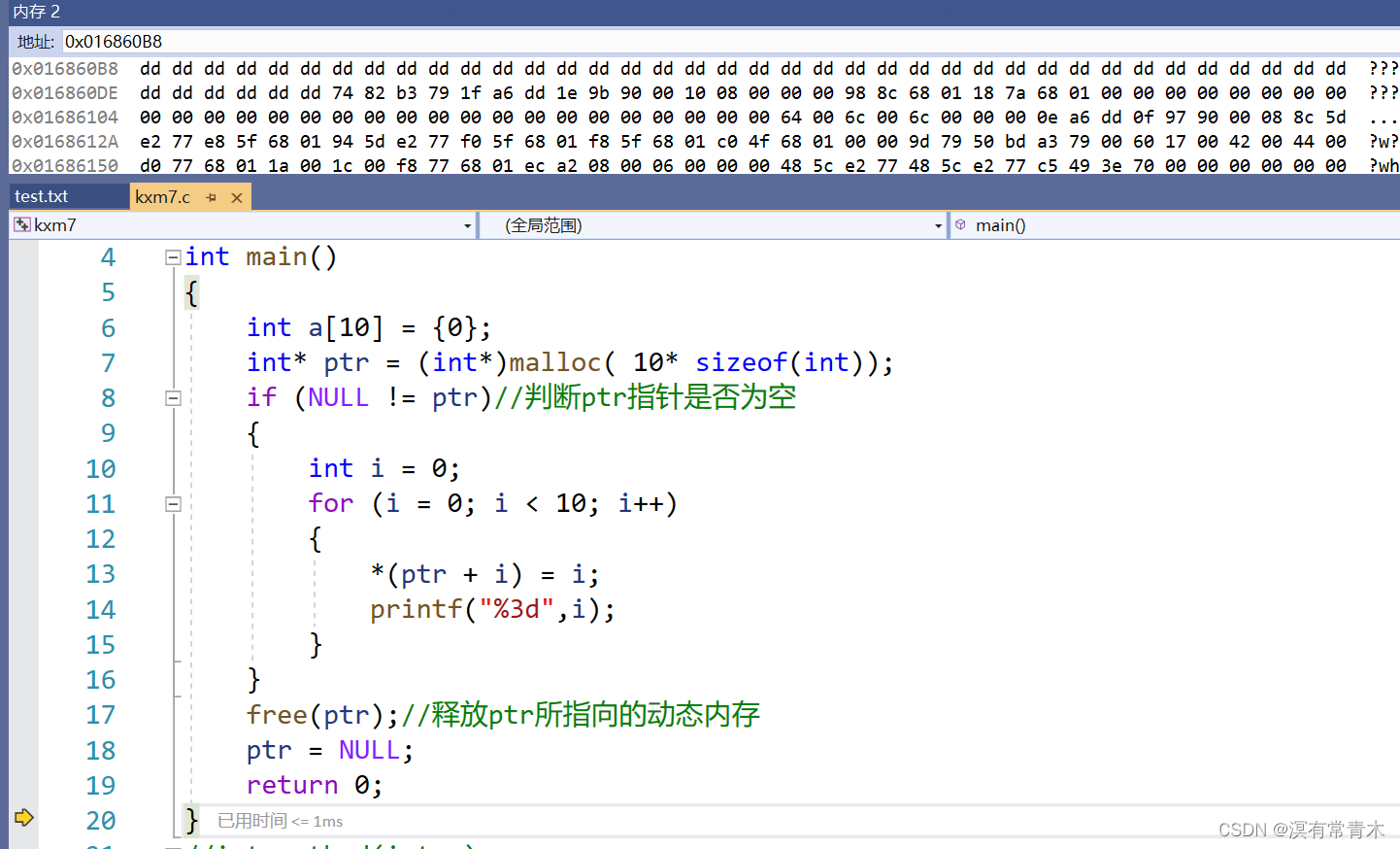
C语言动态内存管理
1.为什么要动态内存分配? int val 20; int a[10]{0};上面我们声明并定义了一个大小为4字节的整型变量,一个容量为10*4字节的整型数组。 开辟方式:我们在栈上开辟。 开辟空间的方式有两个特点: 1. 空间开辟 大小是固定 的。 2. 数组在申明…...
)
小红书商品详情API接口(商品详情页面数据接口)
小红书商品详情API接口(商品详情页面数据接口 小红书商品详情API接口(商品详情页面数据接口)代码对接如下: 1.公共参数 名称类型必须描述keystring是get请求方式拼接在url中,点击获取api_namestring是 api接口名称cachestrin…...

nginx配置文件的内容解释和简化方案
文章目录 配置文件内容理解配置文件精简nginx.confapp1.conf 配置文件内容理解 events {worker_connections 1024; }http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;client_max_body_size 50m;client…...
)
Java设计模式之访问者模式(Visitor Pattern)
访问者模式(Visitor Pattern)是一种行为型设计模式,它允许在不修改现有对象结构的情况下定义新的操作。该模式将操作封装在一个访问者对象中,使得可以在不改变被访问对象的类的前提下,通过访问者对象对被访问对象进行新…...
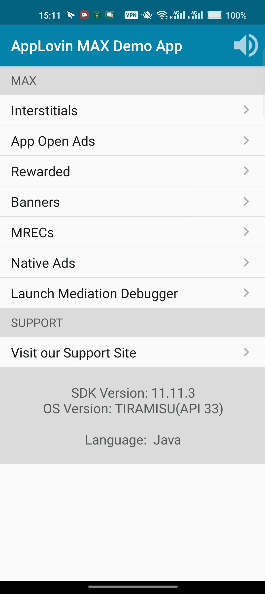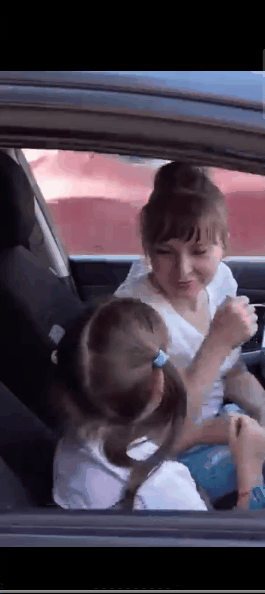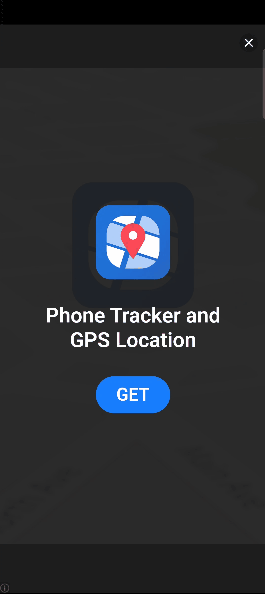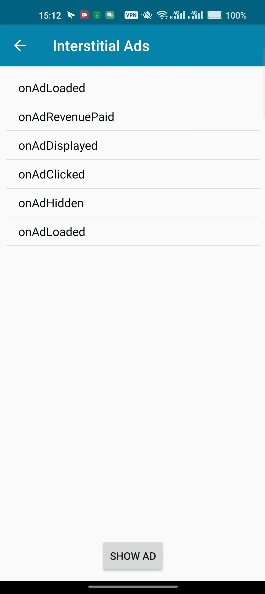
others-AppLovin广告接入
title: others-AppLovin广告接入 categories: Others tags: [广告, AppLovin] date: 2023-10-20 10:07:01 comments: false mathjax: true toc: true others-AppLovin广告接入 前篇 官方 - https://www.applovin.com/ Android sdk - https://github.com/AppLovin/AppLovin-MAX…...
ESP32集成开发环境Espressif-IDE安装 – Windows
陈拓 2023/10/15-2023/10/16 1. 概述 Espressif IDE是一个基于Eclipse CDT的集成开发环境(IDE),用于使用ESP-IDF框架开发物联网应用程序。这是一个专门为ESP-IDF构建的独立定制IDE。Espressif IDE附带了IDF Eclipse插件、重要的Eclipse CDT插…...

python之if else语句介绍
python之if else语句介绍 在Python中,if和else是两种重要的控制流语句,它们用于根据特定的条件来执行不同的代码块。以下是它们的用法和详细介绍: 1)if语句 if语句用于在满足某种条件时执行特定的代码块。它的基本语法如下&#…...
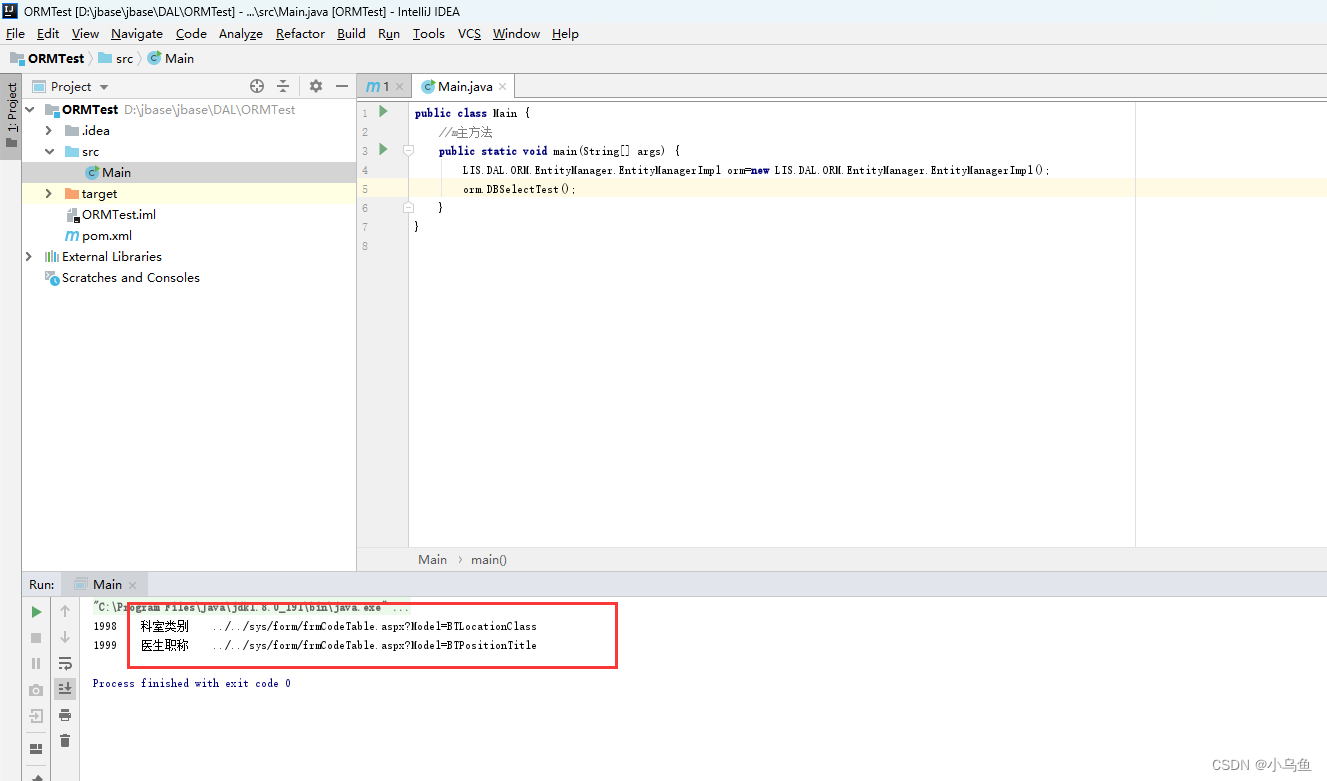
Java版ORM最初雏形
经过一个晚上的加班,终于把ORM初步结构工程搭好了。工程依赖有点难用,编辑器提示比VS差很多。 首先LIS.Core创建一个最初的容器雏形,先能反射得到对象给ORM获得数据库驱动 然后ORM创建数据库驱动差异接口,不同数据库实现接口后配…...
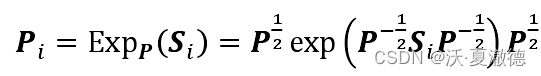
黎曼几何与切空间之间的投影
公式: 从黎曼空间投影到切空间,其中P为黎曼均值,也是切空间的参考中心点,Pi是要投影到切空间的点。 从切空间投影回来,其中Si为切空间中的向量。 function Tcov CovToTan(cov,Mcov)Cm12 Mcov^(-1/2);X_new logm(Cm…...
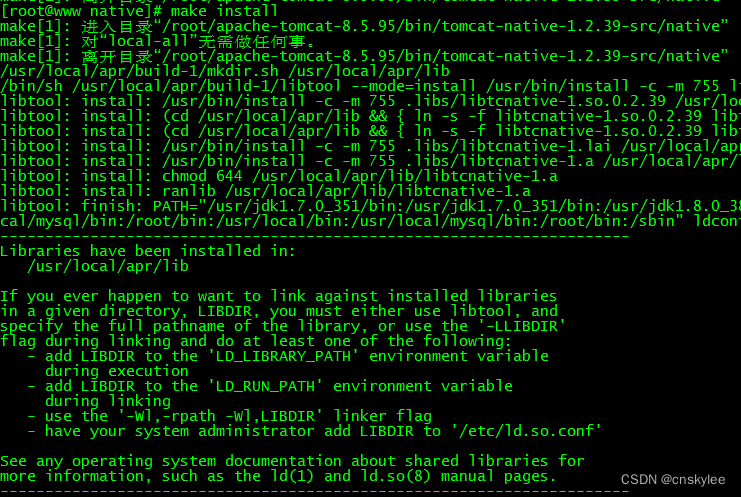
【Tomcat】为Tomcat服务配置本地Apr库以提升性能
关于 apr 和 apr-util 对 Tomcat 服务的性能提升的说明: 要测APR给tomcat带来的好处最好的方法是在慢速网络上(模拟Internet),将Tomcat线程数开到300以上的水平,然后模拟一大堆并发请求。如果不配APR,基本…...

普通人在当前大环境下——少看宏观,多看具体
前言 宏观叙事,简而言之,就是从宏观把握历史社会的发展,寻找其中永恒的共性。我们大概听过此类的话:贸易战导致本地经济下滑、气候变化是因为过去几十年的工业发展、大环境不行导致不赚钱。此类叙事方式,身边人聊的甚欢,在媒体、社交圈、日常社群交流中,随处可见。以前…...

用echarts在vue2中实现3d饼图
先看效果,再看文章: 一、安装插件 3d的图不仅用到echarts,还用到了echarts-gl,因此都需要安装一下哦~ npm install echarts npm install echarts-gl2.0.9 //可以指定版本,也可不指定二、在main.js中引入 import * …...
低代码助力软件开发
低代码开发工具正在日益变得强大,它正不断弥合着前后端开发之间的差距。对于后端来说,基于低代码平台开发应用时,完全不用担心前端的打包、部署等问题,也不用学习各种框架(Vue、React、Angular等等)&#x…...

C嘎嘎之类和对象上
> 作者简介:დ旧言~,目前大二,现在学习Java,c,c,Python等 > 座右铭:松树千年终是朽,槿花一日自为荣。 > 目标:掌握类的引用和定义,熟悉类成员函数的…...
Vue 3使用 Iconify 作为图标库与图标离线加载的方法、 Icones 开源在线图标浏览库的使用
之前一直naive-ui搭配使用的是xicons,后来发现Iconify支持的图标合集更多,因此转而使用Iconify。 与FontAwesome不同的是,Iconify配合Icones相当于是一个合集,Iconify提供了快捷引入图标的方式,而Icones是一个大的图标…...
springboot+vue基于Spark的共享单车数据存储系统的设计与实现【内含源码+文档+部署教程】
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ 🍅由于篇幅限制,想要获取完整文章或者源码,或者代做&am…...

如何使双核心的ESP32开启双核功能同时执行多任务
如何使双核心的ESP32开启双核功能同时执行多任务 简介查看ESP32当前哪一个内核在执行任务双核同时执行任务总结 简介 ESP32-WROOM-32模组内置两个低功耗 Xtensa 32-bit LX6 MCU,两个 CPU 核(core 0与core 1)可以被单独控制。可以在两个内核上…...
Node.js在Python中的应用实例解析
随着互联网的发展,数据爬取成为了获取信息的重要手段。本文将以豆瓣网为案例,通过技术问答的方式,介绍如何使用Node.js在Python中实现数据爬取,并提供详细的实现代码过程。 Node.js是一个基于Chrome V8引擎的JavaScript运行时环境…...
LC-2316. 统计无向图中无法互相到达点对数(DFS、并查集)
2316. 统计无向图中无法互相到达点对数 中等 给你一个整数 n ,表示一张 无向图 中有 n 个节点,编号为 0 到 n - 1 。同时给你一个二维整数数组 edges ,其中 edges[i] [ai, bi] 表示节点 ai 和 bi 之间有一条 无向 边。 请你返回 无法互相…...
的永磁同步电机无位置传感器FOC控制)
从理论到实践:基于扩展卡尔曼滤波(EKF)的永磁同步电机无位置传感器FOC控制
1. 扩展卡尔曼滤波(EKF)基础与电机控制的关系 我第一次接触扩展卡尔曼滤波是在研究生阶段,当时实验室的永磁同步电机总因为编码器故障导致停机。导师扔给我一篇论文说:"试试这个无位置传感器方案"。现在回想起来&#x…...

算法训练营第十二天 | 多数元素
今日训练题:169. 多数元素 哈希表方法 代码如下: 思路: 准备一个 “计数器”:unordered_map<int, int> counts;左边记数字,右边记出现几次。 遍历数组,并实时记录出现次数,counts[num]&am…...

前端测试的 Cypress 最佳实践:从入门到精通
前端测试的 Cypress 最佳实践:从入门到精通 为什么 Cypress 如此重要? 在当今前端开发中,测试是确保代码质量和稳定性的关键环节。传统的测试工具如 Selenium 存在速度慢、不稳定等问题,而 Cypress 作为一款现代的前端测试工具&…...

Java并发编程实战-CompletableFuture异步编排优化聚合接口性能
1. 为什么需要异步编排优化聚合接口 在电商、社交等互联网应用中,聚合接口是非常常见的场景。比如一个用户中心页面,需要展示用户基本信息、订单列表、优惠券数量、积分余额等多个维度的数据。传统的做法可能是串行调用多个服务接口,先查用户…...

OpenShell深度解析:用经典外壳替换重塑Windows效率体验
1. 项目概述:一个被低估的Windows效率革命如果你和我一样,常年与Windows系统打交道,对那个从Windows 95时代沿用至今的“开始菜单”感到审美疲劳和效率低下,那么“NVIDIA/OpenShell”这个项目,绝对值得你花上十分钟了解…...

Progress ShareFile 曝双重严重漏洞:无需认证即可实现远程代码执行
【安全快讯】 2026年4月,网络安全研究机构 watchTowr Labs 披露了一项针对企业级文件传输平台 Progress ShareFile 的严重安全威胁。研究人员在 ShareFile 5.x 分支的 Storage Zones Controller(存储区域控制器,简称 SZC)组件中发…...

5个驱动清理技巧:如何彻底解决Windows系统臃肿问题
5个驱动清理技巧:如何彻底解决Windows系统臃肿问题 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 您是否发现Windows系统盘空间越来越小,却不知道原因ÿ…...

Day 13:朴素贝叶斯分类器
Day 13:朴素贝叶斯分类器 📋 目录 朴素贝叶斯概述贝叶斯定理基础朴素贝叶斯的“朴素”假设三种朴素贝叶斯模型详解朴素贝叶斯的优缺点拉普拉斯平滑第一部分:朴素贝叶斯概述 1.1 什么是朴素贝叶斯? 朴素贝叶斯(Naive Ba…...

小升初英语衔接轻创业,KISSABC 落地全拆解
小升初英语衔接是一个家长付费意愿强、决策周期相对较短的细分市场。小学高年级家长对孩子的英语水平有清醒认知,知道初中英语和小学英语的难度差距,愿意为有效的衔接方案买单。对于想切入教育赛道的创业者来说,锁定这个群体是一个需求明确、…...
在复杂功能实现上如何领先通义灵码)
AI编程助手实战评测:Claude3(Opus)在复杂功能实现上如何领先通义灵码
1. 复杂编程任务下的AI助手对决 最近在开发者圈子里有个热门话题:当遇到稍微复杂的编程需求时,到底该选择哪款AI编程助手?我恰好有个实际需求——用Python整合Azure语音服务开发带图形界面的应用,于是拿通义灵码和Claude3(Opus)做…...