集成学习方法(随机森林和AdaBoost)
释义
集成学习很好的避免了单一学习模型带来的过拟合问题
根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类:
- Bagging(个体学习器间不存在强依赖关系、可同时生成的并行化方法) 流行版本:随机森林(random forest)
- Boosting(个体学习器间存在强依赖关系、必须串行生成的序列化方法) AdaBoost
example:
选男友: 美女选择择偶对象的时候,会问几个闺蜜的建议,最后选择一个综合得分最高的一个作为男朋友(bagging)
追女友: 3个帅哥追同一个美女,第1个帅哥失败->(传授经验: 姓名、家庭情况) 第2个帅哥失败->(传授经验: 兴趣爱好、性格特点) 第3个帅哥成功(boosting)
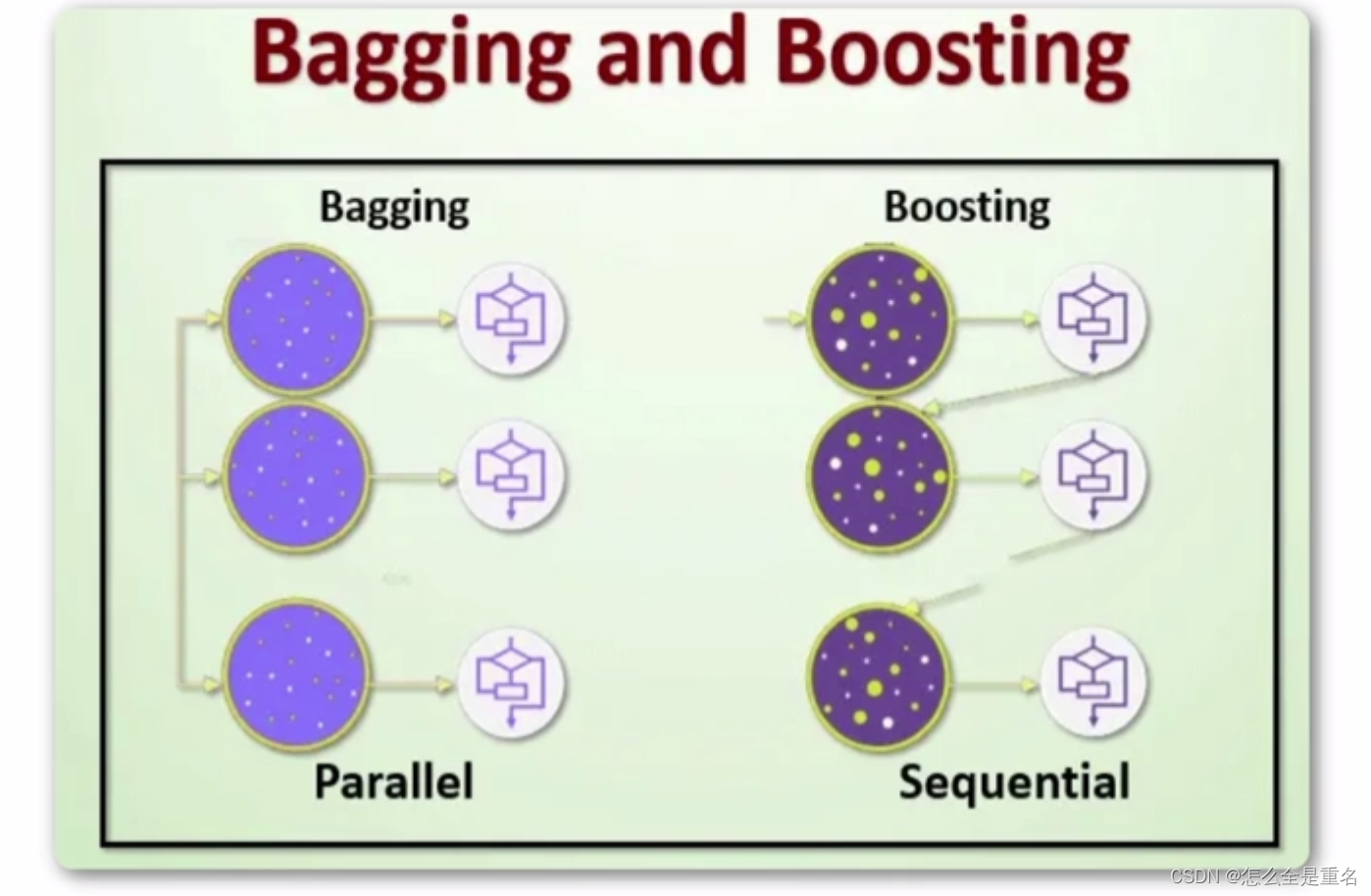
两者区别
bagging 是一种与 boosting 很类似的技术, 所使用的多个分类器的类型(数据量和特征量)都是一致的。
bagging 是由不同的分类器(1.数据随机化 2.特征随机化)经过训练,综合得出的出现最多分类结果;boosting 是通过调整已有分类器错分的那些数据来获得新的分类器,得出目前最优的结果。
bagging 中的分类器权重是相等的;而 boosting 中的分类器加权求和,所以权重并不相等,每个权重代表的是其对应分类器在上一轮迭代中的成功度。
自助采样法(bootstrap sampling):
给定包含m个样本的数据集,先随机取出一个样本放入采样集中并记录,再把该样本放回初始数据集,使得下次采样时该样本仍有可能被选中,这样,经过m次随机采样操作,我们得到含m个样本的采样集,初始训练集中有的样本在采样集里多次出现,有的则从未出现(平均37%没有取到)。
这些未取到的样本称为OOB(Out of Bag),可以使用这部分OOB的数据集作为测试集
Bagging的基本流程
基于每个采样集训练出一个基学习器,再将这些基学习器进行结合
- 对分类任务,使用简单投票法
- 对回归任务,使用简单平均法
随机森林
- 随机森林指的是利用多棵树对样本进行训练并预测的一种分类器。
- 决策树相当于一个大师,通过自己在数据集中学到的知识用于新数据的分类。但是俗话说得好,一个诸葛亮,玩不过三个臭皮匠。随机森林就是希望构建多个臭皮匠,希望最终的分类效果能够超过单个大师的一种算法。
原理
look
数据的随机性化
待选特征的随机化
使得随机森林中的决策树都能够彼此不同,提升系统的多样性,从而提升分类性能。
数据的随机化: 使得随机森林中的决策树更普遍化一点,适合更多的场景。
(有放回的准确率在: 70% 以上, 无放回的准确率在: 60% 以上)
采取有放回的抽样方式 构造子数据集,保证不同子集之间的数量级一样(不同子集/同一子集 之间的元素可以重复)
利用子数据集来构建子决策树,将这个数据放到每个子决策树中,每个子决策树输出一个结果。
然后统计子决策树的投票结果,得到最终的分类 就是 随机森林的输出结果。


RF的简单例子
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 加载鸢尾花数据集
data = load_iris()
X = data.data # 特征
y = data.target # 目标# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建随机森林分类器
clf = RandomForestClassifier(n_estimators=100, random_state=42)# 训练分类器
clf.fit(X_train, y_train)# 使用分类器进行预测
y_pred = clf.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)AdaBoost
Adaboost的原理
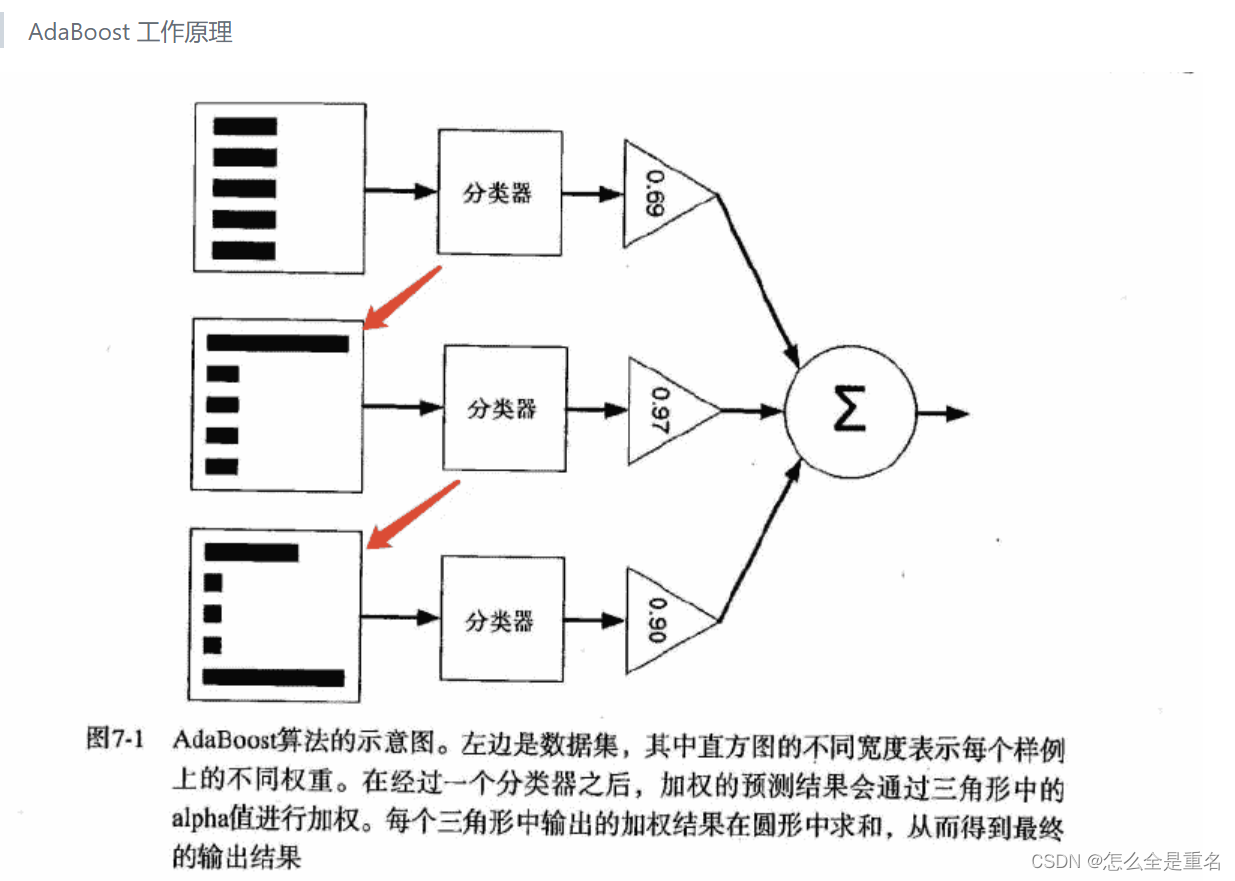
以分类为例,Adaboost算法通过提高前一轮分类器分类错误的样本的权值,而降低那些被分类正确的样本的权值。
需要注意的是,由于每个子模型要使用全部的数据集进行训练,因此 Adaboost算法中没有oob数据集,在使用 Adaboost 算法前,需要划分数据集:train_test_split。
相当于准备个错题本,花更多的时间处理错题
在使用Adaboost与决策树结合解决分类问题时,使用AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
ada_clf = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2), n_estimators=500)
ada_clf.fit(X_train, y_train)
ada_clf.score(X_test, y_test)
同样的简单例子
from sklearn.datasets import load_iris
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 加载鸢尾花数据集
data = load_iris()
X = data.data # 特征
y = data.target # 目标# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建 AdaBoost 分类器(基分类器为决策树)
clf = AdaBoostClassifier(n_estimators=50, random_state=42)# 训练分类器
clf.fit(X_train, y_train)# 使用分类器进行预测
y_pred = clf.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)相关文章:
集成学习方法(随机森林和AdaBoost)
释义 集成学习很好的避免了单一学习模型带来的过拟合问题 根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类: Bagging(个体学习器间不存在强依赖关系、可同时生成的并行化方法) 流行版本:随机森林(random forest)Boosting(个体…...

PeopleCode中Date函数的用法
语法 Date(date_num) 描述 The Date function takes a number in the form YYYYMMDD and returns a corresponding Date value. If the date is invalid, Date displays an error message. Date函数输入是一个形如“YYYYMMDD”的数字,返回一个相应的Date类型的值…...

解决 el-tree setChecked 方法偶尔失效的方法
目前在大多数公司中,菜单的权限控制都是不可或缺的功能 在和后端配合做权限控制的时候不可避免的会用到 el-tree 然而这个组件本身带的坑不少 我们需要回显对应角色拥有的菜单,在不严格的模式下,父节点的选中会连带子节点的选中 如果 &a…...
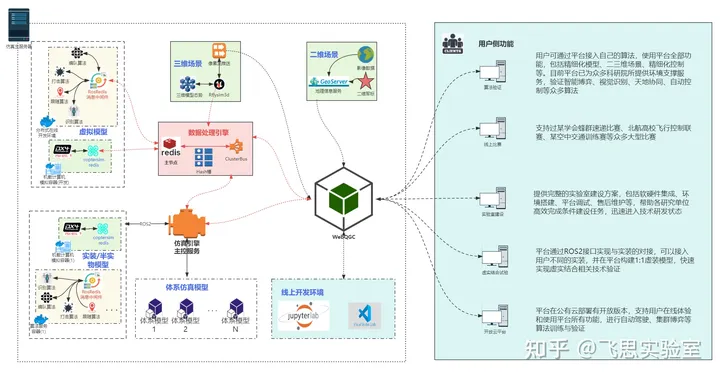
重磅发布!RflySim Cloud 智能算法云仿真平台亮相,助力大规模集群算法高效训练
RflySim Cloud智能算法云仿真平台(以下简称RflySim Cloud平台)是由卓翼智能及飞思实验室为无人平台集群算法验证、大规模博弈对抗仿真、人工智能模型训练等前沿研究领域研发的平台。主要由环境仿真模块、物理效应计算模块、多智能体仿真模块、分布式网络…...
C++ 01.学习C++的意义-狄泰软件学院
一些历史 UNIX操作系统诞生之初是用汇编语言编写的随着UNIX系统的发展,汇编语言的开发效率成为瓶颈,所以需要一个新的语言替代汇编语言1971年通过对B语言改良,使其能直接产生机器代码,C语言诞生UNIX使用C语言重写,同时…...

微软正式发布开源应用平台 Radius平台
“ 10 月 18 日,微软 Azure 孵化团队正式发布开源应用平台 Radius,该平台将应用程序置于每个开发阶段的中心,重新定义应用程序的构建、管理与理解方式。” 简单的概括就是,它和Kubernetes不一样,Radius将应用程序放在每…...
)
排序算法(python)
排序算法 冒泡排序 一次比较相邻的两个数,每轮之后末尾的数字是确定的。 时间复杂度为 O ( n 2 ) O(n^2) O(n2),空间复杂度为 O ( 1 ) O(1) O(1),稳定。 def BUB(nums):for i in range(len(nums)):count 0for j in range(len(nums)-i-1)…...
一款简单漂亮的WPF UI - AduSkin
前言 经常会有同学会问,有没有好看简单的WPF UI库推荐的。今天就给大家推荐一款简单漂亮的WPF UI,融合多个开源框架组件:AduSkin。 WPF是什么? WPF 是一个强大的桌面应用程序框架,用于构建具有丰富用户界面的 Windo…...
)
Java面试题-Java核心基础-第七天(String)
目录 一、String、StringBuffer、StringBuilder的区别 二、String为什么是不可变的 三、字符串拼接用""还是用StringBuilder 四、String 中的equals和Object中的equals的区别 五、字符串常量池的作用了解吗? 六、String s1 new String("abc&qu…...

路飞项目多方式登录、手机号短信验证注册接口
登录注册页面分析 用户板块需要写的接口 用户名密码登录(多方式登录)获取手机验证码接口手机号验证码登录注册接口验证手机号是否存在接口 验证手机号是否存在 视图类 from rest_framework.viewsets import ViewSet from rest_framework.decorator…...

信息学奥赛一本通-编程启蒙3003:练2.1 春节快乐
3003:练2.1 春节快乐 时间限制: 1000 ms 内存限制: 65536 KB 提交数: 10805 通过数: 7830 【题目描述】 一年一度的春节到啦!试着把你的春节祝福表达在代码中吧。 【输入】 无 【输出】 输出一行"Happy Spring Festival!" 【输入…...
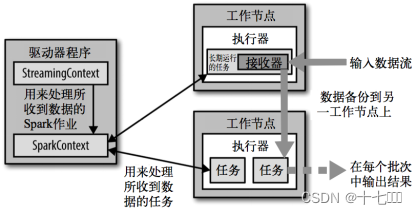
SparkStreaming入门
概述 实时/离线 实时:Spark是每个3秒或者5秒更新一下处理后的数据,这个是按照时间切分的伪实时。真正的实时是根据事件触发的数据计算,处理精度达到ms级别。离线:数据是落盘后再处理,一般处理的数据是昨天的数据&…...
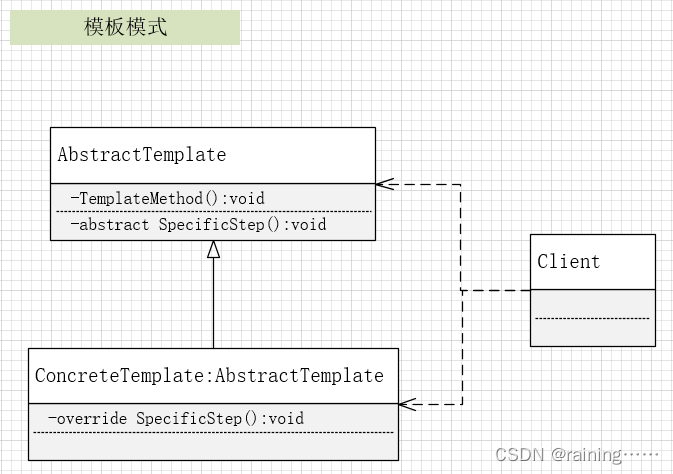
设计模式:模板模式(C#、JAVA、JavaScript、C++、Python、Go、PHP)
简介: 模板模式,它是一种行为型设计模式,它定义了一个操作中的算法的框架,将一些步骤延迟到子类中实现,使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。 通俗地说,模板模式就是将某一行…...
基于Java的图书商城管理系统设计与实现(源码+lw+部署文档+讲解等)
文章目录 前言具体实现截图论文参考详细视频演示为什么选择我自己的网站自己的小程序(小蔡coding) 代码参考数据库参考源码获取 前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作者&am…...
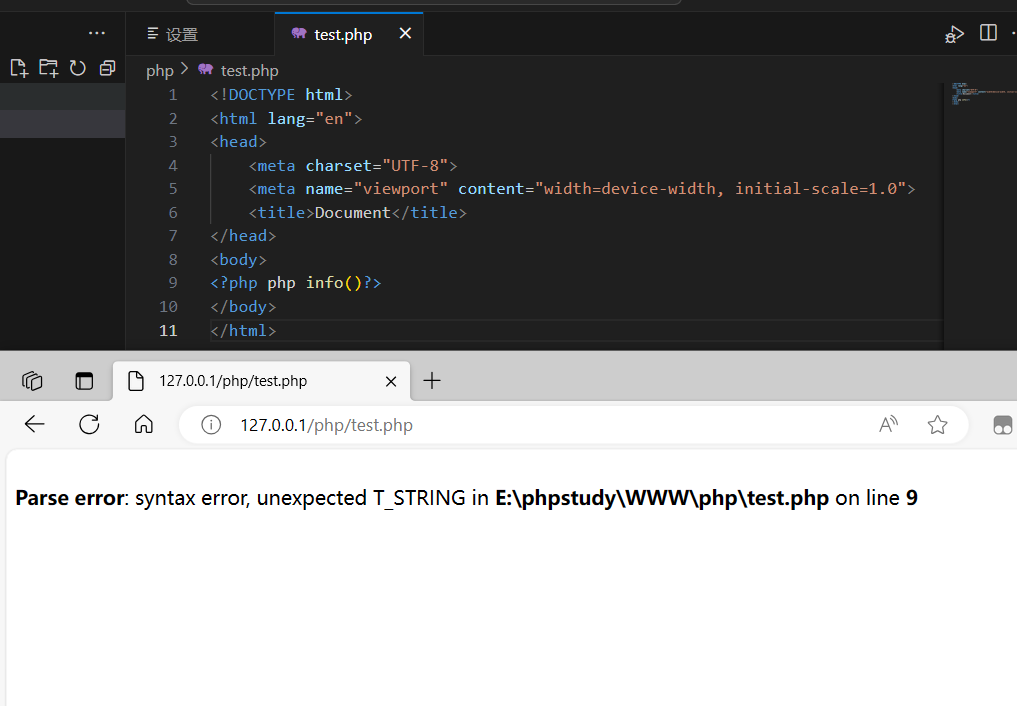
PHP 基础
PHP 基础 概述 在PHP 文件中,可以与HTML 和JavaScript 混编。 开始标记<?php 表示进入PHP 模式,结束标记?>,标识退出PHP 模式。 PHP 模式之外的内容会被作为字符输出到浏览器中。 PHP 在服务端执行,HTML 和 JS 在浏览…...
)
Java RestTemplate使用TLS1.0(关闭SSL验证)
1. 问题 使用RestTemplate调用Http API时,服务器是TLS1.0,但是客户端Java默认禁止TLS1.0,会报错:org.springframework.web.client.ResourceAccessException: I/O error on POST request for “https://10.255.200.114/health”: …...
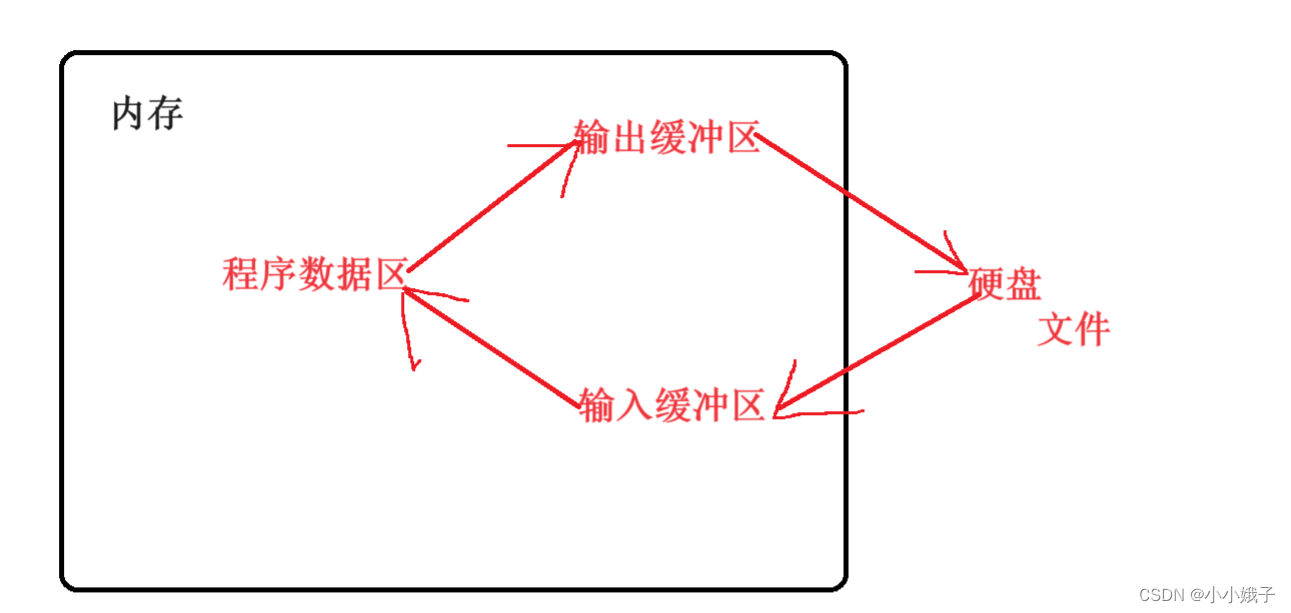
【进阶C语言】C语言文件操作
1. 为什么使用文件 2. 什么是文件 3. 文件的打开和关闭 4. 文件的顺序读写 5. 文件的随机读写 6. 文本文件和二进制文件 7. 文件读取结束的判定 8. 文件缓冲区 一、文件与文件的意义 1.文件的意义 文件的意义,无非就是为什么要使用文件? (1&…...
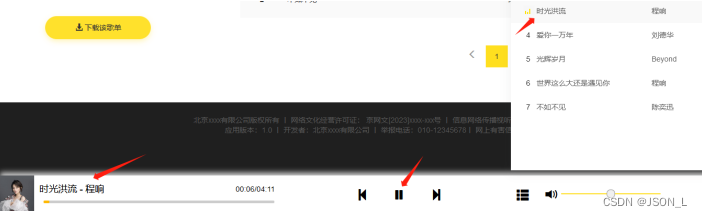
Django实现音乐网站 (21)
使用Python Django框架做一个音乐网站, 本篇音乐播放器功能完善及原有功能修改。 目录 播放列表修改 视图修改 删除、清空播放器 设置路由 视图处理 修改加载播放器脚本 模板修改 脚本设置 清空功能实现 删除列表音乐 播放列表无数据处理 视图修改 播放…...

LeetCode 面试题 10.11. 峰与谷
文章目录 一、题目二、C# 题解 一、题目 在一个整数数组中,“峰”是大于或等于相邻整数的元素,相应地,“谷”是小于或等于相邻整数的元素。例如,在数组{5, 8, 4, 2, 3, 4, 6}中,{8, 6}是峰, {5, 2}是谷。现…...
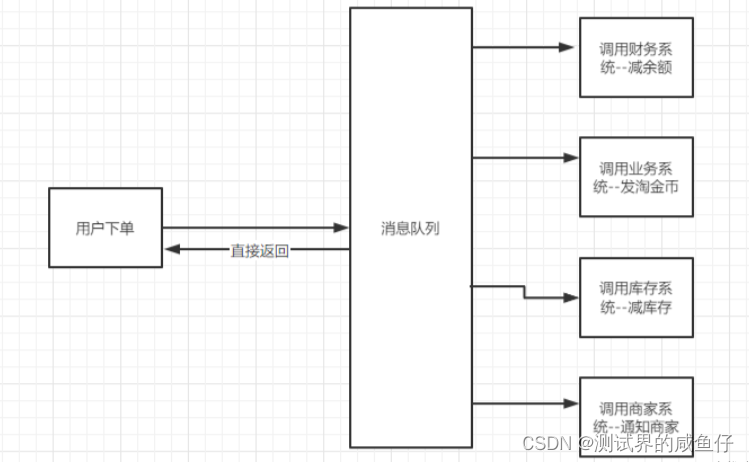
【专题】测试人员为什么需要学会做业务总结?
背景 如何回答以下这个问题的知识支撑:系统的测试重点在哪,难点是什么,怎么攻克,为什么要这样设计?项目交接效率? 同样是做业务测试,为什么有的人是A有的人只能C 二、框架 2.1 测试场景 重点…...

DeepSeek V4 刚刚发布!我第一时间体验了:百万上下文+双SDK兼容,API调用实战
DeepSeek V4 刚刚发布!我第一时间体验了:百万上下文双SDK兼容,API调用实战 📅 2026年4月24日 DeepSeek 正式发布 V4 预览版,全系标配百万上下文,同时兼容 OpenAI 和 Anthropic 双 SDK 格式。本文带你快速上…...

StarRailCopilot终极指南:专业级崩坏星穹铁道自动化脚本解决方案
StarRailCopilot终极指南:专业级崩坏星穹铁道自动化脚本解决方案 【免费下载链接】StarRailCopilot 崩坏:星穹铁道脚本 | Honkai: Star Rail auto bot (简体中文/繁體中文/English/Espaol) 项目地址: https://gitcode.com/gh_mirrors/st/StarRailCopil…...

C# WinForm 工作流设计 工作流程图拖拽设计 +GDI 绘制工作流程图 大概功能说明一...
C# WinForm 工作流设计 工作流程图拖拽设计 GDI 绘制工作流程图 大概功能说明一下:1.支持拖动绘制工作节点2.支持移动每个节点的移动3.支持直线连接节点4.支持节点移动连接线自动跟随5.支持高亮显示选中的节点连线6.支持能删除选中节点和连线7.支持选中节点能显示节…...

终极指南:解决AeroSpace终端窗口尺寸异常的完整方案
终极指南:解决AeroSpace终端窗口尺寸异常的完整方案 【免费下载链接】AeroSpace AeroSpace is an i3-like tiling window manager for macOS 项目地址: https://gitcode.com/GitHub_Trending/ae/AeroSpace AeroSpace是一款为macOS设计的i3-like平铺窗口管理器…...

智能座舱电机的振动噪声研究
智能座舱电机的振动噪声研究 摘要: 随着汽车电动化与智能化进程的加速,智能座舱中的微型驱动电机(座椅调节电机、空调鼓风机电机、屏幕升降电机、HUD调节电机等)在运行过程中产生的振动与噪声问题日益突出,直接影响用户的驾乘舒适性与品牌感知。本文围绕智能座舱电机的振…...

MarkDown时序图进阶:巧用并行、条件与循环构建复杂交互逻辑
1. Markdown时序图的核心价值与应用场景 第一次接触Markdown时序图时,我被它的简洁性惊艳到了。相比传统UML工具繁琐的拖拽操作,用几行文本就能描述复杂的系统交互,这简直就是程序员的福音。在实际项目中,我经常用它来梳理微服务间…...

BsMax深度解析:Blender插件架构与3ds Max工作流迁移的技术实现
BsMax深度解析:Blender插件架构与3ds Max工作流迁移的技术实现 【免费下载链接】BsMax BsMax Blender Addon (UI simulator/ Modeling/ Rigg & Animation/ Render Tools and ... 项目地址: https://gitcode.com/gh_mirrors/bs/BsMax BsMax作为Blender生态…...

如何掌握Python元编程与装饰器:从入门到精通的终极指南
如何掌握Python元编程与装饰器:从入门到精通的终极指南 【免费下载链接】python-guide Python best practices guidebook, written for humans. 项目地址: https://gitcode.com/gh_mirrors/py/python-guide Python作为一门灵活且强大的编程语言,…...

TypeScript | 为什么是TypeScript成为了时代的选择?
在软件工程的历史长河中,编程语言的兴衰更迭如同潮起潮落。有的语言凭借其开创性的理念昙花一现,有的则因其强大的生态和社区支持而历久弥新。进入2026年,我们正见证着一场深刻的范式转移:TypeScript 已从一个“可选项”演变为构建…...

全志A40i开发板USB-WiFi踩坑记:RTL8188FTV/FU驱动编译与配置保姆级教程
全志A40i开发板USB-WiFi实战:RTL8188FTV/FU驱动深度适配与网络优化指南 当嵌入式开发者拿到一块全志A40i开发板时,最常遇到的挑战之一就是外设驱动的适配问题。USB-WiFi模块作为物联网设备的关键组件,其驱动稳定性直接影响产品体验。本文将聚…...