【MySql】8- 实践篇(六)
文章目录
- 1. MySql保证主备一致
- 1.1 MySQL 主备的基本原理
- 1.2 binlog 的三种格式对比
- 1.3 循环复制问题
- 2. MySql保证高可用
- 2.1 主备延迟
- 2.2 主备延迟的来源
- 2.3 可靠性优先策略
- 2.4 可用性优先策略
- 3. 备库为何会延迟很久-备库并行复制能力
- 3.1 MySQL 5.6 版本的并行复制策略
- 3.2 MariaDB 的并行复制策略
- 3.3 MySQL 5.7 的并行复制策略
- 3.4 MySQL 5.7.22 的并行复制策略
1. MySql保证主备一致
binlog 可以用来归档,也可以用来做主备同步,但它的内容是什么样的呢?
为什么备库执行了 binlog 就可以跟主库保持一致了呢?
1.1 MySQL 主备的基本原理
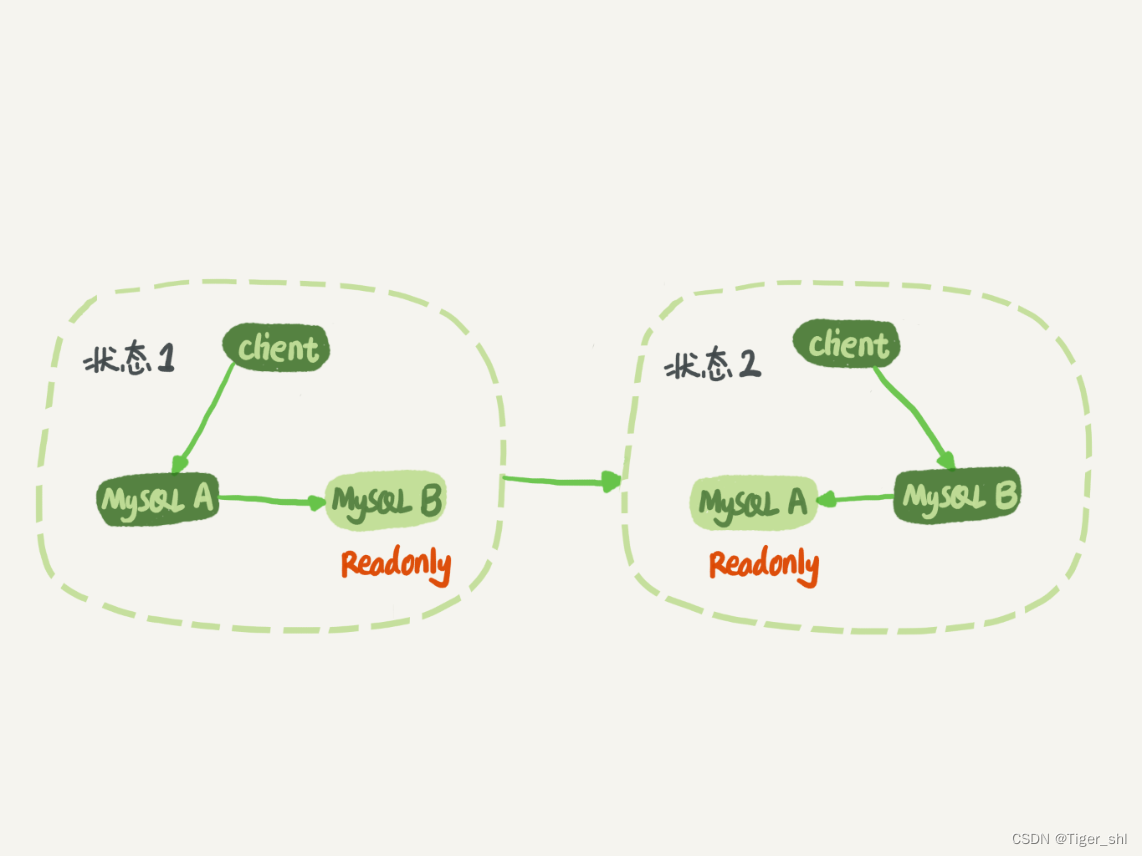
图 1 MySQL 主备切换流程
-
在状态 1 中,客户端的读写都直接访问节点 A,而节点 B 是 A 的备库,只是将 A 的更新都同步过来,到本地执行。这样可以保持节点 B 和 A 的数据是相同的。
-
当需要切换的时候,就切成状态 2。这时候客户端读写访问的都是节点 B,而节点 A 是 B 的备库。
在状态 1 中,虽然节点 B 没有被直接访问,但是依然建议你把节点 B(也就是备库)设置成只读(readonly)模式。原因如下:
- 有时候一些运营类的查询语句会被放到备库上去查,设置为只读可以防止误操作;
- 防止切换逻辑有 bug,比如切换过程中出现双写,造成主备不一致;
- 可以用 readonly 状态,来判断节点的角色。
readonly 设置对超级 (super) 权限用户是无效的,而用于同步更新的线程,就拥有超级权限。
节点 A 到 B 这条线的内部流程是什么样的。
图 2 中画出的就是一个 update 语句在节点 A 执行,然后同步到节点 B 的完整流程图。
图 2 主备流程图
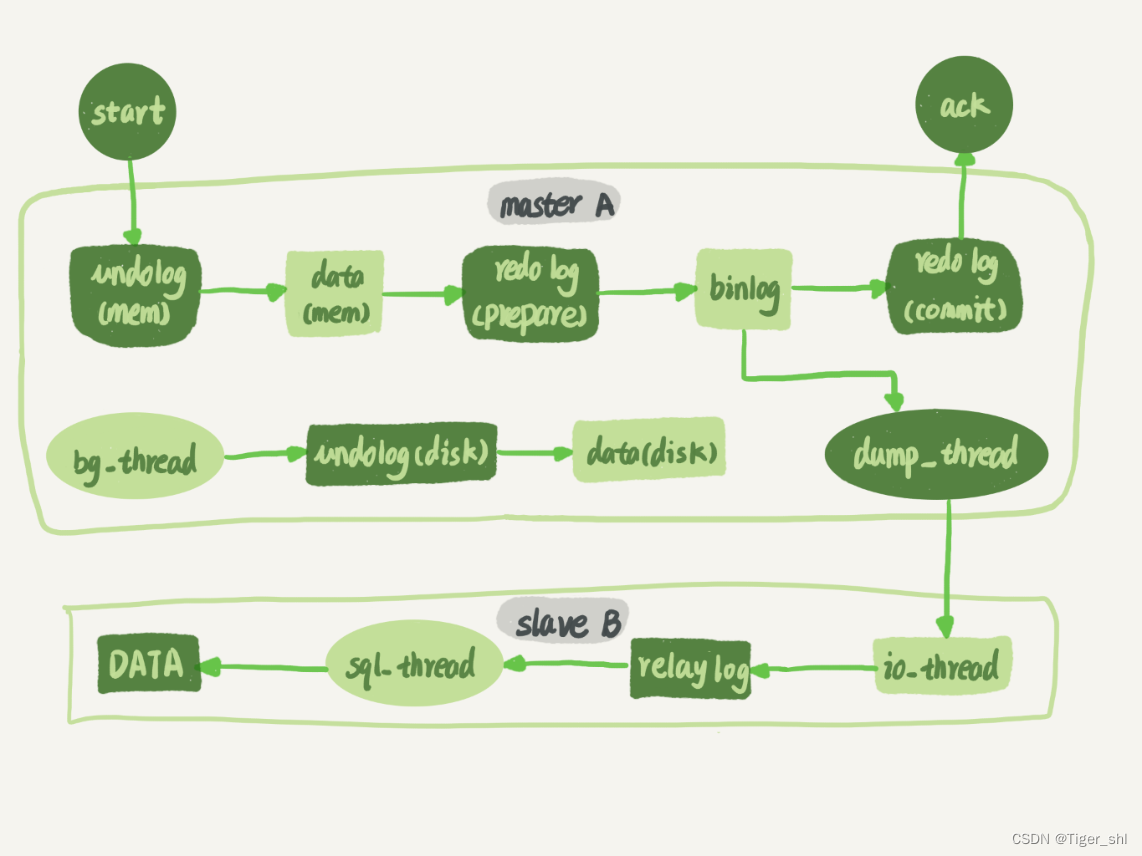
可以看到:主库接收到客户端的更新请求后,执行内部事务的更新逻辑,同时写 binlog。
备库 B 跟主库 A 之间维持了一个长连接。主库 A 内部有一个线程,专门用于服务备库 B 的这个长连接。
一个事务日志同步的完整过程是这样的:
- 在备库 B 上通过 change master 命令,设置主库 A 的 IP、端口、用户名、密码,以及要从哪个位置开始请求 binlog,这个位置包含文件名和日志偏移量。
- 在备库 B 上执行 start slave 命令,这时候备库会启动两个线程,就是图中的 io_thread 和 sql_thread。其中 io_thread 负责与主库建立连接。
- 主库 A 校验完用户名、密码后,开始按照备库 B 传过来的位置,从本地读取 binlog,发给 B。
- 备库 B 拿到 binlog 后,写到本地文件,称为中转日志(relay log)。
- sql_thread 读取中转日志,解析出日志里的命令,并执行。
1.2 binlog 的三种格式对比
binlog三种格式
- statement
- row
- mixed
为了便于描述 binlog 的这三种格式间的区别,我创建了一个表,并初始化几行数据。
mysql> CREATE TABLE `t` (`id` int(11) NOT NULL,`a` int(11) DEFAULT NULL,`t_modified` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,PRIMARY KEY (`id`),KEY `a` (`a`),KEY `t_modified`(`t_modified`)
) ENGINE=InnoDB;insert into t values(1,1,'2018-11-13');
insert into t values(2,2,'2018-11-12');
insert into t values(3,3,'2018-11-11');
insert into t values(4,4,'2018-11-10');
insert into t values(5,5,'2018-11-09');
在表中删除一行数据的话,来看看这个 delete 语句的 binlog 是怎么记录的。
-- 这个语句包含注释,如果你用 MySQL 客户端来做这个实验的话,要记得加 -c 参数,否则客户端会自动去掉注释。
mysql> delete from t /*comment*/ where a>=4 and t_modified<='2018-11-10' limit 1;
当 binlog_format=statement 时,
binlog 里面记录的就是 SQL 语句的原文。可以用下列语句查看binlog内容
mysql> show binlog events in 'master.000001';
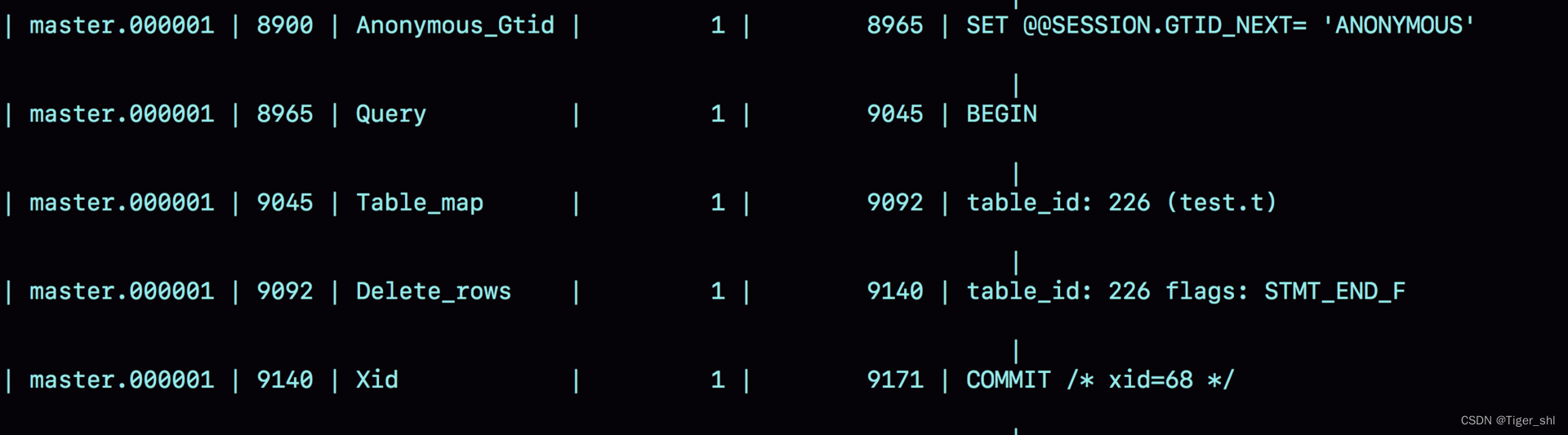
图 3 statement 格式 binlog 示例

图 3 的输出结果
- 第一行 SET @@SESSION.GTID_NEXT='ANONYMOUS’可以先忽略,是主备切换内容;
- 第二行是一个 BEGIN,跟第四行的 commit 对应,表示中间是一个事务;
- 第三行就是真实执行的语句了。可以看到,在真实执行的 delete 命令之前,还有一个“use ‘test’”命令。这条命令不是我们主动执行的,而是 MySQL 根据当前要操作的表所在的数据库,自行添加的。这样做可以保证日志传到备库去执行的时候,不论当前的工作线程在哪个库里,都能够正确地更新到 test 库的表 t。use 'test’命令之后的 delete 语句,就是我们输入的 SQL 原文了。可以看到,binlog“忠实”地记录了 SQL 命令,甚至连注释也一并记录了。
- 最后一行是一个 COMMIT。可以看到里面写着 xid=61。
为了说明 statement 和 row 格式的区别,看一下这条 delete 命令的执行效果图:

运行这条 delete 命令产生了一个 warning,原因是当前 binlog 设置的是 statement 格式,并且语句中有 limit,所以这个命令可能是 unsafe 的。
这是因为 delete 带 limit,很可能会出现主备数据不一致的情况:
- 如果 delete 语句使用的是索引 a,那么会根据索引 a 找到第一个满足条件的行,也就是说删除的是 a=4 这一行;
- 但如果使用的是索引 t_modified,那么删除的就是 t_modified='2018-11-09’也就是 a=5 这一行。
由于 statement 格式下,记录到 binlog 里的是语句原文,因此可能会出现这样一种情况:
在主库执行这条 SQL 语句的时候,用的是索引 a;而在备库执行这条 SQL 语句的时候,却使用了索引 t_modified。因此,MySQL 认为这样写是有风险的。
** binlog 的格式改为 binlog_format=‘row’**
图 5 row 格式 binlog 示例
与 statement 格式的 binlog 相比,前后的 BEGIN 和 COMMIT 是一样的。
但是,row 格式的 binlog 里没有了 SQL 语句的原文,而是替换成了两个 event:Table_map 和 Delete_rows。
- Table_map event,用于说明接下来要操作的表是 test 库的表 t;
- Delete_rows event,用于定义删除的行为。
通过图 5 是看不到详细信息的,还需要借助 mysqlbinlog 工具,用下面这个命令解析和查看 binlog 中的内容
mysqlbinlog -vv data/master.000001 --start-position=8900;
图 6 row 格式 binlog 示例的详细信息
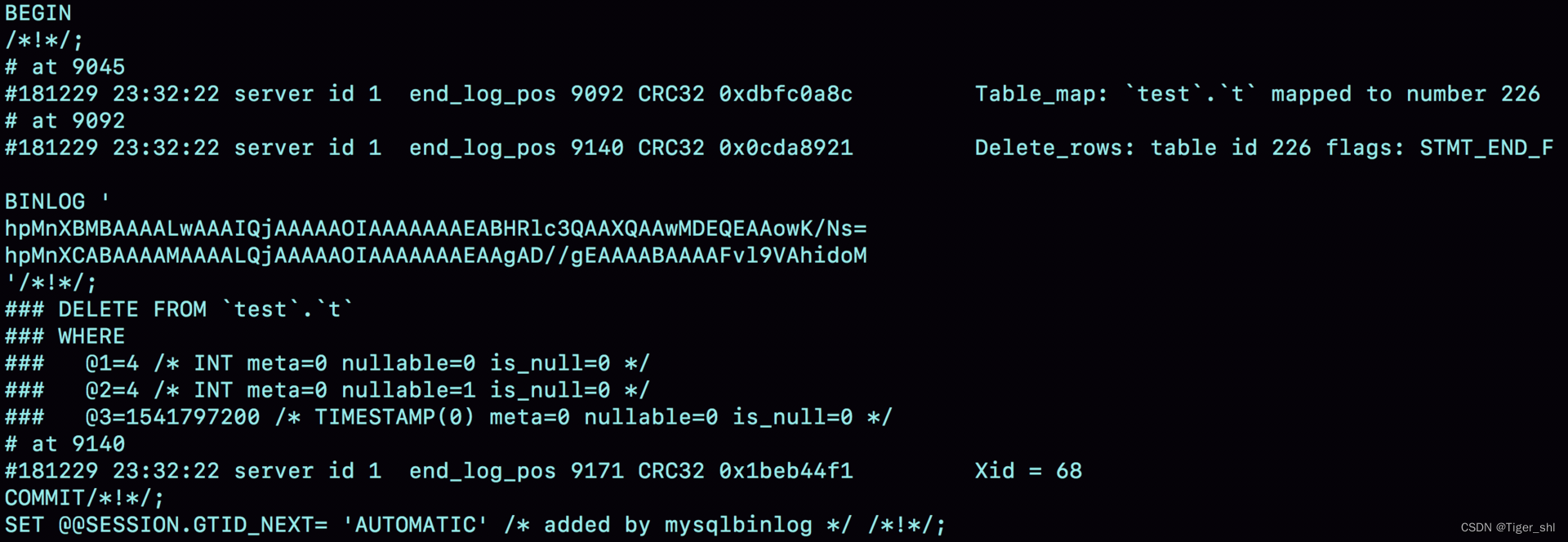
从这个图中,可以看到以下信息:
- server id 1,表示这个事务是在 server_id=1 的这个库上执行的。
- 每个 event 都有 CRC32 的值,这是因为参数 binlog_checksum 设置成了 CRC32。
- Table_map event 跟在图 5 中看到的相同,显示了接下来要打开的表,map 到数字 226。现在我们这条 SQL 语句只操作了一张表,如果要操作多张表呢?每个表都有一个对应的 Table_map event、都会 map 到一个单独的数字,用于区分对不同表的操作。
- 在 mysqlbinlog 的命令中,使用了 -vv 参数是为了把内容都解析出来,所以从结果里面可以看到各个字段的值(比如,@1=4、 @2=4 这些值)。
- binlog_row_image 的默认配置是 FULL,因此 Delete_event 里面,包含了删掉的行的所有字段的值。如果把 binlog_row_image 设置为 MINIMAL,则只会记录必要的信息,在这个例子里,就是只会记录 id=4 这个信息。
- 最后的 Xid event,用于表示事务被正确地提交了。
当 binlog_format 使用 row 格式的时候,binlog 里面记录了真实删除行的主键 id,这样 binlog 传到备库去的时候,就肯定会删除 id=4 的行,不会有主备删除不同行的问题。
为什么会有 mixed 格式的 binlog?
推论过程是这样的:
- 因为有些 statement 格式的 binlog 可能会导致主备不一致,所以要使用 row 格式。
- 但 row 格式的缺点是,很占空间。比如你用一个 delete 语句删掉 10 万行数据,用 statement 的话就是一个 SQL 语句被记录到 binlog 中,占用几十个字节的空间。但如果用 row 格式的 binlog,就要把这 10 万条记录都写到 binlog 中。这样做,不仅会占用更大的空间,同时写 binlog 也要耗费 IO 资源,影响执行速度。
- 所以,MySQL 就取了个折中方案,也就是有了 mixed 格式的 binlog。mixed 格式的意思是,MySQL 自己会判断这条 SQL 语句是否可能引起主备不一致,如果有可能,就用 row 格式,否则就用 statement 格式。
mixed 格式可以利用 statment 格式的优点,同时又避免了数据不一致的风险。
越来越多的场景要求把 MySQL 的 binlog 格式设置成 row。这么做的理由有很多,我来给你举一个可以直接看出来的好处:恢复数据
分别从 delete、insert 和 update 这三种 SQL 语句的角度,来看看数据恢复的问题。
通过图 6 可以看出来,即使执行的是 delete 语句,row 格式的 binlog 也会把被删掉的行的整行信息保存起来。所以,如果在执行完一条 delete 语句以后,发现删错数据了,可以直接把 binlog 中记录的 delete 语句转成 insert,把被错删的数据插入回去就可以恢复了。
如果是执行错了 insert 语句呢?那就更直接了。row 格式下,insert 语句的 binlog 里会记录所有的字段信息,这些信息可以用来精确定位刚刚被插入的那一行。这时,直接把 insert 语句转成 delete 语句,删除掉这被误插入的一行数据就可以了。
如果执行的是 update 语句的话,binlog 里面会记录修改前整行的数据和修改后的整行数据。所以,如果误执行了 update 语句的话,只需要把这个 event 前后的两行信息对调一下,再去数据库里面执行,就能恢复这个更新操作了。
mysql> insert into t values(10,10, now());
上面的SQL,如果把 binlog 格式设置为 mixed,MySQL 会把它记录为 row 格式还是 statement 格式呢?
图 7 mixed 格式和 now()

可以看到,MySQL 用的居然是 statement 格式。如果这个 binlog 过了 1 分钟才传给备库的话,那主备的数据不就不一致了吗?
用 mysqlbinlog 工具来看看:
图 8 TIMESTAMP 命令

原来 binlog 在记录 event 的时候,多记了一条命令:SET TIMESTAMP=1546103491。它用 SET TIMESTAMP 命令约定了接下来的 now() 函数的返回时间。不论这个 binlog 是 1 分钟之后被备库执行,还是 3 天后用来恢复这个库的备份,这个 insert 语句插入的行,值都是固定的
用 binlog 来恢复数据的标准做法是,用 mysqlbinlog 工具解析出来,然后把解析结果整个发给 MySQL 执行。类似下面的命令:
mysqlbinlog master.000001 --start-position=2738 --stop-position=2973 | mysql -h127.0.0.1 -P13000 -u$user -p$pwd;
这个命令的意思是,将 master.000001 文件里面从第 2738 字节到第 2973 字节中间这段内容解析出来,放到 MySQL 去执行。
1.3 循环复制问题
图 9 MySQL 主备切换流程 – 双 M 结构
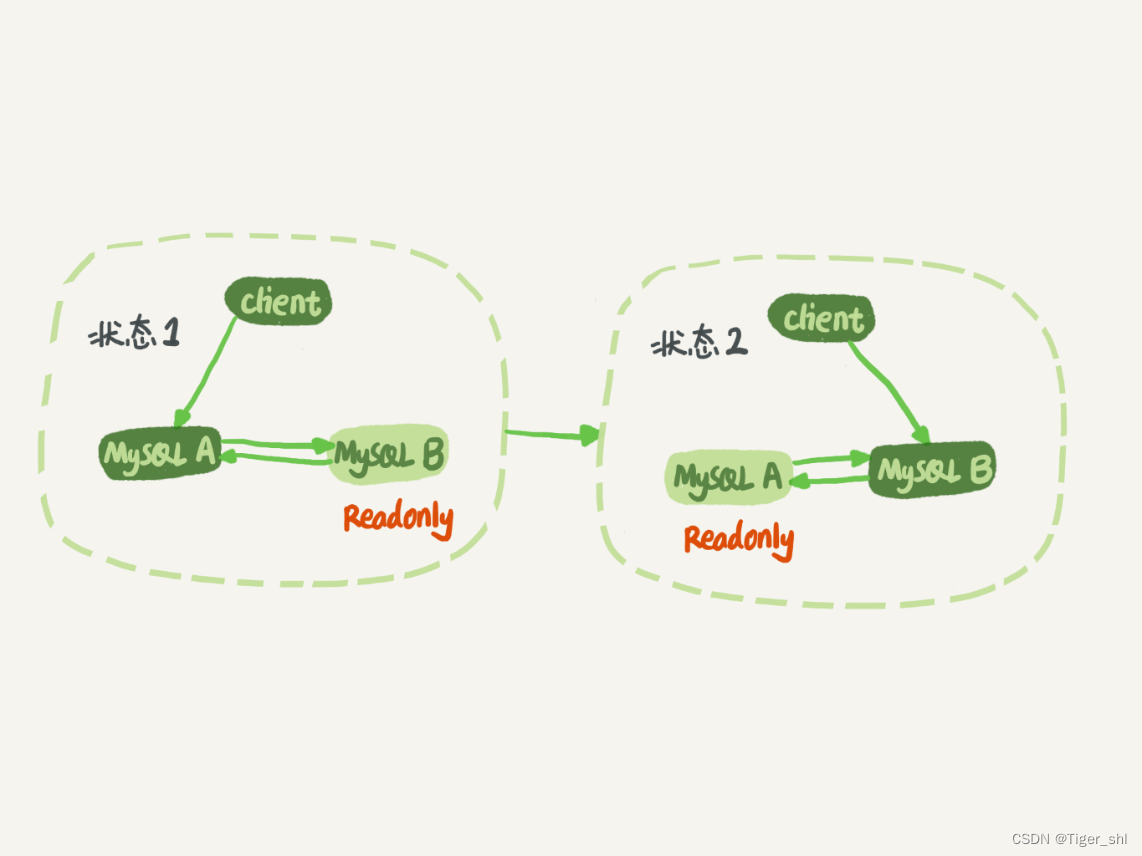
对比图 9 和图 1,可以发现,双 M 结构和 M-S 结构,其实区别只是多了一条线,
即:节点 A 和 B 之间总是互为主备关系。这样在切换的时候就不用再修改主备关系。
问题
业务逻辑在节点 A 上更新了一条语句,然后再把生成的 binlog 发给节点 B,节点 B 执行完这条更新语句后也会生成 binlog。(建议你把参数 log_slave_updates 设置为 on,表示备库执行 relay log 后生成 binlog)。
那么,如果节点 A 同时是节点 B 的备库,相当于又把节点 B 新生成的 binlog 拿过来执行了一次,然后节点 A 和 B 间,会不断地循环执行这个更新语句,也就是循环复制了。这个要怎么解决呢?
MySQL 在 binlog 中记录了这个命令第一次执行时所在实例的 server id。
因此,我们可以用下面的逻辑,来解决两个节点间的循环复制的问题:
- 规定两个库的 server id 必须不同,如果相同,则它们之间不能设定为主备关系;
- 一个备库接到 binlog 并在重放的过程中,生成与原 binlog 的 server id 相同的新的 binlog;
- 每个库在收到从自己的主库发过来的日志后,先判断 server id,如果跟自己的相同,表示这个日志是自己生成的,就直接丢弃这个日志。
2. MySql保证高可用
图 1 MySQL 主备切换流程 – 双 M 结构
2.1 主备延迟
与数据同步有关的时间点主要包括以下三个:
- 主库 A 执行完成一个事务,写入 binlog,把这个时刻记为 T1;
- 之后传给备库 B,把备库 B 接收完这个 binlog 的时刻记为 T2;
- 备库 B 执行完成这个事务,我们把这个时刻记为 T3。
所谓主备延迟,就是同一个事务,在备库执行完成的时间和主库执行完成的时间之间的差值,也就是 T3-T1
可以在备库上执行 show slave status 命令,它的返回结果里面会显示 seconds_behind_master,用于表示当前备库延迟了多少秒。
seconds_behind_master(精度是秒) 的计算方法是这样的:
- 每个事务的 binlog 里面都有一个时间字段,用于记录主库上写入的时间;
- 备库取出当前正在执行的事务的时间字段的值,计算它与当前系统时间的差值,得到 seconds_behind_master。
如果主备库机器的系统时间设置不一致,会不会导致主备延迟的值不准?
不会的。因为,备库连接到主库的时候,会通过执行 SELECT UNIX_TIMESTAMP() 函数来获得当前主库的系统时间。如果这时候发现主库的系统时间与自己不一致,备库在执行 seconds_behind_master 计算的时候会自动扣掉这个差值。
在网络正常的时候,日志从主库传给备库所需的时间是很短的,即 T2-T1 的值是非常小的。也就是说,网络正常情况下,主备延迟的主要来源是备库接收完 binlog 和执行完这个事务之间的时间差。
所以说,主备延迟最直接的表现是,备库消费中转日志(relay log)的速度,比主库生产 binlog 的速度要慢。
2.2 主备延迟的来源
首先,有些部署条件下,备库所在机器的性能要比主库所在的机器性能差。
更新请求对 IOPS 的压力,在主库和备库上是无差别的。所以,做这种部署时,一般都会将备库设置为“非双 1”的模式。
实际上,更新过程中也会触发大量的读操作。所以,当备库主机上的多个备库都在争抢资源的时候,就可能会导致主备延迟了
因为主备可能发生切换,备库随时可能变成主库,所以主备库选用相同规格的机器,并且做对称部署,是现在比较常见的情况。
问题1:做了对称部署以后,还可能会有延迟。这是为什么呢?
备库的压力大。一般的想法是,主库既然提供了写能力,那么备库可以提供一些读能力。或者一些运营后台需要的分析语句,不能影响正常业务,所以只能在备库上跑。反而忽视了备库的压力控制。结果就是,备库上的查询耗费了大量的 CPU 资源,影响了同步速度,造成主备延迟。
处理
- 一主多从。除了备库外,可以多接几个从库,让这些从库来分担读的压力。(一般采用这种方式)
- 通过 binlog 输出到外部系统,比如 Hadoop 这类系统,让外部系统提供统计类查询的能力。
问题2:采用了一主多从,保证备库的压力不会超过主库,还有什么情况可能导致主备延迟吗?
- 大事务。因为主库上必须等事务执行完成才会写入 binlog,再传给备库。所以,如果一个主库上的语句执行 10 分钟,那这个事务很可能就会导致从库延迟 10 分钟。
不要一次性地用 delete 语句删除太多数据。其实,这就是一个典型的大事务场景。- 大表 DDL。处理方案就是,计划内的 DDL,建议使用 gh-ost 方案
问题3:如果主库上也不做大事务了,还有什么原因会导致主备延迟吗?
备库的并行复制能力。
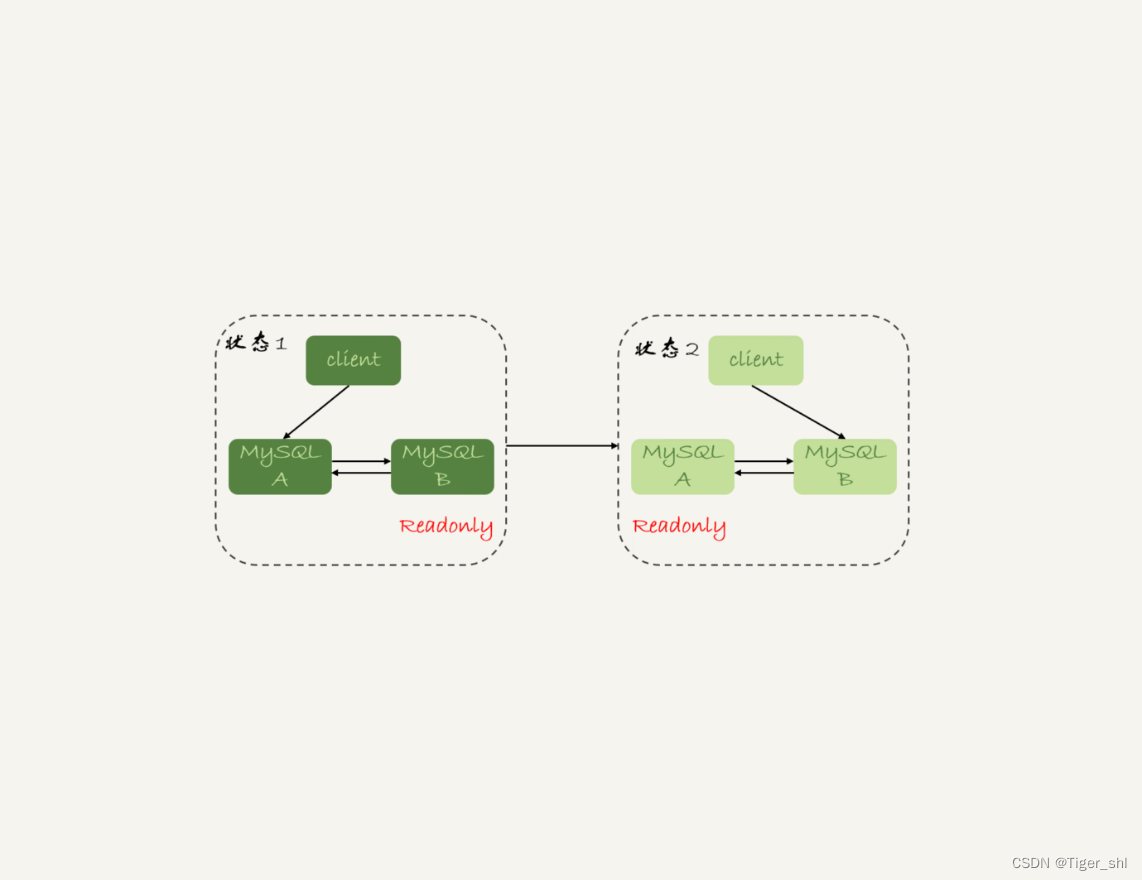
2.3 可靠性优先策略
在图 1 的双 M 结构下,从状态 1 到状态 2 切换的详细过程是这样的:
- 判断备库 B 现在的 seconds_behind_master,如果小于某个值(比如 5 秒)继续下一步,否则持续重试这一步;
- 把主库 A 改成只读状态,即把 readonly 设置为 true;
- 判断备库 B 的 seconds_behind_master 的值,直到这个值变成 0 为止;(较耗时)
- 把备库 B 改成可读写状态,也就是把 readonly 设置为 false;
- 把业务请求切到备库 B。
图 2 MySQL 可靠性优先主备切换流程
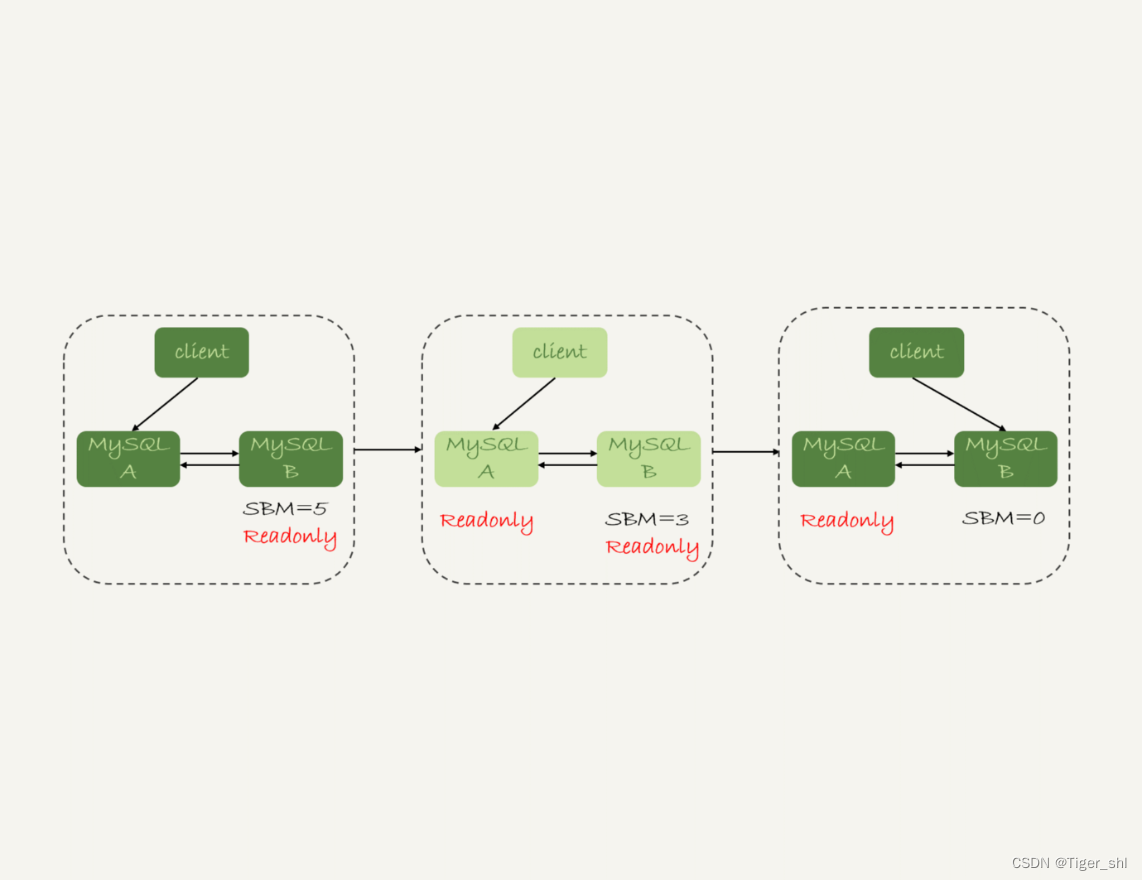
备注:图中的 SBM,是 seconds_behind_master 参数的简写。
这个切换流程中是有不可用时间的。因为在步骤 2 之后,主库 A 和备库 B 都处于 readonly 状态,也就是说这时系统处于不可写状态,直到步骤 5 完成后才能恢复。
系统的不可用时间,是由这个数据可靠性优先的策略决定的。也可以选择可用性优先的策略,来把这个不可用时间几乎降为 0。
2.4 可用性优先策略
如果强行把步骤 4、5 调整到最开始执行,也就是说不等主备数据同步,直接把连接切到备库 B,并且让备库 B 可以读写,那么系统几乎就没有不可用时间了。这个切换流程,暂时称作可用性优先流程。
这个切换流程的代价,就是可能出现数据不一致的情况。
例子
假设有一个表 t:
mysql> CREATE TABLE `t` (`id` int(11) unsigned NOT NULL AUTO_INCREMENT,`c` int(11) unsigned DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB;insert into t(c) values(1),(2),(3);
表定义了一个自增主键 id,初始化数据后,主库和备库上都是 3 行数据。接下来,业务人员要继续在表 t 上执行两条插入语句的命令,依次是:
insert into t(c) values(4);
insert into t(c) values(5);
假设,现在主库上其他的数据表有大量的更新,导致主备延迟达到 5 秒。在插入一条 c=4 的语句后,发起了主备切换。
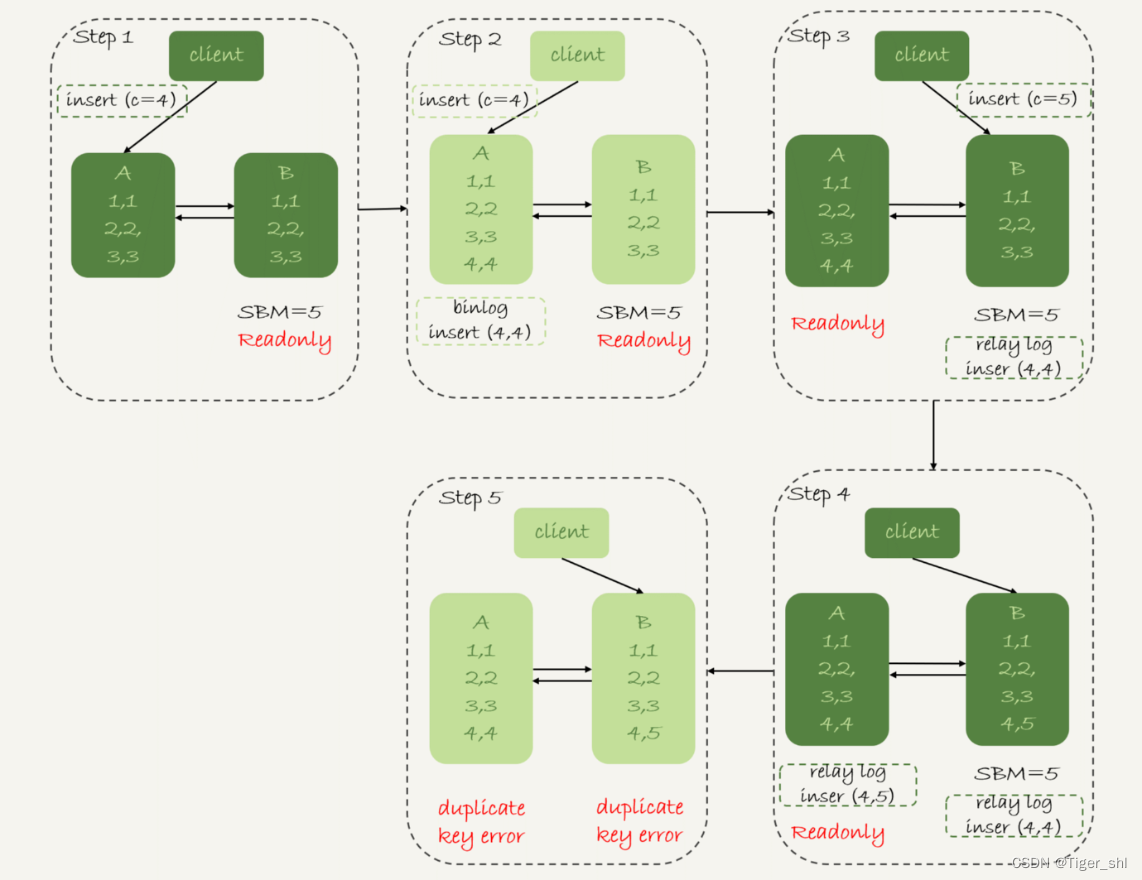
下图是可用性优先策略,且 binlog_format=mixed 时的切换流程和数据结果。
图 3 可用性优先策略,且 binlog_format=mixed
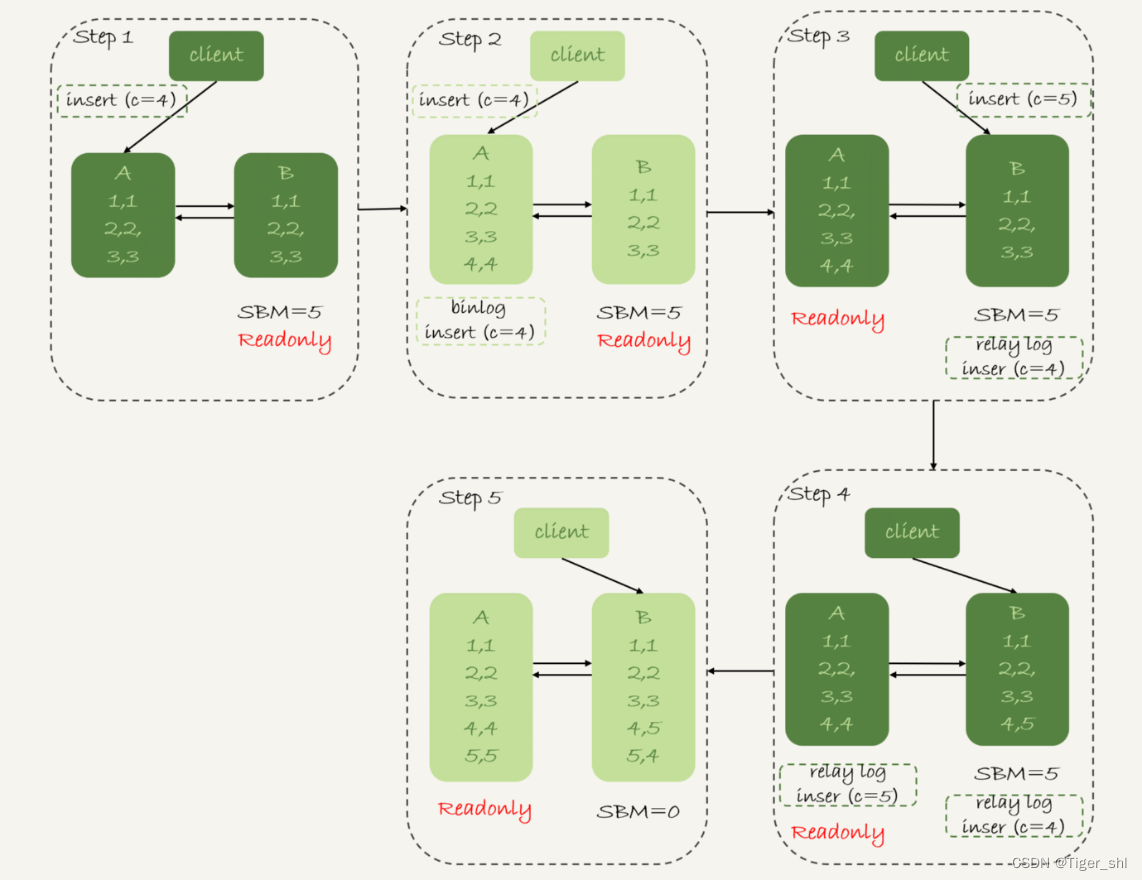
分析下这个切换流程:
- 步骤 2 中,主库 A 执行完 insert 语句,插入了一行数据(4,4),之后开始进行主备切换。
- 步骤 3 中,由于主备之间有 5 秒的延迟,所以备库 B 还没来得及应用“插入 c=4”这个中转日志,就开始接收客户端“插入 c=5”的命令。
- 步骤 4 中,备库 B 插入了一行数据(4,5),并且把这个 binlog 发给主库 A。
- 步骤 5 中,备库 B 执行“插入 c=4”这个中转日志,插入了一行数据(5,4)。而直接在备库 B 执行的“插入 c=5”这个语句,传到主库 A,就插入了一行新数据(5,5)。
最后的结果就是,主库 A 和备库 B 上出现了两行不一致的数据。可以看到,这个数据不一致,是由可用性优先流程导致的。
如果还是用可用性优先策略,但设置 binlog_format=row,情况又会怎样呢?
因为 row 格式在记录 binlog 的时候,会记录新插入的行的所有字段值,所以最后只会有一行不一致。而且,两边的主备同步的应用线程会报错 duplicate key error 并停止。也就是说,这种情况下,备库 B 的 (5,4) 和主库 A 的 (5,5) 这两行数据,都不会被对方执行。
图 4 可用性优先策略,且 binlog_format=row
结论:
- 使用 row 格式的 binlog 时,数据不一致的问题更容易被发现。而使用 mixed 或者 statement 格式的 binlog 时,数据很可能悄悄地就不一致了。如果你过了很久才发现数据不一致的问题,很可能这时的数据不一致已经不可查,或者连带造成了更多的数据逻辑不一致。
- 主备切换的可用性优先策略会导致数据不一致。因此,大多数情况下,都建议使用可靠性优先策略。毕竟对数据服务来说的话,数据的可靠性一般还是要优于可用性的。
按照可靠性优先的思路,异常切换会是什么效果?
假设,主库 A 和备库 B 间的主备延迟是 30 分钟,这时候主库 A 掉电了,HA 系统要切换 B 作为主库。在主动切换的时候,可以等到主备延迟小于 5 秒的时候再启动切换,但这时候已经别无选择了。
图 5 可靠性优先策略,主库不可用
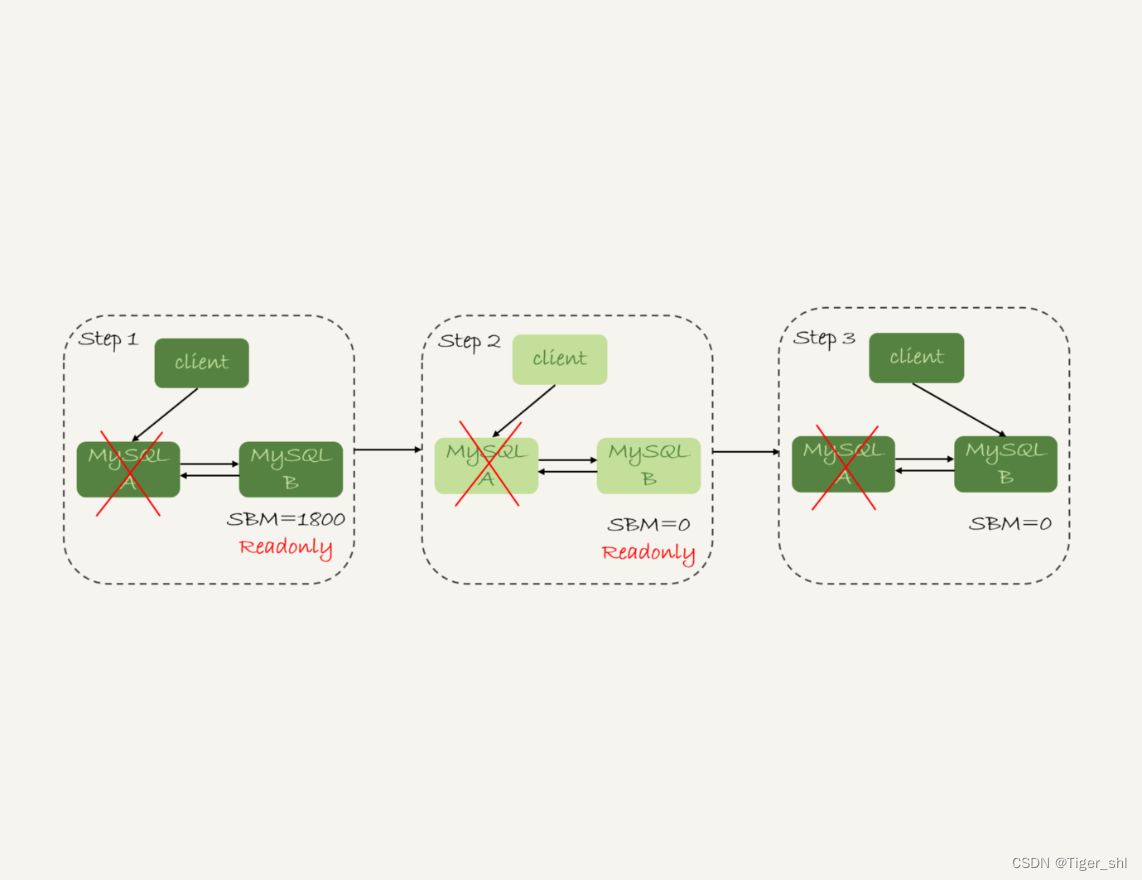
采用可靠性优先策略的话,就必须得等到备库 B 的 seconds_behind_master=0 之后,才能切换。
但现在的情况比刚刚更严重,并不是系统只读、不可写的问题了,而是系统处于完全不可用的状态。因为,主库 A 掉电后,我们的连接还没有切到备库 B。
能不能直接切换到备库 B,但是保持 B 只读呢?
这样也不行。因为,这段时间内,中转日志还没有应用完成,如果直接发起主备切换,客户端查询看不到之前执行完成的事务,会认为有“数据丢失”。虽然随着中转日志的继续应用,这些数据会恢复回来,但是对于一些业务来说,查询到“暂时丢失数据的状态”也是不能被接受的。
在满足数据可靠性的前提下,MySQL 高可用系统的可用性,是依赖于主备延迟的。延迟的时间越小,在主库故障的时候,服务恢复需要的时间就越短,可用性就越高。
思考
一般现在的数据库运维系统都有备库延迟监控,其实就是在备库上执行 show slave status,采集 seconds_behind_master 的值。假设,现在你看到你维护的一个备库,它的延迟监控的图像类似图 6,是一个 45°斜向上的线段,你觉得可能是什么原因导致呢?你又会怎么去确认这个原因呢?
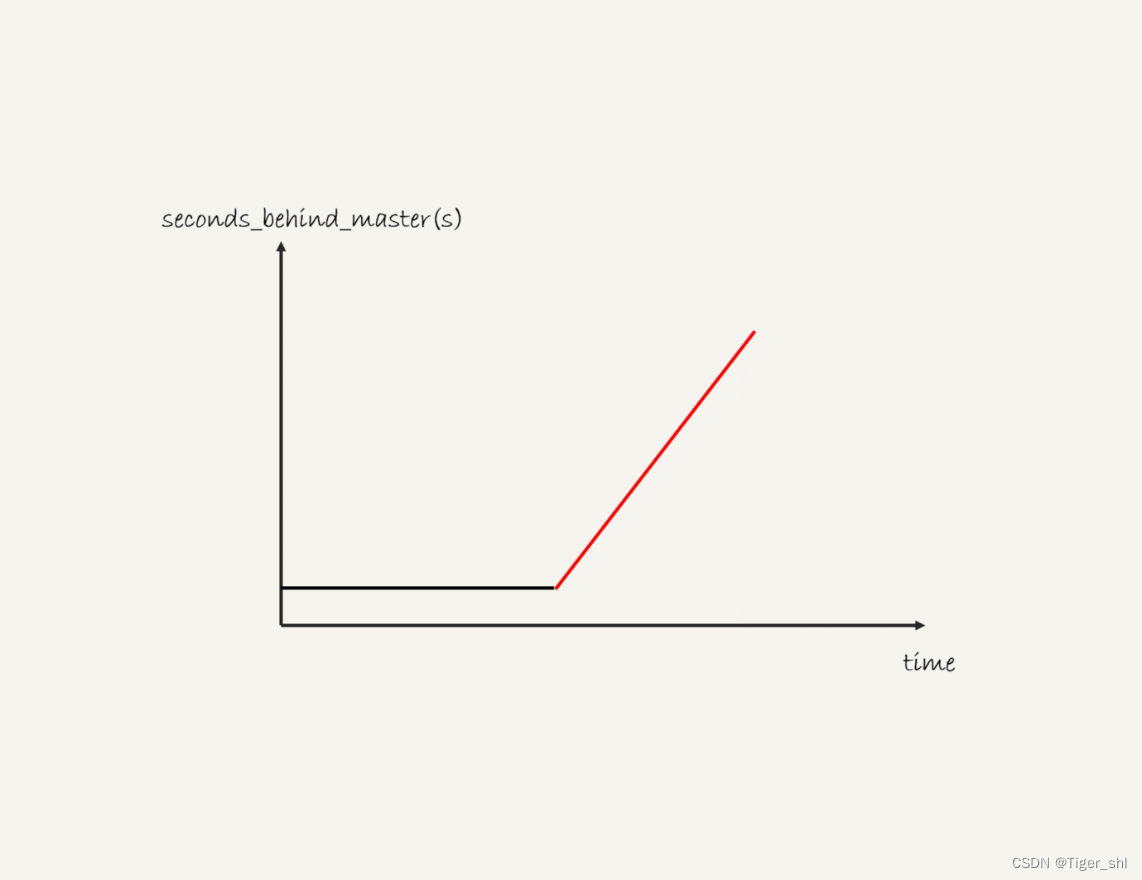
备库的同步在这段时间完全被堵住了。
产生这种现象典型的场景主要包括两种:
- 一种是大事务(包括大表 DDL、一个事务操作很多行);
- 还有一种情况比较隐蔽,就是备库起了一个长事务
3. 备库为何会延迟很久-备库并行复制能力
介绍了几种可能导致备库延迟的原因。这些场景里,不论是偶发性的查询压力,还是备份,对备库延迟的影响一般是分钟级的,而且在备库恢复正常以后都能够追上来。
图 1 主备流程图
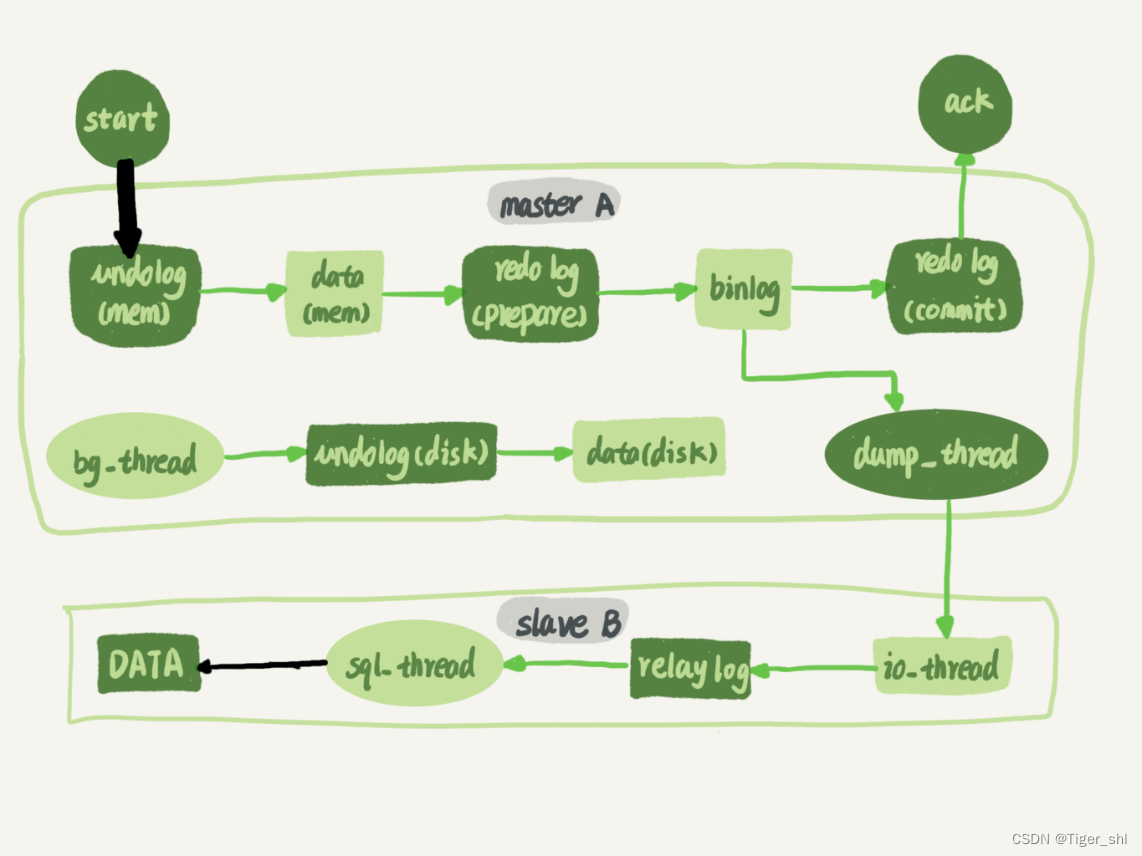
图中黑色的两个箭头。
一个箭头代表了客户端写入主库,另一箭头代表的是备库上 sql_thread 执行中转日志(relay log)。
如果用箭头的粗细来代表并行度的话,那么真实情况就如图 1 所示,第一个箭头要明显粗于第二个箭头。
在主库上,影响并发度的原因是各种锁。由于 InnoDB 引擎支持行锁,除了所有并发事务都在更新同一行(热点行)这种极端场景外,它对业务并发度的支持还是很友好的。所以,在性能测试的时候会发现,并发压测线程 32 就比单线程时,总体吞吐量高。
而日志在备库上的执行,就是图中备库上 sql_thread 更新数据 (DATA) 的逻辑。如果是用单线程的话,就会导致备库应用日志不够快,造成主备延迟。
在官方的 5.6 版本之前,MySQL 只支持单线程复制,由此在主库并发高、TPS 高时就会出现严重的主备延迟问题。
MySQL 多线程复制的演进过程
图 2 多线程模型
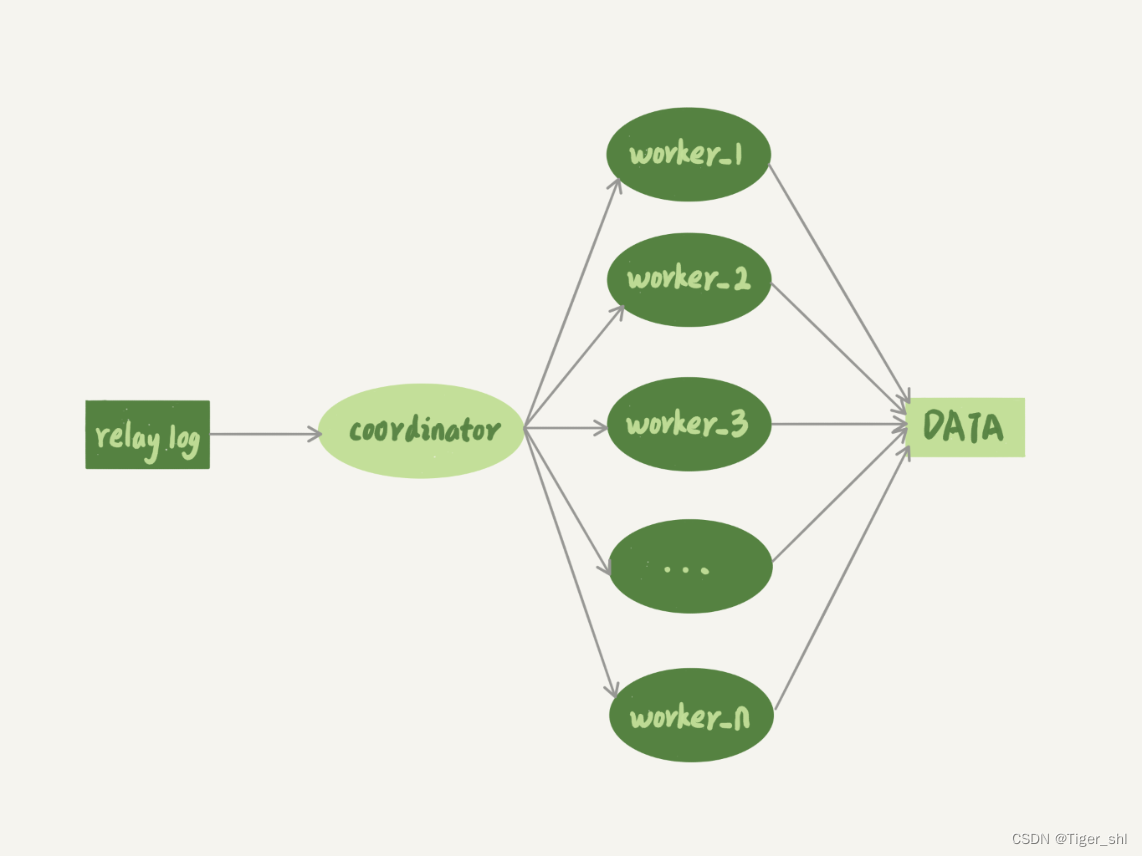
图 2 中,coordinator 就是原来的 sql_thread, 不过现在它不再直接更新数据了,只负责读取中转日志和分发事务。
真正更新日志的,变成了 worker 线程。而 work 线程的个数,就是由参数 slave_parallel_workers 决定的。根据经验,这个值设置为 8~16 之间最好(32 核物理机的情况),毕竟备库还有可能要提供读查询,不能把 CPU 都吃光了。
问题1
事务能不能按照轮询的方式分发给各个 worker,也就是第一个事务分给 worker_1,第二个事务发给 worker_2 呢?
回答
其实是不行的。因为,事务被分发给 worker 以后,不同的 worker 就独立执行了。
但是,由于 CPU 的调度策略,很可能第二个事务最终比第一个事务先执行。而如果这时候刚好这两个事务更新的是同一行,也就意味着,同一行上的两个事务,在主库和备库上的执行顺序相反,会导致主备不一致的问题。
问题2
同一个事务的多个更新语句,能不能分给不同的 worker 来执行呢?
回答
也不行。举个例子,一个事务更新了表 t1 和表 t2 中的各一行,如果这两条更新语句被分到不同 worker 的话,虽然最终的结果是主备一致的,但如果表 t1 执行完成的瞬间,备库上有一个查询,就会看到这个事务“更新了一半的结果”,破坏了事务逻辑的隔离性。
所以,coordinator 在分发的时候,需要满足以下这两个基本要求:
- 不能造成更新覆盖。这就要求更新同一行的两个事务,必须被分发到同一个 worker 中。
- 同一个事务不能被拆开,必须放到同一个 worker 中。
各个版本的多线程复制,都遵循了这两条基本原则。
3.1 MySQL 5.6 版本的并行复制策略
官方 MySQL5.6 版本,支持了并行复制,只是支持的粒度是按库并行。用于决定分发策略的 hash 表里,key 就是数据库。这个策略的并行效果,取决于压力模型。如果在主库上有多个 DB,并且各个 DB 的压力均衡,使用这个策略的效果会很好。
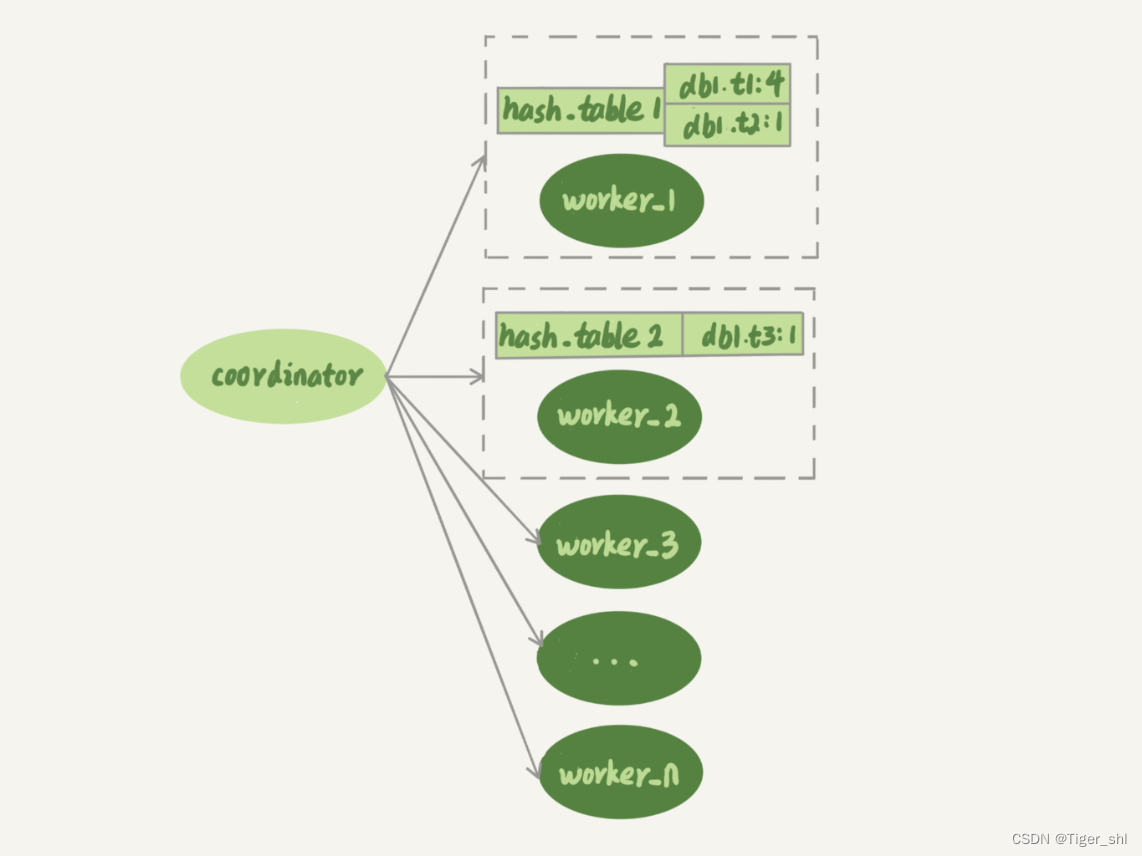
每个 worker 线程对应一个 hash 表,用于保存当前正在这个 worker 的“执行队列”里的事务所涉及的表。hash 表的 key 是“库名”,value 是一个数字,表示队列中有多少个事务修改这个表。
在有事务分配给 worker 时,事务里面涉及的表会被加到对应的 hash 表中。worker 执行完成后,这个表会被从 hash 表中去掉。图 3 中,hash_table_1 表示,现在 worker_1 的“待执行事务队列”里,有 4 个事务涉及到 db1.t1 表,有 1 个事务涉及到 db2.t2 表;hash_table_2 表示,现在 worker_2 中有一个事务会更新到表 t3 的数据。
优势:
- 构造 hash 值的时候很快,只需要库名;而且一个实例上 DB 数也不会很多,不会出现需要构造 100 万个项这种情况。
- 不要求 binlog 的格式。因为 statement 格式的 binlog 也可以很容易拿到库名。
但是,如果你的主库上的表都放在同一个 DB 里面,这个策略就没有效果了;或者如果不同 DB 的热点不同,比如一个是业务逻辑库,一个是系统配置库,那也起不到并行的效果。
理论上可以创建不同的 DB,把相同热度的表均匀分到这些不同的 DB 中,强行使用这个策略。不过,由于需要特地移动数据,这个策略用得并不多
3.2 MariaDB 的并行复制策略
redo log 组提交 (group commit) 优化, MariaDB 的并行复制策略利用的就是这个特性:
- 能够在同一组里提交的事务,一定不会修改同一行;
- 主库上可以并行执行的事务,备库上也一定是可以并行执行的。
在实现上,MariaDB 是这么做的:
- 在一组里面一起提交的事务,有一个相同的 commit_id,下一组就是 commit_id+1;
- commit_id 直接写到 binlog 里面;
- 传到备库应用的时候,相同 commit_id 的事务分发到多个 worker 执行;
- 这一组全部执行完成后,coordinator 再去取下一批。
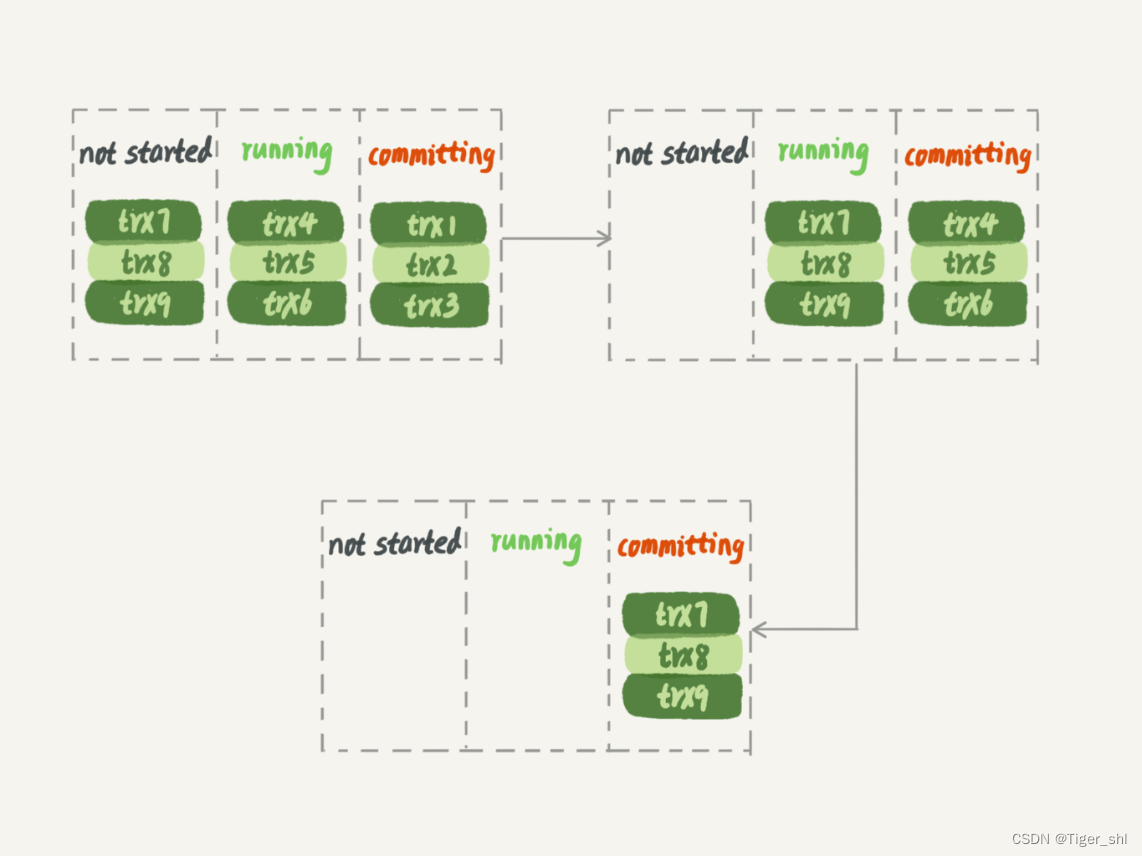
这个策略有一个问题,它并没有实现“真正的模拟主库并发度”这个目标。在主库上,一组事务在 commit 的时候,下一组事务是同时处于“执行中”状态的。
如图 5 所示,假设了三组事务在主库的执行情况,你可以看到在 trx1、trx2 和 trx3 提交的时候,trx4、trx5 和 trx6 是在执行的。这样,在第一组事务提交完成的时候,下一组事务很快就会进入 commit 状态。
图 5 主库并行事务
按照 MariaDB 的并行复制策略,备库上的执行效果如图 6 所示。
图 6 MariaDB 并行复制,备库并行效果
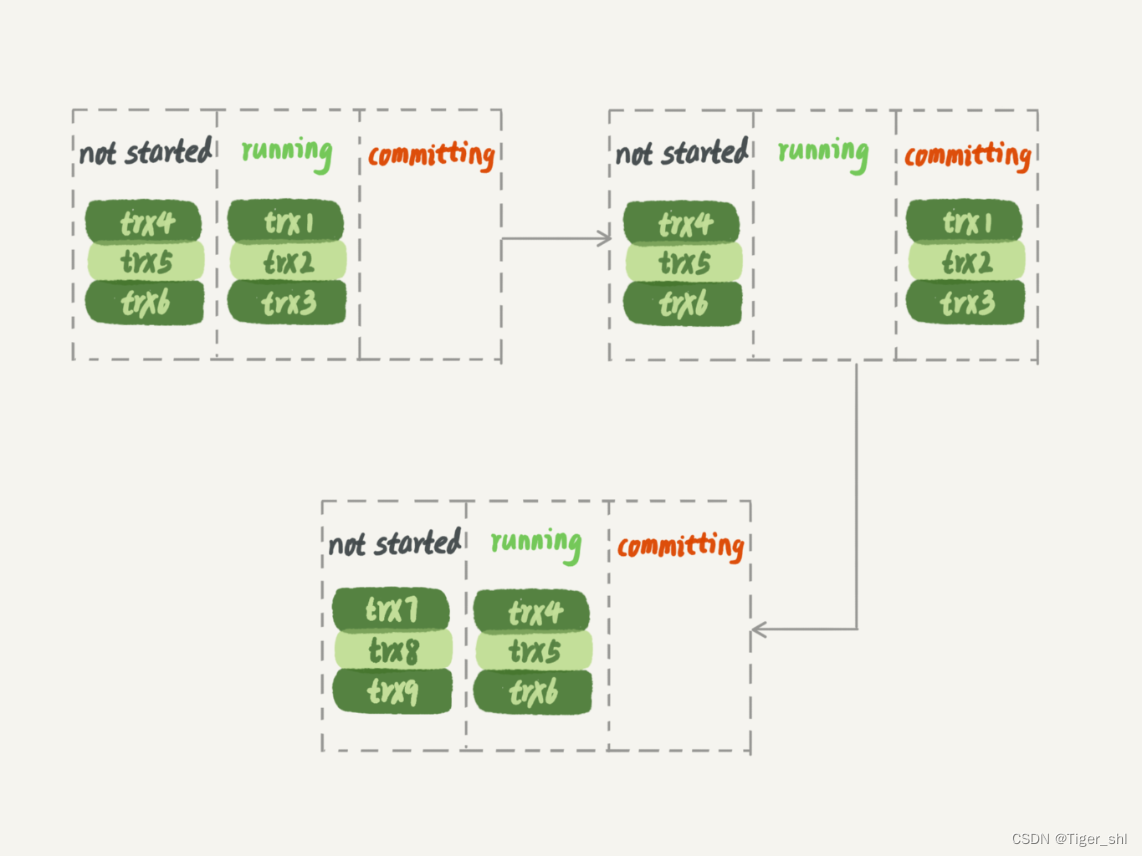
在备库上执行的时候,要等第一组事务完全执行完成后,第二组事务才能开始执行,这样系统的吞吐量就不够。
另外,这个方案很容易被大事务拖后腿。假设 trx2 是一个超大事务,那么在备库应用的时候,trx1 和 trx3 执行完成后,就只能等 trx2 完全执行完成,下一组才能开始执行。这段时间,只有一个 worker 线程在工作,是对资源的浪费。
不过即使如此,这个策略仍然是一个很漂亮的创新。因为,它对原系统的改造非常少,实现也很优雅。
3.3 MySQL 5.7 的并行复制策略
在 MariaDB 并行复制实现之后,官方的 MySQL5.7 版本也提供了类似的功能,由参数 slave-parallel-type 来控制并行复制策略:
- 配置为 DATABASE,表示使用 MySQL 5.6 版本的按库并行策略;
- 配置为 LOGICAL_CLOCK,表示的就是类似 MariaDB 的策略。不过,MySQL 5.7 这个策略,针对并行度做了优化。
问题
同时处于“执行状态”的所有事务,是不是可以并行?
回答
不能。因为,这里面可能有由于锁冲突而处于锁等待状态的事务。如果这些事务在备库上被分配到不同的 worker,就会出现备库跟主库不一致的情况。
上面提到的 MariaDB 这个策略的核心,是“所有处于 commit”状态的事务可以并行。事务处于 commit 状态,表示已经通过了锁冲突的检验了。
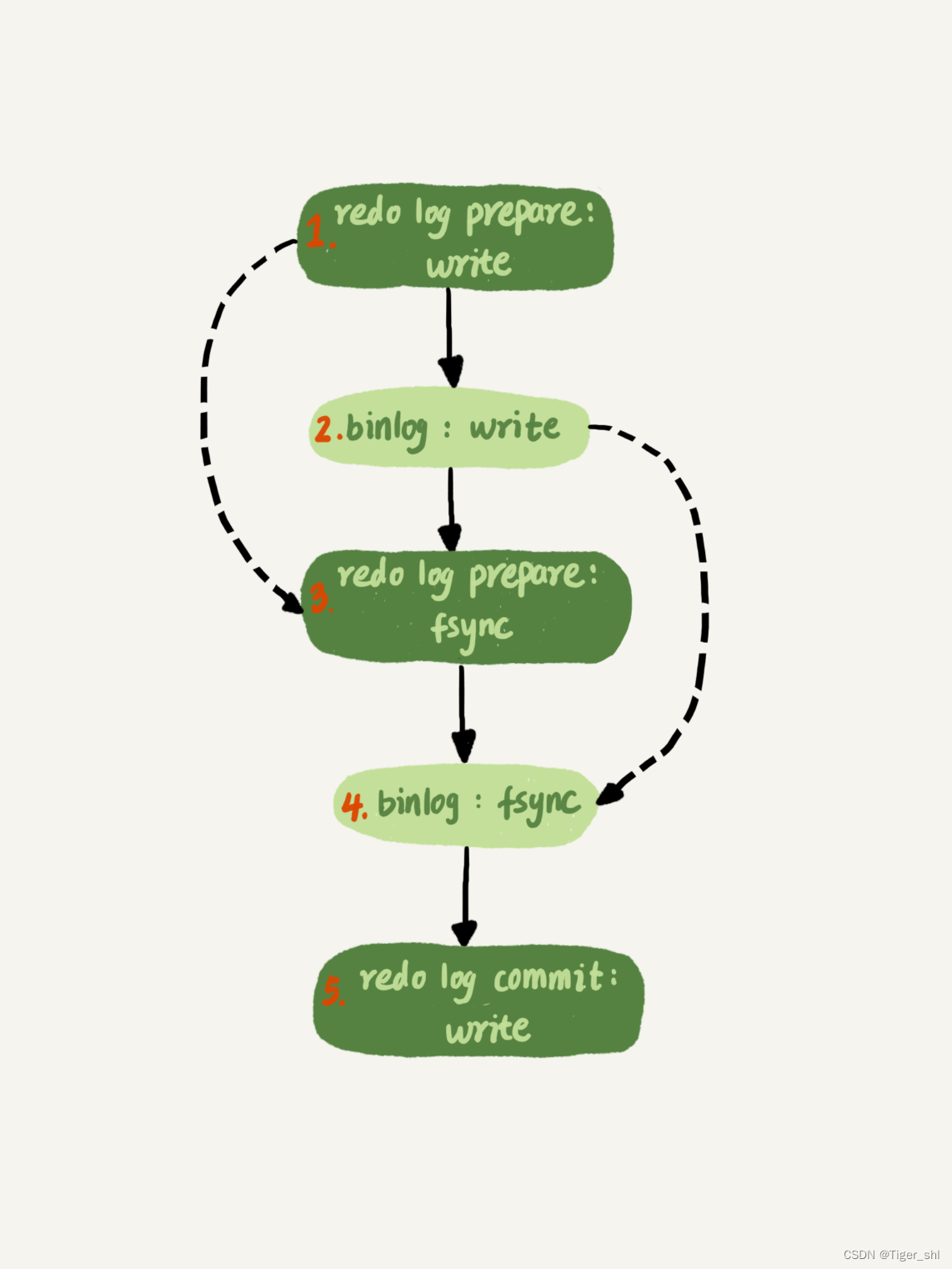
两阶段提交过程中,不用等到 commit 阶段,只要能够到达 redo log prepare 阶段,就表示事务已经通过锁冲突的检验了。
因此,MySQL 5.7 并行复制策略的思想是:
- 同时处于 prepare 状态的事务,在备库执行时是可以并行的;
- 处于 prepare 状态的事务,与处于 commit 状态的事务之间,在备库执行时也是可以并行的。
讲 binlog 的组提交的时候,介绍过两个参数:
- binlog_group_commit_sync_delay 参数,表示延迟多少微秒后才调用 fsync;
- binlog_group_commit_sync_no_delay_count 参数,表示累积多少次以后才调用 fsync。
这两个参数是用于故意拉长 binlog 从 write 到 fsync 的时间,以此减少 binlog 的写盘次数。在 MySQL 5.7 的并行复制策略里,它们可以用来制造更多的“同时处于 prepare 阶段的事务”。这样就增加了备库复制的并行度。
也就是说,这两个参数,既可以“故意”让主库提交得慢些,又可以让备库执行得快些。在 MySQL 5.7 处理备库延迟的时候,可以考虑调整这两个参数值,来达到提升备库复制并发度的目的。
3.4 MySQL 5.7.22 的并行复制策略
基于 WRITESET 的并行复制。
新增了一个参数 binlog-transaction-dependency-tracking,用来控制是否启用这个新策略。这个参数的可选值有以下三种。
- COMMIT_ORDER,表示的就是前面介绍的,根据同时进入 prepare 和 commit 来判断是否可以并行的策略。
- WRITESET,表示的是对于事务涉及更新的每一行,计算出这一行的 hash 值,组成集合 writeset。如果两个事务没有操作相同的行,也就是说它们的 writeset 没有交集,就可以并行。
- WRITESET_SESSION,是在 WRITESET 的基础上多了一个约束,即在主库上同一个线程先后执行的两个事务,在备库执行的时候,要保证相同的先后顺序。
当然为了唯一标识,这个 hash 值是通过“库名 + 表名 + 索引名 + 值”计算出来的。如果一个表上除了有主键索引外,还有其他唯一索引,那么对于每个唯一索引,insert 语句对应的 writeset 就要多增加一个 hash 值。
MySQL 官方的这个实现还是有很大的优势:
- writeset 是在主库生成后直接写入到 binlog 里面的,这样在备库执行的时候,不需要解析 binlog 内容(event 里的行数据),节省了很多计算量;
- 不需要把整个事务的 binlog 都扫一遍才能决定分发到哪个 worker,更省内存;
- 由于备库的分发策略不依赖于 binlog 内容,所以 binlog 是 statement 格式也是可以的。
因此,MySQL 5.7.22 的并行复制策略在通用性上还是有保证的。
对于“表上没主键”和“外键约束”的场景,WRITESET 策略也是没法并行的,也会暂时退化为单线程模型。
来自 林晓斌《MySql实战45讲》
相关文章:
【MySql】8- 实践篇(六)
文章目录 1. MySql保证主备一致1.1 MySQL 主备的基本原理1.2 binlog 的三种格式对比1.3 循环复制问题 2. MySql保证高可用2.1 主备延迟2.2 主备延迟的来源2.3 可靠性优先策略2.4 可用性优先策略 3. 备库为何会延迟很久-备库并行复制能力3.1 MySQL 5.6 版本的并行复制策略3.2 Ma…...

Spring篇---第七篇
系列文章目录 文章目录 系列文章目录一、说说事务的传播级别二、Spring 事务实现方式三、Spring框架的事务管理有哪些优点一、说说事务的传播级别 Spring事务定义了7种传播机制: PROPAGATION_REQUIRED:默认的Spring事物传播级别,若当前存在事务,则加入该事务,若 不存在事务…...
2023年中国轮胎模具需求量、竞争格局及行业市场规模分析[图]
轮胎模具是轮胎生产线中的硫化成形装备,是高技术含量、高精度及高附加值的个性化模具产品,尤其是轮胎的花纹、图案、字体以及其他外观特征的成形都依赖于轮胎模具,因此其制造技术难度较高。其主要功能是通过所成型材料(主要是橡塑…...
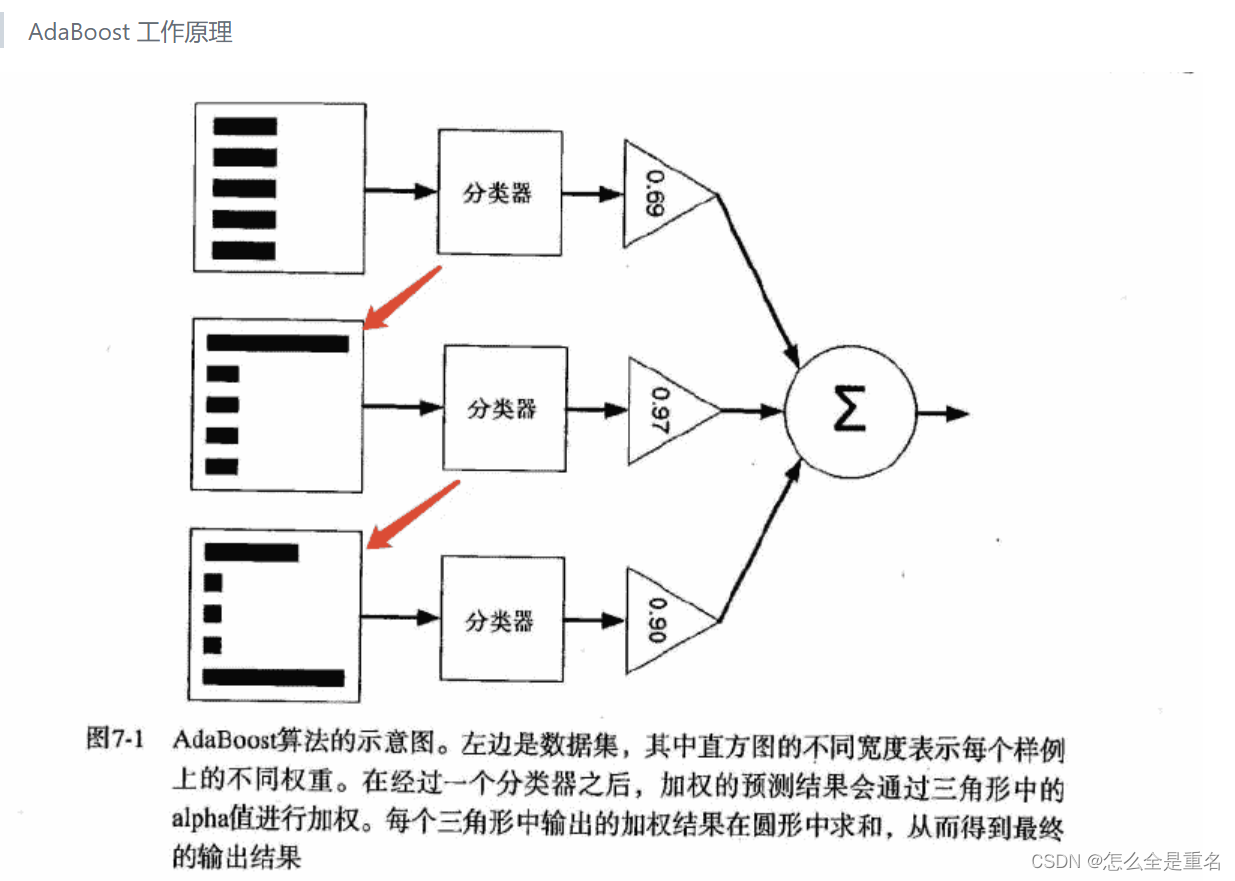
集成学习方法(随机森林和AdaBoost)
释义 集成学习很好的避免了单一学习模型带来的过拟合问题 根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类: Bagging(个体学习器间不存在强依赖关系、可同时生成的并行化方法) 流行版本:随机森林(random forest)Boosting(个体…...

PeopleCode中Date函数的用法
语法 Date(date_num) 描述 The Date function takes a number in the form YYYYMMDD and returns a corresponding Date value. If the date is invalid, Date displays an error message. Date函数输入是一个形如“YYYYMMDD”的数字,返回一个相应的Date类型的值…...

解决 el-tree setChecked 方法偶尔失效的方法
目前在大多数公司中,菜单的权限控制都是不可或缺的功能 在和后端配合做权限控制的时候不可避免的会用到 el-tree 然而这个组件本身带的坑不少 我们需要回显对应角色拥有的菜单,在不严格的模式下,父节点的选中会连带子节点的选中 如果 &a…...
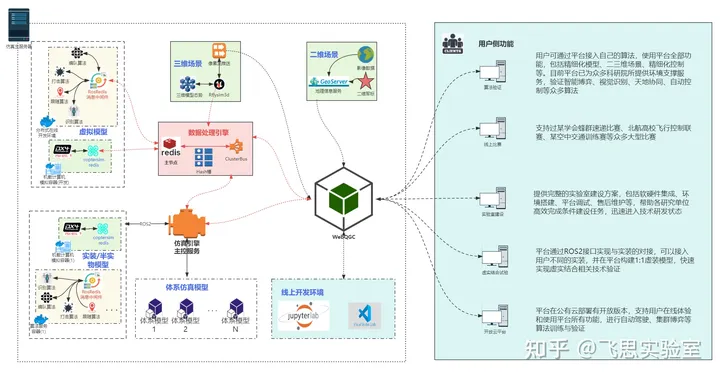
重磅发布!RflySim Cloud 智能算法云仿真平台亮相,助力大规模集群算法高效训练
RflySim Cloud智能算法云仿真平台(以下简称RflySim Cloud平台)是由卓翼智能及飞思实验室为无人平台集群算法验证、大规模博弈对抗仿真、人工智能模型训练等前沿研究领域研发的平台。主要由环境仿真模块、物理效应计算模块、多智能体仿真模块、分布式网络…...
C++ 01.学习C++的意义-狄泰软件学院
一些历史 UNIX操作系统诞生之初是用汇编语言编写的随着UNIX系统的发展,汇编语言的开发效率成为瓶颈,所以需要一个新的语言替代汇编语言1971年通过对B语言改良,使其能直接产生机器代码,C语言诞生UNIX使用C语言重写,同时…...

微软正式发布开源应用平台 Radius平台
“ 10 月 18 日,微软 Azure 孵化团队正式发布开源应用平台 Radius,该平台将应用程序置于每个开发阶段的中心,重新定义应用程序的构建、管理与理解方式。” 简单的概括就是,它和Kubernetes不一样,Radius将应用程序放在每…...
)
排序算法(python)
排序算法 冒泡排序 一次比较相邻的两个数,每轮之后末尾的数字是确定的。 时间复杂度为 O ( n 2 ) O(n^2) O(n2),空间复杂度为 O ( 1 ) O(1) O(1),稳定。 def BUB(nums):for i in range(len(nums)):count 0for j in range(len(nums)-i-1)…...
一款简单漂亮的WPF UI - AduSkin
前言 经常会有同学会问,有没有好看简单的WPF UI库推荐的。今天就给大家推荐一款简单漂亮的WPF UI,融合多个开源框架组件:AduSkin。 WPF是什么? WPF 是一个强大的桌面应用程序框架,用于构建具有丰富用户界面的 Windo…...
)
Java面试题-Java核心基础-第七天(String)
目录 一、String、StringBuffer、StringBuilder的区别 二、String为什么是不可变的 三、字符串拼接用""还是用StringBuilder 四、String 中的equals和Object中的equals的区别 五、字符串常量池的作用了解吗? 六、String s1 new String("abc&qu…...

路飞项目多方式登录、手机号短信验证注册接口
登录注册页面分析 用户板块需要写的接口 用户名密码登录(多方式登录)获取手机验证码接口手机号验证码登录注册接口验证手机号是否存在接口 验证手机号是否存在 视图类 from rest_framework.viewsets import ViewSet from rest_framework.decorator…...

信息学奥赛一本通-编程启蒙3003:练2.1 春节快乐
3003:练2.1 春节快乐 时间限制: 1000 ms 内存限制: 65536 KB 提交数: 10805 通过数: 7830 【题目描述】 一年一度的春节到啦!试着把你的春节祝福表达在代码中吧。 【输入】 无 【输出】 输出一行"Happy Spring Festival!" 【输入…...
SparkStreaming入门
概述 实时/离线 实时:Spark是每个3秒或者5秒更新一下处理后的数据,这个是按照时间切分的伪实时。真正的实时是根据事件触发的数据计算,处理精度达到ms级别。离线:数据是落盘后再处理,一般处理的数据是昨天的数据&…...
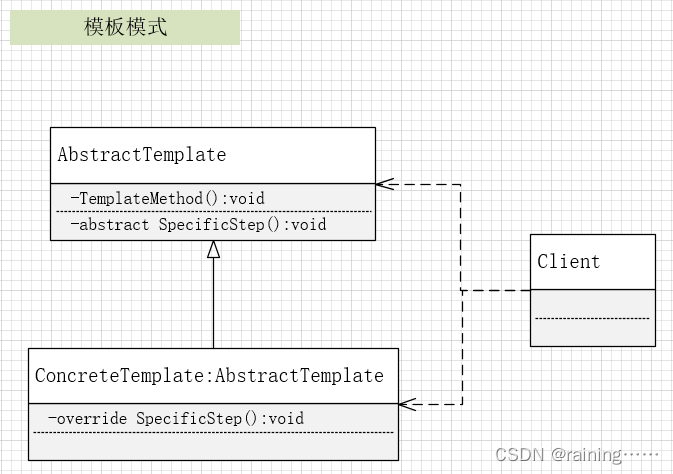
设计模式:模板模式(C#、JAVA、JavaScript、C++、Python、Go、PHP)
简介: 模板模式,它是一种行为型设计模式,它定义了一个操作中的算法的框架,将一些步骤延迟到子类中实现,使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。 通俗地说,模板模式就是将某一行…...
基于Java的图书商城管理系统设计与实现(源码+lw+部署文档+讲解等)
文章目录 前言具体实现截图论文参考详细视频演示为什么选择我自己的网站自己的小程序(小蔡coding) 代码参考数据库参考源码获取 前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作者&am…...
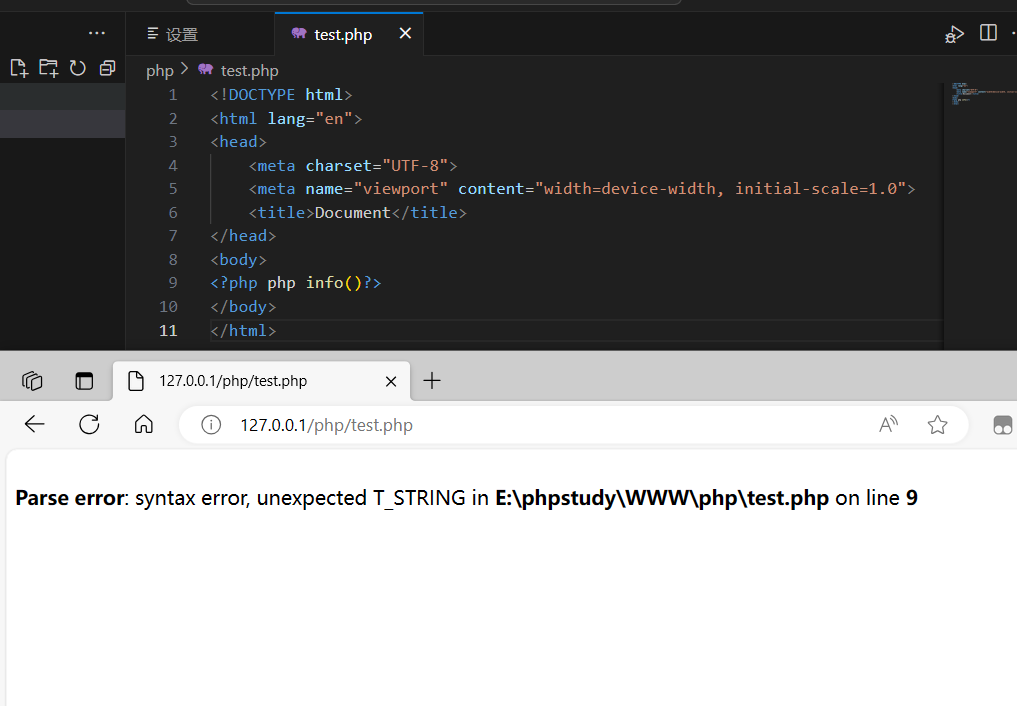
PHP 基础
PHP 基础 概述 在PHP 文件中,可以与HTML 和JavaScript 混编。 开始标记<?php 表示进入PHP 模式,结束标记?>,标识退出PHP 模式。 PHP 模式之外的内容会被作为字符输出到浏览器中。 PHP 在服务端执行,HTML 和 JS 在浏览…...
)
Java RestTemplate使用TLS1.0(关闭SSL验证)
1. 问题 使用RestTemplate调用Http API时,服务器是TLS1.0,但是客户端Java默认禁止TLS1.0,会报错:org.springframework.web.client.ResourceAccessException: I/O error on POST request for “https://10.255.200.114/health”: …...
【进阶C语言】C语言文件操作
1. 为什么使用文件 2. 什么是文件 3. 文件的打开和关闭 4. 文件的顺序读写 5. 文件的随机读写 6. 文本文件和二进制文件 7. 文件读取结束的判定 8. 文件缓冲区 一、文件与文件的意义 1.文件的意义 文件的意义,无非就是为什么要使用文件? (1&…...

WeDLM-7B-BBase助力开源:自动为OpenSource项目生成高质量README与文档
WeDLM-7B-BBase助力开源:自动为OpenSource项目生成高质量README与文档 1. 开源项目的文档困境 每个开源项目维护者都深有体会:写代码容易,写文档难。当你花了几周时间开发出一个功能强大的开源项目,最后却要花同样多的时间来撰写…...

突破性内存级帧率解锁技术:重新定义《原神》高帧率体验的技术哲学与实践
突破性内存级帧率解锁技术:重新定义《原神》高帧率体验的技术哲学与实践 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock 在PC游戏性能优化领域,帧率限制往往成为技…...

DeepSeek-V4来了,百万上下文普惠化,开源模型追平闭源!
DeepSeek-V4 预览版发布:百万上下文普惠化,开源模型追平闭源 2026年4月24日,DeepSeek-V4 预览版正式上线并同步开源。1M 上下文标配化、DSA 稀疏注意力架构、Muon 优化器、mHC 流形约束超连接——这是自 DeepSeek R1 以来十五个月后,深度求索交出的又一份硬核答卷。 一、双…...

XQuery FLWOR 与 HTML 的融合应用
XQuery FLWOR 与 HTML 的融合应用 引言 在当今信息爆炸的时代,HTML 作为网页标准标记语言,在互联网中扮演着至关重要的角色。而 XQuery,作为一种用于查询和处理 XML 和其他结构化数据的语言,与 HTML 的结合使用为开发者提供了强大的数据操作能力。本文将深入探讨 XQuery …...

3步搞定Java智能地址解析:告别混乱的收货地址处理难题
3步搞定Java智能地址解析:告别混乱的收货地址处理难题 【免费下载链接】address-parse Java 版智能解析收货地址 项目地址: https://gitcode.com/gh_mirrors/addr/address-parse 你是否曾经为处理用户输入的混乱收货地址而头疼不已?😫…...

保持上网认证
上网需要账号认证,而且在凌晨系统就会自动将账号踢下线。一家叫Sangfor做的客户端,不安它就上不了网。 需要远程查看设备状态,掉线了就连不进来了。找人去申请长时间在线,结果是1天1掉线,之前还是两天1掉线。 基础的东…...

从一次Docker镜像构建失败说起:深入理解ldconfig在容器环境下的特殊用法
从一次Docker镜像构建失败说起:深入理解ldconfig在容器环境下的特殊用法 那天凌晨三点,监控系统突然报警——我们刚部署的微服务在Kubernetes集群中频繁崩溃。查看日志发现全是libxxx.so.1: cannot open shared object file这类错误。奇怪的是࿰…...

如何零基础快速上手专业网络拓扑图绘制?终极免费开源工具指南
如何零基础快速上手专业网络拓扑图绘制?终极免费开源工具指南 【免费下载链接】easy-topo vuesvgelement-ui 快捷画出网络拓扑图 项目地址: https://gitcode.com/gh_mirrors/ea/easy-topo 你是否曾经为绘制复杂的网络拓扑图而头疼?专业工具太复杂…...

Vue-Toasted源码解析:从Toast对象到动画系统的实现原理
Vue-Toasted源码解析:从Toast对象到动画系统的实现原理 【免费下载链接】vue-toasted 🖖 Responsive Touch Compatible Toast plugin for VueJS 2 项目地址: https://gitcode.com/gh_mirrors/vu/vue-toasted Vue-Toasted是一个响应式且支持触摸操…...
)
别再傻傻串联了!手把手教你用Verilog写4bit超前进位加法器(附完整代码)
别再傻傻串联了!手把手教你用Verilog写4bit超前进位加法器(附完整代码) 第一次接触数字电路设计时,很多工程师都会对加法器的实现方式感到困惑。为什么简单的加法运算会有这么多不同的实现方案?为什么教科书上总是强调…...