《深度学习推荐系统》王喆 笔记
这个笔记,是我记录的阅读该书,对我比较有用的一些点。不算是能完全覆盖全书知识点的笔记。
能完全覆盖全书知识点,比较详尽的笔记,可以参考如下。
《深度学习推荐系统》超级详细读书笔记![]() https://www.zhihu.com/tardis/bd/art/444018628
https://www.zhihu.com/tardis/bd/art/444018628
推荐系统模型——前深度学习时代
| 传统推荐算法 | 优势 | 劣势 |
| 简单协同过滤算法 | 算法简单 不需要领域知识 能发掘新的兴趣点 | 数据稀疏 冷启动问题 头部效应明显 |
| 矩阵分解算法 | 缓解数据稀疏问题 泛化能力加强 | 损失其它相关用户物品和上下文信息 缺乏解释性 |
| 逻辑回归模型 | 模型简单,易于实现 学习各个特征权重,具有可解释性 | 表达能力较差 没有进行特征组合和特征筛选 |
| 因子分解机模型 | 解决稀疏数据交叉特征组合问题 模型表达能力增强 | 模型参数多,训练困难 容易过拟合 无法学习三阶及以上特征 |
| 梯度提升树+逻辑回归组合模型(GBDT+LR 组合模型) | 自动化特征组合端到端训练 减少手工特征组合 | 泛化能力差 容易过拟合 |
强烈推荐延伸阅读资料1

深度学习在推荐学习系统的应用,相关模型简介

相比AutoRec模型过于简单的网络结构带来的一些表达能力不强的问题,Deep Crossing模型完整地解决了从特征工程、稀疏向量稠密化、多层神经网络进行优化目标拟合等一系列深度学习在推荐系统中的应用问题,为后续的研究打下了良好的基础。
因为在阅读本书的过程中,在机器学习的实践方面,刚好遇到了特征稀疏的问题,所以对这里的【稀疏向量稠密化】这个方面比较感兴趣。
在下面的Deep Crossing模型介绍中,其对【稀疏向量稠密化】做了具体的说明,“Embedding 层的作用是将稀疏的类别型特征转换成稠密的Embedding向量”
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Deep Crossing模型的网络结构为完成端到端的训练,Deep Crossing模型要在其内部网络中解决如下问题。
(1)离散类特征编码后过于稀疏,不利于直接输入神经网络进行训练,如何解决稀疏特征向量稠密化的问题。
(2)如何解决特征自动交叉组合的问题。
(3)如何在输出层中达成问题设定的优化目标。
Deep Crossing模型分别设置了不同的神经网络层来解决上述问题。如图3-6所示,其网络结构主要包括4层——Embedding层、Stacking层、Multiple Residual Units层和Scoring层。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Wide&Deep模型
3.6 Wide&Deep模型——记忆能力和泛化能力的综合
Wide&Deep模型的主要思路正如其名,是由单层的Wide部分和多层的Deep部分组成的混合模型。其中,Wide部分的主要作用是让模型具有较强的“记忆能力”(memorization);Deep部分的主要作用是让模型具有“泛化能力”(generalization),正是这样的结构特点,使模型兼具了逻辑回归和深度神经网络的优点——能够快速处理并记忆大量历史行为特征,并且具有强大的表达能力3.6.1 模型的记忆能力与泛化能力
Wide&Deep模型的设计初衷和其最大的价值在于同时具备较强的“记忆能力”和“泛化能力”。“记忆能力”是一个新的概念,“泛化能力”虽在之前的章节中屡有提及,但从没有给出详细的解释,本节就对这两个概念进行详细的解释。“记忆能力”可以被理解为模型直接学习并利用历史数据中物品或者特征的“共现频率”的能力。一般来说,协同过滤、逻辑回归等简单模型有较强的“记忆能力”。由于这类模型的结构简单,原始数据往往可以直接影响推荐结果,产生类似于“如果点击过A,就推荐B”这类规则式的推荐,这就相当于模型直接记住了历史数据的分布特点,并利用这些记忆进行推荐。
因为Wide&Deep是由谷歌应用商店(Google Play)推荐团队提出的,所以这里以App推荐的场景为例,解释什么是模型的“记忆能力”。
假设在Google Play 推荐模型的训练过程中,设置如下组合特征:AND (user_installed_app=netflix,impression_app=pandora)(简称netflix&pandora),它代表用户已经安装了netflix这款应用,而且曾在应用商店中看到过pandora这款应用。如果以“最终是否安装pandora”为数据标签(label),则可以轻而易举地统计出netflix&pandora这个特征和安装pandora这个标签之间的共现频率。假设二者的共现频率高达10%(全局的平均应用安装率为1%),这个特征如此之强,以至于在设计模型时,希望模型一发现有这个特征,就推荐pandora这款应用(就像一个深刻的记忆点一样印在脑海里),这就是所谓的模型的“记忆能力”。
像逻辑回归这类简单模型,如果发现这样的“强特征”,则其相应的权重就会在模型训练过程中被调整得非常大,这样就实现了对这个特征的直接记忆。相反,对于多层神经网络来说,特征会被多层处理,不与其他特征进行交叉,因此模型对这个强特征的记忆反而没有简单模型深刻。
泛化能力”可以被理解为模型传递特征的相关性,以及发掘稀疏甚至从未出现过的稀有特征与最终标签相关性的能力。矩阵分解比协同过滤的泛化能力强,因为矩阵分解引入了隐向量这样的结构,使得数据稀少的用户或者物品也能生成隐向量,从而获得有数据支撑的推荐得分,这就是非常典型的将全局数据传递到稀疏物品上,从而提高泛化能力的例子。再比如,深度神经网络通过特征的多次自动组合,可以深度发掘数据中潜在的模式,即使是非常稀疏的特征向量输入,也能得到较稳定平滑的推荐概率,这就是简单模型所缺乏的“泛化能力”。
在通过交叉积变换层操作完成特征组合之后,Wide 部分将组合特征输入最终的LogLoss输出层,与Deep部分的输出一同参与最后的目标拟合,完成Wide与Deep部分的融合
深度学习,在推荐系统中的应用,总结:
沿着特征工程自动化的思路,深度学习模型从PNN 一路走来,经过了Wide&Deep、Deep&Cross、FNN、DeepFM、NFM等模型,进行了大量的、基于不同特征互操作思路的尝试。但特征工程的思路走到这里几乎已经穷尽了可能的尝试,模型进一步提升的空间非常小,这也是这类模型的局限性所在。从这之后,越来越多的深度学习推荐模型开始探索更多“结构”上的尝试,诸如注意力机制、序列模型、强化学习等在其他领域大放异彩的模型结构也逐渐进入推荐系统领域,并且在推荐模型的效果提升上成果显著。
Embedding技术在推荐系统中的应用(第4章 )
4.1.3 Embedding技术对于深度学习推荐系统的重要性
回到深度学习推荐系统上,为什么说Embedding 技术对于深度学习如此重要,甚至可以说是深度学习的“基础核心操作”呢?原因主要有以下三个:
(1)推荐场景中大量使用one-hot编码对类别、id 型特征进行编码,导致样本特征向量极度稀疏,而深度学习的结构特点使其不利于稀疏特征向量的处理,因此几乎所有深度学习推荐模型都会由Embedding层负责将高维稀疏特征向量转换成稠密低维特征向量。因此,掌握各类Embedding技术是构建深度学习推荐模型的基础性操作。
(2)Embedding本身就是极其重要的特征向量。相比MF等传统方法产生的特征向量,Embedding的表达能力更强,特别是Graph Embedding技术被提出后,Embedding几乎可以引入任何信息进行编码,使其本身就包含大量有价值的信息。在此基础上,Embedding向量往往会与其他推荐系统特征连接后一同输入后续深度学习网络进行训练。
(3)Embedding对物品、用户相似度的计算是常用的推荐系统召回层技术。在局部敏感哈希(Locality-Sensitive Hashing)等快速最近邻搜索技术应用于推荐系统后,Embedding 更适用于对海量备选物品进行快速“初筛”,过滤出几百到几千量级的物品交由深度学习网络进行“精排”。
所以说,Embedding技术在深度学习推荐系统中占有极其重要的位置,熟悉并掌握各类流行的Embedding 方法是构建一个成功的深度学习推荐系统的有力武器。
Embedding相关技术总结

推荐系统应用——特征工程、召回、冷启动
探索与利用
《淮南子》中有一句话非常有名:“先王之法,不涸泽而渔,不焚林而猎。”否定的是做事只顾眼前利益,不做长远打算的做法。那么在推荐系统中,有没有所谓的眼前利益和长远打算呢?当然是有的。所有的用户和物品历史数据就像是一个鱼塘,如果推荐系统只顾着捞鱼,不往里面补充新的鱼苗,那么总有一天鱼塘中鱼的资源会逐渐枯竭,以至最终无鱼可捞。
这里的“捞鱼”行为指的就是推荐系统一味使用历史数据,根据用户历史进行推荐,不注重发掘用户新的兴趣、新的优质物品。那么,“投放鱼苗”的行为自然就是推荐系统主动试探用户新的兴趣点,主动推荐新的物品,发掘有潜力的优质物品。
给用户推荐的机会是有限的,推荐用户喜欢的内容和探索用户的新兴趣这两件事都会占用宝贵的推荐机会,在推荐系统中应该如何权衡这两件事呢?这就是“探索与利用”试图解决的问题
解决“探索与利用”问题目前主要有三大类方法。
(1)传统的探索与利用方法:这类方法将问题简化成多臂老虎机问题。主要的算法有ε-Greedy(ε贪婪)、Thompson Sampling(汤普森采样)和UCB。该类解决方法着重解决新物品的探索和利用,方法中并不考虑用户、上下文等因素,因此是非个性化的探索与利用方法。
(2)个性化的探索与利用方法:该类方法有效地结合了个性化推荐特点和探索与利用的思想,在考虑用户、上下文等因素的基础上进行探索与利用的权衡,因此被称为个性化探索与利用方法。
(3)基于模型的探索与利用方法:该类方法将探索与利用的思想融入推荐模型之中,将深度学习模型和探索与利用的思想有效结合,是近年来的热点方向
深度学习推荐系统——前沿行业内的工程实践(Facebook、Youtube)
CTR预估、Criteo数据集
推荐系统-工程师能力
推荐延伸阅读材料:
1、智能推荐系统研究综述①
http://c-s-a.org.cn/csa/article/pdf/8403
2、特征交叉与特征融合综述
http://www.360doc.com/content/22/0621/10/35712332_1036842363.shtml
3、深度学习推荐系统(五)Deep&Crossing模型及其在Criteo数据集上的应用
深度学习推荐系统(五)Deep&Crossing模型及其在Criteo数据集上的应用-CSDN博客
4、推荐系统-飞浆深度学习实战 清华大学出版社
http://www.tup.tsinghua.edu.cn/upload/books/yz/094994-01.pdf
5、基于PaddleRec复现经典CTR预估算法
仅需24小时,带你基于PaddleRec复现经典CTR预估算法
6、Click-Through Rate Prediction on Criteo
Criteo Benchmark (Click-Through Rate Prediction) | Papers With Code
7、Torch-Rechub学习分享、Torch-Rechub学习分享1
Torch-Rechub学习分享 - 简书
Torch-Rechub学习分享2 - 简书 (jianshu.com)
8、推荐系统研究进展与应用 - 武汉大学学报
武汉大学学报(理学版) (whu.edu.cn)
相关文章:
《深度学习推荐系统》王喆 笔记
这个笔记,是我记录的阅读该书,对我比较有用的一些点。不算是能完全覆盖全书知识点的笔记。 能完全覆盖全书知识点,比较详尽的笔记,可以参考如下。 《深度学习推荐系统》超级详细读书笔记https://www.zhihu.com/tardis/bd/art/44…...
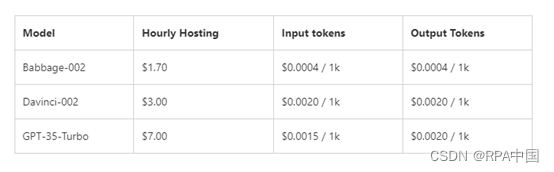
微软Azure OpenAI支持数据微调啦!可打造专属ChatGPT
10月17日,微软在官网宣布,现在可以在Azure OpenAI公共预览版中对GPT-3.5-Turbo、Babbage-002 和Davinci-002模型进行数据微调。 使得开发人员通过自己的数据集,便能打造独一无二的ChatGPT。例如,通过海量医疗数据进行微调&#x…...

Kali Linux 安装搭建 hadoop 平台 详细教程
1)前期环境准备:(虚拟机、jdk、ssh) 2)SSH相关配置 安装SSH Server服务器:apt-get install openssh-server 更改默认的SSH密钥 cd /etc/ssh mkdir ssh_key_backup mv ssh_host_* ssh_key_backup 创建新…...

leetcode做题笔记190. 颠倒二进制位
颠倒给定的 32 位无符号整数的二进制位。 提示: 请注意,在某些语言(如 Java)中,没有无符号整数类型。在这种情况下,输入和输出都将被指定为有符号整数类型,并且不应影响您的实现,因…...

JAVA如何获取服务器ip
一、最简单的方法就是使用InetAddress获取本机ip InetAddress.getLocalHost().getHostAddress(); public static void main(String[] args) {try {//用 getLocalHost() 方法创建的InetAddress的对象InetAddress address InetAddress.getLocalHost();System.out.println(addr…...
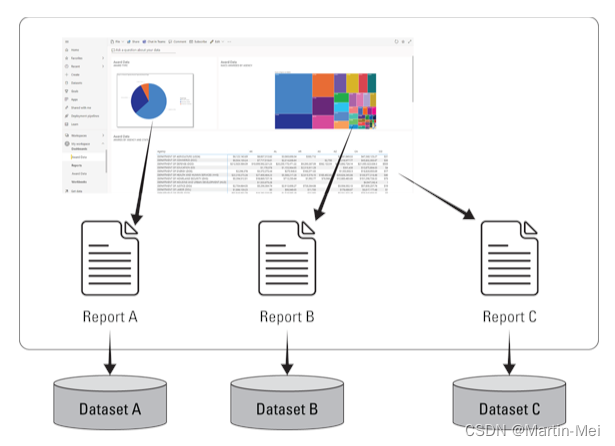
Power BI 傻瓜入门 4. Power BI:亮点
本章内容包含: 在Power BI Desktop上学习诀窍摄入数据使用模型试用Power BI服务 就像评估一个由多种成分组成的蛋糕一样,Power BI要求其用户熟悉商业智能(BI)解决方案中的功能。几乎所有与Power BI交互的用户都是从桌面版开始的…...
)
网络参考资料搬运(3)
(1) Python: 使用Python打开新的终端(terminal)并执行语句 通过Python 打开各系统(MAC, LINUX, WINDOWS)下的终端 (Terminal) python执行shell脚本的几种方法 自己写Linux命令 用Python写个Linux系统命令 Python 使用sftp传输文件…...

Bias in Emotion Recognition with ChatGPT
本文是LLM系列文章,针对《Bias in Emotion Recognition with ChatGPT》的翻译。 chatGPT在情绪识别中的偏差 摘要1 引言2 方法3 结果4 讨论5 结论 摘要 本技术报告探讨了ChatGPT从文本中识别情绪的能力,这可以作为交互式聊天机器人、数据注释和心理健康…...
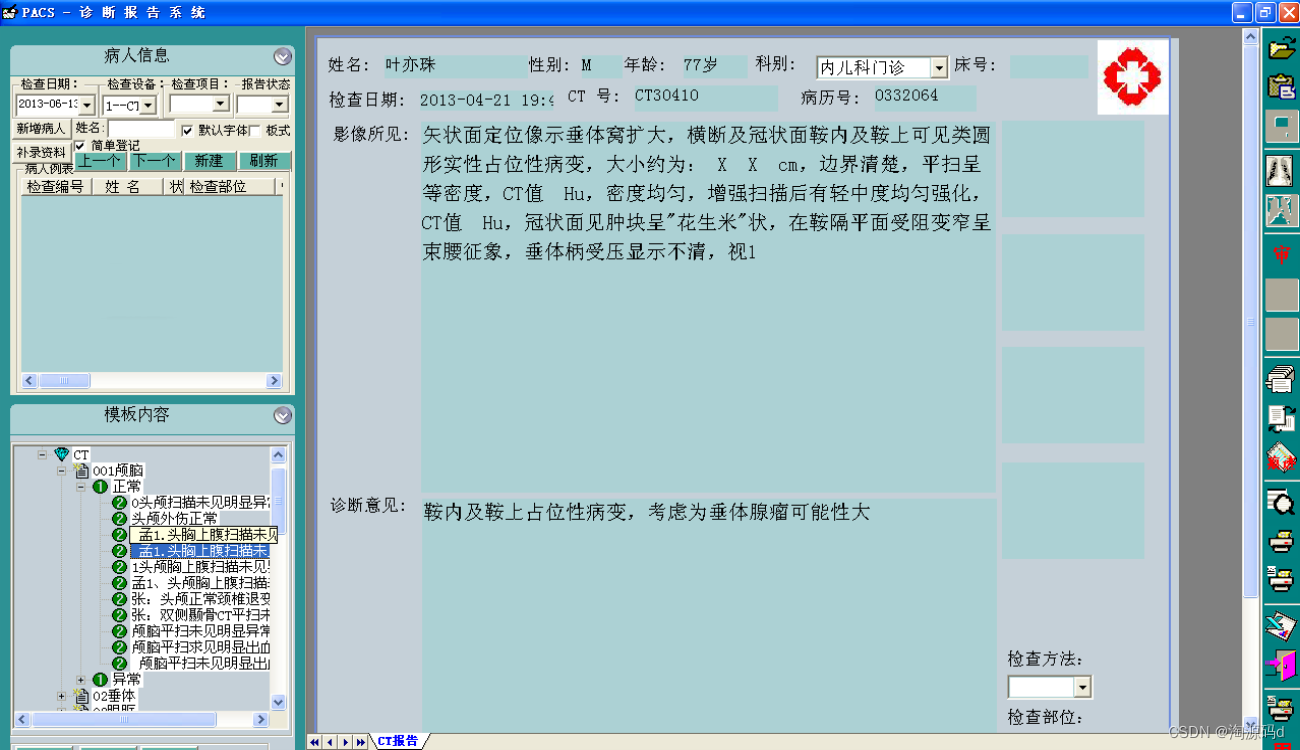
【PACS系统源码】与医院HIS系统双向数据交换,实现医学影像集成与影像后处理功能
医院医学影像PACS系统源码,集成三维影像后处理功能,包括三维多平面重建、三维容积重建、三维表面重建、三维虚拟内窥镜、最大/小密度投影、心脏动脉钙化分析等功能。系统功能强大,代码完整。 PACS系统与医院HIS实现双向数据交换,…...

深度学习中常用的激活函数有sigmoid、tanh、ReLU、LeakyReLU、PReLU、GELU等。
深度学习中常用的激活函数 1. Sigmoid函数2. Tanh函数3. ReLU函数4. LeakyReLU函数5. PReLU函数6. ELU函数:7. GELU函数: 深度学习中常用的激活函数有sigmoid、tanh、ReLU、LeakyReLU、PReLU等。 1. Sigmoid函数 Sigmoid函数公式为 f ( x ) 1 1 e −…...

mysql同时使用order by排序和limit分页数据重复问题
目录 场景再现: 解决方案: 问题分析: mysql官方描述: 场景再现: 最近排查数据时发现使用order by及limit分页时会出现不同页数数据重复问题及有的数据分页不会显示,但是按条件搜索就可以搜索出来。 解决方案&#x…...

英语——歌诀篇——歌诀记忆法
介词用法速记歌 年月季前要用in, 日子前面却不行。 遇到几号要用on, 上午下午又用in。 要说某时上下午, 用on换in才可行。 午夜黄昏和黎明, 要用at不用in。 差儿分到几点, 写个“to”在中间。 若是几点过几分…...

打破运维疆界:异构复杂网络环境的集中监控和管理
在当今多元化的IT环境中,异构环境的管理成为了企业IT团队的一大挑战。如何在多种技术架构、多样的应用环境中实现高效的运维管理,是众多企业正在面临的问题。在本文中,我们将探讨监控易在异构环境中的运维监控表现,并通过实际案例…...

ubuntu安装debian包的命令dpkg和apt的详解
dpkg是Debian Packager的缩写 官方文档https://manpages.ubuntu.com/manpages/jammy/en/man1/dpkg.1.html ubuntu的dpkg命令类似centos的rpm命令,dpkg主要用于对已下载到本地和已安装的.deb软件包进行管理比如安装、构建、删除。dpkg不能自动下载和安装.deb软件包也…...

【暴力剪枝】CF1708D
https://codeforces.com/contest/1708/problem/D 题意 思路 这样的操作下,数列减的速度是非常快的,也就是说,易出现很多的0,0的操作没啥意义,所以我们要找到第一个 >0 的数对其后的序列进行排序,就能大…...

代码格式化的使用
前言 本文主要介绍了代码格式化,以及各个平台如何使用快捷键进行代码格式化,如有错误之处,欢迎在评论区交流讨论~ 代码格式化 代码格式化是一种编程实践,它涉及调整源代码的外观,以提高可读性和一致性。 这包括调整缩进、空格、换行符和括号等元素的使…...

【Unity地编】地形系统搭建入门详解
👨💻个人主页:元宇宙-秩沅 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 秩沅 原创 👨💻 收录于专栏:UI_…...
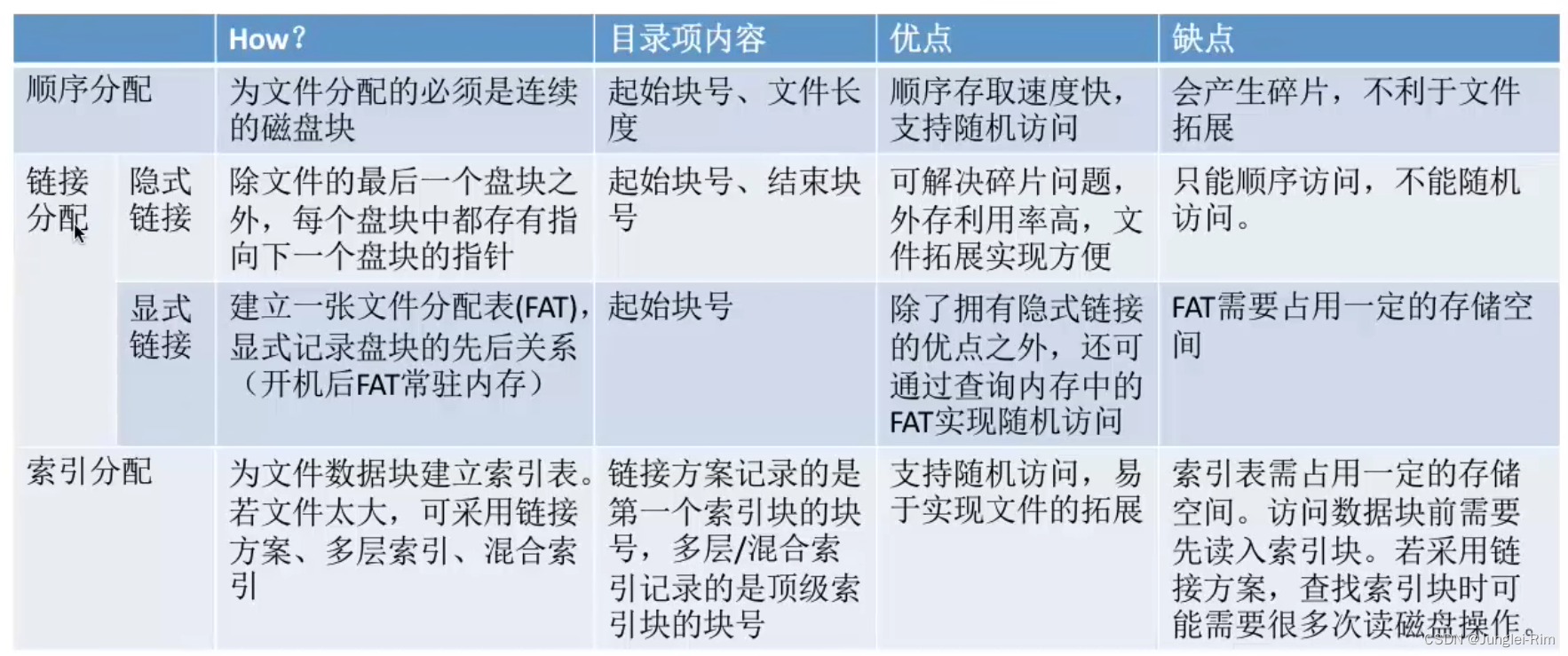
文件的物理结构(连续分配,链接分配,索引分配)
1.文件块,磁盘块 类似于内存分页,磁盘中的存储单元也会被分为一个个“块/磁盘块/物理块”。 很多操作系统中,磁盘块的大小与内存块、页面的大小相同。 内存与磁盘之间的数据交换(即读/写操作、磁盘I/O)都是以“块”为…...
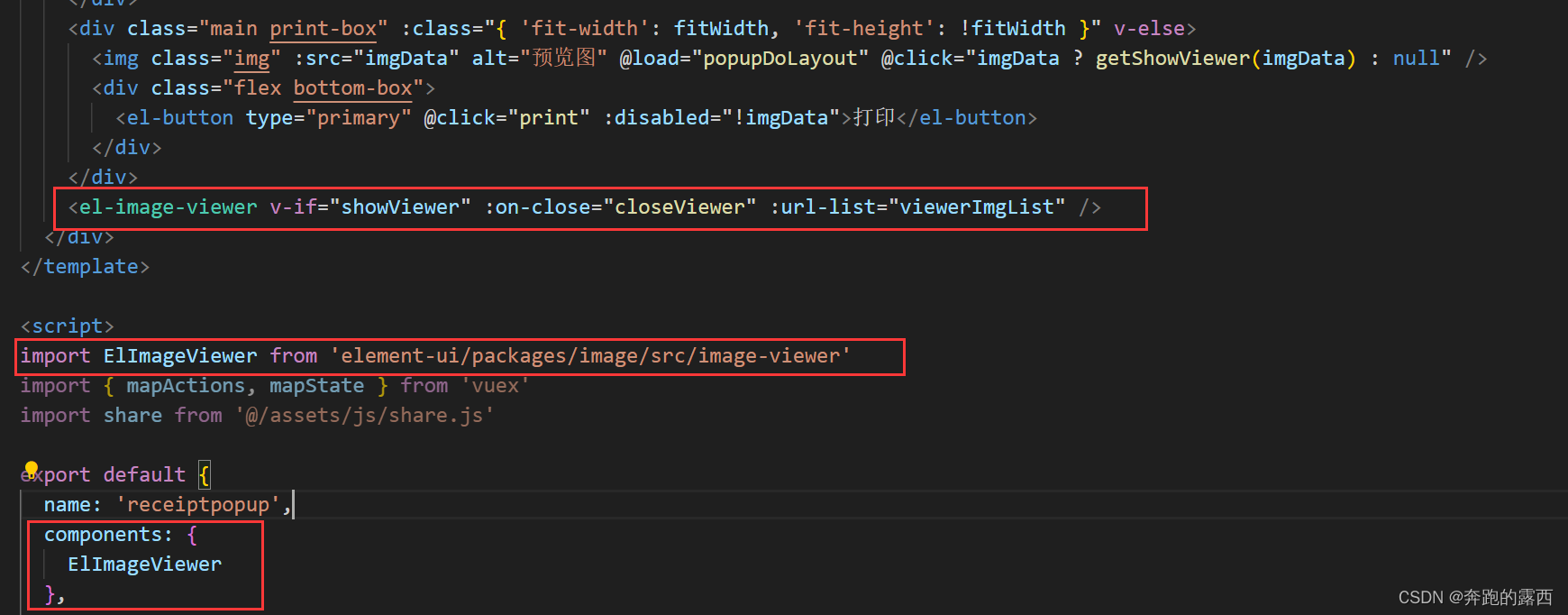
vue2 解密图片地址(url)-使用blob文件-打开png格式图片
一、背景 开发中需要对加密文件进行解码,如图片等静态资源。 根据后端给到的url地址,返回的是图片文件,但是乱码的,需要解码成png图片进行展示 二、请求接口 将后端返回的文件转为文件流,创建Blob对象来存储二进制…...

cuda PyTorch
1. GPU对应的CUDA版本 nvidia-smi CUDA Version: 12.2 GPU diver 大于cuda toolkit, pytorch 版本根据cuda toolkit 2. 查看nvcc的版本(即cuda toolkit 版本) nvcc --version Cuda compilation tools, release 12.2, V12.2.91 Build cud…...

BERT分词器定制指南:从原理到实践
1. 为什么需要定制BERT分词器BERT等预训练语言模型的核心组件之一就是分词器(Tokenizer)。虽然Hugging Face等平台提供了多语言的预训练分词器,但在以下场景中,我们需要从头训练自己的分词器:处理专业领域文本…...

Python缺失值可视化分析实战:以Ames房价数据为例
1. 项目概述:缺失值可视化分析的价值在数据分析领域,缺失值就像隐藏在数据集中的隐形陷阱,稍不注意就会导致模型偏差或结论错误。Ames Housing数据集作为房价预测领域的经典数据集,包含80个特征变量和2930条房产记录,其…...

AI-MVP:以最小模型验证最大价值,聚焦AI智能体研究
MVP(Minimum Viable Product,最小可行产品)是一种产品开发方法论,指用最低成本、最快速度构建出具备核心功能、足以验证基本商业假设的产品初始版本。 其核心目的是通过收集早期用户反馈来验证市场需求,从而指导后续迭…...

nli-MiniLM2-L6-H768详细步骤:RTX 4090 D上GPU推理启用验证与显存占用实测报告
nli-MiniLM2-L6-H768详细步骤:RTX 4090 D上GPU推理启用验证与显存占用实测报告 1. 模型概述 nli-MiniLM2-L6-H768 是一个轻量级自然语言推理(NLI)模型,专注于文本对关系判断而非内容生成。该模型在RTX 4090 D GPU上表现出色,特别适合以下场…...

高性能计算与AI融合:HPC SDK 24.3与NVIDIA工具链解析
1. 高性能计算与AI融合的技术演进在当今计算领域,我们正见证着一个前所未有的技术融合时代。传统的高性能计算(HPC)与新兴的人工智能技术正在相互促进,创造出全新的计算范式。作为一名长期从事加速计算开发的工程师,我…...

在Visual Studio 2019中集成与实战Libtiff:从编译到图像处理
1. 环境准备与源码编译 在Visual Studio 2019中使用Libtiff处理专业图像前,需要先搭建好开发环境。我推荐从官方GitHub仓库下载最新稳定版的Libtiff源码(当前最新为4.5.1版本),相比旧版有更好的兼容性和性能优化。下载后解压到不含…...

独立开发工具站 - ToolAdd:更新4 个新工具
这段时间陆续收到大家的反馈,希望站里能加点更实用的工具。趁着空闲时间搓了几个新的,顺便把之前觉得不错的一个外部神器也收录了进来,方便大家统一放在书签里吃灰(不是)。 密码生成器 大家最头疼的估计就是注册账号时…...

DeerFlow实战手册:DeerFlow生成内容合规性检查与人工审核流程
DeerFlow实战手册:DeerFlow生成内容合规性检查与人工审核流程 1. DeerFlow简介与核心能力 DeerFlow是字节跳动基于LangStack技术框架开发的深度研究开源项目,作为您的个人深度研究助理,它整合了语言模型、网络搜索、Python代码执行等强大工…...

AI如何重塑虚拟与增强现实技术的未来
1. 虚拟与增强现实技术的AI进化论当我在2016年第一次体验微软HoloLens时,那个漂浮在空中的全息键盘让我震撼不已。但当时的技术存在明显缺陷——虚拟物体的边缘会出现锯齿状闪烁,手势识别需要刻意保持固定姿势,环境遮挡也经常出错。如今再看M…...

SQL注入总概述
没问题,咱们不用表格,我给你按模块拆解得更详细、更口语化一点,把每个点的意思、怎么用、有啥区别都讲清楚👇一、SQL注入的「基础分类维度」这部分是你拿到一个网站,判断“它有没有注入、怎么注入”的核心依据…...