模型部署笔记--Pytorch-FX量化
目录
1--Pytorch-FX量化
2--校准模型
3--代码实例
3-1--主函数
3-2--prepare_dataloader函数
3-3--训练和测试函数
1--Pytorch-FX量化
Pytorch在torch.quantization.quantize_fx中提供了两个API,即prepare_fx和convert_fx。
prepare_fx的作用是准备量化,其在输入模型里按照设定的规则qconfig_dict来插入观察节点,进行的工作包括:
1. 将nn.Module转换为GraphModule。
2. 合并算子,例如将Conv、BN和Relu算子进行合并(通过打印模型可以查看合并的算子)。
3. 在Conv和Linear等OP前后插入Observer, 用于观测激活值Feature map的特征(权重的最大最小值),计算scale和zero_point。
convert_fx的作用是根据scale和zero_point来将模型进行量化。
2--校准模型
完整项目代码参考:ljf69/Model-Deployment-Notes
在对原始模型model调用prepare_fx()后得到prepare_model,一般需要对模型进行校准,校准后再调用convert_fx()进行模型的量化。
3--代码实例
3-1--主函数
import os
import copyimport torch
import torch.nn as nn
from torchvision.models.resnet import resnet18
from torch.quantization import get_default_qconfig
from torch.quantization.quantize_fx import prepare_fx, convert_fx
from torch.ao.quantization.fx.graph_module import ObservedGraphModulefrom dataloader import prepare_dataloader
from train_val import train_model, evaluate_model# 量化模型
def quant_fx(model):# 使用Pytorch中的FX模式对模型进行量化model.eval()qconfig = get_default_qconfig("fbgemm") # 默认是静态量化qconfig_dict = {"": qconfig,}model_to_quantize = copy.deepcopy(model)# 通过调用prepare_fx和convert_fx直接量化模型prepared_model = prepare_fx(model_to_quantize, qconfig_dict)# print("prepared model: ", prepared_model) # 打印模型quantized_model = convert_fx(prepared_model)# print("quantized model: ", quantized_model) # 打印模型# 保存量化后的模型torch.save(quantized_model.state_dict(), "r18_quant.pth")# 校准函数
def calib_quant_model(model, calib_dataloader):# 判断model一定是ObservedGraphModule,即一定是量化模型,而不是原始模型nn.moduleassert isinstance(model, ObservedGraphModule), "model must be a perpared fx ObservedGraphModule."model.eval()with torch.inference_mode():for inputs, labels in calib_dataloader:model(inputs)print("calib done.")# 比较校准前后的差异
def quant_calib_and_eval(model, test_loader):model.to(torch.device("cpu"))model.eval()qconfig = get_default_qconfig("fbgemm")qconfig_dict = {"": qconfig,}# 原始模型(未量化前的结果)print("model:")evaluate_model(model, test_loader)# 量化模型(未经过校准的结果)model2 = copy.deepcopy(model)model_prepared = prepare_fx(model2, qconfig_dict)model_int8 = convert_fx(model_prepared)print("Not calibration model_int8:")evaluate_model(model_int8, test_loader)# 通过原始模型转换为量化模型model3 = copy.deepcopy(model)model_prepared = prepare_fx(model3, qconfig_dict) # 将模型准备为量化模型,即插入观察节点calib_quant_model(model_prepared, test_loader) # 使用数据对模型进行校准model_int8 = convert_fx(model_prepared) # 调用convert_fx将模型设置为量化模型torch.save(model_int8.state_dict(), "r18_quant_calib.pth") # 保存校准后的模型# 量化模型(已经过校准的结果)print("Do calibration model_int8:")evaluate_model(model_int8, test_loader)if __name__ == "__main__":# 准备训练数据和测试数据train_loader, test_loader = prepare_dataloader()# 定义模型model = resnet18(pretrained=True)model.fc = nn.Linear(512, 10)# 训练模型(如果事先没有训练)if os.path.exists("r18_row.pth"): # 之前训练过就直接加载权重model.load_state_dict(torch.load("r18_row.pth", map_location="cpu"))else:train_model(model, train_loader, test_loader, torch.device("cuda"))print("train finished.")torch.save(model.state_dict(), "r18_row.pth")# 量化模型quant_fx(model)# 对比是否进行校准的影响quant_calib_and_eval(model, test_loader)3-2--prepare_dataloader函数
# 准备训练数据和测试数据
def prepare_dataloader(num_workers=8, train_batch_size=128, eval_batch_size=256):train_transform = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),])test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),])train_set = torchvision.datasets.CIFAR10(root="data", train=True, download=True, transform=train_transform)test_set = torchvision.datasets.CIFAR10(root="data", train=False, download=True, transform=test_transform)train_sampler = torch.utils.data.RandomSampler(train_set)test_sampler = torch.utils.data.SequentialSampler(test_set)train_loader = torch.utils.data.DataLoader(dataset=train_set,batch_size=train_batch_size,sampler=train_sampler,num_workers=num_workers,)test_loader = torch.utils.data.DataLoader(dataset=test_set,batch_size=eval_batch_size,sampler=test_sampler,num_workers=num_workers,)return train_loader, test_loader3-3--训练和测试函数
# 训练模型,用于后面的量化
def train_model(model, train_loader, test_loader, device):learning_rate = 1e-2num_epochs = 20criterion = nn.CrossEntropyLoss()model.to(device)optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9, weight_decay=1e-5)for epoch in range(num_epochs):# Trainingmodel.train()running_loss = 0running_corrects = 0for inputs, labels in train_loader:inputs = inputs.to(device)labels = labels.to(device)optimizer.zero_grad()outputs = model(inputs)_, preds = torch.max(outputs, 1)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item() * inputs.size(0)running_corrects += torch.sum(preds == labels.data)train_loss = running_loss / len(train_loader.dataset)train_accuracy = running_corrects / len(train_loader.dataset)# Evaluationmodel.eval()eval_loss, eval_accuracy = evaluate_model(model=model, test_loader=test_loader, device=device, criterion=criterion)print("Epoch: {:02d} Train Loss: {:.3f} Train Acc: {:.3f} Eval Loss: {:.3f} Eval Acc: {:.3f}".format(epoch, train_loss, train_accuracy, eval_loss, eval_accuracy))return modeldef evaluate_model(model, test_loader, device=torch.device("cpu"), criterion=None):t0 = time.time()model.eval()model.to(device)running_loss = 0running_corrects = 0for inputs, labels in test_loader:inputs = inputs.to(device)labels = labels.to(device)outputs = model(inputs)_, preds = torch.max(outputs, 1)if criterion is not None:loss = criterion(outputs, labels).item()else:loss = 0# statisticsrunning_loss += loss * inputs.size(0)running_corrects += torch.sum(preds == labels.data)eval_loss = running_loss / len(test_loader.dataset)eval_accuracy = running_corrects / len(test_loader.dataset)t1 = time.time()print(f"eval loss: {eval_loss}, eval acc: {eval_accuracy}, cost: {t1 - t0}")return eval_loss, eval_accuracy相关文章:

模型部署笔记--Pytorch-FX量化
目录 1--Pytorch-FX量化 2--校准模型 3--代码实例 3-1--主函数 3-2--prepare_dataloader函数 3-3--训练和测试函数 1--Pytorch-FX量化 Pytorch在torch.quantization.quantize_fx中提供了两个API,即prepare_fx和convert_fx。 prepare_fx的作用是准备量化&#…...

解决XXLJOB重复执行问题--Redis加锁+注解+AOP
基于Redis加锁注解AOP解决JOB重复执行问题 现象解决方案自定义注解定义AOP策略redis 加锁实践 现象 线上xxljob有时候会遇到同一个任务在调度的时候重复执行,如下图: 线上JOB服务运行了2个实例,有时候会重复调度到同一个实例,有…...
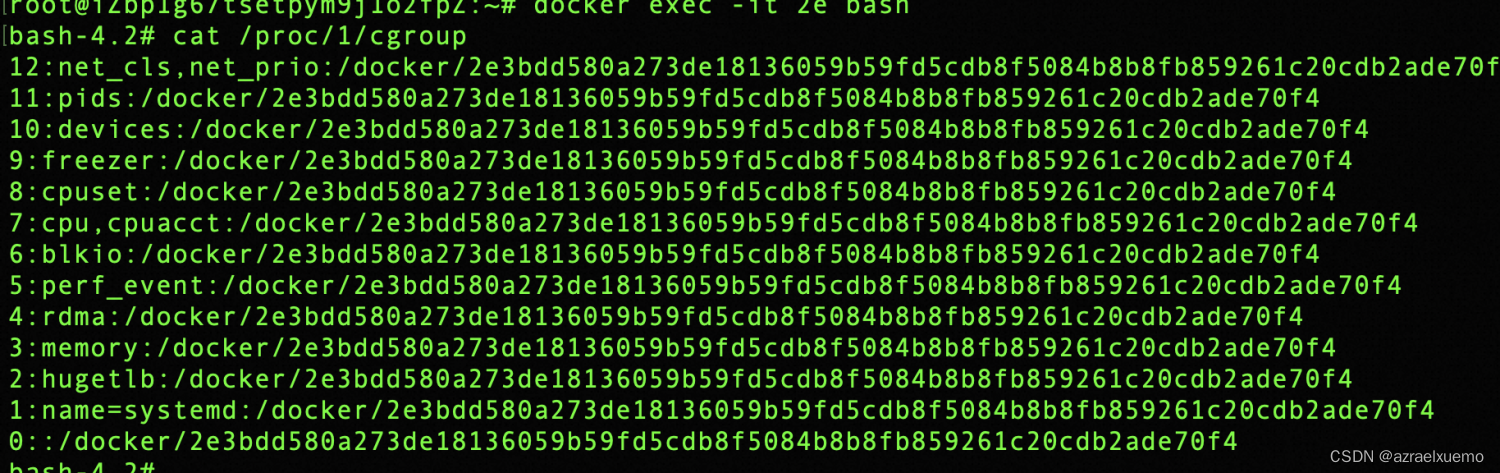
云安全(1)--初识容器逃逸之特权容器逃逸
文章目录 前言privileged,特权容器逃逸环境配置实际利用实际环境利用计划任务/var/spool/cron/crontabs/ 适用于ubuntu debain/var/spool/cron 适用于centos ld.so.preloadssh 前言 在10.15号的上海中华武数杯的渗透赛里做到了一个k8s的题目,这应该是我第一次在比赛…...
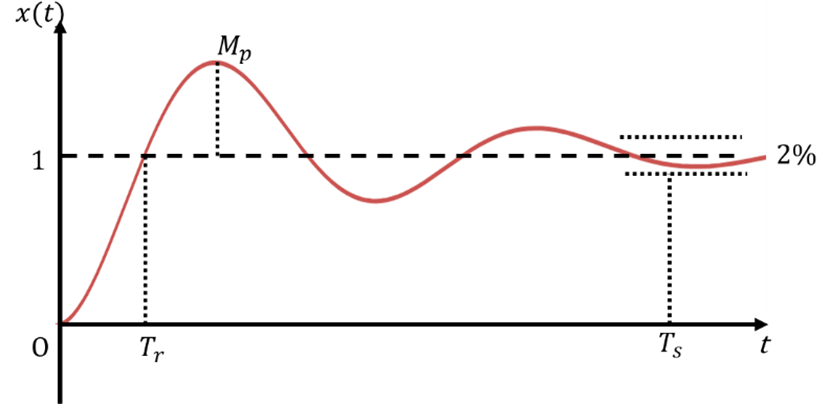
二阶系统时域响应
二阶系统微分方程 二阶系统传递函数 二阶系统单位阶跃响应 过阻尼系统 临界阻尼系统 欠阻尼系统 无阻尼系统 二阶系统阶跃响应仿真 在Matlab中进行仿真,设置不同阻尼比2、1、0.5和0,可以得到结论: 阻尼比越小,系统响应速度越快&…...
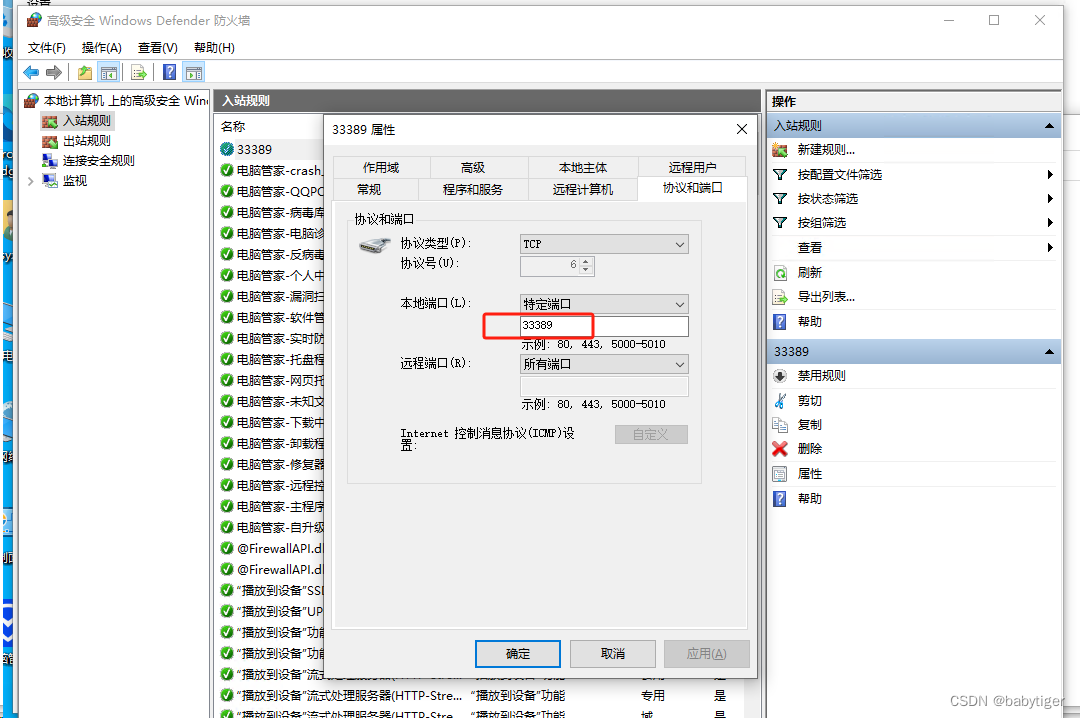
mstsc改端口为33389
windows 远程默认端口3389不太安全,改成33389防下小人 把下面的2个文本存在后缀.reg的文件,双击导入注册表,"PortNumber"dword:0000826d 这个就是33389对应的端口号的16进制值,要想自己改成其它的换下值即可 Windows …...
经典算法试题(二)
文章目录 一、岁数1、题目2、思路讲解3、代码实现4、结果 二、打碎的鸡蛋1、题目2、思路讲解3、代码实现4、结果 三、分糖1、题目2、思路讲解3、代码实现4、结果 四、兔子产子1、题目2、思路讲解3、代码实现4、结果 五、矩阵问题1、题目2、思路讲解3、代码实现4、结果 六、谁是…...

Linux——生产者消费者模型
目录 一.为何要使用生产者消费者模型 二.生产者消费者模型优点 三.基于BlockingQueue的生产者消费者模型 1.BlockingQueue——阻塞队列 2.实现代码 四.POSIX信号量 五.基于环形队列的生产消费模型 一.为何要使用生产者消费者模型 生产者消费者模式就是通过一个容器来解决生…...

Oracle缓存表
Oracle缓存表(db_buffer_pool)由三部分组成: buffer_pool_defualt buffer_pool_keep buffer_pool_recycle 如果要把表钉死在内存中,也就是把表钉在keep区。相关的命令为: alter table 表名 storage(buffer_pool k…...

智能变电站自动化系统的应用与产品选型
摘要:现如今,智能变电站发展已经成为了电力系统发展过程中的内容,如何提高智能变电站的运行效率也成为电力系统发展的一个重要目标,为了能够更好地促进电力系统安全稳定运行,本文则就智能变电站自动化系统的实现进行了…...

reactnative 底部tab页面@react-navigation/bottom-tabs
使用react-navigation/native做的页面导航和tab‘ 官网:https://reactnavigation.org/docs/getting-started 效果图 安装 npm install react-navigation/nativenpm install react-navigation/bottom-tabs封装tabbar.js import { View, StyleSheet, Image } from …...

运维中心—监控大盘
一、监控大盘内容分类 1、告警 2、业务趋势 3、异常码 4、主机 5、服务状态 6、系统账单 二、API分类 【基础数据】 1、分组查询各自子系统 2、子系统查询名下各个微服务 【主机】 根据分组查询主机信息,按照子系统分组,按照CPU和内存排序 步骤…...
Node.js的安装
直接在浏览器中搜索Node.js即可 打开下载好的文件 验证是否安装成功 在cmd中输入 node -v,若结果为版本号那就是成功的 环境配置 配置全局模块所在的路径缓存cache的路径 在安装目录中新建两个文件夹,文件夹名为:node_cache和node_global 输…...

vsCode git 修改、清空、重置、保存账号名密码
1、保存账号名密码,之后拉取代码都不用重新输入: git config --global credential.helper store 2、查看git用户名: git config user.name 3、清空所有的用户名和密码: git config --system --unset credential.helper 4、清…...

Docker 安装oracle12c容器并创建新用户
Docker 安装oracle12c容器并创建新用户 下载镜像 docker pull truevoly/oracle-12c启动镜像 8080和22端口没有映射出来,有需要自己 docker run -d -p 8123:1521 -restartalways --privilegedtrue -v /data/docker/Oracle12c_sichuan:/u01/app/oracle/ --name oracle…...
LabVIEW中管理大型数据
LabVIEW中管理大数据 LabVIEW的最大优势之一是自动内存管理。这种内存管理允许用户轻松创建字符串、数组和集群,而无需C/C用户经常担心。但是,这种内存管理设计为绝对安全,因此数据被非常频繁地复制。这通常不会造成任何问题,但是…...

dirsearch网站目录暴力破解
介绍: dirsearch是一个基于python3的命令行工具,常用于暴力扫描页面结构,包括网页中的目录和文件。相比其他扫描工具disearch的特点是: 支持HTTP代理多线程支持多种形式的网页(asp,php)生成报告࿰…...

【数据结构】线性表(三)循环链表的各种操作(创建、插入、查找、删除、修改、遍历打印、释放内存空间)
目录 线性表的定义及其基本操作(顺序表插入、删除、查找、修改) 四、线性表的链接存储结构 1. 单链表 2. 循环链表 a. 循环链表节点结构体 b. 创建新节点 c. 在循环链表末尾插入节点 d. 删除循环链表中指定值的节点 e. 在循环链表中查找指定值的…...

项目通用pom.xml文件模版
pom.xml模版文件 <?xml version"1.0" encoding"UTF-8"?><project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/…...
短视频矩阵系统源码---开发
一、智能剪辑、矩阵分发、无人直播、爆款文案于一体独立应用开发 抖去推----主要针对本地生活的----移动端(小程序软件系统,目前是全国源头独立开发),开发功能大拆解分享,功能大拆解: 7大模型剪辑法(数学阶乘&#x…...
vue3点击表格某个单元格文本就切换成输入框,其他单元格不变化
<el-table :data"data.tableData" height"60vh" border scrollbar-aways-on><el-table-column label"序号" type"index" width"80" fixed /><el-table-column label"操作" width"120" f…...

021、智能体框架实战:用LangChain构建第一个Agent
一、从一次深夜调试说起 上周三凌晨两点,我在给一个客户演示前的最后一轮测试中遇到了诡异的问题:Agent明明收到了用户查询,却始终卡在“思考中”状态,不输出任何动作。日志里只有一句“Agent stopped due to iteration limit”。折腾半小时才发现,我忘记给Agent的工具调…...

终极指南:如何彻底卸载Windows自带的Microsoft Edge浏览器
终极指南:如何彻底卸载Windows自带的Microsoft Edge浏览器 【免费下载链接】EdgeRemover A PowerShell script that correctly uninstalls or reinstalls Microsoft Edge on Windows 10 & 11. 项目地址: https://gitcode.com/gh_mirrors/ed/EdgeRemover …...

如何5步搞定RTAB-Map多相机视觉对齐:新手的完整实战指南
如何5步搞定RTAB-Map多相机视觉对齐:新手的完整实战指南 【免费下载链接】rtabmap RTAB-Map library and standalone application 项目地址: https://gitcode.com/gh_mirrors/rt/rtabmap RTAB-Map是一个强大的实时定位与建图开源库,特别擅长处理多…...

ArknightsGameResource:如何通过完整素材库提升明日方舟二次创作效率
ArknightsGameResource:如何通过完整素材库提升明日方舟二次创作效率 【免费下载链接】ArknightsGameResource 明日方舟客户端素材 项目地址: https://gitcode.com/gh_mirrors/ar/ArknightsGameResource 在明日方舟的二次创作生态中,无论是开发机…...

免费解锁QQ音乐加密文件:qmcdump终极使用完全指南
免费解锁QQ音乐加密文件:qmcdump终极使用完全指南 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 你是否曾经…...

鸿蒙ArkTS性能不够用?试试用Rust写个‘外挂’:手把手教你集成NAPI模块提升计算效率
鸿蒙ArkTS性能优化实战:用Rust打造高性能NAPI模块 ArkTS作为鸿蒙生态的主力开发语言,在UI构建和业务逻辑处理上表现出色,但遇到复杂计算任务时,性能瓶颈往往成为开发者的痛点。本文将带你深入探索如何通过Rust编写NAPI原生模块&am…...

从Betaflight到PX4:Kakute H7飞控固件刷写实战与避坑指南
1. 为什么需要从Betaflight迁移到PX4? 如果你正在使用Holybro Kakute H7飞控,可能已经习惯了Betaflight系统的简洁高效。但当你需要更复杂的自主飞行功能时,PX4生态系统的优势就显现出来了。Betaflight更适合竞速和花式飞行,而PX4…...

详解计算机网络三大数据交换技术:电路交换、报文交换、分组交换考点全复盘
详解计算机网络三大数据交换技术:电路交换、报文交换、分组交换考点全复盘 作者:培风图南以星河揽胜本文适配国考金管局计算机岗、软考网络工程师、计算机考研408、计算机等级考试、网工面试高频必考核心知识点,从一道经典易错题深度切入&…...

避开蓝桥杯单片机ADC采样的那些坑:PCF8591 I2C通信与光敏电阻电压读取详解
蓝桥杯单片机ADC采样实战:PCF8591光敏电阻数据采集全解析 当光敏电阻的数值始终显示255,或者I2C通信死活不响应时,很多单片机初学者会忍不住反复检查接线——但其实八成是时序问题。我们团队带过上百个蓝桥杯选手,发现ADC采样这个…...
)
告别旧版Ubuntu!在Ubuntu 24.04 LTS上为i.MX6ULL开发板编译U-Boot 2022.04(含设备树)
在Ubuntu 24.04 LTS上为i.MX6ULL开发板构建U-Boot 2022.04全流程指南 当现代开发环境遇上经典嵌入式硬件,总会碰撞出意想不到的火花。最近在为一款基于NXP i.MX6ULL处理器的工业控制设备升级固件时,我遇到了一个典型困境:客户要求使用最新的U…...