[翻译]理解Postgres的IOPS:为什么数据即使都在内存,IOPS也非常重要
理解Postgres的IOPS:为什么数据即使都在内存,IOPS也非常重要
磁盘IOPS(每秒输入/输出操作数)是衡量磁盘系统性能的关键指标。代表每秒可以执行的读写操作数量。对于严重依赖于磁盘访问的PG来说,了解和优化磁盘IOPS对实现最佳性能至关重要。本文讨论IOPS相关主题:IOPS是什么、如何影响PG、如何衡量它以及需要如何调优。
1、PG的IOPS是什么
从高层次看,一个IO操作要么是读数据(“Input”)请求,要么是写数据到磁盘的请求(“Output”),通常以每秒操作数来衡量。
你可能看到WOPS(每秒写操作数)或者ROPS(每秒读操作数)。一般来说,当谈论IOPS时,我们指特定磁盘卷上的读和写操作的综合。这是由操作系统处理的低级操作,应用程序(包括PG)不比担心单个操作可以读取或写入多少数据,甚至不比担心涉及哪种磁盘。事实上,就磁盘而言,操作系统本身通常处理一个抽象 - 它看到一个附加的块设备,该块设备处理读取或写入数据的请求,并且不必担心它是如何实现的。
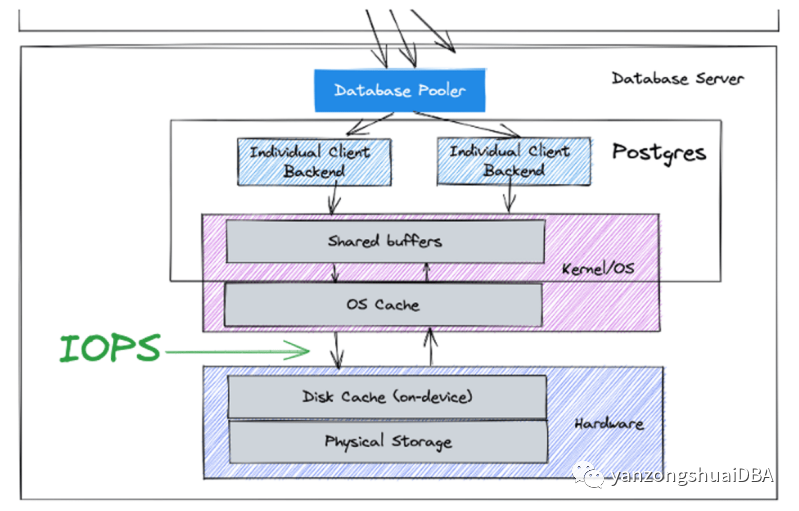
我们数据流介绍:https://www.crunchydata.com/blog/postgres-data-flow 中:数据存储在内存,一些读写请求会达到磁盘。即上图中“Hardware”层,任何数据跨越该层都意味着发生磁盘操作(IOPS)。
当访问数据库时,数据库服务有两种操作选择:
1)返回PG内部cache的数据,即shared_buffers中的数据
2)如果数据不在cache,则需要让操作系统从磁盘读取
当从磁盘读取数据时,操作系统负责处理读取请求并将数据返回给请求进程。所有现代操作系统 - 包括 PostgreSQL 支持的所有操作系统 - 将尝试使用系统内存来缓存磁盘数据,以便从应用程序的角度加速这些请求。这意味着如果您的工作集大于RAM,则磁盘I/O对性能的影响会更大。
2、即使数据在内存,也会使用IOPS
读写磁盘时发生Input和output。如果整个数据都在内存中,还会有IOPS吗?有几个PG操作可能会使用IO,这里列出几点包括:
1)检查点:表文件的脏页需要写到磁盘
2)写WAL日志,以及相关事务控制文件
3)备份
4)读数据到buffer cache中
5)创建或刷新物化视图
6)手动vacuum或者autovacuum:读并且可能修改数据
7)创建索引
8)查询产生临时文件
9)PG15之前版本,数据库统计操作
3、IOPS容量及突发IOPS
磁盘本身将具有 IOPS 容量,这是底层磁盘的一部分。系统可以处理的IOPS数量是有限的,这是操作系统基本配置和硬件限制。
许多基于云的系统允许IOPS爆发,以便可以在一天中某些时间或繁重工作负载时超出基本I/O。通常,突发系统可以让您在一天或一周内累积积分,然后如果您的系统需要超出基本 I/O,您可以使用更多 I/O,直到您完成已建立的突发。
突发I/O允许根据典型使用情况而不是峰值使用情况来配置 IOPS 容量,并且在活动高峰发生时仍然具有突发容量。这可以为您带来更好的价值 - 在某些情况下允许客户每月配置较小的实例并实现成本节省 - 但也有一个显着的缺点。如果您不仔细监控 IOPS 和突发配额使用情况,那么您可能会耗尽突发容量,此时性能将被限制在某个基线。这种情况只会在您已经爆发时发生,因此对性能的影响往往很大,并可能导致中断。
即使您使用不具有突发 IOPS 而是使用提供一致、有保证性能的磁盘,各个云提供商上的某些实例类型也具有其他 I/O 突发功能或缓存,这可能会影响所有磁盘 I/O 的性能。如果使用得当,这些功能可以提供巨大的价值,但同样需要注意 - 了解您的 IOPS 使用情况有哪些限制,并监控您是否正在接近这些限制。
4、IOPS和PG
IOPS可以衡量系统的繁忙程度,但当您接近系统使用限制时,请求可能需要更长时间才能完成,甚至开始排队,这称为 I/O 等待。查询变得更慢,最终用户会遇到延迟。
I/O 限制意味着系统的性能受到 I/O 容量的限制。不同的应用程序工作负载具有不同的查询模式和性能限制,因此您的数据库可能会受到 CPU 限制或内存限制。了解哪些系统资源正在限制性能非常重要,这样当问题始终是磁盘 I/O 性能限制时,您就不会花费时间和金钱升级到具有更多 CPU 或 RAM 的服务器。
5、磁盘IO等待
判断系统是否达到IO瓶颈的一个最佳指标是观察系统的CPU指标中是否出现IO等到。IO等到时间(通常写为iowait)是在有待处理的IO请求时,CPU的空闲时间,即当前运行进程还有可用的CPU容量,但是进程正在等到磁盘请求响应。如果这种情况频繁发生,就意味着磁盘子系统无法跟上请求,因此CPU在本可以工作时却处于空闲状态。
可以使用PG插件pg_proctab从数据库内部访问 /proc 虚拟文件系统下内核公开的各种统计信息。使用pg_cputime()函数可以找到百分之一秒内的IO等待。通常,您可以从服务器上的 shell 运行命令 getconf CLK_TCK 来检查确切的resolution。要获取系统花费在 I/O 等待上的时间百分比的时间点值,您可以运行:
SELECTto_char (iowait / (idle + "user" + system + iowait)::float * 100,'90.99%') AS iowait_pct
FROM
pg_cputime ();这会返回一个百分比数字,如下所示:
iowait_pct
------------
0.07%
(1 row)此处的数字非常小是正常的,除非系统负载很重,正在执行某种 I/O 密集型任务,例如运行备份或导入新数据。如果您经常看到 I/O 等待仅占整个系统时间的个位数百分比,则可能表明您超出了系统的 I/O 容量。
6、track_io_timing和pg_stat_database
track_io_timing 控制服务器是否收集 I/O 性能指标。这个是PG向操作系统发出的请求,和实际磁盘IO略有不同,实际磁盘IO可能发生IO合并。track_io_timing 与 EXPLAIN 命令的 BUFFERS 选项结合使用特别有用,这样您就可以看到执行查询时在磁盘 I/O 上花费了多少时间。这对性能调优很有用。默认情况下会禁用收集,因为某些系统配置对计时调用的开销很高,这意味着收集这些数据可能会对性能产生负面影响。
开启前可以使用pg_test_timing工具来检查下开启后对性能影响,开启后IO数据会写入pg_stat_database和explain plan buffers。
以下是大量IO的示例:
EXPLAIN (ANALYZE, BUFFERS)
SELECTCOUNT(id)
FROM
pages;QUERY PLAN
----------------------------------------------Finalize Aggregate (cost=369672.42..369672.43 rows=1 width=8) (actual time=6041.280..6044.729 rows=1 loops=1)Buffers: shared hit=12855 read=326149 dirtied=580I/O Timings: shared/local read=15953.695-> Gather (cost=369672.21..369672.42 rows=2 width=8) (actual time=6040.119..6044.696 rows=3 loops=1)Workers Planned: 2Workers Launched: 2Buffers: shared hit=12855 read=326149 dirtied=580I/O Timings: shared/local read=15953.695-> Partial Aggregate (cost=368672.21..368672.22 rows=1 width=8) (actual time=6019.362..6019.364 rows=1 loops=3)Buffers: shared hit=12855 read=326149 dirtied=580I/O Timings: shared/local read=15953.695-> Parallel Seq Scan on pages (cost=0.00..362738.57 rows=2373457 width=71) (actual time=2.644..5770.110 rows=1878348 loops=3)Buffers: shared hit=12855 read=326149 dirtied=580I/O Timings: shared/local read=15953.695Planning:Buffers: shared hit=30 dirtied=1Planning Time: 0.216 msJIT:Functions: 11Options: Inlining false, Optimization false, Expressions true, Deforming trueTiming: Generation 1.166 ms, Inlining 0.000 ms, Optimization 0.669 ms, Emission 19.474 ms, Total 21.309 msExecution Time: 6067.862 ms下面是数据从共享缓冲读取的示例:
QUERY PLAN
--------------------------------------------------------------------------------------------Aggregate (cost=746.64..746.65 rows=1 width=8) (actual time=5.224..5.225 rows=1 loops=1)Buffers: shared hit=508-> Seq Scan on nyc_streets (cost=0.00..698.91 rows=19091 width=11) (actual time=0.003..1.428 rows=19091 loops=1)Buffers: shared hit=508Planning:Buffers: shared hit=72Planning Time: 0.238 msExecution Time: 5.308 ms
(8 rows)track_io_timing 还将开始收集多个视图的统计信息,包括 pg_stat_database、pg_stat_all_tables、pg_stat_user_tables。此数据显示块读取(使用的 I/O)和块命中(数据已位于共享缓冲区中)。数据持续更新,通常会找与块命中相比读取块非常高的用户表。
SELECT*
FROM
pg_statio_user_tables;
relid | schemaname | relname | heap_blks_read | heap_blks_hit | idx_blks_read | idx_blks_hit | toast_blks_read | toast_blks_hit | tidx_blks_read | tidx_blks_hit
--------+--------------------+----------------------------------------------------------+----------------+---------------+---------------+--------------+-----------------+----------------+----------------+---------------16716 | segment_production | tracks | 50209 | 5295312 | 1380 | 67935 | 4 | 313 | 5 | 31916836 | segment_production | access_token_created | 25354 | 489153 | 66 | 31543 | 0 | 0 | 0 | 016590 | production | access_token_created | 2765 | 63595 | 2 | 318 | 0 | 0 | 0 | 016626 | production | api_key_created | 4 | 136 | 2 | 318 | 0 | 0 | 0 | 0将这些统计信息转换为字节而不是使用块单位会很有帮助,特别是当统计信息进入全堆栈分析工具时。虽然有适用于某些统计数据的可变块大小设置,但大多数 PostgreSQL 的缓冲区高速缓存个数(包括EXPLAIN BUFFERS)将基于数据库的固定页面大小 8192。
7、PG16中的pg_stat_io
包含一个名为pg_stat_io的新系统视图 ,它提供磁盘 I/O 的每个集群视图。与大多数系统视图一样,这些统计数据是累积的,记录自上次在此服务器上重置统计数据以来的所有 I/O 活动。这看起来像:
SELECT*
FROMpg_stat_io
WHEREreads > 0
OR writes > 0;backend_type | object | context | reads | read_time | writes | write_time | writebacks | writeback_time | extends | extend_time | op_bytes | hits | evictions | reuses | fsyncs | fsync_time | stats_reset
--------------------+----------+----------+-------+-----------+--------+------------+------------+----------------+---------+-------------+----------+-------+-----------+--------+--------+------------+-------------------------------autovacuum worker | relation | normal | 29 | 0 | 0 | 0 | 0 | 0 | 14 | 0 | 8192 | 10468 | 0 | | 0 | 0 | 2023-09-06 14:32:36.930008-05autovacuum worker | relation | vacuum | 13 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 8192 | 379 | 0 | 0 | | | 2023-09-06 14:32:36.930008-05client backend | relation | bulkread | 926 | 0 | 0 | 0 | 0 | 0 | | | 8192 | 14 | 0 | 137 | | | 2023-09-06 14:32:36.930008-05client backend | relation | normal | 105 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 8192 | 7110 | 0 | | 0 | 0 | 2023-09-06 14:32:36.930008-05checkpointer | relation | normal | | | 1031 | 0 | 0 | 0 | | | 8192 | | | | 320 | 0 | 2023-09-06 14:32:36.930008-05standalone backend | relation | normal | 535 | 0 | 1019 | 0 | 0 | 0 | 673 | 0 | 8192 | 88526 | 0 | | 0 | 0 | 2023-09-06 14:32:36.930008-05standalone backend | relation | vacuum | 10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 8192 | 918 | 0 | 0 | | | 2023-09-06 14:32:36.930008-05请注意reads,虽然此视图中的和列中的数字writes确实对应于 PostgreSQL 发出的各个 I/O 操作,但如果您有单独的指标,这些数字可能与存储系统记录的值不匹配。操作系统甚至存储层可能会合并或拆分I/O请求,因此实际记录的数量可能会有所不同,具体取决于您查看的位置。因此,在调整或查看活动随时间的变化时,比较来自同一来源的数字非常重要。
pg_stat_io 表的另一个非常酷的事情是它将显示活动的“上下文”。因此 pg_stat_io 会将 I/O 使用情况分解为批量读取、批量写入、vacuum或正常工作活动等类别。如果您试图找出 I/O 峰值来自何处(例如大量读取,甚至可能是真空进程),这尤其有用。
pg_stat_io 还为自动启动者构建内部 I/O 跟踪并将其随着时间的推移存储在您自己的数据库中敞开了大门。
要重置所有服务器统计信息,请运行:SELECT pg_stat_reset();
pg_stat_statements 模块重置,运行:SELECT pg_stat_statements_reset;
原文
https://www.crunchydata.com/blog/understanding-postgres-iops
相关文章:
[翻译]理解Postgres的IOPS:为什么数据即使都在内存,IOPS也非常重要
理解Postgres的IOPS:为什么数据即使都在内存,IOPS也非常重要 磁盘IOPS(每秒输入/输出操作数)是衡量磁盘系统性能的关键指标。代表每秒可以执行的读写操作数量。对于严重依赖于磁盘访问的PG来说,了解和优化磁盘IOPS对实…...
Day6力扣打卡
打卡记录 统计无向图中无法互相到达点对数(并查集 / DFS) 链接 并查集 思路:用并查集将连通区域的连在一起,再遍历所有点,用hash表存储不同连通块的元素个数,然后 乘积和 便是答案。 注意: /…...

10月面试js基础
作用域 变量的可用范围 作用域链 保存的变量的使用顺序的一个链(也就是路线图), 被称为作用域链。 当在Javascript中使用一个变量的时候,首先Javascript引擎会尝试在当前作用域下去寻找该变量,如果没找到,再…...

研发日常踩坑-Mysql分页数据重复 | 京东云技术团队
踩坑描述: 写分页查询接口,order by和limit混用的时候,出现了排序的混乱情况 在进行第N页查询时,出现与第一前面页码的数据一样的记录。 问题 在MySQL中分页查询,我们经常会用limit,如:limit(0,20)表示查询第一页的…...

Ubuntu18.04安装QGC报错 `GLIBC_2.29‘ not found
按照官网教程,最后运行时出错。 /tmp/.mount_QGroun2NOhPP/QGroundControl: /lib/x86_64-linux-gnu/libm.so.6: version GLIBC_2.29 not found (required by /tmp/.mount_QGroun2NOhPP/QGroundControl) /tmp/.mount_QGroun2NOhPP/QGroundControl: /usr/lib/x86_64-…...

回归预测 | MATLAB实现BO-GRU贝叶斯优化门控循环单元多输入单输出回归预测
回归预测 | MATLAB实现BO-GRU贝叶斯优化门控循环单元多输入单输出回归预测 目录 回归预测 | MATLAB实现BO-GRU贝叶斯优化门控循环单元多输入单输出回归预测效果一览基本介绍模型搭建程序设计参考资料 效果一览 基本介绍 MATLAB实现BO-GRU贝叶斯优化门控循环单元回归预测。基于贝…...

Easyx趣味编程7,鼠标消息读取及音频播放
hello大家好,这里是dark flame master,今天给大家带来Easyx图形库最后一节功能实现的介绍,前边介绍了绘制各种图形及键盘交互,文字,图片等操作,今天就可以使写出的程序更加生动且容易操控。一起学习吧&…...
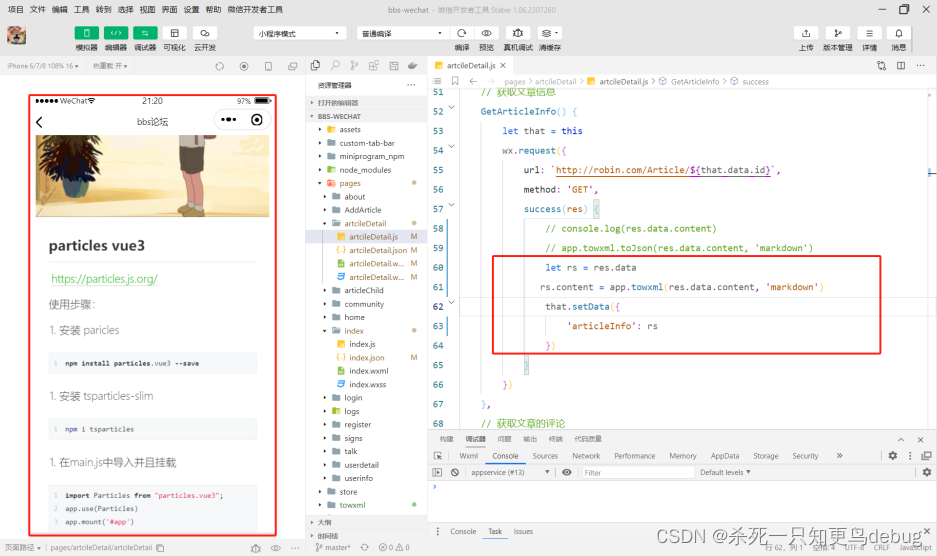
towxml的使用,在微信小程序中快速将markdown格式渲染为wxml文本
towxml的使用,在微信小程序中快速将markdown格式渲染为wxml文本 Towxml概述安装下载 Towxml在小程序中使用 towxml Towxml概述 towxml3.0 支持以下功能: ● echarts图表,默认禁用,需自行构建以开启此功能 ● LaTeX数学公式&#…...
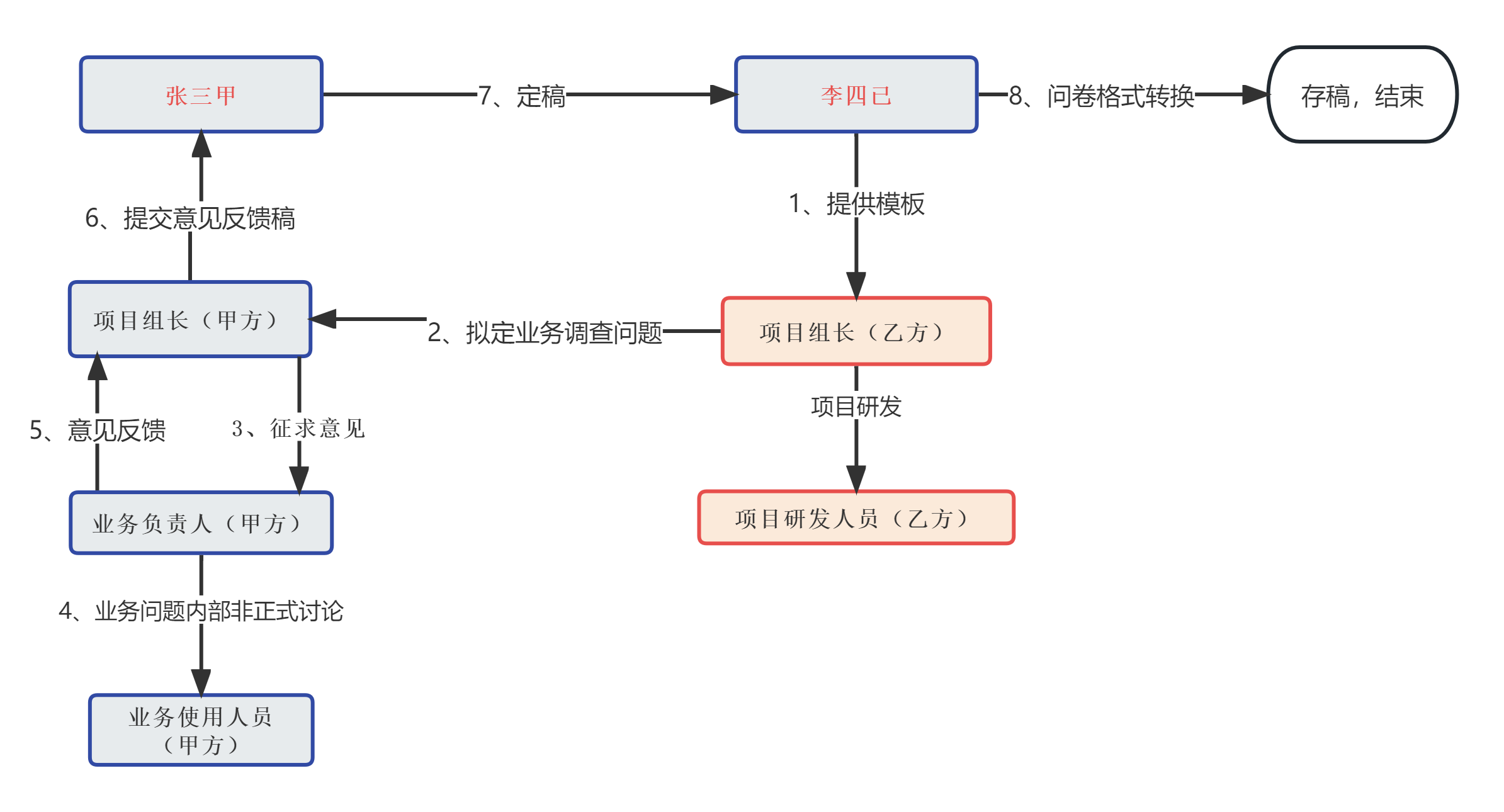
项目管理实战总结(一)-沟通路径问题
前言 那是2021年春节之后,我决定主动申请参与到这个项目,是知道工作强度大、难度大的情况的。有很多的同事是想躲,而我是明知山有虎偏向虎山行。我确定,通过这个项目,一定有我需要的东西。现在项目已经完成了终验专家…...

UE5场景逐渐变亮问题
1、显示 -- 关闭眼部适应 2、项目设置 -- 关闭自动曝光 参考: 虚幻5/UE5 场景亮度逐渐变亮完美解决方法 - 哔哩哔哩...
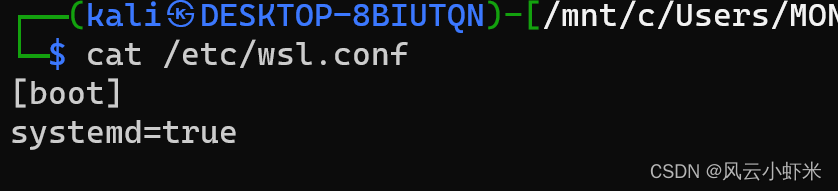
VM16Pro的Win10虚拟机安装Linux子系统Kali
VM16Pro的Win10虚拟机安装Linux子系统Kali 一、启用Windows功能二、配置WSL三、安装Kali四、安装kali基本工具包五、图形化六、适用的报错七、其他问题参考 一、启用Windows功能 启用后需重启二、配置WSL wsl --update #管理员启动Powershell执行,完成后将下面…...

C++中类的声明
C中类的声明 假设您要编写一个模拟人(如您自己)的程序。人有其特征:姓名、出生日期、出生地和性别(这些信息让每个人都是独一无二的),还能做某些事情,如交谈、自我介绍等。 要在程序中模拟人&…...
IDEA常用AI插件
只推荐免费的 一、对话式AI 1. ChatGPT GPT-4 - Bito AI Code Assistant ChatGPT GPT-4 - Bito AI Code Assistant 插件地址:https://plugins.jetbrains.com/plugin/18289-chatgpt-gpt-4–bito-ai-code-assistant支持自定义prompt支持解释代码支持生成代码注释支持…...

【LeetCode】每日一题最后一个单词的长度投票法求解多数元素异或操作符巧解只出现一次的数字整数反转
个人主页直达:小白不是程序媛 LeetCode系列专栏:LeetCode刷题掉发记 目录 LeetCode 58.最后一个单词的长度 LeetCode169.多数元素 LeetCode 136.出现一次的数字 LeetCode 7.整数反转 LeetCode 58.最后一个单词的长度 难度:简单 OJ链接…...
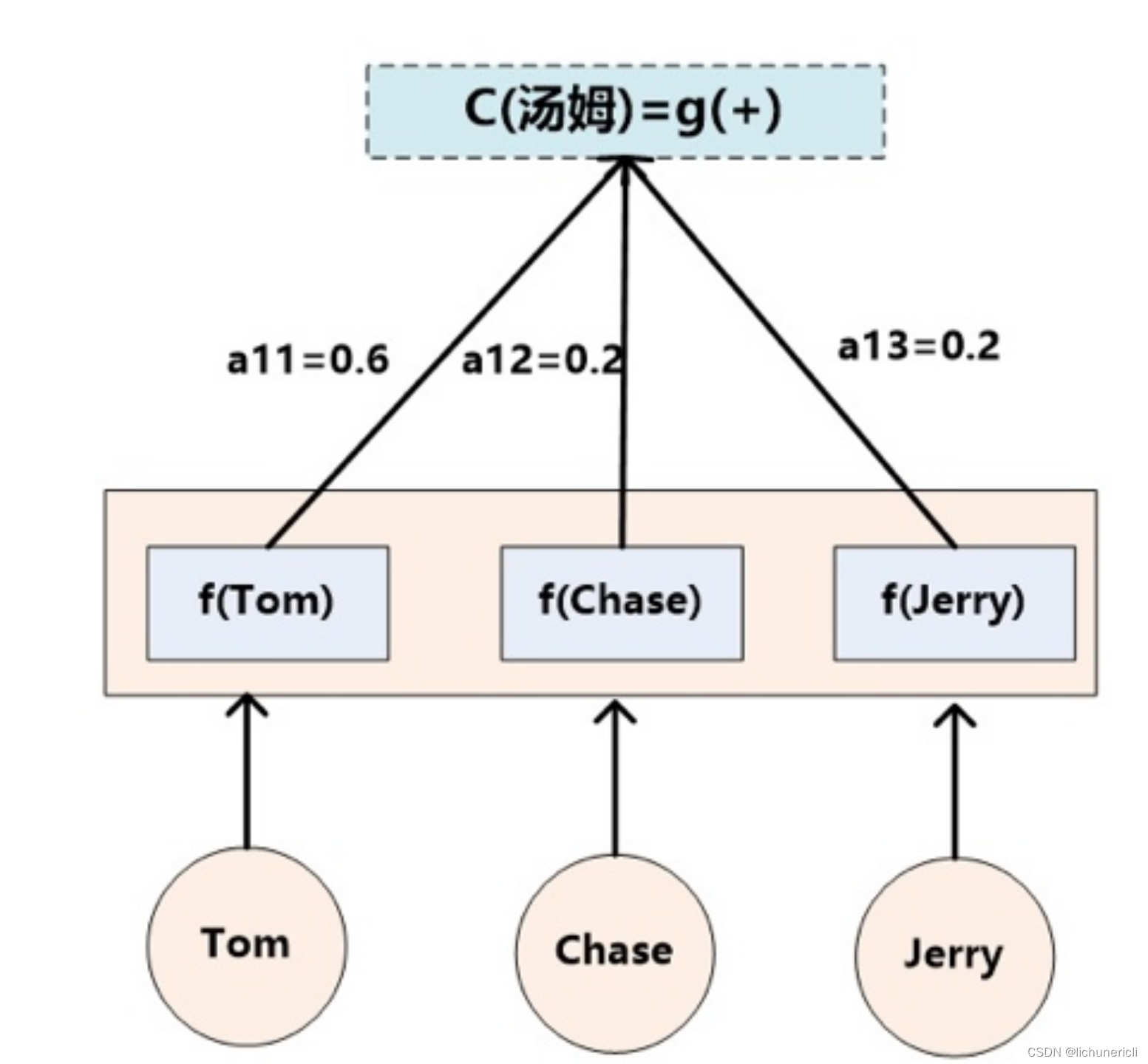
自然语言处理---注意力机制
注意力概念 观察事物时,之所以能够快速判断一种事物(当然允许判断是错误的),是因为大脑能够很快把注意力放在事物最具有辨识度的部分从而作出判断,而并非是从头到尾的观察一遍事物后,才能有判断结果。正是基于这样的理论…...
)
目标检测YOLO实战应用案例100讲-基于改进YOLO v7的智能振动分拣系统开发(续)
目录 3.2 引入EIOU损失函数 3.2.1 CIOU损失函数 3.3.2 基于Focal-EIOU损失函数的网络优化 编辑...

Ubuntu - 用户和权限
sudo sudo(Super User Do)是在Linux和Unix系统中用于执行具有超级用户(root)权限的命令的命令。它允许普通用户以特权身份运行特定命令,通常需要输入密码以确认其身份。 sudo 是一种安全的方式,用于限制哪…...

JAVA实现Jfilechooser搜索功能
JAVA实现Jfilechooser搜索功能 背景介绍需求描述思路和方法Java代码实现和注释相关知识点介绍视频演示结语 背景介绍 Java是一种面向对象的编程语言,广泛应用于各种应用程序开发中。文件搜索是我们在日常工作或者学习中经常会遇到的需求,比如查找某个文…...

iOS上架App Store的全攻略
第一步:申请开发者账号 在开始将应用上架到App Store之前,你需要申请一个开发者账号。 1.1 打开苹果开发者中心网站:Apple Developer 1.2 使用Apple ID和密码登录(如果没有账号则需要注册),要确保使用与公…...

线性代数3:矢量方程
一、前言 欢迎回到系列文章的第三篇文章,内容是线性代数的基础知识,线性代数是机器学习背后的基础数学。在我之前的文章中,我介绍了梯队矩阵形式。本文将介绍向量、跨度和线性组合,并将这些新想法与我们已经学到的内容联系起来。本…...

微服务 第四天
初识MQ 同步...

别再只用 .* 了!Sublime正则跨行匹配的坑与正确姿势:以清理代码注释块为例
Sublime Text正则跨行匹配实战:从清理代码注释到日志分析的深度指南 在代码编辑的日常工作中,我们常常需要处理各种跨行文本——从多行注释块到冗长的日志输出。许多开发者习惯性地使用.*来匹配任意字符,但当遇到换行符时就会束手无策。本文将…...

用户习惯报告:UG/NX用户使用习惯与模块偏好分析
又抢不到软件许可了?别急,别急,我来跟你唠唠过往在项目上线前,我跟团队蹲在机房门口,眼巴巴看着别人用着许可,自己这边却偏偏连个空位都抢不到。你说心塞不?这一年的加班,一半是赶进…...
)
避开这3个坑,你的51单片机电子秤项目就能一次成功(HX711校准心得)
51单片机电子秤项目实战:HX711模块避坑指南与精准校准技巧 第一次用51单片机做电子秤的朋友,十有八九会在HX711模块上栽跟头。上周实验室来了个学弟,拿着他的"蹦极秤"找我求助——放上200g砝码显示175g,空载时数值自己跳…...

终极指南:用MediaCreationTool.bat一键创建Windows安装媒体,支持1507到23H2全版本
终极指南:用MediaCreationTool.bat一键创建Windows安装媒体,支持1507到23H2全版本 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirro…...
)
用Python和Scapy复现SEED实验:手把手教你搭建ARP欺骗攻击靶场(含完整代码)
从零构建ARP欺骗实验环境:PythonScapy实战指南 在虚拟化技术普及的今天,搭建一个安全的网络攻防实验环境变得前所未有的简单。ARP欺骗作为局域网攻击的经典手段,不仅是网络安全课程的必修内容,更是理解二层网络通信原理的绝佳案例…...

Blender 4.0 新手避坑指南:从安装到第一个立方体,辣椒酱教程没讲的10个细节
Blender 4.0 新手避坑指南:从安装到第一个立方体 第一次打开Blender时,那个充满按钮、菜单和英文术语的界面确实容易让人望而生畏。作为一个从零开始学习Blender的过来人,我完全理解这种困惑——明明只是想建个简单的立方体,却被各…...

Android Studio中文界面汉化终极指南:五分钟实现母语开发环境
Android Studio中文界面汉化终极指南:五分钟实现母语开发环境 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还在为A…...

如何用Qwerty Learner打造高效双语键盘肌肉记忆系统
如何用Qwerty Learner打造高效双语键盘肌肉记忆系统 【免费下载链接】qwerty-learner 为键盘工作者设计的单词记忆与英语肌肉记忆锻炼软件 / Words learning and English muscle memory training software designed for keyboard workers 项目地址: https://gitcode.com/GitH…...

终极指南:如何使用Harepacker-resurrected高效编辑MapleStory游戏资源
终极指南:如何使用Harepacker-resurrected高效编辑MapleStory游戏资源 【免费下载链接】Harepacker-resurrected All in one .wz file/map editor for MapleStory game files 项目地址: https://gitcode.com/gh_mirrors/ha/Harepacker-resurrected 你是否曾因…...