自然语言处理---注意力机制
注意力概念
观察事物时,之所以能够快速判断一种事物(当然允许判断是错误的),是因为大脑能够很快把注意力放在事物最具有辨识度的部分从而作出判断,而并非是从头到尾的观察一遍事物后,才能有判断结果。正是基于这样的理论,就产生了注意力机制。
注意力计算规则
-
需要三个指定的输入Q(query),K(key),V(value),然后通过计算公式得到注意力的结果,这个结果代表query在key和value作用下的注意力表示。当输入的Q=K=V时,称作自注意力计算规则。
- 假如有一个问题:给出一段文本,使用一些关键词对它进行描述
- 为了方便统一正确答案,这道题可能预先已经给出了一些关键词作为提示,其中这些给出的提示就可以看作是key,而整个的文本信息就相当于是query,value的含义则更抽象,可以比作是看到这段文本信息后,脑子里浮现的答案信息。
- 假设第一次看到这段文本后,脑子里基本上浮现的信息就只有提示这些信息,因此key与value基本是相同的,但是随着对问题的深入理解,通过思考,脑子里想起来的东西原来越多,并且能够开始对我们query也就是这段文本,提取关键信息进行表示。
- 以上就是注意力作用的过程,通过这个过程,最终脑子里的value发生了变化,根据提示key生成了query的关键词表示方法,也就是另外一种特征表示方法。
- 通常key和value一般情况下默认是相同,与query是不同的,这种是一般的注意力输入形式,但有一种特殊情况,就是query与key和value相同,这种情况我们称为自注意力机制。
- 使用一般注意力机制,是使用不同于给定文本的关键词表示它。而自注意力机制,需要用给定文本自身来表达自己,也就是说需要从给定文本中抽取关键词来表述它,相当于对文本自身的一次特征提取。
常见的注意力计算规则:

注意力机制
- 注意力机制是注意力计算规则能够应用的深度学习网络的载体,同时包括一些必要的全连接层以及相关张量处理,使其与应用网络融为一体。使用自注意力计算规则的注意力机制称为自注意力机制。
- NLP领域中,当前的注意力机制大多数应用于seq2seq架构,即编码器和解码器模型。
注意力机制的作用
- 在解码器端的注意力机制:能够根据模型目标有效的聚焦编码器的输出结果,当其作为解码器的输入时提升效果。改善以往编码器输出是单一定长张量,无法存储过多信息的情况。
- 在编码器端的注意力机制:主要解决表征问题,相当于特征提取过程,得到输入的注意力表示。一般使用自注意力(self-attention)。
- 注意力机制在网络中实现的图形表示:
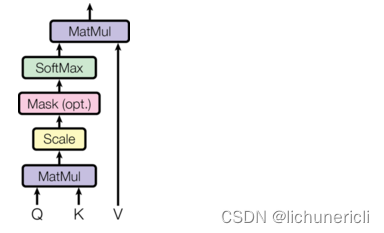
注意力机制实现步骤
- 第一步:根据注意力计算规则,对Q,K,V进行相应的计算。
- 第二步:根据第一步采用的计算方法,如果是拼接方法,则需要将Q与第二步的计算结果再进行拼接,如果是转置点积,一般是自注意力,Q与V相同,则不需要进行与Q的拼接。
- 第三步:最后为了使整个attention机制按照指定尺寸输出,使用线性层作用在第二步的结果上做一个线性变换,得到最终对Q的注意力表示。
注意力机制原理
注意力机制示意图
Attention机制的工作原理并不复杂,可以用下面这张图做一个总结:
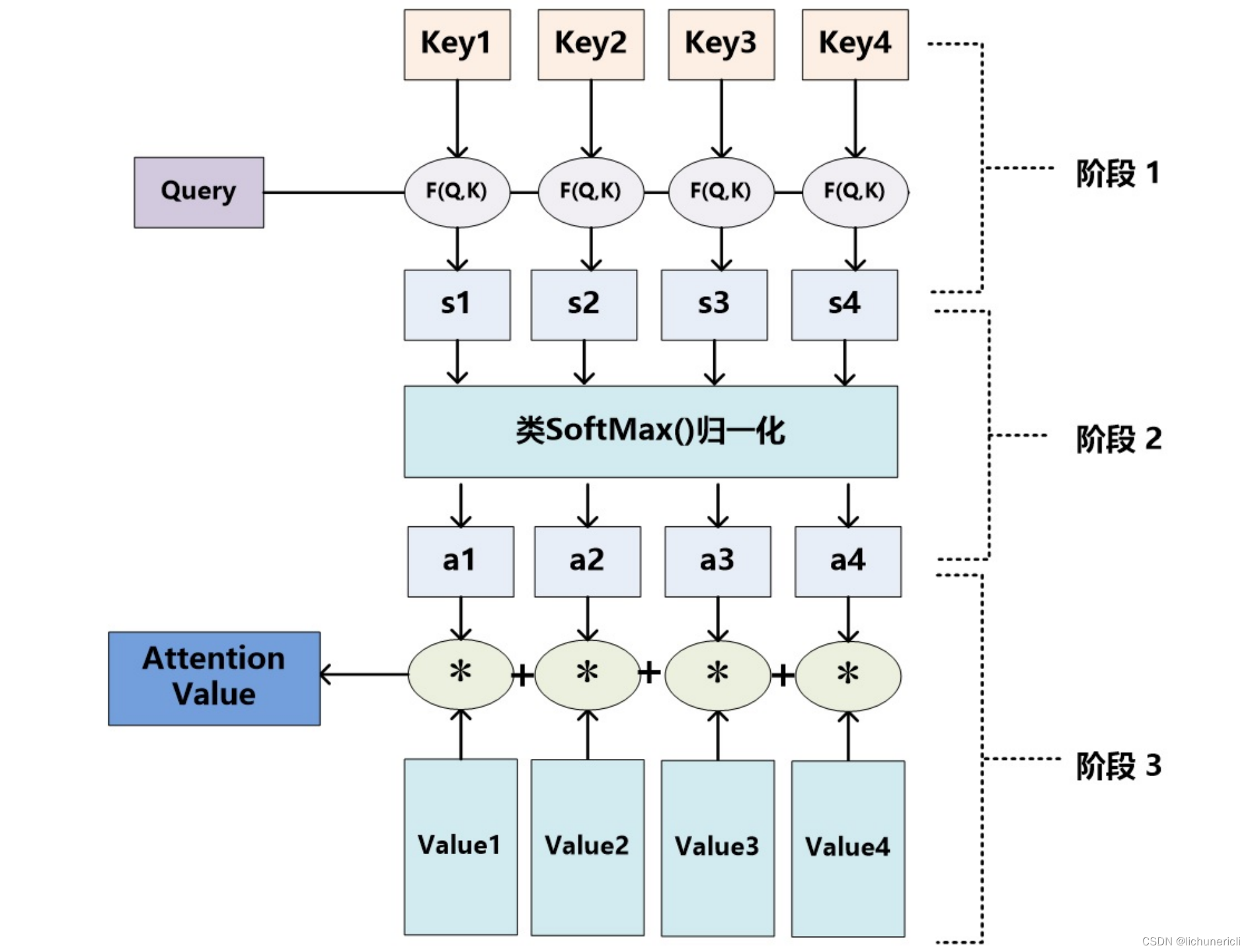
Attention计算过程
- 阶段一:query 和 key 进行相似度计算,得到一个query 和 key 相关性的分值
- 阶段二:将这个分值进行归一化(softmax),得到一个注意力的分布
- 阶段三:使用注意力分布和 value 进行计算,得到一个融合注意力的更好的 value 值
通过注意力来实现机器翻译(NMT) 的任务,机器翻译中,使用 seq2seq 的架构,每个时间步从词典里生成一个翻译的结果,如图:
在没有注意力之前,每次都是根据 Encoder 部分的输出结果来进行生成,提出注意力后,就是想在生成翻译结果时并不是看 Encoder 中所有的输出结果,而是先来看看想生成的这部分和哪些单词可能关系会比较大,关系大的多借鉴些;关系小的,少借鉴些。
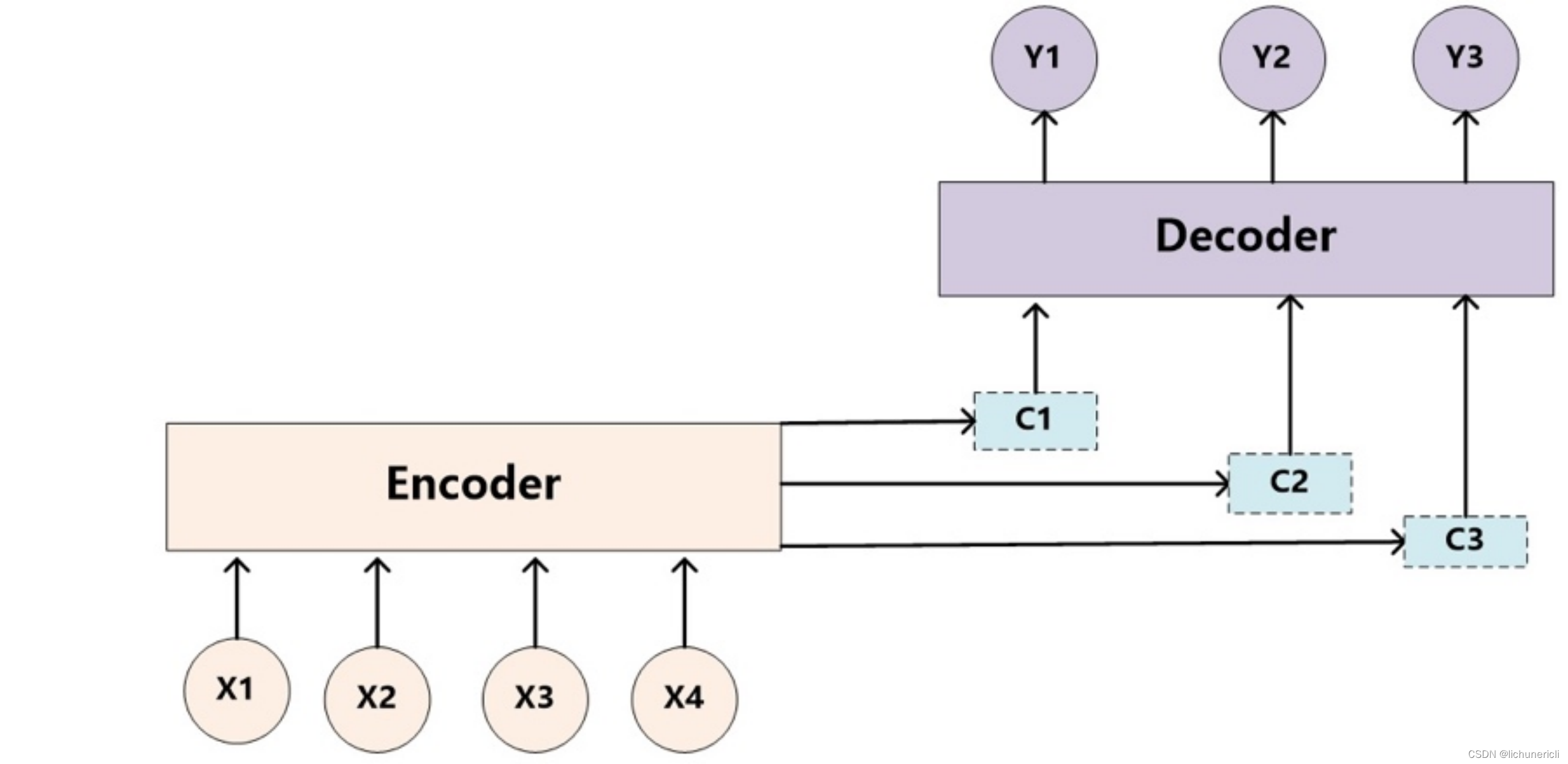
- 这里为了生成单词,把 Decoder 部分输入后得到的向量作为 query;把 Encoder 部分每个单词的向量作为 key。首先把 query 和 每一个单词进行点乘score=query⋅key,得到相关性的分值;
- 有了这些分值后,对这些分值做一个softmax,得到一个注意力的分布;
- 有了这个注意力,就可以用它和 Encoder 的输出值 (value) 进行相乘,得到一个加权求和后的值,这个值就包含注意力的表示,用它来预测要生成的词。
Attention计算逻辑
- query 和 key 进行相似度计算,得到一个query 和 key 相关性的分值
- 将这个分值进行归一化(softmax),得到一个注意力的分布
- 使用注意力分布和 value 进行计算,得到一个融合注意力的更好的 value 值
有无attention模型对比
无attention机制的模型

- 文本处理领域的Encoder-Decoder框架可以这么直观地去理解:可以把它看作适合处理由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。对于句子对,目标是给定输入句子Source,期待通过Encoder-Decoder框架来生成目标句子Target。Source和Target可以是同一种语言,也可以是两种不同的语言。而Source和Target分别由各自的单词序列构成:Source=〈X1,X2⋯Xm〉,Target=〈y1,y2⋯yn〉
- encoder顾名思义就是对输入句子Source进行编码,将输入句子通过非线性变换转化为中间语义表示C:C=F(X1,X2⋯Xm)
- 对于解码器Decoder来说,其任务是根据句子Source的中间语义表示C和之前已经生成的历史信息,y_1,y_2…y_i-1来生成i时刻要生成的单词y_i,yi=G(C,y1,y2⋯yi−1)
- 上述图中展示的Encoder-Decoder框架是没有体现出“注意力模型”的,所以可以把它看作是注意力不集中的分心模型。为什么说它注意力不集中呢?请观察下目标句子Target中每个单词的生成过程如下:y1=f(C),y2=f(C,y1),y3=f(C,y1,y2)
- 其中f是Decoder的非线性变换函数。从这里可以看出,在生成目标句子的单词时,不论生成哪个单词,它们使用的输入句子Source的语义编码C都是一样的,没有任何区别。
- 每个yi都依次这么产生,那么看起来就是整个系统根据输入句子Source生成了目标句子Target。如果Source是中文句子,Target是英文句子,那么这就是解决机器翻译问题的Encoder-Decoder框架;如果Source是一篇文章,Target是概括性的几句描述语句,那么这是文本摘要的Encoder-Decoder框架;如果Source是一句问句,Target是一句回答,那么这是问答系统或者对话机器人的Encoder-Decoder框架。由此可见,在文本处理领域,Encoder-Decoder的应用领域相当广泛。
- 问题点是:语义编码C是由句子Source的每个单词经过Encoder 编码产生的,这意味着不论是生成哪个单词,还是,其实句子Source中任意单词对生成某个目标单词yi来说影响力都是相同的,这是为何说这个模型没有体现出注意力的缘由。这类似于人类看到眼前的画面,但是眼中却没有注意焦点一样。
有attention机制的模型
- 如果拿机器翻译来解释这个分心模型的Encoder-Decoder框架更好理解,比如输入的是英文句子:Tom chase Jerry,Encoder-Decoder框架逐步生成中文单词:“汤姆”,“追逐”,“杰瑞”。在翻译“杰瑞”这个中文单词的时候,分心模型里面的每个英文单词对于翻译目标单词“杰瑞”贡献是相同的,很明显这里不太合理,显然“Jerry”对于翻译成“杰瑞”更重要,但是分心模型是无法体现这一点的,这就是为何说它没有引入注意力的原因。
- 没有引入注意力的模型在输入句子比较短的时候问题不大,但是如果输入句子比较长,此时所有语义完全通过一个中间语义向量来表示,单词自身的信息已经消失,可想而知会丢失很多细节信息,这也是为何要引入注意力模型的重要原因。
- 如果引入Attention模型的话,应该在翻译“杰瑞”的时候,体现出英文单词对于翻译当前中文单词不同的影响程度,比如给出类似下面一个概率分布值:(Tom,0.3),(Chase,0.2),(Jerry,0.5)。每个英文单词的概率代表了翻译当前单词“杰瑞”时,注意力分配模型分配给不同英文单词的注意力大小。这对于正确翻译目标语单词肯定是有帮助的,因为引入了新的信息。
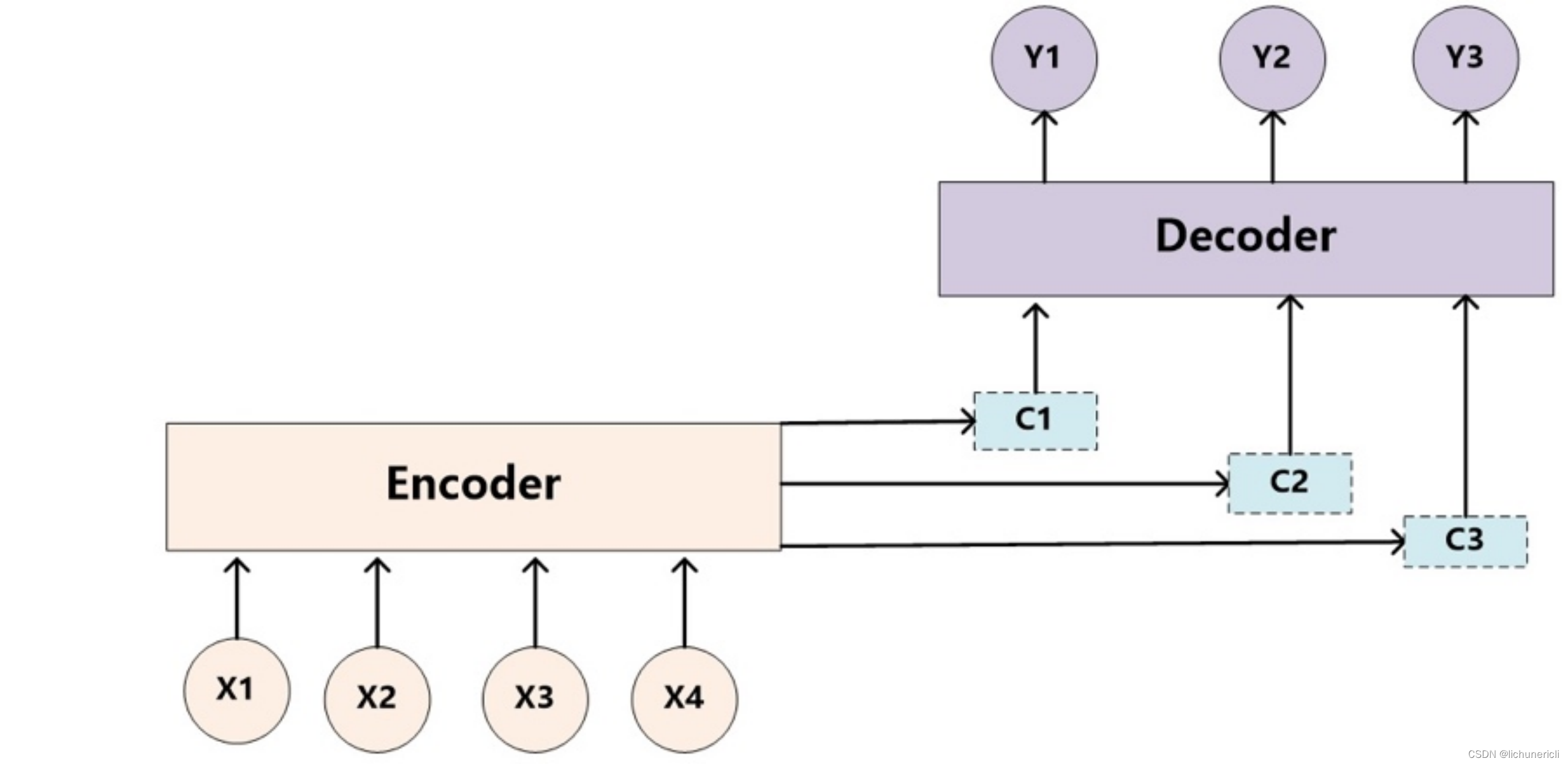
- 目标句子中的每个单词都应该学会其对应的源语句子中单词的注意力分配概率信息。这意味着在生成每个单词的时候,原先都是相同的中间语义表示C会被替换成根据当前生成单词而不断变化的。理解Attention模型的关键就是这里,即由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的。增加了注意力模型的Encoder-Decoder框架,如下图:
- 即生成目标句子单词的过程成了下面的形式:y1=f1(C1),y2=f1(C2,y1),y3=f1(C3,y1,y2)
- 而每个Ci可能对应着不同的源语句子单词的注意力分配概率分布,比如对于上面的英汉翻译来说,其对应的信息可能如下:
- f2函数代表Encoder对输入英文单词的某种变换函数,比如如果Encoder是用的RNN模型的话,这个f2函数的结果往往是某个时刻输入后隐层节点的状态值;g代表Encoder根据单词的中间表示合成整个句子中间语义表示的变换函数,一般的做法中,g函数就是对构成元素加权求和,即下列公式:
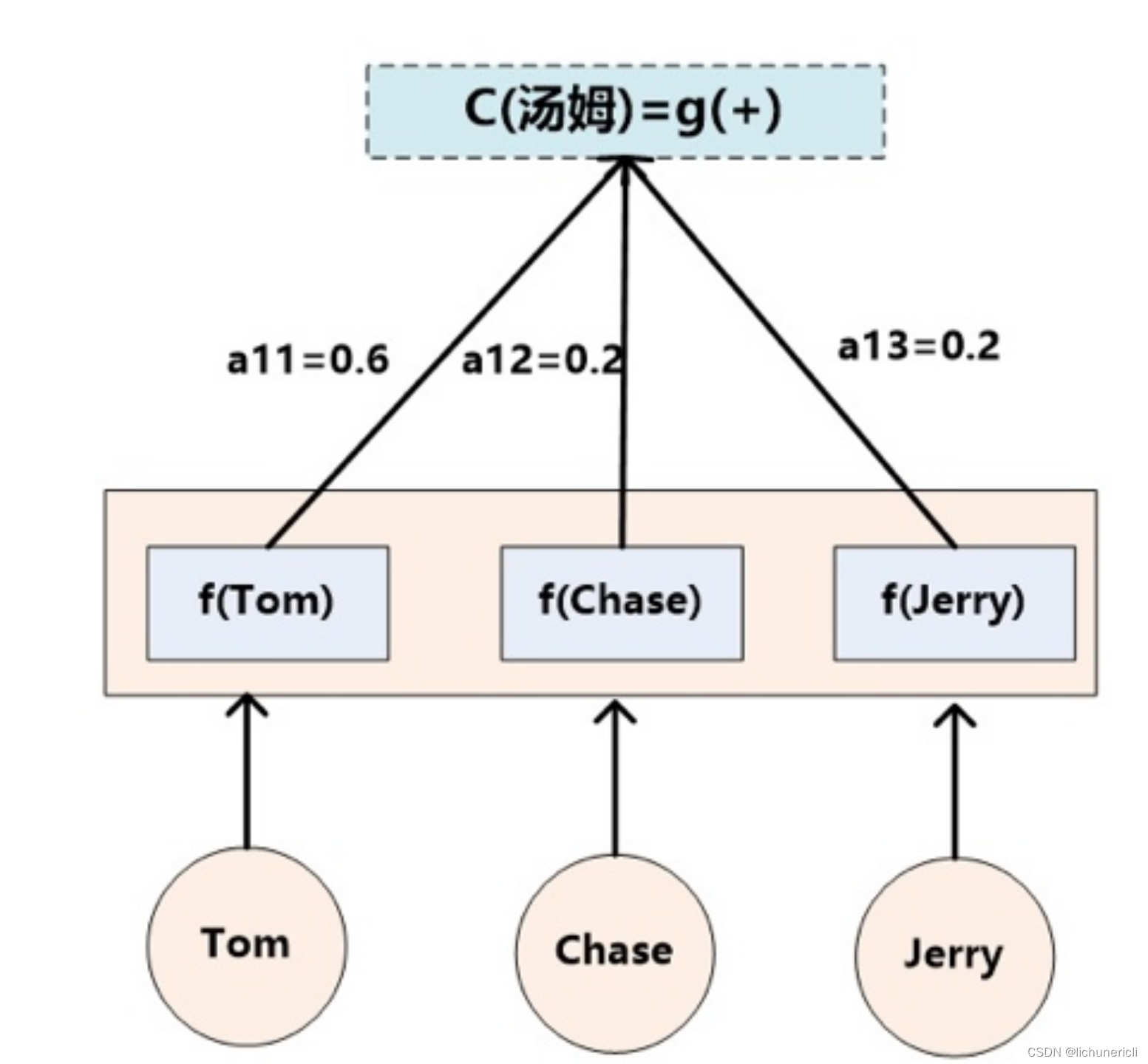
- Lx代表输入句子source的长度, a_ij代表在Target输出第i个单词时source输入句子中的第j个单词的注意力分配系数, 而hj则是source输入句子中第j个单词的语义编码, 假设Ci下标i就是上面例子所说的'汤姆', 那么Lx就是3, h1=f('Tom'), h2=f('Chase'),h3=f('jerry')分别输入句子每个单词的语义编码, 对应的注意力模型权值则分别是0.6, 0.2, 0.2, 所以g函数本质上就是加权求和函数, 如果形象表示的话, 翻译中文单词'汤姆'的时候, 数学公式对应的中间语义表示Ci的形成过程类似下图:
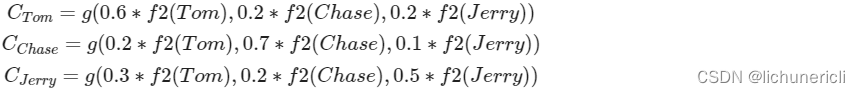

相关文章:
自然语言处理---注意力机制
注意力概念 观察事物时,之所以能够快速判断一种事物(当然允许判断是错误的),是因为大脑能够很快把注意力放在事物最具有辨识度的部分从而作出判断,而并非是从头到尾的观察一遍事物后,才能有判断结果。正是基于这样的理论…...
)
目标检测YOLO实战应用案例100讲-基于改进YOLO v7的智能振动分拣系统开发(续)
目录 3.2 引入EIOU损失函数 3.2.1 CIOU损失函数 3.3.2 基于Focal-EIOU损失函数的网络优化 编辑...

Ubuntu - 用户和权限
sudo sudo(Super User Do)是在Linux和Unix系统中用于执行具有超级用户(root)权限的命令的命令。它允许普通用户以特权身份运行特定命令,通常需要输入密码以确认其身份。 sudo 是一种安全的方式,用于限制哪…...

JAVA实现Jfilechooser搜索功能
JAVA实现Jfilechooser搜索功能 背景介绍需求描述思路和方法Java代码实现和注释相关知识点介绍视频演示结语 背景介绍 Java是一种面向对象的编程语言,广泛应用于各种应用程序开发中。文件搜索是我们在日常工作或者学习中经常会遇到的需求,比如查找某个文…...

iOS上架App Store的全攻略
第一步:申请开发者账号 在开始将应用上架到App Store之前,你需要申请一个开发者账号。 1.1 打开苹果开发者中心网站:Apple Developer 1.2 使用Apple ID和密码登录(如果没有账号则需要注册),要确保使用与公…...

线性代数3:矢量方程
一、前言 欢迎回到系列文章的第三篇文章,内容是线性代数的基础知识,线性代数是机器学习背后的基础数学。在我之前的文章中,我介绍了梯队矩阵形式。本文将介绍向量、跨度和线性组合,并将这些新想法与我们已经学到的内容联系起来。本…...

线性代数的本质笔记
课程来自b站发现的《线性代数的本质》,可以帮助从直觉层面理解线性代数的一些基础概念,以及把一些看似不同的数学概念解释之后,发现其实有内在的关联。 这里只对部分内容做一个记录,完整内容请自行观看视频~ 01-向量究竟是什么 …...
[SQL | MyBatis] MyBatis 简介
目录 一、MyBatis 简介 1、MyBatis 简介 2、工作流程 二、入门案例 1、准备工作 2、示例 三、Mapper 代理开发 1、问题简介 2、工作流程 3、注意事项 4、测试 四、核心配置文件 mybatis-config.xml 1、environment 2、typeAilases 五、基于 xml 的查询操作 1、…...
FreeRTOS介绍 和 将FreeRTOS移植到STM32F103C8T6
一、FreeRTOS 介绍 什么是 FreeRTOS ? Free即免费的,RTOS的全称是Real time operating system,中文就是实时操作系统。 注意:RTOS不是指某一个确定的系统,而是指一类操作系统。比如:uc/OS,Fr…...

zookeeper(目前只有安装)
安装 流程 学kafka的时候安装 Apache ZooKeeper 安装地址:https://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/apache-zookeeper-3.5.7-bin.tar.gz 解压 tar -zxvf kafka_2.12-3.0.0.tgz -C /export/server/ 改配置 cd config cp zoo_sample.cfg z…...
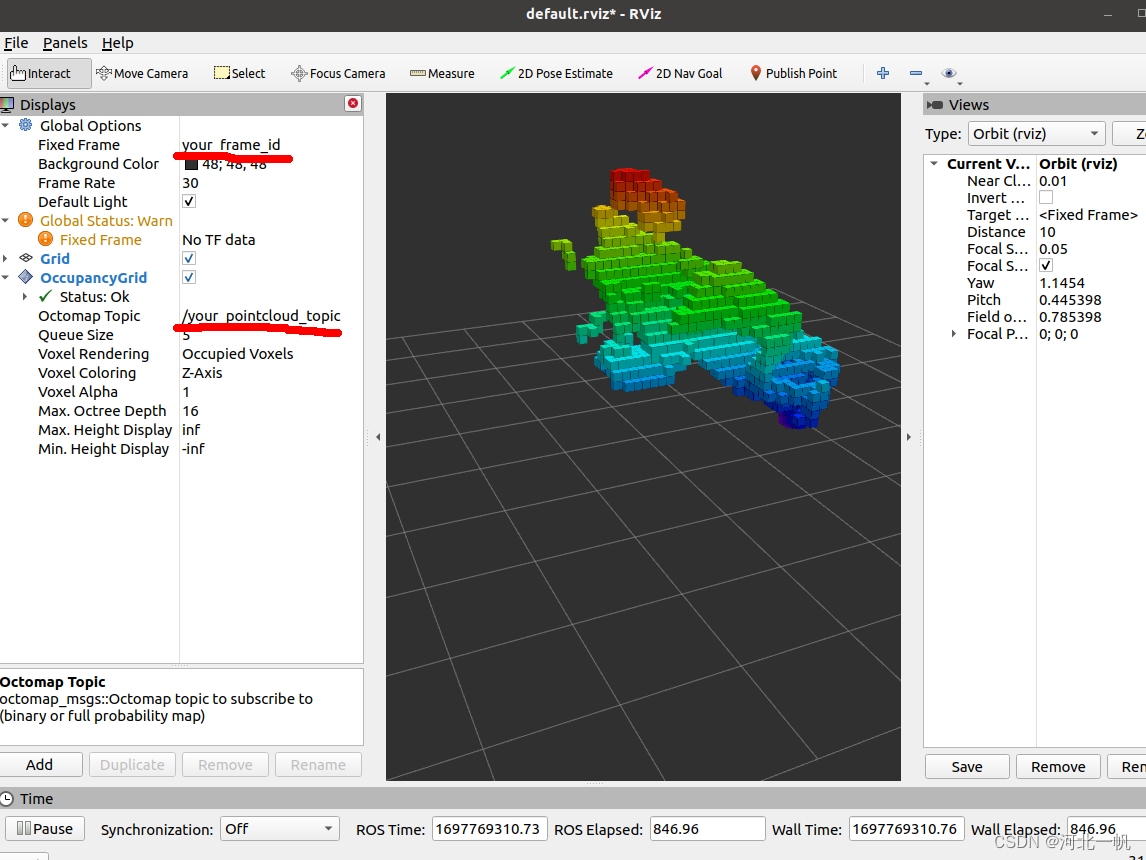
点云cloudpoint生成octomap的OcTree的两种方法以及rviz可视化
第一种:在自己的项目中将点云通过ros的topic发布,用octomap_server订阅点云消息,在octomap_server中生成ocTree 再用rviz进行可视化。 创建工作空间,记得source mkdir temp_ocotmap_test/src cd temp_ocotmap_test catkin_make…...
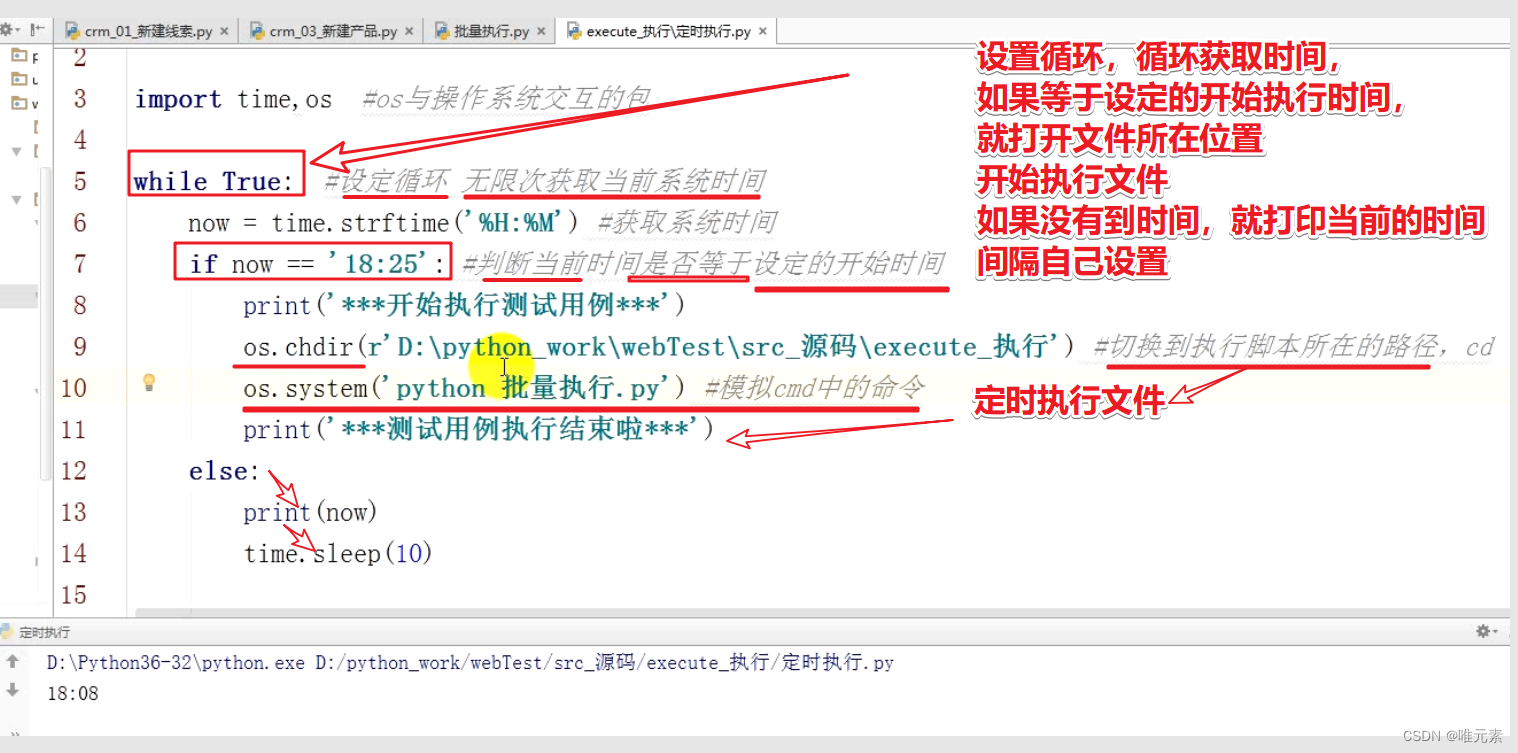
Python---死循环概念---while True
在编程中一个靠自身控制无法终止的程序称为“死循环”。 在Python中,我们也可以使用while True来模拟死循环: 代码: while True: print(每天进步一点点) 图示 应用: 比如,在测试里面,自动化测试用例…...
)
ElasticSearch容器化从0到1实践(问题汇总)
文章目录 ik插件如何安装?6.8.0版本JVM参数调整 ik插件如何安装? ik插件(中文分词插件)无法直接通过install指定插件名称的方式进行安装,可以通过指定zip包的方式对插件进行安装,需要注意的是通过zip包方式…...
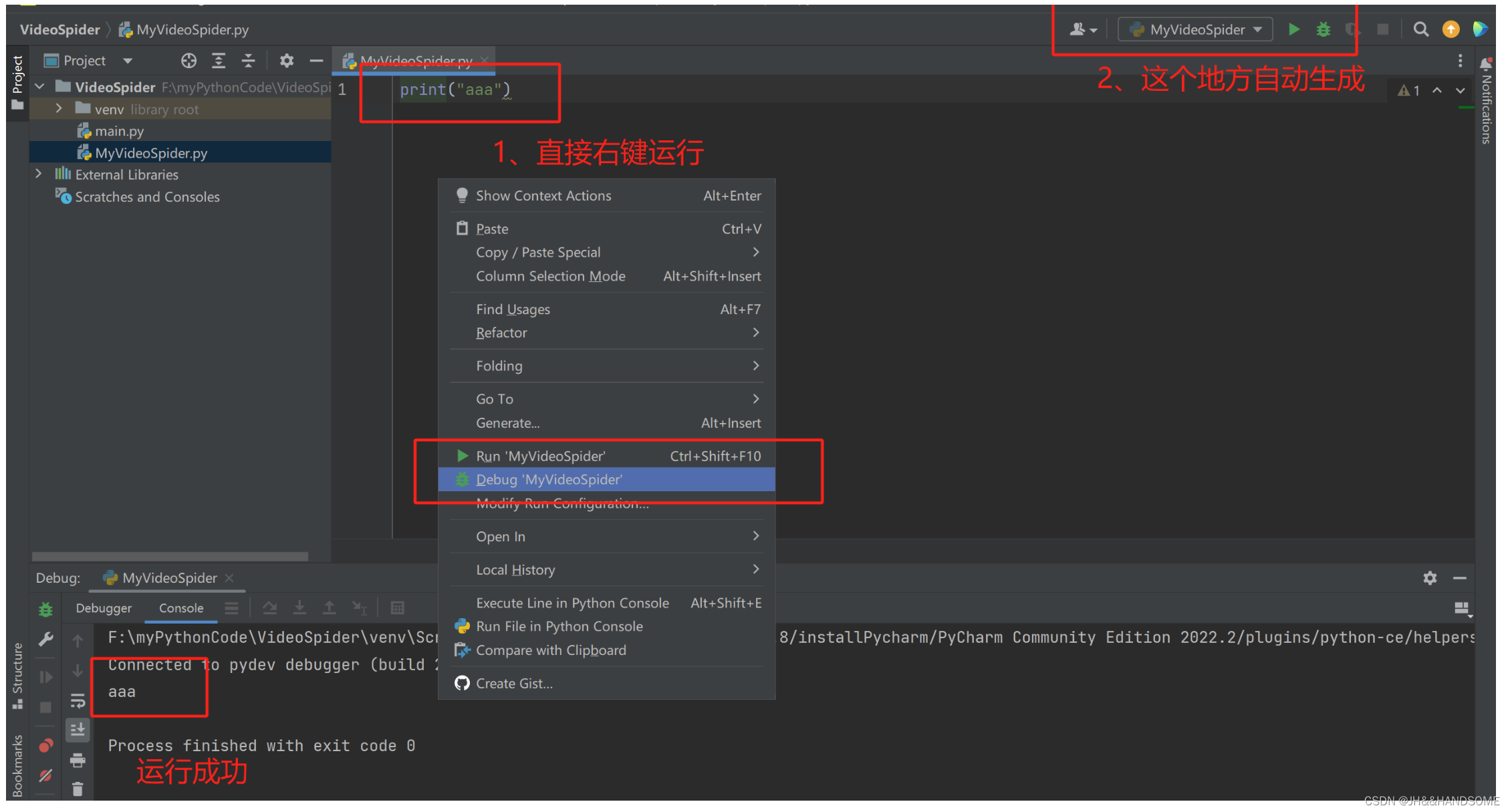
01、Python 安装 ,Pycharm 安装
目录 安装安装 Python安装 Pycharm 创建项目简单添加文件运行 简单爬取下载小视频 安装 python-3.8.10-amd64.exe – 先安装这个 pycharm-community-2022.2.exe 再安装这个 安装 Python python-3.8.10-amd64.exe 安装(这个是其他版本的安装,步骤一样…...
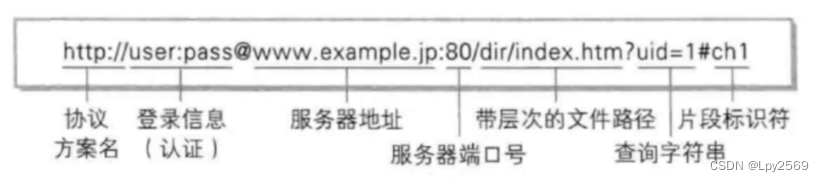
从输入URL到展示出页面
目录 了解URL 1. 输入URL 2. 域名解析 3. 建立连接 4. 服务器处理请求: 5. 返回响应: 6. 浏览器解析HTML: 7. 加载资源: 8. 渲染页面: 9. 执行JavaScript: 10. 页面展示: 从输入URL到…...

【C++】哈希的应用 -- 位图
文章目录 一、位图的概念二、位图的实现三、库中的 bitset四、位图的应用五、哈希切割 一、位图的概念 我们以一道面试题来引入位图的概念: 给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中 我…...
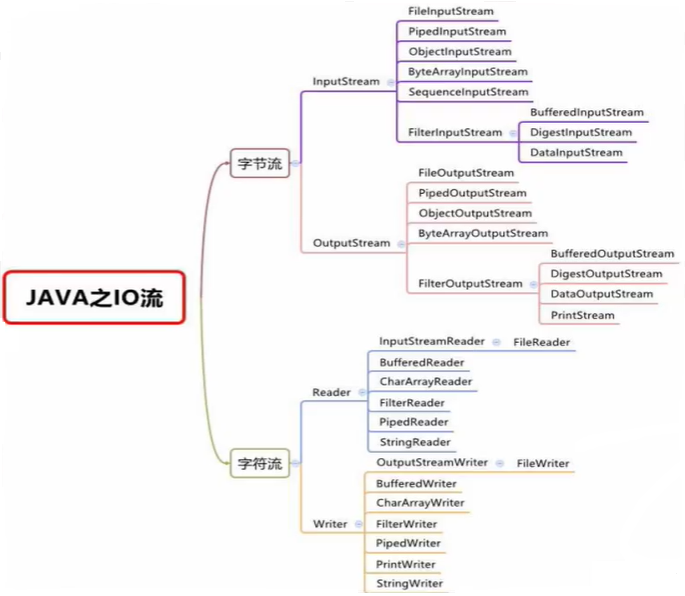
系列二、IO流原理及流的分类
一、概述 IO是Input、Output的缩写,IO流技术是非常实用的技术,用于处理数据传输,例如读写文件,网络通讯等。在Java程序中,对于数据的输入/输出操作以"流(stream)"的方式进行ÿ…...

【算法教程】排列与组合的实现
数据准备 在讲排列与组合之前,我们先定义数据元素类型Fruit class Fruit{constructor(name,price){this.name namethis.price price} }排列 对N个不同元素进行排序,总共有多少不同的排列方式? Step1: 从N个元素中取1个,共N种…...

uniapp实现简单的九宫格抽奖(附源码)
效果展示 uniapp实现大转盘抽奖 实现步骤: 1.该页面可设置8个奖品,每个奖品可设置中奖机会的权重,如下chance越大,中奖概率越高(大于0) // 示例代码 prizeList: [{id: 1,image: "https://img.alicdn…...
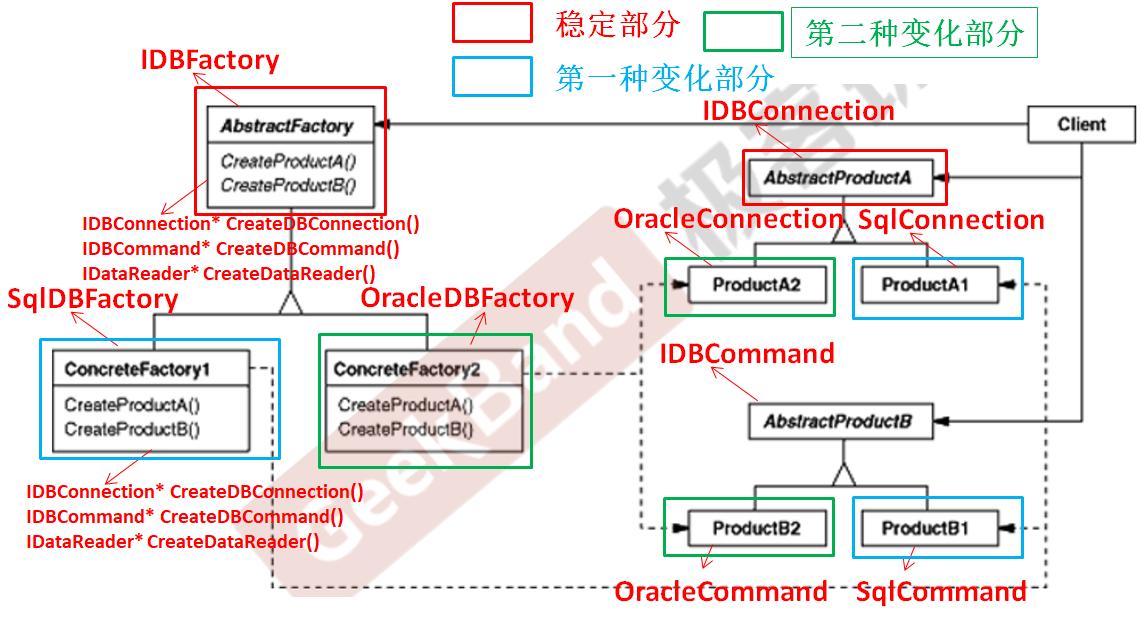
C++设计模式_09_Abstract Factory 抽象工厂
与上篇介绍的Factory Method工厂方法模式一样,Abstract Factory 抽象工厂模式也属于典型的“对象创建模式”模式,解决的问题也极其相似,在理解了Factory Method工厂方法模式的基础上再去理解Abstract Factory 抽象工厂模式就会变得更加容易。…...
)
STM32F4+FreeRTOS以太网实战:DP83848驱动配置避坑指南(附完整代码)
STM32F4FreeRTOS以太网实战:DP83848驱动配置避坑指南(附完整代码) 在工业物联网设备开发中,稳定可靠的以太网通信往往是核心需求之一。STM32F4系列凭借其出色的性能和丰富的外设资源,成为许多开发者的首选平台。而DP8…...

故障排查详解
故障排查详解 本章导读 系统故障不可避免,但快速定位和解决问题的能力决定了系统的可用性。本章系统讲解OOM、CPU飙升、死锁等常见故障的排查方法与工具使用,帮助读者建立完整的故障排查体系,从"盲人摸象"进化到"精准定位"。 学习目标: 目标1:掌握JDK…...

生产环境mysql如何实现高可用_配置主从复制与自动故障切换
主从复制SHOW SLAVE STATUS显示Connecting的常见原因是网络通但权限或配置未对齐:主库需开启binlog且server_id全局唯一;从库CHANGE MASTER TO中MASTER_HOST不能为localhost或127.0.0.1,须填真实IP或域名。主从复制配不起来,SHOW …...

Bootstrap4 导航栏
Bootstrap4 导航栏 概述 Bootstrap4 是一个流行的前端框架,它提供了丰富的组件和工具来帮助开发者快速构建响应式、移动优先的网页。在Bootstrap4中,导航栏是一个重要的组件,用于在网页上创建顶部导航菜单。本文将详细介绍Bootstrap4导航栏的用法、样式和定制选项。 导航…...

从芯片选型到实测优化:你的GNSS模块TTFF总超40秒?可能是这5个坑没避开
从芯片选型到实测优化:GNSS模块TTFF超40秒的5个关键陷阱与解决方案 当你在城市峡谷中焦急等待共享单车解锁,或是物流追踪系统因定位延迟而丢失货物轨迹时,GNSS模块的首次定位时间(TTFF)直接决定了用户体验和商业价值。…...
)
用Python和Scapy复现SEED实验:手把手教你搭建ARP欺骗攻击靶场(含完整代码)
从零构建ARP欺骗实验环境:PythonScapy实战指南 在虚拟化技术普及的今天,搭建一个安全的网络攻防实验环境变得前所未有的简单。ARP欺骗作为局域网攻击的经典手段,不仅是网络安全课程的必修内容,更是理解二层网络通信原理的绝佳案例…...

魔兽争霸III必备神器:WarcraftHelper 增强插件完全指南
魔兽争霸III必备神器:WarcraftHelper 增强插件完全指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸III的种种限制而烦恼…...

3D Tiles Tools实战指南:从GLB到B3DM的格式转换与批量处理技术
3D Tiles Tools实战指南:从GLB到B3DM的格式转换与批量处理技术 【免费下载链接】3d-tiles-tools 项目地址: https://gitcode.com/gh_mirrors/3d/3d-tiles-tools 在3D地理空间数据可视化领域,3D Tiles Tools项目提供了强大的格式转换能力…...

从产品抽检到网站点击率:二项分布近似在实际业务中的5个应用场景与Python实现
二项分布近似在业务决策中的实战指南:5个场景与Python实现 当产品经理需要评估新功能上线后的用户转化率,或是数据分析师要预测广告点击量的波动范围时,二项分布及其近似方法往往能成为决策工具箱里的秘密武器。不同于教科书中的理论推导&…...

高转化网站的共性:都做好了这10个图文排版细节
在网页设计领域,许多作品往往从“动手”开始,却缺乏一套清晰、完整的设计解决方案。即使是经验丰富的设计师,也常会依赖直觉与惯性,凭多年感觉直接铺开设计——这种做法固然高效,但真的能带来最佳效果吗?实…...