阿里面试(持续更新)
一面:
1 HashMap 实现原理,ConcurrentHashMap 实现原理
HashMap和ConcurrentHashMap都是存储键值对的数据结构,不同的是HashMap是线程不安全的,ConcurrentHashMap是线程安全的,HashMap在高并发情况下会出现数据不一致问题。
HashMap实现原理:
1.7 基于数组和链表 ,将数据封装成一个Entry节点 ,通过哈希算法找到节点插入的位置,通过头插法进行插入。当hashMap元素数量到达16*0.75时会将容量翻倍进行扩容操作,会重新计算节点的位置并进行插入。但是使用头插法插入在并发扩容时会出现死链问题。具体在于线程T1,T2同时对一个节点进行操作,该节点有 a,b,c。这时A->B->C 若这时线程T2进行扩容, 线程T1休眠,扩容完成后的指针指向变化对T1不可知,会导致死循环 。
1.8 基于数组和链表和红黑树。在1.7中当链表长度太长,向下查找会影响查找效率。所以在1.8中当链表长度超过8后会进行树化,降低链表的高度。当链表长度超过8后先通过对数组扩容减少链表的长度,当数组长度超过64后会进行树化,树化是一个小概率事件。在节点插入时是通过尾插法,可以方便计算链表的长度的同时也避免了死链问题。
ConcurrentHashMap实现原理;
1.7 在jdk1.7中ConcurrentHashMap被称作分段锁,它由多个Segment组成,每个Segment是一个独立的哈希表。维护一个数组节点。每个Segment维护了一个独立的锁。Segment 继承 ReentrantLock 加锁。Segment默认值为16,也就是说并发度为16.其数组在初始化后被固定不可扩容 。
1.8 在jdk1.8中ConcurrrentHashMap引入了红黑树,同时使用Cas操作来替换分段锁,提供更好的并发和可拓展性。结构为数组+链表+红黑树。在树的内部节点node 也是通过volatile来修饰保证可见性。通过cas保证原子性,它可以被扩容,初始为16 .
2 红黑树,为什么允许局部不平衡
红黑树是一种能够实现自平衡的二叉搜索树,他在每个节点上增加了一个位来表述节点的颜色红色或黑色,他的查找,删除,增加时间复杂度为o(logn).
允许局部不平衡的设计有以下几个原因:
- 保持整体平衡:红黑树通过保持整体平衡来提供高效的插入、删除和查询操作。因为允许局部不平衡,可以在插入和删除节点时进行局部的旋转和颜色调整,从而保持整个树的平衡性。
- 简化平衡调整:如果每次插入或删除后都要求完全平衡,会导致频繁的旋转和调整操作,增加了复杂性和性能开销。允许局部不平衡可以在保持整体平衡的同时,尽量减少平衡调整的次数和幅度,提高了操作的效率。
- 简化实现:红黑树的平衡调整操作相对较复杂。允许局部不平衡可以简化实现,更容易理解和维护。
3 TCP,UDP 区别,为什么可靠和不可靠
Tcp 是一种面向连接的,可靠的,基于字节流的传输层通信协议
Udp是无连接的用户数据报协议 。
区别:
1 Tcp 面向连接 需要三次握手建立连接,四次挥手释放连接Udp是无连接的,不需要建立连接就可以发送数据
2 Tcp是可靠的通信,Tcp会有超时重传,数据校验,拥塞和流量控制,确认机制等保证连接的可靠性,Udp无需连接没有这些措施,将以最大的速度进行传播,不保证数据的可靠性
3 Tcp面向字节流 ,Udp面向报文
4 Tcp是点对点的 Udp 可以一对一 一对多 多对一
4 一次 HTTP 请求的全过程,包括域名解析、定位主机等
1 域名解析,通过找浏览器Dns缓存,本地host文件 域名服务器查找等找到该域名对应的ip地址
2 通过ip地址使用ARP地址解析协议找到对应的服务器
3 发起三次握手连接
4 服务器响应请求
5 浏览器解析相应的数据
7 对数据进行渲染
8 四次挥手断开连接
5 TCP 三次握手
三次握手就是在建立一个Tcp连接时,需要客户端和服务端发送三个包,来保证双方正常的通信能力,并指定初始化序列号为后续的可靠传输做准备。实质上其实就是连接服务器指定端口,建立TCP连接,并同步连接双方的序列号和确认号,交换TCP窗口大小信息。
为什么一定要三次握手而不能是两次握手
如客户端发出连接请求,但因连接请求报文丢失而未收到确认,于是客户端再重传一次连接请求。后来收到了确认,建立了连接。数据传输完毕后,就释放了连接,客户端共发出了两个连接请求报文段,其中第一个丢失,第二个到达了服务端,但是第一个丢失的报文段只是在某些网络结点长时间滞留了,延误到连接释放以后的某个时间才到达服务端,此时服务端误认为客户端又发出一次新的连接请求,于是就向客户端发出确认报文段,同意建立连接,不采用三次握手,只要服务端发出确认,就建立新的连接了,此时客户端忽略服务端发来的确认,也不发送数据,则服务端一致等待客户端发送数据,浪费资源。
6 MySQL 事务是什么?四大特性,四大隔离级别
Mysql事务是数据库的最小工作单元,是一组不可再分的操作集合
四大特性 ACID 原子性,一致性,隔离性,持续性
隔离级别:可重复读,读未提交,不可重复读,串行化
7 ConcurrentHashMap 和 Hashtable 区别
ConcurrentHashMap 和 Hashtable都是并发安全的两个类,不同点在于 1 ConcurrentHashMap的并发度更高,无论在1.7中并发度16还是再1.8中使用cas达到更高的并发度都比Hashtable的并发度1高。Hashtable使用的是Synchronized实现全局锁,性能低 。 在扩容时Hashtable需要锁表。ConcrrentHashmap不需要
8 spring IOC 和 AOP,以及各有什么优点
Spring IOC 控制反转,将对象的创建由程序交由给spring生成Bean . 它将对象的创建和依赖关系的管理交给容器(也就是Spring框架),而不是由应用程序代码直接控制。通过IOC容器,我们只需要在配置文件或注解中声明依赖关系,容器会自动根据配置创建并注入相关的对象。这样可以实现对象之间的解耦,提高代码的灵活性、可维护性和可测试性。
Aop , 面向切面编程,在不更改程序的情况下,通过切面来实现对程序的功能增强,AOP就是把一个业务逻辑功能抽取出来,然后动态把这个功能切入到需要的方法(或行为)中,需要的才切入,这样便于减少系统的重复代码, 降低模块间的耦合度。
9 有哪几种常用的线程池
四种常用的Executor自带的线程池 ,分别是 newCachedThreadPool , newFixThreadPool , newSingleThreadPool,new SchduledThreadPool . 分别代表 可缓存线程池 , 定长线程池 , 单线程池, 周期性线程池 。
在newCachedThreadPool中 ,队列使用的是没有容量限制的SynchronousQueue,适合短期异步任务,可以直接复用已有的线程。在newFIxThreadPool和newSingleThreadPool中使用的是LinkedBlockingQueue基于链表的无界队列,无限提交任务会导致oom , 在newSchduledThreadPool中使用的是DelayedWorkQueue延迟阻塞队列,队列满自动扩容,所以无需设置最大参数。它是基于堆实现优先级,适用于执行延时或周期性任务。
10 什么情况下使用 Runnable 和 Thread 创建线程,Runnable 和 Callable 的区别
Runnable和Thread是创建线程的两种方式 ,但他们也有一点创建上的区别,Runnable是接口,创建线程只需要实现接口run方法,Thread创建线程需要继承Thread类,这也导致了他们的使用情况不一样,一般来讲如果希望任务类实现其他接口或继承其他类时我们可以选择实现Runnable接口以免避免单继承的限制,如果由多个线程需要共享一个资源时,可以将该资源封装在runnable里面达到公用。如果希望对线程类进行更多的拓展时可以使用Thread来创建线程。
Runnable和Callable的区别
1 返回值 Runnable没有返回值,Callable可以有返回值
2 因为Runnable没有返回值所以不能抛出异常,Callable可以抛出异常
3 异步执行:Runnable只能通过Thread来异步执行,Callable可以使用Future来获取异步执行的结果
11 线程方法中的异常如何处理,副线程可以捕获到吗
在线程池中的异常取决于任务的提交方式,当任务是以submit提交时要想获取异常必须通过Get方法获取一个Future对象的返回值,如果任务是以execute提交的话,直接抛出异常或者可以通过tryCatch捕获
对于单个线程而言,Thread方法中提供了setUncaughtExceptionHandler方法可以抛出线程内的异常,不使用这个方法异常会被吃掉。
副线程可以捕获自身的异常.
12 synchronized 和锁的区别,什么情况下使用 synchronized 和 ReentrantLock
其实就是synchronized和Lock的区别
13 JVM 的对象分配在哪个区,Class 对象分配在哪个区
JVM 的对象分配在 Java 堆(Heap)中,而 Class 对象则是分配在方法区(Method Area)。
- 对象的分配:Java 的对象(除了一些特殊对象,如线程对象)都是在 Java 堆上进行分配的。Java 堆是 JVM 在运行时创建的,用于存储对象实例和数组。堆内存分为不同的区域,如新生代(Young Generation)、老年代(Old Generation)等。
2.Class 对象的分配:Class 对象是用来描述 Java 类的方法区对象。方法区是 JVM 用于存储类的信息、静态变量、常量池等数据的区域。在运行时,每个加载的类都会创建一个对应的 Class 对象,用于保存类的结构信息。Class 对象本身也是对象,因此也需要存储在堆上。需要注意的是,方法区和 Java 堆是不同的内存区域,各自有不同的功能和用途。方法区是用于存储类相关信息的,而 Java 堆是用于存储对象实例和数组的。另外,需要注意的是在 JDK 8 之后,永久代(PermGen)已经被元空间(Metaspace)所取代。元空间也是方法区的一种实现,用于存储类的信息。元空间是直接使用本地内存(Native Memory)来实现的,不受限于传统的永久代限制,可以动态调整大小,从而避免了内存溢出的问题。因此,Class 对象的分配通常发生在方法区的元空间中。
二面
## 1 常用的设计模式介绍:单例模式、装饰者模式等
以下是一些常见的设计模式例子:
- 单例模式:保证一个类只有一个实例,并提供一个全局访问点。
- 工厂模式:将对象的创建委托给工厂类,客户端通过工厂类来创建对象。
- 观察者模式:定义了一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都会得到通知并自动更新。
- 装饰器模式:动态地给一个对象添加一些额外的功能,而不需要修改其原始类。
- 策略模式:定义一系列算法,将它们封装起来,使它们可以互相替换。
- 适配器模式:将一个类的接口转换成客户端所期望的接口,解决不兼容接口之间的问题。
- 模板方法模式:定义了操作中的算法骨架,将一些步骤延迟到子类中实现。
- 命令模式:将请求封装成对象,使得可以用不同的请求对客户进行参数化。
- 迭代器模式:提供一种方法可以顺序访问一个聚合对象中的各个元素,而不暴露其内部表示。
- 组合模式:将对象组合成树形结构来表示“部分-整体”的层次结构,使得客户端对单个对象和组合对象的使用具有一致性。
- 门面模式(Facade Pattern)是一种结构型设计模式,它通过提供一个统一的接口,来简化一组复杂的子系统的使用。门面模式隐藏了子系统的复杂性,使得使用者可以更方便地使用子系统的功能。
2 Java 会出现内存溢出吗?什么情况下会出现?
是的,Java 程序也可能出现内存溢出(Out of Memory)的情况。以下是一些常见的情况导致内存溢出的情况:
- 堆内存溢出:Java 程序的对象实例都存放在堆内存中,如果创建的对象过多,或者每个对象占用的内存过大,就有可能导致堆内存溢出。
- 方法区内存溢出:方法区用于存储类的结构信息、常量池、静态变量等,如果加载的类过多,常量池或静态变量占用的内存过多,就可能导致方法区内存溢出。
- 栈内存溢出:每个线程在执行方法时都会创建一个栈帧,栈帧包括方法的局部变量、操作数栈、方法出口等,如果递归调用层数过多或者每个线程的栈帧占用的内存过大,就有可能导致栈内存溢出。
3 双亲委派模型,为什么这样做?
3.1 双亲委派模型指的是我们程序的泪在进行类加载时先由应用程序加载器向上提交,交给拓展类加载器再交给启动类加载器进行加载。如果所有的父类加载器都无法加载这类则会交由子类加载器去加载。
3.2 这种双亲委派的过程可以保证类加载的一致性和唯一性。因为每个类加载器在自己的命名空间中搜索类,避免了类的重复加载,同时也保证了核心类不会被用户自定义的类加载器替换或篡改。这种方式也使得 Java 中的类隔离和模块化成为可能,提供了良好的安全性和可扩展性。
4 对象什么情况下进入老年代?
在minor gc后年龄到达阈值15后会被放入老年代,还有如果是大对象也会直接放入老年代。
快速排序说一下过程
5 AOP 实现原理
Spring AOP(面向切面编程)的实现原理主要基于动态代理和反射机制。Spring AOP 提供了一种在运行时动态地将切面织入到目标对象方法的机制,以实现横切关注点的功能。
在 Spring AOP 中,主要有两种代理方式:基于接口的 JDK 动态代理和基于类的 CGLIB 动态代理。
-
基于接口的 JDK 动态代理:如果目标对象实现了接口,Spring 使用 JDK 提供的 java.lang.reflect.Proxy 类来创建代理对象。当目标对象方法被调用时,代理对象会通过反射机制拦截方法的执行,并在方法的前后织入切面逻辑。
-
基于类的 CGLIB 动态代理:如果目标对象没有实现接口,Spring 会使用 CGLIB(Code Generation Library)动态生成一个继承自目标类的子类,在子类中拦截目标方法的执行并织入切面逻辑。CGLIB 是一个强大的第三方库,通过修改字节码生成子类来实现代理。
Spring AOP 通过 AspectJ 注解或 XML 配置将切面逻辑定义为切面,切面中的切点定义了哪些目标方法会被拦截,并在切点上定义通知(advice),如前置通知、后置通知、异常通知等。在运行时,Spring AOP 在目标对象上动态创建代理对象,代理对象拦截被切点匹配的方法,并执行相应的通知代码。
总结起来,Spring AOP 的实现原理就是通过动态代理和反射机制,在运行时动态生成代理对象,并在代理对象中拦截目标方法的执行,实现对切面逻辑的织入。这样可以将公共的横切关注点与业务逻辑相分离,达到了解耦和代码复用的效果。
6 BIO NIO 如何实现
BIO(Blocking I/O)和 NIO(Non-blocking I/O)是 Java 中用于处理 I/O 操作的两种不同的编程模型。
BIO(阻塞 I/O)模型是最原始的 I/O 编程模型,它以阻塞方式进行 I/O 操作。在 BIO 中,每个 I/O 操作(如读写操作)都会阻塞当前线程,直到操作完成才返回。这意味着每个连接都需要独立的线程进行处理,因此在高并发的环境中,BIO 性能不佳。
NIO(非阻塞 I/O)模型是在 JAVA1.4 中引入的,在 NIO 中,仅当数据准备好时,才会执行 I/O 操作。NIO 使用了非阻塞的 Channel 和 Selector,可以在一个线程中管理多个连接,因此在高并发的场景下,NIO 可以更好地处理大量的连接。
在实现上,BIO 使用了传统的 InputStream 和 OutputStream 来进行 I/O 操作,通常是基于字节流(Byte Stream)来进行读写。而 NIO 使用了 Channel 和 Buffer 来进行 I/O 操作,提供了更灵活和高效的读写方式。
BIO 的典型示例是使用 Socket 进行网络通信,在服务器端,每个客户端连接都需要一个独立的线程来处理;在客户端,将阻塞等待从服务器接收数据。
NIO 则是基于事件驱动的,使用 Selector 来管理多个 Channel,并通过事件通知机制来处理 I/O 操作。NIO 可以通过一个线程管理多个连接,当连接有数据可读时,通过事件通知机制进行处理。
总结来说,BIO 是单线程处理单个连接的阻塞模型,适合连接数较少的场景;而 NIO 是使用 Selector 多路复用模型,适合高并发的场景。
7 垃圾回收算法
JVM(Java Virtual Machine)的垃圾回收(Garbage Collection)算法是用于自动管理内存的一种机制,用于回收不再被程序使用的对象所占用的内存空间。
JVM 垃圾回收算法主要有以下几种:
-
标记-清除算法(Mark and Sweep):这是最基本的垃圾回收算法。首先,它通过一个根对象(如 GC Roots)开始,递归地遍历所有可达对象,并在遍历过程中将这些对象进行标记。然后,遍历整个堆,清除未被标记的对象,并使这些内存空间重新可用。
-
复制算法(Copying):将堆内存空间分为两部分,每次只使用其中一部分。当当前使用的部分满了之后,将存活的对象复制到另一部分,并且顺序排列,之后清除当前部分的所有对象。这种算法适用于对象存活率较低的场景,不会造成太多空间浪费。
-
标记-整理算法(Mark and Compact):结合了标记-清除和复制两种算法的优点。首先,标记阶段标记出所有存活的对象。然后,将这些存活的对象向一端移动,清理掉不再使用的对象,并且更新指针,使得堆空间连续。
-
分代收集算法(Generational):将堆内存空间划分为不同的代,一般是年轻代(Young Generation)和老年代(Old Generation)。年轻代存放新创建的对象,老年代存放经过多次垃圾回收仍然存活的对象。不同代使用不同的垃圾回收算法,如年轻代使用复制算法,老年代使用标记-清除或者标记-整理算法。这种算法充分利用了不同对象的存活特性,提高了回收效率。
-
并发垃圾回收算法(Concurrent):在业务运行的同时进行垃圾回收。常见的并发垃圾回收算法有并发标记清除(CMS)和 G1(Garbage-First)算法。这些算法通常会在业务线程和垃圾回收线程之间进行协调,以最小化对业务线程的影响。
8 OOM内存泄漏,如何排查
使用一些内存监控工具,日志,分析转储的日志文件,使用jps ,jstack等等
三面:
1介绍你实践的性能优化案例,以及你的优化思路
性能优化思路:先确定是哪方面的性能瓶颈,有很多包括硬件指标,操作系统,文件系统,io,中间件和数据库以及应用程序等等。我们说的性能优化一般都是只对于我们编写的应用程序的性能优化。 首先要通过测试衡量当前系统性能比如运行速度,相应时间,请求次数等等。再确定我们需要调优的目标,再找到性能的瓶颈代码,经过相关的优化策略进行优化。
2 SQL 慢查询的优化方案,索引和表的优化方案。
出现慢查询的主要原因是一次性加载了大量的数据以及mysql同时需要分析大量数据行,可以在sql层面和在缓存等层面进行优化。在sql层面需要打开慢查询日志进行分析,找到执行较慢的sql语句,用explain进行分析然后针对性的优化如使用高效的索引和一次性查询过多无用数据等 。 在缓存层面可以 1 前端优化,处理查询次数,合并请求,会话保存等减少查询次数。2使用多级缓存去处理热点数据 3 服务拆分 4 读写分离,分库分表等等
索引的优化主要是通过分析explain执行计划来进行优化,尽量走覆盖索引和全值匹配,复合索引中要满足最左前缀原则等等
对于表的优化主要在与表结构和表大小的优化,尽量避免一个表的过多字段,使用合适的字段类型和大小。过大的表进行拆分等等 。
3 MySQL 与 MongoDB 的区别,海量数据的存储
Mysql是一种关系型数据库,使用表格来存储数据,使用sql查询语言,支持水平拓展,支持acid事务,需要固定表字段,有非常活跃和完善的社区。
mongodb是一种nosql非关系型数据库,使用了类似于json的bosn语言对数据库进行操作,使用文档来存储数据,可以灵活的处理文档的数据和字段,同时提供了海量数据的存储,单个文档最多可存储16m数据,还提供了地理位置的数据结构,支持水平和垂直拓展,但是在单文档下不支持事务,多文档下的事务正在试用中。支持复杂的聚合查询。
请描述一致 hash 算法
一致性hash算法的出现目的是解决普通hash算法使用取模运算使得服务器资源变化导致的所有数据重新计算分布和缓存雪崩的问题。一致性hash算法使用了虚拟的hash环让服务器地址或主机名与2^32取模得到该服务器在这个hash环上的位置。当需要存储数据时通过哈希函数计算得到一个哈希值,并在哈希环上找到离该哈希值最近的节点,将数据存储在该节点上。一致性hash对于服务器的增减都只需要处理该服务器的部分数据,具有更好的容错性同时使用虚拟节点解决hash环的倾斜问题。
一面
ArrayList 和 hashset 有何区别。hashset 存的数是有序的么。
ArrayList和HashSet是Java中的两种不同的数据结构,它们有以下区别:
- 数据存储方式:ArrayList是一个有序的动态数组,它按照添加顺序存储元素,通过索引进行访问。HashSet是一个无序的集合,它使用哈希表来存储元素,不保持添加的顺序。hashSet是基于HashMap的,自然HashSet也不保证有序性。
- 存储重复元素:ArrayList允许存储重复的元素,每个元素在列表中都有自己的索引。HashSet不允许存储重复的元素,如果尝试添加重复元素,添加操作将被忽略,直接返回false。
- 查找和访问元素:在ArrayList中,可以通过索引来直接访问和修改元素,索引访问的时间复杂度为O(1)。而在HashSet中,无法通过索引来直接访问元素,我们只能使用迭代器或者contains方法来查找元素,查找的时间复杂度为O(1)。
- 元素的有序性:ArrayList中的元素是有序的,按照添加的顺序存储。HashSet中的元素是无序的,不保持添加的顺序。
volatile 和 synchronized 区别
两者都是在多线程情况下用于并发控制,都是java中的关键字。有以下区别
实现方式:volatile是轻量级同步机制,不会进行加锁,没有加锁操作,每次获取共享变量都冲内存中获取而不会从缓存中获取,保证每次获取的都是最新的和保证可见性。synchronized底层通过互斥锁和监视器锁来实现,会有锁升级的过程。
作用范围:volatile作用于共享变量,synchronized可以作用于变量,代码块和方法
内存语义:volatile保证可见性,禁止重排序,不保证原子性 synchronized保证可见性,原子性和有序性
线程阻塞:volatile不会引起阻塞(没有加锁操作),synchronized会引起阻塞
多态的原理
多态原理基于继承,方法重写和父类引用指向子类对象
实现机制
- 继承:子类可以继承父类的属性和方法。通过继承,子类可以使用父类中已定义的方法和属性。
- 方法重写:子类可以对继承自父类的方法进行重写。重写是指在子类中重新定义和实现父类中已有的方法,方法名、参数列表和返回类型必须与父类方法一致。
- 父类引用指向子类对象:Java中允许将父类的引用变量指向子类的对象(基于方法区)。这意味着一个父类类型的引用可以调用继承自父类的方法,同时也可以执行子类重写的方法。
实现多态的关键在于父类引用指向子类对象的赋值操作。编译器在编译时会检查父类引用的类型,而在运行时会根据实际的子类对象来执行方法。这样,通过父类引用调用方法时,如果子类重写了该方法,实际执行的将是子类的方法。
数据库引擎 Innodb 和 myisam 区别
索引结构:Innodb是聚簇索引,索引文件和数据记录在一起,找到索引就找到了记录。Myisam基于非聚簇索引,索引文件和记录文件不在一起,需要进行回表操作,先找到了主键再根据地址偏移量去查找。
事务支持: Innodb支持完整的ACID事务,Myisam不支持事务 因为Myisam不支持行锁只支持表锁,无法控制
数据一致性:Innodb支持外键约束,MyIsam不支持外键
Redis 的数据结构
基础数据结构 sds,inset,ziplist,dict ,quicklist,skiplist,redisObject
主要数据结构 String , hash , List , Set , Zset
Redis 是基于内存的么
是
Redis 的 list zset 的底层实现
在3.2版本之后,Redis统一采用QuickList来实现List,Redis的有序集合(Sorted Set,简称Zset)的底层实现使用了跳跃表(Skip List)和哈希表(Hash Table)两种数据结构的组合。
http 和 https 的区别
HTTP(Hypertext Transfer Protocol)和HTTPS(Hypertext Transfer Protocol Secure)是两种用于在客户端和服务器之间传输数据的协议,它们之间的主要区别体现在以下几个方面:
- 安全性:HTTP是明文传输协议,数据在传输过程中不进行加密,容易被恶意截取和篡改。而HTTPS通过使用SSL(Secure Sockets Layer)或TLS(Transport Layer Security)协议对传输的数据进行加密,提供了数据的机密性和完整性,以防止数据被窃取和篡改。
- 传输方式:HTTP使用TCP(Transmission Control Protocol)作为传输协议,只有一个连接是被动的,即客户端主动发起请求,而服务端被动响应。HTTPS在HTTP基础上加入了SSL/TLS层,通过建立安全的SSL/TLS连接进行数据传输。
- 端口:HTTP默认使用80端口进行通信,而HTTPS默认使用443端口。这也是网络防火墙和代理服务器进行流量过滤的一个因素。
- 证书:为了实现加密和身份验证,HTTPS需要使用数字证书(SSL证书),其中包含了服务器的公钥。客户端通过验证证书的合法性来确认连接的安全性,确保正在连接的是合法的服务器。而HTTP不需要证书验证。
- 速度:由于HTTPS需要进行加密和解密操作,相比HTTP而言,会消耗更多的计算资源和时间。因此,HTTPS的传输速度可能会比HTTP略低。
综上所述,HTTPS相当于在HTTP的基础上增加了加密和安全性的层,对于需求隐私保护和数据安全的场景,使用HTTPS更为合适。而对于一般的网站浏览和资源传输等情况,HTTP已经足够。
单例模式
单例模式
Java 线程间怎么实现同步,notify()与 notifyAll()的区别
在Java中,可以使用以下几种方式来实现线程间的同步:
- synchronized关键字:可以使用synchronized关键字来标记一个代码块或方法,使得在不同线程中同时只有一个线程可以访问被标记的代码块或方法,从而实现线程的同步。
- Lock和Condition:Java中的Lock接口提供了更灵活的锁定机制,可以使用Lock和Condition来实现线程间的同步。Lock接口提供了lock()和unlock()方法,用于手动获取和释放锁,而Condition接口提供了await()和signal()/signalAll()方法,用于线程等待和唤醒。
- Wait和Notify:可以使用Object类中的wait()、notify()和notifyAll()方法来实现线程间的等待和唤醒机制。当一个线程调用某个对象的wait()方法时,它会释放该对象的同步锁,并进入等待状态,直到其他线程调用该对象的notify()或notifyAll()来唤醒等待的线程。
notify()和notifyAll()的区别如下:
- notify()方法用于随机选择等待状态的一个线程进行唤醒,并使其进入就绪状态,但是具体唤醒哪个线程无法确定。
- notifyAll()方法则会唤醒所有等待状态的线程,使它们进入就绪状态。
通常情况下,优先使用notifyAll()方法来避免线程的假唤醒。当有多个线程等待同一个条件时,使用notify()方法可能导致只有一个线程被唤醒,而其他线程还处于等待状态,这可能会导致程序出现问题。使用notifyAll()可以确保所有等待线程都被唤醒,从而更安全地实现线程间的同步。
数据库的悲观锁和乐观锁应用场景。
悲观锁和乐观锁是在数据库中用来处理并发访问的两种不同的策略,它们在不同的应用场景下有所区别。
悲观锁的应用场景:
- 需要保证数据的一致性和正确性:当并发访问的操作存在潜在的冲突,且不能容忍数据的不一致或错误时,可以使用悲观锁。悲观锁假设会发生并发冲突,因此在操作之前会先获取锁,避免多个线程同时进行对数据的修改,从而保证数据的一致性和正确性。
- 长事务和复杂操作:一些复杂的数据库操作可能涉及多个表或多个阶段的处理,存在较长的事务,而悲观锁可以保证在整个操作的过程中数据的一致性,避免并发操作对数据造成干扰。
乐观锁的应用场景: - 并发冲突概率较低:当并发冲突的概率较低且可能会发生的频率较低时,可以使用乐观锁。乐观锁不会加锁,而是通过标识或版本号等方式在操作前后判断数据是否发生变化,从而避免加锁操作以提高并发性能。
- 大量读取操作:在读多写少的场景下,使用乐观锁可以避免无谓的锁竞争,提高并发处理能力。
- 乐观且并发操作不会造成数据不一致:在具备乐观锁机制的数据库中,当并发操作不会造成数据不一致或冲突时,可以使用乐观锁进行并发访问处理。
需要注意的是,选择悲观锁还是乐观锁取决于具体的应用场景和系统需求。悲观锁可以确保数据的一致性和正确性,但会增加加锁和解锁的开销,可能影响系统的并发性能。乐观锁不需要加锁操作,可以提高并发性能,但需要额外的机制来检测数据的变化。因此,根据具体的业务需求和系统特点,选择合适的并发控制策略是很重要的。
排序算法的复杂度,快速排序非递归实现。
相关文章:
)
阿里面试(持续更新)
一面: 1 HashMap 实现原理,ConcurrentHashMap 实现原理 HashMap和ConcurrentHashMap都是存储键值对的数据结构,不同的是HashMap是线程不安全的,ConcurrentHashMap是线程安全的,HashMap在高并发情况下会出现数据不一致…...
龙芯3A3000源码编译安装deepin-ide
安装环境 系统为统信专业版1050 CPU为龙芯3A3000 安装步骤 1.安装所有依赖库 sudo apt-get install git debhelper cmake qt5-qmake qtbase5-dev qttools5-dev qttools5-dev-tools lxqt-build-tools libssl-dev llvm llvm-dev libclang-dev libutf8proc-dev libmicrohttpd-d…...
学成在线第二天-查询课程、查询课程分类、新增课程接口实现以及跨域的处理思路和全局异常处理的使用以及面试题
目录 一、接口的实现 二、跨域的处理思路 三、全局异常处理 四、面试题 五、总结 一、接口的实现 1. 查询课程接口 思路: 典型的分页查询 按需查询 模糊查询的查询 controller: ApiOperation(value "课程列表", notes "课程…...

【OpenCV概念】 11— 对象检测
一、说明 这都是关于物体识别的。物体识别是指通过计算机视觉技术,自动识别图像或视频中的物体及其属性和特征,是人工智能领域的一个分支。物体识别可应用于多个领域,包括工业自动化、智能家居、医疗、安防等。请随时阅读这篇文章:…...

TensorRT学习笔记--常用卷积、激活、池化和FC层算子API
目录 1--Tensor算子API 1-1--卷积算子 1-2--激活算子 1-3--池化算子 1-4--FC层算子 2--代码实例 3--编译运行 1--Tensor算子API TensorRT提供了卷积层、激活函数和池化层三种最常用算子的API: // 创建一个空的网络 nvinfer1::INetworkDefinition* network …...

【Edabit 算法 ★☆☆☆☆☆】 Less Than 100?
【Edabit 算法 ★☆☆☆☆☆】 Less Than 100? language_fundamentals math validation Instructions Given two numbers, return true if the sum of both numbers is less than 100. Otherwise return false. Examples lessThan100(22, 15) // true // 22 15 37lessTha…...

C++中的智能指针:更安全、更便利的内存管理
在C++编程中,动态内存管理一直是一个重要且具有挑战性的任务。传统的C++中,程序员需要手动分配和释放内存,这往往会导致内存泄漏和悬挂指针等严重问题。为了解决这些问题,C++11引入了智能指针(Smart Pointers)这一概念,它们是一种高级的内存管理工具,可以自动管理内存的…...
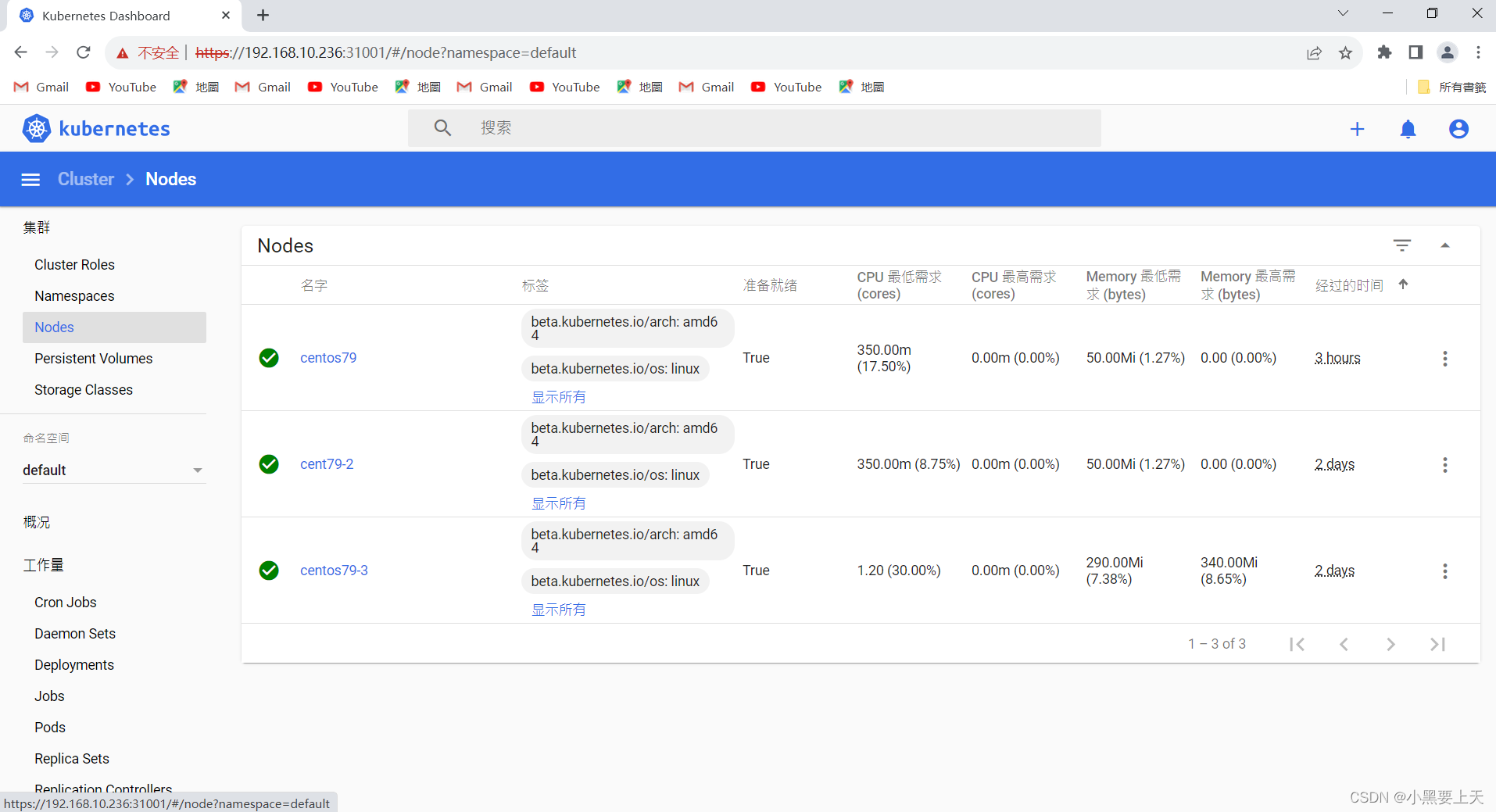
google登录k8s dashboard ui显示“您的连接不是私密连接”问题解决梳理
1.问题描述 OS Version:CentOS Linux release 7.9.2009 (Core) K8S Version:Kubernetes v1.20.4 k8s dashboard ui安装完毕后,通过google浏览器登录返现https网页,发现非官方的https网页无法打开 网址:https://192.168.10.236:31001 2.原…...
MIPS指令集摘要
目录 MIPS指令R I J三种格式 MIPS五种寻址方式 立即数寻址 寄存器寻址 基址寻址 PC相对寻址 伪直接寻址 WinMIPS64汇编指令 助记 从内存中加载数据 lb lbu lh lhu lw lwu ld l.d lui 存储数据到内存 sb sh sw sd s.d 算术运算 daddi daddui dadd…...

数据可视化素材分享 | 数十图表、无数模板
很多人在后台求分享报表、源代码,其实何必这么麻烦,在奥威BI数据可视化平台上点击即可获得大量的可视化素材,如数十种可视化图表,适用于不同分析场景;又如大量不同主题的BI数据可视化报表模板,套用后替换数…...

Hadoop3教程(三十二):(生产调优篇)NameNode故障恢复与集群的安全模式
文章目录 (159)NameNode故障处理(160)集群安全模式&磁盘修复集群安全模式磁盘修复等待安全模式 参考文献 (159)NameNode故障处理 如果NameNode进程挂了并且存储的数据也丢失了,如何恢复Nam…...
ios兼容)
uniapp下载附件保存到手机(文件、图片)ios兼容
downloadFile(file),其中file为下载的文件地址uni.downloadFile图片使用uni.saveImageToPhotosAlbum【安卓、ios都合适】文件使用uni.openDocument【安卓图片也可以用这个,ios会失败】 // 下载文件 export function downloadFile(file) {let acceptArr …...

【Edabit 算法 ★☆☆☆☆☆】 Basketball Points
【Edabit 算法 ★☆☆☆☆☆】 Basketball Points language_fundamentals math numbers Instructions You are counting points for a basketball game, given the amount of 2-pointers scored and 3-pointers scored, find the final points for the team and return that …...
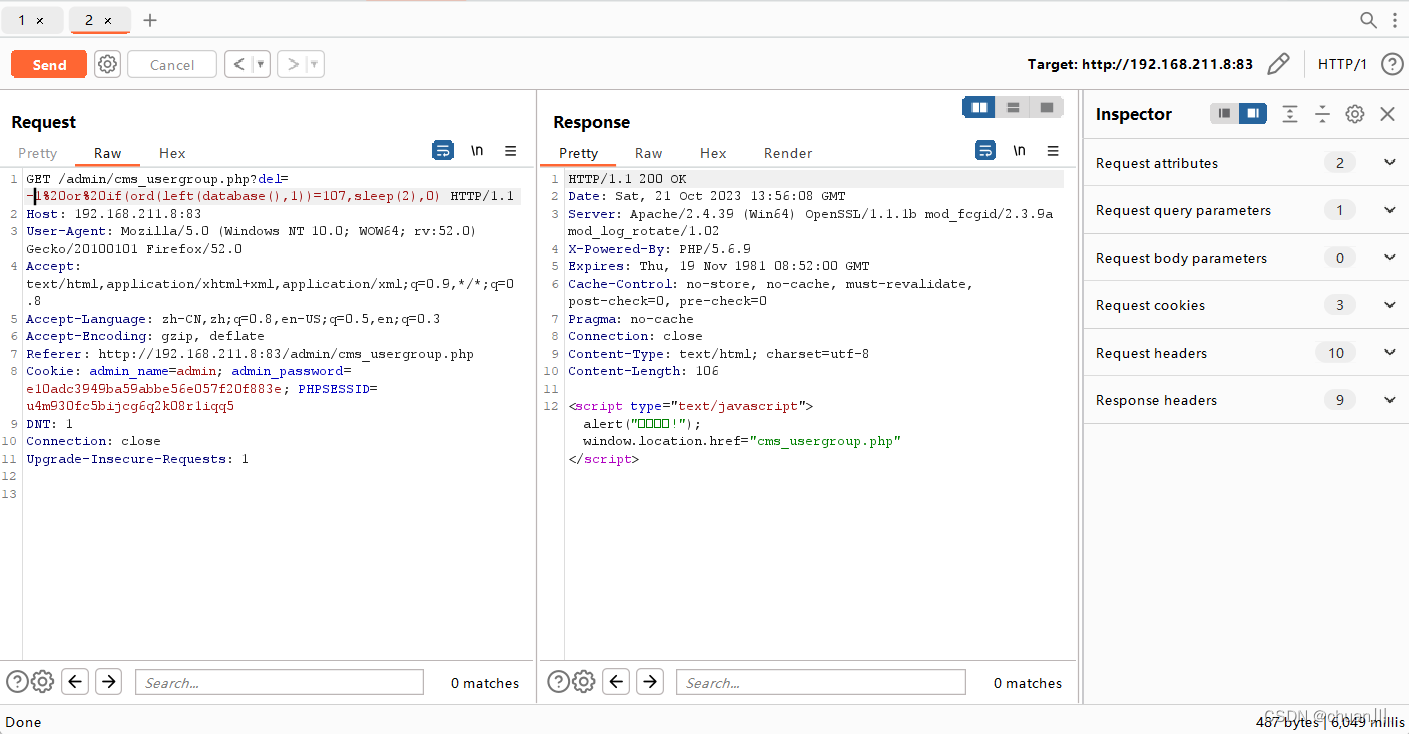
Web攻防04_MySQL注入_盲注
文章目录 MYSQL-SQL操作-增删改查盲注概念盲注分类盲注语句参考&更多盲注语句/函数 注入条件-数据回显&错误处理PHP开发项目-注入相关条件:基于延时:基于布尔:基于报错: CMS案例-插入报错&删除延时-PHP&MYSQL1、x…...

Flask自定义装饰和g的使用
1. 在commons.py文件中新增一个装饰器类: 注:一定要加入wraps进行装饰否则,装饰器在给多个函数进行装饰时会报错 from functools import wraps from flask import session, current_app, g# 定义登陆装饰器,封装用户的登陆数据 def user_log…...
)
【汇编】汇编语言基础知识(学习笔记)
一、汇编语言概述 汇编语言是直接在硬件之上工作的编程语言,首先要了解硬件奈统的结构,才能有效的应用汇编语言对其编程。 二、汇编语言的产生 机器语言:机器语言是机器指令的集合 汇编语言的主体是汇编指令 汇编指令和机器指令的差别在…...

前端 | FormData 用法详解
前端 | FormData 用法详解 介绍 FormData 是 Ajax2.0 对象用以将数据编译成键值对,以便于 XMLHttpRequest 来发送数据。XMLHttpRequest Level 2 提供的一个接口对象,可以使用该对象来模拟和处理表单并方便的进行文件上传操作 如果表单属性设为 mu…...
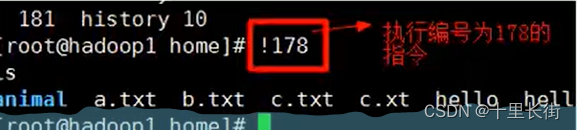
linux常见命令-文件目录类
9.4 文件目录类 (1)pwd 指令:显示当前工作目录的绝对路径 (2)Is指令:查看当前目录的所有内容信息 基本语法: ls [选项,可选多个] [目录或是文件] 常用选项:-a:显示当前目录所有的文件和目录,包括隐藏的…...
2023 10月8日 至 10 月16日学习总结
1.做的题目 [RootersCTF2019]I_<3_Flask_双层小牛堡的博客-CSDN博客 [NCTF2019]SQLi regexp 盲注-CSDN博客 [网鼎杯 2018]Comment git泄露 / 恢复 二次注入 .DS_Store bash_history文件查看-CSDN博客 PHP LFI 利用临时文件Getshell_双层小牛堡的博客-CSDN博客 …...

【Java 进阶篇】深入了解 Bootstrap 表格和菜单
表格和菜单是网页设计中的重要组成部分,它们用于展示数据、导航和用户交互。Bootstrap 是一个强大的前端框架,提供了丰富的表格样式和菜单组件,使开发者能够轻松创建功能丰富的网页。在本文中,我们将深入探讨 Bootstrap 中表格和菜…...

**发散创新:基于Go语言的日志指标采集与可视化实战**在现代分布式系统中,**日志 + 指标*
发散创新:基于Go语言的日志指标采集与可视化实战 在现代分布式系统中,日志 指标已成为运维监控的核心支柱。如何高效地从服务中提取关键指标(如请求耗时、错误率、QPS),并将其结构化存储用于后续分析?本文…...

4步解决抖音内容高效采集难题:douyin-downloader 智能全流程方案
4步解决抖音内容高效采集难题:douyin-downloader 智能全流程方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fall…...

排查STM32 SPI无时钟信号:从CubeMX配置到示波器测量的完整Debug流程
STM32 SPI时钟信号消失?从CubeMX配置到硬件测量的全链路诊断手册 深夜的实验室里,示波器屏幕上那条本该跳动的SPI时钟信号线依然平静如死水。作为嵌入式开发者,这种场景再熟悉不过——明明CubeMX配置看起来一切正常,代码也顺利编译…...

告别手动编译!用ODBC桥接让QT5.14.2轻松操作MySQL8数据库
告别手动编译!用ODBC桥接让QT5.14.2轻松操作MySQL8数据库 在QT开发中连接MySQL数据库时,许多开发者都会遇到一个令人头疼的问题:需要手动编译MySQL驱动。这不仅耗时耗力,还容易因版本不匹配导致各种兼容性问题。本文将介绍一种更…...

13、c#线程
1 简介 1.1 概念 进程:正在运行的程序 线程:正在运行的程序中 正在执行的代码块 比喻:进程是正在开工的工厂线程是正在运行的流水线一个进程中只要有一个线程::::::&…...

3步解锁AMD/Intel显卡的CUDA超能力:ZLUDA兼容层终极指南
3步解锁AMD/Intel显卡的CUDA超能力:ZLUDA兼容层终极指南 【免费下载链接】ZLUDA CUDA on non-NVIDIA GPUs 项目地址: https://gitcode.com/GitHub_Trending/zl/ZLUDA 你是否曾因缺少NVIDIA显卡而无法运行深度学习项目?当AI模型训练需要CUDA环境时…...

易语言实战:绕过‘Content-Type’陷阱,手把手教你上传图片到任意表单
易语言实战:HTTP文件上传协议深度解析与边界处理技巧 在自动化工具开发中,文件上传功能几乎是每个开发者都会遇到的常规需求。但当你用易语言实现图片上传时,是否遇到过服务器返回"Invalid Content-Type"或"Missing boundary&…...
)
ESP32 RMT实战:手把手教你用ESP-IDF驱动WS2812灯带(附完整代码)
ESP32 RMT实战:手把手教你用ESP-IDF驱动WS2812灯带(附完整代码) 在智能家居和物联网项目中,可编程RGB灯带因其丰富的色彩表现和灵活的编程能力而广受欢迎。WS2812作为其中最具代表性的产品之一,仅需单线控制即可实现全…...

2026最权威的六大AI辅助论文工具横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 以深入模仿人类写作自然特征为核心要点,来降低AI生成文本的检测率。其一&#x…...

别再傻傻存多张图了!用MinIO和.NET Core实现按需生成缩略图,省下90%存储空间
智能缩略图方案:用MinIO与.NET Core实现存储成本优化 在数字内容爆炸式增长的今天,图片资源已成为各类应用不可或缺的组成部分。无论是电商平台的商品展示、社交媒体的用户分享,还是企业文档的图文混排,都需要处理大量不同尺寸的图…...