神经网络的梯度优化方法
神经网络的梯度优化是深度学习中至关重要的一部分,它有助于训练神经网络以拟合数据。下面将介绍几种常见的梯度优化方法,包括它们的特点、优缺点以及原理。
-
梯度下降法 (Gradient Descent):
- 特点: 梯度下降是最基本的优化算法,它试图通过迭代更新参数来最小化损失函数。
- 优点:
- 简单易懂。
- 全局收敛性(在凸优化问题中)。
- 缺点:
- 可能收敛速度慢,特别是对于高度非凸的问题。
- 学习率的选择通常需要仔细调整。
- 原理: 参数更新规则如下,其中 η \eta η 是学习率:
θ t + 1 = θ t − η ∇ J ( θ t ) \theta_{t+1} = \theta_{t} - \eta \nabla J(\theta_t) θt+1=θt−η∇J(θt)
-
随机梯度下降法 (Stochastic Gradient Descent, SGD):
- 特点: SGD在每个训练样本上执行参数更新,适用于大型数据集。
- 优点:
- 更快的收敛速度,通常能够在局部最小值附近摆动,有助于跳出局部最小值。
- 可以处理大型数据集。
- 缺点:
- 参数更新噪音较大,不稳定。
- 原理: 参数更新规则如下,其中 η \eta η 是学习率, i i i 表示随机选取的样本索引:
θ t + 1 = θ t − η ∇ J ( θ t ; x i , y i ) \theta_{t+1} = \theta_t - \eta \nabla J(\theta_t; x_i, y_i) θt+1=θt−η∇J(θt;xi,yi)
-
批量梯度下降法 (Mini-Batch Gradient Descent):
- 特点: MBGD是一种折中方法,每次使用一小批量训练数据进行参数更新。
- 优点:
- 收敛速度通常比纯SGD更快。
- 噪音相对较小。
- 缺点:
- 仍然需要手动调整学习率。
- 原理: 参数更新规则如下,其中 η \eta η 是学习率, B B B 表示批量大小:
θ t + 1 = θ t − η 1 B ∑ i = 1 B ∇ J ( θ t ; x i , y i ) \theta_{t+1} = \theta_t - \eta \frac{1}{B} \sum_{i=1}^{B} \nabla J(\theta_t; x_i, y_i) θt+1=θt−ηB1i=1∑B∇J(θt;xi,yi)
-
动量梯度下降 (Momentum):
- 特点: 动量法引入了动量项,有助于加速收敛并减小震荡。
- 优点:
- 加速收敛,特别对于高曲率的损失函数。
- 减小震荡,有助于避免局部最小值。
- 缺点:
- 需要调整动量参数。
- 原理: 参数更新规则如下,其中 η \eta η 是学习率, β \beta β 是动量系数:
v t + 1 = β v t + ( 1 − β ) ∇ J ( θ t ) v_{t+1} = \beta v_t + (1 - \beta) \nabla J(\theta_t) vt+1=βvt+(1−β)∇J(θt)
θ t + 1 = θ t − η v t + 1 \theta_{t+1} = \theta_t - \eta v_{t+1} θt+1=θt−ηvt+1
-
自适应学习率方法 (Adaptive Learning Rate Methods):
- 特点: 这类方法根据参数更新的情况自适应地调整学习率。
- 优点:
- 自适应性,通常无需手动调整学习率。
- 缺点:
- 可能较复杂,不稳定。
- 原理: 代表性方法包括Adagrad、RMSprop、Adam等。以Adam为例,参数更新规则如下,其中 η \eta η是学习率, β 1 \beta_1 β1和 β 2 \beta_2 β2是衰减系数:
m t = β 1 m t − 1 + ( 1 − β 1 ) ∇ J ( θ t ) m_t = \beta_1 m_{t-1} + (1 - \beta_1) \nabla J(\theta_t) mt=β1mt−1+(1−β1)∇J(θt)
v t = β 2 v t − 1 + ( 1 − β 2 ) ( ∇ J ( θ t ) ) 2 v_t = \beta_2 v_{t-1} + (1 - \beta_2) (\nabla J(\theta_t))^2 vt=β2vt−1+(1−β2)(∇J(θt))2
m ^ t = m t 1 − β 1 t \hat{m}_t = \frac{m_t}{1 - \beta_1^t} m^t=1−β1tmt
v ^ t = v t 1 − β 2 t \hat{v}_t = \frac{v_t}{1 - \beta_2^t} v^t=1−β2tvt
θ t + 1 = θ t − η v ^ t + ϵ ⊙ m ^ t \theta_{t+1} = \theta_t - \frac{\eta}{\sqrt{\hat{v}_t} + \epsilon} \odot \hat{m}_t θt+1=θt−v^t+ϵη⊙m^t
不同的优化方法适用于不同的问题,选择哪种方法通常需要根据具体情况和经验来决定。当在深度学习中选择梯度优化方法时,常常需要进行超参数调整和实验来找到最佳性能。
相关文章:

神经网络的梯度优化方法
神经网络的梯度优化是深度学习中至关重要的一部分,它有助于训练神经网络以拟合数据。下面将介绍几种常见的梯度优化方法,包括它们的特点、优缺点以及原理。 梯度下降法 (Gradient Descent): 特点: 梯度下降是最基本的优化算法,它试图通过迭代…...

linux 装机教程(自用备忘)
文章目录 安装 pyenv 管理多版本 python 环境安装使用使用 pyenv 和 virtualenv 管理虚拟 python 环境 vscode 连接远程服务器tmux 美化zsh 安装 pyenv 管理多版本 python 环境 安装 (教程参考:https://www.modb.pro/db/155036) sudo apt-…...
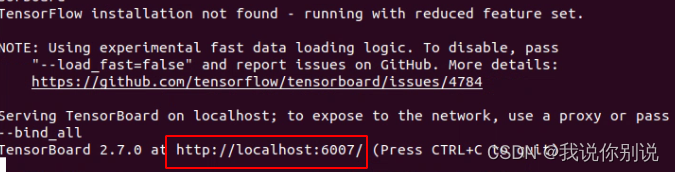
Tensorboard安装及简单使用
Tensorboard 1. tensorboard 简单介绍2. 安装必备环境3. Tensorboard安装4. 可视化命令 1. tensorboard 简单介绍 TensorBoard是一个可视化的模块,该模块功能强大,可用于深度学习网络模型训练查看模型结构和训练效果(预测结果、网络模型结构…...
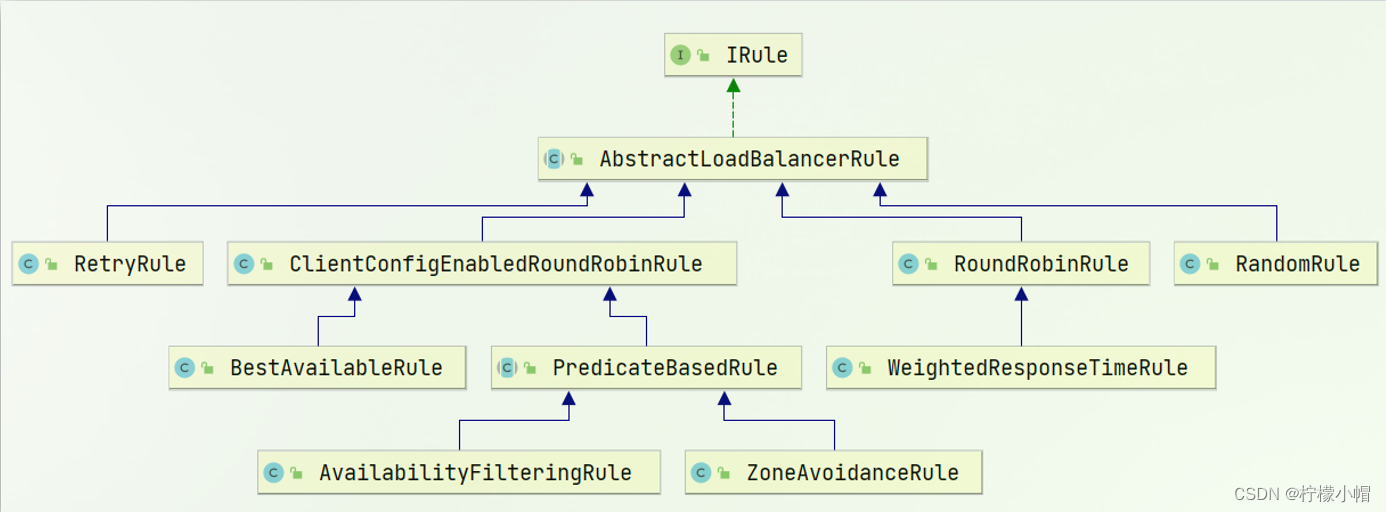
SpringCloud 微服务全栈体系(二)
第三章 Eureka 注册中心 假如我们的服务提供者 user-service 部署了多个实例,如图: 思考几个问题: order-service 在发起远程调用的时候,该如何得知 user-service 实例的 ip 地址和端口?有多个 user-service 实例地址…...

flutter 常用组件:列表ListView
文章目录 总结#1、通过构造方法直接构建 ListView 提供了一个默认构造函数 ListView,我们可以通过设置它的 children 参数,很方便地将所有的子 Widget 包含到 ListView 中。 不过,这种创建方式要求提前将所有子 Widget 一次性创建好,而不是等到它们真正在屏幕上需要显示时才…...
十四天学会C++之第七天:STL(标准模板库)
1. STL容器 什么是STL容器,为什么使用它们。向量(vector):使用向量存储数据。列表(list):使用列表实现双向链表。映射(map):使用映射实现键值对存储。 什么…...

Linux 下安装 miniconda,管理 Python 多环境
安装 miniconda 1、下载安装包 Miniconda3-py37_22.11.1-1-Linux-x86_64.sh,或者自行选择版本 2、把安装包上传到服务器上,这里放在 /home/software 3、安装 bash Miniconda3-py37_22.11.1-1-Linux-x86_64.sh 4、按回车 Welcome to Miniconda3 py37…...
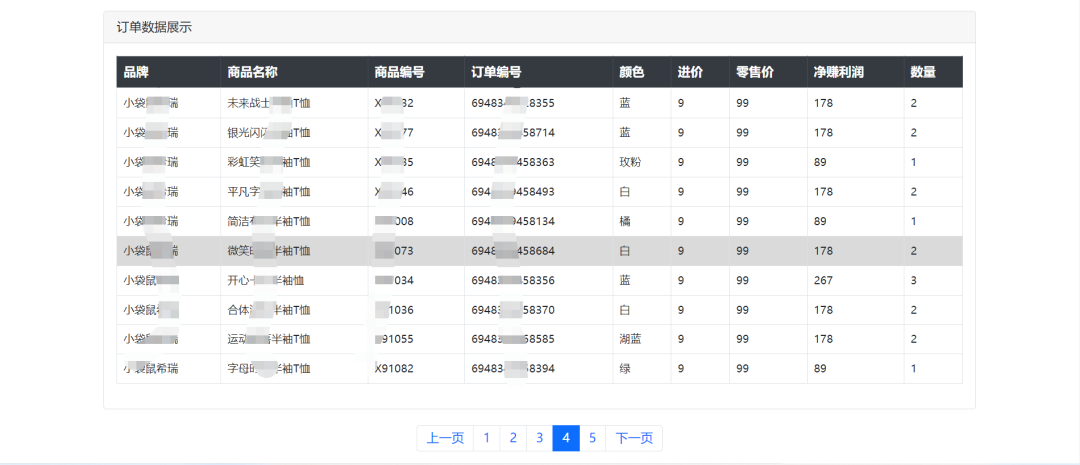
Django和jQuery,实现Ajax表格数据分页展示
1.需求描述 当存在重新请求接口才能返回数据的功能时,若页面的内容很长,每次点击一个功能,页面又回到了顶部,对于用户的体验感不太友好,我们希望当用户点击这类的功能时,能直接加载到数据,请求…...
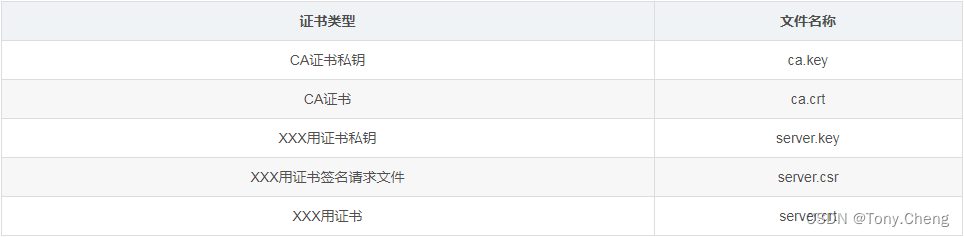
k8s认证
1. 证书介绍 服务端保留公钥和私钥,客户端使用root CA认证服务端的公钥 一共有多少证书: *Etcd: Etcd对外提供服务,要有一套etcd server证书Etcd各节点之间进行通信,要有一套etcd peer证书Kube-APIserver访问Etcd&a…...
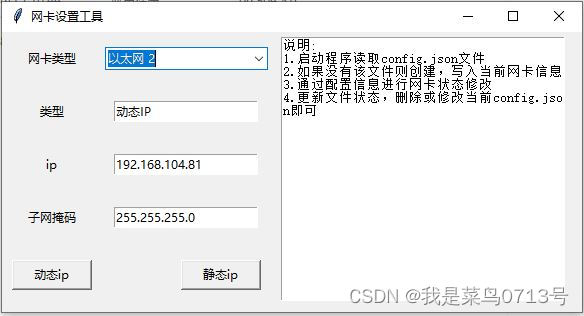
基于python开发的IP修改工具
工作中调试设备需要经常修改电脑IP,非常麻烦,这里使用Pythontkinter做了一个IP修改工具 说明: 1.启动程序读取config.json文件2.如果没有该文件则创建,写入当前网卡信息3.通过配置信息进行网卡状态修改4.更新文件状态,删除或修…...
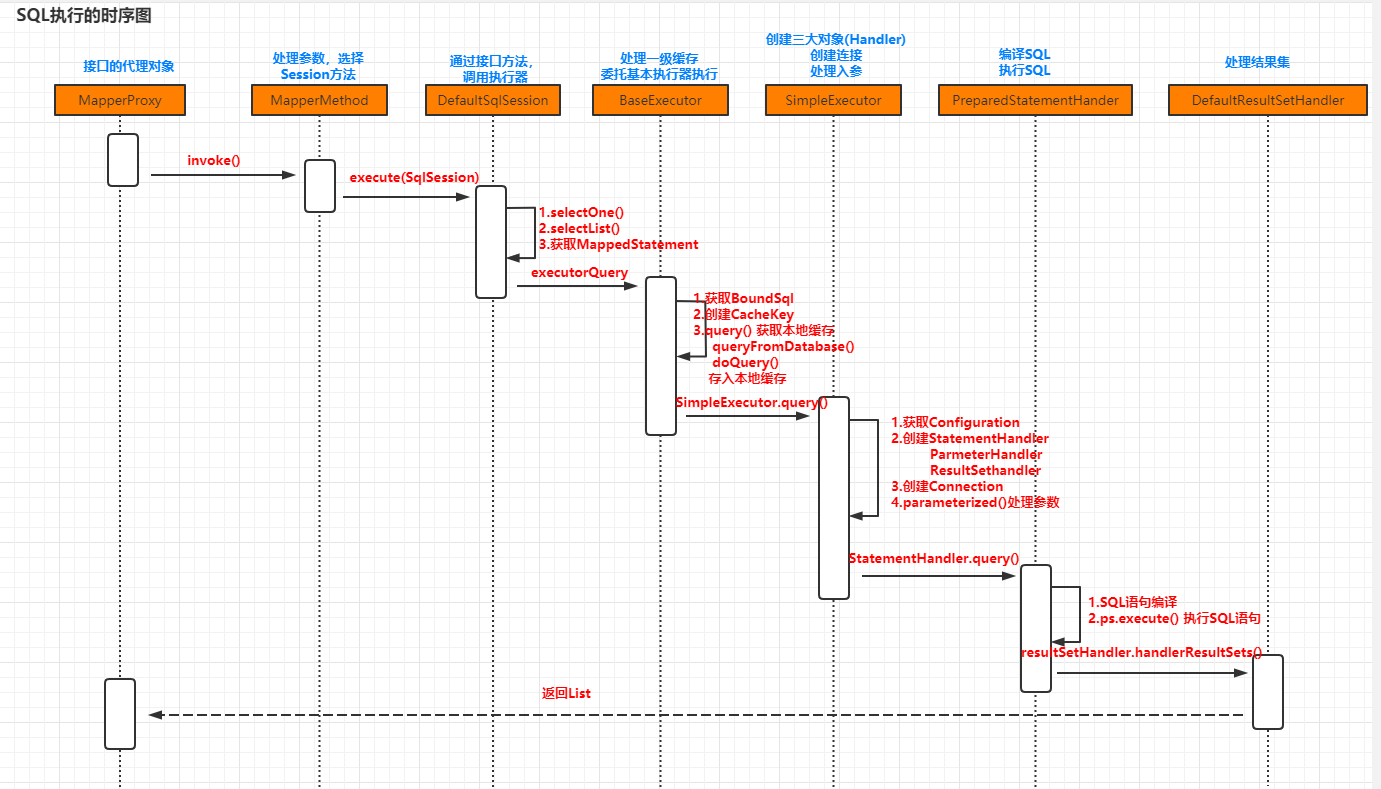
Mybatis源码分析
1. Mybatis整体三层设计 SSM中,Spring、SpringMVC已经在前面文章源码分析总结过了,Mybatis源码相对Spring和SpringMVC而言是的简单的,只有一个项目,项目下分了很多包。从宏观上了解Mybatis的整体框架分为三层,分别是基…...
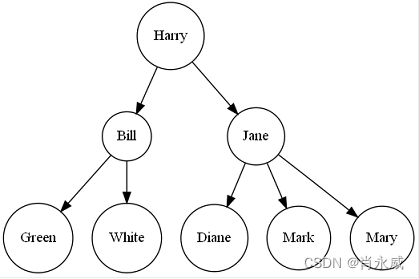
python树结构包treelib入门及其计算应用
树是计算机科学中重要的数据结构。例如决策树等机器学习算法设计、文件系统索引等。创建treelib包是为了在Python中提供树数据结构的有效实现。 Treelib的主要特点包括: 节点搜索的高效操作。支持常见的树操作,如遍历、插入、删除、节点移动、浅/深复制…...
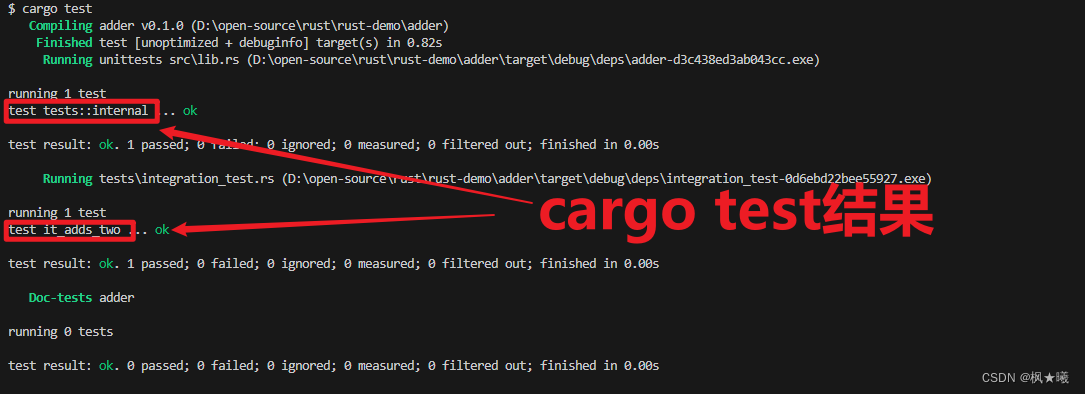
Rust之自动化测试(三): 测试组合
开发环境 Windows 10Rust 1.73.0 VS Code 1.83.1 项目工程 这里继续沿用上次工程rust-demo 测试组合 正如本章开始时提到的,测试是一个复杂的学科,不同的人使用不同的术语和组织。Rust社区根据两个主要类别来考虑测试:单元测试和集成测试。单元测试很…...
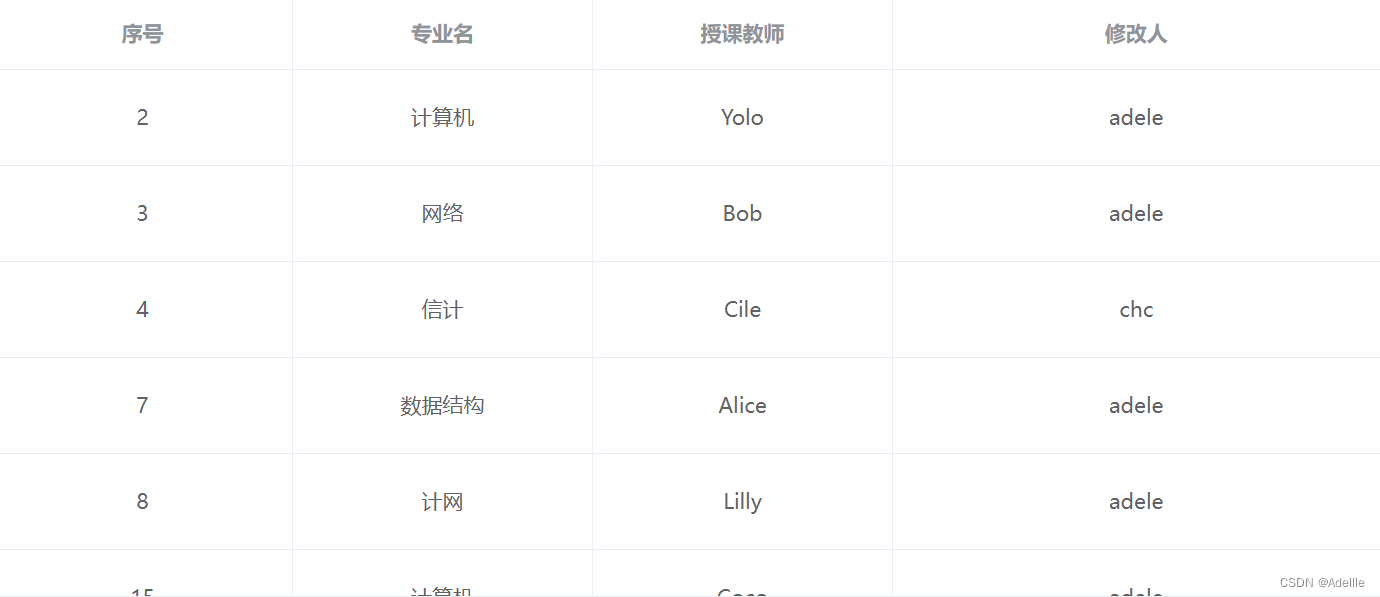
专业管理菜单的增删改、查重
1,点击专业管理菜单------查询所有专业信息列表 ①点击菜单,切换专业组件 ②切换到列表组件后,向后端发送请求到Servlet ③调用DAO层,查询数据库(sql),封装查询到的内容 ④从后端向前端做出…...

vue3插件开发,上传npm
创建插件 在vue3工程下,创建组件vue页: toolset.vue。并设置组件名称。注册全局组件。新建index.js文件。内容如下,可在main.js中引入index.js,注册该组件进行测试。
python【多线程、单线程、异步编程】三个版本--在爬虫中的应用
并发编程在爬虫中的应用 之前的课程,我们已经为大家介绍了 Python 中的多线程、多进程和异步编程,通过这三种手段,我们可以实现并发或并行编程,这一方面可以加速代码的执行,另一方面也可以带来更好的用户体验。爬虫程…...

大模型LLM相关面试题整理-位置编码-tokenizer-激活函数-layernorm
10 LLMs 位置编码篇 10.1.1 什么是位置编码? 位置编码是一种用于在序列数据中为每个位置添加位置信息的技术。在自然语言处理中,位置编码通常用于处理文本序列。由于传统的神经网络无法直接捕捉输入序列中的位置信息,位置编码的引入可以帮助…...

python在nacos注册微服务
安装 首先需要安装python的nacos sdk pip install nacos-sdk-python 注册 注册过程非常简单,需要注意的是,注册完要定时发送心跳,否则服务会被nacos删掉。 import nacos import timeSERVER_ADDRESSES "http://1.2.3.4:8848" …...
tuxera ntfs2024破解版mac电脑磁盘读写软件
大家都知道由于操作系统的原因,在苹果电脑上不能够读写NTFS磁盘,但是,今天小编带来的这款tuxera ntfs 2024 mac版,完美的解决了这个问题。这是一款在macOS平台上使用的磁盘读写软件,能够实现苹果Mac OS X系统读写Micro…...

【源码】C++坦克大战源码
文章目录 题目介绍你收到的所有文件源码效果展示报告内容 题目介绍 代码量:1450 语言:C 你收到的所有文件 其中一个是devc版本,也可以用visual stdio 运行。 源码效果展示 typedef struct //这里的出现次序指的是一个AI_ta…...

PP-DocLayoutV3模型部署避坑指南:解决常见环境配置与依赖冲突
PP-DocLayoutV3模型部署避坑指南:解决常见环境配置与依赖冲突 部署一个AI模型,尤其是像PP-DocLayoutV3这样功能强大的文档版面分析模型,本该是件令人兴奋的事。但很多时候,这份兴奋感在第一步——环境配置上,就可能被…...

AI编程从零起步:手把手教你开发自己的第一个Skill
AI编程从零起步:手把手教你开发自己的第一个Skill AI编程入门:开发自己的Skill 什么是Skill? Skill(技能)是AI助手的扩展功能模块,让AI能够执行特定任务——比如查询天气、发送邮件、计算数学题、调用外部A…...

用 QClaw 打造 AI 小说家,30 万字签约全流程复盘
文章目录前言第一步:下载安装 QClaw第二步:新建自定义 Agent第三步:精心设计小说家人设第四步:对 AI 小说家进行专项培训第五步:明确平台调性,设计世界观第六步:正式派发创作任务总结前言 最近…...

如何将SQL查询结果导出为CSV:SELECT INTO OUTFILE方法
MySQL的SELECT INTO OUTFILE受secure_file_priv限制且需FILE权限,导出无表头、需手动指定字段分隔符,字段含换行符时易解析失败;推荐用mysql命令行加--batch或Python pandas导出并处理编码、NULL及日期格式。MySQL不支持SELECT INTO OUTFILE&…...

Flutter集成华为厂商推送全攻略:解决后台被杀收不到消息的终极方案
Flutter集成华为厂商推送全攻略:解决后台被杀收不到消息的终极方案 在移动应用开发中,推送通知是保持用户活跃度的关键功能。然而,许多Flutter开发者在使用极光推送时都会遇到一个棘手问题:在华为手机上,当应用后台进…...

深入理解 C++ 内存模型与对象底层机制:this 指针的秘密
很多初学者在学习 C 面向对象时,脑海里都会有一个疑问:“既然每个对象都有自己的变量,那类里面的函数是放在哪里的?如果函数是共享的,它怎么知道我现在操作的是哪个对象的数据?”今天,我们就从 …...

从Overleaf回归本地:我为什么选择TeXLive+WinEdt搭建更高效的LaTeX写作环境?
从Overleaf回归本地:为什么TeXLiveWinEdt能打造更高效的LaTeX工作流? 当你在深夜赶论文时突然遭遇Overleaf服务器崩溃,或是需要自定义某个冷门宏包却受限于在线环境权限,那种无力感足以让任何LaTeX用户重新思考工具链的选择。作为…...
帮你选出最佳聚类算法)
别再只盯着K-Means了!用sklearn的轮廓系数(silhouette_score)帮你选出最佳聚类算法
用轮廓系数为聚类算法打分:从K-Means到DBSCAN的科学选择指南 当面对一堆未标注的数据时,很多人的第一反应是直接套用K-Means算法——这就像拿到食材只会做炒饭一样。但真实世界的数据分布千奇百怪,有的像瑞士奶酪布满空洞(适合DBS…...

Halcon镜头畸变矫正后,你的标定板图像真的“干净”了吗?一个容易被忽略的细节
Halcon镜头畸变矫正后,你的标定板图像真的“干净”了吗?一个容易被忽略的细节 当你在Halcon中完成镜头畸变矫正后,看着那些原本弯曲的线条变得笔直,是否觉得大功告成?很多工程师在这一步会直接保存矫正后的图像&#…...
)
手把手教你用SM2246EN主控板DIY 512G MLC固态U盘(含避坑指南)
从零打造高性能MLC固态U盘:SM2246EN主控实战全攻略 在数字存储需求爆炸式增长的今天,传统U盘的速度和容量已难以满足技术爱好者的需求。市面上的消费级U盘大多采用TLC或QLC闪存,虽然价格亲民,但性能和耐用性往往不尽如人意。而采用…...