深度学习笔记_5 经典卷积神经网络LeNet-5 解决MNIST数据集
1、定义LeNet-5模型,包括卷积层和全连接层。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms# 导入必要的库# 定义 LeNet-5 模型
class LeNet5(nn.Module):def __init__(self):super(LeNet5, self).__init__()# 定义卷积层和全连接层self.conv1 = nn.Conv2d(1, 6, kernel_size=5) # 输入通道1,输出通道6,卷积核大小5x5self.conv2 = nn.Conv2d(6, 16, kernel_size=5) # 输入通道6,输出通道16,卷积核大小5x5self.fc1 = nn.Linear(16 * 4 * 4, 120) # 全连接层,输入维度为16*4*4,输出维度为120self.fc2 = nn.Linear(120, 84) # 全连接层,输入维度为120,输出维度为84self.fc3 = nn.Linear(84, 64) # 全连接层,输入维度为84,输出维度为64self.fc4 = nn.Linear(64, 10) # 全连接层,输入维度为64,输出维度为10def forward(self, x):x = torch.relu(self.conv1(x)) # 第一个卷积层后接ReLU激活函数x = torch.max_pool2d(x, 2) # 池化层,执行2x2的最大池化x = torch.relu(self.conv2(x)) # 第二个卷积层后接ReLU激活函数x = torch.max_pool2d(x, 2) # 池化层,执行2x2的最大池化x = x.view(-1, 16 * 4 * 4) # 数据展平,以便输入全连接层x = torch.relu(self.fc1(x)) # 第一个全连接层后接ReLU激活函数x = torch.relu(self.fc2(x)) # 第二个全连接层后接ReLU激活函数x = self.fc3(x) # 第三个全连接层return x2、对MNIST数据集进行加载和预处理,包括将图像转换为张量和标准化。
# 加载 MNIST 训练集和测试集
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
# 定义数据预处理,包括转换为张量和标准化train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
# 下载MNIST数据集,并应用数据预处理train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False)
# 创建训练和测试数据加载器
3、初始化模型和优化器,使用随机梯度下降(SGD)优化器。
# 初始化模型和优化器
model = LeNet5() # 创建LeNet-5模型
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9) # 使用随机梯度下降作为优化器# 训练模型
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 检查是否支持GPU,如果支持则使用GPU
model.to(device) # 将模型移动到GPU或CPU
criterion = nn.CrossEntropyLoss() # 使用交叉熵损失函数4、在每个训练周期内,进行前向传播、反向传播和参数更新。在训练集上进行精度测试,以评估模型性能。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms# 导入必要的库# 定义 LeNet-5 模型
class LeNet5(nn.Module):def __init__(self):super(LeNet5, self).__init__()# 定义卷积层和全连接层self.conv1 = nn.Conv2d(1, 6, kernel_size=5) # 输入通道1,输出通道6,卷积核大小5x5self.conv2 = nn.Conv2d(6, 16, kernel_size=5) # 输入通道6,输出通道16,卷积核大小5x5self.fc1 = nn.Linear(16 * 4 * 4, 120) # 全连接层,输入维度为16*4*4,输出维度为120self.fc2 = nn.Linear(120, 84) # 全连接层,输入维度为120,输出维度为84self.fc3 = nn.Linear(84, 64) # 全连接层,输入维度为84,输出维度为64self.fc4 = nn.Linear(64, 10) # 全连接层,输入维度为64,输出维度为10def forward(self, x):x = torch.relu(self.conv1(x)) # 第一个卷积层后接ReLU激活函数x = torch.max_pool2d(x, 2) # 池化层,执行2x2的最大池化x = torch.relu(self.conv2(x)) # 第二个卷积层后接ReLU激活函数x = torch.max_pool2d(x, 2) # 池化层,执行2x2的最大池化x = x.view(-1, 16 * 4 * 4) # 数据展平,以便输入全连接层x = torch.relu(self.fc1(x)) # 第一个全连接层后接ReLU激活函数x = torch.relu(self.fc2(x)) # 第二个全连接层后接ReLU激活函数x = self.fc3(x) # 第三个全连接层return x# 加载 MNIST 训练集和测试集
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
# 定义数据预处理,包括转换为张量和标准化train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
# 下载MNIST数据集,并应用数据预处理train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False)
# 创建训练和测试数据加载器# 初始化模型和优化器
model = LeNet5() # 创建LeNet-5模型
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9) # 使用随机梯度下降作为优化器# 训练模型
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 检查是否支持GPU,如果支持则使用GPU
model.to(device) # 将模型移动到GPU或CPU
criterion = nn.CrossEntropyLoss() # 使用交叉熵损失函数for epoch in range(10):model.train() # 设置模型为训练模式running_loss = 0.0for images, labels in train_loader:images, labels = images.to(device), labels.to(device) # 将数据移动到GPU或CPUoptimizer.zero_grad() # 梯度清零outputs = model(images) # 前向传播loss = criterion(outputs, labels) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新模型参数running_loss += loss.item()# 在训练集上进行精度测试model.eval() # 设置模型为评估模式correct = 0total = 0with torch.no_grad():for images, labels in test_loader:images, labels = images.to(device), labels.to(device) # 将数据移动到GPU或CPUoutputs = model(images) # 前向传播_, predicted = torch.max(outputs.data, 1) # 获取预测类别total += labels.size(0)correct += (predicted == labels).sum().item()accuracy = 100 * correct / totalprint('Epoch: %d, Loss: %.3f, Accuracy: %.2f%%' % (epoch+1, running_loss, accuracy))
5、实验步骤和关键要点:
-
模型定义:LeNet-5模型被定义为一个经典的卷积神经网络,包括卷积层和全连接层。模型结构包括两个卷积层、两个池化层和三个全连接层。
-
数据加载和预处理:MNIST数据集被加载并进行预处理。预处理包括将图像转换为张量,并进行标准化,以确保输入数据在训练期间具有相似的尺度和分布。
-
初始化模型和优化器:LeNet-5模型被初始化,并使用随机梯度下降(SGD)作为优化器。SGD用于在训练期间调整模型参数以最小化损失函数。
-
模型训练:模型被训练在训练集上进行了多个周期的训练。对于每个训练周期,执行以下步骤:
- 设置模型为训练模式。
- 对每个批次进行前向传播,计算损失,执行反向传播,更新模型参数。
- 记录每个训练周期的损失值。
-
模型测试:在每个训练周期结束后,模型在测试集上进行了精度测试。在测试期间,执行以下步骤:
- 设置模型为评估模式。
- 通过模型进行前向传播,计算测试集上的预测结果。
- 检查模型的准确性,计算正确分类的样本数量,并计算总样本数量。
- 记录每个训练周期的测试精度。
-
打印结果:在每个训练周期结束后,打印出训练周期的损失和测试精度,以便监控模型的性能。
这个实验展示了如何使用PyTorch框架构建、训练和测试深度学习模型。LeNet-5模型在MNIST数据集上取得了不错的手写数字识别性能。通过多个训练周期,模型的损失逐渐减小,测试精度逐渐增加,表明模型在训练过程中逐渐学习到了有效的特征表示,从而提高了在新样本上的分类准确性。
相关文章:

深度学习笔记_5 经典卷积神经网络LeNet-5 解决MNIST数据集
1、定义LeNet-5模型,包括卷积层和全连接层。 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms# 导入必要的库# 定义 LeNet-5 模型 class LeNet5(nn.Module):def __init__(self):super(LeNet5, self…...

国内智能客服机器人都有哪些?
随着人工智能技术的不断发展,智能客服机器人已经成为了企业客户服务的重要工具。国内的智能客服机器人市场也迎来了飞速发展,越来越多的企业开始采用智能客服机器人来提升客户服务效率和质量。 在这篇文章中,我将详细介绍国内知名的智能客服机…...

Matlab/C++源码实现RGB通道与HSV通道的转换(效果对比Halcon)
HSV通道的含义 HSV通道是指图像处理中的一种颜色模型,它由色调(Hue)、饱和度(Saturation)和明度(Value)三个通道组成。色调表示颜色的种类,饱和度表示颜色的纯度或鲜艳程度…...

【C进阶】动态内存管理
一、为什么存在动态内存分配 我们之前学的都是开辟固定大小的空间,但有时候需要空间的大小只有在程序运行时才能知道,那么就引入了动态内存开辟 内存分布所在: 二、动态内存函数的介绍 2.1malloc和free 动态内存开辟的函数 void * malloc…...

神经网络的梯度优化方法
神经网络的梯度优化是深度学习中至关重要的一部分,它有助于训练神经网络以拟合数据。下面将介绍几种常见的梯度优化方法,包括它们的特点、优缺点以及原理。 梯度下降法 (Gradient Descent): 特点: 梯度下降是最基本的优化算法,它试图通过迭代…...

linux 装机教程(自用备忘)
文章目录 安装 pyenv 管理多版本 python 环境安装使用使用 pyenv 和 virtualenv 管理虚拟 python 环境 vscode 连接远程服务器tmux 美化zsh 安装 pyenv 管理多版本 python 环境 安装 (教程参考:https://www.modb.pro/db/155036) sudo apt-…...
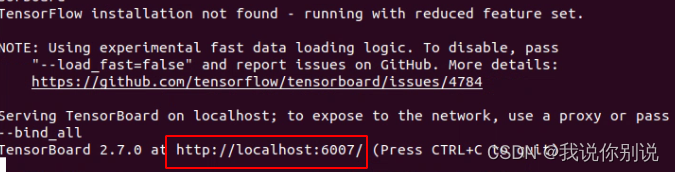
Tensorboard安装及简单使用
Tensorboard 1. tensorboard 简单介绍2. 安装必备环境3. Tensorboard安装4. 可视化命令 1. tensorboard 简单介绍 TensorBoard是一个可视化的模块,该模块功能强大,可用于深度学习网络模型训练查看模型结构和训练效果(预测结果、网络模型结构…...
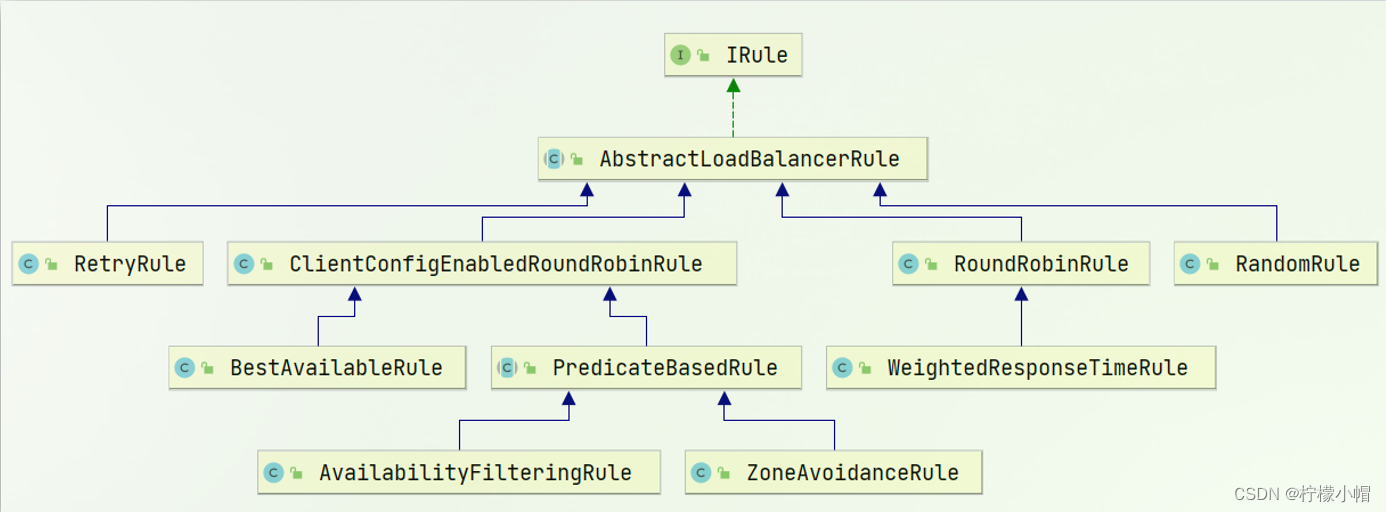
SpringCloud 微服务全栈体系(二)
第三章 Eureka 注册中心 假如我们的服务提供者 user-service 部署了多个实例,如图: 思考几个问题: order-service 在发起远程调用的时候,该如何得知 user-service 实例的 ip 地址和端口?有多个 user-service 实例地址…...

flutter 常用组件:列表ListView
文章目录 总结#1、通过构造方法直接构建 ListView 提供了一个默认构造函数 ListView,我们可以通过设置它的 children 参数,很方便地将所有的子 Widget 包含到 ListView 中。 不过,这种创建方式要求提前将所有子 Widget 一次性创建好,而不是等到它们真正在屏幕上需要显示时才…...
十四天学会C++之第七天:STL(标准模板库)
1. STL容器 什么是STL容器,为什么使用它们。向量(vector):使用向量存储数据。列表(list):使用列表实现双向链表。映射(map):使用映射实现键值对存储。 什么…...

Linux 下安装 miniconda,管理 Python 多环境
安装 miniconda 1、下载安装包 Miniconda3-py37_22.11.1-1-Linux-x86_64.sh,或者自行选择版本 2、把安装包上传到服务器上,这里放在 /home/software 3、安装 bash Miniconda3-py37_22.11.1-1-Linux-x86_64.sh 4、按回车 Welcome to Miniconda3 py37…...
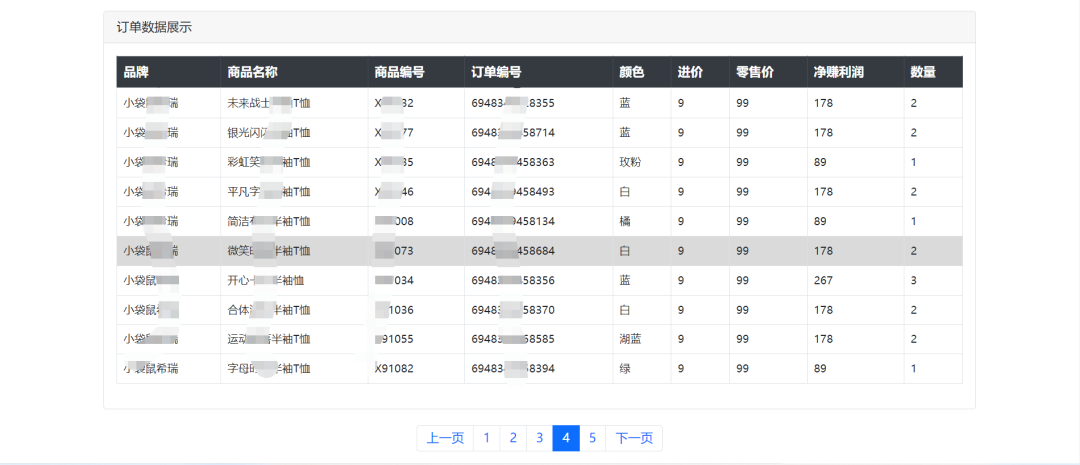
Django和jQuery,实现Ajax表格数据分页展示
1.需求描述 当存在重新请求接口才能返回数据的功能时,若页面的内容很长,每次点击一个功能,页面又回到了顶部,对于用户的体验感不太友好,我们希望当用户点击这类的功能时,能直接加载到数据,请求…...
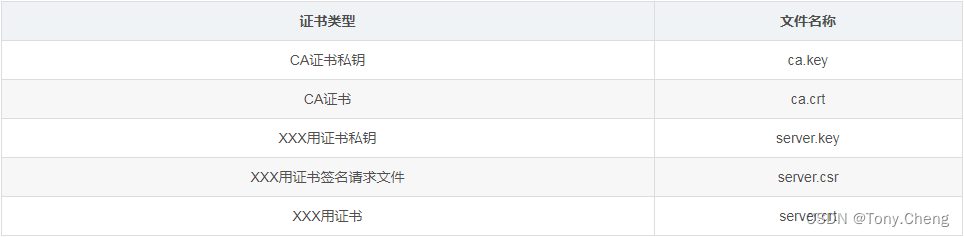
k8s认证
1. 证书介绍 服务端保留公钥和私钥,客户端使用root CA认证服务端的公钥 一共有多少证书: *Etcd: Etcd对外提供服务,要有一套etcd server证书Etcd各节点之间进行通信,要有一套etcd peer证书Kube-APIserver访问Etcd&a…...
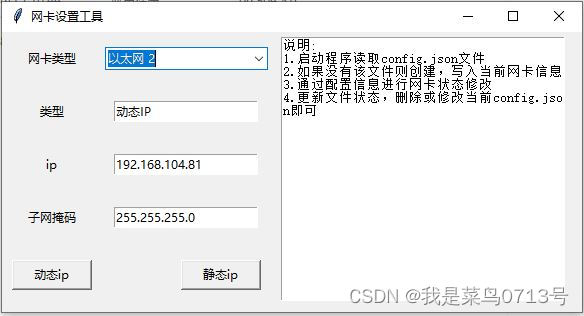
基于python开发的IP修改工具
工作中调试设备需要经常修改电脑IP,非常麻烦,这里使用Pythontkinter做了一个IP修改工具 说明: 1.启动程序读取config.json文件2.如果没有该文件则创建,写入当前网卡信息3.通过配置信息进行网卡状态修改4.更新文件状态,删除或修…...
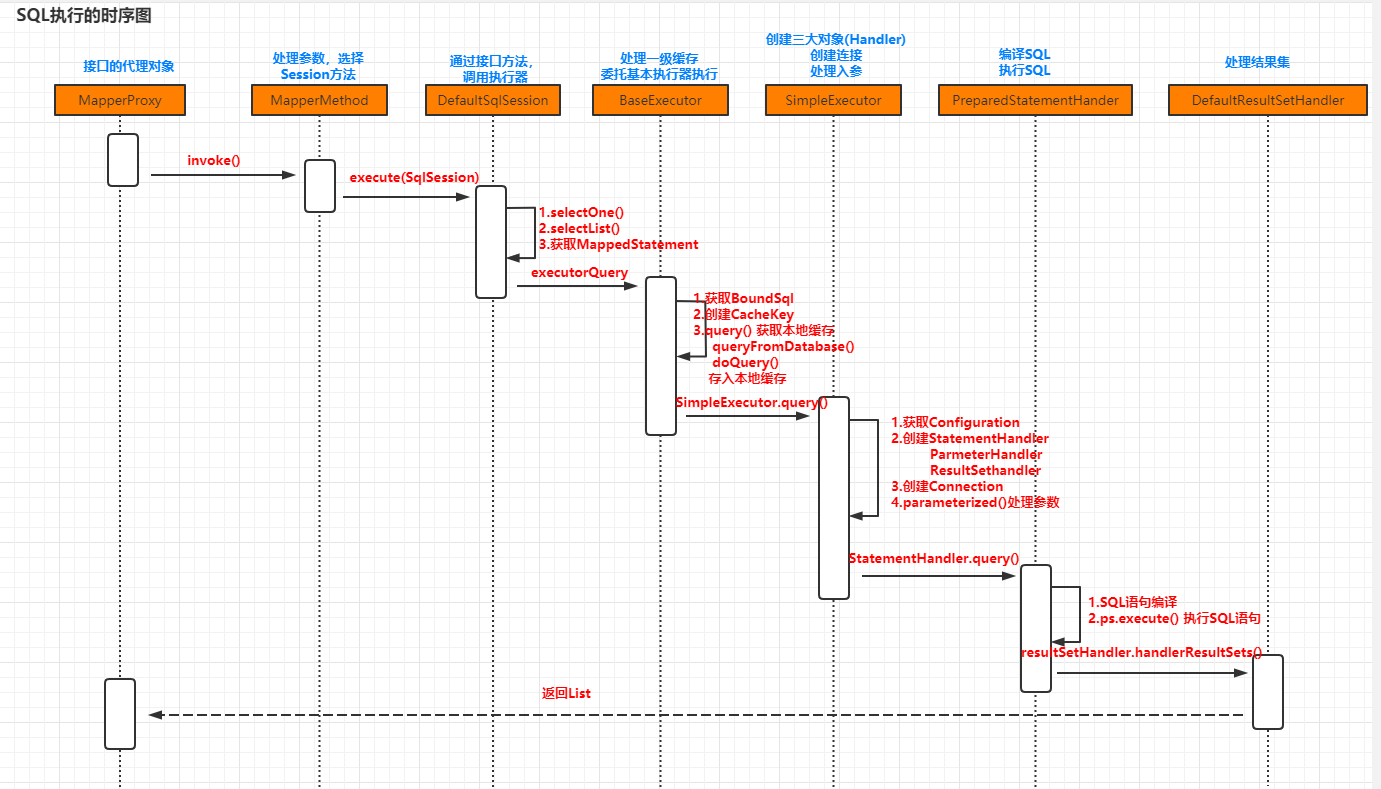
Mybatis源码分析
1. Mybatis整体三层设计 SSM中,Spring、SpringMVC已经在前面文章源码分析总结过了,Mybatis源码相对Spring和SpringMVC而言是的简单的,只有一个项目,项目下分了很多包。从宏观上了解Mybatis的整体框架分为三层,分别是基…...
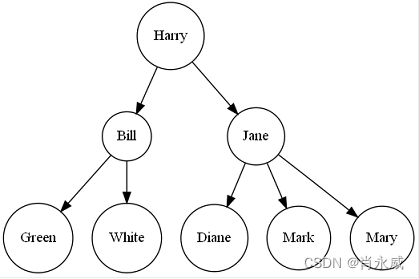
python树结构包treelib入门及其计算应用
树是计算机科学中重要的数据结构。例如决策树等机器学习算法设计、文件系统索引等。创建treelib包是为了在Python中提供树数据结构的有效实现。 Treelib的主要特点包括: 节点搜索的高效操作。支持常见的树操作,如遍历、插入、删除、节点移动、浅/深复制…...
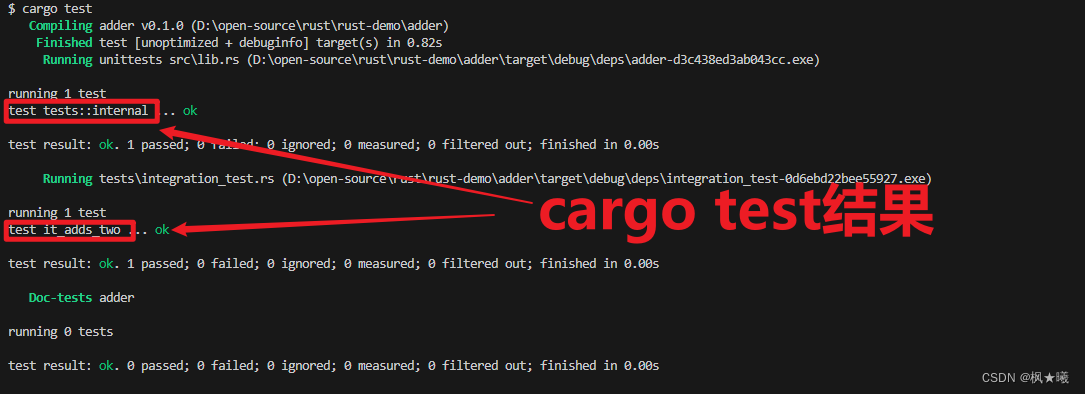
Rust之自动化测试(三): 测试组合
开发环境 Windows 10Rust 1.73.0 VS Code 1.83.1 项目工程 这里继续沿用上次工程rust-demo 测试组合 正如本章开始时提到的,测试是一个复杂的学科,不同的人使用不同的术语和组织。Rust社区根据两个主要类别来考虑测试:单元测试和集成测试。单元测试很…...
专业管理菜单的增删改、查重
1,点击专业管理菜单------查询所有专业信息列表 ①点击菜单,切换专业组件 ②切换到列表组件后,向后端发送请求到Servlet ③调用DAO层,查询数据库(sql),封装查询到的内容 ④从后端向前端做出…...

vue3插件开发,上传npm
创建插件 在vue3工程下,创建组件vue页: toolset.vue。并设置组件名称。注册全局组件。新建index.js文件。内容如下,可在main.js中引入index.js,注册该组件进行测试。
python【多线程、单线程、异步编程】三个版本--在爬虫中的应用
并发编程在爬虫中的应用 之前的课程,我们已经为大家介绍了 Python 中的多线程、多进程和异步编程,通过这三种手段,我们可以实现并发或并行编程,这一方面可以加速代码的执行,另一方面也可以带来更好的用户体验。爬虫程…...

共识的火种:Alpha AI“万家灯火”计划加速全球生态共建
随着前沿人工智能与Web3 技术的不断交融,一场旨在打破技术壁垒的共识运动正在席卷全球。近期,备受瞩目的 Alpha AI “万家灯火”全球宣发计划,正以强劲的势能向世界展示其宏大的生态蓝图。一、核心枢纽引爆:掀起全球技术平权新热潮…...
是 Spring Security 框架在 2013 年底发布的候选版本)
Spring Security 3.2.0.RC1(Release Candidate 1)是 Spring Security 框架在 2013 年底发布的候选版本
Spring Security 3.2.0.RC1(Release Candidate 1)是 Spring Security 框架在 2013 年底发布的候选版本,标志着 3.2.x 系列的初步稳定。该版本引入了多项重要改进与新特性,包括: Java Config 支持增强:进一步…...

Cats Blender插件终极指南:如何快速将3D模型优化并导入VRChat
Cats Blender插件终极指南:如何快速将3D模型优化并导入VRChat 【免费下载链接】cats-blender-plugin :smiley_cat: A tool designed to shorten steps needed to import and optimize models into VRChat. Compatible models are: MMD, XNALara, Mixamo, DAZ/Poser,…...

企业云盘选型标准合同条款:数据归属/服务等级/SLA全解析
作者:巴别鸟技术团队 适用场景:IT采购、合规审查、法务评估 更新时间:2026-04引言:为什么选云盘先看合同? 企业选择云盘时,大多数人盯着功能对比、UI体验、存储价格——但真正踩过坑的IT负责人知道…...

什么是Bootstrap的移动优先响应式设计
Bootstrap移动优先指类名默认从xs断点生效,如.col-6全局有效,.col-md-6仅≥768px生效;须先写基础类(如.col-12),再叠加更大屏类,避免小屏塌陷。移动优先不是口号,是类名生效逻辑Boot…...

为什么GPT-5没提“元学习”?深度起底OpenAI内部技术路线图中被雪藏的快速适应模块
第一章:AGI的元学习与快速适应能力 2026奇点智能技术大会(https://ml-summit.org) 元学习(Meta-Learning)是通向人工通用智能(AGI)的关键范式,其核心在于让系统学会“如何学习”——而非仅针对特定任务优化…...

C语言完美演绎8-11
/* 范例:8-11 */#include <stdio.h>void func(int9, int9); /* 在原型声明上作预设初值 */void fun(){func(); /* 若不是在func()函数的原型声明上设定参数预设初值或函数fun()原型声明的话,此行将会错误 */}/* 若参数a没有传入值,…...

SVG数据处理架构对比:如何选择最适合程序化操作的可扩展转换引擎
SVG数据处理架构对比:如何选择最适合程序化操作的可扩展转换引擎 【免费下载链接】svgson Transform svg files to json notation 项目地址: https://gitcode.com/gh_mirrors/sv/svgson 在前端开发和数据可视化项目中,SVG图形数据的程序化处理一…...

3步搞定Windows软件卸载:Bulk Crap Uninstaller完全指南
3步搞定Windows软件卸载:Bulk Crap Uninstaller完全指南 【免费下载链接】Bulk-Crap-Uninstaller Remove large amounts of unwanted applications quickly. 项目地址: https://gitcode.com/gh_mirrors/bu/Bulk-Crap-Uninstaller 你是否曾为Windows系统上残留…...
的实战心得)
从嵌入式春招到秋招:我用C语言刷动态规划(背包问题)的实战心得
从嵌入式春招到秋招:我用C语言刷动态规划(背包问题)的实战心得 去年春天,当我第一次打开某大厂的在线笔试系统时,手心里全是汗。作为嵌入式专业的学生,我本以为笔试会偏向硬件和底层开发,没想到…...