自然语言处理---Transformer机制详解之BERT模型特点
1 BERT的优点和缺点
1.1 BERT的优点
- 通过预训练, 加上Fine-tunning, 在11项NLP任务上取得最优结果.
- BERT的根基源于Transformer, 相比传统RNN更加高效, 可以并行化处理同时能捕捉长距离的语义和结构依赖.
- BERT采用了Transformer架构中的Encoder模块, 不仅仅获得了真正意义上的bidirectional context, 而且为后续微调任务留出了足够的调整空间.
1.2 BERT的缺点
- BERT模型过于庞大, 参数太多, 不利于资源紧张的应用场景, 也不利于上线的实时处理.
- BERT目前给出的中文模型中, 是以字为基本token单位的, 很多需要词向量的应用无法直接使用. 同时该模型无法识别很多生僻词, 只能以UNK代替.
- BERT中第一个预训练任务MLM中, [MASK]标记只在训练阶段出现, 而在预测阶段不会出现, 这就造成了一定的信息偏差, 因此训练时不能过多的使用[MASK], 否则会影响模型的表现.
- 按照BERT的MLM任务中的约定, 每个batch数据中只有15%的token参与了训练, 被模型学习和预测, 所以BERT收敛的速度比left-to-right模型要慢很多(left-to-right模型中每一个token都会参与训练).
2 BERT的MLM任务
2.1 80%, 10%, 10%的策略
- 首先, 如果所有参与训练的token被100%的[MASK], 那么在fine-tunning的时候所有单词都是已知的, 不存在[MASK], 那么模型就只能根据其他token的信息和语序结构来预测当前词, 而无法利用到这个词本身的信息, 因为它们从未出现在训练过程中, 等于模型从未接触到它们的信息, 等于整个语义空间损失了部分信息. 采用80%的概率下应用[MASK], 既可以让模型去学着预测这些单词, 又以20%的概率保留了语义信息展示给模型.
- 保留下来的信息如果全部使用原始token, 那么模型在预训练的时候可能会偷懒, 直接照抄当前token信息. 采用10%概率下random token来随机替换当前token, 会让模型不能去死记硬背当前的token, 而去尽力学习单词周边的语义表达和远距离的信息依赖, 尝试建模完整的语言信息.
- 最后再以10%的概率保留原始的token, 意义就是保留语言本来的面貌, 让信息不至于完全被遮掩, 使得模型可以"看清"真实的语言面貌.
3 BERT处理长文本的方法
- 首选要明确一点, BERT预训练模型所接收的最大sequence长度是512.
- 那么对于长文本(文本长度超过512的句子), 就需要特殊的方式来构造训练样本. 核心就是如何进行截断.
- head-only方式: 这是只保留长文本头部信息的截断方式, 具体为保存前510个token (要留两个位置给[CLS]和[SEP]).
- tail-only方式: 这是只保留长文本尾部信息的截断方式, 具体为保存最后510个token (要留两个位置给[CLS]和[SEP]).
- head+only方式: 选择前128个token和最后382个token (文本总长度在800以内), 或者前256个token和最后254个token (文本总长度大于800).
4 小结
-
BERT模型的3个优点:
- 在11个NLP任务上取得SOAT成绩.
- 利用了Transformer的并行化能力以及长语句捕捉语义依赖和结构依赖.
- BERT实现了双向Transformer并为后续的微调任务留出足够的空间.
-
BERT模型的4个缺点:
- BERT模型太大, 太慢.
- BERT模型中的中文模型是以字为基本token单位的, 无法利用词向量, 无法识别生僻词.
- BERT模型中的MLM任务, [MASK]标记在训练阶段出现, 预测阶段不出现, 这种偏差会对模型有一定影响.
- BERT模型的MLM任务, 每个batch只有15%的token参与了训练, 造成大量文本数据的"无用", 收敛速度慢, 需要的算力和算时都大大提高.
-
长文本处理如果要利用BERT的话, 需要进行截断处理.
- 第一种方式就是只保留前面510个token.
- 第二种方式就是只保留后面510个token.
- 第三种方式就是前后分别保留一部分token, 总数是510.
-
BERT中MLM任务中的[MASK]是以一种显示的方式告诉模型"这个词我不告诉你, 你自己从上下文里猜", 非常类似于同学们在做完形填空. 如果[MASK]意外的部分全部都用原始token, 模型会学习到"如果当前词是[MASK], 就根据其他词的信息推断这个词; 如果当前词是一个正常的单词, 就直接照抄". 这样一来, 到了fine-tunning阶段, 所有单词都是正常单词了, 模型就会照抄所有单词, 不再提取单词之间的依赖关系了.
-
BERT中MLM任务以10%的概率填入random token, 就是让模型时刻处于"紧张情绪"中, 让模型搞不清楚当前看到的token是真实的单词还是被随机替换掉的单词, 这样模型在任意的token位置就只能把当前token的信息和上下文信息结合起来做综合的判断和建模. 这样一来, 到了fine-tunning阶段, 模型也会同时提取这两方面的信息, 因为模型"心理很紧张", 它不知道当前看到的这个token, 所谓的"正常单词"到底有没有"提前被动过手脚".
相关文章:
自然语言处理---Transformer机制详解之BERT模型特点
1 BERT的优点和缺点 1.1 BERT的优点 通过预训练, 加上Fine-tunning, 在11项NLP任务上取得最优结果.BERT的根基源于Transformer, 相比传统RNN更加高效, 可以并行化处理同时能捕捉长距离的语义和结构依赖.BERT采用了Transformer架构中的Encoder模块, 不仅仅获得了真正意义上的b…...

c语言基础:L1-048 矩阵A乘以B
给定两个矩阵A和B,要求你计算它们的乘积矩阵AB。需要注意的是,只有规模匹配的矩阵才可以相乘即若A有Ra行、Ca列,B有Rb行、Cb列,则只有Ca与Rb相等时,两个矩阵才能相乘。 输入格式: 输入先后给出…...
asp.net乒乓球场地管理系统VS开发sqlserver数据库web结构c#编程Microsoft Visual Studio
一、源码特点 asp.net乒乓球场地管理系统是一套完善的web设计管理系统,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为vs2010,数据库为sqlserver2008,使用c#语 言开发 asp.net 乒乓球场地管理系统 二…...

git仓库中增加子仓库
在 Git 中包含另一个 Git 仓库通常使用 Git 子模块(Git Submodule)来实现。子模块允许你在一个 Git 仓库中包含另一个 Git 仓库,从而在一个仓库中管理多个相关但独立的项目。 以下是如何将一个 Git 仓库包含为另一个 Git 仓库的子模块的步骤…...
html中公用css、js提取、使用
前言 开发中,页面会有引用相同的css、js的情况,如需更改则每个页面都需要调整,重复性工作较多,另外在更改内容之后上传至服务器中会有缓存问题,特针对该情况对公用css、js进行了提取并对引用时增加了版本号 一、提取…...

Jprofiler V14中文使用文档
JProfiler介绍 什么是JProfiler? JProfiler是一个用于分析运行JVM内部情况的专业工具。 在开发中你可以使用它,用于质量保证,也可以解决你的生产系统遇到的问题。 JProfiler处理四个主要问题: 方法调用 这通常被称为"CPU分析"。方法调用可以通过不同的方式进行测…...
基于PHP的蛋糕甜品商店管理系统设计与实现(源码+lw+部署文档+讲解等)
文章目录 前言具体实现截图论文参考详细视频演示为什么选择我自己的网站自己的小程序(小蔡coding) 代码参考数据库参考源码获取 前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作者&am…...
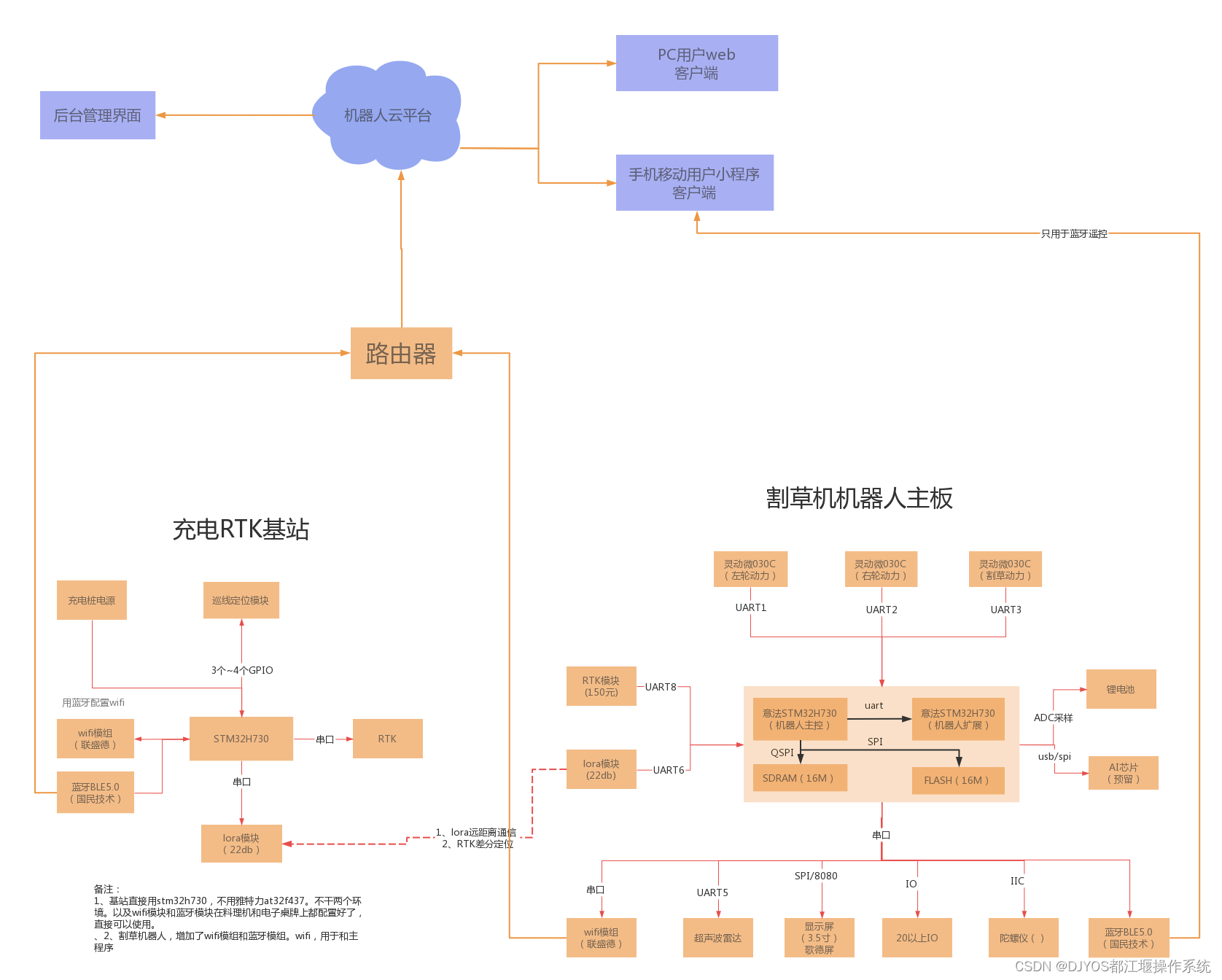
DJYROS产品:基于DJYOS的国产自主割草机器人解决方案
基于都江堰泛计算操作系统的国产自主机器人操作系统即将发布…… 1、都江堰机器人操作系统命名:DJYROS 2、机器人算法:联合行业自主机器人厂家,构建机器人算法库。 3、机器人芯片:联合行业机器人AI芯片公司,构建专用…...

A预测蛋白质结构
基于AlphaFold2进行蛋白质结构预测的文章解析 RoseTTAFold: Tunyasuvunakool, K., Adler, J., Wu, Z. et al. Highly accurate protein structure prediction for the human proteome. Nature 596, 590–596 (2021) AlphaFold2: Accurate prediction of protein structures a…...

rust学习~slice迭代器
背景 pub fn iter(&self) -> Iter<_, T>查看Iter 结构体 pub struct Iter<a, T> whereT: a, {/* private fields */ }对迭代器求和 sum fn sum<S>(self) -> S whereSelf: Sized, // 该函数只能在具有已知大小的类型上调用S: Sum<Self::Item…...
python免杀初探
文章目录 loader基础知识loader参数介绍 evilhiding项目地址免杀方式修改加载器花指令混淆loader源码修改签名加壳远程条件触发修改ico的md5加密 loader基础知识 loader import ctypes #(kali生成payload存放位置) shellcode bytearray(b"shellc…...
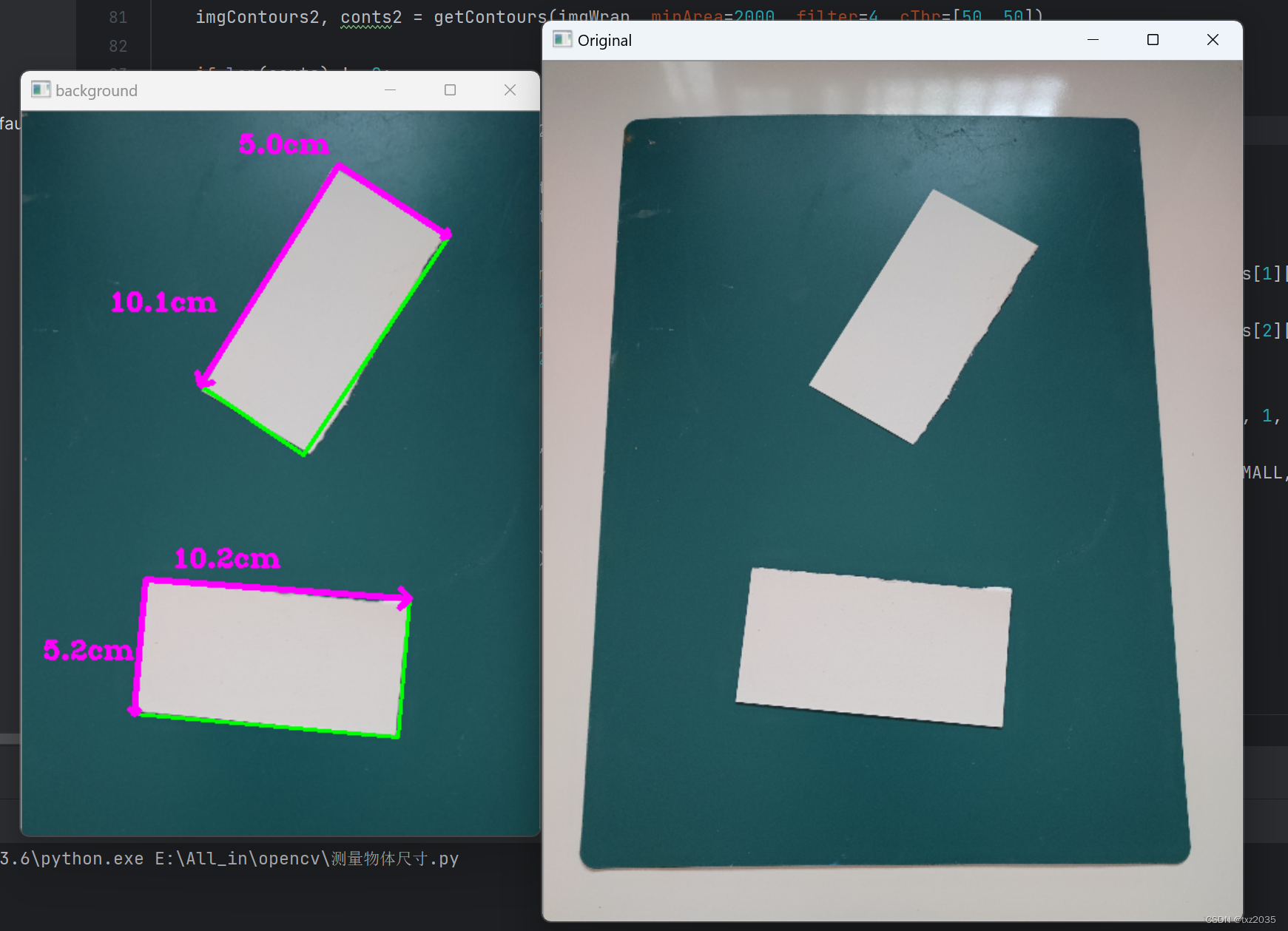
OpenCV实现物体尺寸的测量
一 ,项目分析 物体尺寸测量的思路是找一个确定尺寸的物体作为参照物,根据已知的计算未知物体尺寸。 如下图所示,绿色的板子尺寸为220*300(单位:毫米),通过程序计算白色纸片的长度。 主要是通过…...

投资研报的优质网站
投资研报:https://www.zhihu.com/question/357713923/answer/2304672553...

每日刷题|贪心算法初识
食用指南:本文为作者刷题中认为有必要记录的题目 推荐专栏:每日刷题 ♈️今日夜电波:悬溺—葛东琪 0:34 ━━━━━━️💟──────── 3:17 …...

[python]如何操作Outlook实现邮件自动化
【背景】 邮件自动化存在很多需求场景,有的场景希望会出现Outlook窗口在发送前进行一下人工检查等等的人为干预,有的则希望定时直接发送,有的需要加附件等等。本篇讨论用Python覆盖这些Outlook邮件自动化场景的方法。 【解决方法】 首先Outlook和SMTP的邮件自动化方法所使…...
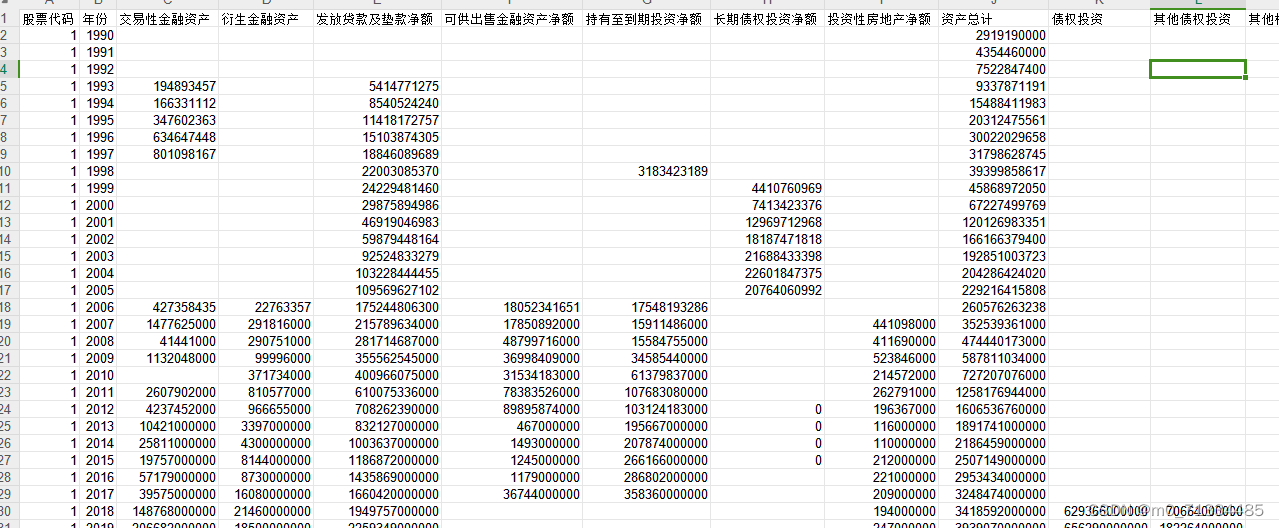
2008-2021年上市公司实体企业金融化程度测算数据(原始数据+stata代码)
2008-2021年上市公司实体企业金融化程度测算(原始数据stata代码) 1、时间:2008-2021年 2、指标:股票代码、年份、交易性金融资产、衍生金融资产、发放贷款及垫款净额、可供出售金融资产净额、持有至到期投资净额、长期债权投资净…...

day02_numpy_demo
Numpy Numpy的优势ndarray属性基本操作 ndarray.func() numpy.func()ndarray的运算:逻辑运算、统计运算、数组间运算合并、分割、IO操作、数据处理,不过这个一般使用的是pandas Numpy的优势 Numpy numerical数值化 python 数值计算的python库,用于快…...

LeetCode 414. Third Maximum Number【数组】简单
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...
FPGA时序分析与约束(6)——综合的基础知识
在使用时序约束的设计过程中,综合(synthesis)是第一步。 一、综合的解释 在电子设计中,综合是指完成特定功能的门级网表的实现。除了特定功能,综合的过程可能还要满足某种其他要求,如功率、操作频率等。 有…...
Python实现一个简单的http服务,Url传参输出html页面
摘要 要实现一个可以接收参数的HTTP服务器,您可以使用Python标准库中的http.server模块。该模块提供了一个简单的HTTP服务器,可以用于开发和测试Web应用程序。 下面是一个示例代码,它实现了一个可以接收参数的HTTP服务器: 代码…...

uni-app怎么使用Vite uni-app Vue3版本构建工具配置【配置】
uni-app Vue3 项目自 v3.9.0 起默认使用 Vite 构建,无需手动切换;需确保 CLI ≥ 3.9.0、使用 Vue3 模板,配置应写在 vite.config.ts 中并调用 defineUniAppConfig,环境变量须以 UNI_APP_ 或 VUE_APP_ 开头,且第三方插件…...

Flutter集成华为厂商推送全攻略:解决后台被杀收不到消息的终极方案
Flutter集成华为厂商推送全攻略:解决后台被杀收不到消息的终极方案 在移动应用开发中,推送通知是保持用户活跃度的关键功能。然而,许多Flutter开发者在使用极光推送时都会遇到一个棘手问题:在华为手机上,当应用后台进…...

基于双向反激变换器的SOC估算与主动均衡仿真的研究
基于双向反激变换器的SOC估算与主动均衡仿真 可以 [1]复现硕士论文:《锂离子电池SOC估算与主动均衡策略研究_王昊》 [2]六节电池模型:使用Simmulink搭建了六节电池主动均衡仿真 [3]均衡策略:选择了电压、SOC及其分阶段使用作为主动均衡变量&a…...

Proteus 8.9安装Arduino仿真库?保姆级图文指南带你绕过‘隐藏文件夹’这个大坑
Proteus 8.9安装Arduino仿真库全流程指南:从隐藏文件夹到实战验证 在电子设计自动化领域,Proteus与Arduino的结合为创客和教育工作者提供了强大的仿真能力。然而,许多用户在第一步——安装Arduino元件库时就遭遇了"隐藏文件夹"这个…...

职业深度解析:AI/ML Engineer——从模型设计到生产落地
摘要:本文对AI/ML工程师岗位进行系统性解构,涵盖职业定位、工作内容拆解、硬性与软性能力要求、知识体系构建、典型工作场景、就业市场现状、薪酬结构、职业发展路径、适配人群画像、进入门槛路径及常见认知误区。适合机器学习从业者、转行意向者及技术管…...

提交的最佳实践:在嵌入式/芯片开发中构建高效的Git工作流
提交的最佳实践:在嵌入式/芯片开发中构建高效的Git工作流 上周调试一块新板子,半夜两点还在跟寄存器死磕。问题出在某个外设驱动上,明明上周还能正常初始化,这周突然就卡死了。翻遍最近提交记录,发现某次提交的注释只写了“fix bug”三个字,改了七八个文件。那一刻真想穿…...

红外遥控模块实战:从解码到智能控制全解析
1. 红外遥控模块基础认知 第一次接触红外遥控模块时,我盯着桌上那个黑色的小方块研究了半天——它看起来就像个普通电子元件,却能隔空控制空调电视。这种神奇的能力其实源于红外光的特性:波长介于可见光和微波之间(通常850-1100nm…...

如何快速提升Mac鼠标体验:专业级滚动优化完整指南
如何快速提升Mac鼠标体验:专业级滚动优化完整指南 【免费下载链接】Mos 一个用于在 macOS 上平滑你的鼠标滚动效果或单独设置滚动方向的小工具, 让你的滚轮爽如触控板 | A lightweight tool used to smooth scrolling and set scroll direction independently for y…...
:实战落地指南)
【进阶专栏】AI时代从好奇心到产品力(进阶):实战落地指南
专栏定位 基础篇:从好奇心到产品力:AI时代的产品构建方法论 进阶篇:AI时代从好奇心到产品力(进阶):实战落地指南 基础篇帮你"看懂",进阶篇帮你"做到"。 基础篇(第1-6篇)建立了GAP模型的理论框架,让你能分析和理解任何产品的行为设计。 进阶篇(第…...

Tool之Jira:从零到一,构建高效敏捷团队的Jira实战配置与核心流程详解
1. 为什么你的团队需要Jira? 第一次接触Jira的团队常会问:为什么不用Excel或Trello?五年前我带创业团队时也这么想,直到一次版本发布前,测试组长凌晨三点打电话问我:"那个优先级为高的Bug到底分给谁了…...