day02_numpy_demo
Numpy
- Numpy的优势
- ndarray属性
- 基本操作
ndarray.func()
numpy.func() - ndarray的运算:逻辑运算、统计运算、数组间运算
- 合并、分割、IO操作、数据处理,不过这个一般使用的是pandas
Numpy的优势
Numpy = numerical数值化 + python 数值计算的python库,用于快速处理任意维度的数组。
ndarrray = n任意个 + d(dimension维度) + array 任意维度的数组的意思
Numpy使用ndarray对象来处理多维数组,该对象是一个快速而灵活的大数据容器
Numpy提供了一个N维数组类型ndarray,他描述相同类型的items的集合
import numpy as npscore = np.array([[80, 89, 86, 67, 79],[78, 97, 89, 67, 81],[90, 94, 78, 67, 74],[91, 91, 90, 67, 69],[76, 87, 75, 67, 86],[70, 79, 84, 67, 84],[94, 92, 93, 67, 64],[86, 85, 83, 67, 80]])
score
array([[80, 89, 86, 67, 79],[78, 97, 89, 67, 81],[90, 94, 78, 67, 74],[91, 91, 90, 67, 69],[76, 87, 75, 67, 86],[70, 79, 84, 67, 84],[94, 92, 93, 67, 64],[86, 85, 83, 67, 80]])
type(score)
numpy.ndarray
## ndarray和list的效率的对比
import random
import time
import numpy as np
a = []
for i in range(5000000):a.append(random.random())
t1 = time.time()
sum1=sum(a)
t2 = time.time()b = np.array(a)
t4 = time.time()
sum3=np.sum(b)
t5 = time.time()
print('使用原生list的求和计算使用的时间:', t2-t1, "\t使用ndarry的时间计算:", t5-t4)
使用原生list的求和计算使用的时间: 0.03126645088195801 使用ndarry的时间计算: 0.0027697086334228516
从上面的结果显示使用ndarray的时间处理和原生的list相比更加快速
Numpy专门的针对ndarray的操作和运算进行了设计,所以数组的存储效率和输入输出性能远远的高于Python中嵌套列表
- 第一个:内存块存储风格:ndarray必须要相同的类型,可以连续存储 list的通用性强,可以不同类型数据,所以list数据之间是依靠引用的形式存储
- 第二个:并行化处理形式:ndarray支持并行化运算
- 第三个:底层语言:Numpy底层语言是c,内部解除了GIL全局解释器的限制
ndarray属性
属性
ndarray.shape:数组维度的元组
ndarray.ndim:数组维度
ndarray.size:数组中元素的个数
ndarray.itemszie:一个数组元素的长度
ndarray.dtype:数组元素的类型
score
print(score.shape) #(8, 5) 8行5列
print(score.ndim) # 2
print(score.size) # 40
print(score.itemsize) # 4
print(score.dtype) # int32
(8, 5)
2
40
4
int32
## ndarray的形状
import numpy as np
a = np.array([1, 2, 3, 4])
b = np.array([[1, 2, 3], [3, 4, 5]])
c = np.array([[[1, 3, 4], [3, 4, 5]], [[1, 5, 7], [4, 7, 8]]])
print(a.shape, b.shape, c.shape)
(4,) (2, 3) (2, 2, 3)
print(a, '\n\n', b, '\n\n', c)
[1 2 3 4] [[1 2 3][3 4 5]] [[[1 3 4][3 4 5]][[1 5 7][4 7 8]]]
data = np.array([1.1, 2.2, 3.3], dtype=np.float32)
data2 = np.array([1.2, 2.2, 3.2], dtype='float32')
print(data, data.dtype, data2, data2.dtype)
[1.1 2.2 3.3] float32 [1.2 2.2 3.2] float32
生成数组
- 生成0和1的:
np.ones(shape[, dtype, order]) np.zeros(shape[, dtype, order])- np.ones(shape=(2, 3), dtype=‘int32’)
- np.zeros(shape=(2, 3), dtype=np.float32)
- 从现有数组中生成:
np.array() np.copy() np.asarray()- data1 = np.array(score) ## 深拷贝
- data2 = np.asarray(score) ## 浅拷贝
- data3 = np.copy(score) ## 深拷贝
- 生成固定范围的数组:
np.linspace(satrt, stop, num, endpoint, restep, detype) np.arange()- np.linspace(0, 10, 100) ## [0, 10]产生100个等距离的数组
- np.arange(a, b, c) ## 产生[a, b) 步长为c的数组
- 生成随机数组:
np.random.rand(d0, d1, d2,....)返回[0.0, 1.0]内的一组均匀分布的数组, d0, d1, d2表示维度的元组数据- np.random.uniform(low=0.0, high=1.0, size=None) 均匀分布[low, high),size-int类型表输出一位样本数,元组表输出的是对应维度数组
- np.random.normal(loc=0.0, scale=1.0, size=None) 正态分布 均值loc 标准差scale 形状size
np.ones(shape=(2, 4))
array([[1., 1., 1., 1.],[1., 1., 1., 1.]])
np.zeros((4, 3))
array([[0., 0., 0.],[0., 0., 0.],[0., 0., 0.],[0., 0., 0.]])
data1 = np.array([1, 3, 4, 5])
data1
array([1, 3, 4, 5])
data2 = np.asarray(data1)
data2
array([1, 3, 4, 5])
data3 = np.copy(data1)
data3
array([1, 3, 4, 5])
np.linspace(0, 10, 100)
array([ 0. , 0.1010101 , 0.2020202 , 0.3030303 , 0.4040404 ,0.50505051, 0.60606061, 0.70707071, 0.80808081, 0.90909091,1.01010101, 1.11111111, 1.21212121, 1.31313131, 1.41414141,1.51515152, 1.61616162, 1.71717172, 1.81818182, 1.91919192,2.02020202, 2.12121212, 2.22222222, 2.32323232, 2.42424242,2.52525253, 2.62626263, 2.72727273, 2.82828283, 2.92929293,3.03030303, 3.13131313, 3.23232323, 3.33333333, 3.43434343,3.53535354, 3.63636364, 3.73737374, 3.83838384, 3.93939394,4.04040404, 4.14141414, 4.24242424, 4.34343434, 4.44444444,4.54545455, 4.64646465, 4.74747475, 4.84848485, 4.94949495,5.05050505, 5.15151515, 5.25252525, 5.35353535, 5.45454545,5.55555556, 5.65656566, 5.75757576, 5.85858586, 5.95959596,6.06060606, 6.16161616, 6.26262626, 6.36363636, 6.46464646,6.56565657, 6.66666667, 6.76767677, 6.86868687, 6.96969697,7.07070707, 7.17171717, 7.27272727, 7.37373737, 7.47474747,7.57575758, 7.67676768, 7.77777778, 7.87878788, 7.97979798,8.08080808, 8.18181818, 8.28282828, 8.38383838, 8.48484848,8.58585859, 8.68686869, 8.78787879, 8.88888889, 8.98989899,9.09090909, 9.19191919, 9.29292929, 9.39393939, 9.49494949,9.5959596 , 9.6969697 , 9.7979798 , 9.8989899 , 10. ])
np.arange(0, 100, 2)
array([ 0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32,34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66,68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98])
np.random.uniform(1, 2, 20)
array([1.08186729, 1.14786875, 1.70033877, 1.21356519, 1.80826522,1.82539046, 1.2411259 , 1.94754535, 1.26016768, 1.95195603,1.83118684, 1.93096164, 1.42540342, 1.01900246, 1.00777939,1.94587154, 1.30147204, 1.85872718, 1.51138215, 1.72144173])
np.random.rand(2, 3)
array([[0.93695681, 0.54056962, 0.05346231],[0.25430123, 0.4679477 , 0.42365386]])
data4 = np.random.normal(0, 1, 10000000)
data4
array([-1.37843425, 0.43112438, 0.74566392, ..., 1.11031839,-0.35627334, -0.49286865])
import matplotlib.pyplot as pltplt.figure(figsize=(15, 8), dpi=80)
plt.hist(data4, 1000)
plt.show()

数组的切片操作和数据索引
import numpy as np
stock_change = np.random.normal(loc=0, scale=1, size=(8, 10))
stock_change
array([[-0.0128315 , 1.36389291, 1.67468755, -1.63839812, 0.50246918,0.40632079, 0.5468709 , -1.51506239, -0.95175431, 0.79676231],[-0.29024725, -0.85783328, -2.88228976, 0.09475102, 0.26886068,-0.72337737, 0.32906655, 1.38442008, 0.22017286, 0.11595155],[-1.48797053, -0.34888996, -0.46878054, 0.06614233, -1.2163201 ,-0.12437208, -0.48048511, 0.92053831, 1.37148844, 0.4052761 ],[-0.68483909, 1.45441467, 0.32439071, 2.09266866, -1.40087978,0.21482243, 1.06350017, -1.12371055, -0.21362273, -0.86489608],[-0.8955743 , -2.80666246, -1.81775787, -0.64719575, -1.03749633,-0.09075791, 0.04027887, 0.88156425, -0.38851649, 0.4366844 ],[-0.6112534 , 0.20743331, -1.10785011, -1.94937533, 0.79183302,-1.43629441, -0.39276676, 1.43465142, -0.77917209, 0.75375268],[-0.45255197, 0.21874378, 0.74356075, 0.89123163, 0.80052696,0.07645454, 1.18475498, 1.21210169, -2.57089921, -0.04719686],[ 1.49996354, 1.73125796, 0.35972564, -0.31768555, -0.23859956,0.14878977, 1.78480518, -0.157626 , 0.52180221, 1.53564593]])
stock_change[0, 0:3] # 二维数组中第一个一维数组中的第0到3个之间的数据,左闭右开
array([-1.23848824, 1.80273454, 0.48612183])
a1 = np.array([[[1, 2, 3],[4, 5, 6]], [[12, 3, 4], [5, 6, 7]]])
a1
array([[[ 1, 2, 3],[ 4, 5, 6]],[[12, 3, 4],[ 5, 6, 7]]])
a1[1, 0, 2] ## 三维数组中第二个二维数组中的第一个一维数组的第三个数据
4
形状的修改
- ndarray.reshape(shape)
- ndarray.resize(shape)
- ndarray.T
print(stock_change.shape)
print(stock_change)
data = stock_change.reshape(10, 8) ## 有返回值 不修改对象stock_change的原始数据
print(data.shape)
print(data)
(10, 8)
[[-1.23848824 1.80273454 0.48612183 -0.72560924 0.70273282 1.0001417-1.50264292 0.07910228][ 0.50097203 -0.30643765 -2.06606864 1.06603865 -0.24707909 -0.435822391.40507793 0.16617008][ 0.90592803 0.42831191 -0.92043446 -0.86909989 1.86906101 -0.27504789-0.85507962 -0.06812796][-0.47386474 -0.12860694 0.78529739 0.6299527 1.35195163 0.52554048-1.44443021 -0.30228474][-2.00270709 -0.93547033 -1.91377025 -0.44282643 0.39398671 -1.157779111.06886255 -0.99258445][ 1.46011953 0.02989662 -0.57156073 0.33255032 1.10206919 1.10728184-0.2309872 -0.36046913][ 0.6419396 0.45193213 -0.28647482 2.35270101 -1.36580147 -0.3416711-0.68923525 0.40515396][-0.65856583 -0.80067154 1.00151152 -0.59024112 1.72517446 0.992832990.32894163 0.29112266][-0.02950995 1.00548516 0.28799688 -0.23560119 -0.27545952 -2.067568870.10599702 1.29010633][ 0.10229354 -1.61937238 -2.19289266 -2.0243394 -1.584921 1.15768340.11722609 1.00201755]]
(10, 8)
[[-1.23848824 1.80273454 0.48612183 -0.72560924 0.70273282 1.0001417-1.50264292 0.07910228][ 0.50097203 -0.30643765 -2.06606864 1.06603865 -0.24707909 -0.435822391.40507793 0.16617008][ 0.90592803 0.42831191 -0.92043446 -0.86909989 1.86906101 -0.27504789-0.85507962 -0.06812796][-0.47386474 -0.12860694 0.78529739 0.6299527 1.35195163 0.52554048-1.44443021 -0.30228474][-2.00270709 -0.93547033 -1.91377025 -0.44282643 0.39398671 -1.157779111.06886255 -0.99258445][ 1.46011953 0.02989662 -0.57156073 0.33255032 1.10206919 1.10728184-0.2309872 -0.36046913][ 0.6419396 0.45193213 -0.28647482 2.35270101 -1.36580147 -0.3416711-0.68923525 0.40515396][-0.65856583 -0.80067154 1.00151152 -0.59024112 1.72517446 0.992832990.32894163 0.29112266][-0.02950995 1.00548516 0.28799688 -0.23560119 -0.27545952 -2.067568870.10599702 1.29010633][ 0.10229354 -1.61937238 -2.19289266 -2.0243394 -1.584921 1.15768340.11722609 1.00201755]]
stock_change.resize((10, 8)) ## 无返回值 直接改变stock_change对象
stock_change
array([[-1.23848824, 1.80273454, 0.48612183, -0.72560924, 0.70273282,1.0001417 , -1.50264292, 0.07910228],[ 0.50097203, -0.30643765, -2.06606864, 1.06603865, -0.24707909,-0.43582239, 1.40507793, 0.16617008],[ 0.90592803, 0.42831191, -0.92043446, -0.86909989, 1.86906101,-0.27504789, -0.85507962, -0.06812796],[-0.47386474, -0.12860694, 0.78529739, 0.6299527 , 1.35195163,0.52554048, -1.44443021, -0.30228474],[-2.00270709, -0.93547033, -1.91377025, -0.44282643, 0.39398671,-1.15777911, 1.06886255, -0.99258445],[ 1.46011953, 0.02989662, -0.57156073, 0.33255032, 1.10206919,1.10728184, -0.2309872 , -0.36046913],[ 0.6419396 , 0.45193213, -0.28647482, 2.35270101, -1.36580147,-0.3416711 , -0.68923525, 0.40515396],[-0.65856583, -0.80067154, 1.00151152, -0.59024112, 1.72517446,0.99283299, 0.32894163, 0.29112266],[-0.02950995, 1.00548516, 0.28799688, -0.23560119, -0.27545952,-2.06756887, 0.10599702, 1.29010633],[ 0.10229354, -1.61937238, -2.19289266, -2.0243394 , -1.584921 ,1.1576834 , 0.11722609, 1.00201755]])
stock_change.T ## 转置
array([[-1.23848824, 0.50097203, 0.90592803, -0.47386474, -2.00270709,1.46011953, 0.6419396 , -0.65856583, -0.02950995, 0.10229354],[ 1.80273454, -0.30643765, 0.42831191, -0.12860694, -0.93547033,0.02989662, 0.45193213, -0.80067154, 1.00548516, -1.61937238],[ 0.48612183, -2.06606864, -0.92043446, 0.78529739, -1.91377025,-0.57156073, -0.28647482, 1.00151152, 0.28799688, -2.19289266],[-0.72560924, 1.06603865, -0.86909989, 0.6299527 , -0.44282643,0.33255032, 2.35270101, -0.59024112, -0.23560119, -2.0243394 ],[ 0.70273282, -0.24707909, 1.86906101, 1.35195163, 0.39398671,1.10206919, -1.36580147, 1.72517446, -0.27545952, -1.584921 ],[ 1.0001417 , -0.43582239, -0.27504789, 0.52554048, -1.15777911,1.10728184, -0.3416711 , 0.99283299, -2.06756887, 1.1576834 ],[-1.50264292, 1.40507793, -0.85507962, -1.44443021, 1.06886255,-0.2309872 , -0.68923525, 0.32894163, 0.10599702, 0.11722609],[ 0.07910228, 0.16617008, -0.06812796, -0.30228474, -0.99258445,-0.36046913, 0.40515396, 0.29112266, 1.29010633, 1.00201755]])
类型的修改和数组去重
- ndarray.astype(type)
- ndarray序列化到本地
- ndarray.tostring()
- ndarray.tobytes()
- np.unique() 去重
stock_change.astype(np.int32)
array([[ 0, 1, 1, -1, 0, 0, 0, -1, 0, 0],[ 0, 0, -2, 0, 0, 0, 0, 1, 0, 0],[-1, 0, 0, 0, -1, 0, 0, 0, 1, 0],[ 0, 1, 0, 2, -1, 0, 1, -1, 0, 0],[ 0, -2, -1, 0, -1, 0, 0, 0, 0, 0],[ 0, 0, -1, -1, 0, -1, 0, 1, 0, 0],[ 0, 0, 0, 0, 0, 0, 1, 1, -2, 0],[ 1, 1, 0, 0, 0, 0, 1, 0, 0, 1]])
stock_change.tobytes() ## 之前可以使用tostring的方法
b"\x10\x83d\xcbfG\x8a\xbf\x06\xcb\n_\x81\xd2\xf5?\xf6i\x89+\x85\xcb\xfa?(\x9dK\xf1\xe06\xfa\xbf\x040\xd3<:\x14\xe0?\xf4\x96\xb4\xeb(\x01\xda?\x9b\xfe\x94e\xf7\x7f\xe1?\x80I\xb5\x10\xb2=\xf8\xbf\xf2\x01\xcbv\xc5t\xee\xbf\x92\xbe9\xac\x13\x7f\xe9?F\x98\xc71i\x93\xd2\xbf\xcf~\x07\xc6^s\xeb\xbf$a\xd4\xee\xed\x0e\x07\xc0\xf2\xf0\x87I\x9aA\xb8?/\x91\xedg\x035\xd1?\xc0\x85\xe6K\xe8%\xe7\xbf9\r\r*m\x0f\xd5?H\x8d\xcb\xab\x95&\xf6?A\xed \xca\x9f.\xcc?\xb0\xce\x0f;\x00\xaf\xbd?\xe4\xa3\x860\xba\xce\xf7\xbf\x9e5\x1b\x8c6T\xd6\xbfv\xdd\xc3\x15\x80\x00\xde\xbf\x19s/\x1c\xb4\xee\xb0?\x9c\xc7I\x11\x0cv\xf3\xbf`\xcb$A\xd9\xd6\xbf\xbf}\xbd\xa6\x99D\xc0\xde\xbf(\xedu\xc2\x0cu\xed?W\x04\xd2\xdd\x9d\xf1\xf5?MD\xf8)\x0b\xf0\xd9?[`\xc0\xaa3\xea\xe5\xbf6ozQHE\xf7?M*CB\xd1\xc2\xd4?{<!\x11\xc9\xbd\x00@\xb3\x0b\xb0\xeb\x00j\xf6\xbf\x86\xfc\xe7*M\x7f\xcb?_\xca\xdc\xbf\x18\x04\xf1?\x85]G\xea\xb7\xfa\xf1\xbfi4gX\xfdW\xcb\xbf\xc2g^\x8b:\xad\xeb\xbf\x06l\x0bo\x8b\xa8\xec\xbf{L4s\x0bt\x06\xc0;\xdd0F\x89\x15\xfd\xbf\xf6\x06\x03\xde\xd3\xb5\xe4\xbf}\x13\xc9\xc0\x95\x99\xf0\xbf\xfb\rF\x14\xe9;\xb7\xbf\xa1\xa1\x9fpn\x9f\xa4?\x19\xa3\x84<\xc65\xec?\xb9^\xa1Ft\xdd\xd8\xbf\x8b,N\x1f\xa3\xf2\xdb?\xe4@UJc\x8f\xe3\xbfC\x02\xa0\xbf,\x8d\xca?\xf5)\x82\t\xc1\xb9\xf1\xbf\xbdxl0\xa40\xff\xbfi\x02C3\xb2V\xe9?Q^\x8d\xd9\x0f\xfb\xf6\xbf\xb0\x9c\x914\x17#\xd9\xbfe\xdf\xd2\x0cU\xf4\xf6?\xf3\xf7\xf4M\xfa\xee\xe8\xbf\xb6R=\xee\xbd\x1e\xe8?\x84o$\x87\x9c\xf6\xdc\xbf\xf5\xc6$\xd6\xcb\xff\xcb?@\xf6@\xeb?\xcb\xe7?\\\xa311\xf8\x84\xec?S\xf6>\xb5\xea\x9d\xe9?\x06\x18\xed_\x86\x92\xb3?_\xaf\x14\xa2\xc1\xf4\xf2?O\xd2\x02\xbd\xc4d\xf3?p\xe7\x80\x9a3\x91\x04\xc0\xeb\xfe#\xf2/*\xa8\xbf\x9a\xfa\\\xc5\xd9\xff\xf7?\xf4\xfe\xb0\x8a;\xb3\xfb?\x97\x89l\xad\xbe\x05\xd7?\x1d\xc4\xce\xc6\xf5T\xd4\xbf\xfd\x99\xf0'n\x8a\xce\xbf:J\xe4\x15\x8b\x0b\xc3??UZ\xe1\x8f\x8e\xfc?\xebph\xb9\x16-\xc4\xbf\x87]\xab\x8b\x9a\xb2\xe0?\xb4\xa2\tw\x01\x92\xf8?"
temp = np.array([[1, 2, 3, 4], [3, 4, 5, 6]])
np.unique(temp)
array([1, 2, 3, 4, 5, 6])
ndarray的运算
- 逻辑运算:
- stock_change > 0.5 数据大于0.5的标记为True 否则为False
- stock_change[stock_change > 0.5] 返回所有大于0.5的数据
- stock_change[stock_change > 0.5] = 1.1 返回所有大于0.5的数据更改为1.1
- np.all(布尔值) 布尔值里面所有True才返回True, 只要有一个False就返回False
- np.all(stock_change[0:2, 0:5] > 0) 判断里面数据是否全部大于0
- np.any(布尔值) 布尔值里面有一个True就返回True,只有全是False才会返回False
- np.any(stock_change[0:2, 0:5] > 0) 判断里面是否有数据大于0
- 三元运算符:np.where(布尔值, True的位置的值, False位置的值)
- np.where(stock_change>0, 1, 0) 将大于0的数据置为1 否则置为0
- np.where(np.logical_and(stock_change > 0.5, stock_change < 1), 1, 0) 将大于0.5并且小于1的置为1,否则置为0
- np.where(np.logical_or(stock_change > 0.5, stock_change < -0.5), 1, 0) 将大于0.5或者小于-0.5的置为1,否则置为0
- 统计运算:
- 统计指标函数:min,max,mean,median,var,std,函数其中有一个参数axis,为1代表使用行去进行统计,为0使用列进行统计计算。
- np.max(a, axis=1) / ndarray.max(axis=1) / np.max(a) / adarray.max()
- 返回最大值、最小值的位置:
- np.argmax(a. axis=) / np.argmin(a, axis=)
- 统计指标函数:min,max,mean,median,var,std,函数其中有一个参数axis,为1代表使用行去进行统计,为0使用列进行统计计算。
- 数组间运算:
- 数组与数的运算:arr ±*/等等直接对数组中的每个元素执行相同的操作
- 数组与数组的运算:需要满足广播机制
- 广播机制:当操作两个数组进行运算的时候,numpy会比较两个数组的shape,只有满足shape对应位置相等或者相对应的一个地方为1的数组才可以进行运算,结果对应shape取相应的位置的最大值。
- 矩阵运算:矩阵matrix 矩阵必须是二维的,但是数组可以是一位的。
- np.mat() 将数组转换为矩阵
- 有两种方法来存储矩阵:ndarray二维数组、matrix数据结构
- 矩阵运算 (m, n) * (n , l) = (m, l) 也就是第一个矩阵的列数和第二个矩阵的行数要相等
- np.matmul() numpy库中用于矩阵乘法的函数,它的作用是计算两个矩阵的乘积
- np.dot() 向量点乘
逻辑运算
import numpy as np
stock_change = np.random.normal(loc=0, scale=1, size=(8, 10))
stock_change > 0.5
array([[False, False, False, False, False, False, True, True, False,False],[False, False, False, False, False, False, False, True, False,False],[False, True, False, False, False, False, True, True, True,True],[False, True, True, False, False, True, False, False, False,False],[False, False, False, True, False, False, False, True, True,False],[False, False, False, False, False, False, False, False, True,False],[False, False, False, True, False, True, False, False, True,True],[False, False, False, False, True, False, True, False, True,False]])
stock_change[stock_change > 0.5]
array([1.36389291, 1.67468755, 0.50246918, 0.5468709 , 0.79676231,1.38442008, 0.92053831, 1.37148844, 1.45441467, 2.09266866,1.06350017, 0.88156425, 0.79183302, 1.43465142, 0.75375268,0.74356075, 0.89123163, 0.80052696, 1.18475498, 1.21210169,1.49996354, 1.73125796, 1.78480518, 0.52180221, 1.53564593])
stock_change[stock_change > 0.5] = 1.1
stock_change
array([[-0.0128315 , 1.1 , 1.1 , -1.63839812, 1.1 ,0.40632079, 1.1 , -1.51506239, -0.95175431, 1.1 ],[-0.29024725, -0.85783328, -2.88228976, 0.09475102, 0.26886068,-0.72337737, 0.32906655, 1.1 , 0.22017286, 0.11595155],[-1.48797053, -0.34888996, -0.46878054, 0.06614233, -1.2163201 ,-0.12437208, -0.48048511, 1.1 , 1.1 , 0.4052761 ],[-0.68483909, 1.1 , 0.32439071, 1.1 , -1.40087978,0.21482243, 1.1 , -1.12371055, -0.21362273, -0.86489608],[-0.8955743 , -2.80666246, -1.81775787, -0.64719575, -1.03749633,-0.09075791, 0.04027887, 1.1 , -0.38851649, 0.4366844 ],[-0.6112534 , 0.20743331, -1.10785011, -1.94937533, 1.1 ,-1.43629441, -0.39276676, 1.1 , -0.77917209, 1.1 ],[-0.45255197, 0.21874378, 1.1 , 1.1 , 1.1 ,0.07645454, 1.1 , 1.1 , -2.57089921, -0.04719686],[ 1.1 , 1.1 , 0.35972564, -0.31768555, -0.23859956,0.14878977, 1.1 , -0.157626 , 1.1 , 1.1 ]])
print(np.all(stock_change[0:2, 0:5] > 0))
print(np.any(stock_change[0:2, 0:5] > 0))
False
True
print(np.where(stock_change>0, 1, 0))
[[0 1 1 0 0 0 1 1 1 0][0 1 0 0 0 1 1 0 0 1][0 1 0 0 0 0 0 1 0 0][1 0 1 0 1 1 0 0 0 1][1 0 0 1 0 1 0 0 1 0][1 1 1 1 0 1 1 1 0 1][0 1 0 1 0 0 1 0 1 0][1 1 1 0 1 1 1 0 0 1]]
print(np.where(np.logical_and(stock_change > 0.5, stock_change < 1), 1 , 0))
[[0 0 0 0 0 0 0 0 0 0][0 0 0 0 0 0 0 0 0 1][0 1 0 0 0 0 0 0 0 0][0 0 0 0 1 0 0 0 0 0][0 0 0 0 0 0 0 0 0 0][0 0 1 0 0 0 1 1 0 0][0 0 0 0 0 0 1 0 0 0][0 0 0 0 0 0 0 0 0 1]]
print(np.where(np.logical_or(stock_change > 0.5, stock_change < -0.5), 1 , 0))
[[1 0 0 0 1 0 0 1 1 0][1 1 1 1 0 1 1 1 0 1][0 1 1 1 1 0 1 0 1 0][1 0 1 0 1 1 1 0 0 1][0 1 0 0 0 1 0 1 1 0][0 1 1 0 0 0 1 1 1 1][1 0 0 0 0 0 1 1 0 0][1 0 1 0 1 0 0 1 1 1]]
统计运算
print(np.max(stock_change), stock_change.max())
2.837073584187165 2.837073584187165
print(np.mean(stock_change, axis=0), np.mean(stock_change, axis=1), np.mean(stock_change))
[-0.9652667 -0.15328082 0.08317861 -0.54300528 -0.42430401 -0.27689675-0.03939256 0.58928582 0.11866925 0.06092911] [-0.24814861 -0.59923979 0.47094442 0.21607003 -0.15542244 -0.36903679-0.12744662 -0.42778684] -0.15500833265906144
print(np.argmax(stock_change), np.argmax(stock_change, axis=1))
32 [7 7 7 2 3 8 5 8]
数组的运算
数组和数的运算
arr = np.array([[1, 2, 3, 2, 1, 4], [5, 6, 1, 2, 3, 1]])
arr
array([[1, 2, 3, 2, 1, 4],[5, 6, 1, 2, 3, 1]])
arr+1
array([[2, 3, 4, 3, 2, 5],[6, 7, 2, 3, 4, 2]])
arr*2
array([[ 2, 4, 6, 4, 2, 8],[10, 12, 2, 4, 6, 2]])
arr/2
array([[0.5, 1. , 1.5, 1. , 0.5, 2. ],[2.5, 3. , 0.5, 1. , 1.5, 0.5]])
arr-2
array([[-1, 0, 1, 0, -1, 2],[ 3, 4, -1, 0, 1, -1]])
数组和数组运算
arr1 = np.array([[1, 2, 3, 2, 1, 4], [5, 6, 1, 2, 3, 1]])
arr2 = np.array([[1], [3]])
print(arr1, "\n\n", arr2)
[[1 2 3 2 1 4][5 6 1 2 3 1]] [[1][3]]
print(arr1 * arr2, '\n\n', arr1 / arr2)
[[ 1 2 3 2 1 4][15 18 3 6 9 3]] [[1. 2. 3. 2. 1. 4. ][1.66666667 2. 0.33333333 0.66666667 1. 0.33333333]]
矩阵运算
data = np.array([[80, 86],[82, 80],[85, 78],[90, 90],[86, 82],[82, 90],[78, 80],[92, 94]])
data
array([[80, 86],[82, 80],[85, 78],[90, 90],[86, 82],[82, 90],[78, 80],[92, 94]])
data2 = np.mat([[80, 86],[82, 80],[85, 78],[90, 90],[86, 82],[82, 90],[78, 80],[92, 94]])
print(data2, '\n\n', type(data2))
[[80 86][82 80][85 78][90 90][86 82][82 90][78 80][92 94]] <class 'numpy.matrix'>
data3 = np.mat([[0.3], [0.7]])
data3
matrix([[0.3],[0.7]])
print(data2 * data3, '\n\n', data @ np.array([[0.3], [0.7]])) ## 计算成绩 第一列乘上0.3 第二列乘上0.7
[[84.2][80.6][80.1][90. ][83.2][87.6][79.4][93.4]] [[84.2][80.6][80.1][90. ][83.2][87.6][79.4][93.4]]
print(np.matmul(data2, data3), '\n\n', np.dot(data2, data3))
[[84.2][80.6][80.1][90. ][83.2][87.6][79.4][93.4]] [[84.2][80.6][80.1][90. ][83.2][87.6][79.4][93.4]]
合并和分割
- 合并:合并可以从水平的方向进行合并,也可以在垂直的方法进行合并
- numpy.hstack(tuple(column, wise)) 水平拼接
- numpy.vstack(tuple(row, wise)) 垂直拼接
- numpy.concatenate((a1, a2, a3…), axis=0) axis=1来表示水平,axis=0表示垂直
- 分割
- np.split(ary, indices_or_sections, axis=0)
合并
import numpy as np
a = np.array([1, 2, 3])
b = np.array([2, 3, 4])
np.hstack((a, b))
array([1, 2, 3, 2, 3, 4])
np.vstack((a, b))
array([[1, 2, 3],[2, 3, 4]])
np.concatenate((a, b), axis=0)
array([1, 2, 3, 2, 3, 4])
x = np.array([[1, 2], [3, 4]])
print(np.concatenate((x, x), axis=0))
print('\n\n', np.concatenate((x, x), axis=1))
[[1 2][3 4][1 2][3 4]][[1 2 1 2][3 4 3 4]]
分割
x1 = np.arange(9.0)
np.split(x1, 3)
[array([0., 1., 2.]), array([3., 4., 5.]), array([6., 7., 8.])]
x1 = np.arange(8.0)
np.split(x1, [3, 5, 6, 8]) ## 按照索引进行分割
[array([0., 1., 2.]),array([3., 4.]),array([5.]),array([6., 7.]),array([], dtype=float64)]
IO操作和数据处理
- numpy数据读取:
- np.genfromtxt(path, delimiter=) ## 文件路径和分隔符号
- np.genfromtxt(‘tes.csv’, delimiter=‘,’)
import numpy as np
data = np.genfromtxt('gh.csv', delimiter=',')
data
array([[ nan, nan, nan],[ 12., 213., 321.],[ 123., 345., 1241.],[ 14., 24., 123.]])
- 对于上面的数组中的nan值的类型是float64,对于这个的一般处理方式有两种
- 将数据存在nan的行删除
- 使用该列的平均值填充到nan的位置
总结
- Numpy的优势:内存存储风格,ndrray存储相同数据,内存连续存储,底层c语言实现,支持多线程
- ndarray的属性:shape、dtype、ndim、size、itemsize
- 基本操作:ndarray.方法() np.函数()
- 生成数组的方法:np.ones(shape) np.zeros(shape)
- 从现有数组中生成:np.array() np.copy() np.asarray()
- 生成固定范围的数组:np.linspace(a, b, c) np.arange(a, b, c)
- 生成随机数:均匀分布:np.random.uniform() 正态分布:np.random.normal()
- 切片索引
- 形状修改:ndarray.reshape((a, b)) ndarray.resize((a, b)) ndarray.T
- 类型修改:ndarray.astype(type) ndarray.tobytes()
- 数组去重:np.unique()
- numpy的运算:
- 逻辑运算:
- 布尔索引
- np.all() np.any()
- np.where(a, b, c) a是布尔值 b是true对应的值 c是false对应的值
- 统计运算
- 统计指标:max min mean median var std
- 最大值最小值位置:np.argmax() np.argmin()
- 数组间运算
- 数组与数的运算:
- 数组与数组的运算:要注意广播机制
- 矩阵运算:np.mat() np.dot() np.matmul()
- 逻辑运算:
相关文章:
day02_numpy_demo
Numpy Numpy的优势ndarray属性基本操作 ndarray.func() numpy.func()ndarray的运算:逻辑运算、统计运算、数组间运算合并、分割、IO操作、数据处理,不过这个一般使用的是pandas Numpy的优势 Numpy numerical数值化 python 数值计算的python库,用于快…...

LeetCode 414. Third Maximum Number【数组】简单
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...
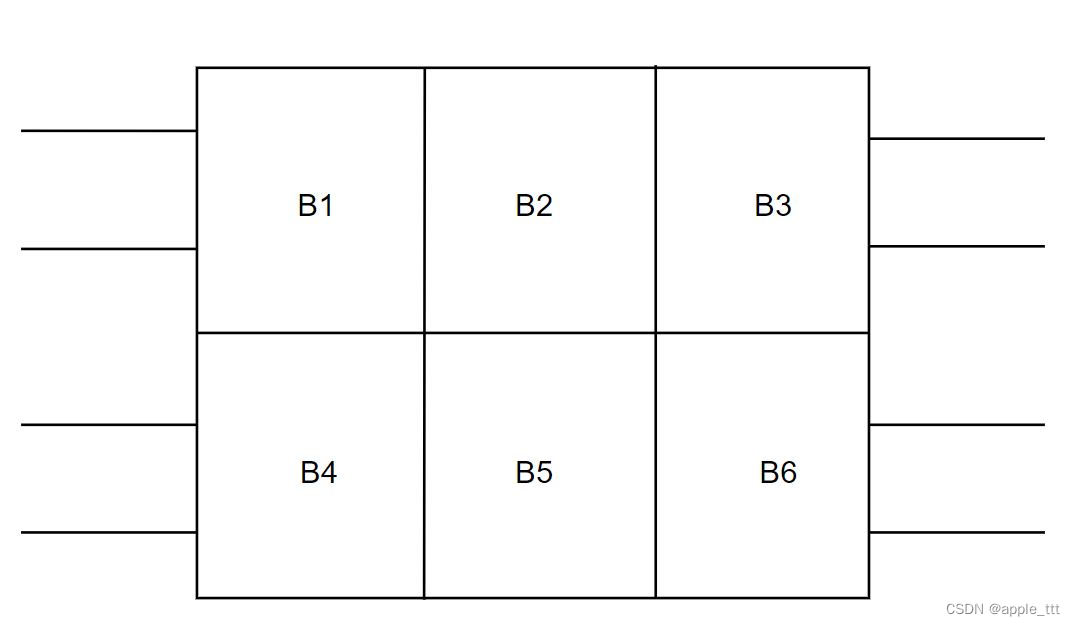
FPGA时序分析与约束(6)——综合的基础知识
在使用时序约束的设计过程中,综合(synthesis)是第一步。 一、综合的解释 在电子设计中,综合是指完成特定功能的门级网表的实现。除了特定功能,综合的过程可能还要满足某种其他要求,如功率、操作频率等。 有…...
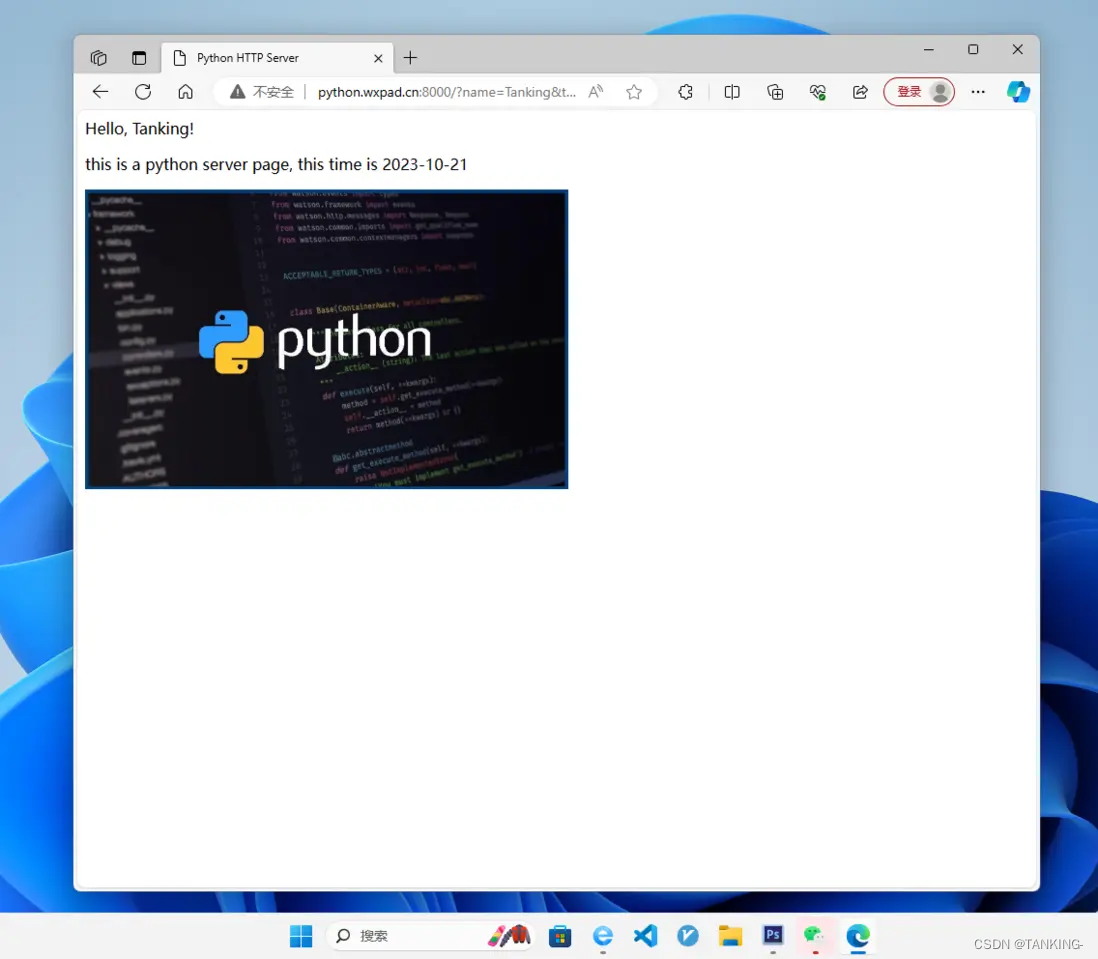
Python实现一个简单的http服务,Url传参输出html页面
摘要 要实现一个可以接收参数的HTTP服务器,您可以使用Python标准库中的http.server模块。该模块提供了一个简单的HTTP服务器,可以用于开发和测试Web应用程序。 下面是一个示例代码,它实现了一个可以接收参数的HTTP服务器: 代码…...

力矩传感器模拟量与ADC采集输出数字量之间的关系
力矩传感器在测量力矩时,会输出一个模拟信号,通常是一个电压或电流信号。这个模拟信号的大小会根据所测量的力矩变化而变化。 ADC(模数转换器)是一种电子设备,可以将模拟信号转换为数字信号。ADC通过采样和量化模拟信…...
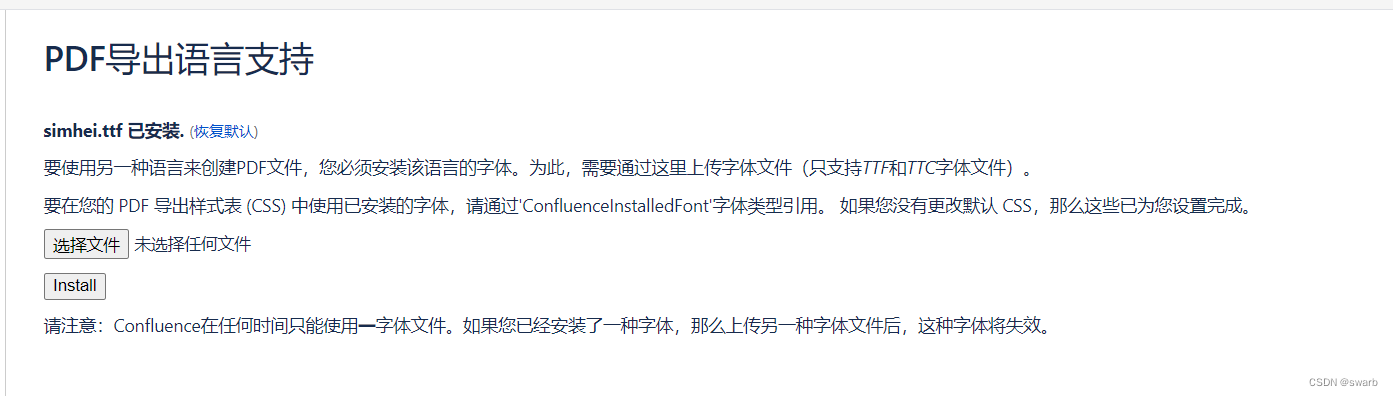
Confluence 解决PDF导出乱码问题
1.原因 PDF导出乱码是因为由于服务器缺少必要字体 2.解决办法 下载字体文件将字体文件重命名为simhei.ttf Confluence→管理→PDF导出语言支持,导入字体即可...
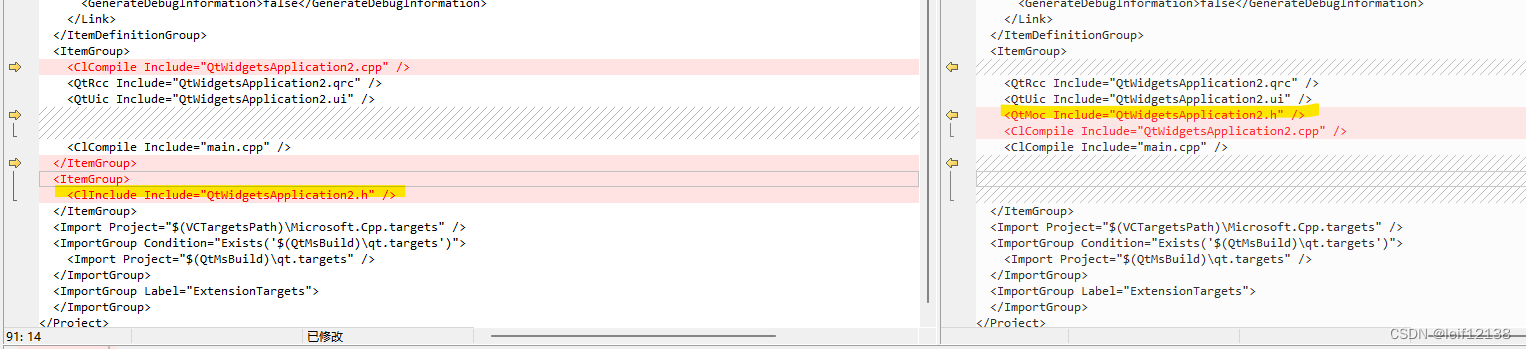
visual studio Qt 开发环境中手动添加 Q_OBJECT 导致编译时出错的问题
问题简述 创建项目的时候,已经添加了类文件,前期认为不需要信号槽,就没有添加宏Q_OBJECT,后面项目需要,又加入了宏Q_OBJECT,但是发现只是添加了一个宏Q_OBJECT,除此之外没有改动其它的代码,原本…...

Addressable使用指南
1、基础用法就不再赘述了,重要的属性配置: Disable Catalog Update on Startup:禁用时在初始化Addressables的时候自动更新远程的catalog(启用后可以通过代码 Addressables.CheckForCatalogUpdates()更新) Use…...
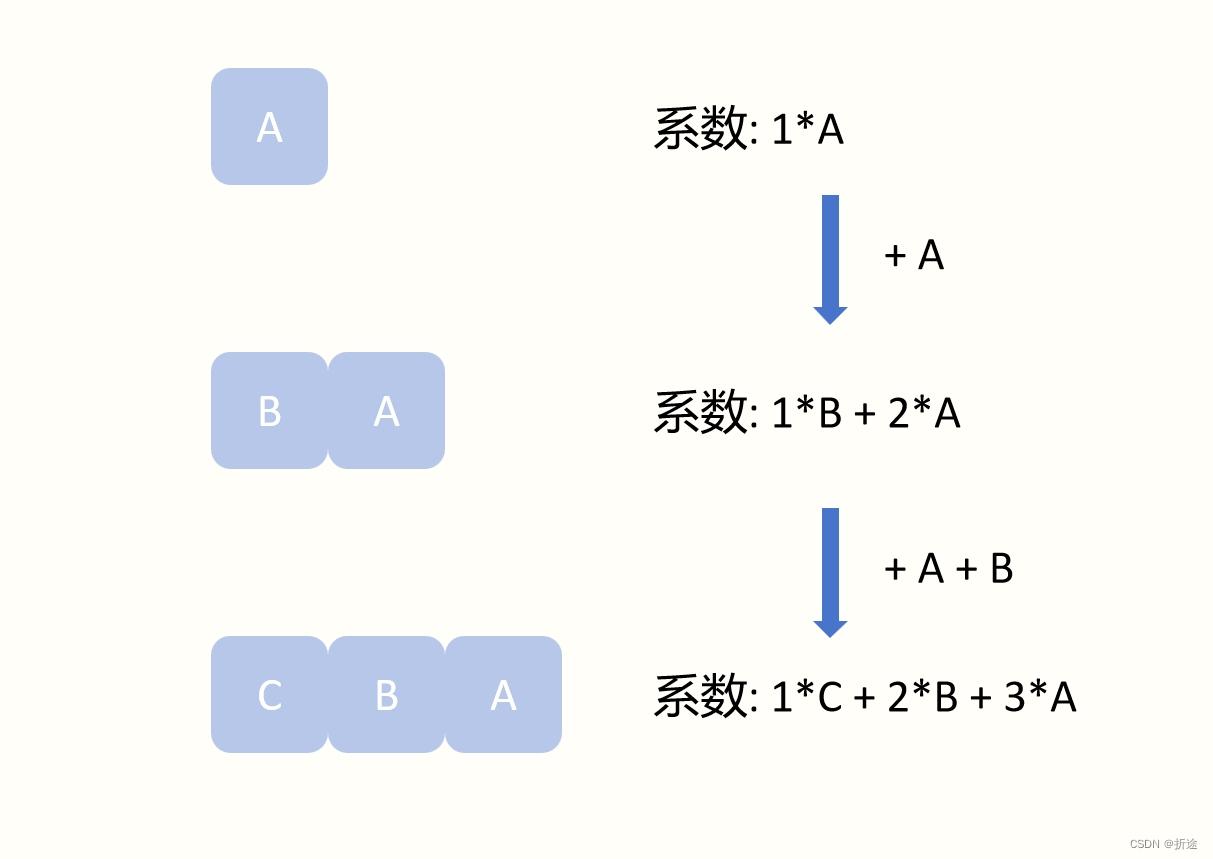
【力扣每日一题】2023.10.22 做菜顺序
目录 题目: 示例: 分析: 代码: 题目: 示例: 分析: 给我们一个数组表示每个菜的满意度,我们可以指定做哪些菜以及做的顺序,需要我们凑到一个系数的最大值,…...

MySQL 排名函数 RANK, DENSE_RANK, ROW_NUMBER
文章目录 1 排名函数有哪些?2 SQL 代码实现2.1 RANK2.2 DENSE_RANK2.3 ROW_NUMBER 1 排名函数有哪些? RANK(): 并列跳跃排名, 并列即相同的值, 相同的值保留重复名次, 遇到下一个不同值时, 跳跃到总共的排名DENSE_RANK(): 并列连续排序, 并列即相同的值, 相同的值保留重复名…...

avi视频协议的理解
可以把avi文件理解为由无数个struct结构组成的: 1. struct avifile { RIFF, AVI, struct. movi, struct hdrl} 2. struct hdrl { LIST, hdal, struct avih, struct stream0,struct stream1,struct stream2}; 3. struct stream {LIST …...
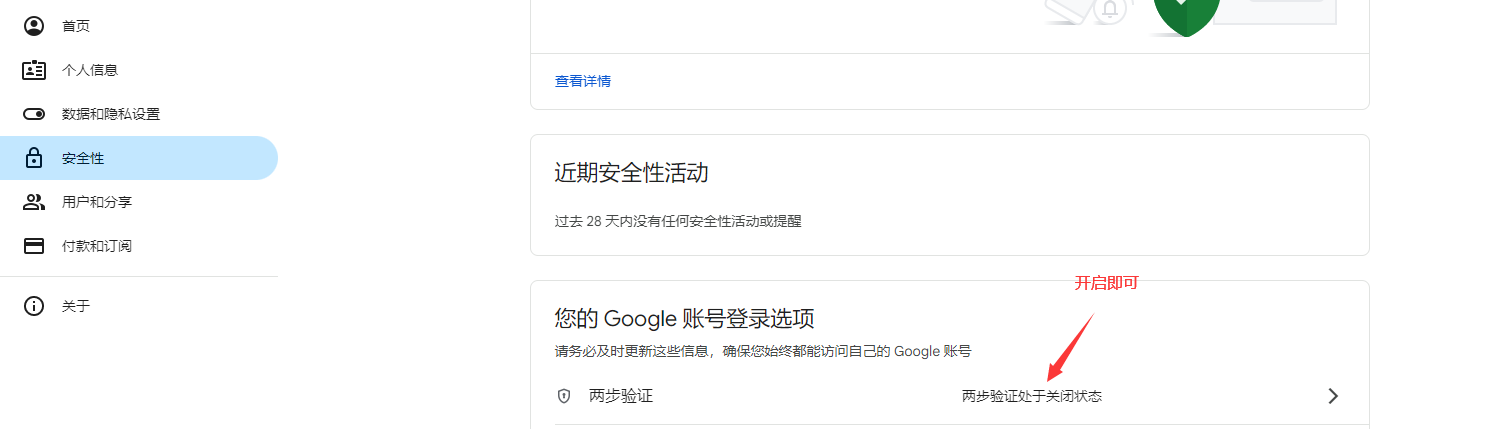
教你注册chrome开发者账号,并发布chrome浏览器插件。
本篇文章主要讲解,注册chrome开发者账号,及发布chrome浏览器插件的流程。包含插件的打包和上传。 日期:2023年10月22日 作者:任聪聪 一、前提准备:注册chrome开发者账号 说明:注册需要5美元,一…...

基于孔雀优化的BP神经网络(分类应用) - 附代码
基于孔雀优化的BP神经网络(分类应用) - 附代码 文章目录 基于孔雀优化的BP神经网络(分类应用) - 附代码1.鸢尾花iris数据介绍2.数据集整理3.孔雀优化BP神经网络3.1 BP神经网络参数设置3.2 孔雀算法应用 4.测试结果:5.M…...
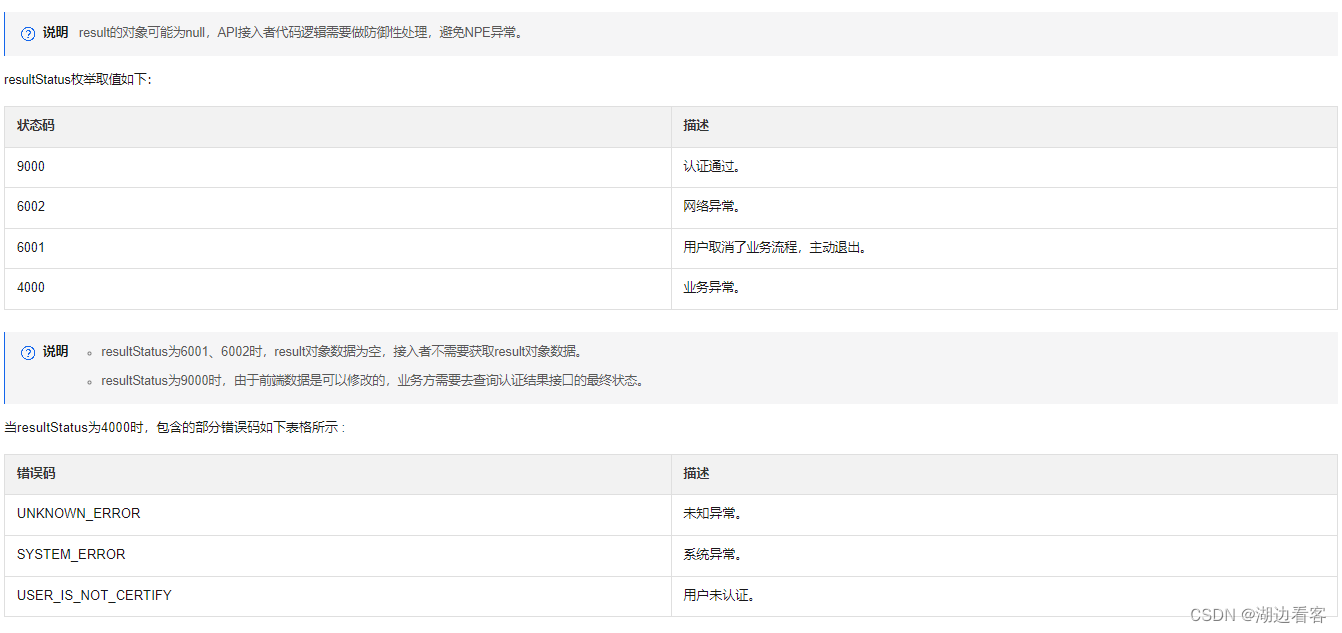
支付宝小程序介入人脸识别(金融级--前端部分)
在这里只做前端部分说明: 详情参考文档:如何通过集成支付宝小程序唤起实人认证服务_实人认证-阿里云帮助中心 操作步骤 调用 API 发起认证。 发起认证服务。 调用 startBizService 接口请求认证。 function startAPVerify(options, callback) {my.call(startBizService, {n…...

设置Oracle环境变量
打开系统变量 1.ORACLE_HOME: 新建一个变量home,再在path中添加:%ORACLE_HOME%\BIN 变量名: ORACLE_HOME 变量值: D:\app\chenzhi\product\11.2.0\dbhome_2(自己的存放地址) 2.NLS_LANG&am…...
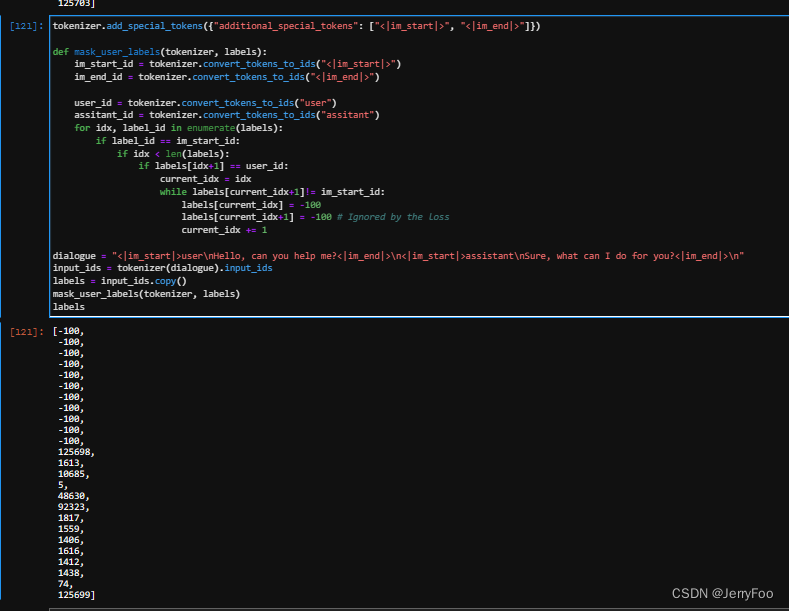
大模型之Chat Markup Language
背景 在笔者应用大模型的场景中,对话模型(即大模型-chat系列)通常具有比较重要的地位,我们通常基于与大模型进行对话来获取我们希望理解的知识。然而大模型对话是依据何种数据格式来进行训练的,他们的数据为什么这么来进行组织,本…...
分布式链路追踪系统Skywalking的部署和应用
一,背景 随着业务的扩张,系统变得越来越复杂,由前端、app、api、微服务、数据库、缓存、消息队列、关系数据库、列式数据库等构成了繁杂的分布式网络。 当出现一个调用失败的问题时,要定位异常在哪个服务,需要进入每一…...

canvas绘制动态视频并且在视频上加上自定义logo
实现的效果:可以在画布上播放动态视频,并且加上自定义的图片logo放在视频的右下角 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><meta name"viewport" content"widthd…...

分类预测 | MATLAB实现基于BiGRU-AdaBoost双向门控循环单元结合AdaBoost多输入分类预测
分类预测 | MATLAB实现基于BiGRU-AdaBoost双向门控循环单元结合AdaBoost多输入分类预测 目录 分类预测 | MATLAB实现基于BiGRU-AdaBoost双向门控循环单元结合AdaBoost多输入分类预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 1.MATLAB实现基于BiGRU-AdaBoos…...
切换)
Kotlin 协程(线程)切换
常用协程切换函数 withContext 是Kotlin协程中的一个常用协程函数,它的作用是切换协程的执行上下文(线程或调度器)。具体来说,withContext 的主要功能如下: 切换执行上下文:withContext 允许你从一个执行上…...

告别裸写I2C!在Keil C51中优雅驱动PCF8591的几种方法对比
在Keil C51中高效驱动PCF8591的工程实践指南 第一次接触PCF8591时,我像大多数初学者一样,直接从网上复制了那段经典的软件模拟I2C代码。但随着项目复杂度增加,这种"裸写"方式让代码变得难以维护——每次修改I2C时序都要重新调试底层…...

Chain-of-Recursive-Thoughts进阶技巧:如何自定义思考策略和评估标准
Chain-of-Recursive-Thoughts进阶技巧:如何自定义思考策略和评估标准 【免费下载链接】Chain-of-Recursive-Thoughts I made my AI think harder by making it argue with itself repeatedly. It works stupidly well. 项目地址: https://gitcode.com/gh_mirrors/…...

2025_NIPS_Sheetpedia: A 300K-Spreadsheet Corpus for Spreadsheet Intelligence and LLM Fine-Tuning
文章主要内容与创新点总结 一、主要内容 数据集构建:提出Sheetpedia,一个包含超29万张独特工作表(源自32.4万+工作簿)的大规模电子表格语料库。数据来源涵盖企业邮件档案(Enron数据集)、网络语料库(Fuse数据集)及Excel论坛爬取内容,经格式标准化、语言过滤(78%+为英…...

2026产线痛点终结者:Java+YOLOv11+ByteTrack,彻底解决光电计数不准的行业难题
一、前言:被光电传感器支配的工业计数噩梦 2026年的今天,绝大多数工厂的传送带零件计数,依然在靠几十年前的光电传感器硬扛。 上个月我接手了一家汽车零部件厂的计数系统改造项目,他们的情况几乎是整个行业的缩影:用了6年的欧姆龙E3Z光电传感器,只要零件出现重叠、倾斜…...
 选型指南:对比libdmtx、ZXing和huBarcode,你的项目该用哪个开源库?)
Data Matrix (ECC200) 选型指南:对比libdmtx、ZXing和huBarcode,你的项目该用哪个开源库?
Data Matrix (ECC200) 开源库选型实战指南 在工业自动化、物流追踪和医疗设备标识等领域,Data Matrix二维码因其高密度编码和小尺寸打印优势成为首选。面对libdmtx、ZXing和huBarcode三大主流开源方案,开发者常陷入选择困境。本文将从实际项目经验出发&a…...

圆弧长度计算公式详解
圆弧长度的计算核心在于其几何定义:圆弧是圆周的一部分,其长度由圆的半径和该圆弧所对应的圆心角决定。 一、 基本计算公式 圆弧长度 L 的计算公式为: L (θ / 360) 2πR (θ / 180) πR 或者,当圆心角 θ 以弧度制表示时…...

用Modbus Poll/Slave和串口助手调试STM32 Modbus主从机的完整流程
用Modbus Poll/Slave和串口助手调试STM32 Modbus主从机的完整流程 在工业自动化领域,Modbus协议因其简单可靠的特点成为最常用的通信协议之一。对于嵌入式开发者而言,掌握Modbus协议的调试技巧至关重要。本文将详细介绍如何使用Modbus Poll、Modbus Slav…...
)
用Python和Pandas手把手实现你的第一个Q-learning寻宝游戏(附完整代码)
用Python和Pandas手把手实现你的第一个Q-learning寻宝游戏(附完整代码) 在人工智能的众多分支中,强化学习因其独特的"试错学习"机制而备受关注。想象一下,你正在教一个孩子玩迷宫游戏——你不会直接告诉他每一步该怎么走…...

3步解锁旧Mac潜能:OpenCore Legacy Patcher完整使用指南
3步解锁旧Mac潜能:OpenCore Legacy Patcher完整使用指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是一款强大的开源…...

AGI驱动的灾害预警系统已上线7省:3大实时决策引擎、5层数据验证链与1秒级灾情推演模型全披露
第一章:SITS2026专家:AGI与灾害预警 2026奇点智能技术大会(https://ml-summit.org) 在SITS2026大会上,来自全球气候建模中心、神经符号AI实验室及联合国减灾署(UNDRR)的跨学科专家组首次公开演示了基于自主通用智能体…...