【java爬虫】使用selenium获取某交易所公司半年报数据
引言
上市公司的财报数据一般都会进行公开,我们可以在某交易所的官方网站上查看这些数据,由于数据很多,如果只是手动收集的话可能会比较耗时耗力,我们可以采用爬虫的方法进行数据的获取。
本文就介绍采用selenium框架进行公司财报数据获取的方法,网页的地址是
上市公司经营业绩概览 | 上海证券交易所
首先来看一下运行的效果
编程环境搭建
本文采用springboot进行开发,首先来看一下pom.xml的内容
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.7.12</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.example</groupId><artifactId>FinanceSpider</artifactId><version>0.0.1-SNAPSHOT</version><name>FinanceSpider</name><description>Demo project for Spring Boot</description><properties><java.version>1.8</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-thymeleaf</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>2.1.0</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.26</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><!-- 爬虫相关的包 --><dependency><groupId>com.squareup.okhttp3</groupId><artifactId>okhttp</artifactId><version>3.10.0</version></dependency><dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.11.3</version></dependency><dependency><!-- fastjson --><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.47</version></dependency><dependency><groupId>cn.hutool</groupId><artifactId>hutool-core</artifactId><version>5.6.5</version></dependency><dependency><groupId>net.lightbody.bmp</groupId><artifactId>browsermob-core</artifactId><version>2.1.5</version></dependency><dependency><groupId>net.lightbody.bmp</groupId><artifactId>browsermob-legacy</artifactId><version>2.1.5</version></dependency><dependency><groupId>org.seleniumhq.selenium</groupId><artifactId>selenium-java</artifactId><version>4.1.1</version><!-- <version>3.141.59</version>--></dependency><dependency><groupId>io.github.bonigarcia</groupId><artifactId>webdrivermanager</artifactId><version>5.0.3</version></dependency><dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>31.0.1-jre</version></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-resources-plugin</artifactId><version>2.4.3</version></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-surefire-plugin</artifactId><version>2.22.2</version><configuration><skipTests>true</skipTests></configuration></plugin></plugins></build></project>
数据库方面采用的是mysql,下面是建表语句
use finance_db;/* 半年报信息表 */
drop table if exists t_report;
create table t_report (u_id BIGINT (20) unsigned NOT NULL AUTO_INCREMENT PRIMARY KEY COMMENT '优惠券id',company VARCHAR (50) NOT NULL COMMENT '公司名称',stock VARCHAR (20) NOT NULL COMMENT '股票代码',income BIGINT (20) NOT NULL COMMENT '营业收入',profit1 BIGINT (20) NOT NULL COMMENT '净利润',profit2 BIGINT (20) NOT NULL COMMENT '扣非净利润',cashflow BIGINT (20) NOT NULL COMMENT '经营现金流',rate1 DOUBLE NOT NULL COMMENT '净资产收益率',rate2 DOUBLE NOT NULL COMMENT '基本每股收益',rate3 DOUBLE NOT NULL COMMENT '资产负债率'
) ENGINE=InnoDB COMMENT '半年报信息表';对应的mapper类和配置文件如下所示
@Mapper
public interface ReportMapper {// 清空表public void clearAll();// 插入一条数据public void insertOneItem(@Param("item")ReportEntity entity);}<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.demo.mapper.ReportMapper"><delete id="clearAll">delete from t_report where 1=1</delete><insert id="insertOneItem" parameterType="ReportEntity">insert into t_report(company, stock, income, profit1, profit2, cashflow, rate1, rate2, rate3)values(#{item.company}, #{item.stock}, #{item.income}, #{item.profit1},#{item.profit2}, #{item.cashflow}, #{item.rate1}, #{item.rate2}, #{item.rate3})</insert></mapper>除此之外,我们还需要编写一个和数据库表对应的实体类
@Data
@AllArgsConstructor
@NoArgsConstructor
public class ReportEntity {// 公司名称private String Company;// 股票代码private String stock;// 营业收入private long income;// 净利润private long profit1;// 扣非净利润private long profit2;// 经营现金流private long cashflow;// 净资产收益率private double rate1;// 基本每股收益private double rate2;// 资产负债率private double rate3;}
爬虫程序编写
环境搭好后接下来就是最重要的爬虫程序编写的部分了,本文采用的是chrome浏览器,使用selenium框架的时候,需要采用和浏览器版本对应的驱动程序,下面是我的浏览器版本

我下载了对应版本的驱动程序,118版本的驱动可以在这个网址下载
https://googlechromelabs.github.io/chrome-for-testing/#stable
如果你的chrome版本较低,驱动程序应该很好找,直接百度就可以了。
下面来介绍具体的爬虫程序编写逻辑。
实际上某交易所的数据还是比较好获取的,就是有一点需要注意一下,网页都是先于数据渲染的,selenium在网页渲染好后就会开始获取元素信息,这时候可能就会获取不到数据,解决办法就是判断当前有没有获取到数据,如果没有获取到数据就等待一会然后继续获取,直到获取到数据位置,具体的代码如下
@Slf4j
@Service
public class ReportServiceImpl implements ReportService {private final String DRIVER_PATH = "E:/视频/电商爬虫/驱动/chromedriver-118.exe";private final String START_URL = "http://www.sse.com.cn/disclosure/listedinfo/listedcompanies/";@Autowiredprivate ReportMapper reportMapper;@Overridepublic void getReportInfo() {reportMapper.clearAll();System.setProperty("webdriver.chrome.driver", DRIVER_PATH);ChromeOptions options = new ChromeOptions();options.addArguments("--remote-allow-origins=*");WebDriver driver = new ChromeDriver(options);// 设置最长等待时间driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);driver.get(START_URL);while(true) {WebElement element = driver.findElement(By.className("list-group-flush"));WebElement ul = element.findElement(By.tagName("ul"));List<WebElement> liList = ul.findElements(By.tagName("li"));String firstname = null;String cmpname = null;for (int i = 0; i < liList.size(); i++) {if (i == 0) {firstname = driver.findElement(By.className("js_one_title")).getText();}// 点击进入新的页面liList.get(i).findElement(By.tagName("div")).click();List<String> handleList = new ArrayList<>(driver.getWindowHandles());driver.switchTo().window(handleList.get(1));// 获取新的数据WebElement title_lev1 = null;title_lev1 = driver.findElement(By.className("title_lev1")).findElement(By.tagName("span"));while(title_lev1.getText().split(" ").length == 1) {log.info("等待公司名称加载");sleep(1000);title_lev1 = driver.findElement(By.className("title_lev1")).findElement(By.tagName("span"));}String tmpstr = title_lev1.getText();// System.out.println(tmpstr);String title = tmpstr.split(" ")[0];String stock = tmpstr.split(" ")[1];List<WebElement> table_ele = driver.findElement(By.className("table-hover")).findElements(By.tagName("tr"));while(table_ele.get(0).findElements(By.tagName("td")).get(1).getText().equals("-")) {log.info("等待详细信息加载");sleep(2000);table_ele = driver.findElement(By.className("table-hover")).findElements(By.tagName("tr"));}// 营业收入long income = parseLongStr(table_ele.get(0).findElements(By.tagName("td")).get(1).getText());// 净利润long profit1 = parseLongStr(table_ele.get(0).findElements(By.tagName("td")).get(3).getText());// 扣非净利润long profit2 = parseLongStr(table_ele.get(2).findElements(By.tagName("td")).get(1).getText());// 经营现金流long cashflow = parseLongStr(table_ele.get(2).findElements(By.tagName("td")).get(3).getText());// 净资产收益率double rate1 = parseDoubleStr(table_ele.get(4).findElements(By.tagName("td")).get(1).getText());// 基本每股收益double rate2 = parseDoubleStr(table_ele.get(4).findElements(By.tagName("td")).get(3).getText());// 资产负债率double rate3 = parseDoubleStr(table_ele.get(6).findElements(By.tagName("td")).get(1).getText());ReportEntity entity = new ReportEntity(title, stock, income, profit1, profit2, cashflow, rate1, rate2, rate3);reportMapper.insertOneItem(entity);log.info("获取信息=>" + JSON.toJSONString(entity));sleep(1000);// 关闭新的页面closeWindow(driver);}// 如果有下一页就点击下一页if (check(driver, By.className("noNext"))) {log.info("已经么有下一页啦");break;}WebElement element1 = driver.findElement(By.className("pagination-box")).findElement(By.className("next"));element1.click();log.info("点击进入下一页");// 等待标签出现变化sleep(1000);cmpname = driver.findElement(By.className("js_one_title")).getText();while(cmpname.equals(firstname)) {log.info("继续等待页面加载");sleep(1000);cmpname = driver.findElement(By.className("js_one_title")).getText();}}}// 等待一定时间public void sleep(long millis) {try {Thread.sleep(millis);} catch (InterruptedException e) {e.printStackTrace();}}// 判断某个元素是否存在public boolean check(WebDriver driver, By selector) {try {driver.findElement(selector);return true;} catch (Exception e) {return false;}}public double parseDoubleStr(String doublestr) {if (doublestr.equals("-")) {return 0.0;} else {return Double.parseDouble(doublestr.replaceAll(",", ""));}}public long parseLongStr(String longstr) {// System.out.println("longstr=" + longstr);int flag = 1;if (longstr.contains("-1")) {flag = -1;}longstr = longstr.replaceAll("-", "");longstr = longstr.replaceAll(",", "");// 如果有小数点if (longstr.contains(".")) {longstr = longstr.replaceAll("\\.", "");return Long.parseLong(longstr) * 100 * flag;} else { // 没有小数点return Long.parseLong(longstr) * 10000 * flag;}}// 关闭当前窗口public void closeWindow(WebDriver driver) {// 获取所有句柄的集合List<String> winHandles = new ArrayList<>(driver.getWindowHandles());driver.switchTo().window((String) winHandles.get(1));driver.close();driver.switchTo().window((String) winHandles.get(0));}
}下面是controller层的代码,用于启动爬虫程序,需要开启一个线程进行执行,因为程序运行的时间会很久
@Controller
public class BootController {@Autowiredprivate ReportService reportService;@RequestMapping("start")@ResponseBodypublic String bootstart() {new Thread(()->{reportService.getReportInfo();}).start();return "success";}}
运行程序后就可以进行数据获取了,下面是获取到的一部分数据
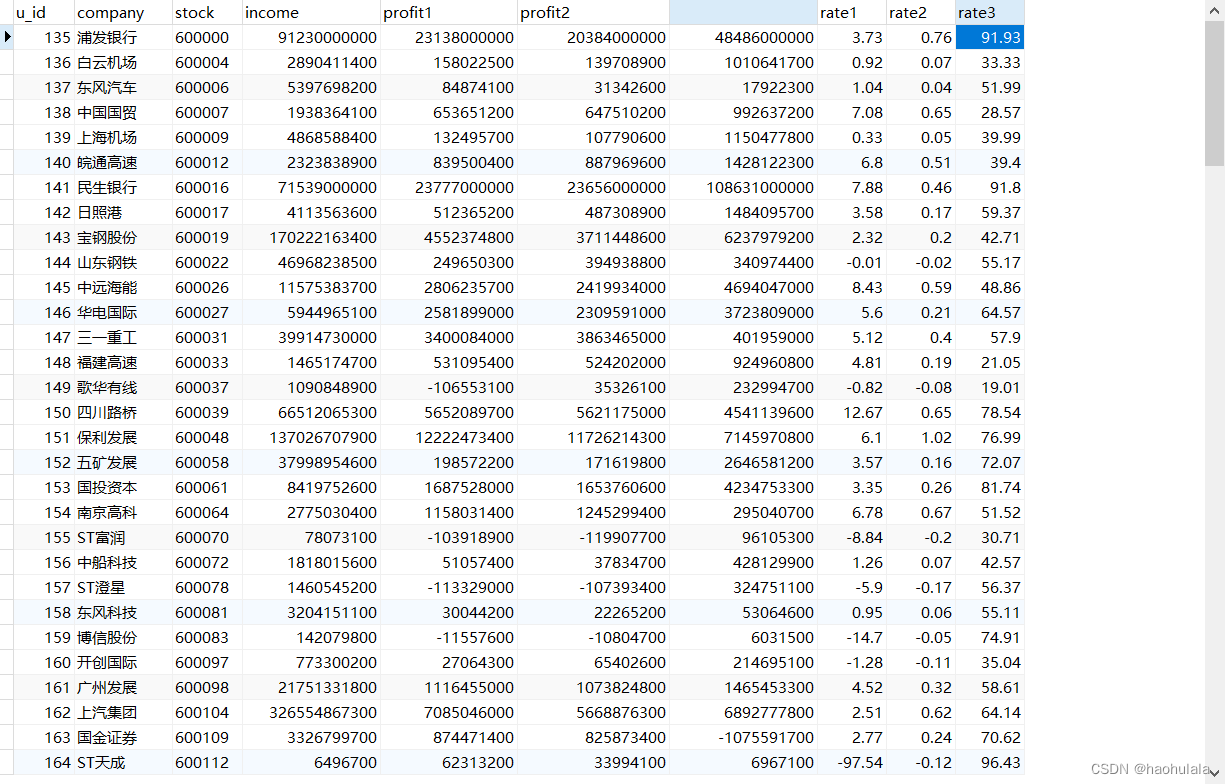
总结
使用爬虫获取数据还是挺快的,也挺方便的。
不过还是要提醒一句,本文分享的内容仅作为学习交流使用,请勿用于任何商业用途!
相关文章:
【java爬虫】使用selenium获取某交易所公司半年报数据
引言 上市公司的财报数据一般都会进行公开,我们可以在某交易所的官方网站上查看这些数据,由于数据很多,如果只是手动收集的话可能会比较耗时耗力,我们可以采用爬虫的方法进行数据的获取。 本文就介绍采用selenium框架进行公司财…...
MATLAB - 不能使用PYTHON,缺少matplotlib模块的解决办法
matlab缺少python-matplotlib模块的解决办法 1. 前言、概述2. 解决办法3. 可能出现问题4. 结果 1. 前言、概述 起因是我用习惯的colormap函数getPyPlot_cMap不能用了:【这个函数要调用PYTHON】 报错的地方: ModuleNotFoundError: No module named ‘ma…...
mk语法示例
这里写自定义目录标题 欢迎使用Markdown编辑器新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants 创建一个自定义列表如何创建一个…...

英语什么时候加s和es
名词变复数一般情况下加s,以s,x,ch,sh结尾加es。一个名词如果表示一个或一样东西,它取单数形式,如果表示两个或更多的这类东西,则需要用名词复数形式。 1 以s,x,sh,ch结尾的词,加es。 2 以辅音字母(除a/e/…...
unity中方向的两种表示:欧拉角和四元数
欧拉角:简单来说就是你可以选择 0度~360度 的范围 四元数:在计算机图像学中,四元数用于物体的旋转,是一种复杂,但效率较高的旋转方式 Quaternion结构体代表一个四元数,包含一个标量和一个三维向量&#x…...

ViT-L-14.pt下载load checkpoint from xxx
load checkpoint from E:\BaiduNetdiskDownload\sd-webui-aki-v4\models\BLIP\model_base_caption_capfilt_large.pth stable diffusion反推提示词出现此提示时,需安装以下模型至sd-webui-aki-v4.cache\clip\目录 ViT-L-14.pt https://openaipublic.azureedge.net/…...
机械设备经营小程序商城的作用是什么
由于机械设备厂商品牌需要各地招商代理,因此在管理方面也需要工具进行高效管理。如今各个行业都在开展数字化转型解决行业所遇难题或通过线上销售解决传统三公里难题及品牌扩张难题、用户消费渠道少等难题,构建会员体系精细化管理,同时还需要…...

小程序跨页面传递参数的几种方式
当我们在开发小程序时,经常会遇到需要在不同页面之间传递数据的情况。为了实现页面间的数据传递,小程序提供了多种方法。下面将介绍几种常用的传递数据的方法。 URL参数传递:这是一种简单直接的传递数据的方式。在跳转页面时,可以…...

【算法与数据结构】--高级算法和数据结构--高级数据结构
一、堆和优先队列 堆(Heap)是一种特殊的树状数据结构,通常用于实现优先队列。堆有两种主要类型:最大堆和最小堆。最大堆是一棵树,其中每个父节点的值都大于或等于其子节点的值,而最小堆是一棵树࿰…...

小工具 - Python图片转PDF文件
前言 主要整理记载一些python实现的小脚本,网上基本转换要会员,懒得搞了,这个一键生成,可以打包成exe文件使用 单张图片转换成pdf、图片批量转换成pdf # coding UTF-8 import os from io import BytesIO from PIL import Imag…...
bitbucket.org 用法
这个网站需要魔法,注册完成后添加厂库时间2023.10 图1 图2 第二张图 ,不要.gitignore文件 sourcetree 1,创建前端项目 npm create vitelatest 2.打开vscode创建本地Git 看到Git代提交的文件 sourcetree,新建 已存在的本地厂库 提交到Git 添…...

lodash常用方法合集
安装lodash 建议安装lodash-es,lodash-es 是 lodash 的 es modules 版本 ,是着具备 ES6 模块化的版本,体积小。按需引入。 示例 npm i lodash-es import { chunk,compact } from lodash-es; /**按需引入*/ 1.chunk 数组分组 chunk(arra…...

Nginx平滑升级重定向rewrite
文章目录 Nginx平滑升级&重定向rewritenginx平滑升级流程环境查看旧版的配置信息下载新版nginx源码包和功能模块包编译配置新版本平滑升级验证 重定向rewrite配置重定向准发访问测试 Nginx平滑升级&重定向rewrite nginx平滑升级 流程 平滑升级: (升级版本、增加新功…...

Mysql基础与高级汇总
SQL语言分类 DDL:定义 DML:操作 DCL:控制(用于定义访问权限和安全级别) DQL:查询 Sql方言 ->sql:结构化查询语言 mysql:limit oracle:rownum sqlserver:top 但是存储过程:每一种数据库软件一样SQL语法要求: SQL语句可以单行或多行书写&…...

为什么避免在循环、条件或嵌套函数中调用 Hooks
为什么避免在循环、条件或嵌套函数中调用 Hooks 为了确保 Hook 在每一次渲染中都按照同样的顺序被调用。这让 React 能够在多次的 useState 和 useEffect 调用之间保持 hook 状态的正确。 我们可以在单个组件中使用多个 State Hook 或 Effect Hook: function Form…...
自然语言处理---Transformer机制详解之BERT模型特点
1 BERT的优点和缺点 1.1 BERT的优点 通过预训练, 加上Fine-tunning, 在11项NLP任务上取得最优结果.BERT的根基源于Transformer, 相比传统RNN更加高效, 可以并行化处理同时能捕捉长距离的语义和结构依赖.BERT采用了Transformer架构中的Encoder模块, 不仅仅获得了真正意义上的b…...

c语言基础:L1-048 矩阵A乘以B
给定两个矩阵A和B,要求你计算它们的乘积矩阵AB。需要注意的是,只有规模匹配的矩阵才可以相乘即若A有Ra行、Ca列,B有Rb行、Cb列,则只有Ca与Rb相等时,两个矩阵才能相乘。 输入格式: 输入先后给出…...
asp.net乒乓球场地管理系统VS开发sqlserver数据库web结构c#编程Microsoft Visual Studio
一、源码特点 asp.net乒乓球场地管理系统是一套完善的web设计管理系统,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为vs2010,数据库为sqlserver2008,使用c#语 言开发 asp.net 乒乓球场地管理系统 二…...

git仓库中增加子仓库
在 Git 中包含另一个 Git 仓库通常使用 Git 子模块(Git Submodule)来实现。子模块允许你在一个 Git 仓库中包含另一个 Git 仓库,从而在一个仓库中管理多个相关但独立的项目。 以下是如何将一个 Git 仓库包含为另一个 Git 仓库的子模块的步骤…...
html中公用css、js提取、使用
前言 开发中,页面会有引用相同的css、js的情况,如需更改则每个页面都需要调整,重复性工作较多,另外在更改内容之后上传至服务器中会有缓存问题,特针对该情况对公用css、js进行了提取并对引用时增加了版本号 一、提取…...

孕囊多大可以人流 听我好好说说
孕囊多大可以人流,孕囊的大小在1.5-2cm左右就可以做人工流产。孕囊多大可以人流,一般孕囊在1-2cm可以做人工流产,因为孕囊过小流产很有可能会出现漏吸,导致失败,而孕囊过大则可能会出现流产不全的情况,导致…...

Go语言如何优化性能_Go语言性能优化技巧教程【深入】
pprof定位CPU热点需先让程序处于真实业务负载状态,HTTP服务启用net/http/pprof并压测后采样,优先查看flat视图中self值高的函数,注意区分GC干扰;string与[]byte转换应避免无谓拷贝,善用sync.Pool复用切片。Go 程序 CPU…...
)
AUTOSAR DEM实战:手把手教你配置KL30电压监控的Debounce参数(含代码示例)
AUTOSAR DEM实战:KL30电压监控Debounce参数配置全解析 在汽车电子系统开发中,电压监控是确保车辆电气系统稳定运行的关键功能。KL30作为常电电源线,其电压异常可能引发一系列连锁反应。本文将深入探讨如何通过AUTOSAR DEM模块的Debounce机制&…...

保姆级教程:用Sentinel-1 SAR和Landsat 9光学影像,手把手教你识别海洋“暗流”——内波
从数据到发现:Sentinel-1与Landsat 9协同解译海洋内波实战指南 当南海的碧波下暗流涌动,卫星的"天眼"正记录着这些肉眼不可见的海洋脉动。内波——这种水下百米深处的能量传递者,通过改变海面微结构,在遥感影像上留下独…...

告别ESP32环境配置噩梦:用Python虚拟环境一劳永逸管理ESP-IDF依赖
ESP32开发者的Python虚拟环境实战指南:彻底解决依赖冲突难题 每次打开ESP-IDF项目时,那些烦人的Python依赖报错是不是让你血压飙升?不同项目间的包版本冲突是否让你在pip install和pip uninstall之间反复横跳?作为一名长期奋战在E…...
)
别再傻傻分不清!5分钟搞懂NPN和PNP三极管的电流流向与电压偏置(附实战电路图)
电子工程师必看:NPN与PNP三极管的实战应用指南 三极管作为电子电路中最基础的放大与开关元件,其核心原理往往被初学者视为"拦路虎"。特别是NPN与PNP两种类型的电流流向差异,常常成为电路设计中的"隐形陷阱"。想象一下&am…...

从航模到创客:手把手教你用Arduino UNO和好盈40A电调DIY一个小型动力测试台
从航模到创客:用Arduino UNO和好盈40A电调构建专业级动力测试平台 当无刷电机从航模领域走向创客工作台,如何安全高效地测试其性能成为每个硬件爱好者的必修课。本文将带你用Arduino UNO和好盈40A电调打造一个可测量转速、绘制特性曲线、适配多种负载的…...

C#与Halcon控件深度集成:打造高交互性图像浏览窗口
1. 为什么需要深度集成Halcon控件? 在工业视觉和图像处理领域,Halcon一直是功能强大的工具库。但很多开发者在使用C#开发界面时,常常会遇到一个尴尬的问题:Halcon自带的图像显示窗口交互体验不够友好。想象一下,当操作…...

vLLM生产环境部署血泪史:10大坑爹问题及保姆级解决方案,助你少走弯路!
本文分享了vLLM在生产环境部署中的实战经验,涵盖GPU显存碎片、延迟雪崩、长文本输入崩溃等10个常见问题,并提供详细的解决方案和优化配置。通过调整参数、优化模型加载和监控策略,有效提升系统性能和稳定性,帮助开发者顺利实现从D…...

2025最权威的十大AI论文平台解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 对于学术写作而言,论文AI工具已然成了辅助开展研究、优化表达的一种重要资源。这…...