散列表:Word文档中的单词拼写检查功能是如何实现的?
文章来源于极客时间前google工程师−王争专栏。
一旦我们在Word里输入一个错误的英文单词,它就会用标红的方式提示“编写错误”。Word的这个单词拼写检查功能,虽然很小但却非常实用。这个功能是如何实现的?
散列别(Hash Table),可以轻松实现这个功能。
散列思想
“Hash Table”我们平时也叫它“哈希表”或者“Hash表”。
散列表用的是数组支持按照下标随机访问数据的特性,所以散列表其实就是数组的一种扩展,由数组演化而来。可以说,如果没有数组,就没有散列表。
场景:假如我们有89名选手参加学校运动会,为了方便记录成绩,每个选手胸前都会贴上自己的参赛号码。89名选手的编号依次是1到89。我们希望编程实现这样一个功能,通过编号快速找到对应的选手信息。怎么做?
将选手放到数组中,编号为k放到数组中下标为k的位置。
需要查询参赛为x的直接取数组下标为x位置就可以,时间复杂度为O(1)。
在这个场景中,参赛编号为自然数,与数组下标形成一一映射,利用数组支持根据下标随机访问的特性,O(1)时间复杂度,就可以实现快速查找编号对应的选手信息。这就是散列的思想。
编号如果详细,比如051167,05表示年级,11表示班级,最后两位代表编号。可以截取参赛编号的后两位作为数组的下标,来存储选手信息。
散列思想:
- 参赛选手的编号我们叫做键(key)或者关键字。
- 参赛编号转化为数组下标的映射方法就叫做散列函数(或“Hash函数”“哈希函数”)。
- 散列函数计算得到的值就叫作散列值(或“Hash值”“哈希值”)。
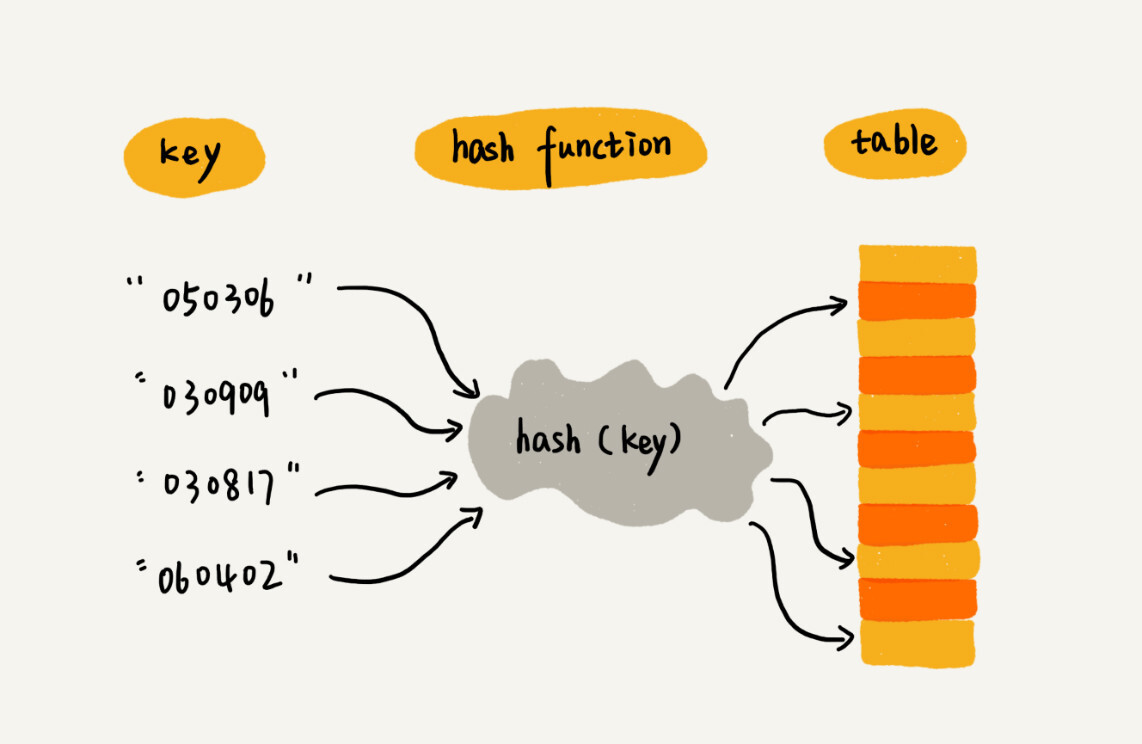
规律总结:散列表用的就是数组支持按照下标随机访问,时间复杂度为O(1)的特性。我们通过散列函数把元素的键值映射为下标,然后将数据存储在数组中对应下标的位置。当我们按照键值查询元素时,我们用同样的散列函数,将键值转化为数组下标,从对应的数组下标的位置取数据。
散列函数
散列函数,我们可以把它定义成hash(Key),其中key表示元素的键值,hash(Key)的值表示经过散列函数计算得到的散列值。
上述场景中,散列函数实现如下:
int hash(String key) {// 获取后两位字符string lastTwoChars = key.substr(length-2, length);// 将后两位字符转换为整数int hashValue = convert lastTwoChas to int-type;return hashValue;
}如果参赛选手的编号是随机生成的6位数字,又或者用的是a到z之间的字符串,该如何构造散列函数呢?三类函数设计有三个基本要求:
- 散列函数计算得到的散列值是一个非负整数
- 如果key1 = key2,那么hash(key1) == hash(key2)
- 如果key1 ≠ key2,那么hash(key1) ≠ hash(key2)
第三点在真是的情况下,几乎是不可能的。著名的MD5、SHA、CRC等哈希算法,也无法避免这种散列冲突。而且,数组的存储空间有限,也会加大散列冲突的概率。
散列冲突
常见的散列冲突解决方法有两类,开放寻址法(open addressing)和链表法(chaining)。
开放寻址法
开放寻址法的核心思想是,如果出现了散列冲突,我们就重新探测一个空闲位置,将其插入。那么如何重新探测新的位置呢?线性探测(Linear Probing)。
当我们往散列表中插入数据时,如果某个数据经过散列函数散列之后,存储位置已经被占用了,我们就从当前位置开始,依次往后查找,看是否有空闲位置,直到找到为止。
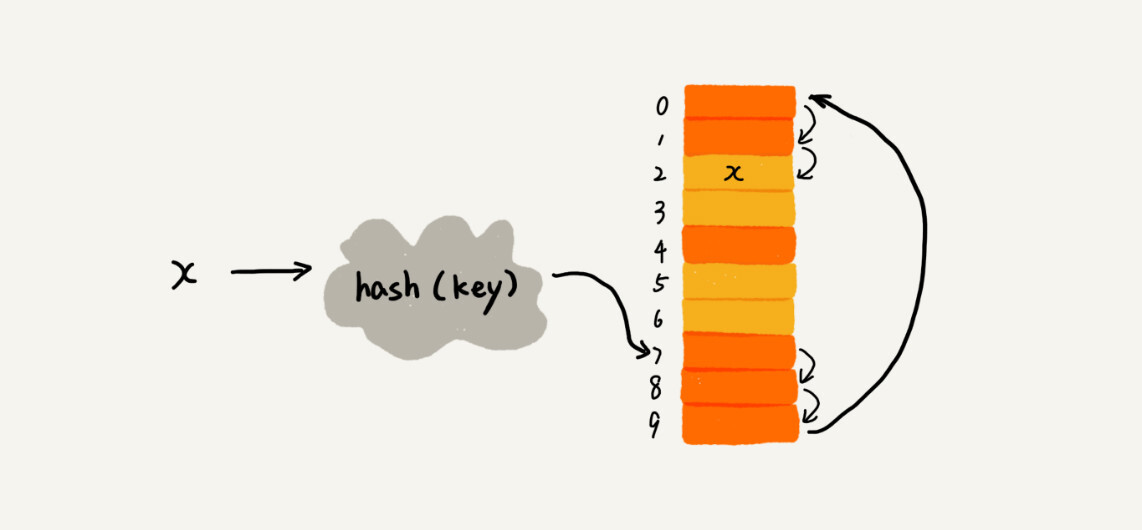
如上图所示,黄色的色块表示空闲位置,橙色的色块表示已经存储了数据。x经过Hash算法之后,被散列到位置下标为7的位置,但是这个位置已经有数据了,所以就产生了冲突。于是我们就顺序地往后一个一个找,看有没有空闲的位置,遍历到尾部都没有找到空闲位置,于是我们再从表头开始找,直到找到空闲位置2,于是将其插入到这个位置。
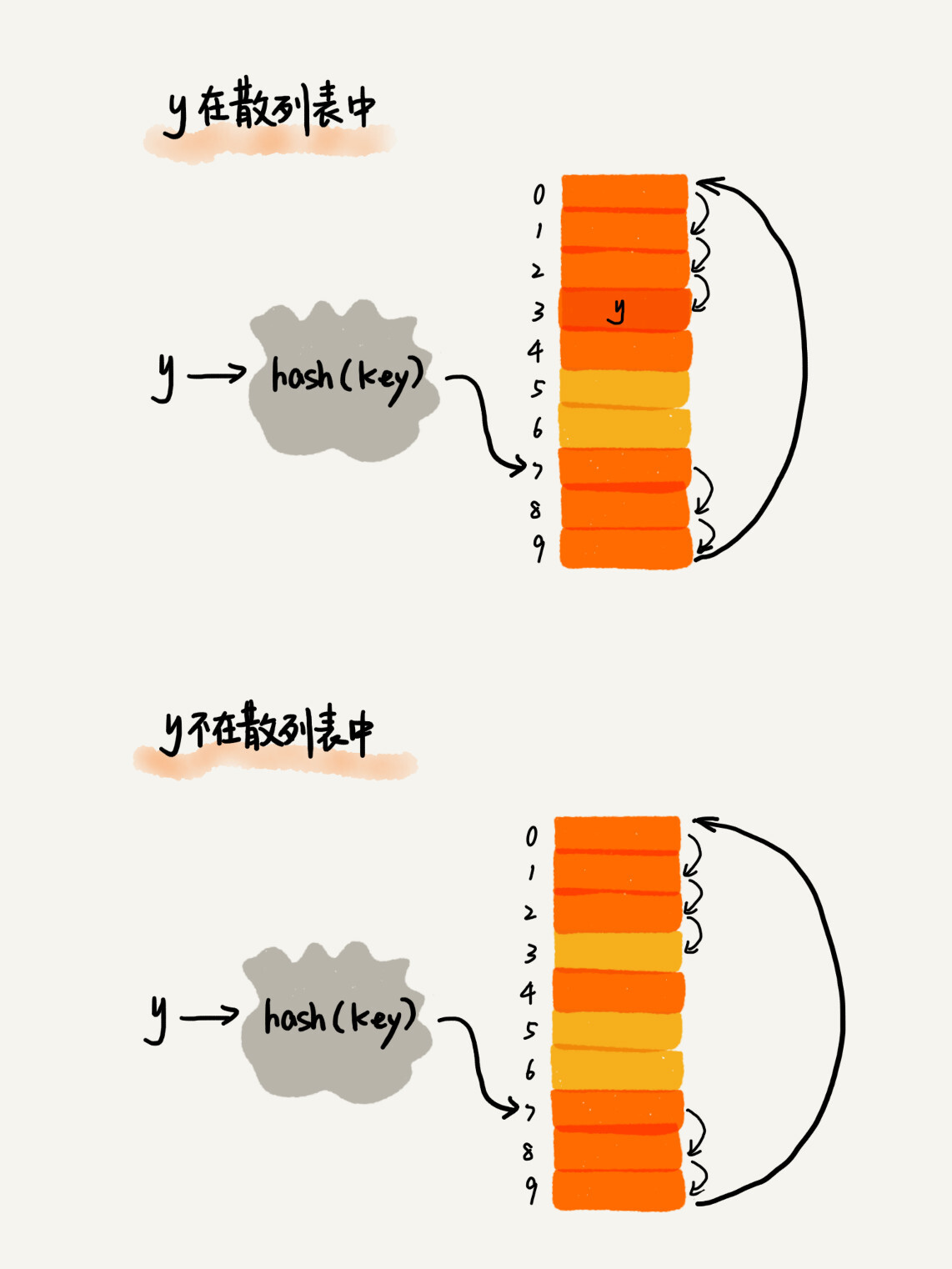
在散列表中查找元素的过程有点类似插入过程。计算出散列值,然后比较数组中下标为散列值的元素和要查找的元素。如果相等,就说明是我们要找的元素;否则就顺序往后依次查找。如果遍历到数组中的空闲位置,还没有找到,就说明要查找的元素并没有在散列表中。(查找建立在插入的基础上)
删除操作,将删除的元素,特殊标记为deleted,不能直接置为空。当线性探测查找的时候,遇到标记为deleted的空间,并不是停下来,而是继续往下探测。
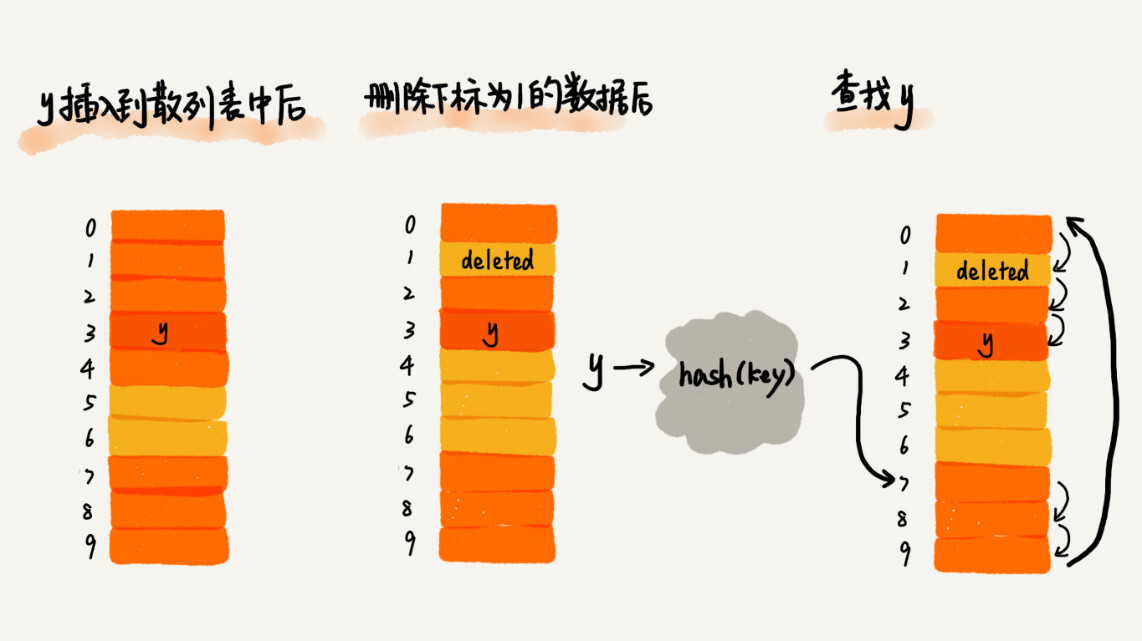
极端情况下,我们可能需要探测整个散列表,所以最坏情况下的时间复杂度为O(n)。
对于开放寻址冲突解决方法,除了线性探测方法之外,还有另外两种比较经典的探测方法,二次探测(Quadratic probing)和双重散列(Double hashing)。
二次探测,跟线性探测很像,线性探测每次探测的步长是1,那它探测的下标序列就是hash(key)+0,hash(key)+1,hash(key)+2……而二次探测探测的步长就变成了原来的“二次方”,也就是说,它探测的下标序列就是hash(key)+0,hash(key)+12,hash(key)+22
双重散列,意思就是不仅要使用一个散列函数。使用一组散列函数hash1(key),hash2(key),hash3(key)…先用第一个散列函数,如果计算得到的存储位置已经被占用,再用第二个散列函数,直到找到空闲的存储位置。
不管哪种探测方法,当散列表中空闲位置不多的时候,散列冲突的概率就会大大提高。为了尽可能保证散列表的操作效率,一般情况下,我们会尽可能保证散列表中有一定比例的空闲槽位。使用**装载因子(load factor)**来表示空位的多少。
装载因子的计算公式是:
散列表的装载因子 = 填入表中的元素个数 / 散列表的长度
装载因子越大,说明空闲位置越少,冲突越多,散列表的性能会下降。
2.链表法
链表法是一种更加常用的散列冲突解决办法,相比开发寻址法,它要简单的多。在散列表中,每个“桶(bucket)”或者“槽(solt)”会对应一条链表,所有散列值相同的元素我们都放到相同槽位对应的链表中。
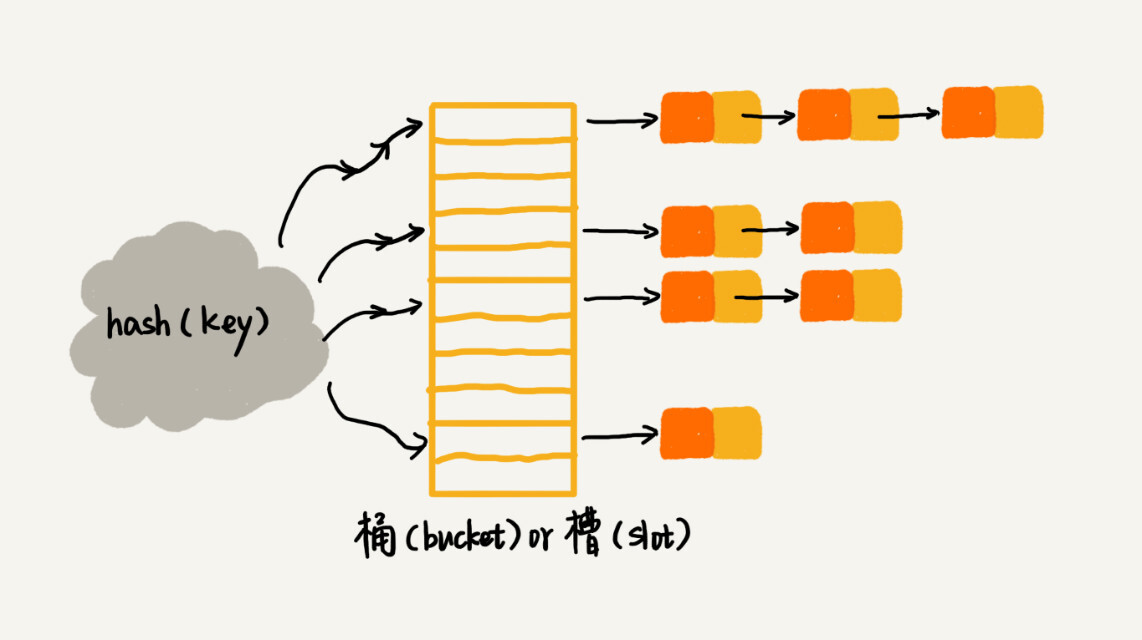
当插入的时候,我们只需要通过散列函数计算出对应的散列槽位,将其插入到对应链表中即可,所以插入的时间复杂度为O(1)。当查找、删除一个元素时,我们同样通过散列函数计算出对应的槽,然后遍历链表查找或者删除。查找删除的复杂度是多少?
查找删除时间复杂度跟链表的长度k成正比,也就是O(k)。对于散列比较均匀的散列函数来说,理论上k=n/m,其中n表示散列中数据的个数,m表示散列表中“槽”的个数。
解答开篇
Word文档中单词拼写检查功能是如何实现的?
常用的英文单词20万个左右,假设单词的平均长度是10个字母,平均一个单词也就是占用10个字节的内存空间,那么20万英文单词大约占2MB的存储空间,就算放大10倍也就是20MB。对于现在的计算机来说,这个大小完全可以放在内存里面。所以可以用散列表来存储整个英文单词词典。
总结
散列表来源于数组,它借助散列函数对数组这种数据结构进行扩展,利用的是数组支持按照下标随机访问元素的特性。散列表的两个核心问题是散列函数设计和散列冲突解决。散列函数设计的好坏决定了散列冲突的概率,也就决定了散列表的性能。
思考
1.假设我们有10万条URL访问日志,如何按照访问次数给URL排序?
遍历 10 万条数据,以 URL 为 key,访问次数为 value,存入散列表,同时记录下访问次数的最大值 K,时间复杂度 O(N)。
如果 K 不是很大,可以使用桶排序,时间复杂度 O(N)。如果 K 非常大(比如大于 10 万),就使用快速排序,复杂度 O(NlogN)。
2.有两个字符串数组,每个数组中大约有10万条字符串,如何快速找出两个数组中相同的字符串?
以第一个字符串数组构建散列表,key 为字符串,value 为出现次数。再遍历第二个字符串数组,以字符串为 key 在散列表中查找,如果 value 大于零,说明存在相同字符串。时间复杂度 O(N)。
相关文章:
散列表:Word文档中的单词拼写检查功能是如何实现的?
文章来源于极客时间前google工程师−王争专栏。 一旦我们在Word里输入一个错误的英文单词,它就会用标红的方式提示“编写错误”。Word的这个单词拼写检查功能,虽然很小但却非常实用。这个功能是如何实现的? 散列别(Hash Table&am…...

智慧公厕蜕变多功能城市智慧驿站公厕的创新
随着城市发展的不断推进,对公共设施的便利性和智能化要求也日益提高。为满足市民对高品质、便捷、舒适的公共厕所的需求,智慧公厕行业的领航厂家广州中期科技有限公司,全新推出了一体化智慧公厕驿站。凭借着“高科技碳中和物联网创意设计新经…...

R语言清洗与处理数据常用代码段
去掉数据框df的某一列: # 删除不必要的变量 data$unnecessary_var <- NULL 选择需要的列进行读入数据框: # 选择需要的列 selected_cols <- c("col1", "col2", "col3") data <- fread("data.csv", s…...

centos 7.9 安装python 3.10的tls问题,
本地开发升级成了py3.10.6,服务器测试时安装py3.10.4 发现无法正常使用pip3 pip is configured with locations that require TLS/SSL, however the ssl module in Python is not available. 印象中py3的高版本依赖高版本的openssl,centos 7下默认的openssl为1.0.x, 问题很简…...

pytorch,tf维度理解RNN
input_t input_t.squeeze(1) 这行代码用于从 input_t 中去除尺寸为1的维度。在深度学习中,经常会出现具有额外尺寸为1的维度,这些维度通常是为了匹配模型的期望输入维度而添加的。 在这里,input_t可能具有形状 (batch_size, 1, feature_dim…...

算法刷题-数组
算法刷题 209. 长度最小的子数组-二分或者滑动窗口 给定一个含有 n 个正整数的数组和一个正整数 target 。 找出该数组中满足其总和大于等于 target 的长度最小的 连续子数组 [numsl, numsl1, ..., numsr-1, numsr] ,并返回其长度**。**如果不存在符合条件的子数…...
可视化数学分析软件 MATLAB R2021b mac中文版软件介绍
MATLAB R2021b mac作为数学类科技应用软件中首屈一指的商业数学软件,可以帮助您进行矩阵运算、绘制函数和数据、实现算法、创建用户界面、连接其他编程语言的程序等,主要应用于工程计算、控制设计、信号处理与通讯、图像处理、信号检测、金融建模设计与分析等领域。…...

罗技摄像头左右翻转
需要下载驱动lws(我的是c310) LWS 罗技摄像头驱动下载 打开驱动程序,高级设置。有个镜像。...
【Linux】操作系统的认识
操作系统 1. 冯诺依曼体系结构2. 操作系统 1. 冯诺依曼体系结构 冯诺依曼体系结构的介绍 冯.诺依曼结构消除了原始计算机体系中,只能依靠硬件控制程序的状况(程序作为控制器的一部分,作为硬件存在),将程序编码存储在…...

【论文阅读】(2023TPAMI)PCRLv2
目录 AbstractMethodMethodnsU-Net中的特征金字塔多尺度像素恢复多尺度特征比较从多剪切到下剪切训练目标 总结 Abstract 现有方法及其缺点:最近的SSL方法大多是对比学习方法,它的目标是通过比较不同图像视图来保留潜在表示中的不变合判别语义ÿ…...
-mapreduce task详解)
大数据学习(17)-mapreduce task详解
&&大数据学习&& 🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博主哦ᾑ…...

HCIA --- DHCP服务、路由器、网络部署及基本配置
带宽计算公式: 速率 约等于 (带宽/8)*85% 网线分类: RJ-45双绞线 非屏蔽线 最佳距离100M; 民用 1000M/S 商用100000M/S 数字 光纤 光信号 RJ-11 电话线 模拟信号 同轴电缆 数字信号 光信号 数字信号--二进制 …...
手把手入门Node框架Egg.js
0.介绍 Egg.js 是一个面向企业级应用开发的 Node.js 框架,它建立在 Koa.js 之上,提供了一种更简单、灵活的开发方式。Egg.js 提供了一些默认约定和最佳实践,可以帮助开发者快速构建可靠、可扩展的应用程序。 基于 Koa.js:Egg.js …...

百度智能云推出,国内首个大模型全链路生态支持体系
在10月17日举行的百度世界2023上,百度智能云宣布,百度智能云千帆大模型服务平台已服务17000多家客户,覆盖近500个场景。 同时,新的企业和开发者还正在不断地涌入千帆,大模型调用量高速攀升。平台上既有年龄仅14岁的小…...
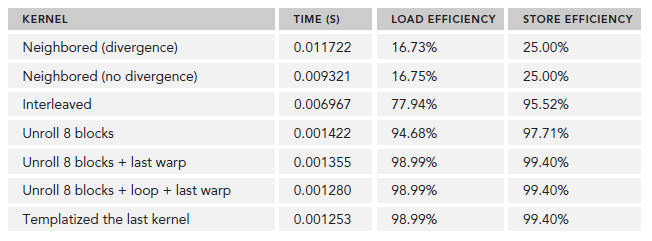
CUDA学习笔记(八)Branch Divergence and Unrolling Loop
Avoiding Branch Divergence 有时,控制流依赖于thread索引。同一个warp中,一个条件分支可能导致很差的性能。通过重新组织数据获取模式可以减少或避免warp divergence(该问题的解释请查看warp解析篇)。 The Parallel Reduction …...
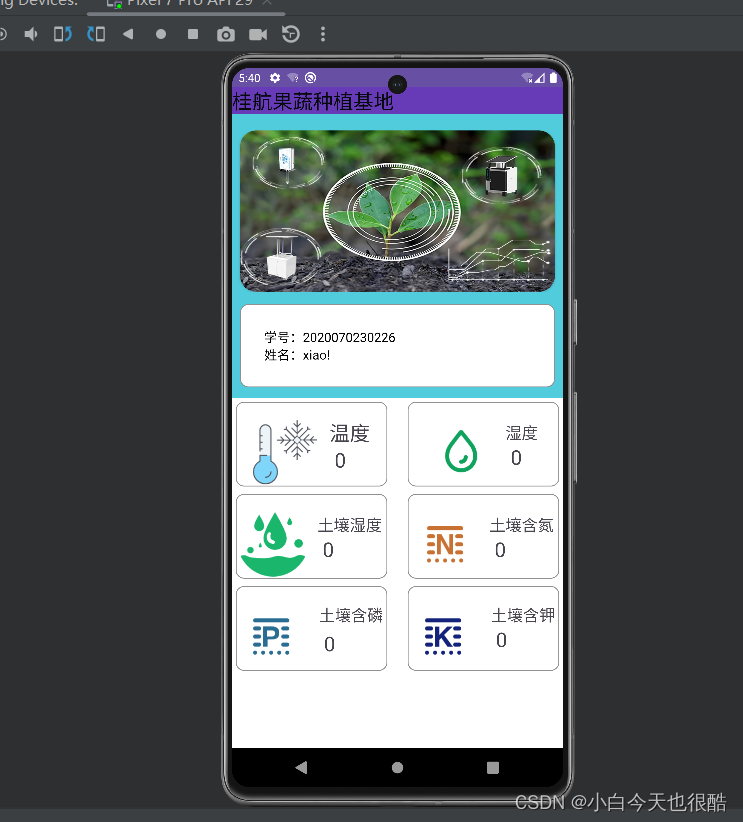
Android MQTT连接阿里云使用Json解析数据
Android Studio 连接阿里云订阅主题然后使用JSON解析数据非常好用 导入MQTT的JAR包1、在项目中添加依赖然后使用Studio 去下载库2、直接下载JAR包,然后作为库进行导入 环境验证:给程序进行联网权限XML布局文件效果如下: MainActitive.java 主…...
生成二维码
Qt本地生成二维码-第三方库Libqrencode Chapter1 Qt本地生成二维码-第三方库Libqrencode一、功能简介二、本地生成二维码三、在线生成二维码 Chapter2 Qt生成二维码图片方法QRCode二维码简介如何选定QR码版本?主要方法(1) 下载qrencode源码(2) 将qrencode源码移植到…...

【C++入门 一 】学习C++背景、开启C++奇妙之旅
目录 1.什么是C2. C的发展史3. C的重要性3.1 语言的使用广泛度3.2 在工作领域1. 操作系统以及大型系统软件开发2. 服务器端开发3. 游戏开发4. 嵌入式和物联网领域5. 数字图像处理6. 人工智能7. 分布式应用 3.3 在校招领域3.3.1 岗位需求3.3.2 笔试题 4. 如何学习C4.1 别人怎么学…...
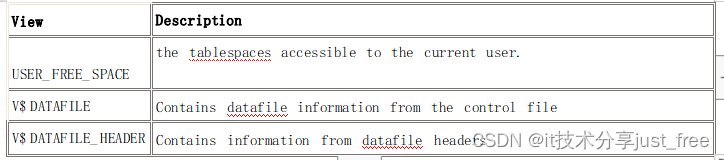
oracle 表空间详解以及配置操作
Oracle 数据库是由若干个表空间构成的。任何数据库对象在存储时都必须存储在某个 表空间中。表空间对应于若干个数据文件,即表空间是由一个或多个数据文件构成的。 1、常用表空间: 系统表空间 (system tablespace) 是每个 Oracle 数据库都必须具备的。…...

php判断是否是email格式
要判断一个字符串是否是有效的电子邮件地址,你可以使用正则表达式和PHP内置函数来完成。以下是一个示例代码: $email "exampleexample.com"; // 你要检查的电子邮件地址// 使用正则表达式检查电子邮件格式 if (filter_var($email, FILTER_VA…...

Qwen3.5-2B部署教程:阿里云ECS轻量应用服务器7860端口开放指南
Qwen3.5-2B部署教程:阿里云ECS轻量应用服务器7860端口开放指南 1. 模型简介 Qwen3.5-2B是阿里云推出的轻量化多模态基础模型,属于Qwen3.5系列的小参数版本(20亿参数)。该模型专为低功耗、低门槛部署场景设计,特别适合…...

解锁RK3588潜力:从4K到8K的HDMI配置实战解析
1. 为什么RK3588默认不支持8K输出? 很多开发者拿到RK3588开发板时,会发现默认配置下HDMI最高只能输出4K分辨率。这其实是一个设计上的权衡结果。RK3588芯片本身具备8K视频解码和显示能力,但在Android 12 SDK中,为了兼顾多个显示接…...

JavaScript Navigator 对象怎么用?
Window Navigator 对象 JavaScript 中的 navigator 对象用于访问用户浏览器的信息。使用 navigator 对象,你可以获取浏览器版本和名称,并检查浏览器中是否启用了 cookie。 navigator 对象是 window 对象的一个属性。通过只读的 window.navigator 属性可…...

Gemma-3-12b-it镜像免配置教程:树莓派5+USB加速棒边缘部署探索
Gemma-3-12b-it镜像免配置教程:树莓派5USB加速棒边缘部署探索 1. 环境准备与硬件要求 1.1 硬件配置清单 树莓派5:推荐8GB内存版本USB加速棒:支持CUDA的AI加速设备(如Google Coral USB Accelerator)存储设备…...

vLLM-v0.17.1部署指南:阿里云ECS + vLLM + NAS共享模型存储
vLLM-v0.17.1部署指南:阿里云ECS vLLM NAS共享模型存储 1. vLLM框架简介 vLLM是一个专为大语言模型(LLM)设计的高性能推理和服务库,由加州大学伯克利分校的天空计算实验室(Sky Computing Lab)开发,现已发展为社区驱动的开源项目。它通过多…...

Gemma-3-12b-it部署教程:bf16精度加载失败排查与CUDA版本兼容清单
Gemma-3-12b-it部署教程:bf16精度加载失败排查与CUDA版本兼容清单 1. 项目概述 Gemma-3-12b-it是基于Google Gemma-3-12b-it大模型开发的本地多模态交互工具,专为图文混合交互场景优化。该工具通过多项技术创新解决了12B大模型在本地部署中的性能瓶颈&…...

Qwen3-TTS快速体验:无需复杂配置,开箱即用语音克隆
Qwen3-TTS快速体验:无需复杂配置,开箱即用语音克隆 1. 开箱即用的语音克隆体验 想象一下,你只需要上传3秒钟的语音样本,就能让AI用一模一样的声音说出任何你想说的话。这不是科幻电影里的场景,而是Qwen3-TTS-12Hz-1.…...

HeyGem数字人系统批量处理教程:高效制作企业宣传视频
HeyGem数字人系统批量处理教程:高效制作企业宣传视频 1. 系统介绍与核心功能 HeyGem数字人视频生成系统是一款基于AI技术的智能视频合成工具,能够将音频与视频完美结合,生成口型同步的数字人视频。这个批量版WebUI版本经过二次开发…...

如何高效备份QQ空间历史说说的完整指南
如何高效备份QQ空间历史说说的完整指南 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 在数字信息时代,个人数据的安全备份变得日益重要。GetQzonehistory作为一款开源工具&…...
批量求逆元,组合数计算效率翻倍(附C++代码))
告别费马小定理!用线性递推O(n)批量求逆元,组合数计算效率翻倍(附C++代码)
告别费马小定理!用线性递推O(n)批量求逆元,组合数计算效率翻倍(附C代码) 在算法竞赛和编程面试中,组合数计算是一个高频出现的难题。想象一下这样的场景:你正在参加ACM比赛,面对一道需要计算大量…...