ELK概述部署和Filebeat 分布式日志管理平台部署
ELK概述部署、Filebeat 分布式日志管理平台部署
- 一、ELK 简介
- 二、ELK部署
- 2.1、部署准备
- 2.2、优化elasticsearch用户拥有的内存权限
- 2.3、启动elasticsearch是否成功开启
- 2.4、浏览器查看节点信息
- 2.5、安装 Elasticsearch-head 插件
- 2.6、ELK Logstash 部署(在 Apache 节点上操作)
- 2.7、ELK Kiabana 部署(在 Node1 节点上操作)
- 三、Filebeat作为日志收集器
一、ELK 简介
ELK平台是一套完整的日志集中处理解决方案,将 ElasticSearch、Logstash 和 Kiabana 三个开源工具配合使用, 完成更强大的用户对日志的查询、排序、统计需求。
-
ElasticSearch:是基于Lucene(一个全文检索引擎的架构)开发的分布式存储检索引擎,用来存储各类日志。
- Elasticsearch 是用 Java 开发的,可通过 RESTful Web 接口,让用户可以通过浏览器与 Elasticsearch 通信。
- Elasticsearch是一个实时的、分布式的可扩展的搜索引擎,允许进行全文、结构化搜索,它通常用于索引和搜索大容量的日志数据,也可用于搜索许多不同类型的文档。
-
Kiabana:Kibana 通常与 Elasticsearch 一起部署,Kibana 是 Elasticsearch 的一个功能强大的数据可视化 Dashboard,Kibana 提供图形化的 web 界面来浏览 Elasticsearch 日志数据,可以用来汇总、分析和搜索重要数据。
-
Logstash:作为数据收集引擎。它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到用户指定的位置,一般会发送给 Elasticsearch。
-
Logstash 由 Ruby 语言编写,运行在 Java 虚拟机(JVM)上,是一款强大的数据处理工具, 可以实现数据传输、格式处理、格式化输出。Logstash 具有强大的插件功能,常用于日志处理。
可以添加的其它组件: -
Filebeat:轻量级的开源日志文件数据搜集器。通常在需要采集数据的客户端安装 Filebeat,并指定目录与日志格式,Filebeat 就能快速收集数据,并发送给 logstash 进行解析,或是直接发给 Elasticsearch 存储,性能上相比运行于 JVM 上的 logstash 优势明显,是对它的替代。
-
常应用于 EFLK 架构当中。
ilebeat 结合 logstash 带来好处:
1.通过 Logstash 具有基于磁盘的自适应缓冲系统,该系统将吸收传入的吞吐量,从而减轻 Elasticsearch 持续写入数据的压力
2.从其他数据源(例如数据库,S3对象存储或消息传递队列)中提取
3.将数据发送到多个目的地,例如S3,HDFS(Hadoop分布式文件系统)或写入文件
4.使用条件数据流逻辑组成更复杂的处理管道
总结:logstash作为日志搜集器,从数据源采集数据,并对数据进行过滤,格式化处理,然后交由Elasticsearch存储,kibana对日志进行可视化处理。
二、ELK部署
2.1、部署准备
| node1节点(2C/4G) | node1/192.168.11.11 | Elasticsearch |
|---|---|---|
| node2节点(2C/4G) | node2/192.168.11.12 | Elasticsearch |
| Apache节点 | apache192.168.11.13 | Logstash Kibana Apache |
关闭防火墙(所有节点)
systemctl stop firewalld
setenforce 0
设置Java环境
ELK是由java开发的必须运行在jvm上
java -version #如果没有安装,yum -y install java
openjdk version "1.8.0_131"
OpenJDK Runtime Environment (build 1.8.0_131-b12)
OpenJDK 64-Bit Server VM (build 25.131-b12, mixed mode)
设置主机名
hostnamectl set-hostname es01 su
hostnamectl set-hostname es02 su
hostnamectl set-hostname apache su



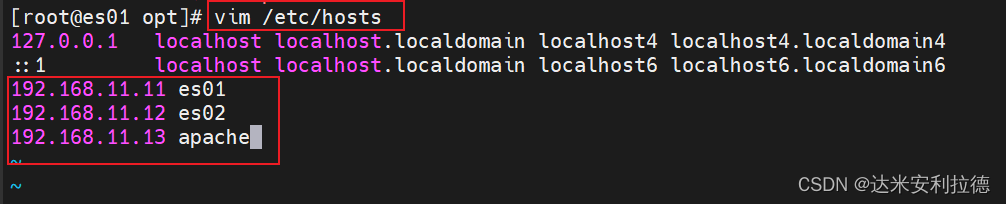
主机名映射(所有节点)
vim /etc/hosts
192.168.11.11 es01
192.168.11.12 es02
192.168.11.13 apache
部署 Elasticsearch 软件
(1)安装elasticsearch—rpm包
#上传elasticsearch-6.7.2.rpm到/opt目录下
cd /opt
rpm -ivh elasticsearch-6.7.2.rpm(2)修改elasticsearch主配置文件
cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak
vim /etc/elasticsearch/elasticsearch.yml
--17--取消注释,指定集群名字
cluster.name: my-elk-cluster
--23--取消注释,指定节点名字:Node1节点为node1,Node2节点为node2
node.name: node1
node.master: true #是否master节点,false为否
node.data: true #是否数据节点,false为否
--33--取消注释,指定数据存放路径
path.data: /var/lib/elasticsearch
--37--取消注释,指定日志存放路径
path.logs: /var/log/elasticsearch
--43--取消注释,避免es使用swap交换分区
bootstrap.memory_lock: true
--55--取消注释,设置监听地址,0.0.0.0代表所有地址
network.host: 0.0.0.0
--59--取消注释,ES 服务的默认监听端口为9200
http.port: 9200 #指定es集群提供外部访问的接口
transport.tcp.port: 9300 #指定es集群内部通信接口
--68--取消注释,集群发现通过单播实现,指定要发现的节点
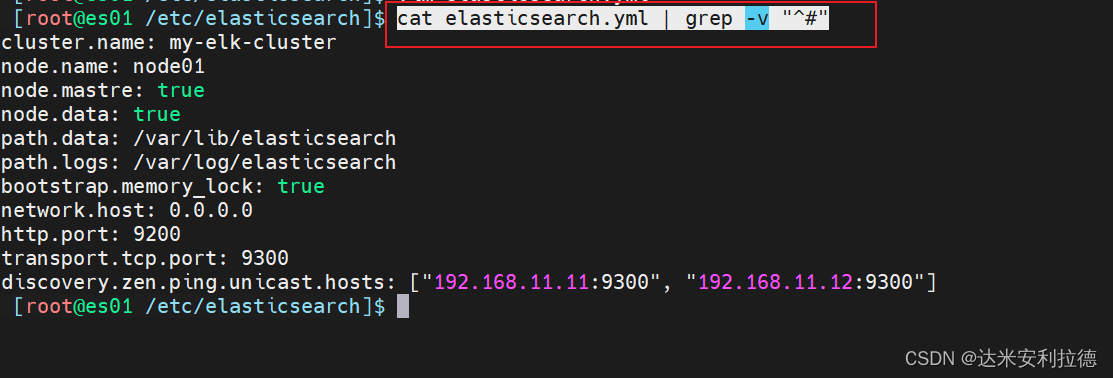
discovery.zen.ping.unicast.hosts: ["192.168.11.11:9300", "192.168.11.12:9300"]grep -v "^#" /etc/elasticsearch/elasticsearch.yml
安装elasticsearch—rpm包(es01)

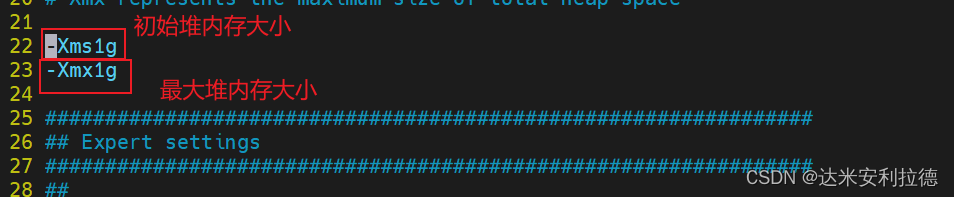
修改jvm配置文件优化


备份配置文件

修改配置文件








过滤一下刚刚配置
cat elasticsearch.yml | grep -v "^#"
配置es02节点
将es01配置导给es02,做简单修改scp elasticsearch.yml es02:`pwd`


es 性能调优参数(es01和es02都要做)
#优化最大内存大小和最大文件描述符的数量
vim /etc/security/limits.conf......
* soft nofile 65536 硬限制
* hard nofile 65536 软限制
* soft nproc 32000 打开进程数
* hard nproc 32000 打开线程数
* soft memlock unlimited 内存锁定不限制
* hard memlock unlimited 内存锁定不限制vim /etc/systemd/system.conf
DefaultLimitNOFILE=65536 文件描述符
DefaultLimitNPROC=32000 进程数
DefaultLimitMEMLOCK=infinity 内存限制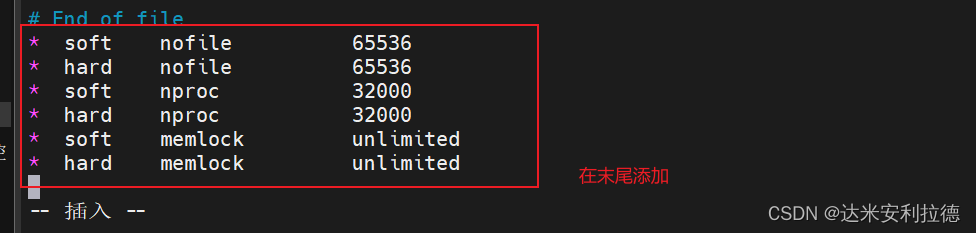

设置好之后重启生效
reboot
重启之后可以看下有没有生效
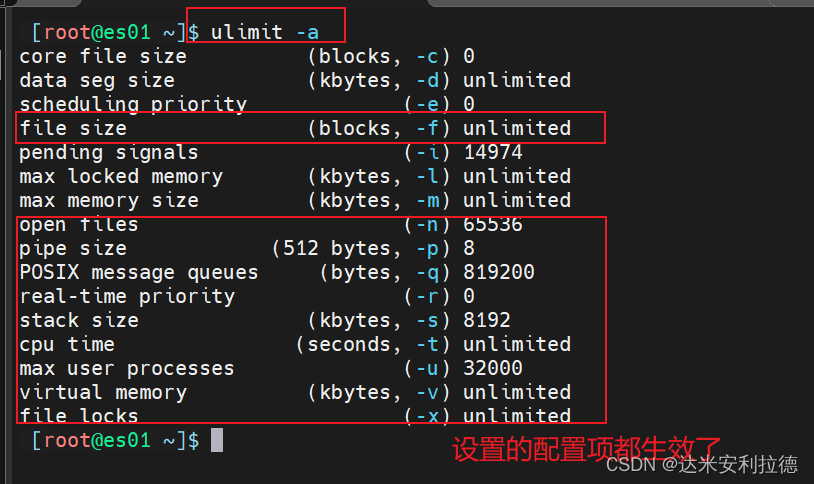
ulimit -a
2.2、优化elasticsearch用户拥有的内存权限
由于ES构建基于lucene, 而lucene设计强大之处在于lucene能够很好的利用操作系统内存来缓存索引数据,以提供快速的查询性能。lucene的索引文件segements是存储在单文件中的,并且不可变,对于OS来说,能够很友好地将索引文件保持在cache中,以便快速访问;因此,我们很有必要将一半的物理内存留给lucene ; 另一半的物理内存留给ES(JVM heap )。所以, 在ES内存设置方面,可以遵循以下原则:
1.当机器内存小于64G时,遵循通用的原则,50%给ES,50%留给操作系统,供lucene使用
2.当机器内存大于64G时,遵循原则:建议分配给ES分配 4~32G 的内存即可,其它内存留给操作系统,供lucene使用
vim /etc/sysctl.conf(es01和es02节点都要做)
#一个进程可以拥有的最大内存映射区域数,参考数据(分配 2g/262144,4g/4194304,8g/8388608)
vm.max_map_count=262144sysctl -p
sysctl -a | grep vm.max_map_count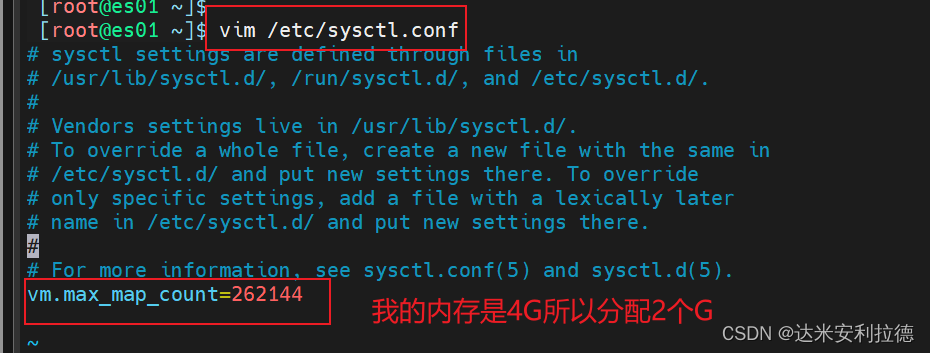
2.3、启动elasticsearch是否成功开启
systemctl start elasticsearch.service
systemctl enable elasticsearch.service
netstat -antp | grep 9200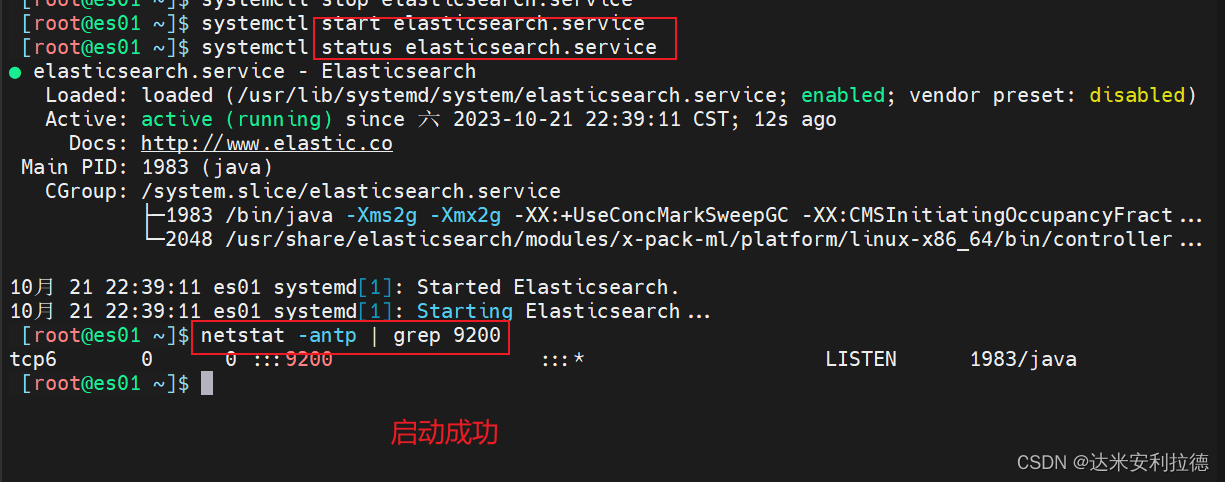
2.4、浏览器查看节点信息
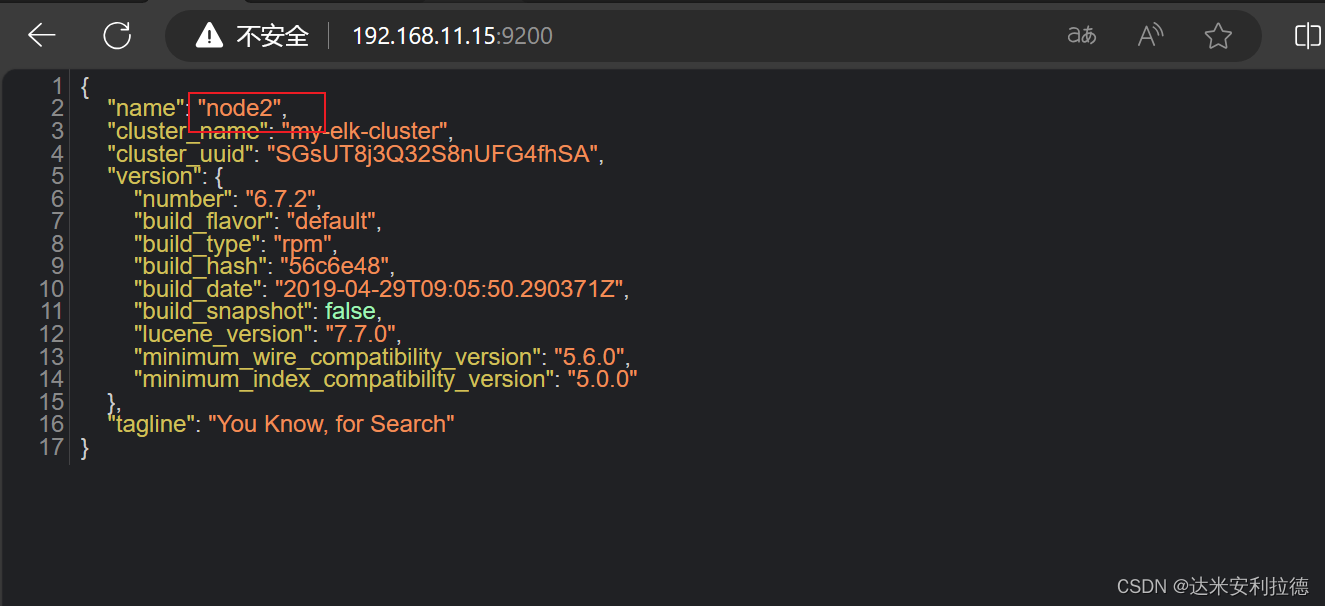
浏览器访问 http://192.168.11.11:9200 、 http://192.168.11.12:9200 查看节点 Node1、Node2 的信息。
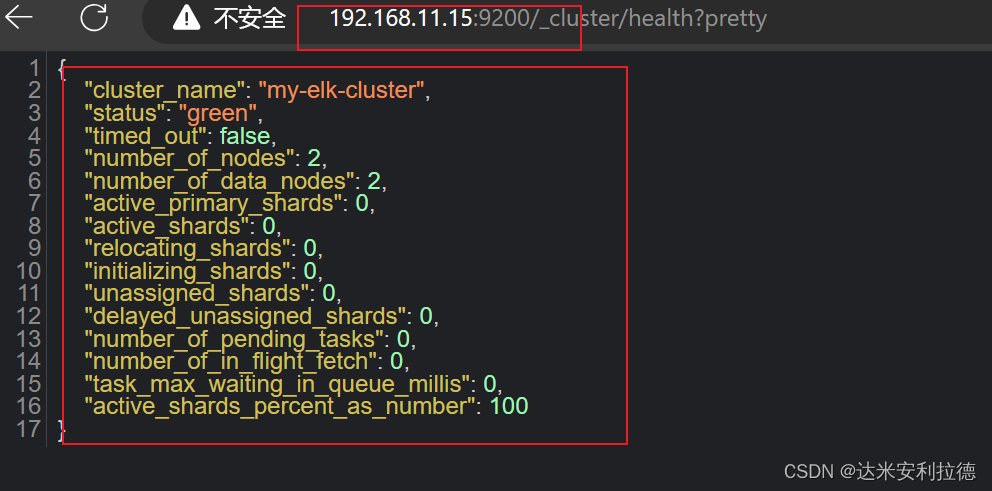
浏览器访问 http://192.168.11.11:9200/_cluster/health?pretty 、 http://192.168.11.12:9200/_cluster/health?pretty查看群集的健康情况,可以看到 status 值为 green(绿色), 表示节点健康运行。浏览器访问 http://192.168.11.11:9200/_cluster/state?pretty 检查群集状态信息。#使用上述方式查看群集的状态对用户并不友好,可以通过安装 Elasticsearch-head 插件,可以更方便地管理群集。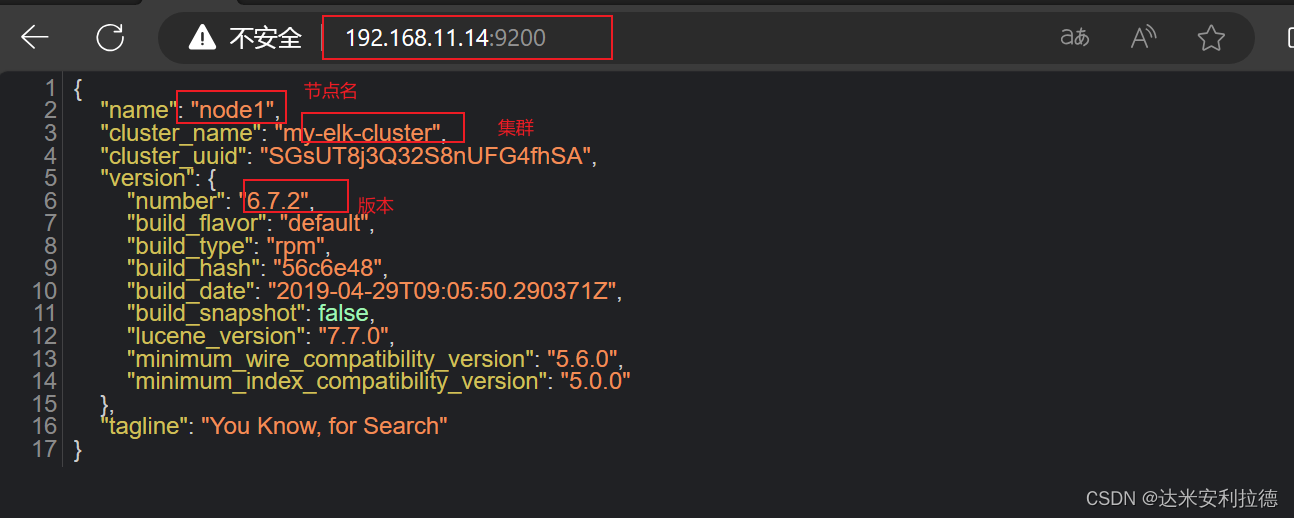

2.5、安装 Elasticsearch-head 插件
Elasticsearch 在 5.0 版本后,Elasticsearch-head 插件需要作为独立服务进行安装,需要使用npm工具(NodeJS的包管理工具)安装。
安装 Elasticsearch-head 需要提前安装好依赖软件 node 和 phantomjs。
node:是一个基于 Chrome V8 引擎的 JavaScript 运行环境。
phantomjs:是一个基于 webkit 的JavaScriptAPI,可以理解为一个隐形的浏览器,任何基于 webkit 浏览器做的事情,它都可以做到。
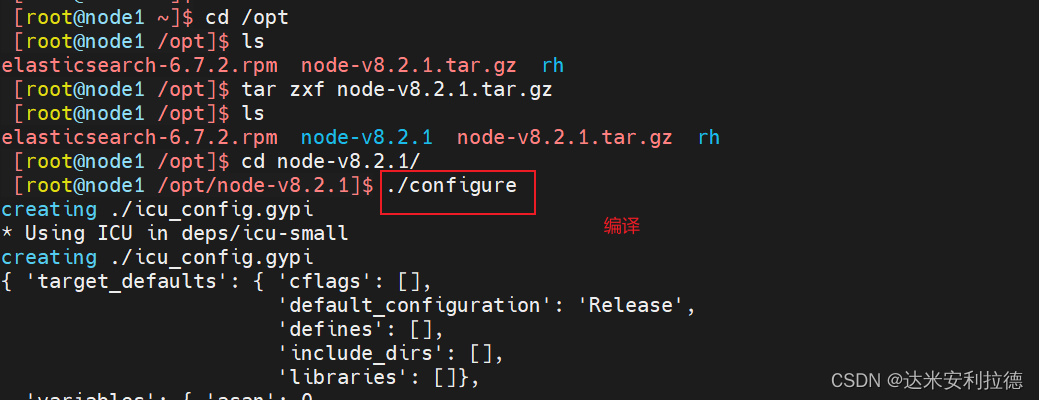
编译安装 node、上传软件包 node-v8.2.1.tar.gz 到/opt
#安装依赖环境
yum install gcc gcc-c++ make -y#解压
cd /opt
tar zxf node-v8.2.1.tar.gz#编译安装
cd node-v8.2.1/
./configure
make -j2 && make install
安装 phantomjs
上传软件包 phantomjs-2.1.1-linux-x86_64.tar.bz2 到/opt。
#解压
cd /opt
tar jxf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /usr/local/src/cd /usr/local/src/phantomjs-2.1.1-linux-x86_64/bin#复制相关文件
cp phantomjs /usr/local/bin
安装 Elasticsearch-head 数据可视化工具上传软件包 elasticsearch-head-master.zip 到/opt。
#解压软件包
cd /opt
unzip elasticsearch-head-master.zip#安装依赖包
cd /opt/elasticsearch-head-master/
npm install 
修改 Elasticsearch 主配置文件
vim /etc/elasticsearch/elasticsearch.yml
......
--末尾添加以下内容--
http.cors.enabled: true #开启跨域访问支持,默认为 false
http.cors.allow-origin: "*" #指定跨域访问允许的域名地址为所有systemctl restart elasticsearch
启动 elasticsearch-head 服务
#必须在解压后的 elasticsearch-head 目录下启动服务
#进程会读取该目录下的 gruntfile.js 文件
#否则可能启动失败
cd /opt/elasticsearch-head-master/
npm run start &#elasticsearch-head 监听的端口是 9100
netstat -natp |grep 9100
通过 Elasticsearch-head 查看 Elasticsearch 信息
#浏览器访问
http://192.168.11.14:9100/
连接群集
#如果看到群集健康值为 green 绿色,代表群集很健康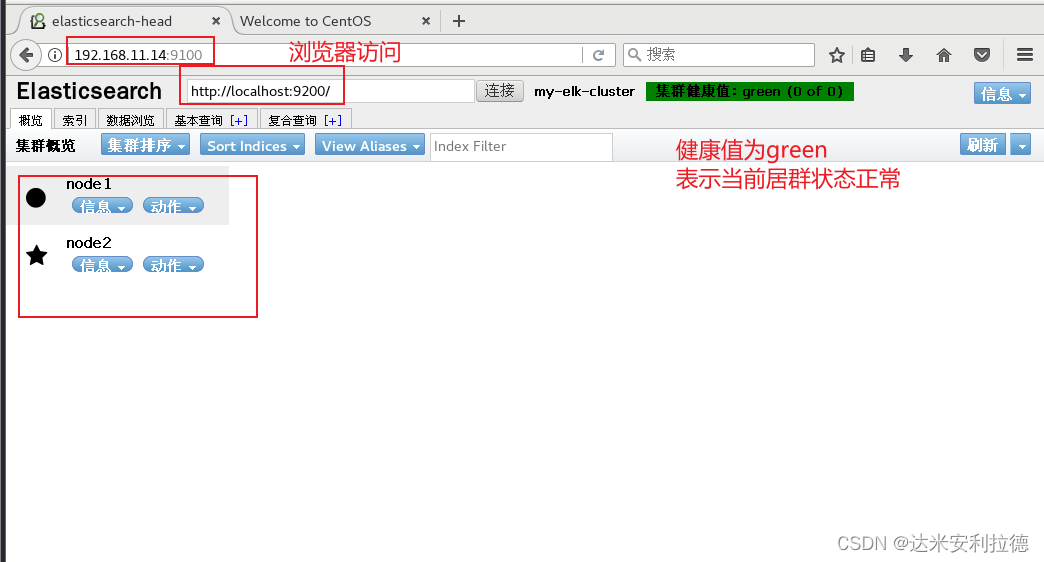
插入索引
#通过命令插入一个测试索引,索引为 index-demo,类型为 test。
curl -X PUT 'localhost:9200/index-demo/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}'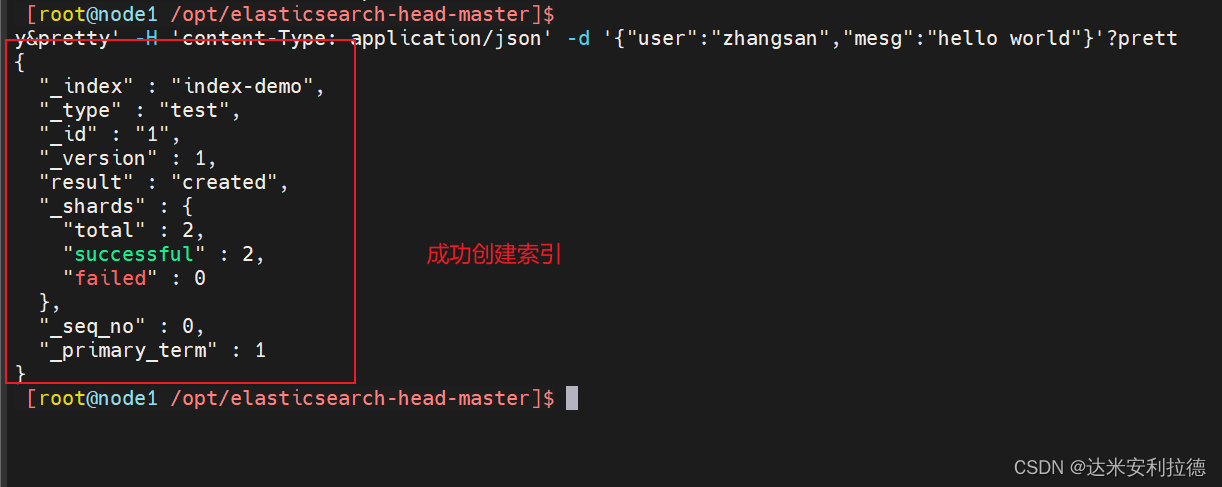
#浏览器访问
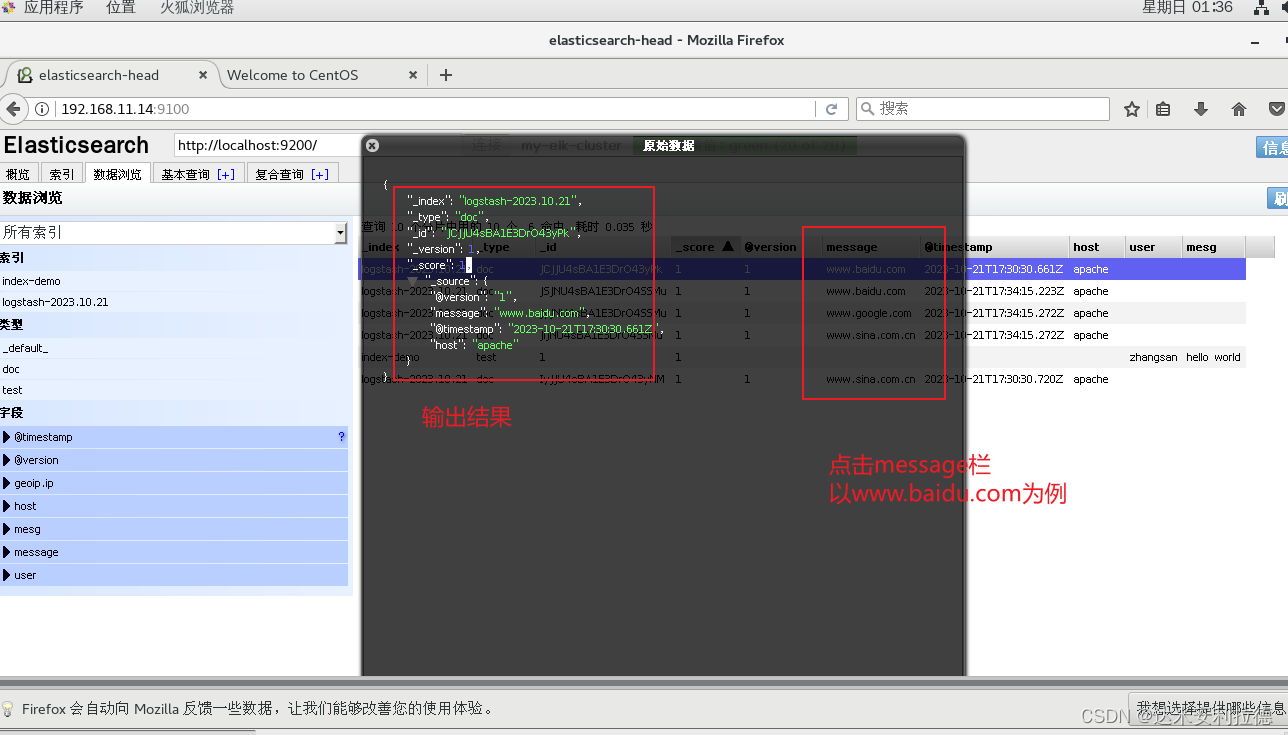
http://192.168.11.14:9100/ #查看索引信!(https://img-blog.csdnimg.cn/14b6ef17fff24f08ba3a8c94c67ef327.png)
息
可以看见索引默认被分片5个,并且有一个副本#点击“数据浏览”
会发现在node1上创建的索引为 index-demo,类型为 test 的相关信息。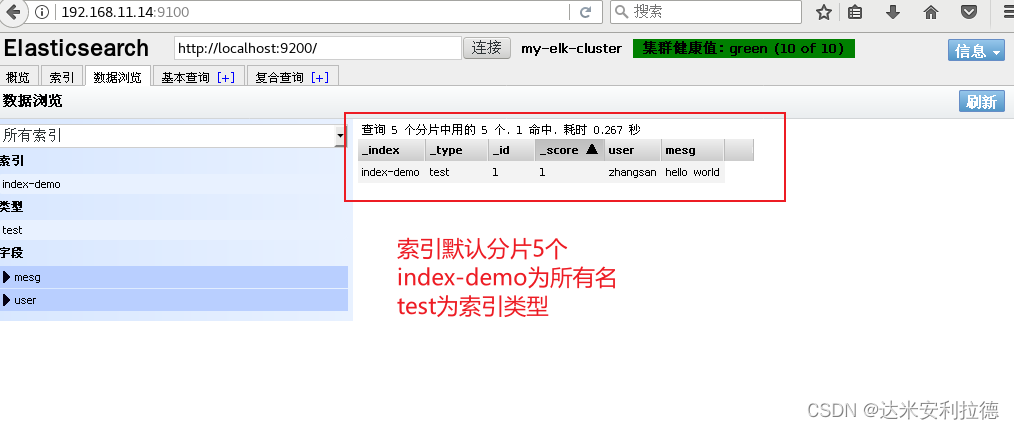
2.6、ELK Logstash 部署(在 Apache 节点上操作)
Logstash 一般部署在需要监控其日志的服务器。
在本案例中,Logstash 部署在 Apache 服务器上,用于收集 Apache 服务器的日志信息并发送到 Elasticsearch。
安装logstash和相关服务
安装Apahce服务(httpd)
yum -y install httpd
systemctl start httpd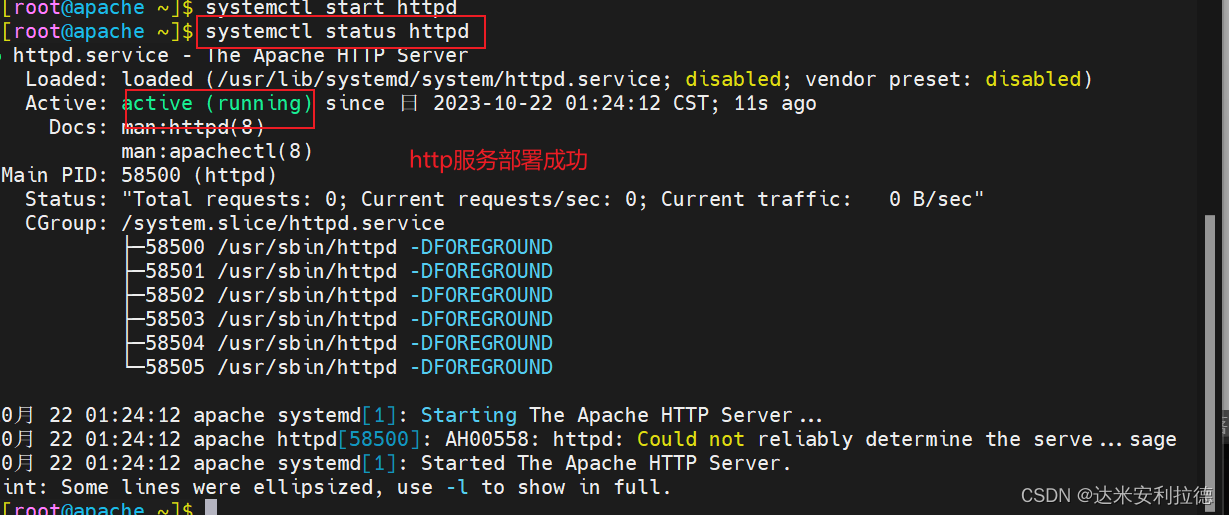
安装Java环境
yum -y install java
java -version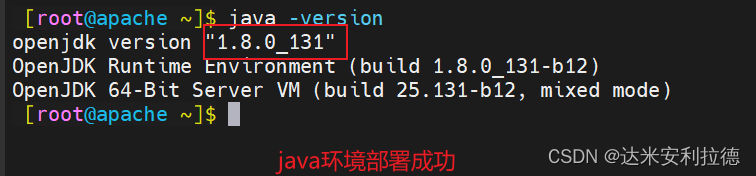
安装logstash
上传软件包 logstash-6.7.2.rpm 到/opt目录下
#rpm安装
cd /opt
rpm -ivh logstash-6.7.2.rpm
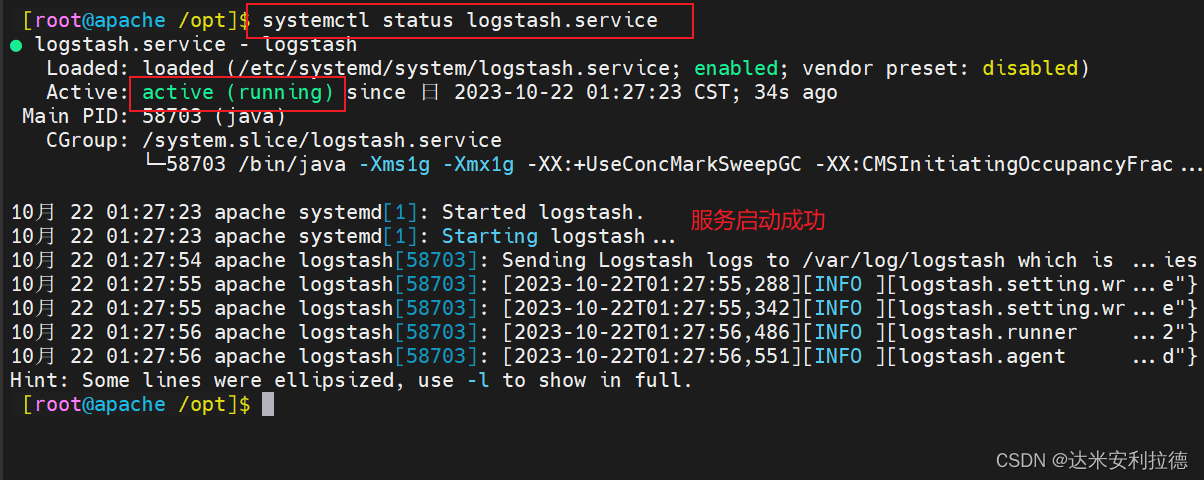
systemctl enable logstash.service --now#做软链接,方便使用
ln -s /usr/share/logstash/bin/logstash /usr/local/bin/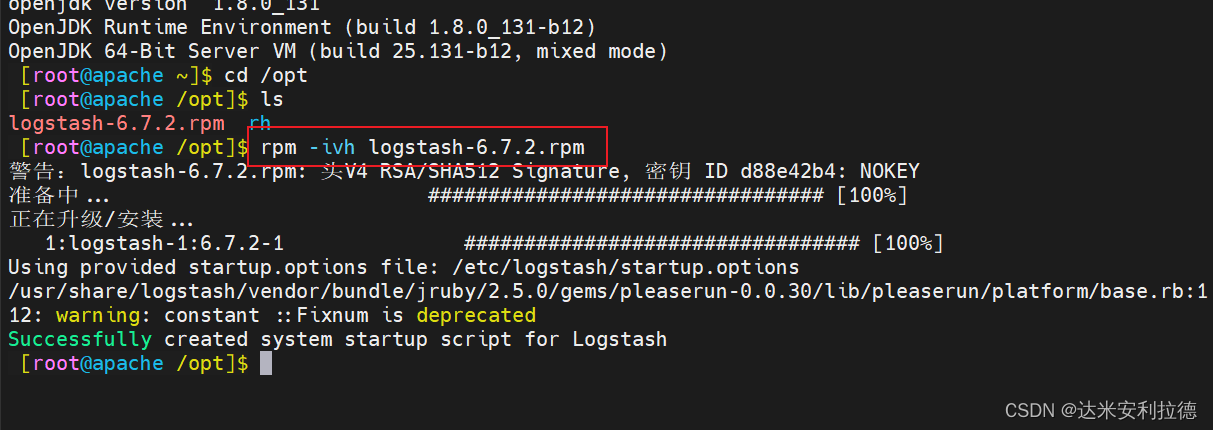
测试 Logstash,将信息写入 Elasticsearch 中
#使用 Logstash 将信息写入 Elasticsearch 中
logstash -e 'input { stdin{} } output { elasticsearch { hosts=>["192.168.11.14:9200"] } }'输入 输出 对接
......
www.baidu.com #键入内容(标准输入)
www.sina.com.cn #键入内容(标准输入)
www.google.com #键入内容(标准输入)#结果不在标准输出显示,而是发送至 Elasticsearch 中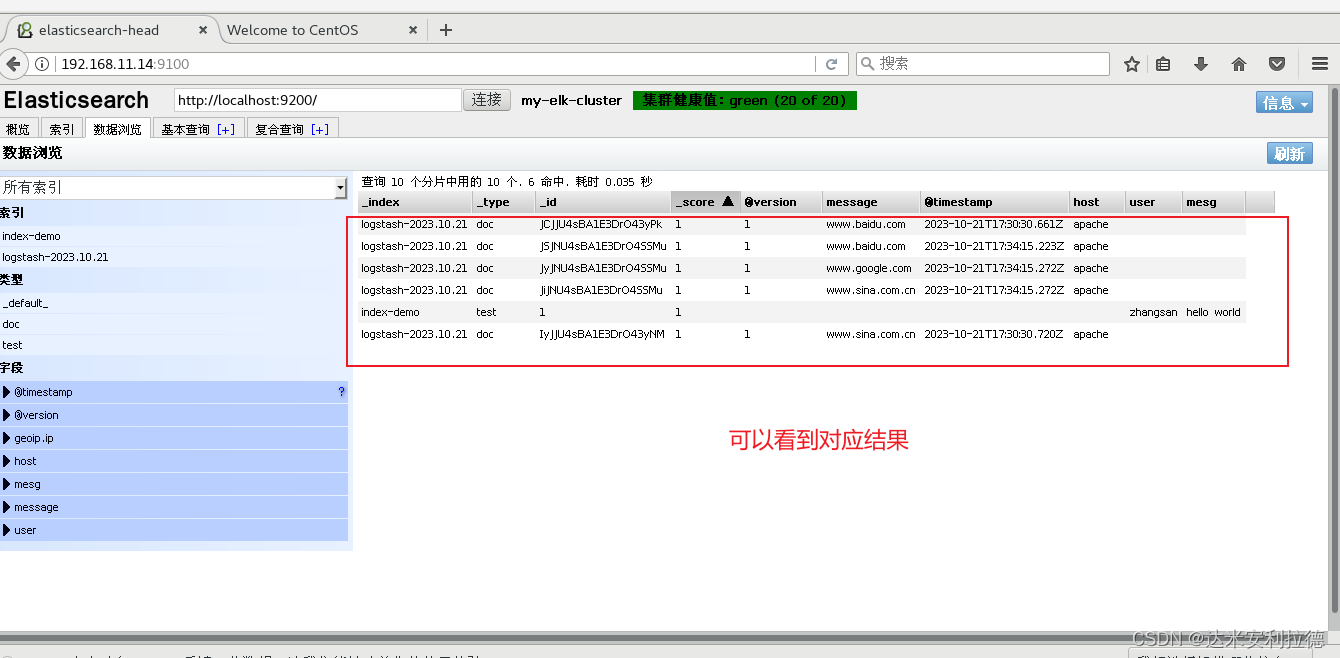
修改 logstash配置文件
#修改 Logstash 配置文件,让其收集系统日志/var/log/messages,并将其输出到 elasticsearch 中。
chmod +r /var/log/messages
#让 Logstash 可以读取日志cd /etc/logstash/conf.d/vim system.conf
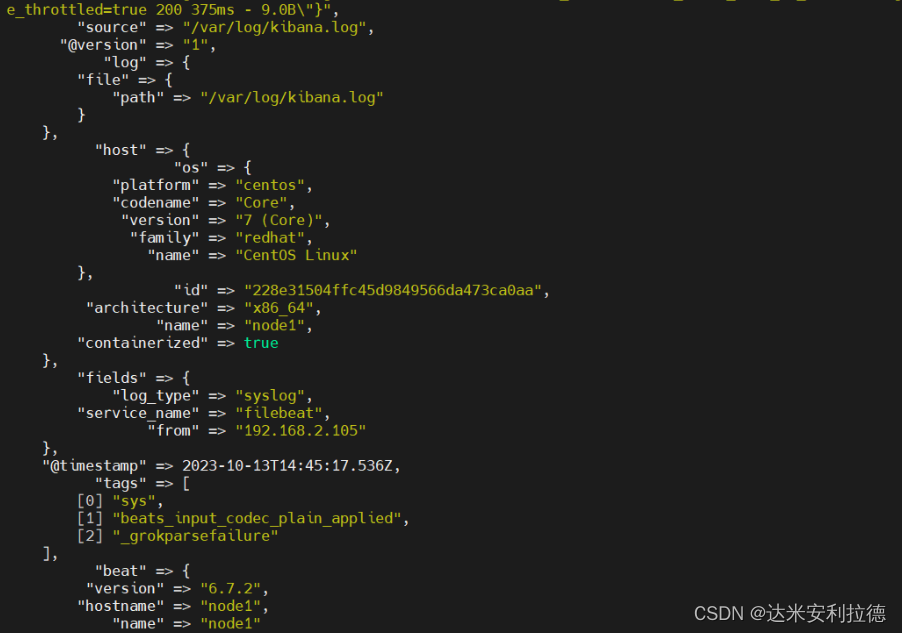
input {file{path =>"/var/log/messages"type =>"system"start_position =>"beginning"# ignore_older => 604800sincedb_path => "/etc/logstash/sincedb_path/log_progress"add_field => {"log_hostname"=>"${HOSTNAME}"}}
}
output {elasticsearch {hosts => ["192.168.11.14:9200","192.168.11.15:9200"]index =>"system-%{+YYYY.MM.dd}" }
}#配置文件详解
#输入部分
input {file{path =>"/var/log/messages"type =>"system"start_position =>"beginning"# ignore_older => 604800sincedb_path => "/etc/logstash/sincedb_path/log_progress"add_field => {"log_hostname"=>"${HOSTNAME}"}}
}
#path表示要收集的日志的文件位置
#type是输入ES时给结果增加一个叫type的属性字段
#start_position可以设置为beginning或者end,beginning表示从头开始读取文件,end表示读取最新的,这个要和ignore_older一起使用
#ignore_older表示了针对多久的文件进行监控,默认一天,单位为秒,可以自己定制,比如默认只读取一天内被修改的文件
#sincedb_path表示文件读取进度的记录,每行表示一个文件,每行有两个数字,第一个表示文件的inode,第二个表示文件读取到的位置(byteoffset)。默认为$HOME/.sincedb*
#add_field增加属性。这里使用了${HOSTNAME},即本机的环境变量,如果要使用本机的环境变量,那么需要在启动命令上加--alow-env##输出
output {elasticsearch { #输出到 elasticsearchhosts => ["192.168.2.100:9200","192.168.2.102:9200"] #指定 elasticsearch 服务器的地址和端口index =>"system-%{+YYYY.MM.dd}" #指定输出到 elasticsearch 的索引格式}
}#新建文件路径
mkdir /etc/logstash/sincedb_path/touch /etc/logstash/sincedb_path/log_progress#修改文件的属主属组
chown logstash:logstash /etc/logstash/sincedb_path/log_progress#使用logstash启动配置文件
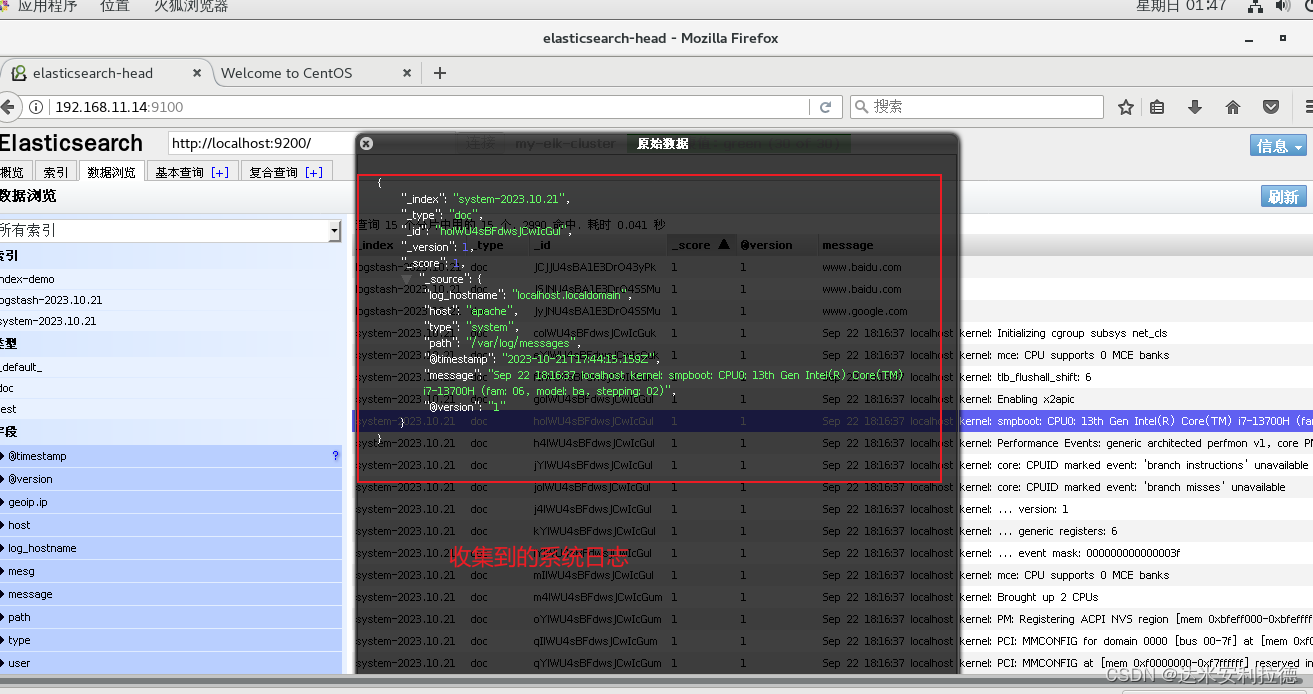
logstash -f system.conf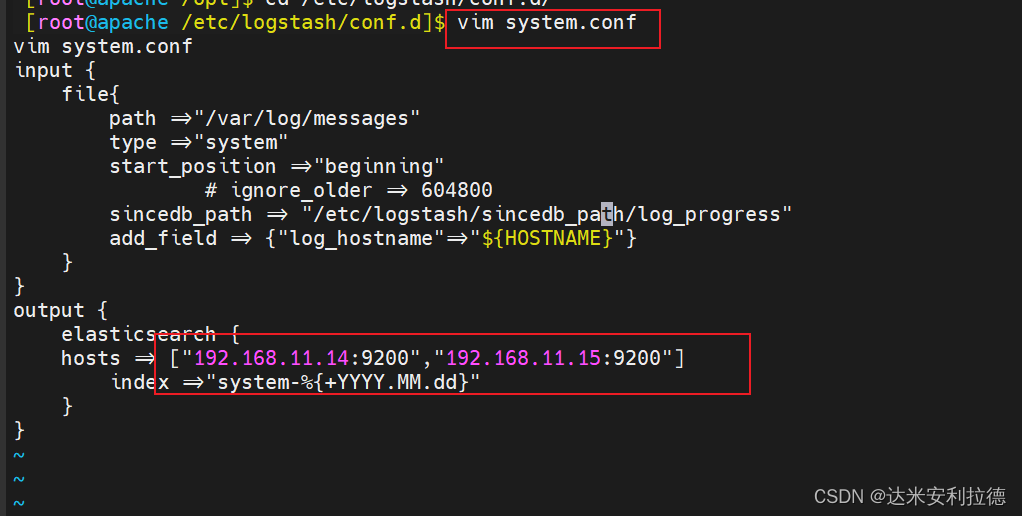
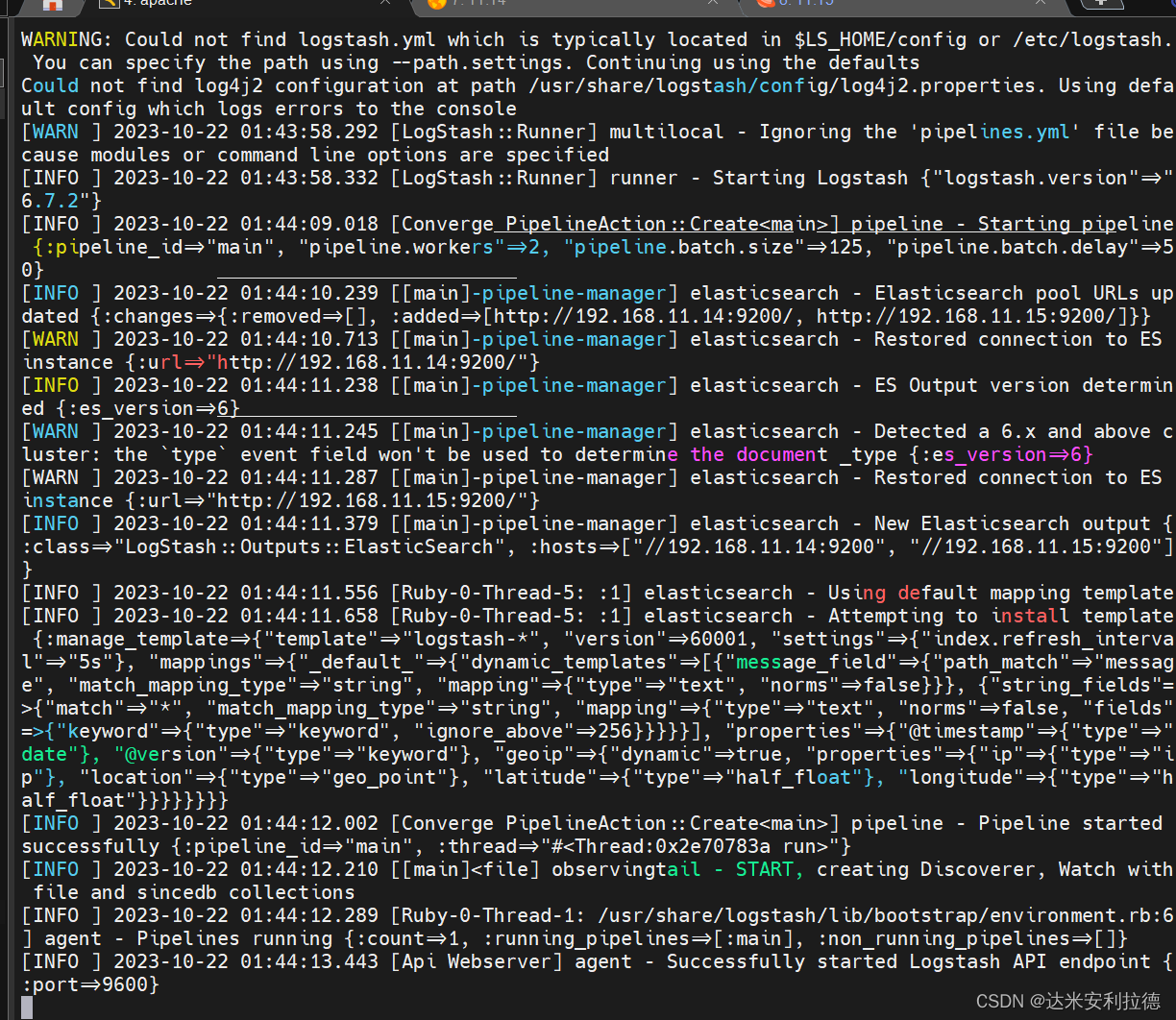
浏览器访问
http://192.168.11.14:9100/
查看索引信息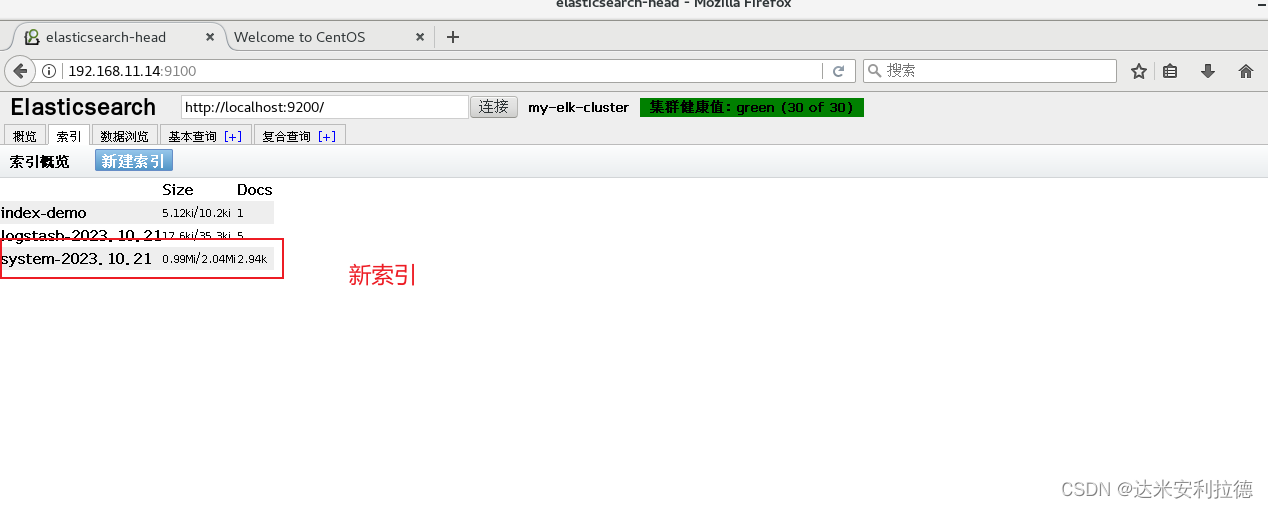
2.7、ELK Kiabana 部署(在 Node1 节点上操作)
安装Kibana
#上传软件包 kibana-6.7.2-x86_64.rpm 到/opt目录
cd /opt
rpm -ivh kibana-6.7.2-x86_64.rpm
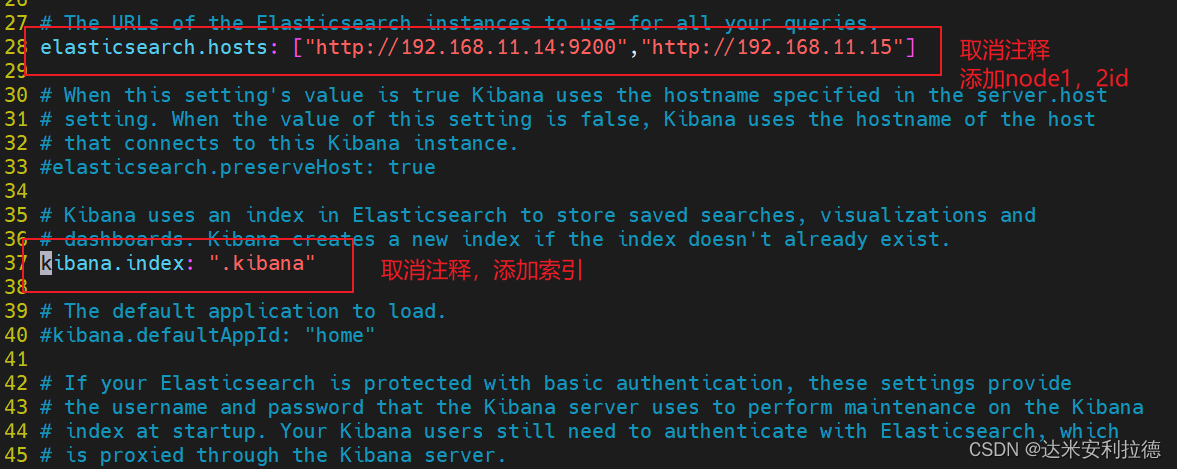
修改kibana主配置文件
vim /etc/kibana/kibana.yml#2行 取消注释,Kiabana 服务的默认监听端口为5601
server.port: 5601#7行 取消注释,设置 Kiabana 的监听地址,0.0.0.0代表所有地址
server.host: "0.0.0.0"#28行 取消注释,配置es服务器的ip,如果是集群则配置该集群中master节点的ip
elasticsearch.url: ["http://192.168.11.14:9200","http://192.168.11.15:9200"] #37行 取消注释,设置在 elasticsearch 中添加.kibana索引
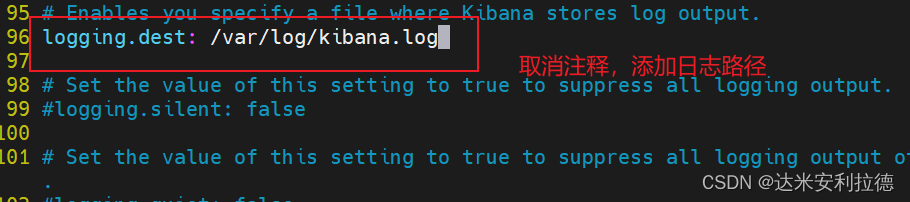
kibana.index: ".kibana"#96行 取消注释,配置kibana的日志文件路径(需手动创建),不然默认是messages里记录日志
logging.dest: /var/log/kibana.log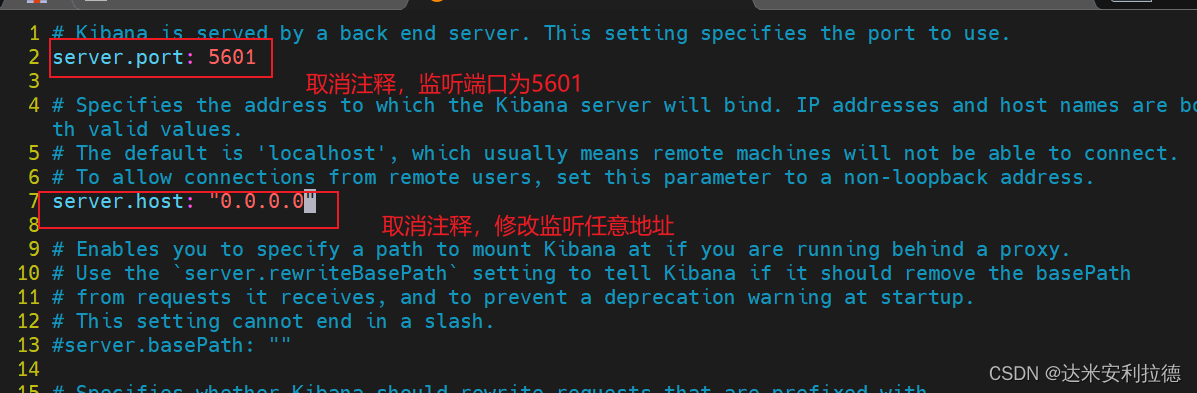
创建日志文件,启动 Kibana 服务
touch /var/log/kibana.log
chown kibana:kibana /var/log/kibana.logsystemctl start kibana.service
systemctl enable kibana.servicess -natp | grep 5601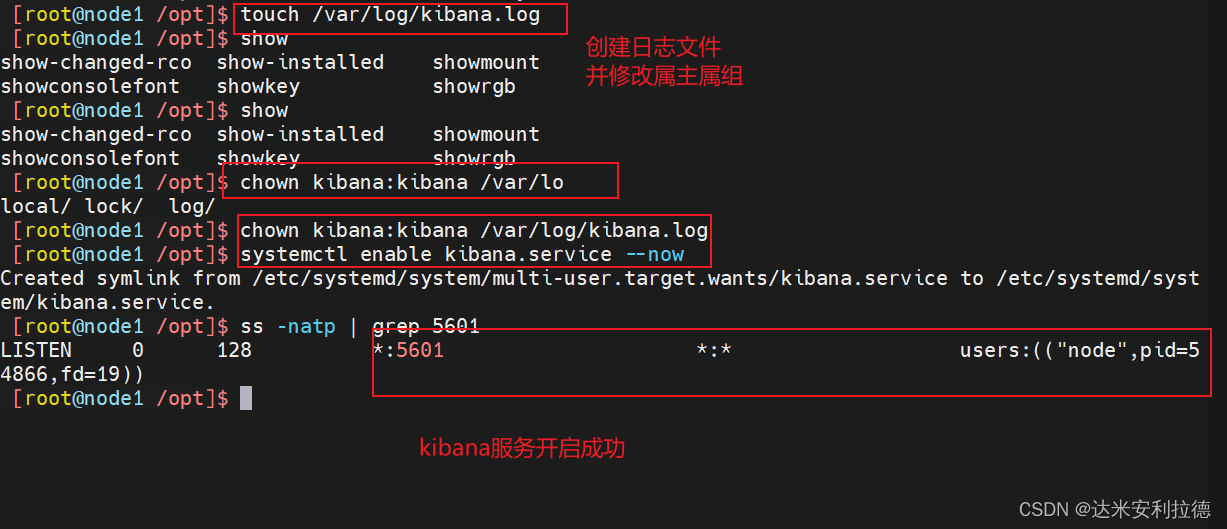
验证 Kibana
浏览器访问
http://192.168.11.14:5601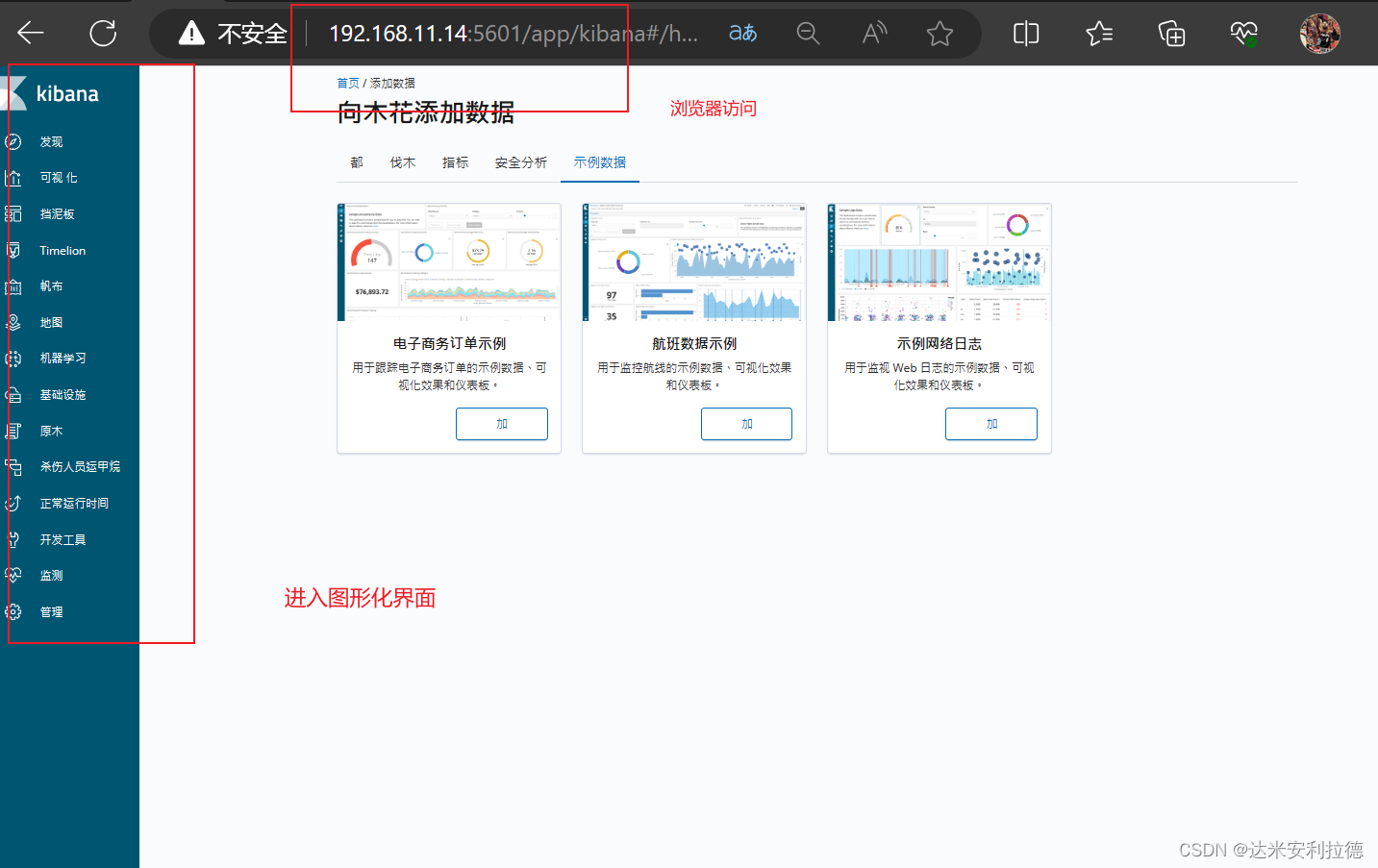
#第一次登录需要添加一个 Elasticsearch 索引
Management -> Index Pattern -> Create index pattern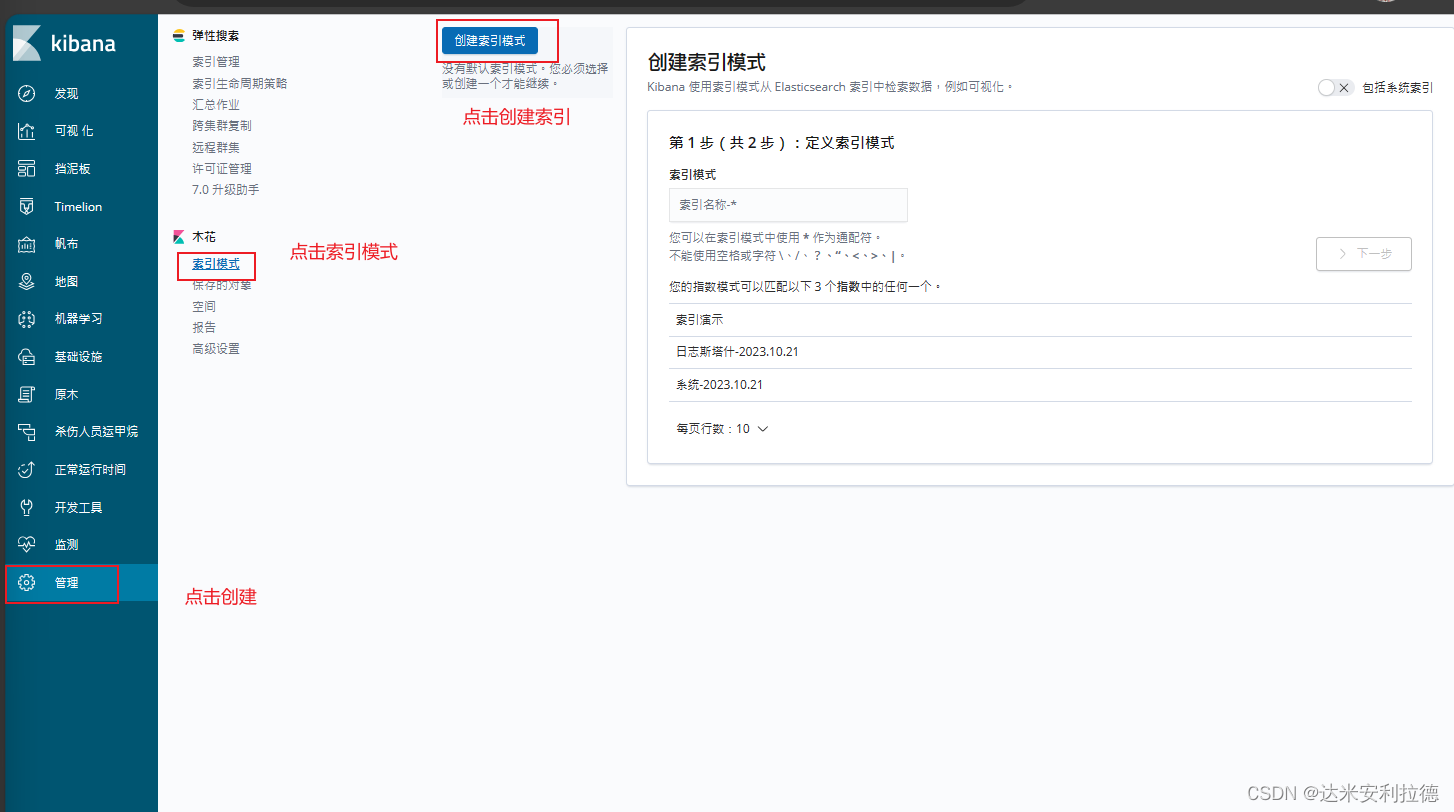
Index pattern 输入:system-*
#在索引名中输入之前配置的 Output 前缀“system”Next step -> Time Filter field name 选择 -> Create index pattern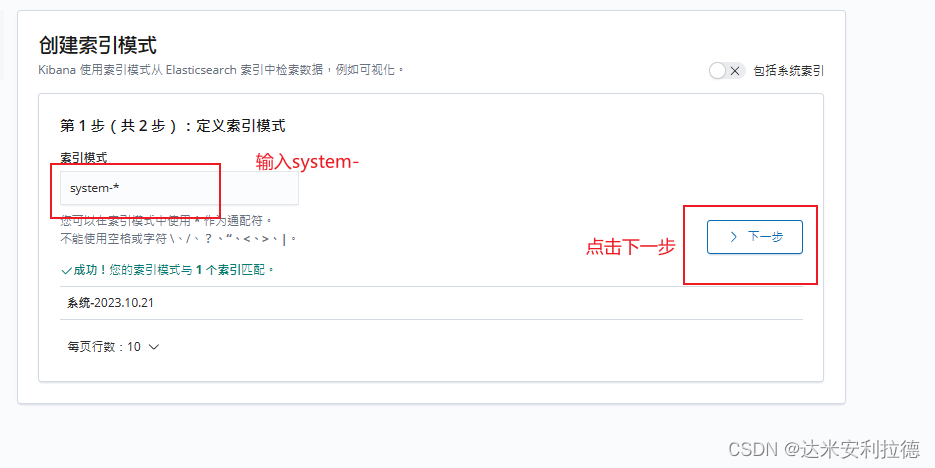
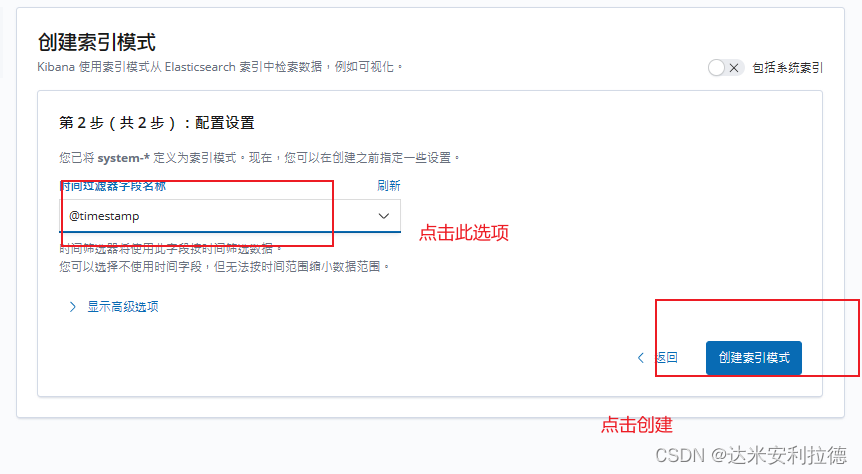
单击 “Discover” 按钮可查看图表信息及日志信息。
数据展示可以分类显示,在“Available Fields”中的“host”,然后单击 “add”按钮,可以看到按照“host”筛选后的结果将 Apache 服务器的日志(访问的、错误的)添加到 Elasticsearch 并通过 Kibana 显示
vim /etc/logstash/conf.d/apache_log.confinput {file{path => "/etc/httpd/logs/access_log"type => "access"start_position => "beginning"}file{path => "/etc/httpd/logs/error_log"type => "error"start_position => "beginning"}
}
output {if [type] == "access" {elasticsearch {hosts => ["192.168.11.14:9200","192.168.11.15:9200"]index => "apache_access-%{+YYYY.MM.dd}"}}if [type] == "error" {elasticsearch {hosts => ["192.168.11.14:9200","192.168.11.15:9200"]index => "apache_error-%{+YYYY.MM.dd}"}}
}cd /etc/logstash/conf.d/
/usr/share/logstash/bin/logstash -f apache_log.conf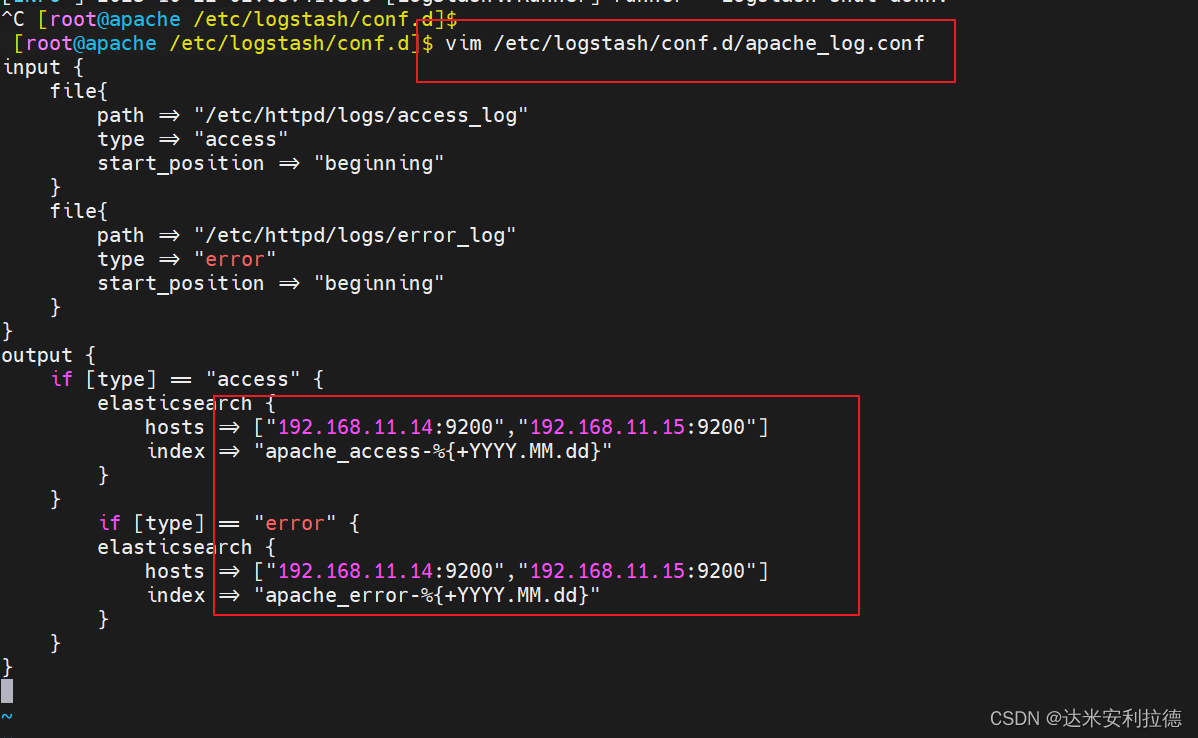

浏览器访问 http://192.168.11.14:9100 查看索引是否创建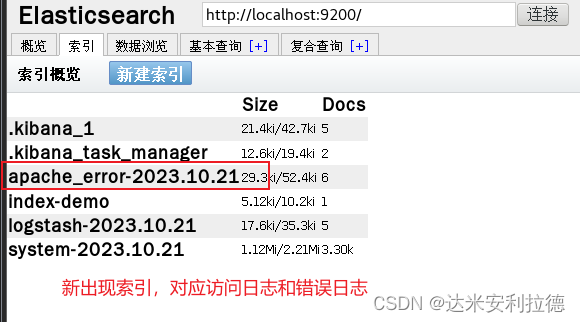
浏览器访问 http://192.168.11.14:5601 登录 Kibana
单击“Index Pattern -> Create Index Pattern”按钮添加索引
在索引名中输入之前配置的 Output 前缀 apache_access-*,并单击“Create”按钮。
再用相同的方法添加 apache_error-*索引。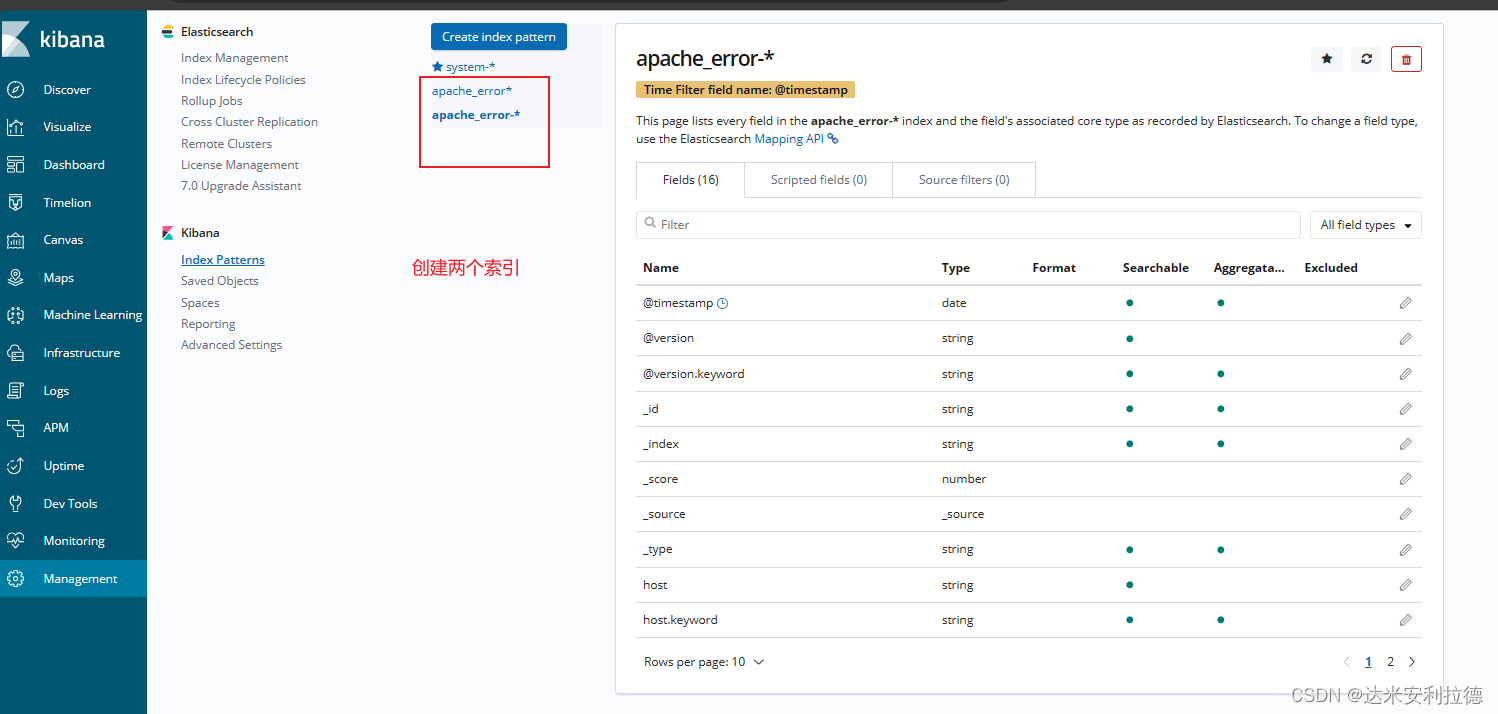
选择“Discover”选项卡
在中间下拉列表中选择刚添加的 apache_access-* 、apache_error-* 索引, 可以查看相应的图表及日志信息。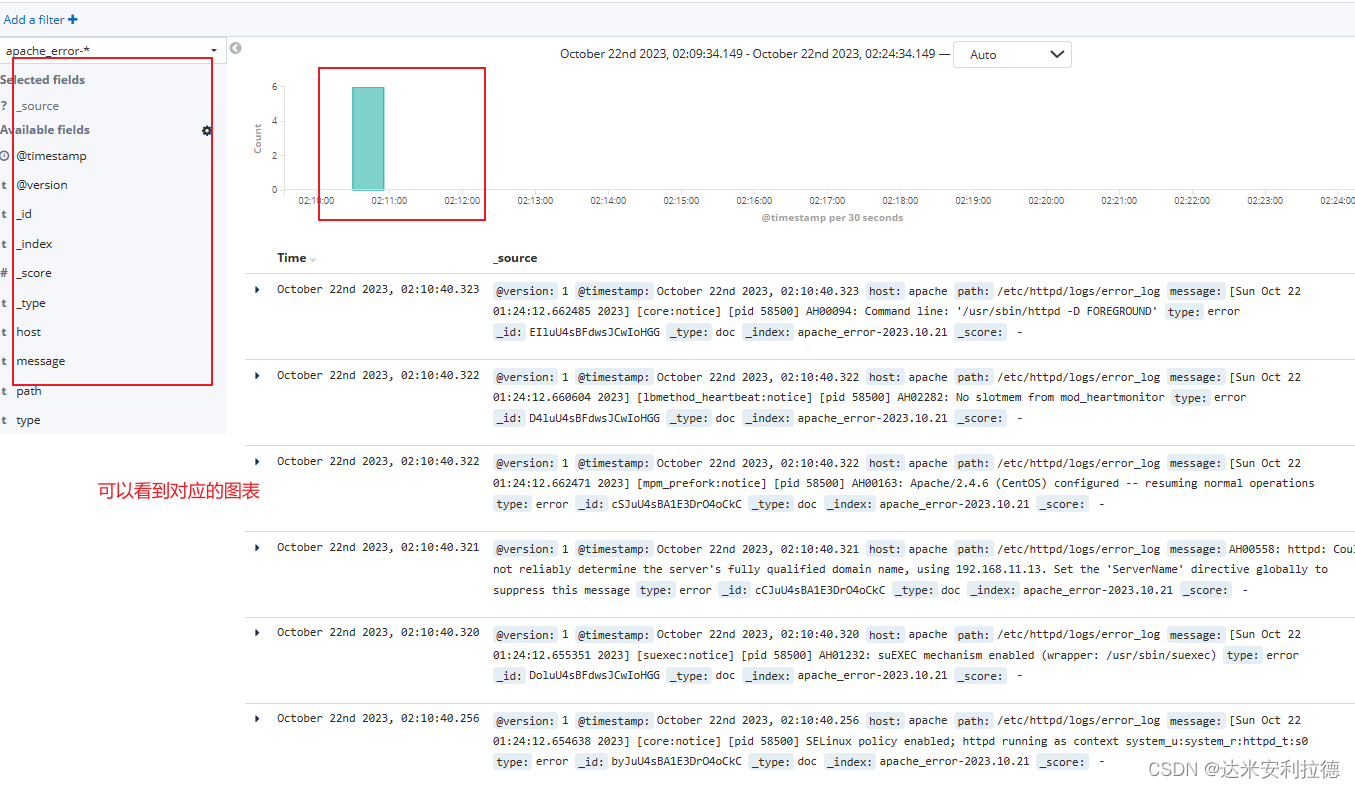
三、Filebeat作为日志收集器
| Server | IP | Components | System |
|---|---|---|---|
| Node1 | 192.168.11.14 | Elasticsearch 、 Kibana | CentOS7.4(64 位) |
| Node2 | 192.168.11.15 | Elasticsearch | CentOS7.4(64 位) |
| Apache | 192.168.11.13 | Logstash Apache | CentOS7.4(64 位) |
| Filebeat节点 | 192.168.11.16 | Filebeat | CentOS7.4(64 位) |
安装Filebeat(Node1节点)
上传软件包 filebeat-6.7.2-linux-x86_64.tar.gz 到/opt目录
#解压软件包
tar zxvf filebeat-6.7.2-linux-x86_64.tar.gzmv filebeat-6.7.2-linux-x86_64/ /usr/local/filebeat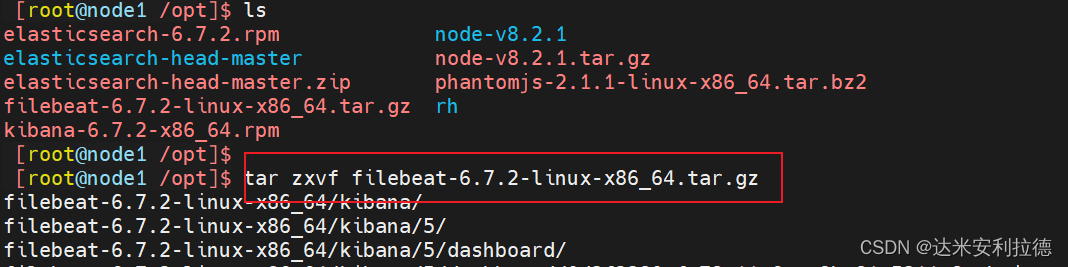

修改filebeat的主配置文件(Node1节点)
cd /usr/local/filebeatvim filebeat.yml
filebeat.inputs:
- type: log
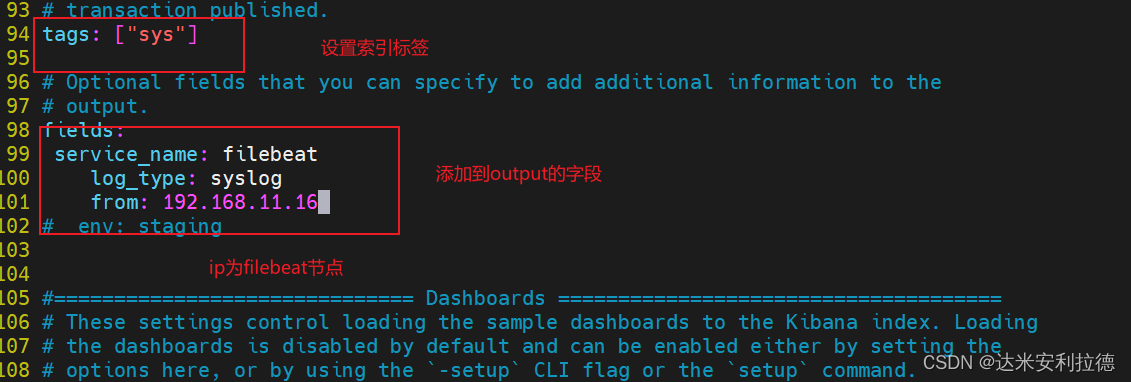
#指定 log 类型,从日志文件中读取消息enabled: truepaths:- /var/log/messages #指定监控的日志文件- /var/log/*.logtags: ["sys"] #设置索引标签fields: #可以使用 fields 配置选项设置一些参数字段添加到 output 中service_name: filebeatlog_type: syslogfrom: 192.168.2.105--------------Elasticsearch output-------------------
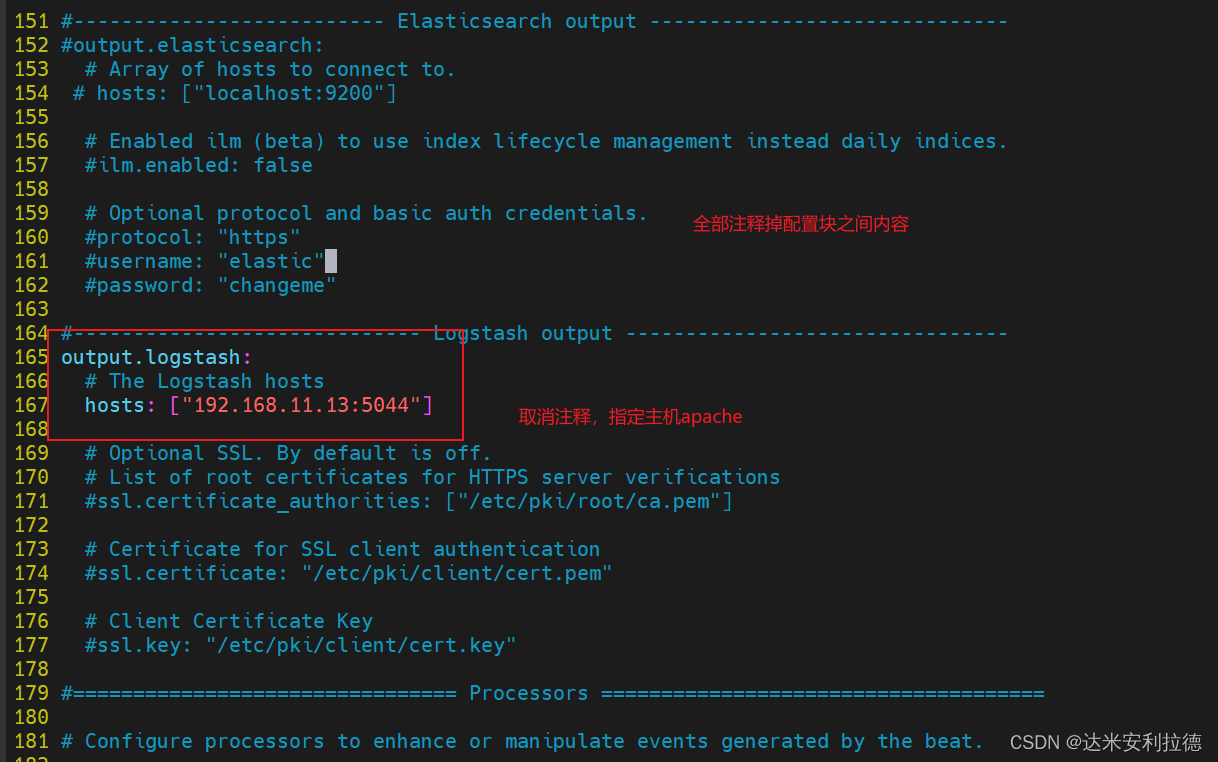
(全部注释掉)----------------Logstash output---------------------
output.logstash:hosts: ["192.168.11.13:5044"] #指定 logstash 的 IP 和端口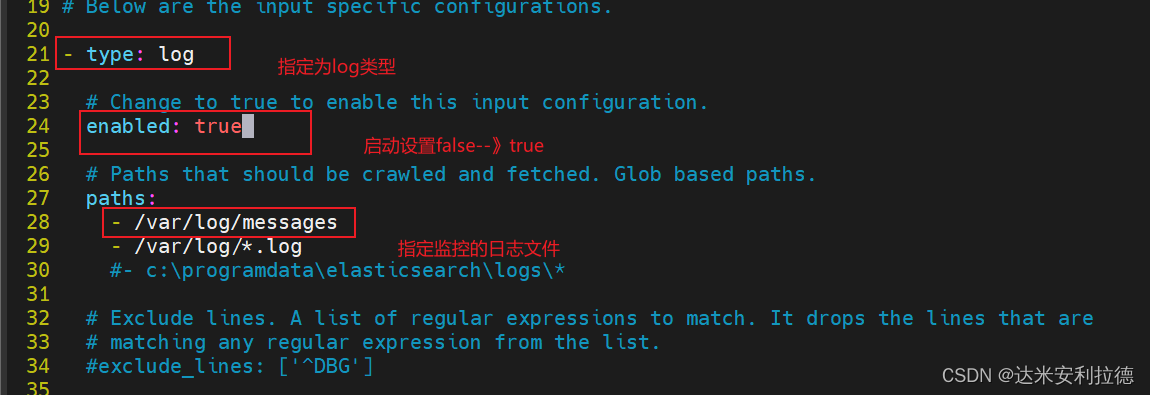
启动 filebeat
#启动 filebeat
nohup ./filebeat -e -c filebeat.yml > filebeat.out &
#-e:输出到标准输出,禁用syslog/文件输出
#-c:指定配置文件
#nohup:在系统后台不挂断地运行命令,退出终端不会影响程序的运行在 Logstash 组件所在节点上新建一个 Logstash 配置文件
cd /etc/logstash/conf.dvim filebeat.conf
input {beats {port => "5044"}
}#filebeat发送给logstash的日志内容会放到message字段里面,logstash使用grok插件正则匹配message字段内容进行字段分割
#Kibana自带grok的正则匹配的工具:http://<your kibana IP>:5601/app/kibana#/dev_tools/grokdebugger
# %{IPV6}|%{IPV4} 为 logstash 自带的 IP 常量
filter {grok {match => ["message", "(?<remote_addr>%{IPV6}|%{IPV4})[\s\-]+\[(?<logTime>.*)\]\s+\"(?<method>\S+)\s+(?<url_path>.+)\"\s+(?<rev_code>\d+) \d+ \"(?<req_addr>.+)\" \"(?<content>.*)\""]}
}output {elasticsearch {hosts => ["192.168.11.14:9200","192.168.11.15:9200"]index => "%{[fields][service_name]}-%{+YYYY.MM.dd}"}stdout {codec => rubydebug}
}#启动 logstash
logstash -f filebeat.conf
浏览器访问验证
浏览器访问 http://192.168.11.14:5601 登录 Kibana
单击“Create Index Pattern”按钮添加索引“filebeat-*”
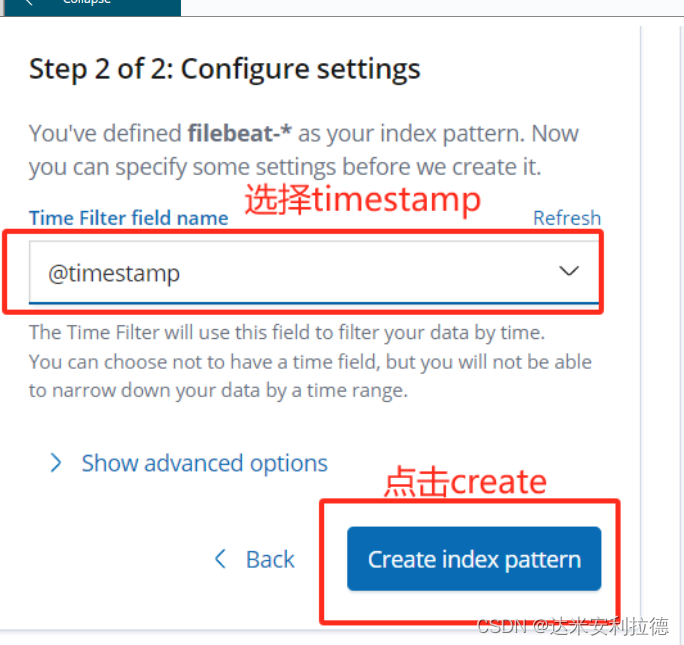
单击 “create” 按钮创建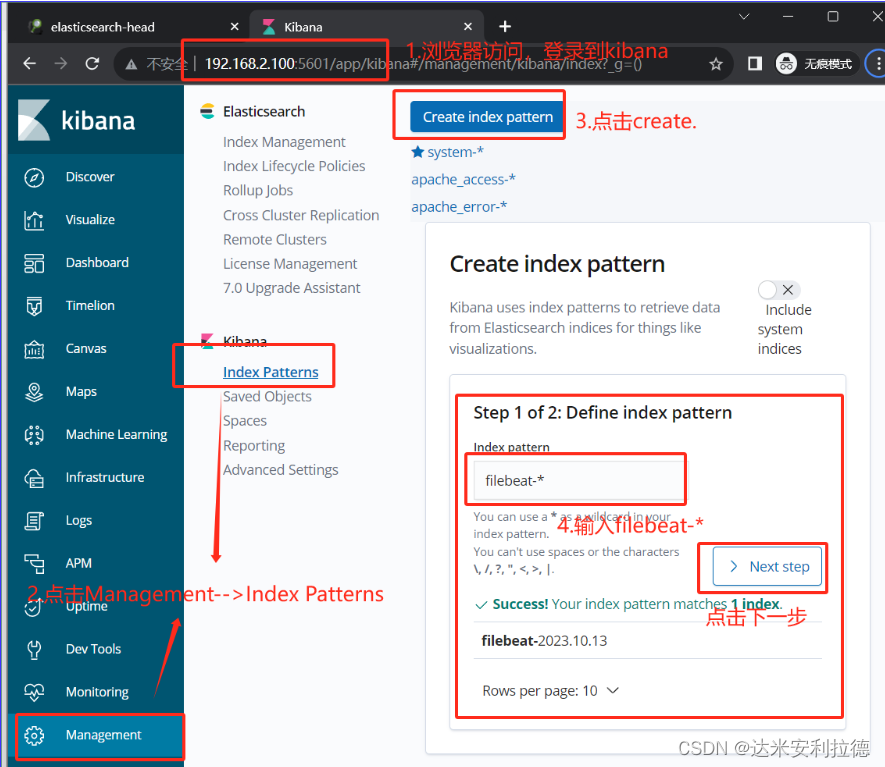
单击 “Discover” 按钮可查看图表信息及日志信息。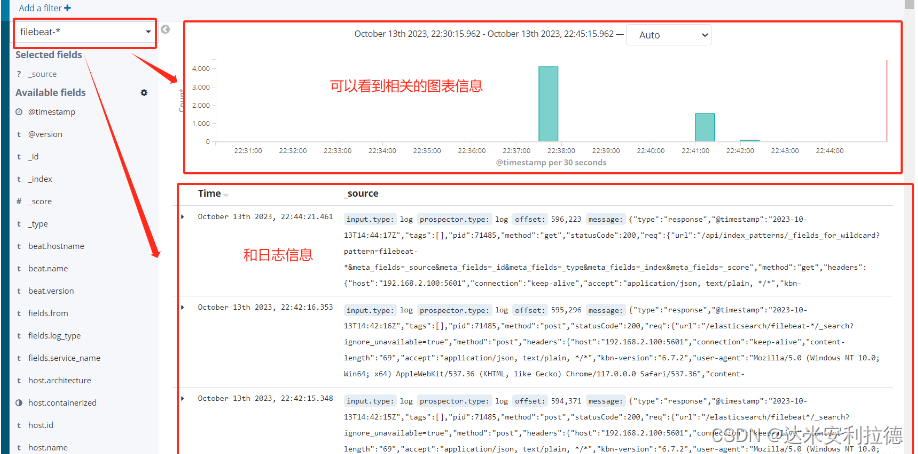
相关文章:
ELK概述部署和Filebeat 分布式日志管理平台部署
ELK概述部署、Filebeat 分布式日志管理平台部署 一、ELK 简介二、ELK部署2.1、部署准备2.2、优化elasticsearch用户拥有的内存权限2.3、启动elasticsearch是否成功开启2.4、浏览器查看节点信息2.5、安装 Elasticsearch-head 插件2.6、ELK Logstash 部署(在 Apache 节…...

分享一下我家网络机柜,家庭网络设备推荐
家里网络机柜搞了几天终于搞好了,非专业的,走线有点乱,勿喷。 从上到下的设备分别是: 无线路由器(当ap用):TL-XDR6088 插排:德木pdu机柜插排 硬盘录像机:TL-NVR6108-L8P 第二排左边…...

uboot移植之mx6ull_alientek_nand.h文件详解三
一. 简介 mx6ull_alientek_nand.h文件是 开发板的 uboot的一个配置文件。每个开发板都有一个 .h的配置文件。 mx6ull_alientek_nand.h 文件其实是 之前针对正点原子ALPHA开发板移植的 Uboot配置文件。 本文继上一篇文章的学习,地址如下:uboot移植之m…...

[Docker]一.Docker 简介与安装
一、Docker简介与为什么要用 Docker 1.1、Docker 介绍 Docker 是一个跨平台的开源的 应用容器引擎 ,诞生于 2013 年初,基于 Go语言 并遵从 Apache2.0 协议开源, Docker 可以把它理解成虚拟机,但是 Docker 和传统虚拟化方式 有所不同 …...
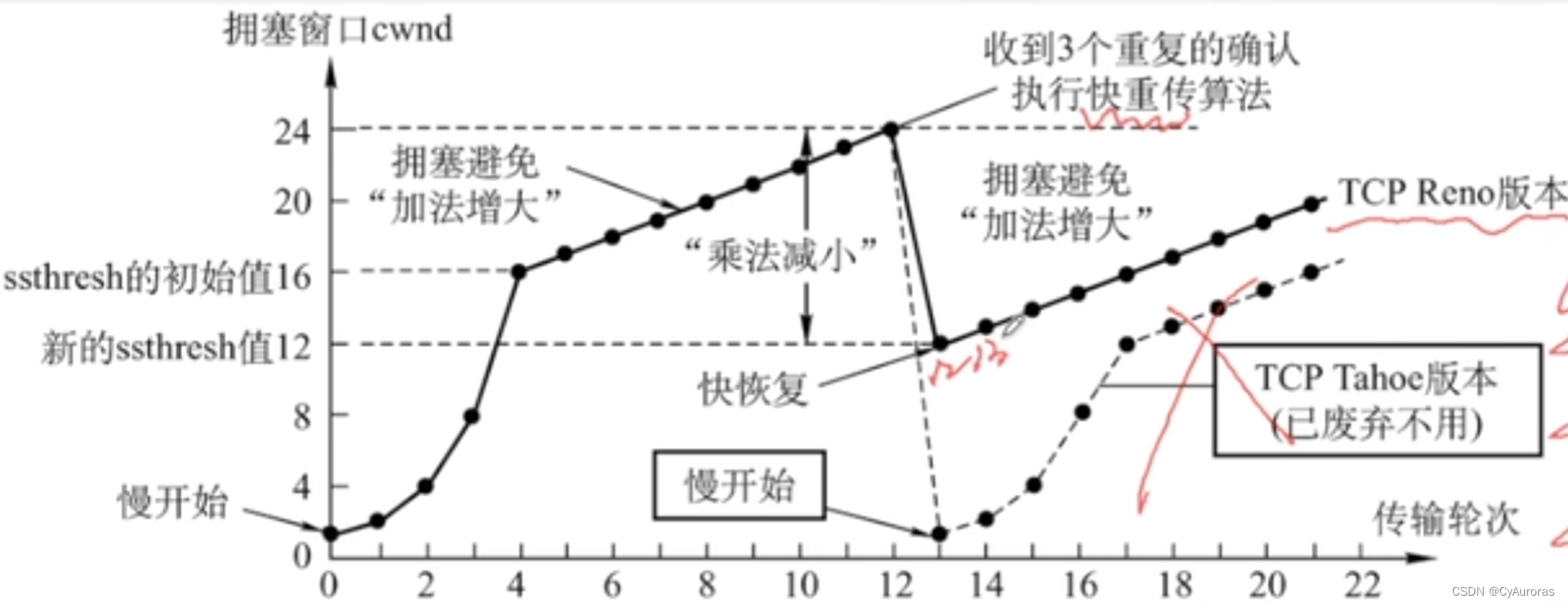
计算机网络-计算机网络体系结构-传输层
目录 一、UDP 二、TCP 特点 首部格式 连接管理 可靠传输 流量控制(点对点) 拥塞控制(全局) 三、拥塞控制算法 慢开始&拥塞避免 快重传&快恢复 功能一:提供进程与进程之间的逻辑通信 功能二:复用和分用 功能三:对收到的报…...

buuctf[HCTF 2018]WarmUp 1
题目环境: 发现除了表情包,再无其他F12试试发现source.php文件访问这个文件,格式如下:url/source.php回显如下:PHP代码审计: <?php highlight_file(__FILE__); class emmm {public static function ch…...
开源博客项目Blog .NET Core源码学习(4:生成验证码)
开源博客项目Blog中的后台管理登录界面中支持输入验证码(如下图所示),本文学习并记录项目中验证码的生成及调用方式。 博客项目中调用VerifyCode类生成验证码,该类位于App.Framwork项目中,命名空间为App.Framwork…...
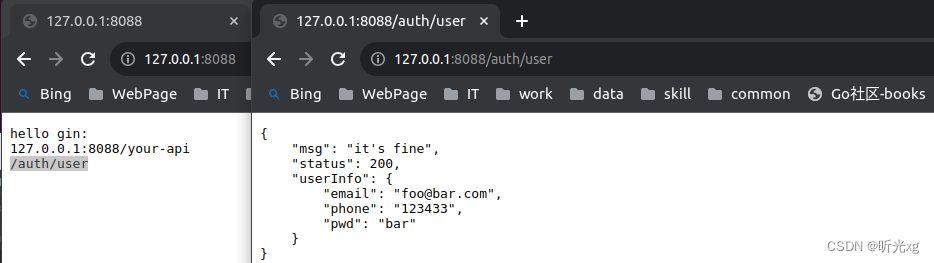
gin框架39--重构 BasicAuth 中间件
gin框架39--重构 BasicAuth 中间件 介绍gin BasicAuth 解析自定义newAuth实现基础认证注意事项说明 介绍 每当我们打开一个网址的时候,会自动弹出一个认证界面,要求我们输入用户名和密码,这种BasicAuth是最基础、最常见的认证方式࿰…...

编译pycaffe过程中遇到的问题及解决
pycaffe是python调用caffe的方式,编译它就是要得到一个so库_pycaffe.so。 如题,在caffe的源码目录下,执行make pycaffe,跳出来一个错误: $ make pycaffe CXX/LD -o python/caffe/_caffe.so python/caffe/_caffe.cpp /usr/bin/ld…...
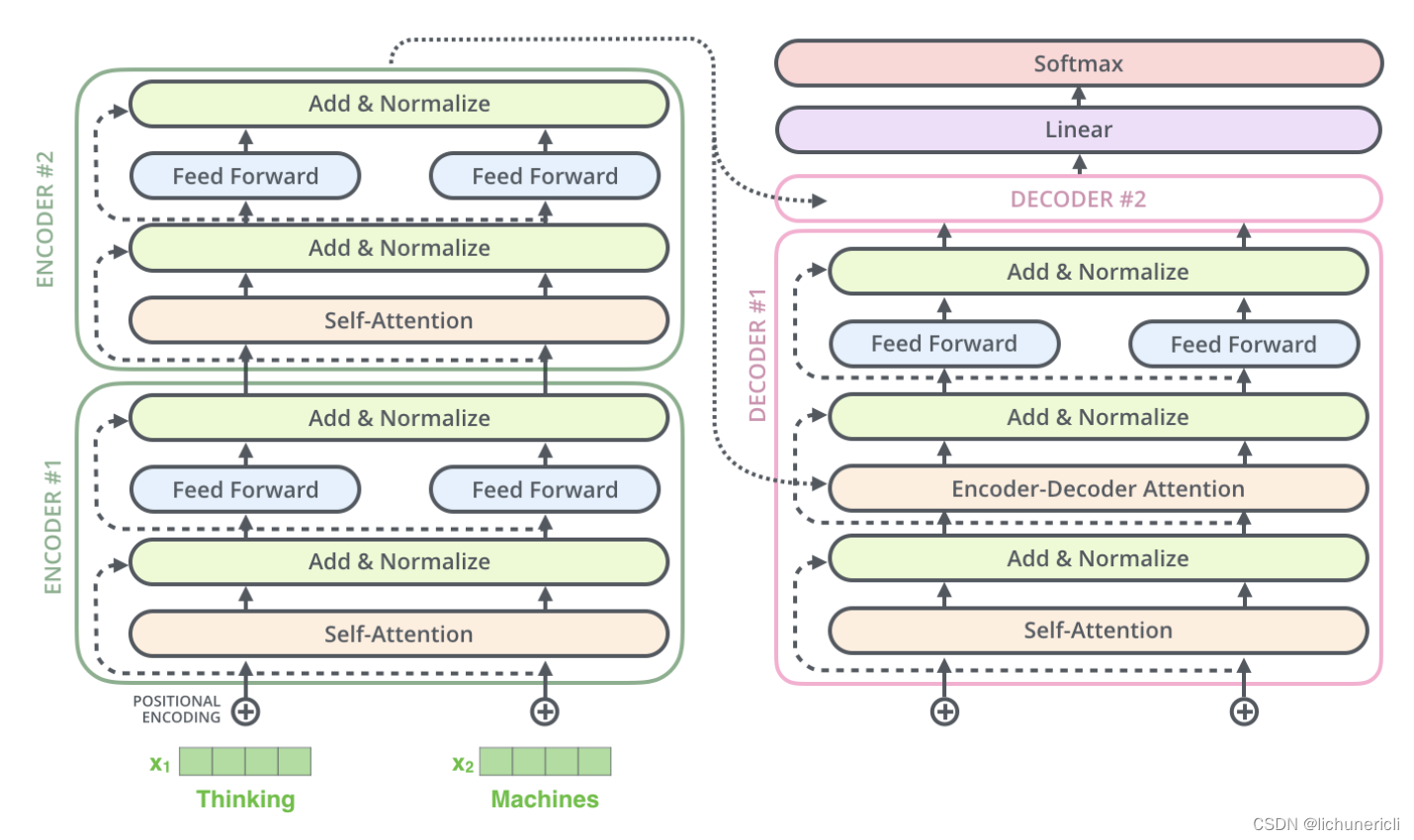
自然语言处理---Transformer机制详解之Transformer优势
1 Transformer的并行计算 对于Transformer比传统序列模型RNN/LSTM具备优势的第一大原因就是强大的并行计算能力. 对于RNN来说,任意时刻t的输入是时刻t的输入x(t)和上一时刻的隐藏层输出h(t-1),经过运算后得到当前时刻隐藏层的输出h(t),这个…...

改进YOLO系列 | YOLOv5/v7 引入 Dynamic Snake Convolution | 动态蛇形卷积
准确分割拓扑管状结构,如血管和道路,在各个领域中至关重要,可以确保下游任务的准确性和效率。然而,许多因素使任务复杂化,包括细小的局部结构和可变的全局形态。在这项工作中,我们注意到管状结构的特殊性,并利用这一知识来引导我们的DSCNet,以在三个阶段同时增强感知:…...
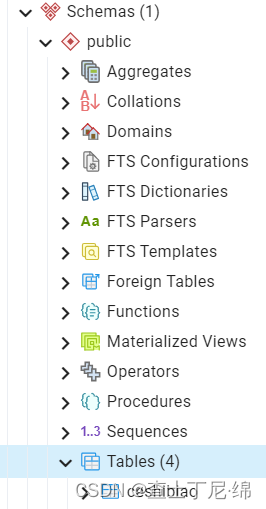
postgresql14-表的管理(四)
表table 创建表 CREATE TABLE table_name --表名 (column_name data_type column_constraint, --字段名、字段类型、约束字段(可选)column_name data_type, --表级别约束字段...,table_constraint );CREATE TABLE emp1 --创建表 AS SELECT * FROM empl…...

Java--Object类
Java中Object类是所有类的父类,是Java中最高层的类。用户创建一个类时,除非指定继承了某个类,否则都是继承于Object类。 由于所有类都继承于Object类,所以所有类都可以重写Object类中的方法。但是Object类中被final修饰的getClass…...
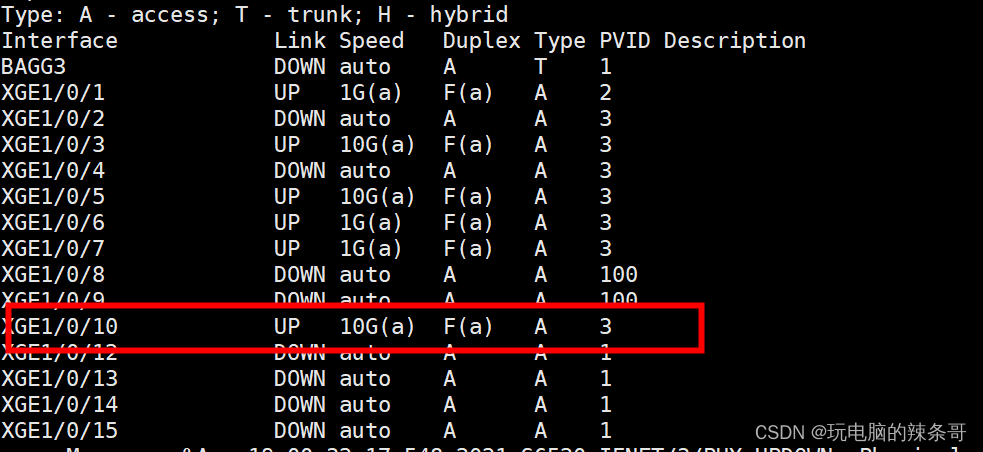
交换机端口灯常亮 端口up状态 服务器设置ip交换机获取不到服务器网卡mac地址 不能通信
环境: 深信服防火墙 8.0.75 AF-2000-FH2130B-SC S6520X-24ST-SI交换机 version 7.1.070, Release 6530P02 问题描述: 交换机一个vlan下有3台服务器,连接端口2、3、4,2和3连接的服务器正常,交换机3端口灯常亮 端口up状态 服务器自动获取不了地址,改为手动设置ip后,交…...
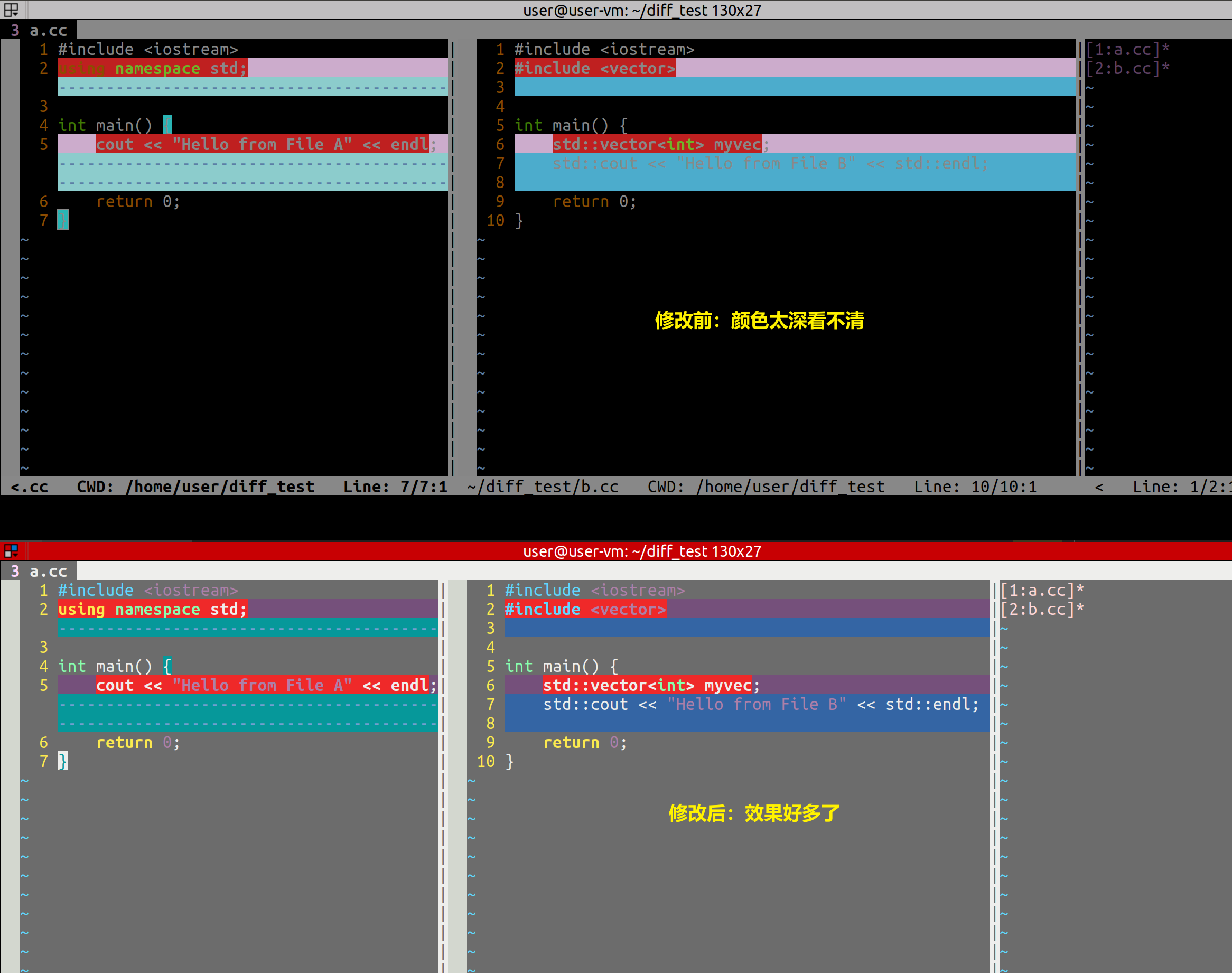
Linux笔记之diff和vimdiff
Linux笔记之diff和vimdiff code review! 文章目录 Linux笔记之diff和vimdiff一.diff1.1.使用diff比较文件夹1.2.使用diff比较文件1.4.colordiff——带颜色输出差异 二.vimdiff2.1.vimdiff颜色差异2.2.vimfiff调整栏宽2.3.修改颜色变谈,使代码可以看清楚2.4.vimdif…...

目标检测YOLO实战应用案例100讲-基于改进的YOLOV5算法的垃圾分类模型
目录 前言 国内外研究现状 目标检测算法发展现状 YOLO算法的发展现状...

我做不到受每个人喜欢
我做不到受每个人喜欢 我想描述一下昨天发生争吵后我个人的观点,希望能够重新呈现出一种积极的态度。 首先,让我简要梳理一下事件的经过,当天我像往常一样去另一个宿舍找人聊天,可能因为说话声音有点大,坐在我后面的那…...
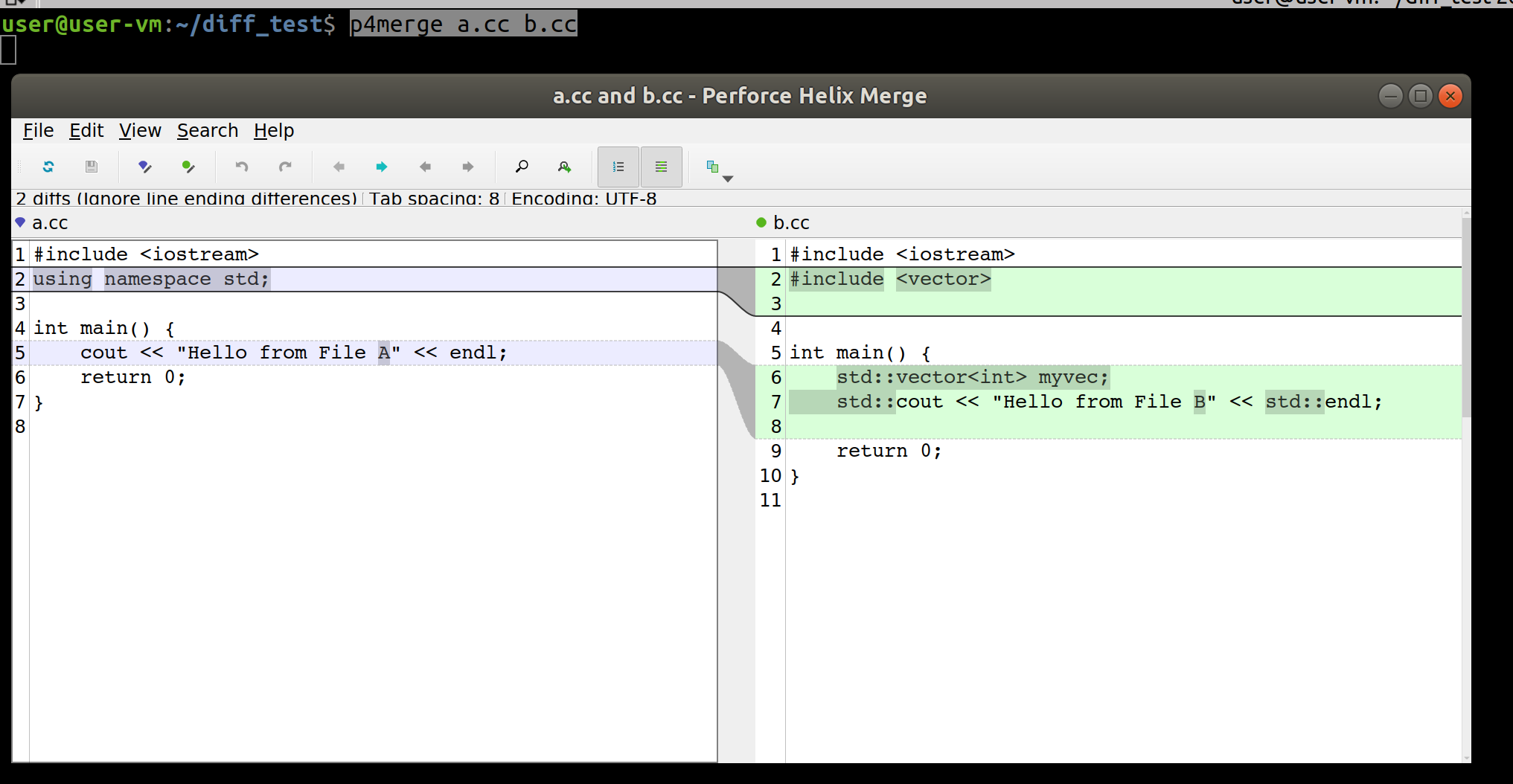
Linux笔记之diff工具软件P4merge的使用
Linux笔记之diff工具软件P4merge的使用 code review! 文章目录 Linux笔记之diff工具软件P4merge的使用1.安装和配置2.使用:p4merge a.cc b.cc3.配置git 参考博文: Ubuntu Git可视化比较工具 P4Merge 的安装/配置及使用 1.安装和配置 $ wget https://cdist2.per…...

使用 OpenSSL 扩展来实现公钥和私钥加密
首先,你需要生成一对公钥和私钥。可以使用 OpenSSL 工具来生成: 1、生成私钥 openssl genpkey -algorithm RSA -out private_key.pem 2、从私钥生成公钥: openssl rsa -pubout -in private_key.pem -out public_key.pem现在你有了一个私钥…...

二、安全与风险管理—安全与风险管理基础
目录 目录 1.什么是信息与信息的生命周期 2.信息安全的基本目标 3.风险管理与控制类型...
)
IntelliJ IDEA 2026.1 安装配置与高效开发环境搭建 (保姆级图文教程)
IDEA 2026.1 部署工具包下载 0. 前言 在 2026 年,IntelliJ IDEA 2026.1 不仅仅是一个编辑器,它已经进化为深度集成 DeepSeek/GPT-4o、支持云原生架构的开发者大脑。对于 Java 程序员来说,环境搭建不仅仅是“装上软件”,更是性能…...

Qwen3-TTS-12Hz-1.7B-Base真实案例:为无障碍考试系统生成标准化语音试卷
Qwen3-TTS-12Hz-1.7B-Base真实案例:为无障碍考试系统生成标准化语音试卷 你有没有想过,对于视障人士来说,参加一场普通的考试有多困难?传统的纸质试卷对他们来说是无法逾越的障碍,而人工朗读试卷又存在效率低、成本高…...

超级智能太过单一!菲尔兹奖得主陶哲轩首提“哥白尼式智能观”:人类智能和AI各有好坏,最会用AI的往往是会“带人”的人
在真实世界中,AI究竟是什么?人类智能又是什么?它们之间有着什么样的关系?近日,“越来越关注如何利用 AI 和其他现代技术来重塑数学,甚至是整个科学体系”的菲尔兹奖得主Terence Tao(陶哲轩&…...
)
保姆级教程:在OpenWrt 22.03上,如何修改并编译你自己的LuCI插件(以ne-cnc为例)
从零开始定制OpenWrt LuCI插件:完整编译与修改实战指南 当你第一次看到OpenWrt路由器上那些功能各异的LuCI插件时,是否曾想过自己也能动手修改它们?本文将带你深入理解LuCI插件的工作原理,并手把手教你如何修改和编译属于自己的定…...

c++ 零知识证明库 c++如何使用bellman或libsnark
Bellman和libsnark均非C“拿来即用”库:Bellman是Rust编写且无C ABI,libsnark依赖严苛(GMP 6.1.x、Boost≤1.65、CMake≤3.10),编译极易失败,推荐改用gnark/gRPC或arkworks导出验证逻辑等替代方案。bellman…...

深入解析图像感知质量指标:从PSNR到Perceptual Index的实践指南
1. 图像质量评估的两种视角:从像素匹配到主观感知 当你用手机拍完照片准备发朋友圈时,可能会纠结要不要加滤镜——原图细节更丰富但略显平淡,滤镜版色彩鲜艳可细节模糊。这种选择困境背后,正是图像质量评估的两大流派:…...

电子产品PCB热仿真建模与热过孔设计的系统化方法
🎓作者简介:科技自媒体优质创作者 🌐个人主页:莱歌数字-CSDN博客 💌公众号:莱歌数字(B站同名) 📱个人微信:yanshanYH 211、985硕士,从业16年 从…...
)
基于stm32室内空气质量监测(有完整资料)
资料查找方式:特纳斯电子(电子校园网):搜索下面编号即可编号:T0882309M设计简介:本设计是基于单片机的空气质量监测系统设计,主要实现以下功能:通过温湿度传感器检测温湿度 通过甲醛…...

如何在普通PC上体验macOS?黑苹果长期维护机型EFI完全指南
如何在普通PC上体验macOS?黑苹果长期维护机型EFI完全指南 【免费下载链接】Hackintosh Hackintosh long-term maintenance model EFI and installation tutorial 项目地址: https://gitcode.com/gh_mirrors/ha/Hackintosh 你是否渴望在普通PC上体验macOS的优…...

媒力无限:坚守初心,做有温度的品牌同行者
在流量喧嚣的时代,总有一群人坚守媒体初心,用专业与温度,做有价值的传播、有意义的事。北京媒力无限品牌文化传播有限公司,由一群深耕中央级媒体十余年的资深媒体人创立,始终以「发现潜力企业,让更多好企业…...