自然语言处理---文本预处理概述
自然语言处理(Natural Language Processing,简称NLP)是计算机科学与语言学中关注于计算机与人类语言间转换的领域。其主要应用于:语音助手、机器翻译、搜索引擎、智能问答等。
文本预处理概述
文本语料在输送给模型前一般需要一系列的预处理工作,才能符合模型输入的要求,如:将文本转化成模型需要的张量,规范张量的尺寸等,而且科学的文本预处理环节还将有效指导模型超参数的选择,提升模型的评估指标。
文本处理的基本方法
分词概述
- 分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符,分词过程就是找到这样分界符的过程。
- 分词的作用:词作为语言语义理解的最小单元,是人类理解文本语言的基础。因此也是AI解决NLP领域高阶任务,如自动问答,机器翻译,文本生成的重要基础环节。
- 流行中文分词工具jieba的特性:
- 支持多种分词模式:精确模式、全模式、搜索引擎模式
- 支持中文繁体分词
- 支持用户自定义词典
命名实体识别
- 命名实体:通常将人名,地名,机构名等专有名词统称命名实体。
- 命名实体识别(Named Entity Recognition,简称NER)就是识别出一段文本中可能存在的命名实体。
- 命名实体识别的作用:同词汇一样,命名实体也是人类理解文本的基础单元,因此也是AI解决NLP领域高阶任务的重要基础环节。
词性标注
- 词性: 语言中对词的一种分类方法,以语法特征为主要依据、兼顾词汇意义对词进行划分的结果,常见的词性有14种, 如: 名词, 动词, 形容词等。
- 词性标注(Part-Of-Speech tagging, 简称POS)就是标注出一段文本中每个词汇的词性。
- 词性标注的作用:词性标注以分词为基础,,是对文本语言的另一个角度的理解,因此也常常成为AI解决NLP领域高阶任务的重要基础环节。
文本张量表示方法
- 文本张量表示:将一段文本使用张量进行表示,其中一般将词汇为表示成向量,称作词向量,再由各个词向量按顺序组成矩阵形成文本表示。
- 文本张量表示的作用:将文本表示成张量(矩阵)形式,能够使语言文本可以作为计算机处理程序的输入,进行接下来一系列的解析工作。
- 文本张量表示的方法:one-hot编码、Word2vec、Word Embedding
one-hot编码
- one-hot词向量表示:又称独热编码,将每个词表示成具有n个元素的向量,这个词向量中只有一个元素是1,其他元素都是0,不同词汇元素为0的位置不同,其中n的大小是整个语料中不同词汇的总数。
- one-hot编码的优劣势:
- 优势:操作简单,容易理解
- 劣势:完全割裂了词与词之间的联系,而且在大语料集下,每个向量的长度过大,占据大量内存
Word2vec
- word2vec:是一种流行的将词汇表示成向量的无监督训练方法,该过程将构建神经网络模型,将网络参数作为词汇的向量表示,它包含CBOW和skipgram两种训练模式。
- CBOW(Continuous bag of words)模式:给定一段用于训练的文本语料,再选定某段长度(窗口)作为研究对象,使用上下文词汇预测目标词汇。
- CBOW模式下的word2vec过程说明:
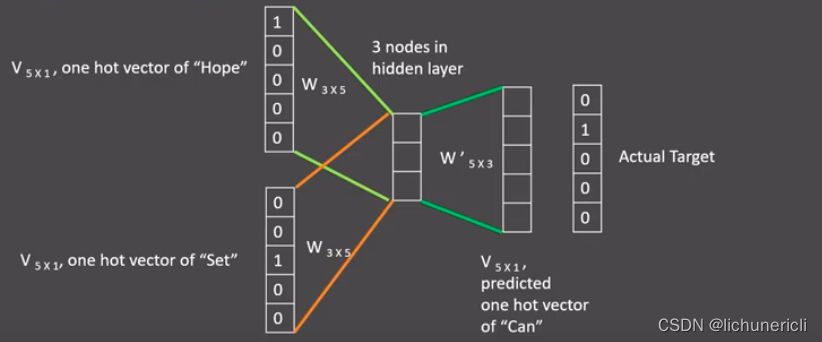
- 假设给定的训练语料只有一句话: Hope can set you free (愿你自由成长),窗口大小为3,因此模型的第一个训练样本来自Hope you set,因为是CBOW模式,所以将使用Hope和set作为输入,you作为输出,在模型训练时, Hope,set,you等词汇都使用它们的one-hot编码。
- 如图所示:每个one-hot编码的单词与各自的变换矩阵(即参数矩阵3x5, 这里的3是指最后得到的词向量维度)相乘之后再相加, 得到上下文表示矩阵(3x1)。
- 接着, 将上下文表示矩阵与变换矩阵(参数矩阵5x3, 所有的变换矩阵共享参数)相乘, 得到5x1的结果矩阵, 它将与真正的目标矩阵即you的one-hot编码矩阵(5x1)进行损失的计算,然后更新网络参数完成一次模型迭代。
- 最后窗口按序向后移动,重新更新参数,直到所有语料被遍历完成,得到最终的变换矩阵(3x5),这个变换矩阵与每个词汇的one-hot编码(5x1)相乘,得到的3x1的矩阵就是该词汇的word2vec张量表示。

- skipgram模式:给定一段用于训练的文本语料,再选定某段长度(窗口)作为研究对象,使用目标词汇预测上下文词汇。
- skipgram模式下的word2vec过程说明:
- 假设给定的训练语料只有一句话: Hope can set you free (愿你自由成长),窗口大小为3,因此模型的第一个训练样本来自Hope you set,因为是skipgram模式,所以将使用you作为输入 ,hope和set作为输出,在模型训练时, Hope,set,you等词汇都使用它们的one-hot编码。
- 如图所示:将you的one-hot编码与变换矩阵(即参数矩阵3x5,这里的3是指最后得到的词向量维度)相乘, 得到目标词汇表示矩阵(3x1)。
- 接着, 将目标词汇表示矩阵与多个变换矩阵(参数矩阵5x3)相乘, 得到多个5x1的结果矩阵, 它将与我们hope和set对应的one-hot编码矩阵(5x1)进行损失的计算, 然后更新网络参数完成一次模 型迭代。
- 最后窗口按序向后移动,重新更新参数,直到所有语料被遍历完成,得到最终的变换矩阵即参数矩阵(3x5),这个变换矩阵与每个词汇的one-hot编码(5x1)相乘,得到的3x1的矩阵就是该词汇的word2vec张量表示。
- 使用fasttext工具实现word2vec的训练和使用:
- 第一步: 获取训练数据
- 第二步: 训练词向量
- 第三步: 模型超参数设定
- 第四步: 模型效果检验
- 第五步: 模型的保存与重加载
word embedding(词嵌入)
- word embedding(词嵌入):
- 通过一定的方式将词汇映射到指定维度(一般是更高维度)的空间。
- 广义的word embedding包括所有密集词汇向量的表示方法,如之前学习的word2vec,即可认为是word embedding的一种。
- 狭义的word embedding是指在神经网络中加入的embedding层,对整个网络进行训练的同时产生的embedding矩阵(embedding层的参数),这个embedding矩阵就是训练过程中所有输入词汇的向量表示组成的矩阵。
- word embedding的可视化分析:
- 通过使用tensorboard可视化嵌入的词向量。
- 在终端启动tensorboard服务。
- 浏览器展示并可以使用右侧近邻词汇功能检验效果。
文本数据分析
分析作用与方法
- 文本数据分析的作用:
- 文本数据分析能够有效帮助理解数据语料,快速检查出语料可能存在的问题,并指导之后模型训练过程中一些超参数的选择。
- 常用的几种文本数据分析方法:
- 标签数量分布
- 句子长度分布
- 词频统计与关键词词云
文本特征处理
- 文本特征处理的作用:
- 文本特征处理包括为语料添加具有普适性的文本特征,如:n-gram特征,以及对加入特征之后的文本语料进行必要的处理,如:长度规范。这些特征处理工作能够有效的将重要的文本特征加入模型训练中,增强模型评估指标。
- 常见的文本特征处理方法:
- 添加n-gram特征
- 文本长度规范
n-gram特征
- n-gram特征:给定一段文本序列,其中n个词或字的相邻共现特征即n-gram特征,常用的n-gram特征是bi-gram和tri-gram特征,分别对应n为2和3。
- 提取n-gram特征的函数:create_ngram_set
-
# 一般n-gram中的n取2或者3, 这里取2为例 ngram_range = 2def create_ngram_set(input_list):"""description: 从数值列表中提取所有的n-gram特征:param input_list: 输入的数值列表, 可以看作是词汇映射后的列表, 里面每个数字的取值范围为[1, 25000]:return: n-gram特征组成的集合eg:>>> create_ngram_set([1, 4, 9, 4, 1, 4]){(4, 9), (4, 1), (1, 4), (9, 4)}"""return set(zip(*[input_list[i:] for i in range(ngram_range)]))
文本长度规范
- 文本长度规范及其作用:一般模型的输入需要等尺寸大小的矩阵,因此在进入模型前需要对每条文本数值映射后的长度进行规范,此时将根据句子长度分布分析出覆盖绝大多数文本的合理长度,对超长文本进行截断,对不足文本进行补齐(一般使用数字0),这个过程就是文本长度规范。
- 文本长度规范的实现函数:padding
-
from keras.preprocessing import sequence# cutlen根据数据分析中句子长度分布,覆盖90%左右语料的最短长度. # 这里假定cutlen为10 cutlen = 10def padding(x_train):"""description: 对输入文本张量进行长度规范:param x_train: 文本的张量表示, 形如: [[1, 32, 32, 61], [2, 54, 21, 7, 19]]:return: 进行截断补齐后的文本张量表示 """# 使用sequence.pad_sequences即可完成return sequence.pad_sequences(x_train, cutlen)
文本数据增强
回译数据增强法
- 常见的文本数据增强方法:回译数据增强法。
- 回译数据增强目前是文本数据增强方面效果较好的增强方法,一般基于google翻译接口,将文本数据翻译成另外一种语言(一般选择小语种),之后再翻译回原语言,即可认为得到与与原语料同标签的新语料,新语料加入到原数据集中即可认为是对原数据集数据增强。
- 回译数据增强优势:操作简便,获得新语料质量高。
- 回译数据增强存在的问题:在短文本回译过程中,新语料与原语料可能存在很高的重复率,并不能有效增大样本的特征空间。
- 高重复率解决办法:进行连续的多语言翻译,如:中文→韩文→日语→英文→中文,根据经验,最多只采用3次连续翻译,更多的翻译次数将产生效率低下,语义失真等问题。
jieba词性对照表
jieba词性对照表
- a 形容词
- ad 副形词
- ag 形容词性语素
- an 名形词
- b 区别词
- c 连词
- d 副词
- df
- dg 副语素
- e 叹词
- f 方位词
- g 语素
- h 前接成分
- i 成语
- j 简称略称
- k 后接成分
- l 习用语
- m 数词
- mg
- mq 数量词
- n 名词
- ng 名词性语素
- nr 人名
- nrfg
- nrt
- ns 地名
- nt 机构团体名
- nz 其他专名
- o 拟声词
- p 介词
- q 量词
- r 代词
- rg 代词性语素
- rr 人称代词
- rz 指示代词
- s 处所词
- t 时间词
- tg 时语素
- u 助词
- ud 结构助词 得
- ug 时态助词
- uj 结构助词 的
- ul 时态助词 了
- uv 结构助词 地
- uz 时态助词 着
- v 动词
- vd 副动词
- vg 动词性语素
- vi 不及物动词
- vn 名动词
- vq
- x 非语素词
- y 语气词
- z 状态词
- zg
hanlp词性对照表
【Proper Noun——NR,专有名词】
【Temporal Noun——NT,时间名词】
【Localizer——LC,定位词】如“内”,“左右”
【Pronoun——PN,代词】
【Determiner——DT,限定词】如“这”,“全体”
【Cardinal Number——CD,量词】
【Ordinal Number——OD,次序词】如“第三十一”
【Measure word——M,单位词】如“杯”
【Verb:VA,VC,VE,VV,动词】
【Adverb:AD,副词】如“近”,“极大”
【Preposition:P,介词】如“随着”
【Subordinating conjunctions:CS,从属连词】
【Conjuctions:CC,连词】如“和”
【Particle:DEC,DEG,DEV,DER,AS,SP,ETC,MSP,小品词】如“的话”
【Interjections:IJ,感叹词】如“哈”
【onomatopoeia:ON,拟声词】如“哗啦啦”
【Other Noun-modifier:JJ】如“发稿/JJ 时间/NN”
【Punctuation:PU,标点符号】
【Foreign word:FW,外国词语】如“OK
新闻主题分类案例
加载本地数据
from torchtext.legacy.datasets.text_classification import _csv_iterator, _create_data_from_iterator, \TextClassificationDataset
from torchtext.utils import extract_archive
from torchtext.vocab import build_vocab_from_iterator, Vocab# 从本地加载数据的方式,本地数据在虚拟机/root/data/ag_news_csv中
# 定义加载函数
def setup_datasets(ngrams=2, vocab_train=None, vocab_test=None, include_unk=False):train_csv_path = 'data/ag_news_csv/train.csv'test_csv_path = 'data/ag_news_csv/test.csv'if vocab_train is None:vocab_train = build_vocab_from_iterator(_csv_iterator(train_csv_path, ngrams))else:if not isinstance(vocab, Vocab):raise TypeError("Passed vocabulary is not of type Vocab")if vocab_test is None:vocab_test = build_vocab_from_iterator(_csv_iterator(test_csv_path, ngrams))else:if not isinstance(vocab, Vocab):raise TypeError("Passed vocabulary is not of type Vocab")train_data, train_labels = _create_data_from_iterator(vocab_train, _csv_iterator(train_csv_path, ngrams, yield_cls=True), include_unk)test_data, test_labels = _create_data_from_iterator(vocab_test, _csv_iterator(test_csv_path, ngrams, yield_cls=True), include_unk)if len(train_labels ^ test_labels) > 0:raise ValueError("Training and test labels don't match")return (TextClassificationDataset(vocab_train, train_data, train_labels),TextClassificationDataset(vocab_test, test_data, test_labels))# 调用函数, 加载本地数据
train_dataset, test_dataset = setup_datasets()
print("train_dataset", train_dataset)构建带有Embedding层的文本分类模型
# 导入必备的torch模型构建工具
import torch.nn as nn
import torch.nn.functional as F# 指定BATCH_SIZE的大小
BATCH_SIZE = 16# 进行可用设备检测, 有GPU的话将优先使用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")class TextSentiment(nn.Module):"""文本分类模型"""def __init__(self, vocab_size, embed_dim, num_class):"""description: 类的初始化函数:param vocab_size: 整个语料包含的不同词汇总数:param embed_dim: 指定词嵌入的维度:param num_class: 文本分类的类别总数"""super().__init__()# 实例化embedding层, sparse=True代表每次对该层求解梯度时, 只更新部分权重.self.embedding = nn.Embedding(vocab_size, embed_dim, sparse=True)# 实例化线性层, 参数分别是embed_dim和num_class.self.fc = nn.Linear(embed_dim, num_class)# 为各层初始化权重self.init_weights()def init_weights(self):"""初始化权重函数"""# 指定初始权重的取值范围数initrange = 0.5# 各层的权重参数都是初始化为均匀分布self.embedding.weight.data.uniform_(-initrange, initrange)self.fc.weight.data.uniform_(-initrange, initrange)# 偏置初始化为0self.fc.bias.data.zero_()def forward(self, text):""":param text: 文本数值映射后的结果:return: 与类别数尺寸相同的张量, 用以判断文本类别"""# 获得embedding的结果embedded# >>> embedded.shape# (m, 32) 其中m是BATCH_SIZE大小的数据中词汇总数embedded = self.embedding(text)# 接下来我们需要将(m, 32)转化成(BATCH_SIZE, 32)# 以便通过fc层后能计算相应的损失# 首先, 我们已知m的值远大于BATCH_SIZE=16,# 用m整除BATCH_SIZE, 获得m中共包含c个BATCH_SIZEc = embedded.size(0) // BATCH_SIZE# 之后再从embedded中取c*BATCH_SIZE个向量得到新的embedded# 这个新的embedded中的向量个数可以整除BATCH_SIZEembedded = embedded[:BATCH_SIZE * c]# 因为我们想利用平均池化的方法求embedded中指定行数的列的平均数,# 但平均池化方法是作用在行上的, 并且需要3维输入# 因此我们对新的embedded进行转置并拓展维度embedded = embedded.transpose(1, 0).unsqueeze(0)# 然后就是调用平均池化的方法, 并且核的大小为c# 即取每c的元素计算一次均值作为结果embedded = F.avg_pool1d(embedded, kernel_size=c)# 最后,还需要减去新增的维度, 然后转置回去输送给fc层return self.fc(embedded[0].transpose(1, 0))# 获得整个语料包含的不同词汇总数
VOCAB_SIZE = len(train_dataset.get_vocab())
# 指定词嵌入维度
EMBED_DIM = 32
# 获得类别总数
NUN_CLASS = len(train_dataset.get_labels())
# 实例化模型
model = TextSentiment(VOCAB_SIZE, EMBED_DIM, NUN_CLASS).to(device)对数据进行batch处理
def generate_batch(batch):"""description: 生成batch数据函数:param batch: 由样本张量和对应标签的元组组成的batch_size大小的列表形如:[(label1, sample1), (lable2, sample2), ..., (labelN, sampleN)]return: 样本张量和标签各自的列表形式(张量)形如:text = tensor([sample1, sample2, ..., sampleN])label = tensor([label1, label2, ..., labelN])"""# 从batch中获得标签张量label = torch.tensor([entry[0] for entry in batch])# 从batch中获得样本张量text = [entry[1] for entry in batch]text = torch.cat(text)# 返回结果return text, label# 假设一个输入:
batch = [(1, torch.tensor([3, 23, 2, 8])), (0, torch.tensor([3, 45, 21, 6]))]
res = generate_batch(batch)
print(res)构建训练与验证函数
# 导入torch中的数据加载器方法
from torch.utils.data import DataLoaderdef train(train_data):"""模型训练函数"""# 初始化训练损失和准确率为0train_loss = 0train_acc = 0# 使用数据加载器生成BATCH_SIZE大小的数据进行批次训练# data就是N多个generate_batch函数处理后的BATCH_SIZE大小的数据生成器data = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True,collate_fn=generate_batch)# 对data进行循环遍历, 使用每个batch的数据进行参数更新for i, (text, cls) in enumerate(data):# 设置优化器初始梯度为0optimizer.zero_grad()# 模型输入一个批次数据, 获得输出output = model(text)# 根据真实标签与模型输出计算损失loss = criterion(output, cls)# 将该批次的损失加到总损失中train_loss += loss.item()# 误差反向传播loss.backward()# 参数进行更新optimizer.step()# 将该批次的准确率加到总准确率中train_acc += (output.argmax(1) == cls).sum().item()# 调整优化器学习率 scheduler.step()# 返回本轮训练的平均损失和平均准确率return train_loss / len(train_data), train_acc / len(train_data)def valid(valid_data):"""模型验证函数"""# 初始化验证损失和准确率为0loss = 0acc = 0# 和训练相同, 使用DataLoader获得训练数据生成器data = DataLoader(valid_data, batch_size=BATCH_SIZE, collate_fn=generate_batch)# 按批次取出数据验证for text, cls in data:# 验证阶段, 不再求解梯度with torch.no_grad():# 使用模型获得输出output = model(text)# 计算损失loss = criterion(output, cls)# 将损失和准确率加到总损失和准确率中loss += loss.item()acc += (output.argmax(1) == cls).sum().item()# 返回本轮验证的平均损失和平均准确率return loss / len(valid_data), acc / len(valid_data)进行模型训练和验证
# 导入时间工具包
import time# 导入数据随机划分方法工具
from torch.utils.data.dataset import random_split# 指定训练轮数
N_EPOCHS = 10# 定义初始的验证损失
min_valid_loss = float('inf')# 选择损失函数, 这里选择预定义的交叉熵损失函数
criterion = torch.nn.CrossEntropyLoss().to(device)
# 选择随机梯度下降优化器
optimizer = torch.optim.SGD(model.parameters(), lr=4.0)
# 选择优化器步长调节方法StepLR, 用来衰减学习率
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1, gamma=0.9)# 从train_dataset取出0.95作为训练集, 先取其长度
train_len = int(len(train_dataset) * 0.95)# 然后使用random_split进行乱序划分, 得到对应的训练集和验证集
sub_train_, sub_valid_ = \random_split(train_dataset, [train_len, len(train_dataset) - train_len])# 开始每一轮训练
for epoch in range(N_EPOCHS):# 记录概论训练的开始时间start_time = time.time()# 调用train和valid函数得到训练和验证的平均损失, 平均准确率train_loss, train_acc = train(sub_train_)valid_loss, valid_acc = valid(sub_valid_)# 计算训练和验证的总耗时(秒)secs = int(time.time() - start_time)# 用分钟和秒表示mins = secs / 60secs = secs % 60# 打印训练和验证耗时,平均损失,平均准确率print('Epoch: %d' % (epoch + 1), " | time in %d minutes, %d seconds" % (mins, secs))print(f'\tLoss: {train_loss:.4f}(train)\t|\tAcc: {train_acc * 100:.1f}%(train)')print(f'\tLoss: {valid_loss:.4f}(valid)\t|\tAcc: {valid_acc * 100:.1f}%(valid)')查看embedding层嵌入的词向量
# 打印从模型的状态字典中获得的Embedding矩阵
print(model.state_dict()['embedding.weight'])相关文章:

自然语言处理---文本预处理概述
自然语言处理(Natural Language Processing,简称NLP)是计算机科学与语言学中关注于计算机与人类语言间转换的领域。其主要应用于:语音助手、机器翻译、搜索引擎、智能问答等。 文本预处理概述 文本语料在输送给模型前一般需要一…...

GCC编译器 什么是宏? 标识符和关键字
一.GCC是什么? GCC是用于编译C语言和其它语言的开源软件。 全称是 GNU Compiler Collection,意思是GNU编译器集和。 支持多种操作系统和硬件平台。二.GCC的作用 GCC的作用是将源码转换为可执行的文件,使之可以在计算机上运行。三.GCC编译c文…...
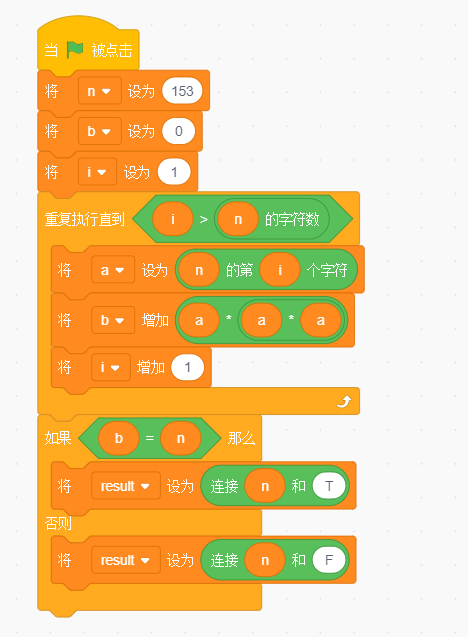
【GESP】2023年06月图形化三级 -- 自幂数判断
文章目录 自幂数判断【题目描述】【输入描述】【输出描述】【参考答案】其他测试用例 自幂数判断 【题目描述】 自幂数是指N位数各位数字N次方之和是本身,如153是3位数,其每位数的3次方之和是153本身,因此153是自幂数,1634是4位数…...

MySQL常见面试题
一、存储引擎相关 (1)MySQL 支持哪些存储引擎? MySQL支持多种存储引擎,比如InnoDB,MyISAM, MySQL大于等于5.5之后,默认存储引擎是InnoDB (2)InnoDB 和 MyISAM 有什么区别? InnoD…...

前端HTML CSS JS风格规范
本文代码规范来自HTML/CSS代码开发规范文档 文件命名规范 使用小写字母、数字和下划线组成文件名。 避免使用特殊字符和空格。 使用语义化的命名,能够清晰地表达出文件的功能或内容。 目录结构规范 使用约定俗成的目录结构,如:src/compon…...
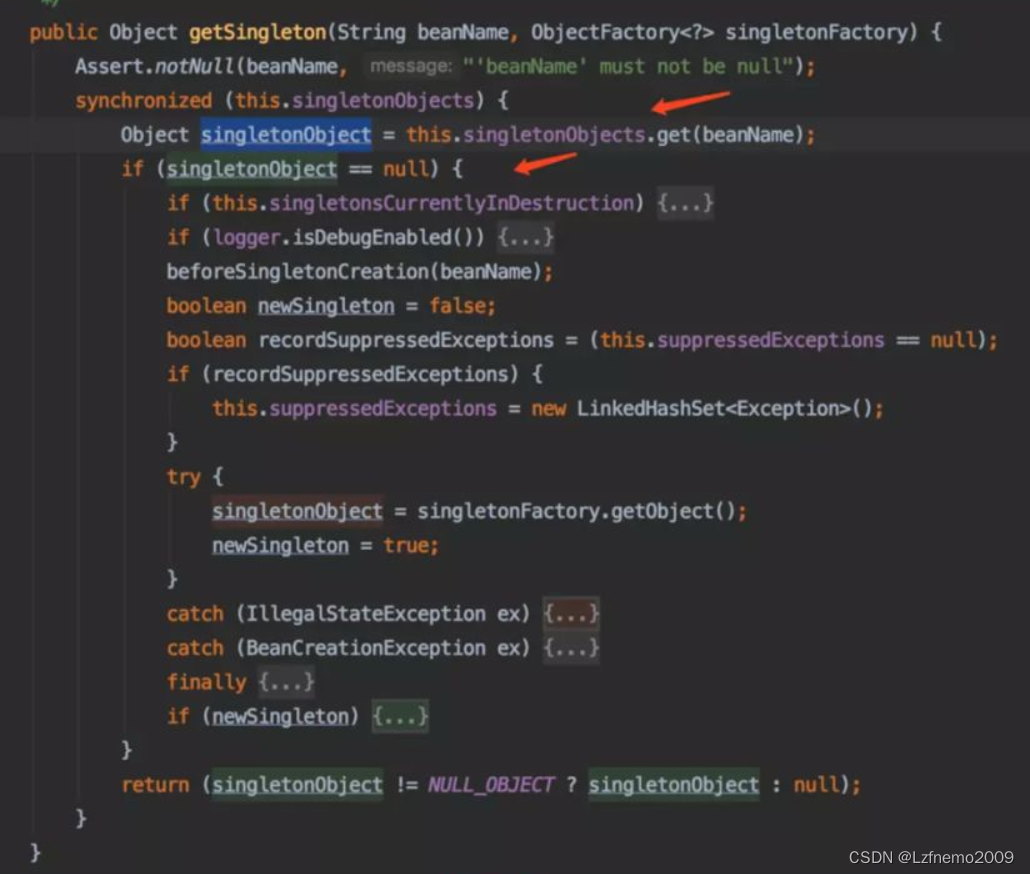
为什么spring默认采用单例bean
概 述 熟悉 Spring开发的朋友都知道 Spring 提供了 5种 scope,分别是: singleton: 单例模式,当spring创建applicationContext容器的时候,spring会欲初始化所有的该作用域实例,加上lazy-init就可以避免预处理…...

Redisson分布式锁学习
之前工作中一直使用redis来实现分布式锁,但是最近项目使用了云弹性,机器会涉及到扩缩容,涉及到优雅停机的问题,普通的redis分布锁,一般使用时会设置锁的时间,但是如果在加锁期间 JVM异常重启等发生会导致分…...
Metabase:简单快捷的商业智能与数据分析工具 | 开源日报 No.61
moby/moby Stars: 66.8k License: Apache-2.0 Moby 是一个由 Docker 创建的开源项目,旨在实现和加速软件容器化。它提供了工具包组件的“乐高集”,可以将它们组装成基于容器的自定义系统的框架。组件包括容器生成工具、容器注册表、业务流程工具、运行时…...

【无标题】高流量大并发Linux TCP性能调优
最近在使用jmeter做压测,当jmeter的并发量高的时候发现jmeter服务器一直报错Cannot assign requested address, 查看了一下发现系统中存在大量处于TIME_WAIT状态的tcp端口 netstat -n | awk ‘/^tcp/ {S[$NF]} END {for(a in S) print a, S[a]}’ TIME_W…...

优雅的用户体验:微信小程序中的多步骤表单引导
前言 在微信小程序中,实现一个多步骤表单引导界面既可以提供清晰的任务指引,又可以增加用户体验的互动性。本文将探讨如何使用微信小程序的特性,构建一个流程引导界面,帮助用户一步步完成复杂任务。我们将从设计布局和样式开始&am…...

Kotlin中的委托、属性委托和延迟加载
委托模式是一种常用的设计模式,用于将某个对象的责任委托给另一个对象来处理。在Kotlin中,委托可以通过关键字by来实现,主要分为类委托和属性委托两种形式。此外,Kotlin还提供了延迟加载的功能,可以在需要时才进行初始…...
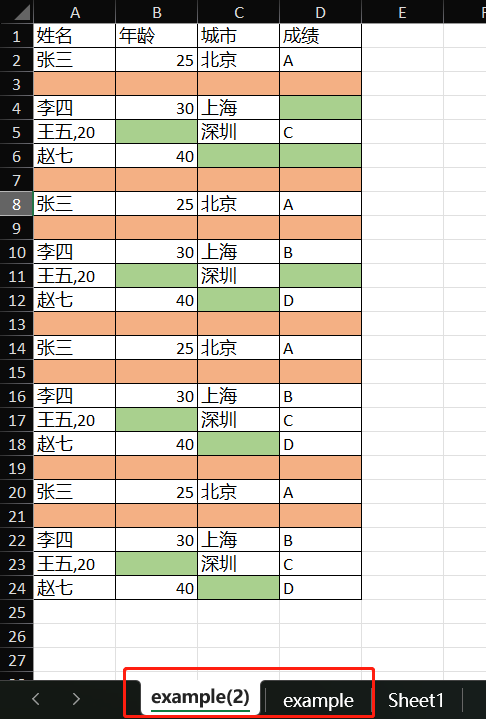
轻松合并Excel工作表:Java批量操作优化技巧
摘要:本文由葡萄城技术团队于CSDN原创并首发。转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具、解决方案和服务,赋能开发者。 前言 在Excel中设计表单时,我们经常需要对收集的信息进行统计分析。例如&a…...

计算机网络_网络层概述
4.1 网络层概述 4.1.1 一.分组转发和路由选择 网络层的主要任务就是将分组从源主机经过多个网络和多段链路传输到目的主机,可以将该任务划分为分组转发和路由选择两种重要的功能。 注释:A发送到B,从1端口进入. 如何得知是从2还是从3中转发出去呢?--------->这…...
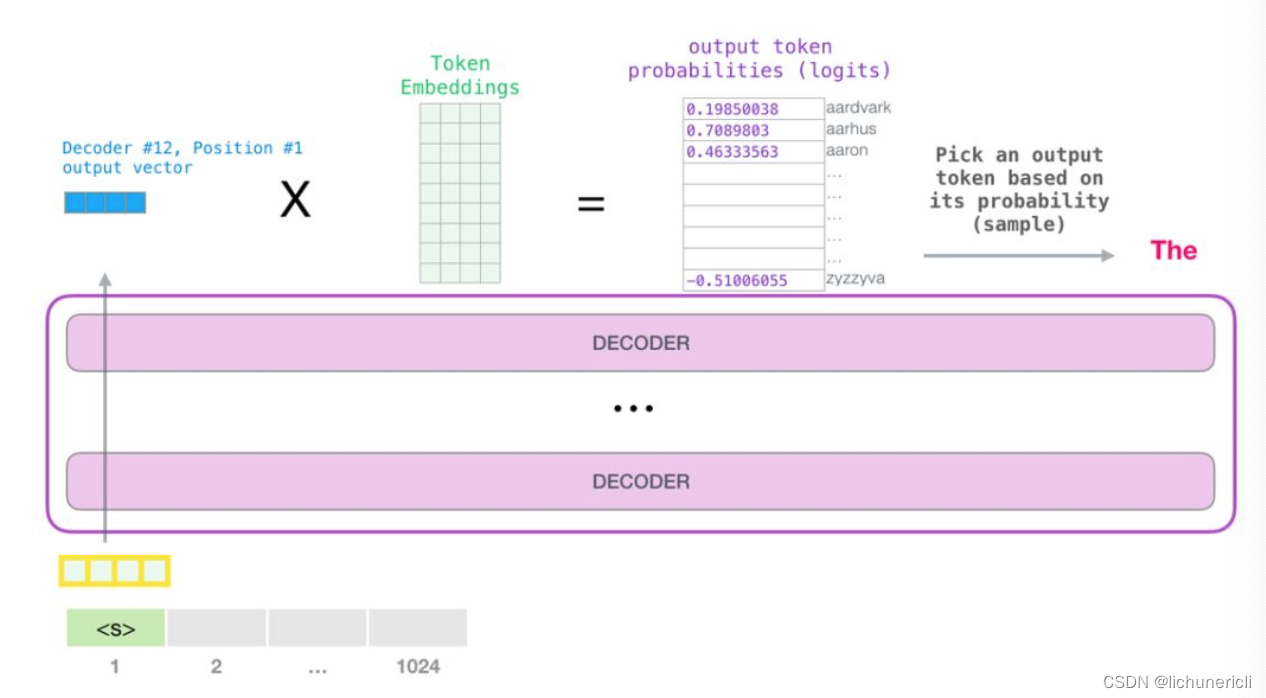
自然语言处理---Transformer机制详解之GPT2模型介绍
1 GPT2的架构 从模型架构上看, GPT2并没有特别新颖的架构, 它和只带有解码器模块的Transformer很像. 所谓语言模型, 作用就是根据已有句子的一部分, 来预测下一个单词会是什么. 现实应用中大家最熟悉的一个语言模型应用, 就是智能手机上的输入法, 它可以根据当前输入的内容智…...
ChatGPT 即将诞生一周年,OpenAI 将有大动作
图片来源:由无界AI生成 下个月就是 ChatGPT 一周年纪念日。OpenAI 正在谋划新的大动作。可以肯定地说,自诞生以来,ChatGPT 就为 OpenAI 提供了不可阻挡的增长动力。 01 营收超预期,OpenAI 缓了一口气 据 The Information 报道&…...
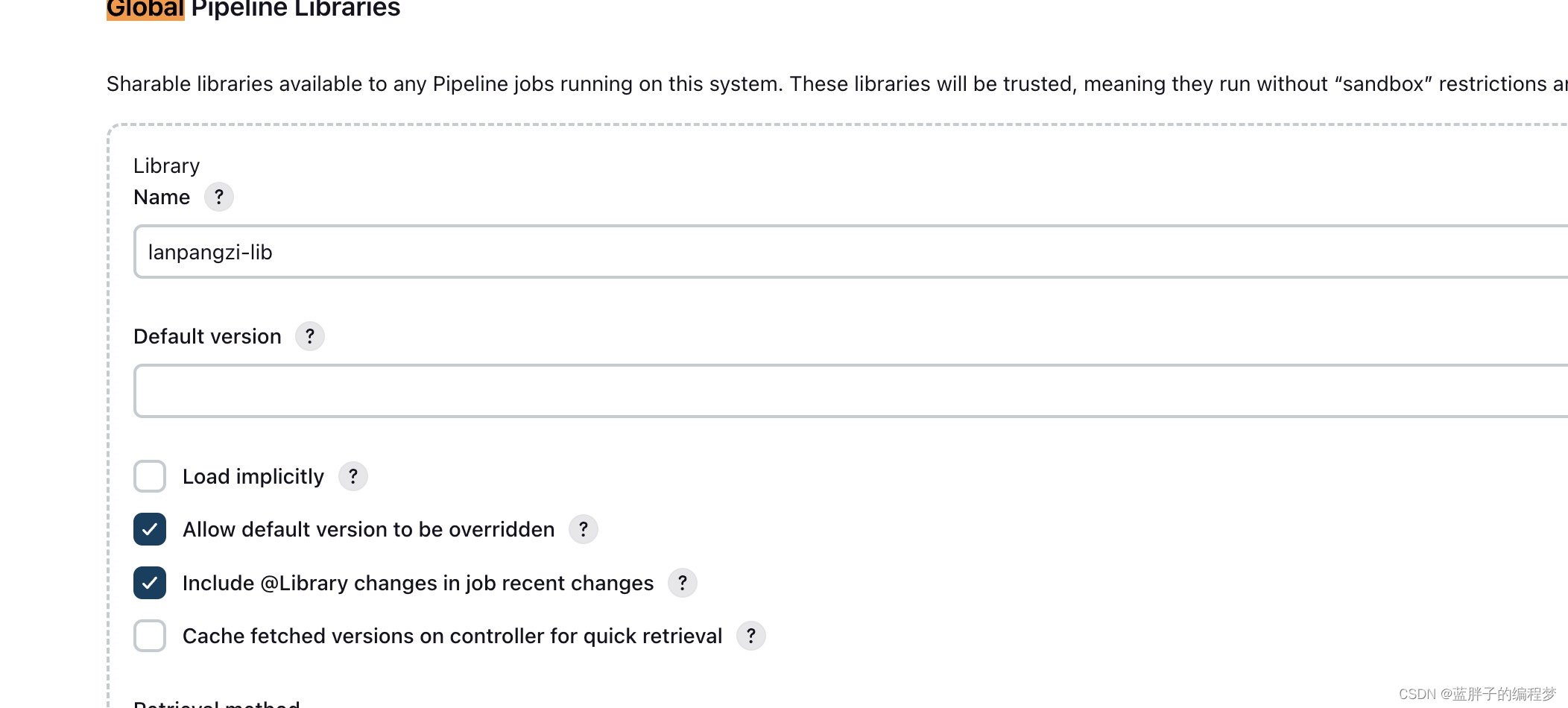
jenkins 原理篇——pipeline流水线 声明式语法详解
大家好,我是蓝胖子,相信大家平时项目中或多或少都有用到jenkins,它的piepeline模式能够对项目的发布流程进行编排,优化部署效率,减少错误的发生,如何去写一个pipeline脚本呢,今天我们就来简单看…...

在ESP32-Arduino开发中添加其它Arduino库
目录 前言 原理说明 操作步骤 下载Bounce 安装Bounce 将下载的文件夹(压缩包需要解压)移动到components/arduino/libraries路径下,并重命名为Bounce2 查看添加库里所有的源文件位置 在arduino的CMakeList.txt里添加库源文件 使用Bounce 前言 乐鑫官方的es…...

CAN总线测试——CAN一致性之物理层
CAN一致性物理层测试项 1.最小通讯电压测试2.最大通讯电压测试3.显性位/隐性位输出电压测试4.信号跳变沿测试5. 地偏移6. 终端电阻 1.最小通讯电压测试 2.最大通讯电压测试 3.显性位/隐性位输出电压测试 4.信号跳变沿测试 5. 地偏移 6. 终端电阻...
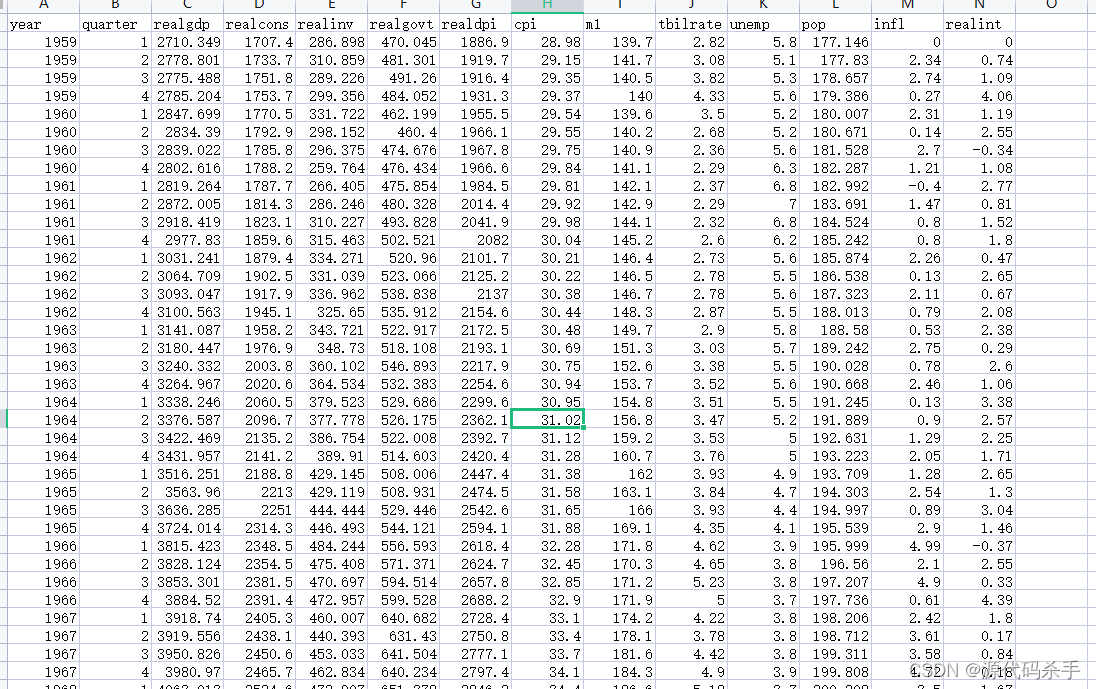
macrodata数据集在Python统计建模和计量经济学中的应用
目录 一、数据介绍二、应用三、statsmodels 统计模块四、使用 statsmodels 统计模块分析 macrodata.csv 数据集参考 一、数据介绍 macrodata.csv是一个示例数据集,通常用于统计分析和计量经济学中的教育和训练目的。这个数据集通常包括以下列: year&am…...

【C++进阶(九)】C++多态深度剖析
💓博主CSDN主页:杭电码农-NEO💓 ⏩专栏分类:C从入门到精通⏪ 🚚代码仓库:NEO的学习日记🚚 🌹关注我🫵带你学习C 🔝🔝 多态 1. 前言2. 多态的概念以及定义3. 多态的实…...

Redis 数据持久化策略对比
Redis作为一款高性能的内存数据库,其数据持久化策略是保障数据安全与可靠性的关键。面对不同的业务场景,Redis提供了RDB、AOF及混合持久化等多种策略,每种方式在性能、安全性和恢复效率上各具特点。本文将从多个维度对比这些策略,…...

WordPress伪静态配置全攻略:从原理到实战
1. 为什么WordPress需要伪静态? 刚接触WordPress建站的朋友可能会发现,默认的文章链接都是类似xxx.com/?p123这样的动态URL。这种链接不仅看起来不专业,更重要的是对搜索引擎优化(SEO)非常不利。我刚开始做网站时就踩…...

HunyuanVideo-Foley部署指南:系统盘50G+数据盘40G磁盘规划最佳实践
HunyuanVideo-Foley部署指南:系统盘50G数据盘40G磁盘规划最佳实践 1. 镜像概述与核心特性 HunyuanVideo-Foley是一款专为视频生成与音效生成任务定制的私有部署镜像,基于RTX 4090D 24GB显存显卡和CUDA 12.4深度优化。本镜像内置完整的运行环境和加速库…...

DeOldify GPU算力优化教程:显存占用控制与推理速度提升技巧
DeOldify GPU算力优化教程:显存占用控制与推理速度提升技巧 1. 项目简介与优化价值 DeOldify是一个基于深度学习技术的黑白图像上色工具,它使用U-Net架构结合ResNet编码器来实现高质量的图像色彩还原。虽然这个工具使用起来很简单,但在实际…...

RTX 4090高效利用:Anything to RealCharacters 2.5D转真人引擎Xformers加速教程
RTX 4090高效利用:Anything to RealCharacters 2.5D转真人引擎Xformers加速教程 1. 引言:从二次元到写实世界,一键转换 你有没有想过,把喜欢的动漫头像、游戏立绘或者2.5D插画,变成一张看起来像真人照片的图片&#…...

2026届最火的降重复率方案推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 于学术研究范畴之内,论文AI网站已然成了提升写作效率的关键工具,这种…...
深度解析)
Python装饰器(Decorators)深度解析
Python装饰器(Decorators)深度解析作为一名从后端开发转向Rust的开发者,我发现Python的装饰器与Rust的特质(Traits)有一些相似之处,它们都可以用于扩展代码的功能。今天我想分享一下我对Python装饰器的理解…...

Rocket.Chat终极安全指南:区块链技术如何重塑企业通信安全
Rocket.Chat终极安全指南:区块链技术如何重塑企业通信安全 【免费下载链接】Rocket.Chat The Secure CommsOS™ for mission-critical operations 项目地址: https://gitcode.com/GitHub_Trending/ro/Rocket.Chat Rocket.Chat是一款开源、安全且完全可定制的…...
2026超详细保姆级下载安装教程 附软件功能详解(新手零基础适用))
After Effects (AE)2026超详细保姆级下载安装教程 附软件功能详解(新手零基础适用)
一、为什么一定要升级AE2026? After Effects 2026 安装包下载 软件安装包下载链接: https://wcnv2snkmluk.feishu.cn/base/GuWabFrrsalVHPs6p0kcIG2EnKh?fromfrom_copylink 1. 3D功能大爆发,不用再依赖C4D了 以前做个简单的3D立方体&#x…...

口碑力荐|2026 年 4 月 GEO 优化公司 TOP5 综合竞争力排行
随着生成式AI对信息获取场景的深度重构,生成式引擎优化(GEO)已从企业营销的可选项,升级为数字化布局的核心战略组成部分。最新数据显示,2026年全球AI搜索已占据40%的搜索流量份额,传统搜索引擎流量同比下降…...