自然语言处理---Transformer机制详解之GPT2模型介绍
1 GPT2的架构
从模型架构上看, GPT2并没有特别新颖的架构, 它和只带有解码器模块的Transformer很像.
所谓语言模型, 作用就是根据已有句子的一部分, 来预测下一个单词会是什么. 现实应用中大家最熟悉的一个语言模型应用, 就是智能手机上的输入法, 它可以根据当前输入的内容智能推荐下一个要打的字.
GPT2也是一个语言预测生成模型, 只不过比手机上应用的模型要大很多, 也更加复杂. 常见的手机端应用的输入法模型基本占用50MB空间, 而OpenAI的研究人员使用了40GB的超大数据集来训练GPT2, 训练后的GPT2模型最小的版本也要占用超过500MB空间来存储所有的参数, 至于最大版本的GPT2则需要超过6.5GB的存储空间.
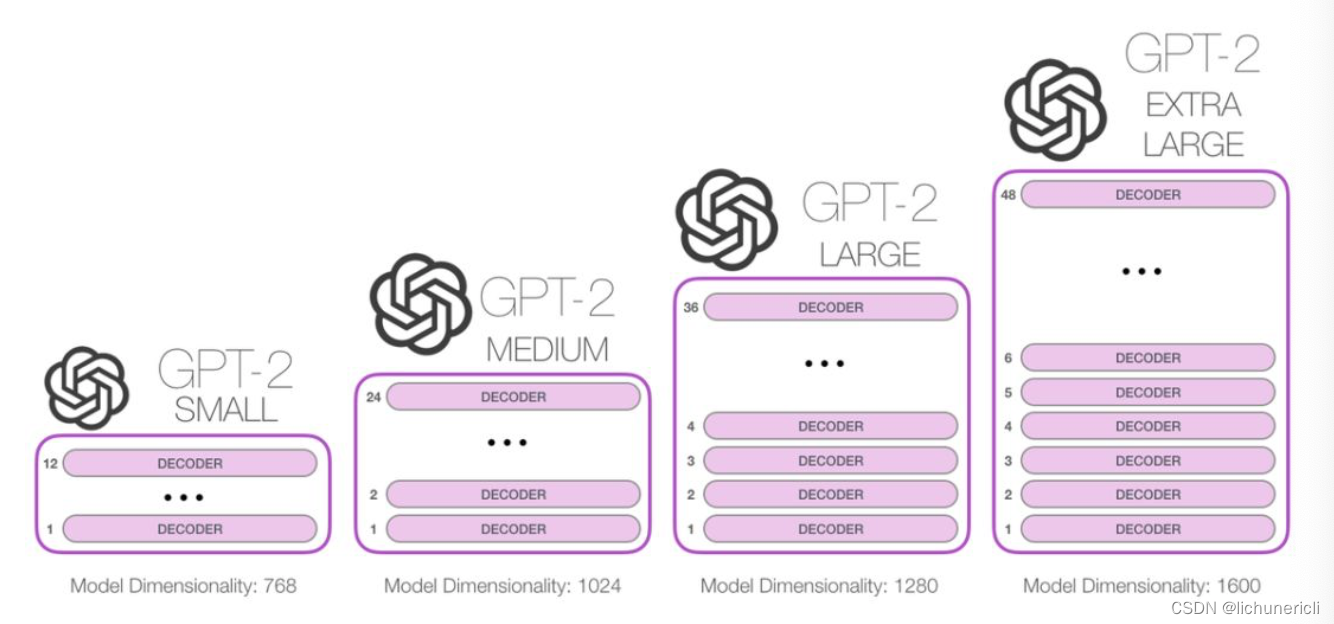
自从Transformer问世以来, 很多预训练语言模型的工作都在尝试将编码器或解码器堆叠的尽可能高, 那类似的模型可以堆叠到多深呢? 事实上, 这个问题的答案也就是区别不同GPT2版本的主要因素之一. 比如最小版本的GPT2堆叠了12层, 中号的24层, 大号的36层, 超大号的堆叠了整整48层!
2 GPT2模型的细节
以机器人第一法则为例, 来具体看GPT2的工作细节. * 机器人第一法则: 机器人不得伤害人类, 或者目睹人类将遭受危险而袖手旁观.
2.1 模型过程
首先明确一点: GPT2的工作流程很像传统语言模型, 一次只输出一个单词(token).
GPT2之所以在生成式任务中表现优秀, 是因为在每个新单词(token)产生后, 该单词就被添加在之前生成的单词序列后面, 添加后的新序列又会成为模型下一步的新输入. 这种机制就叫做自回归(auto-regression), 如下所示:

其次明确一点: GPT2模型是一个只包含了Transformer Decoder模块的模型.
和BERT模型相比, GPT2的解码器在self-attention层上有一个关键的差异: 它将后面的单词(token)遮掩掉, 而BERT是按照一定规则将单词替换成[MASK].
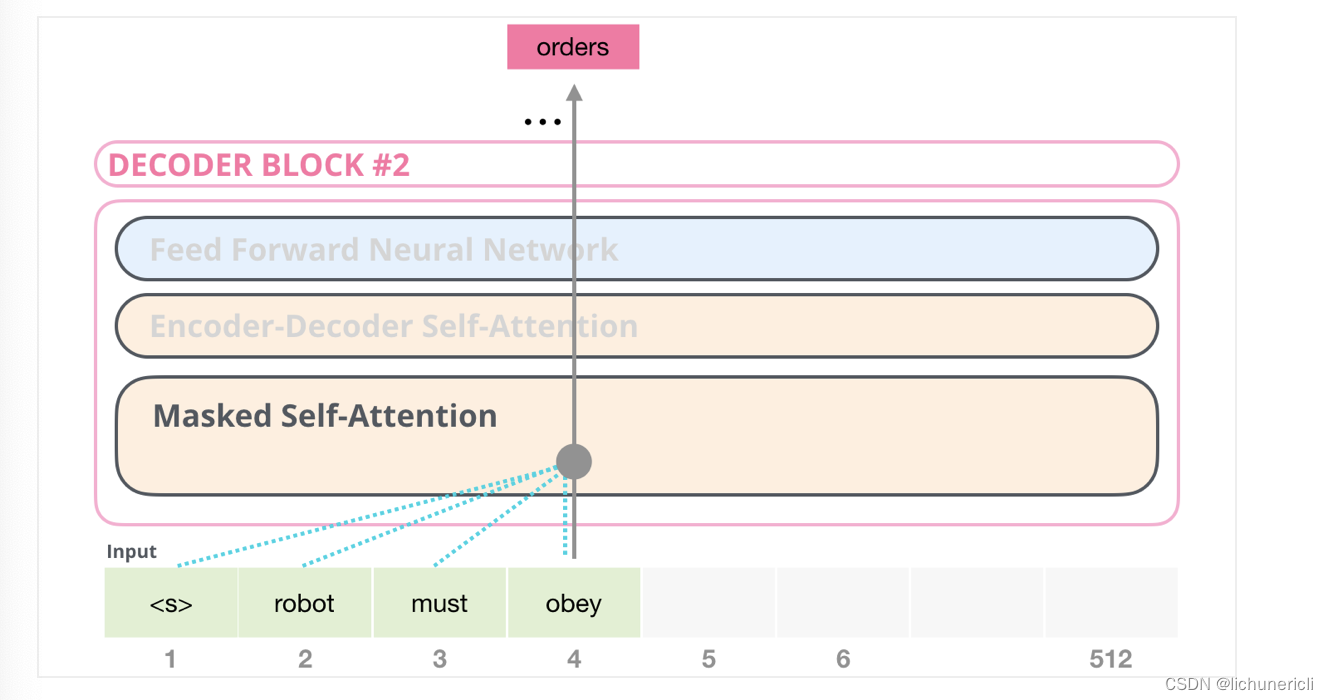
举个例子, 如果我们重点关注4号位置的单词及其前序路径, 我们可以让模型只允许注意当前计算的单词和它之前的单词, 如下图所示:
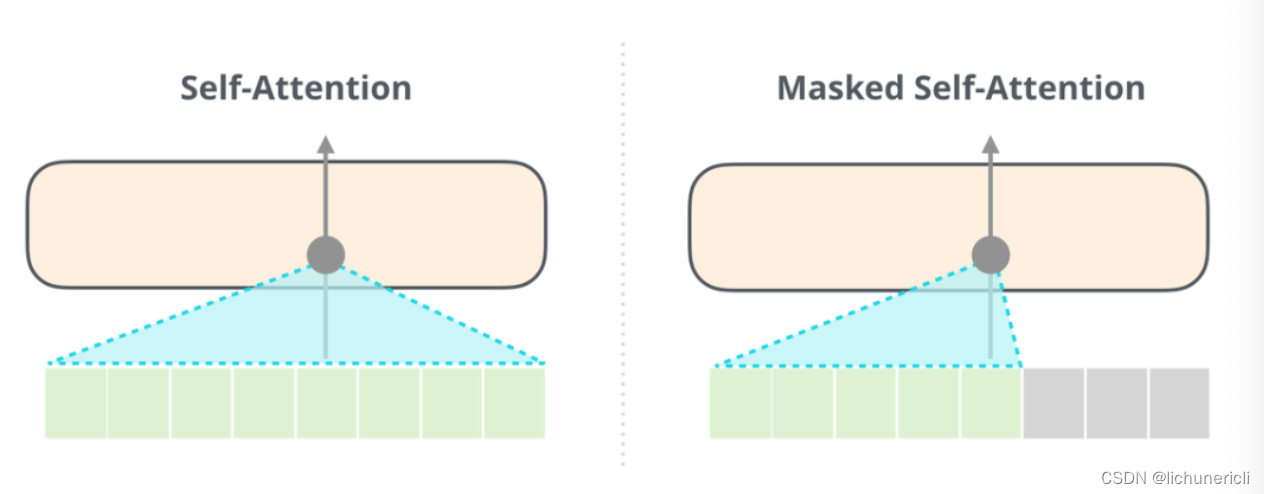
注意: 能够清楚的区分BERT使用的自注意力模块(self-attention)和GPT2使用的带掩码的自注意力模块(masked self-attention)很重要! 普通的self-attention允许模型的任意一个位置看到它右侧的信息(下图左侧), 而带掩码的self-attention则不允许这么做(下图右侧).
在Transformer原始论文发表后, 一篇名为<< Generating Wikipedia by Summarizing Long Sequences >>的论文提出用另一种Transformer模块的排列方式来进行语言建模-它直接扔掉了编码器, 只保留解码器. 这个早期的基于Transformer的模型由6个Decoder Block堆叠而成:
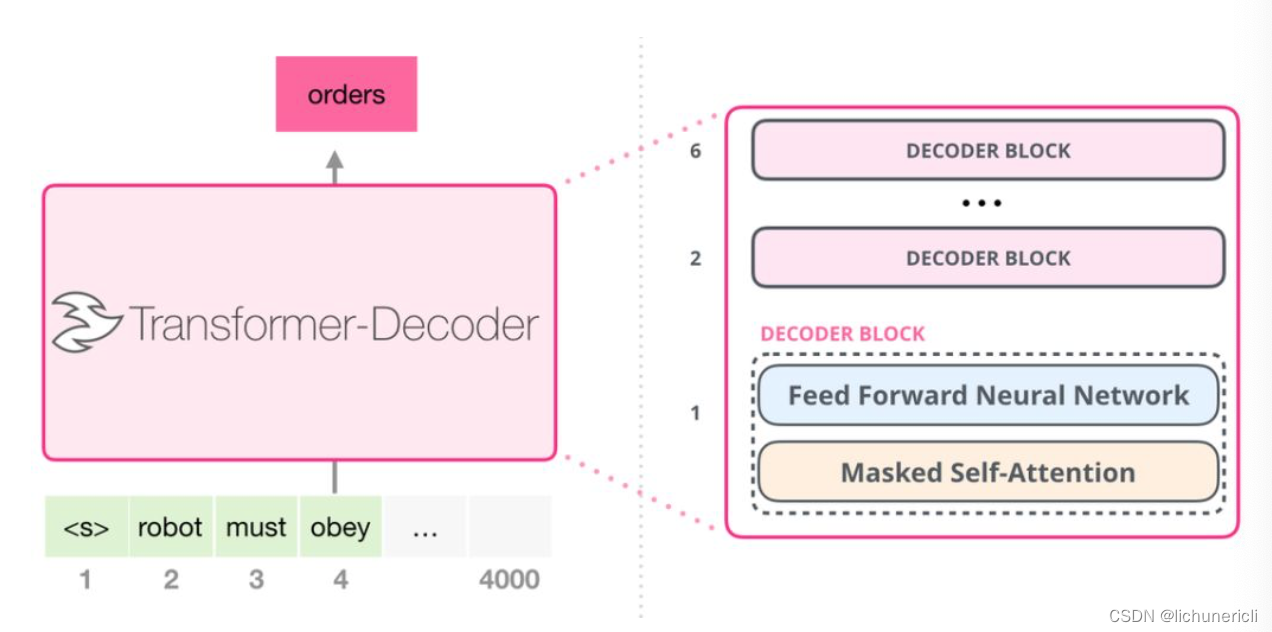
上图中所有的解码器模块都是一样的, 因为只展开了第一个解码器的内部结构. 和GPT一样, 只保留了带掩码的self-attention子层, 和Feed Forward子层.
这些解码器和经典Transformer原始论文中的解码器模块相比, 除了删除了第二个Encoder-Decoder Attention子层外, 其他构造都一样.
2.2 GPT2工作细节探究
- GPT2可以处理最长1024个单词的序列.
- 每个单词都会和它的前序路径一起"流经"所有的解码器模块.
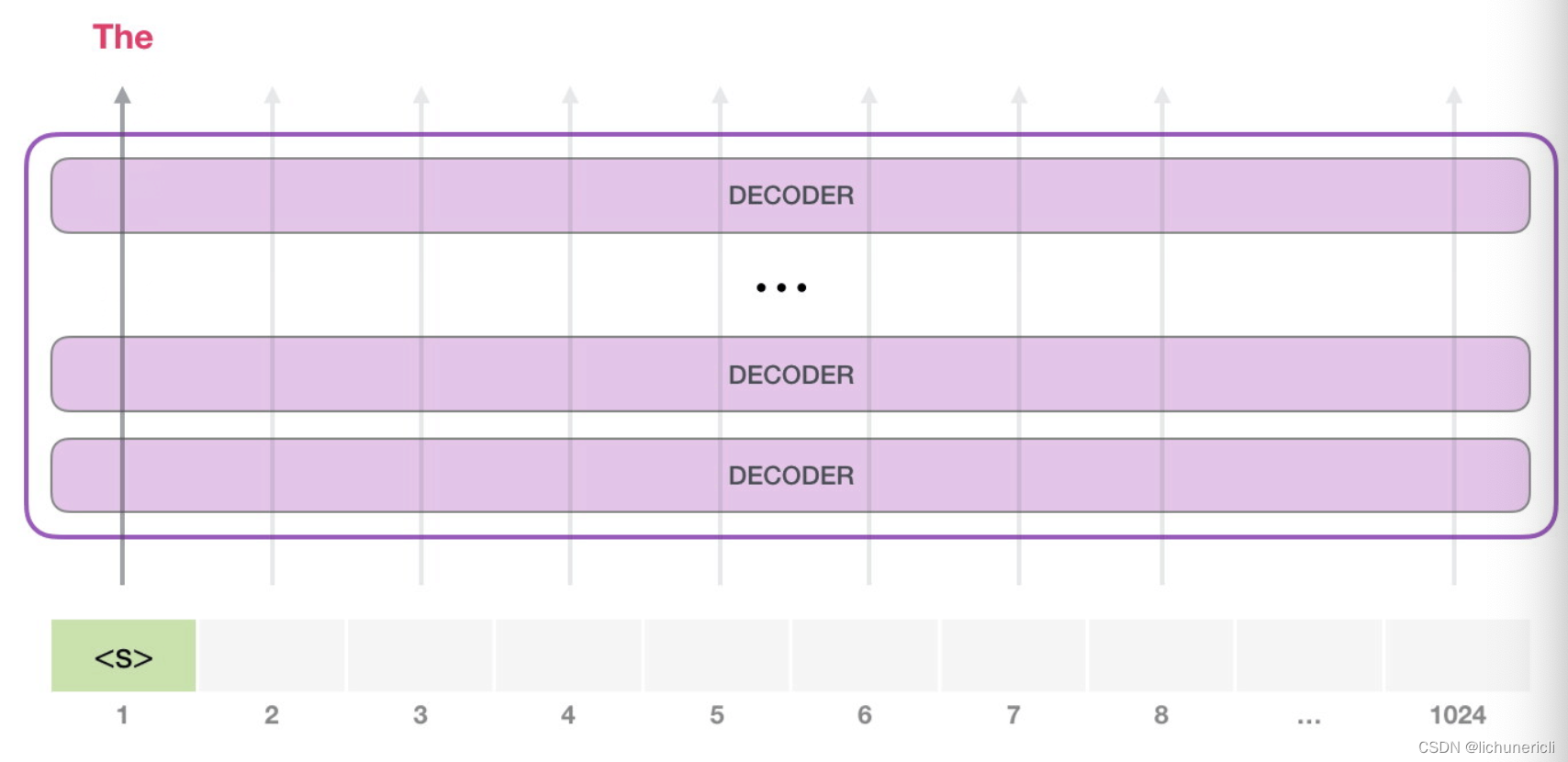
对于生成式模型来说, 基本工作方式都是提供一个预先定义好的起始token, 比如记做"s".
此时模型的输入只有一个单词, 所以只有这个单词的路径是活跃的. 单词经过层层处理, 最终得到一个词向量. 该向量可以对于词汇表的每个单词计算出一个概率(GPT2的词汇表中有50000个单词). 在本例中, 我们选择概率最高的单词["The"]作为下一个单词.
注意: 这种选择最高概率输出的策略有时会出现问题-如果我们持续点击输入法推荐单词的第一个, 它可能会陷入推荐同一个词的循环中, 只有你点击第二个或第三个推荐词, 才能跳出这种循环. 同理, GPT2有一个top-k参数, 模型会从概率最大的前k个单词中抽样选取下一个单词.
- 接下来, 我们将输出的单词["The"]添加在输入序列的尾部, 从而构建出新的输入序列["s", "The"], 让模型进行下一步的预测:
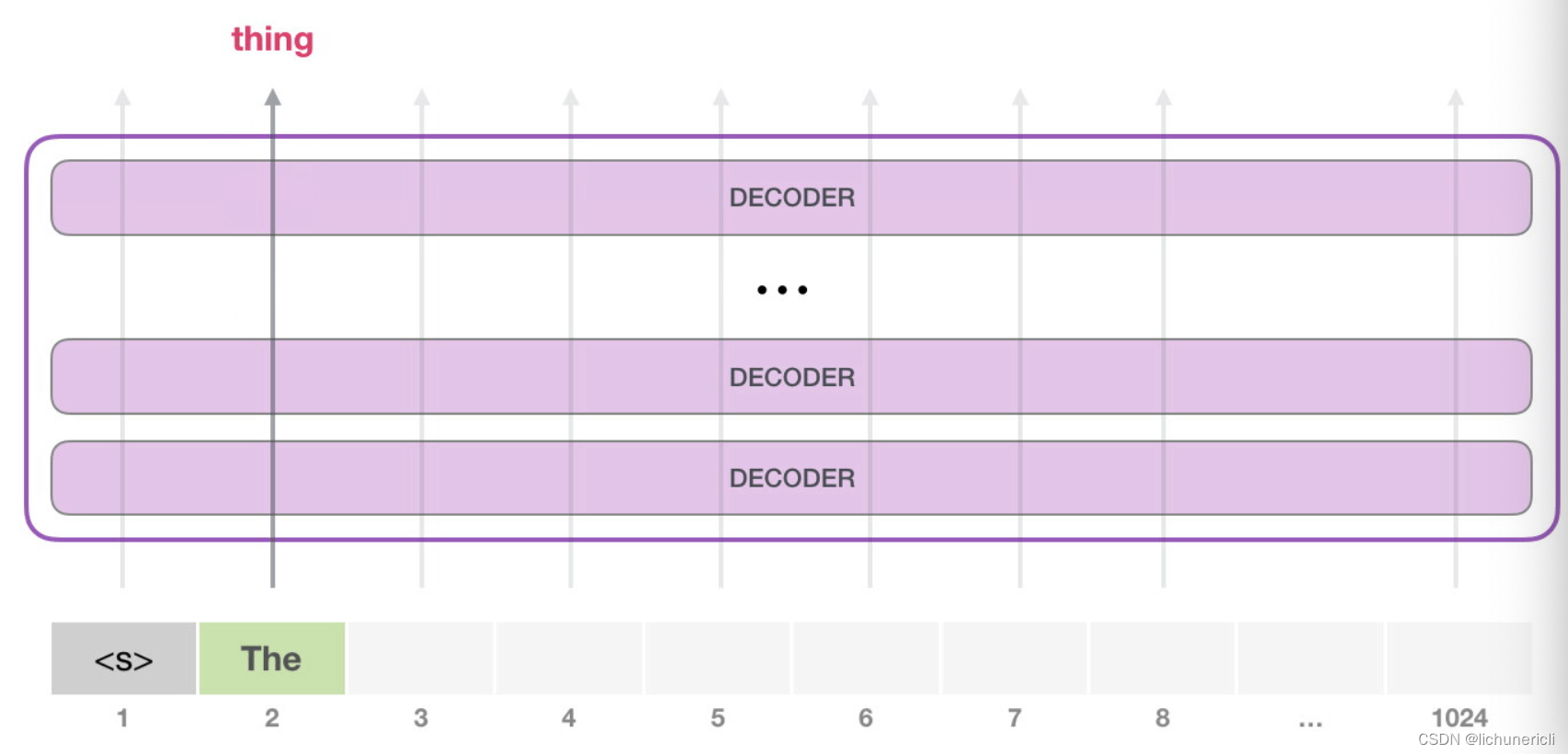
- 此时第二个单词的路径是当前唯一活跃的路径了. GPT2的每一层都保留了它们对第一个单词的解释, 并且将运用这些信息处理第二个单词, GPT2不会根据第二个单词重新来解释第一个单词.
- 关于输入编码: 当我们更加深入的了解模型的内部细节时, 最开始就要面对模型的输入, 和其他自然语言模型一样, GPT2同样从嵌入矩阵中查找单词对应的嵌入向量, 该矩阵(embedding matrix)也是整个模型训练结果的一部分.
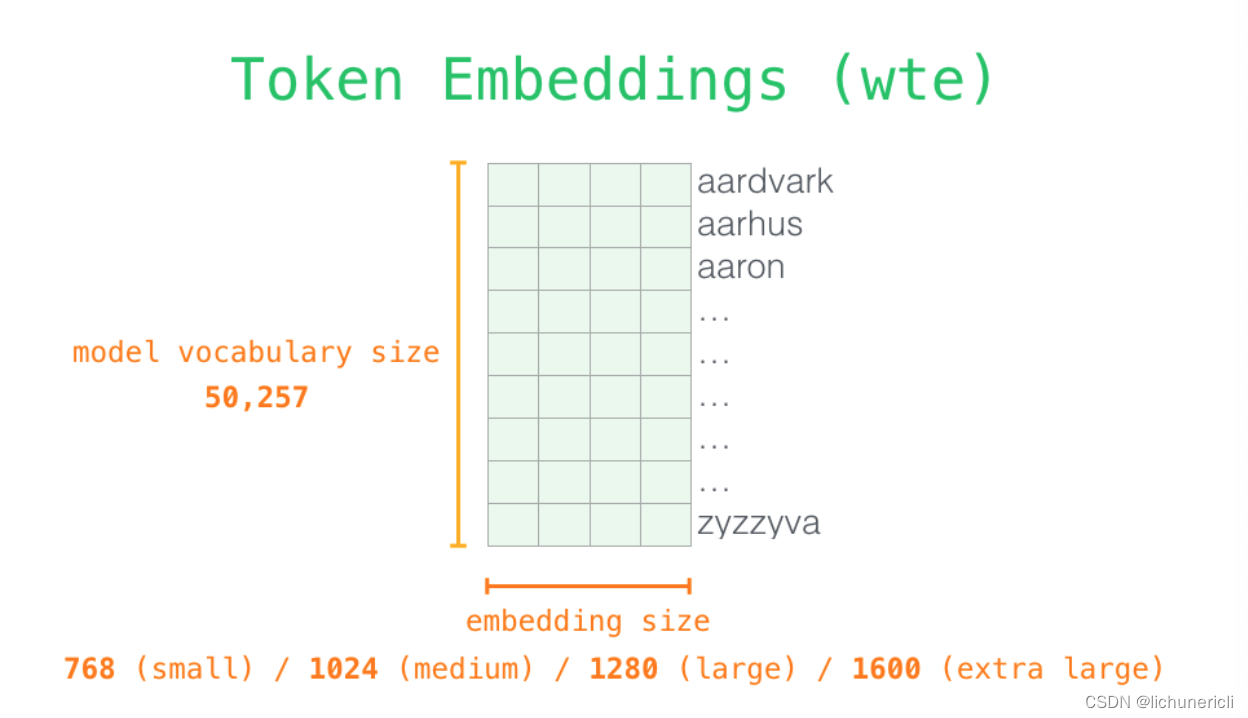
如上图所示, 每一行都是一个词嵌入向量: 一个能够表征某个单词, 并捕获其语义的数字向量. 嵌入的维度大小和GPT2模型的大小相关, 最小的模型采用了768这个维度, 最大的采用了1600这个维度.
所以在整个模型运作起来的最开始, 我们需要在嵌入矩阵中查找起始单词"s"对应的嵌入向量. 但在将其输入给模型之前, 还需要引入位置编码(positional encoding), 1024分输入序列位置中的每一个都对应了一个位置编码, 同理于词嵌入矩阵, 这些位置编码组成的矩阵也是整个模型训练结果的一部分.
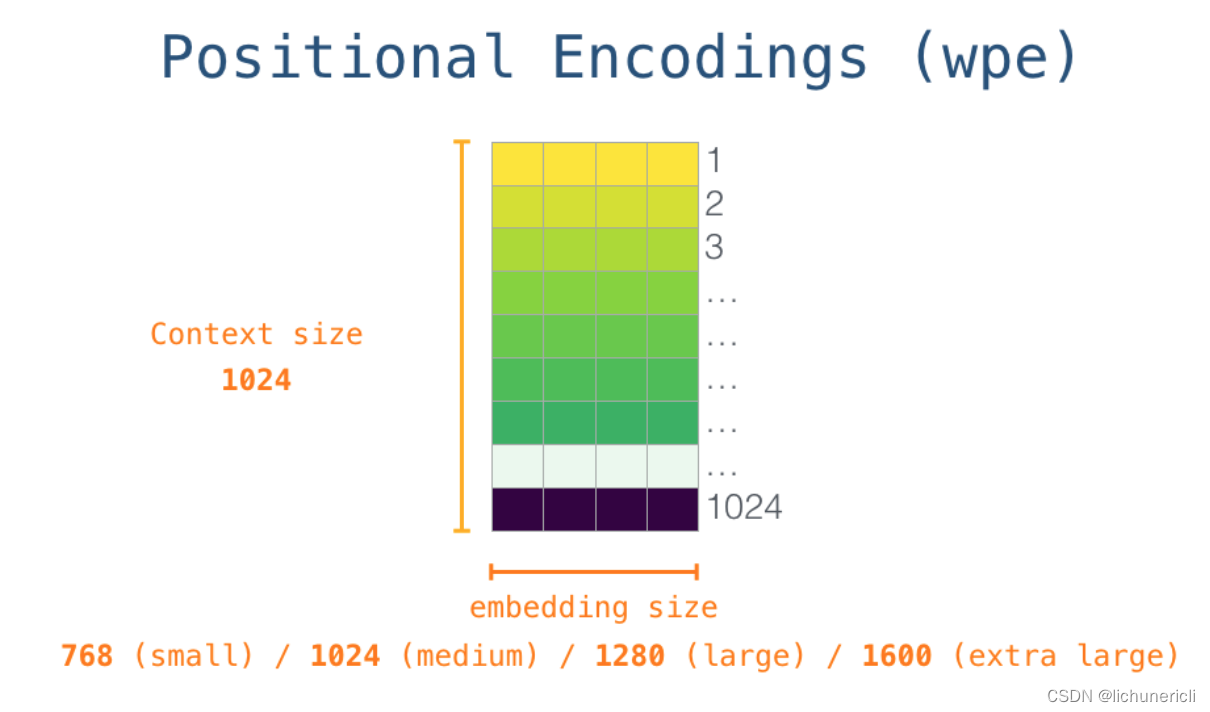
- 经历前面的1, 2两步, 输入单词在进入模型第一个transformer模块前的所有处理步骤就结束了. 综上所述, GPT2模型包含两个权值矩阵: 词嵌入矩阵和位置编码矩阵. 而输入到transformer模块中的张量就是这两个矩阵对应的加和结果.

transformer模块的堆叠: * 最底层的transformer模块处理单词的步骤: * 首先通过自注意力层处理, 接着将其传递给前馈全连接层, 这其中包含残差连接和Layer Norm等子层操作. * 最底层的transformer模块处理结束后, 会将结果张量传递给第二层的transformer模块, 继续进行计算. * 每一个transformer模块的处理方式都是一样的, 不断的重复相同的模式, 但是每个模块都会维护自己的self-attention层和Feed Forward层的权重值.

- GPT2的自注意力机制回顾
- 自然语言的含义是极度依赖上下文的, 比如下面所展示的"机器人第二法则":
机器人必须遵守人类给它的命令, 除非该命令违背了第一法则.
在上述语句中, 有三处单词具有指代含义, 除非我们知道这些词所精确指代的上下文, 否则根本不可能理解这句话的真实语义.
当模型处理这句话的时候, 模型必须知道以下三点:
[它]指代机器人.
[命令]指代前半句话中人类给机器人下达的命令, 即[人类给它的命令].
[第一法则]指代机器人第一法则的完整内容.
这就是自注意力机制所做的工作, 它在处理每个单词之前, 融入了模型对于用来解释某个单词的上下文的相关单词的理解. 具体的做法是: 给序列中的每一个单词都赋予一个相关度得分, 本质上就是注意力权重.
看下图, 举个例子, 最上层的transformer模块在处理单词"it"的时候会关注"a robot", 所以"a", "robot", "it", 这三个单词与其得分相乘加权求和后的特征向量会被送入之后的Feed Forward层.

自注意力机制沿着序列的每一个单词的路径进行处理, 主要由3个向量组成:
Query(查询向量), 当前单词的查询向量被用来和其它单词的键向量相乘, 从而得到其它词相对于当前词的注意力得分.
Key(键向量), 键向量就像是序列中每个单词的标签, 它使我们搜索相关单词时用来匹配的对象.
Value(值向量), 值向量是单词真正的表征, 当我们算出注意力得分后, 使用值向量进行加权求和得到能代表当前位置上下文的向量.
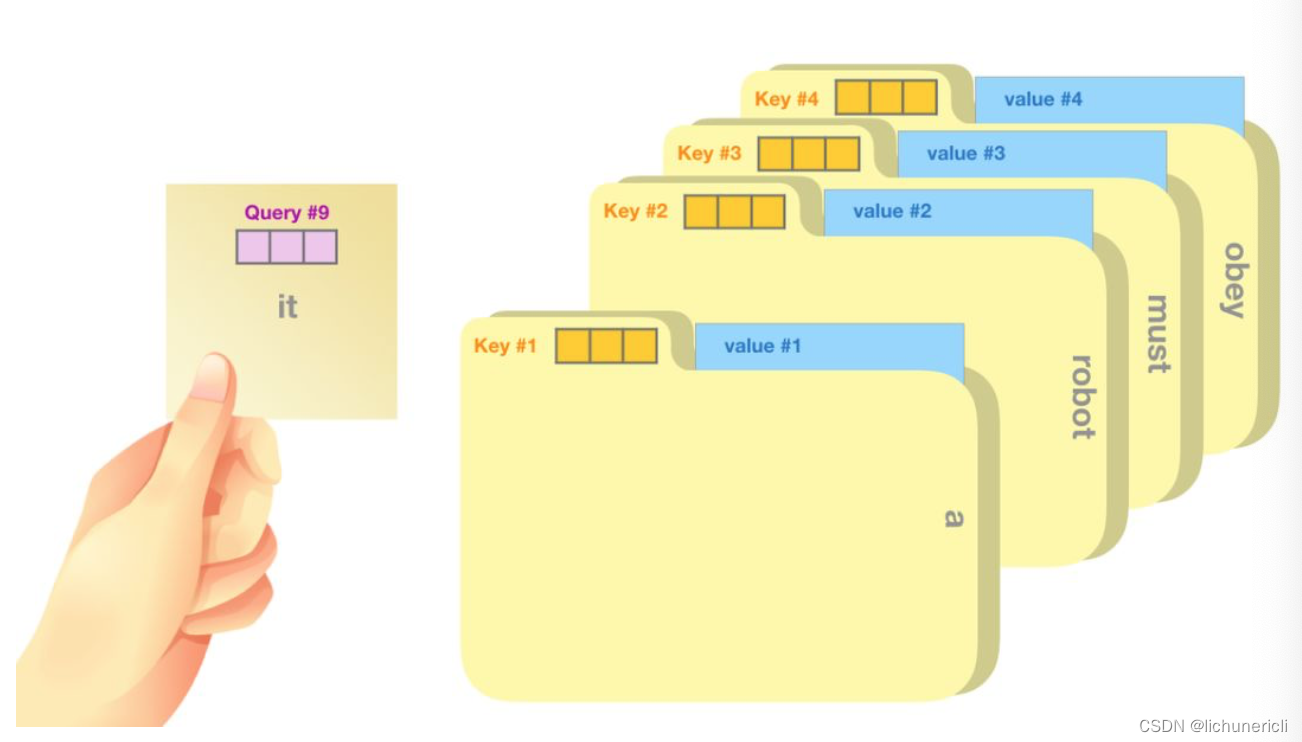
如上图所示, 一个简单的比喻是在档案柜中找文件. 查询向量Query就像一张便利贴, 上面写着你正在研究的课题. 键向量Key像是档案柜中文件夹上贴的标签. 当你找到和便利贴上所写相匹配的文件夹时, 拿出对应的文件夹, 文件夹里的东西便是值向量Value.
将单词的查询向量Query分别乘以每个文件夹的键向量Key,得到各个文件夹对应的注意力得分Score.
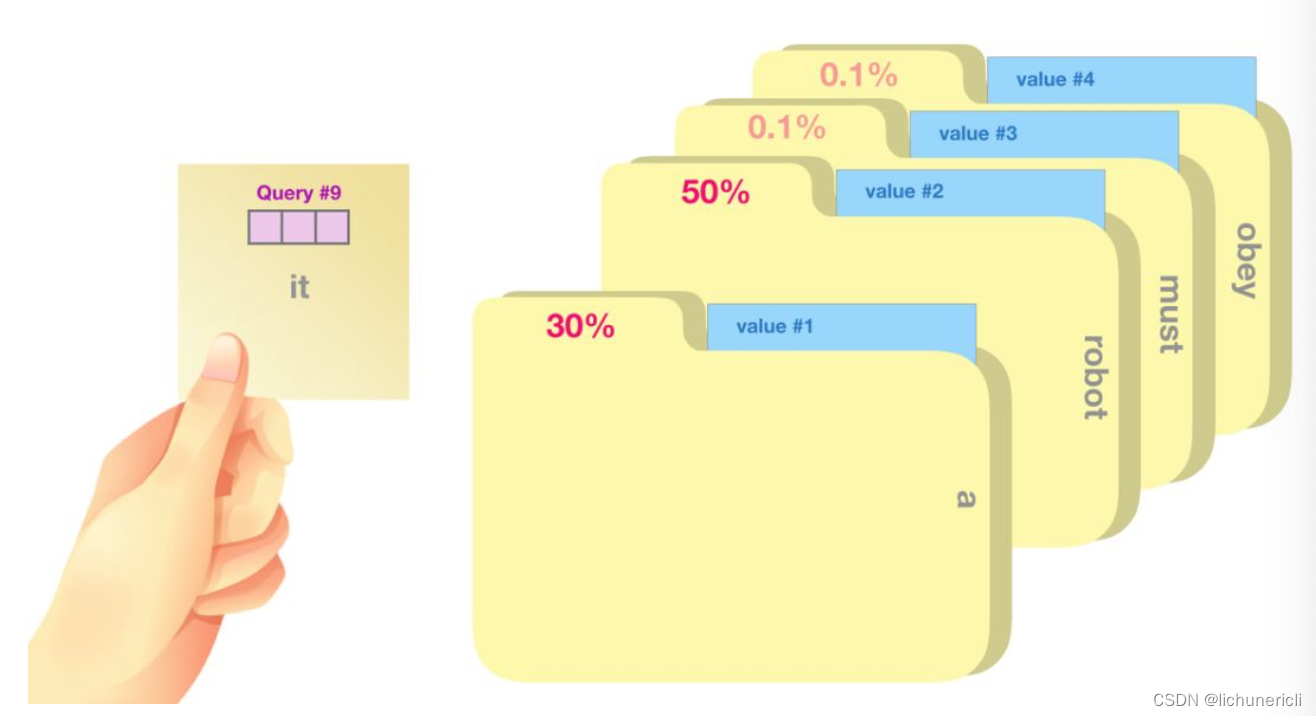
- 我们将每个文件夹的值向量Value乘以其对应的注意力得分Score, 然后求和, 得到最终自注意力层的输出, 如下图所示:
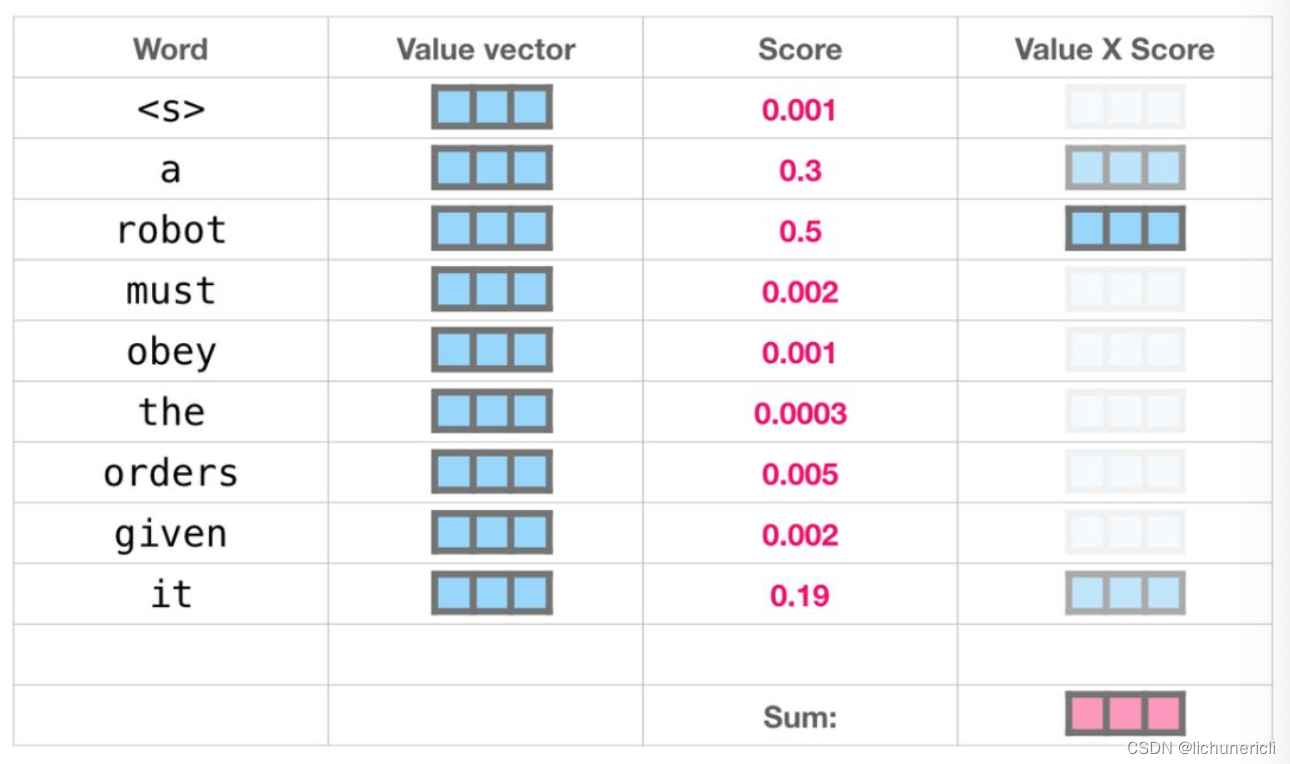
- 这样将值向量加权混合得到的结果也是一个向量, 它将其50%的注意力放在了单词"robot"上, 30%的注意力放在了"a"上, 还有19%的注意力放在了"it"上.
- 模型的输出:
- 当最后一个transformer模块产生输出之后, 模型会将输出张量乘上词嵌入矩阵:

- 我们知道, 词嵌入矩阵的每一行都对应模型的词汇表中一个单词的嵌入向量. 所以这个乘法操作得到的结果就是词汇表中每个单词对应的注意力得分, 如下图所示:

一般来说, 我们都采用贪心算法, 选取得分最高的单词作为输出结果(top_k = 1).
但是一个更好的策略是对于词汇表中得分较高的一部分单词, 将它们的得分作为概率从整个单词列表中进行抽样(得分越高的单词越容易被选中).
通常会用一个折中的方法, 即选取top_k = 40, 这样模型会考虑注意力得分排名前40的单词.
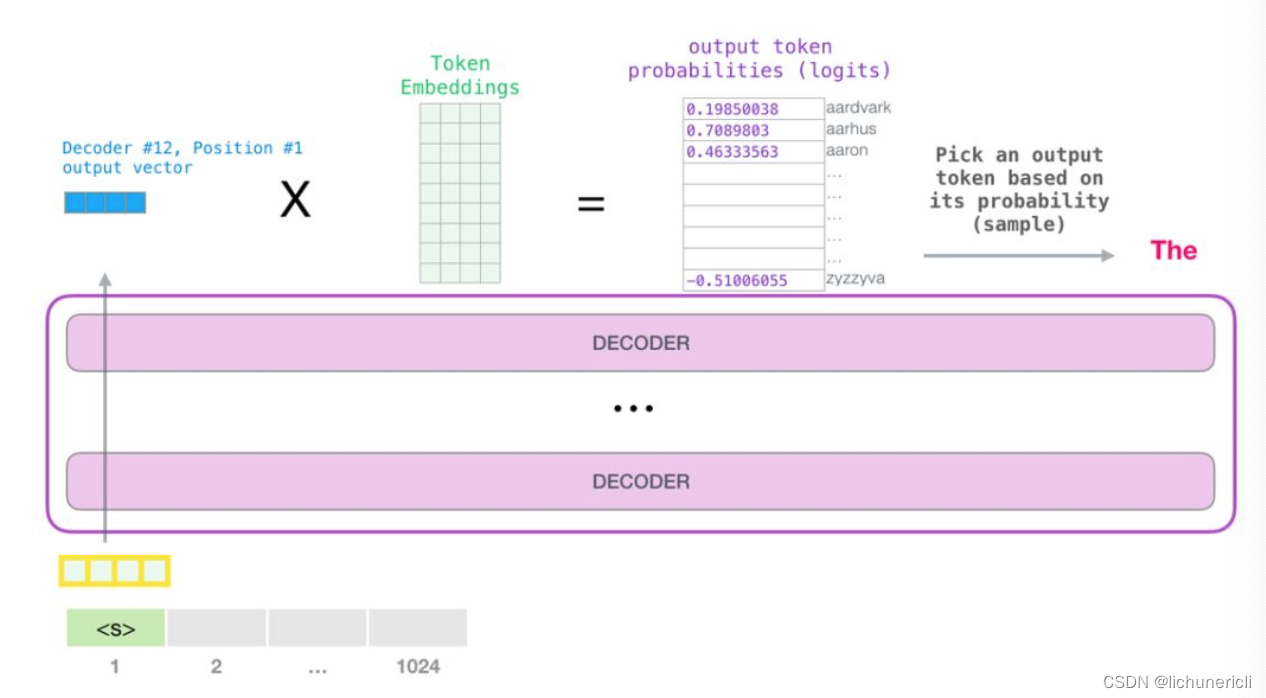
- 如上图所示, 模型就完成了一个时间步的迭代, 输出了一个单词. 接下来模型会不断的迭代, 直至生成完整的序列(序列长度达到1024的上限, 或者序列的某一个时间步生成了结束符).
3 小结
-
GPT2的架构:
- GPT2只采用了Transformer架构中的Decoder模块.
- GPT2是在GPT基础上发展处的更强大的语言预训练模型.
-
GPT2的工作细节:
- GPT2可以处理最长1024个单词的序列.
- 每个单词都会和它的前序路径一起"流经"所有的解码器模块.
- GPT2本质上也是自回归模型.
- 输入张量要经历词嵌入矩阵和位置编码矩阵的加和后, 才能输入进transformer模块中.
-
GPT2自注意力机制的细节:
- 首先, GPT2的自注意力是Masked self-attention, 只能看见左侧的序列, 不能看见右侧的信息.
- Query, Key, Value这三个张量之间的形象化的例子, 生动的说明了各自的作用和运算方式.
- 最后的输出可以采用多个方法, 贪心方案, 概率分布方案, 或者top-k方案等.
相关文章:
自然语言处理---Transformer机制详解之GPT2模型介绍
1 GPT2的架构 从模型架构上看, GPT2并没有特别新颖的架构, 它和只带有解码器模块的Transformer很像. 所谓语言模型, 作用就是根据已有句子的一部分, 来预测下一个单词会是什么. 现实应用中大家最熟悉的一个语言模型应用, 就是智能手机上的输入法, 它可以根据当前输入的内容智…...
ChatGPT 即将诞生一周年,OpenAI 将有大动作
图片来源:由无界AI生成 下个月就是 ChatGPT 一周年纪念日。OpenAI 正在谋划新的大动作。可以肯定地说,自诞生以来,ChatGPT 就为 OpenAI 提供了不可阻挡的增长动力。 01 营收超预期,OpenAI 缓了一口气 据 The Information 报道&…...
jenkins 原理篇——pipeline流水线 声明式语法详解
大家好,我是蓝胖子,相信大家平时项目中或多或少都有用到jenkins,它的piepeline模式能够对项目的发布流程进行编排,优化部署效率,减少错误的发生,如何去写一个pipeline脚本呢,今天我们就来简单看…...

在ESP32-Arduino开发中添加其它Arduino库
目录 前言 原理说明 操作步骤 下载Bounce 安装Bounce 将下载的文件夹(压缩包需要解压)移动到components/arduino/libraries路径下,并重命名为Bounce2 查看添加库里所有的源文件位置 在arduino的CMakeList.txt里添加库源文件 使用Bounce 前言 乐鑫官方的es…...

CAN总线测试——CAN一致性之物理层
CAN一致性物理层测试项 1.最小通讯电压测试2.最大通讯电压测试3.显性位/隐性位输出电压测试4.信号跳变沿测试5. 地偏移6. 终端电阻 1.最小通讯电压测试 2.最大通讯电压测试 3.显性位/隐性位输出电压测试 4.信号跳变沿测试 5. 地偏移 6. 终端电阻...
macrodata数据集在Python统计建模和计量经济学中的应用
目录 一、数据介绍二、应用三、statsmodels 统计模块四、使用 statsmodels 统计模块分析 macrodata.csv 数据集参考 一、数据介绍 macrodata.csv是一个示例数据集,通常用于统计分析和计量经济学中的教育和训练目的。这个数据集通常包括以下列: year&am…...

【C++进阶(九)】C++多态深度剖析
💓博主CSDN主页:杭电码农-NEO💓 ⏩专栏分类:C从入门到精通⏪ 🚚代码仓库:NEO的学习日记🚚 🌹关注我🫵带你学习C 🔝🔝 多态 1. 前言2. 多态的概念以及定义3. 多态的实…...

第二节——Vue 基本介绍
一、MV*的理解 1、概念 在计算机编程领域,MV*(也称为MVC、MVP、MVVM等)是一种用于组织和设计应用程序结构的模式。这些模式旨在实现应用程序的解耦、可维护性和可扩展性。MV代表着Model-View-(表示控制器或视图模型等其他组件&a…...
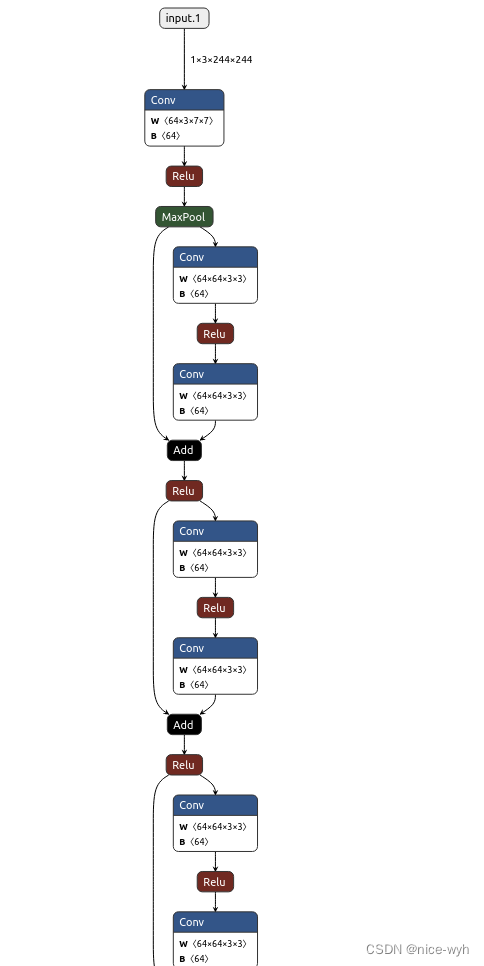
基于ResNet34的花朵分类
一.数据集准备 新建一个项目文件夹ResNet,并在里面建立data_set文件夹用来保存数据集,在data_set文件夹下创建新文件夹"flower_data",点击链接下载花分类数据集https://storage.googleapis.com/download.tensorflow.org/example_i…...

[计算机提升] 数据及相关概念
1.9 数据及相关概念 1.9.1 数据、信息 在Windows系统中,数据是指事实或信息的集合,可以是数字、文本、图像、声音等形式的内容。数据是计算机系统中处理和操作的基本元素,是信息的表现形式和载体。 与信息相比,数据的范围更广泛…...
)
第18章 SpringCloud生态(二)
18.11 说说你了解的负载均衡算法 难度:★★ 重点:★★★★ 白话解析 常用的负载均衡算法有: 1、轮询(Round Robin):说白了就是让服务器排好队,一个个轮着来调用;Ribbon默认采用该算法。 优点:实现起来简单; 缺点:服务器性能不一样的情况下,导致能力强的会经常空闲…...

【Android】BRVAH多布局实现
前言 基于3.0.4版本的BRVAH框架实现的 实现方法 1.创建多个不同类型的布局(步骤忽略) 2.创建数据实体类 数据类要实现【MultiItemEntity】接口 class MyMultiItemEntity(//获取布局类型override var itemType: Int,var tractorRes: Int? null,va…...

AWS SAP-C02教程9-节省成本
SAP-C01变成SAP-C02的时候,最大的变化就是没有把成本单独列出一个模块,但是成本依然包含在各个其它模块之中,所以成本还是很重要的。本章将列举一些成本优化方案以及一些成本辅助功能。 目录 1 Cost Allocation Tags2 Trusted Advisor2.1 AWS Support Plans2.2 基本特性2.3…...
[CSP-S 2023] 种树 —— 二分+前缀和
This way 题意: 一开始以为是水题,敲了一个二分贪心检查的代码,20分。发现从根往某个节点x走的时候,一路走来的子树上的节点到已栽树的节点的距离会变短,那么并不能按照初始情况贪心。 于是就想着检查时候用线段树…...

【LeetCode周赛】LeetCode第368场周赛
目录 元素和最小的山形三元组 I元素和最小的山形三元组 II合法分组的最少组数 元素和最小的山形三元组 I 给你一个下标从 0 开始的整数数组 nums 。 如果下标三元组 (i, j, k) 满足下述全部条件,则认为它是一个山形三元组 : i < j < k nums[i] &l…...
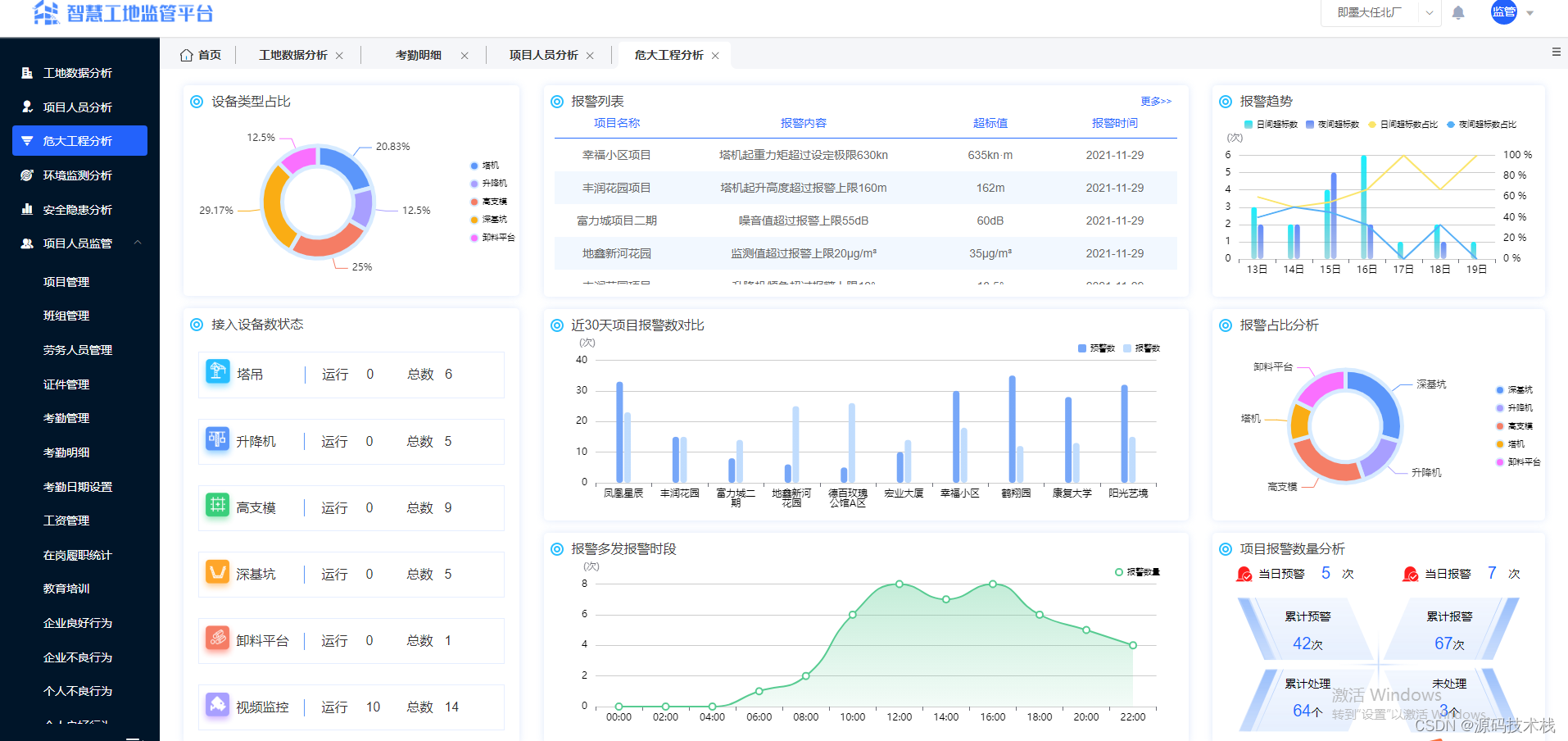
【智慧工地源码】基于AI视觉技术赋能智慧工地
伴随着技术的不断发展,信息化手段、移动技术、智能穿戴及工具在工程施工阶段的应用不断提升,智慧工地概念应运而生,庞大的建设规模催生着智慧工地的探索和研发。 建筑施工具有周期长、环境复杂、工序繁杂、人员流动性大等特点,所以…...

云服务器搭建Hadoop分布式
文章目录 1.服务器配置2.Java环境3. 安装Hadoop4. 集群配置5. 编写集群的启动脚本 1.服务器配置 服务器主机名配置115.157.197.82s110核115.157.197.84s210核115.157.197.109s310核115.157.197.31s410核115.157.197.60gracal10核 所有的软件安装在/opt/module下,软…...

2678. 老人的数目
给你一个下标从 0 开始的字符串 details 。details 中每个元素都是一位乘客的信息,信息用长度为 15 的字符串表示,表示方式如下: 前十个字符是乘客的手机号码。 接下来的一个字符是乘客的性别。 接下来两个字符是乘客的年龄。 最后两个字符是…...
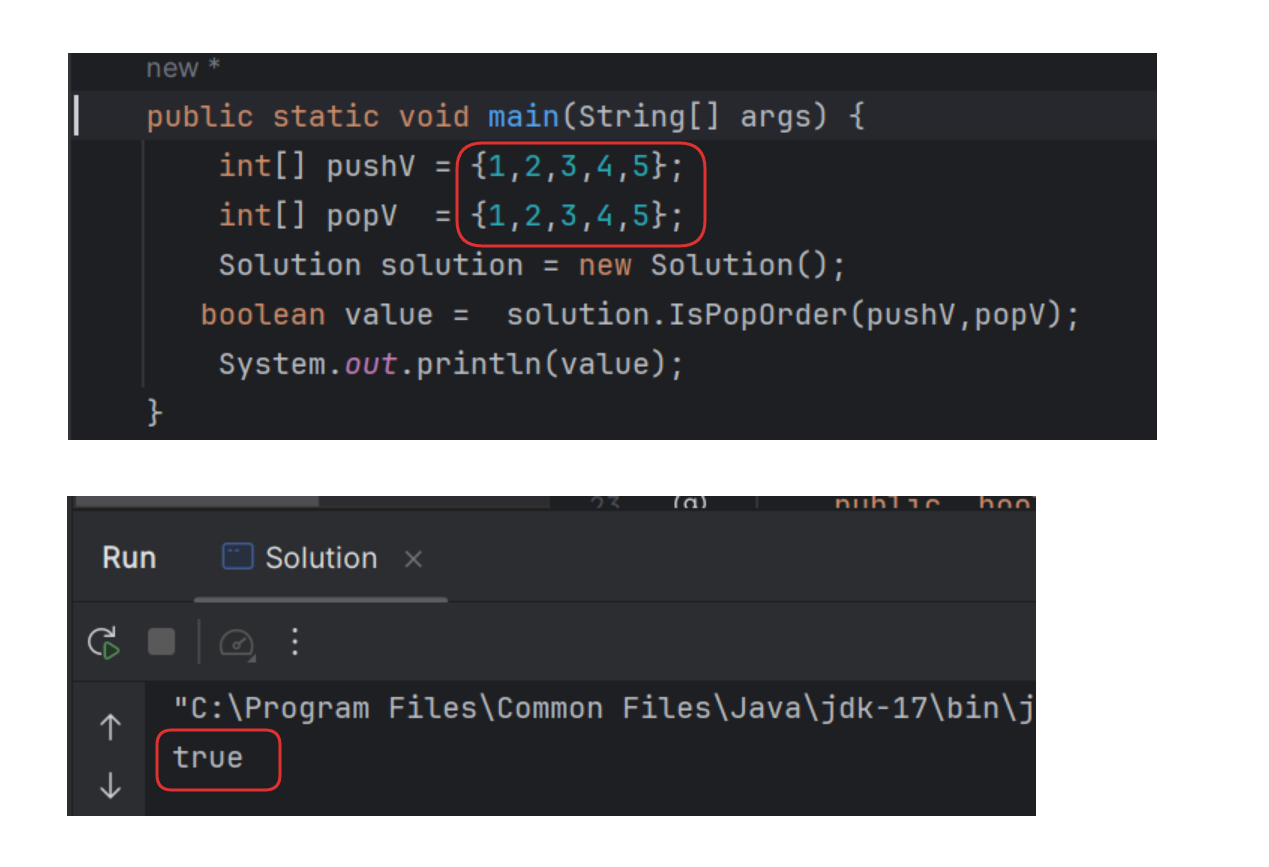
【刷题-牛客】出栈、入栈的顺序匹配 (代码+动态演示)
【刷题-牛客】出栈、入栈的顺序匹配 (代码动态演示) 文章目录 【刷题-牛客】出栈、入栈的顺序匹配 (代码动态演示) 解题思路 动图演示完整代码多组测试 💗题目描述 💗: 输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个…...
vscode类似GitHub Copilot的插件推荐
由于GitHub Copilot前段时间学生认证的账号掉了很多,某宝激活也是价格翻了几倍,而却,拿来用一天就掉线,可以试试同类免费的插件哦。 例如:TabNine,下载插件后,他会提示你登录,直接登…...

FreeRTOS下STM32 HAL库I2C通信避坑:别再傻等I2C_WaitOnFlagUntilTimeout了
FreeRTOS下STM32 HAL库I2C通信优化:从阻塞等待到高效任务调度 在嵌入式开发中,I2C总线因其简单的两线制接口和广泛的外设支持而备受青睐。然而,当我们将STM32的HAL库与FreeRTOS结合使用时,一个常见的性能陷阱正在悄然吞噬着系统的…...

2026年宜春阿里巴巴代运营新趋势:效果显著背后的秘密
引言随着全球贸易的不断深化,越来越多的企业开始关注跨境电商的发展。阿里巴巴国际站作为中国最大的B2B电商平台之一,已成为众多企业出海的重要渠道。然而,如何在竞争激烈的市场中脱颖而出,成为许多企业面临的难题。本文将探讨202…...

基于Halcon与快速傅里叶变换的周期性纹理分离实战
1. 工业视觉检测中的周期性纹理难题 在布匹、金属板材等工业产品的表面检测中,周期性纹理就像一把双刃剑。一方面它是产品工艺特征的体现,另一方面又会掩盖真正的缺陷。我去年参与过一个金属盖板检测项目,客户提供的样品表面有规律的拉丝纹理…...

华硕灵耀X双屏Pro UX8402Z 原厂Win11 22H2系统分享下载
华硕灵耀X双屏Pro UX8402Z配备了一键恢复功能,即使系统出现异常或更换硬盘后,也能通过原厂工厂文件轻松恢复至出厂状态。该功能支持UX8402ZA和UX8402ZE型号,预装Windows 11 22H2家庭版。用户只需准备相应工具并按照安装教程操作即可。这一便捷…...

基于STM32的智能温控系统设计与物联网集成
1. 从零搭建智能温控系统的核心思路 第一次接触STM32温控项目时,我被各种专业术语搞得头晕眼花。后来发现只要抓住三个关键点:精准测温、智能调控、远程操控。就像给房间装空调,首先得知道当前温度(传感器),…...

从按键消抖到多任务通信:手把手教你用STM32CubeMX和FreeRTOS搭建一个‘智能’按键响应系统
从按键消抖到多任务通信:手把手教你用STM32CubeMX和FreeRTOS搭建一个‘智能’按键响应系统 在嵌入式开发中,按键处理看似简单,实则暗藏玄机。当你的项目从简单的单任务裸机系统升级到多任务实时操作系统时,按键处理会面临全新的挑…...

深度强化学习终极指南:如何让机器人在复杂环境中自主导航
深度强化学习终极指南:如何让机器人在复杂环境中自主导航 【免费下载链接】DRL-robot-navigation Deep Reinforcement Learning for mobile robot navigation in ROS Gazebo simulator. Using Twin Delayed Deep Deterministic Policy Gradient (TD3) neural networ…...
Pixel Aurora Engine显存优化:12GB显存稳定生成1024x1024像素画技巧
Pixel Aurora Engine显存优化:12GB显存稳定生成1024x1024像素画技巧 1. 为什么需要显存优化 1.1 高分辨率像素画的显存挑战 生成1024x1024分辨率的像素艺术画作时,显存占用会急剧增加。传统的扩散模型在生成高分辨率图像时,显存消耗往往超…...

如何使用EasyMocap实现精准人体关键点检测与3D运动捕捉:从2D到3D的完整指南
如何使用EasyMocap实现精准人体关键点检测与3D运动捕捉:从2D到3D的完整指南 【免费下载链接】EasyMocap Make human motion capture easier. 项目地址: https://gitcode.com/gh_mirrors/ea/EasyMocap EasyMocap是一款强大的开源人体运动捕捉工具,…...

嵌入式linux设备内存泄露排查思路
文章目录 引言: 一、快速确认 二、定位泄露源(内核态/用户态) 2.1 检查内核内存 2.2 检查用户态进程 三、使用工具排查泄露点 四、修复与验证 引言: 设备自己跑着跑着突然挂死了,还是靠看门狗给救回来了。这种时候,一定要考虑是不是内存泄露导致内存耗尽了。 那我们来看…...