使用GoogleNet网络实现花朵分类
一.数据集准备
新建一个项目文件夹GoogleNet,并在里面建立data_set文件夹用来保存数据集,在data_set文件夹下创建新文件夹"flower_data",点击链接下载花分类数据集https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz,会下载一个压缩包,将它解压到flower_data文件夹下,执行"split_data.py"脚本自动将数据集划分成训练集train和验证集val。
split.py如下:
import os
from shutil import copy, rmtree
import randomdef mk_file(file_path: str):if os.path.exists(file_path):# 如果文件夹存在,则先删除原文件夹在重新创建rmtree(file_path)os.makedirs(file_path)def main():# 保证随机可复现random.seed(0)# 将数据集中10%的数据划分到验证集中split_rate = 0.1# 指向你解压后的flower_photos文件夹cwd = os.getcwd()data_root = os.path.join(cwd, "flower_data")origin_flower_path = os.path.join(data_root, "flower_photos")assert os.path.exists(origin_flower_path), "path '{}' does not exist.".format(origin_flower_path)flower_class = [cla for cla in os.listdir(origin_flower_path)if os.path.isdir(os.path.join(origin_flower_path, cla))]# 建立保存训练集的文件夹train_root = os.path.join(data_root, "train")mk_file(train_root)for cla in flower_class:# 建立每个类别对应的文件夹mk_file(os.path.join(train_root, cla))# 建立保存验证集的文件夹val_root = os.path.join(data_root, "val")mk_file(val_root)for cla in flower_class:# 建立每个类别对应的文件夹mk_file(os.path.join(val_root, cla))for cla in flower_class:cla_path = os.path.join(origin_flower_path, cla)images = os.listdir(cla_path)num = len(images)# 随机采样验证集的索引eval_index = random.sample(images, k=int(num*split_rate))for index, image in enumerate(images):if image in eval_index:# 将分配至验证集中的文件复制到相应目录image_path = os.path.join(cla_path, image)new_path = os.path.join(val_root, cla)copy(image_path, new_path)else:# 将分配至训练集中的文件复制到相应目录image_path = os.path.join(cla_path, image)new_path = os.path.join(train_root, cla)copy(image_path, new_path)print("\r[{}] processing [{}/{}]".format(cla, index+1, num), end="") # processing barprint()print("processing done!")if __name__ == '__main__':main()
之后会在文件夹下生成train和val数据集,到此,完成了数据集的准备。
二.定义网络
新建model.py,参照GoogleNet的网络结构和pytorch官方给出的代码,对代码进行略微的修改即可,在他的代码里首先定义了三个类BasicConv2d、Inception、InceptionAux,即基础卷积、Inception模块、辅助分类器三个部分,接着定义了GoogleNet类,对上述三个类进行调用,完成前向传播。
pytorch官方示例GoogleNet代码
import warnings
from collections import namedtuple
from functools import partial
from typing import Any, Callable, List, Optional, Tupleimport torch
import torch.nn as nn
import torch.nn.functional as F
from torch import Tensorclass GoogLeNet(nn.Module):def __init__(self, num_classes = 1000, aux_logits = True, transform_input = False, init_weights = True):super(GoogLeNet,self).__init__()self.aux_logits = aux_logitsself.transform_input = transform_inputself.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3) #3为输入通道数,64为输出通道数self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)self.conv2 = BasicConv2d(64, 64, kernel_size=1)self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)self.maxpool4 = nn.MaxPool2d(2, stride=2, ceil_mode=True)self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)if aux_logits:self.aux1 = InceptionAux(512, num_classes)self.aux2 = InceptionAux(528, num_classes)self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) #自适应平均池化下采样,对于任意尺寸的特征向量,都得到1*1特征矩阵self.dropout = nn.Dropout(0.4)self.fc = nn.Linear(1024, num_classes)if init_weights:for m in self.modules():if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear):torch.nn.init.trunc_normal_(m.weight, mean=0.0, std=0.01, a=-2, b=2)elif isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)def _transform_input(self, x):if self.transform_input:x_ch0 = torch.unsqueeze(x[:, 0], 1) * (0.229 / 0.5) + (0.485 - 0.5) / 0.5x_ch1 = torch.unsqueeze(x[:, 1], 1) * (0.224 / 0.5) + (0.456 - 0.5) / 0.5x_ch2 = torch.unsqueeze(x[:, 2], 1) * (0.225 / 0.5) + (0.406 - 0.5) / 0.5x = torch.cat((x_ch0, x_ch1, x_ch2), 1)return xdef forward(self, x):x = self._transform_input(x)# N x 3 x 224 x 224 ---- batch_size cahnnel height widthx = self.conv1(x)# N x 64 x 112 x 112x = self.maxpool1(x)# N x 64 x 56 x 56x = self.conv2(x)# N x 64 x 56 x 56x = self.conv3(x)# N x 192 x 56 x 56x = self.maxpool2(x)# N x 192 x 28 x 28x = self.inception3a(x)# N x 256 x 28 x 28x = self.inception3b(x)# N x 480 x 28 x 28x = self.maxpool3(x)# N x 480 x 14 x 14x = self.inception4a(x)# N x 512 x 14 x 14if self.training and self.aux_logits:aux1 = self.aux1(x)x = self.inception4b(x)# N x 512 x 14 x 14x = self.inception4c(x)# N x 512 x 14 x 14x = self.inception4d(x)# N x 528 x 14 x 14if self.training and self.aux_logits:aux2 = self.aux2(x)x = self.inception4e(x)# N x 832 x 14 x 14x = self.maxpool4(x)# N x 832 x 7 x 7x = self.inception5a(x)# N x 832 x 7 x 7x = self.inception5b(x)# N x 1024 x 7 x 7x = self.avgpool(x)# N x 1024 x 1 x 1x = torch.flatten(x, 1)# N x 1024x = self.dropout(x)x = self.fc(x)# N x 1000 (num_classes)if self.training and self.aux_logits:return x, aux2, aux1return xclass Inception(nn.Module):def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):super(Inception, self).__init__()self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)self.branch2 = nn.Sequential(BasicConv2d(in_channels, ch3x3red, kernel_size=1), BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小)self.branch3 = nn.Sequential(BasicConv2d(in_channels, ch5x5red, kernel_size=1),BasicConv2d(ch5x5red, ch5x5, kernel_size=3, padding=1), # 保证输出大小等于输入大小)self.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1, ceil_mode=True),BasicConv2d(in_channels, pool_proj, kernel_size=1),)def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)branch4 = self.branch4(x)outputs = [branch1, branch2, branch3, branch4]return torch.cat(outputs, 1) #batch channel hetght width,在channel上拼接class InceptionAux(nn.Module):def __init__(self, in_channels, num_classes):super(InceptionAux, self).__init__()self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output[batch, 128, 4, 4]self.fc1 = nn.Linear(2048, 1024)self.fc2 = nn.Linear(1024, num_classes)def forward(self, x):# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14x = self.averagePool(x)# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4x = self.conv(x)# N x 128 x 4 x 4x = torch.flatten(x, 1)x = F.dropout(x, 0.5, training=self.training)# N x 2048x = F.relu(self.fc1(x), inplace=True)x = F.dropout(x, 0.5, training=self.training)# N x 1024x = self.fc2(x)# N x 1000 (num_classes)return xclass BasicConv2d(nn.Module):def __init__(self, in_channels, out_channels, **kwargs):super(BasicConv2d, self).__init__()self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)self.bn = nn.BatchNorm2d(out_channels, eps=0.001)def forward(self, x):x = self.conv(x)x = self.bn(x)return F.relu(x, inplace=True)if __name__ == "__main__":googlenet = GoogLeNet(num_classes = 3, aux_logits = True, transform_input = False, init_weights = True)in_data = torch.randn(1, 3, 224, 224)out = googlenet(in_data)print(out)完成网络的定义之后,可以单独执行一下这个文件,用来验证网络定义的是否正确。如果可以正确输出,就没问题。
三.开始训练
加载数据集
首先定义一个字典,用于用于对train和val进行预处理,包括裁剪成224*224大小,训练集随机水平翻转(一般验证集不需要此操作),转换成张量,图像归一化。
然后利用DataLoader模块加载数据集,并设置batch_size为32,同时,设置数据加载器的工作进程数nw,加快速度。
data_transform = {"train": transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),"val": transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}# 获取数据集路径image_path = os.path.join(os.getcwd(), "data_set", "flower_data") # flower data set pathassert os.path.exists(image_path), "{} path does not exist.".format(image_path)# 加载数据集,准备读取train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),transform=data_transform["train"])validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"), transform=data_transform["val"])nw = min([os.cpu_count(), 32 if 32 > 1 else 0, 8]) # number of workersprint(f'Using {nw} dataloader workers every process')# 加载数据集train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=nw)validate_loader = torch.utils.data.DataLoader(validate_dataset, batch_size=32, shuffle=False, num_workers=nw)train_num = len(train_dataset)val_num = len(validate_dataset)print(f"using {train_num} images for training, {val_num} images for validation.") 生成json文件
将训练数据集的类别标签转换为字典格式,并将其写入名为'class_indices.json'的文件中。
- 从
train_dataset中获取类别标签到索引的映射关系,存储在flower_list变量中。 - 使用列表推导式将
flower_list中的键值对反转,得到一个新的字典cla_dict,其中键是原始类别标签,值是对应的索引。 - 使用
json.dumps()函数将cla_dict转换为JSON格式的字符串,设置缩进为4个空格。 - 使用
with open()语句以写入模式打开名为'class_indices.json'的文件,并将JSON字符串写入文件。
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4} 雏菊 蒲公英 玫瑰 向日葵 郁金香# 从训练集中获取类别标签到索引的映射关系,存储在flower_list变量flower_list = train_dataset.class_to_idx# 使用列表推导式将flower_list中的键值对反转,得到一个新的字典cla_dictcla_dict = dict((val, key) for key, val in flower_list.items())# write dict into json file,将cla_dict转换为JSON格式的字符串json_str = json.dumps(cla_dict, indent=4)with open('class_indices.json', 'w') as json_file:json_file.write(json_str)定义网络,开始训练
首先定义网络对象net,传入要分类的类别数为5,使用辅助分类器并初始化权重;在这里训练30轮,并使用train_bar = tqdm(train_loader, file=sys.stdout)来可视化训练进度条,loss计算采用了GoogleNet原论文的方法,进行加权计算,之后再进行反向传播和参数更新;同时,每一轮训练完成都要进行学习率更新;之后开始对验证集进行计算精确度,完成后保存模型。
net = GoogLeNet(num_classes=5, aux_logits=True, init_weights=True)net.to(device)loss_function = nn.CrossEntropyLoss()optimizer = optim.Adam(net.parameters(), lr=0.0003)sculer = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1)epochs = 30best_acc = 0.0train_steps = len(train_loader)for epoch in range(epochs):# trainnet.train()running_loss = 0.0train_bar = tqdm(train_loader, file=sys.stdout)for step, data in enumerate(train_bar):imgs, labels = dataoptimizer.zero_grad()logits, aux_logits2, aux_logits1 = net(imgs.to(device))loss0 = loss_function(logits, labels.to(device))loss1 = loss_function(aux_logits1, labels.to(device))loss2 = loss_function(aux_logits2, labels.to(device))loss = loss0 + loss1 * 0.3 + loss2 * 0.3loss.backward()optimizer.step()# print statisticsrunning_loss += loss.item()train_bar.desc = f"train epoch[{epoch+1}/{epochs}] loss:{loss:.3f}"sculer.step()# validatenet.eval()acc = 0.0 # accumulate accurate number / epochwith torch.no_grad():val_bar = tqdm(validate_loader, file=sys.stdout)for val_data in val_bar:val_imgs, val_labels = val_dataoutputs = net(val_imgs.to(device)) # eval model only have last output layerpredict_y = torch.max(outputs, dim=1)[1]acc += torch.eq(predict_y, val_labels.to(device)).sum().item()val_accurate = acc / val_numprint('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %(epoch + 1, running_loss / train_steps, val_accurate))if val_accurate > best_acc:best_acc = val_accuratetorch.save(net,"./googleNet.pth")print('Finished Training')最后对代码进行整理,完整的train.py如下
import os
import sys
import jsonimport torch
import torch.nn as nn
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
import torch.optim as optim
from tqdm import tqdmfrom model import GoogLeNetdef main():device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(f"using {device} device.")data_transform = {"train": transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),"val": transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}# 获取数据集路径image_path = os.path.join(os.getcwd(), "data_set", "flower_data") # flower data set pathassert os.path.exists(image_path), "{} path does not exist.".format(image_path)# 加载数据集,准备读取train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),transform=data_transform["train"])validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"), transform=data_transform["val"])nw = min([os.cpu_count(), 32 if 32 > 1 else 0, 8]) # number of workersprint(f'Using {nw} dataloader workers every process')# 加载数据集train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=nw)validate_loader = torch.utils.data.DataLoader(validate_dataset, batch_size=32, shuffle=False, num_workers=nw)train_num = len(train_dataset)val_num = len(validate_dataset)print(f"using {train_num} images for training, {val_num} images for validation.") # {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4} 雏菊 蒲公英 玫瑰 向日葵 郁金香# 从训练集中获取类别标签到索引的映射关系,存储在flower_list变量flower_list = train_dataset.class_to_idx# 使用列表推导式将flower_list中的键值对反转,得到一个新的字典cla_dictcla_dict = dict((val, key) for key, val in flower_list.items())# write dict into json file,将cla_dict转换为JSON格式的字符串json_str = json.dumps(cla_dict, indent=4)with open('class_indices.json', 'w') as json_file:json_file.write(json_str)"""如果要使用官方的预训练权重,注意是将权重载入官方的模型,不是我们自己实现的模型官方的模型中使用了bn层以及改了一些参数,不能混用import torchvisionnet = torchvision.models.googlenet(num_classes=5)model_dict = net.state_dict()# 预训练权重下载地址: https://download.pytorch.org/models/googlenet-1378be20.pthpretrain_model = torch.load("googlenet.pth")del_list = ["aux1.fc2.weight", "aux1.fc2.bias","aux2.fc2.weight", "aux2.fc2.bias","fc.weight", "fc.bias"]pretrain_dict = {k: v for k, v in pretrain_model.items() if k not in del_list}model_dict.update(pretrain_dict)net.load_state_dict(model_dict)"""net = GoogLeNet(num_classes=5, aux_logits=True, init_weights=True)net.to(device)loss_function = nn.CrossEntropyLoss()optimizer = optim.Adam(net.parameters(), lr=0.0003)sculer = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1)epochs = 30best_acc = 0.0train_steps = len(train_loader)for epoch in range(epochs):# trainnet.train()running_loss = 0.0train_bar = tqdm(train_loader, file=sys.stdout)for step, data in enumerate(train_bar):imgs, labels = dataoptimizer.zero_grad()logits, aux_logits2, aux_logits1 = net(imgs.to(device))loss0 = loss_function(logits, labels.to(device))loss1 = loss_function(aux_logits1, labels.to(device))loss2 = loss_function(aux_logits2, labels.to(device))loss = loss0 + loss1 * 0.3 + loss2 * 0.3loss.backward()optimizer.step()# print statisticsrunning_loss += loss.item()train_bar.desc = f"train epoch[{epoch+1}/{epochs}] loss:{loss:.3f}"sculer.step()# validatenet.eval()acc = 0.0 # accumulate accurate number / epochwith torch.no_grad():val_bar = tqdm(validate_loader, file=sys.stdout)for val_data in val_bar:val_imgs, val_labels = val_dataoutputs = net(val_imgs.to(device)) # eval model only have last output layerpredict_y = torch.max(outputs, dim=1)[1]acc += torch.eq(predict_y, val_labels.to(device)).sum().item()val_accurate = acc / val_numprint('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %(epoch + 1, running_loss / train_steps, val_accurate))if val_accurate > best_acc:best_acc = val_accuratetorch.save(net,"./googleNet.pth")print('Finished Training')if __name__ == '__main__':main()
四.模型预测
新建一个predict.py文件用于预测,将输入图像处理后转换成张量格式,img = torch.unsqueeze(img, dim=0)是在输入图像张量 img 的第一个维度上增加一个大小为1的维度,因此将图像张量的形状从 [通道数, 高度, 宽度 ] 转换为 [1, 通道数, 高度, 宽度]。然后加载模型进行预测,并打印出结果,同时可视化。
import os
import jsonimport torch
from PIL import Image
from torchvision import transforms
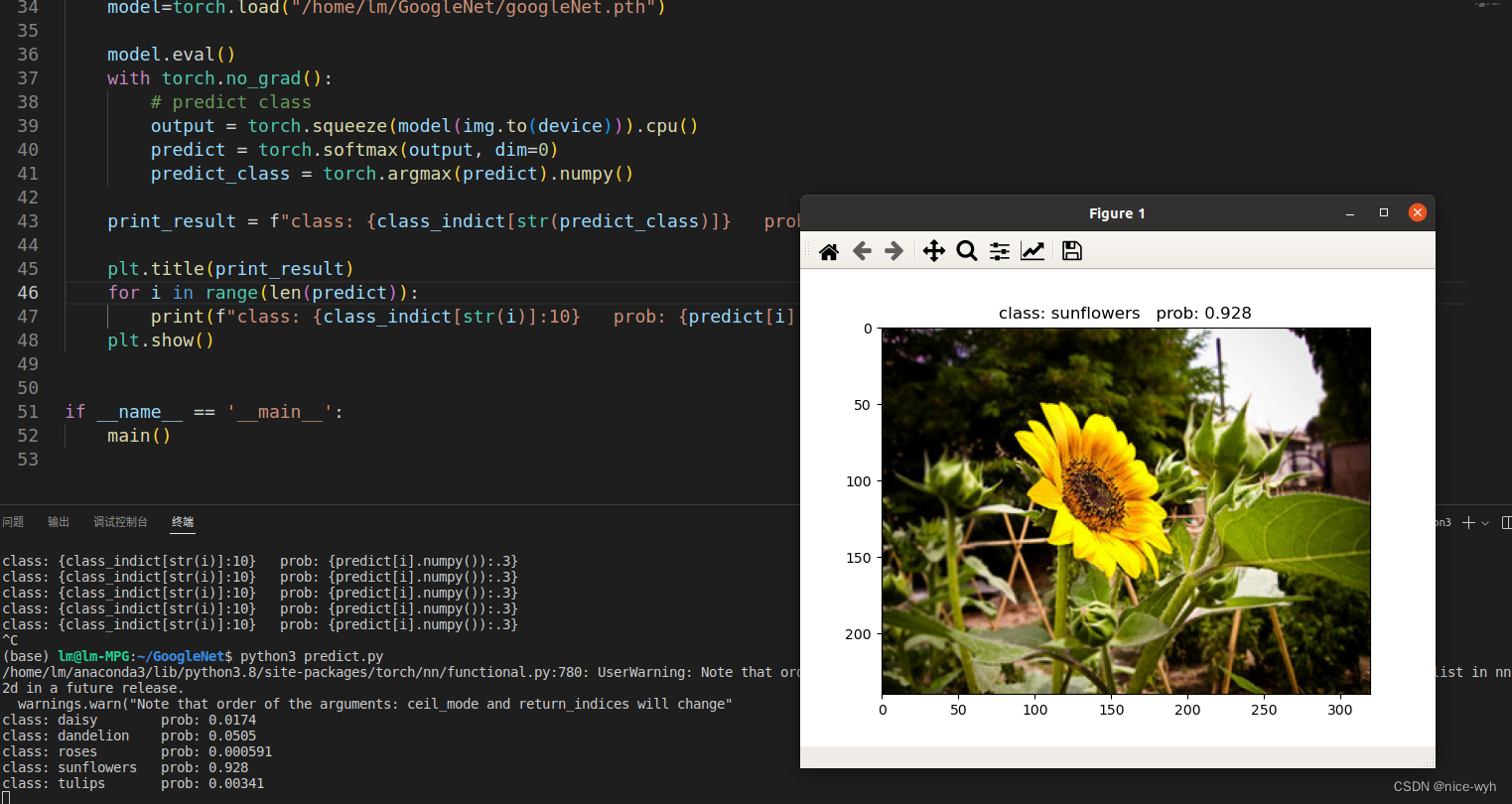
import matplotlib.pyplot as pltfrom model import GoogLeNetdef main():device = torch.device("cuda" if torch.cuda.is_available() else "cpu")data_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])# load imageimg = Image.open("./2678588376_6ca64a4a54_n.jpg")plt.imshow(img)# [N, C, H, W]img = data_transform(img)# expand batch dimensionimg = torch.unsqueeze(img, dim=0)# read class_indictwith open("./class_indices.json", "r") as f:class_indict = json.load(f)# create modelmodel = GoogLeNet(num_classes=5, aux_logits=False).to(device)model=torch.load("/home/lm/GoogleNet/googleNet.pth")model.eval()with torch.no_grad():# predict classoutput = torch.squeeze(model(img.to(device))).cpu()predict = torch.softmax(output, dim=0)predict_class = torch.argmax(predict).numpy()print_result = f"class: {class_indict[str(predict_class)]} prob: {predict[predict_class].numpy():.3}"plt.title(print_result)for i in range(len(predict)):print(f"class: {class_indict[str(i)]:10} prob: {predict[i].numpy():.3}")plt.show()if __name__ == '__main__':main()
预测结果
五.模型可视化
将生成的pth文件导入netron工具,可视化结果为
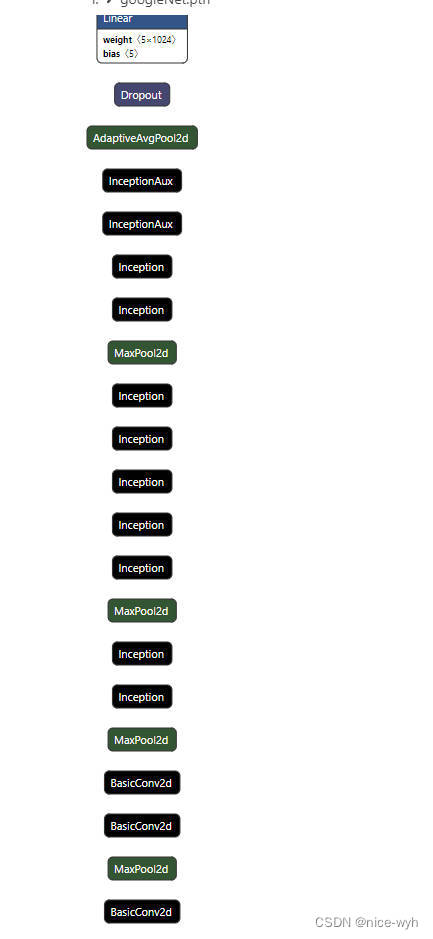
发现很不清晰,因此将它转换成多用于嵌入式设备部署的onnx格式
编写onnx.py
import torch
import torchvision
from model import GoogLeNetdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = GoogLeNet(num_classes=5, aux_logits=False).to(device)
model=torch.load("/home/lm/GoogleNet/googleNet.pth")
model.eval()
example = torch.ones(1, 3, 244, 244)
example = example.to(device)
torch.onnx.export(model, example, "googleNet.onnx", verbose=True, opset_version=11)
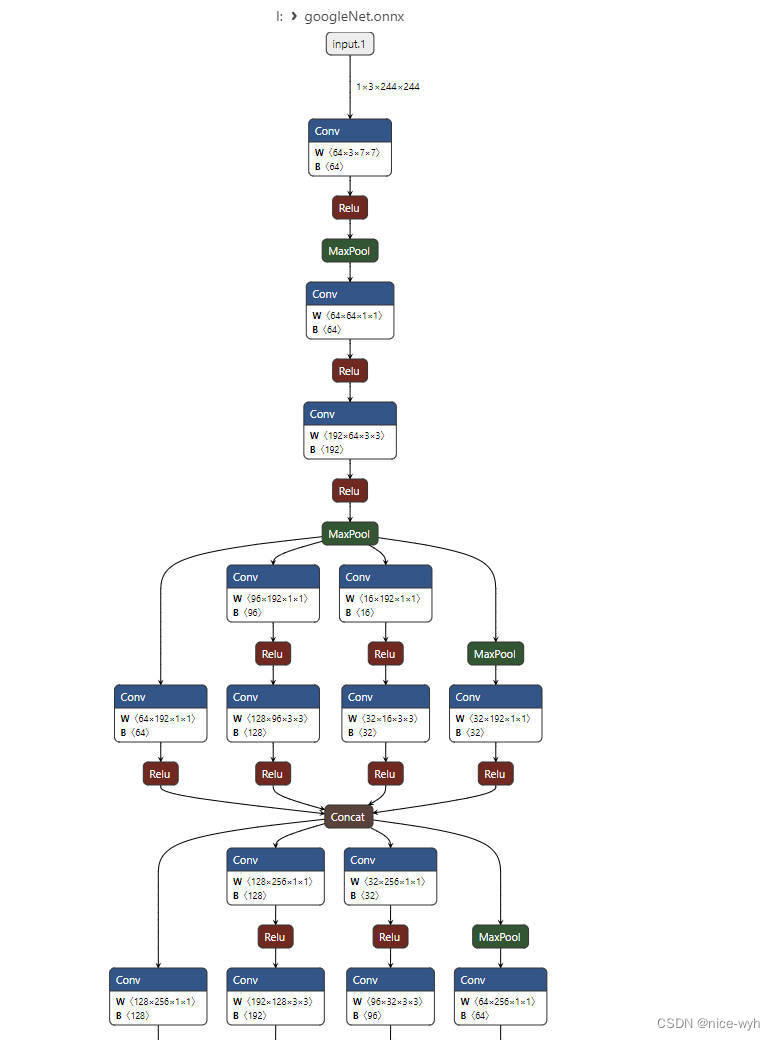
将生成的onnx文件导入,这样的可视化清晰了许多
六.模型改进
发现去掉学习率更新会提高准确率(从70%提升到83%),因此把train.py里面对应部分删掉。
还有其他方法会在之后进行补充。
源码地址:链接: https://pan.baidu.com/s/1FGcGwrNAZZSEocPORD3bZg 提取码: xsfn 复制这段内容后打开百度网盘手机App,操作更方便哦
相关文章:
使用GoogleNet网络实现花朵分类
一.数据集准备 新建一个项目文件夹GoogleNet,并在里面建立data_set文件夹用来保存数据集,在data_set文件夹下创建新文件夹"flower_data",点击链接下载花分类数据集https://storage.googleapis.com/download.tensorflow.org/exampl…...

STM32之Bootloader、USB、IAP/DFU下载
STM32 IAP应用开发——通过内置DFU实现USB升级(方式2) STM32 IAP应用开发——通过内置DFU实现USB升级(方式1) STM32程序下载4:通过STM32CubePro-USB下载 STM32程序下载3:通过STM32CubePro-UART下载 STM…...

解决 Element-ui中 表格(Table)使用 v-if 条件控制列显隐时数据展示错乱的问题
本文 Element-ui 版本 2.x 问题 在 el-table-column 上需根据不同 v-if 条件来控制列显隐时,就会出现列数据展示错乱的情况(要么 A 列的数据显示在 B 列上,或者后端返回有数据的但是显示的为空),如下所示。 <tem…...

Android JNI笔记
JNI、java native interface 。可以实现Java和C、C之间的调用。 在Android开发中是必须要掌握的内容。 在应用开发中,编写JNI代码的注册可分为动态注册和静态注册 动态注册: 声明好方法、注意这些签名 在JNI_OnLoad中进行注册。 static const JNINativ…...
方法)
Web开发中会话跟踪的隐藏表单字段(隐藏input)方法
隐藏表单字段是一种会话跟踪方法,通过在HTML表单中添加一个隐藏字段来存储会话标识符。 这样,每次用户提交表单时,会话标识符将与请求一起发送到服务器,以便服务器可以跟踪用户的会话状态。 以下是一个隐藏表单字段的示例&#…...

线性代数相关笔记
线性基 导入 线性基,顾名思义,就是一个包含数字最少的集合,使得原集合中的任何数都能用线性基中的元素表示。 集合中的元素满足一些性质: 原集合中的任意元素都可以用线性基中的若干元素的异或和表示线性基中任意数异或和不为…...
】69 - Android 侧添加支持 busybox telnetd 服务)
【SA8295P 源码分析 (四)】69 - Android 侧添加支持 busybox telnetd 服务
【SA8295P 源码分析】69 - Android 侧添加支持 busybox telnetd 服务 一、下载 busybox-1.36.1.tar.bz2 源码包二、编译 busybox 源码三、将编译后的 busybox 打包编入Android 镜像中系列文章汇总见:《【SA8295P 源码分析 (四)】网络模块 文章链接汇总 - 持续更新中》 本文链接…...
如何开发一个 Safari 插件
本文字数:2493字 预计阅读时间:15分钟 由于常用浏览器是Safari,而Safari浏览器的插件比不上Chrome,所以就有了自己开发常用的Safari插件的想法。 打算开发当前页面生成二维码的Extension,因为网络原因,AirD…...

n皇后问题,不用递归
注释如下: class Solution:def totalNQueens(self, n: int) -> int:if n < 1: # 如果 n 小于 1,直接返回 0return 0count 0 # 初始化解的个数为 0stack [(0, set(), set(), set())] # 初始化一个栈,元素为当前处理的行数、已经放…...
Verilog基础:$fopen和$fclose系统函数、任务的使用
相关阅读 Verilog基础https://blog.csdn.net/weixin_45791458/category_12263729.html?spm1001.2014.3001.5482 $fopen和$fclose是两个用于打开和关闭文件的系统函数、任务。最初,在Verilog-1995标准中,最多只能同时打开32个文件,其所使用的…...

python之字典的用法
python之字典的用法 Python中的字典是一种无序、可变、可迭代的数据类型,它由键值对组成,每个键都映射到一个值。字典在Python中被视为可变对象,这意味着我们可以随时更新、添加或删除字典中的键值对。 以下是一些关于Python字典的基本用法&a…...
Leetcode1971. 寻找图中是否存在路径
Every day a Leetcode 题目来源:1971. 寻找图中是否存在路径 解法1:并查集 并查集介绍:并查集详解 代码: /** lc appleetcode.cn id1971 langcpp** [1971] 寻找图中是否存在路径*/// lc codestart class UnionFind {vector&…...

程序可以创建多少个用户界面对象?
有人提到这样一个问题:”一个程序最多可以注册多少个窗口类?” 问题的答案不是一个具体的数字。因为大多数用户界面对象都来自一个共享的内存池,我们称之为”桌面堆内存”。尽管我们可以计算一个最大的理论值,但是在实际的场景中࿰…...

业绩不俗,毛利率下滑,股价接连下跌,片仔癀将向何处去?
撰稿|行星 来源|贝多财经 10月16日,中药龙头企业漳州片仔癀药业股份有限公司(600436.SH,下称“片仔癀”)发布截至9月30日的2023年前三季度业绩报告。发布财报后,片仔癀的股价多日下跌。 10月17日、18日、19日和20日…...

云安全—docker容器镜像检测
0x00 前言 docker镜像是属于整个云原生的重要基石之一,如果从镜像开始就没有安全性的话,那么整个云原生也就没有任何的安全性可言。所以镜像检测技术就成为了一个比较重要的点,本篇将通过研究docker镜像工具来整体分析风险以及应对方案。 市…...
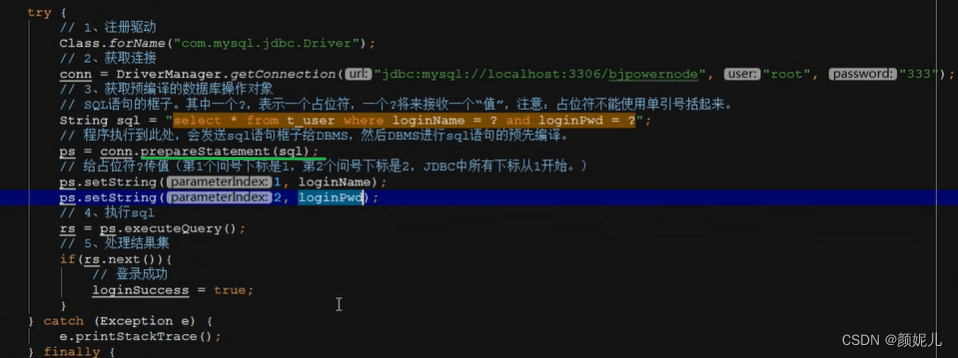
JDBC相关记录
JDBC:Java DadaBase Connectivity 即Java语言连接数据库。 本质:JDBC是SUN公司制定的一套接口(interface)。 作用:不同的数据库有自己独特设计原理,JDBC的可以让Java程序员关注业务本身,而不需要…...
Nginx的基本介绍 安装 配置文件 日志
一、Nginx介绍二、nginx的优点三、多路复用1、I/O multiplexing 多并发 四、nginx内部技术架构五、安装NginxNginx部署-yum安装获取Nginx的yum源yum安装Nginx浏览器访问 编译安装Nginx安装编译环境安装依赖环境创建nginx用户安装nginx启动nginx实现nginx开机自启(脚…...

docker部署nginx并设置挂载
前言: 最近在学习docker和nginx,因为容器在运行过程中,相关的配置文件及日志都会存在容器内。对容器以来较高,当容器不存在的时候。所有的文件也就都没有了。并且当需要查看日志,修改配置文件的时候必须进入到容器内部…...
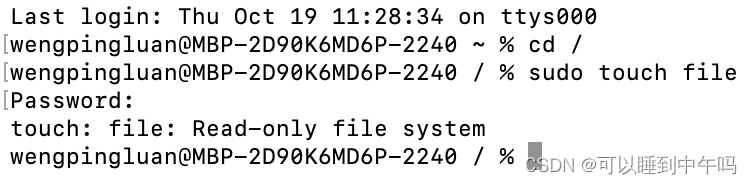
MAC如何在根目录创建文件
在这之前先明确一下啥是根目录。 打开终端,输入cd /,然后输入 ls 查看根目录下有哪些文件 可以看到 usr、etc、opt 这些文件的地方才叫根目录,而不是以用户命名,可以看到音乐、应用程序、影片、桌面的地方哈 介绍一种叫做软连接…...
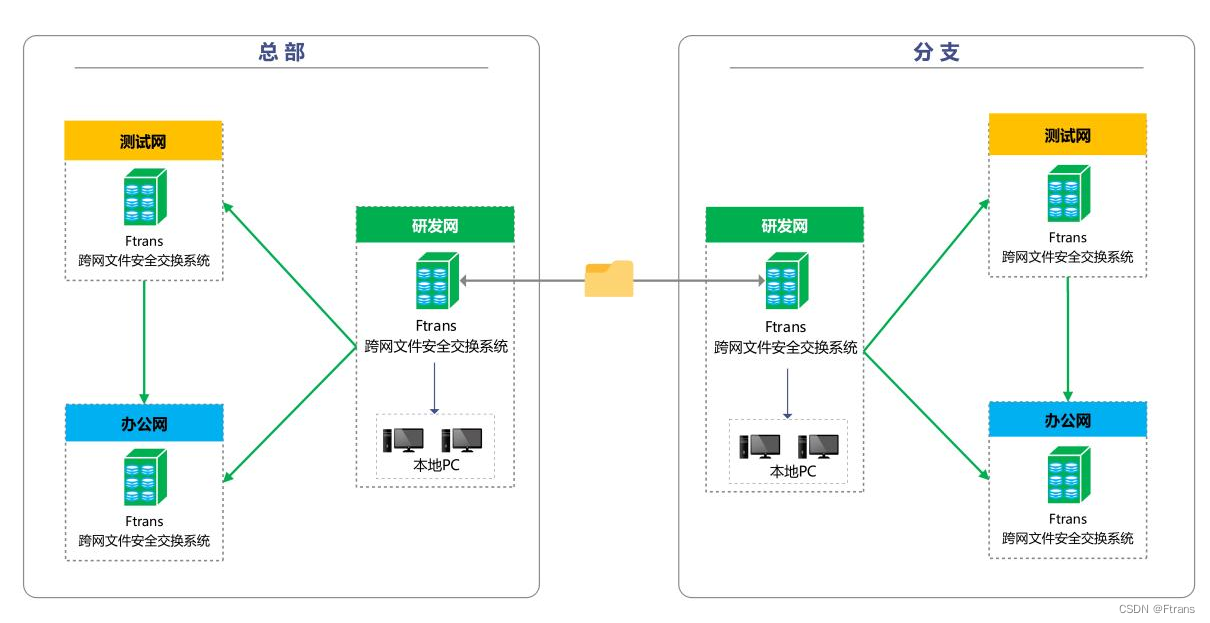
某全球领先的芯片供应商:优化数据跨网交换流程,提高安全管控能力
1、客户介绍 某全球领先的芯片供应商,成立于2005年,总部设于北京,在国内上海、深圳、合肥等地及国外多个国家和地区均设有分支机构和办事处,致力于为客户提供更优质、便捷的服务。 2、建设背景 该公司基于网络安全管理的需求&am…...
)
AIAgent语音识别实战指南:2026奇点大会披露的7个工业级优化参数(附基准测试数据)
第一章:2026奇点智能技术大会:AIAgent语音识别全景洞察 2026奇点智能技术大会(https://ml-summit.org) 技术演进脉络 2026年大会首次系统性披露端到端语音识别模型在AIAgent场景中的泛化瓶颈突破路径。主流框架已从传统CTCAttention转向动态语义对齐&a…...

为什么92%的AIAgent项目卡在世界建模阶段?深度拆解6个被忽略的感知-记忆-推理对齐断点
第一章:世界模型在AIAgent架构中的核心定位与失败率归因 2026奇点智能技术大会(https://ml-summit.org) 世界模型(World Model)并非AIAgent的可选组件,而是其认知闭环的底层基础设施——它承担着环境建模、状态推演、反事实规划与…...
的动画性能优化点)
Android 13手势导航卡顿?深入剖析Launcher3最近任务(Recents)的动画性能优化点
Android 13手势导航卡顿?深入剖析Launcher3最近任务(Recents)的动画性能优化点 在Android 13中,手势导航已经成为主流交互方式,但不少开发者反馈在Launcher3的最近任务(Recents)界面会出现动画卡…...

ESP32驱动ST7789 LCD与FT6336U触摸屏:从硬件选型到LVGL界面旋转的实战指南
1. 硬件选型与连接指南 第一次接触ESP32驱动ST7789 LCD和FT6336U触摸屏时,我被这块3.2寸IPS屏的显示效果惊艳到了。240x320的分辨率在嵌入式设备上已经相当够用,特别是ST7789驱动芯片的色彩表现力,完全超出了我对SPI接口屏幕的预期。不过在实…...

.NET+AI | Agent Skills | File-based Agent Skills 帮你复用成千上万的开源技能
以下内容选自我精心打造的《.NETAI | 智能体开发进阶》课程,如需系统学习,不妨阅读原文了解详情。上一篇我们聊了 Inline Skill。它最大的优点是轻:写得快、调得快、验证也快,非常适合作为 Agent Skills 的第一站。但问题也很明显…...

从‘小白’到‘省流高手’:我是如何通过调整使用习惯,让Cursor免费额度多用一倍的
从‘小白’到‘省流高手’:我是如何通过调整使用习惯,让Cursor免费额度多用一倍的 第一次接触Cursor时,我和大多数人一样,把它当作一个"更聪明的聊天机器人"。每次遇到问题就随手抛出一个模糊的请求,然后看着…...

3步搞定B站视频下载:BiliTools跨平台工具箱终极指南
3步搞定B站视频下载:BiliTools跨平台工具箱终极指南 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliTools 还在…...

HexView 刷写脚本进阶:/FP与/FR参数在固件数据填充中的实战应用
1. 为什么需要精确控制固件数据填充? 在嵌入式开发中,我们经常遇到这样的场景:设备出厂前需要在特定内存区域写入校准数据,或者升级固件时要保留某些关键配置区域。这时候如果直接全盘擦写,就像用油漆桶泼墙——不仅会…...

OpenHarmony 4.1 RK3568编译实战:对比`hb build`与`build.sh`两种编译命令的差异与选择
OpenHarmony 4.1 RK3568编译实战:深度解析hb build与build.sh的工程化选择 当你在RK3568平台上为OpenHarmony 4.1完成基础环境搭建后,编译工具的选择往往成为效率提升的第一个分水岭。作为长期维护嵌入式系统的开发者,我发现不同编译方式对团…...

按 Token 计费是个坑?企业级 Agent 的 FinOps 成本控制策略
按 Token 计费是个坑?企业级 Agent 的 FinOps 成本控制策略 关键词 Token 计费 企业级 Agent FinOps 成本控制 大语言模型(LLM) prompt 工程 资源优化 摘要 随着大语言模型(LLM)在企业中的广泛应用,Token计费模式已成为AI应用成本的主要组成部分。本文深入探讨了企业级Agen…...