自然语言处理---RNN经典案例之使用seq2seq实现英译法
1 seq2seq介绍
1.1 seq2seq模型架构

-
seq2seq模型架构分析:
seq2seq模型架构,包括两部分分别是encoder(编码器)和decoder(解码器),编码器和解码器的内部实现都使用了GRU模型,这里它要完成的是一个中文到英文的翻译:欢迎 来 北京 → welcome to BeiJing。编码器首先处理中文输入"欢迎 来 北京",通过GRU模型获得每个时间步的输出张量,最后将它们拼接成一个中间语义张量c,接着解码器将使用这个中间语义张量c以及每一个时间步的隐层张量,逐个生成对应的翻译语言。
2 数据集介绍
下载地址: https://download.pytorch.org/tutorial/data.zip
3 案例步骤
基于GRU的seq2seq模型架构实现翻译的过程:
- 第一步:导入必备的工具包
- 第二步:对持久化文件中数据进行处理,以满足模型训练要求
- 第三步:构建基于GRU的编码器和解码器
- 第四步:构建模型训练函数,并进行训练
- 第五步:构建模型评估函数,并进行测试以及Attention效果分析
1 导入必备的工具包
# 从io工具包导入open方法
from io import open
# 用于字符规范化
import unicodedata
# 用于正则表达式
import re
# 用于随机生成数据
import random
# 用于构建网络结构和函数的torch工具包
import torch
import torch.nn as nn
import torch.nn.functional as F
# torch中预定义的优化方法工具包
from torch import optim
# 设备选择, 我们可以选择在cuda或者cpu上运行你的代码
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
2 数据预处理
对持久化文件中数据进行处理,以满足模型训练要求
1 将指定语言中的词汇映射成数值
# 起始标志
SOS_token = 0
# 结束标志
EOS_token = 1class Lang:def __init__(self, name):"""初始化函数中参数name代表传入某种语言的名字"""# 将name传入类中self.name = name# 初始化词汇对应自然数值的字典self.word2index = {}# 初始化自然数值对应词汇的字典, 其中0,1对应的SOS和EOS已经在里面了self.index2word = {0: "SOS", 1: "EOS"}# 初始化词汇对应的自然数索引,这里从2开始,因为0,1已经被开始和结束标志占用了self.n_words = 2 def addSentence(self, sentence):"""添加句子函数, 即将句子转化为对应的数值序列, 输入参数sentence是一条句子"""# 根据一般国家的语言特性(我们这里研究的语言都是以空格分个单词)# 对句子进行分割,得到对应的词汇列表for word in sentence.split(' '):# 然后调用addWord进行处理self.addWord(word)def addWord(self, word):"""添加词汇函数, 即将词汇转化为对应的数值, 输入参数word是一个单词"""# 首先判断word是否已经在self.word2index字典的key中if word not in self.word2index:# 如果不在, 则将这个词加入其中, 并为它对应一个数值,即self.n_wordsself.word2index[word] = self.n_words# 同时也将它的反转形式加入到self.index2word中self.index2word[self.n_words] = word# self.n_words一旦被占用之后,逐次加1, 变成新的self.n_wordsself.n_words += 1
2 字符规范化
# 将unicode转为Ascii, 我们可以认为是去掉一些语言中的重音标记:Ślusàrski
def unicodeToAscii(s):return ''.join(c for c in unicodedata.normalize('NFD', s)if unicodedata.category(c) != 'Mn')def normalizeString(s):"""字符串规范化函数, 参数s代表传入的字符串"""# 使字符变为小写并去除两侧空白符, z再使用unicodeToAscii去掉重音标记s = unicodeToAscii(s.lower().strip())# 在.!?前加一个空格s = re.sub(r"([.!?])", r" \1", s)# 使用正则表达式将字符串中不是大小写字母和正常标点的都替换成空格s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)return s
3 将持久化文件中的数据加载到内存, 并实例化类Lang
data_path = './data/eng-fra.txt'def readLangs(lang1, lang2):"""读取语言函数, 参数lang1是源语言的名字, 参数lang2是目标语言的名字返回对应的class Lang对象, 以及语言对列表"""# 从文件中读取语言对并以/n划分存到列表lines中lines = open(data_path, encoding='utf-8').\read().strip().split('\n')# 对lines列表中的句子进行标准化处理,并以\t进行再次划分, 形成子列表, 也就是语言对pairs = [[normalizeString(s) for s in l.split('\t')] for l in lines] # 然后分别将语言名字传入Lang类中, 获得对应的语言对象, 返回结果input_lang = Lang(lang1)output_lang = Lang(lang2)return input_lang, output_lang, pairs
4 过滤出符合我们要求的语言对
# 设置组成句子中单词或标点的最多个数
MAX_LENGTH = 10# 选择带有指定前缀的语言特征数据作为训练数据
eng_prefixes = ("i am ", "i m ","he is", "he s ","she is", "she s ","you are", "you re ","we are", "we re ","they are", "they re "
)def filterPair(p):"""语言对过滤函数, 参数p代表输入的语言对, 如['she is afraid.', 'elle malade.']"""# p[0]代表英语句子,对它进行划分,它的长度应小于最大长度MAX_LENGTH并且要以指定的前缀开头# p[1]代表法文句子, 对它进行划分,它的长度应小于最大长度MAX_LENGTHreturn len(p[0].split(' ')) < MAX_LENGTH and \p[0].startswith(eng_prefixes) and \len(p[1].split(' ')) < MAX_LENGTH def filterPairs(pairs):"""对多个语言对列表进行过滤, 参数pairs代表语言对组成的列表, 简称语言对列表"""# 函数中直接遍历列表中的每个语言对并调用filterPair即可return [pair for pair in pairs if filterPair(pair)]
5 对以上数据准备函数进行整合
使用类Lang对语言对进行数值映射
def prepareData(lang1, lang2):"""数据准备函数, 完成将所有字符串数据向数值型数据的映射以及过滤语言对参数lang1, lang2分别代表源语言和目标语言的名字"""# 首先通过readLangs函数获得input_lang, output_lang对象,以及字符串类型的语言对列表input_lang, output_lang, pairs = readLangs(lang1, lang2)# 对字符串类型的语言对列表进行过滤操作pairs = filterPairs(pairs)# 对过滤后的语言对列表进行遍历for pair in pairs:# 并使用input_lang和output_lang的addSentence方法对其进行数值映射input_lang.addSentence(pair[0])output_lang.addSentence(pair[1])# 返回数值映射后的对象, 和过滤后语言对return input_lang, output_lang, pairs
6 将语言对转化为模型输入需要的张量
def tensorFromSentence(lang, sentence):"""将文本句子转换为张量, 参数lang代表传入的Lang的实例化对象, sentence是预转换的句子"""# 对句子进行分割并遍历每一个词汇, 然后使用lang的word2index方法找到它对应的索引# 这样就得到了该句子对应的数值列表indexes = [lang.word2index[word] for word in sentence.split(' ')]# 然后加入句子结束标志indexes.append(EOS_token)# 将其使用torch.tensor封装成张量, 并改变它的形状为nx1, 以方便后续计算return torch.tensor(indexes, dtype=torch.long, device=device).view(-1, 1)def tensorsFromPair(pair):"""将语言对转换为张量对, 参数pair为一个语言对"""# 调用tensorFromSentence分别将源语言和目标语言分别处理,获得对应的张量表示input_tensor = tensorFromSentence(input_lang, pair[0])target_tensor = tensorFromSentence(output_lang, pair[1])# 最后返回它们组成的元组return (input_tensor, target_tensor)
3 构建基于GRU的编码器和解码器
1 构建基于GRU的编码器
- 编码器结构图:
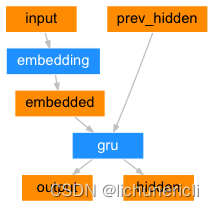
class EncoderRNN(nn.Module):def __init__(self, input_size, hidden_size):"""它的初始化参数有两个, input_size代表解码器的输入尺寸即源语言的词表大小,hidden_size代表GRU的隐层节点数, 也代表词嵌入维度, 同时又是GRU的输入尺寸"""super(EncoderRNN, self).__init__()# 将参数hidden_size传入类中self.hidden_size = hidden_size# 实例化nn中预定义的Embedding层, 它的参数分别是input_size, hidden_size# 这里的词嵌入维度即hidden_size# nn.Embedding的演示在该代码下方self.embedding = nn.Embedding(input_size, hidden_size)# 然后实例化nn中预定义的GRU层, 它的参数是hidden_size# nn.GRU的演示在该代码下方self.gru = nn.GRU(hidden_size, hidden_size)def forward(self, input, hidden):"""编码器前向逻辑函数中参数有两个, input代表源语言的Embedding层输入张量hidden代表编码器层gru的初始隐层张量"""# 将输入张量进行embedding操作, 并使其形状变为(1,1,-1),-1代表自动计算维度# 理论上,我们的编码器每次只以一个词作为输入, 因此词汇映射后的尺寸应该是[1, embedding]# 而这里转换成三维的原因是因为torch中预定义gru必须使用三维张量作为输入, 因此我们拓展了一个维度output = self.embedding(input).view(1, 1, -1)# 然后将embedding层的输出和传入的初始hidden作为gru的输入传入其中, # 获得最终gru的输出output和对应的隐层张量hidden, 并返回结果output, hidden = self.gru(output, hidden)return output, hiddendef initHidden(self):"""初始化隐层张量函数"""# 将隐层张量初始化成为1x1xself.hidden_size大小的0张量return torch.zeros(1, 1, self.hidden_size, device=device)
2 构建基于GRU的解码器
- 解码器结构图:
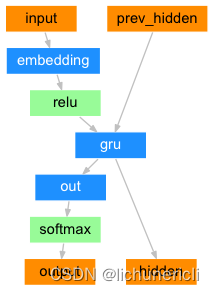
class DecoderRNN(nn.Module):def __init__(self, hidden_size, output_size):"""初始化函数有两个参数,hidden_size代表解码器中GRU的输入尺寸,也是它的隐层节点数output_size代表整个解码器的输出尺寸, 也是我们希望得到的指定尺寸即目标语言的词表大小"""super(DecoderRNN, self).__init__()# 将hidden_size传入到类中self.hidden_size = hidden_size# 实例化一个nn中的Embedding层对象, 它的参数output这里表示目标语言的词表大小# hidden_size表示目标语言的词嵌入维度self.embedding = nn.Embedding(output_size, hidden_size)# 实例化GRU对象,输入参数都是hidden_size,代表它的输入尺寸和隐层节点数相同self.gru = nn.GRU(hidden_size, hidden_size)# 实例化线性层, 对GRU的输出做线性变化, 获我们希望的输出尺寸output_size# 因此它的两个参数分别是hidden_size, output_sizeself.out = nn.Linear(hidden_size, output_size)# 最后使用softmax进行处理,以便于分类self.softmax = nn.LogSoftmax(dim=1)def forward(self, input, hidden):"""解码器的前向逻辑函数中, 参数有两个, input代表目标语言的Embedding层输入张量hidden代表解码器GRU的初始隐层张量"""# 将输入张量进行embedding操作, 并使其形状变为(1,1,-1),-1代表自动计算维度# 原因和解码器相同,因为torch预定义的GRU层只接受三维张量作为输入output = self.embedding(input).view(1, 1, -1)# 然后使用relu函数对输出进行处理,根据relu函数的特性, 将使Embedding矩阵更稀疏,以防止过拟合output = F.relu(output)# 接下来, 将把embedding的输出以及初始化的hidden张量传入到解码器gru中output, hidden = self.gru(output, hidden)# 因为GRU输出的output也是三维张量,第一维没有意义,因此可以通过output[0]来降维# 再传给线性层做变换, 最后用softmax处理以便于分类output = self.softmax(self.out(output[0]))return output, hiddendef initHidden(self):"""初始化隐层张量函数"""# 将隐层张量初始化成为1x1xself.hidden_size大小的0张量return torch.zeros(1, 1, self.hidden_size, device=device)
3 构建基于GRU和Attention的解码器
- 解码器结构图:
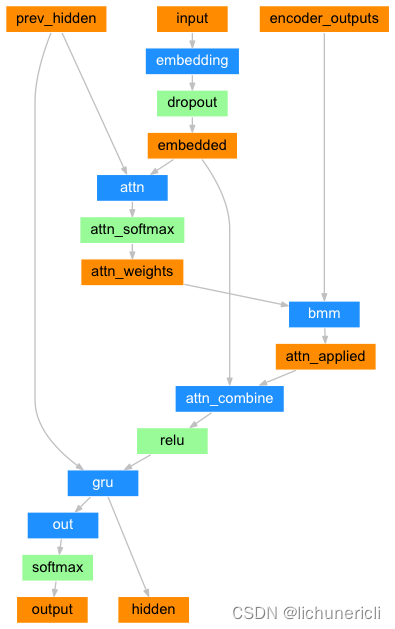
class AttnDecoderRNN(nn.Module):def __init__(self, hidden_size, output_size, dropout_p=0.1, max_length=MAX_LENGTH):"""初始化函数中的参数有4个, hidden_size代表解码器中GRU的输入尺寸,也是它的隐层节点数output_size代表整个解码器的输出尺寸, 也是我们希望得到的指定尺寸即目标语言的词表大小dropout_p代表我们使用dropout层时的置零比率,默认0.1, max_length代表句子的最大长度"""super(AttnDecoderRNN, self).__init__()# 将以下参数传入类中self.hidden_size = hidden_sizeself.output_size = output_sizeself.dropout_p = dropout_pself.max_length = max_length# 实例化一个Embedding层, 输入参数是self.output_size和self.hidden_sizeself.embedding = nn.Embedding(self.output_size, self.hidden_size)# 根据attention的QKV理论,attention的输入参数为三个Q,K,V,# 第一步,使用Q与K进行attention权值计算得到权重矩阵, 再与V做矩阵乘法, 得到V的注意力表示结果.# 这里常见的计算方式有三种:# 1,将Q,K进行纵轴拼接, 做一次线性变化, 再使用softmax处理获得结果最后与V做张量乘法# 2,将Q,K进行纵轴拼接, 做一次线性变化后再使用tanh函数激活, 然后再进行内部求和, 最后使用softmax处理获得结果再与V做张量乘法# 3,将Q与K的转置做点积运算, 然后除以一个缩放系数, 再使用softmax处理获得结果最后与V做张量乘法# 说明:当注意力权重矩阵和V都是三维张量且第一维代表为batch条数时, 则做bmm运算.# 第二步, 根据第一步采用的计算方法, 如果是拼接方法,则需要将Q与第二步的计算结果再进行拼接, # 如果是转置点积, 一般是自注意力, Q与V相同, 则不需要进行与Q的拼接.因此第二步的计算方式与第一步采用的全值计算方法有关.# 第三步,最后为了使整个attention结构按照指定尺寸输出, 使用线性层作用在第二步的结果上做一个线性变换. 得到最终对Q的注意力表示.# 我们这里使用的是第一步中的第一种计算方式, 因此需要一个线性变换的矩阵, 实例化nn.Linear# 因为它的输入是Q,K的拼接, 所以输入的第一个参数是self.hidden_size * 2,第二个参数是self.max_length# 这里的Q是解码器的Embedding层的输出, K是解码器GRU的隐层输出,因为首次隐层还没有任何输出,会使用编码器的隐层输出# 而这里的V是编码器层的输出self.attn = nn.Linear(self.hidden_size * 2, self.max_length)# 接着我们实例化另外一个线性层, 它是attention理论中的第四步的线性层,用于规范输出尺寸# 这里它的输入来自第三步的结果, 因为第三步的结果是将Q与第二步的结果进行拼接, 因此输入维度是self.hidden_size * 2self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)# 接着实例化一个nn.Dropout层,并传入self.dropout_pself.dropout = nn.Dropout(self.dropout_p)# 之后实例化nn.GRU, 它的输入和隐层尺寸都是self.hidden_sizeself.gru = nn.GRU(self.hidden_size, self.hidden_size)# 最后实例化gru后面的线性层,也就是我们的解码器输出层.self.out = nn.Linear(self.hidden_size, self.output_size)def forward(self, input, hidden, encoder_outputs):"""forward函数的输入参数有三个, 分别是源数据输入张量, 初始的隐层张量, 以及解码器的输出张量"""# 根据结构计算图, 输入张量进行Embedding层并扩展维度embedded = self.embedding(input).view(1, 1, -1)# 使用dropout进行随机丢弃,防止过拟合embedded = self.dropout(embedded)# 进行attention的权重计算, 哦我们呢使用第一种计算方式:# 将Q,K进行纵轴拼接, 做一次线性变化, 最后使用softmax处理获得结果attn_weights = F.softmax(self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1)# 然后进行第一步的后半部分, 将得到的权重矩阵与V做矩阵乘法计算, 当二者都是三维张量且第一维代表为batch条数时, 则做bmm运算attn_applied = torch.bmm(attn_weights.unsqueeze(0),encoder_outputs.unsqueeze(0))# 之后进行第二步, 通过取[0]是用来降维, 根据第一步采用的计算方法, 需要将Q与第一步的计算结果再进行拼接output = torch.cat((embedded[0], attn_applied[0]), 1)# 最后是第三步, 使用线性层作用在第三步的结果上做一个线性变换并扩展维度,得到输出output = self.attn_combine(output).unsqueeze(0)# attention结构的结果使用relu激活output = F.relu(output)# 将激活后的结果作为gru的输入和hidden一起传入其中output, hidden = self.gru(output, hidden)# 最后将结果降维并使用softmax处理得到最终的结果output = F.log_softmax(self.out(output[0]), dim=1)# 返回解码器结果,最后的隐层张量以及注意力权重张量return output, hidden, attn_weightsdef initHidden(self):"""初始化隐层张量函数"""# 将隐层张量初始化成为1x1xself.hidden_size大小的0张量return torch.zeros(1, 1, self.hidden_size, device=device)
4 构建模型训练函数, 并进行训练
1 teacher_forcing介绍
它是一种用于序列生成任务的训练技巧, 在seq2seq架构中, 根据循环神经网络理论,解码器每次应该使用上一步的结果作为输入的一部分, 但是训练过程中,一旦上一步的结果是错误的,就会导致这种错误被累积,无法达到训练效果, 因此,我们需要一种机制改变上一步出错的情况,因为训练时我们是已知正确的输出应该是什么,因此可以强制将上一步结果设置成正确的输出, 这种方式就叫做teacher_forcing.
2 teacher_forcing的作用
-
能够在训练的时候矫正模型的预测,避免在序列生成的过程中误差进一步放大.
-
teacher_forcing能够极大的加快模型的收敛速度,令模型训练过程更快更平稳.
3 构建训练函数
# 设置teacher_forcing比率为0.5
teacher_forcing_ratio = 0.5def train(input_tensor, target_tensor, encoder, decoder, encoder_optimizer, decoder_optimizer, criterion, max_length=MAX_LENGTH):"""训练函数, 输入参数有8个, 分别代表input_tensor:源语言输入张量,target_tensor:目标语言输入张量,encoder, decoder:编码器和解码器实例化对象encoder_optimizer, decoder_optimizer:编码器和解码器优化方法,criterion:损失函数计算方法,max_length:句子的最大长度"""# 初始化隐层张量encoder_hidden = encoder.initHidden()# 编码器和解码器优化器梯度归0encoder_optimizer.zero_grad()decoder_optimizer.zero_grad()# 根据源文本和目标文本张量获得对应的长度input_length = input_tensor.size(0)target_length = target_tensor.size(0)# 初始化编码器输出张量,形状是max_lengthxencoder.hidden_size的0张量encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)# 初始设置损失为0loss = 0# 循环遍历输入张量索引for ei in range(input_length):# 根据索引从input_tensor取出对应的单词的张量表示,和初始化隐层张量一同传入encoder对象中encoder_output, encoder_hidden = encoder(input_tensor[ei], encoder_hidden)# 将每次获得的输出encoder_output(三维张量), 使用[0, 0]降两维变成向量依次存入到encoder_outputs# 这样encoder_outputs每一行存的都是对应的句子中每个单词通过编码器的输出结果encoder_outputs[ei] = encoder_output[0, 0]# 初始化解码器的第一个输入,即起始符decoder_input = torch.tensor([[SOS_token]], device=device)# 初始化解码器的隐层张量即编码器的隐层输出decoder_hidden = encoder_hidden# 根据随机数与teacher_forcing_ratio对比判断是否使用teacher_forcinguse_teacher_forcing = True if random.random() < teacher_forcing_ratio else False# 如果使用teacher_forcingif use_teacher_forcing:# 循环遍历目标张量索引for di in range(target_length):# 将decoder_input, decoder_hidden, encoder_outputs即attention中的QKV, # 传入解码器对象, 获得decoder_output, decoder_hidden, decoder_attentiondecoder_output, decoder_hidden, decoder_attention = decoder(decoder_input, decoder_hidden, encoder_outputs)# 因为使用了teacher_forcing, 无论解码器输出的decoder_output是什么, 我们都只# 使用‘正确的答案’,即target_tensor[di]来计算损失loss += criterion(decoder_output, target_tensor[di])# 并强制将下一次的解码器输入设置为‘正确的答案’decoder_input = target_tensor[di] else:# 如果不使用teacher_forcing# 仍然遍历目标张量索引for di in range(target_length):# 将decoder_input, decoder_hidden, encoder_outputs传入解码器对象# 获得decoder_output, decoder_hidden, decoder_attentiondecoder_output, decoder_hidden, decoder_attention = decoder(decoder_input, decoder_hidden, encoder_outputs)# 只不过这里我们将从decoder_output取出答案topv, topi = decoder_output.topk(1)# 损失计算仍然使用decoder_output和target_tensor[di]loss += criterion(decoder_output, target_tensor[di])# 最后如果输出值是终止符,则循环停止if topi.squeeze().item() == EOS_token:break# 否则,并对topi降维并分离赋值给decoder_input以便进行下次运算# 这里的detach的分离作用使得这个decoder_input与模型构建的张量图无关,相当于全新的外界输入decoder_input = topi.squeeze().detach()# 误差进行反向传播loss.backward()# 编码器和解码器进行优化即参数更新encoder_optimizer.step()decoder_optimizer.step()# 最后返回平均损失return loss.item() / target_length
4 构建时间计算函数
# 导入时间和数学工具包
import time
import mathdef timeSince(since):"获得每次打印的训练耗时, since是训练开始时间"# 获得当前时间now = time.time()# 获得时间差,就是训练耗时s = now - since# 将秒转化为分钟, 并取整m = math.floor(s / 60)# 计算剩下不够凑成1分钟的秒数s -= m * 60# 返回指定格式的耗时return '%dm %ds' % (m, s)
5 调用训练函数并打印日志和制图
# 导入plt以便绘制损失曲线
import matplotlib.pyplot as pltdef trainIters(encoder, decoder, n_iters, print_every=1000, plot_every=100, learning_rate=0.01):"""训练迭代函数, 输入参数有6个,分别是encoder, decoder: 编码器和解码器对象,n_iters: 总迭代步数, print_every:打印日志间隔, plot_every:绘制损失曲线间隔, learning_rate学习率"""# 获得训练开始时间戳start = time.time()# 每个损失间隔的平均损失保存列表,用于绘制损失曲线plot_losses = []# 每个打印日志间隔的总损失,初始为0print_loss_total = 0 # 每个绘制损失间隔的总损失,初始为0plot_loss_total = 0 # 使用预定义的SGD作为优化器,将参数和学习率传入其中encoder_optimizer = optim.SGD(encoder.parameters(), lr=learning_rate)decoder_optimizer = optim.SGD(decoder.parameters(), lr=learning_rate)# 选择损失函数criterion = nn.NLLLoss()# 根据设置迭代步进行循环for iter in range(1, n_iters + 1):# 每次从语言对列表中随机取出一条作为训练语句training_pair = tensorsFromPair(random.choice(pairs))# 分别从training_pair中取出输入张量和目标张量input_tensor = training_pair[0]target_tensor = training_pair[1]# 通过train函数获得模型运行的损失loss = train(input_tensor, target_tensor, encoder,decoder, encoder_optimizer, decoder_optimizer, criterion)# 将损失进行累和print_loss_total += lossplot_loss_total += loss# 当迭代步达到日志打印间隔时if iter % print_every == 0:# 通过总损失除以间隔得到平均损失print_loss_avg = print_loss_total / print_every# 将总损失归0print_loss_total = 0# 打印日志,日志内容分别是:训练耗时,当前迭代步,当前进度百分比,当前平均损失print('%s (%d %d%%) %.4f' % (timeSince(start),iter, iter / n_iters * 100, print_loss_avg))# 当迭代步达到损失绘制间隔时if iter % plot_every == 0:# 通过总损失除以间隔得到平均损失plot_loss_avg = plot_loss_total / plot_every# 将平均损失装进plot_losses列表plot_losses.append(plot_loss_avg)# 总损失归0plot_loss_total = 0# 绘制损失曲线plt.figure() plt.plot(plot_losses)# 保存到指定路径plt.savefig("./s2s_loss.png")
6 损失曲线分析
损失下降曲线
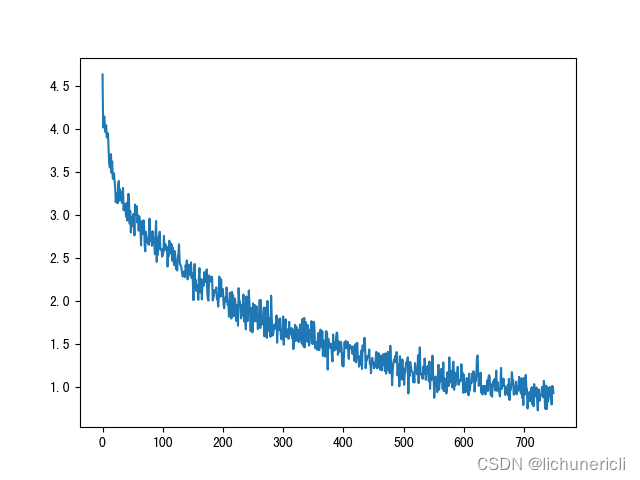
一直下降的损失曲线, 说明模型正在收敛, 能够从数据中找到一些规律应用于数据
5 构建模型评估函数并测试
1 构建模型评估函数
def evaluate(encoder, decoder, sentence, max_length=MAX_LENGTH):"""评估函数,输入参数有4个,分别是encoder, decoder: 编码器和解码器对象,sentence:需要评估的句子,max_length:句子的最大长度"""# 评估阶段不进行梯度计算with torch.no_grad():# 对输入的句子进行张量表示input_tensor = tensorFromSentence(input_lang, sentence)# 获得输入的句子长度input_length = input_tensor.size()[0]# 初始化编码器隐层张量encoder_hidden = encoder.initHidden()# 初始化编码器输出张量,是max_lengthxencoder.hidden_size的0张量encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)# 循环遍历输入张量索引for ei in range(input_length):# 根据索引从input_tensor取出对应的单词的张量表示,和初始化隐层张量一同传入encoder对象中encoder_output, encoder_hidden = encoder(input_tensor[ei],encoder_hidden)#将每次获得的输出encoder_output(三维张量), 使用[0, 0]降两维变成向量依次存入到encoder_outputs# 这样encoder_outputs每一行存的都是对应的句子中每个单词通过编码器的输出结果encoder_outputs[ei] += encoder_output[0, 0]# 初始化解码器的第一个输入,即起始符decoder_input = torch.tensor([[SOS_token]], device=device) # 初始化解码器的隐层张量即编码器的隐层输出decoder_hidden = encoder_hidden# 初始化预测的词汇列表decoded_words = []# 初始化attention张量decoder_attentions = torch.zeros(max_length, max_length)# 开始循环解码for di in range(max_length):# 将decoder_input, decoder_hidden, encoder_outputs传入解码器对象# 获得decoder_output, decoder_hidden, decoder_attentiondecoder_output, decoder_hidden, decoder_attention = decoder(decoder_input, decoder_hidden, encoder_outputs)# 取所有的attention结果存入初始化的attention张量中decoder_attentions[di] = decoder_attention.data# 从解码器输出中获得概率最高的值及其索引对象topv, topi = decoder_output.data.topk(1)# 从索引对象中取出它的值与结束标志值作对比if topi.item() == EOS_token:# 如果是结束标志值,则将结束标志装进decoded_words列表,代表翻译结束decoded_words.append('<EOS>')# 循环退出breakelse:# 否则,根据索引找到它在输出语言的index2word字典中对应的单词装进decoded_wordsdecoded_words.append(output_lang.index2word[topi.item()])# 最后将本次预测的索引降维并分离赋值给decoder_input,以便下次进行预测decoder_input = topi.squeeze().detach()# 返回结果decoded_words, 以及完整注意力张量, 把没有用到的部分切掉return decoded_words, decoder_attentions[:di + 1]
2 随机选择指定数量的数据进行评估
def evaluateRandomly(encoder, decoder, n=6):"""随机测试函数, 输入参数encoder, decoder代表编码器和解码器对象,n代表测试数"""# 对测试数进行循环for i in range(n):# 从pairs随机选择语言对pair = random.choice(pairs)# > 代表输入print('>', pair[0])# = 代表正确的输出print('=', pair[1])# 调用evaluate进行预测output_words, attentions = evaluate(encoder, decoder, pair[0])# 将结果连成句子output_sentence = ' '.join(output_words)# < 代表模型的输出print('<', output_sentence)print('')
3 Attention张量制图
sentence = "we re both teachers ."
# 调用评估函数
output_words, attentions = evaluate(
encoder1, attn_decoder1, sentence)
print(output_words)
# 将attention张量转化成numpy, 使用matshow绘制
plt.matshow(attentions.numpy())
# 保存图像
plt.savefig("./s2s_attn.png")
相关文章:
自然语言处理---RNN经典案例之使用seq2seq实现英译法
1 seq2seq介绍 1.1 seq2seq模型架构 seq2seq模型架构分析: seq2seq模型架构,包括两部分分别是encoder(编码器)和decoder(解码器),编码器和解码器的内部实现都使用了GRU模型,这里它要完成的是一个中文到英文的翻译:欢迎…...

Python【判断列表的存在与否关系】
要求:使用列表判断一个列表是否在另外一个列表中 代码如下: list1 [1, 2, 6, 8, 7, 10, 5] print("列表1为:", list1) list2 [2, 6, 5, 10] print("列表2为:",list2) res False a 0 for i in list2:if …...

MyBatis篇---第三篇
系列文章目录 文章目录 系列文章目录一、如何执行批量插入?二、Xml映射文件中,除了常见的select|insert|updae|delete标签之外,还有哪些标签?三、MyBatis实现一对一有几种方式?具体怎么操作的?一、如何执行批量插入? 首先,创建一个简单的insert语句: <insert id=”…...

uview1.0部分机型u-input组件禁用后无法触发click事件
最近,线上的一个 App 收到用户反馈,输入框禁用状态下点击无法拉起模态框。找了一下身边可用机型进行了测试,起初所有机型都没有复现这个问题,突然有一天 Redmi K30S Ultra 出现了异常,点击输入框无法触发点击事件&…...

Arduino IDE + Esp32 Cam + 实现视频流 + 开发环境部署
1、开发环境 Arduino ide 版本:2.2.1 esp32工具:2.0.5 示例代码 #include "esp_camera.h" #include <WiFi.h>// // WARNING!!! PSRAM IC required for UXGA resolution and high JPEG quality // Ensure ESP32 Wrover Modu…...
Day4力扣打卡
打卡记录 同积元组(哈希表 排列组合) 链接 思路:用哈希表将数组中出现的两不同数乘积依次记录,将出现两次以上的乘积组通过排列组合计算总情况个数。 class Solution { public:int tupleSameProduct(vector<int>& num…...

Paper Reading:《Consistent-Teacher: 减少半监督目标检测中不一致的伪目标》
目录 简介工作重点方法ASA, adaptive anchor assignmentFAM-3D, 3D feature alignment moduleGMM, Gaussian Mixture Model实施细节 实验与SOTA的比较消融实验 总结 简介 题目:《Consistent-Teacher: Towards Reducing Inconsistent Pseudo-targets in Semi-supervi…...
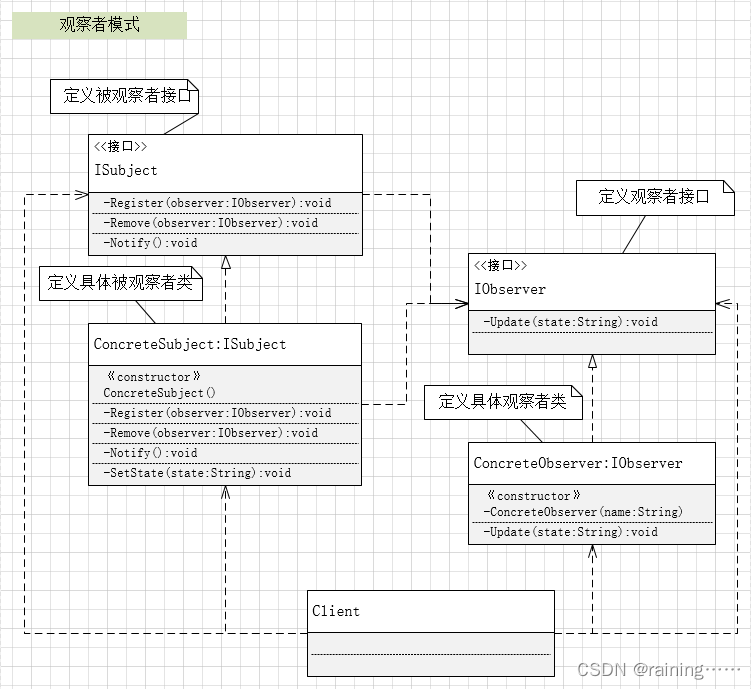
设计模式:观察者模式(C#、JAVA、JavaScript、C++、Python、Go、PHP)
简介: 观察者模式,它是一种行为型设计模式,它允许一个对象自动通知其依赖者(观察者)状态的变化。当被观察者的状态发生改变时,它会通知所有的观察者对象,使他们能够及时做出响应。在观察者模式…...

kotling构造函数
Kotlin-继承与构造函数 - 简书 (jianshu.com) Kotlin语言中的继承与构造函数(详解)_kotlin 继承 构造函数_young螺母的博客-CSDN博客...

SpringMVC - 详解RESTful
文章目录 1. 简介2. RESTful的实现3.HiddenHttpMethodFilter4. RESTful案例1、准备工作2、功能清单3、具体功能:访问首页a>配置view-controllerb>创建页面 4、具体功能:查询所有员工数据a>控制器方法b>创建employee_list.html 5、具体功能&a…...
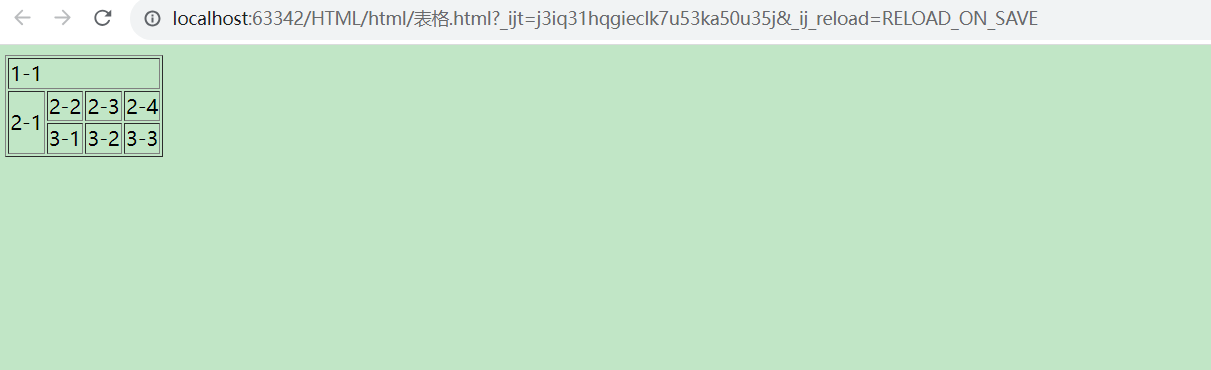
html表格标签
<!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Title</title> </head> <body><!--表格table 行 tr 列 td --> <table border"1px"><tr> <!--colsp…...
Node.JS---npm相关
文章目录 前言一、package.json配置项version:1.0.0devDependenciesdependenciespeerDependenciesoptionalDependencies 二、npm命令1、npm config listxmzs使用2、npm installpackage-lock.json作用 3、npm run4、 查看全局安装的可执行文件 npm生命周期npxnpx简介…...

Flutter的Don‘t use ‘BuildContext‘s across async gaps警告解决方法
文章目录 问题有问题的源码 问题原因问题分析Context的含义BuildContext的作用特殊情况 解决方法 问题 Flutter开发中遇到Don’t use BuildContext’s across async gaps警告 有问题的源码 if (await databaseHelper.isDataExist(task.title)) {showDialog(context: context,…...

Nginx 实战教程
本篇博客我会演示日常的工作中,我们是怎么利用nginx部署项目的。我们以部署一套前后分离的项目为本次讲述的内容 一、搭建后端项目 创建一个最简单的springboot项目: 只需要依赖一个web模块即可: 提供一个api接口,可以获取服务端…...

Web自动化——python
文章目录 1.八大元素定位2.元素基本操作3.浏览器常用操作4.获取元素信息的常用方法5.鼠标和键盘相关操作6.元素等待1.隐式等待2.显示等待 7.下拉选择框8.弹出框9.滚动条操作10.frame表单的切换11.多窗口切换12.窗口截图、验证码处理 1.八大元素定位 元素属性定位:id…...
【java】A卷+B卷)
华为OD 整数最小和(100分)【java】A卷+B卷
华为OD统一考试A卷+B卷 新题库说明 你收到的链接上面会标注A卷还是B卷。目前大部分收到的都是B卷。 B卷对应20022部分考题以及新出的题目,A卷对应的是新出的题目。 我将持续更新最新题目 获取更多免费题目可前往夸克网盘下载,请点击以下链接进入: 我用夸克网盘分享了「华为O…...

正则表达式:文本处理中的瑞士军刀
正则表达式是用于提取字符串规律的规则,通过特定语法表达,以匹配符合该规律的字符串。它具有通用性,不仅适用于Python,也可用于其他编程语言。 下面我用Python的re模块来进行实战演示:(记得import re&…...
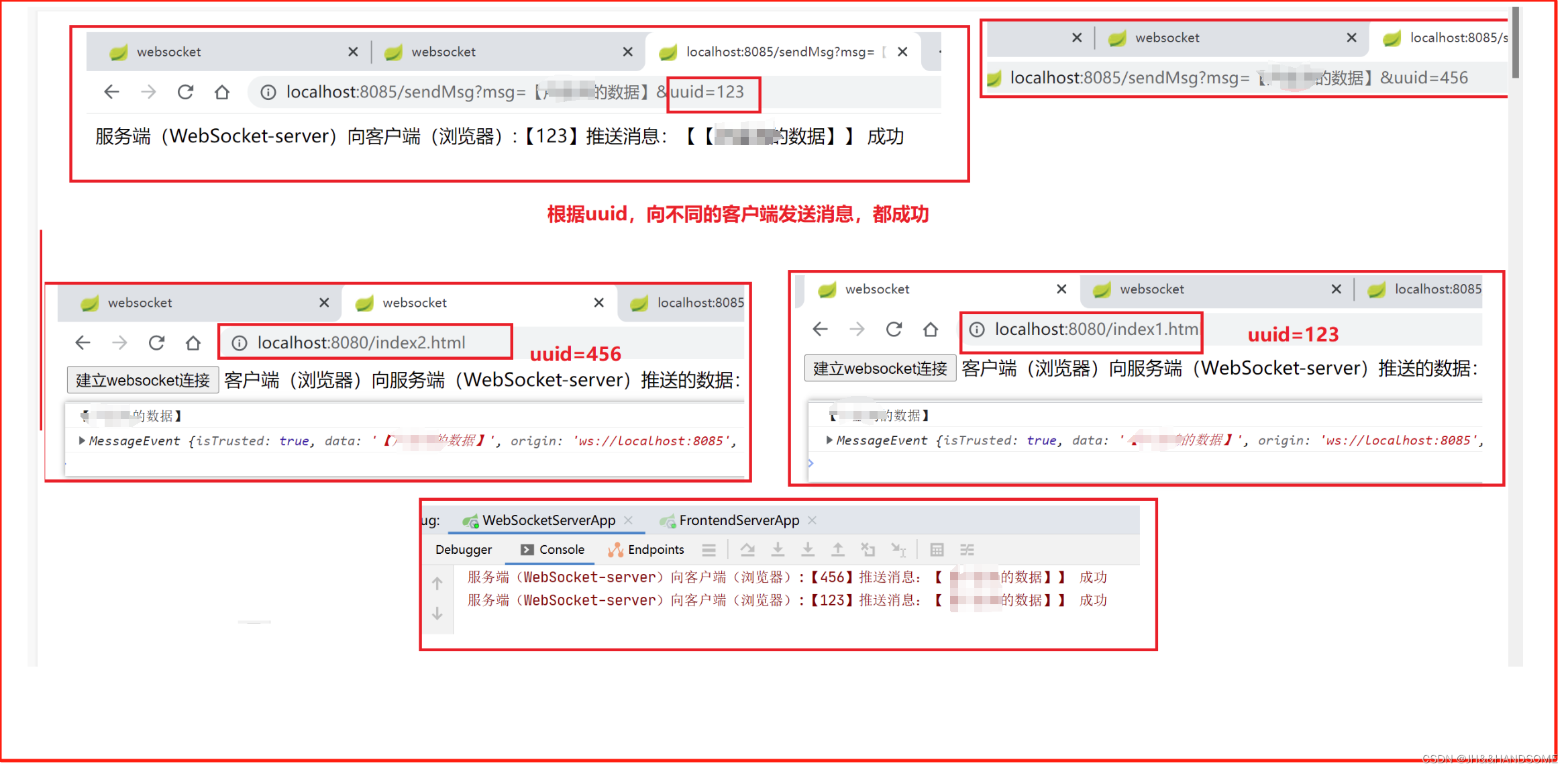
WebSocket 入门案例
目录 WebSocket入门案例WebSocket-server新增项目:添加依赖:yml:启动类: frontend-server前端项目:添加依赖:添加yml:启动类:前端引入JS:前端页面:后端代码:测试: WebSocket 入门案…...
【java】A卷+B卷)
华为OD 最大社交距离(100分)【java】A卷+B卷
华为OD统一考试A卷+B卷 新题库说明 你收到的链接上面会标注A卷还是B卷。目前大部分收到的都是B卷。 B卷对应20022部分考题以及新出的题目,A卷对应的是新出的题目。 我将持续更新最新题目 获取更多免费题目可前往夸克网盘下载,请点击以下链接进入: 我用夸克网盘分享了「华为O…...

Nginx缓存
Nginx缓存 一般情况下系统用到的缓存有三种 服务端缓存:缓存存在后端服务器,如redis 代理缓存:缓存存储在代理服务器或中间件,内容从后端服务器获取,保存在本地 客户端缓存:缓存在浏览器 [ ] 什么时候会出现…...

Function Calling与ReAct:Agent工具调用原理
AgenticRAG比传统RAG更主动,擅长知识召回与更新; Self-Reflection通过自我修正提升输出可靠性,不过耗时略增; Multi-Agent Planner靠多Agent分工协作处理复杂任务,效率高但架构较复杂。 ReAct 全称ReasoningActing,即“先思考&…...

从libil2cpp.so到Frida脚本:一次完整的Unity手游内存修改逆向分析记录
从libil2cpp.so到Frida脚本:Unity手游内存修改实战解析 当你在玩一款单机手游时,是否曾想过那些看似简单的数值背后隐藏着怎样的代码逻辑?作为一名移动安全研究员,我最近对一款采用Unity IL2CPP模式构建的热门单机手游进行了逆向分…...
靶点的分子机制与药物研发技术解析)
生物信息学与免疫药理:CD62L(归巢受体)靶点的分子机制与药物研发技术解析
在生物制药与免疫学研究领域,CD62L(L-选择素/归巢受体)作为调控免疫细胞迁移的关键分子,其在炎症反应与自身免疫性疾病中的核心作用备受关注。本文将从分子结构、信号通路机制、以及药物研发技术路线三个维度,对CD62L靶…...

Qt与MQTT的实战指南:从环境搭建到消息通信
1. MQTT协议与Qt开发环境准备 MQTT协议就像物联网世界的"微信"——它用最轻量级的方式实现设备间的消息传递。想象一下,你家里的智能空调、窗帘和灯光设备需要互相通信,如果每个设备都像打电话一样建立专线连接,那网络开销会大得惊…...

非计算机专业转AI Agent:补哪些基础最有效
【本段核心】现在很多大学生都有转AI的想法,但每天做的却是收藏一堆教程、刷一堆概念、看一堆“LLM 从入门到精通”,然后继续焦虑、继续拖沓、继续投简历没回音。我就是双非野鸡二本经济学转Agent的,成效把 Agent 这条路跑通之后,…...

如何用jsPDF-AutoTable从HTML表格一键生成PDF文档
如何用jsPDF-AutoTable从HTML表格一键生成PDF文档 【免费下载链接】jsPDF-AutoTable jsPDF plugin for generating PDF tables with javascript 项目地址: https://gitcode.com/gh_mirrors/js/jsPDF-AutoTable jsPDF-AutoTable是一款强大的JavaScript插件,能…...

算法面试通关秘籍:30场CV面试总结的深度学习要点
算法面试通关秘籍:30场CV面试总结的深度学习要点 大家好,我是资深AI讲师与学习规划师。专注计算机视觉教学与算法研发,过去三年我帮超过2500名有Python 基础的入门者,从"像素是什么"到"独立跑通CV项目"。今天…...

OpCore Simplify终极指南:5步轻松搞定Hackintosh配置,新手也能快速上手
OpCore Simplify终极指南:5步轻松搞定Hackintosh配置,新手也能快速上手 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为…...

内网多机连接fay使用
课程ID:fay-muli-computer作者:课程作者日期:2026-04-13T14:33版本:1.0.0章节数:7 封面 目录 下载cherry studio启动添加fay配置api选择模型配置默认模型开始对话 第1节 下载cherry studio 请到网站https://www.che…...

2026年最值钱的不是会用AI的人,而是会给AI搭系统的人
2026年最值钱的不是会用AI的人,而是会给AI搭系统的人我这几天一直在想一个问题。我身边有两种人在学AI。一种人学的是工具——ai怎么出图、豆包怎么写文案。另一种人学的是系统——怎么让AI自己去抓热点、自己去写初稿、自己去排版、甚至自己去定时发布。前者每天都…...