自然语言处理---迁移学习实践
1 微调脚本介绍
- 指定任务类型的微调脚本:
- huggingface研究机构提供了针对GLUE数据集合任务类型的微调脚本, 这些微调脚本的核心都是微调模型的最后一个全连接层。
- 通过简单的参数配置来指定GLUE中存在任务类型(如: CoLA对应文本二分类,MRPC对应句子对文本二分类,STS-B对应句子对文本多分类),以及指定需要微调的预训练模型。
2 指定任务类型的微调脚本使用步骤
- 第一步: 下载微调脚本文件
- 第二步: 配置微调脚本参数
- 第三步: 运行并检验效果
2.1 下载微调脚本文件
注意:虚拟机中已经安装transformers,以下安装步骤不需再次执行
# 克隆huggingface的transfomers文件
git clone https://github.com/huggingface/transformers.git# 进行transformers文件夹
cd transformers# 切换transformers到指定版本
git checkout v4.17.0# 安装transformers包
pip install .
# 进入微调脚本所在路径并查看
cd examples/pytorch/text-classificationls# 其中run_glue.py就是针对GLUE数据集合任务类型的微调脚本
2.2 配置微调脚本参数
- 在run_glue.py同级目录执行以下命令
# 定义DATA_DIR: 微调数据所在路径, 这里使用glue_data中的数据作为微调数据
export DATA_DIR="/root/data/glue_data"
# 定义SAVE_DIR: 模型的保存路径, 将模型保存在当前目录的bert_finetuning_test文件中
export SAVE_DIR="./bert_finetuning_test/"# 使用python运行微调脚本
# --model_name_or_path: 选择具体的模型或者变体, 这里是在英文语料上微调, 因此选择bert-base-uncased
# --task_name: 它将代表对应的任务类型, 如MRPC代表句子对二分类任务
# --do_train: 使用微调脚本进行训练
# --do_eval: 使用微调脚本进行验证
# --max_seq_length: 输入句子的最大长度, 超过则截断, 不足则补齐
# --learning_rate: 学习率
# --num_train_epochs: 训练轮数
# --output_dir $SAVE_DIR: 训练后的模型保存路径
# --overwrite_output_dir: 再次训练时将清空之前的保存路径内容重新写入# 因为空间的有限,所以虚拟机中缓存了三个模型bert-base-uncased bert-base-chinese bert-base-cased
# 因为网络原因,如果需要其他模型,需要科学上网才能下载# 虚拟机中执行以下命令耗时较长,建议在有GPU的主机上执行# 模型1,该命令已在虚拟机执行,再次执行会覆盖缓存的模型
python run_glue.py \--model_name_or_path bert-base-uncased \--task_name mrpc \--do_train \--do_eval \--max_seq_length 128 \--learning_rate 2e-5 \--num_train_epochs 1.0 \--output_dir bert-base-uncased-finetuning \--overwrite_output_dir# 模型2,该命令已在虚拟机执行,再次执行会覆盖缓存的模型
python run_glue.py \--model_name_or_path bert-base-chinese \--task_name mrpc \--do_train \--do_eval \--max_seq_length 128 \--learning_rate 2e-5 \--num_train_epochs 1.0 \--output_dir bert-base-chinese-finetuning \--overwrite_output_dir# 模型3,该命令已在虚拟机执行,再次执行会覆盖缓存的模型
python run_glue.py \--model_name_or_path bert-base-cased \--task_name mrpc \--do_train \--do_eval \--max_seq_length 128 \--learning_rate 2e-5 \--num_train_epochs 1.0 \--output_dir bert-base-cased-finetuning \--overwrite_output_dir
2.3 检验效果
1 输出效果
# 最终打印模型的验证结果:
01/05/2020 23:59:53 - INFO - __main__ - Saving features into cached file ../../glue_data/MRPC/cached_dev_bert-base-uncased_128_mrpc
01/05/2020 23:59:53 - INFO - __main__ - ***** Running evaluation *****
01/05/2020 23:59:53 - INFO - __main__ - Num examples = 408
01/05/2020 23:59:53 - INFO - __main__ - Batch size = 8
Evaluating: 100%|█| 51/51 [00:23<00:00, 2.20it/s]
01/06/2020 00:00:16 - INFO - __main__ - ***** Eval results *****
01/06/2020 00:00:16 - INFO - __main__ - acc = 0.7671568627450981
01/06/2020 00:00:16 - INFO - __main__ - acc_and_f1 = 0.8073344506341863
01/06/2020 00:00:16 - INFO - __main__ - f1 = 0.8475120385232745
2 查看文件内容
added_tokens.json
checkpoint-450
checkpoint-400
checkpoint-350
checkpoint-200
checkpoint-300
checkpoint-250
checkpoint-200
checkpoint-150
checkpoint-100
checkpoint-50
pytorch_model.bin
training_args.bin
config.json
special_tokens_map.json
vocab.txt
eval_results.txt
tokenizer_config.json
3 文件说明
- pytorch_model.bin代表模型参数,可以使用torch.load加载查看;
- traning_args.bin代表模型训练时的超参,如batch_size,epoch等,仍可使用torch.load查看;
- config.json是模型配置文件,如多头注意力的头数,编码器的层数等,代表典型的模型结构,如bert,xlnet,一般不更改;
- added_token.json记录在训练时通过代码添加的自定义token对应的数值,即在代码中使用add_token方法添加的自定义词汇;
- special_token_map.json当添加的token具有特殊含义时,如分隔符,该文件存储特殊字符的及其对应的含义,使文本中出现的特殊字符先映射成其含义,之后特殊字符的含义仍然使用add_token方法映射。
- checkpoint: 若干步骤保存的模型参数文件(也叫检测点文件)。
2.4 使用本地微调模型
import torch
from transformers import AutoModel, AutoTokenizer# 1 通过git clone下模型包, 然后再使用
# 2 直接本地加载模型
mypathname = '/root/transformers/examples/pytorch/text-classification/bert-base-uncased-finetuning'
tokenizer = AutoTokenizer.from_pretrained(mypathname)
model = AutoModel.from_pretrained(mypathname)index = tokenizer.encode("Talk is cheap", "Please show me your code!")
# 102是bert模型中的间隔(结束)符号的数值映射
mark = 102# 找到第一个102的索引, 即句子对的间隔符号
k = index.index(mark)# 句子对分割id列表, 由0,1组成, 0的位置代表第一个句子, 1的位置代表第二个句子
segments_ids = [0]*(k + 1) + [1]*(len(index) - k - 1)
# 转化为tensor
tokens_tensor = torch.tensor([index])
segments_tensors = torch.tensor([segments_ids])# 使用评估模式
with torch.no_grad():# 使用模型预测获得结果result = model(tokens_tensor, token_type_ids=segments_tensors)# 打印预测结果以及张量尺寸print(result)print(result[0].shape)
3 通过微调方式进行迁移学习的两种类型
- 类型一: 使用指定任务类型的微调脚本微调预训练模型, 后接带有输出头的预定义网络输出结果.
-
类型二: 直接加载预训练模型进行输入文本的特征表示, 后接自定义网络进行微调输出结果.
-
说明: 所有类型的实战演示, 都将针对中文文本进行.
3.1 类型一实战演示
1 介绍
- 使用文本二分类的任务类型SST-2的微调脚本微调中文预训练模型, 后接带有分类输出头的预定义网络输出结果. 目标是判断句子的情感倾向.
- 准备中文酒店评论的情感分析语料, 语料样式与SST-2数据集相同, 标签0代表差评, 标签1好评.
-
语料存放在与glue_data/同级目录cn_data/下, 其中的SST-2目录包含train.tsv和dev.tsv
-
train.tsv
sentence label
早餐不好,服务不到位,晚餐无西餐,早餐晚餐相同,房间条件不好,餐厅不分吸烟区.房间不分有无烟房. 0
去的时候 ,酒店大厅和餐厅在装修,感觉大厅有点挤.由于餐厅装修本来该享受的早饭,也没有享受(他们是8点开始每个房间送,但是我时间来不及了)不过前台服务员态度好! 1
有很长时间没有在西藏大厦住了,以前去北京在这里住的较多。这次住进来发现换了液晶电视,但网络不是很好,他们自己说是收费的原因造成的。其它还好。 1
非常好的地理位置,住的是豪华海景房,打开窗户就可以看见栈桥和海景。记得很早以前也住过,现在重新装修了。总的来说比较满意,以后还会住 1
交通很方便,房间小了一点,但是干净整洁,很有香港的特色,性价比较高,推荐一下哦 1
酒店的装修比较陈旧,房间的隔音,主要是卫生间的隔音非常差,只能算是一般的 0
酒店有点旧,房间比较小,但酒店的位子不错,就在海边,可以直接去游泳。8楼的海景打开窗户就是海。如果想住在热闹的地带,这里不是一个很好的选择,不过威海城市真的比较小,打车还是相当便宜的。晚上酒店门口出租车比较少。 1
位置很好,走路到文庙、清凉寺5分钟都用不了,周边公交车很多很方便,就是出租车不太爱去(老城区路窄爱堵车),因为是老宾馆所以设施要陈旧些, 1
酒店设备一般,套房里卧室的不能上网,要到客厅去。 0
- dev.tsv
sentence label
房间里有电脑,虽然房间的条件略显简陋,但环境、服务还有饭菜都还是很不错的。如果下次去无锡,我还是会选择这里的。 1
我们是5月1日通过携程网入住的,条件是太差了,根本达不到四星级的标准,所有的东西都很陈旧,卫生间水龙头用完竟关不上,浴缸的漆面都掉了,估计是十年前的四星级吧,总之下次是不会入住了。 0
离火车站很近很方便。住在东楼标间,相比较在九江住的另一家酒店,房间比较大。卫生间设施略旧。服务还好。10元中式早餐也不错,很丰富,居然还有青菜肉片汤。 1
坐落在香港的老城区,可以体验香港居民生活,门口交通很方便,如果时间不紧,坐叮当车很好呀!周围有很多小餐馆,早餐就在中远后面的南北嚼吃的,东西很不错。我们定的大床房,挺安静的,总体来说不错。前台结账没有银联! 1
酒店前台服务差,对待客人不热情。号称携程没有预定。感觉是客人在求他们,我们一定得住。这样的宾馆下次不会入住! 0
价格确实比较高,而且还没有早餐提供。 1
是一家很实惠的酒店,交通方便,房间也宽敞,晚上没有电话骚扰,住了两次,有一次住501房间,洗澡间排水不畅通,也许是个别问题.服务质量很好,刚入住时没有调好宽带,服务员很快就帮忙解决了. 1
位置非常好,就在西街的街口,但是却闹中取静,环境很清新优雅。 1
房间应该超出30平米,是HK同级酒店中少有的大;重装之后,设备也不错. 1
2 运行代码
在run_glue.py同级目录执行以下命令
# 使用python运行微调脚本
# --model_name_or_path: 选择bert-base-chinese
# --task_name: 句子二分类任务sst2
# --do_train: 使用微调脚本进行训练
# --do_eval: 使用微调脚本进行验证
# --max_seq_length: 128,输入句子的最大长度# 该命令已在虚拟机执行,再次执行会覆盖缓存的模型python run_glue.py \--model_name_or_path bert-base-chinese \--task_name sst2 \--do_train \--do_eval \--max_seq_length 128 \--learning_rate 2e-5 \--num_train_epochs 1.0 \--output_dir bert-base-chinese-sst2-finetuning
3 查看文件内容:
added_tokens.json
checkpoint-350
checkpoint-200
checkpoint-300
checkpoint-250
checkpoint-200
checkpoint-150
checkpoint-100
checkpoint-50
pytorch_model.bin
training_args.bin
config.json
special_tokens_map.json
vocab.txt
eval_results.txt
tokenizer_config.json
4 使用本地微调模型
import torch
# 0 找到自己预训练模型的路径
mymodelname = '/root/transformers/examples/pytorch/text-classification/bert-base-chinese-sst2-finetuning'
print(mymodelname)# 1 本地加载预训练模型的tokenizer
tokenizer = AutoTokenizer.from_pretrained(mymodelname)# 2 本地加载 预训练模型 带分类模型头
model = AutoModelForSequenceClassification.from_pretrained(mymodelname)
# model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint, num_labels=2)# 3 默认情况下 加载预训练模型,不带头
# model = AutoModel.from_pretrained('./transformers/examples/pytorch/text-classification/bert_finetuning_test_hug')text = "早餐不好,服务不到位,晚餐无西餐,早餐晚餐相同,房间条件不好"
index = tokenizer.encode(text)
tokens_tensor = torch.tensor([index])# 使用评估模式
with torch.no_grad():# 使用模型预测获得结果result = model(tokens_tensor)print(result[0])predicted_label = torch.argmax(result[0]).item()
print('预测标签为>', predicted_label)text1 = "房间应该超出30平米,是HK同级酒店中少有的大;重装之后,设备也不错."
index = tokenizer.encode(text1)
tokens_tensor = torch.tensor([index])# 使用评估模式
with torch.no_grad():# 使用模型预测获得结果result = model(tokens_tensor)print(result[0])predicted_label = torch.argmax(result[0]).item()
print('预测标签为>', predicted_label)
3.2 类型二实战演示
1 介绍
- 直接加载预训练模型进行输入文本的特征表示, 后接自定义网络进行微调输出结果.
- 使用语料和完成的目标与类型一实战相同.
2 加载预训练模型
直接加载预训练模型进行输入文本的特征表示:
import torch
# 进行句子的截断补齐(规范长度)
from keras.preprocessing import sequence# 因为空间原因,虚拟机中之缓存了huggingface/pytorch-transformers模型# 从本地加载
source = '/root/.cache/torch/hub/huggingface_pytorch-transformers_master'
# 从github加载
# source = 'huggingface/pytorch-transformers'# 直接使用预训练的bert中文模型
model_name = 'bert-base-chinese'# 通过torch.hub获得已经训练好的bert-base-chinese模型
model = torch.hub.load(source, 'model', model_name, source='local')
# 从github加载
# model = torch.hub.load(source, 'model', model_name, source='github')# 获得对应的字符映射器, 它将把中文的每个字映射成一个数字
tokenizer = torch.hub.load(source, 'tokenizer', model_name, source='local')
# 从github加载
# tokenizer = torch.hub.load(source, 'tokenizer', model_name, source='github')# 句子规范长度
cutlen = 32def get_bert_encode(text):"""description: 使用bert-chinese编码中文文本:param text: 要进行编码的文本:return: 使用bert编码后的文本张量表示"""# 首先使用字符映射器对每个汉字进行映射# 这里需要注意, bert的tokenizer映射后会为结果前后添加开始和结束标记即101和102 # 这对于多段文本的编码是有意义的, 但在我们这里没有意义, 因此使用[1:-1]对头和尾进行切片indexed_tokens = tokenizer.encode(text[:cutlen])[1:-1]# 对映射后的句子进行截断补齐indexed_tokens = sequence.pad_sequences([indexed_tokens], cutlen) # 之后将列表结构转化为tensortokens_tensor = torch.LongTensor(indexed_tokens)# 使模型不自动计算梯度with torch.no_grad():# 调用模型获得隐层输出encoded_layers = model(tokens_tensor)# 输出的隐层是一个三维张量, 最外层一维是1, 我们使用[0]降去它.encoded_layers = encoded_layers[0]return encoded_layers
3 自定义单层的全连接网络
自定义单层的全连接网络作为微调网络。根据实际经验, 自定义的微调网络参数总数应大于0.5倍的训练数据量, 小于10倍的训练数据量, 这样有助于模型在合理的时间范围内收敛.
import torch.nn as nn
import torch.nn.functional as Fclass Net(nn.Module):"""定义微调网络的类"""def __init__(self, char_size=32, embedding_size=768):""":param char_size: 输入句子中的字符数量, 即输入句子规范后的长度128.:param embedding_size: 字嵌入的维度, 因为使用的bert中文模型嵌入维度是768, 因此embedding_size为768"""super(Net, self).__init__()# 将char_size和embedding_size传入其中self.char_size = char_sizeself.embedding_size = embedding_size# 实例化一个全连接层self.fc1 = nn.Linear(char_size*embedding_size, 2)def forward(self, x):# 对输入的张量形状进行变换, 以满足接下来层的输入要求x = x.view(-1, self.char_size*self.embedding_size)# 使用一个全连接层x = self.fc1(x)return x
4 构建训练与验证数据批次生成器
import pandas as pd
from collections import Counter
from functools import reduce
from sklearn.utils import shuffledef data_loader(train_data_path, valid_data_path, batch_size):"""description: 从持久化文件中加载数据:param train_data_path: 训练数据路径:param valid_data_path: 验证数据路径:param batch_size: 训练和验证数据集的批次大小:return: 训练数据生成器, 验证数据生成器, 训练数据数量, 验证数据数量"""# 使用pd进行csv数据的读取, 并去除第一行的列名train_data = pd.read_csv(train_data_path, header=None, sep="\t").drop([0])valid_data = pd.read_csv(valid_data_path, header=None, sep="\t").drop([0])# 打印训练集和验证集上的正负样本数量print("训练数据集的正负样本数量:")print(dict(Counter(train_data[1].values)))print("验证数据集的正负样本数量:")print(dict(Counter(valid_data[1].values)))# 验证数据集中的数据总数至少能够满足一个批次if len(valid_data) < batch_size:raise("Batch size or split not match!")def _loader_generator(data):"""description: 获得训练集/验证集的每个批次数据的生成器:param data: 训练数据或验证数据:return: 一个批次的训练数据或验证数据的生成器"""# 以每个批次的间隔遍历数据集for batch in range(0, len(data), batch_size):# 定义batch数据的张量列表batch_encoded = []batch_labels = []# 将一个bitch_size大小的数据转换成列表形式, 并进行逐条遍历for item in shuffle(data.values.tolist())[batch: batch+batch_size]:# 使用bert中文模型进行编码encoded = get_bert_encode(item[0])# 将编码后的每条数据装进预先定义好的列表中batch_encoded.append(encoded)# 同样将对应的该batch的标签装进labels列表中batch_labels.append([int(item[1])])# 使用reduce高阶函数将列表中的数据转换成模型需要的张量形式# encoded的形状是(batch_size*max_len, embedding_size)encoded = reduce(lambda x, y: torch.cat((x, y), dim=0), batch_encoded)labels = torch.tensor(reduce(lambda x, y: x + y, batch_labels))# 以生成器的方式返回数据和标签yield (encoded, labels)# 对训练集和验证集分别使用_loader_generator函数, 返回对应的生成器# 最后还要返回训练集和验证集的样本数量return _loader_generator(train_data), _loader_generator(valid_data), len(train_data), len(valid_data)
5 编写训练和验证函数
import torch.optim as optimdef train(train_data_labels):"""description: 训练函数, 在这个过程中将更新模型参数, 并收集准确率和损失:param train_data_labels: 训练数据和标签的生成器对象:return: 整个训练过程的平均损失之和以及正确标签的累加数"""# 定义训练过程的初始损失和准确率累加数train_running_loss = 0.0train_running_acc = 0.0# 循环遍历训练数据和标签生成器, 每个批次更新一次模型参数for train_tensor, train_labels in train_data_labels:# 初始化该批次的优化器optimizer.zero_grad()# 使用微调网络获得输出train_outputs = net(train_tensor)# 得到该批次下的平均损失train_loss = criterion(train_outputs, train_labels)# 将该批次的平均损失加到train_running_loss中train_running_loss += train_loss.item()# 损失反向传播train_loss.backward()# 优化器更新模型参数optimizer.step()# 将该批次中正确的标签数量进行累加, 以便之后计算准确率train_running_acc += (train_outputs.argmax(1) == train_labels).sum().item()return train_running_loss, train_running_accdef valid(valid_data_labels):"""description: 验证函数, 在这个过程中将验证模型的在新数据集上的标签, 收集损失和准确率:param valid_data_labels: 验证数据和标签的生成器对象:return: 整个验证过程的平均损失之和以及正确标签的累加数"""# 定义训练过程的初始损失和准确率累加数valid_running_loss = 0.0valid_running_acc = 0.0# 循环遍历验证数据和标签生成器for valid_tensor, valid_labels in valid_data_labels:# 不自动更新梯度with torch.no_grad():# 使用微调网络获得输出valid_outputs = net(valid_tensor)# 得到该批次下的平均损失valid_loss = criterion(valid_outputs, valid_labels)# 将该批次的平均损失加到valid_running_loss中valid_running_loss += valid_loss.item()# 将该批次中正确的标签数量进行累加, 以便之后计算准确率valid_running_acc += (valid_outputs.argmax(1) == valid_labels).sum().item()return valid_running_loss, valid_running_acc
6 调用并保存模型
if __name__ == "__main__":# 设定数据路径train_data_path = "/root/data/glue_data/SST-2/train.tsv"valid_data_path = "/root/data/glue_data/SST-2/dev.tsv"# 定义交叉熵损失函数criterion = nn.CrossEntropyLoss()# 定义SGD优化方法optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)# 定义训练轮数epochs = 4# 定义批次样本数量batch_size = 16# 进行指定轮次的训练for epoch in range(epochs):# 打印轮次print("Epoch:", epoch + 1)# 通过数据加载器获得训练数据和验证数据生成器, 以及对应的样本数量train_data_labels, valid_data_labels, train_data_len, \valid_data_len = data_loader(train_data_path, valid_data_path, batch_size)# 调用训练函数进行训练train_running_loss, train_running_acc = train(train_data_labels)# 调用验证函数进行验证valid_running_loss, valid_running_acc = valid(valid_data_labels)# 计算每一轮的平均损失, train_running_loss和valid_running_loss是每个批次的平均损失之和# 因此将它们乘以batch_size就得到了该轮的总损失, 除以样本数即该轮次的平均损失train_average_loss = train_running_loss * batch_size / train_data_lenvalid_average_loss = valid_running_loss * batch_size / valid_data_len# train_running_acc和valid_running_acc是每个批次的正确标签累加和,# 因此只需除以对应样本总数即是该轮次的准确率train_average_acc = train_running_acc / train_data_lenvalid_average_acc = valid_running_acc / valid_data_len# 打印该轮次下的训练损失和准确率以及验证损失和准确率print("Train Loss:", train_average_loss, "|", "Train Acc:", train_average_acc)print("Valid Loss:", valid_average_loss, "|", "Valid Acc:", valid_average_acc)print('Finished Training')# 保存路径MODEL_PATH = './BERT_net.pth'# 保存模型参数torch.save(net.state_dict(), MODEL_PATH) print('Finished Saving')
7 加载模型进行使用
if __name__ == "__main__":MODEL_PATH = './BERT_net.pth'# 加载模型参数net.load_state_dict(torch.load(MODEL_PATH))# text = "酒店设备一般,套房里卧室的不能上网,要到客厅去。"text = "房间应该超出30平米,是HK同级酒店中少有的大;重装之后,设备也不错."print("输入文本为:", text)with torch.no_grad():output = net(get_bert_encode(text))# 从output中取出最大值对应的索引print("预测标签为:", torch.argmax(output).item())
相关文章:

自然语言处理---迁移学习实践
1 微调脚本介绍 指定任务类型的微调脚本: huggingface研究机构提供了针对GLUE数据集合任务类型的微调脚本, 这些微调脚本的核心都是微调模型的最后一个全连接层。通过简单的参数配置来指定GLUE中存在任务类型(如: CoLA对应文本二分类,MRPC对应句子对文本二分类&…...
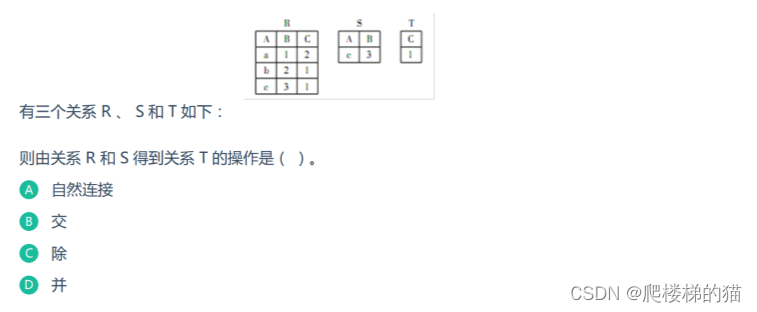
看得懂的——数据库中的“除”操作
通过一个例子来解释数据库中的“除”操作 R➗S其实就是判断关系R中X各个值的象集Y是否包含关系S中属性Y的所有值 求解步骤 第一步 找出关系R和关系S中相同的属性,即Y属性。在关系S中对Y做投影(即将Y列取出);所得结果如下&#x…...
el-input无法输入的问题和表单验证失败问题(亲测有效)-开发bug总结4
大部分无法输入的问题:基本都是没有进行v-model双向数据绑定,这个很好解决。 本人项目中遇到的bug问题如下: 点击添加,表单内可输入用户名 和 用户姓名,但有时会偶发出现无法这两个input框里面无法输入内容。 原因&a…...

OpenCV+QT实现的数字图像处理算法合集
源码下载地址: 基于OpenCV和QT的图像处理源码 图像预处理 灰度处理 灰度直方图 灰度均衡 梯度锐化 Laplace锐化 边缘检测 Roberts Sobel Laplace Prewitt canny Krisch 噪声 椒盐噪声 高斯噪声 滤波 均值滤波 中值滤波 双边滤波 形态学滤波 高斯滤波 图像变…...
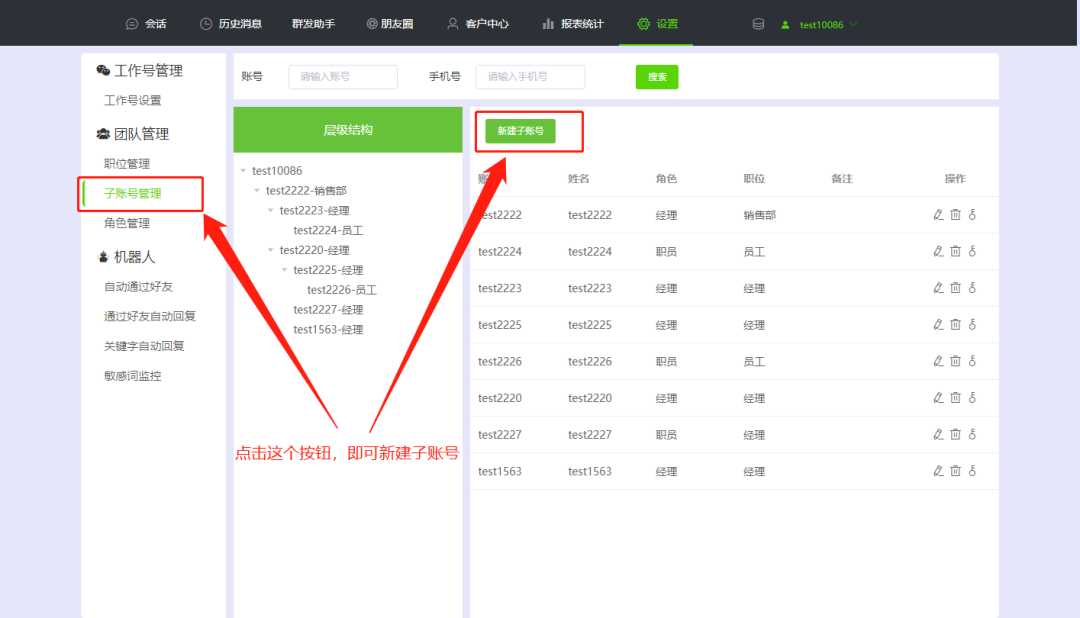
想要查看员工与客户聊天记录和跟进情况,有什么工具推荐吗?
想要查看员工与客户 聊天记录和跟进情况 有什么工具推荐吗? 想要查看员工与客户聊天记录和每天新增客户,可以使用微信管理系统这个工具。 微信管理系统是一个能够同时登录多个微信,实现一个人管理多个微信的工具。它分为两大版块,…...

androdi知识笔记
jbr embed:android studio自带的jdk AGP(android gradle plugin) aar jar 利用java语言可以写应用程序(利用已有库加速开发过程),也可以自己开发库用于特定功能(供引用)。 循环啊是个࿰…...

华为数通方向HCIP-DataCom H12-831题库(多选题:21-40)
第21题 网络管理员A希望使用ACL匹配特定的路由条目,请问以下哪些路由条目将被图中的ACL规侧匹配? acl number 2000 rule 10 permit source 10.0.0.0 0.0.6.0A、10.0.0.1/32 B、10.0.0.0/24 C、10.0.1.0/24 D、10.0.2.0/24 答案: 解析: 通配符十进制6转换二进制为00000110,…...

数据要素安全流通:挑战与解决方案
文章目录 数据要素安全流通:挑战与解决方案一、引言二、数据要素安全流通的挑战数据泄露风险数据隐私保护数据跨境流动监管 三、解决方案加强数据安全防护措施实施数据隐私保护技术建立合规的数据跨境流动机制 四、数据安全流通的未来趋势01 数据价值与产业崛起02 多…...

【Mybatis源码】XMLConfigBuilder构建器 - 加载XML与创建Configuration对象的过程
XMLConfigBuilder是Mybatis中定义的进行构建Configuration对象的类,此类用于读取XML配置文件创建并初始化Configuration对象;本篇我们主要介绍加载XML文件与创建Configuration对象的过程。 一、Configuration对象的创建过程 下面是从Configuration类中取到的代码片段: pu…...

台灯显色指数多少好?推荐显色指数优秀的护眼台灯
台灯的显色指数是其非常重要的指标,它可以表示灯光照射到物体身上,物体颜色的真实程度,一般用平均显色指数Ra来表示,Ra值越高,灯光显色能力越强。常见的台灯显色指数最低要求一般是在Ra80以上即可,比较好的…...
【2024秋招】2023-8-5-小红书-数据引擎团队后端开发提前批面经
1 面试官介绍 OLAP引擎,离线引擎,大数据分析中间件 2 自我介绍 缺点: (1)面试官让重点介绍自己最在行的项目,我真的在自我介绍上扯了一些别的东西… (2)在面试的时候因为想看简…...
【Docker从入门到入土 4】使用Harbor搭建Docker私有仓库
私有仓库 一、Harbor简介1.1 什么是Harbor?1.2 Harbor的特性1.3 Harbor和docker registry的关系1.4 Harbor的构成1.4 Harbor 配置文件中的两类参数1.4.1 所需参数1.4.2 可选参数 二、Harbor部署2.1 部署Docker-Compose服务2.2 部署 Harbor 服务Step1 下载或上传 Harbor 安装程…...

监控易一体化运维:打造机房环境监控的卓越典范
随着信息技术的飞速发展,机房作为企业数据和业务的中心,其运行状态和管理的重要性日益凸显。为确保机房的稳定性和可靠性,越来越多的企业选择使用一体化运维管理软件来进行实时监控。在这方面,监控易品牌提供了一款全面而高效的机…...

【X3m】DDR压力测试
Index of /downloads/unittest/ 设置CPU模式和降频温度# 若设备重启需再次配置这两条指令 echo performance > /sys/devices/system/cpu/cpufreq/policy0/scaling_governor echo 105000 > /sys/devices/virtual/thermal/thermal_zone0/trip_point_1_temp #1 cpu test ec…...

【Linux】32条指令带你玩转 Linux !
目录 1,whoami 2,who 3,pwd 4,ls 1,ls 2,ls -l 3,ls -a 4,ls -al 5,ls -d 6,ls -ld 5,clear 6,cd 1,cd 2&…...
高效恢复丢失的文件的10 款Android数据恢复工具
在当今快节奏的数字时代,从Android设备丢失重要数据可能是一场噩梦。 您需要一个可靠的恢复工具来取回您的数据,例如令人难忘的照片,重要的联系人,重要的工作文档等。 值得庆幸的是,有许多高效的Android数据恢复工具可…...

Python数据挖掘 | 升级版自动查核酸
📕作者简介:热爱跑步的恒川,致力于C/C、Java、Python等多编程语言,热爱跑步,喜爱音乐的一位博主。 📗本文收录于恒川的日常汇报系列,大家有兴趣的可以看一看 📘相关专栏C语言初阶、C…...
港联证券:哪家证券公司开户好?
在现代社会,出资理财已经成为了一个不可或缺的部分。出资者在进行股票生意时,不可避免地需求选择一家证券公司进行开户。可是,哪家证券公司开户好?这是每个出资者都需求考虑的问题。本文将从多个角度分析,为您供给一些…...

RabbitMQ官方案例学习记录
官方文档:RabbitMQ教程 — RabbitMQ (rabbitmq.com) 一、安装RabbitMQ服务 直接使用docker在服务器上安装 docker run -it -d --name rabbitmq -p 5672:5672 -p 15672:15672 rabbitmq:3.12-management 安装完成后,访问15672端口,默认用户…...

Ikigai: 享受生命的意义
你为什么而活?你的存在意义是什么?除了工作、挣钱,还有什么值得投入人生?Ikigai是来自日本的哲学思想,意味着带给你快乐、让你享受生活的东西。知道自己的Ikigai,也许人生可以减少很多焦虑、痛苦和烦恼。世…...
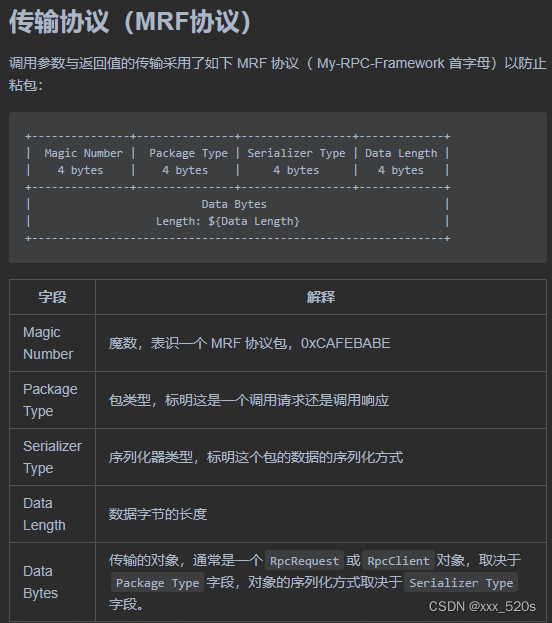
:文件提取工具对)
我用 AI 辅助开发了一系列小工具():文件提取工具对
从0构建WAV文件:读懂计算机文件的本质 虽然接触计算机有一段时间了,但是我的视野一直局限于一个较小的范围之内,往往只能看到于算法竞赛相关的内容,计算机各种文件在我看来十分复杂,认为构建他们并能达到目的是一件困难…...

Heygem数字人系统在教育培训场景的应用:快速生成多讲师教学视频
Heygem数字人系统在教育培训场景的应用:快速生成多讲师教学视频 1. 教育培训行业的视频制作痛点 教育培训机构在制作教学视频时常常面临以下挑战: 讲师资源有限:优秀讲师时间宝贵,难以满足大量课程录制需求制作成本高昂&#x…...

Phi-3-mini-128k-instruct开源模型解析:为何它在<13B参数中推理能力领先?
Phi-3-mini-128k-instruct开源模型解析:为何它在<13B参数中推理能力领先? 你有没有想过,一个只有38亿参数的“小”模型,凭什么能在推理能力上挑战那些动辄百亿、千亿参数的“大块头”?今天我们要聊的Phi-3-mini-12…...
——基于DAC0832的多波形信号生成系统)
51单片机实战指南(4)——基于DAC0832的多波形信号生成系统
1. 硬件系统搭建:从零组装你的信号发生器 第一次接触DAC0832时,我对着密密麻麻的引脚图发呆了半小时。后来发现只要抓住几个关键点,硬件连接就像拼乐高一样简单。这个多波形信号生成系统的核心部件就三个:AT89C51单片机、DAC0832数…...

非线性信号的时间尺度调整
在计算机编程中处理非线性系统模型时,时间尺度常常是需要特别关注的细节。今天我们来探讨如何通过调整时间尺度来优化一个非线性自回归移动平均(NARMA)模型的输出。 背景介绍 在之前的博客中,我们已经讨论过一个基于时间的非线性信号函数NARMA_optimized。这个函数的设计…...

基于STM32F407与W5500的HAL库TCP通信实战指南
1. 硬件准备与连接 搞嵌入式开发的朋友都知道,硬件连接是第一步也是最容易出错的地方。我刚开始用STM32F407和W5500时,就因为SPI接线问题折腾了好几天。这里分享下我的经验,帮你少走弯路。 首先说说W5500这个模块,它是一款全硬件T…...

你的SSH密钥可能已经过期了噬
引言 在现代软件开发中,性能始终是衡量应用质量的重要指标之一。无论是企业级应用、云服务还是桌面程序,性能优化都能显著提升用户体验、降低基础设施成本并增强系统的可扩展性。对于使用 C# 开发的应用程序而言,性能优化涉及多个层面&#x…...

Redis:延迟双删的适用边界与落地细节脚
pagehelper整合 引入依赖com.github.pagehelperpagehelper-spring-boot-starter2.1.0compile编写代码 GetMapping("/list/{pageNo}") public PageInfo findAll(PathVariable int pageNo) {// 设置当前页码和每页显示的条数PageHelper.startPage(pageNo, 10);// 查询数…...

Cadence 17.4 原理图分页符实战:解决‘1 of 1’报错,搞定多页连接
Cadence 17.4 原理图分页符深度解析:从报错诊断到高效设计实践 在复杂电路设计领域,Cadence 17.4作为行业标杆工具,其原理图设计功能直接影响着工程师的工作效率和设计质量。而多页原理图连接问题,尤其是分页符(off-page)配置不当…...

Z-Image-Turbo_Sugar脸部Lora一文详解:Lora微调原理、基础模型关系与使用边界
Z-Image-Turbo_Sugar脸部Lora一文详解:Lora微调原理、基础模型关系与使用边界 你是不是也遇到过这样的烦恼:想用AI生成特定风格的人像,比如那种清透甜美的“糖系”脸蛋,但用通用的大模型试了半天,出来的效果总是不对味…...