Hive SQL 函数高阶应用场景
HIVE作为数据仓库处理常用工具,如同RDBMS关系型数据库中标准SQL语法一样,Hive SQL也内置了不少系统函数,满足于用户在不同场景下的数据分析需求,以提高开发SQL数据分析的效率。
我们可以使用show functions查看当下版本支持的函数,并且可以通过describe function extended funcname来查看函数对应的使用方式和方法,下面我们将描述HIVE SQL中常用函数的高阶使用场景。
1、行转列(explode)
如下活动列表:tb_activities
| 活动ID | 活动名称列表 |
|---|---|
| 1 | 双111,国庆,元旦 |
| 2 | 黄金周,国庆,元旦 |
希望转换为列类型活动表:tb_activitity
| 活动ID | 活动名称 |
|---|---|
| 1 | 双11 |
| 1 | 国庆 |
| 1 | 元旦 |
| 2 | 黄金周 |
| 2 | 国庆 |
| 2 | 元旦 |
使用到Hive内置一个非常著名的UDTF函数,名字叫做explode函数,中文戏称为“爆炸函数”,可以炸开数据转换为多行。
insert into table tb_activitity select id,activity from tb_activities
lateral view explode(split(activities,','))enum_tmp as activity;
2、列转行
如上1所示,希望从tb_activity转换为tb_activities,通过collect_set()方法和group by id 将列转换为行,实现如下:
select id, concat_ws(',',collect_set(activity)) as activities from tb_activity group by id;
3、排名(rank())
可以通过rank() 方法的使用,实现对指定列进行排名,输出排名结果。例如商品总数表:t_item_sum,需要实现排名功能:
| item_id | item_sum |
|---|---|
| 1001 | 20 |
| 1002 | 12 |
| 1003 | 62 |
| 1004 | 15 |
期望得到:
| item_id | item_sum | rank |
|---|---|---|
| 1003 | 62 | 1 |
| 1001 | 20 | 2 |
| 1004 | 15 | 3 |
| 1002 | 12 | 4 |
代码实现如下:
select item_id,item_sum,rank()over(order by item_sum desc) as rank from t_item_sum;
4、分组去重
在查询数据时如果有重复,我们可以使用用distinct 去除重复值,但使用 distinct 只能去除所有查询列都相同的记录,如果某个字段不同,distinct 就无法去重。这时我们可以用 row_number()over(partitioon by column1 order by column2) 先进行分组。
例如:有活动表数据列“活动id,用户id,活动名称,客户群组,过期时间”,希望按照”活动id,活动名称,客户群组”去重,取最新一条数据。
| id | user_id | activity | cust_group | expired_at |
|---|---|---|---|---|
| BCP015 | 1001 | 春节活动A | 高价值 | 2023-10-05 |
| BCP015 | 1001 | 春节活动A | 高价值 | 2023-10-15 |
| BCP015 | 1001 | 春节活动A | 高价值 | 2023-10-28 |
| BCP025 | 1002 | 春节活动B | 中价值 | 2023-10-05 |
| BCP025 | 1002 | 春节活动B | 中价值 | 2023-10-25 |
| BCP030 | 1003 | 春节活动C | 中价值 | 2023-10-25 |
期望得到:
| id | user_id | activity | cust_group | expired_at |
|---|---|---|---|---|
| BCP015 | 1001 | 春节活动A | 高价值 | 2023-10-28 |
| BCP025 | 1002 | 春节活动B | 中价值 | 2023-10-25 |
| BCP030 | 1003 | 春节活动C | 中价值 | 2023-10-25 |
使用row_number()over(partitioon by) 分组去重。
select tt1.* from(select id, user_id, activity,cust_group,row_number() over(partition by concat(id,activity,cust_group)order by expired_at desc)as row_num from tb_acitivity_full)tt1 where tt1.row_num=1;
5、指标统计
GROUPING SETS,GROUPING__ID,CUBE,ROLLUP,这几个hive分析函数通常用于OLAP中,不能累加,而且需要根据不同维度上钻( roll up )和下钻( drill down )的指标统计,比如,分小时、天、月的UV数。上钻是沿着维度的层次向上聚集汇总数据,下钻是在分析时加深维度,对数据进行层层深入的查看。通过逐层下钻,数据更加一目了然,更能充分挖掘数据背后的价值,及时做出更加正确的决策。
| OLAP函数 | 使用说明 |
|---|---|
| GROUPING SETS | 根据不同的维度组合进行聚合,等价于将不同维度的GROUP BY结果集进行UNION ALL |
| GROUPING__ID | 表示结果属于哪一个分组集合,属于虚字段 |
| CUBE | 可根据GROUP BY的维度的所有组合进行聚合 |
| ROLLUP | 作为CUBE的子集,以最左侧的维度为主,从该维度进行层级聚合 |
如4所示,希望对指标值进行统计,期望结果:
| indicator | enum_value | count |
|---|---|---|
| id | BCP015 | 3 |
| id | BCP025 | 2 |
| id | BCP030 | 1 |
| activity | 春节活动A | 3 |
| activity | 春节活动B | 2 |
| activity | 春节活动C | 1 |
| cust_group | 高价值 | 3 |
| cust_group | 中价值 | 3 |
通过grouping__id 内层SQL处理结果,表2:
| groupId | id | activity | cust_group | uv |
|---|---|---|---|---|
| 1728 | id_BCP015 | NULL | NULL | 3 |
| 1724 | id_BCP025 | NULL | NULL | 2 |
| 1723 | id_BCP030 | NULL | NULL | 1 |
| 2728 | NULL | activity_春节活动A | NULL 3 | |
| 2724 | NULL | activity_春节活动B | NULL 2 | |
| 2723 | NULL | activity_春节活动C | NULL 1 | |
| 3723 | NULL | NULL | cust_group_高价值 | 3 |
| 3724 | NULL | NULL | cust_group_中价值 | 3 |
select split(coalesce(id,activity,cust_group),'\\_')[0] as indicator,coalesce(split(id, '\\_')[1],split(activity, '\\_')[1],split(cust_group, '\\_')[1],) as enum_valuesum(uv) as countfrom (-- 内层SQL处理结果,对应上表2select grouping__id as groupId,concat('id|',id) as id,concat('activity|', activity) as activity,concat('cust_group|',cust_group) as cust_group,count(*) as uvfrom tb_acitivity_fullgroup by concat('id|',id),concat('activity|', activity),concat('cust_group|',cust_group)grouping sets(concat('id|',id),concat('activity|', activity),concat('cust_group|',cust_group))as tt1group by split(coalesce(id,activity,cust_group),'\\_')[0],coalesce(split(id, '\\_')[1],split(activity, '\\_')[1],split(cust_group, '\\_')[1],);
6、JSON数据处理
JSON数据作为数据存储和数据处理中最常见的结构化数据格式之一,许多场景下都会将数据以JSON格式存储在文件系统(HDFS/MINIO等)中,当构建数据仓库时,对JSON格式的数据进行处理和分析,就需要在Hive中使用对应函数对JSON格式的数据进行解析读取。
例如,JSON格式的数据如下:
| 商品ID | 商品名称 | 额外信息 |
|---|---|---|
| 1001 | IP15 | “fixedIntegral”:200, “source”:“wechat”,“stages”:12} |
获取商品可使用的固定积分:
select get_json_object(extra_json, '$fixedIntegral) as integral
from t_items;
7、替换
7.1 translate 函数用法
select translate('abcdef', 'adc', '19') tb_translate_exe
输出:
1b9ef
- translate(input,from,to)
- input:输入字符串
- from:需要匹配的字符
- to :用哪些字符来替换被匹配到的字符
注意点:这里from的字符与to字符在位置上存在一 一对应关系,也就是from中每个位置上的字符用to中对应位置的字符替换。
7.1 regexp_replace 函数
正则替换
SELECT aa,REGEXP_REPLACE(aa, '[a-z]', '') -- 替换所有字母,REGEXP_REPLACE(aa, '[abc]', '') -- 替换指定字母,REGEXP_REPLACE(aa, '[^abc]', '') -- 替换所有非字母,REGEXP_REPLACE(aa, '[0-9]', '') -- 替换所有数字,REGEXP_REPLACE(aa, '[\\s\\S]', '') -- 替换空白符、换行,\\s:是匹配所有空白符,包括换行,\\S:非空白符,不包括换行。,REGEXP_REPLACE(aa, '\\w', '') -- 替换所有字母、数字、下划线。等价于 [A-Za-z0-9_],REGEXP_REPLACE(aa, '[-8+]', '') -- 只替换-8这个字符,REGEXP_REPLACE(aa, '[-8*]', '') -- 替换-8、-、8这几个字符
FROM (SELECT '5e40b2b8-0916-42c0-899a-eaf4b2df 5268' AS aaUNION ALLSELECT 'c81b5906-38d7-482c-8b66-be5d3359cbf6' AS aaUNION ALLSELECT '8856fd0a-2337-4605-963f-0d0d059b1937' AS aa) t
;
相关文章:

Hive SQL 函数高阶应用场景
HIVE作为数据仓库处理常用工具,如同RDBMS关系型数据库中标准SQL语法一样,Hive SQL也内置了不少系统函数,满足于用户在不同场景下的数据分析需求,以提高开发SQL数据分析的效率。 我们可以使用show functions查看当下版本支持的函数…...

linux下C++开发环境搭建
一.安装GCC,GDB 1.1 先更新软件包安装源 sudo apt update1.2 安装编译器和调试器 sudo apt install build-essential gdb"build-essential" 是编译代码所需要的工具。 "gdb" 是调试器。1. build-essential:- "build-essential" 是一个用于Ubu…...

报错问题解决办法:Decryption error sun.security.rsa.RSAPadding.unpadV15
报错问题解决办法:Decryption error sun.security.rsa.RSAPadding.unpadV15 出现的问题 javax.crypto.BadPaddingException: Decryption errorat sun.security.rsa.RSAPadding.unpadV15(RSAPadding.java:380) ~[na:1.8.0_131]at sun.security.rsa.RSAPadding.unpa…...

LVS+DR部署
LVS-DR的工作原理: 1.客户端会发送请求到vip 2.LVS的调度器接受请求之后,根据算法选择一台真实服务器,请求转发到后端RS,请求的报文的目的MAC地址,修改成后端真实服务器的MAC地址,转发。 3.后端真实服务器…...

C++项目——云备份-②-第三方库认识
文章目录 专栏导读1. json 认识1.1 JSON 数据结构的特点 2. jsoncpp库认识3. json实现序列化案例4. json实现反序列化案例5. bundle文件压缩库认识6. bundle库实现文件压缩案例7.bundle库实现文件解压缩案例8.httplib库认识9. httplib库搭建简单服务器案例10. httplib库搭建简单…...

Linux入门攻坚——4、shell编程初步、grep及正则表达式
bash的基础特性(续): 1、提供了编程环境: 编程风格:过程式:以指令为中心,数据服务于执行;对象式:以数据为中心,指令服务于数据 shell编程,编译执…...
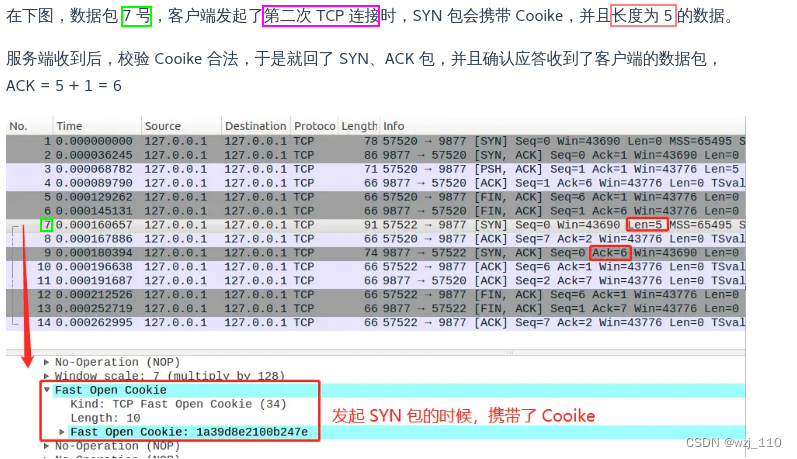
TCP/IP(二十二)TCP 实战抓包分析(六)TCP 快速建立连接
一 TCP Fast Open 快速建立连接 说明: 之前讲解TCP 相关知识点遗漏了这个知识点,补充上 ① TFO简介 ② 请求 Fast Open Cookie过程 "原理图" ③ 真正开始 TCP Fast Open 重点: TFO 使 SYN包 可以包含payload 数据 ④ 抓包分析 1、…...
IDEA如何拉取gitee项目?
1.登录gitee 说明:打开idea,在设置上面搜索框输入gitee,然后登录gitee注册的账号。 2. 创建gitee仓库 说明:创建idea中的gitee仓库。 3.寻找项目文件 说明:为需要添加gitee仓库的项目进行添加。 4.项目右键 说明&a…...
视频编辑不求人,教你一招制胜批量添加封面
视频添加封面是一个相当简单的任务,您只需要一款专门的软件,就能轻松搞定!下面就是详细教程啦! 首先,您需要在浏览器中搜索“固乔智剪软件”,进入官网并下载这款软件。固乔智剪软件是一款非常专业的视频剪辑…...

产品的竞争力是什么
产品的竞争力归根到底是3点:功能,性能,容量。 功能 我这个产品完成了别人没有实现的功能,而且是用户需要的。解决了客户的痛点 性能 我这个产品的功能虽然别人有,但是我性能好,性能好意味着干同样的活给…...

vue3 拖拽插件 Vue3DraggableResizable
Vue3DraggableResizable 拖拽插件的官方文档 一、Vue3DraggableResizable 的属性和事件 1、Vue3DraggableResizable 的属性配置 属性类型默认值功能描述示例initWNumbernull设置初始宽度(px)<Vue3DraggableResizable :initW“100” />initHNumb…...

VUE父组件向子组件传递数据和方法
文章目录 1 父组件写法2 子组件写法 1 父组件写法 父组件参数和方法 data() {return {// 遮罩层loading: true,// 表格数据yfeList: []}}导入组件 import yfTable from "/views/yf/yfTable.vue";组件 components: {yfTabTable},传值使用 <yfTabTable :loadin…...
NPI加速器在烽火科技SMT车间的应用:贴片机程序制作效率的革新
烽火科技,一个在国内颇具知名度的高科技企业,坐落于武汉光谷的SMT车间中,机器嗡嗡作响,作业员们忙碌地进行着生产。工厂使用的是ASM的贴片机,使用Sipalce Pro作为其编程软件。然而,在高效的生产线背后&…...
如何给照片添加水印?请看下面3个简单教程
如何给照片添加水印?随着智能手机的普及和不断提升的拍摄技术,如今人们可以轻松使用手机进行高质量的照片拍摄。从老人到小孩,每个人都可以在日常生活中捕捉到美好瞬间,并将其记录下来。作为一种表达自己的方式,现在手…...

仿写知乎日报第一周
效果图 主要的逻辑 Manager封装网络请求 首先,对于获取网络请求,我是将这些方法封装成了一个类Manager,后续在获取以往的内容时又封装了一个beforeManager类用于网络请求。这里不多赘述,Manager封装网络请求的知识参考我的以往博…...
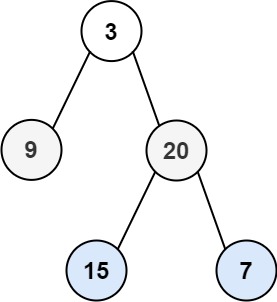
32二叉树——DFS深度优先遍历
目录 深度优先算法(Depth-First Search,DFS) LeetCode之路——102. 二叉树的层序遍历 分析 深度优先算法(Depth-First Search,DFS) DFS是一种用于遍历或搜索树状数据结构的算法,其中它首先探…...
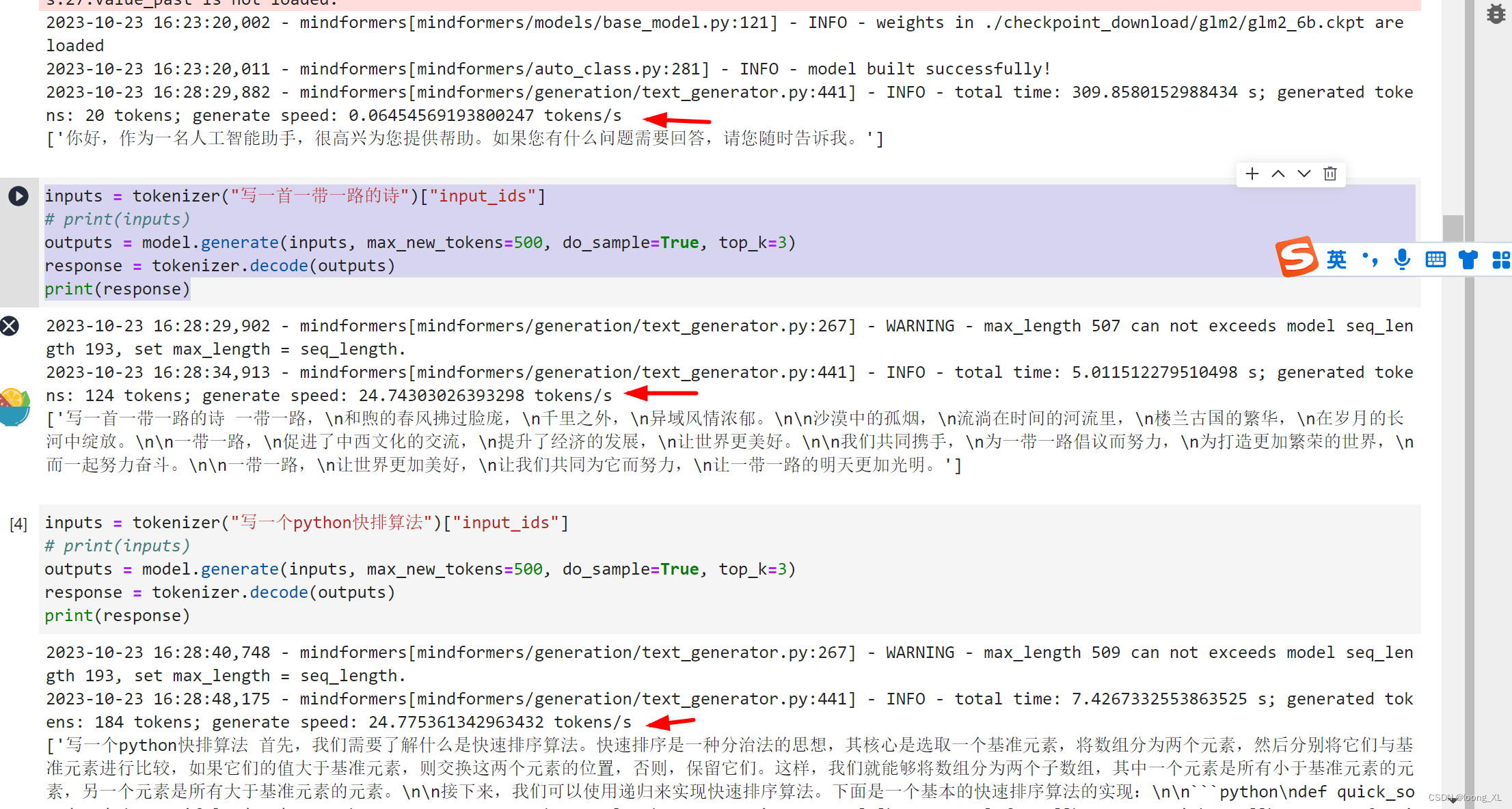
华为昇腾NPU卡 ChatGLM2模型使用
参考:https://gitee.com/mindspore/mindformers/blob/dev/docs/model_cards/glm2.md#chatglm2-6b 1、安装环境: 昇腾NPU卡对应英伟达GPU卡,CANN对应CUDA底层; mindspore对应pytorch;mindformers对应transformers 本…...
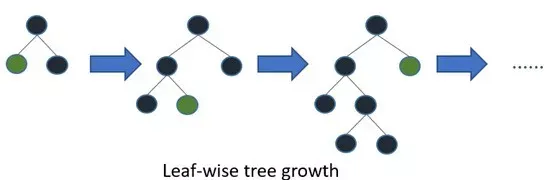
【机器学习】集成模型/集成学习:多个模型相结合实现更好的预测
1. 概述 1.1 什么是集成模型/集成学习 "模型集成"和"集成学习"是相同的概念。它们都指的是将多个机器学习模型组合在一起,以提高预测的准确性和稳定性的技术。通过结合多个模型的预测结果,集成学习可以减少单个模型的偏差和方差&am…...

如何提高广告投放转化率?Share Creators 资产库与Appsflyer营销数据的全面结合
如何提高广告投放转化率?Share Creators 资产库与Appsflyer营销数据的全面结合 全球经济进入了低迷期。 营销成本越来越高, 营销需要更务实,注重投入产出比。众所周知,除了渠道、客群画像以外, 优秀的广告设计图&#…...
《软件方法》2023版第1章(11)1.4.3 具体工作步骤
DDD领域驱动设计批评文集 做强化自测题获得“软件方法建模师”称号 《软件方法》各章合集 1.4 应用UML的建模工作流 1.4.3 使用UML建模的工作流步骤 图1-17中“工件形式”一列所列出的图就是本书推荐的在建模工作流ABCD中的UML用法,我用活动图进一步表示建模的步…...

Z-Image-GGUF文生图模型实战:电商海报、社交配图一键生成教程
Z-Image-GGUF文生图模型实战:电商海报、社交配图一键生成教程 1. 快速开始:30秒生成你的第一张AI图片 你是不是也好奇,那些精美的AI生成图片是怎么做出来的?今天,我就带你用Z-Image-GGUF这个开源模型,30秒…...
)
用C++的string类手搓一个大整数加法器(附完整可运行代码)
用C的string类手搓一个大整数加法器(附完整可运行代码) 在C编程中,处理超大整数一直是个有趣且实用的挑战。标准库中的整数类型如int或long long都有其数值范围限制,当我们需要处理像银行账户余额、加密算法中的大数或者科学计算中…...

RobotDuLAB:面向K-12教育的Arduino机器人教学库设计
1. RobotDuLAB Arduino库:面向教育场景的嵌入式机器人控制抽象层设计与工程实践1.1 教育型开源机器人的系统定位与硬件架构RobotDuLAB并非通用工业机器人平台,而是一个专为K-12阶段编程教学深度定制的开源教育机器人系统。其核心设计理念是“可理解性优先…...

SLAM 技术路线已收敛:这几条才是未来主流!
当前SLAM技术路线已完成收敛,未来主流方向清晰且无争议:激光-IMU紧耦合SLAM凭借厘米级定位与高鲁棒性,仍是工业移动机器人、自动驾驶的核心基石,并向固态激光雷达方向持续降本迭代。激光-视觉-IMU多传感器紧耦合融合为全场景通用标…...

-:RAG 入门-向量存储与企业级向量数据库 milvus匾
起因是我想在搞一些操作windows进程的事情时,老是需要右键以管理员身份运行,感觉很麻烦。就研究了一下怎么提权,顺手瞄了一眼Windows下用户态权限分配,然后也是感谢《深入解析Windows操作系统》这本书给我偷令牌的灵感吧ÿ…...

从停车场管理系统看STM32项目开发:如何规划你的第一个物联网硬件Demo?
从停车场管理系统看STM32项目开发:如何规划你的第一个物联网硬件Demo? 在嵌入式开发领域,STM32系列单片机因其出色的性能和丰富的外设资源,成为物联网硬件原型的首选平台。停车场管理系统作为一个典型的物联网应用场景,…...

终极指南:ComfyUI-Manager节点冲突检测与快速修复方案
终极指南:ComfyUI-Manager节点冲突检测与快速修复方案 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various custo…...

FastAPI子应用挂载:别再让root_path坑你一夜幻
Julia(julialang.org)由Stefan Karpinski、Jeff Bezanson等在2009年创建,目标是融合Python的易用性、C的高性能、R的统计能力、Matlab的科学计算生态。 其核心设计哲学是: 高性能:编译型语言(JIT࿰…...
)
基于HTTP协议的PLC数据交互实战(涵盖欧姆龙、三菱、西门子等主流品牌)
1. 为什么需要HTTP协议与PLC交互? 在工业自动化领域,PLC(可编程逻辑控制器)就像工厂的"大脑",负责控制各种设备的运行。但传统PLC数据交互方式存在明显痛点:比如欧姆龙用FINS协议、三菱用MC协议、…...

UniApp跨平台自定义消息语音播报实战指南
1. 为什么需要自定义消息语音播报 在移动应用开发中,消息推送是提升用户活跃度和留存率的重要手段。但普通的文字通知往往容易被用户忽略,特别是在商户收款、物流提醒、重要事件通知等场景下,语音播报能够更直接有效地触达用户。 举个例子&am…...