linux 安装操作 redis
1、redis概述和安装
1.1、安装redis
1. 下载redis 地址
https://download.redis.io/releases/

2. 将 redis 安装包拷贝到 /opt/ 目录
3. 解压
tar -zvxf redis-6.2.1.tar.gz
4. 安装gcc
yum install gcc
5. 进入目录
cd redis-6.2.1
6. 编译
make
7. 执行 make install 进行安装
8. 查看安装目录:/usr/local/bin
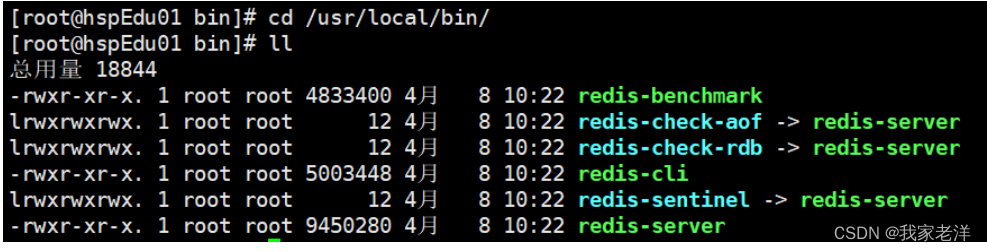
目录介绍
redis-benchmark:性能测试工具,可以在自己本子允许,看看自己本子性能如何
redis-check-aof:修复有问题的AOF文件,rdb和aof后面讲
redis-check-dump:修复有问题的dump.rdb文件
redis-sentinel:redis集群使用
redis-server:redis服务器启动命令
redis-clit:客户端,操作入口
1.2、启动redis
方式1:前台启动(不推荐)
执行 redis-server 命令,这种如果关闭启动窗口,则redis会停止。
方式2:后端启动(推荐)
后台方式启动后,关闭窗口后,redis不会被停止.
步骤如下
1. 复制redis.conf文件到/etc目录
cp /opt/redis-6.2.1/redis.conf /etc
2. 使用vi命令修改/etc/redis.config中的配置,将后台启动设置daemonize改为yes,如下
daemonize yes
3. 启动redis
redis-server /etc/redis.conf
- 查看redis进程
ps -ef|grep redis

1.3、关闭redis
方式1:kill -9 pid
方式2:redis-cli shutdown
1.4、进入redis命令窗口
执行 redis-cli 即可进入redis命令窗口,然后就可以执行redis命令了。

1.5、redis命令大全
地址:http://doc.redisfans.com/
文档地址 :
链接:https://pan.baidu.com/s/1XpefjEZlI6HIXe-5fkUkQg?pwd=03yi
提取码:03yi
2、redis 5大数据类型
这里说的数据类型是value的数据类型,key的类型都是字符串。
5种数据类型:
1. redis字符串(String)
2. redis列表(List)
3. redis集合(Set)
4. redis哈希表(Hash)
5. redis有序集合(Zset)
2.1、redis键(key)
1.keys :查看当前库所有的key
2. exists key: 判断某个key是否存在
3. type key: 查看你的key是什么类型
4. delkey:删除指定的key数据
5. unlink key:根据value删除非阻塞删除,仅仅将keys从keyspace元数据中删除,真正的删除会在 后续异步中操作。
6. expire key 10:为指定的key设置有效期10秒
7. ttl key:查看指定的key还有多少秒过期,-1:表示永不过期,-2:表示已过期
8. select dbindex:切换数据库【0-15】,默认为0
9. dbsize:查看当前数据库key的数量
10. flushdb:清空当前库
11. flushall:通杀全部库
2.2、redis字符串(String)
2.2.1、简介
String是Redis最基本的类型,你可以理解成与Memcached一模一样的类型,一个key对应一个value。
String类型是二进制安全的。意味着Redis的string可以包含任何数据。比如jpg图片或者序列化的对象。
String类型是Redis最基本的数据类型,一个Redis中字符串value最多可以是512M
2.2.2、常用命令
1 . set:添加键值对
2 . get:获取值
示例
127.0.0.1:6379> set name ready
OK
127.0.0.1:6379> get name
"ready"
daemonize yes
3 . apend:追价值
append <key> <value>
将给定的value追加到原值的末尾。
示例
127.0.0.1:6379> set k1 hello
OK
127.0.0.1:6379> append k1 " world"
(integer) 11
127.0.0.1:6379> get k1
"hello world"
4 . strlen:获取值的长度
strlen <key>
示例
127.0.0.1:6379> set name ready
OK
127.0.0.1:6379> strlen name
(integer) 5
5 . setnx:key不存在时,设置key的值
setnx <key> <value>
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> setnx site "itsoku.com" #site不存在,返回1,表示设置成功
(integer) 1
127.0.0.1:6379> setnx site "itsoku.com" #再次通过setnx设置site,由于已经存在了,所以设
置失败,返回0
(integer) 0
6 . incr:原子递增1
incr <key>
将key中存储的值增1,只能对数字值操作,如果key不存在,则会新建一个,值为1
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> set age 30 #age值为30
OK
127.0.0.1:6379> incr age #age增加1,返回31
(integer) 31
127.0.0.1:6379> get age #获取age的值
"31"
127.0.0.1:6379> incr salary #salary不存在,自动创建一个,值为1
(integer) 1
127.0.0.1:6379> get salary #获取salary的值
"1"
7 . decr:原子递减1
decr <key>
将key中存储的值减1,只能对数字值操作,如果为空,新增值为-1
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> set age 30 #age值为30
OK
127.0.0.1:6379> decr age #age递减1,返回29
(integer) 29
127.0.0.1:6379> get age #获取age的值
"29"
127.0.0.1:6379> decr salary #salary不存在,自动创建一个,值为-1
(integer) -1
127.0.0.1:6379> get salary #获取salary
"-1"
8 . incrby/decrby:递增或者递减指定的数字
incrby/decrby <key> <步长>
将key中存储的数字值递增指定的步长,若key不存在,则相当于在原值为0的值上递增指定的步
长。
示例
127.0.0.1:6379> set salary 10000 #设置salary为10000
OK
127.0.0.1:6379> incrby salary 5000 #salary添加5000,返回15000
(integer) 15000
127.0.0.1:6379> get salary #获取salary
"15000"
127.0.0.1:6379> decrby salary 800 #salary减去800,返回14200
(integer) 14200
127.0.0.1:6379> get salary #获取salary
"14200"
9 . mset:同时设置多个key-value
mset < key1> < value1> < key2> < value2>
示例
127.0.0.1:6379> mset name ready age 30
OK
127.0.0.1:6379> get name
"ready"
127.0.0.1:6379> get age
"30"
10 . mget:获取多个key对应的值
mget < key1> < key2>
示例
127.0.0.1:6379> mset name ready age 30 #同时设置name和age
OK
127.0.0.1:6379> mget name age #同时读取name和age的值
1) "ready"
2) "30"
11 . msetnx:当多个key都不存在时,则设置成功
msetnx < key1> < value1> < key2> < value2>
原子性的,要么都成功,或者都失败。
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> set k1 v1 #设置k1
OK
127.0.0.1:6379> msetnx k1 v1 k2 v2 #当k1和k2都不存在的时候,同时设置k1和k2,由于k1已存
在,所以这个操作失败
(integer) 0
127.0.0.1:6379> mget k1 k2 #获取k1、k2,k2不存在
1) "v1"
2) (nil)
127.0.0.1:6379> msetnx k2 v2 k3 v3 #当k2、h3都不存在的时候,同时设置k2和k3,设置成功
(integer) 1
127.0.0.1:6379> mget k1 k2 k3 #后去k1、k2、k3的值
1) "v1"
2) "v2"
3) "v3
12 . getrange:获取值的范围,类似java中的substring
getrange key start开始索引 end结束索引
获取[start,end]返回为的字符串
示例
127.0.0.1:6379> set k1 helloworld
OK
127.0.0.1:6379> getrange k1 0 4
"hello"
13 . setrange:覆盖指定位置的值
setrange <key> <起始位置> <value>
示例
127.0.0.1:6379> set k1 helloworld
OK
127.0.0.1:6379> get k1
"helloworld"
127.0.0.1:6379> setrange k1 1 java
(integer) 10
127.0.0.1:6379> get k1
"hjavaworld"
14 . setrange:覆盖指定位置的值
setrange <key> <起始位置> <value>
从 起始位置替换指定字符
示例
127.0.0.1:6379> set k1 helloworld
OK
127.0.0.1:6379> get k1
"helloworld"
127.0.0.1:6379> setrange k1 1 java
(integer) 10
127.0.0.1:6379> get k1
"hjavaworld"
15 . setex:设置键值&过期时间(秒)
setex <key> <过期时间(秒)> <value>
设置 key的过期时间
示例
127.0.0.1:6379> setex k1 100 v1 #设置k1的值为v1,有效期100秒
OK
127.0.0.1:6379> get k1 #获取k1的值
"v1"
127.0.0.1:6379> ttl k1 #获取k1还有多少秒失效
(integer) 96
16 . getset:以新换旧,设置新值同时返回旧值
getset <key> <value>
示例
127.0.0.1:6379> set name ready #设置name为ready
OK
127.0.0.1:6379> getset name tom #设置name为tom,返回name的旧值
"ready"
127.0.0.1:6379> getset age 30 #设置age为30,age未设置过,返回age的旧值为null
(nil)
2.2.3、数据结构
String的数据结构为简单动态字符串(Simple Dynamic String,缩写SDS)。是可以修改的字符串,内
部结构上类似于Java的ArrayList,采用分配冗余空间的方式来减少内存的频繁分配。

如图所示,内部为当前字符串实际分配的空间capacity一般要高于实际字符串长度len。当字符串长度小
于1M时,扩容都是加倍现有的空间,如果超过1M,扩容时一次会多扩容1M的空间。 要注意的是字符串最大长度为512M。
2.3、redis列表(List)
2.3.1、简介
单键多值 redis列表是简单的字符串列表,按照插入顺序排序。 你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
它的底层实际上是使用双向链表实现的,对两端的操作性能很高,通过索引下标操作中间节点性能会较 差。

2.3.2、常用命令
1 . lpush/rpush:从左边或者右边插入一个或多个值
lpush/rpush <key1> <value1> <key2> <value2> ..
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> rpush name java spring "springboot" "spring cloud" #列表name的左边
插入4个元素
(integer) 4
127.0.0.1:6379> lrange name 1 2 #从左边取出索引位于[1,2]范围内的元素
1) "spring"
2) "springboot
2 . lrange:从列表左边获取指定范围内的值
lrange <key> <star> <stop>
返回列表 key 中指定区间内的元素,区间以偏移量 start 和 stop 指定。 下标(index)参数 start 和 stop 都以
0 为底,也就是说,以 0 表示列表的第一个元素,以 1 表示列表的第二个元素,以此类推。 你也可以使用负数下标,以 -1
表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此 类推。 返回值: 一个列表,包含指定区间内的元素。
示例
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> rpush course java c c++ php js nodejs #course集合的右边插入6个元素
(integer) 6
127.0.0.1:6379> lrange course 0 -1 #取出course集合中所有元素
1) "java"
2) "c"
3) "c++"
4) "php"
5) "js"
6) "nodejs"
127.0.0.1:6379> lrange course 1 3 #获取course集合索引[1,3]范围内的元素
1) "c"
2) "c++"
3) "php"
更
3 . lpop/rpop:从左边或者右边弹出多个元素
lpop/rpop <key> <count>
count:可以省略,默认值为1 lpop/rpop 操作之后,弹出来的值会从列表中删除 值在键在,值光键亡
示例
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> rpush course java c++ php js node js #集合course右边加入6个元素
(integer) 6
127.0.0.1:6379> lpop course #从左边弹出1个元素
"java"
127.0.0.1:6379> rpop course 2 #从右边弹出2个元素
1) "js"
2) "node"
4 . rpoplpush:从一个列表右边弹出一个元素放到另外一个列表中
rpoplpush source destination
从source的右边弹出一个元素放到destination列表的左边
示例
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> rpush k1 1 2 3 #列表k1的右边添加3个元素[1,2,3]
(integer) 3
127.0.0.1:6379> lrange k1 0 -1 #从左到右输出k1列表中的元素
1) "1"
2) "2"
3) "3"
127.0.0.1:6379> rpush k2 4 5 6 #列表k2的右边添加3个元素[4,5,6]
(integer) 3
127.0.0.1:6379> lrange k2 0 -1 #从左到右输出k2列表中的元素
1) "4"
2) "5"
3) "6"
127.0.0.1:6379> rpoplpush k1 k2 #从k1的右边弹出一个元素放到k2的左边
"3"
127.0.0.1:6379> lrange k1 0 -1 #k1中剩下2个元素了
1) "1"
2) "2"
127.0.0.1:6379> lrange k2 0 -1 #k2中变成4个元素了
1) "3"
2) "4"
3) "5"
4) "6"
5 . lindex:获取指定索引位置的元素(从左到右)
lindex key index
返回列表 key 中,下标为 index 的元素。 下标(index)参数 start 和 stop 都以 0 为底,也就是说,以 0
表示列表的第一个元素,以 1 表示列表的第二个元素,以此类推。 你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2
表示列表的倒数第二个元素,以此 类推。 如果 key 不是列表类型,返回一个错误。 返回值: 列表中下标为 index 的元素。 如果
index 参数的值不在列表的区间范围内(out of range),返回 nil
示例
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> rpush course java c c++ php #列表course中放入4个元素
(integer) 4
127.0.0.1:6379> lindex course 2 #返回索引位置2的元素
"c++"
127.0.0.1:6379> lindex course 200 #返回索引位置200的元素,没有
(nil)
127.0.0.1:6379> lindex course -1 #返回最后一个元素
"php"
6 . llen:获得列表长度
llen key
返回列表 key 的长度。
如果 key 不存在,则 key 被解释为一个空列表,返回 0 .
如果 key 不是列表类型,返回一个错误。
示例
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> rpush name ready tom jack
(integer) 3
127.0.0.1:6379> llen name
(integer) 3
7 . linsert:在某个值的前或者后面插入一个值
linsert <key> before|after <value> <newvalue>
将值 newvalue 插入到列表 key 当中,位于值 value 之前或之后。
当 value 不存在于列表 key 时,不执行任何操作。
当 key 不存在时, key 被视为空列表,不执行任何操作。
如果 key 不是列表类型,返回一个错误。
返回值:
如果命令执行成功,返回插入操作完成之后,列表的长度。
如果没有找到 value ,返回 -1 。
如果 key 不存在或为空列表,返回 0
示例
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> rpush name ready tom jack #列表name中添加3个元素
(integer) 3
127.0.0.1:6379> lrange name 0 -1 #name列表所有元素
1) "ready"
2) "tom"
3) "jack"
127.0.0.1:6379> linsert name before tom lily #tom前面添加lily
(integer) 4
127.0.0.1:6379> lrange name 0 -1 #name列表所有元素
1) "ready"
2) "lily"
3) "tom"
4) "jack"
127.0.0.1:6379> linsert name before xxx lucy # 在元素xxx前面插入lucy,由于xxx元素不存
在,插入失败,返回-1
(integer) -1
127.0.0.1:6379> lrange name 0 -1
1) "ready"
2) "lily"
3) "tom"
4) "jack"
8 . lrem:删除指定数量的某个元素
LREM key count value
**根据参数 count 的值,移除列表中与参数 value 相等的元素。
count 的值可以是以下几种:
count > 0 : 从表头开始向表尾搜索,移除与 value 相等的元素,数量为 count 。
count < 0 : 从表尾开始向表头搜索,移除与value 相等的元素,数量为 count 的绝对 值
count = 0 : 移除表中所有与 value 相等的值。返回值: 被移除元素的数量。因为不存在的 key 被视作空表(empty list),所以当 key 不存在时,总是返回 0 。**
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> rpush k1 v1 v2 v3 v2 v2 v1 #k1列表中插入6个元素
(integer) 6
127.0.0.1:6379> lrange k1 0 -1 #输出k1集合中所有元素
1) "v1"
2) "v2"
3) "v3"
4) "v2"
5) "v2"
6) "v1"
127.0.0.1:6379> lrem k1 2 v2 #k1集合中从左边删除2个v2
(integer) 2
127.0.0.1:6379> lrange k1 0 -1 #输出列表,列表中还有1个v2,前面2个v2干掉了
1) "v1"
2) "v3"
3) "v2"
4) "v1"
9 . lset:替换指定位置的值
lset <key> <index> <value>
将列表 key 下标为 index 的元素的值设置为 value 。 当 index 参数超出范围,或对一个空列表( key
不存在)进行lset时,返回一个错误。 返回值: 操作成功返回 ok ,否则返回错误信息。
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> rpush name tom jack ready #name集合中放入3个元素
(integer) 3
127.0.0.1:6379> lrange name 0 -1 #输出name集合元素
1) "tom"
2) "jack"
3) "ready"
127.0.0.1:6379> lset name 1 lily #将name集合中第2个元素替换为liy
OK
127.0.0.1:6379> lrange name 0 -1 #输出name集合元素
1) "tom"
2) "lily"
3) "ready"
127.0.0.1:6379> lset name 10 lily #索引超出范围,报错
(error) ERR index out of range
127.0.0.1:6379> lset course 1 java #course集合不存在,报错
(error) ERR no such key
2.3.4、数据结构
List的数据结构为快速链表quickList
首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist,也就是压缩列表。
它将所有的元素紧挨着一起存储,分配的是一块连续的内存。 当就比较多的时候才会改成quickList。
因为普通的链表需要的附加指针空间太大,会比较浪费空间,比如这个列表里存储的只是int类型的书,
结构上还需要2个额外的指针prev和next。

redis将链表和ziplist结合起来组成了quicklist。也就是将多个ziplist使用双向指针串起来使用,这样既满
足了快速的插入删除性能,又不会出现太大的空间冗余。
**
2.4、redis集合(Set)
2.4.1、简介
redis set对外提供的功与list类似,是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要
存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择。
redis的set是string类型的无序集合,他的底层实际是一个value为null的hash表,收益添加,删除,查
找复杂度都是O(1)。 一个算法,如果时间复杂度是O(1),那么随着数据的增加,查找数据的时间不变,也就是不管数据多 少,查找时间都是一样的
1 . sadd:添加一个或多个元素
sadd <key> <value1> <value2> ...
示例
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> sadd k1 v1 v2 v1 v3 v2 #k1中放入5个元素,会自动去重,成功插入3个
(integer) 3
2. smembers:取出所有元素
smembers <key>
示例
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> sadd k1 v1 v2 v1 v3 v2
(integer) 3
127.0.0.1:6379> smembers k1
1) "v2"
2) "v1"
3) "v3
3 . sismember:判断集合中是否有某个值
sismember <key> <value>
判断集合key中是否包含元素value,1:有,0:没有
示例
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> sadd k1 v1 v2 v1 v3 v2 #k1集合中成功放入3个元素[v1,v2,v3]
(integer) 3
127.0.0.1:6379> sismember k1 v1 #判断k1中是否包含v1,1:有
(integer) 1
127.0.0.1:6379> sismember k1 v5 #判断k1中是否包含v5,0:无
(integer) 0
4 . scard:返回集合中元素的个数
scard <key>
返回集合 key 的基数(集合中元素的数量) 返回值: 集合的基数。 当 key 不存在时,返回 0 。
示例
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> sadd k1 v1 v2 v1 v3 v2
(integer) 3
127.0.0.1:6379> scard k1
(integer) 3
5 . srem:删除多个元素
srem key member [member ...]
移除集合 key 中的一个或多个 member 元素,不存在的 member 元素会被忽略。 当 key 不是集合类型,返回一个错误。 返回值: 被成功移除的元素的数量,不包括被忽略的元素
示例
127.0.0.1:6379> flushdb #清空db,方测试
OK
127.0.0.1:6379> sadd course java c c++ python #集合course中添加4个元素
(integer) 4
127.0.0.1:6379> smembers course #获取course集合所有元素
1) "python"
2) "java"
3) "c++"
4) "c"
127.0.0.1:6379> srem course java c #删除course集合中的java和c
(integer) 2
127.0.0.1:6379> smembers course #获取course集合所有元素,剩下2个了
1) "python"
2) "c++"
6 . spop:随机弹出多个值
spop <key> <count>
随机从key集合中弹出count个元素,count默认值为1 返回值: 被移除的随机元素。 当 key 不存在或 key 是空集时,返回 nil
示例
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> sadd course java c c++ python #course集合中添加4个元素
(integer) 4
127.0.0.1:6379> smembers course #获取course集合中所有元素
1) "python"
2) "java"
3) "c++"
4) "c"
127.0.0.1:6379> spop course #随机弹出1个元素,被弹出的元素会被删除
"c++"
127.0.0.1:6379> spop course 2 #随机弹出2个元素
1) "java"
2) "python"
127.0.0.1:6379> smembers course #输出剩下的元素
1) "c"
7 . srandmember:随机获取多个元素,不会从集合中删除
srandmember <key> <count>
从key指定的集合中随机返回count个元素,count可以不指定,默认值是1。 srandmember 和 spop的区别: 都可以随机获取多个元素,srandmember 不会删除元素,而spop会删除元素。 返回值: 只提供 key
参数时,返回一个元素;如果集合为空,返回 nil 。 如果提供了 count 参数,那么返回一个数组;如果集合为空,返回空数组
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> sadd course java c c++ python #course中放入5个元素
(integer) 4
127.0.0.1:6379> smembers course #输出course集合中所有元素
1) "python"
2) "java"
3) "c++"
4) "c"
127.0.0.1:6379> srandmember course 3 #随机获取3个元素,元素并不会被删除
1) "python"
2) "c++"
3) "c"
127.0.0.1:6379> smembers course #输出course集合中所有元素,元素个数未变
1) "python"
2) "java"
3) "c++"
4) "c"
8 . smove:将某个原创从一个集合移动到另一个集合
smove <source> <destination> member
将 member 元素从 source 集合移动到 destination 集合。
smove 是原子性操作。
如果 source 集合不存在或不包含指定的 member 元素,则 smove 命令不执行任何操作,仅返 回 0 。否则, member 元素从 source集合中被移除,并添加到 destination 集合中去。
当 destination 集合已经包含 member 元素时,smove 命令只是简单地将 source 集合中的 member 元素删除。
当 source 或 destination 不是集合类型时,返回一个错误
返回值 :
如果 member 元素被成功移除,返回 1 。
如果 member 元素不是 source 集合的成员,并且没有任何操作对 destination 集合执行,那
么返回 0 。
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> sadd course1 java php js #集合course1中放入3个元素[java,php,js]
(integer) 3
127.0.0.1:6379> sadd course2 c c++ #集合course2中放入2个元素[c,c++]
(integer) 2
127.0.0.1:6379> smove course1 course2 js #将course1中的js移动到course2
(integer) 1
127.0.0.1:6379> smembers course1 #输出course1中的元素
1) "java"
2) "php"
127.0.0.1:6379> smembers course2 #输出course2中的元素
1) "js"
2) "c++"
3) "c"
9 . sinter:取多个集合的交
sinter key [key ...]
示例
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> sadd course1 java php js #集合course1:[java,php,js]
(integer) 3
127.0.0.1:6379> sadd course2 c c++ js #集合course2:[c,c++,js]
(integer) 3
127.0.0.1:6379> sadd course3 js html #集合course3:[js,html]
(integer) 2
127.0.0.1:6379> sinter course1 course2 course3 #返回三个集合的交集,只有:[js]
1) "js"
10 . interstore:将多个集合的交集放到一个新的集合中
sinterstore destination key [key ...]
这个命令类似于 sinter 命令,但它将结果保存到 destination 集合,而不是简单地返回结果 集。 返回值: 结果集中的成员数量
11 . sunion:取多个集合的并集,自动去重
sunion key [key ...]
示例
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> sadd course1 java php js #集合course1:[java,php,js]
(integer) 3
127.0.0.1:6379> sadd course2 c c++ js #集合course2:[c,c++,js]
(integer) 3
127.0.0.1:6379> sadd course3 js html #集合course3:[js,html]
(integer) 2
127.0.0.1:6379> sunion course1 course2 course3 #返回3个集合的并集,会自动去重
1) "php"
2) "js"
3) "java"
4) "html"
5) "c++"
6) "c"
12 . sunionstore:将多个集合的并集放到一个新的集合中
sunionstore key [key ...]
这个命令类似于 sunion 命令,但它将结果保存到 destination 集合,而不是简单地返回结果 集。 返回值: 结果集中的成员数量。
13 . sdiff:取多个集合的差集
SDIFF key [key ...]
返回一个集合的全部成员,该集合是所有给定集合之间的差集。 不存在的 key 被视为空集。
示例
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> sadd course1 java php js #集合course1:[java,php,js]
(integer) 3
127.0.0.1:6379> sadd course2 c c++ js #集合course2:[c,c++,js]
(integer) 3
127.0.0.1:6379> sadd course3 js html #集合course3:[js,html]
(integer) 2
127.0.0.1:6379> sdiff course1 course2 course3 #返回course1中有的而course2和course3
中都没有的元素
1) "java"
2) "php"
14 . sdiffstore:将多个集合的差集放到一个新的集合中
sdiffstore destination key [key ...]
这个命令类似于 sdiff 命令,但它将结果保存到 destination 集合,而不是简单地返回结果集。 返回值: 结果集中的成员数量。
示例
3.4.3、数据结构
set数据结构是字典,字典是用hash表实现的。
Java中的HashSet的内部实现使用HashMap,只不过所有的value都指向同一个对象。
Redis的set结构也是一样的,它的内部也使用hash结构,所有的value都指向同一个内部值。
2.5、redis哈希(Hash)
2.5.1、简介
Redis hash是一个键值对集合。 Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
类似于java里面的Map<String,Object>
2.5.2、常用命令
1 . hset:设置多个field的值
hset key field value [field value ...]
将哈希表 key 中的域 field 的值设为 value 。 如果 key 不存在,一个新的哈希表被创建并进行 hset 操作。 如果域 field 已经存在于哈希表中,旧值将被覆盖。 返回值: 如果 field 是哈希表中的一个新建域,并且值设置成功,返回 1 。
如果哈希表中域 field 已经存在且旧值已被新值覆盖,返回 0 。
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> hset user name ready age 30 #哈希表user中设置2个域:name和age,name的
值为ready,age的值为30
(integer) 2
2 . hget:获取指定filed的
hget key field
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> hset user name ready age 30 #哈希表user中设置2个域:name和age,name的
值为ready,age的值为30
(integer) 2
127.0.0.1:6379> hget user name #获取user中的name
"ready
3 . hgetall:返回hash表所有的域和值
hgetall key
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> hset user name ready age 30 #哈希表user中设置2个域:name和age,name的
值为ready,age的值为30
(integer) 2
127.0.0.1:6379> hgetall user #获取user所有信息
1) "name"
2) "ready"
3) "age"
4) "30"
4 . hexists 判断给定的field是否存在,1:存在,0:不存在
hexists key field
查看哈希表 key 中,给定域 field 是否存在。 返回值: 如果哈希表含有给定域,返回 1 。 如果哈希表不含有给定域,或 key 不存在,返回 0 。
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> hset user name ready age 30 #哈希表user中设置2个域:name和age,name的
值为ready,age的值为30
(integer) 2
127.0.0.1:6379> hexists user name #user中存在name域
(integer) 1
127.0.0.1:6379> hexists user address #user中不存在address域,返回0
(integer) 0
127.0.0.1:6379> hexists user1 address #user1这个key不存在,返回0
(integer) 0
5 . hkeys:列出所有的filed
hkeys key
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> hset user name ready age 30 #哈希表user中设置2个域:name和age,name的
值为ready,age的值为30
(integer) 2
127.0.0.1:6379> hkeys user #获取user中的所有filed
1) "name"
2) "age"
6 . hlen:返回filed的数量
HLEN key
返回哈希表 key 中域的数量。
返回值:
哈希表中域的数量。
当 key 不存在时,返回 0 。
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> hset user name ready age 30 #哈希表user中设置2个域:name和age,name的
值为ready,age的值为30
(integer) 2
127.0.0.1:6379> hlen user
(integer) 2
7 . hincrby:filed的值加上指定的增量
hincrby key field incremen
为哈希表 key 中的域 field 的值加上增量 increment 。 增量也可以为负数,相当于对给定域进行减法操作。 如果 key 不存在,一个新的哈希表被创建并执行 HINCRBY 命令。 如果域 field 不存在,那么在执行命令前,域的值被初始化为 0 。
对一个储存字符串值的域 field 执行 HINCRBY 命令将造成一个错误。
返回值:
执行 hincrby 命令之后,哈希表 key中域 field 的值。
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> hset siteInfo site itsoku.com pv 1000 #hash表siteInfo中有2个域:
{site:"itsoku.com",pv:1000}
(integer) 2
127.0.0.1:6379> hget siteInfo pv #获取siteInfo中pv的值
"1000"
127.0.0.1:6379> hincrby siteInfo pv 10 #siteInfo中的pv值增加10
(integer) 1010
127.0.0.1:6379> hget siteInfo pv #获取siteInfo中的pv
"1010"
127.0.0.1:6379> hincrby siteInfo uv 500 #siteInfo中的uv值增加500,uv这个域不存在,则会
先添加,然后再执行hincrby
(integer) 500
8 . hsetnx:当filed不存在的时候,设置filed的值
hsetnx key field value
将哈希表 key 中的域 field 的值设置为 value ,当且仅当域 field 不存在。
若域 field 已经存在,该操作无效。
如果 key 不存在,一个新哈希表被创建并执行 hsetnx 命令。
返回值 :
设置成功,返回 1 。
如果给定域已经存在且没有操作被执行,返回 0 。
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> hset user name ready age 30 #创建user,包含2个域:name、age
(integer) 2
127.0.0.1:6379> hsetnx user name tom #name已存在,设置失败,返回0
(integer) 0
127.0.0.1:6379> hget user name #name依旧是ready
"ready"
127.0.0.1:6379> hsetnx user address shanghai #address不存在,设置成功
(integer) 1
127.0.0.1:6379> hget user address #输出address的值
"shanghai"
2.5.3、数据结构
Hash类型对应的数据结构是2中:ziplist(压缩列表),hashtable(哈希表)。
当field-value长度较短个数较少时,使用ziplist,否则使用hashtable。
2.6、redis有序集合zset(sorted set)
2.6.1、简介
redis有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合。 不同之处是有序集合的每个成员都关联了一个评分(score),这个评分(score)被用来按照从最低分 到最高分的方式排序集合中的成员。
集合的成员是唯一的,但是评分是可以重复的。
因为元素是有序的,所以你可以很快的根据评分(score)或者次序(position)来获取一个范围的元 素。
访问有序集合中的中间元素也是非常快的,因为你能够使用有序集合作为一个没有重复成员你的智能列 表。
1 . zadd:添加元素
zadd <key> <score1> <member1> <score2> <member2> ...
将一个或多个 member 元素及其 score 值加入到有序集 key 当中。
如果某个 member 已经是有序集的成员,那么更新这个 member 的 score 值,并通过重新插入 这个 member 元素,来保证该 member 在正确的位置上。
score 值可以是整数值或双精度浮点数。 如果 key 不存在,则创建一个空的有序集并执行 zadd 操作。
当 key 存在但不是有序集类型时,返回一个错误。
返回值 :
被成功添加的新成员的数量,不包括那些被更新的、已经存在的成员。
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> zadd topn 100 java 80 c 90 c++ 50 php 70 js #创建名称为topn的zset,
添加了5个元素
(integer) 5
2 . zrange:score升序,获取指定索引范围的元素
zrange key start top [withscores]

#####示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> zadd topn 100 java 80 c 90 c++ 50 php 70 js #创建名称为topn的zset,
添加了5个元素
(integer) 5
127.0.0.1:6379> zrange topn 0 -1 #按score升序,返回topn中所有元素的值
1) "php"
2) "js"
3) "c"
4) "c++"
5) "java"
127.0.0.1:6379> zrange topn 0 -1 withscores #按score升序,返回所有元素的值以及score
1) "php"
2) "50"
3) "js"
4) "70"
5) "c"
6) "80"
7) "c++"
8) "90"
9) "java"
10) "100"
127.0.0.1:6379> zrange topn 2 4 #返回索引范围[2,4]内的3个元素
1) "c"
2) "c++"
3) "java"
3 . zrevrange:score降序,获取指定索引范围的元素
zrevrange key start stop [WITHSCORES]

#####示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> zadd topn 100 java 80 c 90 c++ 50 php 70 js #创建名称为topn的zset,
添加了5个元素
(integer) 5
127.0.0.1:6379> zrevrange topn 0 -1 #按照score降序获取所有元素
1) "java"
2) "c++"
3) "c"
4) "js"
5) "php"
127.0.0.1:6379> zrevrange topn 0 2 #按照score降序获取前3名
1) "java"
2) "c++"
3) "c"
4 . zrangebyscore:按照score升序,返回指定score范围内的数
zrangebyscore key min max [WITHSCORES] [LIMIT offset count]

#####示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> zadd topn 100 java 80 c 90 c++ 50 php 70 js #创建名称为topn的zset,
添加了5个元素
(integer) 5
127.0.0.1:6379> zrangebyscore topn 70 90 #score升序,获取score位于[70,90]区间中的元素
值
1) "js"
2) "c"
3) "c++"
127.0.0.1:6379> zrangebyscore topn 70 90 withscores #score升序,获取score位于
[70,90]区间中的元素值及score
1) "js"
2) "70"
3) "c"
4) "80"
5) "c++"
6) "90"
127.0.0.1:6379> zrangebyscore topn 70 90 withscores limit 1 2 #相当于:select
value,score from topn集合 where score>=70 and score<=90 order by score asc limit
1,2
1) "c"
2) "80"
3) "c++"
4) "90"
5 . zrevrangebyscore:按照score降序,返回指定score范围内的数据
zrevrangebyscore key max min [WITHSCORES] [LIMIT offset count]
返回有序集 key 中, score 值介于 max 和 min 之间(默认包括等于 max 或 min )的所有的成
员。有序集成员按 score 值递减(从大到小)的次序排列。
具有相同 score 值的成员按字典序的逆序排列。
除了成员按 score 值递减的次序排列这一点外, zrevrangebyscore 命令的其他方面和
zrangebyscore 命令一样。
#####示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> zadd topn 100 java 80 c 90 c++ 50 php 70 js #创建名称为topn的zset,
添加了5个元素
(integer) 5
127.0.0.1:6379> zrevrangebyscore topn 100 90 #score降序,获取score位于[70,90]区间中
的元素值
1) "java"
2) "c++"
127.0.0.1:6379> zrevrangebyscore topn 100 90 withscores #score降序,获取score位于
[70,90]区间中的元素值及score
1) "java"
2) "100"
3) "c++"
4) "90"
6 . zincrby:为指定元素的score加上指定的增量
zincrby key increment member

示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> zadd topx 90 java 70 c 80 c++ #集合topx中添加3个元素:java、c、c++,
对应的score分别是:90、70、80
(integer) 3
127.0.0.1:6379> zrevrange topx 0 -1 withscores #输出集合topx中的元素,包含score
1) "java"
2) "90"
3) "c++"
4) "80"
5) "c"
6) "70"
127.0.0.1:6379> zincrby topx 5 java #对topx中的元素java的score加5,变成95了
"95"
127.0.0.1:6379> zrevrange topx 0 -1 withscores # 输出集合元素,注意java的score是95了
1) "java"
2) "95"
3) "c++"
4) "80"
5) "c"
6) "70"
8 . zrem:删除集合中多个元素
zrem key member [member ...]
移除有序集 key 中的一个或多个成员,不存在的成员将被忽略。
当 key 存在但不是有序集类型时,返回一个错误。
#####示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> zadd topx 90 java 70 c 80 c++ #集合topx中添加3个元素:java、c、c++,
对应的score分别是:90、70、80
(integer) 3
127.0.0.1:6379> zrange topx 0 -1 #输出集合topx中所有元素
1) "c"
2) "c++"
3) "java"
127.0.0.1:6379> zrem topx c c++ #删除集合topx中的2个元素:c、c++
(integer) 2
127.0.0.1:6379> zrange topx 0 -1 #输出集合topx中所有元素
1) "java"
9 . zremrangebyrank:根据索引范围删除元素
zremrangebyrank key start stop

#####示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> zadd topx 90 java 70 c 80 c++ #集合topx中添加3个元素:java、c、c++,
对应的score分别是:90、70、80
(integer) 3
127.0.0.1:6379> zrange topx 0 -1 #输出集合topx中所有元素
1) "c"
2) "c++"
3) "java"
127.0.0.1:6379> zremrangebyrank topx 0 1 #删除索引范围[0,1]的数据
(integer) 2
127.0.0.1:6379> zrange topx 0 -1 #输出鞂topx中所有元素
1) "java"
10 . zremrangebyscore:根据score的范围删除元
zremrangebyscore key min max
移除有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员
#####示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> zadd topx 90 java 70 c 80 c++ 50 php #topx集合中添加4个元素
(integer) 4
127.0.0.1:6379> zrange topx 0 -1 withscores #输出topx中所有元素值、score
1) "php"
2) "50"
3) "c"
4) "70"
5) "c++"
6) "80"
7) "java"
8) "90"
127.0.0.1:6379> zremrangebyscore topx 70 80 #删除score位于[70,80]区间的元素
(integer) 2
127.0.0.1:6379> zrange topx 0 -1 withscores #输出剩下的元素
1) "php"
2) "50"
3) "java"
4) "90"
11 . zcount:统计指定score范围内元素的个数
zcount key min max
返回有序集 key 中, score 值在 min 和 max 之间(默认包括 score 值等于 min 或 max )的 成员的数量
#####示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> zadd topx 90 java 70 c 80 c++ 50 php #topx集合中添加4个元素
(integer) 4
127.0.0.1:6379> zcount topx 80 100 #统计score位于[80,100]区间中的元素个数
(integer) 2
12 . zrank:按照score升序,返回某个元素在集合中的排
zrank key member
返回有序集 key 中成员 member 的排名。其中有序集成员按 score 值递增(从小到大)顺序排 列。
排名以 0 为底,也就是说, score 值最小的成员排名为 0 。
#####示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> zadd topx 90 java 70 c 80 c++ 50 php #topx集合中添加4个元素
(integer) 4
127.0.0.1:6379> zrank topx c #获取元素c的排名,返回1表示排名第2
(integer) 1
127.0.0.1:6379> zrange topx 0 -1 #输出集合中所有元素,看一下c的位置确实是2
1) "php"
2) "c"
3) "c++"
4) "java"
13 . zrevrank:按照score降序,返回某个元素在集合中的排
返回有序集 key 中成员 member 的排名。其中有序集成员按 score 值递减(从大到小)排序。
排名以 0 为底,也就是说, score 值最大的成员排名为 0 。
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> zadd topx 90 java 70 c 80 c++ 50 php #topx集合中添加4个元素
(integer) 4
127.0.0.1:6379> zrange topx 0 -1
1) "php"
2) "c"
3) "c++"
4) "java"
127.0.0.1:6379> zrevrank topx java #score降序,得到java的排名,排在第1位
(integer) 0
14 . zscore:返回集合中指定元素的score
zscore key member
返回有序集 key 中,成员 member 的 score 值。
如果 member 元素不是有序集 key 的成员,或 key 不存在,返回 nil 。
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> zadd topx 90 java 70 c 80 c++ 50 php #topx集合中添加4个元素
(integer) 4
127.0.0.1:6379> zrange topx 0 -1 #输出topx集合所有元素
1) "php"
2) "c"
3) "c++"
4) "java"
127.0.0.1:6379> zscore topx java #获取集合topx中java的score
"90"
2.6.3、数据结构
SortedSet(zset)是redis提供的一个非常特别的数据结构,内部使用到了2种数据结构。
1、hash表 类似于java中的Map<String,score>,key为集合中的元素,value为元素对应的score,可以用来快速定
位元素定义的score,时间复杂度为O(1)
2、跳表 跳表(skiplist)是一个非常优秀的数据结构,实现简单,插入、删除、查找的复杂度均为O(logN)。 类似java中的ConcurrentSkipListSet,根据score的值排序后生成的一个跳表,可以快速按照位置的顺
序或者score的顺序查询元素。 这里我们来看一下跳表的原理: 首先从考虑一个有序表开始:
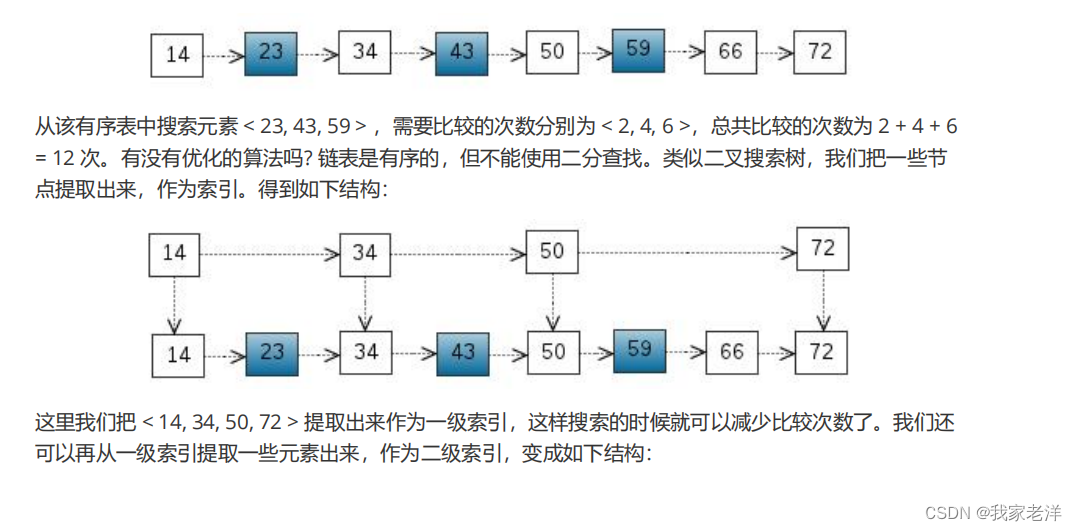
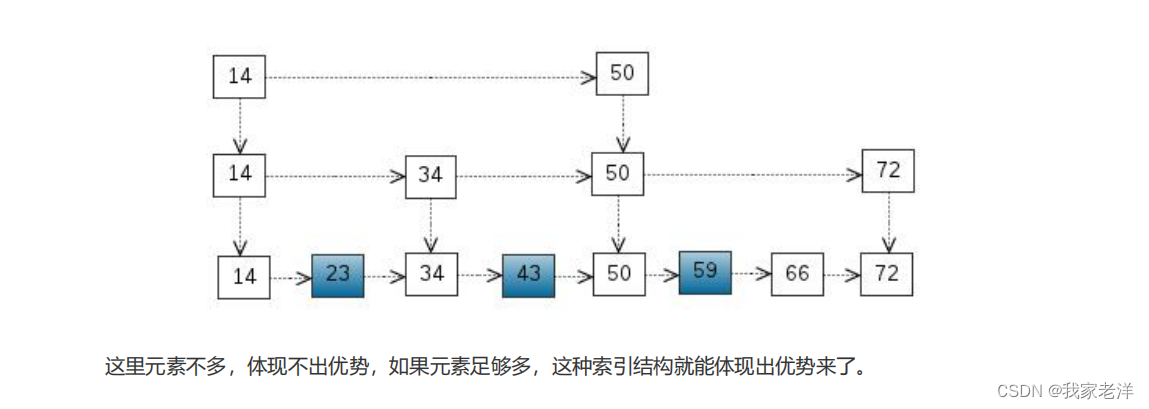
3、redis的发布和订阅
setrange <key> <起始位置> <value>
setrange <key> <起始位置> <value>
setrange <key> <起始位置> <value>
setrange <key> <起始位置> <value>
相关文章:
linux 安装操作 redis
1、redis概述和安装 1.1、安装redis 1. 下载redis 地址 https://download.redis.io/releases/ 2. 将 redis 安装包拷贝到 /opt/ 目录 3. 解压 tar -zvxf redis-6.2.1.tar.gz4. 安装gcc yum install gcc5. 进入目录 cd redis-6.2.16. 编译 make7. 执行 make install 进…...
博客后台模块续更(五)
十一、后台模块-菜单列表 菜单指的是权限菜单,也就是一堆权限字符串 1. 查询菜单 1.1 接口分析 需要展示菜单列表,不需要分页。可以针对菜单名进行模糊查询。也可以针对菜单的状态进行查询。菜单要按照父菜单id和orderNum进行排序 请求方式 请求路径…...

手写一个PrattParser基本运算解析器4: 简述iOS的编译过程
点击查看 基于Swift的PrattParser项目 iOS项目的编译过程与PrattParser解析器 前面三篇我们看到了PrattParser解析器的工作原理, 工作过程, 我们了解到PrattParser解析器实际上是模拟了编译过程中的 词法分析 、语法分析 、语义分析 、 中间代码生成 这几个编译前端过程. 那么P…...

【Java集合类面试六】、 HashMap有什么特点?
文章底部有个人公众号:热爱技术的小郑。主要分享开发知识、学习资料、毕业设计指导等。有兴趣的可以关注一下。为何分享? 踩过的坑没必要让别人在再踩,自己复盘也能加深记忆。利己利人、所谓双赢。 面试官:HashMap有什么特点&…...
基于LSTM的天气预测 - 时间序列预测 计算机竞赛
0 前言 🔥 优质竞赛项目系列,今天要分享的是 机器学习大数据分析项目 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐! 🧿 更多资料, 项目分享: https://gitee.com/dancheng-senior/po…...
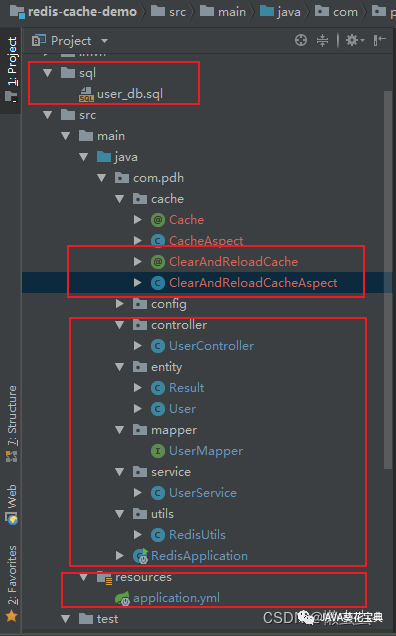
SpringBoot AOP + Redis 延时双删功能实战
一、业务场景 在多线程并发情况下,假设有两个数据库修改请求,为保证数据库与redis的数据一致性,修改请求的实现中需要修改数据库后,级联修改Redis中的数据。 请求一:A修改数据库数据 B修改Redis数据 请求二ÿ…...
【Java集合类面试七】、 JDK7和JDK8中的HashMap有什么区别?
文章底部有个人公众号:热爱技术的小郑。主要分享开发知识、学习资料、毕业设计指导等。有兴趣的可以关注一下。为何分享? 踩过的坑没必要让别人在再踩,自己复盘也能加深记忆。利己利人、所谓双赢。 面试官:JDK7和JDK8中的HashMap有…...

el-tree 获取过滤后的树结构
正常来说element框架应该返回的,但实际上没有,只能自己处理了 递归处理,思路就是赋值,如果是自己过滤到的数据就push进去,不是就不要 let newCheckTree [] let tree get_tree(treeData,newCheckTree); //获取过滤…...

Windows连接SFTP服务
最近有个新需求需要通过SFTP方式连接到一个FTP中下载相关内容 1.使用命令行方式 在cmd中使用如下命令 sftp -P [port] [username]ip #示例 sftp -P 666 ftp123.123.123.123然后弹出的提示输入yes,再输入密码就可以了。 2.使用资源管理器方式 普通FTP可以使用资源…...
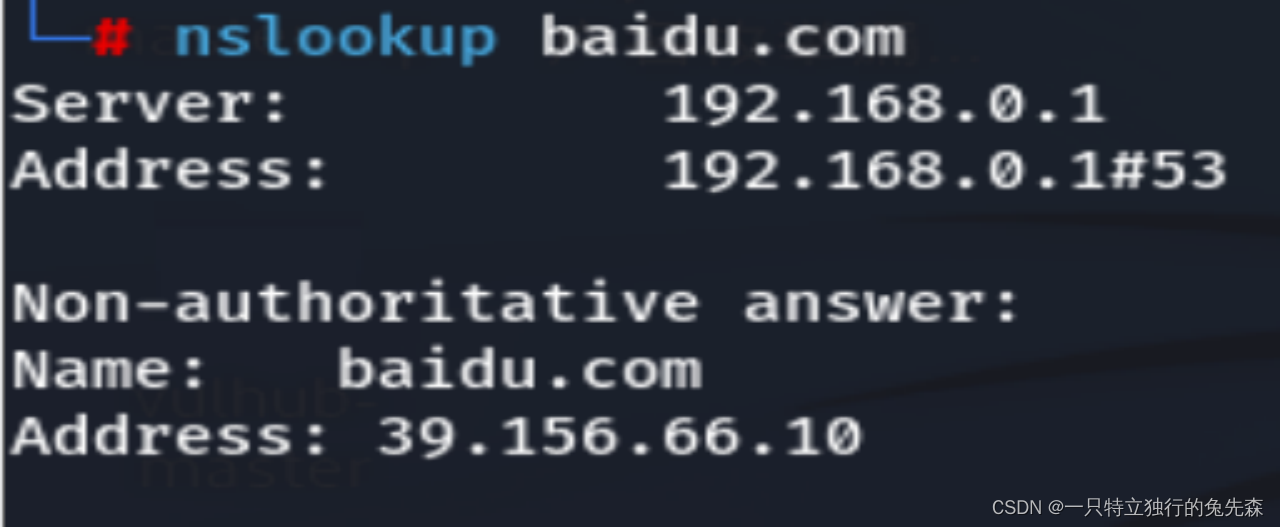
《红蓝攻防对抗实战》五.内网探测协议出网之DNS协议探测出网
DNS(Domain Name System)即域名解析系统,可将域名解析到对应访问IP。下面我们还是以系统自带命令为案例,进行演示DNS协议探测出网。 目录 一.Windows系统探测DNS协议出网 二.Linux系统探测DNS协议出网 1. Dig命令 2.Nslookup命…...

计算机算法分析与设计(18)---回溯法(介绍、子集和问题C++代码)
文章目录 一、回溯法介绍二、子集和问题2.1 知识概述2.2 代码编写 一、回溯法介绍 1. 回溯法(back tracking)是一种选优搜索法,又称为试探法,有“通用的解题法”之称,按选优条件向前搜索,以达到目标。但当探…...
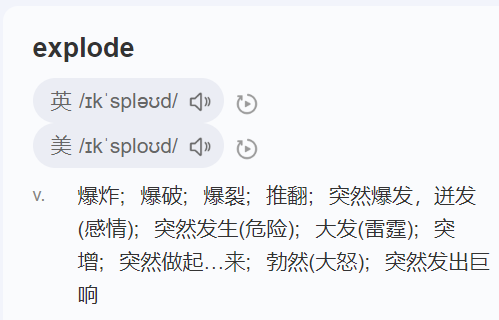
[Hive] explode
在 Hive 中,explode 函数用于将数组(Array)或者Map类型的列拆分成多行, 每个元素或键值对为一行。这允许我们在查询中对数组或 Map 进行扁平化操作。 下面是使用 explode 函数的示例: 假设我们有一个包含数组字段的表…...

2023年10月22日找工作面试交流遇到的基本问题
交叉编译解决的痛点问题 不同硬件体系结构之间的编译问题。嵌入式系统开发需要在主机上编写代码。提高效率和节省时间。软件移植和管理依赖关系。 不同硬件体系结构之间的编译问题:例如,你开发了一个针对Intel x86架构的应用程序,但想要在Ra…...

如何判断要不要用振动技术来进行设备预测性维护
在现代工业设备运行过程中,及时发现设备故障并进行维修对于确保生产线的正常运行至关重要。振动分析技术作为一种先进的设备监测和预测性维护方法,通过实时监测和分析设备的振动信号,可以提前发现潜在故障,降低停机时间和维护成本…...

数据结构和算法——用C语言实现所有树形结构及相关算法
文章目录 前言树和森林基础概念二叉树二叉树的遍历二叉树的构造树和森林与二叉树之间的转化树和森林的遍历 满二叉树完全二叉树线索二叉树线索二叉树的构造寻找前驱和后继线索二叉树的遍历 最优二叉树(哈夫曼树)哈夫曼树的构造哈夫曼编码 二叉排序树&…...
OTA: Optimal Transport Assignment for Object Detection 论文和代码学习
OTA 原因步骤什么是最优传输策略标签分配的OT正标签分配负标签分配损失计算中心点距离保持稳定动态k的选取 整体流程代码使用 论文连接: 原因 1、全部按照一个策略如IOU来分配GT和Anchors不能得到全局最优,可能只能得到局部最优。 2、目前提出的ATSS和P…...
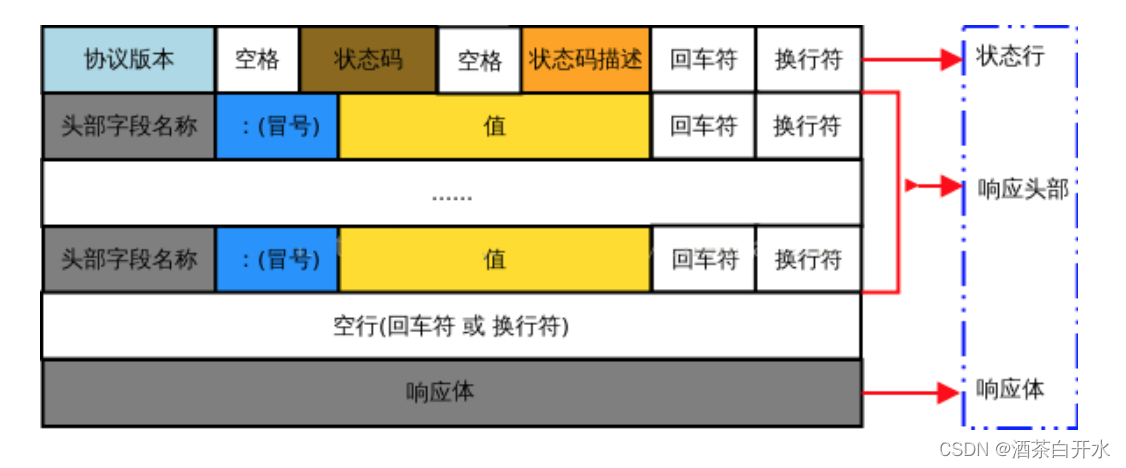
前后端交互—跨域与HTTP
跨域 代码下载 同源策略 同源策略(英文全称 Same origin policy)是浏览器提供的一个安全功能。 MDN 官方给定的概念:同源策略限制了从同一个源加载的文档或脚本如何与来自另一个源的资源进行交互。这 是一个用于隔离潜在恶意文件的重要安全机制。 通俗的理解:浏览器规定&a…...

Error和Exception的关系以及区别
在Java中,Error 和 Exception 是两种不同类型的异常类,它们都继承自 java.lang.Throwable,但在用途和处理方式上有重要区别。 Error: Error 表示在程序运行过程中,通常由于系统或环境的严重问题而引起的异常情况。这些问题通常是无…...

Hive SQL 函数高阶应用场景
HIVE作为数据仓库处理常用工具,如同RDBMS关系型数据库中标准SQL语法一样,Hive SQL也内置了不少系统函数,满足于用户在不同场景下的数据分析需求,以提高开发SQL数据分析的效率。 我们可以使用show functions查看当下版本支持的函数…...

linux下C++开发环境搭建
一.安装GCC,GDB 1.1 先更新软件包安装源 sudo apt update1.2 安装编译器和调试器 sudo apt install build-essential gdb"build-essential" 是编译代码所需要的工具。 "gdb" 是调试器。1. build-essential:- "build-essential" 是一个用于Ubu…...

Ollama部署DeepSeek-R1:解决数学编程问题的智能助手
Ollama部署DeepSeek-R1:解决数学编程问题的智能助手 1. 引言:为什么你需要一个数学和编程助手 如果你经常需要解决数学问题、编写代码或者处理复杂的逻辑推理,可能会遇到这样的困扰:面对一个复杂的方程,需要反复推导…...
)
保姆级教程:在Ubuntu 23.10虚拟机上,从零部署Dify源码(含PostgreSQL 17与Redis配置)
保姆级教程:Ubuntu 23.10虚拟机环境下的Dify全栈部署实战 在开发者的日常工作中,本地隔离环境的搭建往往是最容易被忽视却又至关重要的环节。想象一下这样的场景:你正在为一个重要客户开发基于大语言模型的智能应用,突然某个依赖库…...

TB6612FNG双H桥电机驱动库深度解析与机器人运动控制
1. TB6612FNG_XCR库深度解析:面向嵌入式机器人控制的双路H桥驱动框架TB6612FNG_XCR并非一个简单的Arduino封装库,而是一套为真实机器人工程场景深度定制的电机控制抽象层。它在STMicroelectronics原厂TB6612FNG双H桥驱动芯片(最大持续电流1.2…...

Linux I/O 演进史:从管道到零拷贝,一篇串起个服务端核心原语撑
前言 在使用 kubectl get $KIND -o yaml 查看 k8s 资源时,输出结果中包含大量由集群自动生成的元数据(如 managedFields、resourceVersion、uid 等)。这些信息在实际复用 yaml 清单时需要手动清理,增加了额外的工作量。 使用 kube…...

去哪儿商户端分析
声明: 本文章中所有内容仅供学习交流使用,不用于其他任何目的,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关! 部分python代码data {"departur…...

代码随想录一刷记录Day25——leetcode491.递增子序列
前言 之前就有刷代码随想录,但奈何总是三天打鱼两天晒网,而且刷的也很囫囵吞枣,于是乎决定参加代码随想录训练营,准备精刷一遍,希望自己能坚持下去,结营后自己的算法水平能更上一个level,冲ing…...

嵌入式VGM音频库:轻量级芯片级音源仿真与实时播放
1. 项目概述Video Game Music Library(简称 VGM-Lib)是一个专为嵌入式平台设计的轻量级音频播放库,核心目标是精准复现经典街机与家用游戏机时代的数字音频——特别是基于 SN76489、YM2413、YM2612、RF5C164 等经典音源芯片的原始音色。该库不…...
)
开源可部署StructBERT模型:低成本GPU方案实现企业级语义匹配能力(<2GB显存)
开源可部署StructBERT模型:低成本GPU方案实现企业级语义匹配能力(<2GB显存) 1. 项目简介与核心价值 StructBERT中文句子相似度分析工具是一个基于阿里达摩院开源StructBERT大规模预训练模型开发的本地化语义匹配解决方案。这个工具专门针…...

TimescaleDB 2.26.2 发布,修复多项错误
开源数据库 TimescaleDB 发布 2.26.2 版本,该版本修复了自 2.26.1 版本以来存在的多个错误,官方建议用户尽快升级。 TimescaleDB 简介 TimescaleDB 是基于 PostgreSQL 构建的开源数据库,旨在让 SQL 可扩展到时间序列数据。它被打包为 Postgre…...

Spring AI与注册中心:构建可动态扩展的智能意图驱动系统
1. 为什么需要动态扩展的智能意图驱动系统 记得去年我接手一个电商客服系统改造项目时,遇到一个典型痛点:每次新增业务功能(比如退货政策变更、新增支付方式),都需要停服发布。更麻烦的是,用户问"能用…...