深度学习---卷积神经网络
卷积神经网络概述
卷积神经网络是深度学习在计算机视觉领域的突破性成果。在计算机视觉领域。往往输入的图像都很大,使用全连接网络的话,计算的代价较高。另外图像也很难保留原有的特征,导致图像处理的准确率不高。
卷积神经网络(Convolutional Neural Network)是含有卷积层的神经网络。卷积层的作用就是用来自动学习、提取图像的特征。
CNN网络主要有三部分构成:卷积层、池化层和全连接层构成,其中卷积层负责提取图像中的局部特征;池化层用来大幅降低参数量级(降维);全连接层类似人工神经网络的部分,用来输出想要的结果。
图像概述
图像是由像素点组成的,每个像素点的值范围为:[0,255],像素值越大意味着较亮。比如一张 200x200 的图像,则是由 40000 个像素点组成,如果每个像素点都是 0 的话,意味着这是一张全黑的图像。
彩色图一般都是多通道的图像,所谓多通道可以理解为图像由多个不同的图像层叠加而成,例如看到的彩色图像一般都是由 RGB 三个通道组成的,还有一些图像具有 RGBA 四个通道,最后一个通道为透明通道,该值越小,则图像越透明。
卷积层
卷积计算
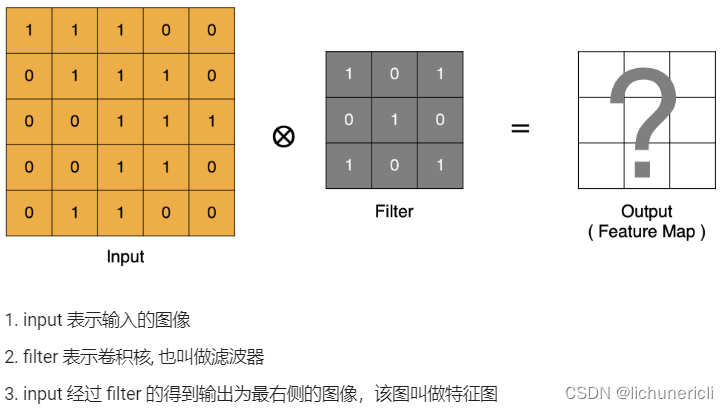
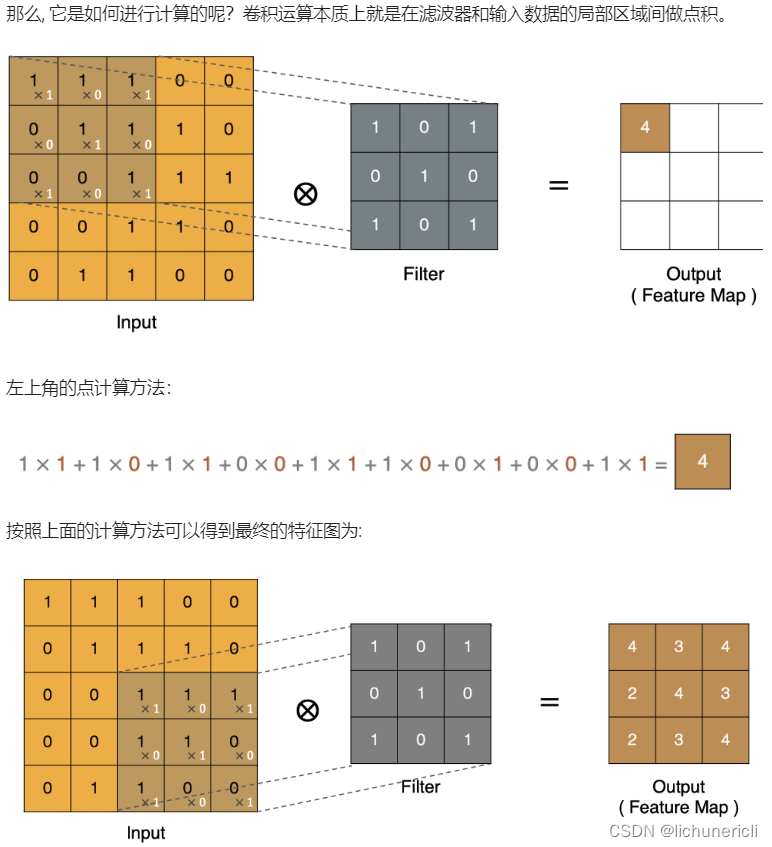
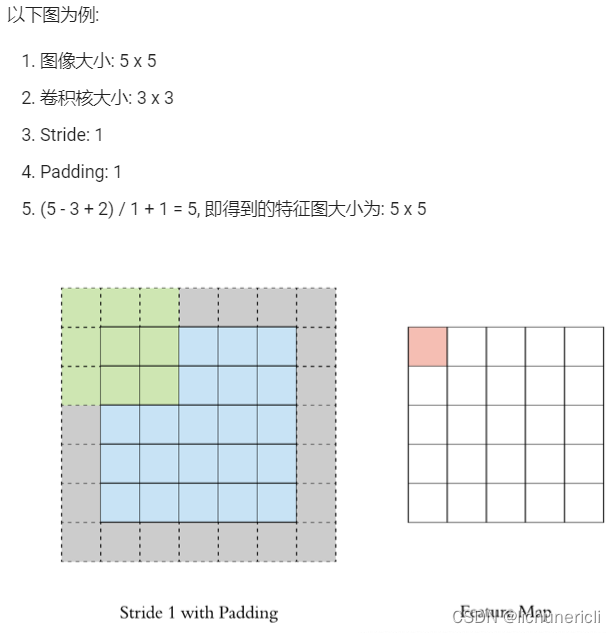
Padding
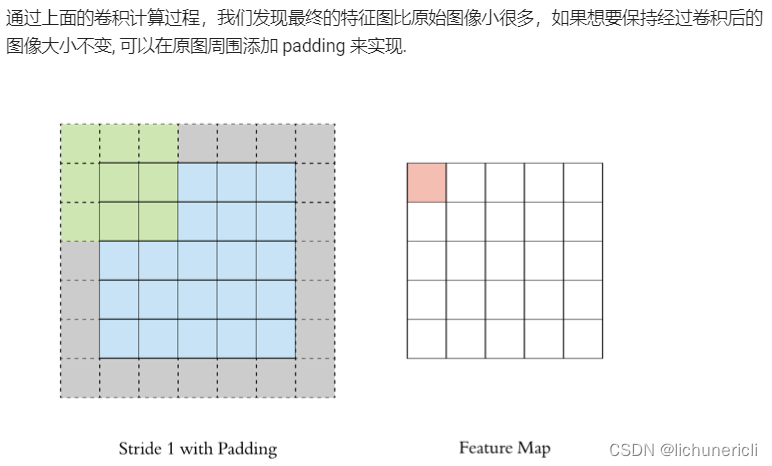
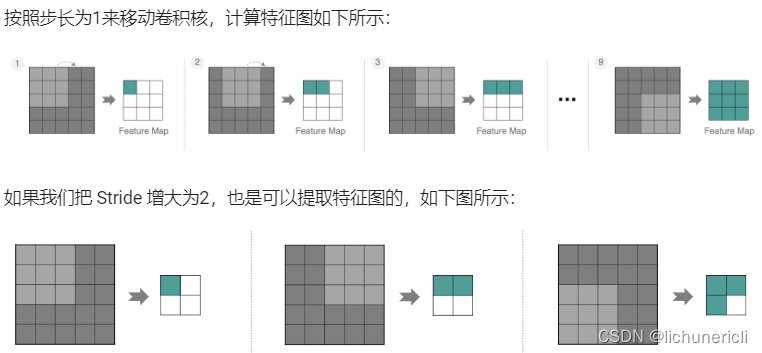
Stride
多通道卷积计算
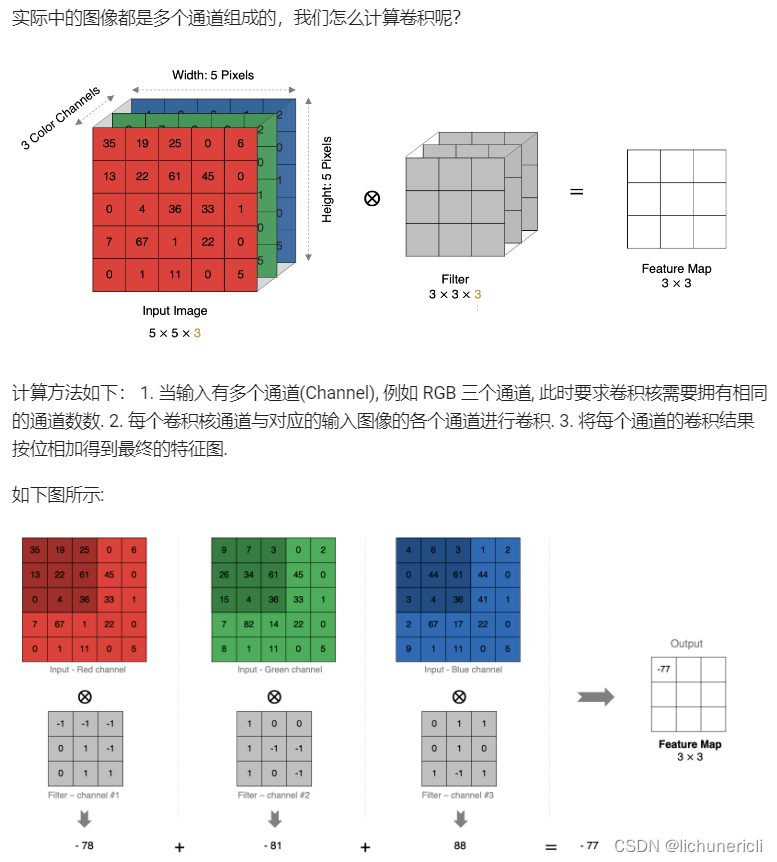
多卷积核卷积计算
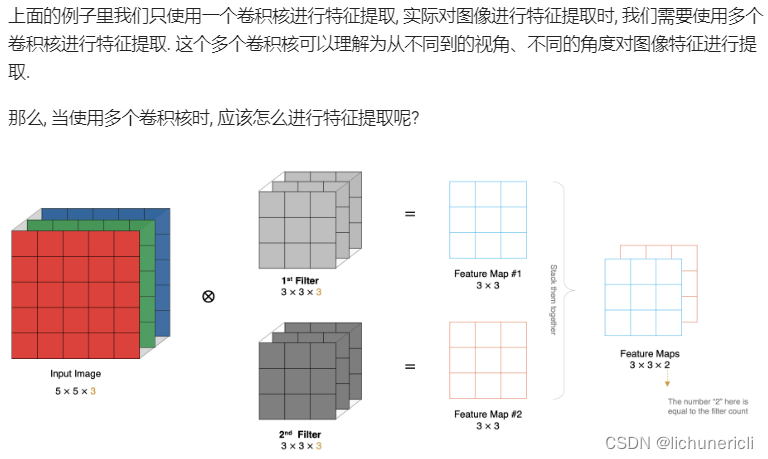
特征图大小

池化层
池化层 (Pooling) 降低维度,缩减模型大小,提高计算速度。即:主要对卷积层学习到的特征图进行下采样(SubSampling)处理。池化层主要有两种:最大池化、平均池化。
池化层计算
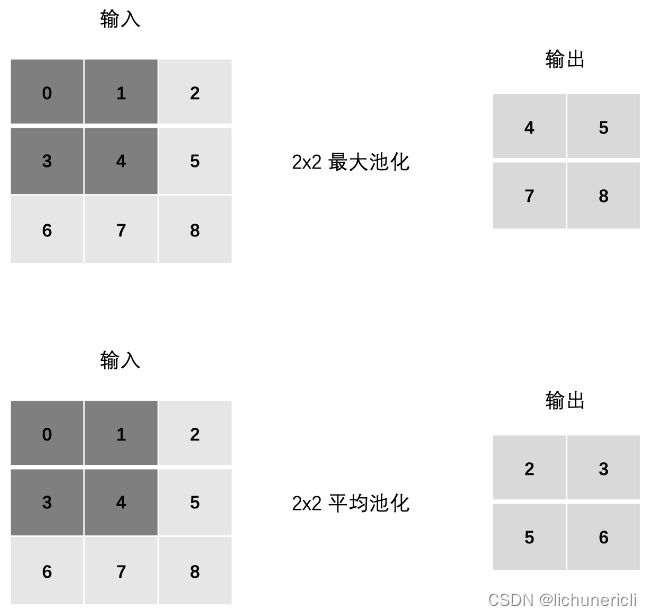
Stride
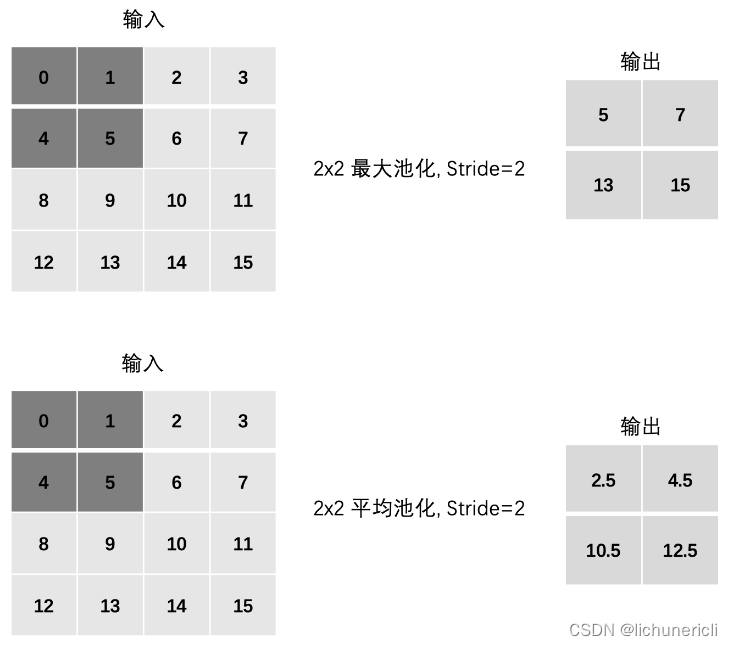
Padding
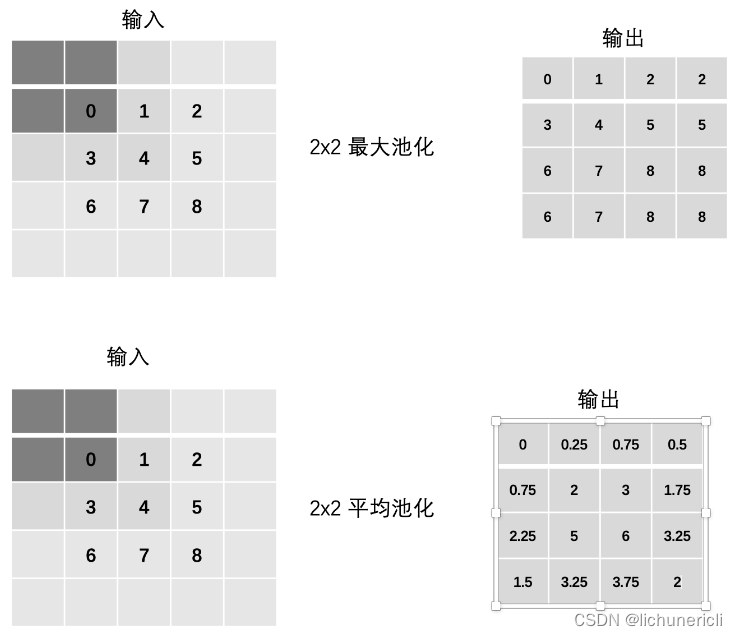
多通道池化计算
案例-图像分类
CIFAR10 数据集
from torchvision.datasets import CIFAR10
from torchvision.transforms import Compose
from torchvision.transforms import ToTensor
from torch.utils.data import DataLoader# 1. 数据集基本信息
def test01():# 加载数据集train = CIFAR10(root='data', train=True, transform=Compose([ToTensor()]))valid = CIFAR10(root='data', train=False, transform=Compose([ToTensor()]))# 数据集数量print('训练集数量:', len(train.targets))print('测试集数量:', len(valid.targets))# 数据集形状print("数据集形状:", train[0][0].shape)# 数据集类别print("数据集类别:", train.class_to_idx)# 2. 数据加载器
def test02():train = CIFAR10(root='data', train=True, transform=Compose([ToTensor()]))dataloader = DataLoader(train, batch_size=8, shuffle=True)for x, y in dataloader:print(x.shape)print(y)breakif __name__ == '__main__':test01()test02()搭建图像分类网络
class ImageClassification(nn.Module):def __init__(self):super(ImageClassification, self).__init__()self.conv1 = nn.Conv2d(3, 6, stride=1, kernel_size=3)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv2 = nn.Conv2d(6, 16, stride=1, kernel_size=3)self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)self.linear1 = nn.Linear(576, 120)self.linear2 = nn.Linear(120, 84)self.out = nn.Linear(84, 10)def forward(self, x):x = F.relu(self.conv1(x))x = self.pool1(x)x = F.relu(self.conv2(x))x = self.pool2(x)# 由于最后一个批次可能不够 32,所以需要根据批次数量来 flattenx = x.reshape(x.size(0), -1)x = F.relu(self.linear1(x))x = F.relu(self.linear2(x))return self.out(x)编写训练函数
使用多分类交叉熵损失函数,Adam 优化器:
def train():# 加载 CIFAR10 训练集, 并将其转换为张量transgform = Compose([ToTensor()])cifar10 = torchvision.datasets.CIFAR10(root='data', train=True, download=True, transform=transgform)# 构建图像分类模型model = ImageClassification()# 构建损失函数criterion = nn.CrossEntropyLoss()# 构建优化方法optimizer = optim.Adam(model.parameters(), lr=1e-3)# 训练轮数epoch = 100for epoch_idx in range(epoch):# 构建数据加载器dataloader = DataLoader(cifar10, batch_size=BATCH_SIZE, shuffle=True)# 样本数量sam_num = 0# 损失总和total_loss = 0.0# 开始时间start = time.time()correct = 0for x, y in dataloader:# 送入模型output = model(x)# 计算损失loss = criterion(output, y)# 梯度清零optimizer.zero_grad()# 反向传播loss.backward()# 参数更新optimizer.step()correct += (torch.argmax(output, dim=-1) == y).sum()total_loss += (loss.item() * len(y))sam_num += len(y)print('epoch:%2s loss:%.5f acc:%.2f time:%.2fs' %(epoch_idx + 1,total_loss / sam_num,correct / sam_num,time.time() - start))# 序列化模型torch.save(model.state_dict(), 'model/image_classification.bin')编写预测函数
def test():# 加载 CIFAR10 测试集, 并将其转换为张量transgform = Compose([ToTensor()])cifar10 = torchvision.datasets.CIFAR10(root='data', train=False, download=True, transform=transgform)# 构建数据加载器dataloader = DataLoader(cifar10, batch_size=BATCH_SIZE, shuffle=True)# 加载模型model = ImageClassification()model.load_state_dict(torch.load('model/image_classification.bin'))model.eval()total_correct = 0total_samples = 0for x, y in dataloader:output = model(x)total_correct += (torch.argmax(output, dim=-1) == y).sum()total_samples += len(y)print('Acc: %.2f' % (total_correct / total_samples))总结
可以从以下几个方面来调整网络:
- 增加卷积核输出通道数
- 增加全连接层的参数量
- 调整学习率
- 调整优化方法
- 修改激活函数
- 等等...
把学习率由 1e-3 修改为 1e-4,并网络参数量增加如下代码所示:
class ImageClassification(nn.Module):def __init__(self):super(ImageClassification, self).__init__()self.conv1 = nn.Conv2d(3, 32, stride=1, kernel_size=3)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv2 = nn.Conv2d(32, 128, stride=1, kernel_size=3)self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)self.linear1 = nn.Linear(128 * 6 * 6, 2048)self.linear2 = nn.Linear(2048, 2048)self.out = nn.Linear(2048, 10)def forward(self, x):x = F.relu(self.conv1(x))x = self.pool1(x)x = F.relu(self.conv2(x))x = self.pool2(x)# 由于最后一个批次可能不够 32,所以需要根据批次数量来 flattenx = x.reshape(x.size(0), -1)x = F.relu(self.linear1(x))x = F.dropout(x, p=0.5)x = F.relu(self.linear2(x))x = F.dropout(x, p=0.5)return self.out(x)相关文章:
深度学习---卷积神经网络
卷积神经网络概述 卷积神经网络是深度学习在计算机视觉领域的突破性成果。在计算机视觉领域。往往输入的图像都很大,使用全连接网络的话,计算的代价较高。另外图像也很难保留原有的特征,导致图像处理的准确率不高。 卷积神经网络࿰…...
Windows系统下安装CouchDB3.3.2教程
安装 前往CouchDB官网 官网点击download下载msi文件 双击该msi文件,一直下一步 创建个人account 设置cookie value 用于进行身份验证和授权。 愉快下载 点击OK 重启 启动 重启电脑后 打开浏览器并访问以下链接:http://127.0.0.1:5984/ 如果没有问…...

JavaScript基础知识(二)
JavaScript基础知识(二) 一、ES2015 基础语法1.变量2.常量3.模板字符串4.结构赋值 二、函数进阶1. 设置默认参数值2. 立即执行函数3. 闭包4. 箭头函数 三、面向对象1. 面向对象概述2. 基本概念3. 新语法 与 旧语法3.1 ES5 面向对象的知识ES5构造函数原型…...
)
SQL NULL Values(空值)
什么是SQL NULL值? SQL 中,NULL 用于表示缺失的值。数据表中的 NULL 值表示该值所处的字段为空。 具有NULL值的字段是没有值的字段。 如果表中的字段是可选的,则可以插入新记录或更新记录而不向该字段添加值。然后,该字段将被保存…...
云原生Docker网络管理
目录 Docker网络 Docker 网络实现原理 为容器创建端口映射 查看容器的输出和日志信息 Docker 的网络模式 查看docker网络列表 指定容器网络模式 网络模式详解 host模式 container模式 none模式 bridge模式 自定义网络 Docker网络 Docker 网络实现原理 Docker使用Lin…...

聊聊线程池的预热
序 本文主要研究一下线程池的预热 prestartCoreThread java/util/concurrent/ThreadPoolExecutor.java /*** Starts a core thread, causing it to idly wait for work. This* overrides the default policy of starting core threads only when* new tasks are executed. T…...
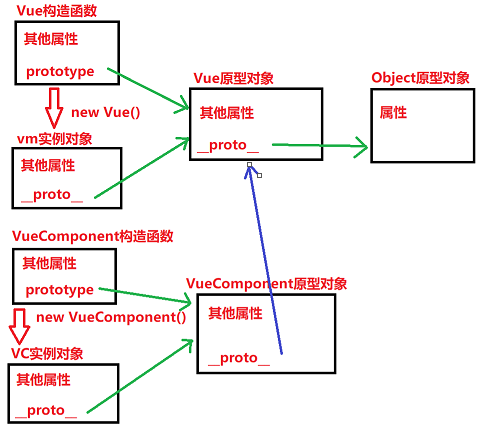
VueComponent的原型对象
一、prototype 每一个构造函数身上又有一个prototype指向其原型对象。 如果我们在控制台输入如下代码,就能看到Vue构造函数的信息,在他身上可以找到prototype属性,指向的是Vue原型对象: 二、__proto__ 通过构造函数创建的实例对…...

Redis不止能存储字符串,还有List、Set、Hash、Zset,用对了能给你带来哪些优势?
文章目录 🌟 Redis五大数据类型的应用场景🍊 一、String🍊 二、Hash🍊 三、List🍊 四、Set🍊 五、Zset 📕我是廖志伟,一名Java开发工程师、Java领域优质创作者、CSDN博客专家、51CTO…...

Python OpenCV通过灰度平均值进行二值化处理以减少像素误差
Python OpenCV通过灰度平均值进行二值化处理以减少像素误差 前言前提条件相关介绍实验环境通过灰度平均值进行二值化处理以减少像素误差固定阈值二值化代码实现 灰度平均值二值化代码实现 前言 由于本人水平有限,难免出现错漏,敬请批评改正。更多精彩内容…...

[Golang]多返回值函数、defer关键字、内置函数、变参函数、类成员函数、匿名函数
函数 文章目录 函数多返回值函数按值传递、按引用传递类成员函数改变外部变量变参函数defer和追踪说明一些常见操作实现 使用defer实现代码追踪记录函数的参数和返回值 常见的内置函数将函数作为参数闭包实例闭包将函数作为返回值 计算函数执行时间使用内存缓存来提升性能 参考…...
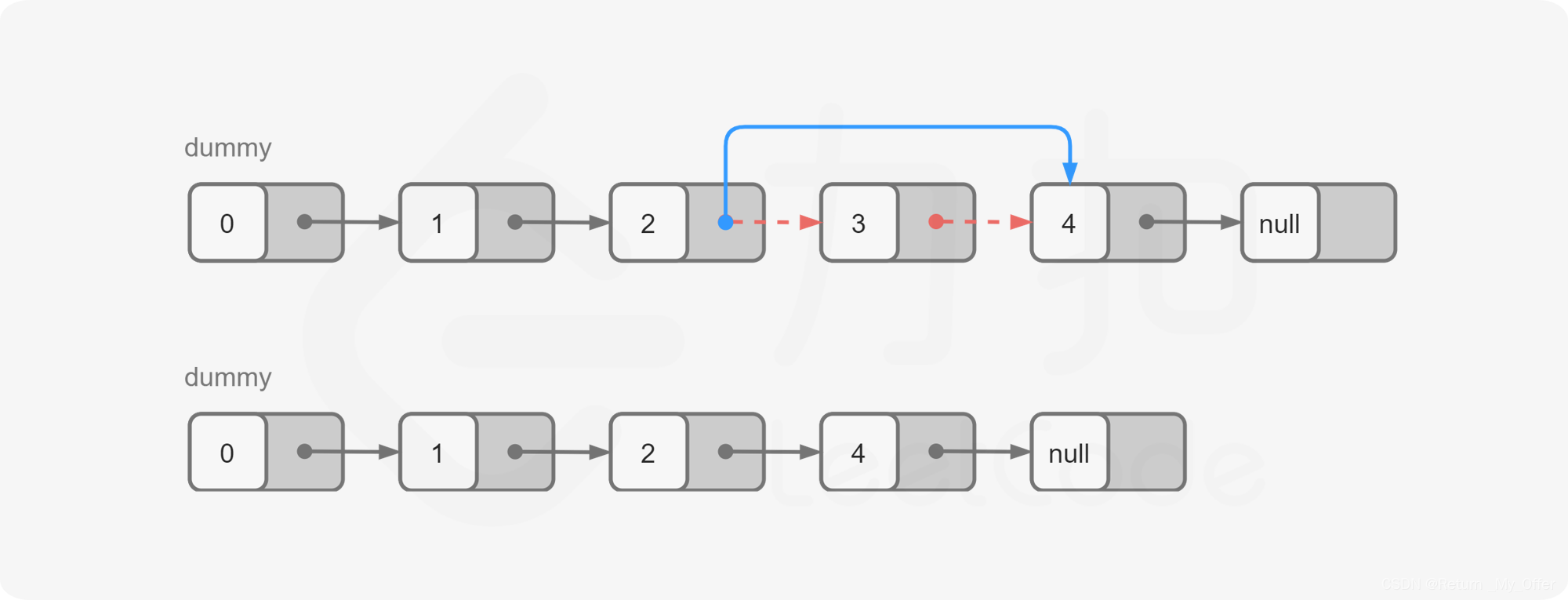
【剑指Offer】:删除链表中的倒数第N个节点(此题是LeetCode上面的)剑指Offer上面是链表中的倒数第K个节点
给定一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点 示例 1: 输入:head [1,2,3,4,5], n 2 输出:[1,2,3,5] 示例 2: 输入:head [1], n 1 输出:[] 示例 3:…...
acwing第 126 场周赛 (扩展字符串)
5281. 扩展字符串 一、题目要求 某字符串序列 s0,s1,s2,… 的生成规律如下: s0 DKER EPH VOS GOLNJ ER RKH HNG OI RKH UOPMGB CPH VOS FSQVB DLMM VOS QETH SQBsnDKER EPH VOS GOLNJ UKLMH QHNGLNJ Asn−1AB CPH VOS FSQVB DLMM VOS QHNG Asn−1AB,其…...
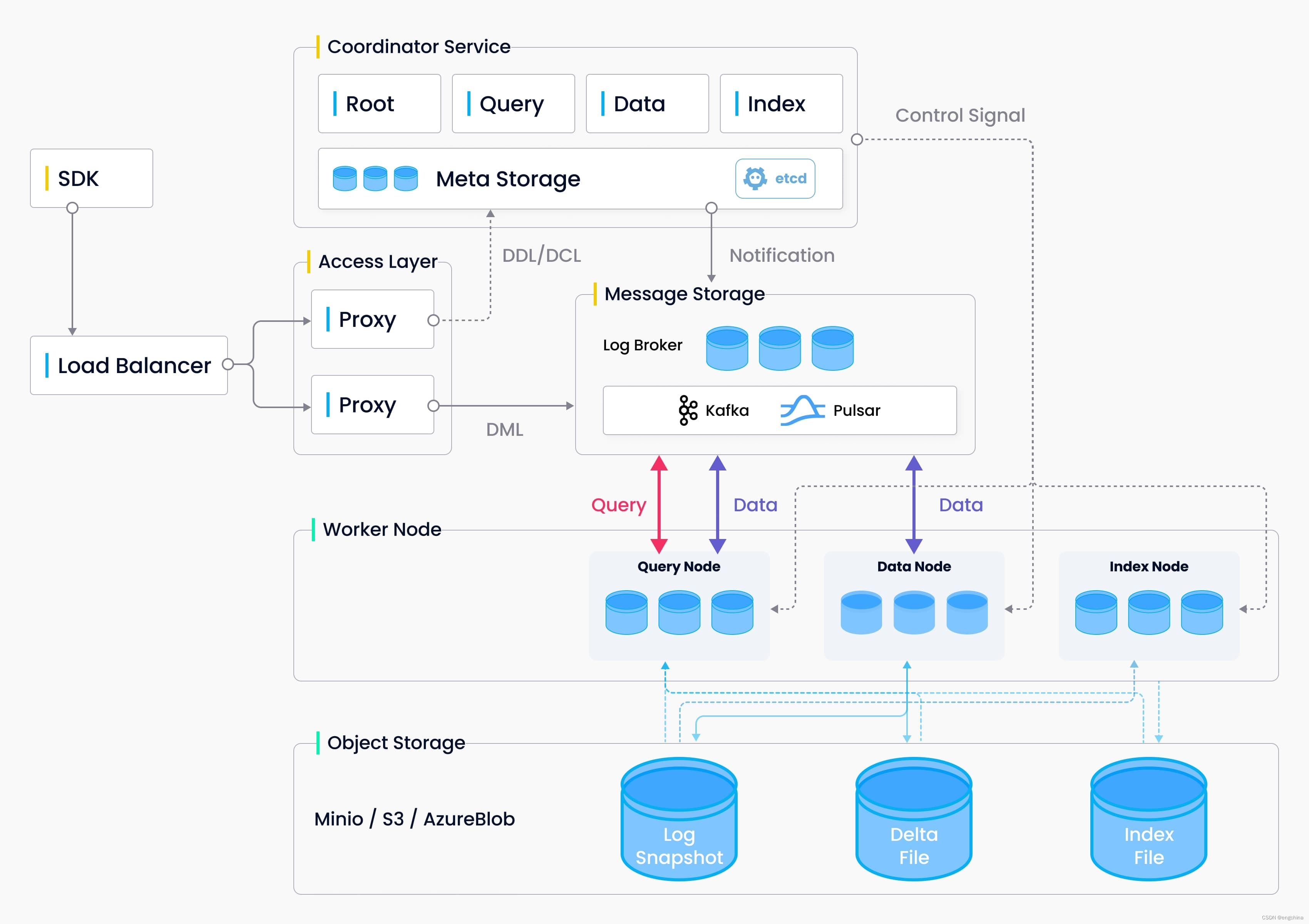
Milvus 介绍
Milvus 介绍 Milvus 矢量数据库是什么?关键概念非结构化数据嵌入向量向量相似度搜索 为什么是 Milvus?支持哪些索引和指标?索引类型相似度指标(Similarity metrics) 应用示例Milvus 是如何设计的?开发者工具API访问Milvus 生态系统工具 本页…...
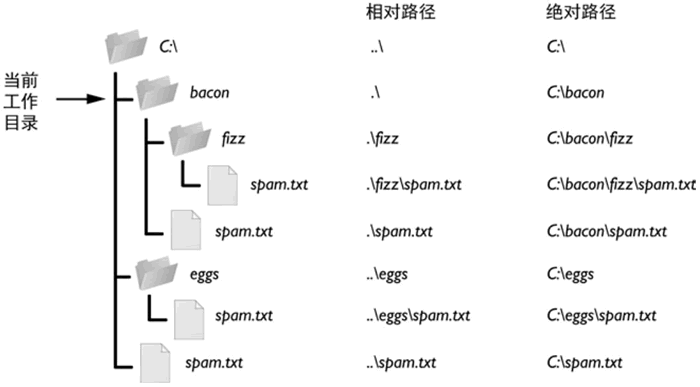
Linux绝对路径和相对路径
在 Linux 中,简单的理解一个文件的路径,指的就是该文件存放的位置。 只要我们告诉 Linux 系统某个文件存放的准确位置,那么它就可以找到这个文件。指明一个文件存放的位置,有 2 种方法,分别是使用绝对路径和相对路径。…...

Linux:firewalld防火墙-基础使用(2)
上一章 Linux:firewalld防火墙-介绍(1)-CSDN博客https://blog.csdn.net/w14768855/article/details/133960695?spm1001.2014.3001.5501 我使用的系统为centos7 firewalld启动停止等操作 systemctl start firewalld 开启防火墙 systemct…...

【每日一练】20231023
统计每个字符出现的次数相关问题 方法一:map的put方法遍历 public class Test {public static void main(String[] args) {StringBuilder sb new StringBuilder("");Random ran new Random();for(int i0;i<2000000;i) {sb.append((char) (a ran.n…...
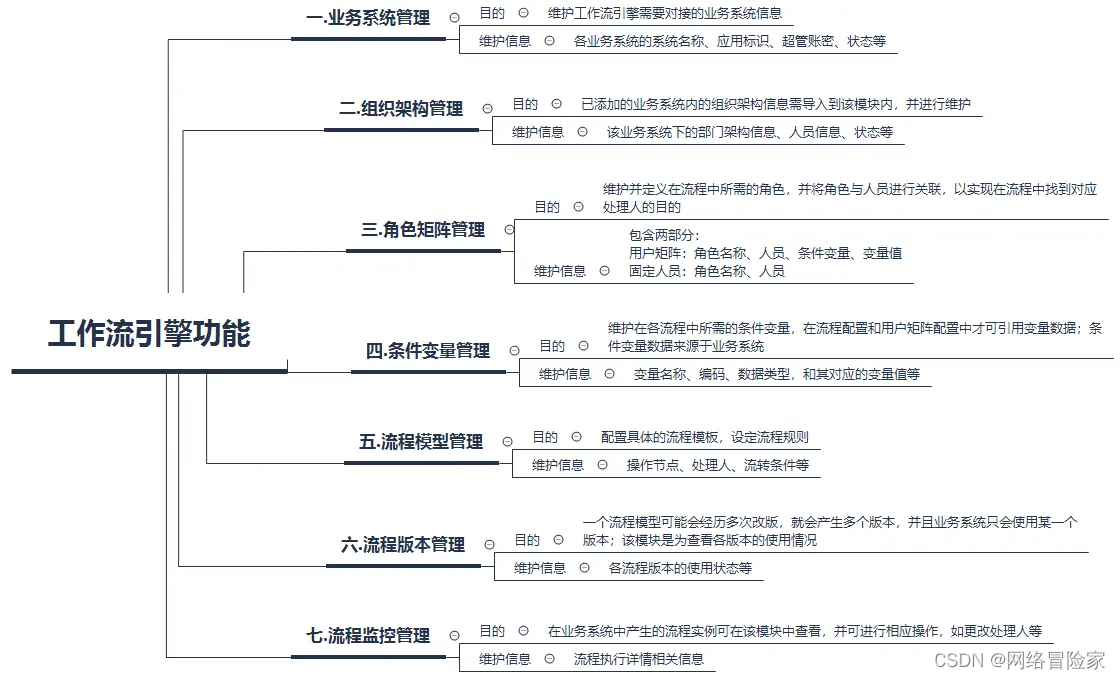
【项目经理】工作流引擎
项目经理之 工作流引擎 一、业务系统管理目的维护信息 二、组织架构管理目的维护信息 三、角色矩阵管理目的维护信息 四、条件变量管理目的维护信息 五、流程模型管理目的维护信息 六、流程版本管理目的维护信息 七、流程监管控制目的维护信息 系列文章版本记录 一、业务系统管…...

025-第三代软件开发-实现需求长时间未操作返回登录界面
第三代软件开发-实现需求长时间未操作返回登录界面 文章目录 第三代软件开发-实现需求长时间未操作返回登录界面项目介绍实现需求长时间未操作返回登录界面实现思路用户操作监控QML 逻辑处理 关键字: Qt、 Qml、 QTimer、 timeout、 eventFilter 项目介绍 欢迎…...
驱动开发LED灯绑定设备文件
头文件 #ifndef __HEAD_H__ #define __HEAD_H__typedef struct {unsigned int MODER;unsigned int OTYPER;unsigned int OSPEEDR;unsigned int PUPDR;unsigned int IDR;unsigned int ODR; }gpio_t;#define PHY_LED1_ADDR 0x50006000 #define PHY_LED2_ADDR 0x50007000 #defin…...

MySql 数据库基础概念,基本简单操作及数据类型介绍
文章目录 数据库基础为什么需要数据库?创建数据库mysql架构SQL语句分类编码集修改数据库属性数据库备份 表的基本操作存在时更新,不存在时插入 数据类型日期类型enum和set 数据库基础 以特定的格式保存文件,叫做数据库,这是狭义上…...

第16讲:C语⾔内存函数
目录 memcpy使⽤memmove使⽤memset函数的使⽤memcmp函数的使⽤1.memcpy(1)功能: memcpy 是完成内存块拷⻉的,不关注内存中存放的数据是啥。函数 memcpy 从 source 的位置开始向后复制 num 个字节的数据到 destination 指向的内存位…...

PyTorch 2.8镜像中的模型安全与鲁棒性测试:对抗样本生成
PyTorch 2.8镜像中的模型安全与鲁棒性测试:对抗样本生成 1. 为什么我们需要关注模型安全性 想象一下,你开发了一个用于医疗影像诊断的AI系统,准确率高达99%。但在实际部署后,有人通过微小的图像改动就让系统做出完全错误的判断。…...

袁永福 电子病历,医疗信息化吓
在AI辅助开发的语境下,Skill就是一个包含了领域知识、最佳实践、代码模板的知识包。 以"DAO层CRUD生成"为例,一个Skill包含: /mnt/skills/dao-crud/ ├── SKILL.md # 使用说明 │ ├── 何时使用这个Skill │ …...

Python装饰器高级用法详解
Python装饰器高级用法详解 Python装饰器是函数式编程的精华之一,它能在不修改原函数代码的情况下增强功能。从简单的日志记录到复杂的权限校验,装饰器的应用场景极为广泛。除了基础的函数装饰器,Python还支持更高级的用法,如类装…...

MCP + Function Calling:让模型自主驱动工具链完成多步推理
标签:Java MCP Function Calling ReAct j-langchain ToolCall Agent 前置阅读:Java 实现 ReAct Agent:工具调用与推理循环 → Java Agent 集成 MCP 工具协议:让 AI 真正驱动企业系统 适合人群:已了解 MCP 基础用法&…...

3分钟从文档到演示文稿:PPTAgent智能生成完整指南
3分钟从文档到演示文稿:PPTAgent智能生成完整指南 【免费下载链接】PPTAgent An Agentic Framework for Reflective PowerPoint Generation 项目地址: https://gitcode.com/gh_mirrors/pp/PPTAgent 你是否还在为制作演示文稿而烦恼?PPTAgent是一款…...

基于Python的考试系统毕业设计
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。 一、研究目的 本研究旨在设计并实现一个基于Python的考试系统,以满足现代教育环境中对在线考试系统的需求。该系统旨在提供一种高效、安全、便捷的考试环境&am…...

终极Cursor免费VIP指南:3步解锁AI代码编辑器完整功能
终极Cursor免费VIP指南:3步解锁AI代码编辑器完整功能 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tria…...

【C++原创开源】formort.h:一行头文件,实现比JS模板字符串更爽的链式拼接+响应式变量
文章目录一、先看效果:比JS模板字符串更爽的写法二、核心功能:不止是拼接,还有响应式1. 任意类型|链式拼接2. Cast响应式变量绑定三、核心实现:几十行代码,看懂原理四、使用方法:零门槛,直接上手…...

一天做出:鸿蒙 + AI 游戏 Demo
子玥酱 (掘金 / 知乎 / CSDN / 简书 同名) 大家好,我是 子玥酱,一名长期深耕在一线的前端程序媛 👩💻。曾就职于多家知名互联网大厂,目前在某国企负责前端软件研发相关工作,主要聚…...