tensorrt安装使用教程
一般的深度学习项目,训练时为了加快速度,会使用多GPU分布式训练。但在部署推理时,为了降低成本,往往使用单个GPU机器甚至嵌入式平台(比如 NVIDIA Jetson)进行部署,部署端也要有与训练时相同的深度学习环境,如caffe,TensorFlow等。由于训练的网络模型可能会很大(比如inception,resnet等),参数很多,而且部署端的机器性能存在差异,就会导致推理速度慢,延迟高。这对于那些高实时性的应用场合是致命的,比如自动驾驶要求实时目标检测,目标追踪等。所以为了提高部署推理的速度,出现了很多轻量级神经网络,比如squeezenet,mobilenet,shufflenet等。基本做法都是基于现有的经典模型提出一种新的模型结构,然后用这些改造过的模型重新训练,再重新部署。而tensorRT 则是对训练好的模型进行优化。 tensorRT就只是推理优化器。当你的网络训练完之后,可以将训练模型文件直接丢进tensorRT中,而不再需要依赖深度学习框架(Caffe,TensorFlow等),如下:

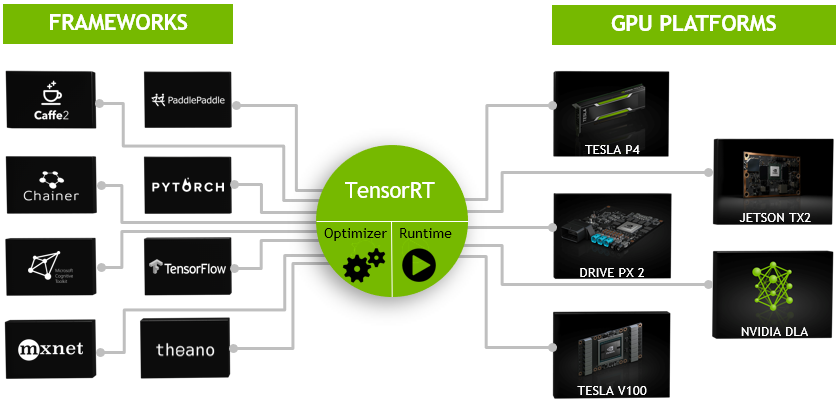
可以认为tensorRT是一个只有前向传播的深度学习框架,这个框架可以将 Caffe,TensorFlow的网络模型解析,然后与tensorRT中对应的层进行一一映射,把其他框架的模型统一全部 转换到tensorRT中,然后在tensorRT中可以针对NVIDIA自家GPU实施优化策略,并进行部署加速。如果想了解更多关于tensorrt的介绍,可参考官网介绍。
一、安装
Installation Guide :: NVIDIA Deep Learning TensorRT Documentation
【精选】TensorRT安装及使用教程-CSDN博客
首先查看电脑是否正常安装cuda以及对应的版本,至于cuda的安装可以查看《ubuntn16.04+cuda9.0+cudnn7.5小白安装教程》,接下来去nvidia官网下载对应的tensorrt安装
包。常见的有两种安装方式:
(1)deb格式文件下载
sudo dpkg -i nv-tensorrt-local-repo-{tag}_1.0-1_amd64.deb
sudo cp /var/nv-tensorrt-local-repo-{tag}/*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get install tensorrt上面的tag号替换成自己下载的版本信息,等install安装结束,输入命令:dpkg -l | grep TensorRT如果显示如下图有关tensorrt的信息,说明tensorrt的c++版本安装成功:

如果想要同时安装python版本,则可以进行如下操作
pip install nvidia-pyindex
pip install nvidia-tensorrt安装完成后可以执行以下命令查看其版本信息
python -c "import tensorrt as trt;print(trt.__version__)"(2)tar下载完成后,进行如下步骤安装
##安装依赖库
pip install pucuda -i https://pypi.douban.com/simple#在home下新建文件夹,命名为tensorrt_tar,然后将下载的压缩文件拷贝进来解压
tar -xzvf TensorRT-7.0.0.11.Ubuntu-18.04.x86_64-gnu.cuda-10.0.cudnn7.6.tar.gz#解压得到TensorRT-5.0.2.6的文件夹,将里边的lib绝对路径添加到环境变量中
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/lthpc/tensorrt_tar/TensorRT-7.0.0.11/lib#安装TensorRT
cd TensorRT-7.0.0.11/python
pip install tensorrt-7.0.0.11-cp37-none-linux_x86_64.whl#安装UFF
cd TensorRT-5.0.2.6/uff
pip install uff-0.6.5-py2.py3-none-any.whl#安装graphsurgeon
cd TensorRT-5.0.2.6/graphsurgeon
pip install graphsurgeon-0.4.1-py2.py3-none-any.whl当一切正常安装结束,在终端下输入python -c "import tensorrt as trt"不报错即表示安装成功。
需要注意的一点就是,TensorRT与Opset版本之间的匹配关系取决于TensorRT的发行版本。TensorRT的每个版本通常支持一组特定的Opset版本,这些Opset版本与不同的深度学习框架和模型格式相关联。
以下是TensorRT的一些主要版本以及它们通常支持的Opset版本:
-
TensorRT 7.0:
- 支持Opset 9和Opset 10。
-
TensorRT 8.0:
- 支持Opset 11。
请注意,这只是一些示例,实际支持的Opset版本可能因TensorRT的更新和不同发行版本而有所变化。您应该查阅TensorRT的官方文档或相应的发行说明,以获取特定版本的详细信息,包括支持的Opset版本。此外,确保您的模型与您使用的TensorRT版本兼容,以获得最佳性能和准确性。如果您使用的是深度学习框架(如TensorFlow、PyTorch等),还需要确保导出模型时使用了TensorRT支持的Opset版本。
二、tensorrt使用分析
TensorRT使用笔记-CSDN博客
TensorRT整个过程可以分三个步骤,即模型的解析(Parser),Engine优化和执行(Execution)。
》模型的解析(Parser)
目前TensorRT支持两种输入方式:
- 一种是Parser的方式。
Parser是模型解析器,输入一个caffe的模型,或者onnx模型,或者TensorFlow转换成的uff模型,可以解析出其中的网络层及网络层之间的连接关系,然后将其输入到TensorRT中。 - API接口可以添加一个convolution或pooling。将Parser解析出来的模型文件,使用API添加到TensorRT中构建网络。
Parser目前有三个:
- 一个是caffe Parser,这个是最古老的也是支持最完善的;
- 另一个是uff,这个是NV定义的网络模型的一种文件结构,现在TensorFlow可以直接转成uff;
- 另外版本3.5或4.0支持的onnx。
目前API支持两种接口实现方式:
- C++
- Python
补:如果有一个网络层不支持?
这个有可能,TensorRT只支持主流的操作,比如说一个神经网络专家开发了一个新的网络层,TensorRT是不知道是做什么的。这个时候涉及到customer layer的功能,即用户自定义层,构建用户自定义层需要告诉TensorRT该层的连接关系和实现方式,这样TensorRT才能去做。
模型解析后,engine会进行优化,得到优化好的engine可以序列化到内存(buffer)或文件(file),读的时候需要反序列化,将其变成engine以供使用。然后在执行的时候创建context,主要是分配预先的资源,engine加context就可以做推断(Inference)。
TensorRT所做的优化?
第一,也是最重要的,它把一些网络层进行了合并。
第二,取消不需要的层,比如concat这一层。
第三,Kernel可以自动选择最合适的算法。
第四,不同的batch size会做tuning。
第五,对硬件做优化。
总结TensorRT的优点
- TensorRT是一个高性能的深度学习推断(Inference)的优化器和运行的引擎;
- TensorRT支持Plugin,对于不支持的层,用户可以通过Plugin来支持自定义创建;
- TensorRT使用低精度的技术获得相对于FP32二到三倍的加速,用户只需要通过相应的代码来实现。
同时附上几个常用的接口,
Network Definition (高阶用法)
网络定义接口提供方法来指定网络的定义。我们可以指定输入输出的Tensor Name以及增加layer。我们可以通过自定义来扩展TensorRT不支持的层和功能。关于网络定义的API,请查看Network Definition API.
Builder
Builder接口让我们可以从一个网络定义中创建一个优化后的引擎。在这个步骤我们可以选择最大batch,workspace size,精度级别等参数,如果你想了解更多,请查看Builder API.
Engine
引擎接口就允许应用来执行推理了。它支持对引擎输入和输出的绑定进行同步和异步执行、分析、枚举和查询。
It supports synchronous and asynchronous execution, profiling, and
enumeration and querying of the bindings for the engine inputs and
outputs.
此外,引擎接口还允许单个引擎拥有多个执行上下文(execution contexts). 这可以让一个引擎同时对多组数据进行执行推理操作。如想了解更多,请查Execution API.
此外,TensorRT还提供了解析训练模型并创建TensorRT内部支持的模型定义的parser:
- Caffe Parser
This parser can be used to parse a Caffe network created in BVLC Caffe
or NVCaffe 0.16. It also provides the ability to register a plugin
factory for custom layers. For more details on the C++ Caffe Parser,
see NvCaffeParser or the Python Caffe Parser.
- UFF Parser
This parser can be used to parse a network in UFF format. It also
provides the ability to register a plugin factory and pass field
attributes for custom layers. For more details on the C++ UFF Parser,
see NvUffParser or the Python UFF Parser.
- ONNX Parser
This parser can be used to parse an ONNX model. For more details on
the C++ ONNX Parser, see NvONNXParser or the Python ONNX Parser.
Restriction: Since the ONNX format is quickly developing, you may
encounter a version mismatch between the model version and the parser
version. The ONNX Parser shipped with TensorRT 5.1.x supports ONNX IR
(Intermediate Representation) version 0.0.3, opset version 9.
三、tensorrt测试
python:TensorRT学习笔记3 - 运行sampleMNIST-CSDN博客
c++:tensorRT学习笔记 C++version
使用TensorRT进行模型推理加速的工作流(Workflow)可以分为以下几个步骤:
- ① 训练神经网络,得到模型。(以Tensorflow为例,我们得到
xx.pb格式的模型文件) - ② 将模型用TensorRT提供的工具进行parsing(解析)。
- ③ 将parsing后的结构通过TensorRT内部的优化选项(optimization options)对计算图结构进行优化。(包括不限于:1. 算子融合 Layer Funsion: 通过将Conv + BN等层的融合降低数据的吞吐量。 2. 精度校准 Precision Calibration : 当用户为了节省计算资源使用INT8进行推理的时候,需要作精度校准,这个操作TensorRT提供了官方的支持。 3. kernel auto-tuning : 根据计算逻辑,自动选择TensorRT实现的更高效的矩阵乘法,卷积运算等逻辑。)
- ④ 通过上述步骤,得到了一个优化后的推理引擎。我们就可以拿这个引擎进行推理了~
》针对tensorflow模型,先将pb模型转化为uff格式,进入到uff包的安装路径,转化命令如下
python convert_to_uff.py xxx.pb参考链接:
1、https://arleyzhang.github.io/articles/7f4b25ce/
2、使用NVIDIA 免费工具TENSORRT 加速推理实践--YOLOV3目标检测_使用tensorrt 加速yolov3-CSDN博客
3、https://www.cnblogs.com/shouhuxianjian/p/10550262.html
4、TensorRT/YoloV3 - eLinux.org
5、yolov3 with tensorRT on NVIDIA Jetson Nano
6、使用NVIDIA 免费工具TENSORRT 加速推理实践--YOLOV3目标检测_使用tensorrt 加速yolov3-CSDN博客
7、https://blog.csdn.net/weixin_43842032/article/details/85336940(tensorrt 安装和对tensorflow模型做推理,附python3.6解决方案)
8、https://blog.csdn.net/qq_36124767/article/details/68484092(tensorRT学习笔记)
9、https://docs.nvidia.com/deeplearning/tensorrt/api/python_api/parsers/Uff/pyUff.html(TensorRT 5.1.5.0 Python文档)
相关文章:
tensorrt安装使用教程
一般的深度学习项目,训练时为了加快速度,会使用多GPU分布式训练。但在部署推理时,为了降低成本,往往使用单个GPU机器甚至嵌入式平台(比如 NVIDIA Jetson)进行部署,部署端也要有与训练时相同的深…...
-- idea(2022版)将 已push 的 远程仓库 的 多条commit记录 进行撤销)
Java后端开发(十)-- idea(2022版)将 已push 的 远程仓库 的 多条commit记录 进行撤销
目录 1.多次 修改Test01类后,提交到本地仓库 。 2.多次重复 1 的步骤,多次commit成功后,在Git =》Log中会显示,commit记录...
常见面试题-Netty专栏(一)
typora-copy-images-to: imgs Netty 是什么呢?Netty 用于做什么呢? 答: Netty 是一个 NIO 客户服务端框架,可以快速开发网络应用程序,如协议服务端和客户端,极大简化了网络编程,如 TCP 和 UDP …...

【iOS】JSONModel的基本使用
文章目录 前言一、导入JSONModel二、JSONModel的基本使用1.基本用法2.模型集合3.模型导出为NSDictionary或JSON4.设置所有属性可选(所有属性值可以为空)5.下划线(蛇式)转驼峰命名法 前言 JSONModel 是一个用于 Objective-C 的开源库,它用于简…...
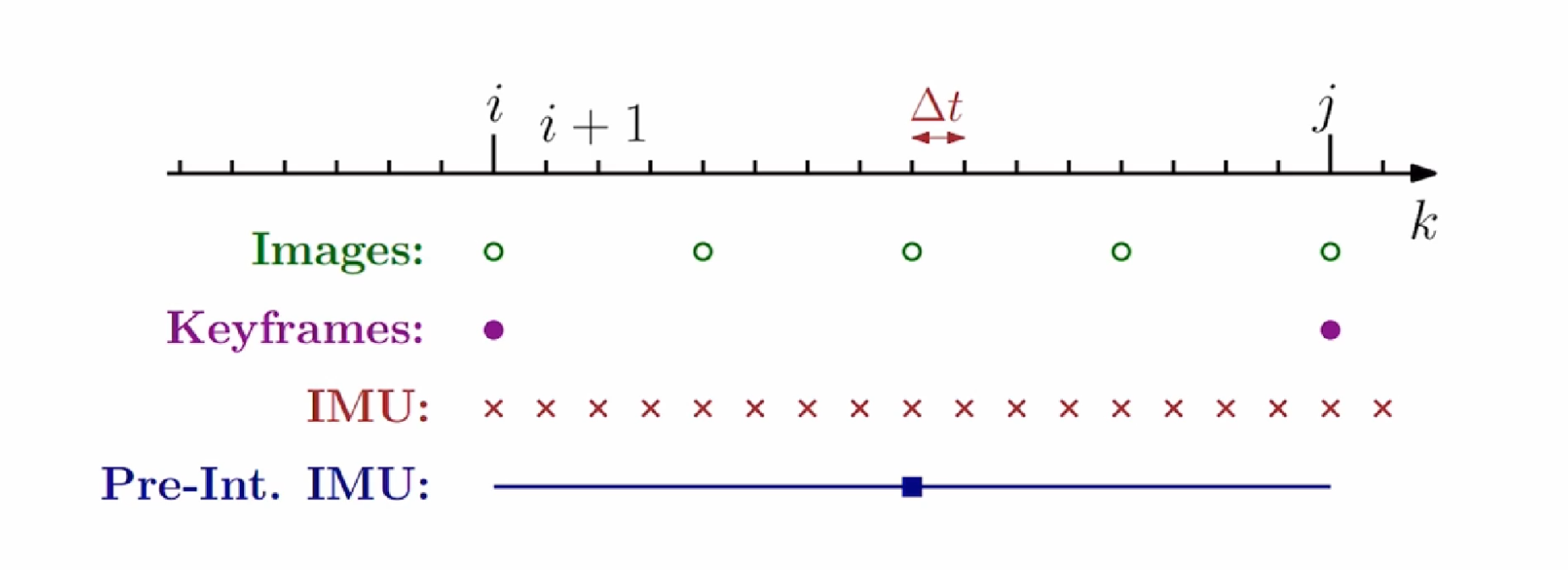
imu预积分学习(更新中)
imu预积分学习(更新中) IMU预积分可以做什么? 以上面那个经典图片为例子,IMU可以通过六轴数据,拿到第i帧和第j帧之间的相对位姿,这样不就可以去用来添加约束了吗 但是有一个比较大的问题是: I…...
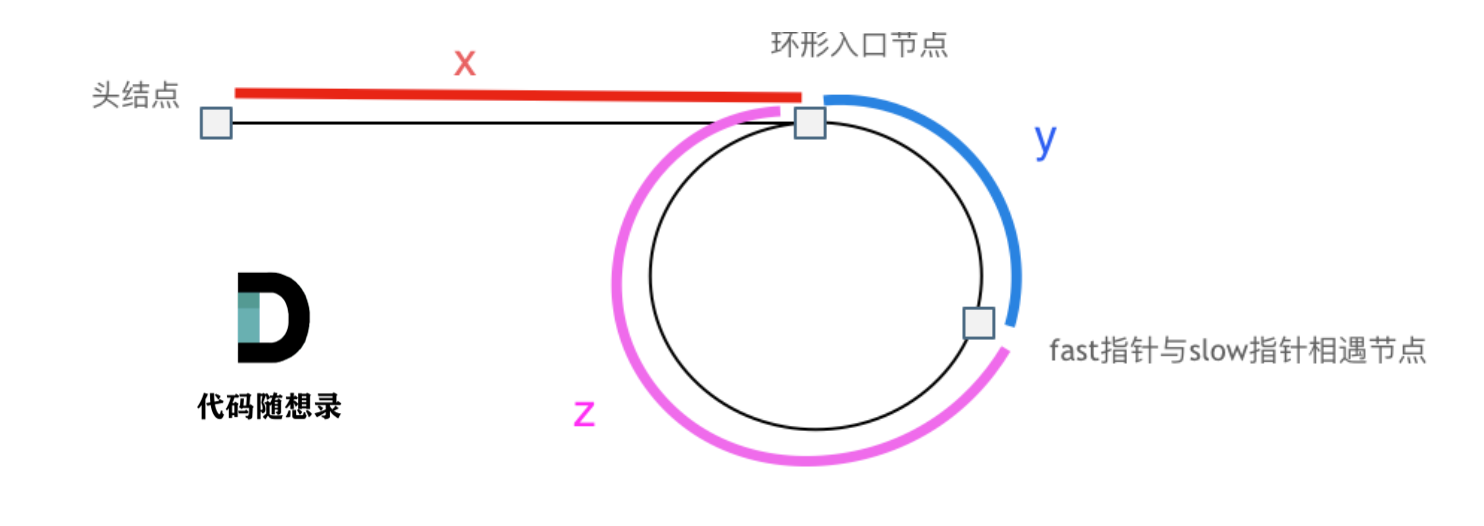
算法刷题-链表
算法刷题-链表 203. 移除链表元素 给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val val 的节点,并返回 新的头节点 。 示例 1: 输入:head [1,2,6,3,4,5,6], val 6 输出:[1,2,3,4,5]…...
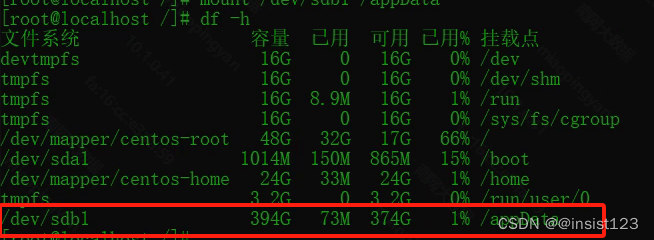
Linux 挂载磁盘到指定目录
问题:公司分配了数据磁盘,但是分区也没有挂载到目录 首先 df -h 查看一下挂载点的情况 查看服务器上未挂载的磁盘 fdisk -l 注:图中sda、sdb (a、b指的是硬盘的序号) 分区操作 我们可以看到b硬盘有536G未分区&…...

ZYNQ linux调试LCD7789
一,硬件管脚 1,参数解释和实物 LVGL是一个开源的图形库,主要用于MCU上屏幕UI的部署,功能完善,封装合理,可裁切性强,也可以实现Linux上fbx的部署。LVGL官网LVGL - Light and Versatile Embedded Graphics Library 每根线的作用...
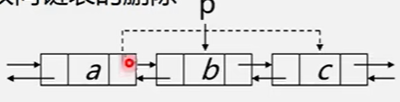
【双向链表的插入和删除】
文章目录 双向链表双向链表的插入双向链表的删除操作 双向链表 双向链表的结构定义如下: //双向链表的结构定义 typedef struct DuLNode {ElemType data;struct DuLNode* prior, * next; }DuLNode,*DuLinkList;双向链表的结点有两个指针域:prior&#…...
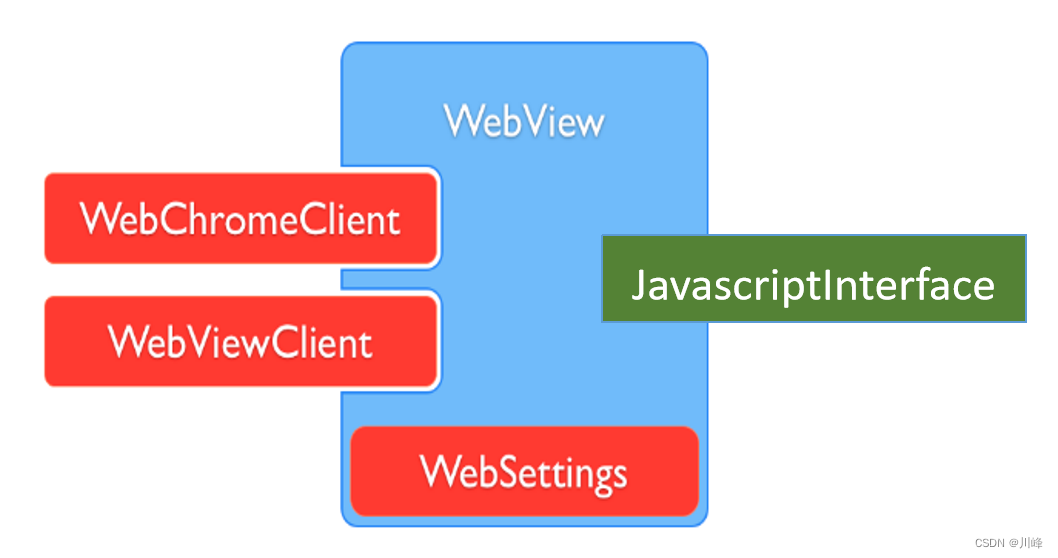
【Android知识笔记】Webview专题
WebView 核心组件 类名作用常用方法WebView创建对象加载URL生命周期管理状态管理loadUrl():加载网页 goBack():后退WebSettings配置&管理 WebView缓存:setCacheMode() 与JS交互:setJavaScriptEnabled()WebViewClient处理各种通知&请求事件should...

Leetcode第 368 场周赛
元素和最小的山形三元组 II 预处理前缀和后缀最小值,记为pre[i]和sa[i] 对于当前编号i,如果前面的最小值和后面的最大值都小于nums[i],则记录ans[i] nums[i]pre[i-1]sa[i1] 结果输出最小的ans[i]即可。 合法分组的最少组数 统计每一个数字出现的次数。将每一个数…...
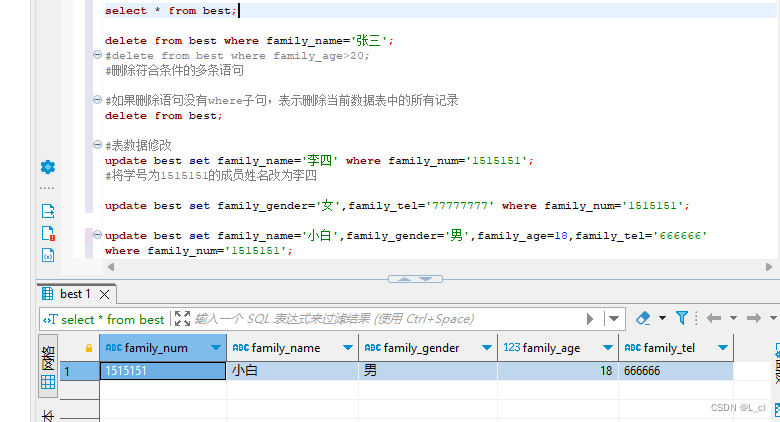
Mysql数据库 3.SQL语言 DML数据操纵语言 增删改
DML语句:用于完成对数据表中数据的插入、删除、修改操作 一.表数据插入 插入数据语法: 步骤例: 1.声明数据库:use 数据库名; 2.删除操作:drop table if exists 表名; 3.创建数据库中的表:create table 表…...

Java中,如何去掉字符串中前面所有的0
大家好,我是三叔,这期主要给大家分享下在开发中使用的字符串的一些常见方法。 例如:00000000110,现在需要去掉前面所有补的0,得到110,相信大家在开发中肯定有遇到过类似的开发需求,如何做&…...

数组能开空间大小
奈何辰星无可奈_leetcode,中等难度,算法-CSDN博客 这个博客介绍的很好,可以参考下...

Python 数据类 - dataclass 的作用与不足
https://docs.python.org/zh-cn/3/library/dataclasses.html https://peps.python.org/pep-0526/ https://peps.python.org/pep-0557/ dataclass 简单示例 from dataclasses import dataclassdataclass class User:name: strage: intif __name__ __main__:response_json {na…...

【C++初阶】类与对象(一)
目录 1、初识面向对象思想2、类 struct2.1 C中的struct及使用 3、类 class3.1 类的定义3.2 类的访问限定符3.2.1 访问限定符是什么3.2.2 访问限定符的使用3.2.3 访问限定符的使用规范3.2.4 访问限定符与封装 3.3 类做声明和定义分离3.3.1 声明和定义分离3.3.2 在函数声明的地方…...

thinkPHP框架详解+部署
目录 什么是ThinkPHP: ThinkPHP的主要特性: 什么是ThinkPHP: ThinkPHP是一个快速、兼容而且简单的轻量级国产PHP开发框架,诞生于2006年初,由国内的技术爱好者创建,遵循Apache2开源协议发布,是为了敏捷WEB应用开发和…...

Java拦截器(Interceptor)和过滤器(Filter)实例详解
一、Java过滤器和拦截器 1.1、过滤器(Filter) Filter过滤器,是Servlet(Server Applet)技术中的技术,开发人员可以通过Filter技术,管理web资源,可以对指定的一些行为进行拦截,例如URL级别的权限…...
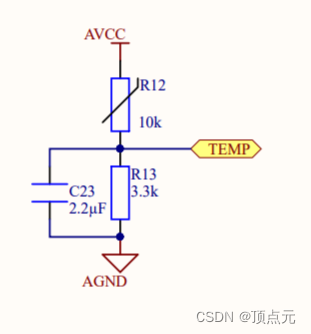
通过热敏电阻计算温度(二)---ODrive实现分析
文章目录 通过热敏电阻计算温度(二)---ODrive实现分析测量原理图计算分析计算拟合的多项式系数根据多项式方程计算温度的函数温度计算调用函数 通过热敏电阻计算温度(二)—ODrive实现分析 ODrive计算热敏电阻的温度采用的时B值的…...

基于typescript+express实现一个简单的接口权限验证
package.json "scripts": {"start": "nodemon src/main.ts","start:a": "nodemon src/a.ts","build": "tsc","build:dev": "tsc src/main.ts"}, express服务器文件 import * as…...

Python的__enter__管理机制
Python中的__enter__管理机制是上下文管理协议的核心,它通过简洁的语法实现了资源的自动化管理。无论是文件操作、数据库连接还是线程锁的控制,__enter__与__exit__这对魔术方法的组合都能确保资源在使用后得到及时释放,避免内存泄漏或资源竞…...

JFlashV7.52反读失败问题解决-Timeout while checking target RAM, RAMCode did not respond in time.
使用JFlash 软件 对GD32F407VET6芯片反读时提示错误Timeout while checking target RAM, RAMCode did not respond in time;如下图:2、options->Project setting --> MCU --> Target RAM settings 检查RAM设置, Size 改为128&#…...

ComfyUI Qwen人脸生成图像应用:电商模特、社交头像一键生成
ComfyUI Qwen人脸生成图像应用:电商模特、社交头像一键生成 1. 引言:从人脸到全身照的AI魔法 你是否遇到过这样的场景:需要一张专业形象照但没时间拍摄,或是想为电商产品展示不同风格的模特?传统解决方案要么成本高昂…...
)
sklearn分类报告看不懂?5分钟搞懂micro和macro的F1差异(附代码示例)
sklearn分类报告看不懂?5分钟搞懂micro和macro的F1差异(附代码示例) 第一次看到sklearn的classification_report输出时,那些密密麻麻的precision、recall、f1-score已经够让人头疼了,更别提最后两行突然冒出的micro和m…...
持续更新)
面试官: 秒杀库存扣减策略(答案深度解析)持续更新
秒杀库存扣减策略 —— 面试官真正想听的深度解析⚠️ 注意:面试官问“秒杀库存扣减”,绝不是想听你背概念,而是考察你是否真正踩过坑、权衡过取舍、理解系统本质。下面我用真实项目视角,带你一层层拆解。一、为什么库存扣减是秒杀…...

【英飞凌 CY8CKIT-062S2-AI评测】---姗姗来迟的开箱与环境搭建
一、引言 实话实说,这是英飞凌进驻21ic后的第一次接触到英飞凌的产品,因此收到开发板有段时间了,但一直在摸索当中,平时时间也比较有限,这不赶上了明天(11月3日)英飞凌在线下举办的AI研讨会&…...

5分钟搭建Vue3管理后台:开源免费的企业级解决方案终极指南
5分钟搭建Vue3管理后台:开源免费的企业级解决方案终极指南 【免费下载链接】vue-pure-admin 全面ESMVue3ViteElement-PlusTypeScript编写的一款后台管理系统(兼容移动端) 项目地址: https://gitcode.com/GitHub_Trending/vu/vue-pure-admin…...

鸿蒙_使用组件导航Navigation搭建应用框架
组件导航封装了页面、标题、菜单栏、工具栏等功能,我们只需要进行简单的设置,就能快速搭建应用的框架,我们直接新建一个独立页面来通过组件导航实现主页、设置页、我的页三个示例页面,并且相互之间可以跳转,并且天然支…...

终极硬件控制指南:如何用OmenSuperHub完全掌控惠普暗影精灵性能
终极硬件控制指南:如何用OmenSuperHub完全掌控惠普暗影精灵性能 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 厌倦了官方软件Omen Gaming Hu…...

Asian Beauty Z-Image Turbo开箱即用:浏览器访问即启东方人像生成服务
Asian Beauty Z-Image Turbo开箱即用:浏览器访问即启东方人像生成服务 1. 项目简介 Asian Beauty Z-Image Turbo是一款专注于东方美学人像生成的本地化工具,基于通义千问Tongyi-MAI Z-Image底座模型,结合专门训练的Asian-beauty权重开发而成…...