Prefix-Tuning源码解析
Prefix-Tuning源码解析
Prefix-Tuning在PEFT包中的源码实现
改写自Based on https://github.com/THUDM/P-tuning-v2/blob/main/model/prefix_encoder.py
import torch
from transformers import PretrainedConfigclass PrefixEncoder(torch.nn.Module):r'''The torch.nn model to encode the prefixInput shape: (batch-size, prefix-length)Output shape: (batch-size, prefix-length, 2*layers*hidden)'''def __init__(self, config):super().__init__()self.prefix_projection = config.prefix_projectionif self.prefix_projection:# Use a two-layer MLP to encode the prefixself.embedding = torch.nn.Embedding(config.prefix_length, config.hidden_size)self.trans = torch.nn.Sequential(torch.nn.Linear(config.hidden_size, config.encoder_hidden_size),torch.nn.Tanh(),torch.nn.Linear(config.encoder_hidden_size, config.num_hidden_layers * 2 * config.hidden_size))else:self.embedding = torch.nn.Embedding(config.prefix_length, config.num_hidden_layers * 2 * config.hidden_size)def forward(self, prefix: torch.Tensor):if self.prefix_projection:prefix_tokens = self.embedding(prefix)past_key_values = self.trans(prefix_tokens)else:past_key_values = self.embedding(prefix)return past_key_valuesif __name__ == "__main__":configs = {"prefix_length":20,"hidden_size":768,"encoder_hidden_size":768,"num_hidden_layers":12,"prefix_projection":False}prefix_encoder = PrefixEncoder(config=PretrainedConfig.from_dict(configs))print(prefix_encoder)batch_size = 8prefix = torch.arange(20).long().expand(batch_size, -1)print(prefix.shape)output = prefix_encoder(prefix)print(output.shape)下面我们以T5-large模型为例子:
不考虑Use a two-layer MLP to encode the prefix的话,prefix tuning主要包括以下代码:
class PrefixEncoder(torch.nn.Module):def __init__(self, config):super().__init__()...self.embedding = torch.nn.Embedding(num_virtual_tokens, num_layers * 2 * token_dim) #num_virtual_tokens=20,token_dim=1024,num_layers=24def forward(self, prefix: torch.Tensor):past_key_values = self.embedding(prefix)return past_key_values得到的PrefixEncoder被传入peft->peft_model.py->prompt_encoder:
PrefixEncoder((embedding): Embedding(20, 49152) # 1024*2*24
)self.prompt_tokens初始化为长度2*20的向量,因为T5有编码器和解码器,需要两次prefix:
self.prompt_tokens[adapter_name] = torch.arange(config.num_virtual_tokens * config.num_transformer_submodules).long() #20*2# tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,
# 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35,
# 36, 37, 38, 39])prompt_tokens = (self.prompt_tokens[self.active_adapter].unsqueeze(0).expand(batch_size, -1).to(prompt_encoder.embedding.weight.device))
prompt_tokens = prompt_tokens[:, : peft_config.num_virtual_tokens]
# 此时prompt_tokens.shape = (batch_size=8, num_virtual_tokens=20)past_key_values = prompt_encoder(prompt_tokens)
torch.Size([8, 20, 49152])但目前的past_key_values还是所有层的集合,我们需要把past_key_values分解为每一层:
past_key_values = past_key_values.view(batch_size, #8peft_config.num_virtual_tokens, #20peft_config.num_layers * 2, #24*2peft_config.num_attention_heads, #16peft_config.token_dim // peft_config.num_attention_heads, #1024/16)
# torch.Size([8, 20, 48, 16, 64])因为有编码器和解码器,所以再复制一次
past_key_values = torch.cat([past_key_values, past_key_values], dim=2)
# torch.Size([8, 20, 96, 16, 64])# 重排:torch.Size([96, 8, 16, 20, 64])
# 然后split成一个长度为24的tuple,每个tuple的shape:torch.Size([4, 8, 16, 20, 64])
past_key_values = past_key_values.permute([2, 0, 3, 1, 4]).split(peft_config.num_transformer_submodules * 2)也就是说past_key_values是24个层的Prefix embedding,形状为`(num_transformer_submodules * 2, batch_size, num_attention_heads, num_virtual_tokens, token_dim/num_attention_heads])
注意这里*2是因为key+value.
transformers->models->t5->modeling_t5.py->T5Attention类,这里的关键步骤是project函数中的hidden_states = torch.cat([past_key_value, hidden_states], dim=2),注意project函数仅仅用于key和value。
def forward(self,hidden_states,mask=None,key_value_states=None,position_bias=None,past_key_value=None,layer_head_mask=None,query_length=None,use_cache=False,output_attentions=False,):"""Self-attention (if key_value_states is None) or attention over source sentence (provided by key_value_states)."""# Input is (batch_size, seq_length, dim)# Mask is (batch_size, key_length) (non-causal) or (batch_size, key_length, key_length)# past_key_value[0] is (batch_size, n_heads, q_len - 1, dim_per_head)batch_size, seq_length = hidden_states.shape[:2]real_seq_length = seq_lengthif past_key_value is not None:if len(past_key_value) != 2:raise ValueError(f"past_key_value should have 2 past states: keys and values. Got { len(past_key_value)} past states")real_seq_length += past_key_value[0].shape[2] if query_length is None else query_lengthkey_length = real_seq_length if key_value_states is None else key_value_states.shape[1]def shape(states):"""projection"""return states.view(batch_size, -1, self.n_heads, self.key_value_proj_dim).transpose(1, 2)def unshape(states):"""reshape"""return states.transpose(1, 2).contiguous().view(batch_size, -1, self.inner_dim)def project(hidden_states, proj_layer, key_value_states, past_key_value):"""projects hidden states correctly to key/query states"""if key_value_states is None:# self-attn# (batch_size, n_heads, seq_length, dim_per_head)hidden_states = shape(proj_layer(hidden_states))elif past_key_value is None:# cross-attn# (batch_size, n_heads, seq_length, dim_per_head)hidden_states = shape(proj_layer(key_value_states))if past_key_value is not None:if key_value_states is None:# self-attn# (batch_size, n_heads, key_length, dim_per_head)# 注意这里是重点:用串联方式hidden_states = torch.cat([past_key_value, hidden_states], dim=2)elif past_key_value.shape[2] != key_value_states.shape[1]:# checking that the ` sequence_length` of the `past_key_value` is the same as# the provided `key_value_states` to support prefix tuning# cross-attn# (batch_size, n_heads, seq_length, dim_per_head)hidden_states = shape(proj_layer(key_value_states))else:# cross-attnhidden_states = past_key_valuereturn hidden_statesreal_seq_length += past_key_value[0].shape[2] if query_length is None else query_length分别计算query_states、key_states、value_states,用query和key计算attention score,得到score形状为torch.Size([8, 16, 2, 22]),所以输入X可以attend to itself以及prefix。
# hidden_states shape: torch.Size([8, 2, 1024]) # get query statesquery_states = shape(self.q(hidden_states)) # (batch_size, n_heads, seq_length, dim_per_head) # query_states shape: torch.Size([8, 16, 2, 64])# get key/value stateskey_states = project(hidden_states, self.k, key_value_states, past_key_value[0] if past_key_value is not None else None)# key_states shape: torch.Size([8, 16, 22, 64])value_states = project(hidden_states, self.v, key_value_states, past_key_value[1] if past_key_value is not None else None)# value_states shape: torch.Size([8, 16, 22, 64])# compute scores# torch.Size([8, 16, 2, 22])scores = torch.matmul(query_states, key_states.transpose(3, 2)) # equivalent of torch.einsum("bnqd,bnkd->bnqk", query_states, key_states), compatible with onnx op>9接下来就是经典的attention操作了。用attn_weights ([8, 16, 2, 22]) 和value_states ([8, 16, 22, 64])相乘,把22消掉,就是每个输入X的输出了。
# if key and values are already calculated
# we want only the last query position bias
# position_bias.shape: torch.Size([8, 16, 2, 22])scores += position_bias_maskedattn_weights = nn.functional.softmax(scores.float(), dim=-1).type_as(scores) # (batch_size, n_heads, seq_length, key_length)attn_weights = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training) # (batch_size, n_heads, seq_length, key_length)attn_output = unshape(torch.matmul(attn_weights, value_states)) # (batch_size, seq_length, dim) torch.Size([8, 2, 1024])attn_output = self.o(attn_output)present_key_value_state = (key_states, value_states) if (self.is_decoder and use_cache) else Noneoutputs = (attn_output,) + (present_key_value_state,) + (position_bias,)if output_attentions:outputs = outputs + (attn_weights,)return outputs参考
https://huggingface.co/docs/peft/task_guides/seq2seq-prefix-tuning
相关文章:

Prefix-Tuning源码解析
Prefix-Tuning源码解析 Prefix-Tuning在PEFT包中的源码实现 改写自Based on https://github.com/THUDM/P-tuning-v2/blob/main/model/prefix_encoder.py import torch from transformers import PretrainedConfigclass PrefixEncoder(torch.nn.Module):rThe torch.nn model t…...
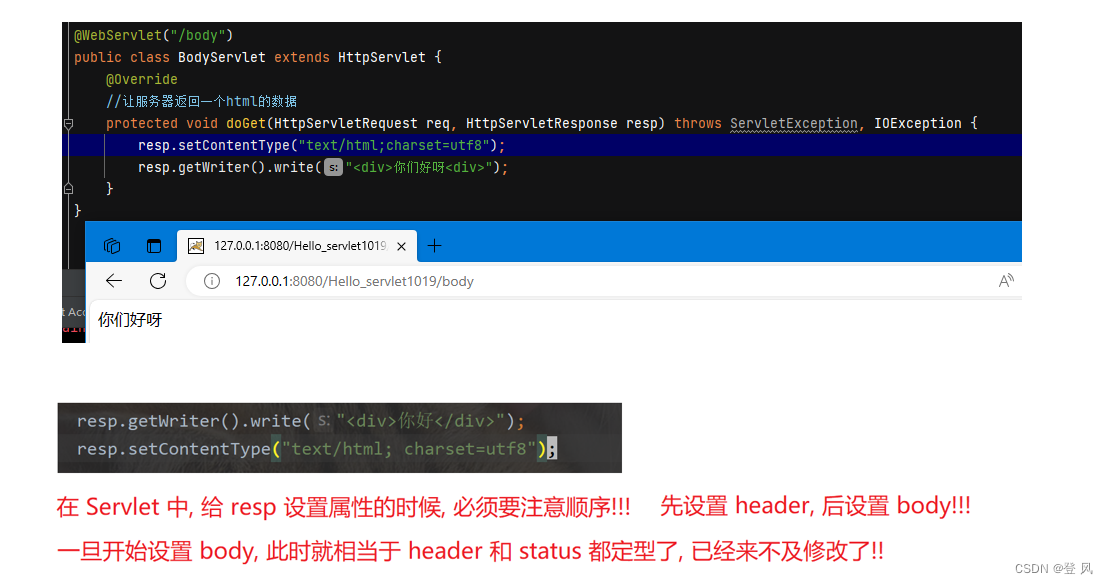
Java EE-servlet API 三种主要的类
上述的代码如下: import javax.servlet.ServletException; import javax.servlet.annotation.WebServlet; import javax.servlet.http.HttpServlet; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; import java.i…...

简单谈谈我参加数据分析省赛的感受与体会
数据分析省赛的感受与体会 概要考试前的感受与体会考试注意事项小结 概要 大数据分析省赛指的是在省级范围内举办的大数据分析竞赛活动。该竞赛旨在鼓励和推动大数据分析领域的技术创新和人才培养,促进大数据技术与应用的深度融合,切实解决实际问题。参…...
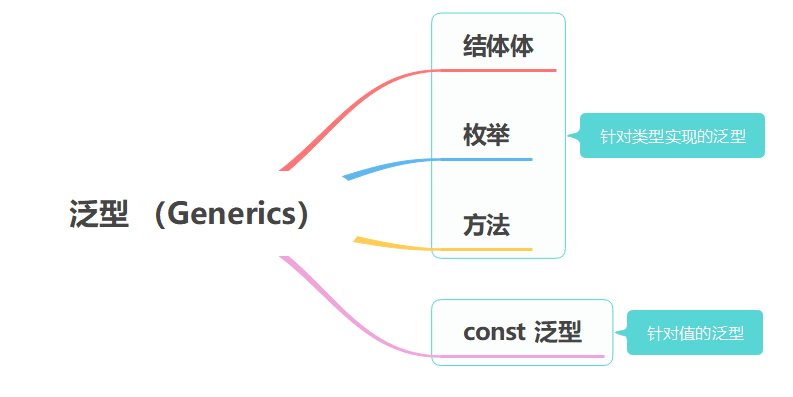
rust学习——泛型 (Generics)
文章目录 泛型 Generics泛型详解结构体中使用泛型枚举中使用泛型方法中使用泛型为具体的泛型类型实现方法 const 泛型(Rust 1.51 版本引入的重要特性)const 泛型表达式 泛型的性能 泛型 Generics Go 语言在 2022 年,就要正式引入泛型…...

【USRP】通信之有线通信
有线通信: 有线通信是指使用物理线路或媒体(例如,铜线、同轴电缆、光纤)进行数据、声音和视频传输的通信方式。由于它依赖于实体传输媒介,有线通信通常具有较高的稳定性和可靠性,并能支持长距离的高带宽通…...

【算法】BFS
BFS广度优先搜索 1. 概念理解 广度优先搜索(BFS)是指,以一个起点(原点、结点、根)为基本点,向其所要搜索的方向扩散,并最终到达目标点的搜索方法。 2. 应用方向 有迷宫问题、层序遍历等应用。 3. 迷宫问题 以迷宫问题为例。 当想要从左…...
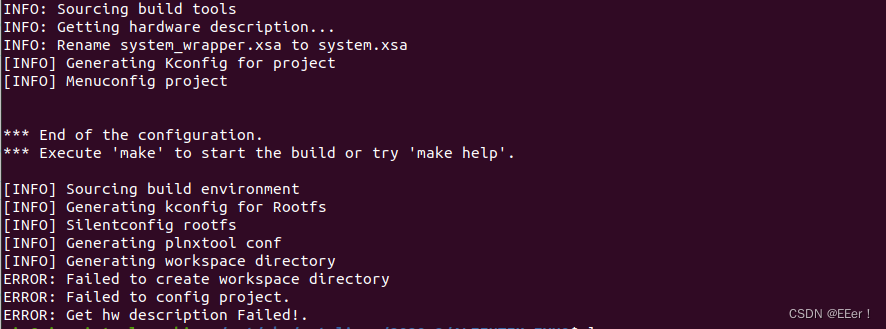
ZYNQ7020开发(二):zynq linux系统编译
文章目录 一、编译前准备二、SDK编译三、编译步骤总结四、问题汇总 一、编译前准备 1.设置环境变量 source /opt/pkg/petalinux/2020.2/settings.sh/opt/pkg/petalinux/2020.2是上一节petalinux的安装目录 2.创建 petalinux 工程 进入petalinux安装目录(例如:/op…...

Kafka 自动配置部署信息的脚本记录
自动配置 Kafka 整理服务器内容时,发现一个测试 Kafka 的的一个脚本,它可以自动部署 Kafka ,指定三个参数,完成 Kafka 的配置过程。 basePath$1 brokerId$2 zookeeperConnect$3 localIpifconfig |grep inet| awk {print $2}| he…...

数据分析入门
B站:01第一课 数据分析岗位职责和数据分析师_哔哩哔哩_bilibili 一、岗位:数据分析师 Q1 数据分析师在公司做什么工作? 数据来源于公司核心业务,通过监测业务健康度来确定业务的健康状况; 通过对用户精细化分析&am…...
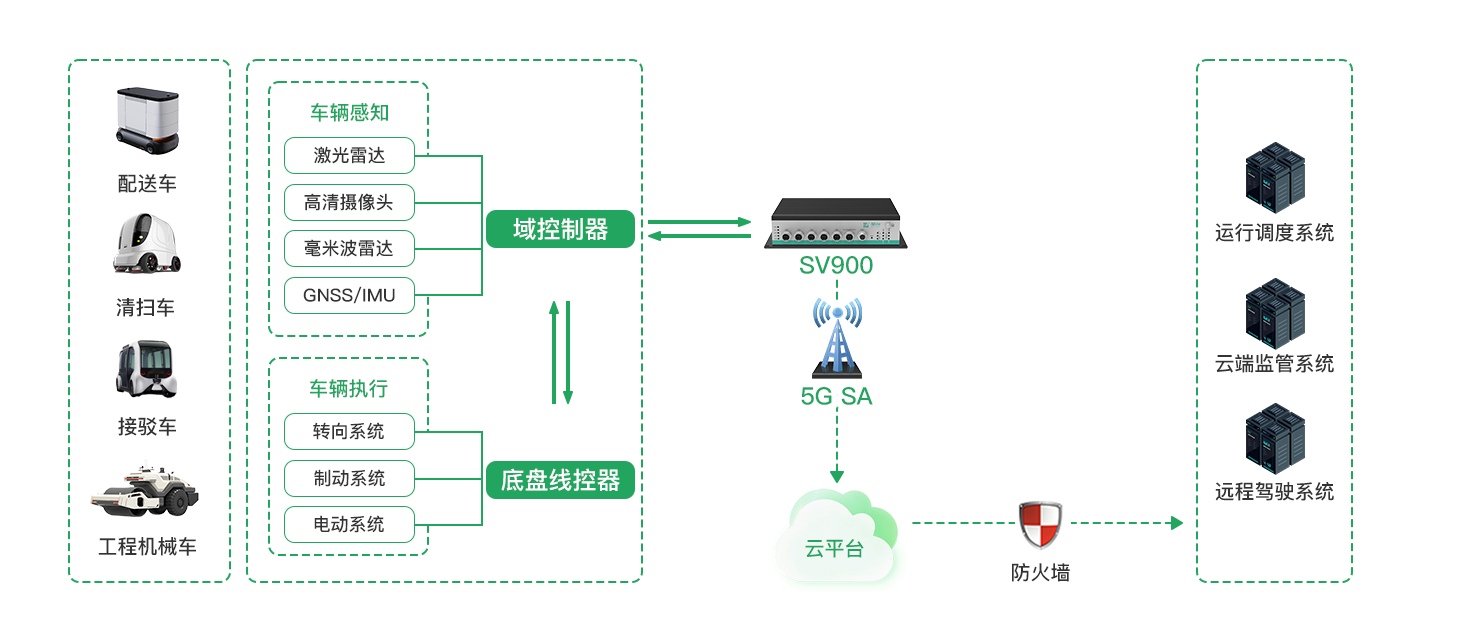
车载网关通信能力解析——SV900-5G车载网关推荐
随着车联网的发展,各类车载设备对车载网关的需求日益增长。车载网关作为车与车、车与路、车与云之间连接的关键设备,其通信能力直接影响整个系统的性能。本文将详细解析车载网关的通信能力,并推荐性价比高的SV900-5G车载网关。 链接直达:https://www.key-iot.com/i…...

服务器中了mkp勒索病毒怎么处理,mkp勒索病毒解密,数据恢复
10月份以来,云天数据恢复中心陆续接到很多企业的求助,企业的服务器遭到了mkp勒索病毒攻击,导致企业的服务器数据库被加密,严重影响了企业工作,通过这一波mkp勒索病毒的攻击,云天数据恢复工程师为大家总结了…...

义乌再次位列第一档!2022年跨境电商综试区评估结果揭晓!
义乌跨境电商综试区捷报频传,在商务部公布的“2022年跨境电子商务综合试验区评估”结果中,中国(义乌)跨境电子商务综合试验区(以下简称:“跨境综试区”)评估结果为成效明显,综合排名…...
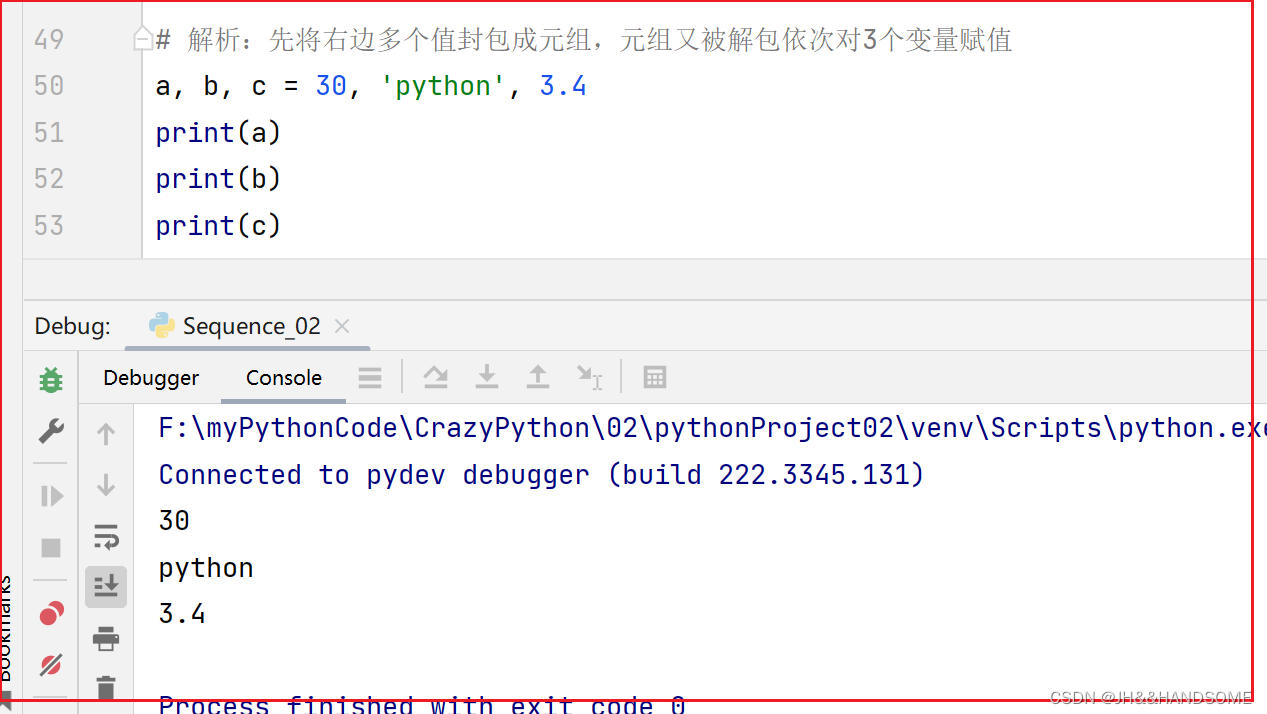
07、Python -- 序列相关函数与封包解包
目录 使用函数字符串也能比较大小序列封包序列解包多变量同时赋值 最大值、最小值、长度 序列解包与封包 使用函数 len()、max()、min() 函数可获取元组、列表的长度、最大值和最小值。 字符串也能比较大小 字符串比较大小时,将会依次按字符串中每个字符对应的编…...
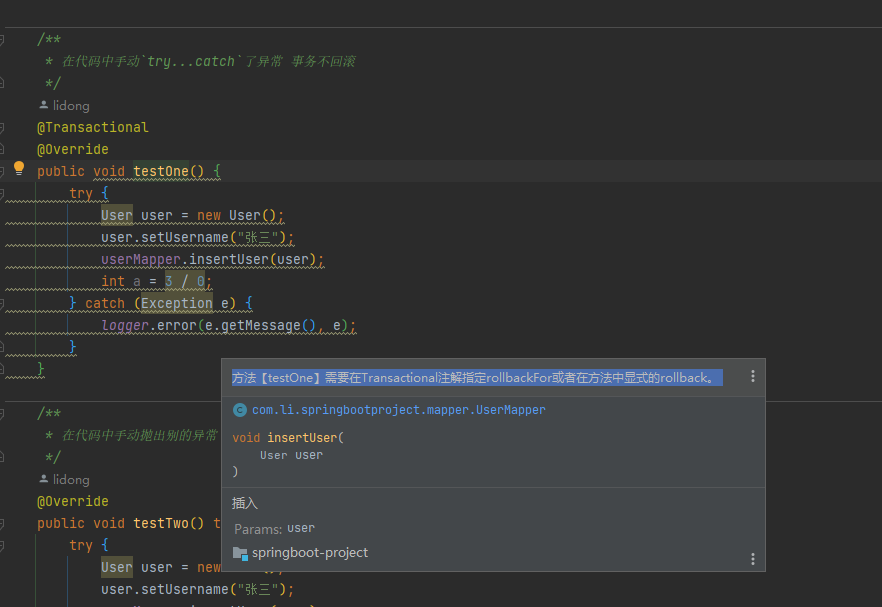
# Spring 事务失效场景
Spring 事务失效场景 文章目录 Spring 事务失效场景前言事务不生效未开启事务事务方法未被Spring管理访问权限问题基于接口的代理源码解读 CGLIB代理 方法用final修饰同一类中的方法调用多线程调用不支持事务 事务不回滚设置错误的事务传播机制捕获了异常手动抛了别的异常自定义…...
【java】A卷+B卷)
华为OD 停车场车辆统计(100分)【java】A卷+B卷
华为OD统一考试A卷+B卷 新题库说明 你收到的链接上面会标注A卷还是B卷。目前大部分收到的都是B卷。 B卷对应20022部分考题以及新出的题目,A卷对应的是新出的题目。 我将持续更新最新题目 获取更多免费题目可前往夸克网盘下载,请点击以下链接进入: 我用夸克网盘分享了「华为O…...

出差学小白知识No6:LD_PRELOAD变量路径不对找不到库文件
交叉编译的时候出现以下问题,显示LD_PRELOAD变量找不到路劲 首先先查看一下LD_PRELOAD的路径:echo $LD_PRELOAD 如果输出一大串,那么先进行清空:unset LD_PRELOAD 重新给LD_PRELOAD进行赋值他的路径和库文件: expor…...

利用dns协议发起ddos反射攻击
利用DNS服务器发起反射型DDOS,攻击带宽 基本思路: 1、利用any类型的dns查询,可完成发送少量请求数据,获得大量返回数据。 2、将原请求地址改为受害者地址,则dns会向受害者返回大量数据,占用带宽 警告&…...

Tcl基础知识
一、概述 Tcl 语言的全称 Tool Command Language,即工具命令语言。这种需要在 EDA 工具中使用的相当之多,或者说几乎每个 EDA 工具都支持 Tcl 语言,并将它作为自己的命令shell。 静态时序分析中多用的 Synopsys Tcl 语言,…...

Go中的编程模式:Pipeline
本文章我们重点来介绍一下 Go 编程中的 Pipeline 模式。用过 Linux 命令行的人都不会陌生,它是一种把各种命令拼接起来完成一个更强功能的技术方法,在C语言中也有pipe管道的叫法,具体的有兴趣的同学也可以去了解。 现在的流式处理、函数式编程、应用网关对微服务进行简单的…...
2023最新pytorch安装教程,简单易懂,面向初学者(Anaconda+GPU)
一、前言 目前是2023.1.27,鉴于本人安装过程中踩得坑,安装之前我先给即将安装pytorch的各位提个醒,有以下几点需要注意 1.判断自己电脑是否有GPU 注意这点很重要,本教程面向有NVIDA显卡的电脑,如果你的电脑没有GPU或者使用AMD显…...

打字不如说话,说话不如截图——AI 代码助手的多模态输入实践仝
整体排查思路 我们的目标是验证以下三个环节是否正常: 登录成功时:服务器是否正确生成了Session并返回了包含正确 JSESSIONID的Cookie给浏览器。 浏览器端:浏览器是否成功接收并存储了该Cookie。 后续请求:浏览器在执行查询等操作…...

构建具备批判性思维的AI Agent
构建具备批判性思维的AI Agent:从理论到生产级RAG反思循环系统 副标题:拆解GPT-4o、Claude Opus的「逻辑过滤」核心,用LangChain AutoGen Python落地高准确率Agent第一部分:引言与基础 1. 引人注目的标题 (本文已单独…...

Avian Physics vs 其他物理引擎:为什么选择基于XPBD的解决方案 [特殊字符]
Avian Physics vs 其他物理引擎:为什么选择基于XPBD的解决方案 🚀 【免费下载链接】avian ECS-driven 2D and 3D physics engine for the Bevy game engine. 项目地址: https://gitcode.com/gh_mirrors/be/avian 在游戏开发的世界中,物…...

暗黑3技能连点器终极指南:三步解决重复操作难题
暗黑3技能连点器终极指南:三步解决重复操作难题 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 还在为暗黑3中重复的技能按键感到疲惫吗&…...

燃料电池热管理控制,接受定制,单循环,双循环定制,效率
代码逻辑分析 数据构建:由于没有原始数据,代码中通过分段函数模拟了图中的趋势: 0-600s:保持为 0。 600-700s:出现一个向下的尖峰(约 -0.4),随后迅速反弹至 0.2。 700-1100s…...

RAGFlow服务报错排查:如何快速解决429 Too Many Requests错误
RAGFlow服务429错误全链路诊断与高可用架构设计实战 第一次在RAGFlow日志里看到"HTTP 429 Too Many Requests"时,我正端着咖啡准备验收新上线的智能文档分析系统。监控大屏突然变红的那一刻,整个运维团队的手指都悬在了键盘上方——这个看似简…...

CP2K-2024.2 编译实战:在 Ubuntu 22.04 上构建高性能量子化学计算环境
1. 环境准备:从零搭建量子化学计算平台 量子化学计算是材料模拟和药物设计的重要工具,而CP2K作为一款开源的高性能计算软件,在学术界和工业界都有广泛应用。最近我在实验室的Ubuntu 22.04服务器上成功部署了最新版CP2K-2024.2,整个…...

3步掌握微信数据解密:本地安全解密方案的终极指南
3步掌握微信数据解密:本地安全解密方案的终极指南 【免费下载链接】WechatDecrypt 微信消息解密工具 项目地址: https://gitcode.com/gh_mirrors/we/WechatDecrypt 当微信聊天记录被加密存储在数据库中,你是否曾感到束手无策?那些珍贵…...
)
【绝密工作流】R 4.5下TCGA批量下载→准确定量→生存分析→可视化交付(全程无GUI,纯R脚本,含NCBI API密钥安全注入方案)
第一章:R 4.5基因测序数据分析教程概览R 4.5 版本引入了对 Bioconductor 3.19 的原生兼容性增强、更高效的稀疏矩阵处理能力,以及针对单细胞RNA-seq和ChIP-seq数据的底层内存优化。本教程面向具备基础R编程经验的生物信息学实践者,聚焦于从原…...

【书生·浦语】internlm2-chat-1.8b在医疗健康领域应用:症状自查与报告解读
【书生浦语】internlm2-chat-1.8b在医疗健康领域应用:症状自查与报告解读 1. 医疗AI助手带来的改变 想象一下这样的场景:深夜突然感觉身体不适,但又不想半夜跑急诊;或者拿到一份体检报告,看着一堆专业术语和指标数值…...