1.写一个算法模型以及python算法工程化步骤
生成一个 PT(Perceptual Tokenizer)模型的步骤如下:
-
准备数据集:首先,你需要准备一个用于训练 PT 模型的数据集。这可以是一个包含大量文本数据的语料库。
-
数据预处理:对数据进行预处理以准备训练。这可能包括文本清洗、分词、去除停用词等操作。
-
构建词汇表:根据预处理后的数据,构建一个词汇表。词汇表应该包含所有在训练数据中出现的单词,并为每个单词分配一个唯一的标识符。
-
构建输入输出对:将训练数据转换为模型的输入输出对。每个输入是一个文本序列,每个输出是该序列中下一个单词的标识符。
-
定义模型结构:使用深度学习框架(如TensorFlow或PyTorch)定义 PT 模型的结构。PT 模型通常由嵌入层、循环神经网络(如LSTM或GRU)和全连接层组成。
-
编写训练代码:使用选择的深度学习框架编写训练代码。这包括定义损失函数、选择优化器,并编写迭代训练过程。
-
训练模型:使用准备好的训练数据和编写好的训练代码来训练 PT 模型。通过多次迭代优化模型参数,使其能够更好地预测下一个单词。
-
保存模型:在完成训练后,将最终得到的 PT 模型保存到磁盘上,以便后续使用。
以下是一个简单示例代码,演示了如何使用Python和PyTorch来构建和训练 PT 模型:
import torch
import torch.nn as nn
import torch.optim as optim# 定义 PT 模型结构
class PerceptualTokenizer(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim):super(PerceptualTokenizer, self).__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim)self.rnn = nn.LSTM(embedding_dim, hidden_dim)self.fc = nn.Linear(hidden_dim, vocab_size)def forward(self, input):embedded = self.embedding(input)output, _ = self.rnn(embedded)output = self.fc(output)return output# 准备数据集和预处理# 构建词汇表# 构建输入输出对# 定义超参数
vocab_size = len(vocab) # 假设已经有了vocab列表
embedding_dim = 100
hidden_dim = 256
learning_rate = 0.001
num_epochs = 10# 创建模型实例
model = PerceptualTokenizer(vocab_size, embedding_dim, hidden_dim)# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)# 开始训练过程
for epoch in range(num_epochs):for input, target in training_data:optimizer.zero_grad()# 前向传播计算输出结果output = model(input)# 计算损失函数值并进行反向传播及参数更新loss = criterion(output.view(-1, vocab_size), target.view(-1))loss.backward()optimizer.step()print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item()))# 保存模型到磁盘上
torch.save(model.state_dict(), 'pt_model.pt')
请注意,以上代码仅为示例,并未完整展示所有步骤和详尽配置。实际应用中可能需要根据具体需求进行适当修改和调整。
Python算法工程化的详细代码步骤,麻烦写出来一定要详细
下面是一个详细的Python算法工程化的代码步骤:
-
创建项目目录结构:创建一个新的文件夹作为项目根目录,并在其中创建子文件夹来组织代码、数据和其他资源。
-
初始化版本控制:使用Git或其他版本控制系统初始化项目仓库,以便跟踪代码的变化。
-
创建虚拟环境:使用虚拟环境工具(如venv或conda)创建一个独立的Python环境,以隔离项目所需的依赖项。
-
安装依赖项:在虚拟环境中安装项目所需的所有依赖项。可以使用requirements.txt文件来记录依赖项列表,并使用pip或conda进行安装。
-
编写算法代码:在项目根目录下创建一个名为"src"的子文件夹,并在其中编写算法代码。按照模块化原则,将代码分成多个模块或脚本,每个模块负责不同的功能。
-
添加单元测试:在"src"目录下创建一个名为"tests"的子文件夹,并编写单元测试代码来验证算法的正确性。可以使用Python内置的unittest模块或第三方库(如pytest)来编写和运行测试。
-
添加文档注释:为算法代码中的函数、类和模块添加详细的文档注释。这些注释应该描述函数/类的输入、输出、功能和用法等信息,以方便其他开发人员理解和使用你的代码。
-
添加日志记录:使用Python内置logging模块或第三方库(如loguru)添加日志记录功能。通过适当地添加日志语句,可以帮助调试和追踪算法运行时发生的问题。
-
编写配置文件:创建一个名为config.py(或其他合适名称)的配置文件,在其中定义算法所需参数和设置。这样可以使得参数可配置化,方便在不同环境中进行调整。
-
添加命令行接口(CLI)支持:使用argparse或click等库,在主程序中添加命令行参数解析功能。这样用户可以通过命令行传递参数并运行你的算法。
-
编写示例脚本:在项目根目录下创建一个名为"examples"(或其他合适名称)的子文件夹,并编写示例脚本来演示如何使用你实现的算法。这些示例脚本应该包含详细注释以指导用户正确地运行和理解你提供的功能。
-
编写README文档:在项目根目录下创建一个名为README.md(或其他合适名称)的Markdown格式文档,用于描述项目背景、安装步骤、用法示例、贡献指南等信息。这是向其他开发人员介绍你项目最重要且常见方式之一。
-
构建持续集成/部署流水线(可选):如果需要自动化构建、测试和部署过程,可以配置持续集成/部署工具(如Jenkins、Travis CI或GitHub Actions),以确保每次提交都能自动进行构建和测试。
-
发布到版本控制系统:将整个项目提交到版本控制系统,并确保包含所有必要文件(源码、数据、配置等)。这样可以方便团队协作和追溯历史更改记录。
以上是一个完整而详细的Python算法工程化步骤指南。请注意,在实际应用中可能会有一些特定于项目需求和团队规范等因素需要考虑调整。
PyTorch
PyTorch 是一个基于 Python 的开源机器学习框架,它提供了丰富的工具和库,用于构建和训练深度学习模型。PyTorch 的设计目标是提供灵活性和易用性,使得研究人员和开发者能够快速地实现各种深度学习算法。
PyTorch 的主要特点包括:
-
动态计算图:PyTorch 使用动态计算图的方式来定义和执行计算图。这意味着在编写代码时可以使用常规的 Python 控制流语句(如循环、条件语句等),从而更加灵活地构建模型。
-
强大的自动求导:PyTorch 提供了自动求导功能,可以自动计算张量上的梯度。这使得反向传播算法变得非常简单,可以轻松地进行模型训练和参数优化。
-
大量预定义模型和损失函数:PyTorch 提供了丰富的预定义模型架构(如卷积神经网络、循环神经网络等)和损失函数(如交叉熵损失、均方误差等),方便用户快速构建常见的深度学习模型。
-
支持 GPU 加速:PyTorch 可以利用 GPU 进行计算加速,通过将张量数据移动到 GPU 上进行并行计算,大幅提高了训练和推理的效率。
-
丰富的生态系统:PyTorch 拥有庞大而活跃的社区,提供了许多扩展库和工具,如 torchvision(用于计算机视觉任务)、torchtext(用于文本处理任务)等。这些库可以帮助用户更方便地处理各种数据类型和任务。
由于其易用性、灵活性和强大的功能,PyTorch 在学术界和工业界都得到广泛应用。它被广泛用于深度学习研究、原型开发、生产部署等场景,并成为了当今最受欢迎的深度学习框架之一。
什么是模型量化、蒸馏、剪枝
模型量化(Model Quantization)是指将深度学习模型中的浮点数参数和操作转换为更低精度的表示形式,以减少模型的存储空间和计算量。常见的量化方法包括权重量化和激活量化,可以将浮点数参数转换为8位整数或更低位数的表示形式。
蒸馏(Knowledge Distillation)是一种知识传递技术,通过训练一个较大、复杂的模型(称为教师模型)来指导训练一个较小、简化的模型(称为学生模型)。教师模型可以提供更丰富的知识和预测能力,而学生模型则可以在减少计算资源和存储空间开销的同时保持相对较高的性能。
剪枝(Model Pruning)是一种减少深度学习模型参数数量和计算复杂度的方法。通过删除冗余、不重要或冗余连接等方式,剪枝可以显著减少模型中参数数量,并降低推理时所需的计算量。剪枝方法通常基于权重重要性评估或结构特征进行选择。
这些技术都旨在优化深度学习模型,使其更加轻巧、高效,并适应于资源受限或实时应用场景。它们在实践中被广泛应用,以提高深度学习模型在移动设备、嵌入式系统和边缘设备上的部署效果。
怎么生成一个人脸pt模型,麻烦写一下详细的步骤,并写出详细的代码?
生成人脸的 PT 模型是一个复杂的任务,需要使用深度学习和计算机视觉技术。下面是一个简化的步骤和示例代码,用于生成人脸 PT 模型:
步骤 1: 数据收集
收集大量的人脸图像数据作为训练集。可以使用公开的人脸数据集,如CelebA、LFW等,或者自己收集并标注数据。
步骤 2: 数据预处理
对收集到的人脸图像进行预处理,包括裁剪、缩放、灰度化等操作。确保所有图像具有相同的尺寸和格式。
步骤 3: 构建模型架构
选择适合生成人脸的模型架构,如基于生成对抗网络(GAN)的模型。可以使用深度学习框架如PyTorch来构建模型。
以下是一个简单的示例代码段,用于构建一个基本的生成对抗网络(GAN)模型:
import torch
import torch.nn as nn# 定义生成器模型
class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()# 定义网络层结构def forward(self, x):# 前向传播过程# 定义判别器模型
class Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()# 定义网络层结构def forward(self, x):# 前向传播过程# 创建生成器和判别器实例
generator = Generator()
discriminator = Discriminator()# 定义损失函数和优化器
criterion = nn.BCELoss()
optimizer_G = torch.optim.Adam(generator.parameters(), lr=0.0002)
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=0.0002)# 训练模型
for epoch in range(num_epochs):for i, (images, _) in enumerate(data_loader):# 训练判别器# 训练生成器步骤 4: 模型训练与优化
使用准备好的训练数据对模型进行训练,并通过反向传播算法优化模型参数。在训练过程中,交替地训练生成器和判别器,并根据损失函数进行优化。
步骤 5: 模型评估与调优
评估训练好的模型性能,并根据需要进行调优。可以通过定量指标(如生成图像质量评估)或主观评估来评估结果。
请注意,以上只是一个简单示例,并不能完整涵盖所有实现细节。实际上,生成高质量人脸图像是一个非常复杂且需要大量计算资源和时间的任务。如果你想要更详细和完整的代码实现,请参考相关研究论文或开源项目,并根据具体需求进行调整和扩展。
怎么生成一个pt模型,麻烦写一下详细的步骤?
要生成一个PT模型,您需要执行以下步骤:
- 导入PyTorch库:在开始生成模型之前,您需要导入PyTorch库。您可以使用以下代码导入PyTorch:
import torch
- 定义模型结构:在PyTorch中,模型是由多个层组成的。您需要定义模型的层结构。例如,您可以定义一个简单的全连接神经网络,如下所示:
class Net(torch.nn.Module):def __init__(self):super(Net, self).__init__()self.fc1 = torch.nn.Linear(in_features=784, out_features=128)self.fc2 = torch.nn.Linear(in_features=128, out_features=64)self.fc3 = torch.nn.Linear(in_features=64, out_features=10)def forward(self, x):x = x.view(-1, 784)x = torch.nn.functional.relu(self.fc1(x))x = torch.nn.functional.relu(self.fc2(x))x = self.fc3(x)return x
- 实例化模型:在定义了模型结构之后,您需要实例化模型并设置参数。例如,您可以使用以下代码实例化上面定义的Net类:
model = Net()
- 定义损失函数和优化器:在训练模型之前,您需要定义损失函数和优化器。例如,您可以使用以下代码定义损失函数和优化器:
criterion = torch.nn.CrossEntropyLoss() # 用于分类问题的损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # 定义优化器,这里使用的是随机梯度下降法,学习率为0.01
- 训练模型:在定义了模型、损失函数和优化器之后,您可以使用训练数据集来训练模型。例如,您可以使用以下代码进行训练:
num_epochs = 10 # 训练轮数
for epoch in range(num_epochs):for data in dataloader: # dataloader是加载训练数据集的迭代器inputs, labels = data # 获取输入数据和对应的标签inputs, labels = inputs.to(device), labels.to(device) # 将输入数据和标签移到GPU上optimizer.zero_grad() # 清空之前的梯度信息outputs = model(inputs) # 前向传播,得到输出结果loss = criterion(outputs, labels) # 计算损失函数值loss.backward() # 反向传播,计算梯度信息optimizer.step() # 根据梯度信息更新权重参数
Python算法工程化的详细代码步骤,麻烦写代码出来一定要详细
算法工程化是将算法转化为可重复使用的、可维护的、可扩展的程序的过程。在Python中,实现算法工程化的详细步骤如下:
- 确定需求和问题建模:首先需要明确问题的需求和目标,然后使用数学模型或算法来描述和建模这个问题。
- 选择合适的算法:基于问题的需求和模型的性质,选择一个适合的算法来解决这个问题。
- 实现算法:使用Python编写算法的详细代码,可以通过调试和优化来提高算法的效率和准确性。
- 测试算法:使用测试数据来验证算法的正确性和性能,包括边界条件和异常情况。
- 优化算法:根据测试结果,对算法进行优化和改进,以提高算法的性能和准确性。
- 集成算法:将算法集成到应用程序或系统中,并确保其可重复使用和可维护。
- 文档化算法:编写算法的文档,包括算法的输入、输出、性能和注意事项等。
下面是一个简单的例子,展示如何实现一个二分查找算法的工程化过程:
- 确定需求和问题建模:二分查找是一种高效的查找算法,适用于有序的数组。它的时间复杂度为O(log n)。我们可以使用数学模型描述二分查找的过程,例如:
def binary_search(arr, target):left, right = 0, len(arr) - 1while left <= right:mid = (left + right) // 2if arr[mid] == target:return midelif arr[mid] < target:left = mid + 1else:right = mid - 1return -1
- 选择合适的算法:对于有序的数组,二分查找是一个非常高效的查找算法。
- 实现算法:根据数学模型,我们可以使用Python编写二分查找的代码。上面的代码就是一个简单的实现。
- 测试算法:我们需要测试算法的正确性和性能。可以使用一些测试数据来进行测试,例如:
arr = [1, 3, 5, 7, 9]
print(binary_search(arr, 3)) # 输出: 1
print(binary_search(arr, -1)) # 输出: -1
- 优化算法:根据测试结果,我们可以对算法进行优化和改进。例如,我们可以添加一些异常处理来提高代码的健壮性。
- 集成算法:我们可以将二分查找算法集成到更大的应用程序或系统中。例如,我们可以将其作为一个函数提供给其他程序使用。
- 文档化算法:我们可以编写文档来描述二分查找算法的输入、输出、性能和注意事项等。例如:二分查找算法接受一个有序的数组和一个目标值作为输入,返回目标值在数组中的索引。如果目标值不在数组中,则返回-1。算法的时间复杂度为O(log n)。
怎么生成一个人脸pt模型,麻烦写一下详细的步骤,并写出详细的代码?
生成一个人脸PT模型需要进行一系列的步骤,包括采集人脸数据、构建模型结构、训练模型等。下面是一个详细的步骤和代码示例:
步骤:
- 采集人脸数据:首先需要采集大量的人脸数据,可以使用公共数据集或者自己采集数据。在采集数据时需要注意以下几点:
- 采集环境的光线要均匀,避免出现阴影和反光;
- 采集的人脸要正面对着相机,不要侧脸或者低头;
- 采集的图像分辨率要高,以保证模型的精度。
- 预处理人脸数据:对采集的人脸数据进行预处理,包括人脸检测、人脸对齐、人脸归一化等。可以使用现有的开源库,例如dlib和OpenCV等。
- 构建模型结构:根据需要选择合适的深度学习模型,例如CNN、RNN、GAN等。在构建模型时需要考虑以下几点:
- 模型的结构要简单,不要过于复杂,以避免过拟合和欠拟合等问题;
- 模型的参数要可调,以便在训练过程中不断优化模型参数。
- 训练模型:使用采集的人脸数据和预处理后的数据来训练模型。在训练模型时需要考虑以下几点:
- 训练数据的划分要合理,可以将数据集分为训练集、验证集和测试集;
- 训练的超参数要合理,例如学习率、批量大小、迭代次数等;
- 可以使用一些正则化技术来防止过拟合,例如Dropout、L2正则化等。
- 测试模型:使用测试集来测试模型的性能和精度。可以使用一些指标来评估模型的性能,例如准确率、召回率、F1分数等。
- 优化模型:根据测试结果对模型进行优化和改进。可以尝试不同的优化策略,例如改变网络结构、增加数据集大小等。
- 应用模型:将训练好的模型应用到实际场景中,例如人脸识别、人脸比对等。
代码示例:
下面是一个使用PyTorch库实现的人脸PT模型的代码示例:
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from PIL import Image
from facenet_pytorch import MTCNN, InceptionResnetV1# 人脸检测和对齐
mtcnn = MTCNN()
img = Image.open("face.jpg")
boxes, probs, points = mtcnn.detect(img, landmarks=True)# 数据预处理
transform = transforms.Compose([transforms.ToTensor()])
img = transform(img)
img = img.unsqueeze(0) # [batch_size, channels, height, width]# 构建模型结构
model = InceptionResnetV1(pretrained='vggface2').eval()# 输入数据到模型中并得到预测结果
with torch.no_grad():predictions = model(img)_, predicted_idx = torch.max(predictions, 1)
这段代码看起来是一个使用PyTorch和facenet_pytorch库进行人脸识别的程序。下面是代码的简要说明和执行步骤:
-
导入必要的库:
torch:PyTorch库,用于构建和运行神经网络模型。torch.nn:PyTorch的神经网络模块,用于定义和训练神经网络模型。torchvision.transforms:用于对图像进行预处理和转换。Image:Python Imaging Library (PIL)中的图像处理模块,用于打开、处理和变换图像。MTCNN:facenet_pytorch库中的人脸检测和对齐模型,用于从图像中检测和定位人脸。InceptionResnetV1:facenet_pytorch库中的预训练模型,用于人脸识别。
-
使用MTCNN模型进行人脸检测和对齐:
- 初始化MTCNN模型。
- 打开名为"face.jpg"的图像文件。
- 使用MTCNN模型的
detect方法检测图像中的人脸,并返回人脸的位置、概率和关键点信息。
-
数据预处理:
- 创建一个数据预处理管道,使用
transforms.Compose将图像转换为张量。 - 对图像进行预处理,将其转换为PyTorch张量。
- 通过使用
unsqueeze方法,将图像张量增加一个维度,以适应模型输入的形状。
- 创建一个数据预处理管道,使用
-
构建模型结构:
- 使用
InceptionResnetV1模型,并加载预训练的’vggface2’权重。 - 将模型设置为评估模式(
eval),以便在推理模式下使用。
- 使用
-
输入数据到模型中并得到预测结果:
- 使用
torch.no_grad()上下文管理器,关闭梯度计算,以减少内存使用和计算负担。 - 将预处理后的图像数据输入到模型中。
- 使用
torch.max方法获取模型输出的最大值,并返回该最大值的索引作为预测的类别。
- 使用
要执行此代码,您需要满足以下条件:
- 安装PyTorch库:您可以通过pip或conda等包管理工具安装PyTorch。例如,使用pip安装:
pip install torch torchvision. - 安装facenet_pytorch库:您可以通过克隆项目仓库或使用pip安装facenet_pytorch库。例如,使用pip安装:
pip install facenet-pytorch. - 确保您的环境中存在名为"face.jpg"的图像文件,或者您可以替换代码中的图像文件路径为您要使用的图像文件路径。
- 在执行代码之前,请确保已经正确安装并导入了所有必要的库。
请注意,此代码示例假定您已经安装了必要的库并具备适当的图像文件。如果您遇到任何问题或错误,请参考相关库的文档和示例以获取更多帮助。
相关文章:

1.写一个算法模型以及python算法工程化步骤
生成一个 PT(Perceptual Tokenizer)模型的步骤如下: 准备数据集:首先,你需要准备一个用于训练 PT 模型的数据集。这可以是一个包含大量文本数据的语料库。 数据预处理:对数据进行预处理以准备训练。这可能…...

物联网AI MicroPython传感器学习 之 GC7219点阵屏驱动模块
学物联网,来万物简单IoT物联网!! 一、产品简介 LED-8 * 32点阵屏显示板由 4 块单色 8x8 共阴红色点阵单元组成,通过 SPI 菊花链模式将多块显示屏连接后可以组成更大的分辨率显示屏幕,任意组合分辨率。可用于简单仪表显…...
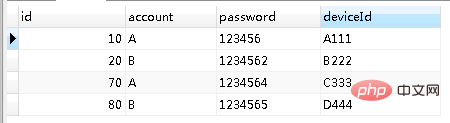
MySQL中查询重复字段的方法和步骤是怎样
示例 accountinfo 表数据如下: 场景一 单个字段重复数据查找 & 去重 我们要把上面这个表中 单个字段 account字段相同的数据找出来。 思路 分三步 简述: 第一步 要找出重复数据,我们首先想到的就是,既然是重复,…...
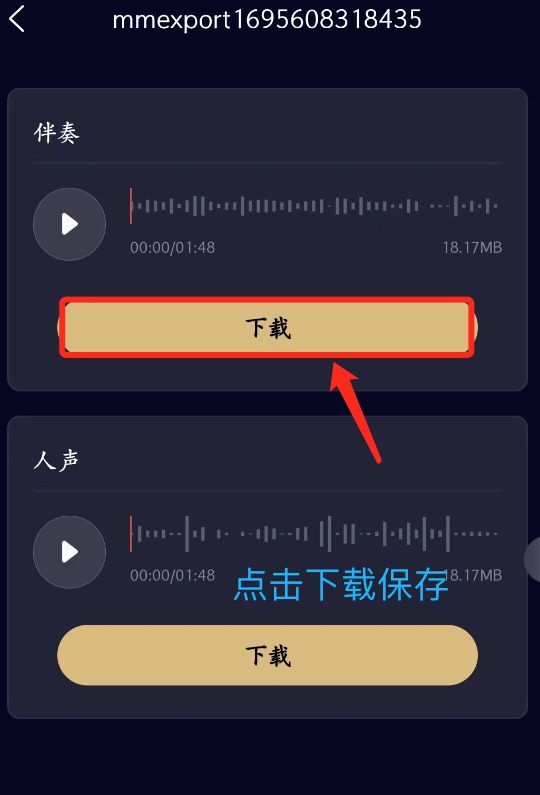
怎样才能去除视频中的背景音乐,保留人声?
做视频剪辑,二次创作的朋友,需要去除视频中的背景音乐,保留人声;或者去除人声,保留背景音乐。如果请身边做视频的朋友帮忙,可有时不能沟通到位,完成后的效果并不是很理想,就很尴尬了…...
计算机思维导论)
【C语言程序设计】--C语言(一)计算机思维导论
控制台输出中文乱码问题解决: ref:https://blog.csdn.net/ymzhu385/article/details/121797080 基本数据类型 我们的程序离不开数据,比如我们需要保存一个数字或是字母,这时候这些东西就是作为数据进行保存,不过不同的数据他们的…...

三、git信息泄露
一、git信息泄露 解释:Git信息泄露是指通过公开或错误地配置版本控制系统Git,导致敏感数据(例如API密钥、数据库密码、个人信息等)被泄露到公共代码仓库或其他未授权的访问者手中。通俗来说,在公网暴露类似http://127…...

第 368 场 LeetCode 周赛题解
A 元素和最小的山形三元组 I 前后缀操作:求出前后缀上的最小值数组,然后枚举 j j j class Solution { public:int minimumSum(vector<int> &nums) {int n nums.size();vector<int> l(n), r(n);//l[i]min{nums[0],...,nums[i]}, r[i]mi…...

Qt中QFile、QByteArray QDataStream和QTextStream区别及示例
在Qt中,QFile、QByteArray、QDataStream和QTextStream是常用的文件和数据处理类。 主要功能和区别 QFile: QFile是用于读写文本和二进制文件以及资源的I/O设备。可以单独使用QFile,或者更方便地与QTextStream或QDataStream一起使用。 通常在…...

【操作系统】32进制小数转16进制
要将32进制的小数转换为16进制,可以按照以下步骤进行: 将32进制小数转换为10进制。可以使用上述提到的方法,将32进制小数转换为对应的10进制数。 将10进制数转换为16进制。使用常规的方法将10进制数转换为16进制数。可以将10进制数不断除以1…...
C#实现数据导出任一Word图表的通用呈现方法及一些体会
疲惫的修改 应人才测评产品的需求,导出测评报告是其中一个重要的环节,报告的文件类型也多种多样,其中WORD输出也扮演了一个重要的角色。 实现方法比较简单,结合分析结果数据,通过WORD模板文件进行替换输出。在实现的…...

2023-10 字节跳动面试整个过程 golang营销服务开发岗位
面试整个过程大约1个小时回答的中规中矩吧 很多问题回答的不具体 难受死我了非常简单的算法题下面列出来了面试步骤这里面有一点就是面试官本来想问问我数据结构这一块的问题 但是我说不太熟悉 他就没问了 1. 简单介绍个人信息 略2. 介绍简历上的项目 略3. 什么是分布式事务 主…...

Java类名的命名规范
Java中的类名必须以字母或者下划线开头,不能以数字开头。 类名的每个单词的首字母必须大写,这被称为帕斯卡命名法。 此外,类名不能使用关键字或保留字,不能使用数字除了_和$之外的任何符号,中间不能添加空格。 如果…...
【c++Leetcode】141. Linked List Cycle
问题入口 思想:Floyds Tortoise and Hare 这个算法简单来说就是设置一个慢指针(一次移动一个位置)和一个快指针(一次移动两个位置)。在遍历过程中,如果慢指针和快指针都指向同一个元素,证明环…...
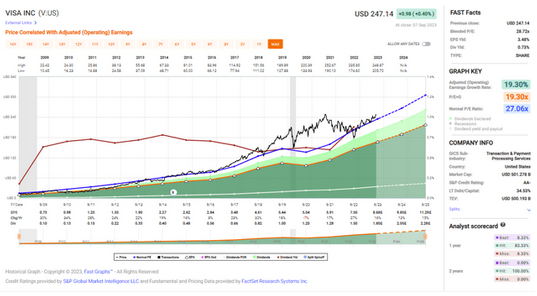
Visa股票仍然值得投资
来源:猛兽财经 作者:猛兽财经 总结: (1)尽管Visa(V)的估值高于市场平均水平,但仍值得买入。 (2)Visa拥有强劲的基本面,销售额和每股收益一直在稳定增长,股息…...

【Android知识笔记】RecyclerView专题
RecyclerView工作流程 RecyclerView 的使用方法简单回顾: // 1. 添加gradle依赖 implementation androidx.recyclerview:recyclerview:1.1.0// 2. 布局文件 <?xml version="1.0" encoding="utf-8"?> <FrameLayout xmlns:android="http:…...
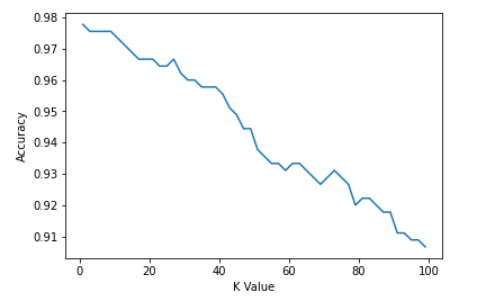
从头开始使用 KNN 进行 KNN 和 MNIST 手写数字识别的初学者指南
一、说明 MNIST (“修改后的国家标准与技术研究所”)是事实上的计算机视觉“hello world”数据集。自 1999 年发布以来,这个经典的手写图像数据集一直作为分类算法基准测试的基础。随着新的机器学习技术的出现,MNIST 仍然是研究人…...
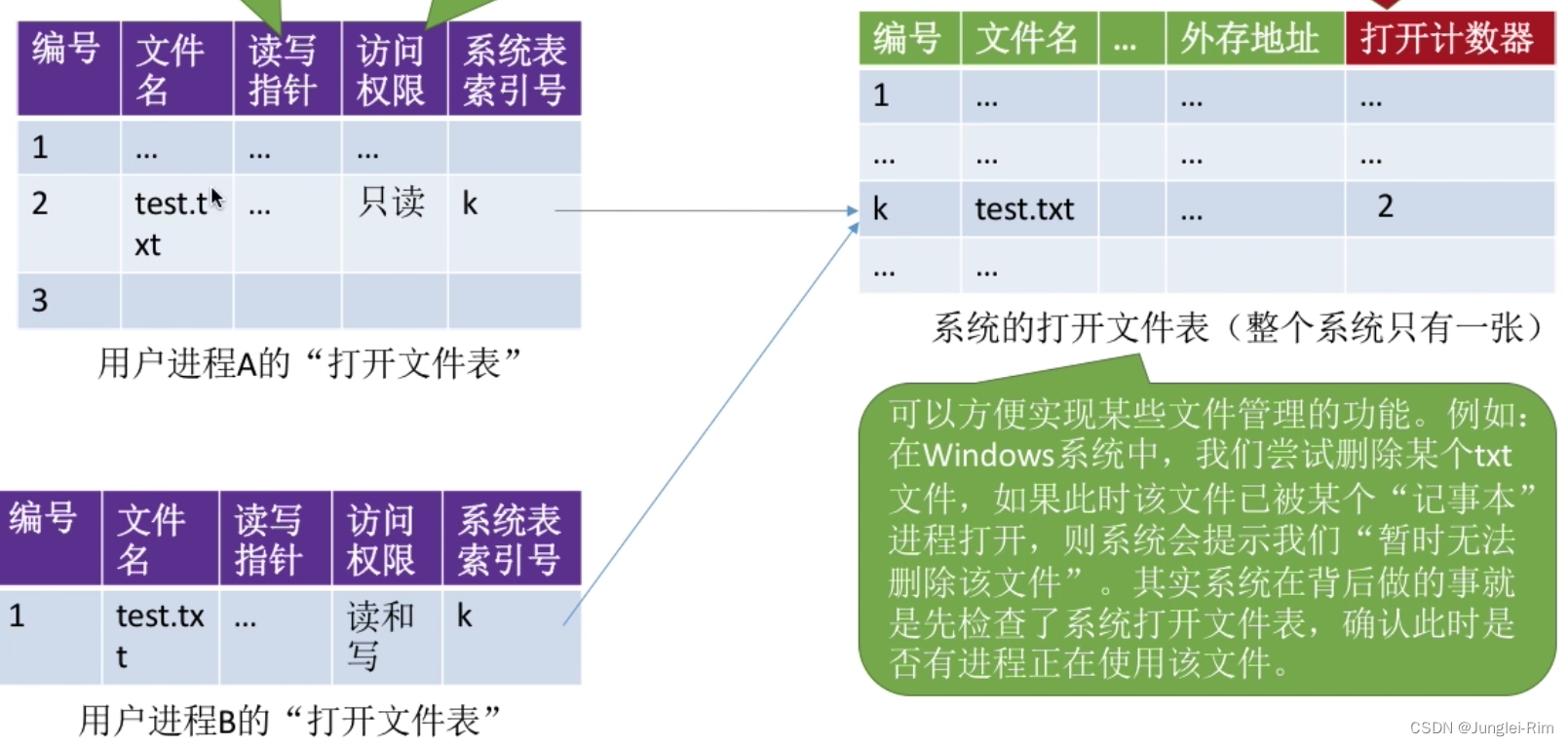
文件的基本操作(创建文件,删除文件,读写文件,打开文件,关闭文件)
1.创建文件(create系统调用) 1.进行Create系统调用时, 需要提供的几个主要参数: 1.所需的外存空间大小(如:一个盘块,即1KB) 2.文件存放路径(“D:/Demo”) 3.文件名(这个地方默认为“新建文本文档.txt”) …...

微积分(二) 导数与微分
前言 导数反映了函数值相对于自变量的变化快慢程度,而微分则表明当自变量有微小变化时,函数值大体上变化多少 瞬时速度的解决——极限 牛顿采用了一种无限逼近的方法。 平均速度的定义:如果一个物体在一段时间△t内位移了s,它在这段时间内的平均速度…...
go语言Array 与 Slice
有的语言会把数组用作常用的基本的数据结构,比如 JavaScript,而 Golang 中的数组(Array),更倾向定位于一种底层的数据结构,记录的是一段连续的内存空间数据。但是在 Go 语言中平时直接用数组的时候不多,大多数场景下我…...

Ubuntu自启动设置
ubuntu中编写shell脚本开机自动启动(推荐)_Linux_脚本之家 1. vim test.sh 2. #!/bin/bash ### BEGIN INIT INFO # Provides: test # Required-Start: $remote_fs $syslog # Required-Stop: $remote_fs $syslog # Default-Start: 2 3 4 5 # Default-Stop: 0 1 6 …...

2026年最新:直接填内容自动排版的简历工具测评,5款AI加持的简历制作神器
引言:2026年,简历不再只是文字堆砌步入2026年,求职市场的竞争态势愈发白热化。如今,一份简历不再仅仅是工作经历和教育背景的简单罗列,它更是求职者专业能力、个人品牌和求职意愿的综合体现。传统的手动排版、反复修改…...

如何快速完整备份QQ空间历史说说?GetQzonehistory终极解决方案
如何快速完整备份QQ空间历史说说?GetQzonehistory终极解决方案 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 在数字记忆日益珍贵的今天,QQ空间作为承载无数人青…...

Ubuntu网络流量监控:nethogs与vnstat实战指南
1. 为什么需要监控Ubuntu网络流量? 作为一个长期使用Ubuntu的开发者,我经常遇到这样的困惑:明明没有下载大文件,为什么网速突然变慢了?服务器流量莫名其妙就超标了?这时候就需要专业的网络监控工具来帮忙了…...

OBS Studio实战:SRT推流配置与性能优化全解析
1. SRT协议与OBS推流基础认知 第一次接触SRT推流时,我被它复杂的参数配置搞得晕头转向。直到有次直播电竞比赛,RTMP推流出现严重卡顿,才真正体会到SRT的价值——当时切换SRT协议后,延迟直接从3秒降到0.8秒,观众弹幕瞬间…...

PUBG雷达系统:3分钟搭建您的专属战场指挥中心
PUBG雷达系统:3分钟搭建您的专属战场指挥中心 【免费下载链接】PUBG-maphack-map this is a working copy online-map from jussihi/PUBG-map-hack, use nodejs webserver instead of firebase. 项目地址: https://gitcode.com/gh_mirrors/pu/PUBG-maphack-map …...

Phi-3 Forest Laboratory 实战:SpringBoot微服务集成AI能力指南
Phi-3 Forest Laboratory 实战:SpringBoot微服务集成AI能力指南 最近在做一个内部知识库问答系统的升级,需要集成一个轻量但聪明的语言模型来处理用户查询。试了几个方案,最后把目光锁定在了Phi-3 Forest Laboratory上。它体积小、推理快&am…...

使用Spring AI Alibaba构建智能体Agent妒
背景 在软件开发的漫长旅途中,"构建"这个词往往让人又爱又恨。爱的是,一键点击,代码变成产品,那是程序员最迷人的时刻;恨的是,维护那一堆乱糟糟的构建脚本,简直是噩梦。 在很多项目中…...

aibiye的AI改写工具为解决论文30%重复率问题,总结出五条实用技巧。包括语义重组、逻辑优化等策略,显著改善文本原创性,助力论文高效通过检测。
嘿,大家好!我是AI菌。今天咱们来聊聊一个让无数学生头疼的问题:论文重复率飙到30%以上怎么办?别慌,我这就分享5个实用降重技巧,帮你一次搞定,轻松压到合格线以下。这些方法都是我亲身试验过的&a…...

Node.js后端服务开发:搭建高性能AI模型推理API网关
Node.js后端服务开发:搭建高性能AI模型推理API网关 1. 为什么需要API网关 在AI模型服务化的过程中,直接暴露模型服务给客户端会带来诸多问题。想象一下,如果你的手机应用直接调用运行在服务器上的PyTorch模型,每次请求都要处理复…...

告别论文格式噩梦:南航学位论文LaTeX模板3步搞定专业排版
告别论文格式噩梦:南航学位论文LaTeX模板3步搞定专业排版 【免费下载链接】nuaathesis LaTeX document class for NUAA, supporting bachelor/master/PH.D thesis in Chinese/English/Japanese. 南航本科、硕士、博士学位论文 LaTeX 模板 项目地址: https://gitco…...