数据集-特征降维
1、降维
降维是指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程
- 降低随机变量的个数
- 相关特征(correlated feature)
- 相对湿度与降雨量之间的相关
- 等等
正是因为在进行训练的时候,我们都是使用特征进行学习。如果特征本身存在问题或者特征之间相关性较强,对于算法学习预测会影响较大
1.2、降维的两种方式
- 特征选择
- 主成分分析(可以理解一种特征提取的方式)
2、什么是特征选择
2.1、定义
数据中包含冗余或无关变量(或称特征、属性、指标等),旨在从原有特征中找出主要特征。

2.2、方法
- Filter(过滤式):主要探究特征本身特点、特征与特征和目标值之间关联
- 方差选择法:低方差特征过滤
- Embedded (嵌入式):算法自动选择特征(特征与目标值之间的关联)
- 决策树:信息熵、信息增益
- 正则化:L1、L2
- 深度学习:卷积等
3、 过滤式
3.1、低方差特征过滤
-
删除低方差的一些特征,前面讲过方差的意义。再结合方差的大小来考虑这个方式的角度。
- 特征方差小:某个特征大多样本的值比较相近
- 特征方差大:某个特征很多样本的值都有差别
3.2、API
- sklearn.feature_selection.VarianceThreshold(threshold = 0.0)
- threshold:过滤多少小于多少阈值的数据
- 删除所有低方差特征
- Variance.fit_transform(X)
- X:numpy array格式的数据[n_samples,n_features]
- 返回值:训练集差异低于threshold的特征将被删除。默认值是保留所有非零方差特征,即删除所有样本中具有相同值的特征。
3.3、代码
数据:数据集下载链接
示例:
index,pe_ratio,pb_ratio,market_cap,return_on_asset_net_profit,du_return_on_equity,ev,earnings_per_share,revenue,total_expense,date,return
0,000001.XSHE,5.9572,1.1818,85252550922.0,0.8008,14.9403,1211444855670.0,2.01,20701401000.0,10882540000.0,2012-01-31,0.027657228229937388
1,000002.XSHE,7.0289,1.588,84113358168.0,1.6463,7.8656,300252061695.0,0.326,29308369223.2,23783476901.2,2012-01-31,0.08235182370820669
2,000008.XSHE,-262.7461,7.0003,517045520.0,-0.5678,-0.5943,770517752.56,-0.006,11679829.03,12030080.04,2012-01-31,0.09978900335112327
3,000060.XSHE,16.476,3.7146,19680455995.0,5.6036,14.617,28009159184.6,0.35,9189386877.65,7935542726.05,2012-01-31,0.12159482758620697
4,000069.XSHE,12.5878,2.5616,41727214853.0,2.8729,10.9097,81247380359.0,0.271,8951453490.28,7091397989.13,2012-01-31,-0.0026808154146886697
import pandas as pd
from sklearn.feature_selection import VarianceThresholddef variance_demo():"""删除低方差特征——特征选择:return: None"""data = pd.read_csv("factor_returns.csv")print(data)# 1、实例化一个转换器类transfer = VarianceThreshold(threshold=10)# 2、调用fit_transformdata = transfer.fit_transform(data.iloc[:, 1:10]) # index,date, return 三个不需要的特征print("删除低方差特征的结果:\n", data)print("形状:\n", data.shape)print(data)return Noneif __name__ == '__main__':variance_demo()结果:
index pe_ratio pb_ratio ... total_expense date return
0 000001.XSHE 5.9572 1.1818 ... 1.088254e+10 2012-01-31 0.027657
1 000002.XSHE 7.0289 1.5880 ... 2.378348e+10 2012-01-31 0.082352
2 000008.XSHE -262.7461 7.0003 ... 1.203008e+07 2012-01-31 0.099789
3 000060.XSHE 16.4760 3.7146 ... 7.935543e+09 2012-01-31 0.121595
4 000069.XSHE 12.5878 2.5616 ... 7.091398e+09 2012-01-31 -0.002681
... ... ... ... ... ... ... ...
2313 601888.XSHG 25.0848 4.2323 ... 1.041419e+10 2012-11-30 0.060727
2314 601901.XSHG 59.4849 1.6392 ... 1.089783e+09 2012-11-30 0.179148
2315 601933.XSHG 39.5523 4.0052 ... 1.749295e+10 2012-11-30 0.137134
2316 601958.XSHG 52.5408 2.4646 ... 6.009007e+09 2012-11-30 0.149167
2317 601989.XSHG 14.2203 1.4103 ... 4.132842e+10 2012-11-30 0.183629[2318 rows x 12 columns]
删除低方差特征的结果:[[ 5.95720000e+00 8.52525509e+10 8.00800000e-01 ... 1.21144486e+122.07014010e+10 1.08825400e+10][ 7.02890000e+00 8.41133582e+10 1.64630000e+00 ... 3.00252062e+112.93083692e+10 2.37834769e+10][-2.62746100e+02 5.17045520e+08 -5.67800000e-01 ... 7.70517753e+081.16798290e+07 1.20300800e+07]...[ 3.95523000e+01 1.70243430e+10 3.34400000e+00 ... 2.42081699e+101.78908166e+10 1.74929478e+10][ 5.25408000e+01 3.28790988e+10 2.74440000e+00 ... 3.88380258e+106.46539204e+09 6.00900728e+09][ 1.42203000e+01 5.91108572e+10 2.03830000e+00 ... 2.02066110e+114.50987171e+10 4.13284212e+10]]
形状:(2318, 7)4、相关系数
- 皮尔逊相关系数(Pearson Correlation Coefficient)
- 反映变量之间相关关系密切程度的统计指标
4.1、公式计算案例
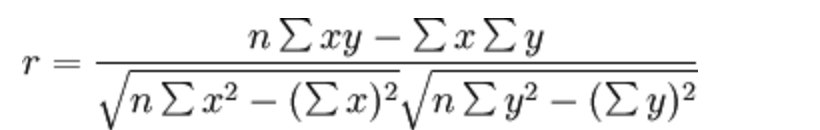
- 比如说我们计算年广告费投入与月均销售额
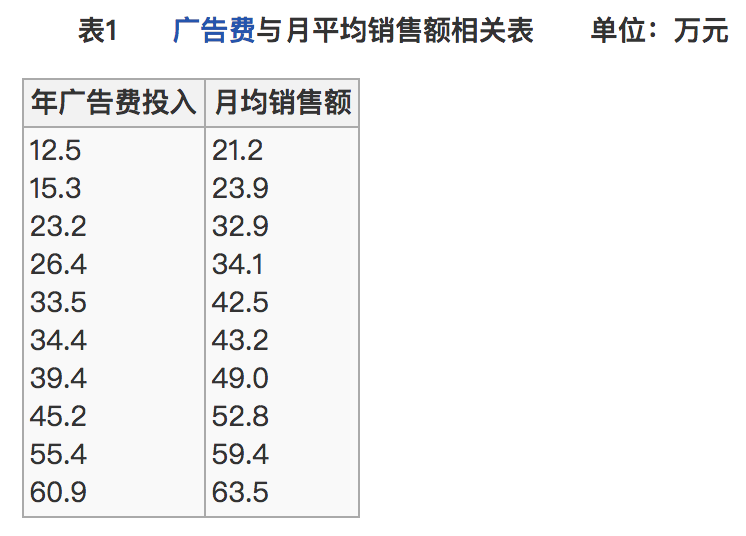
那么之间的相关系数怎么计算
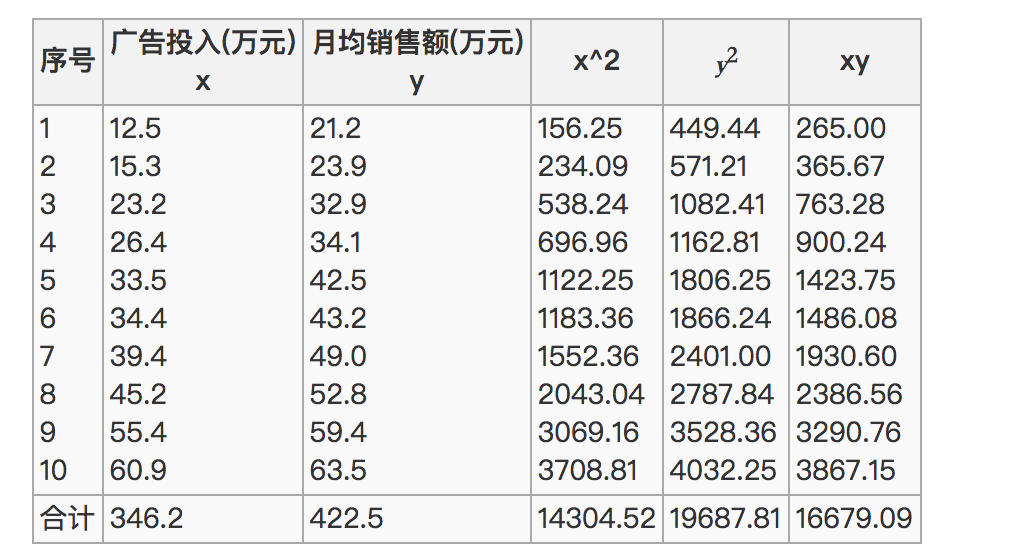 最终计算:
最终计算:
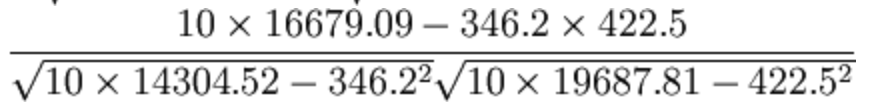
= 0.9942
所以我们最终得出结论是广告投入费与月平均销售额之间有高度的正相关关系。
4.2、特点
相关系数的值介于–1与+1之间,即–1≤ r ≤+1。其性质如下:
- 当r>0时,表示两变量正相关,r<0时,两变量为负相关
- 当|r|=1时,表示两变量为完全相关,当r=0时,表示两变量间无相关关系
- 当0<|r|<1时,表示两变量存在一定程度的相关。且|r|越接近1,两变量间线性关系越密切;|r|越接近于0,表示两变量的线性相关越弱
- 一般可按三级划分:|r|<0.4为低度相关;0.4≤|r|<0.7为显著性相关;0.7≤|r|<1为高度线性相关
这个符号:|r|为r的绝对值, |-5| = 5
4.3、API
- from scipy.stats import pearsonr
- x : (N,) array_like
- y : (N,) array_like Returns: (Pearson’s correlation coefficient, p-value)
import pandas as pd
from scipy.stats import pearsonrdef pearsonr_demo():"""相关系数计算:return: None"""data = pd.read_csv("factor_returns.csv")factor = ['pe_ratio', 'pb_ratio', 'market_cap', 'return_on_asset_net_profit', 'du_return_on_equity', 'ev','earnings_per_share', 'revenue', 'total_expense']for i in range(len(factor)):for j in range(i, len(factor) - 1):print("指标%s与指标%s之间的相关性大小为%f" % (factor[i], factor[j + 1], pearsonr(data[factor[i]], data[factor[j + 1]])[0]))return Noneif __name__ == '__main__':pearsonr_demo()指标pe_ratio与指标pb_ratio之间的相关性大小为-0.004389
指标pe_ratio与指标market_cap之间的相关性大小为-0.068861
指标pe_ratio与指标return_on_asset_net_profit之间的相关性大小为-0.066009
指标pe_ratio与指标du_return_on_equity之间的相关性大小为-0.082364
指标pe_ratio与指标ev之间的相关性大小为-0.046159
指标pe_ratio与指标earnings_per_share之间的相关性大小为-0.072082
指标pe_ratio与指标revenue之间的相关性大小为-0.058693
指标pe_ratio与指标total_expense之间的相关性大小为-0.055551
指标pb_ratio与指标market_cap之间的相关性大小为0.009336
指标pb_ratio与指标return_on_asset_net_profit之间的相关性大小为0.445381
指标pb_ratio与指标du_return_on_equity之间的相关性大小为0.291367
指标pb_ratio与指标ev之间的相关性大小为-0.183232
指标pb_ratio与指标earnings_per_share之间的相关性大小为0.198708
指标pb_ratio与指标revenue之间的相关性大小为-0.177671
指标pb_ratio与指标total_expense之间的相关性大小为-0.173339
指标market_cap与指标return_on_asset_net_profit之间的相关性大小为0.214774
指标market_cap与指标du_return_on_equity之间的相关性大小为0.316288
指标market_cap与指标ev之间的相关性大小为0.565533
指标market_cap与指标earnings_per_share之间的相关性大小为0.524179
指标market_cap与指标revenue之间的相关性大小为0.440653
指标market_cap与指标total_expense之间的相关性大小为0.386550
指标return_on_asset_net_profit与指标du_return_on_equity之间的相关性大小为0.818697
指标return_on_asset_net_profit与指标ev之间的相关性大小为-0.101225
指标return_on_asset_net_profit与指标earnings_per_share之间的相关性大小为0.635933
指标return_on_asset_net_profit与指标revenue之间的相关性大小为0.038582
指标return_on_asset_net_profit与指标total_expense之间的相关性大小为0.027014
指标du_return_on_equity与指标ev之间的相关性大小为0.118807
指标du_return_on_equity与指标earnings_per_share之间的相关性大小为0.651996
指标du_return_on_equity与指标revenue之间的相关性大小为0.163214
指标du_return_on_equity与指标total_expense之间的相关性大小为0.135412
指标ev与指标earnings_per_share之间的相关性大小为0.196033
指标ev与指标revenue之间的相关性大小为0.224363
指标ev与指标total_expense之间的相关性大小为0.149857
指标earnings_per_share与指标revenue之间的相关性大小为0.141473
指标earnings_per_share与指标total_expense之间的相关性大小为0.105022
指标revenue与指标total_expense之间的相关性大小为0.995845
从中我们得出
- 指标revenue与指标total_expense之间的相关性大小为0.995845
- 指标return_on_asset_net_profit与指标du_return_on_equity之间的相关性大小为0.818697
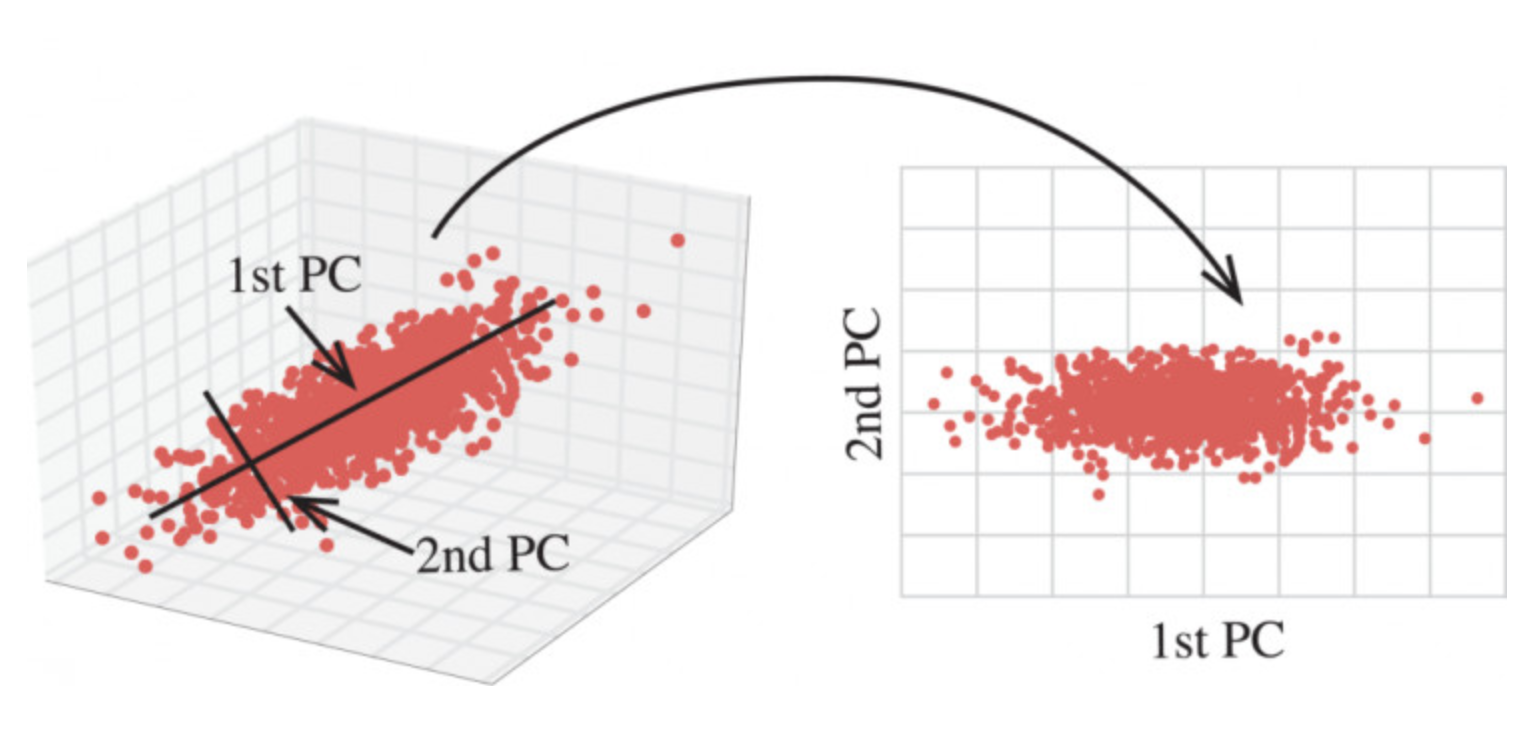
5、主成分分析
什么是主成分分析(PCA)
- 定义:高维数据转化为低维数据的过程,在此过程中可能会舍弃原有数据、创造新的变量
- 作用:是数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息。
- 应用:回归分析或者聚类分析当中
5.1、计算案例理解
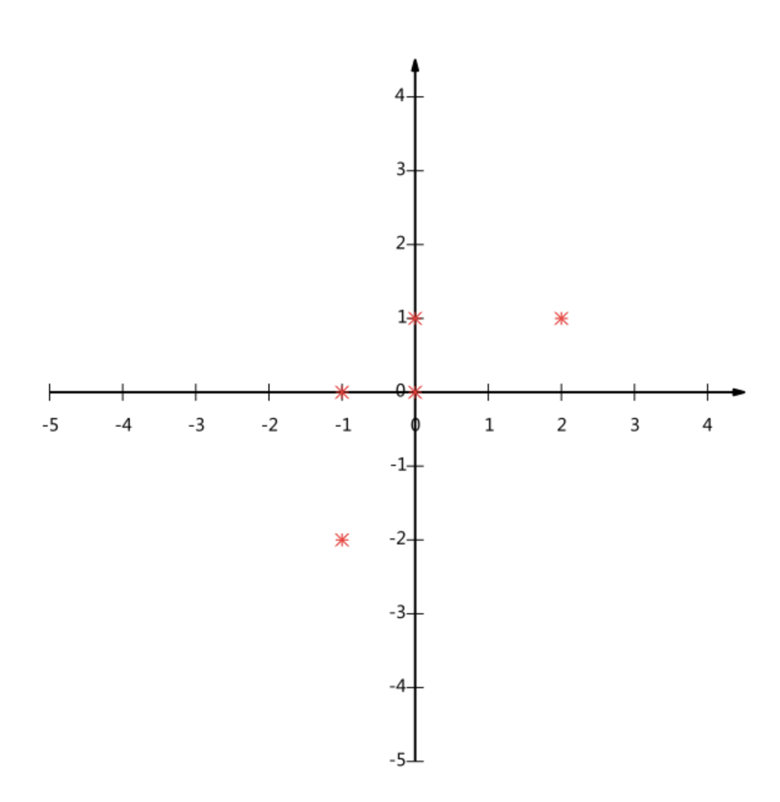
假设对于给定5个点,数据如下
(-1,-2)
(-1, 0)
( 0, 0)
( 2, 1)
( 0, 1)
要求:将这个二维的数据简化成一维? 并且损失少量的信息
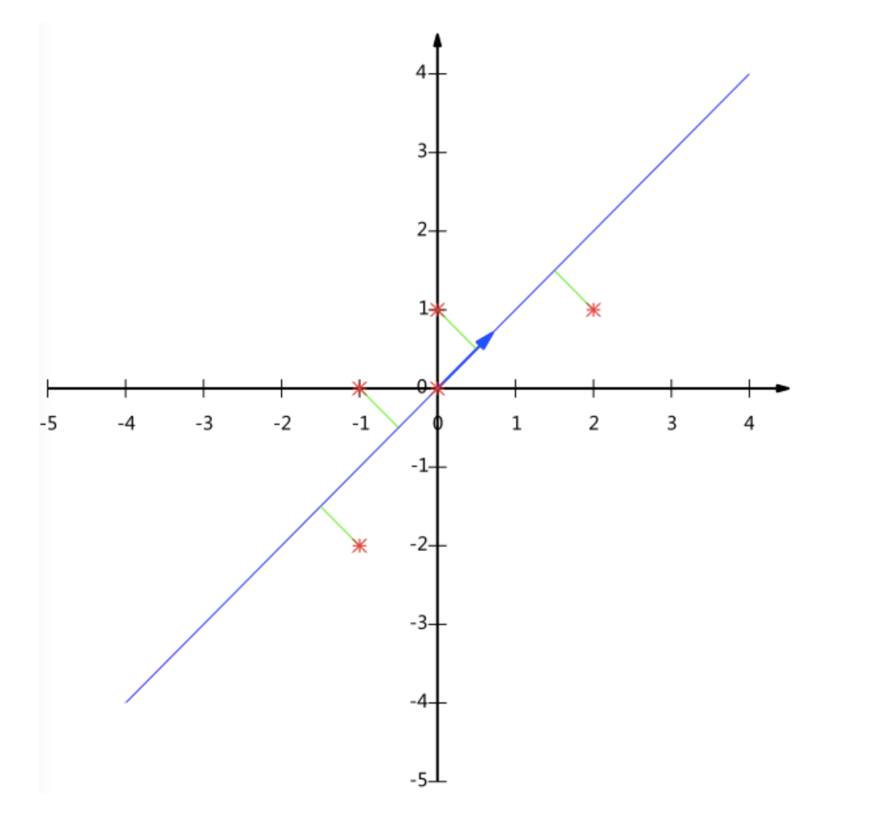
这个过程如何计算的呢?找到一个合适的直线,通过一个矩阵运算得出主成分分析的结果(不需要理解)
5.2、API
- sklearn.decomposition.PCA(n_components=None)
- 将数据分解为较低维数空间
- n_components:
- 小数:表示保留百分之多少的信息
- 整数:减少到多少特征
- PCA.fit_transform(X) X:numpy array格式的数据[n_samples,n_features]
- 返回值:转换后指定维度的array
5.3、数据计算
数据计算
[[2,8,4,5],
[6,3,0,8],
[5,4,9,1]]
from sklearn.decomposition import PCAdef pca_demo():"""对数据进行PCA降维:return: None"""data = [[2,8,4,5], [6,3,0,8], [5,4,9,1]]# 1、实例化PCA, 小数——保留多少信息transfer = PCA(n_components=0.9)# 2、调用fit_transformdata1 = transfer.fit_transform(data)print("保留90%的信息,降维结果为:\n", data1)# 1、实例化PCA, 整数——指定降维到的维数transfer2 = PCA(n_components=3)# 2、调用fit_transformdata2 = transfer2.fit_transform(data)print("降维到3维的结果:\n", data2)return Noneif __name__ == '__main__':pca_demo()保留90%的信息,降维结果为:[[ 1.28620952e-15 3.82970843e+00][ 5.74456265e+00 -1.91485422e+00][-5.74456265e+00 -1.91485422e+00]]
降维到3维的结果:[[ 1.28620952e-15 3.82970843e+00 5.26052119e-16][ 5.74456265e+00 -1.91485422e+00 5.26052119e-16][-5.74456265e+00 -1.91485422e+00 5.26052119e-16]]
相关文章:

数据集-特征降维
1、降维 降维是指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程 降低随机变量的个数 相关特征(correlated feature) 相对湿度与降雨量之间的相关等等 正是因为在进行训练的时候,我们都是使用特征进行学习。如果…...

【C语言】字符串+内存函数的介绍
🎈个人主页:.满船清梦压星河_-CSDN博客 🌂c/c领域新星创作者 🎉欢迎👍点赞✍评论❤️收藏 😛😛😛希望我的文章能对你有所帮助,有不足的地方还请各位看官多多指教…...

C#WPF资源字典应用实例
本文实例演示C#WPF资源字典应用 目录 一、资源字典 二、实例 1新建一个资源字典 2添加到资源文件App.xaml...

如何在国际腾讯云服务器上设置IP节点的密码?
跟着云计算技术的发展,越来越多的企业和个人开始运用云服务器来存储和处理数据。腾讯云服务器是一款非常受欢迎的云服务器产品,它提供了高效稳定的计算能力。在运用腾讯云服务器的过程中,咱们可能需求设置IP节点的暗码,以便维护咱…...

浅谈基于敏捷开发交付应对突发项目
软件项目开发的全过程是一个很大的范畴,从确定需求,到编码设计,到集成发布,到运维、运营、设计方方面面。在这个过程中,交付过程是非常关键的,因为它影响着软件的质量、稳定性和用户体验。 在当今竞争激烈的…...

1.工具-VSCode有哪些常用快捷键
题记 记录一些vscode的常用快捷键 基本编辑 Ctrl C:复制选定内容。Ctrl X:剪切选定内容。Ctrl V:粘贴剪贴板内容。Ctrl Z:撤销上一步操作。Ctrl Shift Z:恢复上一步操作。Ctrl D:选择下一个匹配项…...

行业模型应该如何去拆解?
行业模型应该如何去拆解? 拆解行业模型是一个复杂的过程,涉及对整个行业的深入分析和理解。下面是一些步骤和方法,可以帮助你系统地拆解行业模型: 1. 确定行业范围 定义行业:明确你要分析的行业是什么,包括…...

【开题报告】基于微信小程序的签到打卡系统的设计与实现
1.研究背景与意义 考勤管理是企业日常管理的重要内容之一。随着企业规模的扩大和员工数量的增加,传统的考勤管理方式已经不能满足需求。而基于微信小程序的签到打卡系统可以提供方便快捷的签到打卡服务,为企业管理人员提高工作效率和员工考勤管理提供了…...

1.写一个算法模型以及python算法工程化步骤
生成一个 PT(Perceptual Tokenizer)模型的步骤如下: 准备数据集:首先,你需要准备一个用于训练 PT 模型的数据集。这可以是一个包含大量文本数据的语料库。 数据预处理:对数据进行预处理以准备训练。这可能…...

物联网AI MicroPython传感器学习 之 GC7219点阵屏驱动模块
学物联网,来万物简单IoT物联网!! 一、产品简介 LED-8 * 32点阵屏显示板由 4 块单色 8x8 共阴红色点阵单元组成,通过 SPI 菊花链模式将多块显示屏连接后可以组成更大的分辨率显示屏幕,任意组合分辨率。可用于简单仪表显…...
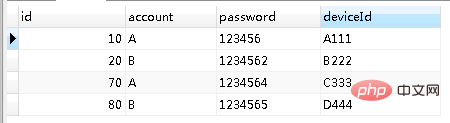
MySQL中查询重复字段的方法和步骤是怎样
示例 accountinfo 表数据如下: 场景一 单个字段重复数据查找 & 去重 我们要把上面这个表中 单个字段 account字段相同的数据找出来。 思路 分三步 简述: 第一步 要找出重复数据,我们首先想到的就是,既然是重复,…...
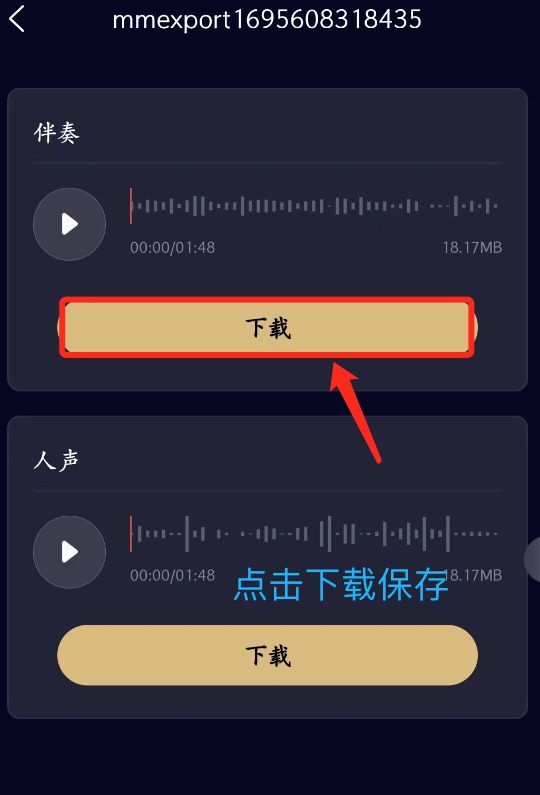
怎样才能去除视频中的背景音乐,保留人声?
做视频剪辑,二次创作的朋友,需要去除视频中的背景音乐,保留人声;或者去除人声,保留背景音乐。如果请身边做视频的朋友帮忙,可有时不能沟通到位,完成后的效果并不是很理想,就很尴尬了…...
计算机思维导论)
【C语言程序设计】--C语言(一)计算机思维导论
控制台输出中文乱码问题解决: ref:https://blog.csdn.net/ymzhu385/article/details/121797080 基本数据类型 我们的程序离不开数据,比如我们需要保存一个数字或是字母,这时候这些东西就是作为数据进行保存,不过不同的数据他们的…...

三、git信息泄露
一、git信息泄露 解释:Git信息泄露是指通过公开或错误地配置版本控制系统Git,导致敏感数据(例如API密钥、数据库密码、个人信息等)被泄露到公共代码仓库或其他未授权的访问者手中。通俗来说,在公网暴露类似http://127…...

第 368 场 LeetCode 周赛题解
A 元素和最小的山形三元组 I 前后缀操作:求出前后缀上的最小值数组,然后枚举 j j j class Solution { public:int minimumSum(vector<int> &nums) {int n nums.size();vector<int> l(n), r(n);//l[i]min{nums[0],...,nums[i]}, r[i]mi…...

Qt中QFile、QByteArray QDataStream和QTextStream区别及示例
在Qt中,QFile、QByteArray、QDataStream和QTextStream是常用的文件和数据处理类。 主要功能和区别 QFile: QFile是用于读写文本和二进制文件以及资源的I/O设备。可以单独使用QFile,或者更方便地与QTextStream或QDataStream一起使用。 通常在…...

【操作系统】32进制小数转16进制
要将32进制的小数转换为16进制,可以按照以下步骤进行: 将32进制小数转换为10进制。可以使用上述提到的方法,将32进制小数转换为对应的10进制数。 将10进制数转换为16进制。使用常规的方法将10进制数转换为16进制数。可以将10进制数不断除以1…...
C#实现数据导出任一Word图表的通用呈现方法及一些体会
疲惫的修改 应人才测评产品的需求,导出测评报告是其中一个重要的环节,报告的文件类型也多种多样,其中WORD输出也扮演了一个重要的角色。 实现方法比较简单,结合分析结果数据,通过WORD模板文件进行替换输出。在实现的…...

2023-10 字节跳动面试整个过程 golang营销服务开发岗位
面试整个过程大约1个小时回答的中规中矩吧 很多问题回答的不具体 难受死我了非常简单的算法题下面列出来了面试步骤这里面有一点就是面试官本来想问问我数据结构这一块的问题 但是我说不太熟悉 他就没问了 1. 简单介绍个人信息 略2. 介绍简历上的项目 略3. 什么是分布式事务 主…...

Java类名的命名规范
Java中的类名必须以字母或者下划线开头,不能以数字开头。 类名的每个单词的首字母必须大写,这被称为帕斯卡命名法。 此外,类名不能使用关键字或保留字,不能使用数字除了_和$之外的任何符号,中间不能添加空格。 如果…...

Kafka-King:现代化Kafka管理GUI工具的技术解析与使用指南
Kafka-King:现代化Kafka管理GUI工具的技术解析与使用指南 【免费下载链接】Kafka-King A modern and practical kafka GUI client 💕🎉Kafka-King 是一款现代化、实用的 Kafka GUI 客户端,旨在通过直观的桌面界面简化 Apache Kafk…...

PyTorch 2.8虚拟机开发环境:VMware中配置Ubuntu并连接云端GPU
PyTorch 2.8虚拟机开发环境:VMware中配置Ubuntu并连接云端GPU 1. 为什么选择这种开发方式? 对于深度学习开发者来说,本地开发环境配置往往是个头疼的问题。特别是当你的笔记本显卡性能有限,又不想完全依赖云端开发时,…...

低空经济新引擎:一文读懂固定翼无人机
低空经济新引擎:一文读懂固定翼无人机 引言 随着低空经济被正式确立为国家战略性新兴产业,无人机技术正从“小众极客”走向“大众应用”的广阔天地。在众多无人机形态中,固定翼无人机以其长航时、大载重、高效率的独特优势,成为物…...
邻域特异性基因表达)
脚本更新--(Xenium、CosMx、HD)邻域特异性基因表达
作者,Evil Genius 今天我们需要更新脚本,大家应该知道推文经常更新脚本,有没有知道为什么?最核心的原因在于做项目的时候和客户沟通,挖空心思分析数据,然后结合阅读大量的文献,最后整理出来思路,用代码实现,以后一旦遇到相同的售后分析,就会重复使用这套代码。 反正…...

如何高效处理生命科学图像数据:Bio-Formats完全实战指南
如何高效处理生命科学图像数据:Bio-Formats完全实战指南 【免费下载链接】bioformats Bio-Formats is a Java library for reading and writing data in life sciences image file formats. It is developed by the Open Microscopy Environment. Bio-Formats is re…...

互联网工程与Agent下的Skill MCP:标准接口与逻辑负载的完美类比
在探索AI Agent的技术架构时,我们可以从成熟的互联网工程实践中找到极具启发性的类比。MCP(模型上下文协议)就像是整个互联网的“标准化数据传输层”,而Agent的Skill则对应着不同逻辑负载的“后端服务”——从简单的工具函数到复杂…...

深度解析NxNandManager:Nintendo Switch NAND管理工具的技术实现
深度解析NxNandManager:Nintendo Switch NAND管理工具的技术实现 【免费下载链接】NxNandManager Nintendo Switch NAND management tool : explore, backup, restore, mount, resize, create emunand, etc. (Windows) 项目地址: https://gitcode.com/gh_mirrors/…...

复旦微FM33 MCU 底层开发实战——从寄存器到外设精通
1. 初识复旦微FM33系列MCU 第一次拿到复旦微FM33LC0XX开发板时,我和大多数嵌入式开发者一样,习惯性地打开标准外设库开始写代码。但很快发现,当需要实现特定功能或优化性能时,库函数的封装反而成了障碍。这就像开车时只能使用自动…...

Rust 异步 ORM 新选择:Toasty 初探
Rust 异步 ORM 新选择:Toasty 初探 2026年4月,Rust 生态迎来了一款新异步 ORM 框架 Toasty。为什么它如此收到 Rust 开发者的广泛关注呢?因为它是来自于鼎鼎大名的 Tokio 团队,该团队研发的 tokio(异步运行时…...

如何在5分钟内为Unity游戏实现实时翻译:XUnity.AutoTranslator完整实战指南
如何在5分钟内为Unity游戏实现实时翻译:XUnity.AutoTranslator完整实战指南 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator XUnity.AutoTranslator是一款功能强大的Unity游戏实时翻译插件&…...