循环神经网络(Recurrent Neural Network)
1. 为什么需要循环神经网络 RNN

上图是一幅全连接神经网络图,我们可以看到输入层-隐藏层-输出层,他们每一层之间是相互独立地,(框框里面代表同一层),每一次输入生成一个节点,同一层中每个节点之间又相互独立的话,那么我们每一次的输入其实跟前面的输入是没有关系地。这样在某一些任务中便不能很好的处理序列信息。
什么是序列信息呢?
通俗理解就是一段连续的信息,前后信息之间是有关系地,必须将不同时刻的信息放在一起理解。
比如一句话,虽然可以拆分成多个词语,但是需要将这些词语连起来理解才能得到一句话的意思。
RNN就是用来处理这些序列信息的任务,比如NLP中的语句生成问题,一句话中的每个词并不是单独存在地,而是根据上下文信息,与他的前后词有关。
为了解决这一问题,循环神经网络 RNN也就应运而生了。
2. 循环神经网络 RNN的结构

先看左半边图,如果不看隐藏层中的W,把它忽略,那么这其实就相当于是一个全连接神经网络的结构。那么从左图中就可以看出RNN呢其实就只是相当于在全连接神经网络的隐藏层增加了一个循环的操作。至于这个循环的操作具体是怎样的呢?单看左图可能有些懵逼,那么现在看上右图。上右图是RNN网络结构按照时间线展开图。
Xt是t时刻的输入,是一个[x0,x1,x2…xn]的向量
U是输入层到隐藏层的权重矩阵
St是t时刻的隐藏层的值
W是上一时刻的隐藏层的值传入到下一时刻的隐藏层时的权重矩阵
V是隐藏层到输出层的权重矩阵
Ot是t时刻RNN网络的输出
从上右图中可以看出这个RNN网络在t时刻接受了输入Xt之后,隐藏层的值是St,输出的值是Ot。但是从结构图中我们可以发现St并不单单只是由Xt决定,还与t-1时刻的隐藏层的值St-1有关。
这样,所谓的隐藏层的循环操作也就不难理解了,就是每一时刻计算一个隐藏层地值,然后再把该隐藏层地值传入到下一时刻,达到信息传递的目的。
具体隐藏层值St计算公式如下:

得到t时刻隐藏层的值后,再计算输出层的值:

注意:在同一层隐藏层中,不同时刻的W,V,U均是相等地,这也就是RNN的参数共享。

3. 循环神经网络 RNN的训练方法
训练RNN常用的一种方法是 BPTT算法(back-propagation through time),其本质也是BP算法(Backpropagation Algorithm),BP算法的本质其实又是梯度下降法,这边默认大家已经了解了梯度下降和反向传播算法的原理。

上图是带入了RNN 损失函数Loss的按时间线结构展开图。ht相当于是之前介绍过的隐藏层的值St
在RNN的训练调参过程中,需要调优的参数只有W,U,V三个


因为ht与h{t-1}有关,而h{t-1}中也有W和U,因此W和U的偏导的求解需要涉及到历史所有时刻的数据,其偏导求起来相对复杂,我们先假设只有三个时刻,那么在第三个时刻也就是t=3时 L对W的偏导数为:

整体的偏导公式就是将所有时刻的偏导数加起来

来看看蓝框部分是一个连乘的形式,ht的计算公式引入激活函数f()后如下:

诶,现在想起来之前上面是不是还有一个坑没填,就是为什么要选择tanh作为隐藏层的激活函数呢?
从上面的式子我们可以看到,引入了激活函数tanh和sigmoid的导数连乘,那我们再看看这两个激活函数导数的图像:


可以看到sigmoid函数和tanh函数的导数始终是小于1地,如果把众多小于1的数连乘,那么就会出现梯度消失的情况。
sigmoid函数的导数介于[0,0.25]之间,tanh函数的导入为[0,1]之间,虽然他们两者都存在梯度消失的问题,但tanh比sigmoid函数的表现要好,梯度消失得没有那么快。
你可能会要问之前在CNN中为了解决梯度消失问题是采用了ReLU激活函数,那么为什么RNN中不选用ReLU激活函数来彻底解决梯度消失的问题呢?
其实在RNN中使用ReLU函数确实也是能解决梯度消失的问题地,但是又会引入一个新问题梯度爆炸,先看看ReLU函数和其导数图:

因为ReLu的导数恒为1,由上面的公式我们发现

激活函数的导数每次需要乘上一个Ws,只要Ws的值大于1的话,经过多次连乘就会发生梯度爆炸的现象。但是这里的梯度爆炸问题也不是不能解决,可以通过设定合适的阈值解决梯度爆炸的问题。
但是目前大家在解决梯度消失问题地时候一般都会选择使用LSTM这一RNN的变种结构来解决梯度消失问题,而LSTM的激活函数又是选择的tanh,还不会引入梯度爆炸这种新问题,所以可能也就没有必要在基础的RNN上过多的纠结是选用ReLU还是tanh了吧,因为大家实际中用的都是LSTM,只需要理解RNN的思想就行了,于是就选择了一个折中的比sigmoid效果好,又不会引入新的梯度爆炸问题地tanh作为激活函数。
总之需要知道RNN中也能够使用ReLU激活函数来解决梯度消失问题,但是用来ReLU之后引入了新的梯度爆炸问题就得不偿失了,因此在梯度消失这个问题上选择用LSTM来优化是更好的选择。
4. 循环神经网络RNN的多种类型任务

4.1 one-to-one

输入的是独立地数据,输出的也是独立地数据,基本上不能算作是RNN,跟全连接神经网络没有什么区别。
4.2 one-to-n

输入的是一个独立数据,需要输出一个序列数据,常见的任务类型有:
基于图像生成文字描述
基于类别生成一段语言,文字描述
4.3 n-to-n

最为经典地RNN任务,输入和输出都是等长地序列
常见的任务有:
计算视频中每一帧的分类标签
输入一句话,判断一句话中每个词的词性
4.4 n-to-one

输入一段序列,最后输出一个概率,通常用来处理序列分类问题。
常见任务:
文本情感分析
文本分类
4.5 n-to-m
这种结构是Encoder-Decoder,也叫Seq2Seq,是RNN的一个重要变种。原始的n-to-n的RNN要求序列等长,然而我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。为此,Encoder-Decoder结构先将输入数据编码成一个上下文语义向量c:

语义向量c可以有多种表达方式,最简单的方法就是把Encoder的最后一个隐状态赋值给c,还可以对最后的隐状态做一个变换得到c,也可以对所有的隐状态做变换。
拿到c之后,就用另一个RNN网络对其进行解码,这部分RNN网络被称为Decoder。Decoder的RNN可以与Encoder的一样,也可以不一样。具体做法就是将c当做之前的初始状态h0输入到Decoder中:

还有一种做法是将c当做每一步的输入:

输入序列和输出序列不等长地任务,也就是Encoder-Decoder结构,这种结构有非常多的用法:
机器翻译:Encoder-Decoder的最经典应用,事实上这结构就是在机器翻译领域最先提出的
文本摘要:输入是一段文本序列,输出是这段文本序列的摘要序列
阅读理解:将输入的文章和问题分别编码,再对其进行解码得到问题的答案
语音识别:输入是语音信号序列,输出是文字序列
基于Encoder-Decoder的结构后续有改良出了NLP中的大杀器transformer和Bert
5. BiRNN 双向RNN
虽然RNN达到了传递信息的目的,但是只是将上一时刻的信息传递到了下一时刻,也就是只考虑到了当前节点前的信息,没有考虑到该节点后的信息。具体到NLP中,也就是一句话,不仅要考虑某个词上文的意思,也还要考虑下文的意思,这个时候普通的RNN就做不到了。于是就有了双向RNN(Bidirectional RNN)。
5.1 BiRNN结构

上面是BiRNN的结构图,蓝框和绿框分别代表一个隐藏层,BiRNN在RNN的基础上增加了一层隐藏层,这层隐藏层中同样会进行信息传递,两个隐藏层值地计算方式也完全相同,只不过这次信息不是从前往后传,而是从后往前传,这样不仅能考虑到前文的信息而且能考虑到后文的信息了。
实现起来也很简单,比如一句话,“我爱NLP”,进行分词后是[“我”,“爱”,“NLP”],输入[[“我”],[“爱”],[“NLP”]],计算forward layer隐藏层值,然后将输入数据翻转成[[“NLP”],[“爱”],[“我”]],计算backward layer 隐藏层值,然后将两个隐藏层的值进行拼接,再输出就行啦。
这就是BiRNN的原理,理解了RNN的原理,应该来说还是比较简单地。
6. DRNN 深层RNN
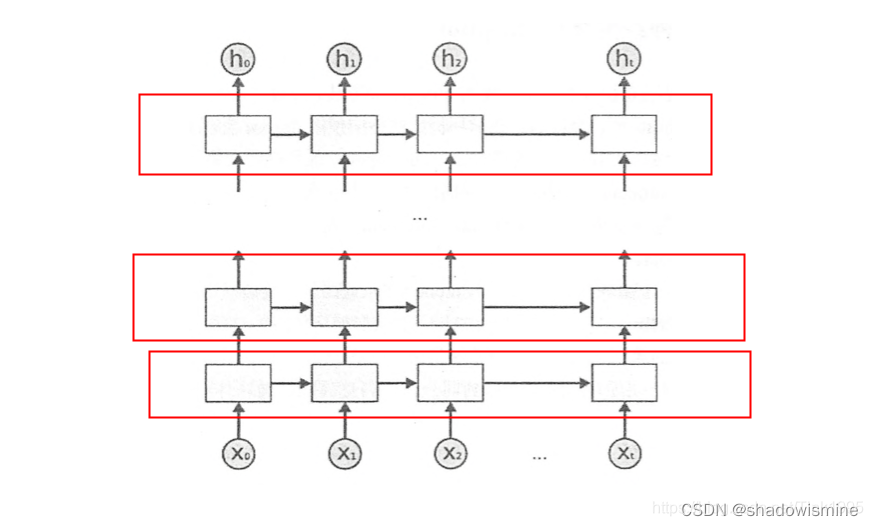
上图是DRNN的结构图,很简单,每一个红框里面都是一个BiRNN,然后一层BiRNN的输出值再作为另一个BiRNN的输入。多个BiRNN堆叠起来就成了DRNN。
原文链接:https://blog.csdn.net/Tink1995/article/details/104868903
RNN 结构详解 | 机器之心
相关文章:
循环神经网络(Recurrent Neural Network)
1. 为什么需要循环神经网络 RNN 上图是一幅全连接神经网络图,我们可以看到输入层-隐藏层-输出层,他们每一层之间是相互独立地,(框框里面代表同一层),每一次输入生成一个节点,同一层中每个节点之间又相互独立的话&#…...

管理类联考——英语二——阅读篇——题材:经济
文章目录 2011 年,Text 2——题材:经济句意理解题-原词复现一般不选,但是要留意无中生有推断题-原词复现,注意是否“无中生有”“对象错误”“词意相反”推断题推断题主旨题-不了解阅读意思,很难做出选择 2011 年&…...

【Java】ListIterator
列表迭代器: ListIterator listIterator():List 集合特有的迭代器该迭代器继承了 Iterator 迭代器,所以,就可以直接使用 hasNext()和next()方法。特有功能: Object previous():获取上一个元素boolean hasPr…...

EV SSL数字证书贵吗
EVSSL证书通常适用于具有高需求的网站和企业,特别是涉及在线交易、金融服务、电子商务平台等需要建立用户信任的场景。大型企业、金融机构、电子商务平台等可以受益于使用EV证书来提升品牌形象和安全性。 申请EVSSL证书(Extended Validation SSL certifi…...
nginx安装详细步骤和使用说明
下载地址: https://download.csdn.net/download/jinhuding/88463932 详细说明和使用参考: 地址:http://www.gxcode.top/code 一 nginx安装步骤: 1.nginx安装与运行 官网 http://nginx.org/1.1安装gcc环境 # yum install gcc-c…...
11 Self-Attention相比较 RNN和LSTM的优缺点
博客配套视频链接: https://space.bilibili.com/383551518?spm_id_from=333.1007.0.0 b 站直接看 配套 github 链接:https://github.com/nickchen121/Pre-training-language-model 配套博客链接:https://www.cnblogs.com/nickchen121/p/15105048.html RNN 无法做长序列,当一…...

数据集-特征降维
1、降维 降维是指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程 降低随机变量的个数 相关特征(correlated feature) 相对湿度与降雨量之间的相关等等 正是因为在进行训练的时候,我们都是使用特征进行学习。如果…...

【C语言】字符串+内存函数的介绍
🎈个人主页:.满船清梦压星河_-CSDN博客 🌂c/c领域新星创作者 🎉欢迎👍点赞✍评论❤️收藏 😛😛😛希望我的文章能对你有所帮助,有不足的地方还请各位看官多多指教…...

C#WPF资源字典应用实例
本文实例演示C#WPF资源字典应用 目录 一、资源字典 二、实例 1新建一个资源字典 2添加到资源文件App.xaml...

如何在国际腾讯云服务器上设置IP节点的密码?
跟着云计算技术的发展,越来越多的企业和个人开始运用云服务器来存储和处理数据。腾讯云服务器是一款非常受欢迎的云服务器产品,它提供了高效稳定的计算能力。在运用腾讯云服务器的过程中,咱们可能需求设置IP节点的暗码,以便维护咱…...

浅谈基于敏捷开发交付应对突发项目
软件项目开发的全过程是一个很大的范畴,从确定需求,到编码设计,到集成发布,到运维、运营、设计方方面面。在这个过程中,交付过程是非常关键的,因为它影响着软件的质量、稳定性和用户体验。 在当今竞争激烈的…...

1.工具-VSCode有哪些常用快捷键
题记 记录一些vscode的常用快捷键 基本编辑 Ctrl C:复制选定内容。Ctrl X:剪切选定内容。Ctrl V:粘贴剪贴板内容。Ctrl Z:撤销上一步操作。Ctrl Shift Z:恢复上一步操作。Ctrl D:选择下一个匹配项…...

行业模型应该如何去拆解?
行业模型应该如何去拆解? 拆解行业模型是一个复杂的过程,涉及对整个行业的深入分析和理解。下面是一些步骤和方法,可以帮助你系统地拆解行业模型: 1. 确定行业范围 定义行业:明确你要分析的行业是什么,包括…...

【开题报告】基于微信小程序的签到打卡系统的设计与实现
1.研究背景与意义 考勤管理是企业日常管理的重要内容之一。随着企业规模的扩大和员工数量的增加,传统的考勤管理方式已经不能满足需求。而基于微信小程序的签到打卡系统可以提供方便快捷的签到打卡服务,为企业管理人员提高工作效率和员工考勤管理提供了…...

1.写一个算法模型以及python算法工程化步骤
生成一个 PT(Perceptual Tokenizer)模型的步骤如下: 准备数据集:首先,你需要准备一个用于训练 PT 模型的数据集。这可以是一个包含大量文本数据的语料库。 数据预处理:对数据进行预处理以准备训练。这可能…...

物联网AI MicroPython传感器学习 之 GC7219点阵屏驱动模块
学物联网,来万物简单IoT物联网!! 一、产品简介 LED-8 * 32点阵屏显示板由 4 块单色 8x8 共阴红色点阵单元组成,通过 SPI 菊花链模式将多块显示屏连接后可以组成更大的分辨率显示屏幕,任意组合分辨率。可用于简单仪表显…...
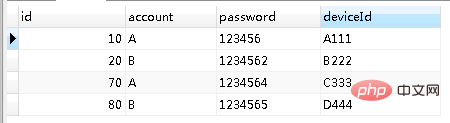
MySQL中查询重复字段的方法和步骤是怎样
示例 accountinfo 表数据如下: 场景一 单个字段重复数据查找 & 去重 我们要把上面这个表中 单个字段 account字段相同的数据找出来。 思路 分三步 简述: 第一步 要找出重复数据,我们首先想到的就是,既然是重复,…...
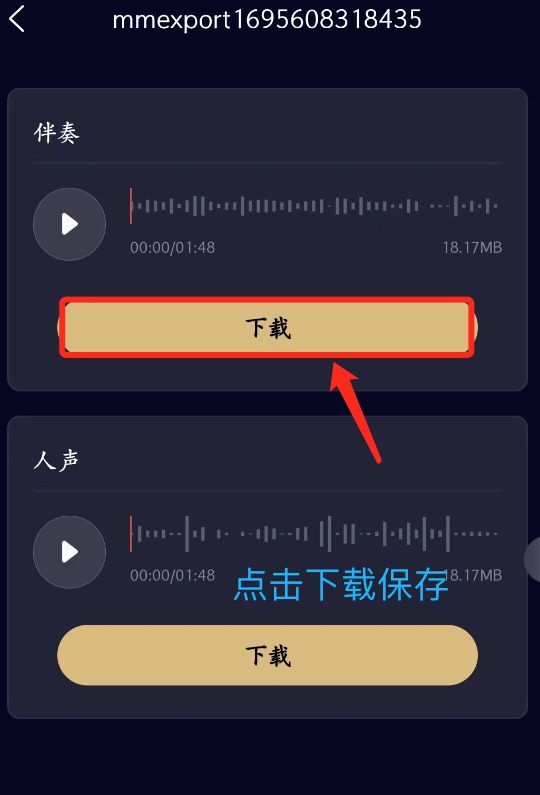
怎样才能去除视频中的背景音乐,保留人声?
做视频剪辑,二次创作的朋友,需要去除视频中的背景音乐,保留人声;或者去除人声,保留背景音乐。如果请身边做视频的朋友帮忙,可有时不能沟通到位,完成后的效果并不是很理想,就很尴尬了…...
计算机思维导论)
【C语言程序设计】--C语言(一)计算机思维导论
控制台输出中文乱码问题解决: ref:https://blog.csdn.net/ymzhu385/article/details/121797080 基本数据类型 我们的程序离不开数据,比如我们需要保存一个数字或是字母,这时候这些东西就是作为数据进行保存,不过不同的数据他们的…...

三、git信息泄露
一、git信息泄露 解释:Git信息泄露是指通过公开或错误地配置版本控制系统Git,导致敏感数据(例如API密钥、数据库密码、个人信息等)被泄露到公共代码仓库或其他未授权的访问者手中。通俗来说,在公网暴露类似http://127…...
高效清洗数据中的数字陷阱)
从混乱到有序:用pd.to_numeric()高效清洗数据中的数字陷阱
1. 数据清洗中的数字陷阱:为什么需要pd.to_numeric() 刚入行数据分析时,我接手过一个电商价格分析项目。原始数据是从20个Excel表格合并而来,打开一看差点崩溃——价格字段里混着"199"、"199元"、"199.00"、&…...

如何绕过Windows驱动签名:终极内核研究实战指南
如何绕过Windows驱动签名:终极内核研究实战指南 【免费下载链接】kdmapper KDMapper is a simple tool that exploits iqvw64e.sys Intel driver to manually map non-signed drivers in memory 项目地址: https://gitcode.com/gh_mirrors/kd/kdmapper 还在为…...
)
手把手复现DiffusionDet:基于PyTorch从论文到代码的完整实践指南(含COCO数据集)
从零实现DiffusionDet:基于PyTorch的扩散式目标检测实战指南 1. 环境配置与工具准备 在开始DiffusionDet项目之前,确保你的开发环境满足以下要求。我们将使用PyTorch作为主要框架,配合CUDA加速计算。 硬件建议: GPU࿱…...
)
告别代码复制:用GD32F3x0固件库V2.2.0优雅配置PWM互补输出(Keil MDK环境)
告别代码复制:用GD32F3x0固件库V2.2.0优雅配置PWM互补输出(Keil MDK环境) 在嵌入式开发中,PWM(脉冲宽度调制)技术广泛应用于电机控制、电源管理等领域。对于GD32F3x0系列微控制器,官方提供的固件…...

4步快速上手:用APK-Installer在Windows上轻松安装安卓应用,告别模拟器烦恼
4步快速上手:用APK-Installer在Windows上轻松安装安卓应用,告别模拟器烦恼 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为在Windows电脑…...

手把手教你用UTM在Mac M1上轻松运行Win11虚拟机
1. 为什么要在Mac M1上运行Win11虚拟机? 作为一个长期使用Mac的开发者,我完全理解那种偶尔需要Windows应用的痛苦。特别是遇到银行插件、专业工业软件或者某些游戏时,双系统切换实在太麻烦。UTM虚拟机给了我一个完美的解决方案——在M1芯片的…...

D3KeyHelper:如何通过智能宏技术解决暗黑3玩家的操作疲劳难题
D3KeyHelper:如何通过智能宏技术解决暗黑3玩家的操作疲劳难题 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 暗黑破坏神3作为一款动作角…...

Leather Dress Collection 保姆级部署教程:Windows 系统下的完整指南
Leather Dress Collection 保姆级部署教程:Windows 系统下的完整指南 如果你是一名 Windows 用户,想体验最近很火的 Leather Dress Collection 这个 AI 模型,但看到一堆 Linux 命令就头疼,那这篇教程就是为你准备的。我知道&…...

PD诱骗取电芯片XSP28Q应用简介
PD快充是近几年非常流行的一种USB快充标准协议,主要使用USB Type-C接口作为传输途径。目前主流的快充协议主要是PD协议、QC协议、AFC协议、SCP协议、VOOC等。所有的快充协议有分为供电端和受电端(或者说取电端、用电端等),一般我们…...

Anko库、AppCompat库
Anko库Anko 是一个由 JetBrains 公司开发的 Kotlin 库,旨在简化 Android 应用程序的开发过程。它通过提供简洁的 API 和基于 Kotlin 的领域特定语言(DSL),减少了样板代码,提升了开发效率和代码可读性。Anko 的最后一个…...