深度学习 | Pytorch深度学习实践 (Chapter 10、11 CNN)
十、CNN 卷积神经网络 基础篇
首先引入 ——
- 二维卷积:卷积层保留原空间信息
- 关键:判断输入输出的维度大小
- 特征提取:卷积层、下采样
- 分类器:全连接

引例:RGB图像(栅格图像)
- 首先,老师介绍了CCD相机模型,这是一种通过光敏电阻,利用光强对电阻的阻值影响,对应地影响色彩亮度实现不同亮度等级像素采集的原件。三色图像是采用不同敏感度的光敏电阻实现的。
- 还介绍了矢量图像(也就是PPT里通过圆心、边、填充信息描述而来的图像,而非采集的图像)
- 红绿蓝 Channel
- 拿出一个图像块做卷积,通道高度宽度都可能会改变,将整个图像遍历,每个块分别做卷积
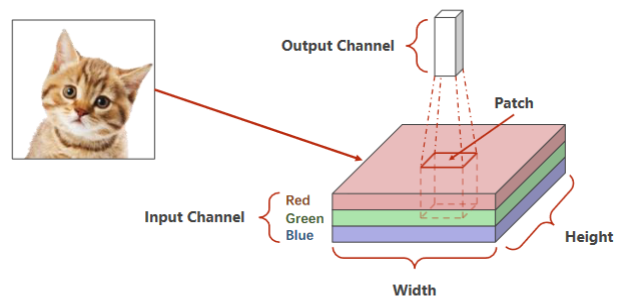
引例:
深度学习 | CNN卷积核与通道-CSDN博客
实现:A Simple Convolutional Neural Network
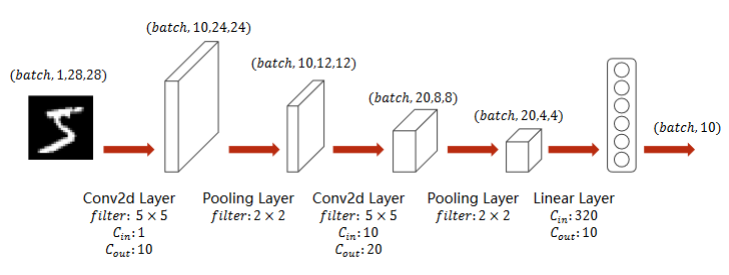
- 池化层一个就行,因为他没有权重,但是有权重的,必须每一层做一个实例
- relu 非线性激活
- 交叉熵损失 最后一层不做激活!

代码实现:
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim# 1、数据准备
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))
])train_dataset = datasets.MNIST(root='../dataset/mnist',train=True,download=True,transform=transform)
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size)test_dataset = datasets.MNIST(root='../dataset/mnist',train=False,download=True,transform=transform)
test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size)# 2、构建模型
class Net(torch.nn.Module):def __init__(self):super(Net,self).__init__()self.conv1 = torch.nn.Conv2d(1,10,kernel_size=5)self.conv2 = torch.nn.Conv2d(10,20,kernel_size=5)self.pooling = torch.nn.MaxPool2d(2)self.fc = torch.nn.Linear(320,10)def forward(self,x):# Flatten data from (n,1,28,28) to (n,784)batch_size = x.size(0)x = self.pooling(F.relu(self.conv1(x)))x = self.pooling(F.relu(self.conv2(x)))x = x.view(batch_size,-1) #flattenx = self.fc(x)return xmodel = Net()# 3、损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.01,momentum=0.5)# 4、训练和测试
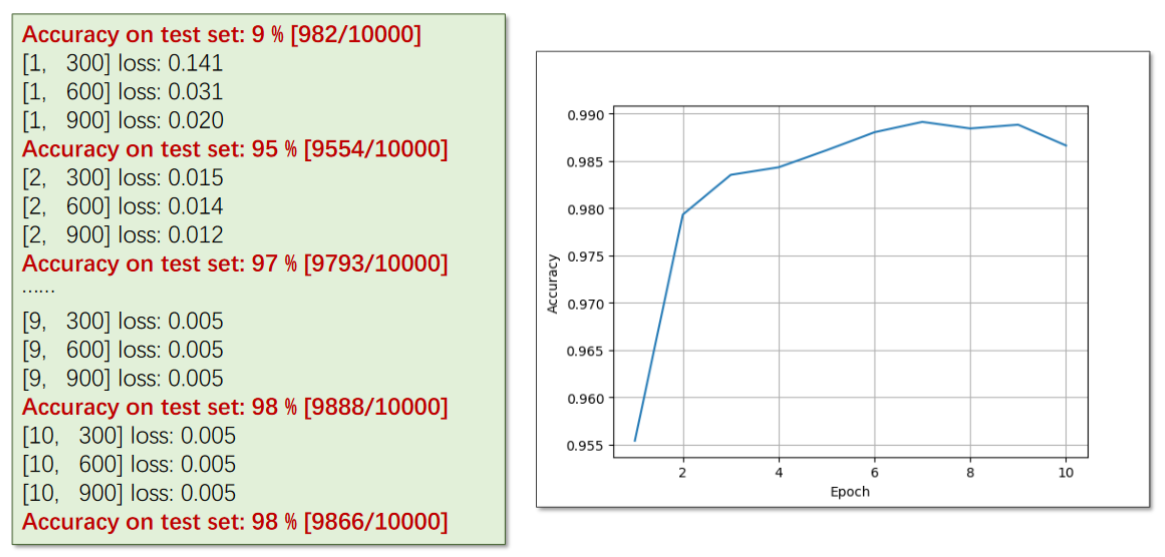
def train(epoch):running_loss = 0.0for batch_idx,data in enumerate(train_loader,0):inputs,target = dataoptimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs,target)loss.backward()optimizer.step()running_loss += loss.item()if batch_idx % 300 == 299: # 每三百次迭代输出一次print('[%d , %5d] loss: %.3f' % (epoch + 1 ,batch_idx + 1,running_loss / 300))running_loss = 0.0def test():correct = 0total = 0with torch.no_grad():for data in test_loader:images,labels = dataoutputs = model(images) # 输出为一个矩阵,下面要求每一行最大值(即分类)的下标_,predicted = torch.max(outputs.data,dim=1)total += labels.size(0)correct += (predicted == labels).sum().item()print('Accuracy on test set: %d %%' % (100 * correct / total))if __name__ == '__main__':for epoch in range(10):train(epoch)test()实验结果:


十一、CNN 卷积神经网络 高级篇
基础篇中设计的模型类似于LeNet5
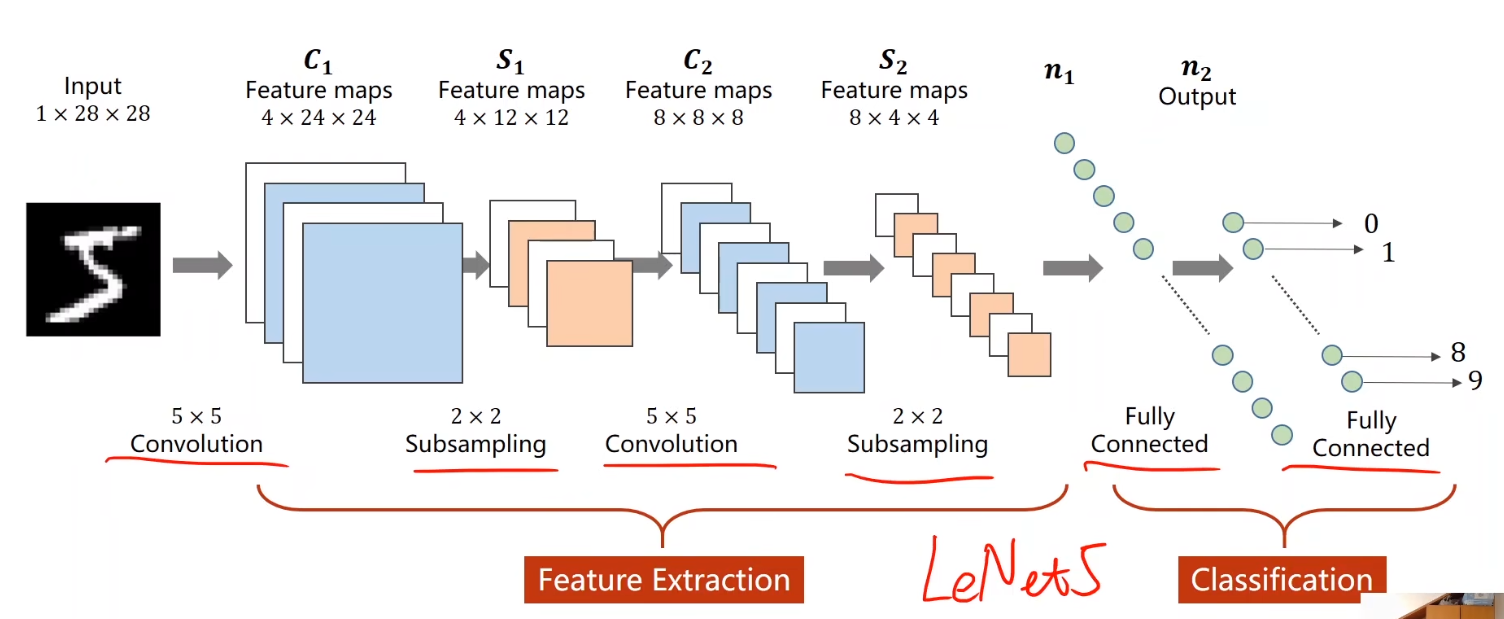
再来看一些更为复杂的结构:
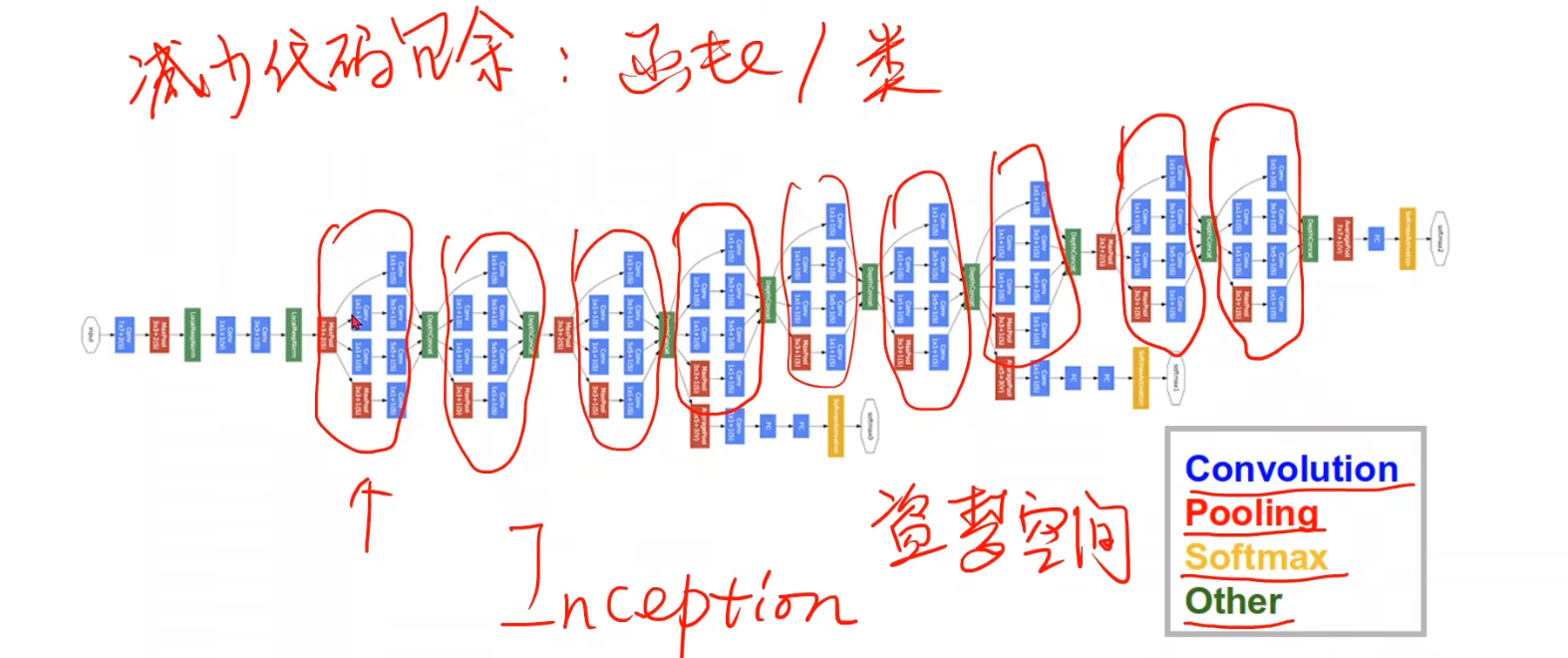
11.1、GoogLeNet
GoogLeNet是一种串行结构的复杂网络;想要实现复杂网络,并且较少代码冗余和多次重写相同功能的程序,面向过程的语言使用函数,面向对象的语言python使用类,
而在CNN当中,使用Module和block这种模块将具有复用价值的代码块封装成一块积木,供拼接使用;
GoogLeNet为自己框架里被重复使用的Module命名为Inception,这也电影盗梦空间的英文名,意为:梦中梦、嵌套;
Inception Module的构造方式之一:
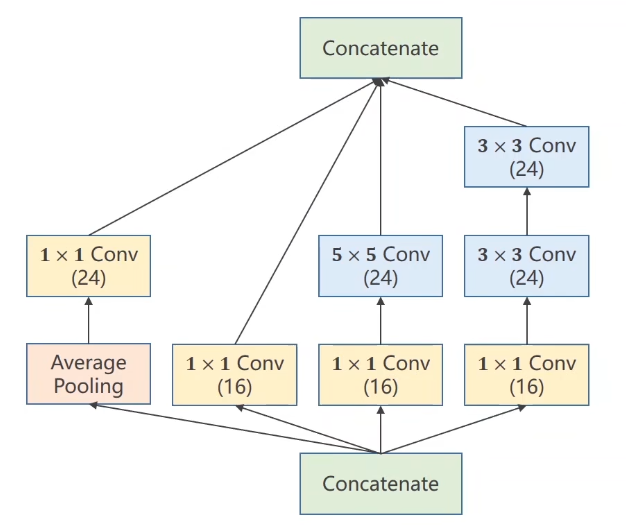
- 为什么要做成这个样子?
- —— 在构建神经网络时,一些超参数我们是难以确定的,比如卷积核的大小,所以你不知道哪个好用,那我就都用一下,将来通过训练,找到最优的卷积组合。
GoogLeNet的设计思路是:我把各种形式的核都写进我的Block当中,至于每一个支路的权重,让网络训练的时候自己去搭配;
- Concatenate:将四条通道算出来的张量拼接到一起
GoogLeNet设计了四条通路支线,并要求他们保证图像的宽和高W、H必须相同,只有通道数C可以不相同,因为各支线进行过卷积和池化等操作后,要将W和H构成的面为粘合面,按照C的方向,拼接concatenate起来;- Average Pooling:均值池化
- 1x1的卷积可以将信息融合:也叫network in network(网络里的网络)
1 * 1的卷积核:以往我只是表面上觉得,单位像素大小的卷积核,他的意义不过是调整输入和输出的通道数之间的关系;刘老师举了个例子,让我对这个卷积核有了新的认识:- 就是加速运算,他的作用的确是加速运算,不过其中的原理是:通过
1*1的核处理过的图像,可以减少后续卷积层的输入通道数;

Inception块 代码实现:
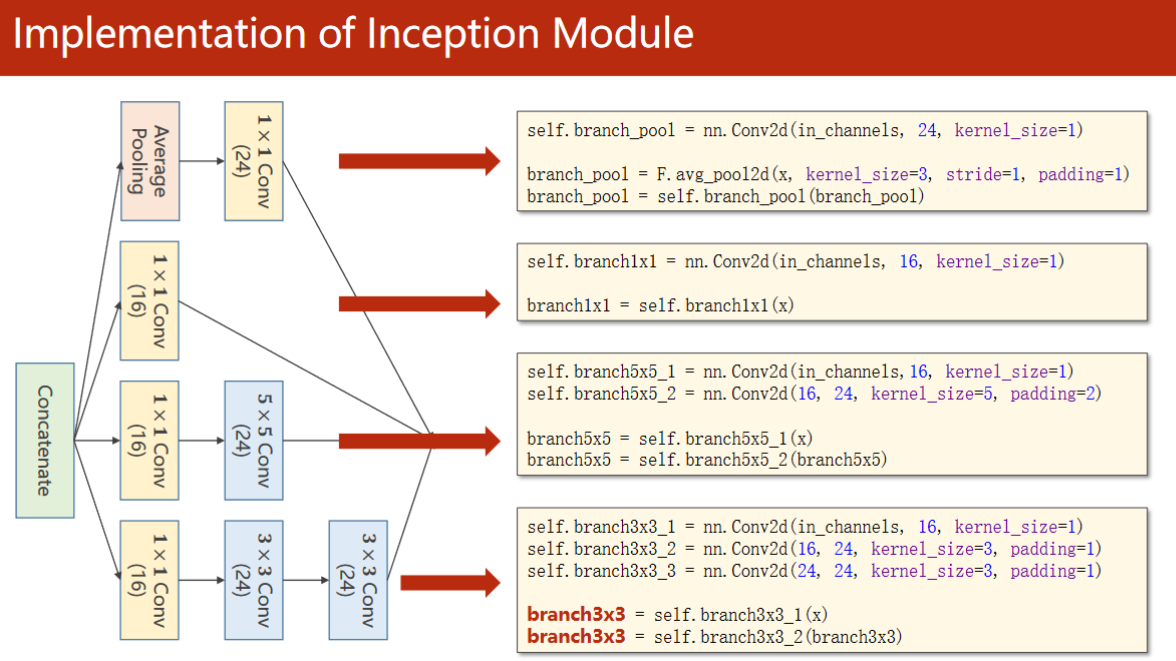
然后再沿着通道将他们拼接在一起:
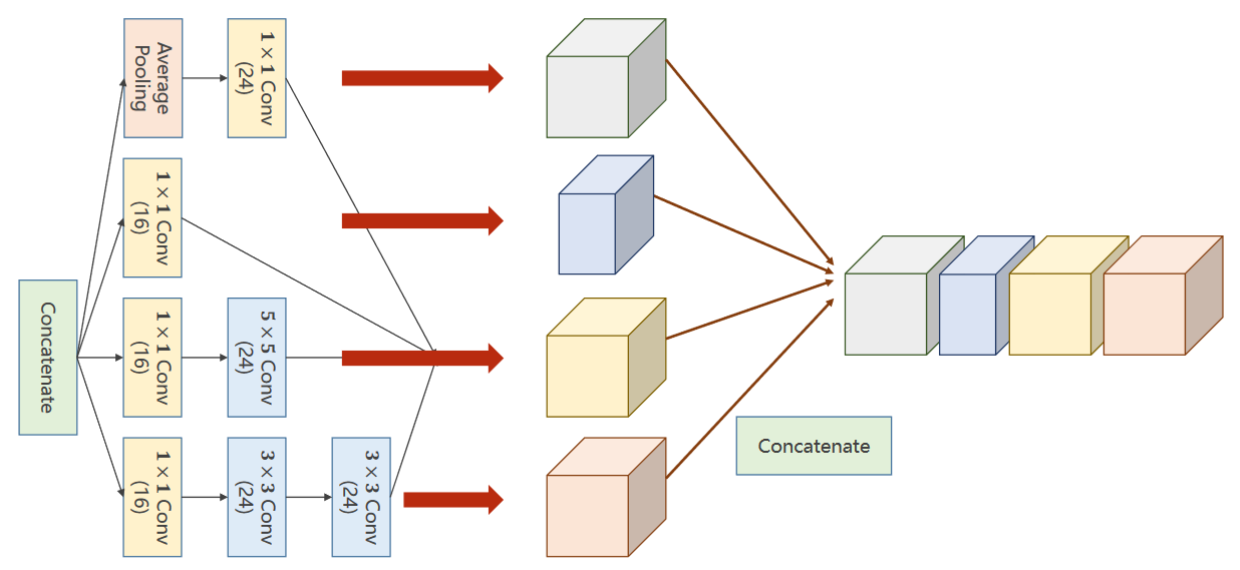
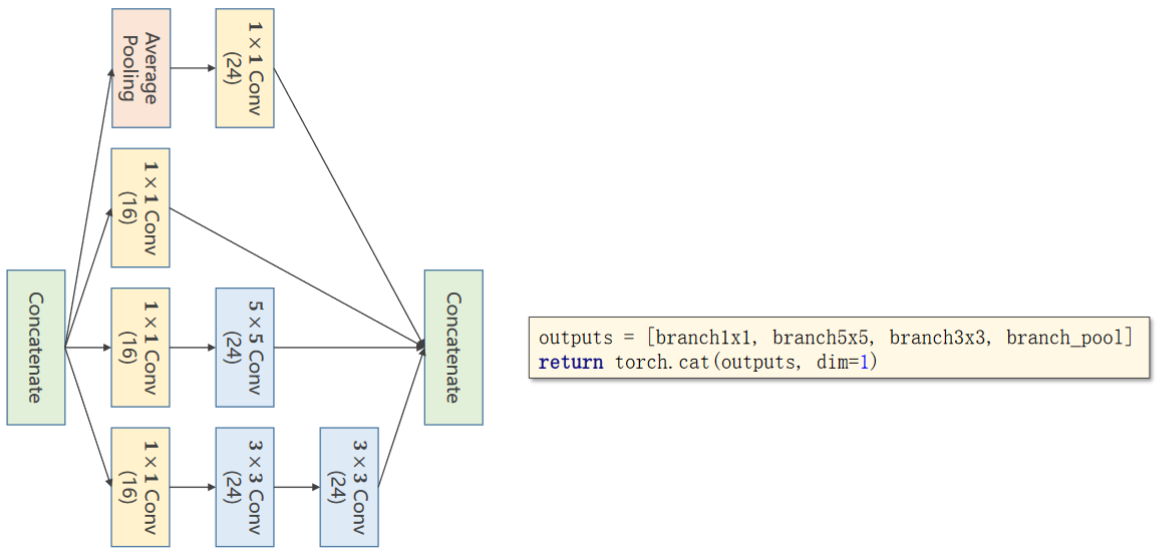
将四个分支可以放到一个列表里,然后用torch提供的函数cat沿着dim=1的维度将他们拼接起来
因为我们的维度是 batch,channel,width,height ,所以是第一个维度dim=1,索引从零开始,C的位置是1
MNIST数据集 代码实现:
初始的输入通道并没有写死,而是作为构造函数里的参数,这是因为我们将来实例化时可以指明输入通道是多少。
先是1个卷积层(conv,maxpooling,relu),然后inceptionA模块(输出的channels是24+16+24+24=88),接下来又是一个卷积层(conv,mp,relu),然后inceptionA模块,最后一个全连接层(fc)。
1408这个数据可以通过x = x.view(in_size, -1)后调用x.shape得到。
也可通过查看网络结构:
最后一层线性层的输入尺寸(input size)1408是根据倒数第二个InceptionA模块的输出形状推导出来的。在该模块中,输入形状为[-1, 88, 4, 4],其中-1表示批量大小(Batch Size)。因此,通过展平这个特征图(Flatten),我们可以将其转换为一维向量,即 [-1, 88 * 4 * 4] = [-1, 1408]。
所以,线性层的输入尺寸为1408,它接收展平后的特征向量作为输入,并将其映射到10个输出类别的向量。
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optimfrom torchvision import models
from torchsummary import summary# 1、数据准备
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))
])train_dataset = datasets.MNIST(root='../dataset/mnist',train=True,download=True,transform=transform)
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size)test_dataset = datasets.MNIST(root='../dataset/mnist',train=False,download=True,transform=transform)
test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size)# 2、构建模型
class InceptionA(torch.nn.Module):def __init__(self,in_channels):super(InceptionA,self).__init__()self.branch1x1 = torch.nn.Conv2d(in_channels,16,kernel_size=1)self.branch5x5_1 = torch.nn.Conv2d(in_channels,16,kernel_size=1)self.branch5x5_2 = torch.nn.Conv2d(16, 24, kernel_size=5,padding=2)self.branch3x3_1 = torch.nn.Conv2d(in_channels,16,kernel_size=1)self.branch3x3_2 = torch.nn.Conv2d(16, 24,kernel_size=3,padding=1)self.branch3x3_3 = torch.nn.Conv2d(24, 24, kernel_size=3, padding=1)self.branch_pool = torch.nn.Conv2d(in_channels,24,kernel_size=1)def forward(self,x):branch1x1 = self.branch1x1(x)branch5x5 = self.branch5x5_1(x)branch5x5 = self.branch5x5_2(branch5x5)branch3x3 = self.branch3x3_1(x)branch3x3 = self.branch3x3_2(branch3x3)branch3x3 = self.branch3x3_3(branch3x3)branch_pool = F.avg_pool2d(x,kernel_size=3,stride=1,padding=1)branch_pool = self.branch_pool(branch_pool)outputs = [branch1x1,branch5x5,branch3x3,branch_pool]return torch.cat(outputs,dim=1)class Net(torch.nn.Module):def __init__(self):super(Net,self).__init__()self.conv1 = torch.nn.Conv2d(1,10,kernel_size=5)self.conv2 = torch.nn.Conv2d(88,20,kernel_size=5)self.incep1 = InceptionA(in_channels=10)self.incep2 = InceptionA(in_channels=20)self.mp = torch.nn.MaxPool2d(2)self.fc = torch.nn.Linear(1408,10)def forward(self,x):in_size = x.size(0)x = F.relu(self.mp(self.conv1(x)))x = self.incep1(x)x = F.relu(self.mp(self.conv2(x)))x = self.incep2(x)x = x.view(in_size,-1)x = self.fc(x)return xmodel = Net()
#summary(model,(1,28,28),device='cpu')# 3、损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.01,momentum=0.5)# 4、训练和测试
def train(epoch):running_loss = 0.0for batch_idx,data in enumerate(train_loader,0):inputs,target = dataoptimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs,target)loss.backward()optimizer.step()running_loss += loss.item()if batch_idx % 300 == 299: # 每三百次迭代输出一次print('[%d , %5d] loss: %.3f' % (epoch + 1 ,batch_idx + 1,running_loss / 300))running_loss = 0.0def test():correct = 0total = 0with torch.no_grad():for data in test_loader:images,labels = dataoutputs = model(images) # 输出为一个矩阵,下面要求每一行最大值(即分类)的下标_,predicted = torch.max(outputs.data,dim=1)total += labels.size(0)correct += (predicted == labels).sum().item()print('Accuracy on test set: %d %%' % (100 * correct / total))if __name__ == '__main__':for epoch in range(10):train(epoch)test() Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 10, 24, 24] 260
MaxPool2d-2 [-1, 10, 12, 12] 0
Conv2d-3 [-1, 16, 12, 12] 176
Conv2d-4 [-1, 16, 12, 12] 176
Conv2d-5 [-1, 24, 12, 12] 9,624
Conv2d-6 [-1, 16, 12, 12] 176
Conv2d-7 [-1, 24, 12, 12] 3,480
Conv2d-8 [-1, 24, 12, 12] 5,208
Conv2d-9 [-1, 24, 12, 12] 264
InceptionA-10 [-1, 88, 12, 12] 0
Conv2d-11 [-1, 20, 8, 8] 44,020
MaxPool2d-12 [-1, 20, 4, 4] 0
Conv2d-13 [-1, 16, 4, 4] 336
Conv2d-14 [-1, 16, 4, 4] 336
Conv2d-15 [-1, 24, 4, 4] 9,624
Conv2d-16 [-1, 16, 4, 4] 336
Conv2d-17 [-1, 24, 4, 4] 3,480
Conv2d-18 [-1, 24, 4, 4] 5,208
Conv2d-19 [-1, 24, 4, 4] 504
InceptionA-20 [-1, 88, 4, 4] 0
Linear-21 [-1, 10] 14,090

11.2、ResNet
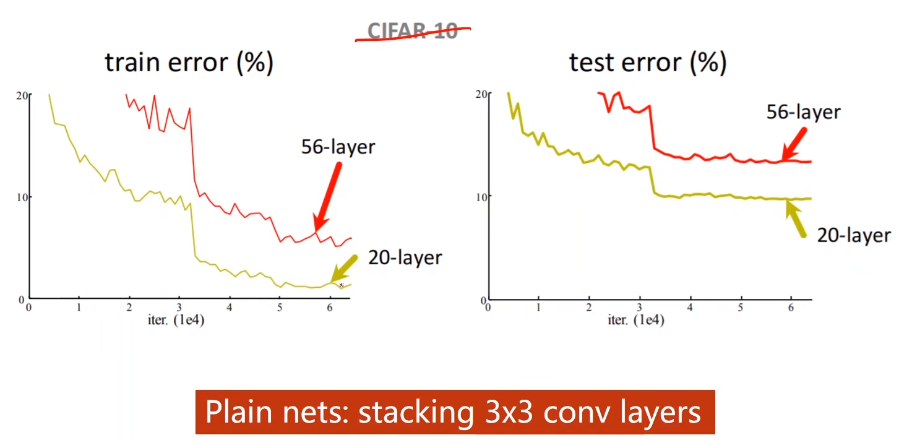
GoogLeNet最后留下了一个问题:通过测试,网络的层数会影响模型的精度,但当时没有意识到梯度消失的问题,
所以GoogLeNet认为We Need To Go Deeper;
直到何凯明大神的ResNet的出现,提出了层数越多,模型效果不一定越好的问题,
并针对这个问题提出了解决方案ResNet网络结构。
Residual Net提出了这样一种块:跳连接
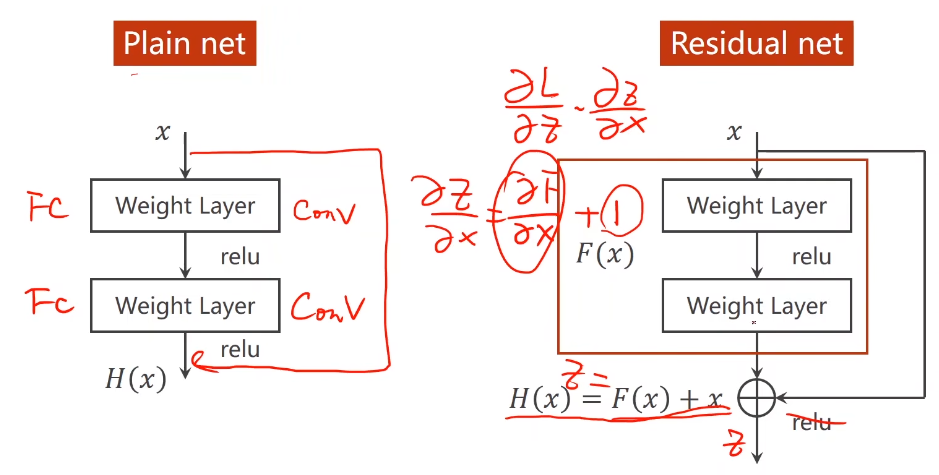
以往的网络模型是这种Plain Net形式:
输入数据x,经过Weight Layer(可以是卷积层,也可以是池化或者线性层),再通过激活函数加入非线性影响因素,最后输出结果H(x);
这种方式使得H(x)对x的偏导数的值分布在(0,1)之间,这在反向传播、复合函数的偏导数逐步累乘的过程中,必然会导致损失函数L对x的偏导数的值,趋近于0,而且,网络层数越深,这种现象就会越明显,最终导致最开始的(也就是靠近输入的)层没有获得有效的权重更新,甚至模型失效;
即梯度消失:假如每一处的梯度都小于1,由于我们使用的是反向传播,当梯度趋近于0时,那么权重得不到更新:,也就是说离输入近的块没办法得到充分的训练。
解决方法:逐层训练,但层数过多会很难
ResNet采用了一个非常巧妙的方式解决了H(x)对x的偏导数的值分布在(0,1)之间这个问题:
在以往的框架中,加入一个跳跃,再原有的网络输出F(x)的基础上,将输入x累加到上面,这样一来,在最终输出H(x)对输入数据x求偏导数的时候,这个结果就会分布在(1,2)之间,这样就不怕网络在更新权重梯度累乘的过程中,出现乘积越来越趋于0而导致的梯度消失问题;
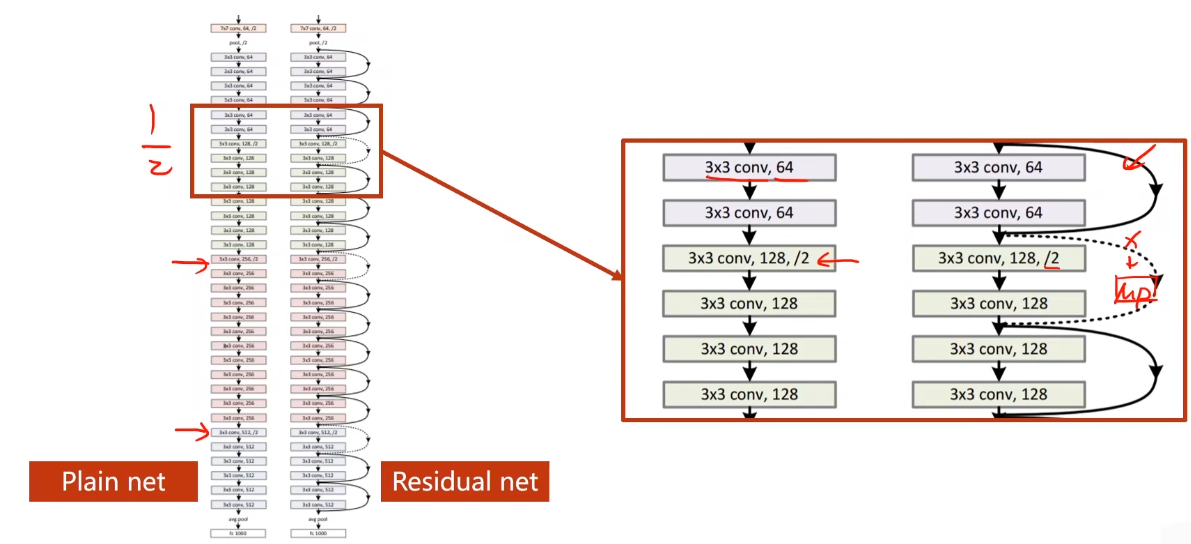
与GoogLeNet类似,ResNet的Residual Block在搭建时,留了一个传入参数的机会,这个参数留给了通道数channel,Residual Block的要求是输入与输出的C,W,H分别对应相同,B是一定要相同的,所以就是说,经过残差模块Residual Block处理过的图像,并不改变原有的尺寸和通道数;(TBD)
但是注意,因为要和x做加法,所以图中的两层输出和输入x 张量维度必须完全一样,即通道高度宽度都要一样
若输出和输入的维度不一样,也可以做跳连接,可以将x过一个最大池化层转换成同样的大小,如下图
利用残差结构块的网络:

先来看一下residual block的代码实现:
为了保持输入输出的大小不变,所以要将padding设置为1,输入通道和输出通道都和x保持一致
注意第二个卷积之后,先做求和再激活

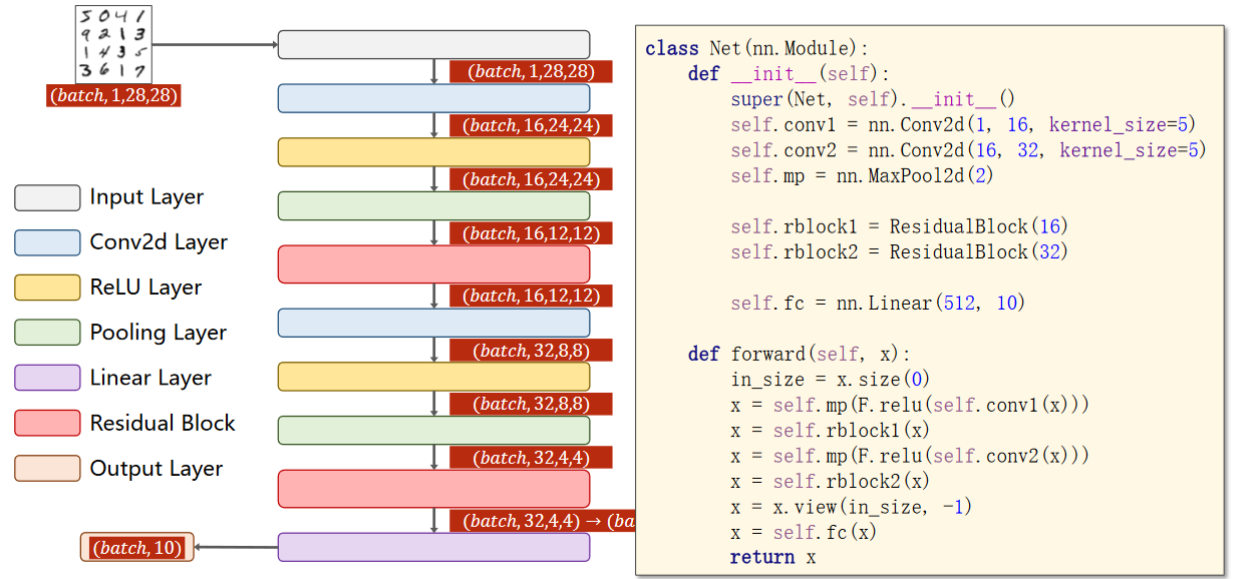
MNIST数据集 代码实现:
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optimfrom torchvision import models
from torchsummary import summary
from torchviz import make_dot# 1、数据准备
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))
])train_dataset = datasets.MNIST(root='../dataset/mnist',train=True,download=True,transform=transform)
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size)test_dataset = datasets.MNIST(root='../dataset/mnist',train=False,download=True,transform=transform)
test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size)# 2、构建模型
class InceptionA(torch.nn.Module):def __init__(self,in_channels):super(InceptionA,self).__init__()self.branch1x1 = torch.nn.Conv2d(in_channels,16,kernel_size=1)self.branch5x5_1 = torch.nn.Conv2d(in_channels,16,kernel_size=1)self.branch5x5_2 = torch.nn.Conv2d(16, 24, kernel_size=5,padding=2)self.branch3x3_1 = torch.nn.Conv2d(in_channels,16,kernel_size=1)self.branch3x3_2 = torch.nn.Conv2d(16, 24,kernel_size=3,padding=1)self.branch3x3_3 = torch.nn.Conv2d(24, 24, kernel_size=3, padding=1)self.branch_pool = torch.nn.Conv2d(in_channels,24,kernel_size=1)def forward(self,x):branch1x1 = self.branch1x1(x)branch5x5 = self.branch5x5_1(x)branch5x5 = self.branch5x5_2(branch5x5)branch3x3 = self.branch3x3_1(x)branch3x3 = self.branch3x3_2(branch3x3)branch3x3 = self.branch3x3_3(branch3x3)branch_pool = F.avg_pool2d(x,kernel_size=3,stride=1,padding=1)branch_pool = self.branch_pool(branch_pool)outputs = [branch1x1,branch5x5,branch3x3,branch_pool]return torch.cat(outputs,dim=1)class ResidualBlock(torch.nn.Module):def __init__(self,channels):super(ResidualBlock,self).__init__()self.channels = channelsself.conv1 = torch.nn.Conv2d(channels,channels,kernel_size=3,padding=1)self.conv2 = torch.nn.Conv2d(channels, channels, kernel_size=3, padding=1)def forward(self,x):y = F.relu(self.conv1(x))y = self.conv2(y)return F.relu(x+y)class Net(torch.nn.Module):def __init__(self):super(Net,self).__init__()self.conv1 = torch.nn.Conv2d(1,16,kernel_size=5)self.conv2 = torch.nn.Conv2d(16,32,kernel_size=5)self.rblock1 = ResidualBlock(16)self.rblock2 = ResidualBlock(32)self.mp = torch.nn.MaxPool2d(2)self.fc = torch.nn.Linear(512,10)def forward(self,x):in_size = x.size(0)x = self.mp(F.relu(self.conv1(x)))x = self.rblock1(x)x = self.mp(F.relu(self.conv2(x)))x = self.rblock2(x)x = x.view(in_size,-1)x = self.fc(x)return xmodel = Net()
#x = torch.randn(1,1,28,28)
#y = model(x)
#vise=make_dot(y, params=dict(model.named_parameters()))
#vise.view()
#print(model)
#summary(model,(1,28,28),device='cpu')# 3、损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.01,momentum=0.5)# 4、训练和测试
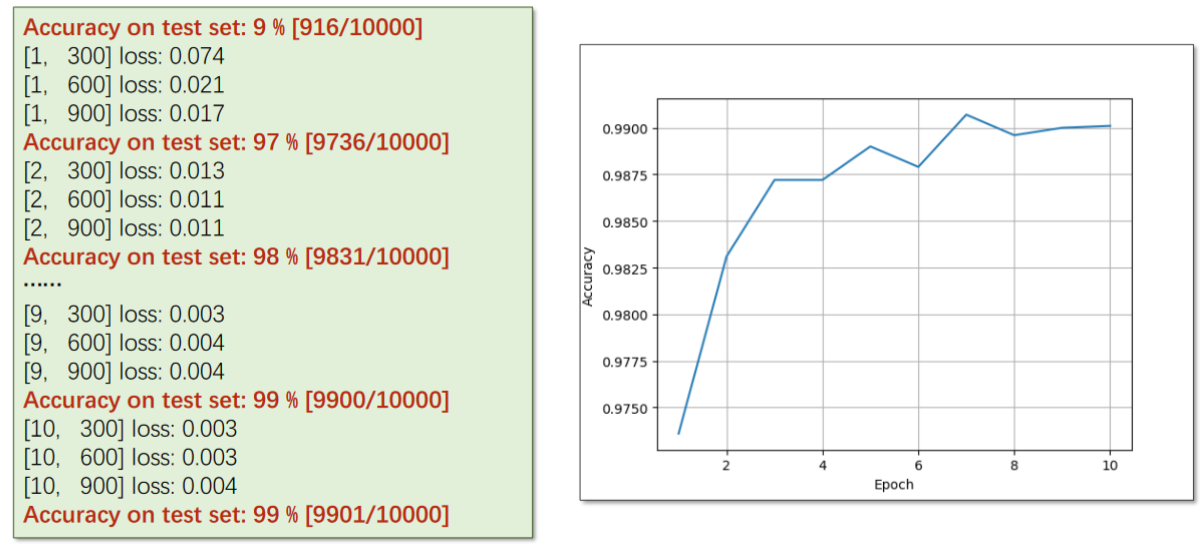
def train(epoch):running_loss = 0.0for batch_idx,data in enumerate(train_loader,0):inputs,target = dataoptimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs,target)loss.backward()optimizer.step()running_loss += loss.item()if batch_idx % 300 == 299: # 每三百次迭代输出一次print('[%d , %5d] loss: %.3f' % (epoch + 1 ,batch_idx + 1,running_loss / 300))running_loss = 0.0def test():correct = 0total = 0with torch.no_grad():for data in test_loader:images,labels = dataoutputs = model(images) # 输出为一个矩阵,下面要求每一行最大值(即分类)的下标_,predicted = torch.max(outputs.data,dim=1)total += labels.size(0)correct += (predicted == labels).sum().item()print('Accuracy on test set: %d %%' % (100 * correct / total))if __name__ == '__main__':for epoch in range(10):train(epoch)test()实验结果:
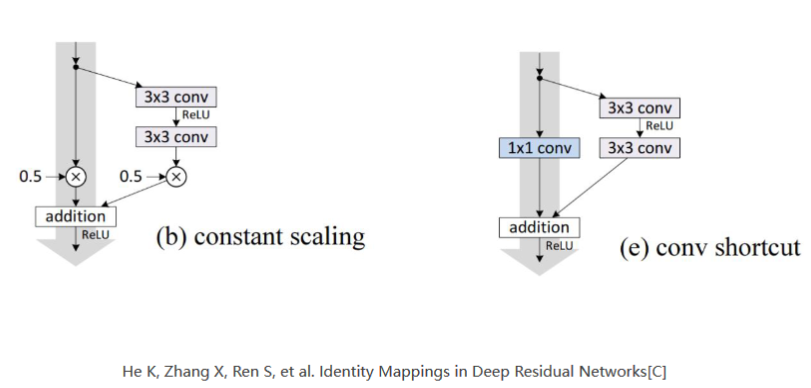
课程最后刘老师推荐了两篇论文:
Identity Mappings in Deep Residual Networks:
He K, Zhang X, Ren S, et al. Identity Mappings in Deep Residual Networks[C]
其中给出了很多不同种类的Residual Block变化的构造形式;
Densely Connected Convolutional Networks:
Huang G, Liu Z, Laurens V D M, et al. Densely Connected Convolutional Networks[J]. 2016:2261-2269.
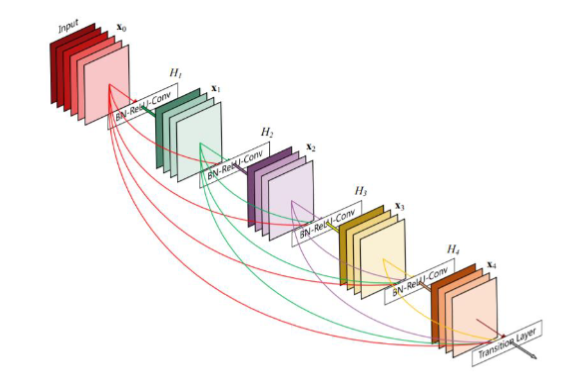
大名鼎鼎的DenseNet,这个网络结构基于ResNet跳跃传递的思想,实现了多次跳跃的网络结构,以后很多通过神经网络提取多尺度、多层级的特征,都在利用这种方式,通过Encoder对不同层级的语义特征进行逐步提取,在穿插着传递到Decoder过程中不同的层级上去,旨在融合不同层级的特征,尽可能地挖掘图像全部的特征;
学习方法

全文资料及部分文字来源于 ——
【Pytorch深度学习实践】B站up刘二大人之BasicCNN & Advanced CNN -代码理解与实现(9/9)_b站讲神经网络的up土堆-CSDN博客
11.卷积神经网络(高级篇)_哔哩哔哩_bilibili
相关文章:
深度学习 | Pytorch深度学习实践 (Chapter 10、11 CNN)
十、CNN 卷积神经网络 基础篇 首先引入 —— 二维卷积:卷积层保留原空间信息关键:判断输入输出的维度大小特征提取:卷积层、下采样分类器:全连接 引例:RGB图像(栅格图像) 首先,老师…...
谈谈你对spring boot 3.0的理解
谈谈你对spring boot 3.0的理解 一,Spring Boot 3.0 的兼容性 Spring Boot 3.0 在兼容性方面做出了很大的努力,以支持存量项目和老项目。尽管如此,仍需注意以下几点: Java 版本要求:Spring Boot 3.0 要求使用 Java 1…...
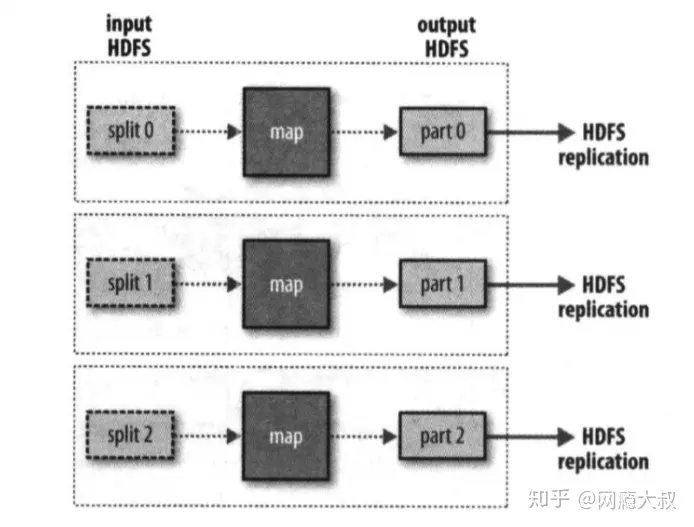
【大数据】Hadoop
文章目录 概述Hadoop组成HDFSMapReduce写MapReduce程序(Hadoop streaming) YARNHadoop 启动 工作方式Hadoop的主从工作方式Hadoop的守护进程 运行模式本地运行模式伪分布式运行模式完全分布式运行模式 Hadoop高可用的解决方案ZooKeeper quorumZKFC 环境搭…...
Spring实例化源码解析之Bean的实例化(十二)
前言 本章开始分析finishBeanFactoryInitialization(beanFactory)方法,直译过来就是完成Bean工厂的初始化,这中间就是非lazy单例Bean的实例化流程。ConversionService在第十章已经提前分析了。重点就是最后一句,我们的bean实例化分析就从这里…...

git常用的几条命令介绍
必须了解的命令整理 1,git init 初始化一个新的Git仓库。 这将在当前目录中创建一个名为".git"的子目录,Git会将所有仓库的元数据存储在其中。 2,git clone 克隆一个已存在的仓库。 这会创建一个本地仓库的副本,包…...

使用VisualSVN在Windows系统上设置SVN服务器,并结合内网穿透实现公网访问
文章目录 前言1. VisualSVN安装与配置2. VisualSVN Server管理界面配置3. 安装cpolar内网穿透3.1 注册账号3.2 下载cpolar客户端3.3 登录cpolar web ui管理界面3.4 创建公网地址 4. 固定公网地址访问 前言 SVN 是 subversion 的缩写,是一个开放源代码的版本控制系统…...
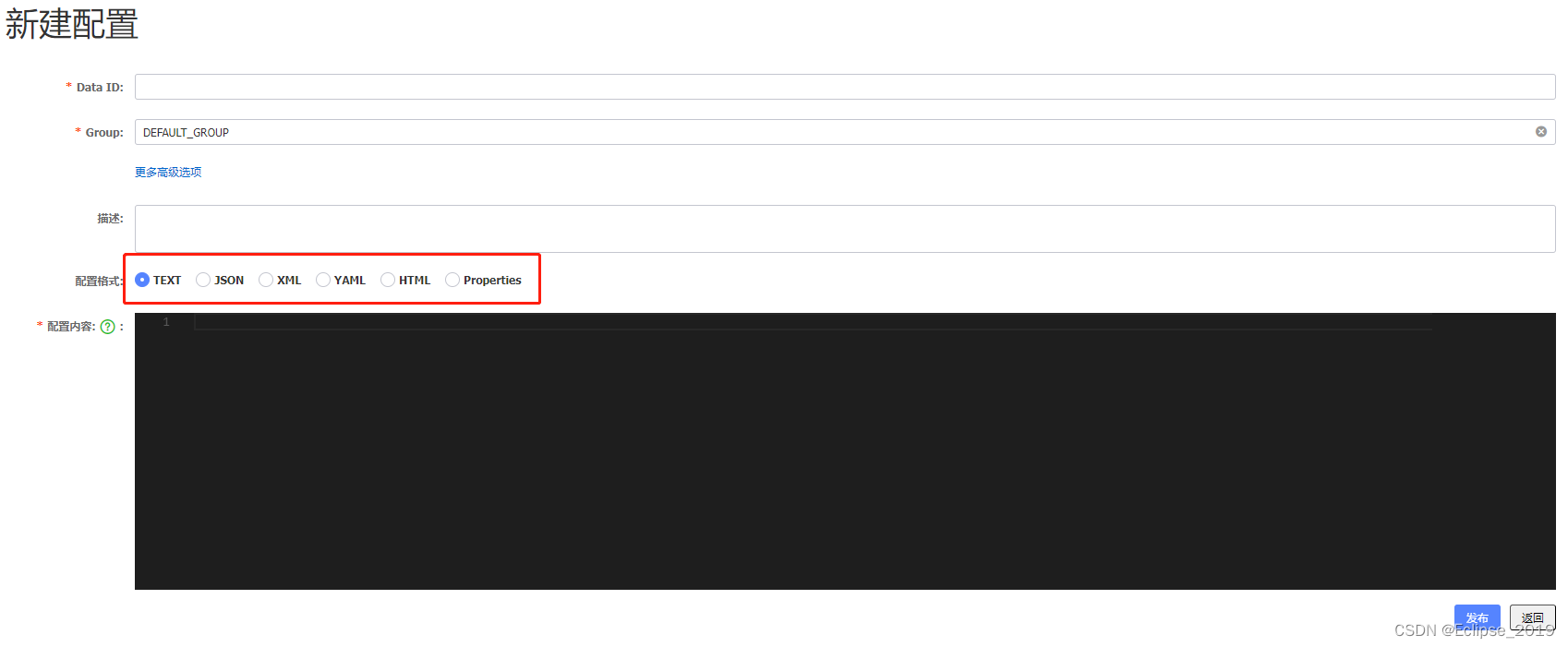
第18章 SpringCloud生态(三)
18.21 Nacos能存储什么样格式的数据(配置中心) 难度:★ 重点:★ 白话解析 看下面这副Nacos控制台的截图就明白了 参考答案 六种格式数据:Text、JSON、XML、Yaml、HTML和Properties格式。 18.22 Nacos是如何实现配置动态更新的(配置中心) 难度:★★ 重点:★★★ 白话…...
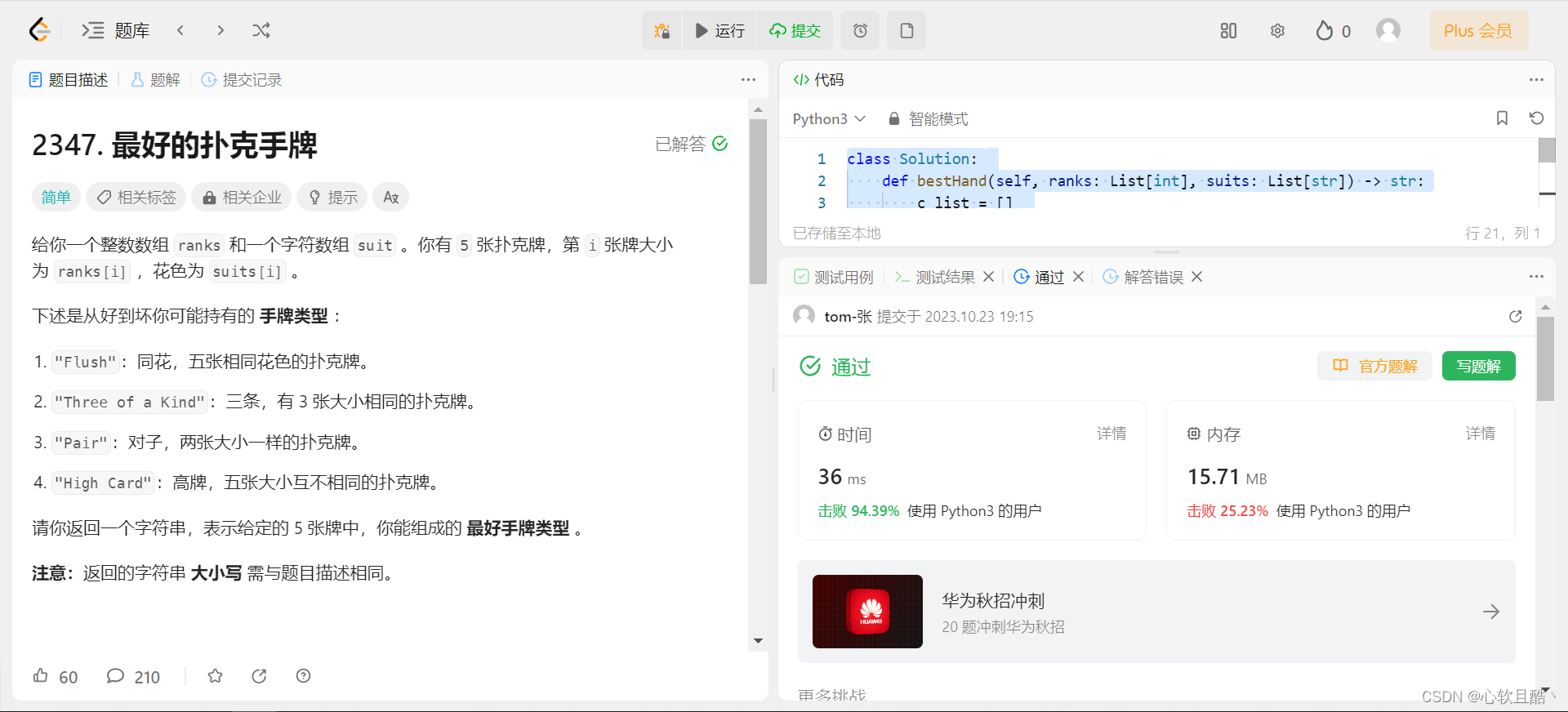
leetcode:2347. 最好的扑克手牌(python3解法)
难度:简单 给你一个整数数组 ranks 和一个字符数组 suit 。你有 5 张扑克牌,第 i 张牌大小为 ranks[i] ,花色为 suits[i] 。 下述是从好到坏你可能持有的 手牌类型 : "Flush":同花,五张相同花色的…...
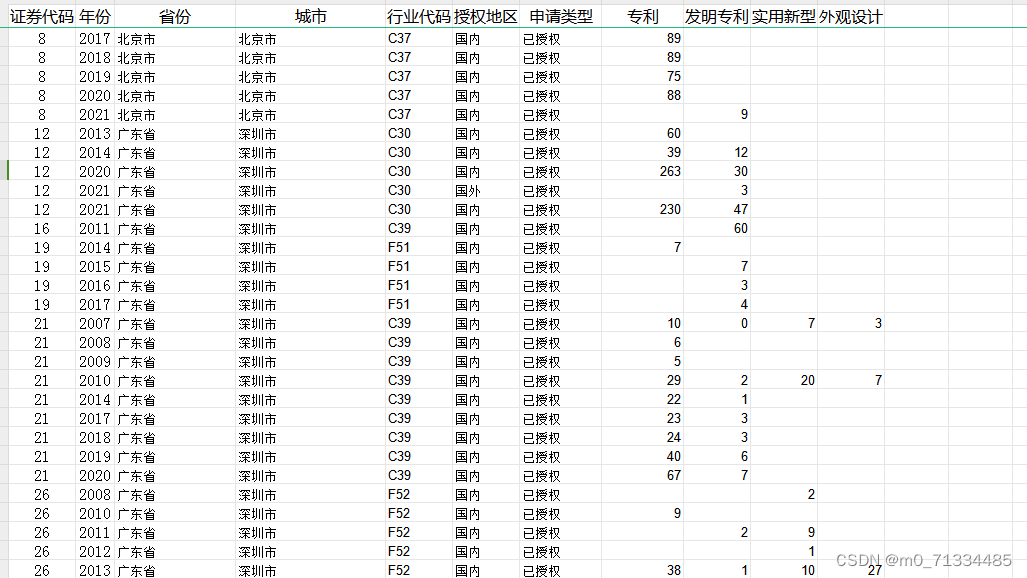
2007-2022 年上市公司国内外专利授权情况数据
2007-2022 年上市公司国内外专利授权情况 1、来源:国家知识产权局 2、时间:2007-2022 年 3、范围:上市公司 4、指标: 证券代码、年份、省份、城市、行业代码、授权地区、申请类型、专利、发明专利、实用新型、外观设计 5、…...

安全渗透测试网络基础知识之路由技术
#1.静态路由技术 ##1.1路由技术种类: 静态路由技术、动态路由技术 ##1.2静态路由原理 静态路由是网络中一种手动配置的路由方式,用于指定数据包在网络中的传输路径。与动态路由协议不同,静态路由需要管理员手动配置路由表,指定目的网络和下一跳路由器的关联关系。 比较适合…...
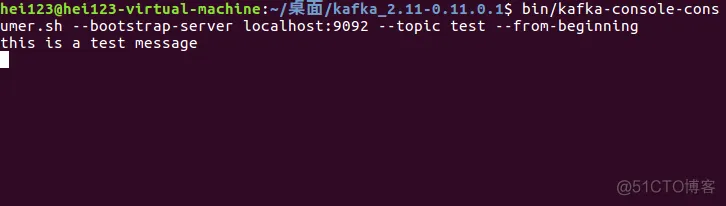
【大数据】Kafka 实战教程(二)
Kafka 实战教程(二) 1.下载2.安装3.配置4.运行4.1 启动 Zookeeper4.2 启动 Kafka 5.第一个消息5.1 创建一个 Topic5.2 创建一个消息消费者5.3 创建一个消息生产者 1.下载 你可以在 Kafka 官网:http://kafka.apache.org/downloads,…...
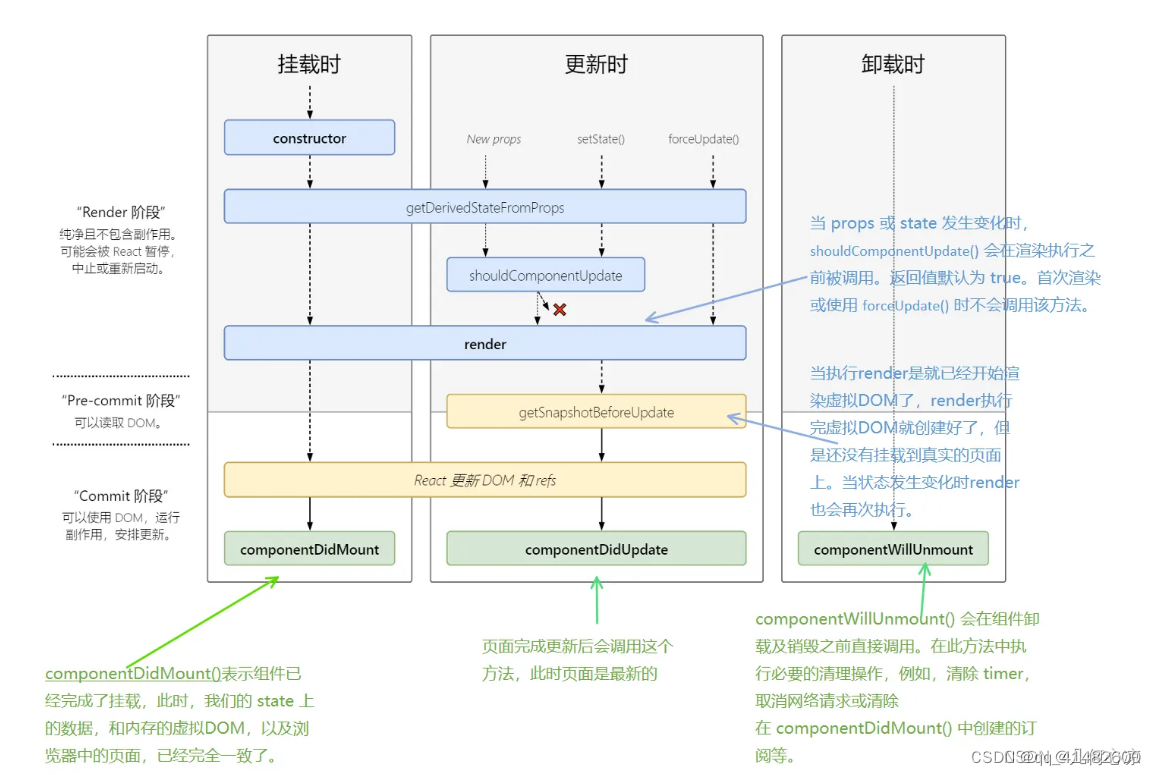
React 框架
1、React 框架简介 1.1、介绍 CS 与 BS结合:像 React,Vue 此类框架,转移了部分服务器的功能到客户端。将CS 和 BS 加以结合。客户端只用请求一次服务器,服务器就将所有js代码返回给客户端,所有交互类操作都不再依赖服…...

数据结构与算法之图: Leetcode 133. 克隆图 (Typescript版)
克隆图 https://leetcode.cn/problems/clone-graph/description/ 描述 给你无向 连通 图中一个节点的引用,请你返回该图的 深拷贝(克隆)。 图中的每个节点都包含它的值 val(int) 和其邻居的列表(list[No…...

illuminate/database 使用 一
illuminate/database 是完整的php数据库工具包,即ORM(Object-Relational Mapping)类库。 提供丰富的查询构造器,和多个驱动的服务。作为Laravel的数据库层使用,也可以单独使用。 一 使用 加载composer之后ÿ…...
前端koa搭建服务器(保姆级教程)——part1
目录 koa简介前端项目搭建koa环境第一步:新建项目第二步:环境初始化,安装依赖初始化项目,生成package.json文件安装koa依赖安装koa-router 路由管理依赖安装dotenv 环境变量依赖安装nodemon 热启动依赖 第三步:代码调用…...

js逆向第一课 密码学介绍
什么是密码学? 密码学(Cryptology)是一种用来混淆的技术,它希望将正常的、可识别的信息转变为无法识别的信息。 目前密码学的研究,一种是偏应用,把现有的,别人研究出来的密码学算法,放在一个合…...
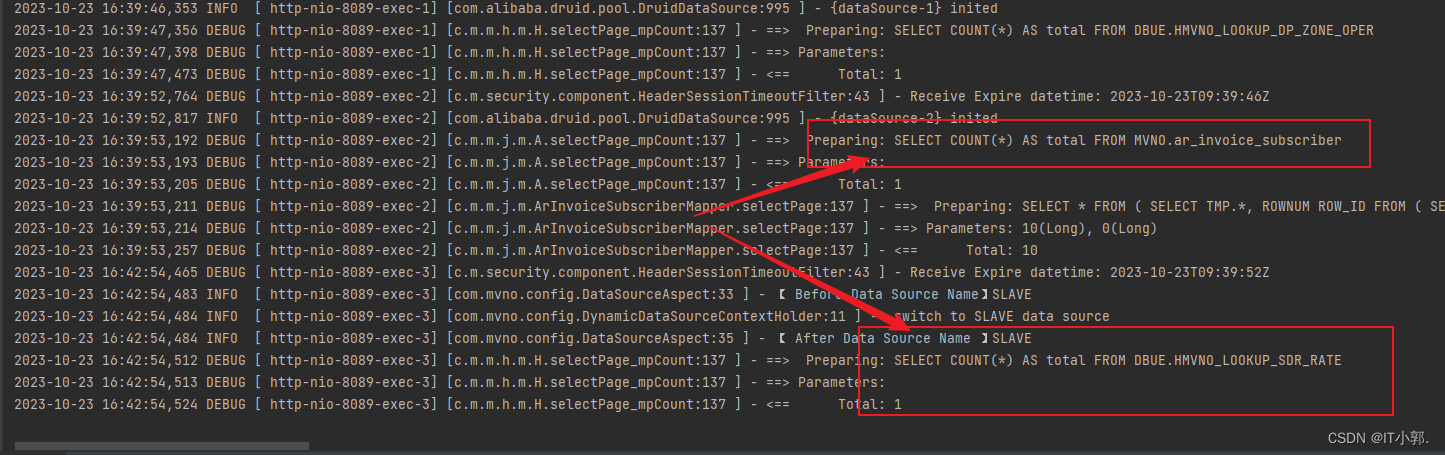
Dynamic DataSource 多数据源配置【 Springboot + DataSource + MyBatis Plus + Druid】
一、前言 MybatisPlus多数据源配置主要解决的是多数据库连接和切换的问题。在一些大型应用中,由于数据量的增长或者业务模块的增多,可能需要访问多个数据库。这时,就需要配置多个数据源。 二、Springboot MyBatis Plus 数据源配置 2.1、单数…...

MyBatis:配置文件
MyBatis 前言全局配置文件映射配置文件注 前言 在 MyBatis 中,配置文件分为 全局配置文件(核心配置文件) 和 映射配置文件 。通过这两个配置文件,MyBatis 可以根据需要动态地生成 SQL 语句并执行,同时将结果集转换成 …...

ARM,基础、寄存器
1.认识ARM 1)是一家公司 2)做RISC处理器内核 3)不生产芯片 2.ARM处理器的最新发展(重要) 高端产品线: cortex-A9 主要做音视频开发,例如:手机 平板..... 中端产品线:cortex-R 主要做实时性要求比较高的系统 例如&#…...

FC-TSGAS-1624 CP451-10 MVI56E-MNETC IC697CMM742
FC-TSGAS-1624 CP451-10 MVI56E-MNETC IC697CMM742. Variscite的DART-MX8M-PLUS和VAR-SOM-MX8M-PLUS基于恩智浦i.MX 8M Plus SoC,集成人工智能能力高达每秒2.3万亿次运算(TOPS)。这些产品,结合海螺-8 AI处理器提供多达26个top,显著优于市场…...
【详细讲解】电网电压不平衡时PWM整流器控制:基于双电流功率平衡算法抑制二次谐波)
整流器专题(2)【详细讲解】电网电压不平衡时PWM整流器控制:基于双电流功率平衡算法抑制二次谐波
整流器专题(2)【详细讲解】电网电压不平衡时PWM整流器控制:基于双电流功率平衡算法抑制二次谐波阅读前注意: 1、 此平台私信不回复,统一在b站回复,展示内容与b站一致,视频链接如下:https://www.…...
)
手把手调试:用逻辑分析仪抓取Camera Sensor的DVP和SPI时序波形(附MIPI对比)
实战指南:用逻辑分析仪精准捕捉Camera Sensor的DVP与SPI时序问题 调试摄像头Sensor时,图像花屏、颜色异常或帧率不稳定往往是工程师最头疼的问题。上周在调试一款安防摄像头模组时,客户反馈夜间画面出现规律性条纹,经过逻辑分析仪…...

编写程序让智能鱼缸换水提醒,水质指标超标提示“及时换水”。
项目名称:Aquarium Guardian (智能鱼缸管家)一、 实际应用场景描述在一个典型的家庭或办公室观赏鱼缸场景中,鱼友(用户)通常依赖经验或日历提醒来进行换水。然而,鱼缸的水质受多种因素影响:* 生物因素&…...

OpenAI呼吁重新审视税收政策,迎接AI带来的新经济时代
ChatGPT的开发商OpenAI近日呼吁政策制定者重新思考税收体系的结构,并提出了一系列针对人工智能潜在经济与社会影响的政策建议。在周一发布的一份政策文件中,OpenAI表示,AI可能从根本上重塑经济格局,其中包括若干潜在风险ÿ…...

Phi-4-mini-reasoning推理模型快速入门:Docker一键部署全攻略
Phi-4-mini-reasoning推理模型快速入门:Docker一键部署全攻略 1. 认识Phi-4-mini-reasoning推理模型 Phi-4-mini-reasoning是微软推出的轻量级开源推理模型,专为数学推理、逻辑推导和多步解题等强逻辑任务设计。这个3.8B参数的模型虽然体积小巧&#x…...

Dynamic-Datasource数据源类型注册:SPI配置终极指南
Dynamic-Datasource数据源类型注册:SPI配置终极指南 【免费下载链接】dynamic-datasource dynamic datasource for springboot 多数据源 动态数据源 主从分离 读写分离 分布式事务 项目地址: https://gitcode.com/gh_mirrors/dy/dynamic-datasource Dynamic…...

智能抖音批量下载工具:自动化无水印资源获取的高效解决方案
智能抖音批量下载工具:自动化无水印资源获取的高效解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback …...

为什么你的GraalVM镜像比JVM运行时多占62%内存?20年HotSpot/Graal双栈专家首次公开12项静态编译内存压缩清单
第一章:GraalVM静态镜像内存膨胀的本质归因GraalVM 静态原生镜像(Native Image)在启动性能与资源占用方面具有显著优势,但实践中常观察到生成的二进制文件体积远超预期,且运行时堆外内存(尤其是元数据区、字…...

英雄联盟智能对局分析系统:数据驱动的排位赛胜率提升方案
英雄联盟智能对局分析系统:数据驱动的排位赛胜率提升方案 【免费下载链接】hh-lol-prophet lol 对局先知 上等马 牛马分析程序 选人阶段判断己方大爹 大坑, 明确对局目标 基于lol client api 合法不封号 项目地址: https://gitcode.com/gh_mirrors/hh/hh-lol-prop…...
)
Java静态镜像内存优化实战手册(含GC策略调优+SubstrateVM内存布局图解)
第一章:Java静态镜像内存优化全景概览Java静态镜像(Static Image)是GraalVM原生镜像(Native Image)技术演进的重要方向,它将Java应用在构建时完成类加载、字节码解析、即时编译与内存布局固化,生…...