解密一致性哈希算法:实现高可用和负载均衡的秘诀
解密一致性哈希算法:实现高可用和负载均衡的秘诀
- 前言
- 第一:分布式系统中的数据分布问题,为什么需要一致性哈希算法
- 第二:一致性hash算法的原理
- 第三:一致性哈希算法的优点和局限性
- 第四:一致性哈希算法的安全性和故障处理机制
- 第五:一致性哈希算法的负载均衡特性
- 第六:实际应用
- 第七:示例
- java示例
- Nginx负载均衡实现
前言
在构建大规模分布式系统时,如何分布数据成为一个复杂的问题。一致性哈希算法是一项引人注目的技术,它能够在高负载和故障时保持数据一致性。在这篇博客中,我们将揭开一致性哈希算法的神秘面纱,分享如何利用这一黑科技来构建可靠的分布式系统。
第一:分布式系统中的数据分布问题,为什么需要一致性哈希算法
在分布式系统中,数据分布是一个关键的问题,因为数据通常需要存储在多个节点上,以提高性能、可伸缩性和容错性。数据分布问题的核心是如何将数据合理地分散到不同的节点上,以便系统能够高效地处理数据请求。一致性哈希算法是一种用于解决数据分布问题的重要工具。
数据分布问题的主要挑战包括:
-
负载均衡:确保每个节点上的数据负载相对均衡,以避免某些节点过载,而其他节点处于低负载状态。
-
可伸缩性:允许系统动态扩展或缩小,而无需重组所有数据。
-
故障容忍性:当节点故障或新增时,数据分布仍然能够保持高可用性和数据完整性。
-
易于计算数据的位置:客户端需要能够有效地确定数据位于哪个节点上,以发送请求。
一致性哈希算法是一种解决上述问题的算法,它的核心思想是将数据和节点映射到一个统一的哈希环上。具体来说,它包括以下关键步骤:
-
为每个节点和数据计算哈希值:将每个节点和数据映射到哈希环上,使用相同的哈希函数,将它们的名称或标识转换为哈希值。
-
数据定位:当需要访问数据时,客户端通过计算数据的哈希值来确定数据在哈希环上的位置。然后,它沿着哈希环顺时针查找,直到找到最近的节点。
-
负载均衡:一致性哈希算法通过将数据均匀地分布在哈希环上,实现了相对均衡的数据分布。当节点加入或退出系统时,只会影响与该节点相邻的数据,而不会影响整个数据分布。
-
故障容忍:当节点故障时,一致性哈希算法会自动将故障节点的数据重新分配到其他节点,从而保持数据的可用性。
一致性哈希算法的优点是它能够有效地解决数据分布问题,同时具有高度的可伸缩性和故障容忍性。这使它成为许多分布式系统中的首选选择,例如负载均衡、分布式缓存和分布式数据库系统。此算法的实现通常需要添加注释,以便开发人员能够更好地理解和维护分布式系统中的数据分布策略。
第二:一致性hash算法的原理
一致性哈希算法的背后原理涉及哈希环和虚拟节点的概念。这些元素帮助解决数据分布问题,并确保负载均衡以及在节点动态加入或退出时的故障容忍性。下面我们将深入解释这些原理:
-
哈希环(Hash Ring):哈希环是一种抽象数据结构,它实际上是一个环状结构,其中每个点代表一个可能的数据节点或物理节点。哈希环的范围通常是从0到2^32-1(或其他合适的范围),对应了一个32位的哈希空间。
-
虚拟节点(Virtual Nodes):为了增加一致性哈希算法的负载均衡和故障容忍性,物理节点通常被映射到哈希环上的多个虚拟节点。每个物理节点会对应多个虚拟节点,而每个虚拟节点也会有一个唯一的哈希值。这样,一个物理节点在哈希环上就占据了多个位置,增加了均匀性。
-
数据映射到哈希环:当需要将数据存储或查找时,数据也会通过相同的哈希函数计算出一个哈希值。这个哈希值在哈希环上沿着顺时针方向查找,直到找到离它最近的节点或虚拟节点。数据就会被映射到这个节点。
下面是一致性哈希算法的工作过程:
-
节点加入:当一个物理节点加入系统时,它会被映射到多个虚拟节点,每个虚拟节点在哈希环上找到合适的位置。现有数据仍然映射到原来的节点或虚拟节点,但一部分新的数据会映射到新节点。
-
节点退出:当一个物理节点故障或退出系统时,它的虚拟节点会被从哈希环上移除,这导致它的数据重新映射到其他节点,保持了负载均衡。
-
数据查找:当需要查找数据时,通过计算数据的哈希值,找到离这个哈希值最近的节点或虚拟节点,然后将数据存储在这个节点上,或者从这个节点上获取数据。
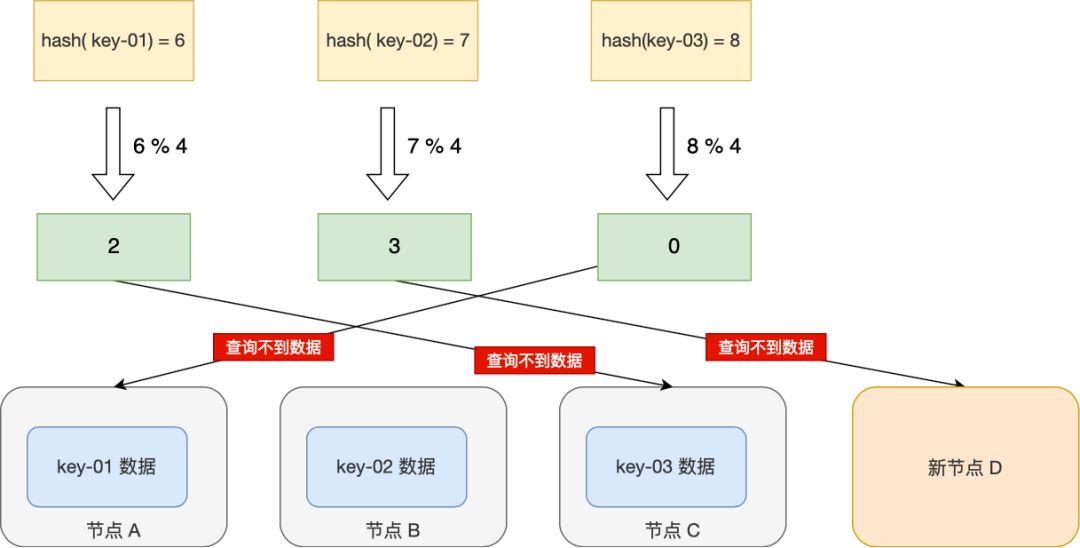
一致性哈希算法的优点在于它提供了负载均衡和故障容忍,而且不需要全局数据重新分布。虚拟节点的使用使得节点的加入和退出相对平滑,降低了系统的不稳定性。这是分布式系统中常用的数据分布策略之一,能够满足大规模系统的需求。
第三:一致性哈希算法的优点和局限性
一致性哈希算法是在分布式系统中用于负载均衡和数据分布的重要算法。它具有一些显著的优点,同时也有一些局限性。下面讨论了一致性哈希算法的优点、局限性,以及何时使用它。
优点:
-
负载均衡: 一致性哈希算法可以确保数据或请求在服务器节点之间均匀分布,避免了热点问题,提高了系统的性能和可伸缩性。
-
故障容忍: 当服务器节点故障或新增时,一致性哈希算法使数据分布的变化相对平滑。这有助于维持系统的稳定性,减少了数据迁移的需求,降低了风险。
-
可扩展性: 一致性哈希允许系统轻松地扩展,只需增加或减少服务器节点,而不需要重新分布所有数据。
-
有效的查找时间: 一致性哈希的查询时间通常是O(log n),其中n是服务器节点的数量,这在大规模系统中是非常高效的。
-
减少节点之间的通信: 数据或请求的路由只需要与一个节点交互,而不需要与所有节点通信,从而降低了网络开销。
局限性:
-
数据不平衡: 一致性哈希算法并不总是能够确保数据均匀分布。在某些情况下,可能会出现不均衡,导致一些节点过载,而其他节点处于低负载状态。
-
虚拟节点设置: 虚拟节点的数量设置可能需要调整以实现最佳负载均衡。不正确的设置可能导致不均匀的数据分布。
-
不适用于所有场景: 一致性哈希算法适用于特定的应用场景,如负载均衡和分布式存储。对于其他场景,如点对点通信或高度动态的系统,可能需要不同的算法。
何时使用一致性哈希算法:
一致性哈希算法适合以下情况:
-
负载均衡:当你需要将请求均匀分配给后端服务器节点时,一致性哈希是一个有效的选择,特别是在服务器节点动态变化频繁的情况下。
-
分布式存储:一致性哈希在分布式数据库、分布式文件系统和分布式缓存等应用中有广泛的应用。它确保数据均匀分布并允许动态扩展。
-
CDN和代理服务器:一致性哈希用于内容分发网络(CDN)和反向代理服务器,以提高性能和可用性。
总之,一致性哈希算法是一种强大的工具,特别适用于需要负载均衡和数据分布的分布式系统。然而,在选择使用它之前,需要仔细考虑特定应用的需求和潜在的局限性。
第四:一致性哈希算法的安全性和故障处理机制
一致性哈希算法在负载均衡和数据分布中具有许多优势,但也有一些与安全性和故障处理相关的注意事项。以下是对一致性哈希算法的安全性和故障处理机制的深入研究:
1. 安全性考虑:
一致性哈希算法通常不专注于安全性,而是侧重于负载均衡和数据分布。在一致性哈希算法中,没有内置的机制来保护数据的隐私或防止数据泄漏。这意味着如果节点不受适当的访问控制保护,数据可能会被未经授权的用户或服务访问。
为了提高一致性哈希算法的安全性,你可以采取以下措施:
- 使用适当的访问控制列表(ACL)来限制对节点的访问,以确保只有授权的服务可以连接和使用节点。
- 使用加密和身份验证机制来保护节点之间的通信,确保数据在传输过程中不容易被截获或篡改。
2. 故障处理机制:
一致性哈希算法对于节点的故障处理有一些内在的机制,但它并不是一个完整的故障处理解决方案。以下是一些故障处理方面的注意事项:
-
节点故障:当一个节点故障时,一致性哈希算法会自动将该节点上的数据重新分布到其他节点。这有助于保持数据的可用性,但需要确保备用节点能够容纳额外的数据负载。
-
节点添加和移除:一致性哈希算法使节点的添加和移除相对平滑。新节点加入时,数据会在一定程度上重新分布到新节点,从而避免了数据热点。然而,节点的移除可能需要一些额外的处理,以确保数据不会丢失。在某些情况下,你可能需要手动迁移数据。
-
数据丢失:如果一个节点在故障期间丢失了数据,一致性哈希算法无法提供完全的数据恢复。因此,定期的备份和数据冗余策略仍然是必要的,以防止数据丢失。
总之,一致性哈希算法在负载均衡和数据分布中提供了强大的工具,但在安全性和故障处理方面仍需额外的措施和策略。安全性需要额外的安全层面控制,而故障处理需要配合其他技术和策略来确保数据的可用性和完整性。
第五:一致性哈希算法的负载均衡特性
一致性哈希算法具有出色的负载均衡特性,这是因为它通过哈希环和虚拟节点的组合,使数据分布和节点的添加/移除更为平滑和高效。以下是一些关于一致性哈希算法的负载均衡特性的深入讨论:
1. 数据分布均匀:一致性哈希算法的核心目标之一是确保数据在各个节点上均匀分布。由于数据和节点都被映射到哈希环上,数据会在哈希环上均匀分散。这导致了较为均匀的数据分布,而不会导致某些节点负载过重,而其他节点负载过轻。这是因为数据查找是在哈希环上进行的,而不依赖于节点的物理位置。
2. 节点添加/移除的平滑性:一致性哈希算法的另一个优点是,当节点需要被添加或移除时,只会影响到与这些节点或虚拟节点相邻的数据,而不会引起全局的数据迁移。这是因为哈希环上的数据仅与最接近的节点或虚拟节点相关。因此,节点的添加或移除不会导致系统的整体不稳定性,而只会对局部数据分布产生影响。这降低了维护和扩展分布式系统的复杂性。
3. 故障容忍:一致性哈希算法还具有良好的故障容忍特性。当一个节点故障时,它的虚拟节点从哈希环上移除,这使得系统可以快速适应节点的故障。数据迁移只会影响到那些原本映射到故障节点或虚拟节点的数据,而不会引起整个系统的数据迁移。这有助于保持系统的可用性。
4. 均衡性调整:一致性哈希算法还允许节点配置不同数量的虚拟节点,以进一步调整负载均衡。通常,高负载的节点可以配置更多的虚拟节点,而低负载的节点可以配置较少的虚拟节点,以实现更平均的数据分布。
总的来说,一致性哈希算法通过哈希环和虚拟节点的组合,提供了出色的负载均衡特性,使数据分布均匀、节点的添加和移除更加平滑,同时具有良好的故障容忍性。这使得它成为许多分布式系统中的首选算法,如负载均衡、分布式缓存和分布式数据库系统。
第六:实际应用
一致性哈希算法在缓存、负载均衡和分布式存储等领域具有广泛的实际应用。以下是这些应用的探讨:
1. 缓存:
-
分布式缓存:一致性哈希算法常用于分布式缓存系统,如Redis和Memcached。数据被分散存储在多个缓存节点上,通过哈希算法决定将数据存储在哪个节点上。这确保了缓存系统的负载均衡,避免了热点数据的问题。当缓存节点需要扩展或缩减时,一致性哈希算法使数据迁移相对平滑。
-
内容分发网络(CDN):CDNs使用一致性哈希来确定哪个缓存节点应该提供用户请求的内容。这提高了内容的快速分发,减少了延迟,同时确保数据在CDN节点之间均匀分布。
2. 负载均衡:
-
负载均衡器:负载均衡器使用一致性哈希来决定将请求路由到哪个后端服务器。这确保了每个服务器接收大致相等数量的请求,防止某些服务器过载,提高了系统的性能和可用性。节点的添加或移除也可以平滑地处理,而不会引起大规模的流量重定向。
-
分布式系统:在分布式系统中,一致性哈希可用于将请求路由到特定的服务节点。这对于微服务架构非常有用,因为它允许根据服务名称或关键字路由请求,并确保负载均衡。
3. 分布式存储:
-
分布式文件系统:一致性哈希算法在分布式文件系统中用于将文件块分散存储在不同的存储节点上。这确保了文件数据均匀分布,而且在节点故障或新增时,数据迁移的代价较小。
-
分布式数据库:一致性哈希可用于分布式数据库系统,如Cassandra、Couchbase和Amazon DynamoDB。它确保了数据的均匀分布,而节点的加入和退出不会导致全局的数据迁移,减小了维护成本。
总的来说,一致性哈希算法在分布式系统中的应用非常广泛,尤其在需要负载均衡和数据分布的场景下。它允许系统实现高性能、高可用性,并能够有效地适应节点的动态变化,使系统更加灵活和可扩展。这使得一致性哈希成为许多大规模分布式应用的核心技术之一。
第七:示例
java示例
当使用Java实现一致性哈希算法时,你可以使用如下的示例代码,包含了尽可能多的中文注释:
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.util.ArrayList;
import java.util.List;
import java.util.SortedMap;
import java.util.TreeMap;public class ConsistentHashing {// 服务器节点列表private List<String> nodes = new ArrayList<>();// 虚拟节点数,用于增加数据分布均匀性private int numberOfReplicas = 3;// 哈希环,用于存放虚拟节点private SortedMap<Integer, String> ring = new TreeMap<>();public ConsistentHashing(List<String> nodes) {this.nodes.addAll(nodes);// 初始化哈希环initializeRing();}// 初始化哈希环private void initializeRing() {for (String node : nodes) {for (int i = 0; i < numberOfReplicas; i++) {// 使用哈希函数计算虚拟节点的哈希值int hash = getHash(node + i);ring.put(hash, node);}}}// 根据数据的键值获取对应的服务器节点public String getNode(String key) {int hash = getHash(key);// 获取大于等于此哈希值的服务器节点SortedMap<Integer, String> tailMap = ring.tailMap(hash);if (tailMap.isEmpty()) {// 如果没有大于等于此哈希值的节点,取第一个节点return ring.get(ring.firstKey());}// 否则,取第一个大于等于此哈希值的节点return tailMap.get(tailMap.firstKey());}// 使用MD5哈希函数计算哈希值private int getHash(String input) {try {MessageDigest md5 = MessageDigest.getInstance("MD5");byte[] digest = md5.digest(input.getBytes());return byteArrayToInt(digest);} catch (NoSuchAlgorithmException e) {e.printStackTrace();return 0;}}// 将字节数组转换为整数private int byteArrayToInt(byte[] bytes) {int value = 0;for (int i = 0; i < 4; i++) {value += ((bytes[i] & 0xFF) << (8 * (3 - i)));}return value;}public static void main(String[] args) {// 服务器节点列表List<String> nodes = new ArrayList<>();nodes.add("Server-1");nodes.add("Server-2");nodes.add("Server-3");ConsistentHashing consistentHashing = new ConsistentHashing(nodes);// 模拟数据请求String[] keys = {"Key-1", "Key-2", "Key-3", "Key-4"};for (String key : keys) {String node = consistentHashing.getNode(key);System.out.println("Key '" + key + "' 被路由到服务器节点 " + node);}}
}
这个Java示例演示了如何使用一致性哈希算法实现负载均衡,并包含了详细的中文注释。你可以根据需要扩展节点列表、调整虚拟节点数量或添加更多数据请求以测试一致性哈希的性能和均衡性。
Nginx负载均衡实现
在Nginx中使用一致性哈希算法作为负载均衡的示例,你可以使用Nginx的ngx_http_upstream_consistent模块来实现。此模块允许你配置一致性哈希算法用于分配请求到后端服务器。以下是一个简单的Nginx配置示例:
首先,确保你已经编译了Nginx并包括了ngx_http_upstream_consistent模块。在Nginx的配置文件中,可以按照以下示例进行配置:
http {upstream my_backend {consistent;server server1 weight=3;server server2 weight=2;server server3;}server {location / {proxy_pass http://my_backend;}}
}
在这个配置示例中,我们创建了一个名为my_backend的上游组,并配置了一致性哈希负载均衡。在upstream块中,我们列出了后端服务器节点,包括它们的权重(可选)。Nginx将使用一致性哈希算法将请求分发到这些服务器。
关于配置的解释:
consistent;:启用一致性哈希算法。server server1 weight=3;:定义一个服务器节点server1,并指定权重为3。这意味着它将获得更多的请求。server server2 weight=2;:定义另一个服务器节点server2,并指定权重为2。server server3;:定义另一个服务器节点server3,没有指定权重,默认为1。
现在,Nginx将使用一致性哈希算法将请求路由到后端服务器。这允许你保持较好的负载均衡,同时允许动态添加或删除服务器节点而不会大规模改变分布。
这只是一个简单示例,你可以根据你的需求进行更详细的Nginx配置,包括添加其他选项,如健康检查和故障恢复策略。
相关文章:
解密一致性哈希算法:实现高可用和负载均衡的秘诀
解密一致性哈希算法:实现高可用和负载均衡的秘诀 前言第一:分布式系统中的数据分布问题,为什么需要一致性哈希算法第二:一致性hash算法的原理第三:一致性哈希算法的优点和局限性第四:一致性哈希算法的安全性…...

Python脚本:让工作自动化起来
Python是一种流行的编程语言,以其简洁和易读性而闻名。它提供了大量的库和模块,使其成为自动化各种任务的绝佳选择。 本文将探讨Python脚本及其代码,可以帮助您自动化各种任务并提高工作效率。无论您是开发人员、数据分析师还是只是想简化工…...

香港科技大学广州|可持续能源与环境学域博士招生宣讲会—广州大学城专场!!!(暨全额奖学金政策)
香港科技大学广州|可持续能源与环境学域博士招生宣讲会—广州大学城专场!!!(暨全额奖学金政策) “面向未来改变游戏规则的——可持续能源与环境学域” ���专注于能源环…...
uni-app:多种方法写入图片路径
一、文件在前端文件夹中 1、相对路径引用 从当前文件所在位置开始寻找图片文件的路径。../../ 表示返回两级目录,即从当前文件所在的 wind.vue 所在的位置开始向上回退两级。接着,进入 static 目录,再进入 look 目录,最后定位到 …...

共谋工业3D视觉发展,深眸科技以自研解决方案拓宽场景应用边界
随着中国工业领域自动化程度逐渐攀升,“机器换人”这一需求进一步提升。在传统2D工业视觉易受环境光干扰、无法进一步获取物体深度信息的限制条件下,工业3D视觉凭借着更强的空间和深度感知能力,以及通过点云数据获取物体距离和三维坐标信息的…...

前端面试基础面试题——11
1.什么是 vue 的计算属性? 2.vue怎么实现页面的权限控制 3.watch的作用是什么 4.响应式系统的基本原理 5.vue-loader 是什么?使用它的用途有哪些? 6.vuex 工作原理详解 7.vuex 有哪几种属性? 8.什么是 MVVM? 9…...
)
SQL server中内连接和外连接的区别、表达(表的连接)
SQL server中内连接与外连接的区别、表达 区别表达内连接外连接 待续 首先,内连接和外连接都是对表的连接操作 区别 内连接:连接结果仅包含符合连接条件的行,其中至少一个属性是共同的;注意区分在嵌套查询时使用的any以及all的区…...
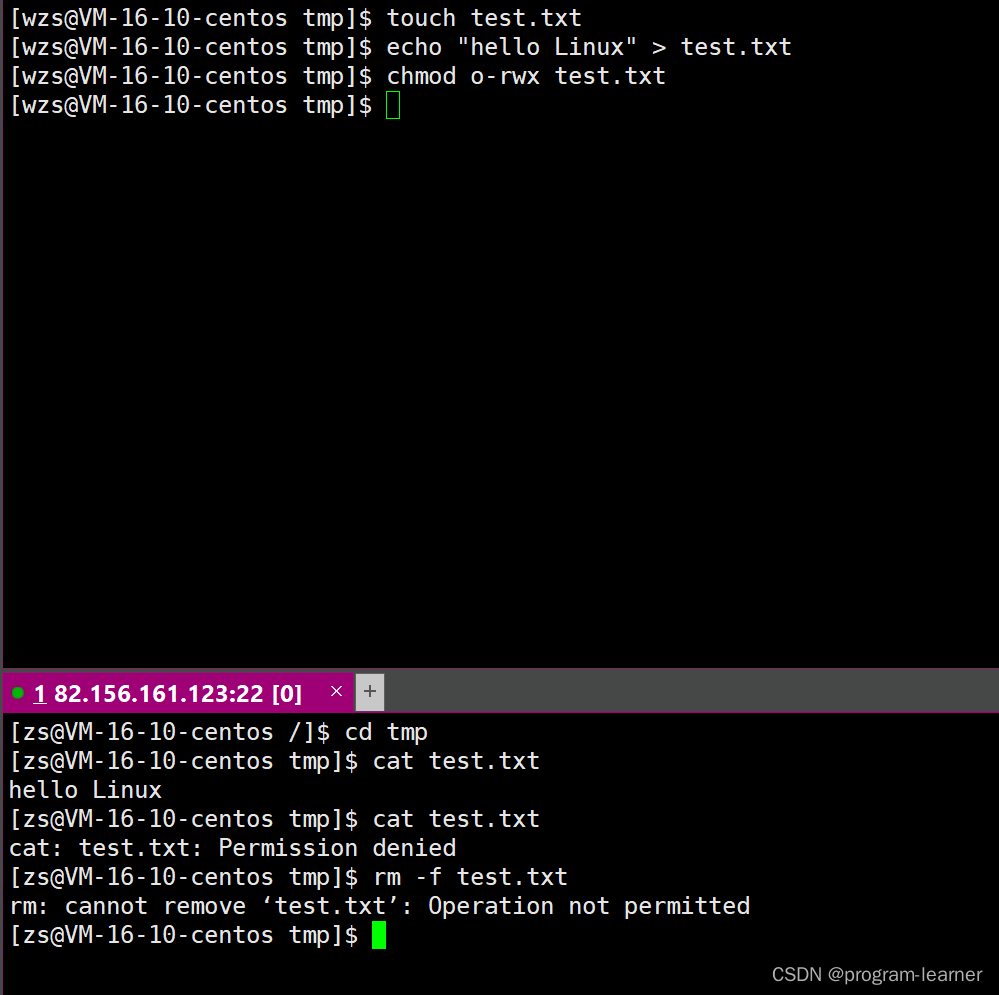
Linux中的shell外壳与权限(包含目录文件的权限,粘滞位的来龙去脉)
Linux中的shell外壳与权限[包含目录文件的权限,粘滞位的来龙去脉] 一.shell外壳的理解1.为什么需要有shell外壳的存在?2.什么是shell外壳?3.shell外壳的运行原理是什么?4.shell和bash的关系 二.Linux中的用户权限1.用户分类与身份切换1.用户分类2.root用户切换为普通用户1.s…...

力扣第45题 跳跃游戏II c++ 贪心算法
题目 45. 跳跃游戏 II 中等 相关标签 贪心 数组 动态规划 给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。 每个元素 nums[i] 表示从索引 i 向前跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i j] 处…...

1024动态
感叹一下当前行情 从事码农这些年今年是最难的一年...
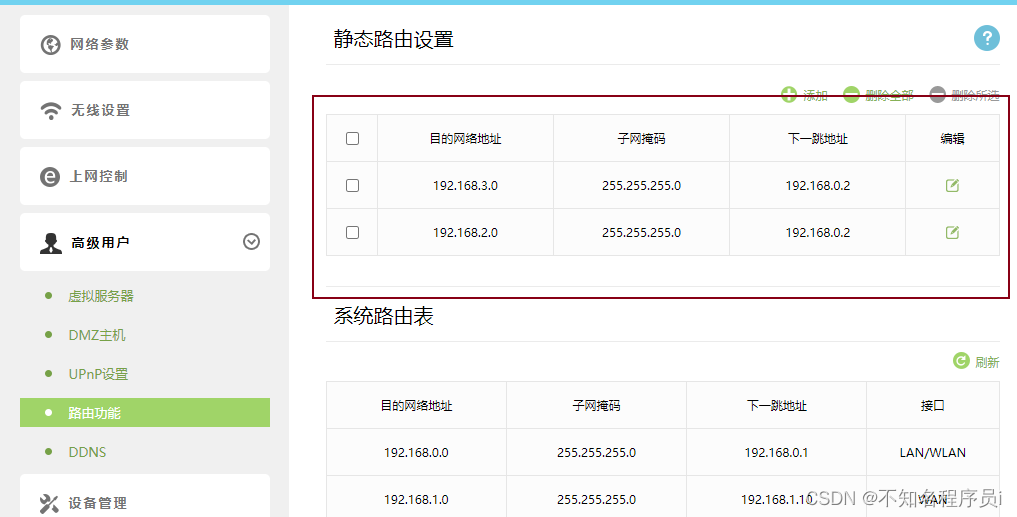
中心胖AP(AD9430DN)+远端管理单元RU(R240D)+出口网关,实现组网
适用于:V200R008至V200R019C00版本的万兆中心胖AP(AD9431DN-24X)。 组网规划 RU管理:VLAN 100,网段为192.168.100.0/24。 无线业务:VLAN 3,SSID为“wlan-net”,密码为“88888888”…...

shell_45.Linux在脚本中使用 getopt
在脚本中使用 getopt $ cat extractwithgetopt.sh #!/bin/bash # Extract command-line options and values with getopt # set -- $(getopt -q ab:cd "$") # echo while [ -n "$1" ] do case "$1" in -a) echo "Found the -a opt…...

2023-8-20 CVTE视源股份后端开发实习一面
自我介绍 操作系统 1 有了解进程和线程的特点吗 2 在linux层面的话是怎么创建一个进程或者一个线程的(具体的系统调用的命令) 答: 3 如果是java层面讲,怎么去启动一个线程,要实现哪些方法呢 Thread类实现run()方法的…...
二叉树进阶
欢迎来到Cefler的博客😁 🕌博客主页:那个传说中的man的主页 🏠个人专栏:题目解析 🌎推荐文章:题目大解析(3) 目录 👉🏻二叉搜索树概念 Ǵ…...
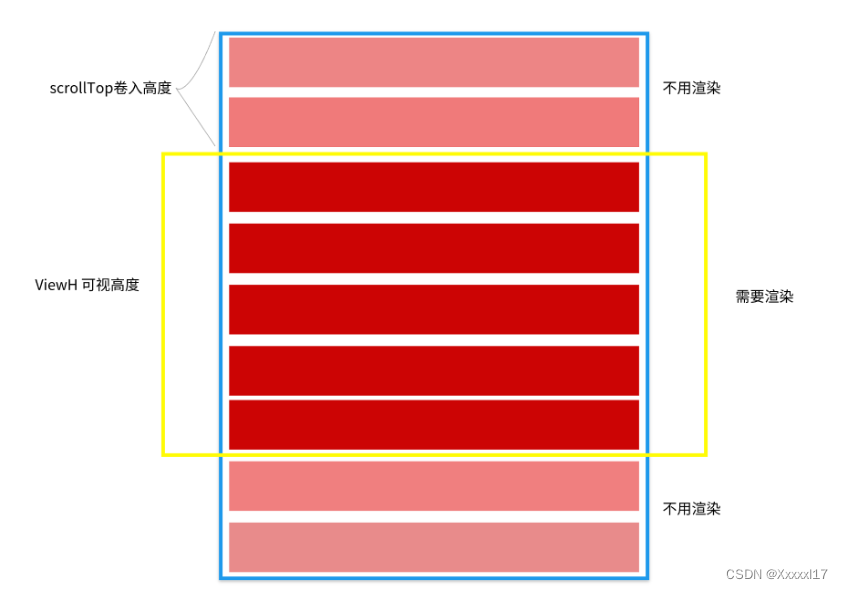
前端性能优化 - 虚拟滚动
一 需求背景 需求:在一个表格里面一次性渲染全部数据,不采用分页形式,每行数据都有Echart图插入。 问题:图表渲染卡顿 技术栈:Vue、Element UI 卡顿原因:页面渲染时大量的元素参与到了重排的动作中&#x…...
手写 Promise(1)核心功能的实现
一:什么是 Promise Promise 是异步编程的一种解决方案,其实是一个构造函数,自己身上有all、reject、resolve这几个方法,原型上有then、catch等方法。 Promise对象有以下两个特点。 (1)对象的状态不受…...

深入探究Java内存模型
文章目录 🌟 Java虚拟机内存模型🍊 一、方法区🍊 二、堆🎉 堆的基本概念🎉 堆的结构📝 新生代📝 老年代 🎉 堆的分配策略📝 对象优先分配📝 空间优先分配 &am…...

深度学习 | Pytorch深度学习实践 (Chapter 10、11 CNN)
十、CNN 卷积神经网络 基础篇 首先引入 —— 二维卷积:卷积层保留原空间信息关键:判断输入输出的维度大小特征提取:卷积层、下采样分类器:全连接 引例:RGB图像(栅格图像) 首先,老师…...
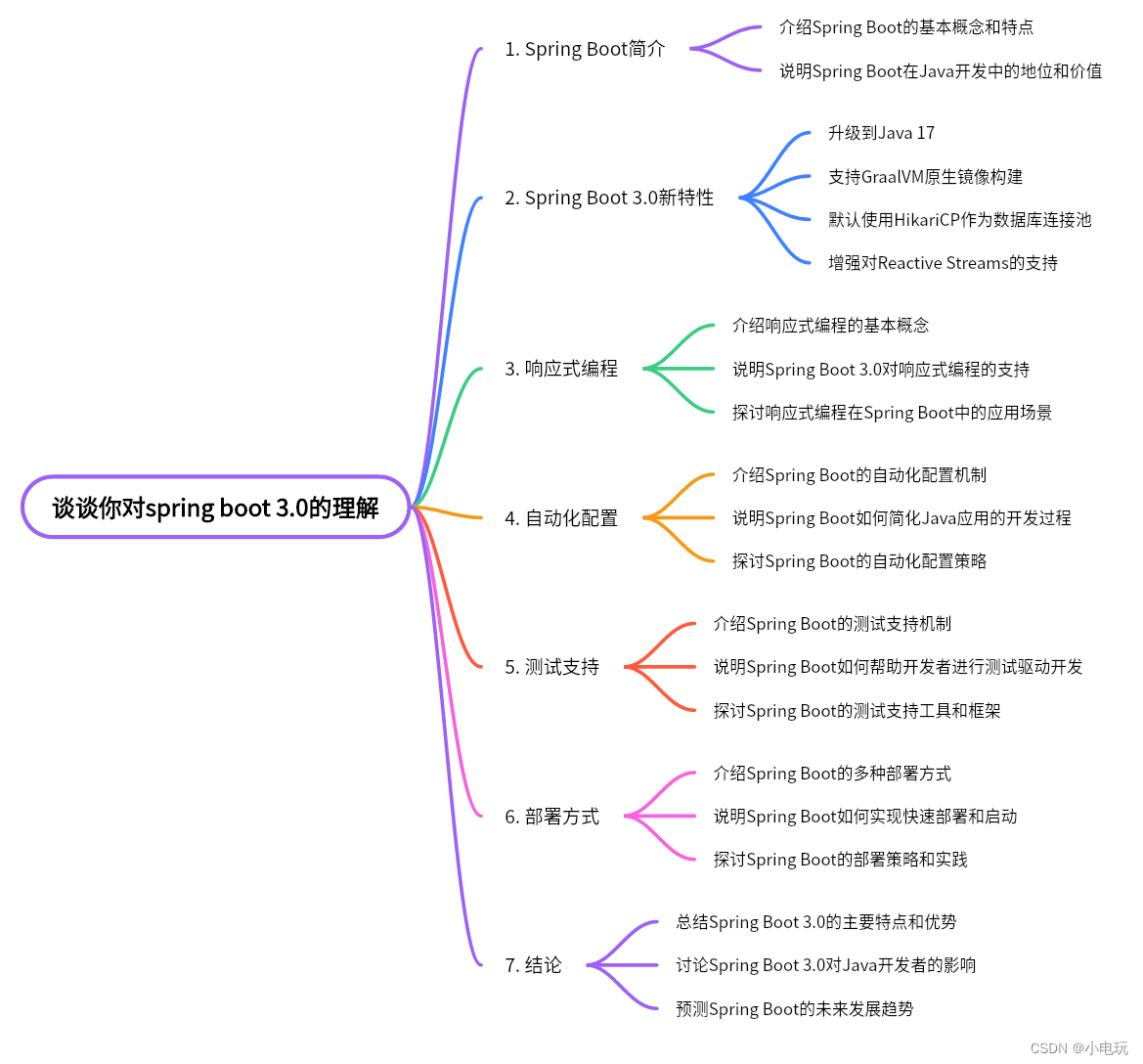
谈谈你对spring boot 3.0的理解
谈谈你对spring boot 3.0的理解 一,Spring Boot 3.0 的兼容性 Spring Boot 3.0 在兼容性方面做出了很大的努力,以支持存量项目和老项目。尽管如此,仍需注意以下几点: Java 版本要求:Spring Boot 3.0 要求使用 Java 1…...
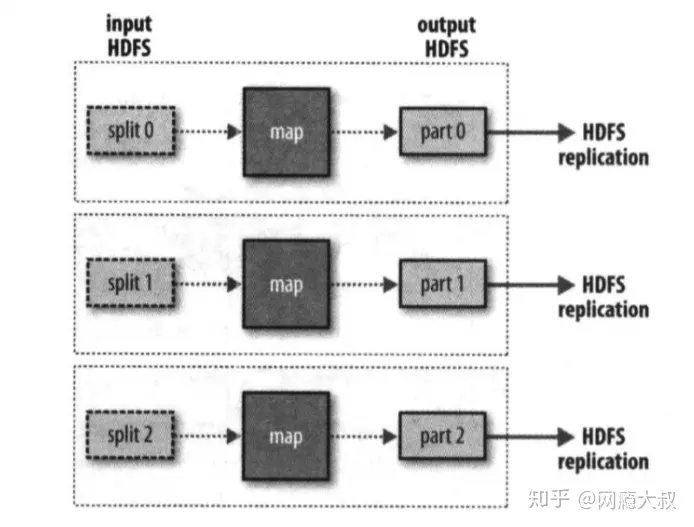
【大数据】Hadoop
文章目录 概述Hadoop组成HDFSMapReduce写MapReduce程序(Hadoop streaming) YARNHadoop 启动 工作方式Hadoop的主从工作方式Hadoop的守护进程 运行模式本地运行模式伪分布式运行模式完全分布式运行模式 Hadoop高可用的解决方案ZooKeeper quorumZKFC 环境搭…...

为什么90%的GraalVM项目内存优化失败?——源于忽略这2个编译期元数据约束与1个运行时堆布局陷阱
第一章:为什么90%的GraalVM项目内存优化失败?——源于忽略这2个编译期元数据约束与1个运行时堆布局陷阱 GraalVM 原生镜像(Native Image)的内存优化常被误认为仅依赖 --optimize 或 --enable-http 等运行时参数,实则…...

Burpsuite之暴力破解+验证码识别 | 添柴不加火敢
springboot自动配置 自动配置了大量组件,配置信息可以在application.properties文件中修改。 当添加了特定的Starter POM后,springboot会根据类路径上的jar包来自动配置bean(比如:springboot发现类路径上的MyBatis相关类ÿ…...
分布式仓储货物管理系统)
【系统架构师-案例题-分布式数据缓存架构】22年下(3)分布式仓储货物管理系统
一、完整题目 【说明】 某大型电商平台建立了一个在线B2B商店系统,并在全国多地建设了货物仓储中心,通过提前备货的方式来提高货物的运送效率。但是在运营过程中,发现会出现很多跨仓储中心调货从而延误货物运送的情况。为此,该企业…...

Pyplot在图表显示中文--配置文件法
希望所有 Matplotlib 图表都默认使用黑体、红色线条、圆形标记步骤1:找到/创建配置文件 运行以下代码找到配置文件路径: import matplotlib print(matplotlib.matplotlib_fname())假设输出:C:\Users\你的用户名\.matplotlib\matplotlibrc 如果…...

高阶 HDI 同行参考:40 层>5 阶 HDI 技术难点
【实战复盘】19 天拿下 40 层>5 阶板的工艺 项目管理方案 标签:高阶HDI、激光钻孔、电镀均匀性、多次压合最近刚完成一款40层且大于5阶的高阶HDI项目。坦白说,这板子难度不小:多次压合对位、激光钻孔一致性、电镀填孔均匀性&…...

Degrees of Lewdity游戏中文本地化完全指南:从认知到进阶的全流程解决方案
Degrees of Lewdity游戏中文本地化完全指南:从认知到进阶的全流程解决方案 【免费下载链接】Degrees-of-Lewdity-Chinese-Localization Degrees of Lewdity 游戏的授权中文社区本地化版本 项目地址: https://gitcode.com/gh_mirrors/de/Degrees-of-Lewdity-Chines…...
仍保持82%+抽取准确率)
SiameseUIE效果实测:中文OCR后文本(含错别字)仍保持82%+抽取准确率
SiameseUIE效果实测:中文OCR后文本(含错别字)仍保持82%抽取准确率 1. 引言:当AI遇到不完美的中文文本 你有没有遇到过这样的情况:从扫描文档或图片中提取的中文文字,总是带着各种错别字和格式问题&#x…...

原子化失业期PHP程序员,别轻易放弃。但方向真错了,也别硬撑,及时掉头不丢人。
这句话是失业期 PHP 程序员在“坚持”与“止损”之间寻找动态平衡的战略智慧。 它的本质是:区分“战术上的困难”与“战略上的错误”。对于前者,需要韧性(Grit)去克服;对于后者,需要勇气(Courag…...

Simulink仿真避坑指南:如何设置步长、powergui和模块采样时间才能让控制周期更稳定
Simulink控制系统仿真参数配置实战:从步长到采样时间的精准调优 在电机控制、电力电子系统等工业仿真场景中,Simulink参数的合理配置直接决定了仿真结果的可靠性与工程指导价值。许多工程师第一次搭建控制系统模型时,往往被各种时间参数搞得晕…...

从零到精通:Ryujinx模拟器全方位技术指南
从零到精通:Ryujinx模拟器全方位技术指南 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx Ryujinx是一款采用C#开发的开源Nintendo Switch模拟器,通过动态编译和…...