自然语言处理---迁移学习
fasttext介绍
- 作为NLP工程领域常用的工具包,fasttext有两大作用:进行文本分类、训练词向量。
- 在保持较高精度的情况下,快速的进行训练和预测是fasttext的最大优势。
- fasttext优势的原因:
- fasttext工具包中内含的fasttext模型具有十分简单的网络结构。
- 使用fasttext模型训练词向量时使用层次softmax结构,来提升超多类别下的模型性能。
- 由于fasttext模型过于简单无法捕捉词序特征,因此会进行n-gram特征提取以弥补模型缺陷提升精度。
fasttext文本分类
文本分类概念
文本分类的是将文档(例如电子邮件,帖子,文本消息,产品评论等)分配给一个或多个类别。当今文本分类的实现多是使用机器学习方法从训练数据中提取分类规则以进行分类,因此构建文本分类器需要带标签的数据。
文本分类种类
- 二分类:文本被分类到两个类别中,往往这两个类别是对立面,比如:判断一句评论是好评还是差评。
- 单标签多分类:文本被分入到多个类别中,且每条文本只能属于某一个类别(即被打上某一个标签),比如:输入一个人名,判断它是来自哪个国家的人名。
- 多标签多分类:文本被分入到多个类别中,但每条文本可以属于多个类别(即被打上多个标签),比如:输入一段描述,判断可能是和哪些兴趣爱好有关,一段描述中可能即讨论了美食,又太讨论了游戏爱好。
文本分类的过程
- 第一步: 获取数据
- 第二步: 训练集与验证集的划分
- 第三步: 训练模型
- 第四步: 使用模型进行预测并评估
- 第五步: 模型调优
1 原始数据处理
2 数据处理后进行训练并测试
3 增加训练轮数
4 调整学习率
5 增加n-gram特征
6 修改损失计算方式
7 自动超参数调优
8 实际生产中多标签多分类问题的损失计算方式
- 第六步: 模型保存与重加载
训练词向量
用向量表示文本中的词汇(或字符)是现代机器学习中最流行的做法,这些向量能够很好的捕捉语言之间的关系,从而提升基于词向量的各种NLP任务的效果。
训练词向量的过程
- 第一步:获取数据
- 第二步:训练词向量
- 第三步:模型超参数设定
- 第四步:模型效果检验
- 第五步:模型的保存与重加载
词向量迁移
- 使用在大型语料库上已经进行训练完成的词向量模型
- fasttext工具中可以提供的可迁移的词向量:
- fasttext提供了157种语言的在CommonCrawl和Wikipedia语料上进行训练的可迁移词向量模型,它们采用CBOW模式进行训练,词向量维度为300维。可通过该地址查看具体语言词向量模型:Word vectors for 157 languages · fastText
- fasttext提供了294种语言的在Wikipedia语料上进行训练的可迁移词向量模型,它们采用skipgram模式进行训练,词向量维度同样是300维。可通过该地址查看具体语言词向量模型:Wiki word vectors · fastText
进行词向量迁移
- 第一步:下载词向量模型压缩的bin.gz文件
- 第二步:解压bin.gz文件到bin文件
- 第三步:加载bin文件获取词向量
- 第四步:利用邻近词进行效果检验
迁移学习
1.1 预训练模型(Pretrained model)
- 一般情况下预训练模型都是大型模型,具备复杂的网络结构,众多的参数量,以及在足够大的数据集下进行训练而产生的模型。在NLP领域,预训练模型往往是语言模型,因为语言模型的训练是无监督的,可以获得大规模语料,同时语言模型又是许多典型NLP任务的基础,如机器翻译,文本生成,阅读理解等,常见的预训练模型有BERT、GPT、 roBERTa、transformer-XL等。
1.2 微调(Fine-tuning)
- 根据给定的预训练模型,改变它的部分参数或者为其新增部分输出结构后,通过在小部分数据集上训练,来使整个模型更好的适应特定任务.
1.3 微调脚本(Fine-tuning script)
- 实现微调过程的代码文件。这些脚本文件中,应包括对预训练模型的调用,对微调参数的选定以及对微调结构的更改等,同时,因为微调是一个训练过程,它同样需要一些超参数的设定,以及损失函数和优化器的选取等,因此微调脚本往往也包含了整个迁移学习的过程。
- 关于微调脚本的说明:
- 一般情况下,微调脚本应该由不同的任务类型开发者自己编写,但是由于目前研究的NLP任务类型(分类,提取,生成)以及对应的微调输出结构都是有限的,有些微调方式已经在很多数据集上被验证是有效的,因此微调脚本也可以使用已经完成的规范脚本。
1.4 两种迁移方式
- 直接使用预训练模型,进行相同任务的处理,不需要调整参数或模型结构,这些模型开箱即用。但是这种情况一般只适用于普适任务,如:fasttest工具包中预训练的词向量模型。另外,很多预训练模型开发者为了达到开箱即用的效果,将模型结构分各个部分保存为不同的预训练模型,提供对应的加载方法来完成特定目标。
- 更加主流的迁移学习方式是发挥预训练模型特征抽象的能力,然后再通过微调的方式,通过训练更新小部分参数以此来适应不同的任务。这种迁移方式需要提供小部分的标注数据来进行监督学习。
- 关于迁移方式的说明:
- 直接使用预训练模型的方式,已经在fasttext的词向量迁移中学习。接下来的迁移学习实践将主要讲解通过微调的方式进行迁移学习。
NLP中的标准数据集
GLUE由纽约大学,华盛顿大学,Google联合推出,涵盖不同NLP任务类型,截止至2020年1月其中包括11个子任务数据集,成为衡量NLP研究发展的衡量标准。
CoLA数据集文件样式
- 数据集释义:CoLA(The Corpus of Linguistic Acceptability,语言可接受性语料库)纽约大学发布的有关语法的数据集。
- 本质:是对一个给定句子,判定其是否语法正确的单个句子的**文本二分类任务**。
SST-2数据集文件样式
- 数据集释义:SST-2(The Stanford Sentiment Treebank,斯坦福情感树库),单句子分类任务,包含电影评论中的句子和它们情感的人类注释。
- 本质:句子级别的**二分类任务**。
MRPC数据集文件样式
- 数据集释义:MRPC(The Microsoft Research Paraphrase Corpus,微软研究院释义语料库),相似性和释义任务,是从在线新闻源中自动抽取句子对语料库,并人工注释句子对中的句子是否在语义上等效。
- 本质:句子级别的**二分类任务**。
STS-B数据集文件样式
- 数据集释义:STSB(The Semantic Textual Similarity Benchmark,语义文本相似性基准测试)。
- 本质:回归任务/句子对的文本五分类任务。
QQP数据集文件样式
- 数据集释义:QQP(The Quora Question Pairs,Quora问题对数集),相似性和释义任务,是社区问答网站Quora中问题对的集合。
- 本质:句子对的**二分类任务**。
(MNLI/SNLI)数据集文件样式
- 数据集释义:
- MNLI(The Multi-Genre Natural Language Inference Corpus, 多类型自然语言推理数据库)。
- 本质:句子对的**三分类任务**。
(QNLI/RTE/WNLI)数据集文件样式
- 数据集释义:
- QNLI(Qusetion-answering NLI,问答自然语言推断),自然语言推断任务。QNLI是从另一个数据集The Stanford Question Answering Dataset(斯坦福问答数据集, SQuAD 1.0)[3]转换而来的。
- RTE(The Recognizing Textual Entailment datasets,识别文本蕴含数据集),自然语言推断任务,它是将一系列的年度文本蕴含挑战赛的数据集进行整合合并而来的。
- WNLI(Winograd NLI,Winograd自然语言推断),自然语言推断任务,数据集来自于竞赛数据的转换。
- 本质:QNLI是二分类任务,RTE是二分类任务,WNLI是二分类任务。
- QNLI, RTE, WNLI三个数据集的样式基本相同。
NLP中的预训练模型
1.1 BERT及其变体
- bert-base-uncased: 编码器具有12个隐层, 输出768维张量, 12个自注意力头, 共110M参数量, 在小写的英文文本上进行训练而得到.
- bert-large-uncased: 编码器具有24个隐层, 输出1024维张量, 16个自注意力头, 共340M参数量, 在小写的英文文本上进行训练而得到.
- bert-base-cased: 编码器具有12个隐层, 输出768维张量, 12个自注意力头, 共110M参数量, 在不区分大小写的英文文本上进行训练而得到.
- bert-large-cased: 编码器具有24个隐层, 输出1024维张量, 16个自注意力头, 共340M参数量, 在不区分大小写的英文文本上进行训练而得到.
- bert-base-multilingual-uncased: 编码器具有12个隐层, 输出768维张量, 12个自注意力头, 共110M参数量, 在小写的102种语言文本上进行训练而得到.
- bert-large-multilingual-uncased: 编码器具有24个隐层, 输出1024维张量, 16个自注意力头, 共340M参数量, 在小写的102种语言文本上进行训练而得到.
- bert-base-chinese: 编码器具有12个隐层, 输出768维张量, 12个自注意力头, 共110M参数量, 在简体和繁体中文文本上进行训练而得到.
1.2 GPT
- openai-gpt: 编码器具有12个隐层, 输出768维张量, 12个自注意力头, 共110M参数量, 由OpenAI在英文语料上进行训练而得到.
1.3 GPT-2及其变体
- gpt2: 编码器具有12个隐层, 输出768维张量, 12个自注意力头, 共117M参数量, 在OpenAI GPT-2英文语料上进行训练而得到.
- gpt2-xl: 编码器具有48个隐层, 输出1600维张量, 25个自注意力头, 共1558M参数量, 在大型的OpenAI GPT-2英文语料上进行训练而得到.
1.4 Transformer-XL
- transfo-xl-wt103: 编码器具有18个隐层, 输出1024维张量, 16个自注意力头, 共257M参数量, 在wikitext-103英文语料进行训练而得到.
1.5 XLNet及其变体
- xlnet-base-cased: 编码器具有12个隐层, 输出768维张量, 12个自注意力头, 共110M参数量, 在英文语料上进行训练而得到.
- xlnet-large-cased: 编码器具有24个隐层, 输出1024维张量, 16个自注意力头, 共240参数量, 在英文语料上进行训练而得到.
1.6 XLM
- xlm-mlm-en-2048: 编码器具有12个隐层, 输出2048维张量, 16个自注意力头, 在英文文本上进行训练而得到.
1.7 RoBERTa及其变体
- roberta-base: 编码器具有12个隐层, 输出768维张量, 12个自注意力头, 共125M参数量, 在英文文本上进行训练而得到.
- roberta-large: 编码器具有24个隐层, 输出1024维张量, 16个自注意力头, 共355M参数量, 在英文文本上进行训练而得到.
1.8 DistilBERT及其变体
- distilbert-base-uncased: 基于bert-base-uncased的蒸馏(压缩)模型, 编码器具有6个隐层, 输出768维张量, 12个自注意力头, 共66M参数量.
- distilbert-base-multilingual-cased: 基于bert-base-multilingual-uncased的蒸馏(压缩)模型, 编码器具有6个隐层, 输出768维张量, 12个自注意力头, 共66M参数量.
1.9 ALBERT
- albert-base-v1: 编码器具有12个隐层, 输出768维张量, 12个自注意力头, 共125M参数量, 在英文文本上进行训练而得到.
- albert-base-v2: 编码器具有12个隐层, 输出768维张量, 12个自注意力头, 共125M参数量, 在英文文本上进行训练而得到, 相比v1使用了更多的数据量, 花费更长的训练时间.
1.10 T5及其变体
- t5-small: 编码器具有6个隐层, 输出512维张量, 8个自注意力头, 共60M参数量, 在C4语料上进行训练而得到.
- t5-base: 编码器具有12个隐层, 输出768维张量, 12个自注意力头, 共220M参数量, 在C4语料上进行训练而得到.
- t5-large: 编码器具有24个隐层, 输出1024维张量, 16个自注意力头, 共770M参数量, 在C4语料上进行训练而得到.
1.11 XLM-RoBERTa及其变体
- xlm-roberta-base: 编码器具有12个隐层, 输出768维张量, 8个自注意力头, 共125M参数量, 在2.5TB的100种语言文本上进行训练而得到.
- xlm-roberta-large: 编码器具有24个隐层, 输出1027维张量, 16个自注意力头, 共355M参数量, 在2.5TB的100种语言文本上进行训练而得到.
预训练模型说明
- 所有上述预训练模型及其变体都是以transformer为基础,只是在模型结构如神经元连接方式,编码器隐层数,多头注意力的头数等发生改变,这些改变方式的大部分依据都是由在标准数据集上的表现而定,因此对于使用者而言,不需要从理论上深度探究这些预训练模型的结构设计的优劣,只需要在自己处理的目标数据上,尽量遍历所有可用的模型对比得到最优效果即可。
加载和使用预训练模型
- 加载和使用预训练模型的工具
- 在这里使用transformers工具进行模型的加载和使用。
- 这些预训练模型由世界先进的NLP研发团队huggingface提供。
- 加载和使用预训练模型的步骤
- 第一步:确定需要加载的预训练模型并安装依赖包。
- 第二步:加载预训练模型的映射器tokenizer。
- 第三步:加载带/不带头的预训练模型。
- 这里的'头'是指模型的任务输出层,选择加载不带头的模型,相当于使用模型对输入文本进行特征表示。
- 选择加载带头的模型时,有三种类型的'头'可供选择,AutoModelForMaskedLM (语言模型头),AutoModelForSequenceClassification (分类模型头), AutoModelForQuestionAnswering (问答模型头)。
- 不同类型的'头',可以使预训练模型输出指定的张量维度。如使用'分类模型头',则输出尺寸为(1,2)的张量,用于进行分类任务判定结果。
- 第四步:使用模型获得输出结果。
- 使用不带头的模型进行输出
- 使用带有语言模型头的模型进行输出
- 使用带有分类模型头的模型进行输出
- 使用带有问答模型头的模型进行输出
相关文章:

自然语言处理---迁移学习
fasttext介绍 作为NLP工程领域常用的工具包,fasttext有两大作用:进行文本分类、训练词向量。在保持较高精度的情况下,快速的进行训练和预测是fasttext的最大优势。fasttext优势的原因: fasttext工具包中内含的fasttext模型具有十分简单的网络…...

node 第十天 原生node封装一个简易的服务器
原生node封装一个简易的服务器, 把前面几天的知识揉和起来做一个服务器基础实现, 首页访问, 静态资源服务器, 特定接口封装, 404app.js 服务器入口文件 app.js node app.js即可启动服务器 const { start } require(./modules/server); start();require_modules.js 整合模块导…...
intval函数的用法)
php实战案例记录(25)intval函数的用法
在PHP中,intval()函数用于将一个字符串转换为整数。它的语法如下: intval(string $value, int $base 10): int参数说明: $value:要转换的字符串。$base(可选):进制数,默认为10。如…...
laravel框架介绍(二) composer命令下载laravel报错
1.composer命令下载laravel报如下错 : curl error 18 while downloading https://repo.packagist.org/p2/symfony/uid.j son: transfer closed with 3808 bytes remaining to read,具体为 解决方案:执行以下命令切换镜像 >composer con…...

代码签名证书到期了怎么续费?
我们都知道代码签名证书最长期限可以申请3年,但有的首次申请也会申请1年,这种情况下证书到期了就意味着要重新办理,同样的实名验证步骤还需要再走一遍,尤其目前无论是哪种类型的代码签名证书都会有物理硬件,即使交钱实…...

JAVA 同城服务预约家政小程序开发的优势和运营
随着社会节奏的加快,人们对家庭清洁和维护的需求日益增长。为了满足这一需求,JAVA同城服务预约家政小程序应运而生。本文将详细介绍该小程序开发的优势及运营策略,帮助读者更好地了解其价值和潜力。 一、开发优势 方便快捷:用户…...

基于粒子群算法的无人机航迹规划-附代码
基于粒子群算法的无人机航迹规划 文章目录 基于粒子群算法的无人机航迹规划1.粒子群搜索算法2.无人机飞行环境建模3.无人机航迹规划建模4.实验结果4.1地图创建4.2 航迹规划 5.参考文献6.Matlab代码 摘要:本文主要介绍利用粒子群算法来优化无人机航迹规划。 1.粒子群…...
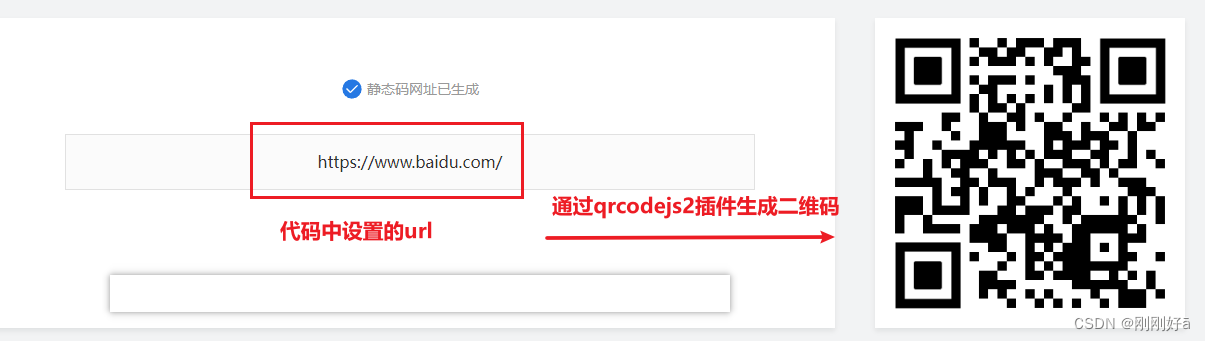
前端使用qrcodejs2插件实现根据网址生成二维码
实现效果: 实现方法: 1.安装插件 npm install --save qrcodejs2 2.可以全局引入,也可以只在使用的vue文件中引入 import QRCode from qrcodejs2; 3.在vue文件的template中设置放置二维码的div <div id"qrcode"></di…...
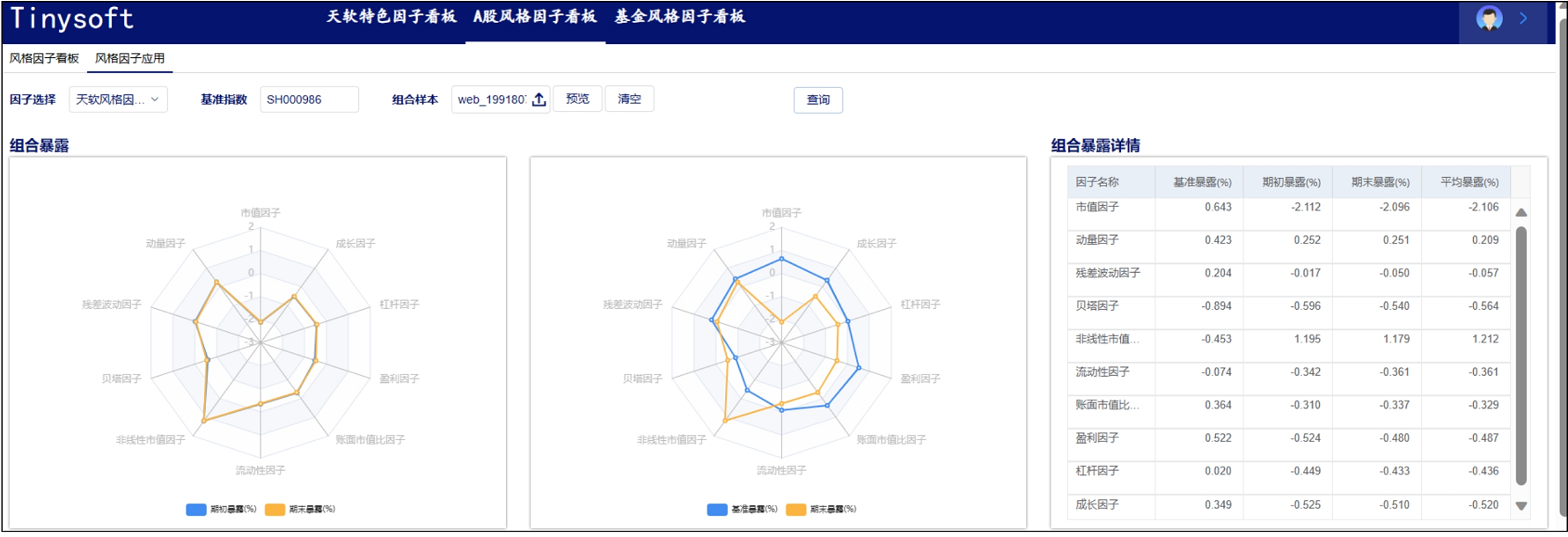
A股风格因子看板 (2023.10 第11期)
该因子看板跟踪A股风格因子,该因子主要解释沪深两市的市场收益、刻画市场风格趋势的系列风格因子,用以分析市场风格切换、组合风格暴露等。 今日为该因子跟踪第11期,指数组合数据截止日2023-09-30,要点如下 近1年A股风格因子检验统…...

anaconda安装python 3.11
最近需要测试gpt researcher项目,gpt researcher项目的环境是3.11,于是用anaconda创建一个虚拟环境,结果报错了: UnsatisfiableError: The following specifications were found to be incompatible with each other:Package xz c…...

问题:EventSource 收不到流数据及 EventSource 的 onmessage 方法为null
文章目录 问题分析问题 在开发时,有用到 EventSource,但是在 new EventSource 的时候,打印 new EventSource 如下: onmessage : null, onerror : null, onopen: f(event)前端...

P2 B+树索引
文章目录 Task1 B树页B树页B树内部结点B树叶子结点 Task2 B树操作Task2 B树插入和搜索的单一值插入单一值搜索单一值 Task2 B树删除 Task3 叶子扫描的迭代器Task4 并行索引 Task1 B树页 B树页 实际上是每个B树页面的标题部分,包含叶子页面和内部页面共享的信息。 …...

爬虫知识之BeautifulSoup库安装及简单介绍
一. 前言 在前面的几篇文章中我介绍了如何通过Python分析源代码来爬取博客、维基百科InfoBox和图片,其文章链接如下: 其中核心代码如下: # coding=utf-8 import urllib import re #下载静态HTML网页 url=http://www.csdn.net/ content = urllib.urlopen(url).read…...

如何有效取代FTP来帮助企业快速传输大文件
在互联网的发展历史上,FTP是一种具有里程碑意义的协议,它最早出现在1971年,是实现网络上文件传输的基础。FTP的优点是简单、稳定、兼容性强,可以在不同的操作系统和平台之间进行文件交换。然而,时代在进步,…...

免登陆积分商城原理
有客户需要免登陆积分商城,研究了一下发现免登陆用途广泛,实现原理也很简单。如果是浏览器无非就是使用fingerprintjs2之类的扩展来实现获取浏览器指纹ID,如果是APP就获取设备唯一标识,然后在使用cryptojs加密来传递到php…...

muduo源码学习base——Atomic(原子操作与原子整数)
Atomic(原子操作与原子整数) 前置知识AtomicIntegerTget()getAndAdd()getAndSet() 关于原子操作实现无锁队列(lock-free-queue) 前置知识 happens-before: 用来描述两个操作的内存可见性 如果操作 X happens-before 操作 Y,那么 X 的结果对于…...
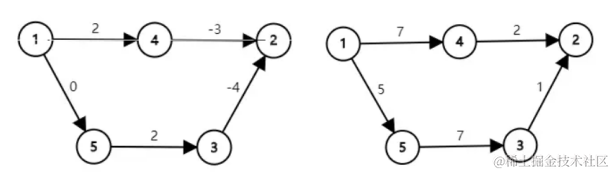
最短路相关笔记
Floyd Floyd 算法,是一种在图中求任意两点间最短路径的算法。 Floyd 算法适用于求解无负边权回路的图。 时间复杂度为 O ( n 3 ) O(n^3) O(n3),空间复杂度 O ( n 2 ) O(n^2) O(n2)。 对于两点 ( i , j ) (i,j) (i,j) 之间的最短路径,有…...

Web前端-Vue2+Vue3基础入门到实战项目-Day5(自定义指令, 插槽, 案例商品列表, 路由入门)
自定义指令 基本使用 自定义指令: 自己定义的指令, 可以封装一些dom操作, 扩展额外功能全局注册// 1. 全局注册指令 Vue.directive(focus, {// inserted 会在 指令所在的元素, 被插入到页面中时触发inserted (el) {// el 就是指令所绑定的元素// console.log(el)el.focus()} …...

mysql json数据类型 相关函数
创建JSON文本的函数 1.JSON_ARRAY(转换json数组) 2.JSON_OBJECT(转换json对象) 3.JSON_QUOTE(转义字符串) 搜索JSON文本的函数 1.JSON_CONTAINS(json当中是否包含指定value) 2.J…...

如何实现前端实时通信(WebSocket、Socket.io等)?
聚沙成塔每天进步一点点 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 欢迎来到前端入门之旅!感兴趣的可以订阅本专栏哦!这个专栏是为那些对Web开发感兴趣、刚刚踏入前端领域的朋友们量身打造的。无论你是完全的新手还是有一些基础的开发…...

ThinkPad风扇控制终极指南:TPFanCtrl2让你的笔记本电脑静音又凉爽 [特殊字符]
ThinkPad风扇控制终极指南:TPFanCtrl2让你的笔记本电脑静音又凉爽 🚀 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 还在为ThinkPad风扇噪音烦…...

3步实现智能自动化操作:面向安卓用户的图像识别工具
3步实现智能自动化操作:面向安卓用户的图像识别工具 【免费下载链接】Smart-AutoClicker An open-source auto clicker on images for Android 项目地址: https://gitcode.com/gh_mirrors/smar/Smart-AutoClicker 在数字化生活中,重复操作消耗着我…...

微信聊天记录全掌控:PyWxDump本地化备份与深度管理指南
微信聊天记录全掌控:PyWxDump本地化备份与深度管理指南 【免费下载链接】PyWxDump 删库 项目地址: https://gitcode.com/GitHub_Trending/py/PyWxDump 在数字时代,微信聊天记录已成为个人和企业重要的信息资产。无论是商务沟通的关键凭证、项目协…...

ModbusRTU上位机系统功能说明文档
C# ModbusRtu或者TCP协议上位机源码,包括存储,数据到SQL SERVER数据库,趋势曲线图,数据报表,实时和历史报警界面,有详细注释,需要哪个协议版本一、系统概述 ModbusRTU上位机系统是基于C#语言开发…...

智能车调参手记:我是如何用VOFA+和MATLAB,把云台电机调得‘跟手’的
智能车调参手记:从云台抖动到丝滑跟手的实战全记录 第一次参加智能车比赛时,云台电机给我上了深刻的一课——当目标快速移动时,镜头像醉汉一样摇晃不定,滞后和超调让自动瞄准成了笑话。经过72小时不眠不休的调试,终于让…...

树莓派5 MIPI摄像头配置与实战:从CSI/DSI接口到图像采集
1. 树莓派5的MIPI摄像头接口解析 树莓派5最大的硬件改进之一就是将CSI和DSI接口合并为两个通用的CSI/DSI(MIPI)端口。这种设计让接口使用更加灵活,你可以根据需要自由选择连接摄像头或显示屏。这两个接口都采用15针FPC排线连接器,…...
Pixel Language Portal入门必看:基于Hunyuan-MT-7B的怀旧风翻译工具从零搭建
Pixel Language Portal入门必看:基于Hunyuan-MT-7B的怀旧风翻译工具从零搭建 1. 项目介绍与核心价值 Pixel Language Portal(像素语言跨维传送门)是一款融合了复古游戏美学与现代AI翻译技术的创新工具。与传统翻译软件不同,它将…...

OFA模型解析Mathtype公式截图:辅助数学内容无障碍访问
OFA模型解析Mathtype公式截图:辅助数学内容无障碍访问 1. 引言 想象一下,你面前有一份重要的学术论文或者一份数学教材,但其中关键的公式部分,对你来说却是一片空白。这不是因为公式不存在,而是因为你的眼睛无法直接…...

WorkBuddy技能系统详解:推荐6大实用Skill
文章目录一、给你的AI同事装上"专业技能包"二、Excel智能处理:表格操作的"一键魔法"三、PPT智能生成:从构思到成稿的"全自动流水线"四、浏览器自动化:让AI替你去"网上冲浪"五、智能文件整理…...

LFM2.5-1.2B-Thinking-GGUF保姆级教程:Windows/Mac/Linux三平台本地部署
LFM2.5-1.2B-Thinking-GGUF保姆级教程:Windows/Mac/Linux三平台本地部署 1. 平台介绍 LFM2.5-1.2B-Thinking-GGUF是Liquid AI推出的一款轻量级文本生成模型,特别适合在资源有限的设备上快速部署和使用。这个模型采用了GGUF格式,配合llama.c…...