Modeling Deep Learning Accelerator Enabled GPUs
Modeling Deep Learning Accelerator Enabled GPUs 发表在 ISPASS 2019 上。文章研究了 NVIDIA 的 Volta 和 Turing 架构中张量核的设计,并提出了 Volta 中张量核的架构模型。 基于 GPGPU-Sim 实现该模型,并且支持 CUTLASS 运行。发现其性能与硬件非常吻合,与 Titan V GPU 相比,获得了99.6%的 IPC 相关性。文中还展示了 Turing 架构中张量核的操作数矩阵元素到线程的映射,并发现它们与 Volta 张量核的行为不同。
Related Work
论文的相关工作:
-
Demystifying GPU Microarchitecture through Microbenchmarking 使用广泛的微基准对 NVIDIA GT200进行了透彻的分析。他们探索了处理核和内存层次结构的架构细节。描述了先前未公开的屏障同步和内存层次结构的细节,包括 GPU 中的 TLB 组织。
-
Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking 详细研究了张量核。他们在混合精度模式下解码了 Volta 张量核的集合和步骤。
-
NVIDIA Tensor Core Programmability, Performance & Precision 研究了 Tensor Core 的精度损失和可编程性方面对 HPC 应用的影响。
-
Exploring Modern GPU Memory System Design Challenges through Accurate Modeling 研究了包括 Volta 在内的现代 GPU 的内存系统,并发现了内存系统中许多重要的设计决策。他们在 GPGPU-Sim 中对其进行建模,并在广泛的 GPGPU 工作负载上实现了非常高的相关性。
Background
Volta Microarchitecture
Volta 是 NVIDIA 第一代包含机器学习加速器的 GPU 架构。NVIDIA GPU 通常由多个流式多处理器 (Streaming Multiprocessor, SM) 组成,这些处理器通过片上网络连接到多个内存分区。 每个内存分区都包含最后一级缓存的一部分,并将 GPU 连接到片外 DRAM。 正如 NVIDIA 所描述的,每个 SM 内包含多个张量核。Volta 中的 SM 设计分为四个处理块,NVIDIA 将其称为 Sub-Core。如图 1所示,Volta 中的每个子核都有两个张量核、一个 Warp 调度器、一个调度单元和一个64KB 的寄存器文件。

除了新增张量核之外,Volta 还包括与机器学习工作负载性能相关的其他增强功能:
- 每个流式多处理器 (SM) 的调度单元数量是上一代 Pascal 架构的两倍;
- 拥有独立的整数和 32 位浮点 (FP32) 核;
- 对发散线程,分支后面的两条路径都可以由单个 warp 内的线程以交错的方式执行。
Tensor Core
每个张量核都是一个可编程计算单元,专门用于加速机器学习工作负载。Tesla Titan V GPU 包含分布在80个 SM 中的640个张量核,每个 SM 有8个张量核,在1530 MHz 的工作频率下提供125 TFLOPS 的理论性能。根据 NVIDIA TESLA V100 GPU ARCHITECTURE,每个张量核可以在每个时钟周期完成一次 4 × 4 4\times 4 4×4 矩阵乘法累加 (MACC),即 D = A × B + C D=A\times B+C D=A×B+C,其中 A , B , C A ,B,C A,B,C 是 4 × 4 4\times 4 4×4 矩阵,如图 3 所示。

虽然单个张量核在任何时候都对 4 × 4 4 \times 4 4×4 矩阵进行操作,但 WMMA API 在更大的图块大小上公开张量核。自然地,两个 16 × 16 16 \times 16 16×16 矩阵的乘法分解为一个分块矩阵乘法,结果矩阵由十六个 4 × 4 4 \times 4 4×4 子矩阵构成,每个涉及四个 4 × 4 4 \times 4 4×4 矩阵相乘累加。因此,CUDA C++ WMMA 级别的每个mma_sync或 PTX 级别的每个 wmma.mma操作可以用64个独立的张量核操作来实现。
张量核有 FP16 和混合精度两种工作模式:
- 在 FP16模式下,张量核读取三个 4 × 4 4 \times 4 4×4 16位浮点矩阵作为源操作数;
- 而在混合精度模式下,它读取两个 4 × 4 4 \times 4 4×4 16位浮点矩阵以及第三个 4 × 4 4 \times 4 4×4 32位浮点累加矩阵。
Demystifying NVIDIA’s Tensor Cores
Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking 研究了列主布局中混合精度模式的矩阵操作数元素到寄存器的分布情况。文中将线程束内的一组四个连续线程称为“线程组”。
为了描述方便,论文余下部分中将其缩写为 threadgroup。由于一个 warp 中有32个线程,因此一个线程束中有 8 8 8 个 threadgroup。给定线程的 threadgroup id(类似于 Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking 中的“group id”)根据 ⌊ t h r e a d I d x 4 ⌋ \lfloor\frac{threadIdx}{4}\rfloor ⌊4threadIdx⌋ 得到。
Microbenchmarks
本节讨论了用于分析张量核实现的微基准测试。其包含两种类型的微基准测试:
- 一种旨在确定数据如何移入和移出张量核;
- 另一种用于确定张量核执行操作所需的时间。
Fragment to thread mapping
图 4包含 III-B 节中使用的 CUDA 代码的一部分,用于确定操作数矩阵元素和线程之间的映射。此代码是在 16 × 16 16\times16 16×16 矩阵上运行的更大的通用矩阵乘法 (GEMM) 内核的一部分。每个线程加载输入矩阵的一个段并将其打印到输出控制台。通过使用不同的值初始化输入矩阵的每个元素,可以直接揭示从操作数矩阵元素到线程束内线程的映射。

Analyzing machine instructions
正如在 III-C. Machine ISA interface 节中详细描述的那样,PTX 指令被映射为多个HMMA SASS 指令。图 5 在高层次上说明了用微基准测试分析HMMA指令如何访问数据时的操作。作者使用 radare2 将HMMA操作替换为“无操作” ( NOP) 指令的操作,仅保留一个HMMA操作。

图 6 概括地说明了微基准测试用于分析张量核心上低级操作的时序的方法。为了开发这些微基准测试,作者使用 radare2 添加了在 1 s t 1^{st} 1st 之前和 n t h n^{th} nth HMMA指令之后读取时钟寄存器的代码。

Operand matrix element mapping
本节总结了矩阵元素到线程的分布的分析结果。
Volta Tensor Cores
图 7a 和 7b 总结了矩阵操作数的元素如何映射到线程束内各个线程的寄存器。
- 大矩形 ( 1 ◯ \textcircled{1} 1◯) 表示 FP16和混合精度操作模式的 16 × 16 16\times16 16×16 操作数矩阵 A 或 B。
- 较小的方块是操作数矩阵中的各个元素,同一行中的元素在内存中连续存储。
- 每个 threadgroup 加载一个不同的 4 × 16 4\times16 4×16 子矩阵,文中将其称为一个段。组成操作数矩阵的四个段用不同的着色突出显示。

图 7a 的右上部分 ( 2 ◯ , 3 ◯ \textcircled{2},\textcircled{3} 2◯,3◯) 显示了段内的元素如何分布在一个线程组的线程中。在 Volta 上,每个段都由两个不同的 threadgroup 加载。因此,A 和 B 操作数矩阵的每个元素 由 Volta 上的线程束中的两个不同线程加载。图 7a 的底部部分 ( 4 ◯ \textcircled{4} 4◯) 与左上角部分 ( 1 ◯ \textcircled{1} 1◯) 相结合,总结了确切的映射。例如,实验发现操作数矩阵 A 的连续前四行由 threadgroup 0和2加载。
以行优先布局存储的操作数矩阵 A 的矩阵元素到线程的分布与以列优先布局存储的操作数矩阵 B 的分布相同,反之亦然。
- 对于行主布局中的操作数矩阵 A,threadgroup 内的每个线程使用两个合并的 128 位宽加载指令,加载一行中的 16 16 16 个连续元素 ( 2 ◯ \textcircled{2} 2◯);
- 而在列主布局中为了加载4行, threadgroup 内的每个线程通过四个合并的 64 位宽加载指令加载四个块,每个块内四个连续元素,每个加载指令的跨距为 64 个元素 ( 3 ◯ \textcircled{3} 3◯)。
如图 7b 所示,对于操作数矩阵 C,矩阵元素到线程的分布是不同的。具体来说,
- 对于操作数矩阵 C,每个 threadgroup 加载矩阵 C 的一个 8 × 4 8\times 4 8×4 段。
- threadgroup 内的具体分布取决于矩阵 C 是 FP16还是 FP32,并且与布局无关。
在两种工作模式下,均使用32位宽(部分合并)的加载指令访问矩阵 C 的元素。
Turing Tensor Cores
图 8 总结了 NVIDIA Turing 架构中张量核的操作数矩阵元素到线程的分布。Turing 的张量核心支持三种新的精度模式:1位、4位和8位,以及三种新的图块大小:8位和16位模式的 32 × 8 × 16 32\times 8\times 16 32×8×16 和 8 × 32 × 16 8\times 32\times 16 8×32×16,4位模式为 8 × 8 × 32 8\times 8\times 32 8×8×32。
 Figure 8: Distribution of operand matrix elements to threads for tensor cores in the RTX 2080 (Turing).
Figure 8: Distribution of operand matrix elements to threads for tensor cores in the RTX 2080 (Turing).
在撰写本文时,对1位模式的支持才启用,并且似乎不适用于文中的系统。因此,本文其余部分不提供1位模式的分析。
Turing 的元素到线程的分布比 Volta 更简单。具体而言,
- 每个操作数矩阵元素仅加载一次。
- 两种图块尺寸 32 × 8 × 16 32\times 8\times 16 32×8×16 和 8 × 32 × 16 8\times 32\times 16 8×32×16 都采用相同的分布。
- 对于所有模式和配置,每行或列(取决于模式和操作数矩阵)由 threadgroup 加载,并且连续的 threadgroup 加载连续的行或列。
Machine ISA interface
本节总结了作者所了解的有关如何在机器指令集架构级别访问 Tensor Core 的知识。 对于 NVIDIA GPU,这个层次通常称为 SASS。这里的分析基于使用 NVIDIA 的 cuobjdump 工具检查 SASS 反汇编。
论文发现wmma.load和wmma.store PTX 指令是通过分解为一组普通的 SASS 加载(LD.E.64、LD.E.64、LD.E.SYS) 和存储 (ST.E.SYS) 指令来实现的。这表明 Tensor Core 直接从普通 GPU 寄存器文件中访问操作数矩阵片段。更详细地说,发现wmma.load.c PTX 指令被分解为一组LD.E.SYS指令。
对于操作数矩阵 A 和 B,根据操作数矩阵布局是行优先还是列优先,将wmma.load PTX 指令拆分为四个 64 位加载 (LD.E.64) 或两个 128 位负载 (LD.E.128)。
图 9 说明了单个wmma.mma PTX 指令所对应的 Volta 的 SASS 代码。

从图中可以看出,
- 矩阵乘法累加运算是通过新的 SASS 指令
HMMA实现的。 - 每个
HMMA指令有四个操作数,每个操作数使用一对寄存器。 - 由不同内存操作访问的一对相邻寄存器使用单个寄存器标识符编码在
HMMA指令中(通过比较HMMA以及加载和存储使用的寄存器可以推断出)。例如,论文分析图 9 中第一条HMMA指令中的R8表示寄存器对<R8,R7>。 - 寄存器对中较高位的寄存器标识符是指令中编码的寄存器标识符。例如,对于图 9 第一行的
HMMA指令,目标寄存器R8实际上代表<R8,R7>对。 类似地,剩余的寄存器标识符实际上代表三对源操作数寄存器(<R24,R23>、<R22,R21>和<R8, R7>)。 - 一些寄存器在图 9 中用“
reuse”注释。 SGEMM Implementation 分析了 NVIDIA 针对早期 Maxwell 架构的 SASS 指令集,其中经常出现类似的注释。根据他的分析和 NVIDIA 关于 GPU 寄存器文件缓存的相关论文[43],作者认为“reuse”符号表示相关操作数在下一步中被重用,因此缓存在操作数重用缓存以避免寄存器读取并可能减少 bank冲突。
Volta Tensor Cores
每个wmma.mma PTX 指令被分解为一组HMMA指令:
- 图 9a 说明了混合精度模式的 SASS 代码。在该模式下,
- 每条 PTX
wmma.mma指令被分解成16条HMMA指令。 - 16条
HMMA指令被组织为4条HMMA指令的4个集合。 - 每条
HMMA指令用"STEP<n>"标注,其中<n>的取值范围从0到3。因此,每个集合包括四个步骤。
- 每条 PTX
- 图 9b 说明了 FP16 模式的 SASS 代码,其中,
- 单条 PTX
wmma.mma指令分为四组; - 仅包含 2 个步骤。
- 单条 PTX
图 9 还显示了 Volta Tensor Core 的累积时钟周期。wmma.mma API 在混合精度模式下的延迟比 FP16模式下低十个周期。
Turing Tensor Cores
对于 Turing,每条 PTX wmma.mma指令
- 在4位模式下转换为单条
HMMA指令; - 其他模式下均都分为一组四个
HMMA指令。
表 I 显示了 Turing 架构上HMMA指令的累积时钟周期。 对于 16 × 16 × 16 16\times 16\times 16 16×16×16 图块大小,Turing 上混合精度模式下 wmma.mma的延迟为99个周期(表 I), 多于 Volta 的54个周期(图 9a)。混合精度模式的延迟大于 FP16模式。8位模式速度最快。4位模式的延迟最高,这可能是因为它是2080 RTX 上的一个实验特性。

HMMA Instruction Analysis
本节将更详细地探讨HMMA执行。
Volta
作者考察了图 9 中HMMA指令的每个"集合"的操作。如图 10a 所示,无论模式如何,当执行集合中的HMMA指令时,每个 threadgroup 将操作数矩阵 A 的 4 × 4 4\times4 4×4 图块与操作数矩阵 B 的 4 × 8 4\times 8 4×8 图块相乘,并将结果与操作数矩阵 C 相加。例如,当 threadgroup 0 执行第一组HMMA指令 (Set 1) 时,它将由操作数矩阵 A 的前四行和前四列组成的子图块与由操作数矩阵 B 的前四行和前八列组成的子图块相乘。结果通过操作数矩阵 C 的 4 × 8 4\times8 4×8 子图块进行累加,并存储在操作数矩阵 D 的 4 × 8 4\times8 4×8 子图块中。串联4个集合,threadgroup 0 完成操作数矩阵 A 的 4 × 16 4 \times 16 4×16 图块与操作数矩阵 B 的 16 × 8 16 \times 8 16×8 图块的乘法。

图 10b 显示了混合精度模式下 threadgroup 0 的“集合”中每个HMMA “步骤”的详细操作。HMMA指令的每个“集合”包含四个“步骤”。在每个步骤中,操作数矩阵 A 的 2 × 4 2\times4 2×4 子图块与操作数矩阵 B 的 4 × 4 4\times4 4×4 子图块相乘,并与操作数矩阵 C 的 2 × 4 2\times4 2×4 子图块累加。
类似地,图 10c 显示了 FP16模式下 threadgroup 0 的“集合”中每个HMMA“步骤”的详细操作。每组HMMA指令包含两个“步骤”。在每个步骤中,每个线程组将操作数矩阵 A 的 4 × 4 4\times4 4×4 子图块与操作数矩阵 B 的 4 × 4 4\times4 4×4 子图块相乘,并将结果与矩阵 C 累加。
经过以上步骤,threadgroup 0 完成操作数矩阵 A 的 8 × 4 8\times4 8×4 子图块与操作数矩阵 B 的 4 × 8 4\times8 4×8 子图块的乘法。
Turing
图 11 说明了 Turing GPU 架构上HMMA指令访问的元素。 Volta 中HMMA SASS 指令上发现的“step”注释在 Turing 中不存在。
 考虑到表 I 中的延迟结果并不表明并行性增加,一种可能性是类似的“步骤”由微体系结构使用状态机排序。作者认为:
考虑到表 I 中的延迟结果并不表明并行性增加,一种可能性是类似的“步骤”由微体系结构使用状态机排序。作者认为:
- 对于不同的图块配置,特定模式访问的元素是相似的。
- 在 FP16 和混合精度模式下,计算模式是两个子图块之间的乘积,其中一个子图块是 8 × 8 8\times 8 8×8,另一个子图块是 16 × 8 16\times 8 16×8 或 8 × 16 8\times 16 8×16。 例如,对于图块大小 16 × 16 × 16 16\times 16\times 16 16×16×16 或 32 × 8 × 16 32\times 8\times 16 32×8×16,SET 1 中的计算是矩阵 A 的 16 × 8 16\times 8 16×8 子图块与矩阵 B 的 8 × 8 8\times 8 8×8 子图块之间的乘积,而对于图块大小 8 × 32 × 16 8\times 32\times 16 8×32×16,乘积在矩阵 A 的 8 × 8 8\times 8 8×8 子图块与矩阵 B 的 8 × 16 8\times 16 8×16 子图块之间。
- 对于8位模式,计算模式为矩阵 A 的 8 × 16 8\times16 8×16 子图块与矩阵 B 的 16 × 8 16\times8 16×8 子图块之间的乘积。
在4位模式下,每个 wmma.mma PTX 指令都是用单个HMMA SASS 指令实现的,因此在图 11 中省略了4位模式。
Discussion
本节对上面给出的 Volta 结果进行分析,并推断出将执行分解为“集合”和“步骤”的可能理由。
回想一下,输入矩阵的每个元素都由两个不同的 threadgroup 加载。作者编写了一个微基准测试来帮助确定HMMA指令如何使用不同线程加载的片段。例如,为了确定如何使用由 thread 0 加载的操作数矩阵元素,作者更改了这些值并观察结果如何受到影响。论文发现 threadgroup 成对工作以计算结果的 8 × 8 8\times8 8×8 子图块,并将每对这样的线程组称为 octet。一个线程束中有四个 octet。
表 II 显示了构成每个 octet 的 threadgroup 对,一般可以表示为 o c t e t X = t h r e a d g r o u p X ⋃ t h r e a d g r o u p X + 4 \mathrm{octet}\, X = \mathrm{threadgroup}\, X \bigcup\mathrm{threadgroup}\, X+4 octetX=threadgroupX⋃threadgroupX+4,其中 X X X 介于 0 到 3 之间。表 II 还使用符号[Row_Start: Row_End, Col_Start: Col_End]来表示每个 threadgroup 内的线程访问的操作数矩阵 A 和 B 的子图块。无论操作数矩阵的存储布局如何,threadgroup 加载的元素都保持不变。

表 II 显示操作数矩阵 A 和 B 的每个元素被不同 threadgroup 中的线程加载两次。这使得每个 octet 能够独立工作。具体来说,每个 octet 读取操作数矩阵 A 的 8 × 16 8\times 16 8×16 子图块、操作数矩阵 B 的 16 × 8 16\times 8 16×8 子图块和操作数矩阵 C 的 8 × 8 8\times 8 8×8 子图块,如图 12a 所示。
 为了更好地理解 octet 中线程的组织,作者分析了 octet 在不同“集合”和“步骤”中执行的计算。如图 12b 所示,在每个集合中,每个 octet 执行输入子图块之间的外积。例如,在 Set 1 中,完成输入子图块 [ a ] , [ e ] [a],[e] [a],[e] 和 [ A ] , [ E ] [A],[E] [A],[E] 之间外积,生成部分结果 [ a A ] , [ a E ] , [ e A ] [aA], [aE], [eA ] [aA],[aE],[eA] 和 [ e E ] [eE] [eE]。这里每个 [ a ] , [ e ] , [ A ] , [ E ] [a],[e],[A],[E] [a],[e],[A],[E] 代表一个 4 × 4 4 \times 4 4×4 子图块。为了计算 [ a E ] [aE] [aE],threadgroup 0 需要操作数矩阵 B 子图块 [ E ] [E] [E],它仅由 threadgroup 4 加载。类似地,要计算 [ e A ] [eA] [eA],threadgroup 4 需要操作数矩阵 B 子图块 [ A ] [A] [A],它仅由 threadgroup 0 加载。因此,虽然 threadgroup 不能,但 octet 可以独立工作。表 III 在图 12b 的基础上进行了扩展,将在不同集合和步骤中执行的所有外积计算制成表格。
为了更好地理解 octet 中线程的组织,作者分析了 octet 在不同“集合”和“步骤”中执行的计算。如图 12b 所示,在每个集合中,每个 octet 执行输入子图块之间的外积。例如,在 Set 1 中,完成输入子图块 [ a ] , [ e ] [a],[e] [a],[e] 和 [ A ] , [ E ] [A],[E] [A],[E] 之间外积,生成部分结果 [ a A ] , [ a E ] , [ e A ] [aA], [aE], [eA ] [aA],[aE],[eA] 和 [ e E ] [eE] [eE]。这里每个 [ a ] , [ e ] , [ A ] , [ E ] [a],[e],[A],[E] [a],[e],[A],[E] 代表一个 4 × 4 4 \times 4 4×4 子图块。为了计算 [ a E ] [aE] [aE],threadgroup 0 需要操作数矩阵 B 子图块 [ E ] [E] [E],它仅由 threadgroup 4 加载。类似地,要计算 [ e A ] [eA] [eA],threadgroup 4 需要操作数矩阵 B 子图块 [ A ] [A] [A],它仅由 threadgroup 0 加载。因此,虽然 threadgroup 不能,但 octet 可以独立工作。表 III 在图 12b 的基础上进行了扩展,将在不同集合和步骤中执行的所有外积计算制成表格。

A Tensor Core Microarchitecture
本节提出了一个张量核微架构,其与本文前面对 Volta 的观察结果一致。
回想一下,每个张量核每个周期完成 4 × 4 4\times4 4×4 矩阵乘法并累加。 为了实现这一目标,每个张量核必须能够在每个周期执行16个四元素点积(four-element dot-products,FEDP)。如图 9 和 图 10b 所示,在稳定状态下, threadgroup 需要两个周期来生成输出矩阵的 2 × 4 2\times 4 2×4 子图块。 因此,在 warp 内的所有线程中,HMMA指令每个周期执行32个 FEDP。由于每个张量核每个周期只能完成16个 FEDP,因此 SM 中每个子核需要两个张量核才能达到满吞吐量。为了证实这一点,作者编写了一个微基准测试,它重复执行HMMA操作,改变每个线程块内的 warp 数量,并保持并发执行的线程块数量不变。如图 12c 所示,该微基准测试显示单个 SM 上只能同时执行 4 个 warp,但 Titan V SM 每个 SM 有 8 个张量核。 因此,每个 warp 似乎都利用了两个张量核。
接下来,考虑寄存器访问带宽。图 9a 中的数据表明HMMA指令的最小启动间隔是两个周期。有三个源操作数,并且如第 III-C 节中所述,对于每个源操作数,读取一对32位寄存器。综合考虑这些因素,总寄存器读取带宽为每个线程束每两个周期 32 × 2 × 3 × 32 = 6 k b 32\times2\times3\times32 = 6\mathrm{kb} 32×2×3×32=6kb。 此带宽足以让线程束每两个周期获取以下值:
- 操作数 A 的八个 2 × 4 2\times4 2×4 FP16子图,
- 操作数 B 的八个 4 × 4 4\times4 4×4 FP16子图,
- 以及操作数 C 的八个 2 × 4 2\times4 2×4 FP32子图或八个 4 × 4 4\times4 4×4 FP16子图。
假设每个线程束访问两个张量核,每个张量核的寄存器带宽为每个时钟周期每个线程束1.5kb。
NVIDIA 指出在 Volta 中 INT 和 FP32指令可以共同下发[26]。另一方面,Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking 报告张量核运算不能与整数和浮点算术指令共同发出。 论文认为原因是张量核可能正在使用与 INT 和 FP32核关联的寄存器文件访问端口。Titan V SM 内部有64个 INT 和64个 FP32 ALU,共计128个 ALU。由于一个 SM 中的8个张量核共享对寄存器文件的访问权限,每个张量核每个周期应该能够访问每个源操作的 128 8 × 32 = 16 × 32 = 512 \frac{128}{8}\times32=16\times32=512 8128×32=16×32=512 比特。假设每个 ALU 有3个源操作数(以支持乘法累加运算),这意味着每个张量核可以访问1.5kb/cycle。
图 13 展示了论文提出的张量核微架构。每个线程束使用两个张量核。假设线程束内每个张量核经由两个不同的 octet 访问。每个张量核有16个专用 SIMD 通道,每个 octet 有8个通道,每个 threadgroup 有 4 个通道。每个 threadgroup 通道将操作数送入内部缓冲区。

对于操作数矩阵 A 和 C,每个 threadgroup 将操作数提取到其单独的缓冲区,而对于操作数矩阵 B,两个 threadgroup 都将操作数提取到共享缓冲区。操作模式和步骤决定了从中获取每个操作数的 threadgroup 通道。缓冲器为16个 FP16 FEDP 单元提供数据。在每个 FEDP 单元内部,乘法在第一阶段并行执行,累加发生在三个阶段,总共四个流水线阶段。由于每个张量核由16个 FP16 FEDP 单元组成,因此每个周期能够完成一个 4 × 4 4\times4 4×4 矩阵乘法。
参考资料:
- # [DOC] Where does cutlass’ detailed GEMM kernel? #526
- Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking
- Modeling Deep Learning Accelerator Enabled GPUs
- NVIDIA Tensor Core微架构解析
相关文章:
Modeling Deep Learning Accelerator Enabled GPUs
Modeling Deep Learning Accelerator Enabled GPUs 发表在 ISPASS 2019 上。文章研究了 NVIDIA 的 Volta 和 Turing 架构中张量核的设计,并提出了 Volta 中张量核的架构模型。 基于 GPGPU-Sim 实现该模型,并且支持 CUTLASS 运行。发现其性能与硬件非常吻…...

《动手学深度学习 Pytorch版》 9.5 机器翻译与数据集
机器翻译(machine translation)指的是将序列从一种语言自动翻译成另一种语言,基于神经网络的方法通常被称为神经机器翻译(neural machine translation)。 import os import torch from d2l import torch as d2l9.5.1 …...
网络入门基础
网络入门基础 文章目录 网络入门基础网络的发展协议的概念网络协议初识协议分层层状结构OSI七层模型TCP/IP五层(或四层)模型TCP/IP模型和计算机软硬体系结构的关系 网络传输基本流程同局域网的两台主机通信不同局域网的两台主机通信 网络中的地址管理认识IP地址认识MAC地址 网络…...

Towards a Rigorous Evaluation of Time-series Anomaly Detection(论文翻译)
1 Introduction 随着工业4.0加速系统自动化,系统故障的后果可能会产生重大的社会影响(Baheti和Gill 2011; Lee 2008; Lee,Bagheri和Kao 2015)。为了防止这种故障,检测系统的异常状态比以往任何时候都更加重要ÿ…...

理解Python装饰器
本文将从多个方面对Python装饰器进行详细的阐述,并给出完整的代码示例。 一、装饰器的概念 装饰器是Python中非常重要的概念,它可以在不修改函数本身的情况下对函数的功能进行扩展或修改。装饰器本质上是一个函数,它接收一个函数作为参数&a…...

VR智慧景区,为游客开启智慧旅游新时代
近年来,文旅部加强了5G、VR虚拟技术等在文旅产业行业的运用,随着科技的不断发展,VR技术的运用越来越广泛,VR智慧景区作为一种全新的旅游方式,也渐渐的受到了人们广泛的关注,它可以让人们足不出户就欣赏到各…...

蓝桥杯 Java 青蛙过河
import java.util.Scanner; // 1:无需package // 2: 类名必须Main, 不可修改/**二分法从大(n)到小找足够小的步长前缀和记录每个位置的前面有的总石头数(一个石头表示可以容纳一个青蛙,一位置有多少个石头hi就是多少)&…...

雷达图应该如何去绘制?
雷达图(又称为蜘蛛网图、星形图)是一种用来显示多变量数据的图表,它可以直观地展示出数据在多个维度上的表现。雷达图中,每个轴代表一个维度,所有的轴都从中心点射出并均匀分布在圆周上,形成一个星形。每个…...

1024 蓝屏漏洞攻防战(第十九课)
1024 蓝屏漏洞攻防战(第十九课) 思维导图 一 永恒之蓝的介绍 漏洞为外界所知源于勒索病毒的爆发,该病毒利用NSA(美国国家安全局)泄露的网络攻击工具 永恒之蓝( EternalBlue )改造而成,漏洞通过TCP的445和139端口,利用SMB远程代码执行漏洞,攻击者可以在目标系统上执行…...

短视频矩阵系统软件源码
短视频矩阵系统软件源码 视频成为获得免费流量最便宜的渠道,平台给所有视频最基础的保底流量。如果按照一个视频最低500流量计算,5个账户就是2500的流量,200个视频就是50W流量,如果从其他渠道获得50W流量是个很困难的事情。短视频…...
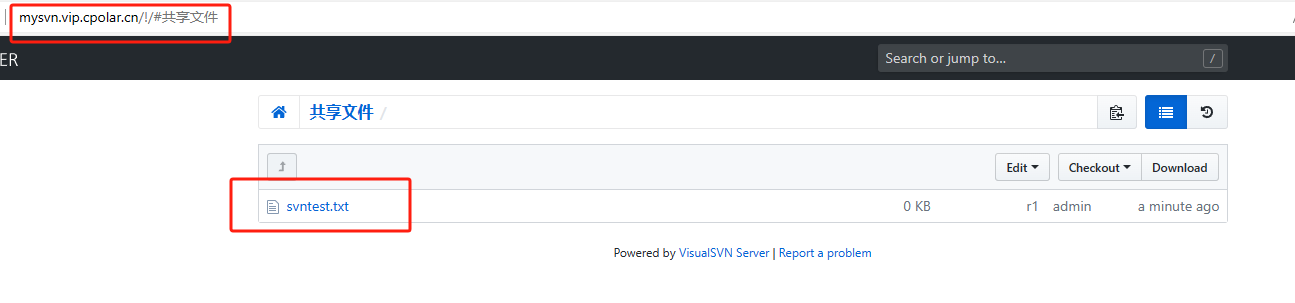
内网穿透的应用-如何通过TortoiseSVN+内网穿透,实现公网提交文件到内网SVN服务器?
文章目录 前言1. TortoiseSVN 客户端下载安装2. 创建检出文件夹3. 创建与提交文件4. 公网访问测试 前言 TortoiseSVN是一个开源的版本控制系统,它与Apache Subversion(SVN)集成在一起,提供了一个用户友好的界面,方便用…...
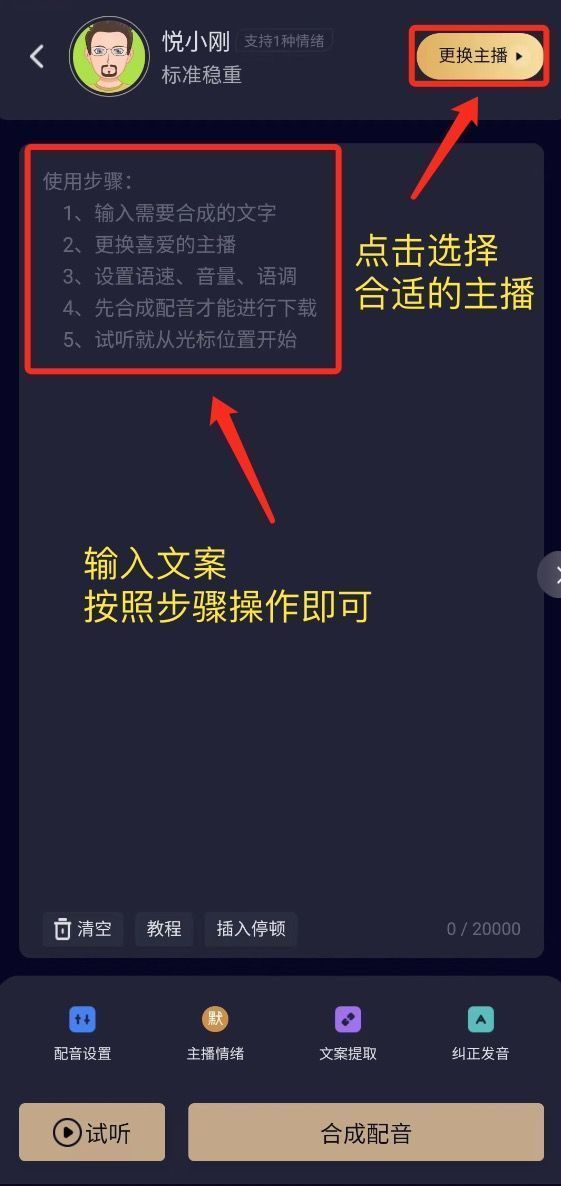
有没有PC端的配音软件推荐?(免下载)
配音软件还是电脑上使用最方便,而且电脑上可以使用的配音软件也非常多。只是你平时使用的不多,所有想用的时候才会找不到,对于经常使用配音软件的人来说,那真的太多了。今天给大家推荐一个免下载的配音网站,微信扫码即…...

clickhouse
官方链接 <insert id"insertTable" parameterType"com.ioc.orm.ck.model.TableModel">insert into table_name<trim prefix"(" suffix")" suffixOverrides","><if test"ts ! null">ts,</if…...

linux下创建文件夹软链接
软链接: 软链接是Linux下常用的一种共享文件方式、目录的方式,这种方式类似于Windows下的快捷方式。一般一个文件或者目录在不同的路径都需要的时候,可以通过创建软链接的方式来共享,这样系统下面只有一份源文件、目录。另外&…...

常用的工具网站
1.免费的在线pdf解密网站:https://smallpdf.com/unlock-pdf 2.常用的梯子登录页面:https://3.akkcloud1.com/auth/login 3.chatgpt登录页面:https://chat.openai.com/auth/login 4.国外短信收发平台:https://sms-activate.org/cn/…...
号外!百度Comate代码助手全新上线SaaS服务 - 免费申请试用+深入教程解读!
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...
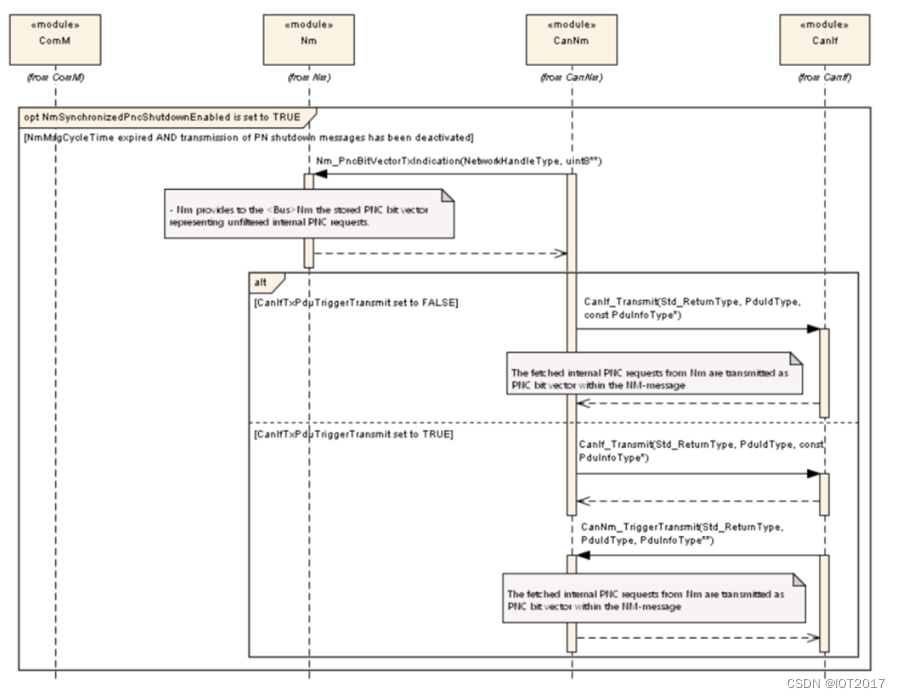
AUTOSAR通信篇 - CAN网络通信(七:Nm)
文章目录 基础功能NM协调器功能NM协调器功能的适用性保持协调总线活动总线关闭的协调嵌套子总线的协调关闭定时器的计算同步用例1 – 同步指令同步用例2-同步启动同步用例3 -同步网络睡眠示例 唤醒和中止协调关闭外部的网络唤醒协调唤醒协调关闭的中止 部分网络功能PNC位向量过…...

CentOS 7 中安装Kafka
文章目录 安装JDK解压环境变量验证 安装ZooKeeper下载解压环境变量配置启动开放端口 安装Kafka下载解压配置启动 CentOS 7.6 JDK 1.8 ZooKeeper 3.5.7 Kafka 2.11-2.4.0 安装JDK 解压 # 解压 tar -xzvf jdk-8u181-linux-x64.tar.gz mv jdk1.8.0_181 /usr/local/jdk1.8环境变量…...

Centos 7 部署Docker CE和docker-compose教程
一、Docker CE 1、Docker CE 安装 ①、安装依赖包 yum install -y yum-utils device-mapper-persistent-data lvm2②、设置yum源 # 官方源(二选一) yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo # 阿里源…...

【数据结构】模拟实现无头单向非循环链表
链表的概念 学过ArrayList后我们知道它的底层是用数组来存储元素的,是连续的存储空间,当我们要从ArrayList任意位置删除或插入元素时,我们要把后续整体向前或后移动,时间复杂度为O(n),效率比较低,因此Arra…...

新手入门指南:在快马平台上用openclaw重启版本实现首个爬虫项目
最近在学习网络爬虫,发现openclaw重启版本对新手特别友好,于是尝试在InsCode(快马)平台上做了一个简单的新闻头条抓取项目。整个过程比想象中顺利,分享下我的学习路径和踩坑经验。 环境准备与库安装 传统爬虫项目最头疼的就是环境配置&#x…...

Windows 11系统优化终极指南:如何用Win11Debloat让你的电脑重获新生
Windows 11系统优化终极指南:如何用Win11Debloat让你的电脑重获新生 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to dec…...

混合储能系统容量优化配置中的信号分解与容量分配算法解析
混合储能容量优化配置(钠硫电池、超级电容) 基于emd和vmd容量配置 1、先用vmd进行输入功率分解,通过分解出高频信号和低频信号,混合储能的功率分配,分给钠硫电池、超级电容。 2、分解后再求出储能的额定容量和额定功率…...

Zabbix监控Docker化部署避坑指南:从镜像版本选择到安全加固的完整配置
Zabbix监控Docker化部署避坑指南:从镜像版本选择到安全加固的完整配置 在容器化技术席卷运维领域的今天,将Zabbix监控系统部署在Docker环境中已成为主流选择。但看似简单的docker-compose up -d背后,隐藏着无数可能让运维工程师深夜加班的&qu…...

【2026最新】AIGC率从60%降至5%只需零成本?10款免费工具实测红黑榜,一键解锁知网自救通关
四月一到,查重和AIGC检测成了两座大山。 自己熬夜敲的字被判AI生成,或者润色后满篇通红,这绝望感谁懂? 为了搞定论文降aigc这个大坑,我拿手头几篇废稿,去市面上热门的10款降ai率工具滚了一圈。今天这篇吐…...

【实战指南】利用逐飞库实现printf函数重定向至蓝牙串口的完整步骤
1. 为什么需要printf重定向到蓝牙串口 在嵌入式开发中,printf函数是最常用的调试工具之一。传统的调试方式是通过有线串口将调试信息输出到电脑终端,但在很多实际应用场景中,有线连接会带来诸多不便。比如智能小车调试时,拖着一条…...

智能调压突破性能极限:AMD Ryzen处理器调试工具让多核效率提升150%
智能调压突破性能极限:AMD Ryzen处理器调试工具让多核效率提升150% 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址…...

Windows系统Btrfs文件系统实用指南
Windows系统Btrfs文件系统实用指南 【免费下载链接】btrfs WinBtrfs - an open-source btrfs driver for Windows 项目地址: https://gitcode.com/gh_mirrors/bt/btrfs 在数字化存储需求日益增长的今天,文件系统的选择直接影响数据安全性与存储效率。WinBtrf…...

MATLAB App Designer打包实战:从GUI到独立安装包的完整部署指南
1. MATLAB App Designer打包前的准备工作 第一次把MATLAB开发的GUI程序打包成独立安装包时,我踩了不少坑。记得当时给合作方演示算法,对方电脑没有MATLAB环境,只能干着急。后来花了三天时间才搞明白整个打包流程,现在把这些经验系…...

掌控微信数据:从信息丢失到价值挖掘的完整解决方案
掌控微信数据:从信息丢失到价值挖掘的完整解决方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeChatMs…...