Hadoop3教程(三十五):(生产调优篇)HDFS小文件优化与MR集群简单压测
文章目录
- (168)HDFS小文件优化方法
- (169)MapReduce集群压测
- 参考文献
(168)HDFS小文件优化方法
小文件的弊端,之前也讲过,一是大量占用NameNode的空间,二是会使得寻址速度变慢。
另外,过多的小文件,在进行MR的时候,会生成过多切片,从而启动过多的MapTask,很容易造成,启动MapTask的时间比MapTask计算的时间还长,浪费资源。
那怎么解决小文件问题,有这么几个解决方向:
- 从数据源头上控制:
- 就是数据在采集的时候,就不让上传小文件,如果有小文件的话,就先合并成大文件之后,再上传到HDFS;
- 从存储上来控制:
- Hadoop Archive,即文件归档,将多个小文件压缩归档成一个大文件,可以减少NN的使用。
- 从计算方向上来控制:
- 采用CombineTextInputFormat,在切片过程中,将多个小文件生成一个切片;
- 开启uber模式,实现JVM重用。默认情况下,每个Task任务都需要开启一个JVM来运行,如果Task任务的计算量很小,那我们完全可以让多个Task运行在同一个JVM中,不需要开启多余的JVM。
下面举一下例子,在未开启Uber模式的情况下,我们在/input路径上上传多个小文件并执行wordcount程序:
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output2
观察控制台,里面会有行这样的输出:
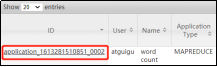
2021-02-14 16:13:50,607 INFO mapreduce.Job: Job job_1613281510851_0002 running in uber mode : false
提示我们本次没有开启uber模式。
然后在yarn的网页里,查看刚刚运行完成的这个任务,如下图,会发现,它一共开启了5个容器:

接下来让我们开启uber模式,在mapred-site.xml中添加如下配置:
<!-- 开启uber模式,默认关闭 -->
<property><name>mapreduce.job.ubertask.enable</name><value>true</value>
</property><!-- uber模式中最大的mapTask数量,即JVM重用的次数,只能向下修改,即小于9 -->
<property><name>mapreduce.job.ubertask.maxmaps</name><value>9</value>
</property>
<!-- uber模式中最大的reduce数量,只能向下修改,即要不是0,要不是1 -->
<property><name>mapreduce.job.ubertask.maxreduces</name><value>1</value>
</property>
<!-- uber模式中最大的输入数据量,默认使用dfs.blocksize 的值,可向下修改 -->
<property><name>mapreduce.job.ubertask.maxbytes</name><value></value>
</property>
然后分发配置:
[atguigu@hadoop102 hadoop]$ xsync mapred-site.xml
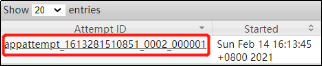
继续执行刚才执行过的WordCount程序,这时候我们可以从控制台里观察到这么一行输出:
2021-02-14 16:28:36,198 INFO mapreduce.Job: Job job_1613281510851_0003 running in uber mode : true
同时查看yarn,如下图,会发现当前任务,其实只用了一个容器:

所以uber模式的开启,实现了共用容器的效果。
(169)MapReduce集群压测
集群搭建好后,可以通过压测,来了解下当前集群的计算能力。
比如说可以执行下面的任务,查看多长时间内,可以执行完这个任务,就可以大概估算出数据量和执行时间之间的关系。
(1)使用RandomWriter来产生随机数,每个节点运行10个Map任务,每个Map产生大约1G大小的二进制随机数
[atguigu@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar randomwriter random-data
(2)执行Sort程序
[atguigu@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar sort random-data sorted-data
(3)验证数据是否真正排好序了
[atguigu@hadoop102 mapreduce]$
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar testmapredsort -sortInput random-data -sortOutput sorted-data
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】
相关文章:
Hadoop3教程(三十五):(生产调优篇)HDFS小文件优化与MR集群简单压测
文章目录 (168)HDFS小文件优化方法(169)MapReduce集群压测参考文献 (168)HDFS小文件优化方法 小文件的弊端,之前也讲过,一是大量占用NameNode的空间,二是会使得寻址速度…...

metersphere 接口自动化
Metersphere 使用步骤大致如下: 安装 Metersphere Metersphere 是一款基于 Docker 的应用程序,因此在使用 Metersphere 之前,需要先安装 Docker。安装 Docker 后,再下载 Metersphere 的安装包并解压缩。 启动 Metersphere 在终…...

Mac上安装和配置Git
在Mac上安装和配置Git是一个相对简单的过程,以下是一份详细的步骤指南。 首先,你需要确保你的Mac已经安装了Homebrew(如果还没有安装,可以通过以下命令安装:),Homebrew是一个包管理器ÿ…...

【文件操作】Java -操作File对象
个人简介:Java领域新星创作者;阿里云技术博主、星级博主、专家博主;正在Java学习的路上摸爬滚打,记录学习的过程~ 个人主页:.29.的博客 学习社区:进去逛一逛~ 文件操作 Java - File对象 Java - File对象 Fi…...

Socks5代理技术:驱动数字化时代跨界发展的利器
随着全球数字化进程的加速推进,Socks5代理技术作为一项关键的网络技术正日益成为推动跨界电商、爬虫数据分析、企业出海以及游戏体验优化等领域发展的重要驱动力。其高效稳定的网络连接能力以及灵活的应用方式,不仅为企业提供了全球市场拓展的无限可能&a…...

基于二维小波变换的散斑相位奇异构造算法matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 图(1)表示散斑原图像,(2)表示对(1)图像进行x轴方向的极化分析的小波相位图,呈周期的水平条纹,(3)表示对(1)图像…...

为啥么有奖章
6.1 域名系统 DNS 应用层的许多协议都是基于客户服务器方式。即使是 P2P 对等通信方式,实质上也是一种特殊的客户服务器方式。这里再明确一下,客户(client)和服务器(server)都是指通信中所涉及的两个应用进程。客户服务器方式所描述的是进程之间服务和被…...

【报错】Unbalanced delimiter found in string
Unbalanced delimiter found in string uniapp报错Unbalanced delimiter found in string 查看代码发现原来是粗心导致的。条件编译删漏了一条 hid.close()// #endif加上前面的条件编译 or减去后面的即可...

Python(一)关键字、内置函数
程序员的公众号:源1024,获取更多资料,无加密无套路! 最近整理了一波电子书籍资料,包含《Effective Java中文版 第2版》《深入JAVA虚拟机》,《重构改善既有代码设计》,《MySQL高性能-第3版》&am…...
聊聊分布式架构10——Zookeeper入门详解
目录 01ZooKeeper的ZAB协议 ZAB协议概念 ZAB协议基本模式 消息广播 崩溃恢复 选举出新的Leader服务器 数据同步 02Zookeeper的核心 ZooKeeper 的核心特点 ZooKeeper 的核心组件 选举算法概述 服务器启动时的Leader选举 服务器运行期间的Leader选举 03ZooKeeper的…...
springmvc视图格式——模板引擎freemarker输出HTML文本
目录 1. freemarker 介绍创建测试工程2.2.2) 配置文件2.2.3) 创建模型类2.2.4) 创建模板2.2.5) 创建controller2.2.6) 创建启动类2.2.7) 测试 2.3) freemarker基础2.3.1) 基础语法种类2.3.2) 集合指令(List和Map)2.3.3) if指令2.3.4) 运算符2.3.5) 空值处…...

用长tree方式做等长线
我正在「拾陆楼」和朋友们讨论有趣的话题,你⼀起来吧? 拾陆楼知识星球入口 相关文章链接: 用set_data_check的方式做等长线 前面讲过了如何用set_data_check做等长线,这里再讲一下如何用cts的方式做。 1)写一个sdc,把等长线的起点设置成clock source,用于创建create_…...

C# out参数out多个参数
文章目录 C# out参数out多个参数背景说明作用方法定义调用方法测试结果注意 C# out参数out多个参数 背景说明 一个方法返回多个相同数据类型的变量,可以采用数据的方式; 我需要返回多个不同数据类型的方法,在这里采用out多个参数的方式。 …...

选择Android还是IOS?我终于明白了!
选择Android还是iOS,取决于个人的喜好和需求。以下是一些可能帮助您做出决策的考虑因素: 用户界面和易用性: iOS系统的界面比Android更加简单、易用,而且应用程序布局更加一致,可以更快地学会如何使用。Android系统除了…...

uniapp高德地图ios 使用uni.chooseLocation选取位置显示没有搜索到相关数据
uniapp云打包后,高德地图ios选取位置显示“ 对不起,没有搜索到相关数据” 详细问题描述 废话不多说,直接上图 解决方案 1.打开高德地图开发平台 2.重新创建key 3.获取云打包时的ios报名作为安全码 4.使用生成的高德key更改manifest.json里…...

Python绘制论文中的图形
一、条形图 使用场景:对多个实验方法的性能进行比较。代码: #条形图 import matplotlib.pyplot as plt import numpy as np#实验数据,每一行代表一个method,每一列代表一个性能指标 dataacc [[0.9504, 0.9315, 0.9420, 0.9409]…...

flutter复制口令返回app监听粘贴板
overridevoid didChangeAppLifecycleState(AppLifecycleState state) {switch (state) {case AppLifecycleState.inactive: // 处于这种状态的应用程序应该假设它们可能在任何时候暂停。break;case AppLifecycleState.resumed: //从后台切换前台,界面可见handle();b…...
学习pytorch14 损失函数与反向传播
神经网络-损失函数与反向传播 官网损失函数L1Loss MAE 平均MSELoss 平方差CROSSENTROPYLOSS 交叉熵损失注意code 反向传播在debug中的显示code B站小土堆pytorch视频学习 官网 https://pytorch.org/docs/stable/nn.html#loss-functions 损失函数 L1Loss MAE 平均 import to…...
windows平台下Qt Creator的下载与安装流程
下载 下载地址:https://download.qt.io/archive/ 下载界面 进入qt或者qtcreator都可以 版本选择 这里我选择进入qt进行下载,进入之后有多个版本可以选择。 注意:从Qt5.15版本开始,Qt公司不在提供开源离线安装程序,此…...
在 Python 中使用 Pillow 进行图像处理【3/4】
第三部分 一、腐蚀和膨胀 您可以查看名为 的图像文件dot_and_hole.jpg,您可以从本教程链接的存储库中下载该文件: 该二值图像的左侧显示黑色背景上的白点,而右侧显示纯白色部分中的黑洞。 侵蚀是从图像边界去除白色像素的过程。您可以通过使用…...

稳定性与生态性的平衡:Windows 11 LTSC系统微软商店完整解决方案
稳定性与生态性的平衡:Windows 11 LTSC系统微软商店完整解决方案 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore Windows 11 LTSC…...

d2s-editor:让暗黑破坏神2存档修改变得简单安全
d2s-editor:让暗黑破坏神2存档修改变得简单安全 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 对于暗黑破坏神2玩家而言,修改存档往往是一把双刃剑——既想个性化角色体验,又担心损坏文件或失…...
Hunyuan-MT-7B开源镜像实操:Pixel Language Portal在Jetson Orin边缘设备上的轻量部署
Hunyuan-MT-7B开源镜像实操:Pixel Language Portal在Jetson Orin边缘设备上的轻量部署 1. 项目概览 Pixel Language Portal(像素语言跨维传送门)是一款基于Tencent Hunyuan-MT-7B核心引擎构建的创新翻译工具。与传统翻译软件不同࿰…...

AI辅助开发:让快马平台智能生成期刊官网架构与核心业务代码
AI辅助开发:让快马平台智能生成期刊官网架构与核心业务代码 最近在做一个学术期刊官网的项目,发现从头开始搭建整个系统的工作量巨大。幸运的是,我发现了InsCode(快马)平台的AI辅助开发功能,它帮我智能生成了整个项目的骨架代码和…...

利用快马平台与ccswitch快速构建可切换功能模块的web应用原型
今天想和大家分享一个快速验证前端功能模块切换方案的小技巧。最近在做一个需要动态切换不同功能模块的项目,尝试了用ccswitch工具配合InsCode(快马)平台来搭建原型,效果出乎意料地好。 为什么选择ccswitch ccswitch是一个轻量级的JavaScript工具&…...
扩展方案)
Hunyuan-MT Pro快速上手:添加语音输入/输出模块(Whisper+VITS)扩展方案
Hunyuan-MT Pro快速上手:添加语音输入/输出模块(WhisperVITS)扩展方案 1. 项目概述与扩展价值 Hunyuan-MT Pro是一个基于腾讯混元大模型的多语言翻译终端,原本专注于文本翻译。但实际使用中,我们经常遇到这样的场景&…...

Intv_AI_MK11 Java开发环境快速搭建:从JDK安装到模型调用
Intv_AI_MK11 Java开发环境快速搭建:从JDK安装到模型调用 1. 前言:为什么选择Java调用AI模型 Java作为企业级开发的主流语言,在AI应用开发中同样能发挥重要作用。Intv_AI_MK11作为新一代AI模型,提供了完善的Java SDK支持&#x…...

Scarab:自动化解决《空洞骑士》模组依赖冲突的跨平台管理工具
Scarab:自动化解决《空洞骑士》模组依赖冲突的跨平台管理工具 【免费下载链接】Scarab An installer for Hollow Knight mods written in Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 引言:告别模组安装的技术门槛 《空洞骑士…...

如何用MVP.css快速创建响应式网站:终极完整指南
如何用MVP.css快速创建响应式网站:终极完整指南 【免费下载链接】mvp MVP.css — Minimalist classless CSS stylesheet for HTML elements 项目地址: https://gitcode.com/gh_mirrors/mv/mvp MVP.css是一个极简主义的无类CSS样式表,专为快速创建…...

OpenClaw技能开发入门:为Phi-3-vision-128k-instruct编写图片转Markdown插件
OpenClaw技能开发入门:为Phi-3-vision-128k-instruct编写图片转Markdown插件 1. 为什么需要这个技能 上周整理技术文档时,我遇到了一个典型痛点:需要将十几张包含代码片段的截图转换成可编辑的Markdown格式。手动转录不仅耗时,还…...