YOLOv8训练自己的数据集+改进方法复现
yolov8已经出来好几个月了,并且yolov8从刚开始出来之后的小版本也升级好几次,总体变化不大,个别文件存放位置发生了变化,以下以最新版本的YOLOv8来详细学习和使用YOLOv8完成一次目标检测。
一、环境按照
深度学习环境搭建就不再重复了,可以查看上篇文章:如何安装 Anaconda,安装好之后使用conda命令创建一个新的环境,此环境还需包含PyTorch>=1.8,命令如下:
-- 创建环境
conda create -n yolov8 python=3.8-- 激活环境
conda activate yolov8
安装依赖:
pip install ultralytics--验证环境是否安装成功
yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'
安装完ultralytics之后就可以通过命令使用yolov8进行目标检测了,使用命令可以参考YOLO官网的快速开始教程:YOLO官网快速开始教程,但我们并不只是想用官方的模型权重,而是要训练和改进为自己的数据集,所以要下载下来源码进行运行改进
Yolov8 的源代码下载:
https://github.com/ultralytics/ultralytics
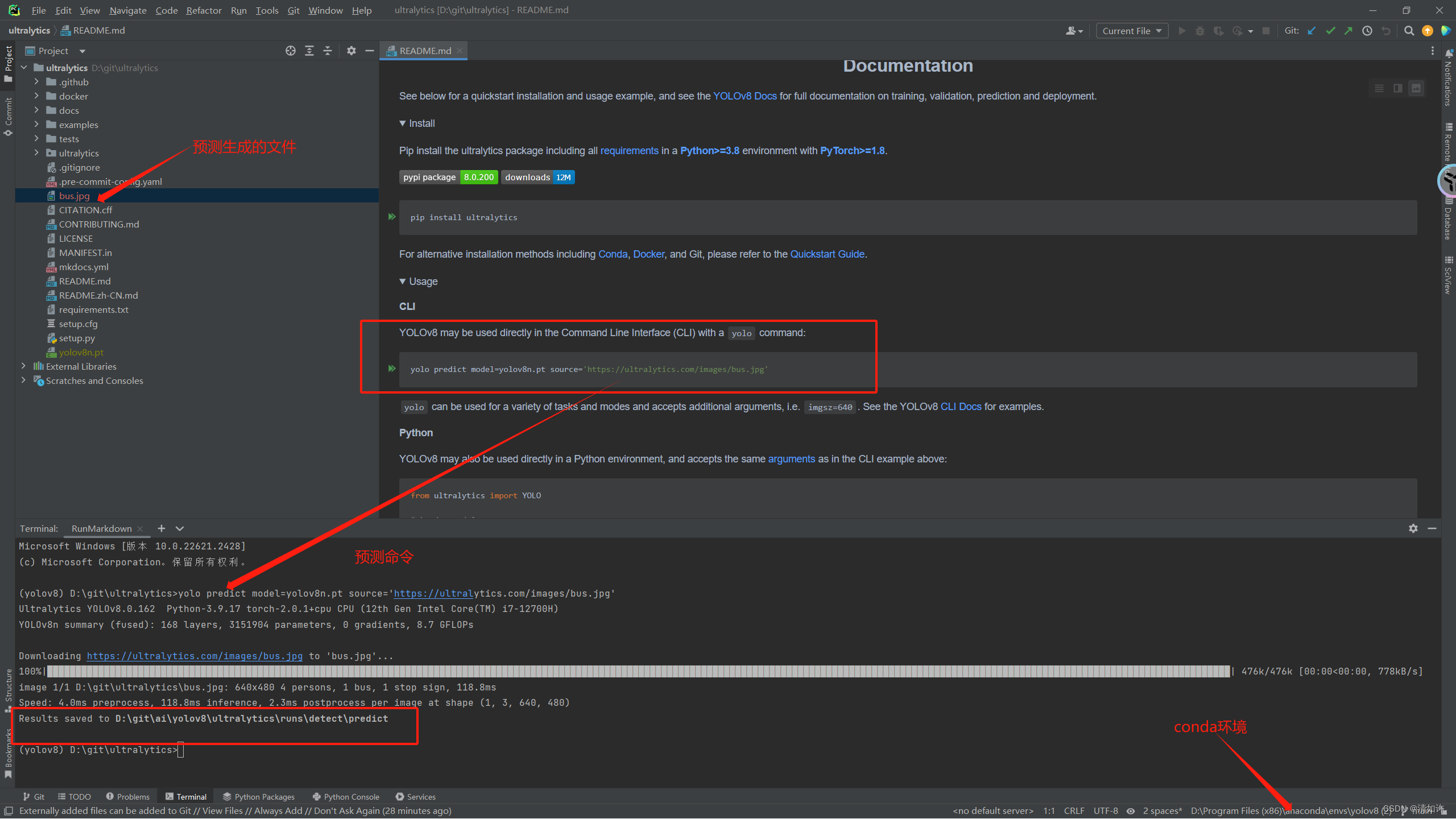
可见我这里环境已配置好,运行结果正常,并且运行结果保存在D:\git\ai\yolov8\ultralytics\runs\detect\predict
二、制作自己的数据集
2.1 准备工作
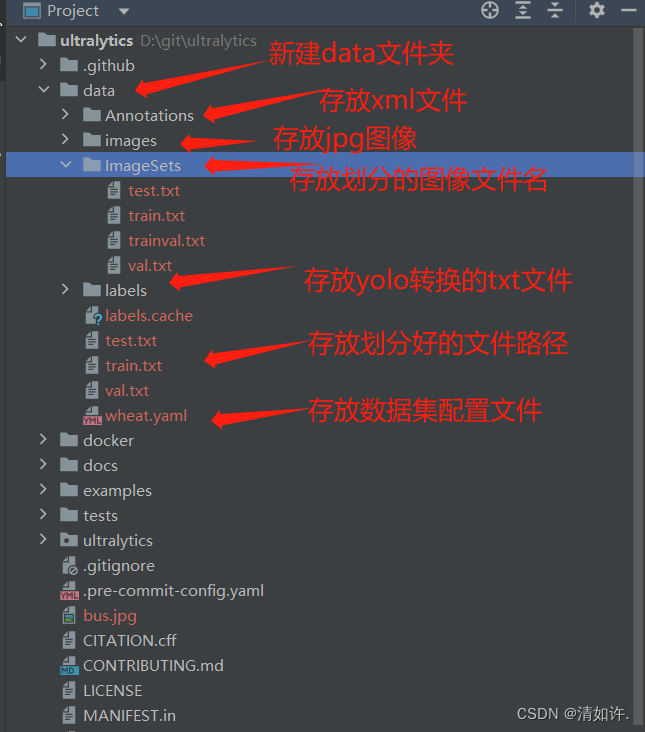
在ultralytics目录下新建data文件夹,下再新建四个文件夹,先说明这四个文件夹分别是用来干什么的,后面会往里面一一加入需要添加的内容。
- Annotations文件夹:用来存放使用labelimg给每张图片标注后的xml文件,后面会讲解如何使用labelimg进行标注。
- Images文件夹:用来存放原始的需要训练的数据集图片,图片格式为jpg格式。
- ImageSets文件夹:用来存放将数据集划分后的用于训练、验证、测试的文件。
- Labels文件夹:用来存放将xml格式的标注文件转换后的txt格式的标注文件。
先在根目录下创建好对应的文件夹,最终效果如图所示:
2.2 准备数据集
我做的是关于小麦病害的检测,根据采集的数据集将小麦病害划分为7个种类,分别为白粉病、赤霉病、叶锈病、条锈病、颖枯病、正常麦穗、正常麦叶。下图为数据集的一部分,共准备了四千多张原始图片,大约每个种类600张。此处会用到一个非常高效的重命名方式,就不用一张一张图片的进行重命名。批量重命名的代码如下。4000张图片准备好后就放在images文件夹中即可。

python批量重命名:
import os
class BatchRename():'''批量重命名文件夹中的图片文件'''def __init__(self):self.path = 'D:\git\ultralytics\data\images' #表示需要命名处理的文件夹self.new_path='D:\git\ultralytics\data\images\new'def rename(self):filelist = os.listdir(self.path) #获取文件夹中文件的所有的文件total_num = len(filelist) #获取文件长度(个数)i = 1 #表示文件的命名是从1开始的for item in filelist:if 1: #初始的图片的格式为jpg格式的(或者源文件是png格式及其他格式,后面的转换格式就可以调整为自己需要的格式即可)src = os.path.join(os.path.abspath(self.path), item) #连接两个或更多的路径名组件# dst = os.path.join(os.path.abspath(self.new_path), ''+str(i) + '.jpg')#处理后的格式也为jpg格式的,当然这里可以改成png格式dst = os.path.join(os.path.abspath(self.path), 'wheat' + format(str(i), '0>3s') + '.jpg') #这种情况下的命名格式为0000000.jpg形式,可以自主定义想要的格式try:os.rename(src, dst) #src – 要修改的目录名 dst – 修改后的目录名print('converting %s to %s ...' % (src, dst))i = i + 1except:continueprint ('total %d to rename & converted %d jpgs' % (total_num, i))if __name__ == '__main__':demo = BatchRename()demo.rename()
2.3 使用labelimg进行标注
labelimg的安装很简单,直接使用pip命令安装就可以
安装labelimgpip install labelimg启动
labelimgLabelimg是一个图像标注工具,软件使用非常简单,安装成功后直接输入labelimg就可以直接启动
使用说明:
(1)Open就是打开图片,我们不需要一张一张的打开,太麻烦了,使用下面的Open Dir
(2)Open Dir就是打开需要标注的图片的文件夹,这里就选择images文件夹
(3)change save dir就是标注后保存标记文件的位置,选择需要保存标注信息的文件夹,这里就选择Annotations文件夹
(4)特别注意需要选择好所需要的标注文件的类型。有yolo(txt), pascalVOC (xml)两种类型。yolo需要txt文件格式的标注文件,但是这里我们选择pascalVOC,后面再将xml格式的标注文件转化为所需的txt格式。
(5)按W键或点击Create\nRectBox开始创建矩形框,把要进行识别训练的区域标记出来就行,选好框后我们选是什么类别(predefined_classes文件,在里面提前写好要训练的类型的原因),整张图片的所有目标都标记好了之后按Ctrl+S或点击Save保存 ,然后切换下一张继续,快捷键为按D键,每一张图片标记后都要保存,这个过程是一个比较繁琐的过程

整张图片的所有目标都标记好了之后按Ctrl+S或点击Save保存 ,然后切换下一张继续,快捷键为按D键,每一张图片标记后都要保存,这个过程是一个比较繁琐的过程.
标注之后的效果如下图所示,会在目标目录生成对应的xml文件
2.4 4.数据集的划分
在ultralytics的根目录下创建一个脚本,创建一个split_train_val.py文件,运行文件之后会在imageSets文件夹下将数据集划分为训练集、验证集、测试集,里面存放的就是用于训练、验证、测试的图片名称。代码内容如下:
import os
import randomtrainval_percent = 0.9
train_percent = 0.9
xmlfilepath = 'data/Annotations'
txtsavepath = 'data/ImageSets'
total_xml = os.listdir(xmlfilepath)num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)ftrainval = open('data/ImageSets/trainval.txt', 'w')
ftest = open('data/ImageSets/test.txt', 'w')
ftrain = open('data/ImageSets/train.txt', 'w')
fval = open('data/ImageSets/val.txt', 'w')for i in list:name = total_xml[i][:-4] + '\n'if i in trainval:ftrainval.write(name)if i in train:ftrain.write(name)else:fval.write(name)else:ftest.write(name)ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
2.5 5.转换数据集格式
创建voc_label.py文件,他的作用:(1)就是把Annoctions里面的xml格式的标注文件转换为txt格式的标注文件,每个图像对应一个txt文件,文件每一行为一个目标的信息,包括class, x_center, y_center, width, height。
(2)就是运行后除了会生成转换后labels文件夹下的60张图片的txt文件,还会在data文件夹下得到三个包含数据集路径的txt文件,train.tx,tes.txt,val.txt这3个txt文件为划分后图像所在位置的绝对路径,如train.txt就含有所有训练集图像的绝对路径。
import xml.etree.ElementTree as ET
import os
from os import getcwdsets = ['train', 'val', 'test']
classes = ['High Ripeness','Low Ripeness','Medium Ripeness']
abs_path = os.getcwd()
print(abs_path)def convert(size, box):dw = 1. / (size[0])dh = 1. / (size[1])x = (box[0] + box[1]) / 2.0 - 1y = (box[2] + box[3]) / 2.0 - 1w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn x, y, w, hdef convert_annotation(image_id):in_file = open('data/Annotations/%s.xml' % (image_id), encoding='UTF-8')out_file = open('data/labels/%s.txt' % (image_id), 'w')tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):# difficult = obj.find('difficult').textdifficult = obj.find('difficult').textcls = obj.find('name').textif cls not in classes or int(difficult) == 1:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))b1, b2, b3, b4 = b# 标注越界修正if b2 > w:b2 = wif b4 > h:b4 = hb = (b1, b2, b3, b4)bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')wd = getcwd()
for image_set in sets:if not os.path.exists('data/labels/'):os.makedirs('data/labels/')image_ids = open('data/ImageSets/%s.txt' % (image_set)).read().strip().split()list_file = open('data/%s.txt' % (image_set), 'w')for image_id in image_ids:list_file.write(abs_path + 'data/images/%s.jpg\n' % (image_id))convert_annotation(image_id)list_file.close()
2.6 编写数据集配置文件
创建 wheat.yaml
内容如下,其文件路径正是上文生成的划分配置集文件
nc代表类别数量,比如我这里是7个分类
names是每个分类名称
train: D:\git\ai\yolov8\data\train.txt
val: D:\git\ai\yolov8\data\val.txt
test: D:\git\ai\yolov8\data\test.txtnc: 7
names:0: Powdery Mildew # 白粉病1: Scab # 赤霉病2: Leaf Rust # 叶锈病3: Stripe Rust # 条锈病4: Glume Blotch # 颖枯病5: Wheat Ear # 正常麦穗6: Wheat Leaf # 正常麦叶
到这一步,数据集就算制作好了!下一步就开始训练吧
三、训练自己的数据集
(1)yolo提供自己的指令模式,在调参方面十分方便,可以直接用命令来完成
yolo train data=你的配置文件(xx.yaml)的绝对路径 model=yolov8n.pt epochs=300 imgsz=640 batch=8 workers=0 device=0(3)训练过程首先会显示你所使用的训练的硬件设备信息,然后下一段话则是你的参数配置,紧接着是backbone信息,最后是加载信息,并告知你训练的结果会保存在runs\detect\trainxx。如图所示,如果正常的话就会输出下面的信息
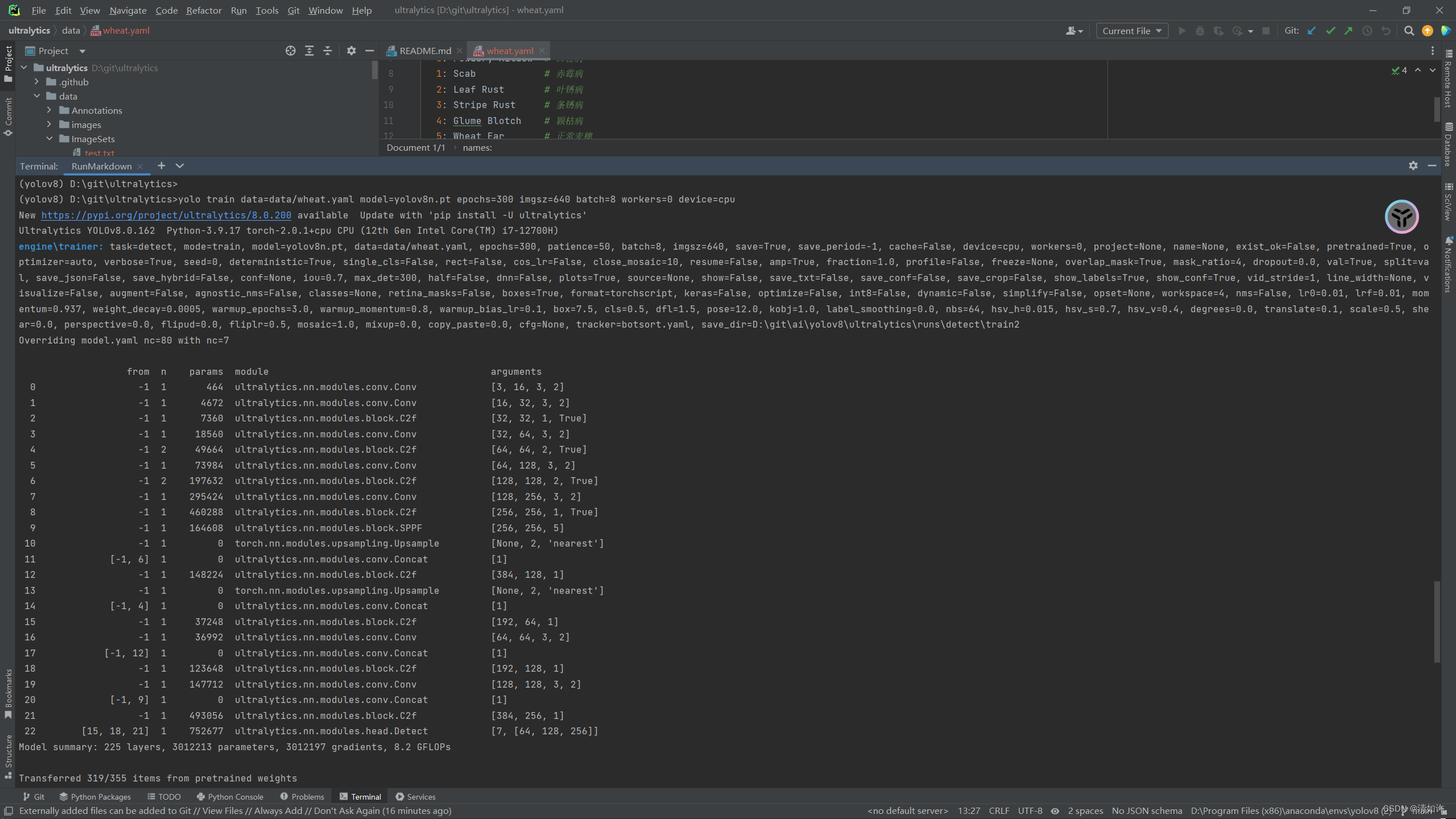
然后就能开始训练了!
下面的改进方法有时间再接着写,先吃饭去~
相关文章:
YOLOv8训练自己的数据集+改进方法复现
yolov8已经出来好几个月了,并且yolov8从刚开始出来之后的小版本也升级好几次,总体变化不大,个别文件存放位置发生了变化,以下以最新版本的YOLOv8来详细学习和使用YOLOv8完成一次目标检测。 一、环境按照 深度学习环境搭建就不再…...
尚硅谷kafka3.0.0
目录 💃概述 ⛹定义 编辑⛹消息队列 🤸♂️消息队列应用场景 编辑🤸♂️两种模式:点对点、发布订阅 编辑⛹基本概念 💃Kafka安装 ⛹ zookeeper安装 ⛹集群规划 编辑⛹流程 ⛹原神启动 🤸♂️…...

【Andriod】Appium的不同版本(Appium GUI、Appium Desktop、Appium Server )的安装教程
文章目录 前言一.Appium GUI二.Appium Desktop三.Appium Server 命令行版本1.安装node.js2.安装Appium Server 前言 Appium 安装提供两2方式:桌面版和命令行版。其中桌面版又分为 Appium GUI 和 Appium Desktop。 建议:使用Appium Desktop 一.Appium …...

leetcode:面试题 17.04. 消失的数字(找单身狗/排序/公式)
一、题目: 函数原型:int missingNumber(int* nums, int numsSize) 二、思路: 思路1 利用“找单身狗”的思路(n^n0;0^nn),数组中有0-n的数字,但缺失了一个数字x。将这些数字按位异或0…...
基于SpringBoot的时间管理系统
基于SpringBoot的时间管理系统的设计与实现~ 开发语言:Java数据库:MySQL技术:SpringBootMyBatis工具:IDEA/Ecilpse、Navicat、Maven 系统展示 登录界面 管理员界面 用户界面 摘要 基于Spring Boot的时间管理系统是一款功能丰富…...

centos搭建elastic集群
1、环境可以在同一台集群上搭建elastic,也可以在三台机器上搭建,这次演示的是在同一台机器搭建机器。 2、下载elastic :https://www.elastic.co/cn/downloads/past-releases#elasticsearch 2、 tar -zxvf elasticsearch-xxx-版…...
CUDA学习笔记(九)Dynamic Parallelism
本篇博文转载于https://www.cnblogs.com/1024incn/tag/CUDA/,仅用于学习。 Dynamic Parallelism 到目前为止,所有kernel都是在host端调用,CUDA Dynamic Parallelism允许GPU kernel在device端创建调用。Dynamic Parallelism使递归更容易实现…...

周记之马上要答辩了
“ 要变得温柔和强大,就算哪天突然孤身一人,也能平静地活下去,不至于崩溃。” 10.16 今天提前写完了一篇六级阅读,积累了一些词组: speak out against 公然反对,印象最深刻的就这个; 先了解…...

git简介和指令
git是一个开源的的分布式版本控制系统,用于高效的管理各种大小项目和文件 用途:防止代码丢失,做备份 项目的版本管理和控制,可以通过设置节点进行跳转 建立各自的开发环境分支,互不影响,方便合并 在多终端开…...
-- Json数组字符串 ==》 JSONArray)
alibaba.fastjson的使用(五)-- Json数组字符串 ==》 JSONArray
目录 1. 使用到的方法 2. 实例演示 1. 使用到的方法 static JSONArray parseArray(String text) 2. 实例演示 /*** 将Json数组字符串转JsonArray*/@Testpublic void test5() {String jsonArrStr = "[{\"name\":\"郭靖\",\"age\":35},{\…...

ts json的中boolean布尔值或者int数字都是字符串,转成对象对应类型
没啥好写的再水一篇 json中都是字符串,转换一下就好,简单来说就是转换一次不行,再转换换一次,整体转换不够,细分的再转换一次 这是vue中 ts写法 ,我这里是拿对象做对比,不好字符和对象做对比,…...

【OpenGL】七、混合
混合 文章目录 混合混合公式glBlendFunc(混合函数)glBlendFuncSeparate渲染半透明纹理 参考链接 混合(Blending)通常是实现物体透明度(Transparency)的一种技术 简而言之:混合就是如何将输出颜色和目标缓冲区颜色结合起来。 混合公式 C_fina…...

JVM——堆内存调优(Jprofiler使用)Jprofile下载和安装很容易,故没有记录,如有需要,在评论区留言)
堆内存调优 当遇到OOM时,可以进行调参 1、尝试扩大堆内存看结果 2、分析内存,看哪个地方出现了问题(专业工具) 调整初始分配内存为1024M,调整最大分配内存为1024M,打印GC细节(如何添加JVM操…...

Android cmdline-tools 版本与其最小JDK关系
关键词:Android cmdline-tools 历史版本、Android cmdline-tools 最小JDK版本、JDK 对应 major version、JDK LTS 信息 由于 JDK8 是一个常用的、较低的版本,因此只需要关注 JDK8 及以上版本的运行情况。 cmdline-tools 版本和最低 JDK 最终结论&…...

基于ARM+FPGA+AD的多通道精密数据采集仪方案
XM 系列具备了数据采集仪应具备的“操作简单、便于携带、满足各种测量需求”等功能的产品。具有超小、超轻量的手掌大小尺寸,支持8 种测量模块,还可进行最多576 Ch的多通道测量。另外,支持省配线系统,可大幅削减配线工时。使用时不…...
【JAVA学习笔记】43 - 枚举类
项目代码 https://github.com/yinhai1114/Java_Learning_Code/tree/main/IDEA_Chapter11/src/com/yinhai/enum_ 〇、创建时自动填入版权 作者等信息 如何在每个文件创建的时候打入自己的信息以及版权呢 菜单栏-File-setting-Editor-File and Code Templaters -Includes-输入信…...

Springcloud介绍
1.基本介绍 Spring Cloud是一系列框架的有序集合。它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用Spring Boot的开发风格做到一键启动和部署。Spring …...
)
LK光流法和LK金字塔光流法(含python和c++代码示例)
0 引言 本文主要记录LK光流算法及LK金字塔光流算法的详细原理,最后还调用OpenCV中的cv2.calcOpticalFlowPyrLK()函数实现LK金字塔光流算法,其中第3部分是python语言实现版本,第4部分是c++语言实现版本。 1 LK光流算法 1.1 简述 LK光流法是一种计算图像序列中物体运动的光…...

数据库索引是什么?创建索引的注意事项
数据库索引: 索引(index)是帮助MySQL高效获取数据的数据结构(有效),在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向&#x…...

java中的异常,以及出现异常后的处理【try,catch,finally】
一、异常概念 异常 :指的是程序在执行过程中,出现的非正常的情况,最终会导致JVM的非正常停止。 注意: 在Java等面向对象的编程语言中,异常本身是一个类,产生异常就是创建异常对象并抛出了一个异常对象。Java处理异常的…...

DIY迷你平衡摩托车:从PID控制到机械设计全解析
1. 迷你平衡摩托车项目概述作为一名嵌入式开发爱好者,我最近完成了一个迷你平衡摩托车的DIY项目。这个项目的灵感来源于大学生智能车竞赛中的平衡单车组别,但相比那些专业竞赛车模,这个迷你版本更适合个人爱好者动手实现。整个项目从原理分析…...

OpenClaw极简安装:Docker版Qwen3-32B镜像五分钟部署
OpenClaw极简安装:Docker版Qwen3-32B镜像五分钟部署 1. 为什么选择Docker部署OpenClaw 上周我在本地尝试手动部署OpenClaw时,被各种依赖冲突折磨得够呛。从Node.js版本不兼容到CUDA驱动问题,整整浪费了两天时间。直到发现星图平台的Qwen3-3…...

gallery应用商店优化:提升本地AI平台的发现率与下载量
gallery应用商店优化:提升本地AI平台的发现率与下载量 【免费下载链接】gallery A gallery that showcases on-device ML/GenAI use cases and allows people to try and use models locally. 项目地址: https://gitcode.com/GitHub_Trending/gallery44/gallery …...

Mac环境OpenClaw深度配置:Qwen3.5-9B-AWQ-4bit多模态任务优化
Mac环境OpenClaw深度配置:Qwen3.5-9B-AWQ-4bit多模态任务优化 1. 为什么需要深度配置? 第一次在Mac上跑通OpenClaw对接Qwen3.5-9B-AWQ-4bit模型时,我天真地以为安装完就能顺畅处理多模态任务。直到尝试分析一批产品截图,系统频繁…...

MySQL后端开发核心知识点
一、存储引擎(只重点 InnoDB)MySQL 5.5 以后默认引擎是 InnoDB,也是现代企业项目唯一使用的引擎。InnoDB 特点:支持 事务支持 行级锁,并发性能好支持 外键(实际开发基本不用)基于 B 树索引结构依…...

ADC类型解析与选型指南:从闪存到ΔΣ
1. ADC基础概念与核心原理在电子系统中,模拟信号到数字信号的转换(ADC)是实现物理世界与数字世界交互的关键桥梁。作为一名嵌入式开发者,我经常需要根据项目需求选择不同类型的ADC拓扑结构。让我们先拆解ADC的核心工作机制。ADC转…...

网站推广seo优化公司如何做好移动端优化_网站推广seo优化公司如何提高网站的权重
网站推广seo优化公司如何做好移动端优化 在当前互联网市场的发展背景下,移动端的重要性日益凸显。无论是用户访问还是企业推广,移动端已经成为不可忽视的一部分。因此,网站推广seo优化公司在提升网站权重的过程中,移动端优化显得…...
)
手把手教你用WouoUI-PageVersion打造128*64 OLED炫酷UI(附Air001移植避坑指南)
嵌入式UI开发实战:WouoUI-PageVersion在128*64 OLED屏上的高效移植与优化 在资源受限的嵌入式设备上实现流畅的UI动画一直是个技术挑战。本文将带你深入探索如何利用WouoUI-PageVersion框架,在仅有4KB RAM和32KB Flash的Air001等微控制器上,打…...
 与 Self-Correction(自我修正) 能力的企业级 Agent)
构建具备 Cyclic Loop(循环反思) 与 Self-Correction(自我修正) 能力的企业级 Agent
摘要:当"降本增效"成为常态,企业知识流失的速度远超你的想象。本文将不再停留在简单的 RAG demo 层面,而是深入 LangGraph 的底层架构,带你从零构建一个具备 Cyclic Loop(循环反思) 与 Self-Corr…...

微服务七大核心组件详解:搞懂架构运行底层逻辑
从实战视角拆解微服务架构的"五脏六腑",掌握每个组件的设计哲学与落地细节一、为什么需要这七大组件? 微服务架构的本质是分布式系统的工程化实践。当单体应用拆分为数十个甚至上百个独立服务后,我们面临的核心挑战:挑战…...