Python深度学习实战-基于Sequential方法搭建BP神经网络实现分类任务(附源码和实现效果)
实现功能
-
第一步:导入模块:import tensorflow as tf
-
第二步:制定输入网络的训练集和测试集
-
第三步:搭建网络结构:tf.keras.models.Sequential()
-
第四步:配置训练方法:model.compile():
-
第五步:执行训练过程:model.fit():
-
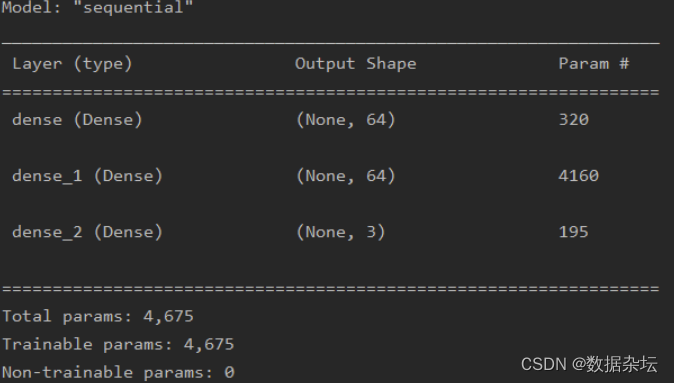
第六步:打印网络结构:model.summary()
-
第七步:执行验证过程:model.evaluate()
实现代码
import tensorflow as tf
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target# 数据预处理
scaler = StandardScaler()
X = scaler.fit_transform(X)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建模型
model = tf.keras.Sequential([tf.keras.layers.Dense(64, activation='relu', input_shape=(X.shape[1],)),tf.keras.layers.Dense(64, activation='relu'),tf.keras.layers.Dense(len(set(y)), activation='softmax')
])# 编译模型
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32)
model.summary()
# 评估模型
test_loss, test_accuracy = model.evaluate(X_test, y_test)实现效果
本人读研期间发表5篇SCI数据挖掘相关论文,现在某研究院从事数据挖掘相关科研工作,对数据挖掘有一定认知和理解,会结合自身科研实践经历不定期分享关于python、机器学习、深度学习基础知识与案例。
致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。
邀请三个朋友关注本订阅号V:数据杂坛,即可在后台联系我获取相关数据集和源码,送有关数据分析、数据挖掘、机器学习、深度学习相关的电子书籍。
相关文章:
Python深度学习实战-基于Sequential方法搭建BP神经网络实现分类任务(附源码和实现效果)
实现功能 第一步:导入模块:import tensorflow as tf 第二步:制定输入网络的训练集和测试集 第三步:搭建网络结构:tf.keras.models.Sequential() 第四步:配置训练方法:model.compile()&#x…...

【前端】Webpack5中Html和CSS的压缩打包
1.Webpack5简介 1.1.Webpack简介 (1)webpack的发展历程 2012.3—webpack(问世) 2014.2—webpack1 2016.12—webpack2 2017.6—webpack3 2018.2—webpack4 2020.10—webpack5(要求node版本10.13) &a…...
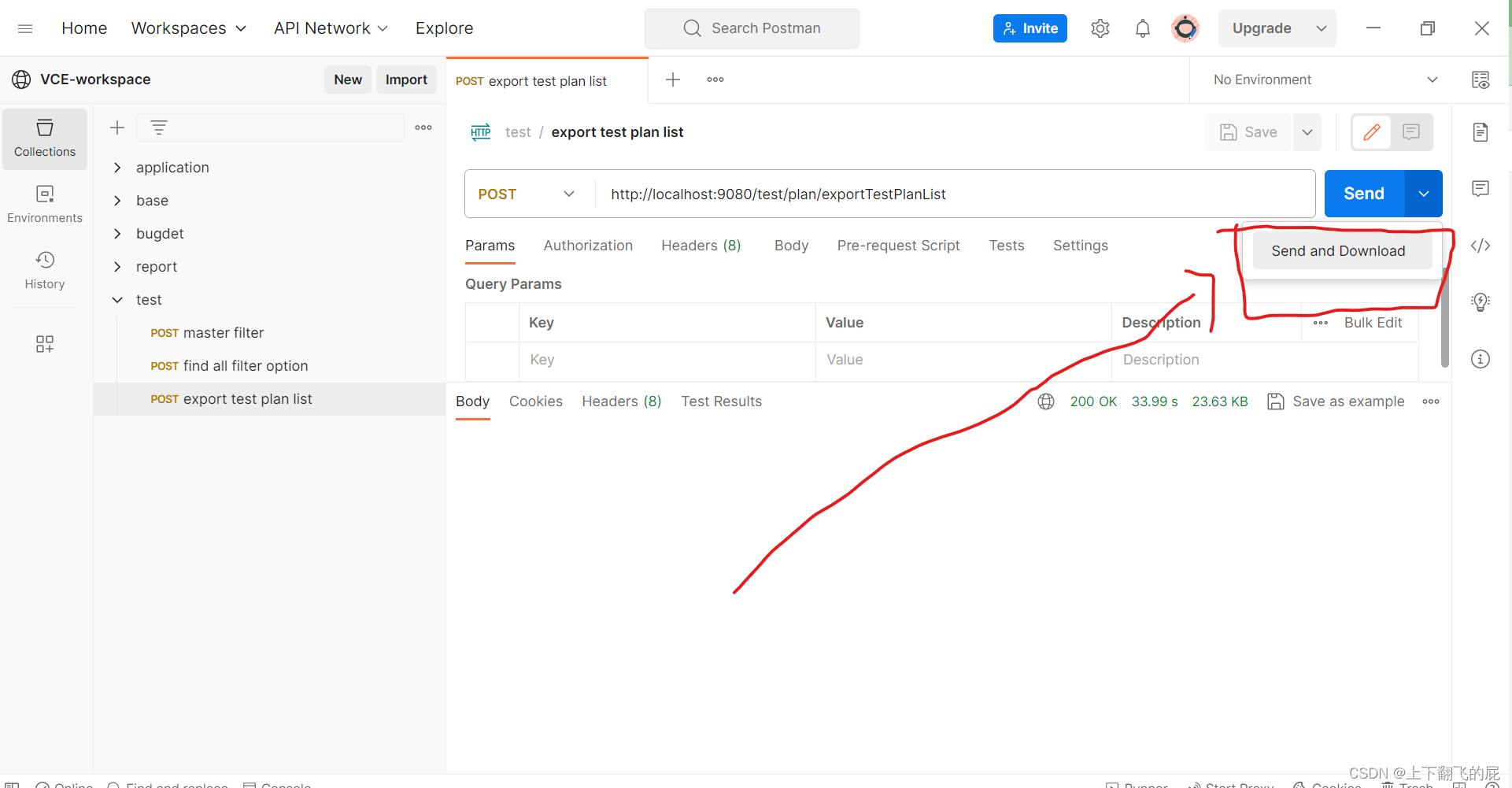
postman接收后端返回的文件流并自动下载
不要点send,点send and download,postman接受完文件流会弹出文件保存框让你选择保存路径...

谈谈Net-SNMP软件
Net-SNMP是一个开源的SNMP软件套件,它提供了SNMP代理(snmpd)和SNMP工具(如snmpget、snmpwalk等),可以用于监控和管理网络设备。 Net-SNMP最初是从UC Davis的SNMP软件衍生而来,现在已经成为广泛…...

前端对普通数字数组排序示例
1. arr.sort(fn) // 升序排序arr.sort((a, b) > a - b);// 降序排序arr.sort((a, b) > b - a); 2. 冒泡排序 冒泡排序-升序原理: eg: [1, 6, 7, 9, 10, 3, 4, 5, 2] 1) 先遍历第一遍数组, 前一个数字大于后一个数字, 就交换位置, 最后最大值10放在数组的最后, 此时是…...
SQL server中:常见问题汇总(如:修改表时不允许修改表结构、将截断字符串或二进制数据等)
SQL server中:常见问题汇总 1.修改表时提示:不允许修改表结构步骤图例注意 2.将截断字符串或二进制数据。3.在将 varchar 值 null 转换成数据类型 int 时失败。4.插入insert 、更新update、删除drop数据失败,主外键FOREIGN KEY 冲突5.列不允许…...

无线通信中CSI的含义
在无线通信中,CSI代表"Channel State Information",即信道状态信息。CSI是一种关键的信息,用于评估和描述通信信道的特性,以帮助发送器和接收器在通信过程中做出智能的调整和决策。 CSI包括有关通信信道的以下信息&…...
如何一键核实验证身份证的真伪?
据报道,今年10月10日,广东省佛山市朱某因生活琐事与丈夫发生争吵,民警发现她的身份证有问题。 在民警打算进一步了解情况,查看夫妻二人的身份证件时,朱某的身份证引起了民警的注意。这张身份证表面很光滑,…...

冒泡排序:了解原理与实现
目录 原理 实现 性能分析 结论 冒泡排序(Bubble Sort)是一种简单但效率较低的排序算法。它重复地比较相邻的元素并交换位置,直到整个序列有序为止。虽然冒泡排序的时间复杂度较高,但在小规模数据集上仍然具有一定的实际应用价…...
springboot maven项目环境搭建idea
springboot maven项目环境搭建idea 文章目录 springboot maven项目环境搭建idea用到的软件idea下载和安装java下载和安装maven下载和安装安装maven添加JAVA_HOME路径,增加JRE环境修改conf/settings.xml,请参考以下 项目idea配置打开现有项目run或build打…...
vue3检测是手机还是pc端,监测视图窗口变化
1.超小屏幕(手机) 768px以下 2.小屏设备(平板) 768px-992px 3.中等屏幕(旧式电脑) 992px-1200px 4.大屏设备(现代电脑) 1200px以上 <script setup name"welcome"> i…...
)
B - Magical Subsequence (CCPC2021哈尔滨)
思路: (1)问题:对于已知数组,每组依次选两个,尽量选更多组,选的每组和相等;(假定和为x) (2)于是问题拆分为两步, x是多少x确定时&a…...
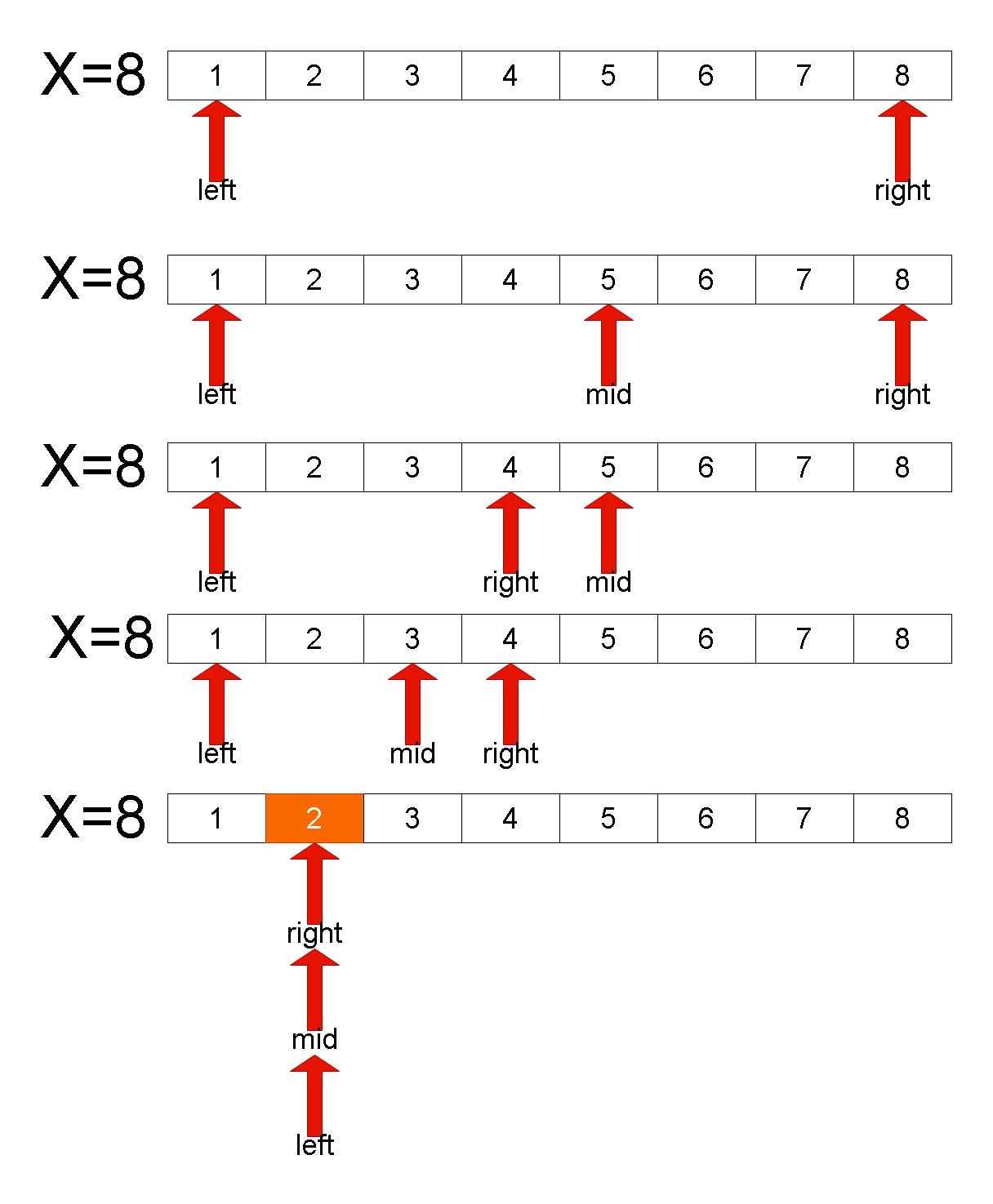
Leetcode刷题详解——x的平方根
1. 题目链接:69. x 的平方根 2. 题目描述: 给你一个非负整数 x ,计算并返回 x 的 算术平方根 。 由于返回类型是整数,结果只保留 整数部分 ,小数部分将被 舍去 。 **注意:**不允许使用任何内置指数函数和…...
windows安装docker,解决require wsl 2问题
想在windows上安装桌面版docker,上官网下载了安装包,安装完后,启动报错,忘了截图了。 大概意思就是require wsl 2。 于是就是docker FAQ中找相关问题解决方案,点,点,点然后就点到微软了。 ws…...

建立复数类
目录 程序设计 程序分析 系列文章 在课堂示例的基础上,显示复数时如果虚部为0时只显示实部,实部为0时只显示虚部,虚部为负数时以a-bi的形式显示,并为复数类增加减法功能。 程序设计 Work4类: package work;import java.util.Scanner;public class Work4 {private in…...
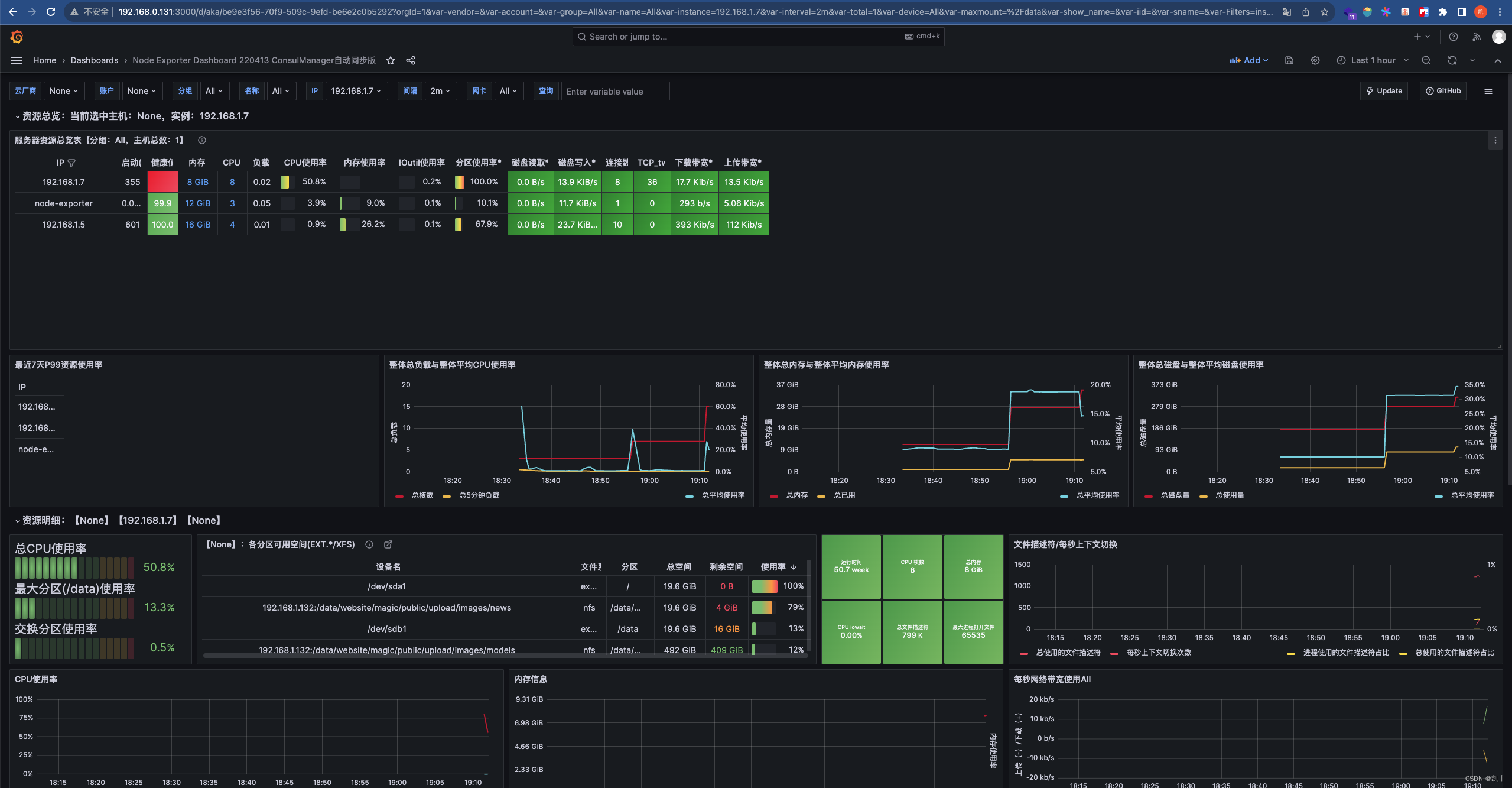
docker部署prometheus+grafana服务器监控(三) - 配置grafana
查看 prometheus 访问 http://ip:9090/targets,效果如下,上面我们通过 node_exporter 收集的节点状态是 up 状态。 配置 Grafana 访问 http://ip:3000,登录 Grafana,默认的账号密码是 admin:admin,首次登录需要修改…...

面试题:说一下加密后的数据如何进行模糊查询?
文章目录 正文如何对加密后的数据进行模糊查询沙雕做法沙雕一沙雕二 常规做法常规一常规二超神做法 总结 正文 我们知道加密后的数据对模糊查询不是很友好,本篇就针对加密数据模糊查询这个问题来展开讲一讲实现的思路,希望对大家有所启发。 为了数据安…...

LeetCode75——Day15
文章目录 一、题目二、题解 一、题目 1456. Maximum Number of Vowels in a Substring of Given Length Given a string s and an integer k, return the maximum number of vowel letters in any substring of s with length k. Vowel letters in English are ‘a’, ‘e’…...
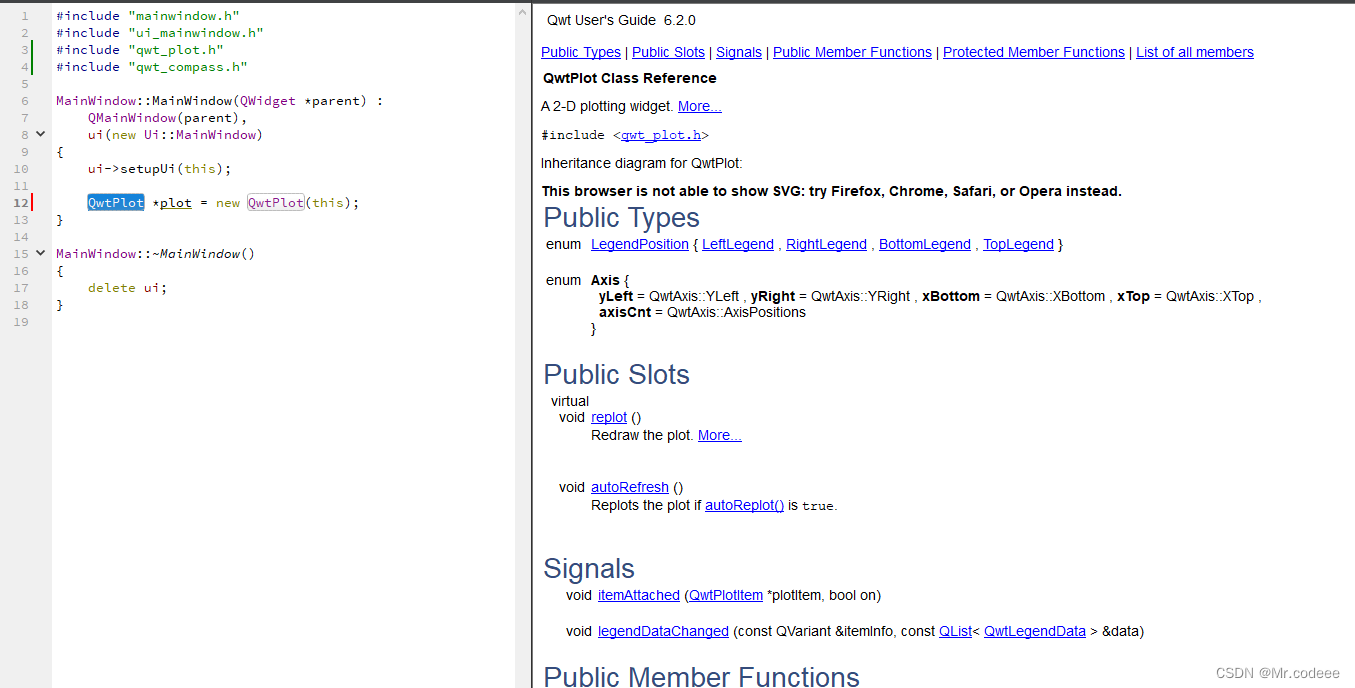
Qwt开发环境搭建(保姆级教程)
1.简介 QWT,即Qt Widgets for Technical Applications,其目标是以基于2D方式的窗体部件来显示数据, 数据源以数值,数组或一组浮点数等方式提供, 输出方式可以是Curves(曲线),Slider…...
【供应链】仓储、物流、车辆管理
...

构建多模型备援策略以提升企业级 AI 应用可靠性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 构建多模型备援策略以提升企业级 AI 应用可靠性 在构建企业级 AI 应用时,服务的稳定性与可靠性是核心考量之一。单一模…...

自适应滤波器提取胎儿心电信号的MATLAB及FPGA实现
自适应滤波器提取胎儿心电信号的MATLAB及FPGA实现 【下载地址】自适应滤波器提取胎儿心电信号的MATLAB及FPGA实现 本项目提供了一个完整的工程代码,用于实现自适应滤波器提取胎儿心电信号的MATLAB及FPGA实现。自适应滤波器是一种能够根据环境变化自动调整滤波器参数…...

【亲测免费】 OpenCV 4.5.5 + opencv-contrib-4.5.5 编译所需下载文件说明
OpenCV 4.5.5 opencv-contrib-4.5.5 编译所需下载文件说明 【下载地址】OpenCV4.5.5opencv-contrib-4.5.5编译所需下载文件说明 OpenCV 4.5.5 opencv-contrib-4.5.5 编译所需下载文件说明本仓库提供了编译OpenCV 4.5.5及其贡献模块(opencv-contrib)所需的第三方依赖文件和额外…...

如何在MATLAB中调用Taotoken聚合大模型API进行智能分析
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何在MATLAB中调用Taotoken聚合大模型API进行智能分析 对于使用MATLAB进行科学计算、数据分析或算法开发的工程师和研究人员而言&…...

epub_to_audiobook开发者指南:如何扩展新的TTS提供商
epub_to_audiobook开发者指南:如何扩展新的TTS提供商 【免费下载链接】epub_to_audiobook EPUB to audiobook converter, optimized for Audiobookshelf, WebUI included 项目地址: https://gitcode.com/gh_mirrors/ep/epub_to_audiobook 想要为epub_to_audi…...

智能车视觉巡线:从图像处理到PID控制的嵌入式实战解析
1. 项目概述:一场关于速度与精度的极限挑战十多年前,当飞思卡尔(Freescale)智能车竞赛还是校园里最硬核的科技赛事之一时,摄像头组的较量无疑是皇冠上的明珠。它不像光电组依赖地面反射,也不像电磁组追寻导…...

如何用Nucleus Co-Op将单机游戏变身为本地多人派对游戏
如何用Nucleus Co-Op将单机游戏变身为本地多人派对游戏 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 你是否曾经羡慕那些支持本地多人游戏的乐趣…...

Python迭代器实战:构建高性能懒加载积分榜系统
1. 项目概述:从“可迭代”到“可控制”的数据流在Python的世界里,处理数据集合是家常便饭。无论是从数据库拉取用户列表,还是逐行读取一个巨大的日志文件,我们总在和各种序列打交道。但你是否想过,当你写下一个简单的f…...

Captain AI助力Ozon大卖店群高效管理,实现规模化运营
随着Ozon商家运营规模的扩大,多店铺运营(店群)成为很多资深大卖的选择,通过多店铺布局,可扩大市场覆盖、分散运营风险、提升整体销量。但店群运营过程中,商家常常面临“管理繁琐、数据混乱、效率低下”的问…...

2025届最火的十大降重复率平台实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 知网所具备的降AI技术,目的在于使论文里人工智能生成部分的内容重复率得以降低&…...