计算机毕设 flink大数据淘宝用户行为数据实时分析与可视化
文章目录
- 0 前言
- 1、环境准备
- 1.1 flink 下载相关 jar 包
- 1.2 生成 kafka 数据
- 1.3 开发前的三个小 tip
- 2、flink-sql 客户端编写运行 sql
- 2.1 创建 kafka 数据源表
- 2.2 指标统计:每小时成交量
- 2.2.1 创建 es 结果表, 存放每小时的成交量
- 2.2.2 执行 sql ,统计每小时的成交量
- 2.3 指标统计:每10分钟累计独立用户数
- 2.3.1 创建 es 结果表,存放每10分钟累计独立用户数
- 2.3.2 创建视图
- 2.3.3 执行 sql ,统计每10分钟的累计独立用户数
- 2.4 指标统计:商品类目销量排行
- 2.4.1 创建商品类目维表
- 2.4.1 创建 es 结果表,存放商品类目排行表
- 2.4.2 创建视图
- 2.4.3 执行 sql , 统计商品类目销量排行
- 3、最终效果与体验心得
- 3.1 最终效果
- 3.2 体验心得
- 3.2.1 执行
- 3.2.2 存储
- 4 最后
0 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 flink大数据淘宝用户行为数据实时分析与可视化
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
1、环境准备
1.1 flink 下载相关 jar 包
flink-sql 连接外部系统时,需要依赖特定的 jar 包,所以需要事先把这些 jar 包准备好。说明与下载入口
本项目使用到了以下的 jar 包 ,下载后直接放在了 flink/lib 里面。
需要注意的是 flink-sql 执行时,是转化为 flink-job 提交到集群执行的,所以 flink 集群的每一台机器都要添加以下的 jar 包。
| 外部 | 版本 | jar |
|---|---|---|
| kafka | 4.1 | flink-sql-connector-kafka_2.11-1.10.2.jar flink-json-1.10.2-sql-jar.jar |
| elasticsearch | 7.6 | flink-sql-connector-elasticsearch7_2.11-1.10.2.jar |
| mysql | 5.7 | flink-jdbc_2.11-1.10.2.jar mysql-connector-java-8.0.11.jar |
1.2 生成 kafka 数据
用户行为数据来源: 阿里云天池公开数据集
网盘:https://pan.baidu.com/s/1wDVQpRV7giIlLJJgRZAInQ 提取码:gja5
商品类目纬度数据来源: category.sql
数据生成器:datagen.py
有了数据文件之后,使用 python 读取文件数据,然后并发写入到 kafka。
修改生成器中的 kafka 地址配置,然后运行 以下命令,开始不断往 kafka 写数据
# 5000 并发
nohup python3 datagen.py 5000 &
1.3 开发前的三个小 tip
-
生成器往 kafka 写数据,会自动创建主题,无需事先创建
-
flink 往 elasticsearch 写数据,会自动创建索引,无需事先创建
-
Kibana 使用索引模式从 Elasticsearch 索引中检索数据,以实现诸如可视化等功能。
使用的逻辑为:创建索引模式 》Discover (发现) 查看索引数据 》visualize(可视化)创建可视化图表》dashboards(仪表板)创建大屏,即汇总多个可视化的图表
2、flink-sql 客户端编写运行 sql
# 进入 flink-sql 客户端, 需要指定刚刚下载的 jar 包目录
./bin/sql-client.sh embedded -l lib
2.1 创建 kafka 数据源表
-- 创建 kafka 表, 读取 kafka 数据
CREATE TABLE user_behavior (user_id BIGINT,item_id BIGINT,category_id BIGINT,behavior STRING,ts TIMESTAMP(3),proctime as PROCTIME(),WATERMARK FOR ts as ts - INTERVAL '5' SECOND
) WITH ('connector.type' = 'kafka', 'connector.version' = 'universal', 'connector.topic' = 'user_behavior', 'connector.startup-mode' = 'earliest-offset', 'connector.properties.zookeeper.connect' = '172.16.122.24:2181', 'connector.properties.bootstrap.servers' = '172.16.122.17:9092', 'format.type' = 'json'
);
SELECT * FROM user_behavior;
2.2 指标统计:每小时成交量
2.2.1 创建 es 结果表, 存放每小时的成交量
CREATE TABLE buy_cnt_per_hour (hour_of_day BIGINT,buy_cnt BIGINT
) WITH ('connector.type' = 'elasticsearch', 'connector.version' = '7', 'connector.hosts' = 'http://172.16.122.13:9200', 'connector.index' = 'buy_cnt_per_hour','connector.document-type' = 'user_behavior','connector.bulk-flush.max-actions' = '1','update-mode' = 'append','format.type' = 'json'
);
2.2.2 执行 sql ,统计每小时的成交量
INSERT INTO buy_cnt_per_hour
SELECT HOUR(TUMBLE_START(ts, INTERVAL '1' HOUR)), COUNT(*)
FROM user_behavior
WHERE behavior = 'buy'
GROUP BY TUMBLE(ts, INTERVAL '1' HOUR);
2.3 指标统计:每10分钟累计独立用户数
2.3.1 创建 es 结果表,存放每10分钟累计独立用户数
CREATE TABLE cumulative_uv (time_str STRING,uv BIGINT
) WITH ('connector.type' = 'elasticsearch', 'connector.version' = '7', 'connector.hosts' = 'http://172.16.122.13:9200', 'connector.index' = 'cumulative_uv','connector.document-type' = 'user_behavior', 'update-mode' = 'upsert','format.type' = 'json'
);
2.3.2 创建视图
CREATE VIEW uv_per_10min AS
SELECTMAX(SUBSTR(DATE_FORMAT(ts, 'HH:mm'),1,4) || '0') OVER w AS time_str,COUNT(DISTINCT user_id) OVER w AS uv
FROM user_behavior
WINDOW w AS (ORDER BY proctime ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW);
2.3.3 执行 sql ,统计每10分钟的累计独立用户数
INSERT INTO cumulative_uv
SELECT time_str, MAX(uv)
FROM uv_per_10min
GROUP BY time_str;
2.4 指标统计:商品类目销量排行
2.4.1 创建商品类目维表
先在 mysql 创建一张商品类目的维表,然后配置 flink 读取 mysql。
CREATE TABLE category_dim (sub_category_id BIGINT,parent_category_name STRING
) WITH ('connector.type' = 'jdbc','connector.url' = 'jdbc:mysql://172.16.122.25:3306/flink','connector.table' = 'category','connector.driver' = 'com.mysql.jdbc.Driver','connector.username' = 'root','connector.password' = 'root','connector.lookup.cache.max-rows' = '5000','connector.lookup.cache.ttl' = '10min'
);
2.4.1 创建 es 结果表,存放商品类目排行表
CREATE TABLE top_category (category_name STRING,buy_cnt BIGINT
) WITH ('connector.type' = 'elasticsearch', 'connector.version' = '7', 'connector.hosts' = 'http://172.16.122.13:9200', 'connector.index' = 'top_category','connector.document-type' = 'user_behavior','update-mode' = 'upsert','format.type' = 'json'
);
2.4.2 创建视图
CREATE VIEW rich_user_behavior AS
SELECT U.user_id, U.item_id, U.behavior, C.parent_category_name as category_name
FROM user_behavior AS U LEFT JOIN category_dim FOR SYSTEM_TIME AS OF U.proctime AS C
ON U.category_id = C.sub_category_id;
2.4.3 执行 sql , 统计商品类目销量排行
INSERT INTO top_category
SELECT category_name, COUNT(*) buy_cnt
FROM rich_user_behavior
WHERE behavior = 'buy'
GROUP BY category_name;
3、最终效果与体验心得
3.1 最终效果
整个开发过程,只用到了 flink-sql ,无需写 java 或者其它代码,就完成了这样一个实时报表。
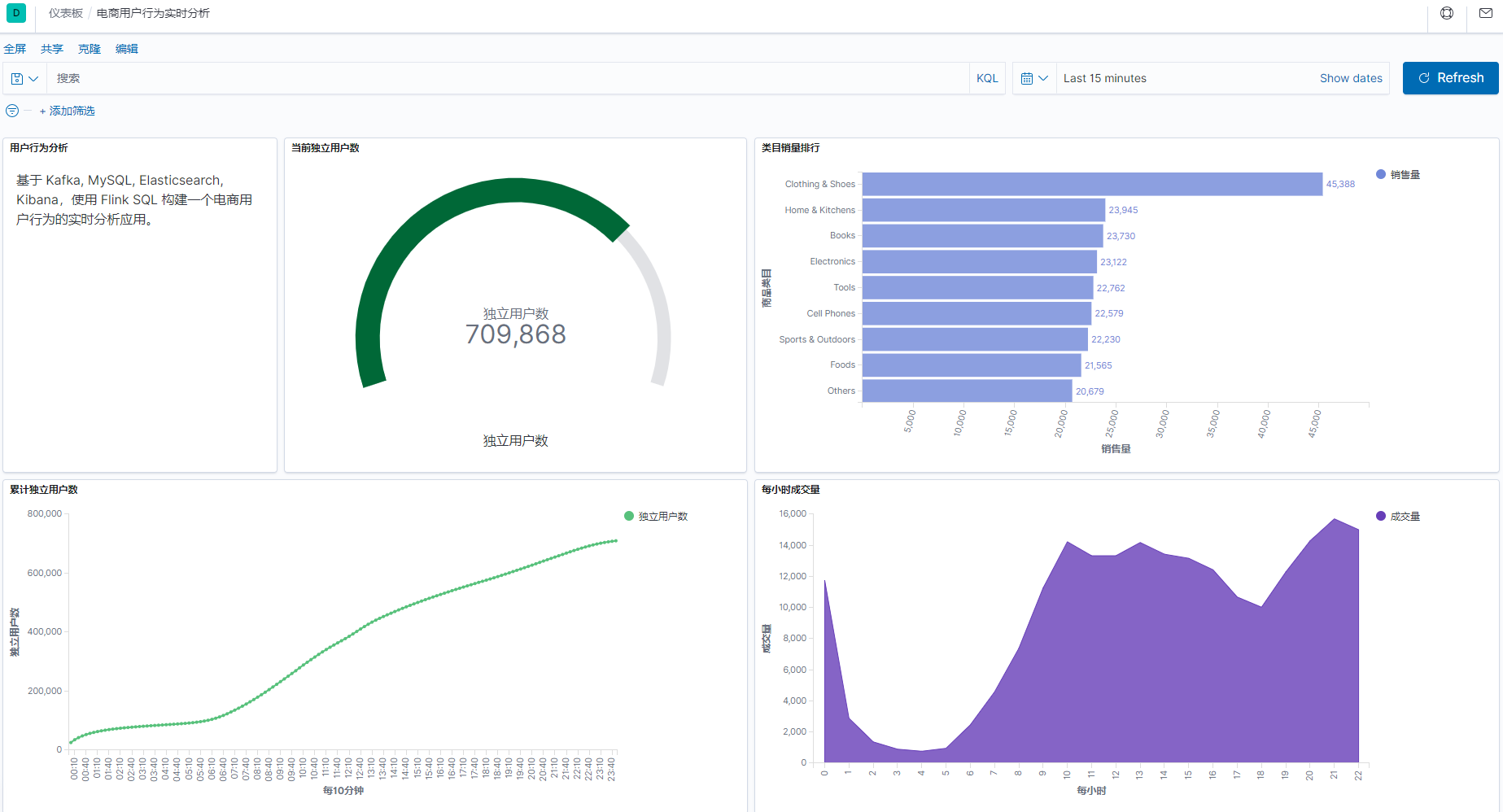
3.2 体验心得
3.2.1 执行
-
flink-sql 的 ddl 语句不会触发 flink-job , 同时创建的表、视图仅在会话级别有效。
-
对于连接表的 insert、select 等操作,则会触发相应的流 job, 并自动提交到 flink 集群,无限地运行下去,直到主动取消或者 job 报错。
-
flink-sql 客户端关闭后,对于已经提交到 flink 集群的 job 不会有任何影响。
本次开发,执行了 3 个 insert , 因此打开 flink 集群面板,可以看到有 3 个无限的流 job 。即使 kafka 数据全部写入完毕,关闭 flink-sql 客户端,这个 3 个 job 都不会停止。
3.2.2 存储
-
flnik 本身不存储业务数据,只作为流批一体的引擎存在,所以主要的用法为读取外部系统的数据,处理后,再写到外部系统。
-
flink 本身的元数据,包括表、函数等,默认情况下只是存放在内存里面,所以仅会话级别有效。但是,似乎可以存储到 Hive Metastore 中,关于这一点就留到以后再实践。
4 最后
相关文章:
计算机毕设 flink大数据淘宝用户行为数据实时分析与可视化
文章目录 0 前言1、环境准备1.1 flink 下载相关 jar 包1.2 生成 kafka 数据1.3 开发前的三个小 tip 2、flink-sql 客户端编写运行 sql2.1 创建 kafka 数据源表2.2 指标统计:每小时成交量2.2.1 创建 es 结果表, 存放每小时的成交量2.2.2 执行 sql &#x…...
8.2 矢量图层点要素单一符号使用一
文章目录 前言单一符号(Single symbol)渲染简单标记(Simple Marker)QGis代码实现 SVG标记(SVG marker)QGis代码实现 总结 前言 上一篇教程对矢量图层符号化做了一个整体介绍,并以点图层为例介绍了可以使用的渲染器&am…...

SQL企业微信群机器人消息推送
--参考资料地址 --微软官方地址: https://learn.microsoft.com/zh-cn/sql/relational-databases/system-stored-procedures/ole-automation-stored-procedures-transact-sql?view=sql-server-ver16 --腾讯官方地址:https://developer.work.weixin.qq.com/ --使…...
vscode远程连接ubuntu
修改环境变量,改使用git自带的ssh工具 openssh: C:\Windows\System32\OpenSSH\ssh.exeGit ssh: C:\Program Files\Git\usr\bin\ssh.exe vscode安装插件remote-ssh 重开软件,在左侧拓展入口下方,进入远程资源管理器 点击设置,进…...

Positive Technologies 在迪拜宣布与地区网络安全解决方案提供商开展合作
在中东最大的信息技术展 GITEX GLOBAL 2023 的间隙,Positive Technologies 同意与八家组织(网络安全服务和解决方案提供商)合作,在该地区开展合作,推广最先进的产品,并分享信息安全领域的经验。该公司强调了…...
Pyside6 QTextEdit
Pyside6 QTextEdit QTextEdit使用QTextEdit常用函数文本编辑类函数文本框格式设置函数设置文字颜色设置文字背景颜色设置文字格式设置文本框样式程序设置界面设置 QTextEdit信号textChanged信号 完整程序界面程序主程序 QTextEdit类提供了一个用于编辑和显示纯文本和富文本的组…...

Hadoop核心机制详细解析
Hadoop核心机制详细解析 Hadoop的核心机制是通过HDFS文件系统和MapReduce算法进行存储资源、内存和程序的有效利用与管理。在现实的实例中,通过Hadoop,可以轻易的将多台普通的或低性能的服务器组合成分布式的运算-存储集群,提供大数据量的存…...
Chromium源码由浅入深(一)
工作中需要对Chromium源码、尤其是源码中图形部分进行深入研究,所以借此机会边学习边写文章,分享一下我的实时学习研究Chromium源码的由浅入深的过程。 闲言少叙,书归正传。 通过命令行启动Chrome浏览器,命令及结果如下…...

Spring Authorization Server 1.1 扩展 OAuth2 密码模式与 Spring Cloud Gateway 整合实战
目录 前言无图无真相创建数据库授权服务器maven 依赖application.yml授权服务器配置AuthorizationServierConfigDefaultSecutiryConfig 密码模式扩展PasswordAuthenticationTokenPasswordAuthenticationConverterPasswordAuthenticationProvider JWT 自定义字段自定义认证响应认…...

UE4 UltraDynamicSky 天气与水体交互
最上面的Lerp的A通道为之前的水面效果,B是做的冰面效果 用Dynamic_Landscape_Weather_Effects的BaseColor的R通道四舍五入作为Lerp的Alpha值 使用一张贴图,乘以RadialGradientExponential对材质边缘做弱化,RadialGradientExponential的Raid…...

Liunx 实时调度策略 SCHED_RR SCHED_FIFO 区别 适用情况
SCHED_RR SCHED_FIFO 适用情况 SCHED_FIFO 先进先出调度。只能在静态优先级高于0的情况下使用,这意味着当 SCHED_FIFO 线程变得可运行时,它总是立即抢占当前正在运行的任何 SCHED_OTHER、SCHED_BATCH 或 SCHED_IDLE 线程。SCHED_FIFO 线程一直运行到被…...

mac上使用虚拟机vm, 里面的镜像挂起会占用电脑的内存吗, 挂起和关机的区别是什么, 会影响正常电脑的内存和硬盘使用吗
解释 在Mac(或任何其他操作系统)上使用虚拟机(如VMware Fusion、Parallels Desktop、VirtualBox等)时,“挂起”(Suspend)和“关机”(Power Off或Shut Down)是两种不同的虚…...

AIGC时代 浪潮信息积极推动存储产品创新
近几年,AIGC的兴起,进一步驱动了全闪、混闪等存储产品的创新,也为市场带来了新的机遇,对于厂家而言,也需要升级存储产品的容量、性能及功能,方能满足场景诉求。对此,浪潮信息面向AIGC应用场景打…...

【PG】PostgreSQL字符集
目录 设置字符集 1 设置集群默认的字符集编码 2 设置数据库的字符集编码 查看字符集 1 查看数据字符集编码 2 查看服务端字符集 3 查看客户端字符集 4 查看默认的排序规则和字符分类 被支持的字符集 PostgreSQL里面的字符集支持你能够以各种字符集存储文本,…...
)
力扣:137. 只出现一次的数字 II(Python3)
题目: 给你一个整数数组 nums ,除某个元素仅出现 一次 外,其余每个元素都恰出现 三次 。请你找出并返回那个只出现了一次的元素。 你必须设计并实现线性时间复杂度的算法且使用常数级空间来解决此问题。 来源:力扣(Lee…...
orb-slam3编译手册(Ubuntu20.04)
orb-slam3编译手册(Ubuntu20.04) 一、环境要求1.安装git2.安装g3.安装CMake4.安装vi编辑器 二、源代码下载三、依赖库下载1.Eigen安装2.Pangolin安装3.opencv安装4.安装Python & libssl-dev5.安装boost库 三、安装orb-slam3四、数据集下载及测试 写在…...
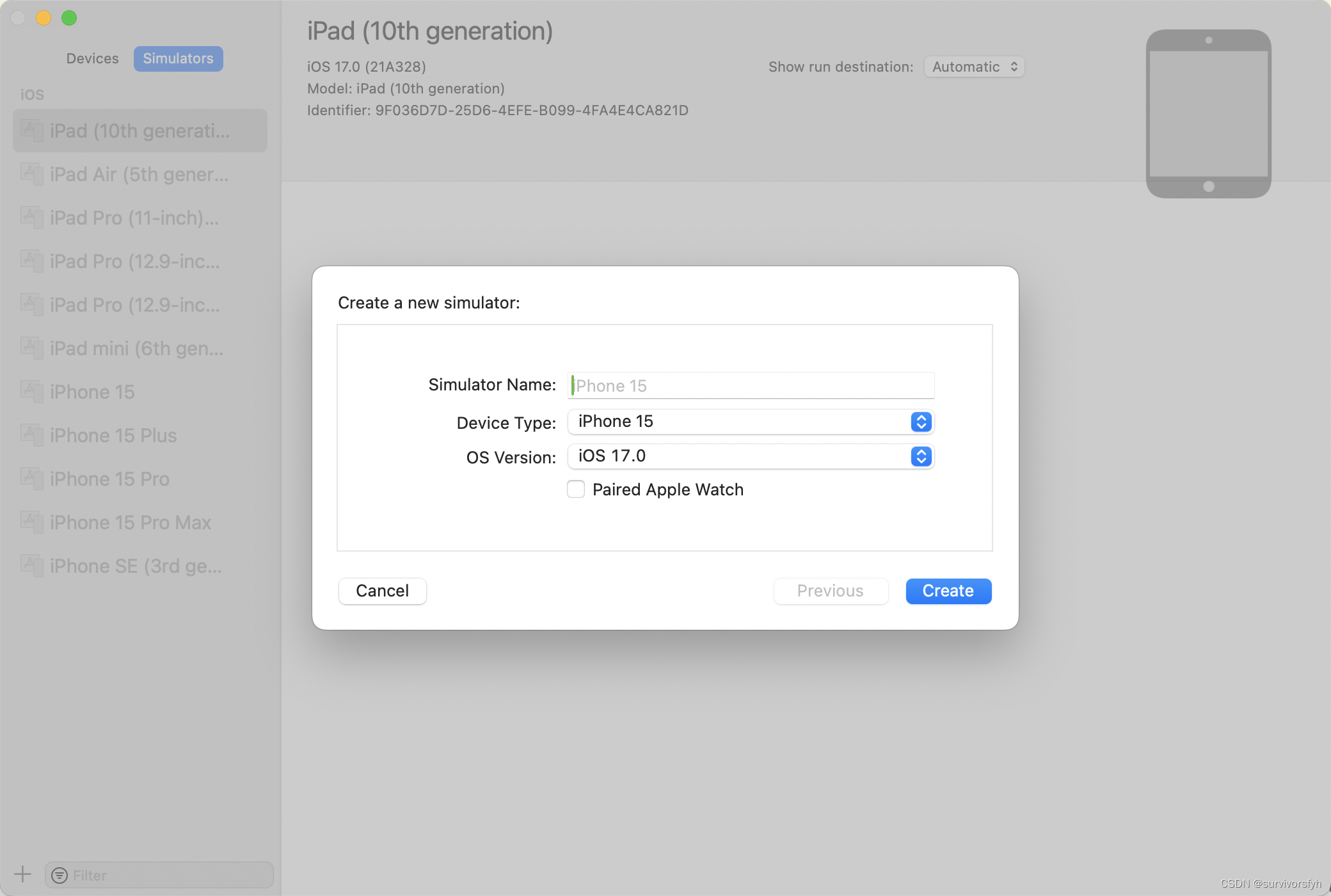
升级 Xcode 15模拟器 iOS 17.0 Simulator(21A328) 下载失败
升级 IDE Xcode 15 后本地模拟器 Simulator 全被清空,反复重新尝试 Get 下载频频因网络异常断开而导致失败 ... 注:通过 Get 方式下载一定要保证当前网络环境足够平稳,网络环境不好的情况下该方法几乎成不了 解决办法 Get 方式行不通可以尝试通过 官网 途径先下载 模拟器安装包…...
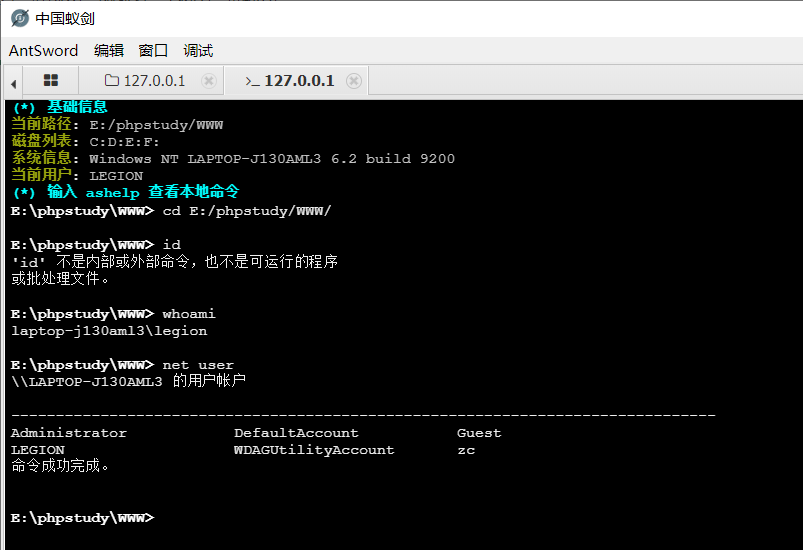
PHP 函数、PHP 简单后门
函数 基本结构 语法结构 function 函数名(形式参数1,形式参数2...){//函数体return 返回值 }定义并执行一个简单函数 // funtion.phpfunction test(){echo "This is function ".__FUNCTION__; }test();函数传参 // function.phpfunction add($x, $y){$sum $x …...
前端实现菜单按钮级权限
核心思想就是通过登录请求此用户对应的权限菜单,然后跳转首页,触发全局前置导航守卫,在全局导航守卫中通过 addRoute 添加动态路由进去。addRoute有一个需要注意的地方,就是我们添加完动态路由后,地址栏上立即访问添加…...
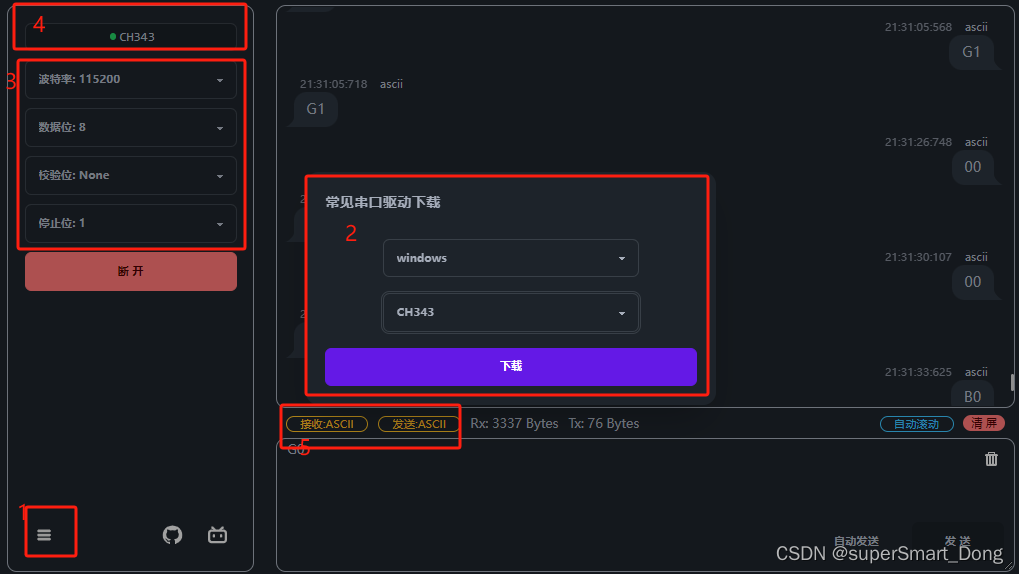
STM32:TTL串口调试
一.TTL串口概要 TTL只需要两个线就可以完成两个设备之间的双向通信,一个发送电平的I/O称之为TX,与另一个设备的接收I/O口RX相互连接。两设备之间还需要连接地线(GND),这样两设备就有相同的0V参考电势。 二.TTL串口调试 实现电脑通过STM32发送…...

5分钟掌握MAA:解放双手的明日方舟智能助手终极指南
5分钟掌握MAA:解放双手的明日方舟智能助手终极指南 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https://gitcod…...

Python迭代器实战:构建高性能懒加载积分榜系统
1. 项目概述:从“可迭代”到“可控制”的数据流在Python的世界里,处理数据集合是家常便饭。无论是从数据库拉取用户列表,还是逐行读取一个巨大的日志文件,我们总在和各种序列打交道。但你是否想过,当你写下一个简单的f…...

Captain AI助力Ozon大卖店群高效管理,实现规模化运营
随着Ozon商家运营规模的扩大,多店铺运营(店群)成为很多资深大卖的选择,通过多店铺布局,可扩大市场覆盖、分散运营风险、提升整体销量。但店群运营过程中,商家常常面临“管理繁琐、数据混乱、效率低下”的问…...

RoboMaster新手必看:CAN通讯驱动GM6020电机,从ID配置到线序接法的保姆级避坑指南
RoboMaster新手必看:CAN通讯驱动GM6020电机,从ID配置到线序接法的保姆级避坑指南 第一次接触RoboMaster比赛的新手们,面对CAN总线驱动GM6020这类电调电机一体式设备时,常常会遇到"明明发送了CAN包但电机就是不转"的困扰…...

如何设计 Agent Harness 的默认行为与异常处理
Agent Harness 架构设计实战:默认行为规范与全链路异常处理体系从0到1落地 摘要/引言 你是否遇到过Agent Demo跑得好好的,一上线就频繁崩溃?大模型返回格式错乱导致整个业务链路报错?工具调用超时直接给用户返回500错误?多Agent协同的时候状态莫名丢失,只能让用户重新发…...

Centos9安装MySQL8.0数据库
1.这次使用rpm包进行安装MySQL数据库首先下在包,我这里是使用wget进行下载的,这里是下载地址。下载好后使用ls看看rpm包是不是6个,如果不是需要重新下载。2.安装相关软件yum install -y net-tools.x86_64 libaio.x86_64 perl.x86_6…...

Ultimate ASI Loader 专业指南:深入解析游戏MOD加载器的完整配置与开发
Ultimate ASI Loader 专业指南:深入解析游戏MOD加载器的完整配置与开发 【免费下载链接】Ultimate-ASI-Loader The Ultimate ASI Loader is a proxy DLL that loads custom .asi libraries into any game process. 项目地址: https://gitcode.com/gh_mirrors/ul/U…...

3个神奇步骤:用QRazyBox轻松修复任何损坏的二维码
3个神奇步骤:用QRazyBox轻松修复任何损坏的二维码 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 你是否曾经遇到过这种情况:一张重要的二维码因为打印模糊、表面划伤或…...
)
深入STM32中断系统:从EXTI触发到NVIC裁决的完整流程剖析(附流程图详解)
深入STM32中断系统:从EXTI触发到NVIC裁决的完整流程剖析 在嵌入式开发中,中断系统是实时响应的核心机制。对于STM32开发者而言,深入理解从外部信号触发到CPU执行中断服务程序(ISR)的完整链路,是优化系统实时性、排查异常问题的关…...

【DBC专题】-12-基于Cantools的CAN/CANFD DBC文件自动化C代码生成实战指南
1. 环境准备与工具链搭建 第一次接触CAN总线开发时,我被DBC文件到C代码的手动转换折磨得够呛。直到发现Cantools这个神器,才真正体会到什么叫"一劳永逸"。这个Python工具链能自动将DBC描述文件转换为可直接编译的C代码,特别适合需要…...