Hadoop3教程(二十六):(生产调优篇)NameNode核心参数配置与回收站的启用
文章目录
- (143)NameNode内存配置
- (144)NN心跳并发配置
- (145)开启回收站
- 参考文献
(143)NameNode内存配置
每个文件块(的元数据等)在内存中大概 占用150byte,一台服务器128G内存的话,大概能存储9.1亿个文件块。
在Hadoop2.x里,如何配置NameNode内存?
NameNode默认内存2000M。如果你的服务器内存是4G,那一般可以把NN内存设置成3G,留1G给服务器维持基本运行(如系统运行需要、DataNode运行需要等)所需就行。
在hadoop-env.sh文件中设置:
HADOOP_NAMENODE_OPTS=-Xmx3072m
Hadoop3.x系列,如何配置NameNode内存?
答案是动态分配的。hadoop-env.sh有描述:
# The maximum amount of heap to use (Java -Xmx). If no unit
# is provided, it will be converted to MB. Daemons will
# prefer any Xmx setting in their respective _OPT variable.
# There is no default; the JVM will autoscale based upon machine
# memory size.
# export HADOOP_HEAPSIZE_MAX=# The minimum amount of heap to use (Java -Xms). If no unit
# is provided, it will be converted to MB. Daemons will
# prefer any Xms setting in their respective _OPT variable.
# There is no default; the JVM will autoscale based upon machine
# memory size.
# export HADOOP_HEAPSIZE_MIN=
HADOOP_NAMENODE_OPTS=-Xmx102400m
如何查看NN所占用内存?
[atguigu@hadoop102 ~]$ jps
3088 NodeManager
2611 NameNode
3271 JobHistoryServer
2744 DataNode
3579 Jps
[atguigu@hadoop102 ~]$ jmap -heap 2611
Heap Configuration:MaxHeapSize = 1031798784 (984.0MB)
如何查看DataNode所占内存?
[atguigu@hadoop102 ~]$ jmap -heap 2744
Heap Configuration:MaxHeapSize = 1031798784 (984.0MB)
DN和NN的内存在默认情况下都是自动分配的,且NN和DN相等。这个就不太合理了,万一两个加起来超过了节点总内存怎么办,可能会崩掉。
经验参考:
https://docs.cloudera.com/documentation/enterprise/6/release-notes/topics/rg_hardware_requirements.html#concept_fzz_dq4_gbb


NameNode是每增加100万个文件块,就增加1G内存;
DataNode是每增加100万个副本,就增加1G内存。
本质上都是管理元数据,可以理解成,各自管理的数据单位量在上100w之后,就增加1G内存。
具体修改:hadoop-env.sh
export HDFS_NAMENODE_OPTS="-Dhadoop.security.logger=INFO,RFAS -Xmx1024m"
export HDFS_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS -Xmx1024m"
(144)NN心跳并发配置
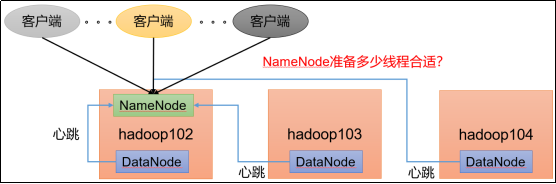
在实际生产运行时,每台DataNode会跟NameNode通信,客户端也会并发向NameNode发出申请,那么NameNode准备多少个线程是合适的呢,即NameNode的并发线程数设置成多少合适呢?
一般在hdfs-sit.xml文件中配置:
The number of Namenode RPC server threads that listen to requests from clients. If dfs.namenode.servicerpc-address is not configured then Namenode RPC server threads listen to requests from all nodes.
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。
对于大集群或者有大量客户端的集群来说,通常需要增大该参数。默认值是10。
<property><name>dfs.namenode.handler.count</name><value>21</value>
</property>
企业经验:dfs.namenode.handler.count=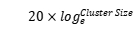
,比如集群规模(DataNode台数)为3台时,此参数设置为21。
可通过简单的python代码计算该值,代码如下:
[atguigu@hadoop102 ~]$ sudo yum install -y python
[atguigu@hadoop102 ~]$ python
Python 2.7.5 (default, Apr 11 2018, 07:36:10)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import math
>>> print int(20*math.log(3))
21
>>> quit()
(145)开启回收站
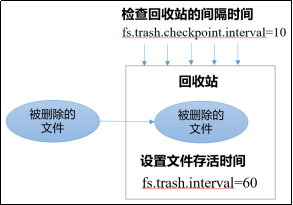
开启回收站之后,删除的文件会送进回收站,等待超时后再彻底删除,这样子方便恢复原数据,起到防止误删除、备份等作用。本质上是将文件放在特定目录存储,跟windows的回收站功能一样。
单位是min
参数说明:
- 默认值
fs.trash.interval = 0,0表示禁用回收站;其他值表示设置文件的存活时间; - 默认值
fs.trash.checkpoint.interval = 0,检查回收站的间隔时间,意思是多长时间去检查一次,准备删除文件。如果该值为0,则该值设置和fs.trash.interval的参数值相等; - 要求
fs.trash.checkpoint.interval <= fs.trash.interval
具体启用的话,是修改core-site.xml,配置垃圾回收时间是1分钟:
<property><name>fs.trash.interval</name><value>1</value>
</property>
那回收站文件的路径在哪儿呢?
回收站目录在HDFS集群中的路径:/user/atguigu/.Trash/….
需要注意,通过网页上HDFS目录管理里删除的文件并不会走回收站。
通过程序删除的文件同样也不会走回收站,除非你在代码里显式调用了moveToTrash()
Trash trash = New Trash(conf);
trash.moveToTrash(path);
所以只有命令行里,通过hadoop fs -rm指令删除的文件,才会走回收站。且当你执行这个指令的时候,会有以下提示:
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -rm -r /user/atguigu/input
2021-07-14 16:13:42,643 INFO fs.TrashPolicyDefault: Moved: 'hdfs://hadoop102:9820/user/atguigu/input' to trash at: hdfs://hadoop102:9820/user/atguigu/.Trash/Current/user/atguigu/input
那如何恢复回收站数据呢?
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv
/user/atguigu/.Trash/Current/user/atguigu/input /user/atguigu/input
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】
相关文章:
Hadoop3教程(二十六):(生产调优篇)NameNode核心参数配置与回收站的启用
文章目录 (143)NameNode内存配置(144)NN心跳并发配置(145)开启回收站参考文献 (143)NameNode内存配置 每个文件块(的元数据等)在内存中大概 占用150byte&…...
PaddleX场景实战:PP-TS在电压预测场景上的应用
时间序列是按照时间发生的先后顺序进行排列的数据点序列,简称时序。时间序列预测即运用历史的多维数据进行统计分析,推测出事物未来的发展趋势。时间序列预测是最常见的时序问题之一,在很多行业都有其应用,且通常时序预测效果对业…...
pdf误删恢复如何恢复?分享4种恢复方法!
如何将pdf误删恢复?使用电脑的时候,经常会需要使用到pdf文件,但是有时候,因为一些操作上的失误,我们会丢失一些重要的文件。如果你不小心将pdf误删了,该如何进行恢复呢? PDF文件丢失的原因可以…...

简析新能源汽车充电桩设计与应用
叶根胜 安科瑞电气股份有限公司 上海嘉定 201801 摘要:本文针对新能源汽车充电桩建设工作进行探究,采用案例分析法、文献查阅法,指出了新能源汽车充电桩建设存在的问题,阐述了充电桩建设与优化的对策。研究表明:目前…...

Java零基础入门-算术运算符
本文旨在帮助零基础的读者快速了解Java中的算术运算符,包括基本的加减乘除运算符、取余运算符、自增自减运算符等常见的数学运算符。 在学习本文前,需要先掌握基本的Java语法,包括数据类型、变量、赋值语句等。 前言 在编写Java程序时&…...

java实现hbase数据导出
1. HBase-client方式实现 1.1 依赖 <!--HBase依赖坐标--><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>1.2.6</version></dependency><dependency><group…...

Unity之ShaderGraph如何实现旋涡效果
前言 今天我们来通过ShaderGraph来实现一个旋涡的效果 如下图所示: 主要节点 Distance:返回输入 A 和输入 B 的值之间的欧几里德距离。除了其他方面的用途,这对于计算空间中两点之间的距离很有用,通常用于计算有符号距离函数 (…...
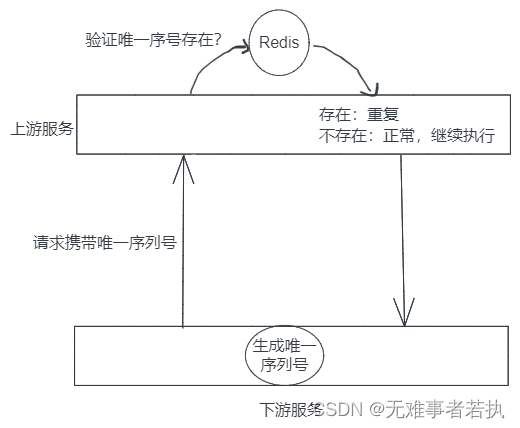
【分布式】: 幂等性和实现方式
【分布式】: 幂等性和实现方式 幂等(idempotent、idempotence)是一个数学与计算机学概念, 常见于抽象代数中。在编程中一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。幂等函数,或幂等方法,是…...
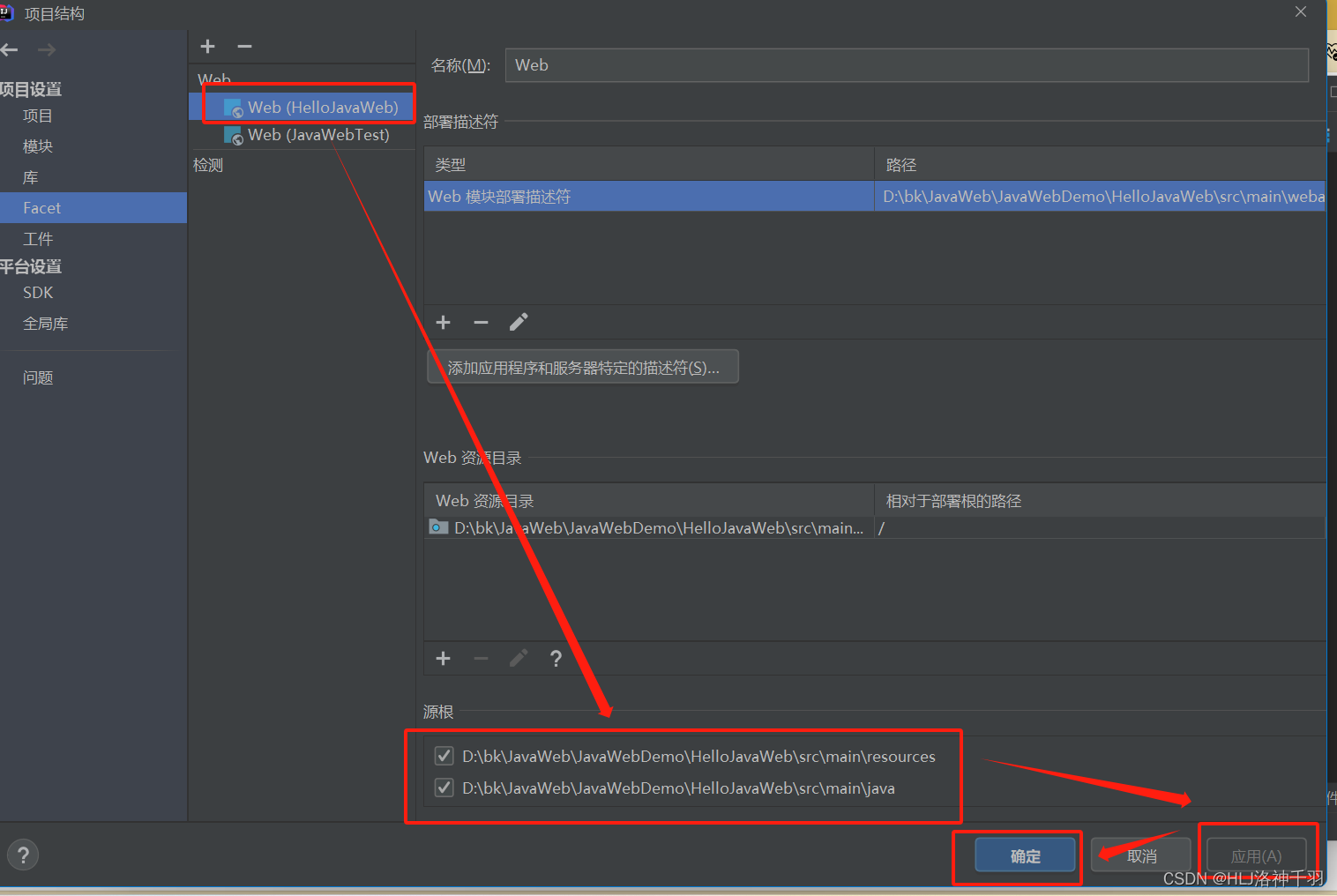
idea 设置serlvet 类模板(快捷生成servlet类)
我的版本是idea2020.3.4,博客中有相应安装教程,其他版本设置类似: 1.选择文件-->设置 2.选择编辑器-->文件和代码模板-->其他 3.选择Web-->Servlet Annotated Class.java-->复制相应模板,下面顺便设置了注释模板 …...
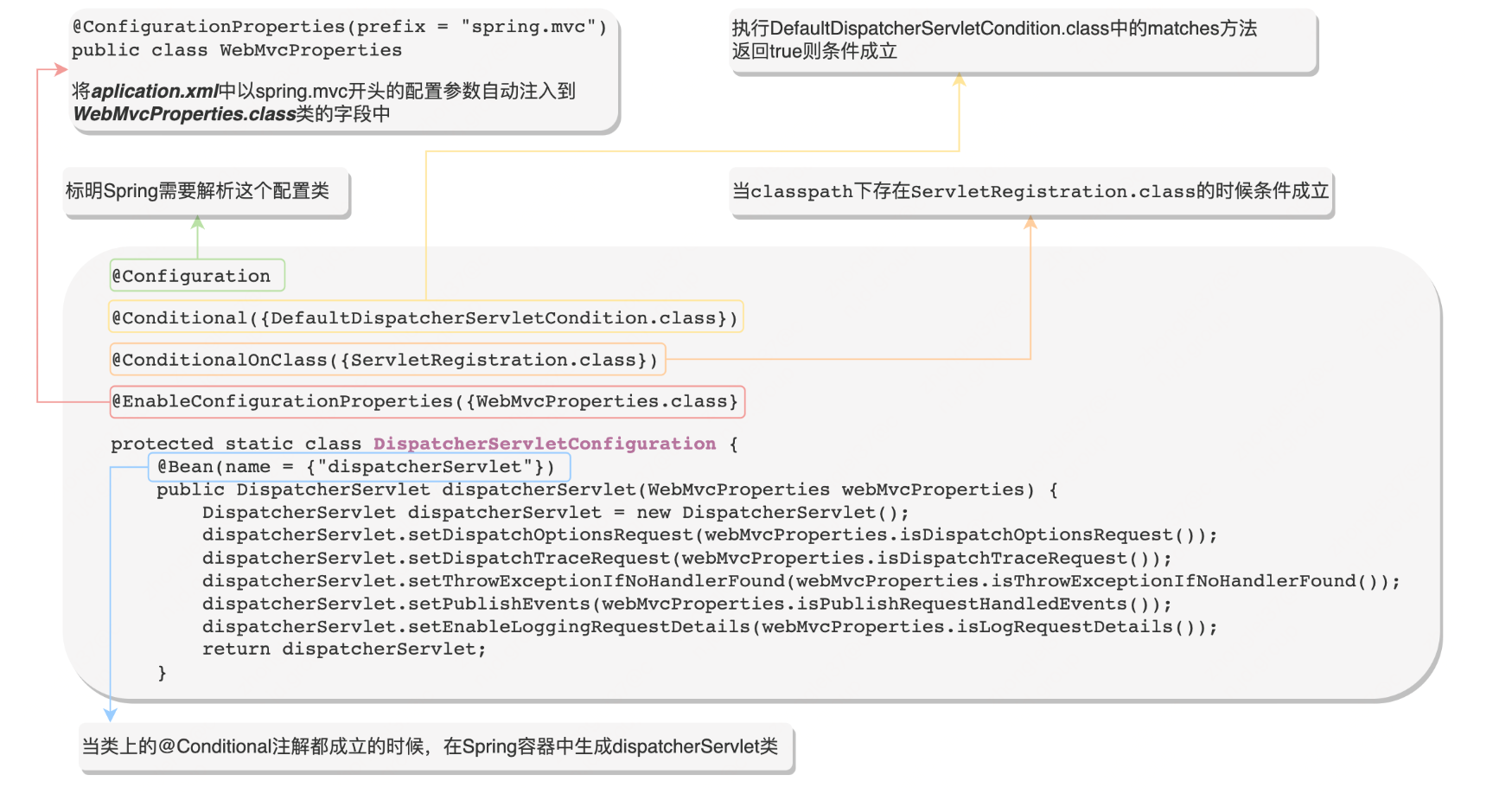
SpringBoot自动配置原理解析 | 京东物流技术团队
1: 什么是SpringBoot自动配置 首先介绍一下什么是SpringBoot,SpringBoost是基于Spring框架开发出来的功能更强大的Java程序开发框架,其最主要的特点是:能使程序开发者快速搭建一套开发环境。SpringBoot能将主流的开发框架(例如Sp…...

AOP 笔记
AOP【面向切面编程】 作用:在不惊动原始设计的基础上进行功能增强。 无侵入式编程 连接点:程序执行的任意位置,SpringAOP中,理解为方法的执行。 切入点:匹配连接点的式子,要追加功能的方法 通知(写在通…...
)
微信小程序导航退回及跳转 传参(navigateBack,navigateTo)
一、uniapp navigateBack 退回上一级 当前页面-传递参数 uni.$emit(update, params)uni.navigateBack({delta: 1});退回的页面-接收参数 可以写在 onLoad 和 onShow 里面 onLoad(o) {uni.$on(update, function(e) {//参数e}}onShow() {}返回前两级 uni.navigateBack({delta: 2}…...

python实例代码介绍python基础知识
TODO: 知识点仍有待整理 import 使用 import 关键字可以让你选择性地导入所需的模块,而不必导入整个模块库。这样可以减少内存占用和加载时间,尤其是当你只需要使用模块中的某些功能时。 同时,使用 import 可以提高代码的可读性和可维护性&…...

【每日一题】掷骰子等于目标和的方法数
文章目录 Tag题目来源题目解读解题思路方法一:动态规划 写在最后 Tag 【动态规划】【数组】 题目来源 1155. 掷骰子等于目标和的方法数 题目解读 你手里有 n 个一样的骰子,每个骰子都有 k 个面,分别标号 1 到 n。给定三个整数 n࿰…...

霸王条款惹品牌争议,京东双11站在商家对立面?
作者 | 江北 来源 | 洞见新研社 双11活动第一天,京东就站上了风口浪尖。 与烘焙烤箱品牌海氏的话题接连登上微博热搜,海氏控诉京东滥用市场竞争地位,破坏市场竞争秩序。在海氏的声明中,京东的行为让吃瓜群众大开眼界:…...

深度神经网络为何成功?其中的过程、思想和关键主张选择
LeNet(1989)在小数据集上取得了很好的效果,但是在更大、更真实地数据集上训练卷积神经网络地性能和可行性还有待研究。 与神经网络竞争的是传统机器学习方法,比如SVM(支持向量机)。这个阶段性能比神经网络方…...

什么是服务器节点?
一.服务器节点的概念: 服务器节点是一种服务器装置,节点服务器是针对服务器集群来说的。主要应用在WEB、FTP等等的服务上。所以节点服务器并不是单指某一种服务器。它由多个节点和管理装置整体的管理单元构成,其特征在于:各节点具…...

水电站与数据可视化:洞察未来能源趋势的窗口
在信息时代的浪潮中,数据可视化正成为推动能源领域发展的重要工具。今天,我们将带您一起探索水电站与数据可视化的结合,如何成为洞察未来能源趋势的窗口。水电站作为传统能源领域的重要组成部分,它的运行与管理涉及大量的数据。然…...
Mac运行Docker报错
Mac运行Docker报错 📔 千寻简笔记介绍 千寻简笔记已开源,Gitee与GitHub搜索chihiro-notes,包含笔记源文件.md,以及PDF版本方便阅读,且是用了精美主题,阅读体验更佳,如果文章对你有帮助请帮我点…...
.click(function(){ 和代码 $(document).ready(function() 有啥区别?)
代码 $(“.btn“).click(function(){ 和代码 $(document).ready(function() 有啥区别?
看下面的内容前可以先看下博文:https://blog.csdn.net/wenhao_ir/article/details/134029389 $(".btn").click(function(){...}) 和 $(document).ready(function(){...}) 是两种不同的 jQuery 事件处理方式,它们有不同的用途和时机࿱…...

【Perplexity×知网双引擎文献检索术】:20年科研老炮亲授3步精准定位高引论文的私密工作流
更多请点击: https://kaifayun.com 第一章:【Perplexity知网双引擎文献检索术】:20年科研老炮亲授3步精准定位高引论文的私密工作流 为什么单靠知网或Google Scholar总在“相关文献”里打转? 单一学术搜索引擎存在固有偏见&…...

2009-2024年日本人口统计数据
本数据集为日本多层级行政区划的人口统计数据,涵盖都道府县、城市以及政令指定都市的市区三级空间单元,记录了人口规模、结构及动态变化等核心指标。数据可用于人口演变分析、区域发展研究及空间计量模型构建。基于此数据集,可系统开展以下研…...

Windows热键冲突终结者:3步精准定位占用进程的智能方案
Windows热键冲突终结者:3步精准定位占用进程的智能方案 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否曾…...
的三大优势)
EMD过时了?从故障诊断实战看经验小波变换(EWT)的三大优势
EMD过时了?从故障诊断实战看经验小波变换(EWT)的三大优势 在工业设备状态监测领域,振动信号分析一直是故障诊断的黄金标准。传统方法如经验模态分解(EMD)曾因其自适应特性广受推崇,但工程师们逐渐发现它在处理轴承点蚀、齿轮断齿等典型故障时…...
)
别再手动reshape了!用einops.rearrange优雅处理PyTorch张量维度(附实战代码)
用einops.rearrange重塑PyTorch张量:告别混乱的维度操作 深度学习开发中最令人头疼的莫过于张量维度的变换。你是否曾在凌晨三点盯着屏幕,试图理解自己昨天写的permute和reshape组合到底在做什么?或者花费半小时调试一个维度不匹配的错误&…...

04_运算符表达式与类型转换
运算符、表达式与类型转换 一、本篇文章要解决什么问题 你已经知道怎么定义变量、怎么输入输出了。但程序光有数据不行,还得对数据做运算——加减乘除、比较大小、逻辑判断。 这篇文章就帮你搞定三件事: C 语言里有哪些运算符?算术的、赋值的…...
的第一个步骤是**识别问题域中的对象和类**(也称为“识别对象与类”或“确定问题域中的概念类”))
面向对象分析(OOA)的第一个步骤是**识别问题域中的对象和类**(也称为“识别对象与类”或“确定问题域中的概念类”)
面向对象分析(OOA)的第一个步骤是识别问题域中的对象和类(也称为“识别对象与类”或“确定问题域中的概念类”)。 这一步要求分析师深入理解用户需求和现实世界的问题背景,通过用例分析、领域建模、名词提取等方法&…...

如何彻底解决C盘空间不足:Windows Cleaner终极清理指南
如何彻底解决C盘空间不足:Windows Cleaner终极清理指南 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否经常遇到C盘空间不足的困扰?…...

在 Elasticsearch 中使用带有确定性护栏的 Agentic AI 搜索,以实现安全的查询执行
作者:来自 Elastic Alexander Marquardt, Honza Krl 及 Taylor Roy 当 LLM 直接生成查询时, Agentic AI 搜索系统通常会失败。了解确定性护栏和控制平面架构如何通过 Elasticsearch 实现安全、可靠且受治理的查询执行。 刚接触 Elasticsearch࿱…...

AI 挖洞新思路、深度解析两大间接提示词注入漏洞攻防思路,注入也能获得上万美金
0x01 简介 在移动 AI 领域,我已经很久没有关注过提示词注入漏洞了,在前两天关注到 Gemini 的漏洞之前,我对提示词注入的印象还停留在两年前,当时搞搞越狱,觉得这东西是纯内容安全,也只能等未来对能够进…...