第87步 时间序列建模实战:LSTM回归建模
基于WIN10的64位系统演示
一、写在前面
这一期,我们介绍大名鼎鼎的LSTM回归。
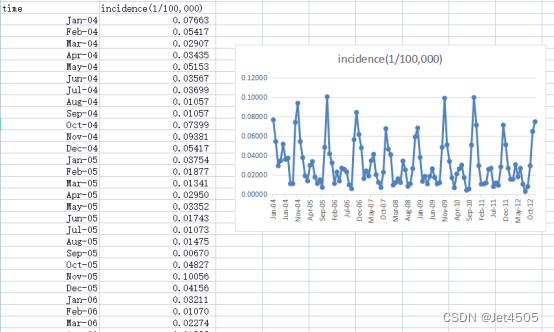
同样,这里使用这个数据:
《PLoS One》2015年一篇题目为《Comparison of Two Hybrid Models for Forecasting the Incidence of Hemorrhagic Fever with Renal Syndrome in Jiangsu Province, China》文章的公开数据做演示。数据为江苏省2004年1月至2012年12月肾综合症出血热月发病率。运用2004年1月至2011年12月的数据预测2012年12个月的发病率数据。
二、LSTM回归
(1)LSTM简介
LSTM (Long Short-Term Memory) 是一种特殊的RNN(递归神经网络)结构,由Hochreiter和Schmidhuber在1997年首次提出。LSTM 被设计出来是为了避免长序列在训练过程中的长期依赖问题,这是传统 RNNs 所普遍遇到问题。
(a)LSTM 的主要特点:
(a1)三个门结构:LSTM 包含三个门结构:输入门、遗忘门和输出门。这些门决定了信息如何进入、被存储或被遗忘,以及如何输出。
(a2)记忆细胞:LSTM的核心是称为记忆细胞的结构。它可以保留、修改或访问的内部状态。通过门结构,模型可以学会在记忆细胞中何时存储、忘记或检索信息。
(a3)长期依赖问题:LSTM特别擅长学习、存储和使用长期信息,从而避免了传统RNN在长序列上的梯度消失问题。
(b)为什么LSTM适合时间序列建模:
(b1)序列数据的特性:时间序列数据具有顺序性,先前的数据点可能会影响后面的数据点。LSTM设计之初就是为了处理带有时间间隔、延迟和长期依赖关系的序列数据。
(b2)长期依赖:在时间序列分析中,某个事件可能会受到很早之前事件的影响。传统的RNNs由于梯度消失的问题,很难捕捉这些长期依赖关系。但是,LSTM结构可以有效地处理这种依赖关系。
(b3)记忆细胞:对于时间序列预测,能够记住过去的信息是至关重要的。LSTM的记忆细胞可以为模型提供这种存储和检索长期信息的能力。
(b4)灵活性:LSTM模型可以与其他神经网络结构(如CNN)结合,用于更复杂的时间序列任务,例如多变量时间序列或序列生成。
综上所述,由于LSTM的设计和特性,它非常适合时间序列建模,尤其是当数据具有长期依赖关系时。
(2)单步滚动预测
import pandas as pd
import numpy as np
from sklearn.metrics import mean_absolute_error, mean_squared_error
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras import layers, models, optimizers
from tensorflow.python.keras.optimizers import adam_v2# 读取数据
data = pd.read_csv('data.csv')# 将时间列转换为日期格式
data['time'] = pd.to_datetime(data['time'], format='%b-%y')# 创建滞后期特征
lag_period = 6
for i in range(lag_period, 0, -1):data[f'lag_{i}'] = data['incidence'].shift(lag_period - i + 1)# 删除包含 NaN 的行
data = data.dropna().reset_index(drop=True)# 划分训练集和验证集
train_data = data[(data['time'] >= '2004-01-01') & (data['time'] <= '2011-12-31')]
validation_data = data[(data['time'] >= '2012-01-01') & (data['time'] <= '2012-12-31')]# 定义特征和目标变量
X_train = train_data[['lag_1', 'lag_2', 'lag_3', 'lag_4', 'lag_5', 'lag_6']].values
y_train = train_data['incidence'].values
X_validation = validation_data[['lag_1', 'lag_2', 'lag_3', 'lag_4', 'lag_5', 'lag_6']].values
y_validation = validation_data['incidence'].values# 对于LSTM,我们需要将输入数据重塑为 [samples, timesteps, features]
X_train = X_train.reshape(X_train.shape[0], X_train.shape[1], 1)
X_validation = X_validation.reshape(X_validation.shape[0], X_validation.shape[1], 1)# 构建LSTM回归模型
input_layer = layers.Input(shape=(X_train.shape[1], 1))x = layers.LSTM(50, return_sequences=True)(input_layer)
x = layers.LSTM(25, return_sequences=False)(x)
x = layers.Dropout(0.1)(x)
x = layers.Dense(25, activation='relu')(x)
x = layers.Dropout(0.1)(x)
output_layer = layers.Dense(1)(x)model = models.Model(inputs=input_layer, outputs=output_layer)model.compile(optimizer=adam_v2.Adam(learning_rate=0.001), loss='mse')# 训练模型
history = model.fit(X_train, y_train, epochs=200, batch_size=32, validation_data=(X_validation, y_validation), verbose=0)# 单步滚动预测函数
def rolling_forecast(model, initial_features, n_forecasts):forecasts = []current_features = initial_features.copy()for i in range(n_forecasts):# 使用当前的特征进行预测forecast = model.predict(current_features.reshape(1, len(current_features), 1)).flatten()[0]forecasts.append(forecast)# 更新特征,用新的预测值替换最旧的特征current_features = np.roll(current_features, shift=-1)current_features[-1] = forecastreturn np.array(forecasts)# 使用训练集的最后6个数据点作为初始特征
initial_features = X_train[-1].flatten()# 使用单步滚动预测方法预测验证集
y_validation_pred = rolling_forecast(model, initial_features, len(X_validation))# 计算训练集上的MAE, MAPE, MSE 和 RMSE
mae_train = mean_absolute_error(y_train, model.predict(X_train).flatten())
mape_train = np.mean(np.abs((y_train - model.predict(X_train).flatten()) / y_train))
mse_train = mean_squared_error(y_train, model.predict(X_train).flatten())
rmse_train = np.sqrt(mse_train)# 计算验证集上的MAE, MAPE, MSE 和 RMSE
mae_validation = mean_absolute_error(y_validation, y_validation_pred)
mape_validation = np.mean(np.abs((y_validation - y_validation_pred) / y_validation))
mse_validation = mean_squared_error(y_validation, y_validation_pred)
rmse_validation = np.sqrt(mse_validation)print("验证集:", mae_validation, mape_validation, mse_validation, rmse_validation)
print("训练集:", mae_train, mape_train, mse_train, rmse_train)看结果:

(3)多步滚动预测-vol. 1
import pandas as pd
import numpy as np
from sklearn.metrics import mean_absolute_error, mean_squared_error
import tensorflow as tf
from tensorflow.python.keras.models import Model
from tensorflow.python.keras.layers import Input, LSTM, Dense, Dropout, Flatten
from tensorflow.python.keras.optimizers import adam_v2# 读取数据
data = pd.read_csv('data.csv')
data['time'] = pd.to_datetime(data['time'], format='%b-%y')n = 6
m = 2# 创建滞后期特征
for i in range(n, 0, -1):data[f'lag_{i}'] = data['incidence'].shift(n - i + 1)data = data.dropna().reset_index(drop=True)train_data = data[(data['time'] >= '2004-01-01') & (data['time'] <= '2011-12-31')]
validation_data = data[(data['time'] >= '2012-01-01') & (data['time'] <= '2012-12-31')]# 准备训练数据
X_train = []
y_train = []for i in range(len(train_data) - n - m + 1):X_train.append(train_data.iloc[i+n-1][[f'lag_{j}' for j in range(1, n+1)]].values)y_train.append(train_data.iloc[i+n:i+n+m]['incidence'].values)X_train = np.array(X_train)
y_train = np.array(y_train)
X_train = X_train.astype(np.float32)
y_train = y_train.astype(np.float32)# 构建LSTM模型
inputs = Input(shape=(n, 1))
x = LSTM(64, return_sequences=True)(inputs)
x = LSTM(32)(x)
x = Dense(50, activation='relu')(x)
x = Dropout(0.1)(x)
outputs = Dense(m)(x)model = Model(inputs=inputs, outputs=outputs)model.compile(optimizer=adam_v2.Adam(learning_rate=0.001), loss='mse')# 训练模型
model.fit(X_train, y_train, epochs=200, batch_size=32, verbose=0)def lstm_rolling_forecast(data, model, n, m):y_pred = []for i in range(len(data) - n):input_data = data.iloc[i+n-1][[f'lag_{j}' for j in range(1, n+1)]].values.astype(np.float32).reshape(1, n, 1)pred = model.predict(input_data)y_pred.extend(pred[0])for i in range(1, m):for j in range(len(y_pred) - i):y_pred[j+i] = (y_pred[j+i] + y_pred[j]) / 2return np.array(y_pred)# Predict for train_data and validation_data
y_train_pred_lstm = lstm_rolling_forecast(train_data, model, n, m)[:len(y_train)]
y_validation_pred_lstm = lstm_rolling_forecast(validation_data, model, n, m)[:len(validation_data) - n]# Calculate performance metrics for train_data
mae_train = mean_absolute_error(train_data['incidence'].values[n:len(y_train_pred_lstm)+n], y_train_pred_lstm)
mape_train = np.mean(np.abs((train_data['incidence'].values[n:len(y_train_pred_lstm)+n] - y_train_pred_lstm) / train_data['incidence'].values[n:len(y_train_pred_lstm)+n]))
mse_train = mean_squared_error(train_data['incidence'].values[n:len(y_train_pred_lstm)+n], y_train_pred_lstm)
rmse_train = np.sqrt(mse_train)# Calculate performance metrics for validation_data
mae_validation = mean_absolute_error(validation_data['incidence'].values[n:len(y_validation_pred_lstm)+n], y_validation_pred_lstm)
mape_validation = np.mean(np.abs((validation_data['incidence'].values[n:len(y_validation_pred_lstm)+n] - y_validation_pred_lstm) / validation_data['incidence'].values[n:len(y_validation_pred_lstm)+n]))
mse_validation = mean_squared_error(validation_data['incidence'].values[n:len(y_validation_pred_lstm)+n], y_validation_pred_lstm)
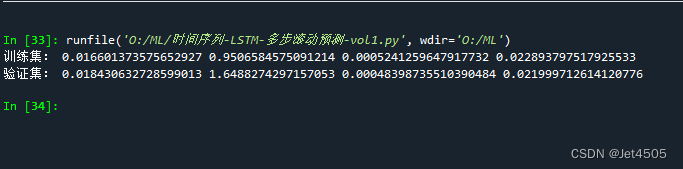
rmse_validation = np.sqrt(mse_validation)print("训练集:", mae_train, mape_train, mse_train, rmse_train)
print("验证集:", mae_validation, mape_validation, mse_validation, rmse_validation)结果:
(4)多步滚动预测-vol. 2
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error, mean_squared_error
from tensorflow.python.keras.models import Sequential, Model
from tensorflow.python.keras.layers import Dense, LSTM, Input
from tensorflow.python.keras.optimizers import adam_v2# Loading and preprocessing the data
data = pd.read_csv('data.csv')
data['time'] = pd.to_datetime(data['time'], format='%b-%y')n = 6
m = 2# 创建滞后期特征
for i in range(n, 0, -1):data[f'lag_{i}'] = data['incidence'].shift(n - i + 1)data = data.dropna().reset_index(drop=True)train_data = data[(data['time'] >= '2004-01-01') & (data['time'] <= '2011-12-31')]
validation_data = data[(data['time'] >= '2012-01-01') & (data['time'] <= '2012-12-31')]# 只对X_train、y_train、X_validation取奇数行
X_train = train_data[[f'lag_{i}' for i in range(1, n+1)]].iloc[::2].reset_index(drop=True).values
X_train = X_train.reshape(X_train.shape[0], X_train.shape[1], 1)y_train_list = [train_data['incidence'].shift(-i) for i in range(m)]
y_train = pd.concat(y_train_list, axis=1)
y_train.columns = [f'target_{i+1}' for i in range(m)]
y_train = y_train.iloc[::2].reset_index(drop=True).dropna().values[:, 0]X_validation = validation_data[[f'lag_{i}' for i in range(1, n+1)]].iloc[::2].reset_index(drop=True).values
X_validation = X_validation.reshape(X_validation.shape[0], X_validation.shape[1], 1)y_validation = validation_data['incidence'].values# Building the LSTM model
inputs = Input(shape=(n, 1))
x = LSTM(50, activation='relu')(inputs)
x = Dense(50, activation='relu')(x)
outputs = Dense(1)(x)model = Model(inputs=inputs, outputs=outputs)
optimizer = adam_v2.Adam(learning_rate=0.001)
model.compile(optimizer=optimizer, loss='mse')# Train the model
model.fit(X_train, y_train, epochs=200, batch_size=32, verbose=0)# Predict on validation set
y_validation_pred = model.predict(X_validation).flatten()# Compute metrics for validation set
mae_validation = mean_absolute_error(y_validation[:len(y_validation_pred)], y_validation_pred)
mape_validation = np.mean(np.abs((y_validation[:len(y_validation_pred)] - y_validation_pred) / y_validation[:len(y_validation_pred)]))
mse_validation = mean_squared_error(y_validation[:len(y_validation_pred)], y_validation_pred)
rmse_validation = np.sqrt(mse_validation)# Predict on training set
y_train_pred = model.predict(X_train).flatten()# Compute metrics for training set
mae_train = mean_absolute_error(y_train, y_train_pred)
mape_train = np.mean(np.abs((y_train - y_train_pred) / y_train))
mse_train = mean_squared_error(y_train, y_train_pred)
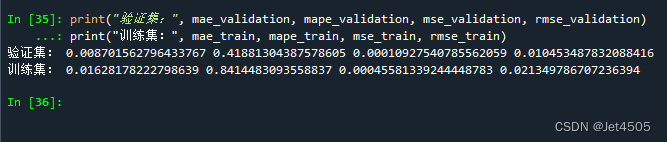
rmse_train = np.sqrt(mse_train)print("验证集:", mae_validation, mape_validation, mse_validation, rmse_validation)
print("训练集:", mae_train, mape_train, mse_train, rmse_train)结果:
(5)多步滚动预测-vol. 3
import pandas as pd
import numpy as np
from sklearn.metrics import mean_absolute_error, mean_squared_error
from tensorflow.python.keras.models import Sequential, Model
from tensorflow.python.keras.layers import Dense, LSTM, Input
from tensorflow.python.keras.optimizers import adam_v2# 数据读取和预处理
data = pd.read_csv('data.csv')
data_y = pd.read_csv('data.csv')
data['time'] = pd.to_datetime(data['time'], format='%b-%y')
data_y['time'] = pd.to_datetime(data_y['time'], format='%b-%y')n = 6for i in range(n, 0, -1):data[f'lag_{i}'] = data['incidence'].shift(n - i + 1)data = data.dropna().reset_index(drop=True)
train_data = data[(data['time'] >= '2004-01-01') & (data['time'] <= '2011-12-31')]
X_train = train_data[[f'lag_{i}' for i in range(1, n+1)]]
m = 3X_train_list = []
y_train_list = []for i in range(m):X_temp = X_trainy_temp = data_y['incidence'].iloc[n + i:len(data_y) - m + 1 + i]X_train_list.append(X_temp)y_train_list.append(y_temp)for i in range(m):X_train_list[i] = X_train_list[i].iloc[:-(m-1)].valuesX_train_list[i] = X_train_list[i].reshape(X_train_list[i].shape[0], X_train_list[i].shape[1], 1)y_train_list[i] = y_train_list[i].iloc[:len(X_train_list[i])].values# 模型训练
models = []
for i in range(m):# Building the LSTM modelinputs = Input(shape=(n, 1))x = LSTM(50, activation='relu')(inputs)x = Dense(50, activation='relu')(x)outputs = Dense(1)(x)model = Model(inputs=inputs, outputs=outputs)optimizer = adam_v2.Adam(learning_rate=0.001)model.compile(optimizer=optimizer, loss='mse')model.fit(X_train_list[i], y_train_list[i], epochs=200, batch_size=32, verbose=0)models.append(model)validation_start_time = train_data['time'].iloc[-1] + pd.DateOffset(months=1)
validation_data = data[data['time'] >= validation_start_time]
X_validation = validation_data[[f'lag_{i}' for i in range(1, n+1)]].values
X_validation = X_validation.reshape(X_validation.shape[0], X_validation.shape[1], 1)y_validation_pred_list = [model.predict(X_validation) for model in models]
y_train_pred_list = [model.predict(X_train_list[i]) for i, model in enumerate(models)]def concatenate_predictions(pred_list):concatenated = []for j in range(len(pred_list[0])):for i in range(m):concatenated.append(pred_list[i][j])return concatenatedy_validation_pred = np.array(concatenate_predictions(y_validation_pred_list))[:len(validation_data['incidence'])]
y_train_pred = np.array(concatenate_predictions(y_train_pred_list))[:len(train_data['incidence']) - m + 1]
y_validation_pred = y_validation_pred.flatten()
y_train_pred = y_train_pred.flatten()mae_validation = mean_absolute_error(validation_data['incidence'], y_validation_pred)
mape_validation = np.mean(np.abs((validation_data['incidence'] - y_validation_pred) / validation_data['incidence']))
mse_validation = mean_squared_error(validation_data['incidence'], y_validation_pred)
rmse_validation = np.sqrt(mse_validation)mae_train = mean_absolute_error(train_data['incidence'][:-(m-1)], y_train_pred)
mape_train = np.mean(np.abs((train_data['incidence'][:-(m-1)] - y_train_pred) / train_data['incidence'][:-(m-1)]))
mse_train = mean_squared_error(train_data['incidence'][:-(m-1)], y_train_pred)
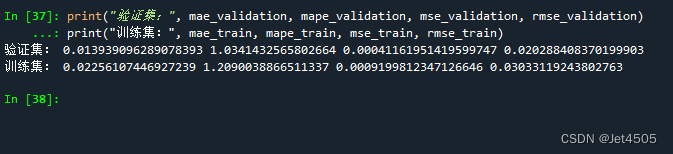
rmse_train = np.sqrt(mse_train)print("验证集:", mae_validation, mape_validation, mse_validation, rmse_validation)
print("训练集:", mae_train, mape_train, mse_train, rmse_train)结果:
三、数据
链接:https://pan.baidu.com/s/1EFaWfHoG14h15KCEhn1STg?pwd=q41n
提取码:q41n
相关文章:
第87步 时间序列建模实战:LSTM回归建模
基于WIN10的64位系统演示 一、写在前面 这一期,我们介绍大名鼎鼎的LSTM回归。 同样,这里使用这个数据: 《PLoS One》2015年一篇题目为《Comparison of Two Hybrid Models for Forecasting the Incidence of Hemorrhagic Fever with Renal…...
GB/T28181协议介绍
GB/T28181协议介绍 文章目录 GB/T28181协议介绍总体介绍GB/T28181基本结构GB/T28181关键协议流程设备注册设备目录查询实时视频播放流程 GB/T28181协议总结 说到GB/T28181协议,如果你是从事视频监控领域的工作,那对他一定不陌生,在公共安全、…...

光致发光荧光量子检测的作用
光致发光荧光量子检测是一种测试技术,可以用来测量荧光材料的荧光光谱、荧光量子效率和发光寿命等参数,具有高灵敏度、高分辨率和自动化程度高等优点。 光致发光荧光量子检测的应用范围广泛,可以应用于材料科学、生物科学、医学、光学器件、能…...
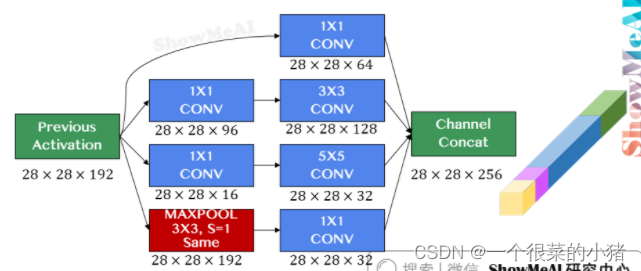
深度学习第四课
第九章 卷积神经网络解读 9.1 计算机视觉 目标分类 目标识别 64x64x312288 1000x1000x33000000 使用传统神经网络处理机器视觉面临的一个挑战是:数据的输入会非常大 一般的神经网络很难处理海量图像数据。解决这一问题的方法就是卷积神经网络 9.2 卷积运算 …...
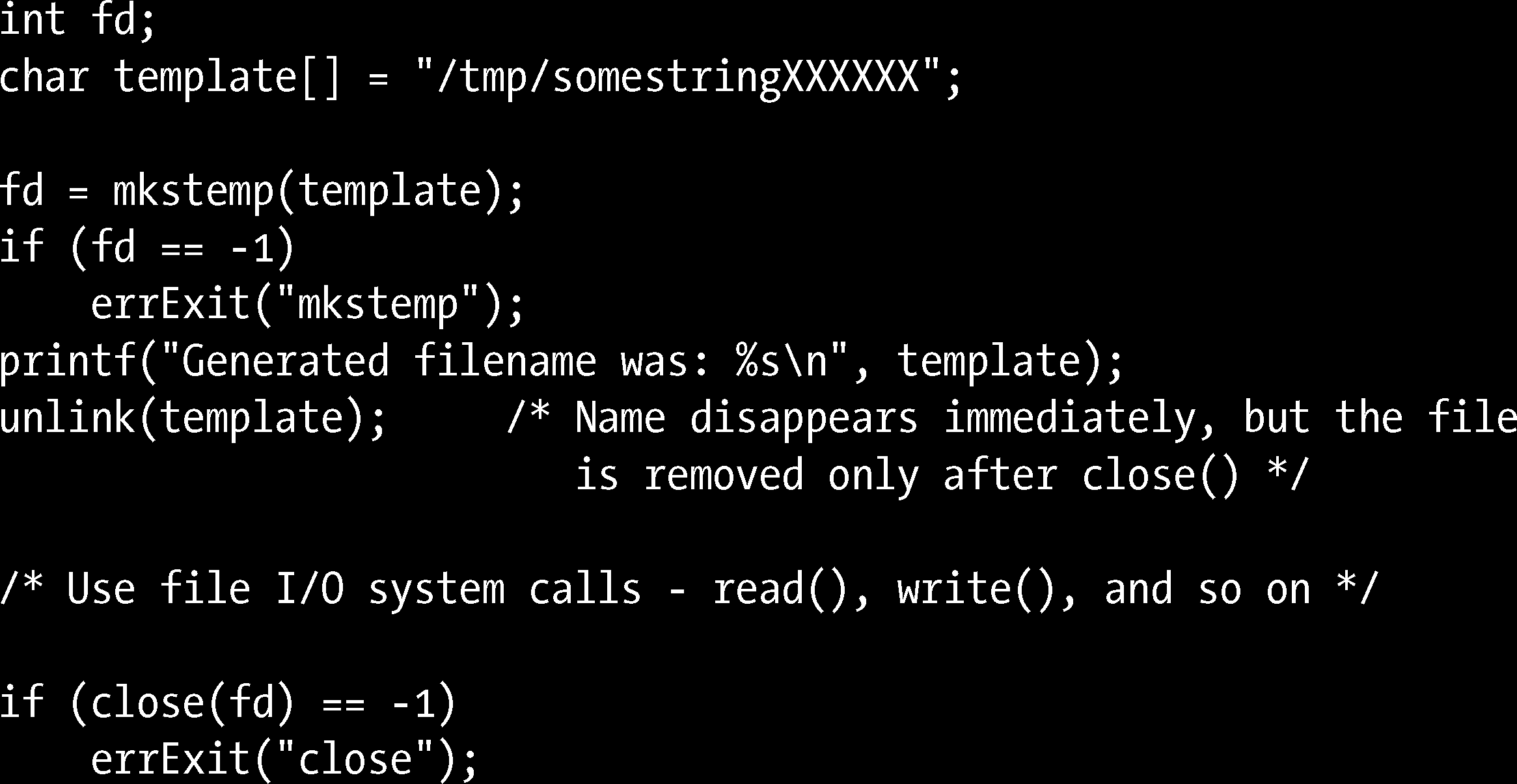
Linux创建临时文件mkstemp()tmpfile()
有些程序需要创建一些临时文件,仅供其在运行期间使用,程序终止后即行删除。 很多编译器程序会在编译过程中创建临时文件。GNU C 语言函数库为此而提供了一系列库函数。(之所以有“一系列”的库函数,部分原因是由于这些函数分别继…...

js的节流和防抖详解
防抖和节流是JavaScript中的常见优化技巧,它们可以帮助我们控制代码在特定的时间间隔内执行的频率,从而优化性能。下面详细讲解它们的原理和使用方法。 防抖(Debounce): 防抖的原理是当一个事件频繁触发时࿰…...
基于SpringBoot的水果销售网站
基于SpringBootVue的水果销售网站系统的设计与实现~ 开发语言:Java数据库:MySQL技术:SpringBootMyBatis工具:IDEA/Ecilpse、Navicat、Maven角色:管理员、商家、用户 系统展示 主页 水果详情 可直接购买,…...
vue2进阶学习知识汇总
目录 1.组件之处理边界情况 1.1 子组件访问根组件数据 1.2 子组件访问父组件数据 1.3 父组件访问子组件 1.4 依赖注入 1.5 程序化的事件侦听器 1.6 递归组件 1.7 内联模板 1.8 X-Template 1.9 强制更新 1.10 v-once 2.过渡效果与状态 2.1 过渡效果 2.1.1 单元素/…...

SQL SERVER连接oracle数据库几种方法
--1 方式 --查询oracle数据库中的表 SELECT * FROM OPENDATASOURCE( MSDAORA, Data SourceGE160;User IDDAIMIN;PasswordDAIMIN )..DAIMIN.JOBS 举一反三:在查询分析器中输入: SELECT * FROM OPENDATASOURCE( MSDAORA, Data SourceORCL;User…...
存储优化知识复习三详细版解析
存储优化 知识复习三 一、 选择题 1、 数据库领域的三位图灵奖得主是( )。 A、C.W.Bachman B、E.F.Codd C、Peter Naur D、James Gray 【参考答案】ABD2、 数据库DB、数据库系统DBS、数据库管理系统DBMS三者之间得关系是( )。 A、DB&#…...

HotReload for unity支持的代码修改
HotReload for unity支持的代码修改 HotReload的版本:1.2.4 Unity版本:2020,2021,2023 创作日期:2023.10.25 总结一下 支持在运行的时候修改异步,同步,重命名方法,修改方法参数,返回值,out,refÿ…...

写一个呼吸灯要几行代码?
module breathe( input clk, output reg led ); reg [26:0]cnt 1b0;always (posedge clk) begin cnt < cnt 1b1;if(cnt[15:6]>cnt[25:16])beginled < cnt[26];end else begin led < ~cnt[26];end endendmodule 笔者的clk是50M...

Banana Pi BPI-W3(Armsom W3)RK3588开当板之调试UART
前言 本文主要讲解如何关于RK3588开发板UART的使用和调试方法,包括UART作为普通串口和控制台两种不同使用场景 一. 功能特点 Rockchip UART (Universal Asynchronous Receiver/Transmitter) 基于16550A串口标准,完整模块支持以下功能: 支…...
LeetCode88——合并两个有序数组
LeetCode88——合并两个有序数组 1.题目描述: 给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。 请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减…...
C++ BinarySercahTree recursion version
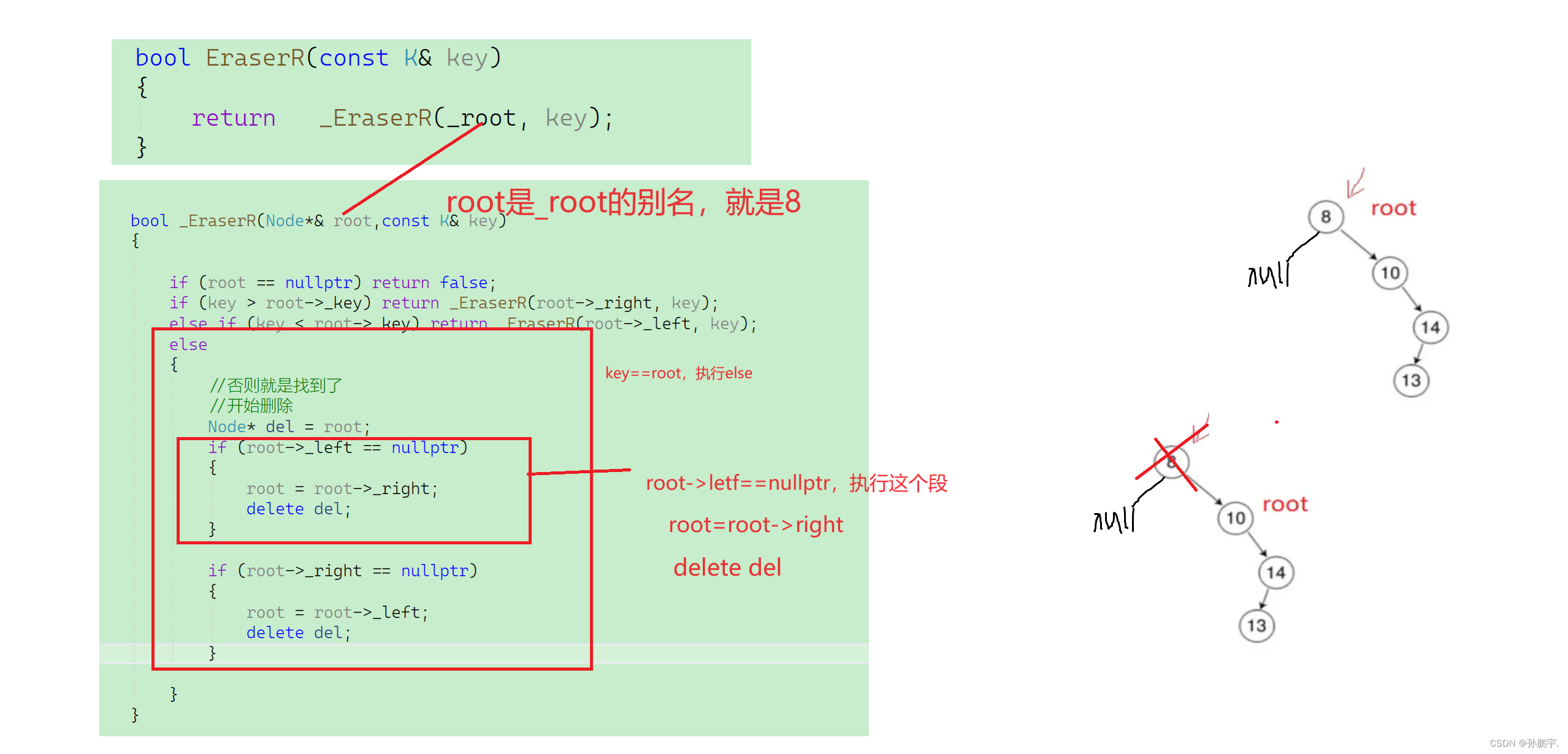
for循环版本的:C BinarySercahTree for version-CSDN博客 Inorder()在c BinarySerschTree for verison写了。 还是按照那种嵌套的方式来写递归。 现在来写查找 FindR() bool FindR(){return _FindR(_root);}然后_FindR()函数写递归具体实现: 假设要…...
)
兑换码生成与解析-个人笔记(java)
1.需求分析 兑换码长度为10字符,包含24个大写字母和8个数字。兑换码需要保证唯一性,不可重复兑换。需要防止猜测和爆刷攻击。兑换码生成和验证的算法需要高效,避免对数据库带来较大的压力。 导航 1.需求分析2.实现方案3.加密过程4.解密过程5…...

2023/10/25MySQL学习
外键约束 在子表添加外键后,不能在主表删除或更新记录,因为存在外键关联 删除外键,注意外键名称时我们添加外键时起的名称 使用cascade操作后,可以操作主表数据,并且子表的外键也会对应改变 set null的话,删除主表对应主键信息后,子表对应外键信息变为空 多表关系 创建中间表 可…...

网络协议--Ping程序
7.1 引言 “ping”这个名字源于声纳定位操作。Ping程序由Mike Muuss编写,目的是为了测试另一台主机是否可达。该程序发送一份ICMP回显请求报文给主机,并等待返回ICMP回显应答(图6-3列出了所有的ICMP报文类型)。 一般来说&#x…...
如何在 Azure 容器应用程序上部署具有 Elastic Observability 的 Hello World Web 应用程序
作者:Jonathan Simon Elastic Observability 是提供对正在运行的 Web 应用程序的可见性的最佳工具。 Microsoft Azure 容器应用程序是一个完全托管的环境,使你能够在无服务器平台上运行容器化应用程序,以便你的应用程序可以扩展和缩减。 这使…...
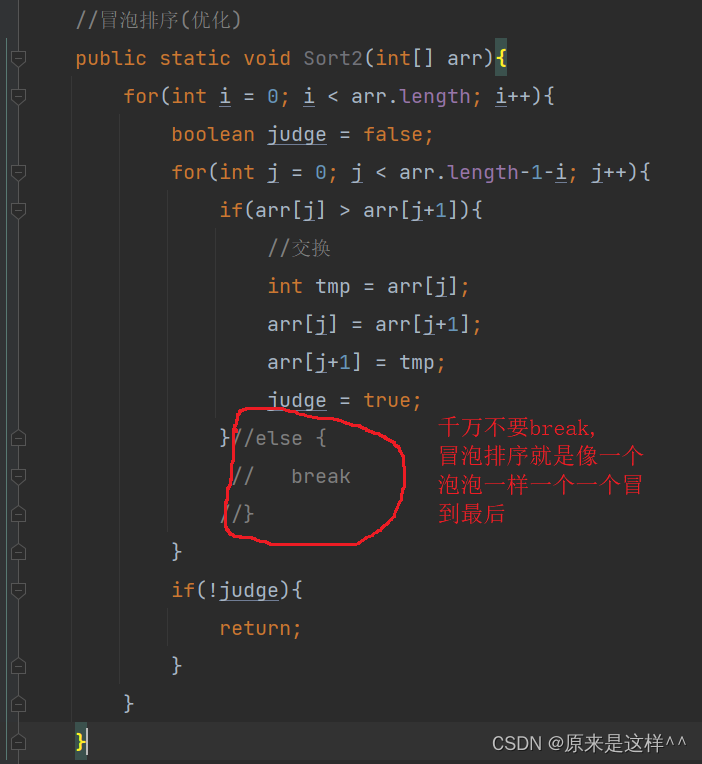
JAVA排序
再看各种排序前我们先了解一下什么叫 稳定性 比如一组数据arr[i]下标与arr[j下标]相等,arr[i]在前面,arr[j]在arr[i]后面,排序后这两个数据仍然是arr[i]在arr[j]前面,arr[j]在arr[i]后面,这就叫稳定 插入排序: 优势: 越有序查找速度越快 时间复杂度: O(N^2) 空间复…...

桌面整理神器:NoFences让你的Windows桌面焕然一新 [特殊字符]
桌面整理神器:NoFences让你的Windows桌面焕然一新 🚀 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是不是也厌倦了Windows桌面上杂乱无章的图标&a…...

浏览器资源嗅探神器猫抓Cat-Catch:3分钟学会抓取网页视频音频资源
浏览器资源嗅探神器猫抓Cat-Catch:3分钟学会抓取网页视频音频资源 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾经遇到过想下…...

ComfyUI MixLab Nodes:3分钟掌握AI多模态创作平台,彻底改变你的创意工作流
ComfyUI MixLab Nodes:3分钟掌握AI多模态创作平台,彻底改变你的创意工作流 【免费下载链接】comfyui-mixlab-nodes Workflow-to-APP、ScreenShare&FloatingVideo、GPT & 3D、SpeechRecognition&TTS 项目地址: https://gitcode.com/gh_mirr…...

RakkasJS深度解析:基于Bun的全栈React框架性能与迁移实践
1. 项目概述:下一代全栈React框架的探索如果你和我一样,在过去几年里深度使用过Next.js、Remix或者SvelteKit这类全栈框架,那你肯定对它们带来的开发体验又爱又恨。爱的是它们统一了前后端,让全栈开发变得前所未有的顺畅ÿ…...

告别混合写法!详解Nginx 1.25.1中独立的http2指令配置与性能影响
Nginx 1.25.1 HTTP/2配置革新:架构演进与性能实践指南 当Nginx 1.25.1的更新日志中出现"http2指令独立"这一行文字时,许多资深运维工程师的配置管理哲学正在被悄然改写。这不仅仅是语法糖的调整,而是反映了Web服务器架构设计从&quo…...

多智能体AI如何自动化代码分析与项目规划:从原理到实践
1. 项目概述:当AI项目经理走进你的代码库 最近在GitHub上看到一个挺有意思的项目,叫“Harness_Multi-Agent_AI_PM”。光看名字,你可能会觉得这又是一个蹭AI热度的概念性玩具。但作为一个在软件工程和项目管理一线摸爬滚打了十多年的老鸟&…...

初创团队如何利用Taotoken控制AI实验成本并快速迭代产品
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何利用Taotoken控制AI实验成本并快速迭代产品 对于资源有限的初创团队而言,在开发AI功能原型时,…...

i.MX8MP NPU实战:TensorFlow Lite模型移植与VSI-NPU优化全流程
1. 项目概述与核心价值最近在折腾一块基于NXP i.MX8M Plus的开发板,这块板子最大的亮点就是集成了一个专为边缘AI设计的神经处理单元(NPU)。官方文档里提了一嘴TensorFlow Lite的例程,但真上手去移植,发现坑是一个接一…...

Hyper-V DDA图形工具:告别PowerShell命令行的设备直通新时代
Hyper-V DDA图形工具:告别PowerShell命令行的设备直通新时代 【免费下载链接】DDA 实现Hyper-V离散设备分配功能的图形界面工具。A GUI Tool For Hyper-Vs Discrete Device Assignment(DDA). 项目地址: https://gitcode.com/gh_mirrors/dd/DDA 还在为Hyper-…...

终极指南:如何永久冻结IDM试用期实现终身免费使用
终极指南:如何永久冻结IDM试用期实现终身免费使用 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script 你是否曾经为IDM(Internet Download Ma…...